RAG入门 - Retriever(1)
文章目录
- 环境准备
- 知识库加载
- 1. Retriever - embeddings 🗂️
- 1.1 将文档拆分为chunks
- 1.2 词嵌入
- 1.3 构建向量数据库
- Nearest Neighbor search algorithm (最近邻搜索算法)
- Distances (距离)
- 点积(Dot Product):
- 余弦相似度(Cosine Similarity):
- 欧式距离(Euclidean Distance)公式
- 1.4 重排序(Reranking)
- Colbertv2
- Bi-encoder vs Cross-encoder
众所周知,RAG 系统很复杂,包含很多部分,下图描述了 RAG 中的关键部分,蓝色标注的内容是需要被持续优化的。

💡 从上图能看出来,RAG 架构中有许多步骤是可以优化的,正确的优化会带来显著的效果提升。
在这篇文章中,我们会重点关注蓝色内容,来调整我们自己的 RAG 系统来获得最佳效果。
现在,让我们把手弄脏,直接跟着文章的思路来了解RAG的优化过程。
环境准备
在开始之前,我们需要装好如下依赖:
# 建议使用conda创建一个干净的虚拟环境
conda create --name huggingface python=3.10 -y
conda activate huggingface
pip install torch transformers accelerate bitsandbytes langchain sentence-transformers openpyxl pacmap datasets langchain-community ragatouille faiss
faiss安装可能会出现问题,解决方案:
$ pip install faiss-cpu
# or:
$ pip install faiss-gpu-cu12 # CUDA 12.x, Python 3.8+
$ pip install faiss-gpu-cu11 # CUDA 11.x, Python 3.8+
$ pip install faiss-gpu # Python 3.6-3.10 (legacy, no longer available after version 1.7.3)
torch、cuda 等安装验证及版本查看:
import torch # 获取 PyTorch 版本信息 print("PyTorch Version: {}".format(torch.version.__version__)) # 或直接使用 torch.__version__ print("PyTorch CUDA Version: {}".format(torch.version.cuda)) # 获取 CUDA 版本 print("PyTorch cuDNN Version: {}".format(torch.backends.cudnn.version())) # 获取 cuDNN 版本
因为在文章代码中会自动下载huggingface上的模型和数据集,会默认存储在~/.cache/huggingface目录下。如果你担心系统盘不够存储这些数据,你也可以修改huggingface cache的默认根目录:
export HF_HOME="/{to_path}/huggingface"# 为了不用每次都执行,你可以直接写入bash配置
echo 'export HF_HOME="/{to_path}/huggingface"' >> ~/.bashrc
另外,国内访问huggingface是受限的(墙),我们可以使用huggingface 国内镜像站运行python脚本:
HF_ENDPOINT=https://hf-mirror.com python advanced_rag.py
from tqdm.notebook import tqdm
import pandas as pd
from typing import Optional, List, Tuple
from datasets import Dataset
import matplotlib.pyplot as plt
pd.set_option("display.max_colwidth", None) # This will be helpful when visualizing retriever outputs
知识库加载
import datasets
ds = datasets.load_dataset("m-ric/huggingface_doc", split="train")
from langchain.docstore.document import Document as LangchainDocument
RAW_KNOWLEDGE_BASE = [LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]}) for doc in tqdm(ds)]
1. Retriever - embeddings 🗂️
retriever像一个内置的搜索引擎:接收用户的查询,返回知识库中的一些相关片段。这些片段会输入到Reader Model(如deepseek)中,来帮助它生成答案。因此,现在我们的目标就是,基于用户的问题,从我们的知识库中找到最相关的片段来回答这个问题。这是一个宽泛的目标,它引申出了一堆问题。比如我们应该检索多少个片段?这个关于片段数量的参数就被命名为 top_k 。再比如,每个片段应该有多长?这个片段长度的参数就被称为 chunk size 。这些问题没有唯一的适合所有情况的答案,但有一些相关知识我们可以了解下:
-
🔀 不同的片段可以有不同的
chunk size。 -
由于检索内容中总会有一些噪音,增加
top_k的值会增加在检索到的片段中获得相关内容的机会。类似射箭🎯, 射出更多的箭会增加你击中目标的概率。 -
同时,检索到的文档的总长度不应太长:比如,对于目前大多数的模型,16k的token数量可能会让模型因为“Lost in the middle phenomemon”而淹没在信息中。所以,只给模型提供最相关的见解,而不是一大堆内容!
