ElasticSearch迁移至openGauss
Elasticsearch 作为一种高效的全文搜索引擎,广泛应用于实时搜索、日志分析等场景。而 openGauss,作为一款企业级关系型数据库,强调事务处理与数据一致性。那么,当这两者的应用场景和技术架构发生交集时,如何实现它们之间的平滑迁移呢?
本文将探讨 Elasticsearch 基础数据数据迁移至 openGauss 的解决方案,在此,我们首先根据等价实例来看一下 Elasticsearch 和关系型数据库(如 openGauss)的基础数据结构:
关系型数据库操作:
CREATE TABLE products (id INT PRIMARY KEY,name VARCHAR(100),price DECIMAL(10,2));INSERT INTO products VALUES (1, 'Laptop', 999.99);
Elasticsearch等价操作:
PUT /products{"mappings": {"properties": {"id": { "type": "integer" },"name": { "type": "text" },"price": { "type": "double" }}}}POST /products/_doc/1{"id": 1,"name": "Laptop","price": 999.99}
数据组织层级:
-
关系型数据库:
Database → Table → Row/Column
-
Elasticsearch:
6.x之前:Index → Type → Document (类似Database → Table → Row)
7.x之后:Index → Document (Type被移除,强化了Index≈Table的对应关系)
| Elasticsearch 概念 | 关系型数据库(如openGauss)概念 | 说明 |
|---|---|---|
| 索引(Index) | 库-表(Table) | 对应关系 |
| 类型(Type) | (已弃用,7.x后无对应) | 早期版本中类似表分区 |
| 文档(Document) | 行(Row) | 一条记录 |
| 字段(Field) | 列(Column) | 数据属性 |
| 映射(Mapping) | 表结构定义(Schema) | 定义字段类型等 |
| 索引别名(Alias) | 视图(View) | 虚拟索引/表 |
| 分片(Shard) | 分区(Partition) | 数据水平拆分 |
检索方式
1、向量检索
Elasticsearch 向量检索
# 1. 创建包含向量字段的索引PUT /image_vectors{"mappings": {"properties": {"image_name": {"type": "text"},"image_vector": {"type": "dense_vector","dims": 512}}}}# 2. 插入向量数据POST /image_vectors/_doc{"image_name": "sunset.jpg","image_vector": [0.12, 0.34, ..., 0.56] // 512维向量}# 3. 精确向量检索 (script_score)GET /image_vectors/_search{"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "cosineSimilarity(params.query_vector, 'image_vector') + 1.0","params": {"query_vector": [0.23, 0.45, ..., 0.67] // 查询向量}}}}}# 4. 近似最近邻搜索 (kNN search)GET /image_vectors/_search{"knn": {"field": "image_vector","query_vector": [0.23, 0.45, ..., 0.67],"k": 10,"num_candidates": 100}}
openGauss 向量检索(openGauss 从 7.0 版本开始支持向量检索功能)
# 1. 创建包含向量字段的表-- 创建表CREATE TABLE image_vectors (id SERIAL PRIMARY KEY,image_name TEXT,image_vector VECTOR(512) -- 512维向量);#2. 插入向量数据INSERT INTO image_vectors (image_name, image_vector)VALUES ('sunset.jpg', '[0.12, 0.34, ..., 0.56]');# 3. 精确向量检索 (余弦相似度)-- 使用余弦相似度SELECT id, image_name,1 - (image_vector <=> '[0.23, 0.45, ..., 0.67]') AS cosine_similarityFROM image_vectorsORDER BY cosine_similarity DESCLIMIT 10;# 4. 近似最近邻搜索 (使用IVFFLAT索引)-- 创建IVFFLAT索引CREATE INDEX idx_image_vector ON image_vectorsUSING IVFFLAT(image_vector) WITH (lists = 100);-- 近似最近邻查询SELECT id, image_name,image_vector <=> '[0.23, 0.45, ..., 0.67]' AS distanceFROM image_vectorsORDER BY distanceLIMIT 10;
2、全文检索
es全文检索 相当于 openGauss的LIKE和正则表达式
# es 全文检索GET /products/_search{"query": {"match": {"description": "search term"}}}# openGauss 模糊查询SELECT * FROM productsWHERE description LIKE '%search term%';# openGauss 正则表达式匹配SELECT * FROM logsWHERE message ~ 'error|warning';
因此,根据数据层级及检索方式分析,迁移时将es的索引迁移到openGauss的一张表里。
环境准备
-
已部署7.3 及以上(支持向量)版本的ElasticSearch实例
-
已部署7.0.0-RC1 及以上版本(支持向量)的openGauss实例
-
已安装3.8 及以上版本的Python环境
-
已安装涉及的Python库
pip3 install psycopg2pip3 install requestspip3 install pyOpenSSL#如果安装失败,可以考虑在一个新的虚拟环境中重新安装所需的库,执行以下命令:python3 -m venv venvsource venv/bin/activatepip install requests pyOpenSSL
前置条件
远程连接权限:
openGauss端:
#修改openGauss配置文件。将迁移脚本所在机器IP地址加入白名单,修改openGauss监听地址。# 执行以下命令gs_guc set -D {DATADIR} -c " listen_addresses = '\*'"gs_guc set -D {DATADIR} -h "host all all x.x.x.x/32 sha256"# 修改完毕后重启openGauss。gs_ctl restart -D {DATADIR}
elasticsearch端:
vim /path/to/your_elasticsearch/config/elasticsearch.yml#修改network.hostnetwork.host: 0.0.0.0
openGauss端创建普通用户(赋权)、迁移的目标数据库:
create user mig_test identified by 'Simple@123';grant all privileges to mig_test;create database es_to_og with owner mig_test;
迁移操作
1、根据本地部署的elasticsearch与openGauss对脚本进行配置修改,需要修改的内容如下:
# Elasticsearch 配置信息es_url = 'http://ip:port' # Elasticsearch 服务器地址es_index = 'your_es_index' # Elasticsearch 索引名# openGauss 配置信息db_host = '127.0.0.1' # openGauss服务器地址db_port = 5432 # openGauss 端口号db_name = 'your_opengauss_db' # 迁移到openGauss的数据库名称db_user = 'user_name' # 连接openGauss的普通用户db_password = 'xxxxxx' # 连接openGauss的用户密码
elasticsearchToOpenGauss.py迁移脚本如下:
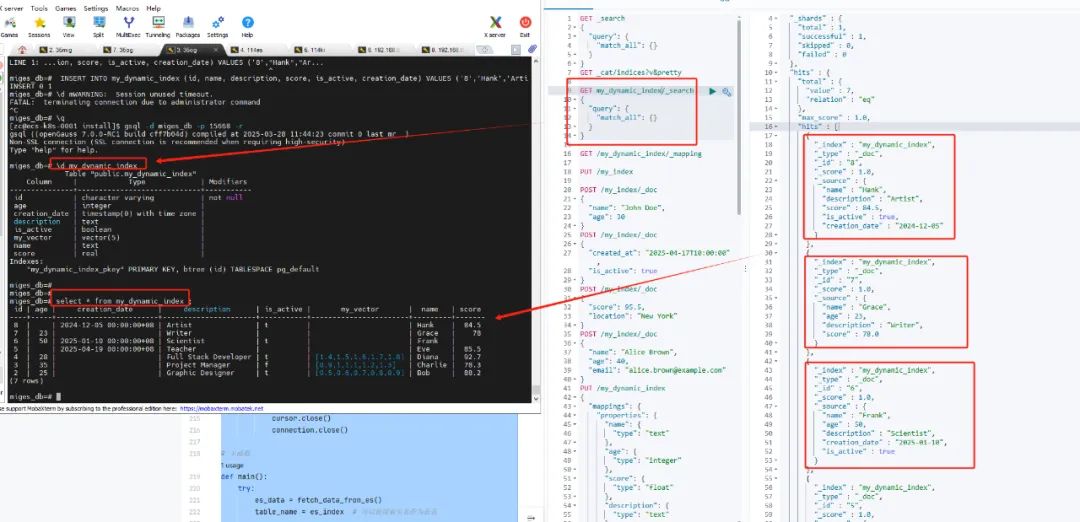
import requestsimport psycopg2import jsonimport refrom typing import List, Dict, Any, Optional, Union# Elasticsearch 配置信息es_url = 'http://192.168.0.114:9200' # Elasticsearch 服务器地址es_index = 'my_dynamic_index' # Elasticsearch 索引名# openGauss 配置信息db_host = '192.168.0.219' # openGauss服务器地址db_port = 15620 # openGauss 端口号db_name = 'es_to_og' # 迁移到openGauss的数据库名称db_user = 'mig_test' # 连接openGauss的普通用户db_password = 'xxxxxx' # 连接openGauss的用户密码RESERVED_KEYWORDS = {"select", "insert", "update", "delete", "drop", "table", "from", "where", "group","by", "having", "order", "limit", "join", "inner", "left", "right", "full", "union","all", "distinct", "as", "on", "and", "or", "not", "null", "true", "false", "case","when", "then", "else", "end", "exists", "like", "in", "between", "is", "like","references", "foreign", "primary", "key", "unique", "check", "default", "constraint","index", "unique", "varchar", "text", "int", "bigint", "smallint", "boolean", "timestamp"}# 从 Elasticsearch 获取数据def fetch_data_from_es():query = {"query": {"match_all": {}},"_source": True # 获取所有字段}response = requests.get(f'{es_url}/{es_index}/_search', json=query)if response.status_code == 200:return response.json()['hits']['hits']else:raise Exception(f"Failed to fetch data from Elasticsearch: {response.status_code}, {response.text}")# 获取索引映射信息def fetch_mapping(es_url, es_index):response = requests.get(f'{es_url}/{es_index}/_mapping')if response.status_code == 200:return response.json()else:raise Exception(f"Failed to fetch mapping: {response.status_code}, {response.text}")def get_field_type(es_url: str, es_index: str, field_name: str) -> str:""" 获取 Elasticsearch 字段的类型 """mappings = fetch_mapping(es_url, es_index)print(f"Field name: {field_name}")print(f"map: {mappings}")# 获取 properties 字段properties = mappings.get(es_index, {}).get('mappings', {}).get('properties', {})# 遍历并查找字段的类型field_type = 'text' # 默认类型为 'text'if field_name in properties:field_type = properties[field_name].get('type', 'text')elif 'fields' in properties.get(field_name, {}):# 如果字段有子字段(比如 keyword),获取 'keyword' 类型field_type = properties[field_name]['fields'].get('keyword', {}).get('type', 'text')return field_typedef convert_dict_to_jsonb(value):# 如果 value 是字典类型,递归调用该函数处理其中的每个元素if isinstance(value, dict):return json.dumps({k: convert_dict_to_jsonb(v) for k, v in value.items()})# 如果 value 是列表类型,递归处理其中的每个元素elif isinstance(value, list):return json.dumps([convert_dict_to_jsonb(v) for v in value])# 如果是其他类型(如字符串、数字),直接返回该值else:return value# 映射 Elasticsearch 数据类型到 openGauss 类型def map_to_opengauss_type(es_type: str, dim: Optional[int] = None) -> str:"""Map Elasticsearch types to openGauss types"""if isinstance(es_type, (dict, list)): # 如果 es_type 是字典类型,则需要特殊处理return 'JSONB'type_map = {"long": "BIGINT", # 大整数"integer": "INTEGER", # 整数"short": "SMALLINT", # 小整数"byte": "SMALLINT", # 小字节"float": "REAL", # 浮点数"double": "DOUBLE PRECISION", # 双精度浮点数"boolean": "BOOLEAN", # 布尔值"keyword": "VARCHAR", # 关键字(字符串类型)"text": "TEXT", # 长文本"date": "TIMESTAMP", # 日期类型"binary": "BYTEA", # 二进制数据"geo_point": "POINT", # 地理坐标(经纬度)"geo_shape": "GEOMETRY", # 复杂地理形状"nested": "JSONB", # 嵌套对象"object": "JSONB", # 对象"ip": "INET", # IP 地址"scaled_float": "REAL", # 扩展浮动类型(带缩放的浮动)"float_vector": f"VECTOR({dim})" if dim else "VECTOR", # 浮动向量类型"dense_vector": f"VECTOR({dim})" if dim else "VECTOR", # 稠密向量类型"binary_vector": f"BIT({dim})" if dim else "BIT", # 二进制向量类型"half_float": "REAL", # 