判断使用什么技术来爬取数据详细讲解
判断目标网站使用哪种数据加载形式是爬虫开发的第一步,也是最关键的一步。以下是系统化的诊断方法和步骤:
核心诊断流程 (使用浏览器开发者工具 - Chrome/Firefox为例)
-
初始观察 (肉眼判断)
- 页面加载后数据是否立刻可见?
- 是 → 可能是静态HTML或服务器端渲染。
- 否 → 数据区域显示"Loading…"或空白 → 强烈提示JavaScript动态渲染 (AJAX/前端框架)。
- 交互行为: 滚动页面、点击标签/分页按钮后,新数据是否动态出现?
- 是 → 几乎肯定是JS动态加载 (API) 或 WebSocket。
- 数据呈现方式:
- 清晰文本 → 易于解析。
- 图片/Canvas → 可能使用图片反爬。
- 页面加载后数据是否立刻可见?
-
查看网页源代码 (
右键 -> 查看网页源代码或Ctrl+U)- 搜索目标数据: 在源代码文本中直接搜索你想要的关键数据 (如产品名称、价格、用户名)。
- 找到数据:
- 数据在可见的HTML标签内 → 纯静态HTML。
- 数据在
<script>标签内的JSON对象中 (如window.__DATA__ = {...}) → 服务器端渲染中的内联JSON。 - 数据在HTML元素的
data-*属性中 (如<div data-product='{"name": "..."}'>) → 服务器端渲染中的隐藏属性。 - 数据在HTML注释中
<!-- {"name": "..."} -->→ 服务器端渲染中的注释数据 (较少见)。
- 找不到数据: 目标数据完全不存在于源代码中 → 极大概率是JS动态渲染。
- 找到数据:
- 搜索目标数据: 在源代码文本中直接搜索你想要的关键数据 (如产品名称、价格、用户名)。
-
分析网络请求 (
F12 -> Network 面板)- 刷新页面/触发数据加载: 清空面板 (点 🚫),然后刷新页面或执行触发数据加载的操作 (如滚动、点击按钮)。
- 筛选请求类型 (重点看):
XHR或Fetch: 这是 AJAX/API 请求的主要来源!绝大多数动态数据通过这里加载。JS: 加载的JavaScript文件,可能包含数据或生成动态参数/Token的逻辑。Doc: 初始的HTML文档请求。WS(WebSocket): 实时数据流连接。Img/Font/CSS: 通常不是数据源。
- 检查响应内容:
- 在
XHR/Fetch请求中:- 找到目标数据加载时发出的请求。
- 点击该请求,查看
Preview或Response标签页。 - 看到清晰的
JSON或XML结构数据 → 恭喜!这是最理想的API 接口。 - 看到
HTML片段 → 可能是服务器返回的HTML块,需要像解析静态HTML一样处理 (复杂度较高)。 - 看到乱码或加密数据 → 可能使用了动态参数签名/加密,需要逆向JS。
- 在
WS请求中: 查看Frames标签页,看是否有持续的、结构化的数据推送。
- 在
- 分析请求细节:
Headers标签页:Request Headers: 检查Cookie,Authorization,User-Agent,Referer以及是否有自定义签名Header (如X-Sign)。这些都是模拟请求的关键。Query String Parameters/Payload: 查看请求参数。注意是否有看起来像时间戳 (ts,_t)、随机数 (nonce,rand)、或加密字符串 (sign,token) 的参数。这些是动态签名/加密的标志。
Initiator列: 点击可以跳转到是哪个JS文件发起了这个请求,帮助定位生成参数的JS代码。
-
检查DOM结构与JS执行 (
Elements面板 和Console面板)Elements面板:- 查看渲染完成后的DOM树 (包含JS动态插入的内容)。
- 对比
View Source的原始HTML,确认哪些元素是动态添加的。 - 搜索目标数据是否存在于
data-*属性中 (即使不在View Source里,也可能在动态渲染后的DOM里)。
Console面板:- 尝试输入可能的全局变量名 (如
window, 然后按Tab键查看属性),看是否能找到包含数据的对象 (如window.initialData,app.state)。如果找到,数据可能来自内联JSON。
- 尝试输入可能的全局变量名 (如
- 全局搜索 (
Ctrl+Shift+F):- 在整个页面资源 (HTML, JS, CSS) 中搜索关键数据字段名 (如
"productName","price") 或数据片段。这有助于定位内联JSON或API URL。
- 在整个页面资源 (HTML, JS, CSS) 中搜索关键数据字段名 (如
-
禁用JavaScript测试
- 在浏览器设置中临时禁用JavaScript,然后刷新目标页面。
- 观察:
- 页面布局崩了,但目标数据以文本形式可见 → 数据是服务器端渲染 (存在于初始HTML)。
- 页面基本框架在,但目标数据区域完全空白 → 数据依赖JS动态加载。
- 这是区分服务器端渲染和纯客户端渲染的终极方法之一。
判断类型的关键特征总结表
| 数据加载形式 | 关键判断特征 | 网络请求线索 | 源代码线索 |
|---|---|---|---|
| 1. 纯静态HTML | 数据在 View Source 中直接可见;禁用JS后数据仍在。 | 主要请求是 Doc (HTML);无相关XHR。 | 数据在 <body> 内的普通标签中。 |
| 2. JS动态渲染 (API) | View Source 无目标数据;禁用JS后数据消失;滚动/点击加载新数据。 | 有明确的 XHR/Fetch 请求返回 JSON/XML/HTML;请求可能含动态参数/Token。 | 无目标数据;可能包含初始化框架的JS。 |
| 3. API接口 (理想) | 同JS动态渲染,但返回数据是干净的JSON/XML。 | XHR/Fetch请求的 Response 是结构化的JSON/XML;URL常含 api, data, graphql 等词。 | 无目标数据。 |
| 4. WebSocket | 数据持续、实时更新(如股票行情、聊天)。 | Network 面板有 WS 或 WebSocket 类型连接;查看 Frames 有数据流。 | 无目标数据;包含建立WebSocket连接的JS代码。 |
| 5. 服务器渲染-内联JSON | View Source 中数据存在于 <script> 标签内(如 window.__INITIAL_STATE__);禁用JS后数据可能可见。 | 无加载数据的额外XHR(数据在初始HTML里)。 | 在 <script> 标签内找到JSON字符串。 |
| 6. 服务器渲染-隐藏属性 | View Source 或渲染后DOM中,数据在元素的 data-* 属性里。 | 无加载数据的额外XHR(数据在初始HTML里)。 | 在HTML标签属性中找到数据 (如 <div data-product='{"id": 123}'>)。 |
| 7. 图片/Canvas反爬 | 关键信息(价格、电话号)显示为图片或Canvas绘制,无法选中复制。 | 有加载图片 (Img) 或包含绘制逻辑的JS (JS) 请求。 | 包含 <img>, <canvas> 标签或操作Canvas的JS代码;无对应文本。 |
实用技巧与注意事项
- 从易到难: 优先检查
View Source和Network -> XHR,这是最高效的起点。 - 关键词搜索: 在
View Source和Network面板全局搜索数据片段或字段名。 - 关注时序: 在
Network面板按时间线 (Timing列) 排序,找到数据加载时刻发生的请求。 - 模拟操作: 精确触发你关心的数据加载动作(如点击“加载更多”),观察此时新增的网络请求。
- 参数分析: 对可疑的XHR请求,重点看
Headers(尤其是Cookie/Token) 和Payload/Query String(找动态参数)。 - JS调试: 当遇到加密参数时,利用
Initiator跳转或全局搜索参数名/加密函数名,在Sources面板打断点调试JS。 - 无头浏览器备用: 当所有分析失败或网站极度复杂时,直接用
Selenium/Playwright获取渲染后HTML,但这应是最后手段。 - 留意框架特征: 现代前端框架 (React, Vue, Angular) 基本都走API路线。查看网页源码中的JS文件名或
<meta>标签有时能发现框架线索。
总结: 判断的核心在于 View Source 有无数据 + Network 面板的XHR/Fetch请求分析。熟练掌握开发者工具,尤其是Network面板的使用,是高效识别数据来源的不二法门。遇到困难时,按上述流程一步步排查,绝大多数网站的数据加载方式都能被准确识别。
相关文章:

