【Go-6】数据结构与集合
6. 数据结构与集合
数据结构是编程中用于组织和存储数据的方式,直接影响程序的效率和性能。Go语言提供了多种内置的数据结构,如数组、切片、Map和结构体,支持不同类型的数据管理和操作。本章将详细介绍Go语言中的主要数据结构与集合,涵盖它们的定义、使用方法、操作技巧以及底层原理。通过丰富的示例和深入的解释,帮助你全面掌握Go语言的数据结构,为构建高效、可维护的程序奠定坚实的基础。
6.1 数组
数组是具有固定大小和相同类型元素的有序集合。在Go语言中,数组的长度是其类型的一部分,这意味着具有不同长度的数组属于不同的类型。
数组的声明与初始化
1. 声明数组
使用var关键字声明数组时,需要指定数组的长度和元素类型。
var arr [5]int
解释:
arr是一个长度为5的整型数组。- 所有元素默认初始化为0。
2. 声明并初始化数组
可以在声明数组的同时为其元素赋值。
var arr [3]string = [3]string{"apple", "banana", "cherry"}
简化声明:
当声明和初始化数组时,Go可以根据初始化的元素数量自动推断数组的长度。
arr := [3]string{"apple", "banana", "cherry"}
使用省略长度
通过使用...,Go可以根据初始化的元素数量自动确定数组的长度。
arr := [...]float64{1.1, 2.2, 3.3, 4.4}
3. 多维数组
Go支持多维数组,最常见的是二维数组。
var matrix [3][4]int
初始化二维数组:
matrix := [2][3]int{{1, 2, 3},{4, 5, 6},
}
完整示例:
package mainimport "fmt"func main() {// 声明并初始化一维数组var arr [5]int = [5]int{1, 2, 3, 4, 5}fmt.Println("一维数组:", arr)// 使用省略长度声明数组arr2 := [...]string{"Go", "Python", "Java"}fmt.Println("省略长度的一维数组:", arr2)// 声明并初始化二维数组matrix := [2][3]int{{1, 2, 3},{4, 5, 6},}fmt.Println("二维数组:", matrix)
}
输出:
一维数组: [1 2 3 4 5]
省略长度的一维数组: [Go Python Java]
二维数组: [[1 2 3] [4 5 6]]
数组的操作
1. 访问数组元素
通过索引访问数组元素,索引从0开始。
package mainimport "fmt"func main() {arr := [3]string{"apple", "banana", "cherry"}fmt.Println("第一个元素:", arr[0]) // 输出: applefmt.Println("第二个元素:", arr[1]) // 输出: bananafmt.Println("第三个元素:", arr[2]) // 输出: cherry
}
2. 修改数组元素
数组元素是可修改的,只需通过索引赋值。
package mainimport "fmt"func main() {arr := [3]int{10, 20, 30}fmt.Println("原数组:", arr)arr[1] = 25fmt.Println("修改后的数组:", arr) // 输出: [10 25 30]
}
3. 遍历数组
使用for循环或range关键字遍历数组。
使用传统for循环:
package mainimport "fmt"func main() {arr := [3]string{"apple", "banana", "cherry"}for i := 0; i < len(arr); i++ {fmt.Printf("元素 %d: %s\n", i, arr[i])}
}
使用range遍历:
package mainimport "fmt"func main() {arr := [3]string{"apple", "banana", "cherry"}for index, value := range arr {fmt.Printf("元素 %d: %s\n", index, value)}
}
4. 数组长度
数组的长度是其类型的一部分,可以通过len函数获取。
package mainimport "fmt"func main() {arr := [5]int{1, 2, 3, 4, 5}fmt.Println("数组长度:", len(arr)) // 输出: 5
}
5. 数组作为函数参数
在Go中,数组作为函数参数时,会复制整个数组。因此,对于大数组,推荐使用指针或切片。
package mainimport "fmt"// 函数接收数组参数
func printArray(arr [3]int) {for _, v := range arr {fmt.Println(v)}
}func main() {arr := [3]int{1, 2, 3}printArray(arr)
}
输出:
1
2
3
注意事项
-
固定长度:数组的长度在声明时固定,无法动态改变。如果需要动态长度,建议使用切片。
-
类型区别:不同长度的数组属于不同类型,即
[3]int与[4]int是不同的类型。var a [3]int var b [4]int // a = b // 编译错误: cannot use b (type [4]int) as type [3]int in assignment -
数组拷贝:数组作为值类型会被复制。因此,在函数中修改数组不会影响原数组,除非使用指针传递。
6.2 切片
切片是基于数组的动态数据结构,比数组更灵活和强大。切片的长度和容量可以动态变化,是Go语言中最常用的数据结构之一。
切片的声明与初始化
1. 声明切片
切片不需要在声明时指定长度,可以通过多种方式声明。
var s []int
解释:
s是一个整型切片,初始为nil。
2. 使用make函数创建切片
make函数用于创建切片、Map和Channel。对于切片,make需要指定类型、长度和可选的容量。
s1 := make([]int, 5) // 长度为5,容量为5,元素初始化为0
s2 := make([]int, 3, 10) // 长度为3,容量为10
3. 字面量初始化
可以在声明时通过字面量赋值初始化切片。
s3 := []string{"Go", "Python", "Java"}
4. 从数组或其他切片创建切片
arr := [5]int{1, 2, 3, 4, 5}
s4 := arr[1:4] // 包含索引1、2、3,即 [2, 3, 4]
5. 使用append函数扩展切片
切片的长度可以通过append函数动态增长。
s := []int{1, 2, 3}
s = append(s, 4, 5) // s现在为 [1, 2, 3, 4, 5]
完整示例:
package mainimport "fmt"func main() {// 使用make创建切片s1 := make([]int, 5)fmt.Println("s1:", s1) // 输出: [0 0 0 0 0]s2 := make([]int, 3, 10)fmt.Println("s2:", s2) // 输出: [0 0 0]// 字面量初始化s3 := []string{"Go", "Python", "Java"}fmt.Println("s3:", s3) // 输出: [Go Python Java]// 从数组创建切片arr := [5]int{1, 2, 3, 4, 5}s4 := arr[1:4]fmt.Println("s4:", s4) // 输出: [2 3 4]// 使用append扩展切片s4 = append(s4, 6, 7)fmt.Println("s4 after append:", s4) // 输出: [2 3 4 6 7]
}
输出:
s1: [0 0 0 0 0]
s2: [0 0 0]
s3: [Go Python Java]
s4: [2 3 4]
s4 after append: [2 3 4 6 7]
切片的操作
1. 添加元素
使用append函数向切片添加元素,可以添加单个或多个元素。
package mainimport "fmt"func main() {s := []int{1, 2, 3}s = append(s, 4)fmt.Println("添加一个元素:", s) // 输出: [1 2 3 4]s = append(s, 5, 6)fmt.Println("添加多个元素:", s) // 输出: [1 2 3 4 5 6]
}
2. 删除元素
Go语言没有内置的删除函数,但可以通过切片操作实现。
示例:删除索引为2的元素
package mainimport "fmt"func main() {s := []int{1, 2, 3, 4, 5}index := 2 // 删除元素3s = append(s[:index], s[index+1:]...)fmt.Println("删除元素后的切片:", s) // 输出: [1 2 4 5]
}
3. 修改元素
直接通过索引修改切片中的元素。
package mainimport "fmt"func main() {s := []string{"apple", "banana", "cherry"}s[1] = "blueberry"fmt.Println("修改后的切片:", s) // 输出: [apple blueberry cherry]
}
4. 切片截取
通过切片操作可以创建子切片,指定起始和结束索引。
package mainimport "fmt"func main() {s := []int{10, 20, 30, 40, 50}sub1 := s[1:4]fmt.Println("sub1:", sub1) // 输出: [20 30 40]sub2 := s[:3]fmt.Println("sub2:", sub2) // 输出: [10 20 30]sub3 := s[2:]fmt.Println("sub3:", sub3) // 输出: [30 40 50]
}
5. 复制切片
使用copy函数复制切片内容。
package mainimport "fmt"func main() {src := []int{1, 2, 3, 4, 5}dst := make([]int, len(src))copy(dst, src)fmt.Println("源切片:", src)fmt.Println("目标切片:", dst)
}
输出:
源切片: [1 2 3 4 5]
目标切片: [1 2 3 4 5]
6. 切片的容量
切片的容量是从切片的起始位置到底层数组末尾的元素数量。使用cap函数可以获取切片的容量。
package mainimport "fmt"func main() {s := make([]int, 3, 5)fmt.Println("切片:", s) // 输出: [0 0 0]fmt.Println("长度:", len(s)) // 输出: 3fmt.Println("容量:", cap(s)) // 输出: 5s = append(s, 1, 2)fmt.Println("切片 after append:", s) // 输出: [0 0 0 1 2]fmt.Println("长度:", len(s)) // 输出: 5fmt.Println("容量:", cap(s)) // 输出: 5// 再次添加元素,容量会自动增长s = append(s, 3)fmt.Println("切片 after second append:", s) // 输出: [0 0 0 1 2 3]fmt.Println("长度:", len(s)) // 输出: 6fmt.Println("容量:", cap(s)) // 输出: 10 (通常会翻倍)
}
输出:
切片: [0 0 0]
长度: 3
容量: 5
切片 after append: [0 0 0 1 2]
长度: 5
容量: 5
切片 after second append: [0 0 0 1 2 3]
长度: 6
容量: 10
切片的底层原理
切片在Go语言中是一个引用类型,包含三个部分:
- 指针:指向底层数组的第一个元素。
- 长度(len):切片中的元素数量。
- 容量(cap):从切片的起始位置到底层数组末尾的元素数量。
示例:
package mainimport "fmt"func main() {arr := [5]int{1, 2, 3, 4, 5}s := arr[1:4]fmt.Printf("数组: %v\n", arr)fmt.Printf("切片: %v, len=%d, cap=%d\n", s, len(s), cap(s)) // 输出: [2 3 4], len=3, cap=4// 修改切片中的元素s[0] = 20fmt.Println("修改后的数组:", arr) // 输出: [1 20 3 4 5]
}
输出:
数组: [1 2 3 4 5]
切片: [2 3 4], len=3, cap=4
修改后的数组: [1 20 3 4 5]
解释:
- 切片
s指向数组arr的索引1到3。 - 修改切片中的元素也会影响底层数组。
容量的影响:
- 当切片的容量足够时,使用
append不会重新分配底层数组。 - 当容量不足时,
append会分配一个新的底层数组,将原有数据复制过来。
示例:
package mainimport "fmt"func main() {arr := [3]int{1, 2, 3}s := arr[:]fmt.Printf("切片: %v, len=%d, cap=%d\n", s, len(s), cap(s)) // 输出: [1 2 3], len=3, cap=3// 使用append添加元素,容量不足,会创建新数组s = append(s, 4)fmt.Printf("切片 after append: %v, len=%d, cap=%d\n", s, len(s), cap(s)) // 输出: [1 2 3 4], len=4, cap=6// 修改新切片,不影响原数组s[0] = 10fmt.Println("切片 after modification:", s) // 输出: [10 2 3 4]fmt.Println("原数组:", arr) // 输出: [1 2 3]
}
输出:
切片: [1 2 3], len=3, cap=3
切片 after append: [1 2 3 4], len=4, cap=6
切片 after modification: [10 2 3 4]
原数组: [1 2 3]
解释:
- 初始切片
s的容量为3。 append操作导致切片容量增长,并分配了新的底层数组。- 修改新切片不影响原数组。
注意事项
- 切片与数组的关系:切片是对数组的引用,修改切片会影响底层数组,反之亦然。