半精度浮动"unsigned_long": "BIGINT", # 无符号长整数"date_nanos": "TIMESTAMP", # 高精度日期时间"alias": "TEXT", # 别名(通常是字段的别名)}# 如果 es_type 在映射表中,直接返回映射后的类型if es_type in type_map:print(f"es_type:{es_type} ----- og_type: {type_map[es_type]}")return type_map[es_type]else:print(f"Warning: Unsupported Elasticsearch type '{es_type}', defaulting to 'TEXT'")return 'TEXT' # 默认使用 TEXT 类型# 函数:将非法字符替换为下划线def sanitize_name(field_name: str) -> str:"""处理字段名,确保不会与保留字冲突,且将非字母数字字符替换为下划线"""# 将所有非字母数字字符替换为下划线sanitized_name = re.sub(r'[^a-zA-Z0-9_]', '_', field_name)# 如果是保留字,则加双引号if sanitized_name.lower() in RESERVED_KEYWORDS:return f'"{sanitized_name}"'return sanitized_name# 创建 openGauss 表def create_table_in_opengauss(es_url, es_index, table_name):columns_definition = ['id VARCHAR PRIMARY KEY'] # 增加 id 主键字段seen_fields = set() # 用于记录已经处理过的字段名# 获取 properties 字段properties = fetch_mapping(es_url, es_index).get(es_index, {}).get('mappings', {}).get('properties', {})# 遍历每个字段for field, field_info in properties.items():# 如果该字段已经处理过,跳过if field in seen_fields:continue# 获取字段的类型es_type = field_info.get('type', 'text')dim = field_info.get('dims', 0) if isinstance(field_info, dict) else 0field_type = map_to_opengauss_type(es_type, dim)sanitized_field_name = sanitize_name(field)seen_fields.add(field)columns_definition.append(f"{sanitized_field_name} {field_type}")# 生成表创建 SQLcolumns_str = ", ".join(columns_definition)create_table_sql = f"DROP TABLE IF EXISTS {sanitize_name(table_name)}; CREATE TABLE {sanitize_name(table_name)} ({columns_str});"try:# 建立数据库连接并执行创建表 SQLconnection = psycopg2.connect(host=db_host,port=db_port,dbname=db_name,user=db_user,password=db_password)cursor = connection.cursor()cursor.execute(create_table_sql)connection.commit()print(f"Table {sanitize_name(table_name)} created successfully.")except Exception as e:print(f"Error while creating table {sanitize_name(table_name)}: {e}")finally:if connection:cursor.close()connection.close()# 将数据插入到 openGauss 表中def insert_data_to_opengauss(table_name, es_source, es_id):try:# 建立数据库连接connection = psycopg2.connect(host=db_host,port=db_port,dbname=db_name,user=db_user,password=db_password)cursor = connection.cursor()# 动态生成插入 SQL 语句sanitized_columns = ['id'] + [sanitize_name(col) for col in es_source.keys()] # 清理列名values = [es_id]# 处理每一列的数据类型,必要时进行转换for column in es_source:value = es_source[column]if isinstance(value, (dict, list)):# 如果是字典类型,转换为 JSONBvalue = convert_dict_to_jsonb(value)values.append(value)columns_str = ', '.join(sanitized_columns)values_str = ', '.join(['%s'] * len(values))insert_sql = f"INSERT INTO {sanitize_name(table_name)} ({columns_str}) VALUES ({values_str})"cursor.execute(insert_sql, values)# 提交事务connection.commit()except Exception as e:print(f"Error while inserting data into {table_name}: {e}")finally:if connection:cursor.close()connection.close()# 主函数def main():try:es_data = fetch_data_from_es()table_name = es_index # 可以使用索引名作为表名create_table_in_opengauss(es_url, es_index, table_name)for record in es_data:es_source = record['_source'] # 获取 Elasticsearch 文档中的数据es_id = record['_id']insert_data_to_opengauss(table_name, es_source, es_id)print(f"Successfully inserted data into table {table_name}.")except Exception as e:print(f"Migration failed: {e}")if __name__ == "__main__":main()
2、执行脚本
python3 ./elasticsearchToOpenGauss.py3、openGauss端查看数据
#切换到迁移目标数据库openGauss=# \c es_to_og#查看迁移的表es_to_og=# \d#查看表结构es_to_og=# \d my_dynamic_index#查看表数据es_to_og=# select c
-END-
相关文章:
ElasticSearch迁移至openGauss
Elasticsearch 作为一种高效的全文搜索引擎,广泛应用于实时搜索、日志分析等场景。而 openGauss,作为一款企业级关系型数据库,强调事务处理与数据一致性。那么,当这两者的应用场景和技术架构发生交集时,如何实现它们之…...
【C语言极简自学笔记】项目开发——扫雷游戏
一、项目概述 1.项目背景 扫雷是一款经典的益智游戏,由于它简单而富有挑战性的玩法深受人们喜爱。在 C 语言学习过程中,开发扫雷游戏是一个非常合适的实践项目,它能够综合运用 C 语言的多种基础知识,如数组、函数、循环、条件判…...

