StarRocks x Iceberg:云原生湖仓分析技术揭秘与最佳实践

导读:
本文将深入探讨基于 StarRocks 和 Iceberg 构建的云原生湖仓分析技术,详细解析两者结合如何实现高效的查询性能优化。内容涵盖 StarRocks Lakehouse 架构、与 Iceberg 的性能协同、最佳实践应用以及未来的发展规划,为您提供全面的技术解读。
作者:杨关锁,北京镜舟科技研发工程师
一、StarRocks Lakehouse 架构介绍
1.1 什么是 Lakehouse
Lakehouse 湖仓一体架构是一种融合数据湖与数据仓库优势的新型架构,既具备数据湖开放统一的存储能力(支持多源异构数据低成本存储),又拥有数据仓库的高性能分析特性。其核心是构建统一数据存储底座(即 Single Source of Truth),基于同一套标准化数据资产,同时支撑多样化业务负载,覆盖企业 AI 建模、BI 分析等数据应用场景,实现从数据存储、治理到分析的全链路效率提升。

1.2 如何构建 Lakehouse
构建 Lakehouse 通常以低成本对象存储(如 S3、OSS)为统一存储底座,采用Iceberg、Hudi 等开放数据格式管理数据,以 Catalog 的形式向上层提供统一的数据访问控制和数据治理。上层整合 Spark、Flink、StarRocks 等计算引擎,可利用 Catalog 服务便捷地访问湖仓数据,实现“存储统一、计算灵活、治理可控”的湖仓一体架构。

1.3 基于 StarRocks 构建 Lakehouse
基于 StarRocks 来构建 Lakehouse 的核心路径为,首先选择一个开放的湖格式作为统一存储底座,在此之上创建 Catalog Service,然后即可直接使用 StarRocks 对湖上数据进行查询,同时可利用物化视图对查询进行透明加速。
与传统分层架构相比,Lakehouse 具有显著优势:
-
从数据处理流程来看,不需要维护 ETL 作业,整个流程更为简单。
-
从数据可信度来看,Lakehouse 始终遵循 Single Source of Truth,能够保证数据一致性。
-
从数据新鲜度来看,Lakehouse 在数据入湖之后就可以查询,消除了同步延迟,可以保证数据的时效性。
-
从数据存储成本来看,Lakehouse 只存储一份数据,避免了冗余存储带来的成本。

二、StarRocks x lceberg 极致性能揭秘
下文重点介绍 StarRocks 针对 Iceberg 的一些性能优化工作。
2.1 StarRocks 查询 lceberg 基本流程
在介绍具体的性能优化工作之前,先简单了解一下 StarRocks 查询 Iceberg 的基本流程。
FE 去 HMS 上获取对应的 Iceberg 元数据信息,包括表结构、分区的信息以及相关的需要访问的文件信息。
随后,FE 会将这些需要访问到的文件信息切成不同的 Scan Range,并基于一致性哈希路由到对应的 BE 上,BE 再对 Scan Range 进行执行和访问,必要的时候BE会去访问远端存储系统来获取相应的数据。
在上述流程中,性能瓶颈通常源于以下几个方面:
-
执行计划不优,初始方向错误,严重影响查询性能;
-
Iceberg 元数据的获取与解析速度不足;
-
本地 Reader 处理 Parquet 和 ORC 文件效率不高;
-
访问远端存储时,网络 I/O 也可能成为瓶颈。

接下来介绍 StarRocks 针对这些问题的优化方案。
2.2 Iceberg Metadata Cache
元数据解析效率是影响 StarRocks 极速查询性能的关键因素。Iceberg 单个 Manifest 文件(约 8MB)解析通常耗时 1 秒左右,对于追求极速查询的 StarRocks 来说,这样的延迟不可接受。而实际查询往往只涉及少量数据,解析收益偏低。针对这一问题,StarRocks 引入 Iceberg 元数据缓存机制,缓存解析后的元数据,避免重复解析开销,加速元数据访问,从而提升整体查询效率。

2.3 Iceberg Distributed Metadata Plan
在 Iceberg 的作业规划(Job Plan)过程中,元数据解析速度较慢会导致规划阶段耗时显著增加,且当前 Iceberg 元数据解析完全由 FE 侧承担,在表元数据规模较大时,会对 FE 的 CPU 和内存资源造成沉重压力,进一步延长作业规划时间。
针对上述问题,StarRocks 通过分布式 Metadata Plan 机制进行优化:将元数据的读取与解析任务从单一 FE 节点迁移至多个 BE 节点并行执行,利用分布式计算框架的并行处理能力,使元数据解析性能提升数倍。此方案不仅缩短了作业规划耗时,还通过分散计算负载,有效缓解了 FE 节点的资源压力,提升了系统整体的稳定性与扩展性。