判断使用什么技术来爬取数据详细讲解
判断目标网站使用哪种数据加载形式是爬虫开发的第一步,也是最关键的一步。以下是系统化的诊断方法和步骤: 核心诊断流程 (使用浏览器开发者工具 - Chrome/Firefox为例) 初始观察 (肉眼判断) 页面加载后数据是否立刻可见? 是 → 可能是静态HTM…...
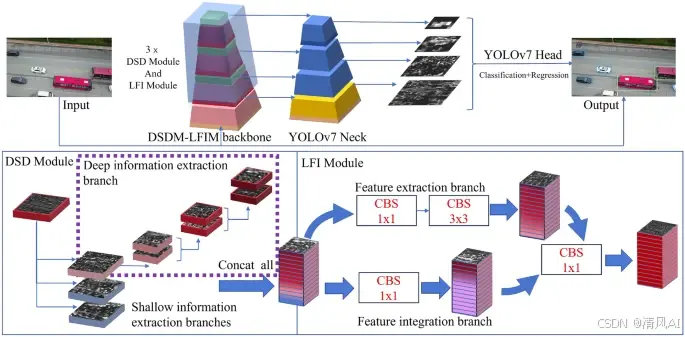
YOLOV7改进之融合深浅下采样模块(DSD Module)和轻量特征融合模块(LFI Module)
目录 一、研究背景 二. 核心创新点 2.1 避免高MAC操作 2.2 DSDM-LFIM主干网络 2.3 P2小目标检测分支 3. 代码复现指南 环境配置 关键修改点 4. 实验结果对比 4.1 VisDrone数据集性能 4.2 边缘设备部署 4.3 检测效果可视化 5. 应用场景 …...

【仿生机器人】仿生机器人认知-情感系统架构设计报告
来自 gemini 2.5 1. 执行摘要 本报告旨在为仿生机器人头部设计一个全面的认知-情感软件架构,以实现自然、情感智能的互动。拟议的架构将使机器人能够像人类一样,动态生成情绪、进行复杂的表情表达(包括情绪掩饰)、拥有强大的记忆…...

