Docker安装Redis集群(3主3从+动态扩容、缩容)保姆级教程含踩坑及安装中遇到的问题解决
前言
部署集群前,我们需要先掌握Redis分布式存储的核心算法。了解这些算法能帮助我们在实际工作中做出合理选择,同时清晰认识各方案的优缺点。
一、分布式存储算法
我们通过一道大厂面试题来进行阐述。
如下:1-2亿条数据需要缓存,请问用Redis该如何设计?现在,针对这道面试题来进行分析。
1. 哈希取余分区
这种算是比较常见的算法方式,2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key)%N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
这样存储的优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息)起到负载均衡+分而治之的作用。
那必然也会存在缺点:
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key)/?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
2. 一致性哈希算法分区
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
提出一致性Hash解决方案目的:是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
2.1 算法构建一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[ 0~232-1 ]这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0=2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对232取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0~232-1.(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方同组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到232-1,也就是说0点左侧的第一个点代表232-1, 0和232-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。

2.2 服务器IP节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash算法进行一个哈希,具体可以选择服务器的!P或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:

2.3 key落到服务器的落键规则
当我们需要存储一个k,v键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Obiect A、Obiect B、Obiect C、ObiectD四个数据对象,经过哈希计算后,在环空间上的位置如下;根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到NodeC上,D被定为到Node D上。

2.4 一致性哈希算法分区的优缺点
优点:
解决了哈希取余算法的容错性和扩张性问题
容错性
假设NodeC宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那受到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可。不会导致hash取余全部数据重新洗牌。


缺点
一致性哈希算法的数据倾斜问题
Hash环的数据倾斜问题:一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器:

为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在首尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
3. 哈希槽分区
为什么会出现哈希槽分区?主要目的就是为了解决一致性哈希数据倾斜的问题。哈希槽实质就是一个数组,数组【0,214 -1】形成的hash slot 空间。
在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
槽解决的是粒度问题,相当于粒度变大了,这样便于数据移动。

哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
有多少个hash槽?16384的由来
一个集群只能有16384个槽,编号0-16383(0-214-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot=CRC16(key)% 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
16384个槽由来:https://github.com/redis/redis/issues/2576
哈希槽的计算
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在: Redis 集群中放置一个key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个key 都会对应一个编号在 0-16383之间的哈希槽,也就是映射到某个节点上。如下代码,key之A、B在Node2,key之C落在Node3上。
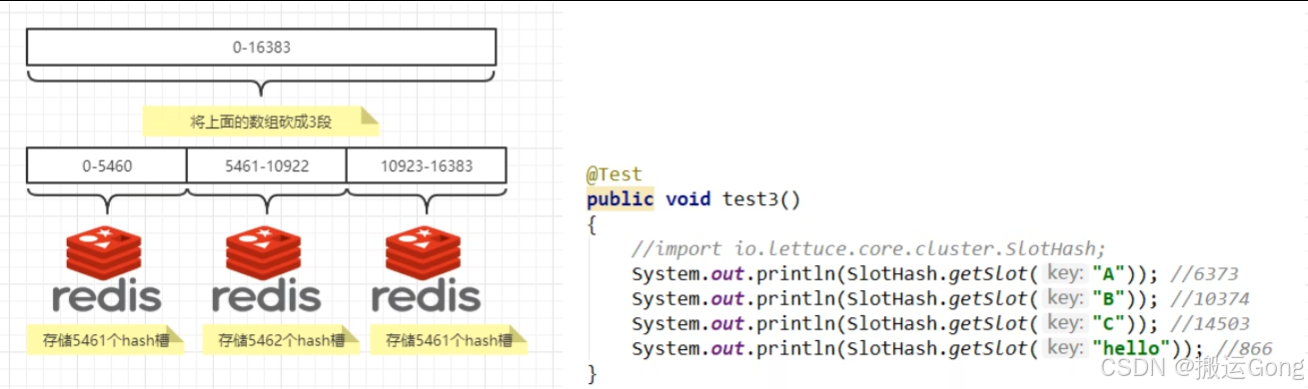
二、3主3从集群搭建
在搭建集群服务之前,我们先来考虑一个问题:生产环境下,我们到底需要用几台服务器来搭建集群呢?
是一台服务器搭建6个Docker容器,还是多台分别搭建?我这里使用的是3台服务器,每台服务器上分别搭建1主1从,具体分析如下:
核心目标:避免单点故障
Redis 集群设计的主要目标之一就是高可用。如果一个主节点故障,它的从节点会被提升为主节点。
关键点在于:故障域是物理服务器(或虚拟机)本身。如果一台服务器宕机、断电、网络中断或硬件故障,运行在其上的所有 Docker 容器(无论是主节点还是从节点)都会同时失效。
不同部署方案的风险分析:
方案一:1台服务器部署所有6个节点(1主1从容器混部)
风险极高: 这台服务器一旦故障,整个 Redis 集群(所有主节点和从节点)完全不可用,服务彻底中断。完全不满足高可用要求。
资源争抢: CPU、内存、网络、磁盘 I/O 等资源竞争激烈,性能可能成为瓶颈。
结论:❌ 绝对不可取。
方案二:2台服务器(每台部署3个节点,例如 1主2从 或 2主1从)
风险较高: 假设服务器 A 部署了主1、主2、从3;服务器 B 部署了主3、从1、从2。
如果服务器 A 宕机:主1 和 主2 同时失效。
主1 的从节点(假设在 B 上)会被提升为新主1。
主2 的从节点(也在宕机的 A 上!)也失效了,导致主2 没有存活的从节点可用! 此时主2 负责的哈希槽数据将不可用(集群进入 FAIL 状态,部分数据无法访问),直到管理员手动介入修复。
虽然部分数据可能还能访问(主3 和 新主1 的数据),但集群整体可用性和数据完整性受到严重损害。不能保证在单台服务器故障时集群整体可用。
结论:⚠️ 不推荐用于生产。
方案三:3台服务器(每台部署1主1从)
推荐方案: 服务器 A:主1 + 从X (比如从3);服务器 B:主2 + 从Y (比如从1);服务器 C:主3 + 从Z (比如从2)。
高可用保障:
如果服务器 A 宕机:主1 和 从3 失效。
集群检测到主1 失效,会将主1 对应的从节点(从X)提升为新的主1。由于这个从节点(从X)部署在另一台健康的服务器(例如 B 或 C)上,提升操作可以成功完成。新主1 接管原主1 的哈希槽。虽然服务器 A 上的节点丢失了,但集群整体依然可用,只损失了该服务器上的一个主节点和一个从节点实例。
其他主节点(主2、主3)及其从节点不受影响。
这样设计确保了任意一台服务器故障时,集群都能通过自动故障转移保持整体可用性(可能伴随短暂的性能下降或重连)。没有单点故障。
资源隔离: CPU、内存、网络、磁盘资源在物理层面得到更好的隔离,减少争抢。
结论:✅ 这是满足高可用生产环境要求的最低推荐配置。
方案四:6台服务器(每台部署1个节点)
理想方案: 每台服务器只运行一个 Redis 节点(主或从)。
最高可用性: 单台服务器故障只会影响一个节点。
如果是主节点故障:其对应的从节点(在另一台服务器上)会被提升,集群无损。
如果是从节点故障:只影响该副本的可用性,主节点和其他从节点不受影响,集群读写功能完全正常。
最佳资源隔离: 每个节点独占服务器资源,性能最优,无干扰。
缺点: 成本最高(6台服务器)。
结论:✅ 最佳实践,但成本较高。3台是成本和高可用之间的良好平衡点。
为什么 3 台是最低推荐?
满足故障域隔离: 3 台服务器提供了足够的物理隔离,确保单台故障不会导致集群不可用或数据丢失(通过其他服务器上的从节点成功故障转移)。
满足 Redis 集群要求: Redis 集群需要至少 3 个主节点才能正常工作(形成多数派进行故障检测和主节点选举)。3 台服务器刚好承载这 3 个主节点及其对应从节点。
成本效益: 相比 6 台方案,3 台方案显著降低了硬件成本,同时仍然提供了可靠的高可用性。
其他重要考虑因素:
服务器规格: 每台服务器的 CPU、内存(尤其重要,必须能容纳分配给主节点和从节点的最大数据集)、磁盘(如果开启 AOF 或 RDB,需要足够空间和 IOPS)、网络带宽都需要足够支撑运行在其上的 Redis 实例负载。
Docker 编排: 使用 Kubernetes、Docker Swarm 等编排工具可以简化部署、管理和故障恢复(如自动重启容器),但不能替代物理服务器层面的高可用设计。编排器也需要运行在可靠的服务器基础设施上。
网络: 确保服务器之间网络延迟低(最好在同一机房或可用区内)、带宽足够支持节点间的数据同步和 Gossip 通信。跨可用区部署会增加延迟,需评估业务容忍度。
端口映射: Docker 部署时需正确映射 Redis 服务端口(6379)和集群总线端口(通常是 16379)。
存储: 考虑使用 Docker 卷持久化 Redis 数据,避免容器重启数据丢失。确保卷存储在可靠的存储系统上。
总结:
对于生产环境的 Docker 部署 Redis 集群(3 主 3 从),强烈推荐使用至少 3 台物理服务器(或虚拟机)。每台服务器上部署一个主节点容器和一个从节点容器(该从节点是其另一台服务器上主节点的副本)。这是平衡高可用性要求与基础设施成本的最低可行且可靠的配置。
最低要求 (高可用):3台服务器 (每台 1主 + 1从)
最佳实践 (最高可用):6台服务器 (每台 1节点 - 主或从)
绝对避免:1台或2台服务器部署全部节点。
1. 服务器准备
搞清楚方案后,我们先来准备3台服务器,我这里使用3台虚拟机,分别是:192.168.152.130【主节点1 + 从节点3(对应主节点3)】
192.168.152.131【主节点2 + 从节点1(对应主节点1)】
192.168.152.132【主节点3 + 从节点2(对应主节点2)】
分别在三台虚拟机上创建目录
mkdir -p /data/redis/share/{redis-node-1,redis-node-2}# 授权,避免启动时出现异常
chown -R 999:999 /data/redis/
chmod -R 770 /data/redis/生成redis配置文件,针对每一个容器进行具体参数调整
port 7001
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
bind 0.0.0.0
daemonize no
# 当前宿主机IP
cluster-announce-ip 192.168.152.130
# 主节点端口
cluster-announce-port 7001
# 集群总线端口
cluster-announce-bus-port 17001
执行命令整理如下:
docker run -d --name redis-node-1 --privileged=true \-v /data/redis/share/redis-node-1:/data \-p 7001:7001 -p 17001:17001 \redis redis-server /data/redis.confdocker run -d --name redis-node-2 --privileged=true \-v /data/redis/share/redis-node-2:/data \-p 7002:7002 -p 17002:17002 \redis redis-server /data/redis.confdocker run -d --name redis-node-3 --privileged=true \-v /data/redis/share/redis-node-3:/data \-p 7003:7003 -p 17003:17003 \redis redis-server /data/redis.confdocker run -d --name redis-node-4 --privileged=true \-v /data/redis/share/redis-node-4:/data \-p 7004:7004 -p 17004:17004 \redis redis-server /data/redis.confdocker run -d --name redis-node-5 --privileged=true \-v /data/redis/share/redis-node-5:/data \-p 7005:7005 -p 17005:17005 \redis redis-server /data/redis.confdocker run -d --name redis-node-6 --privileged=true \-v /data/redis/share/redis-node-6:/data \-p 7006:7006 -p 17006:17006 \redis redis-server /data/redis.conf
执行完毕之后,效果如下:
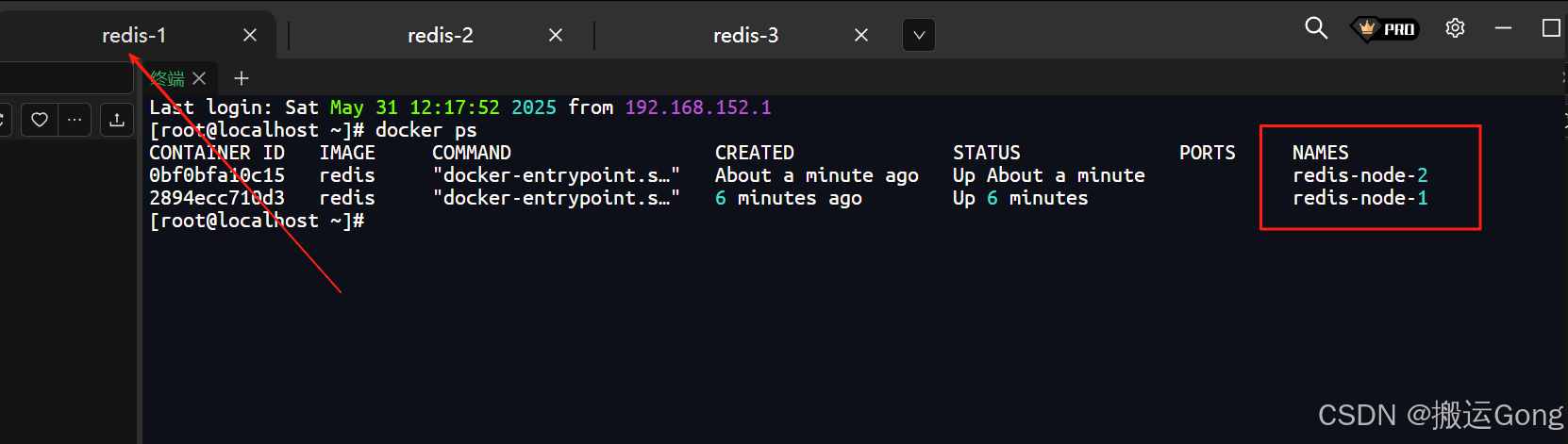
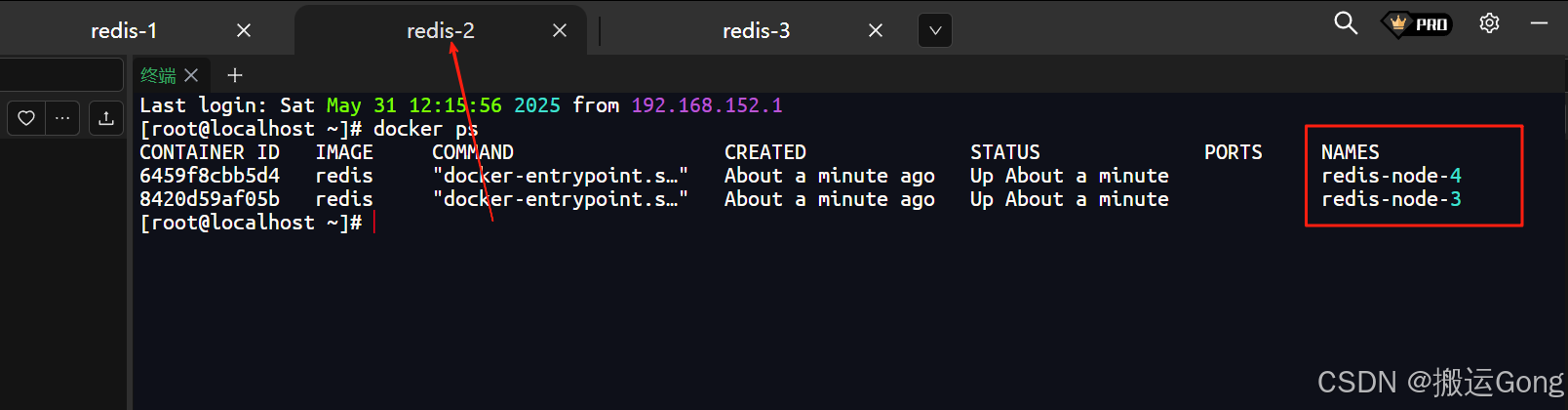
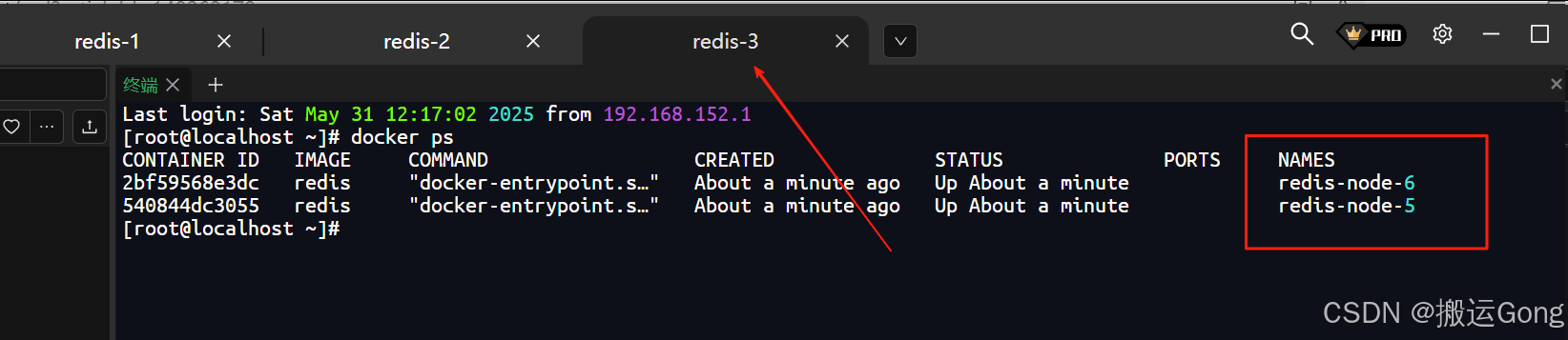
2. 构建主从关系
三台服务器上的redis容器均已运行ok,但是现在他们并没有任何联系,下面进行主从关系构建,使用如下命令:
# 使用交互式命令行,随便进入到一个redis容器内容
docker exec -it redis-node-1 /bin/bash
# 下面这个是具体的构建主从关系的执行语句,需要替换为自己的IP
# --cluster-replicas 1 表示为每一个master创建一个slave节点
redis-cli --cluster create 192.168.152.130:7001 192.168.152.130:7002 192.168.152.131:7003 192.168.152.131:7004 192.168.152.132:7005 192.168.152.132:7006 --cluster-replicas 1
效果如下:
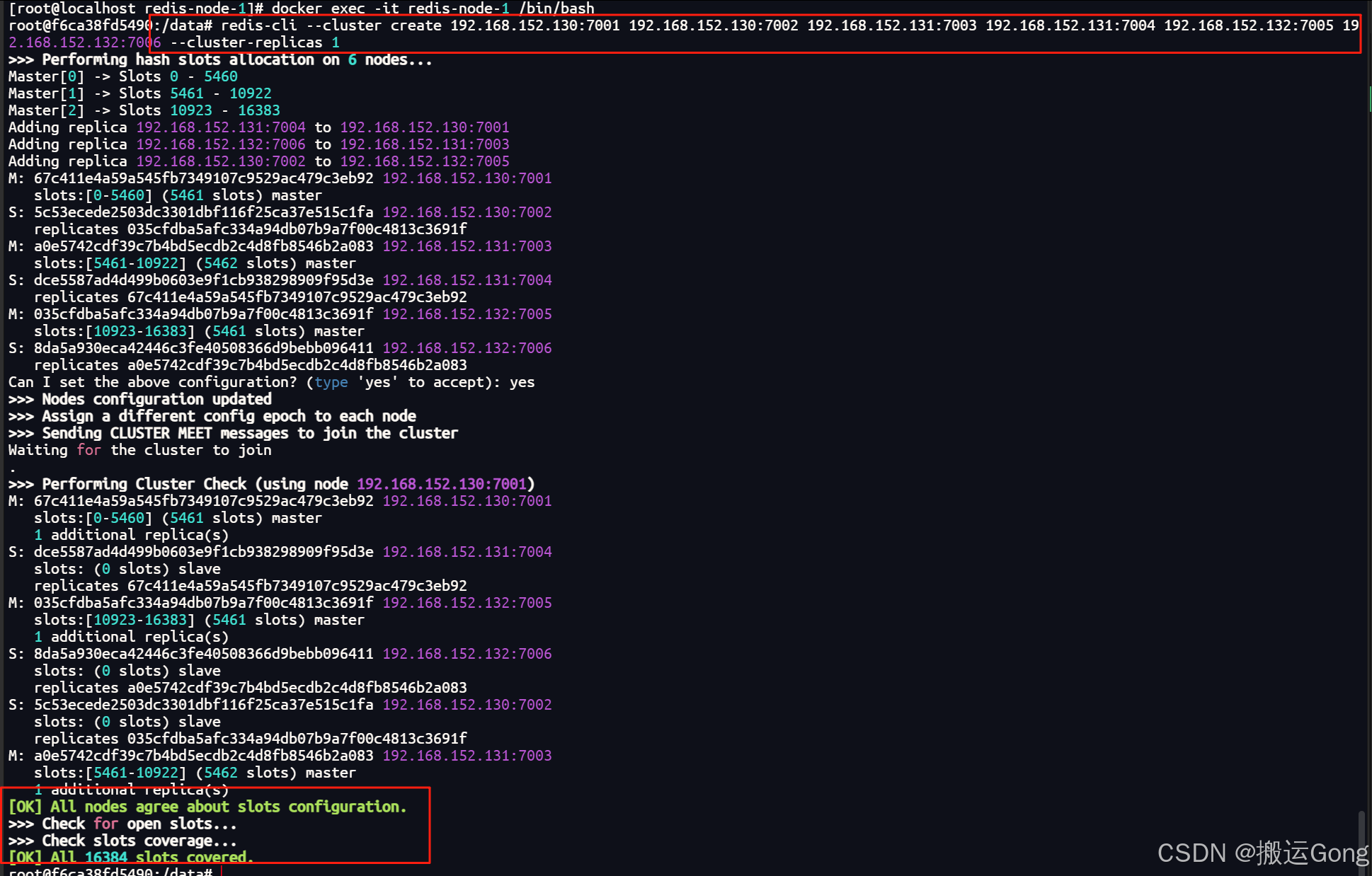
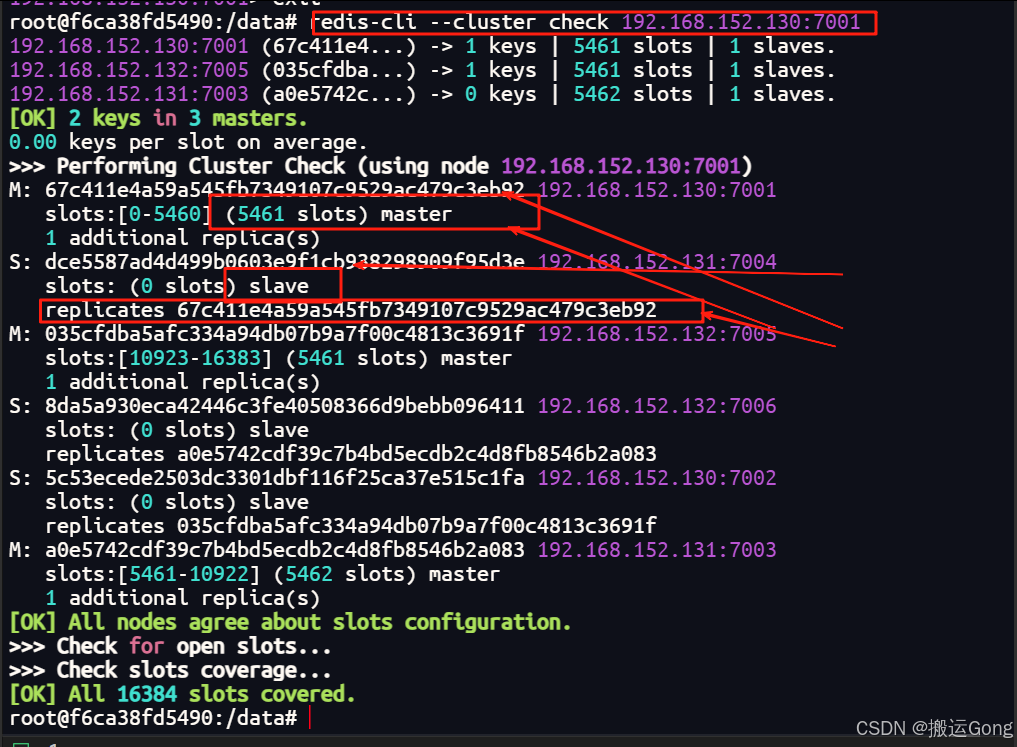
通过上面的构建过程图中,我们可以看到redis集群分配槽位的具体方式以及构建主从关系的分配。master1槽位分配为【0-5460】,master2槽位分配为【5461-10922】,master3的槽位分配为【10923-16383】。
在执行上面命令的时候,有可能会遇到几个问题:
connect to address 192.168.152.131: No route to host
这是虚拟机的防火墙导致,针对端口进行放行或者关闭防火墙即可解决。
一直卡在 Waiting for the cluster to join... 状态
这种情况是因为虚拟机之间网络没有互通导致,两种解决办法:
①关闭防火墙(不推荐)
②指定端口进行放行(推荐)
可以使用telnet 命令进行验证
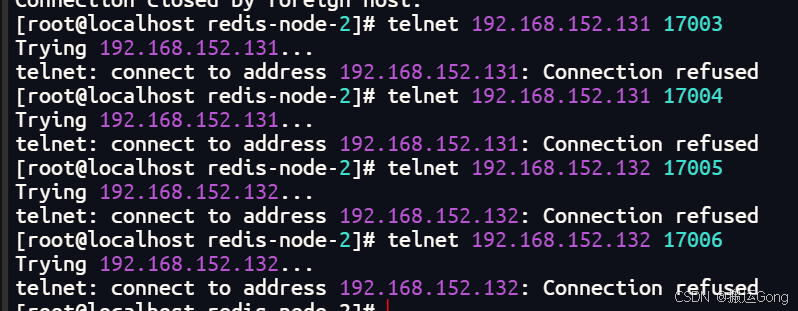
我这里是因为容器运行的时候,只映射了服务端口,没有映射总线端口导致,上面的docker run 命令是后续修改后的,将每一个容器的总线端口也进行了映射。这里要明白,虚拟机有防火墙,容器内部也有防火墙。
3. 查看集群状态
随机进入一个redis节点,使用如下命令查看:
docker exec -it redis-node-1 /bin/bash
# 登录redis
redis-cli -p 7001
# 查看集群信息
cluster info
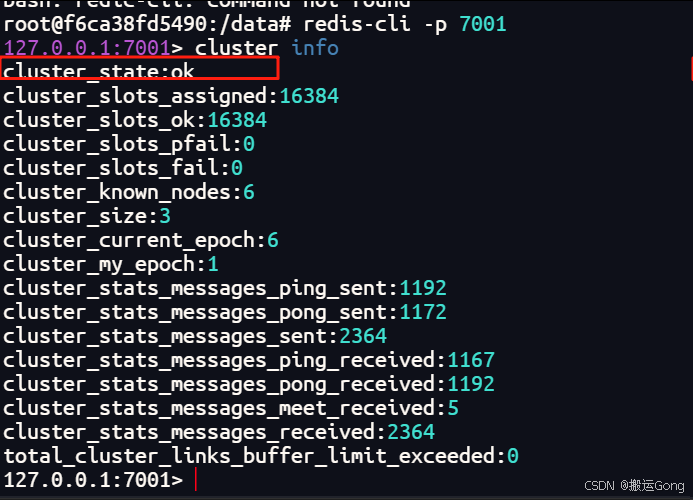
# 查看集群节点信息
cluster nodes