在这篇文章中,我们使用 Langchain 库,因为它提供了大量的向量数据库选项,并允许我们在处理过程中保持文档的元数据。
1.1 将文档拆分为chunks
在这一部分,我们将知识库中的文档拆分为更小的chunks,chat LLM 会基于这些chunks进行回答。我们的目标是得到一组语义相关的片段。因此,它们的大小需要适应具体的主题或者说是中心思想:太小的话会截断中心思想,太大可能就会稀释中心思想,被其他不相关内容干扰。
💡 现在有许多拆分文本内容的方案,比如:按词拆分、按句子边界拆分、递归拆分(以树状方式处理文档以保留结构信息)……要了解更多关于文本拆分的内容,可以参考这篇文档。
递归分块通过使用一组按重要性排序的分隔符,将文本逐步分解为更小的部分。如果第一次拆分没有给出正确大小的块,它就会在新的块上使用不同的分隔符来重复这个步骤。比如,我们可以使用这样的分隔符列表 ["\n\n", "\n", ".", ""] :
这种方法很好的保留了文档的整体结构,但代价是块大小会有轻微的变化。
这里可以让你看到不同的拆分选项会如何影响你得到的块。
🔬 让我们先用一个任意大小的块来做一个实验,看看拆分具体是怎么工作的。我们直接使用 Langchain 的递归拆分类 RecursiveCharacterTextSplitter 。
from langchain.text_splitter import RecursiveCharacterTextSplitter# We use a hierarchical list of separators specifically tailored for splitting Markdown documents
# This list is taken from LangChain's MarkdownTextSplitter class
MARKDOWN_SEPARATORS = ["\n#{1,6} ","```\n","\n\\*\\*\\*+\n","\n---+\n","\n___+\n","\n\n","\n"," ","",
]text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, # The maximum number of characters in a chunk: we selected this value arbitrarilychunk_overlap=100, # The number of characters to overlap between chunksadd_start_index=True, # If `True`, includes chunk's start index in metadatastrip_whitespace=True, # If `True`, strips whitespace from the start and end of every documentseparators=MARKDOWN_SEPARATORS,
)docs_processed = []
for doc in RAW_KNOWLEDGE_BASE:docs_processed += text_splitter.split_documents([doc])
-
其中,参数
chunk_size控制单个块的长度:这个长度默认是按块中的字符数来计算的。 -
参数
chunk_overlap是为了允许相邻的块之间有一些重叠,这能够减少一个主题可能在两个相邻块的分割中被切成两半的概率。我们把它设置为块大小的 1/10,当然你也可以自己尝试其他不同的值!
我们利用以下代码看看chunk的长度分布:
lengths = [len(doc.page_content) for doc in tqdm(docs_processed)]# Plot the distribution of document lengths, counted as the number of chars
fig = pd.Series(lengths).hist()
plt.title("Distribution of document lengths in the knowledge base (in count of chars)")
plt.show()
💡如果你使用了远程设备不支持直接使用
plt.show()可视化,可以换成用如下代码直接保存成图片。plt.savefig("chunk_sizes_char.png", dpi=300, bbox_inches="tight")
可视化结果如下,我们可以看到最大的块的字符长度不会超过1000,这和我们预先设置的参数一致。

1.2 词嵌入
接下来,我们需要使用词嵌入模型来对分块进行向量化。在使用词嵌入模型时,我们需要知道模型能接受的最大序列长度max_seq_length(按照token数统计)。需要确保分块的token数低于这个值,因为超过max_seq_length的块在处理之前都会被截断,从而失去相关性。这里我们使用的嵌入模型是thenlper/gte-small, 下面代码先打印了该模型支持的最大长度,然后再对分块结果进行token数量的分布统计。
from sentence_transformers import SentenceTransformer# To get the value of the max sequence_length, we will query the underlying `SentenceTransformer` object used in the RecursiveCharacterTextSplitter
print(f"Model's maximum sequence length: {SentenceTransformer('thenlper/gte-small').max_seq_length}")from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
lengths = [len(tokenizer.encode(doc.page_content)) for doc in tqdm(docs_processed)]# Plot the distribution of document lengths, counted as the number of tokens
fig = pd.Series(lengths).hist()
plt.title("Distribution of document lengths in the knowledge base (in count of tokens)")
plt.show()
上面代码会先输出:
Model's maximum sequence length: 512
表示thenlper/gte-small 支持的最大块长度是 512
可视化结果如下:

👀 可以看到,某些分块的token数量超过了 512 的限制,这样就会导致分块中的一部分内容会因截断而丢失!