数学建模期末速成 多目标规划
内容整理自2-6-2 运筹优化类-多目标规划模型Python版讲解_哔哩哔哩_bilibili 求有效解的几种常用方法 线性加权法√ 根据目标的重要性确定一个权重,以目标函数的加权平均值为评价函数,使其达到最优。ɛ约束法 根据决策者的偏好,选择一个主要…...

常见ADB指令
目录 1. 设备连接与管理 2. 应用管理 3. 文件操作 4. 日志与调试 5. 屏幕与输入控制 6. 高级操作(需Root权限) 7. 无线调试(无需USB线) 常用组合示例 注意事项 以下是一些常用的 ADB(Android Debug Bridge&a…...

IoTGateway项目生成Api并通过swagger和Postman调用
IoTGateway项目生成Api并通过swagger和Postman调用-CSDN博客...

sl4j+log4j日志框架
sl4jlog4j日志框架 slf4j (Simple Loging Facade For Java) 即它仅仅是一个为 Java 程序提供日志输出的统一接口,并不是一个具体的日志实现方案,所以单独的 slf4j 是不能工作的,必须搭配其他具体的日志实现方案(例如:…...

小白的进阶之路系列之九----人工智能从初步到精通pytorch综合运用的讲解第二部分
张量是PyTorch中的核心数据抽象。这个交互式笔记本提供了一个深入的介绍torch. Tensor 类., 首先,让我们导入PyTorch模块。我们还将添加Python的数学模块来简化一些示例。 import torch import math创建张量 创建张量最简单的方法是调用torch.empty(): x = torch.empty(…...

深度学习与神经网络 前馈神经网络
1.神经网络特征 无需人去告知神经网络具体的特征是什么,神经网络可以自主学习 2.激活函数性质 (1)连续并可导(允许少数点不可导)的非线性函数 (2)单调递增 (3)函数本…...
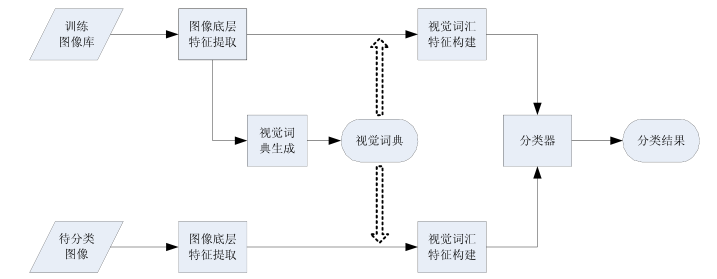
NLP学习路线图(十四):词袋模型(Bag of Words)
在自然语言处理(NLP)的广阔天地中,词袋模型(Bag of Words, BoW) 宛如一块历经岁月沉淀的基石。它虽非当今最耀眼的明星,却为整个领域奠定了至关重要的基础,深刻影响了我们让计算机“理解”文本的…...

Oracle数据库事务学习
目录 一、什么是事务,事务的作用是什么 二、事务的四大特性(ACID) 1. 原子性(Atomicity) 2. 一致性(Consistency) 3. 隔离性(Isolation) 4. 持久性(Durability) 三、关于锁的概念——表锁、行锁、死锁、乐观/悲观锁、 1.行锁 2.表锁 3.死锁 4.乐观锁 5.…...

MySQL 全量 增量备份与恢复
目录 前言 一、MySQL 数据库备份概述 1. 数据备份的重要性 2. 数据库备份类型 2.1 从物理与逻辑的角度分类 2.2 从数据库的备份策略角度分类 3. 常见的备份方法 二、数据库完全备份操作 1. 物理冷备份与恢复 1.1 备份数据库 1.2 恢复数据库 2. mysqldump 备份与恢复…...

【仿生机器人系统设计】涉及到的伦理与安全问题
随着材料科学、人工智能与生物工程学的融合突破,仿生机器人正从科幻走向现实。它们被寄予厚望——在医疗康复、老年照护、极端环境作业甚至社交陪伴等领域释放巨大价值。然而,当机器无限趋近于“生命体”,其设计过程中潜伏的伦理与安全迷宫便…...

