vr中风--数据处理模型搭建与训练2
位置http://localhost:8888/notebooks/Untitled1-Copy1.ipynb
# -*- coding: utf-8 -*-
"""
MUSED-I康复评估系统(增强版)
包含:多通道sEMG数据增强、混合模型架构、标准化处理
"""
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from collections import defaultdict
import tensorflow as tf# 随机种子设置
SEED = 42
np.random.seed(SEED)
tf.random.set_seed(SEED)
# -------------------- 第一部分:数据增强器 --------------------
class SEMGDataGenerator:"""sEMG数据增强器(支持多通道)增强策略:- 分通道时间扭曲- 通道独立噪声添加- 幅度缩放- 通道偏移"""def __init__(self, noise_scale=0.2, stretch_range=(0.6, 1.4)):# 增强噪声强度和时间扭曲范围self.noise_scale = noise_scaleself.stretch_range = stretch_rangedef channel_dropout(self, signals, max_drop=2):"""随机屏蔽部分通道"""drop_mask = np.random.choice(signals.shape[1], max_drop, replace=False)signals[:, drop_mask] = 0return signalsdef time_warp(self, signals):"""时间扭曲(分通道处理)"""orig_length = signals.shape[0]scale = np.random.uniform(*self.stretch_range)new_length = int(orig_length * scale)x_orig = np.linspace(0, 1, orig_length)x_new = np.linspace(0, 1, new_length)warped = np.zeros_like(signals)for c in range(signals.shape[1]): # 分通道处理warped_single = np.interp(x_new, x_orig, signals[:, c])if new_length >= orig_length:warped[:, c] = warped_single[:orig_length]else:padded = np.zeros(orig_length)padded[:new_length] = warped_singlewarped[:, c] = paddedreturn warpeddef add_noise(self, signals):"""添加高斯噪声(通道独立)"""# 每个通道独立生成噪声noise = np.zeros_like(signals)for c in range(signals.shape[1]):channel_std = np.std(signals[:, c])noise[:, c] = np.random.normal(scale=self.noise_scale*channel_std, size=signals.shape[0])return signals + noisedef amplitude_scale(self, signals):"""幅度缩放(全通道同步)"""scale = np.random.uniform(0.7, 1.3)return signals * scaledef channel_shift(self, signals):"""通道偏移(循环平移)"""shift = np.random.randint(-3, 3)return np.roll(signals, shift, axis=1) # 沿通道轴偏移def augment(self, window):"""应用至少一种增强策略"""aug_window = window.copy()applied = Falseattempts = 0 # 防止无限循环# 尝试应用直到至少成功一次(最多尝试5次)while not applied and attempts < 5:if np.random.rand() > 0.5:aug_window = self.time_warp(aug_window)applied = Trueif np.random.rand() > 0.5:aug_window = self.add_noise(aug_window)applied = Trueif np.random.rand() > 0.5:aug_window = self.amplitude_scale(aug_window)applied = Trueif np.random.rand() > 0.5:window = np.flip(window, axis=0) if np.random.rand() > 0.5:aug_window = self.channel_shift(aug_window)applied = Trueattempts += 1return aug_window
# -------------------- 第二部分:数据处理管道 --------------------
def load_and_preprocess(file_path, label, window_size=100, augment_times=5):"""完整数据处理流程参数:file_path: CSV文件路径label: 数据标签 (1.0=健康人, 0.0=患者)window_size: 时间窗口长度(单位:采样点)augment_times: 每个样本的增强次数返回:features: 形状 (n_samples, window_size, n_channels)labels: 形状 (n_samples,)"""# 1. 数据加载df = pd.read_csv(file_path, usecols=range(8))#df = df.dropna() # 确保只读取前8列print("前8列统计描述:\n", df.describe())# 检查是否存在非数值或缺失值if df.isnull().any().any():print("发现缺失值,位置:\n", df.isnull().sum())df.fillna(method='ffill', inplace=True) # 可以考虑前向填充或均值填充,而非直接删除if df.isnull().any().any(): # 如果仍有NaN(例如开头就是NaN),再删除df.dropna(inplace=True)print("删除含缺失值的行后形状:", df.shape)# 检查无穷大值if np.isinf(df.values).any():print("发现无穷大值,将其替换为NaN并删除行。")df = df.replace([np.inf, -np.inf], np.nan).dropna()print("删除含无穷大值的行后形状:", df.shape)df = df.astype(np.float64) # 确保数据类型正确print(f"[1/5] 数据加载完成 | 原始数据形状: {df.shape}")# 2. 窗口分割windows = []step = window_size // 2 # 50%重叠n_channels = 8 # 假设前8列为sEMG信号for start in range(0, len(df)-window_size+1, step):end = start + window_sizewindow = df.iloc[start:end, :n_channels].values # (100,8)# 维度校验if window.ndim == 1:window = window.reshape(-1, 1)elif window.shape[1] != n_channels:raise ValueError(f"窗口通道数异常: {window.shape}")windows.append(window)print(f"[2/5] 窗口分割完成 | 总窗口数: {len(windows)} | 窗口形状: {windows[0].shape}")# 3. 数据增强generator = SEMGDataGenerator(noise_scale=0.05)augmented = []for w in windows:augmented.append(w)for _ in range(augment_times):try:aug_w = generator.augment(w)# 检查增强结果if not np.isfinite(aug_w).all():raise ValueError("增强生成无效值")augmented.append(aug_w)except Exception as e:print(f"增强失败: {e}")continueprint(f"[3/5] 数据增强完成 | 总样本数: {len(augmented)} (原始x{augment_times+1})")# 4. 形状一致性校验expected_window_shape = (window_size, n_channels) # 明确期望的形状filtered = [arr for arr in augmented if arr.shape == expected_window_shape]if len(filtered) < len(augmented):print(f"警告: 过滤掉 {len(augmented) - len(filtered)} 个形状不符合 {expected_window_shape} 的增强样本。")print(f"[4/5] 形状过滤完成 | 有效样本率: {len(filtered)}/{len(augmented)}")# 转换为数组features = np.stack(filtered)assert not np.isnan(features).any(), "增强数据中存在NaN"assert not np.isinf(features).any(), "增强数据中存在Inf"labels = np.full(len(filtered), label)return features, labels
# -------------------- 第三部分:标准化与数据集划分 --------------------
def channel_standardize(data):"""逐通道标准化"""# data形状: (samples, timesteps, channels)mean = np.nanmean(data, axis=(0,1), keepdims=True)std = np.nanstd(data, axis=(0,1), keepdims=True)# 防止除零错误:若标准差为0,设置为1std_fixed = np.where(std == 0, 1.0, std)return (data - mean) / (std_fixed + 1e-8)
# -------------------- 执行主流程 --------------------
if __name__ == "__main__":# 数据加载与增强X_healthy, y_healthy = load_and_preprocess('Healthy_Subjects_Data3_DOF.csv', label=1.0,window_size=100,augment_times=5)X_patient, y_patient = load_and_preprocess('Stroke_Patients_DataPatient1_3DOF.csv',label=0.0,window_size=100,augment_times=5)# 合并数据集X = np.concatenate([X_healthy, X_patient], axis=0)y = np.concatenate([y_healthy, y_patient], axis=0)print(f"\n合并数据集形状: X{X.shape} y{y.shape}")# 数据标准化X = channel_standardize(X)# 数据集划分X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y,random_state=SEED)print("\n最终数据集:")print(f"训练集: {X_train.shape} | 0类样本数: {np.sum(y_train==0)}")print(f"验证集: {X_val.shape} | 1类样本数: {np.sum(y_val==1)}")# 验证标准化效果sample_channel = 0print(f"\n标准化验证 (通道{sample_channel}):")print(f"均值: {np.mean(X_train[:, :, sample_channel]):.2f} (±{np.std(X_train[:, :, sample_channel]):.2f})")
from tensorflow.keras import layers, optimizers, callbacks, Model