-
既然是基于token数来统计,那我们就应该将
RecursiveCharacterTextSplitter类更改为以token数量而不是字符数量来计算长度。 -
然后我们可以选择一个特定的块大小,这里我们选择一个低于 512 的阈值:
-
较小的文档可以使分块更专注于特定的主题。
-
但过小的块又会将完整的句子一分为二,从而再次失去意义,所以这也需要我们根据实际情况进行权衡。
-
from langchain.text_splitter import RecursiveCharacterTextSplitter
from transformers import AutoTokenizerEMBEDDING_MODEL_NAME = "thenlper/gte-small"def split_documents(chunk_size: int,knowledge_base: List[LangchainDocument],tokenizer_name: Optional[str] = EMBEDDING_MODEL_NAME,
) -> List[LangchainDocument]:"""Split documents into chunks of maximum size `chunk_size` tokens and return a list of documents."""text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(AutoTokenizer.from_pretrained(tokenizer_name),chunk_size=chunk_size,chunk_overlap=int(chunk_size / 10),add_start_index=True, # 是否在每个分块的 metadata 中添加该分块在原始文档中的起始字符索引strip_whitespace=True, # 是否去除每个分块开头和结尾的空白字符(如空格、换行等)separators=MARKDOWN_SEPARATORS,)docs_processed = []for doc in knowledge_base:docs_processed += text_splitter.split_documents([doc])# Remove duplicatesunique_texts = {}docs_processed_unique = []for doc in docs_processed:if doc.page_content not in unique_texts:unique_texts[doc.page_content] = Truedocs_processed_unique.append(doc)return docs_processed_uniquedocs_processed = split_documents(512, # We choose a chunk size adapted to our modelRAW_KNOWLEDGE_BASE,tokenizer_name=EMBEDDING_MODEL_NAME,
)# Let's visualize the chunk sizes we would have in tokens from a common model
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained(EMBEDDING_MODEL_NAME)
lengths = [len(tokenizer.encode(doc.page_content)) for doc in tqdm(docs_processed)]
fig = pd.Series(lengths).hist()
plt.title("Distribution of document lengths in the knowledge base (in count of tokens)")
plt.show()
可视化结果如下图,可以看到,现在块长度的分布看起来比之前好很多了!

1.3 构建向量数据库
接下来,我们需要把所有块的词嵌入结果存到向量数据库中,当用户输入问题时,问题本身也会被先前使用的相同词嵌入模型进行词嵌入(向量化),并通过相似性搜索返回向量数据库中最接近的文档。如果你想了解更多词嵌入的信息,可以参考这篇指南。这里的难点在于,给定一个查询向量,快速找到该向量在向量数据库中的最近邻。为此,我们需要确定两个东西:一种距离度量方式和一种搜索算法,以便在数千条记录的数据库中快速找到最近邻。
Nearest Neighbor search algorithm (最近邻搜索算法)
最近邻搜索算法有很多,这里我们直接选择 Facebook 的 FAISS (Facebook AI Similarity Search)。它既能用于高效相似性搜索,又能作为密集向量存储库。
FAISS能够:
-
将文档、图像等数据转换为向量后进行高效的相似度搜索
-
支持多种距离计算方式(如代码中使用的余弦相似度
DistanceStrategy.COSINE) -
处理大规模向量数据集
FAISS特点:
-
支持 CPU 和 GPU 加速
-
提供多种索引类型以平衡速度和准确性
-
可以本地保存和加载索引(如代码中的
save_local和load_local) -
内存效率高,适合处理大规模数据
FAISS优势:
-
搜索速度快
-
资源消耗相对较低
-
集成简单,特别是与 LangChain 等框架配合使用
-
支持增量更新索引
Distances (距离)
关于向量间的距离,我们先来回忆三个数学概念。
点积(Dot Product):
对于两个 n n n维向量 A = [ a 1 , a 2 , … , a n ] \mathbf{A} = [a_1, a_2, \dots, a_n] A=[a1,a2,…,an]和 B = [ b 1 , b 2 , … , b n ] \mathbf{B} = [b_1, b_2, \dots, b_n] B=[b1,b2,…,bn],它们的点积定义为:
A ⋅ B = ∑ i = 1 n a i ⋅ b i = a 1 b 1 + a 2 b 2 + ⋯ + a n b n \mathbf{A} \cdot \mathbf{B} = \sum_{i=1}^{n} a_i \cdot b_i = a_1 b_1 + a_2 b_2 + \cdots + a_n b_n A⋅B=∑i=1nai⋅bi=a1b1+a2b2+⋯+anbn
几何意义:点积反映两个向量的方向关系与模长的乘积,即:
A ⋅ B = ∥ A ∥ ⋅ ∥ B ∥ ⋅ cos θ \mathbf{A} \cdot \mathbf{B} = \|\mathbf{A}\| \cdot \|\mathbf{B}\| \cdot \cos\theta A⋅B=∥A∥⋅∥B∥⋅cosθ