Global Security Markets 第5章知识点总结
一、章节核心内容概述 《Global Securities Markets》第五章聚焦全球主要证券交易所、关联存管机构及跨境交易实务,重点解析“乘客市场(Passenger Markets)”概念与合规风险,同时涵盖交易费用、监管规则等实操要点。考虑到市场的…...

电子电路:4017计数器工作原理解析
4017是CMOS十进制计数器/分频器,它属于CD4000系列,工作电压范围比较宽,可能3V到15V。我记得它有10个译码输出端,每个输出端依次在高电平和低电平之间循环,可能用于时序控制或者LED显示什么的。 4017内部应该由计数器和译码器两部分组成。计数器部分可能是一个约翰逊计数器…...

Vim 中设置插入模式下输入中文
在 Vim 中设置插入模式下输入中文需要配置输入法切换和 Vim 的相关设置。以下是详细步骤: 1. 确保系统已安装中文输入法 在 Linux 系统中,常用的中文输入法有: IBus(推荐):支持拼音、五笔等Fcitx…...
)
GitHub 趋势日报 (2025年05月31日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1153 prompt-eng-interactive-tutorial 509 BillionMail 435 ai-agents-for-begin…...
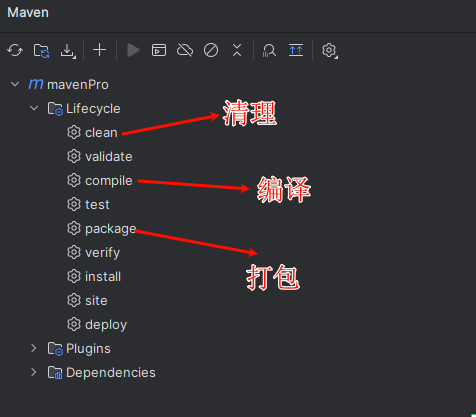
Maven概述,搭建,使用
一.Maven概述 Maven是Apache软件基金会的一个开源项目,是一个有优秀的项目构建(创建)工具,它用来帮助开发者管理项目中的jar,以及jar之间的依赖关系,完成项目的编译,测试,打包和发布等工作. 我在当前学习阶段遇到过的jar文件: MySQL官方提供的JDBC驱动文件,通常命名为mysql-…...