2.4 Iceberg Job Planning
结合 Iceberg 元数据缓存与分布式 Metadata Plan 机制,FE 在元数据解析流程中,首先检查内存中是否缓存了已经解析后的 Manifest 数据,如果存在,则直接使用避免重复解析;否则,进一步检查本地内存或者磁盘中是否缓存了原始的 Manifest 文件。
若仍未命中,FE 会通过一定的策略来决策到底是由 FE 直接去远端获取对应的Manifest 文件进行解析,还是由 FE 触发一个分布式的 job plan,分发给 BE,由各个 BE 再去远端获取并解析。
此策略通过缓存优先、按需分发的机制,既可减少 FE 单点压力,又能够提升大规模元数据场景下的分布式处理能力。

2.5 统计信息收集
在 StarRocks 的查询流程中,统计信息是 CBO 优化器进行成本估算的核心依据,直接影响执行计划的选择效率。当前 StarRocks 支持两类统计信息:
-
基础统计信息:涵盖表行数、列数据量、最大值、最小值等基础指标,为优化器提供数据规模的全局认知。
-
直方图统计信息:针对数据分布倾斜场景,通过分桶统计值分布特征,校正基础统计信息的估算偏差,提升数据分布刻画的准确性。
在收集策略上,支持全量收集(覆盖全量数据)与抽样收集(基于样本数据快速生成)两种模式,并支持多种收集方式:手动收集、自动收集和查询触发收集。

查询触发收集,当用户发起查询时,系统自动识别查询涉及的列与分区,异步触发针对性统计任务,仅收集本次查询所需的统计信息。该机制通过后台非阻塞执行,避免对前台查询性能产生影响,同时可显著减少冗余计算开销。

2.6 Scan Range 增量投递
在 StarRocks 的查询流程中,FE 会将待访问的文件切分为多个 Scan Range,并投递至 BE 执行。早期版本采用全量同步投递机制,即 FE 的 Scan Node 需等待本次查询中所涉及到的所有 Scan Range 加载完成后一次性投递,此模式存在以下问题:
-
BE 必须同步等待,无法提前启动计算,延长查询耗时;
-
一次性加载所有 Scan Range,加大 FE 和 BE 的内存压力;
-
对 limit 短路查询不友好,即便只需少量数据,也需等待全量加载,造成资源浪费。
为此,StarRocks 在最新版本引入了 Scan Range 异步增量投递机制。FE 将 Scan Range 切分为小块,分批投递,每获取一部分即交由 BE 处理,BE 无需等待全量加载即可并行启动计算,大幅缩短查询时间。分批传输也有效降低了内存压力,提升系统稳定性。对于 limit 等短路查询场景,BE 可在满足查询条件后提前终止后续处理,进一步避免无效计算,提升资源利用率。

2.7 低基数优化
在实际数据中,用户往往存在大量字符串类型字段。相比基本整型数据,字符串处理存在内存占用高、传输开销大、难以向量化、匹配成本高等问题。为此,StarRocks 引入了低基数优化功能,通过预构建字典,将有限的字符串值转换为整数后处理,大幅提升字符串处理性能。

低基数优化的具体实现是通过轻量采样构建全局字典,此功能开箱即用。在执行过程中,若低基数优化执行失败,系统会自动重试,整个过程用户无感知。同时,系统会自动增强该模块的能力,以便下次能提供更优的匹配服务。

2.8 Parquet Reader - 自适应 I/O 合并
自适应 I/O 合并是一种针对对象存储特性优化数据读取效率的策略。其核心逻辑基于“单次大 I/O 读取耗时显著低于多次小I/O 累加”的共识,通过合并零散小 I/O 为大 I/O,减少远端存储的 IOPS 压力,提升数据读取性能并降低访问成本。
StarRocks 早期的 I/O 合并策略,会将本次查询所涉及的列统一合并,再以较大的粒度去访问。这一策略虽实现了 I/O 聚合,但存在读放大问题。
优化后的自适应 I/O 合并策略引入了智能判断逻辑。例如,针对图中的查询,并不是一开始就将三列进行合并。而是根据 c1 列的选择度来判断,如果 c1 列的选择度不够高,就会按照原有的方式将三列进行统一合并,再去请求远端。如果 c1 列的选择度够高,也就意味着读取 c1 之后,能够基于 c1 过滤掉大量无效数据,这时若将 c1 和另外两列进行合并就会导致读到大量无效数据。在这种情况下,就不会将 c1 与另外两列进行统一合并。
该策略通过动态匹配查询特征与数据分布,在 I/O 聚合效率与数据过滤精度间取得平衡。

2.9 Parquet Reader - 性能优化
对 Parquet Reader 进行了性能优化,例如支持 PageIndex 和 Bloom Filter,实现数据高效过滤;优化早期延迟物化机制,依据过滤度优先选高效谓词,尽量跳过无效数据访问;开展向量化优化,确保操作高效等。