其中 θ \theta θ是两向量之间的夹角, ∥ A ∥ \|\mathbf{A}\| ∥A∥和 ∥ B ∥ \|\mathbf{B}\| ∥B∥分别为向量的模长(L2范数)。
余弦相似度(Cosine Similarity):
余弦相似度通过归一化点积来消除向量长度的影响,其定义为:
Cosine Similarity = cos θ = A ⋅ B ∥ A ∥ ⋅ ∥ B ∥ \text{Cosine Similarity} = \cos\theta = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \cdot \|\mathbf{B}\|} Cosine Similarity=cosθ=∥A∥⋅∥B∥A⋅B
其中:
-
分子为两向量的点积;
-
分母为两向量模长的乘积(即归一化因子)。
几何意义:仅关注向量方向的一致性,取值范围为 [ − 1 , 1 ] [-1, 1] [−1,1]:
-
1:方向完全相同;
-
0:正交(无相关性);
-
-1:方向完全相反。
欧式距离(Euclidean Distance)公式
用于衡量两个向量在空间中的绝对距离,是最直观的几何距离度量方式。
数学定义
对于 n n n维向量 A = [ a 1 , a 2 , … , a n ] \mathbf{A} = [a_1, a_2, \dots, a_n] A=[a1,a2,…,an]和 B = [ b 1 , b 2 , … , b n ] \mathbf{B} = [b_1, b_2, \dots, b_n] B=[b1,b2,…,bn],其欧式距离公式为:
Euclidean Distance = ∑ i = 1 n ( a i − b i ) 2 \text{Euclidean Distance}=\sqrt{\sum_{i=1}^{n}(a_i-b_i)^2} Euclidean Distance=∑i=1n(ai−bi)2
即: ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + ⋯ + ( a n − b n ) 2 \sqrt{(a_1-b_1)^2+(a_2-b_2)^2+\cdots+(a_n-b_n)^2} (a1−b1)2+(a2−b2)2+⋯+(an−bn)2
几何意义
在几何空间中,欧式距离表示两点之间的直线距离。例如:
-
二维空间中,点 ( x 1 , y 1 ) (x_1, y_1) (x1,y1)和 ( x 2 , y 2 ) (x_2, y_2) (x2,y2)的欧式距离为: ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2} (x2−x1)2+(y2−y1)2
-
三维空间中,点 ( x 1 , y 1 , z 1 ) (x_1, y_1, z_1) (x1,y1,z1)和 ( x 2 , y 2 , z 2 ) (x_2, y_2, z_2) (x2,y2,z2)的距离为: ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 + ( z 2 − z 1 ) 2 \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2 + (z_2 - z_1)^2} (x2−x1)2+(y2−y1)2+(z2−z1)2
公式关系:
Euclidean Distance 2 = ∥ A ∥ 2 + ∥ B ∥ 2 − 2 ∥ A ∥ ∥ B ∥ cos θ \text{Euclidean Distance}^2=\|\mathbf{A}\|^2+\|\mathbf{B}\|^2-2\|\mathbf{A}\|\|\mathbf{B}\|\cos\theta Euclidean Distance2=∥A∥2+∥B∥2−2∥A∥∥B∥cosθ(其中 cos θ \cos\theta cosθ为余弦相似度)
关于距离,还可以参考这篇指南。关键概念如下:
-
余弦相似度通过计算两个向量夹角的余弦来得到这两个向量的相似性,这种方法允许我们只比较向量方向,而不用考虑它们的大小。使用这种方法需要对所有向量进行归一化,来把它们缩放为单位向量,可以理解成归一化后的点积。
-
点积考虑了向量的长度,但有时会产生不好的效果,有时增加向量的长度可能会让它和所有其他向量变得相似。
-
而欧几里得距离是向量末端之间的距离。
我们这里使用的嵌入模型在余弦相似度下表现良好,因此我们就选择这个距离,并在我们的嵌入模型和 FAISS 索引的 distance_strategy 参数中进行设置。使用余弦相似度时,记得对嵌入向量进行归一化!
🚨👇 以下代码就是通过嵌入模型将所有文本分块向量化之后存储到FAISS向量数据库中:
import osFAISS_INDEX_PATH = "faiss_index"from langchain.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.utils import DistanceStrategyembedding_model = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL_NAME,multi_process=True,model_kwargs={"device": "cpu"},encode_kwargs={"normalize_embeddings": True}, # Set `True` for cosine similarity
)if os.path.exists(FAISS_INDEX_PATH):KNOWLEDGE_VECTOR_DATABASE = FAISS.load_local(FAISS_INDEX_PATH, embedding_model, allow_dangerous_deserialization=True # 明确允许反序列化)print(f"FAISS 索引已存在,已从 {FAISS_INDEX_PATH} 加载。")
else:KNOWLEDGE_VECTOR_DATABASE = FAISS.from_documents(docs_processed, embedding_model, distance_strategy=DistanceStrategy.COSINE)KNOWLEDGE_VECTOR_DATABASE.save_local(FAISS_INDEX_PATH)print(f"FAISS 索引不存在,已创建并保存到 {FAISS_INDEX_PATH}。")
接下来,我们就要尝试在向量数据库中搜索我们指定的内容了。首先我们对查询内容也进行嵌入操作,如下代码。
# Embed a user query in the same space
user_query = "How to create a pipeline object?"