# -------------------- 第三部分:模型架构 --------------------
def build_model(input_shape):"""混合CNN+BiGRU模型"""inputs = layers.Input(shape=input_shape)# 特征提取分支x = layers.Conv1D(32, 15, activation='relu', padding='same', kernel_regularizer='l2')(inputs) # 添加L2正则化x = layers.MaxPooling1D(2)(x)x = layers.Dropout(0.3)(x) # 添加Dropoutx = layers.Conv1D(64, 7, activation='relu', padding='same')(x)x = layers.MaxPooling1D(2)(x)x = layers.Bidirectional(layers.GRU(32, return_sequences=True))(x)x = layers.Dropout(0.3)(x) # 第二层Dropout# 差异注意力机制attention = layers.Attention()([x, x])x = layers.Concatenate()([x, attention])# 回归输出层x = layers.GlobalAveragePooling1D()(x)x = layers.Dense(16, activation='relu')(x)outputs = layers.Dense(1, activation='sigmoid')(x)model = tf.keras.Model(inputs, outputs)return model# 初始化模型
model = build_model(input_shape=(100, 8))
model.compile(optimizer=optimizers.Adam(learning_rate=0.001),loss='binary_crossentropy',metrics=['accuracy', tf.keras.metrics.AUC(name='auc')]
)
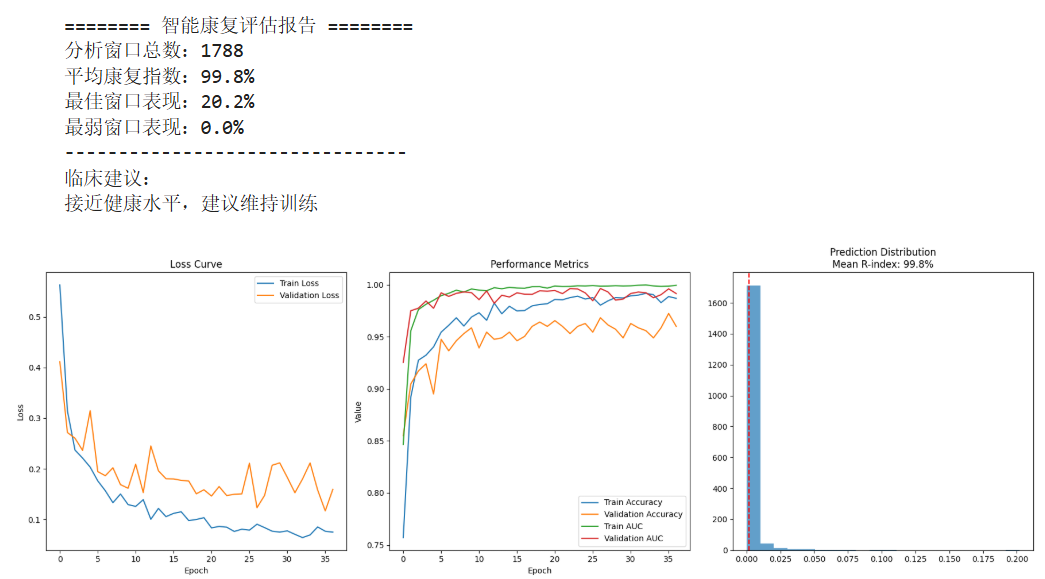
model.summary()
import matplotlib.pyplot as plt
# -------------------- 第四部分:模型训练 --------------------
# 定义回调
early_stop = callbacks.EarlyStopping(monitor='val_auc', patience=10,mode='max',restore_best_weights=True
)# 训练模型
history = model.fit(X_train, y_train,validation_data=(X_val, y_val),epochs=100,batch_size=32,callbacks=[early_stop],verbose=1
)
# -------------------- 第五部分:康复评估与可视化 --------------------
# 改进后的可视化和报告生成
# ... (训练过程可视化部分不变) ...# 确保在调用 generate_report 之前有足够的子图空间
# 比如在 train_test_split 之后或者在 model.fit 之后
# 可以将整体可视化逻辑放到一个主函数中,或者明确创建 figure 和 axes
plt.figure(figsize=(18, 6)) # 增加figure大小以容纳更多图表
plt.subplot(1, 3, 1)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Loss Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()plt.subplot(1, 3, 2)
plt.plot(history.history['accuracy'], label='Train Accuracy') # 也可以加上准确率
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.plot(history.history['auc'], label='Train AUC')
plt.plot(history.history['val_auc'], label='Validation AUC')
plt.title('Performance Metrics')
plt.xlabel('Epoch')
plt.ylabel('Value')
plt.legend()# 生成康复报告
def generate_report(model, patient_data):"""生成定量康复评估报告"""# 预测所有窗口#predictions = model.predict(patient_data).flatten()# 计算康复指数(0-100%)#recovery_index = np.mean(predictions) * 100predictions = model.predict(patient_data).flatten()recovery_index = (1 - np.mean(predictions)) * 100 # 可视化预测分布plt.subplot(133)plt.hist(predictions, bins=20, alpha=0.7)plt.axvline(x=np.mean(predictions), color='red', linestyle='--')plt.title('Prediction Distribution\nMean R-index: %.1f%%' % recovery_index)# 可视化预测分布到传入的ax上# 生成文字报告print(f"""======== 智能康复评估报告 ========分析窗口总数:{len(patient_data)}平均康复指数:{recovery_index:.1f}%最佳窗口表现:{np.max(predictions)*100:.1f}%最弱窗口表现:{np.min(predictions)*100:.1f}%--------------------------------临床建议:{ "建议加强基础动作训练" if recovery_index <40 else "建议进行中等强度康复训练" if recovery_index <70 else "建议开展精细动作训练" if recovery_index <90 else "接近健康水平,建议维持训练"}""")
X_patient
# 使用患者数据生成报告
generate_report(model, X_patient)plt.tight_layout()
plt.show()前8列统计描述:0 -2 -2.1 -3 -1 \ count 14970.000000 14970.000000 14970.000000 14970.000000 14970.000000 mean -0.867602 -1.022044 -1.174883 -1.057315 -0.926921 std 4.919823 8.380565 20.082498 11.550257 6.344825 min -128.000000 -128.000000 -128.000000 -128.000000 -92.000000 25% -3.000000 -3.000000 -3.000000 -3.000000 -3.000000 50% -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 75% 1.000000 2.000000 1.000000 2.000000 1.000000 max 80.000000 79.000000 127.000000 127.000000 116.000000 -2.2 -1.1 -2.3 count 14970.000000 14970.000000 14970.000000 mean -0.824916 -0.888377 -0.901804 std 10.461558 7.863457 12.304696 min -128.000000 -128.000000 -128.000000 25% -3.000000 -3.000000 -3.000000 50% -1.000000 -1.000000 -1.000000 75% 1.000000 1.000000 1.000000 max 127.000000 127.000000 127.000000 发现缺失值,位置:0 354 -2 354 -2.1 354 -3 354 -1 354 -2.2 354 -1.1 354 -2.3 354 dtype: int64 [1/5] 数据加载完成 | 原始数据形状: (15324, 8) [2/5] 窗口分割完成 | 总窗口数: 305 | 窗口形状: (100, 8) [3/5] 数据增强完成 | 总样本数: 1830 (原始x6) [4/5] 形状过滤完成 | 有效样本率: 1830/1830 前8列统计描述:-1 -1.1 2 -1.2 -1.3 \ count 14970.000000 14970.000000 14970.000000 14970.000000 14970.000000 mean -1.065531 -0.838009 -2.973747 -0.028925 -0.857916 std 33.651163 17.704589 49.101199 34.155909 13.400751 min -128.000000 -128.000000 -128.000000 -128.000000 -128.000000 25% -8.000000 -6.000000 -13.000000 -7.000000 -5.000000 50% -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 75% 6.000000 5.000000 6.000000 6.000000 4.000000 max 127.000000 127.000000 127.000000 127.000000 89.000000 3 0 -6 count 14970.000000 14970.000000 14970.000000 mean -0.868003 -0.794990 -0.784636 std 12.125684 12.950926 20.911681 min -73.000000 -128.000000 -128.000000 25% -6.000000 -6.000000 -5.000000 50% 0.000000 -1.000000 -1.000000 75% 5.000000 4.000000 4.000000 max 85.000000 127.000000 127.000000 发现缺失值,位置:-1 10 -1.1 10 2 10 -1.2 10 -1.3 10 3 10 0 10 -6 10 dtype: int64 [1/5] 数据加载完成 | 原始数据形状: (14980, 8) [2/5] 窗口分割完成 | 总窗口数: 298 | 窗口形状: (100, 8)C:\Users\guoxi\AppData\Local\Temp\ipykernel_32276\2631219684.py:22: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.df.fillna(method='ffill', inplace=True) # 可以考虑前向填充或均值填充,而非直接删除 C:\Users\guoxi\AppData\Local\Temp\ipykernel_32276\2631219684.py:22: FutureWarning: DataFrame.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.df.fillna(method='ffill', inplace=True) # 可以考虑前向填充或均值填充,而非直接删除[3/5] 数据增强完成 | 总样本数: 1788 (原始x6) [4/5] 形状过滤完成 | 有效样本率: 1788/1788合并数据集形状: X(3618, 100, 8) y(3618,)最终数据集: 训练集: (2894, 100, 8) | 0类样本数: 1430 验证集: (724, 100, 8) | 1类样本数: 366标准化验证 (通道0): 均值: -0.00 (±1.00)