基于大模型的数据库MCP Server设计与实现
基于大模型的数据库MCP Server设计与实现 引言 随着大语言模型(LLM, Large Language Model)能力的不断提升,AI Agent(智能体)正在从简单的对话问答,向更复杂的自动化任务执行和业务流程管理演进。在企业和开发者的实际需求中,数据库操作是最常见、最核心的场景之一。如…...

【前端】macOS 的 Gatekeeper 安全机制阻止你加载 bcrypt_lib.node 文件 如何解决
这个弹窗是 macOS 的 Gatekeeper 安全机制阻止你加载 bcrypt_lib.node 文件,因为它不是 Apple 签名的文件。 你想 “忽视” 它,其实是让系统允许这个 .node 原生模块运行,解决方式如下: sudo xattr -d com.apple.quarantine nod…...
Unity 环境搭建
Unity是一款游戏引擎,可用于开发各种类型的游戏和交互式应用程序。它由Unity Technologies开发,并在多个平台上运行,包括Windows、macOS、Linux、iOS、Android和WebGL。Unity也支持虚拟现实(VR)和增强现实(AR)技术,允许用户构建逼…...
【入门】【练9.3】 加四密码
| 时间限制:C/C 1000MS,其他语言 2000MS 内存限制:C/C 64MB,其他语言 128MB 难度:中等 分数:100 OI排行榜得分:12(0.1*分数2*难度) 出题人:root | 描述 要将 China…...

使用 SASS 与 CSS Grid 实现鼠标悬停动态布局变换效果
最终效果概述 页面为 3x3 的彩色格子网格;当鼠标悬停任意格子,所在的行和列被放大;使用纯 CSS 实现,无需 JavaScript;利用 SASS 的模块能力大幅减少冗余代码。 HTML 结构 我们使用非常基础的结构,9 个 .i…...

Node.js 全栈开发方向常见面试题
Node.js 全栈开发”方向的面试题**,这类岗位通常包括: 后端:Node.js(Express/Nest)、数据库、REST API、安全、部署等 前端:React/Vue(部分可能含 Next.js)、API 调用、状态管理等 …...

Spring如何实现组件扫描与@Component注解原理
Spring如何实现组件扫描与Component注解原理 注解配置与包扫描的实现机制一、概述:什么是注解配置与包扫描?二、处理流程概览三、注解定义ComponentScope 四、核心代码结构1. ClassPathScanningCandidateComponentProvider2. ClassPathBeanDefinitionSca…...

历年四川大学计算机保研上机真题
2025四川大学计算机保研上机真题 2024四川大学计算机保研上机真题 2023四川大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 分数求和 题目描述 有一分数序列: 2 / 1 2/1 2/1, 3 / 2 3/2 3/2, 5 / 3 5/3 5/3, 8 / 5 8/5 8/5, 13 /…...

gcc符号表生成机制
符号表生成机制 我们以C语言的编译链接过程为例,详细讲解符号表(Symbol Table)的流程,涵盖编译和链接两个阶段。理解符号表是理解链接器如何解决符号引用(如函数、变量)的关键。 符号表分为两种ÿ…...
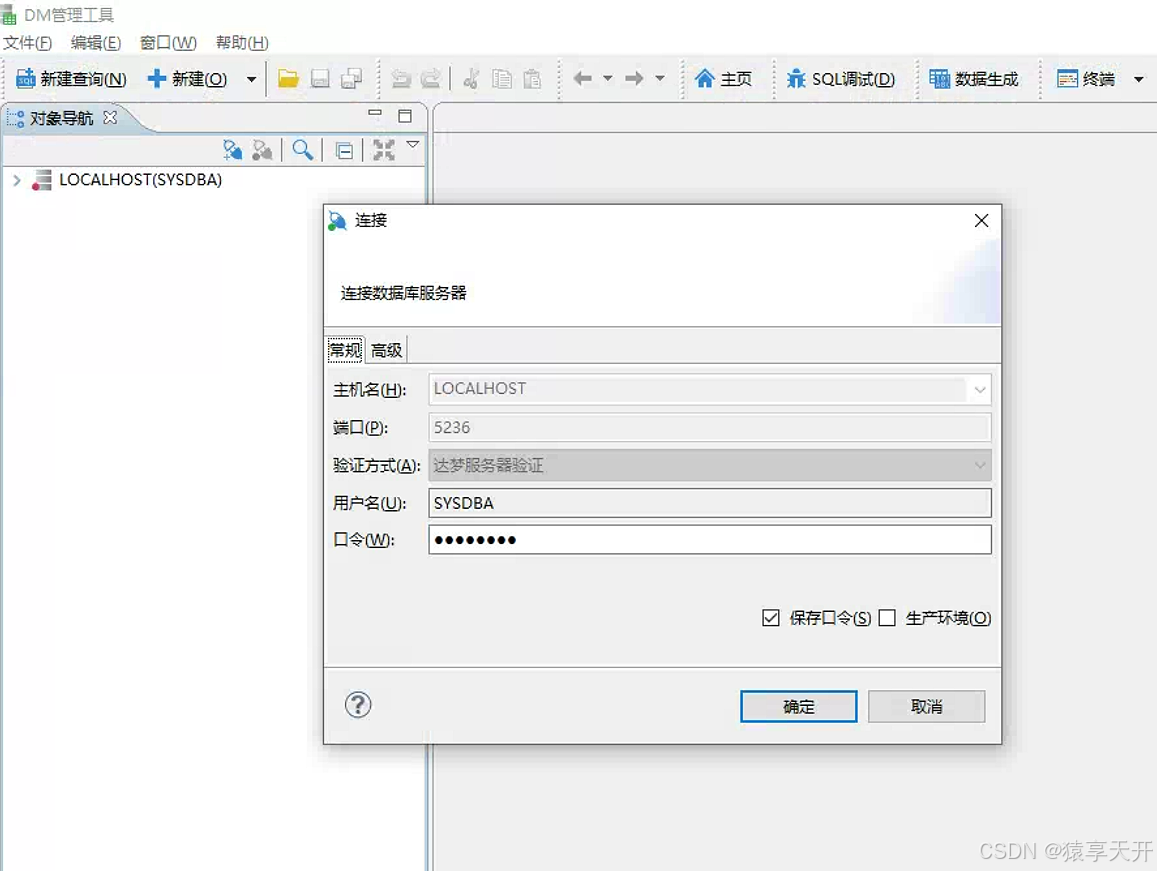
达梦数据库 Windows 系统安装教程
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