query_vector = embedding_model.embed_query(user_query)
为了方便对比文本块向量之间的距离,我们会先将他们可视化出来。 为了方便观察,需要在2维坐标系中可视化结果,我们使用 PaCMAP把块向量的维度从 384 维降到 2 维。下面是对向量数据库中所有向量数据以及查询向量数据的可视化代码 。
💡这里我们选择了 PaCMAP 来降维而不是其他技术,比如 t-SNE 或 UMAP,因为PaCMAP更加高效,并且能够保留局部和全局结构。
import pacmap
import numpy as np
import plotly.express as pxembedding_projector = pacmap.PaCMAP(n_components=2, n_neighbors=None, MN_ratio=0.5, FP_ratio=2.0, random_state=1)embeddings_2d = [list(KNOWLEDGE_VECTOR_DATABASE.index.reconstruct_n(idx, 1)[0]) for idx in range(len(docs_processed))
] + [query_vector]# Fit the data (the index of transformed data corresponds to the index of the original data)
documents_projected = embedding_projector.fit_transform(np.array(embeddings_2d), init="pca")df = pd.DataFrame.from_dict([{"x": documents_projected[i, 0],"y": documents_projected[i, 1],"source": docs_processed[i].metadata["source"].split("/")[1],"extract": docs_processed[i].page_content[:100] + "...","symbol": "circle","size_col": 4,}for i in range(len(docs_processed))]+ [{"x": documents_projected[-1, 0],"y": documents_projected[-1, 1],"source": "User query","extract": user_query,"size_col": 100,"symbol": "star",}]
)# Visualize the embedding
fig = px.scatter(df,x="x",y="y",color="source",hover_data="extract",size="size_col",symbol="symbol",color_discrete_map={"User query": "black"},width=1000,height=700,
)
fig.update_traces(marker=dict(opacity=1, line=dict(width=0, color="DarkSlateGrey")),selector=dict(mode="markers"),
)
fig.update_layout(legend_title_text="<b>Chunk source</b>",title="<b>2D Projection of Chunk Embeddings via PaCMAP</b>",
)
fig.show()# 如果需要保存成图片 ,需要先安装kaleido
# pip install --upgrade kaleido
# fig.write_image("embedding_projection.png") # 保存为图片
可视化结果如下:

从图中你可以看到向量数据库中的所有向量数据(按照二维点的坐标形式呈现),点的颜色表示文本分块的来源,即相同颜色就表示来源相同的文本分块向量。由于向量能够表达文本分块chunk的含义,因此它们在含义上的接近程度可以反映在对应向量的接近程度上(相同颜色的点聚集在一起)。另外,用户输入的查询向量也显示在图上(黑色方块)。
如果我们想要找到 k 个和查询内容含义接近的文档,那我们就可以直接选择 k 个与查询向量最接近的向量。在LangChain的向量数据库中,这个搜索操作可以通过方法vector_database.similarity_search(query) 来实现。
print(f"\nStarting retrieval for {user_query=}...")
retrieved_docs = KNOWLEDGE_VECTOR_DATABASE.similarity_search(query=user_query, k=5)
print("\n==================================Top document==================================")
print(retrieved_docs[0].page_content)
print("==================================Metadata==================================")
print(retrieved_docs[0].metadata)
输出内容如下:
Starting retrieval for user_query='How to create a pipeline object?'...==================================Top document==================================
```
</tf>
</frameworkcontent>## Pipeline<Youtube id="tiZFewofSLM"/>The [`pipeline`] is the easiest and fastest way to use a pretrained model for inference. You can use the [`pipeline`] out-of-the-box for many tasks across different modalities, some of which are shown in the table below:<Tip>For a complete list of available tasks, check out the [pipeline API reference](./main_classes/pipelines).</Tip>
==================================Metadata==================================
{'source': 'huggingface/transformers/blob/main/docs/source/en/quicktour.md', 'start_index': 1585}
1.4 重排序(Reranking)
聪明的你可能会想到,一个更好的检索策略应该是先检索出尽可能多的结果内容,然后再利用一个强大的检索模型对结果进行重排序,最后再保留排序后 top_k 的内容。
For this, Colbertv2 is a great choice: instead of a bi-encoder like our classical embedding models, it is a cross-encoder that computes more fine-grained interactions between the query tokens and each document’s tokens.
为了实现这一点,我们选择了Colbertv2。
Colbertv2
ColBERT v2.0 是一个高效的神经信息检索模型,它是 ColBERT 的改进版本。主要特点:
-
延迟编码技术
-
使用 BERT 风格的编码器对查询和文档进行编码
-
将查询和文档的交互推迟到搜索时进行
-
支持更细粒度的相关性匹配
-
-
性能优势
-
相比传统的检索模型具有更高的准确性
-
支持快速检索和重排序
-
在处理长文本时表现出色
-
-
应用场景
-
文档检索
-
问答系统
-
信息检索
-
重排序任务
-
ColBERT v2.0 关键的优势在于它使用了交叉编码器,而不是通常嵌入模型的双编码器。
Bi-encoder vs Cross-encoder
Bi-encoder(双编码器)
-
工作方式:
-
分别对查询和文档进行独立编码
-
生成固定维度的向量表示
-
通过向量相似度(如余弦相似度)计算匹配程度
-
# Bi-encoder 示例
query_vector = encoder(query) # 查询编码
document_vector = encoder(document) # 文档编码
similarity = cosine_similarity(query_vector, document_vector)
Cross-encoder(交叉编码器)
-
工作方式:
-
同时处理查询和文档
-
直接对查询-文档对进行交互建模
-
计算更细粒度的 token 级别相关性
-
# Cross-encoder 示例
relevance_score = cross_encoder([query, document]) # 直接对查询和文档进行交互编码
主要优势对比
-
计算精度:
-
Cross-encoder 能捕获更细粒度的语义关系
-
可以识别更复杂的查询-文档匹配模式
-
-
计算效率:
-
Bi-encoder 更高效,因为可以预计算文档向量
-
Cross-encoder 需要实时计算,但精度更高
-
我们可以直接在代码里使用 ragatouille 库。
relevant_docs = knowledge_index.similarity_search(query=user_query, k=30)
relevant_docs = [doc.page_content for doc in relevant_docs] # Keep only the text
from ragatouille import RAGPretrainedModelRERANKER = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
print("=> Reranking documents...")