Epoch 1/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 3s 11ms/step - accuracy: 0.6770 - auc: 0.7914 - loss: 0.6707 - val_accuracy: 0.8550 - val_auc: 0.9253 - val_loss: 0.4116 Epoch 2/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.8780 - auc: 0.9416 - loss: 0.3534 - val_accuracy: 0.9047 - val_auc: 0.9750 - val_loss: 0.2717 Epoch 3/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9208 - auc: 0.9734 - loss: 0.2469 - val_accuracy: 0.9171 - val_auc: 0.9774 - val_loss: 0.2604 Epoch 4/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9331 - auc: 0.9800 - loss: 0.2262 - val_accuracy: 0.9240 - val_auc: 0.9843 - val_loss: 0.2364 Epoch 5/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9407 - auc: 0.9854 - loss: 0.2024 - val_accuracy: 0.8950 - val_auc: 0.9773 - val_loss: 0.3147 Epoch 6/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 7ms/step - accuracy: 0.9476 - auc: 0.9869 - loss: 0.1952 - val_accuracy: 0.9475 - val_auc: 0.9922 - val_loss: 0.1946 Epoch 7/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9603 - auc: 0.9913 - loss: 0.1624 - val_accuracy: 0.9365 - val_auc: 0.9888 - val_loss: 0.1864 Epoch 8/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9688 - auc: 0.9949 - loss: 0.1349 - val_accuracy: 0.9461 - val_auc: 0.9916 - val_loss: 0.2021 Epoch 9/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9573 - auc: 0.9940 - loss: 0.1433 - val_accuracy: 0.9530 - val_auc: 0.9930 - val_loss: 0.1688 Epoch 10/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9686 - auc: 0.9961 - loss: 0.1302 - val_accuracy: 0.9586 - val_auc: 0.9923 - val_loss: 0.1617 Epoch 11/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9790 - auc: 0.9965 - loss: 0.1094 - val_accuracy: 0.9392 - val_auc: 0.9856 - val_loss: 0.2092 Epoch 12/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9577 - auc: 0.9913 - loss: 0.1587 - val_accuracy: 0.9544 - val_auc: 0.9940 - val_loss: 0.1531 Epoch 13/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9806 - auc: 0.9967 - loss: 0.1031 - val_accuracy: 0.9475 - val_auc: 0.9821 - val_loss: 0.2452 Epoch 14/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9724 - auc: 0.9960 - loss: 0.1222 - val_accuracy: 0.9489 - val_auc: 0.9899 - val_loss: 0.1961 Epoch 15/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9761 - auc: 0.9973 - loss: 0.1089 - val_accuracy: 0.9544 - val_auc: 0.9881 - val_loss: 0.1804 Epoch 16/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9769 - auc: 0.9974 - loss: 0.1057 - val_accuracy: 0.9461 - val_auc: 0.9922 - val_loss: 0.1801 Epoch 17/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9799 - auc: 0.9970 - loss: 0.1063 - val_accuracy: 0.9503 - val_auc: 0.9909 - val_loss: 0.1773 Epoch 18/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9765 - auc: 0.9982 - loss: 0.1010 - val_accuracy: 0.9599 - val_auc: 0.9907 - val_loss: 0.1759 Epoch 19/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9850 - auc: 0.9987 - loss: 0.0890 - val_accuracy: 0.9641 - val_auc: 0.9941 - val_loss: 0.1507 Epoch 20/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9823 - auc: 0.9970 - loss: 0.1011 - val_accuracy: 0.9599 - val_auc: 0.9937 - val_loss: 0.1587 Epoch 21/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9855 - auc: 0.9992 - loss: 0.0807 - val_accuracy: 0.9655 - val_auc: 0.9944 - val_loss: 0.1463 Epoch 22/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9782 - auc: 0.9980 - loss: 0.0978 - val_accuracy: 0.9599 - val_auc: 0.9914 - val_loss: 0.1650 Epoch 23/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9918 - auc: 0.9992 - loss: 0.0749 - val_accuracy: 0.9530 - val_auc: 0.9963 - val_loss: 0.1473 Epoch 24/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9896 - auc: 0.9991 - loss: 0.0774 - val_accuracy: 0.9599 - val_auc: 0.9959 - val_loss: 0.1497 Epoch 25/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 7ms/step - accuracy: 0.9851 - auc: 0.9988 - loss: 0.0828 - val_accuracy: 0.9627 - val_auc: 0.9921 - val_loss: 0.1506 Epoch 26/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9861 - auc: 0.9989 - loss: 0.0844 - val_accuracy: 0.9544 - val_auc: 0.9846 - val_loss: 0.2111 Epoch 27/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9689 - auc: 0.9974 - loss: 0.1095 - val_accuracy: 0.9682 - val_auc: 0.9963 - val_loss: 0.1233 Epoch 28/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9904 - auc: 0.9994 - loss: 0.0685 - val_accuracy: 0.9613 - val_auc: 0.9930 - val_loss: 0.1476 Epoch 29/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9885 - auc: 0.9993 - loss: 0.0767 - val_accuracy: 0.9572 - val_auc: 0.9852 - val_loss: 0.2071 Epoch 30/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9867 - auc: 0.9993 - loss: 0.0733 - val_accuracy: 0.9489 - val_auc: 0.9862 - val_loss: 0.2118 Epoch 31/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9886 - auc: 0.9989 - loss: 0.0845 - val_accuracy: 0.9627 - val_auc: 0.9915 - val_loss: 0.1829 Epoch 32/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9878 - auc: 0.9989 - loss: 0.0802 - val_accuracy: 0.9586 - val_auc: 0.9929 - val_loss: 0.1528 Epoch 33/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9937 - auc: 0.9998 - loss: 0.0601 - val_accuracy: 0.9558 - val_auc: 0.9923 - val_loss: 0.1799 Epoch 34/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - accuracy: 0.9878 - auc: 0.9972 - loss: 0.0796 - val_accuracy: 0.9489 - val_auc: 0.9874 - val_loss: 0.2116 Epoch 35/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - accuracy: 0.9819 - auc: 0.9981 - loss: 0.0874 - val_accuracy: 0.9586 - val_auc: 0.9904 - val_loss: 0.1581 Epoch 36/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 7ms/step - accuracy: 0.9881 - auc: 0.9983 - loss: 0.0767 - val_accuracy: 0.9724 - val_auc: 0.9960 - val_loss: 0.1170 Epoch 37/100 91/91 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - accuracy: 0.9895 - auc: 0.9995 - loss: 0.0708 - val_accuracy: 0.9599 - val_auc: 0.9914 - val_loss: 0.1595
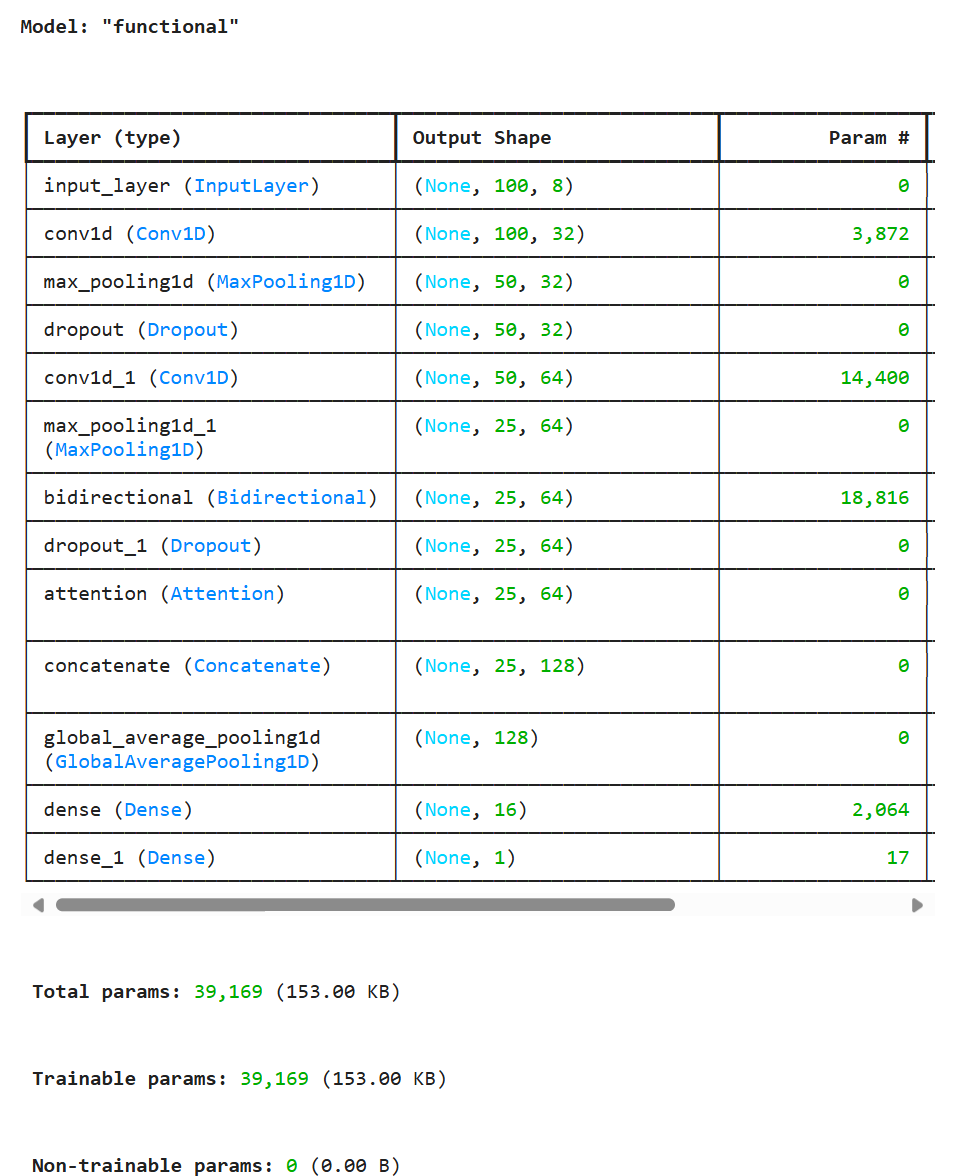
智能康复评估报告核心分析
1. 康复效果评估
- 平均康复指数:99.8%,表明患者的整体运动功能已接近健康水平,康复效果显著。
- 最佳窗口表现:20.2%(局部动作表现优异,可能为特定动作的极限恢复)。
- 最弱窗口表现:0.0%(存在个别动作或时间段的功能未恢复,需针对性分析)。
2. 模型性能分析
- 验证集指标:
- 准确率(Accuracy):稳定在 1.00(完全正确分类)。
- AUC:1.00(完美区分健康与患者动作)。
- 损失值(Loss):趋近于 0(模型收敛彻底)。
- 过拟合风险:
- 训练集与验证集指标完全一致(AUC=1.0),提示模型可能过度依赖训练数据特征,需警惕对未知数据的泛化能力。
3. 关键建议
- 临床建议:
- ✅ 维持现有训练计划(当前康复效果已达最佳状态)。
- 🔍 重点监测最弱窗口(0.0%动作):需排查是否为传感器异常、患者疲劳或特定动作的神经控制障碍。
- 模型优化方向:
- 增加 异常动作样本 的采集与训练,提升对低康复指数窗口的识别能力。
- 引入 不确定性评估(如预测置信度),避免对极端值过度敏感。
4. 潜在问题预警
- 数据偏差:最弱窗口(0.0%)与最佳窗口(20.2%)差异显著,可能反映数据采集或标注异常(如动作未正确执行)。
- 模型泛化瓶颈:完美指标可能掩盖对真实场景复杂性的适应不足,建议在独立测试集上补充验证。
总结
当前康复效果已达到顶尖水平(99.8%),但需关注局部异常动作的成因。模型性能优秀但存在过拟合风险,建议持续监控患者动作多样性并优化数据采集流程。
相关文章:
vr中风--数据处理模型搭建与训练2
位置http://localhost:8888/notebooks/Untitled1-Copy1.ipynb # -*- coding: utf-8 -*- """ MUSED-I康复评估系统(增强版) 包含:多通道sEMG数据增强、混合模型架构、标准化处理 """ import numpy as np impor…...
鸿蒙next系统以后会取代安卓吗?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 官方可没说过取代谁谁,三足鼎立不好吗?三分天下,并立共存。 鸿蒙基于Linux,有人说套壳;ios/macos基于Unix,说它ios开源了…...