- 内存管理:切片本身不存储数据,数据存储在底层数组中。切片可以通过多个切片引用同一个底层数组,可能导致数据共享和竞态条件。
- 切片的零值:
var s []int声明的切片是nil,长度和容量均为0。可以通过append或make初始化切片。
6.3 Map
Map是键值对的无序集合,键和值可以是不同的类型。Map在Go中作为内置数据类型提供,类似于Python的字典或Java的HashMap。它在快速查找、插入和删除数据方面表现出色。
Map 的声明与使用
1. 声明Map
使用var关键字声明Map时,需要指定键和值的类型。
var capitals map[string]string
解释:
capitals是一个键类型为string,值类型为string的Map。- 初始值为
nil,需要使用make函数初始化。
2. 使用make初始化Map
capitals = make(map[string]string)
3. 声明并初始化Map
可以在声明时通过字面量赋值初始化Map。
capitals := map[string]string{"中国": "北京","美国": "华盛顿","日本": "东京",
}
4. 添加和访问元素
通过键访问或添加元素。
capitals["德国"] = "柏林" // 添加元素
capital := capitals["美国"] // 访问元素
fmt.Println("美国的首都是:", capital) // 输出: 美国的首都是: 华盛顿
5. 完整示例
package mainimport "fmt"func main() {// 声明并初始化Mapcapitals := map[string]string{"中国": "北京","美国": "华盛顿","日本": "东京",}fmt.Println("原始Map:", capitals)// 添加元素capitals["德国"] = "柏林"fmt.Println("添加德国后的Map:", capitals)// 访问元素capital := capitals["美国"]fmt.Println("美国的首都是:", capital)// 修改元素capitals["日本"] = "大阪"fmt.Println("修改日本后的Map:", capitals)// 删除元素delete(capitals, "德国")fmt.Println("删除德国后的Map:", capitals)
}
输出:
原始Map: map[中国:北京 美国:华盛顿 日本:东京]
添加德国后的Map: map[中国:北京 美国:华盛顿 德国:柏林 日本:东京]
美国的首都是: 华盛顿
修改日本后的Map: map[中国:北京 美国:华盛顿 德国:柏林 日本:大阪]
删除德国后的Map: map[中国:北京 美国:华盛顿 日本:大阪]
Map 的遍历与修改
1. 遍历Map
使用for循环结合range关键字遍历Map。
package mainimport "fmt"func main() {capitals := map[string]string{"中国": "北京","美国": "华盛顿","日本": "东京",}for country, capital := range capitals {fmt.Printf("%s 的首都是 %s\n", country, capital)}
}
输出示例:
中国 的首都是 北京
美国 的首都是 华盛顿
日本 的首都是 东京
2. 仅遍历键或值
如果只需要键或值,可以使用_忽略不需要的部分。
仅遍历键:
for country := range capitals {fmt.Println("国家:", country)
}
仅遍历值:
for _, capital := range capitals {fmt.Println("首都:", capital)
}
3. 修改Map元素
在遍历过程中可以直接修改Map的元素。
package mainimport "fmt"func main() {capitals := map[string]string{"中国": "北京","美国": "华盛顿","日本": "东京",}// 修改所有首都名称for country := range capitals {capitals[country] = "首都-" + capitals[country]}fmt.Println("修改后的Map:", capitals)
}
输出:
修改后的Map: map[中国:首都-北京 美国:首都-华盛顿 日本:首都-东京]
4. 检查键是否存在
在访问Map的元素时,可以同时检查键是否存在。
package mainimport "fmt"func main() {capitals := map[string]string{"中国": "北京","美国": "华盛顿",}capital, exists := capitals["日本"]if exists {fmt.Println("日本的首都是:", capital)} else {fmt.Println("日本的首都不存在")}
}
输出:
日本的首都不存在
5. 使用delete函数删除元素
package mainimport "fmt"func main() {capitals := map[string]string{"中国": "北京","美国": "华盛顿","日本": "东京",}delete(capitals, "美国")fmt.Println("删除美国后的Map:", capitals)
}
输出:
删除美国后的Map: map[中国:北京 日本:东京]
注意事项
-
Map的零值:未初始化的Map为
nil,不能进行读写操作。需要使用make或字面量初始化Map。var m map[string]int // m["key"] = 1 // 运行时错误: assignment to entry in nil mapm = make(map[string]int) m["key"] = 1 // 正确 -
Map的无序性:Map中的元素是无序的,遍历时元素的顺序是不确定的。如果需要有序的数据结构,建议使用切片或其他结构。
示例:
package mainimport "fmt"func main() {m := map[string]int{"apple": 5,"banana": 3,"cherry": 7,}for k, v := range m {fmt.Printf("%s: %d\n", k, v)}// 输出顺序不确定 } -
Map的键类型:Map的键必须是可比较的类型,如布尔型、数字、字符串、指针、接口和结构体(前提是结构体的所有字段都是可比较的)。切片、Map和函数类型不能作为键。
// 合法键类型 m1 := map[string]int{} m2 := map[int]bool{} m3 := map[struct{ a int; b string }]float64{}// 非法键类型 // m4 := map[[]int]string{} // 编译错误: invalid map key type []int // m5 := map[map[string]int]int{} // 编译错误: invalid map key type map[string]int // m6 := map[func(){}]bool{} // 编译错误: invalid map key type func()
6.4 结构体
结构体是由多个字段组成的复合数据类型,可以包含不同类型的数据。结构体在Go语言中用于创建自定义的数据类型,方便组织和管理复杂的数据。
定义结构体
使用type关键字定义结构体。
基本语法:
type StructName struct {Field1 Type1Field2 Type2// ...
}
示例:
type Person struct {Name stringAge int
}
嵌入结构体
结构体可以嵌入其他结构体,实现类似继承的功能。
type Address struct {City stringZipCode string
}type Employee struct {PersonAddressPosition string
}
结构体实例化
1. 使用字面量
p1 := Person{Name: "Alice", Age: 30}
2. 不指定字段名
p2 := Person{"Bob", 25}
3. 使用new关键字
new函数返回指向新分配的零值的指针。
p3 := new(Person)
p3.Name = "Charlie"
p3.Age = 28
4. 部分初始化
未初始化的字段会使用类型的零值。
p4 := Person{Name: "Diana"}
fmt.Println(p4.Age) // 输出: 0
完整示例:
package mainimport "fmt"// 定义结构体
type Person struct {Name stringAge int
}func main() {// 使用字面量初始化p1 := Person{Name: "Alice", Age: 30}fmt.Println("p1:", p1)// 不指定字段名p2 := Person{"Bob", 25}fmt.Println("p2:", p2)// 使用new关键字p3 := new(Person)p3.Name = "Charlie"p3.Age = 28fmt.Println("p3:", *p3)// 部分初始化p4 := Person{Name: "Diana"}fmt.Println("p4:", p4)
}
输出:
p1: {Alice 30}
p2: {Bob 25}
p3: {Charlie 28}
p4: {Diana 0}
嵌套结构体
结构体可以嵌入其他结构体,实现数据的层次化管理。
package mainimport "fmt"// 定义Address结构体
type Address struct {City stringZipCode string
}// 定义Person结构体
type Person struct {Name stringAge intAddress Address
}func main() {p := Person{Name: "Eve",Age: 35,Address: Address{City: "New York",ZipCode: "10001",},}fmt.Println("Person:", p)fmt.Println("City:", p.Address.City)
}
输出:
Person: {Eve 35 {New York 10001}}
City: New York
匿名嵌入结构体
通过匿名字段,可以直接访问嵌套结构体的字段,类似于继承。
package mainimport "fmt"// 定义Address结构体
type Address struct {City stringZipCode string
}// 定义Person结构体,匿名嵌入Address
type Person struct {Name stringAge intAddress
}func main() {p := Person{Name: "Frank",Age: 40,Address: Address{City: "Los Angeles",ZipCode: "90001",},}fmt.Println("Person:", p)fmt.Println("City:", p.City) // 直接访问嵌套结构体的字段
}
输出:
Person: {Frank 40 {Los Angeles 90001}}
City: Los Angeles
方法与结构体
Go语言支持为结构体类型定义方法,使得结构体更具行为性。
1. 定义方法
方法是在特定类型上定义的函数。通过方法,可以操作结构体的字段。
基本语法:
func (receiver StructType) MethodName(params) returnTypes {// 方法体
}
示例:
package mainimport "fmt"// 定义结构体
type Rectangle struct {Width, Height float64
}// 定义方法计算面积
func (r Rectangle) Area() float64 {return r.Width * r.Height
}// 定义方法计算周长
func (r Rectangle) Perimeter() float64 {return 2*(r.Width + r.Height)
}func main() {rect := Rectangle{Width: 10, Height: 5}fmt.Println("面积:", rect.Area()) // 输出: 面积: 50fmt.Println("周长:", rect.Perimeter()) // 输出: 周长: 30
}
2. 方法的接收者
接收者可以是值类型或指针类型。使用指针接收者可以修改结构体的字段,避免复制整个结构体。
示例:
package mainimport "fmt"// 定义结构体
type Counter struct {count int
}// 值接收者方法
func (c Counter) Increment() {c.count++fmt.Println("Inside Increment (value receiver):", c.count)
}// 指针接收者方法
func (c *Counter) IncrementPointer() {c.count++fmt.Println("Inside IncrementPointer (pointer receiver):", c.count)
}func main() {c := Counter{count: 10}c.Increment() // 修改的是副本fmt.Println("After Increment:", c.count) // 输出: 10c.IncrementPointer() // 修改的是原始值fmt.Println("After IncrementPointer:", c.count) // 输出: 11// 使用指针变量cp := &ccp.IncrementPointer()fmt.Println("After cp.IncrementPointer:", c.count) // 输出: 12
}
输出:
Inside Increment (value receiver): 11
After Increment: 10
Inside IncrementPointer (pointer receiver): 11
After IncrementPointer: 11
Inside IncrementPointer (pointer receiver): 12
After cp.IncrementPointer: 12
3. 方法的作用
方法可以提供结构体的行为和操作,增强代码的可读性和可维护性。例如,可以为结构体定义打印、验证、计算等功能。
示例:验证结构体字段
package mainimport ("fmt""errors"
)// 定义结构体