通过上面的图,就可以清楚的看到集群之间的主从关系了。
三、主从容错迁移案例
上面看到了集群已成功搭建完毕,那么集群中的一台master宕机后,会怎么样呢?下面来验证一下。
1. redis 集群读写路由增强
首先随机登录一个节点进行正常测试,如下:
docker exec -it redis-node-1 /bin/bash
redis-cli -p 7001
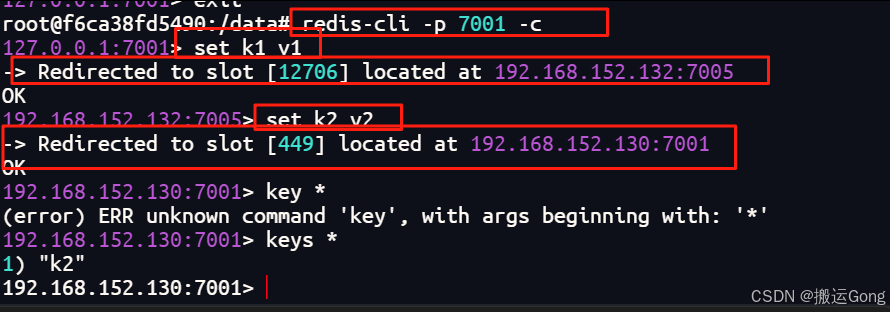
set k1 v1 出现了一个问题,并没有像想象中的那样,这种问题是因为一致性哈希算法分区导致的,计算出来的key的槽位在7005号机器上,为了正常使用不再出现这种情况,在连接的时候可以加一个参数,如下:
出现了一个问题,并没有像想象中的那样,这种问题是因为一致性哈希算法分区导致的,计算出来的key的槽位在7005号机器上,为了正常使用不再出现这种情况,在连接的时候可以加一个参数,如下:
redis-cli -p 7001 -c
2. 查看集群信息cluster check
redis-cli --cluster check 192.168.152.130:7001
3. 模拟节点宕机,查看主从切换迁移
现在,让节点7001宕机,然后再查看集群状态:
docker stop redis-node-1
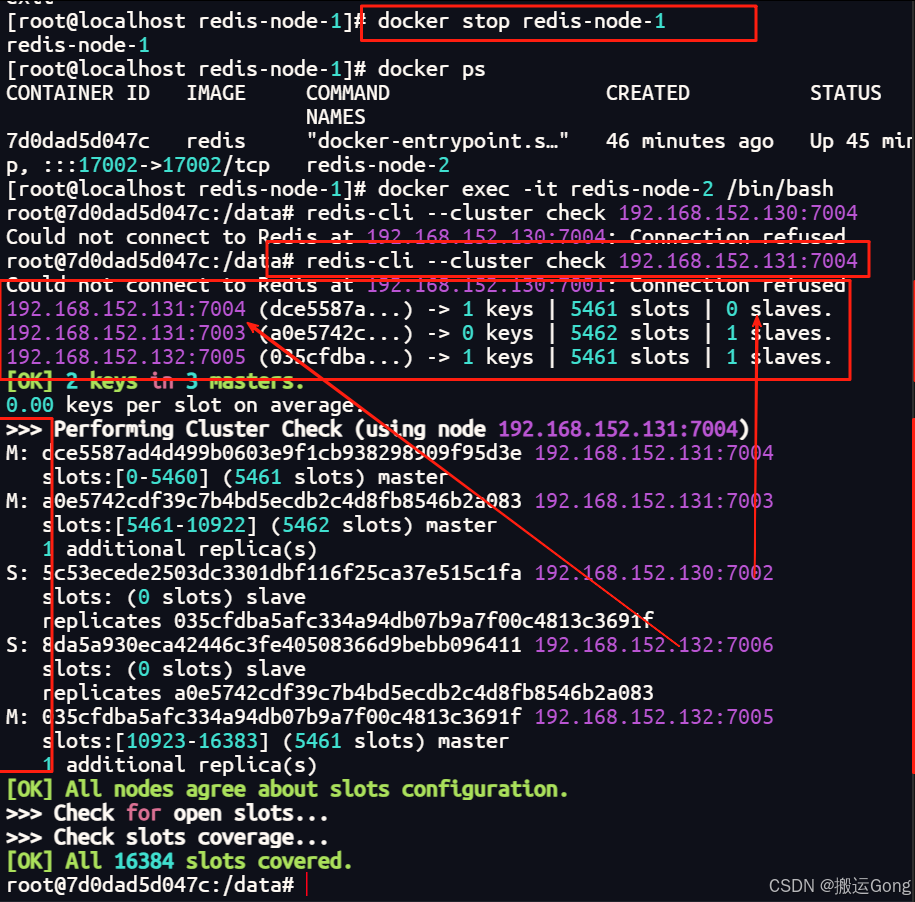 可以看到,7001宕机后,它的从节点自动升级为了master状态,来查看一下数据是否丢失:
可以看到,7001宕机后,它的从节点自动升级为了master状态,来查看一下数据是否丢失:
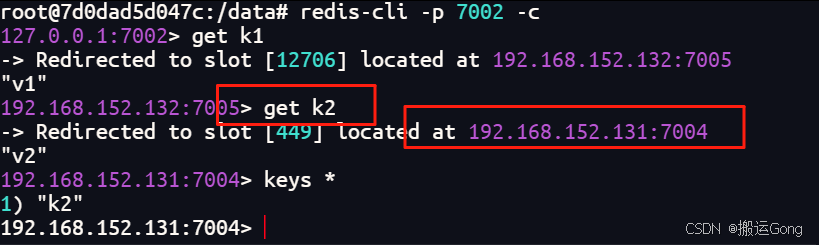
数据依旧存在,主从切换正常。
这个时候,我们将原来的7001 master节点重新启动,会发生什么?7001还会成为原来的master节点吗?来查看一下:
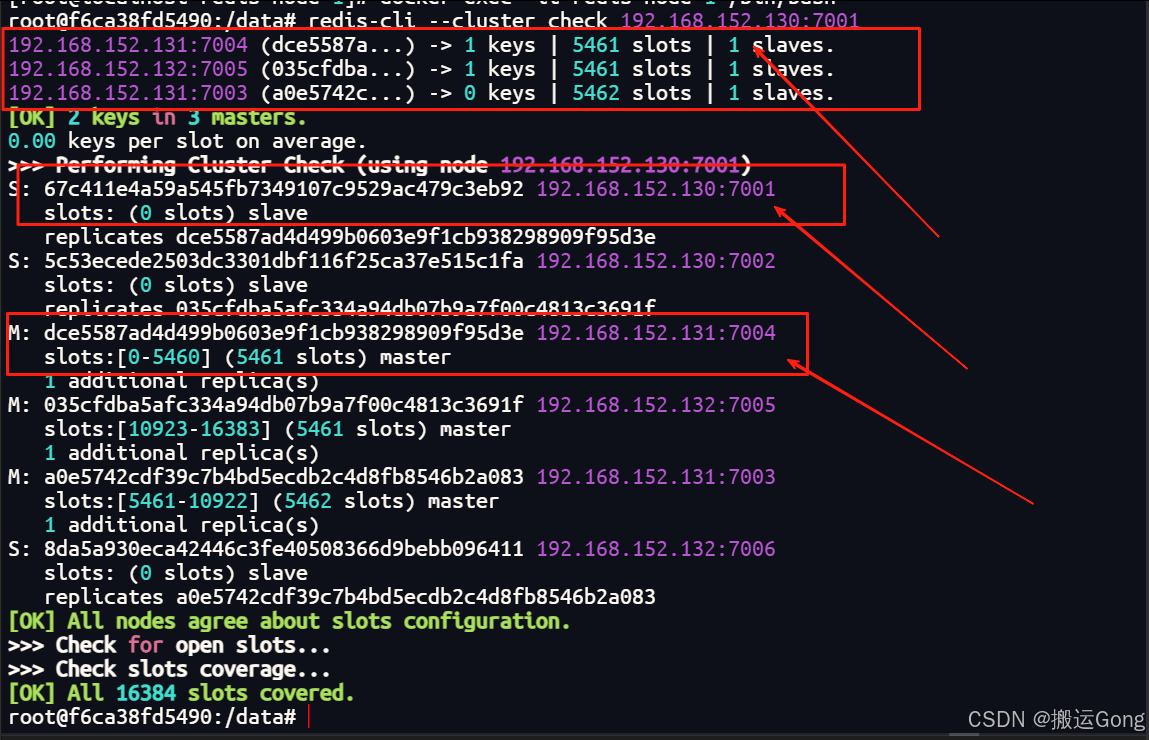
可以发现,原来宕机后的master节点,重新启动后,并不会重新成为master,而是以slave的身份启动。
四、主从扩容案例
假设我们需要举办一个大型线上促销活动,预计并发访问量将达到现有集群承载能力的3倍。当流量突增时,现有集群已无法满足峰值需求,需要实施弹性扩容方案。那么该怎么做呢?下面一起来看一下:
1. 增加虚拟机节点并启动redis容器
首先新增一台虚拟机,IP分配为192.168.152.133,在新的机器上执行以下命令:
docker run -d --name redis-node-7 --privileged=true \-v /data/redis/share/redis-node-7:/data \-p 7007:7007 -p 17007:17007 \redis redis-server /data/redis.confdocker run -d --name redis-node-8 --privileged=true \-v /data/redis/share/redis-node-8:/data \-p 7008:7008 -p 17008:17008 \redis redis-server /data/redis.conf
启动后,查看容器运行状态:

2. 将新增的节点加入原集群
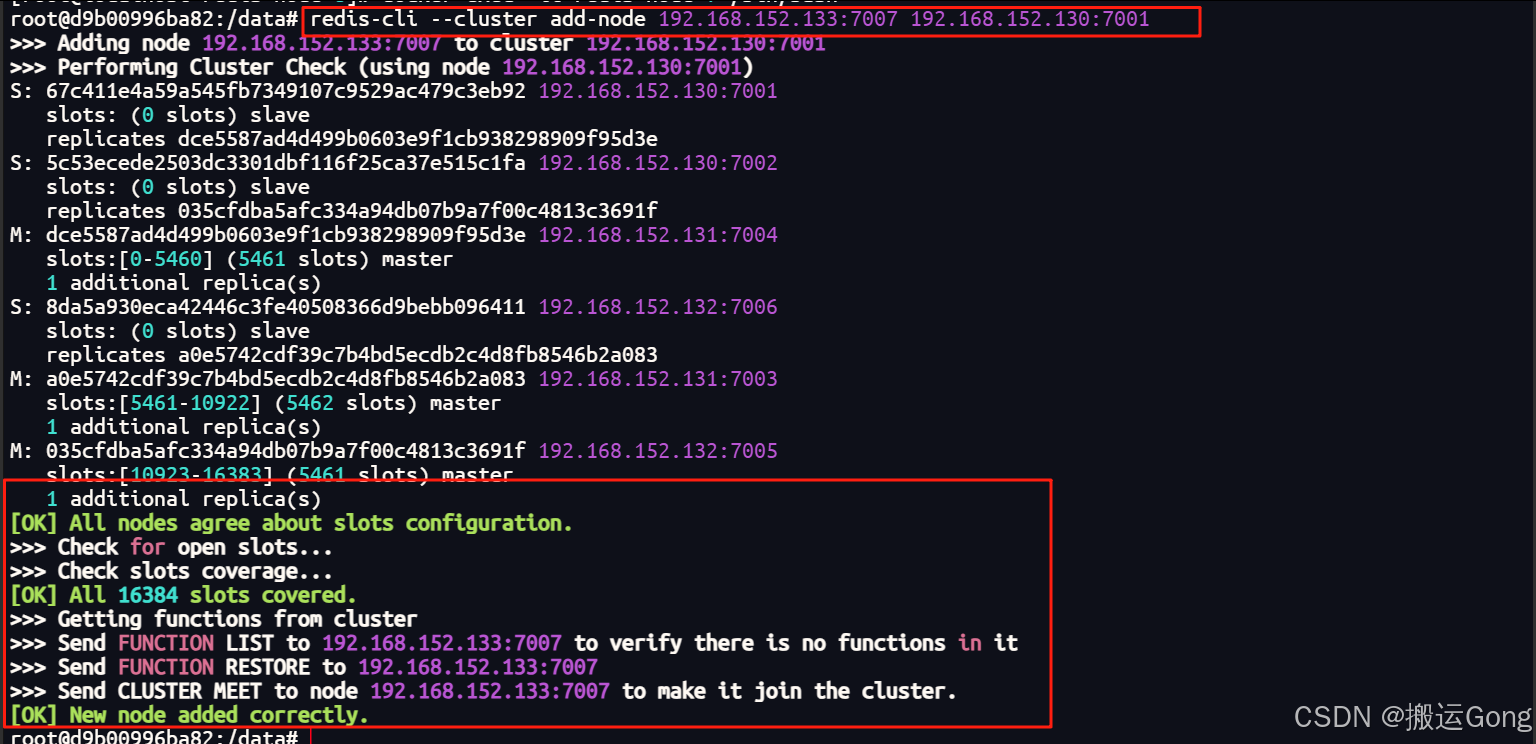
新启动的两个节点目前和原集群没有关联,我们执行下面的命令,使redis-node-7加入到集群中:
使用add-node命令
# 7007 是新启动的redis-node-7节点,使用命令加入到原集群中
redis-cli --cluster add-node 192.168.152.133:7007 192.168.152.130:7001
3. 检查集群情况
执行完上面的命令后,查看一下最新的集群信息,使用 cluster check 命令:
redis-cli --cluster check 192.168.152.133:7007
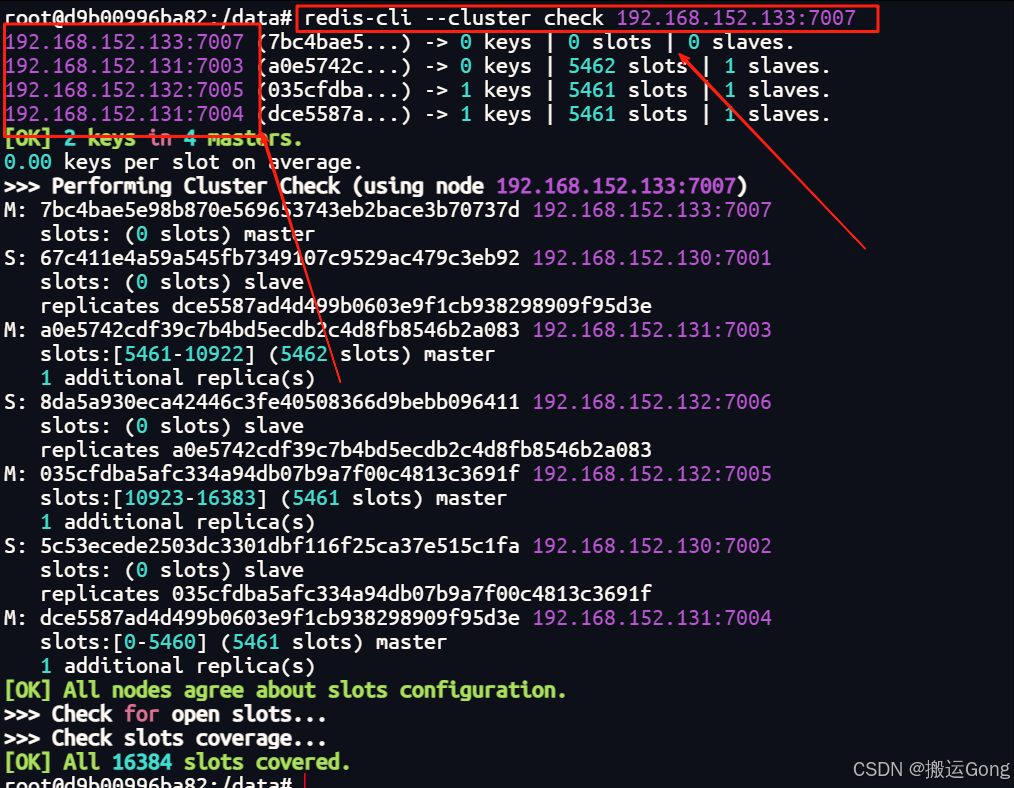
可以看到,新的节点已经成功加入到集群中。但是目前是没有分配到任何槽位信息的,这样来看,暂时还不算成功,下面来给新的master节点分配槽位。
4. 重新分配槽号
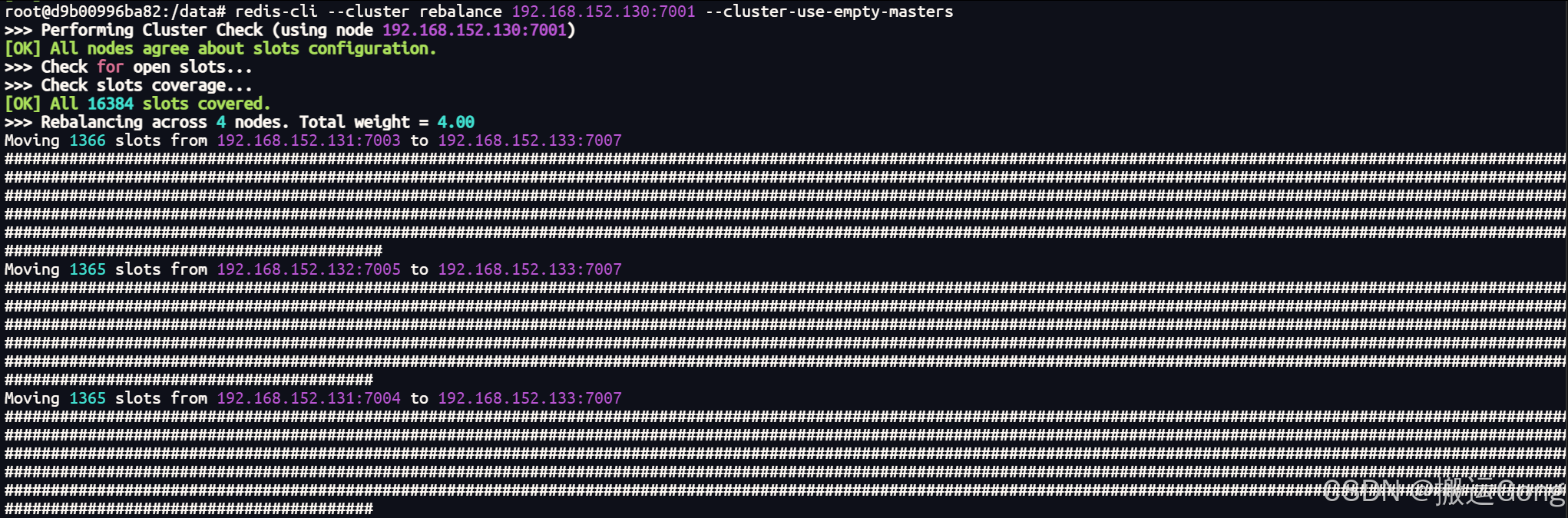
在上面集群扩容后(添加了新节点),需要手动重新分配槽位(slots) 以使新节点开始承载数据负载,并平衡整个集群的数据分布。这个过程称为重新分片(resharding)。
# 可以使用任意集群节点IP:端口
redis-cli --cluster rebalance 192.168.152.130:7001 --cluster-use-empty-masters
参数说明:
rebalance:命令工具自动计算如何最均匀地在所有主节点(包括新节点)之间分配槽位。
--cluster-use-empty-masters:强制将槽位分配给当前没有槽位的新主节点。这是让新节点获得槽位的关键参数!
执行此命令后,工具会询问你是否接受它提出的槽位迁移计划。仔细检查计划(显示了哪些槽位从哪些节点迁移到哪些节点),确认无误后输入 yes即可。
5. 再次检查集群情况
重新分配完槽位之后,来看一下最新的群集槽位分布信息:
redis-cli --cluster check 192.168.152.133:7007
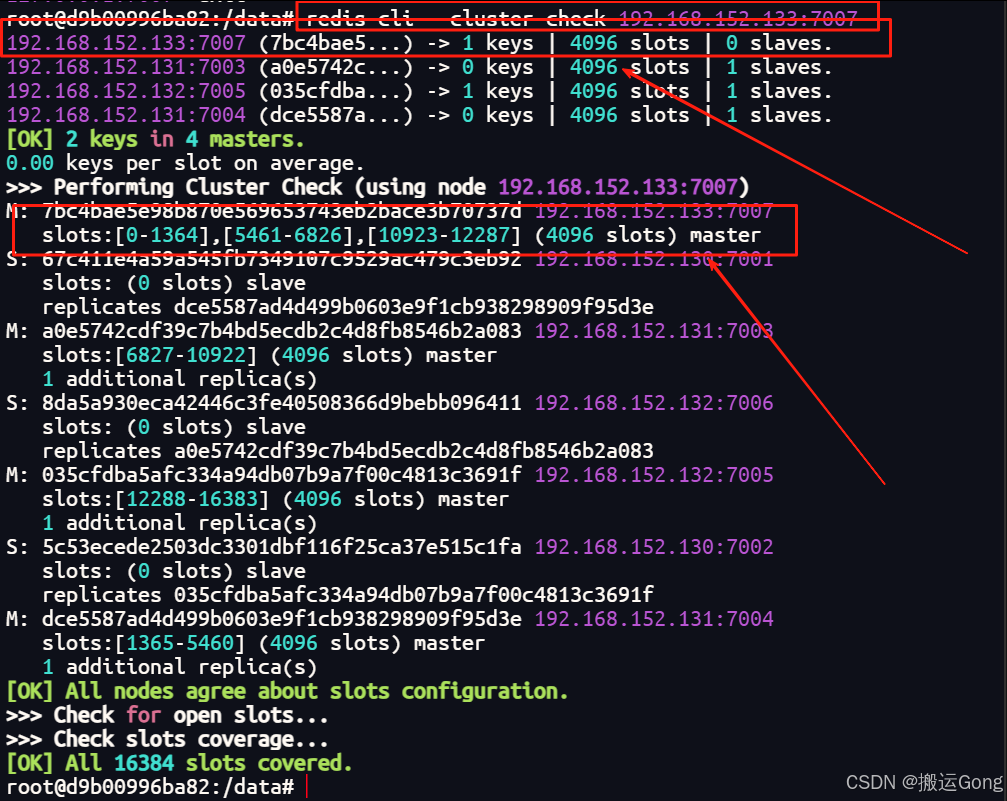 重新分配后的集群,所有的master节点平均分配了16384个槽位,每个master上面都分配了4096个槽位。但是新的7007master节点,可以看到槽位的分布情况是:[0-1364],[5461-6826],[10923-12287]三个段位的槽号。由此可见,新的master槽位是通过原来的3个master节点,每个节点匀了一部分未使用的凑够了4096给新节点。
重新分配后的集群,所有的master节点平均分配了16384个槽位,每个master上面都分配了4096个槽位。但是新的7007master节点,可以看到槽位的分布情况是:[0-1364],[5461-6826],[10923-12287]三个段位的槽号。由此可见,新的master槽位是通过原来的3个master节点,每个节点匀了一部分未使用的凑够了4096给新节点。
那么这是为什么呢?
Redis 集群在扩容后,新节点的槽位确实是由集群中原有的每一个主节点(master)各自匀出一部分槽位组成的。这种设计并非偶然,而是基于 Redis 集群的核心设计理念和目标:
1. 保持数据均匀分布 (Load Balancing):
Redis 集群的核心目标之一是将 16384 个槽位尽可能均匀地分布到所有主节点上。
当新节点加入时,为了维持这种均匀性,最公平、最有效的方式就是让所有现有的主节点都贡献一部分自己负责的槽位给新节点。
如果只从一个或少数几个现有节点迁移大量槽位给新节点,会导致:
数据倾斜 (Data Skew): 被“抽走”槽位的节点负载会相对降低,而其他未被抽取的节点和新节点可能负载不均衡。
热点风险: 如果被抽槽的节点原本是热点节点(承载了大量访问),单纯减少其槽位数不一定能完全解决热点问题(因为剩下的槽位可能更热)。而均匀抽取则更有可能将热点键也分散开。
迁移效率: 从多个节点并行迁移槽位通常比从一个节点迁移所有槽位更快,因为可以充分利用多个节点的网络和 I/O 资源。
2. 最小化单个节点的影响 (Minimizing Per-Node Impact):
从每个现有主节点迁移一小部分槽位(例如,每个节点迁移几百个槽位),相比于从一个节点迁移几千个槽位,对单个节点的性能影响(网络带宽、CPU、磁盘 I/O)要小得多。
这使得重新分片操作对集群整体服务的干扰更平滑,更不容易在迁移过程中因为单个节点过载而引发问题。
3. 维持集群线性扩展性 (Linear Scalability):
这种“均匀分摊”的方式是实现 Redis 集群线性扩展能力的关键。
每增加一个新节点,集群的总容量和处理能力理论上就增加一份(该节点能承载的槽位数和数据量/请求量)。
为了充分利用新节点的能力,并将集群负载均匀分摊到所有节点(包括新节点),从每个旧节点迁移一部分槽位是最直接的实现方式。这确保了集群性能随节点增加而线性增长。
4. rebalance 工具的智能计算:
当你使用 redis-cli --cluster rebalance 命令时,工具背后的算法会做以下事情:
- 统计当前集群中所有主节点的槽位数量。
- 计算理论上的平均槽位数 (16384 / 总主节点数)。
- 找出槽位数高于平均值的节点(即需要迁出槽位的源节点)。
- 找出槽位数低于平均值的节点(即需要迁入槽位的目标节点,主要是新加入的空节点)。
- 制定一个迁移计划:从每个需要迁出的源节点上,计算它需要迁出多少槽位才能接近平均值;将这些计算出的槽位(或槽位范围)分配给需要迁入的目标节点(新节点)。目标是让所有主节点的槽位数尽可能接近平均值。
因此,新节点获得的槽位,自然就是由各个“超额”的旧主节点各自贡献一部分组合而成。
总结来说:
新节点的槽位由原来每个 master “匀”出来一部分组成,是 Redis 集群为了实现其核心目标——数据均匀分布、负载均衡、最小化迁移影响、维持线性扩展性——而采取的最优策略。redis-cli --cluster rebalance 工具正是基于这些原则,自动计算并执行了这种“均匀分摊”的迁移计划,使得集群在扩容后能迅速达到一个新的、更优的平衡状态。这就像给一个大家庭添了新成员,大家(原有节点)都从自己的盘子里匀出一点食物(槽位)给新成员,以保证每个人(节点)都能吃饱(负载均衡)且公平。
6. 为新加入集群的主节点分配从节点
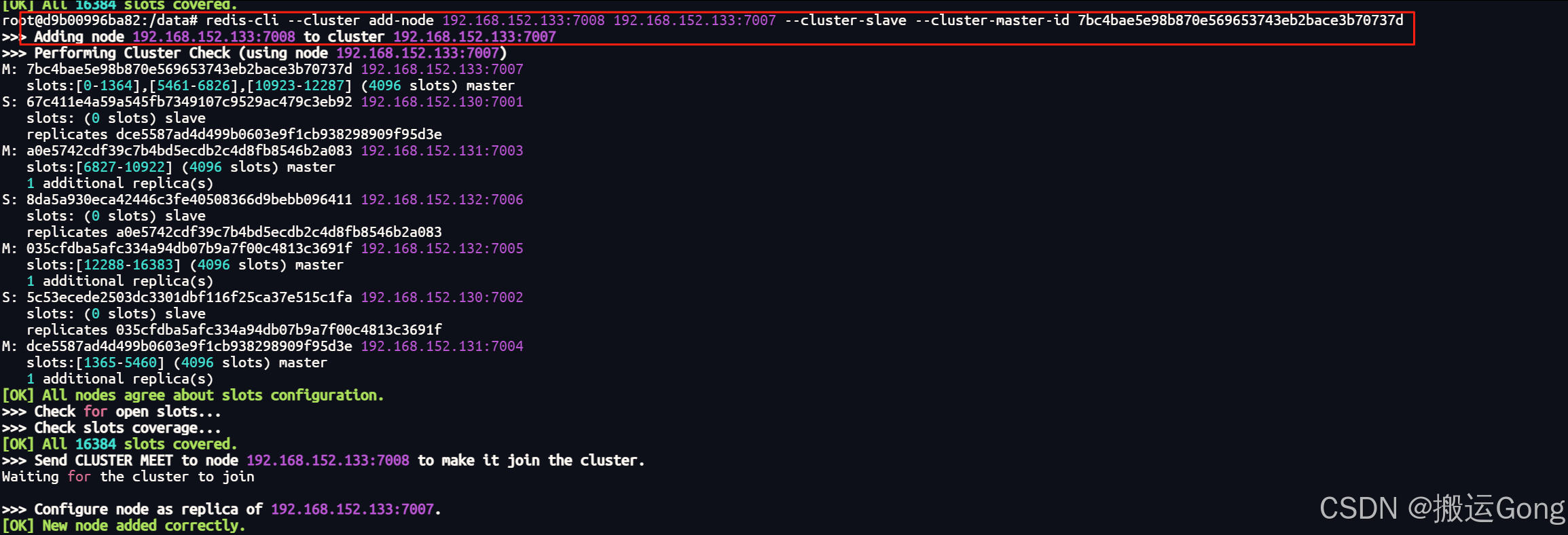
redis-cli --cluster add-node 192.168.152.133:7008 192.168.152.133:7007 --cluster-slave --cluster-master-id 7bc4bae5e98b870e569653743eb2bace3b70737d
参数说明:
192.168.152.133:7008 # 需要加入集群的slave节点IP及端口
192.168.152.133:7007 # 需要挂在master节点下的IP及端口
--cluster-slave # 以slave角色加入集群
--cluster-master-id 7bc4bae5e98b870e569653743eb2bace3b70737d # 通过查看集群信息中,可以找到这个信息,为节点的id