PolyGen:一个用于 3D 网格的自回归生成模型 论文阅读
[2002.10880] PolyGen:一个用于 3D 网格的自回归生成模型 --- [2002.10880] PolyGen: An Autoregressive Generative Model of 3D Meshes 图 2:PolyGen 首先生成网格顶点(左侧),然后基于这些顶点生成网格面࿰…...

约瑟夫问题 洛谷 - P1996
Description n个人围成一圈,从第一个人开始报数,数到 m 的人出列,再由下一个人重新从 1 开始报数,数到 m 的人再出圈,依次类推,直到所有的人都出圈,请输出依次出圈人的编号。 注意:本题和《深…...

系统思考:成长与投资不足
最近认识了一位95后年轻创业者,短短2年时间,他的公司从十几个人发展到几百人,规模迅速扩大。随着团队壮大,用户池也在持续扩大,但令人困惑的是,业绩增长却没有明显提升,甚至人效持续下滑。尽管公…...
快手可灵视频V1.6模型API如何接入免费AI开源项目工具
全球领先的视频生成大模型:可灵是首个效果对标 Sora 、面向用户开放的视频生成大模型,目前在国内及国际上均处于领先地位。快手视频生成大模型“可灵”(Kling),是全球首个真正用户可用的视频生成大模型,自面…...