NodeJS全栈WEB3面试题——P5全栈集成与 DApp 构建
5.1 如何实现一个完整的 Web3 登录流程(前端 后端)? ✅ 核心机制:钱包签名 后端验签 Web3 登录是基于“消息签名”来验证用户链上身份,而非传统用户名/密码。 💻 前端(使用 MetaMask&#…...
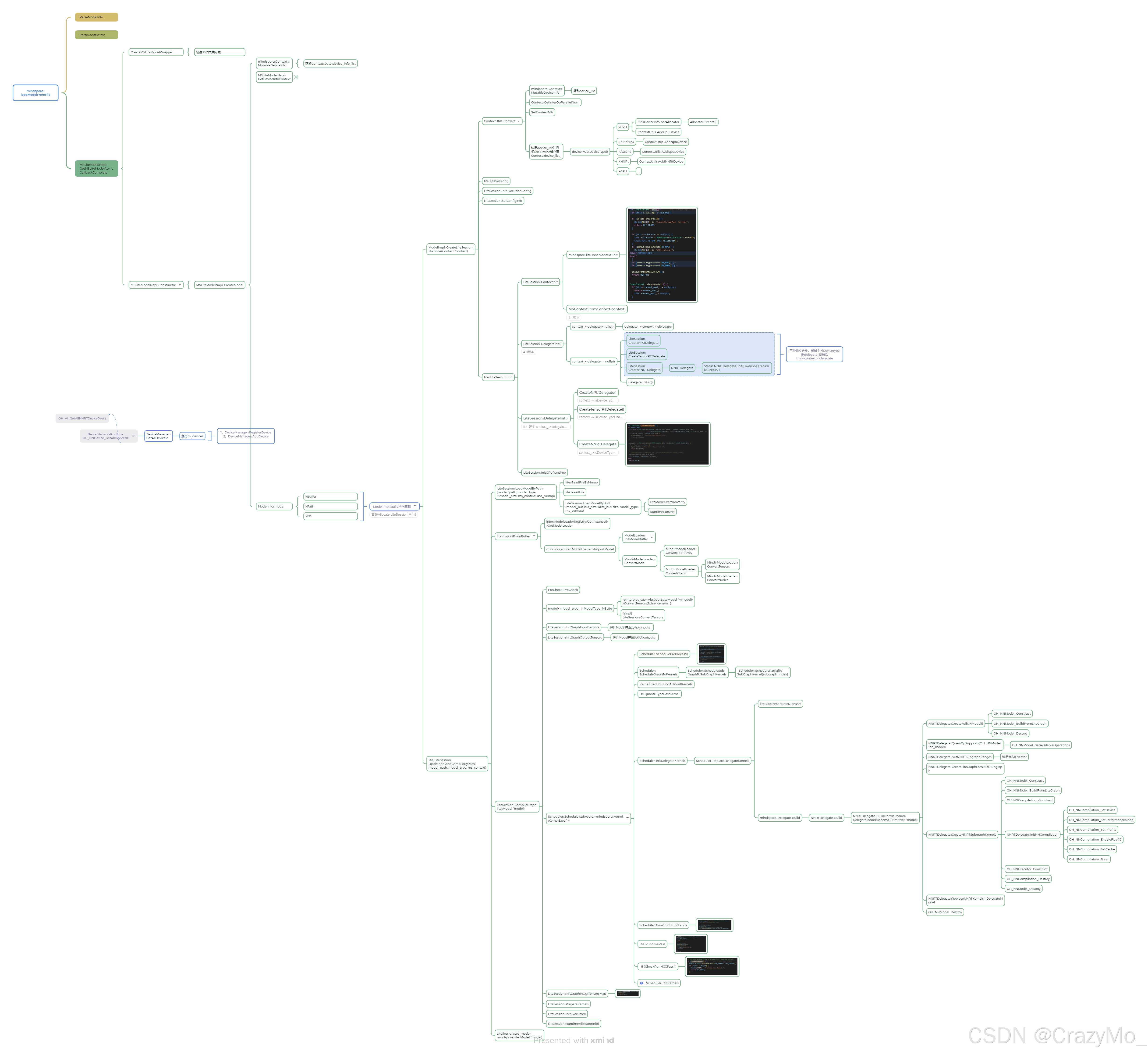
鸿蒙进阶——Mindspore Lite AI框架源码解读之模型加载详解(一)
文章大纲 引言一、模型加载概述二、核心数据结构三、模型加载核心流程 引言 Mindspore 是一款华为开发开源的AI推理框架,而Mindspore Lite则是华为为了适配在移动终端设备上运行专门定制的版本,使得我们可以在OpenHarmony快速实现模型加载和推理等功能&…...

【数据结构】图论核心算法解析:深度优先搜索(DFS)的纵深遍历与生成树实战指南
深度优先搜索 导读:从广度到深度,探索图的遍历奥秘一、深度优先搜索二、算法思路三、算法逻辑四、算法评价五、深度优先生成树六、有向图与无向图结语:深潜与回溯,揭开图论世界的另一面 导读:从广度到深度,…...