2.10 Data Cache
StarRocks 的 Data Cache 具备降本增效、提升稳定性等功能。它可减少对远端存储的访问,显著优化成本;利用本地内存和磁盘替代远端存储访问,提升 I/O 性能,还能减少性能抖动。
基于一致性哈希的分布式缓存,在扩缩容时可避免大量缓存失效,且无需外部依赖即可使用。采用 Block 粒度进行数据缓存,能减少读写放大,还会校验数据有效性,避免读取过期数据。此外,Data Cache 能透明加速外表查询,使外表查询性能与内表差距在 12% 以内。

Data Cache 的具体设计如下图所示:

StarRocks 从 3.3 版本开始支持 Data Cache 的开箱即用,用户无需修改任何配置,透明加速。同时引入多种机制自动处理默认开启后各类问题。例如异步填充解决缓存填充影响读性能;I/O 自适应解决慢盘缓存导致性能恶化;缓存容量自动调整解决和其它资源模块的资源抢占;增加缓存可视化指标解决缓存状态不可见,等等。

借助 I/O 自适应机制,可解决慢盘情况下缓存的负优化问题。当 BE 访问 Data Cache 时,若磁盘性能不佳或负载过高,可能出现访问本地磁盘的耗时超过访问远端存储的情况。此时,系统会自动将部分请求导向远端存储,以减轻本地磁盘压力。同时,通过协同利用本地磁盘和网络资源,可提升整体吞吐量,使系统的总吞吐量尽可能接近本地磁盘与网络吞吐量之和。

在查询过程中,StarRocks 除了在 cache miss 时会触发缓存填充外,还支持缓存主动预热功能,允许用户提前将所需数据缓存至本地。通过对 CACHE SELECT 语法进行深度性能优化,显著提升预热效率。在预热策略上,支持单次手动预热与周期性自动预热,满足不同场景下的数据预加载需求,进一步降低查询延迟,提升热点数据访问性能。

在多种内存与磁盘缓存并存的场景下,StarRocks 面临配置复杂、易引发 OOM 或磁盘空间耗尽、资源调度受限、代码复用困难,以及不同缓存策略冲突等挑战。为此,StarRocks 自研高效缓存组件,统一管理各类缓存实例,用户无需单独配置容量,系统可根据实时负载自动优化资源分配。

同时,Cache Sharing 机制通过网络实现 BE 集群间的缓存共享,可有效缓解弹性扩缩容期间的性能抖动问题,提升集群整体资源利用率与稳定性。

2.11 物化视图
除了 Data Cache,StarRocks 还支持通过物化视图加速查询。针对复杂操作,可预计算并构建物化视图,降低查询过程中的 I/O 和计算开销。StarRocks 的物化视图支持查询自动改写,能够基于物化视图透明实现查询加速。

同时,它支持分区级别的数据刷新,仅对数据有更改的分区进行刷新。

三、StarRocks x lceberg 最佳实践
在进行性能调优前,首先需要充分了解当前的性能状况,明确主要瓶颈。可以借助 dstat 等系统工具监控资源利用率,或通过 Profile 和 Metrics 等工具观测集群内部状态,快速定位问题。

针对慢查询,可按照如下过程来进行排查和优化:
-
执行计划是否最优。首先检查查询执行计划是否为最优解。若计划不够优,需确认是否已收集表与列的统计信息(如行数、数据分布、直方图等),确保 CBO 优化器能基于统计信息进行成本估算与计划生成。
-
元数据解析性能排查。若执行计划已最优,需进一步分析元数据解析是否成为瓶颈。可通过以下方式优化:启用 Iceberg 元数据缓存,避免重复解析 Manifest 文件;采用分布式 Metadata Plan,将元数据解析任务分发至 BE 节点并行处理,减少 FE 单点压力。
-
I/O 性能瓶颈定位。若 I/O 成为性能瓶颈,可采取以下措施:Data Cache 优化,增加缓存容量或提升本地磁盘性能,减少对远端存储的访问次数。
-
查询性能是否满足要求。如果通过以上排查手段后发现查询性能依然不能满足要求,可以通过构建物化视图来提升查询效率。

四、未来规划
性能方面
-
缓存优化:支持 decompress cache,避免二次解压带来的 CPU 开销。进一步优化缓存链路中的拷贝开销,实现 zero-copy。
-
优化 Parquet/ORC Reader 性能。
功能方面
-
完善 StarRocks 写入 Iceberg 的功能,提升写入性能。
-
健全 StarRocks Iceberg Rest Catalog 鉴权体系。
易用性
-
进一步完善各类缓存的统一和自动调整,简化用户配置。
-
支持表级别缓存状态展示。
-
保证更多功能开箱即用。
相关文章:
StarRocks x Iceberg:云原生湖仓分析技术揭秘与最佳实践
导读: 本文将深入探讨基于 StarRocks 和 Iceberg 构建的云原生湖仓分析技术,详细解析两者结合如何实现高效的查询性能优化。内容涵盖 StarRocks Lakehouse 架构、与 Iceberg 的性能协同、最佳实践应用以及未来的发展规划,为您提供全面的技术解…...