type User struct {Username stringEmail stringAge int
}// 定义方法验证User
func (u *User) Validate() error {if u.Username == "" {return errors.New("用户名不能为空")}if u.Email == "" {return errors.New("邮箱不能为空")}if u.Age < 0 || u.Age > 150 {return errors.New("年龄不合法")}return nil
}func main() {user := User{Username: "john_doe",Email: "john@example.com",Age: 28,}if err := user.Validate(); err != nil {fmt.Println("验证失败:", err)} else {fmt.Println("用户信息合法")}// 测试不合法的用户invalidUser := User{Username: "",Email: "invalid@example.com",Age: 200,}if err := invalidUser.Validate(); err != nil {fmt.Println("验证失败:", err) // 输出: 验证失败: 用户名不能为空} else {fmt.Println("用户信息合法")}
}
输出:
用户信息合法
验证失败: 用户名不能为空
注意事项
-
接收者的选择:根据方法是否需要修改结构体的字段,选择值接收者或指针接收者。一般情况下,使用指针接收者可以避免复制结构体,提升性能,且可以修改结构体的字段。
// 修改结构体字段 func (p *Person) SetName(name string) {p.Name = name } -
方法的命名:方法名应简洁明了,能够清晰描述方法的功能。例如,
CalculateArea、PrintDetails等。 -
方法与函数的区别:方法是与特定类型相关联的函数,而函数是独立的。合理使用方法可以提升代码的可读性和组织性。
6.5 指针与结构体
指针是存储变量内存地址的变量。在Go语言中,指针与结构体结合使用,可以提高程序的性能,避免大量数据的复制,同时实现对结构体的修改和共享。
指针基础
1. 声明指针
使用*符号声明指针类型。
var p *int
解释:
p是一个指向int类型的指针,初始值为nil。
2. 获取变量的地址
使用&符号获取变量的内存地址。
a := 10
p := &a
fmt.Println("a的地址:", p) // 输出: a的地址: 0xc0000140b0
3. 解引用指针
使用*符号访问指针指向的值。
fmt.Println("p指向的值:", *p) // 输出: p指向的值: 10
4. 修改指针指向的值
通过指针修改变量的值。
*p = 20
fmt.Println("修改后的a:", a) // 输出: 修改后的a: 20
完整示例:
package mainimport "fmt"func main() {var a int = 10var p *int = &afmt.Println("变量a的值:", a) // 输出: 10fmt.Println("指针p的地址:", p) // 输出: a的地址fmt.Println("指针p指向的值:", *p) // 输出: 10// 修改指针指向的值*p = 30fmt.Println("修改后的a:", a) // 输出: 30
}
输出:
变量a的值: 10
指针p的地址: 0xc0000140b0
指针p指向的值: 10
修改后的a: 30
指针与结构体
将指针与结构体结合使用,可以避免复制整个结构体,尤其是当结构体较大时,提高程序的性能。此外,通过指针,可以在函数中修改结构体的字段。
1. 定义结构体并使用指针
package mainimport "fmt"// 定义结构体
type Person struct {Name stringAge int
}func main() {p := Person{Name: "Alice", Age: 25}fmt.Println("原始结构体:", p) // 输出: {Alice 25}// 获取结构体的指针ptr := &p// 修改指针指向的结构体字段ptr.Age = 26fmt.Println("修改后的结构体:", p) // 输出: {Alice 26}
}
2. 结构体指针作为函数参数
通过将结构体指针作为函数参数,可以在函数中修改结构体的字段,而无需返回修改后的结构体。
package mainimport "fmt"// 定义结构体
type Rectangle struct {Width, Height float64
}// 定义函数,接受结构体指针并修改字段
func Resize(r *Rectangle, width, height float64) {r.Width = widthr.Height = height
}func main() {rect := Rectangle{Width: 10, Height: 5}fmt.Println("原始矩形:", rect) // 输出: {10 5}Resize(&rect, 20, 10)fmt.Println("修改后的矩形:", rect) // 输出: {20 10}
}
3. 指针与方法接收者
前面章节中提到方法接收者可以是指针类型,这样可以在方法中修改结构体的字段。
package mainimport "fmt"// 定义结构体
type Counter struct {count int
}// 定义指针接收者方法
func (c *Counter) Increment() {c.count++
}func main() {c := Counter{count: 0}fmt.Println("初始计数:", c.count) // 输出: 0c.Increment()fmt.Println("计数 after Increment:", c.count) // 输出: 1// 使用指针变量cp := &ccp.Increment()fmt.Println("计数 after cp.Increment:", c.count) // 输出: 2
}
输出:
初始计数: 0
计数 after Increment: 1
计数 after cp.Increment: 2
指针的高级用法
1. 指针与切片
切片本身是一个引用类型,包含指向底层数组的指针。可以通过指针修改切片元素。
package mainimport "fmt"func main() {s := []int{1, 2, 3}ptr := &s// 修改切片元素(*ptr)[1] = 20fmt.Println("修改后的切片:", s) // 输出: [1 20 3]
}
2. 指针与Map
Map是引用类型,使用指针传递Map不会带来额外的性能开销。通常不需要使用指针传递Map,但在某些情况下可以提高灵活性。
package mainimport "fmt"func main() {capitals := make(map[string]string)capitals["中国"] = "北京"capitals["美国"] = "华盛顿"modifyMap(&capitals)fmt.Println("修改后的Map:", capitals) // 输出: map[中国:北京 美国:纽约]
}func modifyMap(m *map[string]string) {(*m)["美国"] = "纽约"
}
3. 指针数组
数组中可以存储指针类型的元素,适用于需要引用和共享数据的场景。
package mainimport "fmt"func main() {a, b, c := 1, 2, 3ptrArr := []*int{&a, &b, &c}for i, ptr := range ptrArr {fmt.Printf("ptrArr[%d] 指向的值: %d\n", i, *ptr)}// 修改通过指针数组修改原始变量*ptrArr[0] = 10fmt.Println("修改后的a:", a) // 输出: 10
}
输出:
ptrArr[0] 指向的值: 1
ptrArr[1] 指向的值: 2
ptrArr[2] 指向的值: 3
修改后的a: 10
注意事项
-
指针的零值:未初始化的指针为
nil。在使用指针前,确保其已被正确初始化,避免运行时错误。var p *int // fmt.Println(*p) // 运行时错误: invalid memory address or nil pointer dereference -
避免悬挂指针:确保指针指向的变量在指针使用期间保持有效,避免指针指向已经释放或超出作用域的变量。
func getPointer() *int {x := 10return &x }func main() {p := getPointer()fmt.Println(*p) // 不安全:x已经超出作用域,可能导致未定义行为 } -
使用指针优化性能:对于大型结构体,使用指针传递可以避免复制整个结构体,提高性能。
type LargeStruct struct {Data [1000]int }func process(ls LargeStruct) { // 复制整个结构体// ... }func processPointer(ls *LargeStruct) { // 传递指针// ... } -
nil指针检查:在使用指针前,最好检查指针是否为
nil,以避免运行时错误。if p != nil {fmt.Println(*p) } else {fmt.Println("指针为nil") }
6.6 组合与接口(拓展内容)
虽然用户没有列出组合与接口,在数据结构与集合章节中,了解结构体的组合以及接口的使用也是非常重要的。因此,这里提供对组合和接口的简要介绍。
组合(Composition)
组合是通过嵌入一个结构体到另一个结构体中,实现代码复用和功能扩展的一种方式。通过组合,可以创建复杂的数据结构,同时保持代码的简洁和模块化。
示例:
package mainimport "fmt"// 定义基本结构体
type Address struct {City stringZipCode string
}// 定义复合结构体,通过组合Address
type Person struct {Name stringAge intAddress // 组合
}func main() {p := Person{Name: "Grace",Age: 28,Address: Address{City: "San Francisco",ZipCode: "94105",},}fmt.Printf("Person: %+v\n", p)fmt.Println("City:", p.City) // 直接访问组合结构体的字段
}
输出:
Person: {Name:Grace Age:28 Address:{City:San Francisco ZipCode:94105}}
City: San Francisco
优势:
- 代码复用:通过组合,可以复用已有的结构体,减少重复代码。
- 灵活性:组合比继承更灵活,避免了继承带来的复杂性。
接口(Interface)
接口定义了一组方法签名,任何实现了这些方法的类型都满足该接口。接口提供了多态性,使得代码更加灵活和可扩展。
示例:
package mainimport "fmt"// 定义接口
type Greeter interface {Greet(name string) string
}// 定义实现接口的结构体
type EnglishGreeter struct{}func (eg EnglishGreeter) Greet(name string) string {return "Hello, " + name + "!"
}type ChineseGreeter struct{}func (cg ChineseGreeter) Greet(name string) string {return "你好," + name + "!"
}func main() {var g Greeterg = EnglishGreeter{}fmt.Println(g.Greet("Alice")) // 输出: Hello, Alice!g = ChineseGreeter{}fmt.Println(g.Greet("Bob")) // 输出: 你好,Bob!
}
输出:
Hello, Alice!
你好,Bob!
解释:
Greeter接口定义了一个Greet方法。EnglishGreeter和ChineseGreeter结构体实现了Greet方法,满足Greeter接口。- 通过接口类型变量
g,可以调用不同实现的Greet方法,实现多态性。
接口的优势:
- 解耦合:通过接口,可以将代码模块之间的依赖解耦,提高代码的灵活性和可维护性。
- 多态性:同一接口可以由不同类型实现,允许不同的对象以统一的方式被处理。
- 可扩展性:无需修改现有代码,只需实现新的接口即可扩展功能。
注意事项
-
接口隐式实现:在Go语言中,类型只需实现接口的方法,不需要显式声明实现关系。这种隐式实现提高了代码的灵活性和简洁性。
type Reader interface {Read(p []byte) (n int, err error) }type MyReader struct{}func (r MyReader) Read(p []byte) (n int, err error) {// 实现Read方法return 0, nil }func main() {var r Readerr = MyReader{} } -
空接口(
interface{}):空接口可以表示任何类型,是实现通用数据结构和函数的重要工具。func printAnything(a interface{}) {fmt.Println(a) }func main() {printAnything(100)printAnything("Hello")printAnything(true) }输出:
100 Hello true -
类型断言和类型切换:在使用接口时,可能需要进行类型断言或类型切换,以访问具体类型的方法或字段。
类型断言示例:
func main() {var i interface{} = "Go Language"s, ok := i.(string)if ok {fmt.Println("字符串长度:", len(s))} else {fmt.Println("不是字符串类型")} }类型切换示例:
func main() {var i interface{} = 3.14switch v := i.(type) {case int:fmt.Println("整数:", v)case float64:fmt.Println("浮点数:", v)case string:fmt.Println("字符串:", v)default:fmt.Println("未知类型")} }
相关文章:

【Go-6】数据结构与集合
6. 数据结构与集合 数据结构是编程中用于组织和存储数据的方式,直接影响程序的效率和性能。Go语言提供了多种内置的数据结构,如数组、切片、Map和结构体,支持不同类型的数据管理和操作。本章将详细介绍Go语言中的主要数据结构与集合…...

支持向量机(SVM)例题
对于图中所示的线性可分的20个样本数据,利用支持向量机进行预测分类,有三个支持向量 A ( 0 , 2 ) A\left(0, 2\right) A(0,2)、 B ( 2 , 0 ) B\left(2, 0\right) B(2,0) 和 C ( − 1 , − 1 ) C\left(-1, -1\right) C(−1,−1)。 求支持向量机分类器的线…...
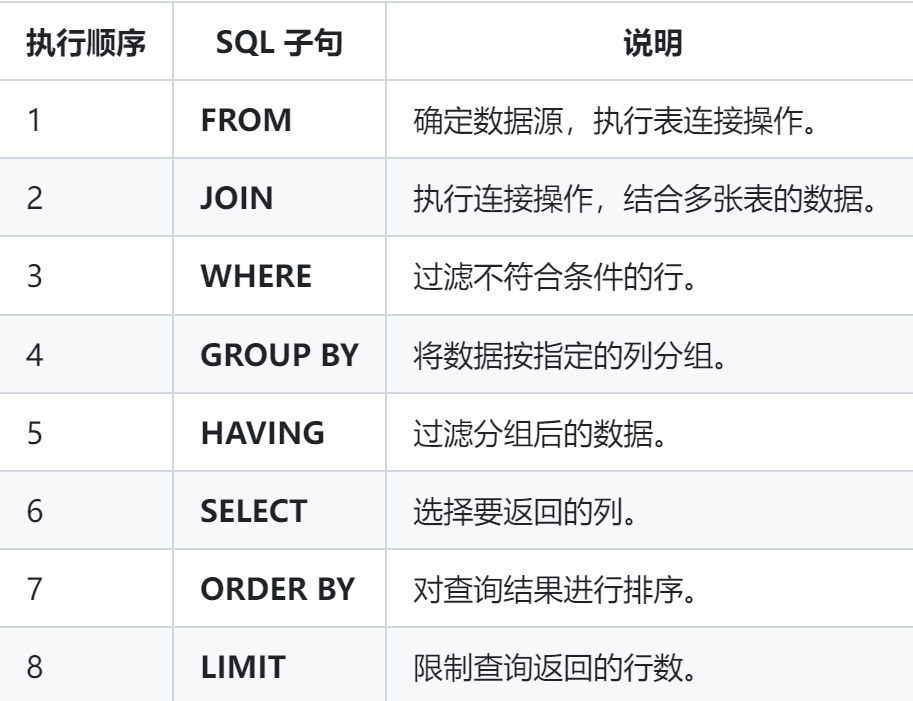
SQL中各个子句的执行顺序
select、from、 join、where、order by、group by、having、limit 解释 1) FROM (确定数据源) 查询的执行首先从FROM子句开始,确定数据的来源(表、视图、连接等)。 2) JOIN (如果有JOIN操作) 在FROM子句之后,SQL引擎会执行连接操作(JOIN),…...