7. 检查新的集群情况
加入成功,再次查看最新的集群信息:
redis-cli --cluster check 192.168.152.133:7007
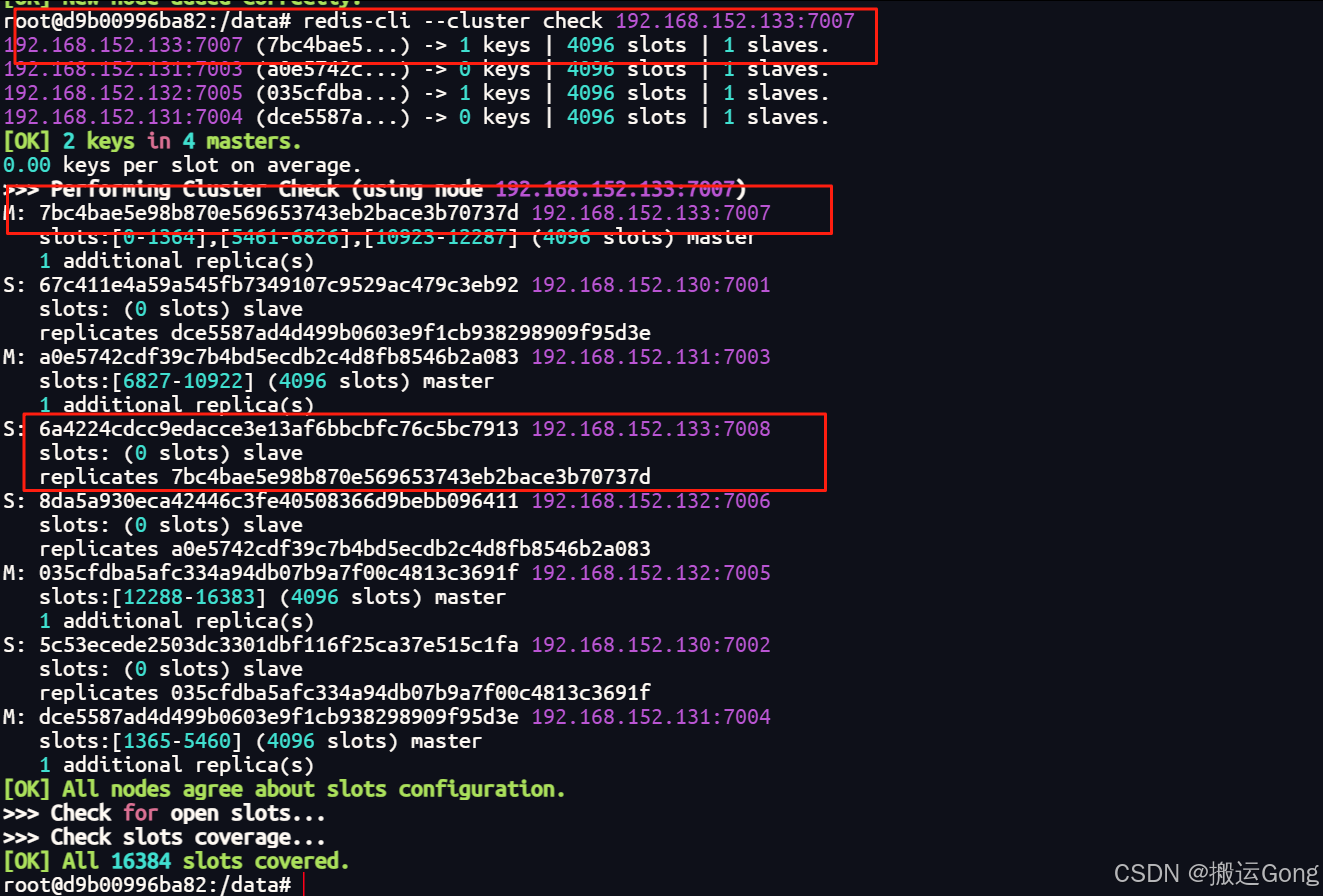
至此,redis集群的扩容已完成。
五、主从缩容案例
当业务流量高峰逐渐平稳后,为优化资源使用和降低成本,我们需要对Redis集群进行缩容操作,恢复至3主3从的模式。
1. 查看集群节点情况,如果有slave节点,需要先移除slave节点
redis-cli --cluster check 192.168.152.133:7007
查看集群情况,复制一下需要移除的节点id。
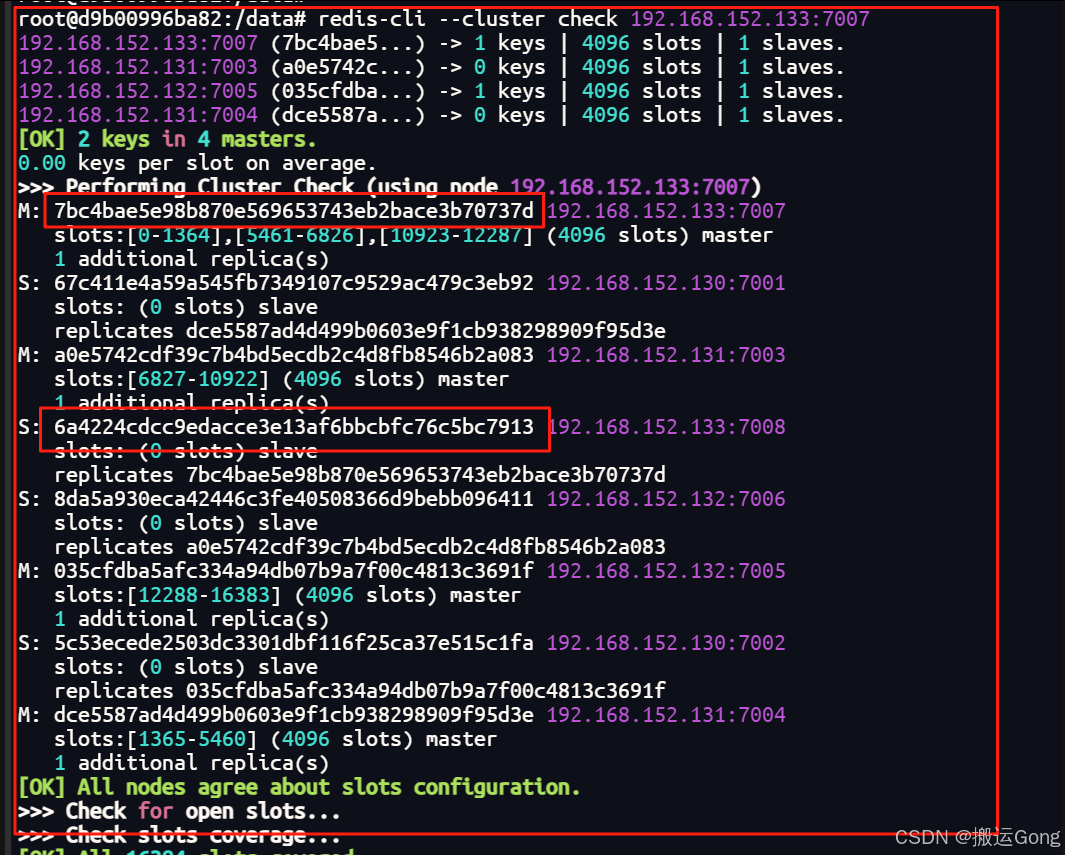
使用以下命令,进行移除slave节点。
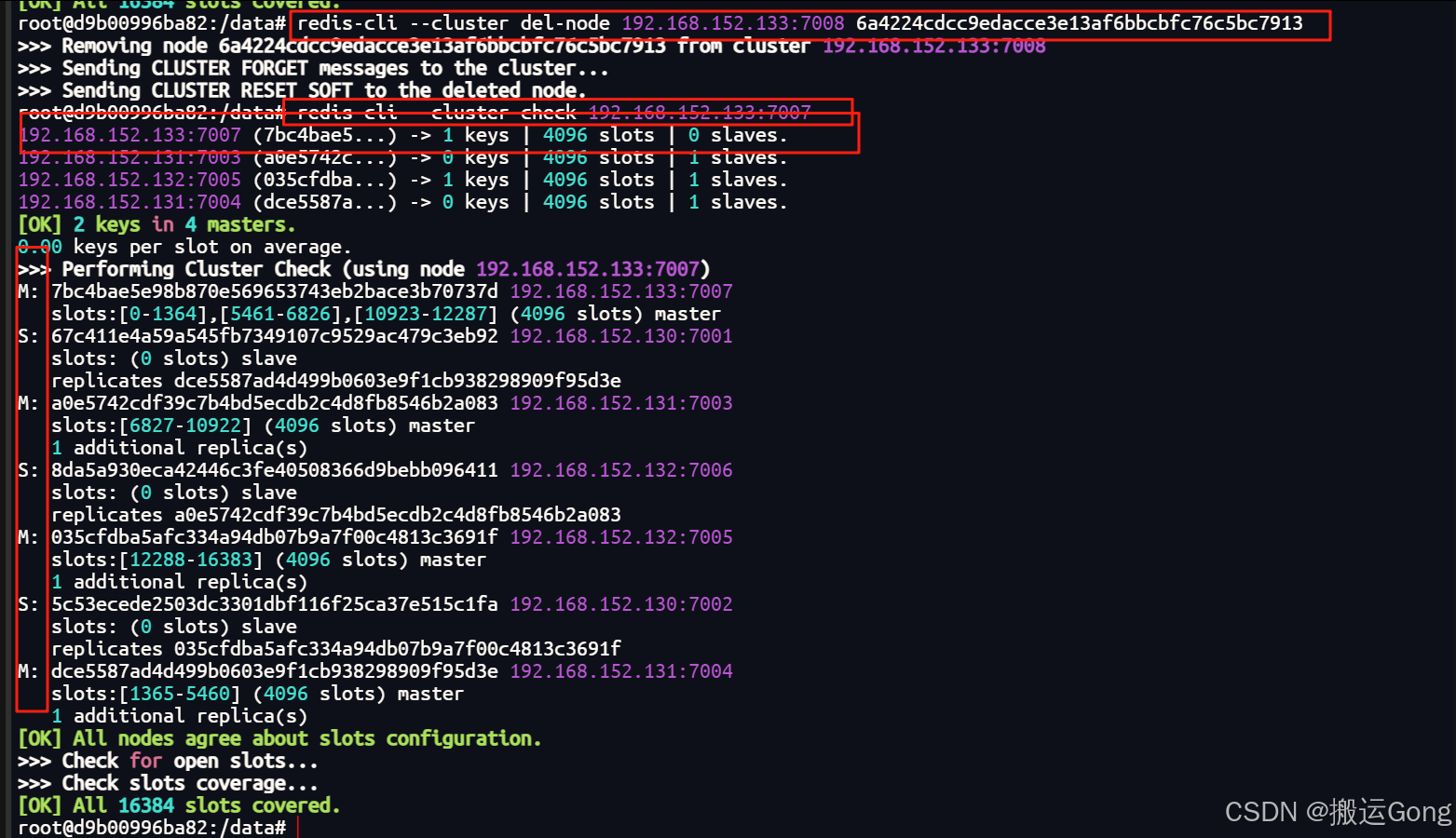
redis-cli --cluster del-node ip:从机端口 从机节点id#对应我这里的环境如下
redis-cli --cluster del-node 192.168.152.133:7008 6a4224cdcc9edacce3e13af6bbcbfc76c5bc7913
2. 重新分配master槽位及删除master节点
# 自动化迁移所有槽位(推荐)
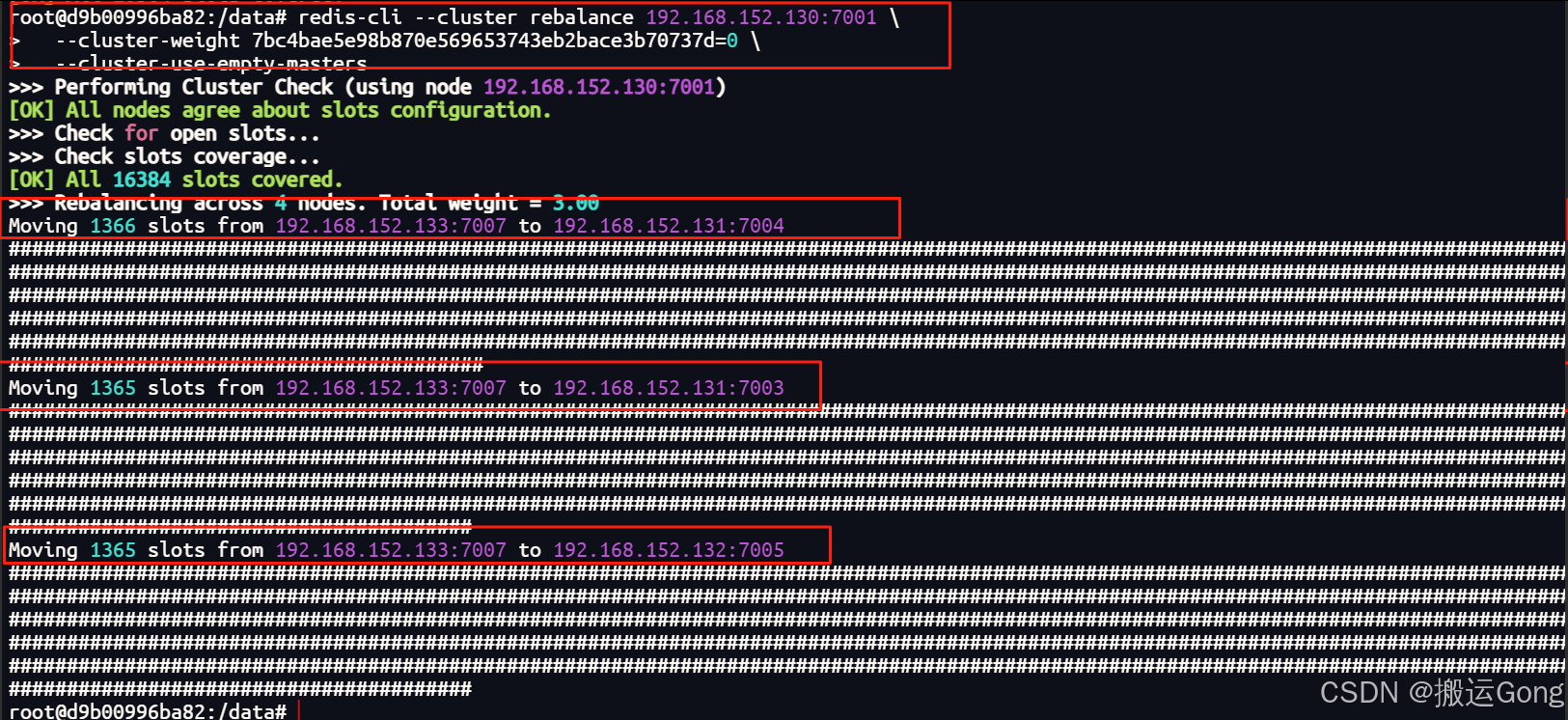
redis-cli --cluster rebalance <集群节点IP:端口> \--cluster-weight <待移除节点ID>=0 \--cluster-use-empty-masters# 对应我这里的命令为
# 自动化迁移所有槽位(推荐)
redis-cli --cluster rebalance 192.168.152.130:7001 \--cluster-weight 7bc4bae5e98b870e569653743eb2bace3b70737d=0 \--cluster-use-empty-masters
参数说明
–cluster-weight # 用于按自定义比例分配槽位。特殊值 =0,完全清空节点槽位(缩容前准备)