Mysql数据库 索引,事务
Mysql数据库 索引,事务 一.索引 简介 索引是数据库中用于提高查询效率的一种数据结构,它通过预先排序和存储特定列的值,帮助数据库快速定位符合条件的数据行,避免全表扫描。以下是关于索引的核心简介: 1. 核心作用…...
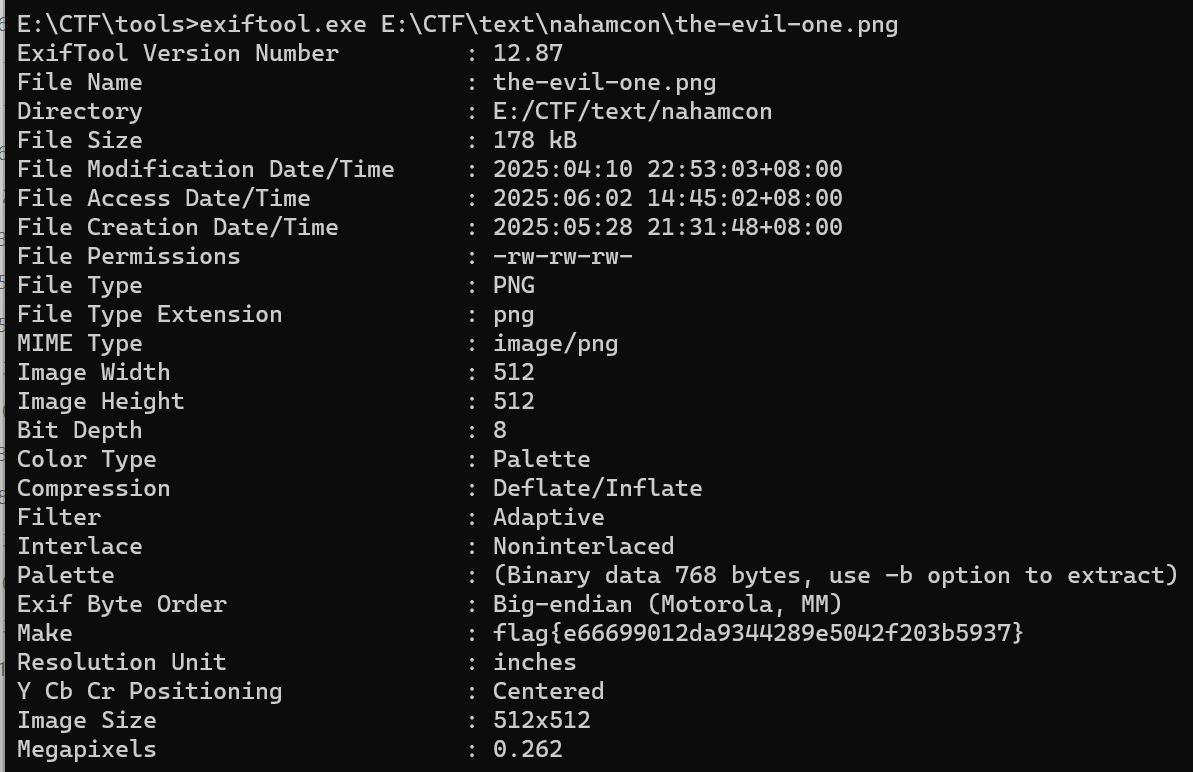
RESTful APInahamcon Fuzzies-write-up
RESTful API 路径详解 RESTful API(Representational State Transfer)是一种 基于 HTTP 协议的 API 设计风格,它通过 URL 路径 和 HTTP 方法(GET、POST、PUT、DELETE 等)来定义资源的访问方式。它的核心思想是 将数据…...

安装DockerDocker-Compose
Docker 1、换掉关键文件 vim /etc/yum.repos.d/CentOS-Base.repo ▽ [base] nameCentOS-$releasever - Base - Mirrors Aliyun baseurlhttp://mirrors.aliyun.com/centos/$releasever/os/$basearch/ gpgcheck1 enabled1 gpgkeyhttp://mirrors.aliyun.com/centos/RPM-GPG-KEY-C…...

2025年机械化设计制造与计算机工程国际会议(MDMCE 2025)
2025年机械化设计制造与计算机工程国际会议(MDMCE 2025) 2025 International Conference on Mechanized Design, Manufacturing, and Computer Engineering 一、大会信息 会议简称:MDMCE 2025 大会地点:中国贵阳 审稿通知&#…...

Java生态中的NLP框架
Java生态系统中提供了多个强大的自然语言处理(NLP)框架,以下是主要的NLP框架及其详细说明: 1、Apache OpenNLP 简介:Apache OpenNLP是Apache软件基金会的开源项目,提供了一系列常用的NLP工具。 主要功能: …...

NVM,Node.Js 管理工具
node_mirror: https://npmmirror.com/mirrors/node/ npm_mirror: https://npmmirror.com/mirrors/npm/ 一、什么是 NVM? NVM 是一个命令行工具,允许你在同一台机器上安装、切换和管理多个 Node.js 版本,解决项目间版本冲突问题。 二、安装 …...
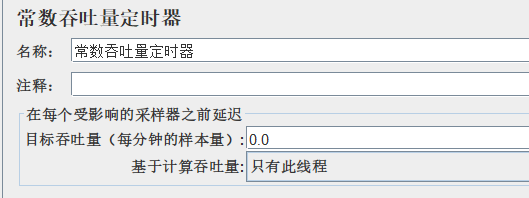
Jmeter逻辑控制器、定时器
目录 一、Jmeter逻辑控制器 ①IF(如果)控制器 作用: 位置: 参数介绍: 步骤: ②循环控制器 作用: 位置: 步骤: 线程组属性VS循环控制器 ③ForEach控制器 作用: 位置&am…...