PHP下实现RSA的加密,解密,加签和验签
前言: RSA下加密,解密,加签和验签是四种不同的操作,有时候会搞错,记录一下。 1.公钥加密,私钥解密 发送方通过公钥将原数据加密成一个sign参数,相当于就是信息的载体,接收方能通过si…...
本地部署消息代理软件 RabbitMQ 并实现外部访问( Windows 版本 )
RabbitMQ 是由 Erlang 语言开发的 消息中间件,是一种应用程序之间的通信方法。支持多种编程和语言和协议发展,用于实现分布式系统的可靠消息传递和异步通信等方面。 本文将详细介绍如何在 Windows 系统本地部署 RabbitMQ 并结合路由侠实现外网访问本…...
)
每日c/c++题 备战蓝桥杯(P2240 【深基12.例1】部分背包问题)
P2240 【深基12.例1】部分背包问题 - 详解与代码实现 一、题目概述 阿里巴巴要在承重为 T 的背包中装走尽可能多价值的金币,共有 N 堆金币,每堆金币有总重量和总价值。金币可分割,且分割后单位价格不变。目标是求出能装走的最大价值。 二、…...

Java异步编程:CompletionStage接口详解
CompletionStage 接口分析 接口能力概述 CompletionStage 是 Java 8 引入的接口,用于表示异步计算的一个阶段,它提供了强大的异步编程能力: 链式异步操作:允许将一个异步操作的结果传递给下一个操作组合操作&a…...