3. 重新分配后,查看一下最新的槽位分配情况
redis-cli --cluster check 192.168.152.133:7007
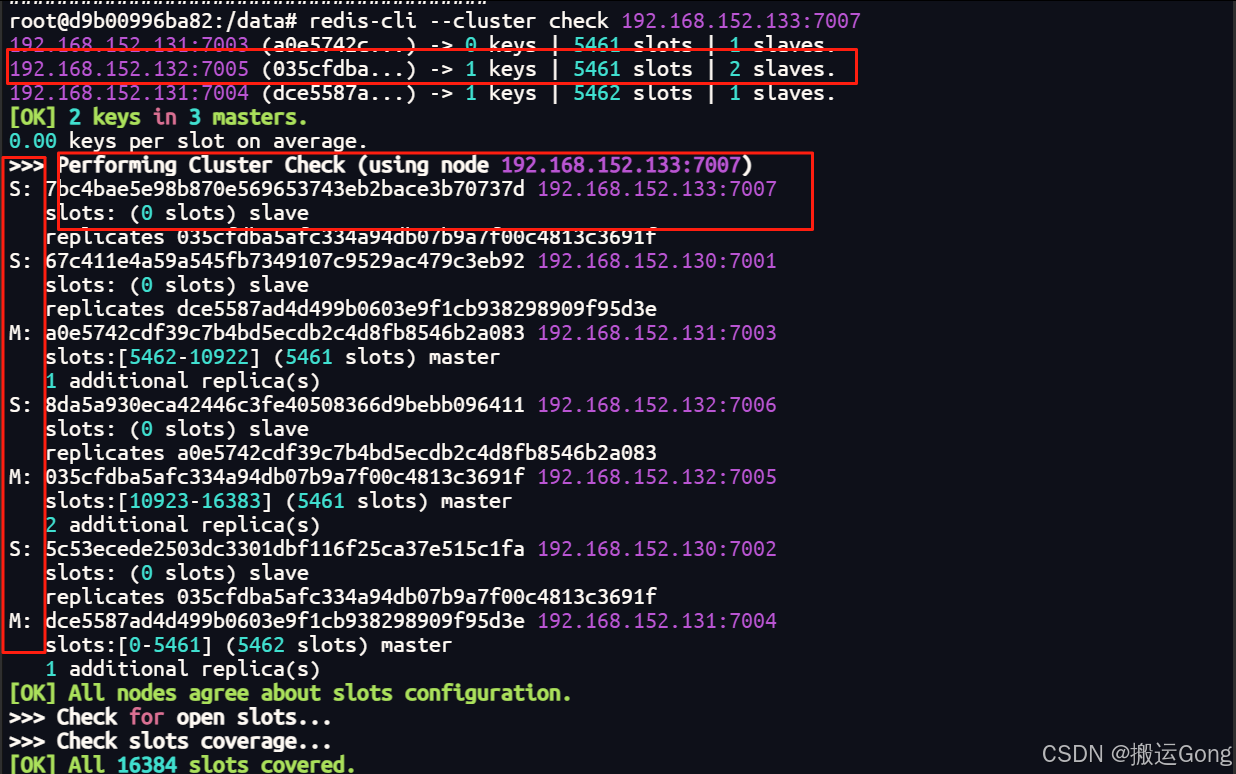
从图中可以看到,原7007节点中的slots 已经被清空,并且平均分配到了其他三个master节点中。
4. 移除多余节点
redis-cli --cluster del-node ip:从机端口 从机节点id
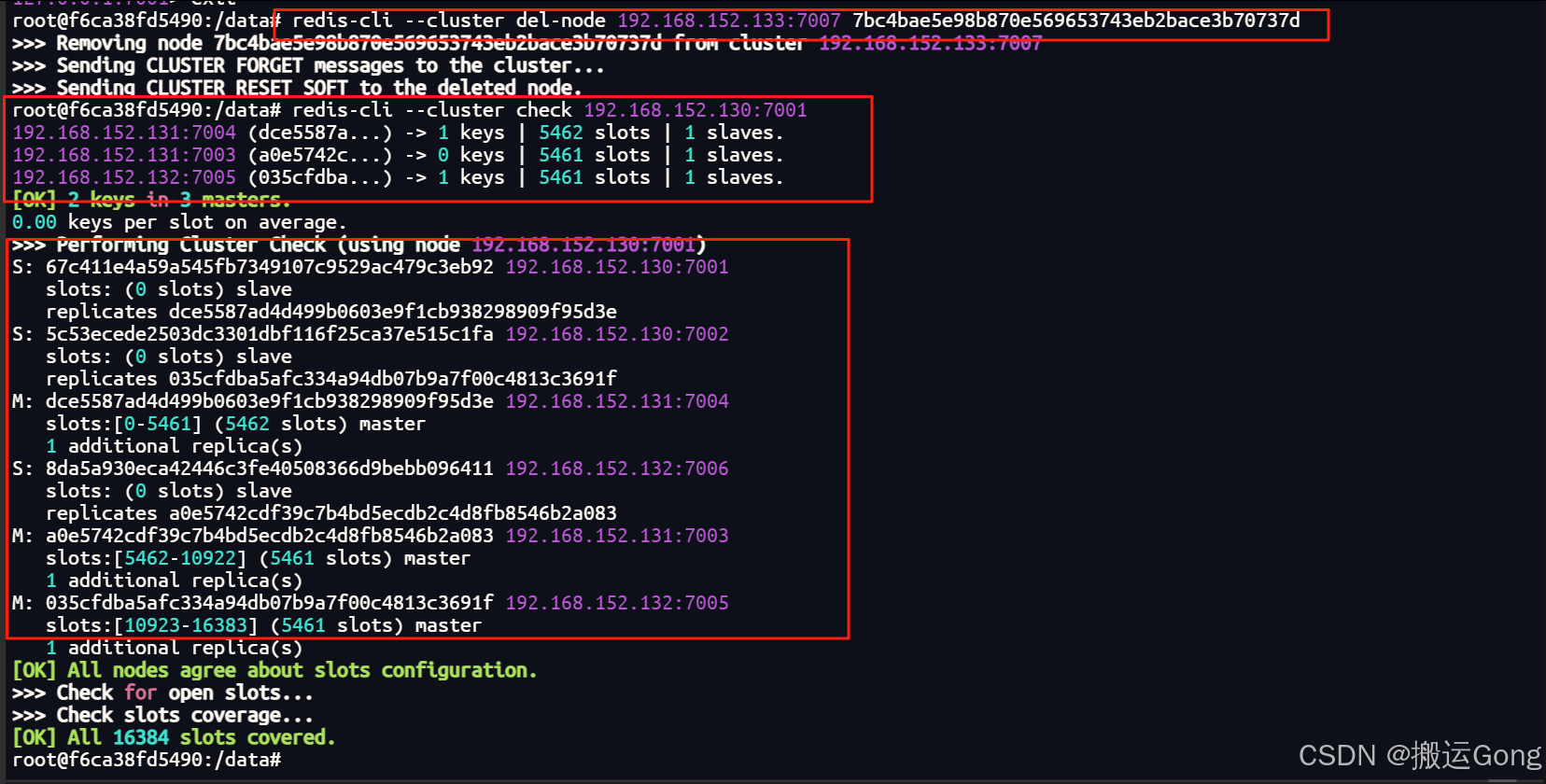 到这里,就完成了redis集群的缩容操作。完成了最初的模样(3主3从)。
到这里,就完成了redis集群的缩容操作。完成了最初的模样(3主3从)。
相关文章:
Docker安装Redis集群(3主3从+动态扩容、缩容)保姆级教程含踩坑及安装中遇到的问题解决
前言 部署集群前,我们需要先掌握Redis分布式存储的核心算法。了解这些算法能帮助我们在实际工作中做出合理选择,同时清晰认识各方案的优缺点。 一、分布式存储算法 我们通过一道大厂面试题来进行阐述。 如下:1-2亿条数据需要缓存ÿ…...
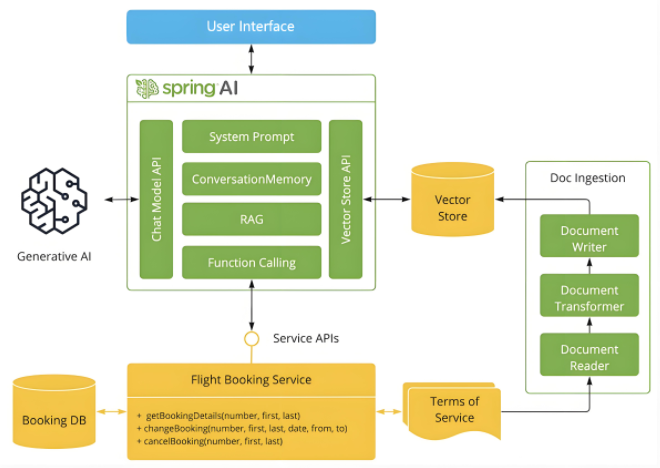
企业级 AI 开发新范式:Spring AI 深度解析与实践
一、Spring AI 的核心架构与设计哲学 1.1 技术定位与价值主张 Spring AI 作为 Spring 生态系统的重要组成部分,其核心使命是将人工智能能力无缝注入企业级 Java 应用。它通过标准化的 API 抽象和 Spring Boot 的自动装配机制,让开发者能够以熟悉的 Spr…...
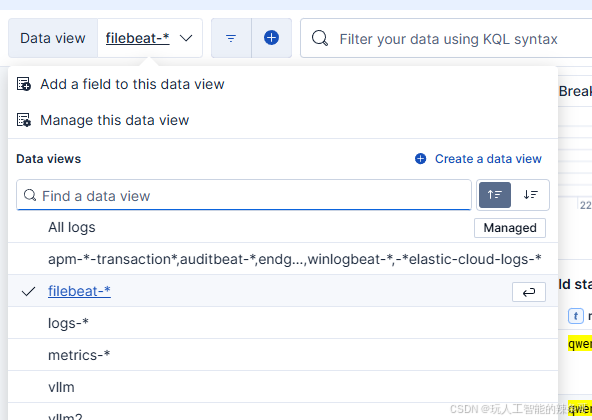
如何用docker部署ELK?
环境: ELK 8.8.0 Ubuntu20.04 问题描述: 如何用docker部署ELK? 解决方案: 一、环境准备 (一)主机设置 安装 Docker Engine :版本需为 18.06.0 或更新。可通过命令 docker --version 检查…...