每日八股文6.2
每日八股-6.2 Go1.GMP调度原理(这部分多去看看golang三关加深理解)2.GC(同样多去看看golang三关加深理解)3.闭包4.go语言函数是一等公民是什么意思5.sync.Mutex和sync.RWMutex6.sync.WaitGroup7.sync.Cond8.sync.Pool9.panic和rec…...
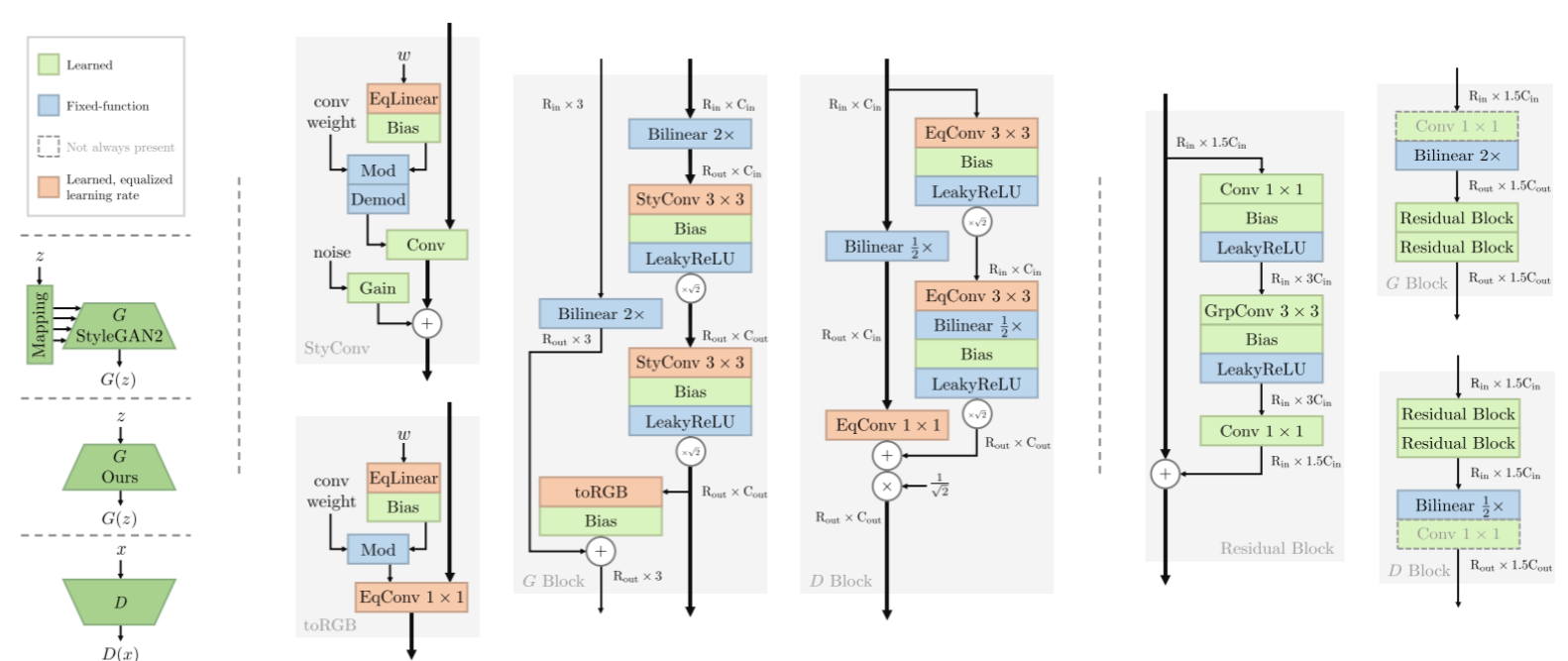
R3GAN利用配置好的Pytorch训练自己的数据集
简介 简介:这篇论文挑战了"GANs难以训练"的广泛观点,通过提出一个更稳定的损失函数和现代化的网络架构,构建了一个简洁而高效的GAN基线模型R3GAN。作者证明了通过合适的理论基础和架构设计,GANs可以稳定训练并达到优异性能。 论文题目:The GAN is dead; long l…...
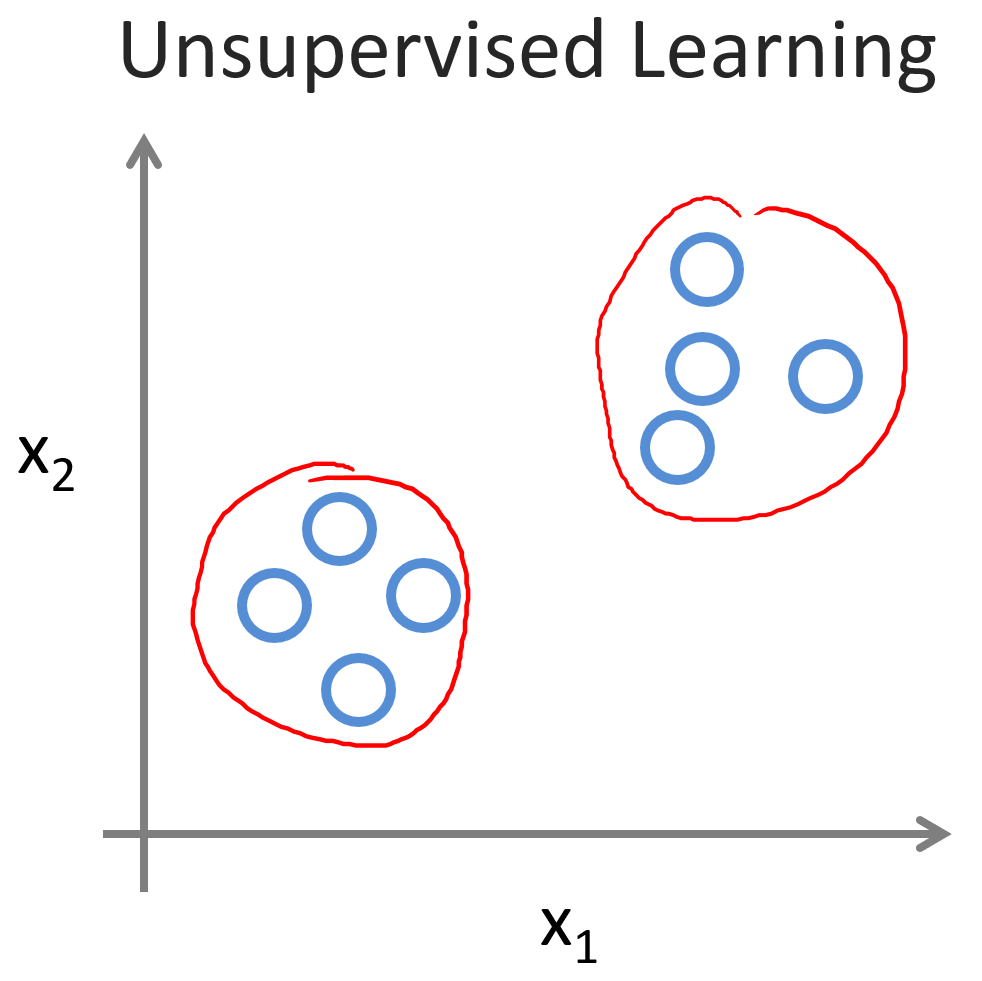
吴恩达机器学习笔记(1)—引言
目录 一、欢迎 二、机器学习是什么 三、监督学习 四、无监督学习 一、欢迎 机器学习是当前信息技术领域中最令人兴奋的方向之一。在这门课程中,你不仅会学习机器学习的前沿知识,还将亲手实现相关算法,从而深入理解其内部机理。 事实上&…...