Java后端接受前端数据的几种方法
在前后端分离的开发模式中,前端(Vue)与后端(Java)的数据交互有多种格式,下面详细介绍几种常见的格式以及后端对应的接收方式。 一、JSON 格式 前端传输 在 Vue 里,可借助 axios 把数据以 JSO…...

Oracle OCP认证的技术定位怎么样?
一、引言:Oracle OCP认证的技术定位 Oracle Certified Professional(OCP)认证是数据库领域含金量最高的国际认证之一,其核心价值在于培养具备企业级数据库全生命周期管理能力的专业人才。随着数字化转型加速,OCP认证…...

powershell7.5@.net环境@pwsh7.5在部分windows10系统下的运行问题
文章目录 powershell7.5及更高版本和.net 9解决方案 powershell7.5及更高版本和.net 9 相对较新的.Net 9版本在老一些的windows10系统上(比如内核版本号:10.0.19044.1288以及之前的),由于默认启用了CET,导致编译运行失败,需要自己在项目中添加关闭CET的配置语句才能够顺利编译…...
基于微信小程序的垃圾分类系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

CSS3 渐变、阴影和遮罩的使用
全文目录: 开篇语**前言****1. CSS3 渐变 (Gradient)****1.1 线性渐变 (linear-gradient)****1.2 径向渐变 (radial-gradient)** **2. CSS3 阴影 (Shadow)****2.1 盒子阴影 (box-shadow)****2.2 文本阴影 (text-shadow)** **3. CSS3 遮罩 (Mask)****3.1 基本遮罩 (m…...

Spring Boot 全局配置文件优先级
好的,Spring Boot的全局配置文件优先级是一个非常重要的概念,它决定了在不同位置的同名配置属性以哪个为准。 Spring Boot 全局配置文件优先级核心知识点 📌 文件格式优先级: 在同一目录下,如果同时存在 application.properties 和…...
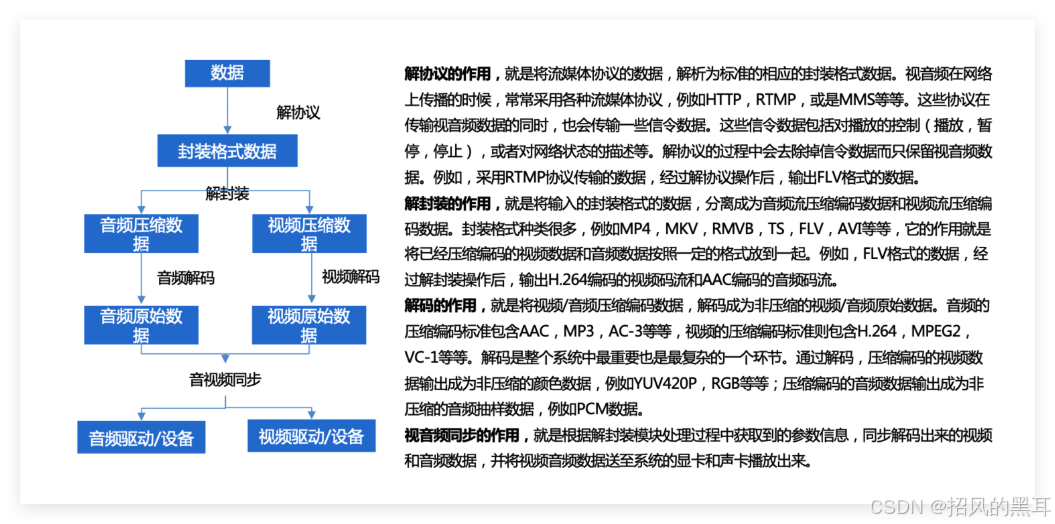
流媒体基础解析:视频清晰度的关键因素
在视频处理的过程中,编码解码及码率是影响视频清晰度的关键因素。今天,我们将深入探讨这些概念,并解析它们如何共同作用于视频质量。 编码解码概述 编码,简单来说,就是压缩。视频编码的目的是将原始视频数据压缩成较…...

grid网格布局
使用flex布局的痛点 如果使用justify-content: space-between;让子元素两端对齐,自动分配中间间距,假设一行4个,如果每一行都是4的倍数那没任何问题,但如果最后一行是2、3个的时候就会出现下面的状况: /* flex布局 两…...