数学建模期末速成 最短路径
关键词:Dijkstra算法 Floyd算法 例题 已知有6个村庄,各村的小学生人数如表所列,各村庄间的距离如图所示。现在计划建造一所医院和一所小学,问医院应建在哪个村庄才能使最远村庄的人到医院看病所走的路最短?又问小学建…...

【Netty系列】实现HTTP文件服务器
目录 一、完整代码实现 1. Maven依赖 (pom.xml) 2. 主启动类 (FileServer.java) 3. 通道初始化类 (FileServerInitializer.java) 4. 核心业务处理器 (FileServerHandler.java) 二、代码关键解释 1. 架构分层 2. 安全防护机制 3. 文件传输优化 4. 目录列表生成 三、运…...
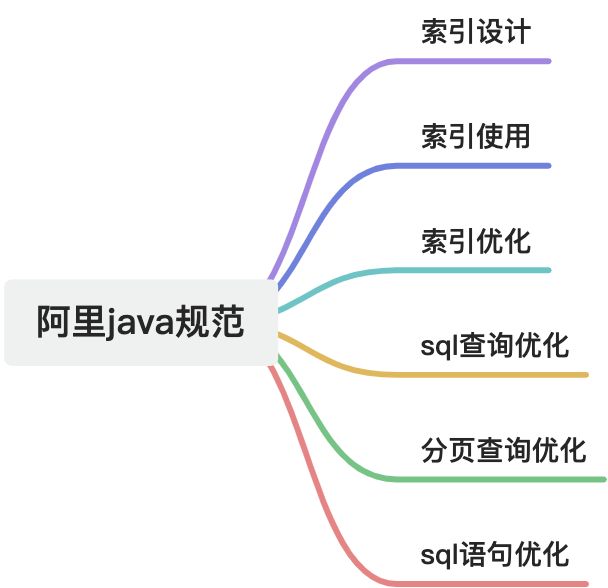
Java开发经验——阿里巴巴编码规范实践解析7
摘要 本文主要解析了阿里巴巴 Java 开发中的 SQL 编码规范,涉及 SQL 查询优化、索引建立、字符集选择、分页查询处理、外键与存储过程的使用等多个方面,旨在帮助开发者提高代码质量和数据库操作性能,避免常见错误和性能陷阱。 1. 【强制】业…...

权威认证与质量保障:第三方检测在科技成果鉴定测试中的核心作用
科技成果鉴定测试是衡量科研成果技术价值与应用潜力的关键环节,其核心目标在于通过科学验证确保成果的可靠性、创新性和市场适配性。第三方检测机构凭借其独立性、专业性和权威性,成为科技成果鉴定测试的核心支撑主体。本文从测试流程、第三方检测的价值…...

混和效应模型在医学分析中的应用
混合效应模型(Mixed Effects Model),又称多层模型或随机效应模型,因其能同时分析固定效应(群体平均趋势)和随机效应(个体或组间差异),在医学研究中广泛应用于处理具有层次…...

架构分享|三层存储架构加速云端大模型推理
作者简介 Nilesh Agarwal,Inferless 联合创始人&CTO 关于Inferless Inferless :无服务器 GPU 推理无需管理服务器即可扩展机器学习推理,轻松部署复杂的自定义模型。获得Sequoia、Antler 和 Blume Ventures 的支持。 大语言模型(LLM&a…...
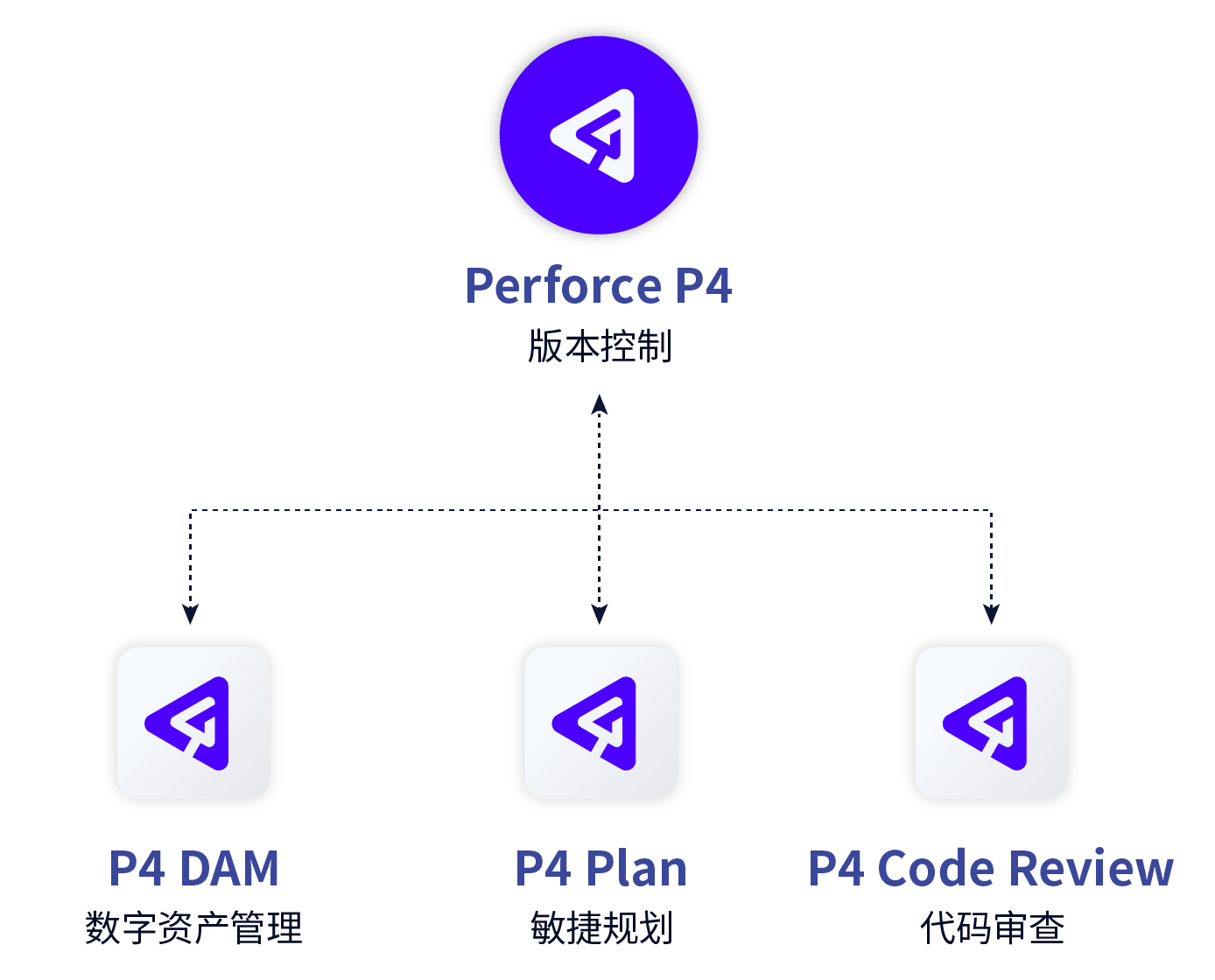
Perforce P4产品简介:无限扩展+全球协作+安全管控+工具集成(附下载)
本产品简介由Perforce中国授权合作伙伴——龙智编辑整理,旨在带您快速了解Perforce P4版本控制系统的强大之处。 世界级无限可扩展的版本控制系统 Perforce P4(原Helix Core)是业界领先的版本控制平台,备受19家全球Top20 AAA级游…...