Redis最佳实践——安全与稳定性保障之高可用架构详解
全面详解 Java 中 Redis 在电商应用的高可用架构设计 一、高可用架构核心模型 1. 多层级高可用体系 #mermaid-svg-Ffzq72Onkv7wgNKQ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Ffzq72Onkv7wgNKQ .error-icon{f…...
【Python 算法零基础 4.排序 ⑥ 快速排序】
既有锦绣前程可奔赴,亦有往日岁月可回首 —— 25.5.25 选择排序回顾 ① 遍历数组:从索引 0 到 n-1(n 为数组长度)。 ② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i1 到 n-1 遍历,若找到…...

Java面试实战:从Spring Boot到微服务与AI的全栈挑战
场景一:初步了解和基本技术问题 面试官:我们先从基础开始,谢先生,你能简单介绍一下你在Java SE上的经验吗? 谢飞机:当然!Java就像是我的老朋友,尤其是8和11版本。我用它们做过很多…...
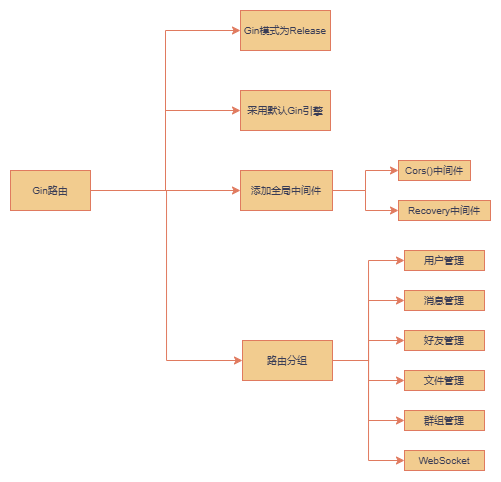
Go 即时通讯系统:日志模块重构,并从main函数开始
重构logger 上次写的logger.go过于繁琐,有很多没用到的功能;重构后只提供了简洁的日志接口,支持日志轮转、多级别日志记录等功能,并采用单例模式确保全局只有一个日志实例 全局变量 var (once sync.Once // 用于实现…...

CppCon 2014 学习:Exception-Safe Coding
以下是你提到的内容(例如 “Exception-Safe Coding 理解” 和 “Easier to Read!” 等)翻译成中文并进一步解释: 承诺:理解异常安全(Exception-Safe Coding) 什么是异常安全? 异常安全是指&a…...
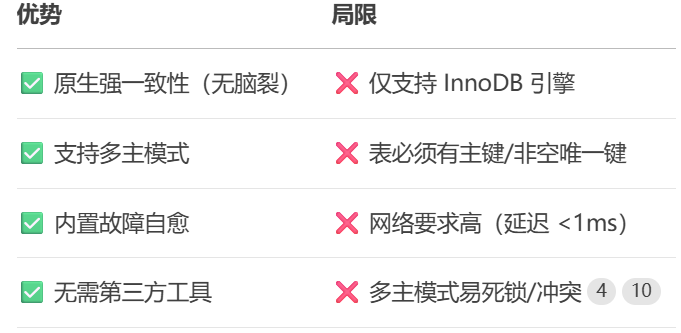
MYSQL MGR高可用
1,MYSQL MGR高可用是什么 简单来说,MySQL MGR 的核心目标就是:确保数据库服务在部分节点(服务器)发生故障时,整个数据库集群依然能够继续提供读写服务,最大限度地减少停机时间。 2. 核心优势 v…...

阿里通义实验室突破空间音频新纪元!OmniAudio让360°全景视频“声”临其境
在虚拟现实和沉浸式娱乐快速发展的今天,视觉体验已经远远不够,声音的沉浸感成为打动用户的关键。然而,传统的视频配音技术往往停留在“平面”的音频层面,难以提供真正的空间感。阿里巴巴通义实验室(Qwen Lab࿰…...
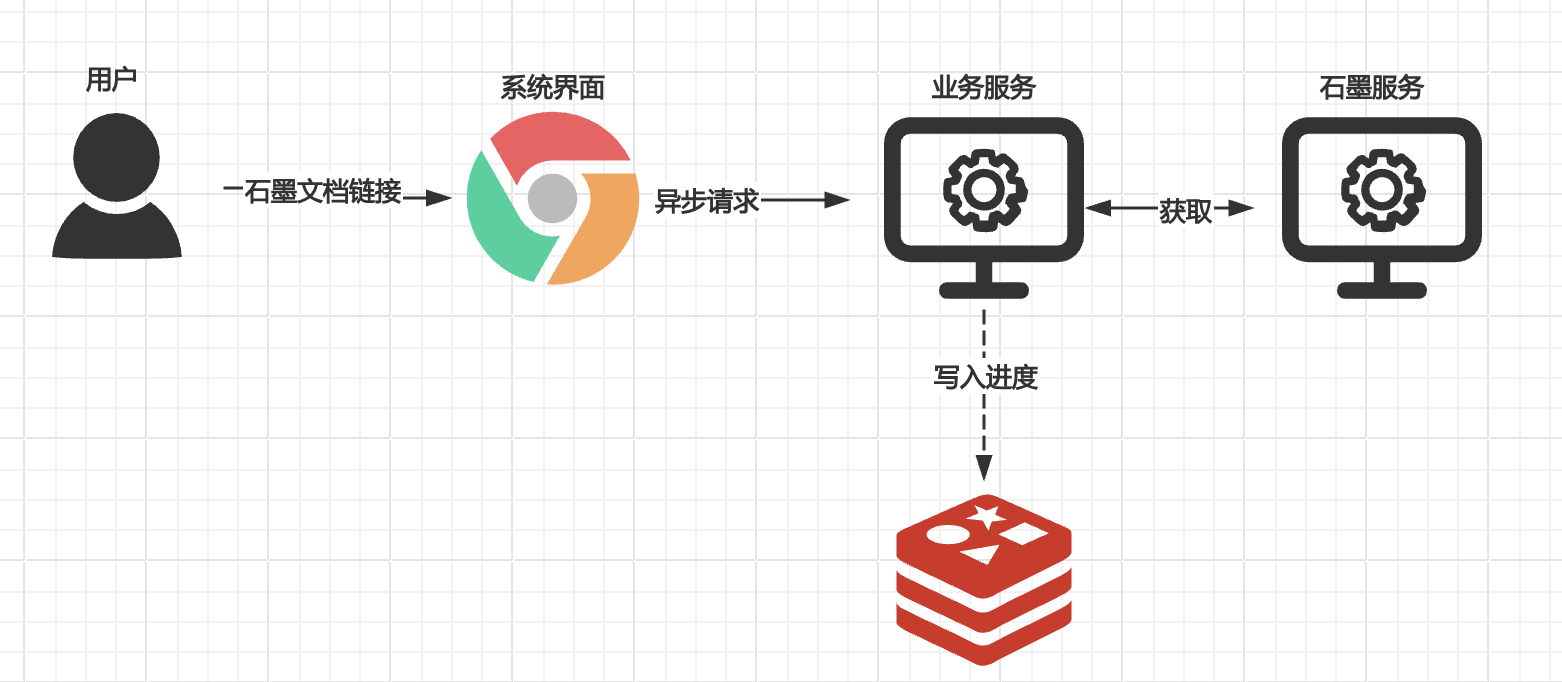
异步上传石墨文件进度条前端展示记录(采用Redis中String数据结构实现-苏东坡版本)
昔者,有客临门,亟需自石墨文库中撷取卷帙若干。此等文册,非止一卷,乃累牍连篇,亟需批量转置。然吾辈虑及用户体验,当效东坡"腹有诗书气自华"之雅意,使操作如行云流水,遂定…...
处理知识库文件_编写powershell脚本文件_批量转换其他格式文件到pdf文件---人工智能工作笔记0249
最近在做部门知识库,选用的dify,作为rag的工具,但是经过多个对比,最后发现, 比较好用的是,纳米搜索,但是可惜纳米搜索无法在内网使用,无法把知识库放到本地,导致 有信息…...
rtpmixsound:实现音频混音攻击!全参数详细教程!Kali Linux教程!
简介 一种将预先录制的音频与指定目标音频流中的音频(即 RTP)实时混合的工具。 一款用于将预先录制的音频与指定目标音频流中的音频(即 RTP)实时混合的工具。该工具创建于 2006 年 8 月至 9 月之间。该工具名为 rtpmixsound。它…...