笔试笔记(运维)
(数据库,SQL) limit1 随机返回其中一个聚合函数不可以嵌套使用 【^】这个里面的数据任何形式组合都没有 sql常用语句顺序:from-->where-->group by-->having-->select-->order by-->limit 只要其中一个表存在匹…...

JVM——云原生时代JVM的演进之路
引入 在风云变幻的技术世界里,JVM(Java Virtual Machine)作为 Java 语言的基石,长久以来承载着无数开发者构建软件系统的梦想。从 20 世纪 90 年代 Java 的诞生,到如今云原生时代的大幕拉开,JVM 经历了岁月…...
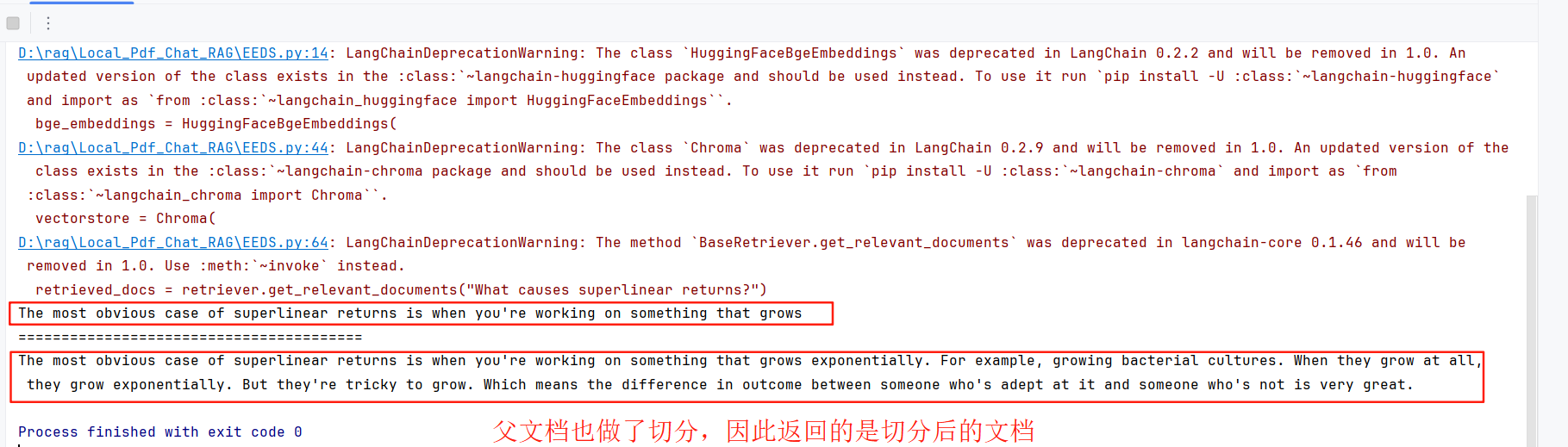
使用langchain实现五种分块策略:语义分块、父文档分块、递归分块、特殊格式、固定长度分块
文章目录 分块策略详解1. 固定长度拆分(简单粗暴)2. 递归字符拆分(智能切割)3. 特殊格式拆分(定向打击)Markdown分块 4. 语义分割(更智能切割)基于Embedding的语义分块基于模型的端到…...
【项目记录】登录认证(下)
1 过滤器 Filter 刚才通过浏览器的开发者工具,可以看到在后续的请求当中,都会在请求头中携带JWT令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT令牌。 那怎么样来统一拦截到所有的请求校验令牌的有…...

Debian上安装PostgreSQL的故障和排除
命令如下: apt install postgresql#可能是apt信息错误,报错 E: Failed to fetch http://deb.debian.org/debian/pool/main/p/postgresql-15/postgresql-client-15_15.12-0%2bdeb12u2_amd64.deb 404 Not Found [IP: 146.75.46.132 80] E: Failed to f…...
linux文件管理(补充)
1、查看文件命令 1.1 cat 用于连接文件并打印到标准输出设备上,它的主要作用是用于查看和连接文件。 用法: cat 参数 文件名 参数: -n:显示行号,会在输出的每一行前加上行号。 -b:显示行号,…...
Python训练营---Day42
DAY 42 Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 1、回调函数 回调函数(Callback Function)是一种特殊的函数,它作为参数传递给另一个函数&#…...