unix/linux source 命令,其基本概念、定义、性质、定理
从计算机科学的角度,特别是形式语言、操作系统和编程语言设计的角度来看,source (或 .) 命令虽然看似简单,但其背后也蕴含着一些核心的概念、定义、性质和可以类比的“定理”(或者说,更准确地是“设计原则”或“行为模式”)。 让我们尝试从一个更理论和结构化的视角来剖…...

【Java EE初阶】计算机是如何⼯作的
计算机是如何⼯作的 计算机发展史冯诺依曼体系(Von Neumann Architecture)CPU指令(Instruction)CPU 是如何执行指令的(重点) 操作系统(Operating System)进程(process) 进程 PCB 中的…...

RAG理论基础总结
目录 概念 流程 文档收集和切割 读取文档 转换文档 写入文档 向量转换和存储 搜索请求构建 向量存储工作原理 向量数据库 文档过滤和检索 检索前 检索 检索后 查询增强和关联 QuestionAnswerAdvisor查询增强 高级RAG架构 自纠错 RAG(C-RAG…...
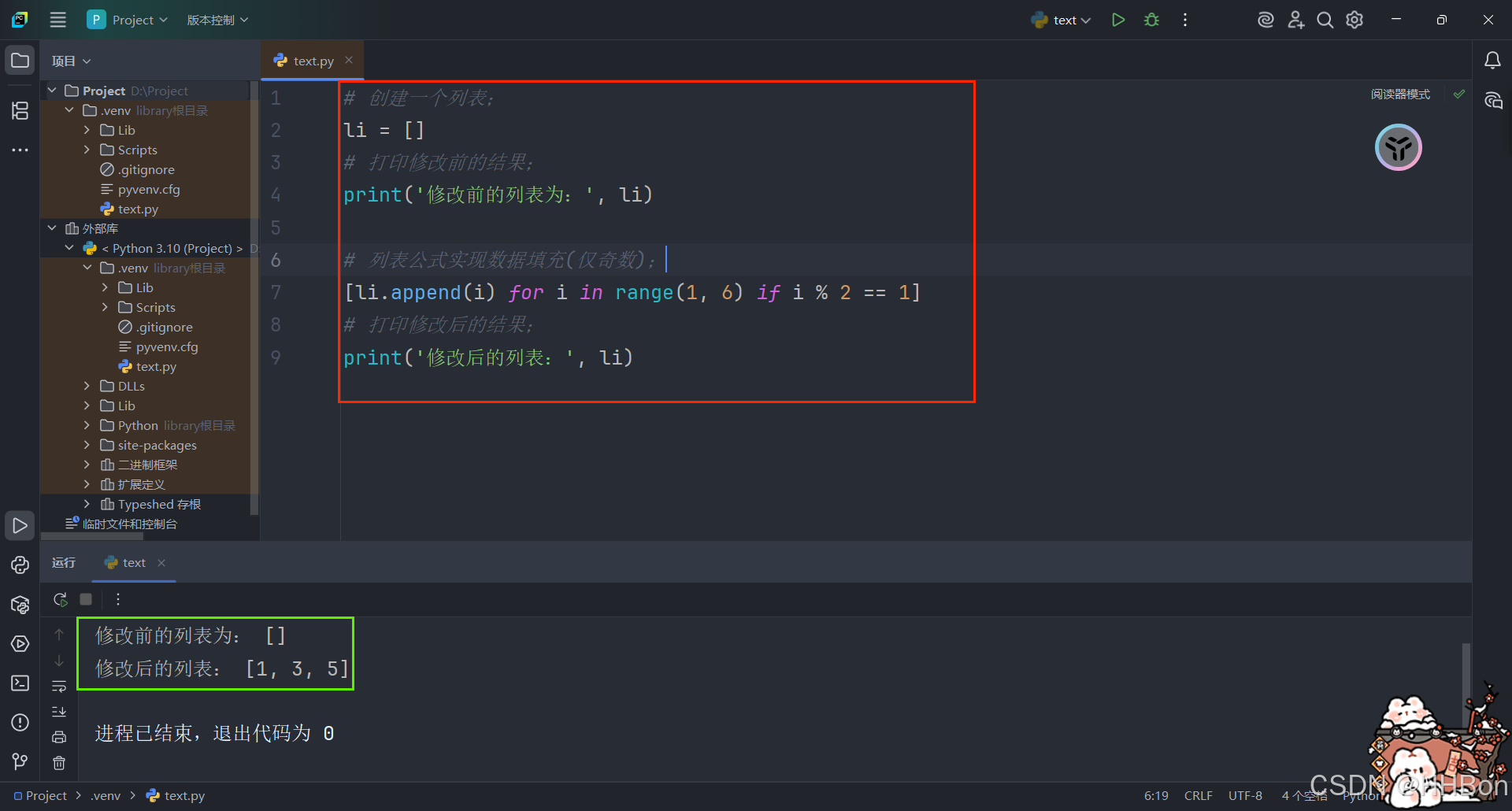
列表推导式(Python)
[表达式 for 变量 in 列表] 注意:in后面不仅可以放列表,还可以放range ()可迭代对象 [表达式 for 变量 in 列表 if 条件]...