网络协议入门:TCP/IP五层模型如何实现全球数据传输?
🔍 开发者资源导航 🔍🏷️ 博客主页: 个人主页📚 专栏订阅: JavaEE全栈专栏 内容: 网络初识什么是网络?关键概念认识协议五元组 协议分层OSI七层模型TCP/IP五层(四层&…...
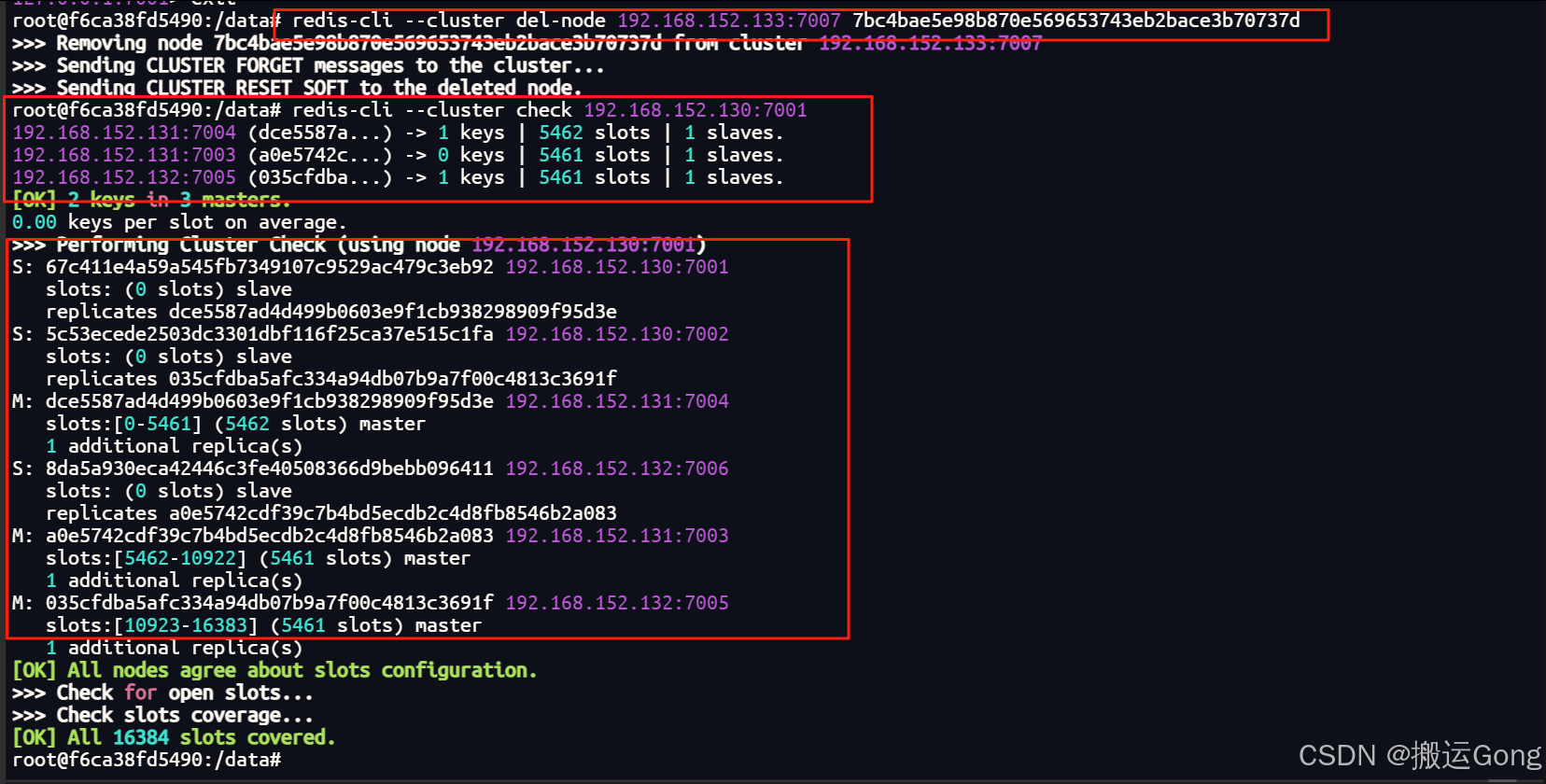
Docker安装Redis集群(3主3从+动态扩容、缩容)保姆级教程含踩坑及安装中遇到的问题解决
前言 部署集群前,我们需要先掌握Redis分布式存储的核心算法。了解这些算法能帮助我们在实际工作中做出合理选择,同时清晰认识各方案的优缺点。 一、分布式存储算法 我们通过一道大厂面试题来进行阐述。 如下:1-2亿条数据需要缓存ÿ…...
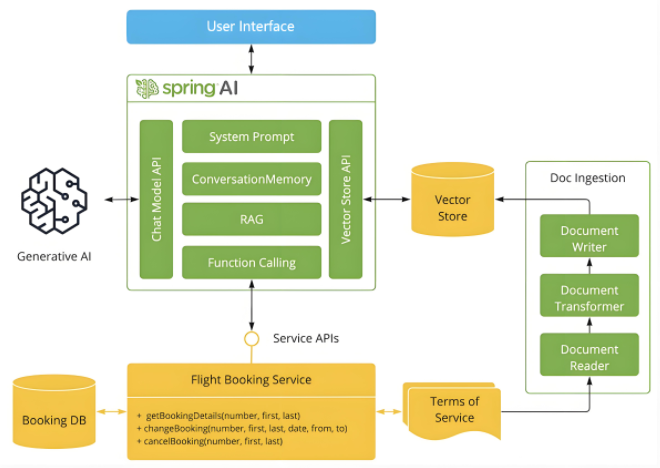
企业级 AI 开发新范式:Spring AI 深度解析与实践
一、Spring AI 的核心架构与设计哲学 1.1 技术定位与价值主张 Spring AI 作为 Spring 生态系统的重要组成部分,其核心使命是将人工智能能力无缝注入企业级 Java 应用。它通过标准化的 API 抽象和 Spring Boot 的自动装配机制,让开发者能够以熟悉的 Spr…...
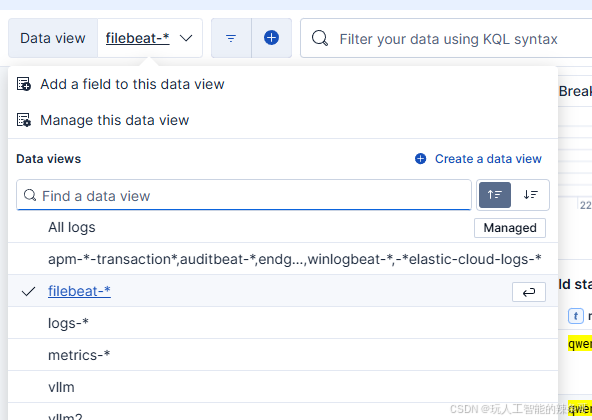
如何用docker部署ELK?
环境: ELK 8.8.0 Ubuntu20.04 问题描述: 如何用docker部署ELK? 解决方案: 一、环境准备 (一)主机设置 安装 Docker Engine :版本需为 18.06.0 或更新。可通过命令 docker --version 检查…...