基于空天地一体化网络的通信系统matlab性能分析
目录 1.引言 2.算法仿真效果演示 3.数据集格式或算法参数简介 4.MATLAB核心程序 5.算法涉及理论知识概要 5.1 QPSK调制原理 5.2 空天地一体化网络信道模型 5.3 空天地一体化网络信道特性 6.参考文献 7.完整算法代码文件获得 1.引言 空天地一体化网络是一种将卫星通信…...
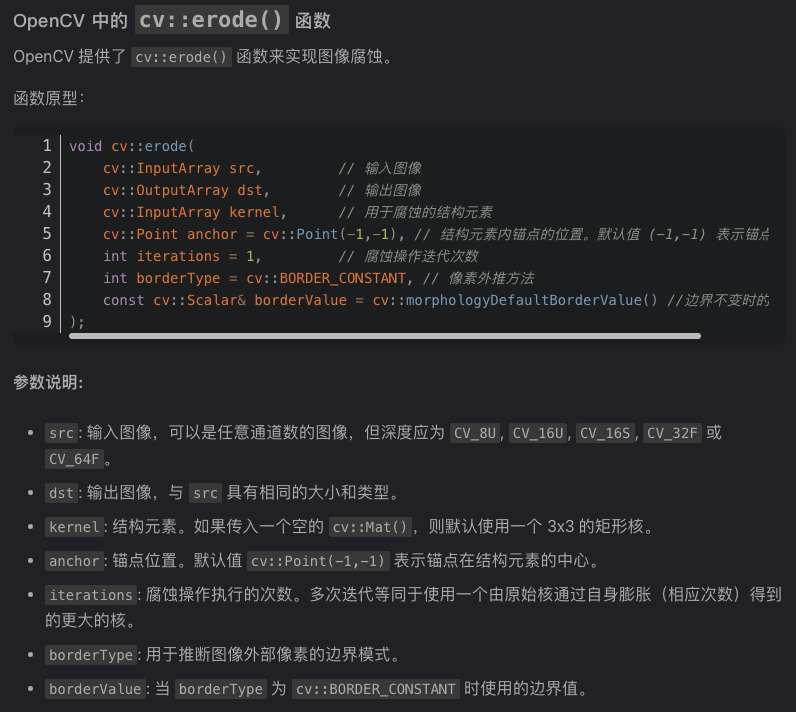
c++ opencv 形态学操作腐蚀和膨胀
https://www.jb51.net/article/247894.htm(上图图片来自这个博客) https://codec.wang/docs/opencv/basic/erode-and-dilate(上图图片参考博客) cv::Mat kernel cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3)); cv::erode(src, dst, kern…...
)
Axure组件即拖即用:横向拖动菜单(支持左右拖动选中交互)
亲爱的小伙伴,在您浏览之前,请关注一下,在此深表感谢!如有帮助请订阅专栏!免费哦! Axure横向菜单拖不动?一拖就乱?你缺的是这个"防手残"组件! 💢…...

Hadoop MapReduce:大数据处理利器
Hadoop 的 MapReduce 是一种用于处理大规模数据集的分布式计算框架,基于“分而治之”思想设计。以下从核心概念、工作流程、代码结构、优缺点和应用场景等方面详细讲解: 一、MapReduce 核心概念 核心思想: Map࿰…...

RabbitMQ-Go 性能分析
更多个人笔记见: github个人笔记仓库 gitee 个人笔记仓库 个人学习,学习过程中还会不断补充~ (后续会更新在github和 gitee上) 文章目录 对比功能没有rabbitMQ有rabbitMQwrk 测试分析 链接: 项目连接,完整…...

【c++】【数据结构】红黑树
目录 红黑树的定义红黑树的部分模拟实现颜色的向上更新旋转算法单旋算法双旋算法 红黑树与AVL树的对比 红黑树的定义 红黑树是一种自平衡的二叉搜索树,通过特定的规则维持树的平衡。红黑树在每个结点上都增加一个存储位表示结点的颜色,结点的颜色可以是…...
基于SpringBoot+Redis实现RabbitMQ幂等性设计,解决MQ重复消费问题
解决MQ重复消费问题 一、实现方案 本方案参考 「RabbitMQ消息可靠性深度解析|从零构建高可靠消息系统的实战指南」,向开源致敬! 1、业务层幂等处理: 每个消息携带一个全局唯一ID,在业务处理过程中,首先检查…...

React从基础入门到高级实战:React 生态与工具 - React 单元测试
React 单元测试 引言 在现代软件开发中,单元测试是确保代码质量和可靠性的关键环节。对于React开发者而言,单元测试不仅能帮助捕获潜在的错误,还能提升代码的可维护性和团队协作效率。随着React应用的复杂性不断增加,掌握单元测…...

使用lighttpd和开发板进行交互
文章目录 🧠 一、Lighttpd 与开发板的交互原理1. 什么是 Lighttpd?2. 与开发板交互的方式? 🧾 二、lighttpd.conf 配置文件讲解⚠️ 注意事项: 📁 三、目录结构说明💡 四、使用 C 编写 CGI 脚本…...
DRF的使用
1. DRF概述 DRF即django rest framework,是一个基于Django的Web API框架,专门用于构建RESTful API接口。DRF的核心特点包括: 序列化:通过序列化工具,DRF能够轻松地将Django模型转换为JSON格式,也可以将JS…...