嵌入式RTC工作原理及应用场景
20ppm 是衡量 RTC(实时时钟)精度的关键指标,表示 每百万秒(约11.57天)的最大时间误差范围。以下是通俗易懂的解释: 1. ppm 的含义 ppm Parts Per Million(百万分之一) 1 ppm 1/1,…...

一天搞懂深度学习--李宏毅教程笔记
目录 1. Introduction of Deep Learning1.1. Neural Network - A Set of Function1.2. Learning Target - Define the goodness of a function1.3. Learn! - Pick the best functionLocal minimaBackpropagation 2. Tips for Training Deep Neural Network3. Variant of Neural…...

Go语言常见接口设计技巧-《Go语言实战指南》
在 Go 中,接口是连接代码组件的桥梁。合理设计接口可以大幅提升程序的可维护性、可扩展性和测试友好性。本章将分享 Go 开发中常见的接口设计技巧与最佳实践。 一、接口设计原则 1. 面向接口编程,而非面向实现编程 尽量使用接口类型作为函数参数或返回值…...

python打卡训练营打卡记录day43
复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 数据集来源:Flowers Recognition 选择该数据集原因: 中等规模:4242张图片 - 训练快速但足够展示效…...
检测流程详解)
Camera相机人脸识别系列专题分析之十一:人脸特征检测FFD算法之低功耗libvega_face.so人脸属性(年龄,性别,肤色,微笑,种族等)检测流程详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:Camera相机人脸识别系列专题分析之十:人脸特征检测FFD算法之低功耗libvega_face.so人脸识别检测流程详解 这一篇我们开始讲: Camera相机人脸识别系列专题分析之十一:人脸特征检测FFD算法之低功耗lib…...