C#数字金额转中文大写金额:代码解析
C#数字金额转中文大写金额:代码解析 在金融相关的业务场景中,我们常常需要将数字金额转换为中文大写金额,以避免金额被篡改,增加金额的准确性和安全性。本文将深入解析一段 C# 代码,这段代码通过巧妙的设计࿰…...
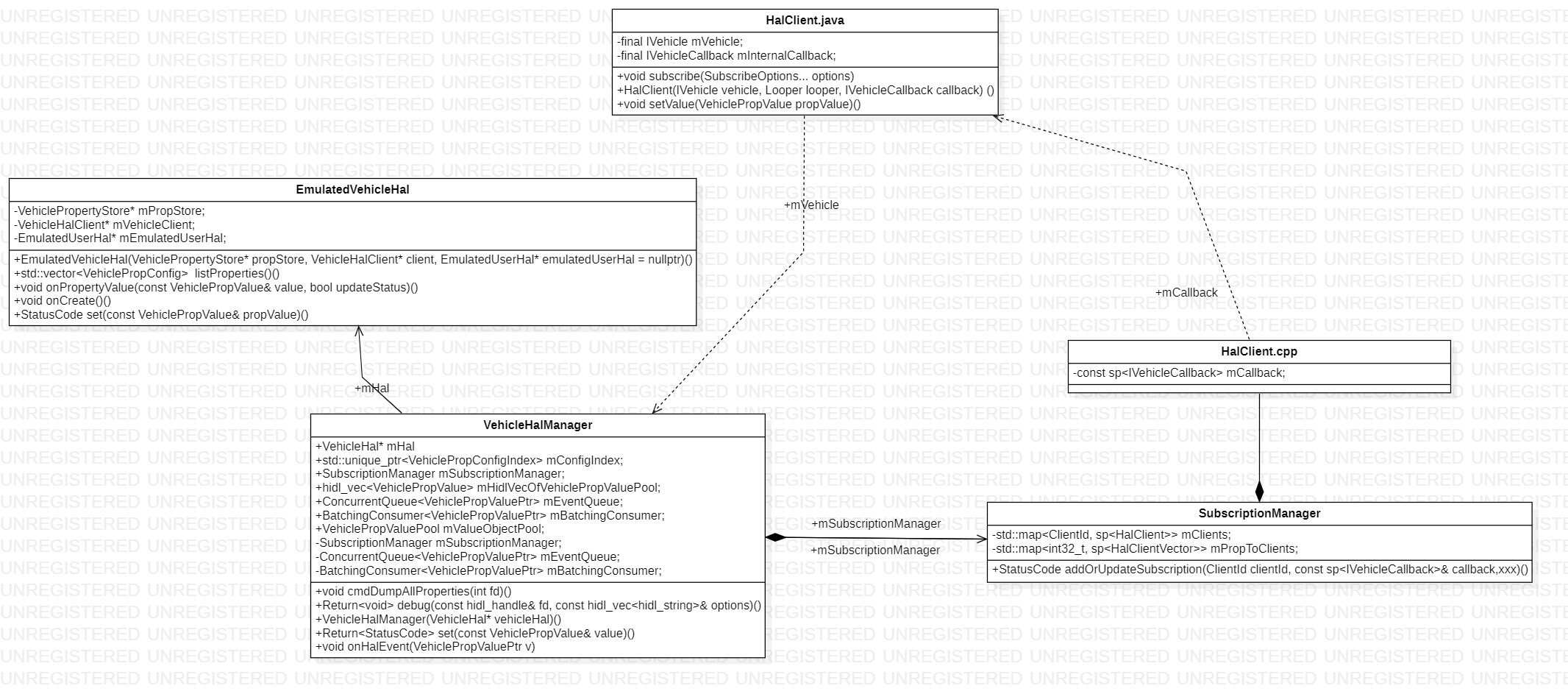
Vehicle HAL(2)--Vehicle HAL 的启动
目录 1. VehicleService-main 函数分析 2. 构建EmulatedVehicleHal 2.1 EmulatedVehicleHal::EmulatedVehicleHal(xxx) 2.2 EmulatedVehicleHal::initStaticConfig() 2.3 EmulatedVehicleHal::onPropertyValue() 3. 构建VehicleEmulator 4. 构建VehicleHalManager (1)初…...

JS中的函数防抖和节流:提升性能的关键技术
在JavaScript开发中,函数防抖和节流是两种常用的优化技术,用于处理那些可能会被频繁触发的事件,如resize、scroll、mousemove等。本文将详细介绍函数防抖和节流的概念、实现方法以及它们之间的区别。 一、什么是函数防抖和节流? …...

Android Compose开发架构选择指南:单Activity vs 多Activity
简介 掌握Jetpack Compose的Activity架构选择,是构建高性能、易维护Android应用的关键一步。在2025年的Android开发领域,随着Jetpack Compose的成熟和Android系统对多窗口模式的支持,开发者面临架构选择时需要更加全面地考虑各种因素。本文将深入探讨单Activity架构和多Act…...

【Netty系列】Reactor 模式 1
目录 一、Reactor 模式的核心思想 二、Netty 中的 Reactor 模式实现 1. 服务端代码示例 2. 处理请求的 Handler 三、运行流程解析(结合 Reactor 模式) 四、关键点说明 五、与传统模型的对比 六、总结 Reactor 模式是 Netty 高性能的核心设计思想…...

vue3 el-input type=“textarea“ 字体样式 及高度设置
在Vue 3中,如果你使用的是Element Plus库中的<el-input>组件作为文本域(type"textarea"),你可以通过几种方式来设置字体样式和高度。 1. 直接在<el-input>组件上使用style属性 你可以直接在<el-input&…...

并发解析hea,转为pdf格式
由于每次解析一个heap需要时间有点久,就写了一个自动解析程pdf的一个脚本。 down_lib.sh是需要自己写的哦,主要是用于下载自己所需程序的库,用于解析heap。 #!/bin/bash# 优化版通用解析脚本(并发加速):批…...
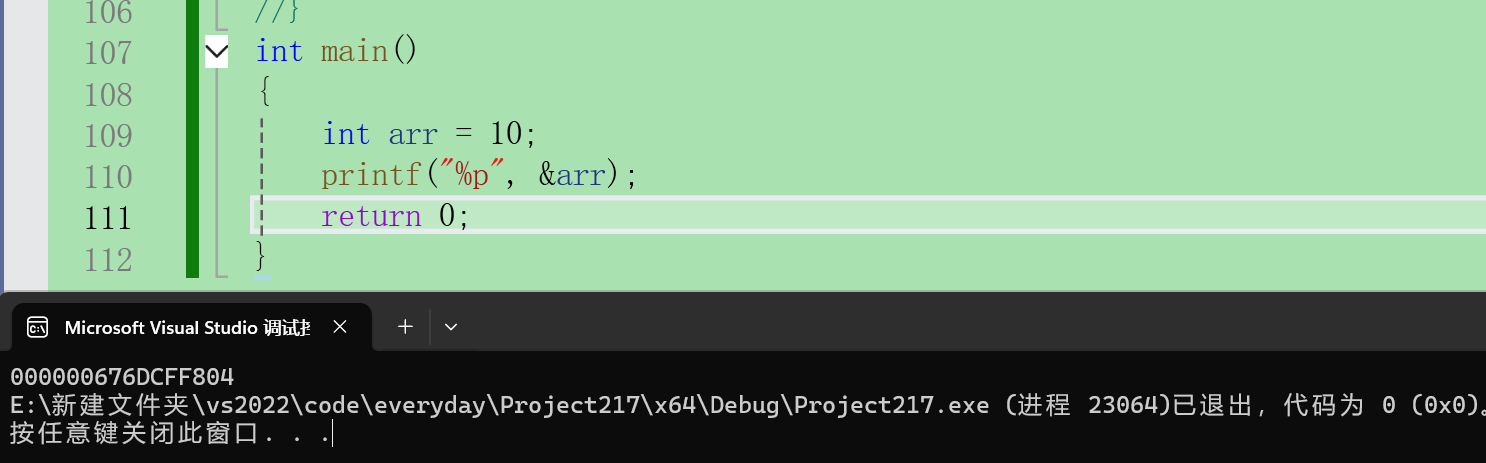
【C语言】详解 指针
前言: 在学习指针前,通过比喻的方法,让大家知道指针的作用。 想象一下,你在一栋巨大的图书馆里找一本书。如果没有书架编号和目录,这几乎是不可能完成的任务。 在 C 语言中,指针就像是图书馆的索引系统&…...