2024年09月 C/C++(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:有几个PAT 字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位,第 4 位(A),第 6 位(T);第二个 PAT 是第 3 位,第 4 位(A),第 6 位(T)。 现给定字符串,问一共可以形成多少个 PAT? 时间限制:1000 内存限制:26214…...
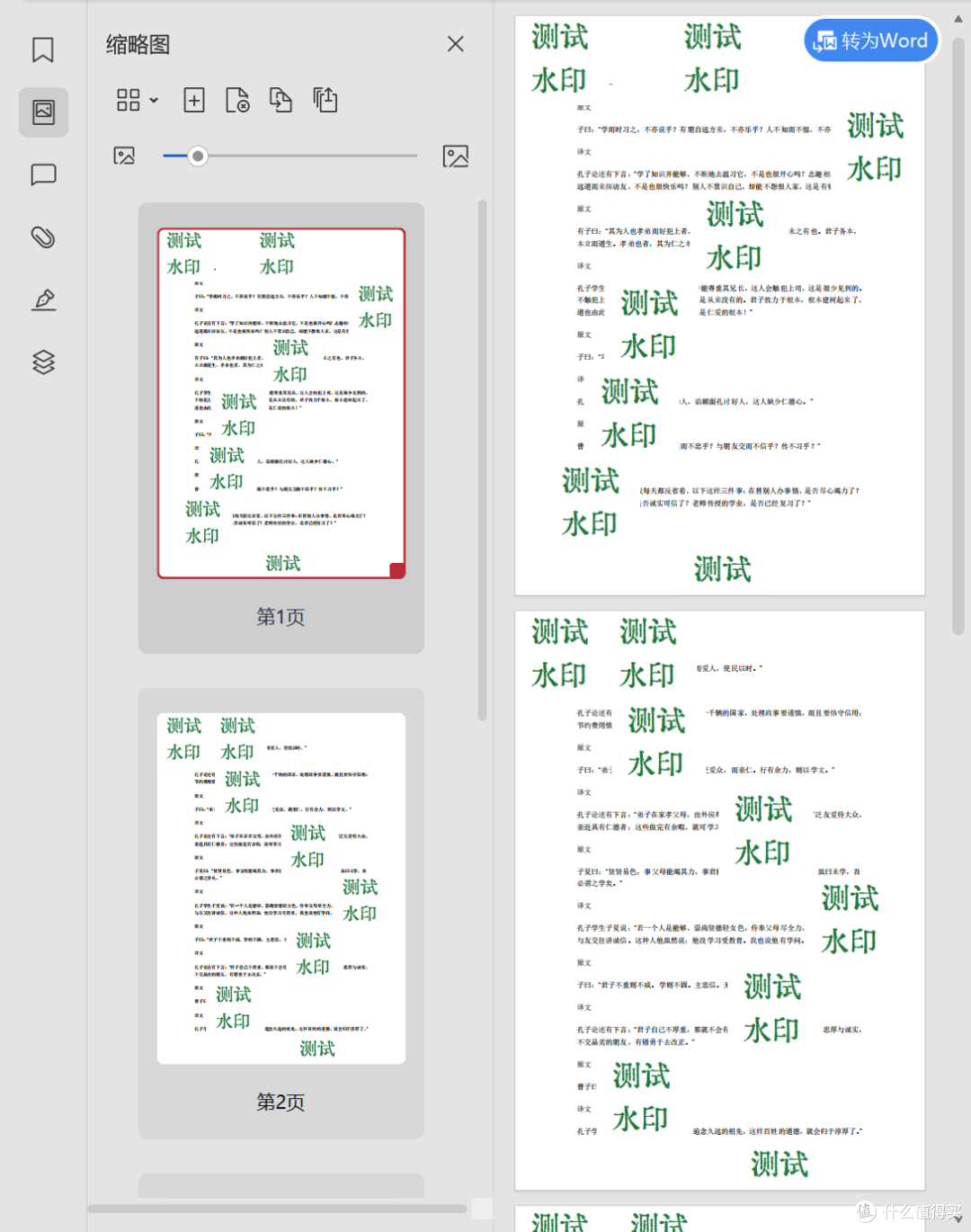
免费且好用的PDF水印添加工具
软件介绍 琥珀扫描.zip下载链接:https://pan.quark.cn/s/3a8f432b29aa 今天要给大家推荐一款超实用的PDF添加水印工具,它能够满足用户给PDF文件添加水印的需求,而且完全免费。 这款PDF添加水印的软件有着简洁的界面,操作简便&a…...