relevant_docs = reranker.rerank(user_query, relevant_docs, k=5)
relevant_docs = [doc["content"] for doc in relevant_docs]
relevant_docs = relevant_docs[:5]
相关文章:
RAG入门 - Retriever(1)
文章目录 环境准备知识库加载1. Retriever - embeddings 🗂️1.1 将文档拆分为chunks1.2 词嵌入1.3 构建向量数据库Nearest Neighbor search algorithm (最近邻搜索算法)Distances (距离)点积(Dot Product&…...
pyspark实践
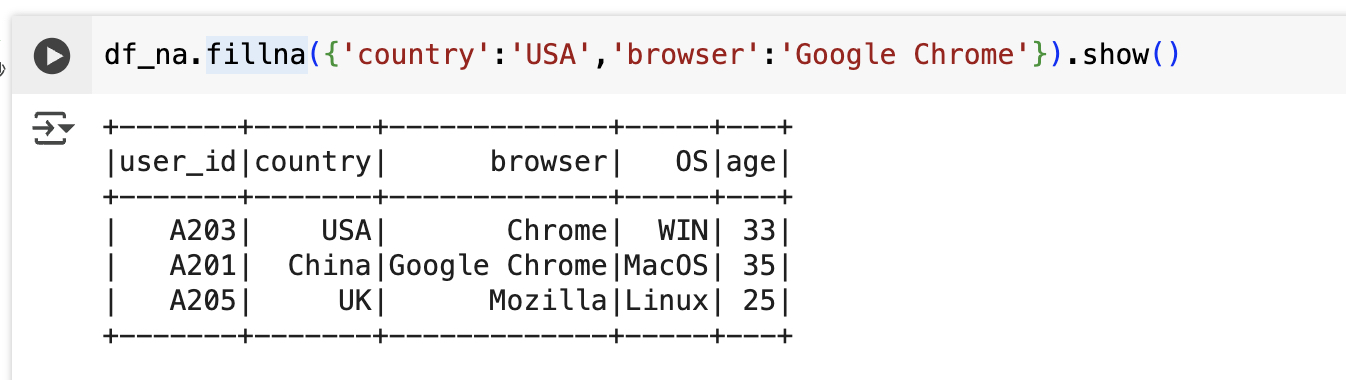
1。pyspark是什么 PySpark 是 Apache Spark 的官方 Python 接口,它使得 Python 开发者能够访问 Spark 的核心功能,如: Spark SQL:用于执行 SQL 查询以及读取数据的库,支持多种数据格式和存储系统。py.qizhen.xyz Data…...

内网怎么映射外网ip? 内网的地址快速映射给外网访问用方法
本文章向大家介绍内网怎么映射外网ip,主要包括如何将内网 IP 端口的网络服务映射到外网使用实例、应用技巧、基本知识点总结和需要注意事项,具有一定的参考价值,需要的朋友可以参考一下。内容主要包括路由映射公网IP和无公网IP通过nat123映射…...

【深度学习新浪潮】多模态模型如何处理任意分辨率输入?
多模态模型处理任意分辨率输入的能力主要依赖于架构设计的灵活性和预处理技术的结合。以下是核心方法及技术细节: 一、图像模态的分辨率处理 1. 基于Transformer的可变补丁划分(ViT架构) 补丁化(Patch Embedding): 将图像分割为固定大小的补丁(如1616或3232像素),不…...

ZYNQ移植FreeRTOS和固化和openAMP双核
想象一下:一颗拥有“双脑”的ZYNQ芯片,左脑运行Linux处理复杂网络协议,右脑运行FreeRTOS以微秒级精度控制电机,双脑通过“量子纠缠”般的技术实时对话——这就是OpenAMP框架创造的工程奇迹!今天,我们将揭开这项技术的神秘面纱,带你从零构建一个双核异构的智能系统。 🧠…...

K-匿名模型
K-匿名模型是隐私保护领域的一项基础技术,防止通过链接攻击从公开数据中重新识别特定个体。其核心思想是让每个个体在发布的数据中“隐匿于人群”,确保任意一条记录至少与其他K-1条记录在准标识符(Quasi-Identifiers, QIDs)上不可…...