Redis最佳实践——安全与稳定性保障之高可用架构详解
全面详解 Java 中 Redis 在电商应用的高可用架构设计 一、高可用架构核心模型 1. 多层级高可用体系 #mermaid-svg-Ffzq72Onkv7wgNKQ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Ffzq72Onkv7wgNKQ .error-icon{f…...
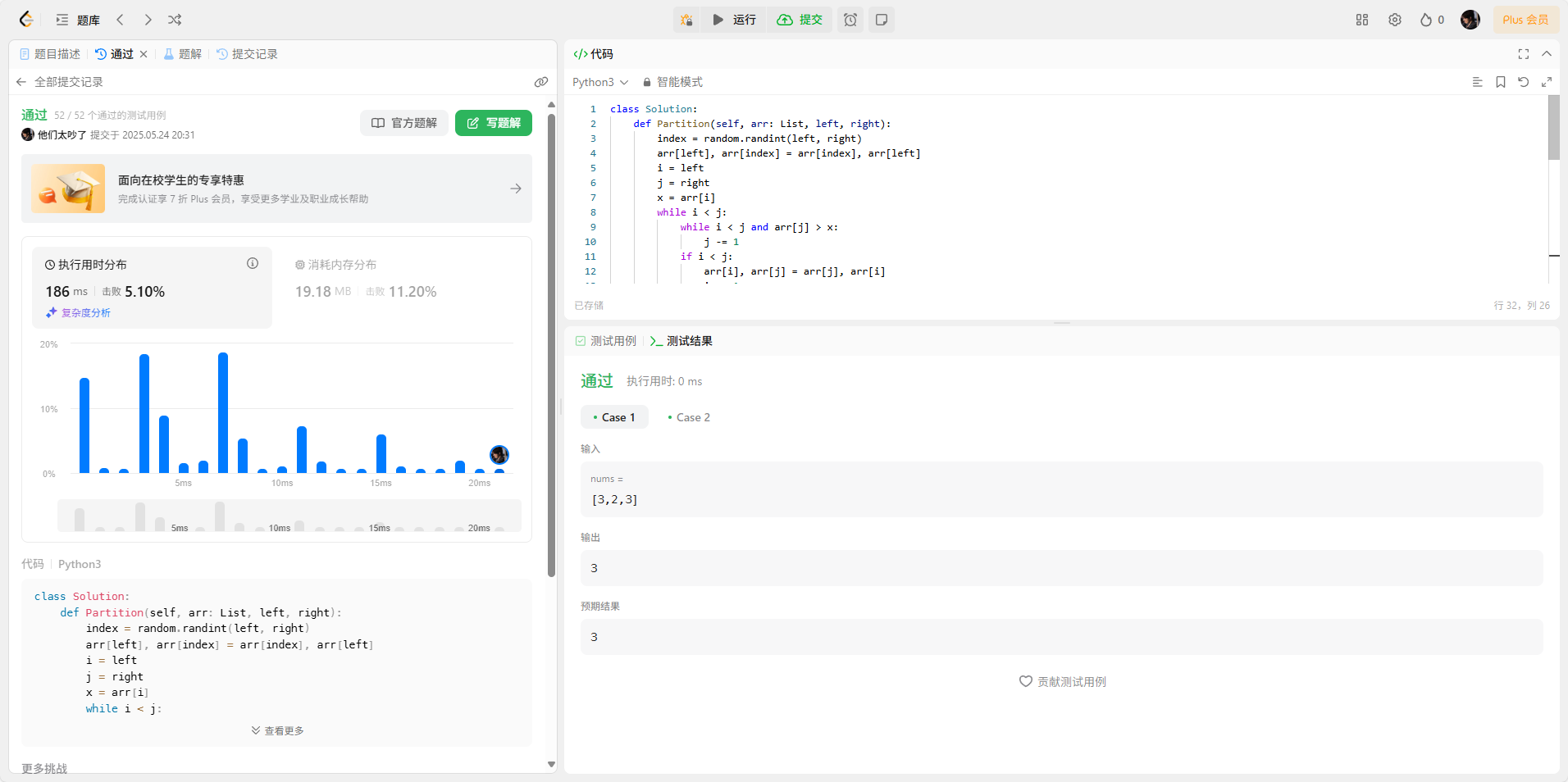
【Python 算法零基础 4.排序 ⑥ 快速排序】
既有锦绣前程可奔赴,亦有往日岁月可回首 —— 25.5.25 选择排序回顾 ① 遍历数组:从索引 0 到 n-1(n 为数组长度)。 ② 每轮确定最小值:假设当前索引 i 为最小值索引 min_index。从 i1 到 n-1 遍历,若找到…...

Java面试实战:从Spring Boot到微服务与AI的全栈挑战
场景一:初步了解和基本技术问题 面试官:我们先从基础开始,谢先生,你能简单介绍一下你在Java SE上的经验吗? 谢飞机:当然!Java就像是我的老朋友,尤其是8和11版本。我用它们做过很多…...
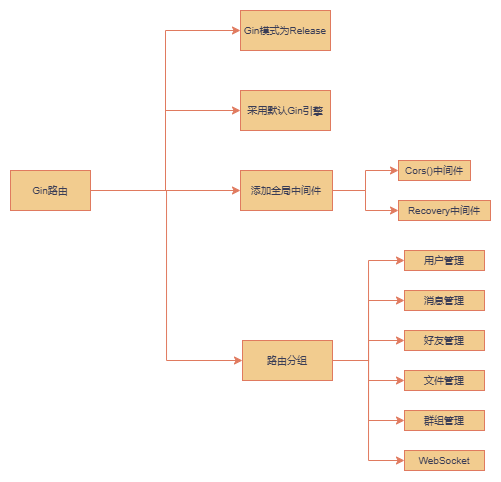
Go 即时通讯系统:日志模块重构,并从main函数开始
重构logger 上次写的logger.go过于繁琐,有很多没用到的功能;重构后只提供了简洁的日志接口,支持日志轮转、多级别日志记录等功能,并采用单例模式确保全局只有一个日志实例 全局变量 var (once sync.Once // 用于实现…...

CppCon 2014 学习:Exception-Safe Coding
以下是你提到的内容(例如 “Exception-Safe Coding 理解” 和 “Easier to Read!” 等)翻译成中文并进一步解释: 承诺:理解异常安全(Exception-Safe Coding) 什么是异常安全? 异常安全是指&a…...
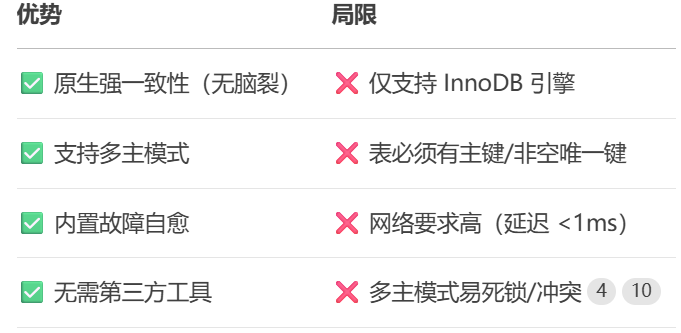
MYSQL MGR高可用
1,MYSQL MGR高可用是什么 简单来说,MySQL MGR 的核心目标就是:确保数据库服务在部分节点(服务器)发生故障时,整个数据库集群依然能够继续提供读写服务,最大限度地减少停机时间。 2. 核心优势 v…...