mqtt协议连接阿里云平台
首先现在的阿里云物联网平台已经不在新购了,如下图所示: 解决办法:在咸鱼上租用一个账号,先用起来。 搭建阿里云平台,参考博客: (一)MQTT连接阿里云物联网平台(小白向&…...
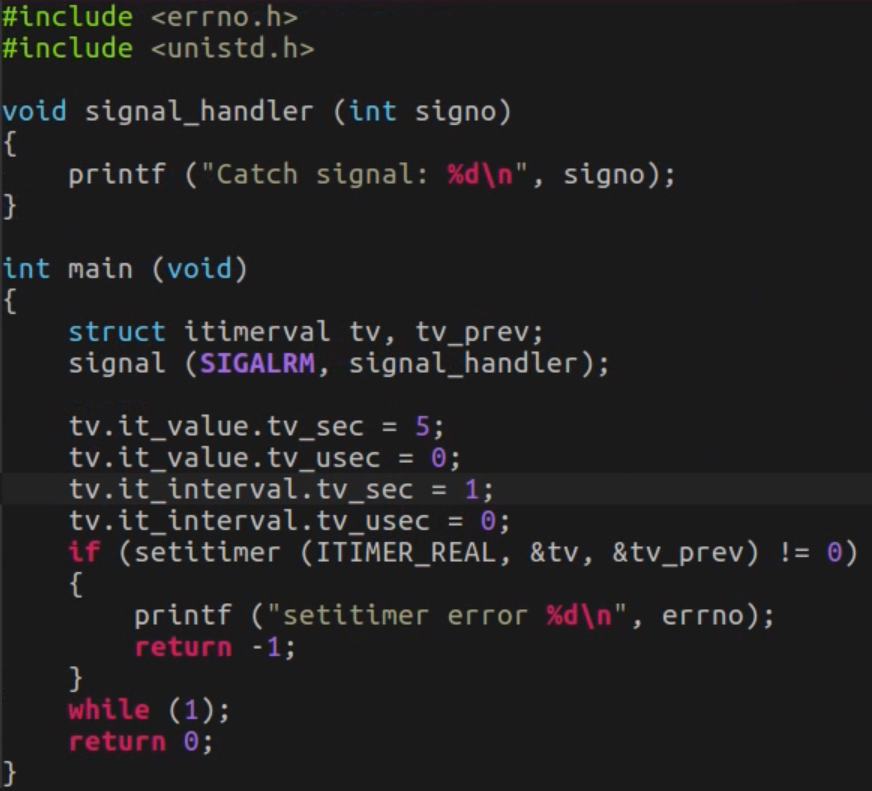
一文详谈Linux中的时间管理和定时器编程
(目录) 先说一些在计算机中需要用到时间的地方:系统日志log、OS调度(时间片、定时器)等等~~ 时间的计量 计时的方式发展:日晷、沙漏 -> 机械钟 -> 石英振荡器、晶振 -> 铯原子钟 -> 氢原子钟 计算机中的计时方式&…...

Ubuntu 安装 Miniconda 及配置国内镜像源完整指南
目录 Miniconda 安装Conda 镜像源配置Pip 镜像源配置验证配置基本使用常见问题 1. Miniconda 安装 1.1 下载安装脚本 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh1.2 执行安装 bash Miniconda3-latest-Linux-x86_64.sh按回车查看许可协议…...

性能优化 - 理论篇:常见指标及切入点
文章目录 引言一、 Java 性能优化的核心思路二、为什么要度量?三、常用性能衡量指标详解3.1 吞吐量与响应速度3.2 响应时间的具体度量:平均响应时间与百分位数3.3 并发量3.4 秒开率(页面秒开)3.5 正确性(功能可用性&am…...

青少年编程与数学 02-020 C#程序设计基础 08课题、字符和字符串
青少年编程与数学 02-020 C#程序设计基础 08课题、字符和字符串 一、字符和字符集1. 字符(Character)定义特点示例 2. 字符集(Character Set)定义特点常见字符集 小结 二、char数据类型1. 定义2. 特点3. 声明和初始化4. 转义字符示…...

【论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合】
论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合 1.摘要&&引言2.方法2.1 架构2.2 双模态特征融合(DMFF)2.2.1 跨模态特征增强(CFE)2.2.2 空间特征压缩(SFS)…...

Spring Security加密模块深度解析
Spring Security加密模块概述 Spring Security Crypto模块(简称SSCM)是Spring Security框架中专门处理密码学相关操作的组件。由于Java语言本身并未提供开箱即用的加密/解密功能及密钥生成能力,开发者在实现这些功能时往往需要引入额外依赖库。SSCM通过提供内置解决方案,有…...