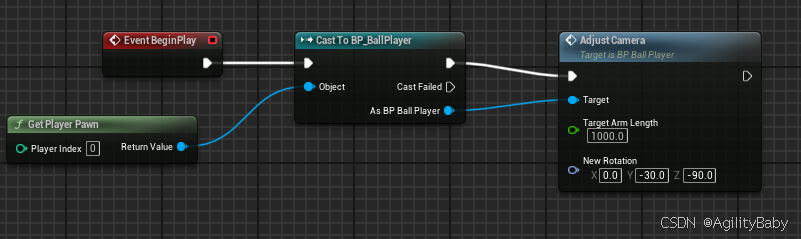
UE5蓝图暴露变量,在游戏运行时修改变量实时变化、看向目标跟随目标Find Look at Rotation、修改玩家自身弹簧臂
UE5蓝图中暴露变量,类似Unity中public一个变量,在游戏运行时修改变量实时变化 1,添加变量 2,设置变量的值 3,点开小眼睛,此变量显示在编辑器中,可以运行时修改 看向目标跟随目标Find Look at R…...

C语言进阶知识:深入探索编程的奥秘
一、指针:C语言的灵魂 指针是C语言中最核心的概念之一,它为程序员提供了对内存的直接操作能力。指针变量存储的是一个地址,通过这个地址可以访问和修改内存中的数据。 (一)指针的基本操作 指针的声明 指针的声明格式…...

机器视觉2D定位引导一般步骤
机器视觉的2D定位引导是工业自动化中的核心应用,主要用于精确确定目标物体的位置(X, Y坐标)和角度(旋转角度θ),并引导机器人或运动机构进行抓取、装配、对位、检测等操作。其一般步骤可概括如下: 一、系统规划与硬件选型 明确需求: 定位精度要求(多少毫米/像素,多少…...
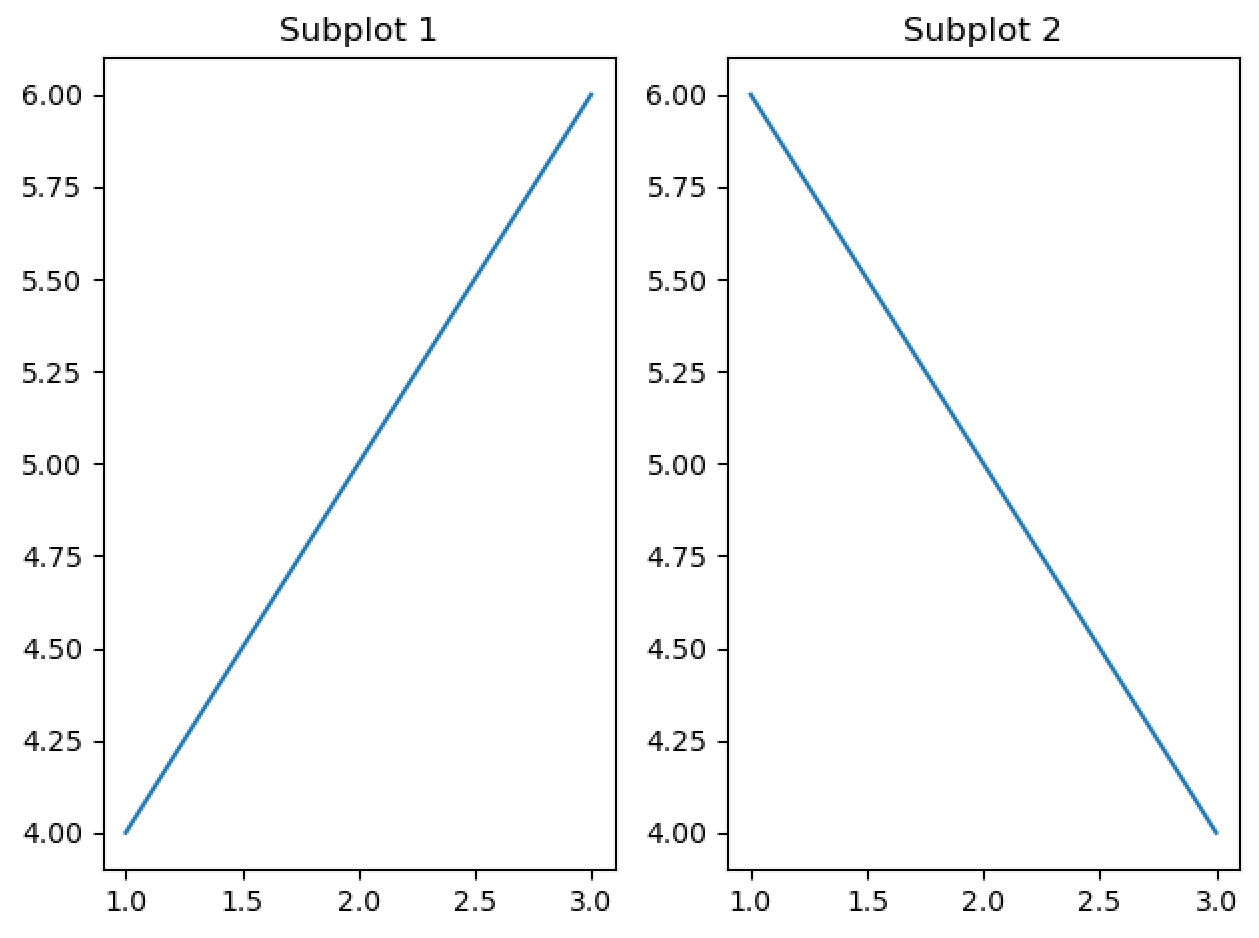
Python-matplotlib中的Pyplot API和面向对象 API
matplotlib中的Pyplot API和面向对象 API Pyplot API(状态机模式)面向对象 API 详解二者差别核心区别方法命名差异注意事项差别举例 🍅 Pyplot API(状态机模式)和面向对象 API 是两种不同的编程接口.🍅 它们…...