RabbitMQ仲裁队列高可用架构解析
#作者:闫乾苓 文章目录 概述工作原理1.节点之间的交互2.消息复制3.共识机制4.选举领导者5.消息持久化6.自动故障转移 集群环境节点管理仲裁队列增加集群节点重新平衡仲裁队列leader所在节点仲裁队列减少集群节点 副本管理add_member 在给定节点上添加仲裁队列成员&…...

刚出炉热乎的。UniApp X 封装 uni.request
HBuilder X v4.66 当前最新版本 由于 uniapp x 使用的是自己包装的 ts 语言 uts。目前语言还没有稳定下来,各种不支持 ts 各种报错各种不兼容问题。我一个个问题调通的,代码如下: 封装方法 // my-app/utils/request.uts const UNI_APP_BASE…...

Apache Kafka 实现原理深度解析:生产、存储与消费全流程
Apache Kafka 实现原理深度解析:生产、存储与消费全流程 引言 Apache Kafka 作为分布式流处理平台的核心,其高吞吐、低延迟、持久化存储的设计使其成为现代数据管道的事实标准。本文将从消息生产、持久化存储、消息消费三个阶段拆解 Kafka 的核心实现原…...
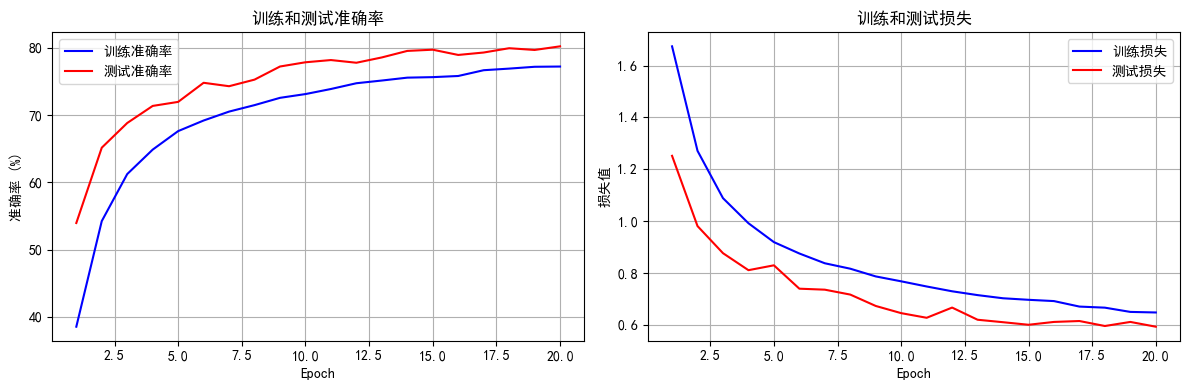
Python 训练营打卡 Day 41
简单CNN 一、数据预处理 在图像数据预处理环节,为提升数据多样性,可采用数据增强(数据增广)策略。该策略通常不改变单次训练的样本总数,而是通过对现有图像进行多样化变换,使每次训练输入的样本呈现更丰富…...
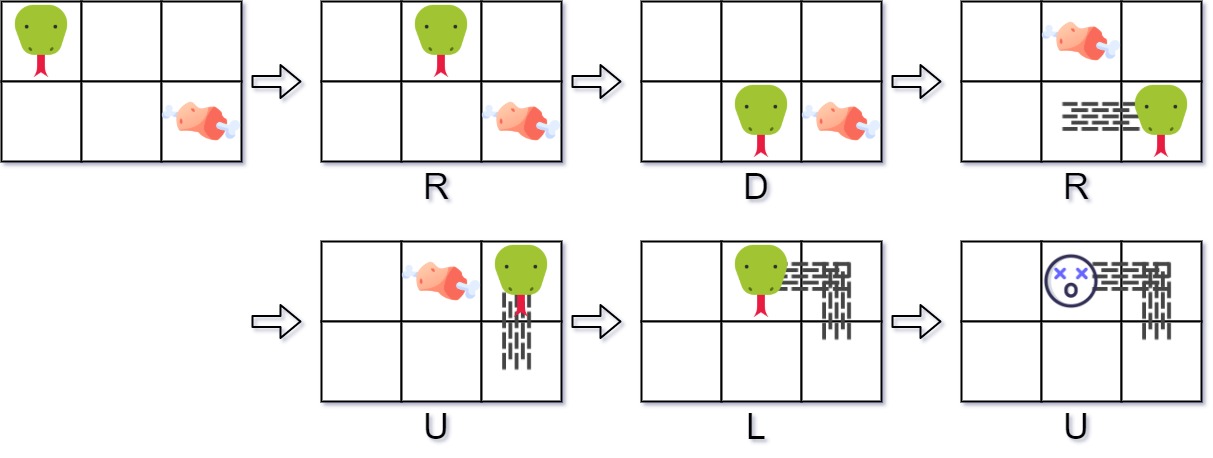
leetcode付费题 353. 贪吃蛇游戏解题思路
贪吃蛇游戏试玩:https://patorjk.com/games/snake/ 问题描述 设计一个贪吃蛇游戏,要求实现以下功能: 初始化游戏:给定网格宽度、高度和食物位置序列移动操作:根据指令(上、下、左、右)移动蛇头规则: 蛇头碰到边界或自身身体时游戏结束(返回-1)吃到食物时蛇身长度增加…...

CCPC dongbei 2025 I
题目链接:https://codeforces.com/gym/105924 题目背景: 给定一个二分图,左图编号 1 ~ n,右图 n 1 ~ 2n,左图的每个城市都会与右图的某个城市犯冲(每个城市都只与一个城市犯冲),除…...

系统性学习C语言-第十三讲-深入理解指针(3)
系统性学习C语言-第十三讲-深入理解指针(3) 1. 数组名的理解2. 使用指针访问数组3. ⼀维数组传参的本质4. 冒泡排序5. ⼆级指针 6. 指针数组7. 指针数组模拟二维数组 1. 数组名的理解 在上⼀个章节我们在使用指针访问数组的内容时,有这样的代…...