华为OD机试真题——模拟消息队列(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录+全流程解析/备考攻略/经验分享 华为OD机试真题《模拟消息队列》: 目录 题…...
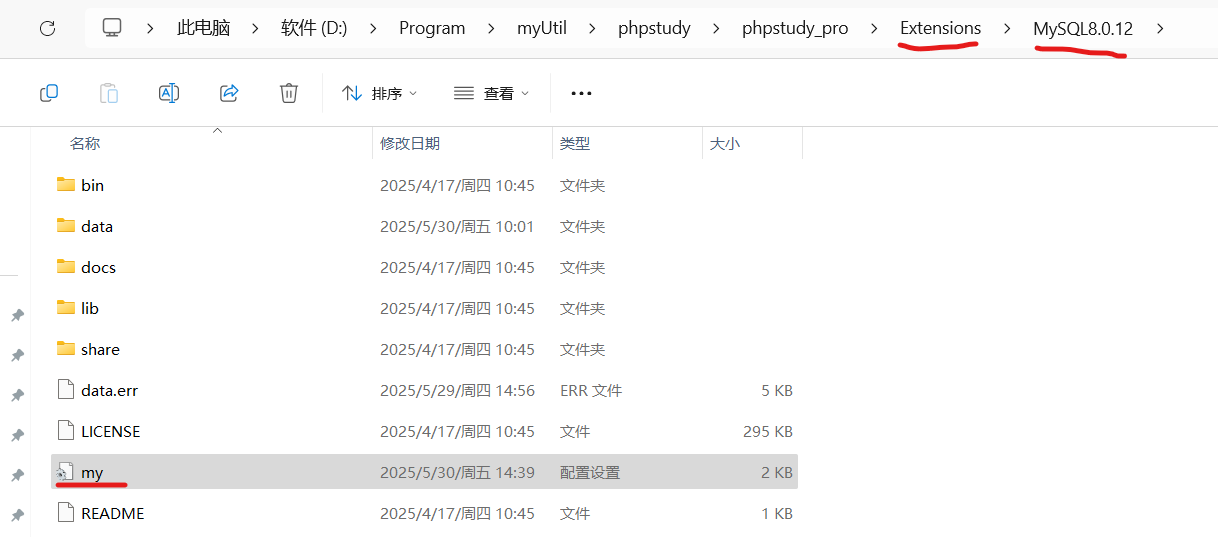
MySql(十三)
目录 mysql外键约束 准备工作 创建表 插入数据 创建表时添加外键 1..格式 2..创建表student表时,为其添加外键 3.插入数据测试 正常数据 异常数据 3.使用alter添加外键 删除外键 添加外键 4.Mysql外键不生效的原因 修改引擎 phpystudy的mysql位置 mysql外键约束 注&…...
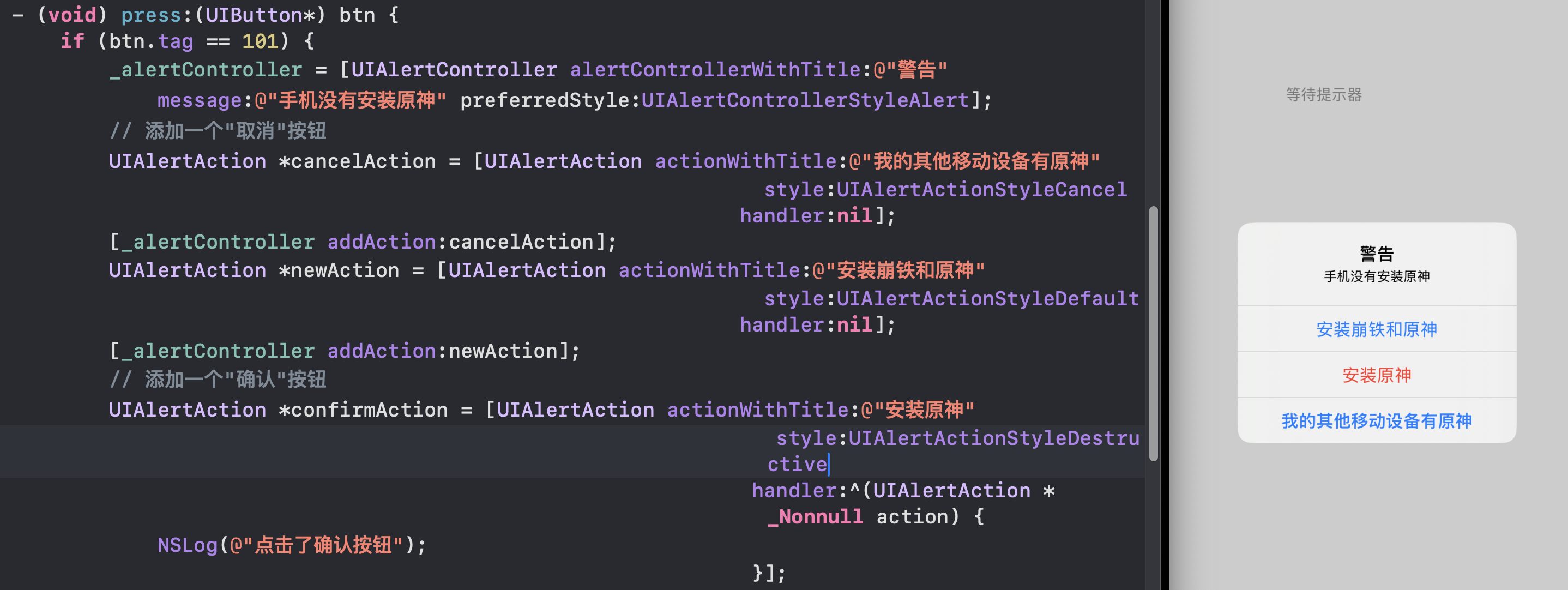
iOS —— UI 初探
简介 第一次新建时,你可能会好奇。为什么有这么多文件,他们都有什么用? App 启动与生命周期管理相关 文件名 类型 作用 main.m m 程序入口,main() 函数定义在这里 AppDelegate.h/.m h/m App 启动/进入后台/退出等全局事…...