阿里通义实验室突破空间音频新纪元!OmniAudio让360°全景视频“声”临其境
在虚拟现实和沉浸式娱乐快速发展的今天,视觉体验已经远远不够,声音的沉浸感成为打动用户的关键。然而,传统的视频配音技术往往停留在“平面”的音频层面,难以提供真正的空间感。阿里巴巴通义实验室(Qwen Lab࿰…...
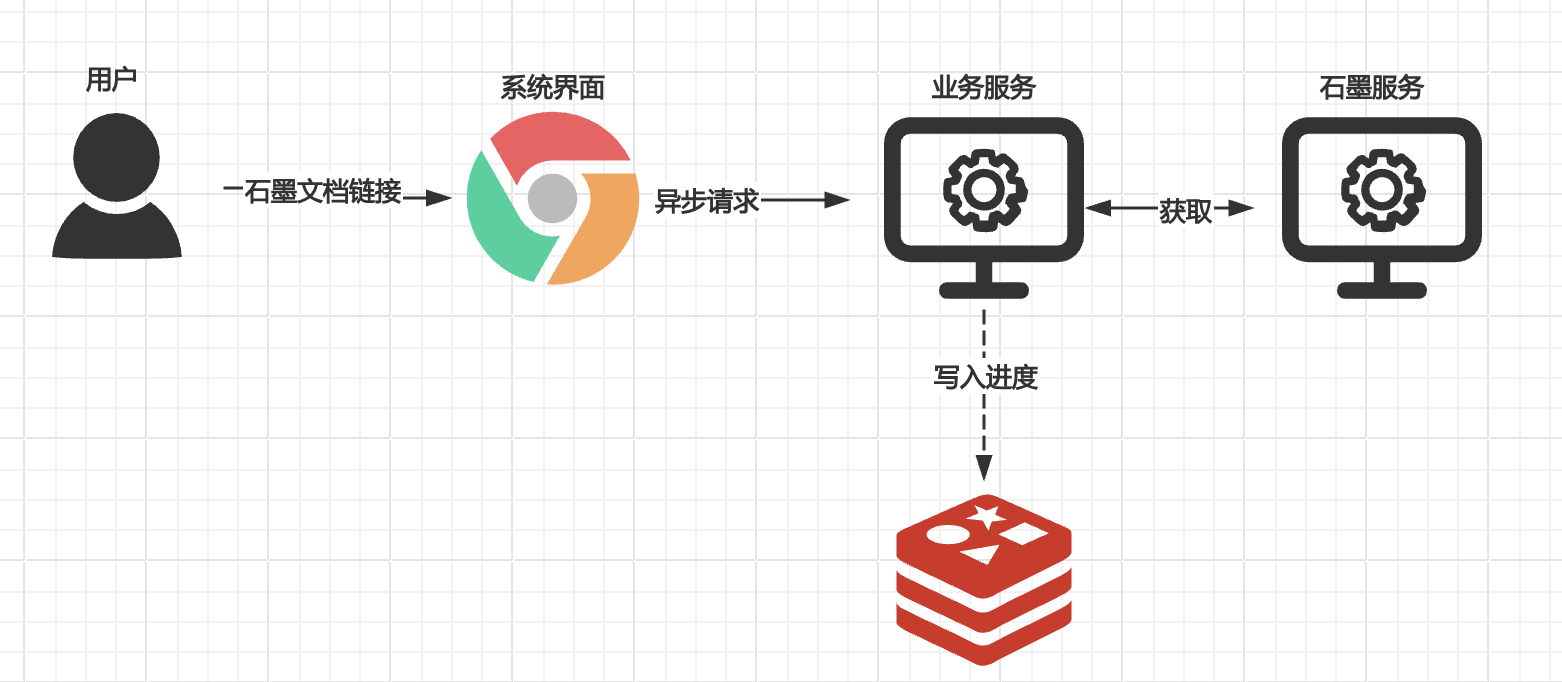
异步上传石墨文件进度条前端展示记录(采用Redis中String数据结构实现-苏东坡版本)
昔者,有客临门,亟需自石墨文库中撷取卷帙若干。此等文册,非止一卷,乃累牍连篇,亟需批量转置。然吾辈虑及用户体验,当效东坡"腹有诗书气自华"之雅意,使操作如行云流水,遂定…...
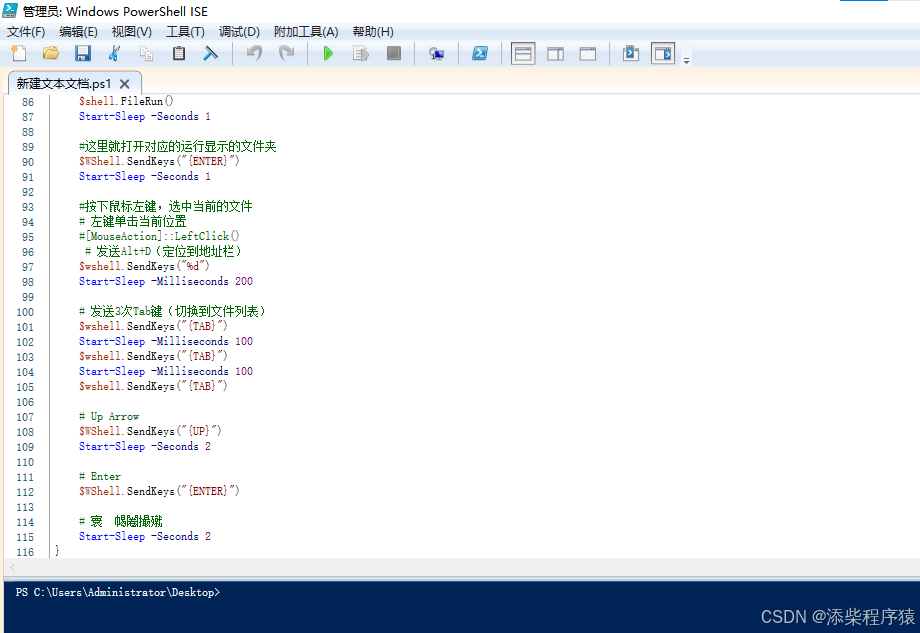
处理知识库文件_编写powershell脚本文件_批量转换其他格式文件到pdf文件---人工智能工作笔记0249
最近在做部门知识库,选用的dify,作为rag的工具,但是经过多个对比,最后发现, 比较好用的是,纳米搜索,但是可惜纳米搜索无法在内网使用,无法把知识库放到本地,导致 有信息…...
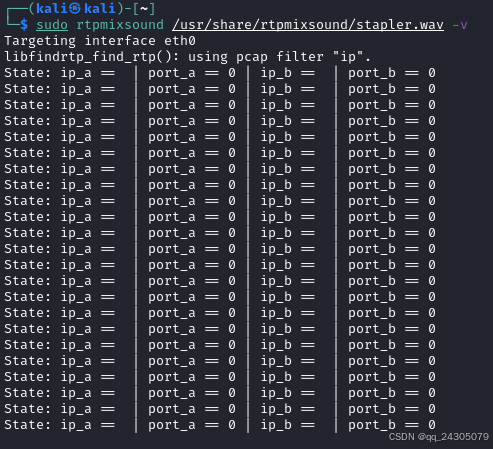
rtpmixsound:实现音频混音攻击!全参数详细教程!Kali Linux教程!
简介 一种将预先录制的音频与指定目标音频流中的音频(即 RTP)实时混合的工具。 一款用于将预先录制的音频与指定目标音频流中的音频(即 RTP)实时混合的工具。该工具创建于 2006 年 8 月至 9 月之间。该工具名为 rtpmixsound。它…...

【Netty系列】解决TCP粘包和拆包:LengthFieldBasedFrameDecoder
目录 如何使用? 1. 示例代码(基于Netty) 2. 关键参数解释 3. 协议格式示例 4. 常见配置场景 场景1:长度字段包含自身 场景2:长度字段在消息中间 5. 注意事项 举个例子 完整示例:客户端与服务端交互…...

stm与51单片机哪个更适合新手学
一句话总结 51单片机:像学骑自行车,简单便宜,但只能在小路上骑。 STM32:像学开汽车,复杂但功能强,能上高速公路,还能拉货载人(做复杂项目)。 1. 为啥有人说“先学51单片…...

【计算机网络】第3章:传输层—面向连接的传输:TCP
目录 一、PPT 二、总结 TCP(传输控制协议)详解 1. 概述 核心特性: 2. TCP报文段结构 关键字段说明: 3. TCP连接管理 3.1 三次握手(建立连接) 3.2 四次挥手(终止连接) 4. 可…...