.)
解决:输入SSH后,仍无法通过网址登录以及紧接着的新问题Permission denied(publickey,password).
现象: 管理员: Windows PowerShell输入SSH后,仍无法通过网址登录 例如输入你的ssh命令:ssh -CNg -L xxxx:127.0.0.1:xxxx rootaaaaaaaaa.com -p yyyyy 得到终端提示:ssh无法识别为 cmdlet、函数、脚本文件或可运行程序的名称。 解…...
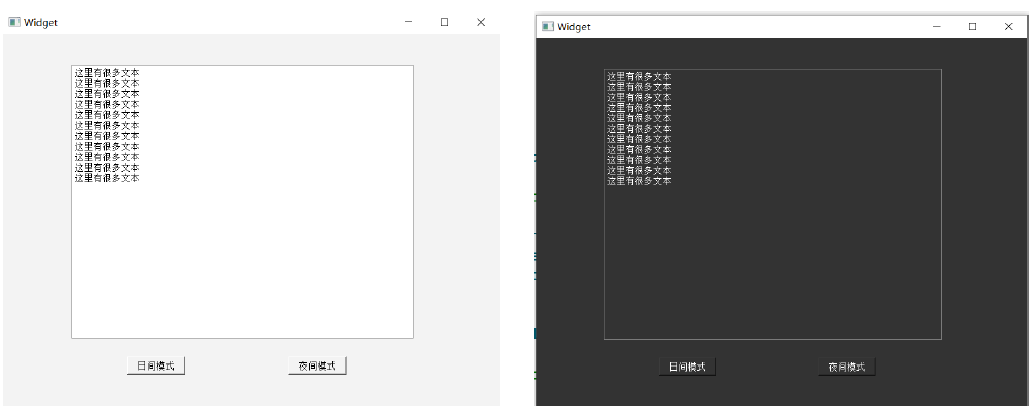
【QT控件】QWidget 常用核心属性介绍 -- 万字详解
目录 一、控件概述 二、QWidget 核心属性 2.1 核心属性概览 2.2 enabled 编辑 2.3 geometry 2.4 windowTitle 2.5 windowIcon 使用qrc文件管理资源 2.6 windowOpacity 2.7 cursor 2.8 font 编辑 2.9 toolTip 2.10 focusPolicy 2.11 styleSheet QT专栏&…...
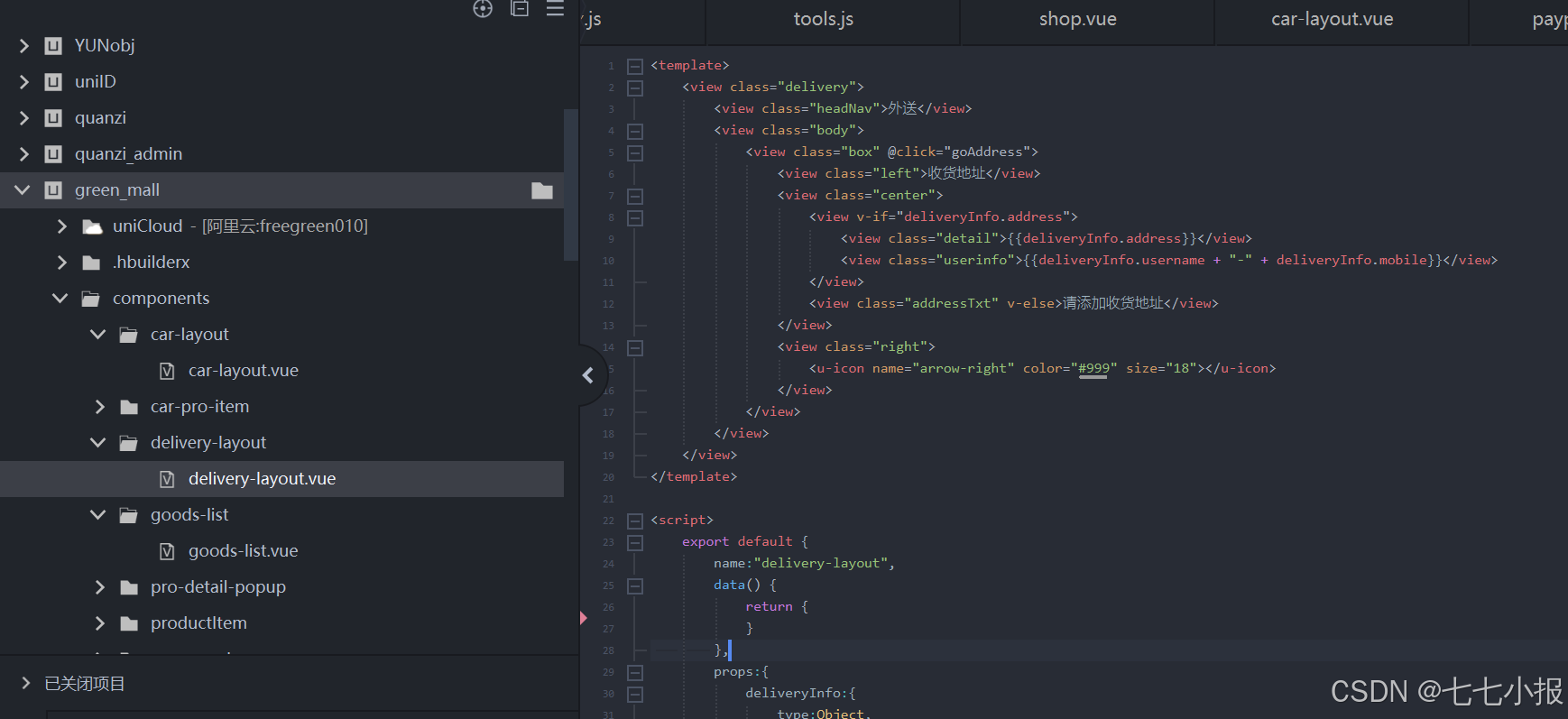
uniapp-商城-77-shop(8.2-商品列表,地址信息添加,级联选择器picker)
地址信息,在我们支付订单上有这样一个接口,就是物流方式,一个自提,我们就显示商家地址。一个是外送,就是用户自己填写的地址。 这里先说说用户的地址添加。需要使用到的一些方式方法,主要有关于地址选择器,就是uni-data-picker级联选择。 该文介绍了电商应用中地址信息处…...

HTTPS加密通信详解及在Spring Boot中的实现
HTTPS(Hyper Text Transfer Protocol Secure)是HTTP的安全版本,通过SSL/TLS协议为通讯提供加密、身份验证和数据完整性保护。 一、HTTPS核心原理 1.加密流程概述 客户端发起HTTPS请求(连接到服务器443端口)服务器返…...