【Netty系列】解决TCP粘包和拆包:LengthFieldBasedFrameDecoder
目录 如何使用? 1. 示例代码(基于Netty) 2. 关键参数解释 3. 协议格式示例 4. 常见配置场景 场景1:长度字段包含自身 场景2:长度字段在消息中间 5. 注意事项 举个例子 完整示例:客户端与服务端交互…...

stm与51单片机哪个更适合新手学
一句话总结 51单片机:像学骑自行车,简单便宜,但只能在小路上骑。 STM32:像学开汽车,复杂但功能强,能上高速公路,还能拉货载人(做复杂项目)。 1. 为啥有人说“先学51单片…...

【计算机网络】第3章:传输层—面向连接的传输:TCP
目录 一、PPT 二、总结 TCP(传输控制协议)详解 1. 概述 核心特性: 2. TCP报文段结构 关键字段说明: 3. TCP连接管理 3.1 三次握手(建立连接) 3.2 四次挥手(终止连接) 4. 可…...

从架构视角设计统一网络请求体系 —— 基于 uni-app 的前后端通信模型
在使用 uni-app 开发跨平台应用时,设计一套清晰、统一、可扩展的网络请求模块 是前期架构的关键环节。良好的请求模块不仅提高开发效率,更是保证后期维护、调试和业务扩展的基础。 一、网络请求设计目标 在uni-app中设计网络请求模块,应遵循…...
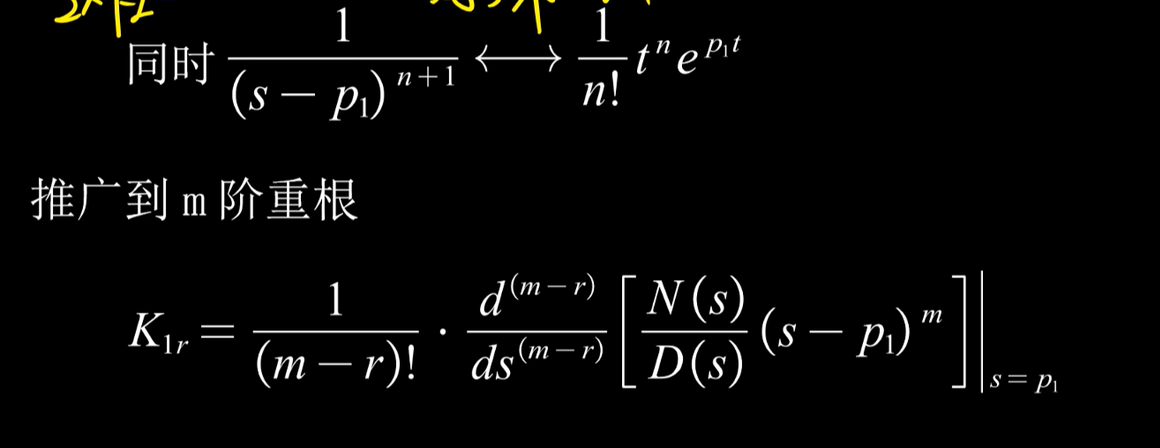
《信号与系统》--期末总结V1.0
《信号与系统》–期末总结V1.0 学习链接 入门:【拯救期末】期末必备!8小时速成信号与系统!【拯救期末】期末必备!8小时速成信号与系统!_哔哩哔哩_bilibili 精通:2022浙江大学信号与系统(含配…...

第32次CCF计算机软件能力认证-2-因子化简
因子化简 刷新 时间限制: 2.0 秒 空间限制: 512 MiB 下载题目目录(样例文件) 题目背景 质数(又称“素数”)是指在大于 11 的自然数中,除了 11 和它本身以外不再有其他因数的自然数。 题…...
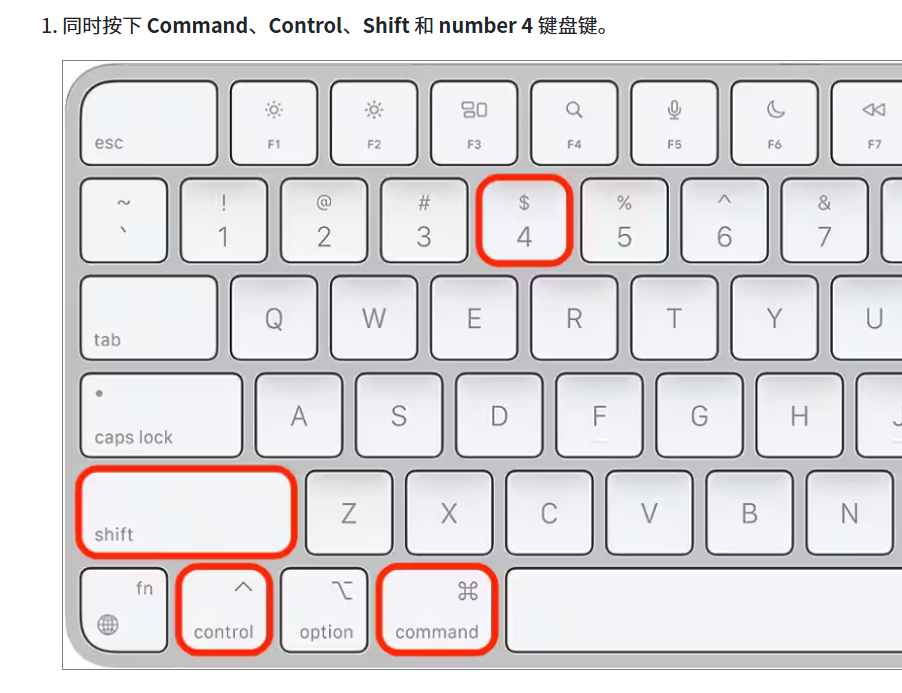
mac笔记本如何快捷键截图后自动复制到粘贴板
前提:之前只会进行部分区域截图操作(commandshift4)操作,截图后发现未自动保存在剪贴板,还要进行一步手动复制到剪贴板的操作。 mac笔记本如何快捷键截图后自动复制到粘贴板 截取 Mac 屏幕的一部分并将其自动复制到剪…...
高考加油!UI界面生成器!
这个高考助力标语生成器具有以下特点: 视觉设计:采用了蓝色为主色调,搭配渐变背景和圆形装饰元素,营造出宁静而充满希望的氛围,非常适合高考主题。 标语生成:内置了超过 100 条精心挑选的高考加油标语&a…...
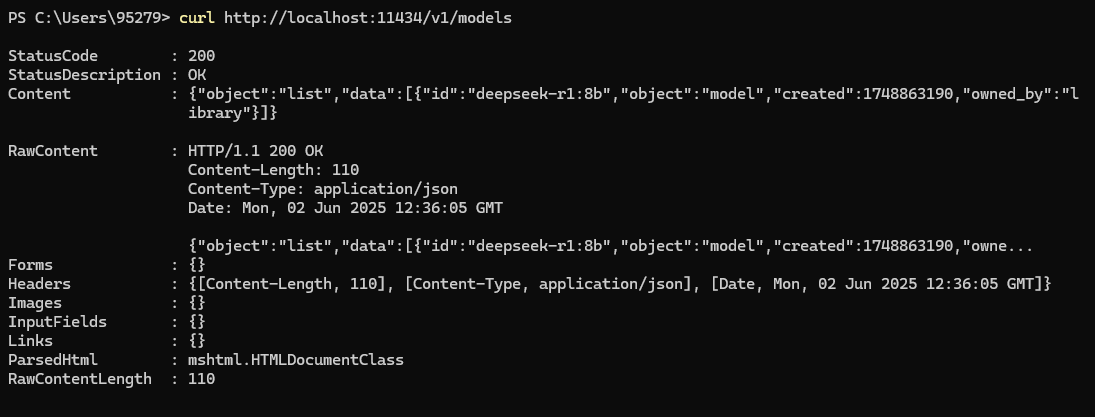
window ollama部署模型
注意去官网下载ollama,这个win和linux差别不大,win下载exe,linux用官网提供的curl命令 模型下载表:deepseek-r1 使用命令:Ollama API 交互 | 菜鸟教程 示例: 1.查看已加载模型: 2.文本生成接口 curl -X POST http://localhost:11434/v1/completions -H "Conte…...

用mediamtx搭建简易rtmp,rtsp视频服务器
简述: 平常测试的时候搭建rtmp服务器很麻烦,这个mediamtx服务器,只要下载就能运行,不用安装、编译、配置等,简单易用、ffmpeg推流、vlc拉流 基础环境: vmware17,centos10 64位,wi…...
ubuntu安装devkitPro
建议开个魔法 wget https://apt.devkitpro.org/install-devkitpro-pacman chmod x ./install-devkitpro-pacman sudo ./install-devkitpro-pacman(下面这句如果报错也没事) sudo ln -s /proc/self/mounts /etc/mtab往~.bashrc添加 export DEVKITPRO/o…...

Linux(10)——第二个小程序(自制shell)
目录 编辑 一、引言与动机 📝背景 📝主要内容概括 二、全局数据 三、环境变量的初始化 ✅ 代码实现 四、构造动态提示符 ✅ 打印提示符函数 ✅ 提示符生成函数 ✅获取用户名函数 ✅获取主机名函数 ✅获取当前目录名函数 五、命令的读取与…...

github actions入门指南
GitHub Actions 是 GitHub 提供的持续集成和持续交付(CI/CD)平台,允许开发者自动化软件工作流程(如构建、测试、部署)。以下是详细介绍: 一、核心概念 Workflow(工作流程) 持续集成的…...
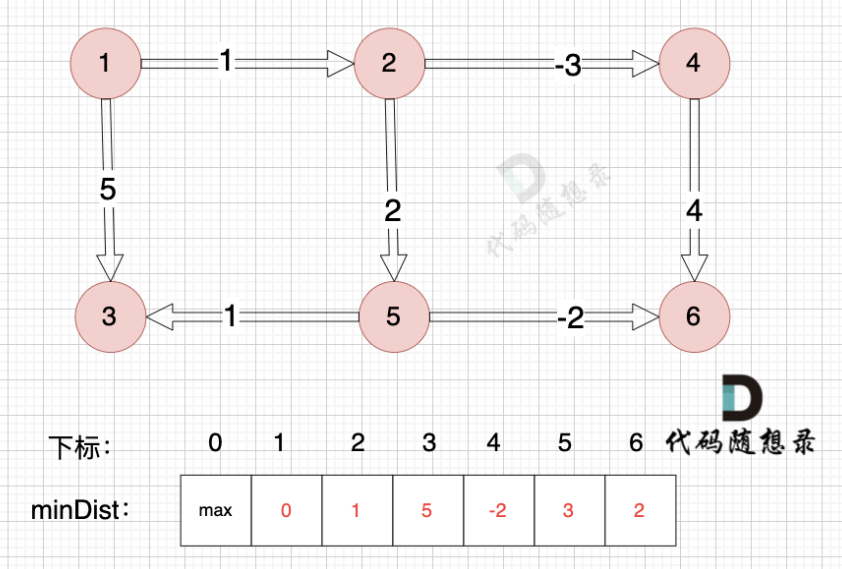
代码随想录算法训练营 Day59 图论Ⅸ dijkstra优化版 bellman_ford
图论 题目 47. 参加科学大会(第六期模拟笔试) 改进版本的 dijkstra 算法(堆优化版本) 朴素版本的 dijkstra 算法解法的时间复杂度为 O ( n 2 ) O(n^2) O(n2) 时间复杂度与 n 有关系,与边无关系 类似于 prim 对应点多…...

HTML实战:响应式个人资料页面
我将创建一个现代化的响应式个人资料页面,展示HTML在实际应用中的强大功能。这个页面将包含多个实战元素:导航栏、个人简介、技能展示、作品集和联系表单。 设计思路 使用Flexbox和Grid布局实现响应式设计 添加CSS过渡效果增强交互体验 实现深色/浅色模式切换功能 创建悬停动…...

Mac电脑上本地安装 MySQL并配置开启自启完整流程
文章目录 一、mysql安装1.1 使用 Homebrew 安装(推荐)1.2 手动下载 MySQL 社区版1.3 常见问题1.4 图形化管理工具(可选) 二、Mac 上配置 MySQL 开机自动启动2.1 使用 launchd 系统服务(原生支持)2.2 通过 H…...
)
JavaSE:面向对象进阶之内部类(Inner Class)
JavaSE 面向对象进阶之内部类(Inner Class) 一、内部类的核心概念 内部类是定义在另一个类内部的类,它与外部类存在紧密的逻辑关联,主要作用: 封装细节:隐藏实现细节,对外提供简洁接口。访问…...