信贷风控规则策略累计增益lift测算
在大数据风控业务实践过程中,目前业内主要还是采用规则叠加的办法做策略,但是会遇到一些问题: 1.我们有10条规则,我上了前7条后,后面3条的绝对风险增益是多少? 2.我的规则之间应该做排序吗,最重…...
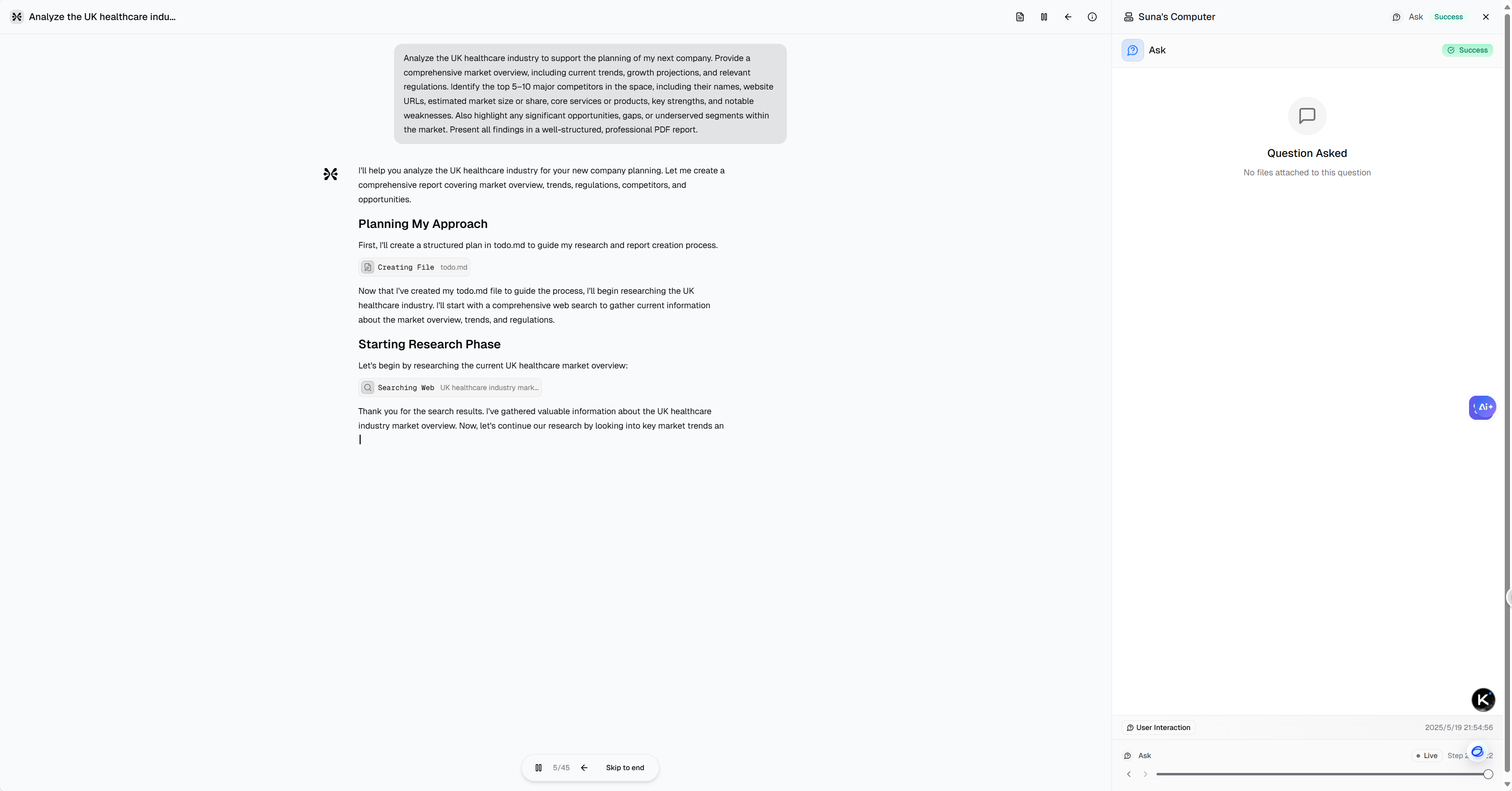
【笔记】Windows 部署 Suna 开源项目完整流程记录
#工作记录 因篇幅有限,所有涉及处理步骤的详细处理办法请参考文末资料。 Microsoft Windows [Version 10.0.27868.1000] (c) Microsoft Corporation. All rights reserved.(suna-py3.12) F:\PythonProjects\suna>python setup.py --admin███████╗██╗…...
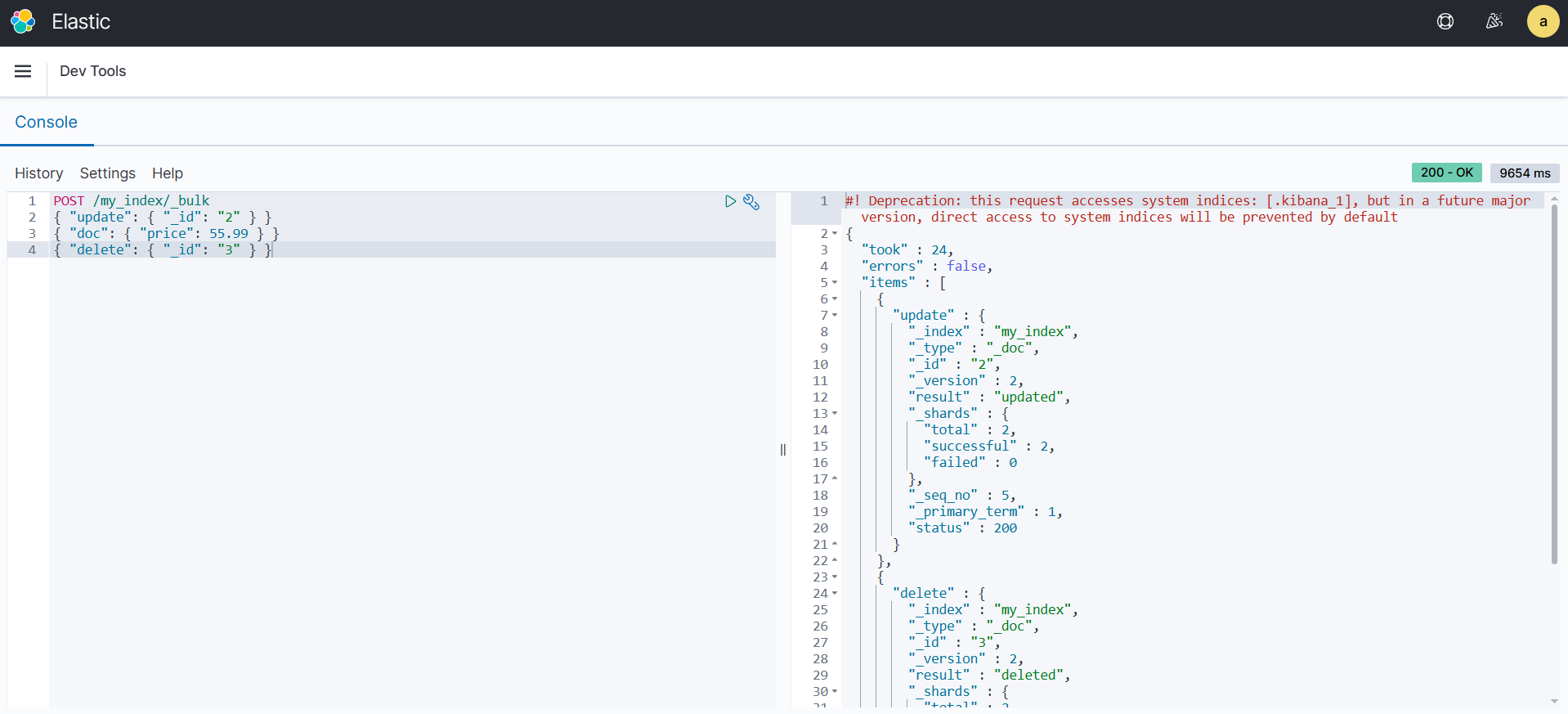
【Elasticsearch】Elasticsearch 核心技术(一):索引
Elasticsearch 核心技术(一):索引 1.索引的定义2.索引的命名规范3.索引的增、删、改、查3.1 创建索引3.1.1 创建空索引 3.2 删除索引3.3 文档操作3.3.1 添加/更新文档(指定ID)3.3.2 添加文档(自动生成ID&am…...

AudioTrack的理解
采样率说的是一秒钟采样多少点 波形频率说的是一个采样周期内有多少个波形 pcm编码说的是 16 还是8 直接决定write的时候使用short还是byte 一、初始化配置 参数设定 需定义音频格式、采样率及缓冲区大小,确保符合硬件支持范围 // 音频参数配置 int sample…...