FastAPI安全认证:从密码到令牌的魔法之旅
title: FastAPI安全认证:从密码到令牌的魔法之旅 date: 2025/06/02 13:24:43 updated: 2025/06/02 13:24:43 author: cmdragon excerpt: 在FastAPI中实现OAuth2密码流程的认证机制。通过创建令牌端点,用户可以使用用户名和密码获取JWT访问令牌。代码示例展示了如何使用Cry…...

人工智能时代教师角色的重塑与应对策略研究:从理论到实践的转型
一、引言 1.1 研究背景 近年来,人工智能技术迅猛发展,已经逐渐渗透到社会的各个领域,对人类的生产、生活和学习方式产生了深远影响。作为社会发展的重要组成部分,教育领域也不可避免地受到人工智能的冲击,正经历着前…...
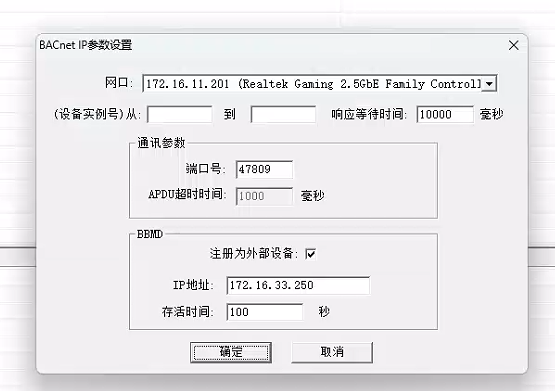
java对接bacnet ip协议(跨网段方式)
1、环境准备 #maven环境<repositories><repository><id>ias-releases</id><url>https://maven.mangoautomation.net/repository/ias-release/</url></repository></repositories><dependencies><dependency><…...
LabVIEW超宽带紧凑场测量系统
采用 LabVIEW 开发超宽带紧凑场测量系统,实现天线方向图、目标雷达散射截面(RCS)及天线增益的自动化测量。通过品牌硬件设备,优化系统架构,解决传统测量系统在兼容性、数据处理效率及操作便捷性等方面的问题࿰…...
编译rustdesk,使用flutter、hwcodec硬件编解码、支持Windows 7系统
目录 安装相应的环境安装visual studio安装vpkg安装rust开发环境安装llvm和clang编译源码下载源码使用Sciter作为UI的(已弃用)使用flutter作为UI的(主流)下载flutter sdk桥接静默安装支持Windows 7系统最近某desk免费的限制越来越多,实在没办法,平时远程控制用的比较多,…...
ROS机器人和NPU的往事和新知-250602
往事: 回顾一篇五年前的博客: ROS2机器人笔记20-12-04_ros2 移植到vxworks-CSDN博客 里面提及专用的机器人处理器,那时候只有那么1-2款专用机器人处理器。 无关: 01: 每代人的智商和注意力差异是如何出现的-250602-…...

【从零开始学习QT】信号和槽
目录 一、信号和槽概述 信号的本质 槽的本质 二、信号和槽的使用 2.1 连接信号和槽 2.2 查看内置信号和槽 2.3 通过 Qt Creator 生成信号槽代码 自定义槽函数 自定义信号 自定义信号和槽 2.4 带参数的信号和槽 三、信号与槽的连接方式 3.1 一对一 (1&…...
MCP调研
什么是 MCP MCP(Model Context Protocol,模型上下文协议),是由 Anthropic 在 2024 年 11 月底推出的开放标准协议,旨在统一大型语言模型(LLM)与外部数据源、工具的通信方式。MCP 的主要目的在于…...

TDengine 运维——巡检工具(定期检查)
背景 TDengine 在运行一段时间后需要针对运行环境和 TDengine 本身的运行状态进行定期巡检,本文档旨在说明如何使用巡检工具对 TDengine 的运行环境进行自动化检查。 安装工具使用方法 工具支持通过 help 参数查看支持的语法 Usage: taosinspect [OPTIONS]Check…...

8.7 基于EAP-AKA的订阅转移
8.7 基于EAP-AKA的订阅转移 以下场景描述如下情况: • 主ODSA设备应用程序被允许用于该类型主设备,且已获得服务提供商(SP)授权。 • 终端用户在存有活跃订阅的旧主设备上发起订阅转移请求,且可访问eSIM数据。 • 由于…...
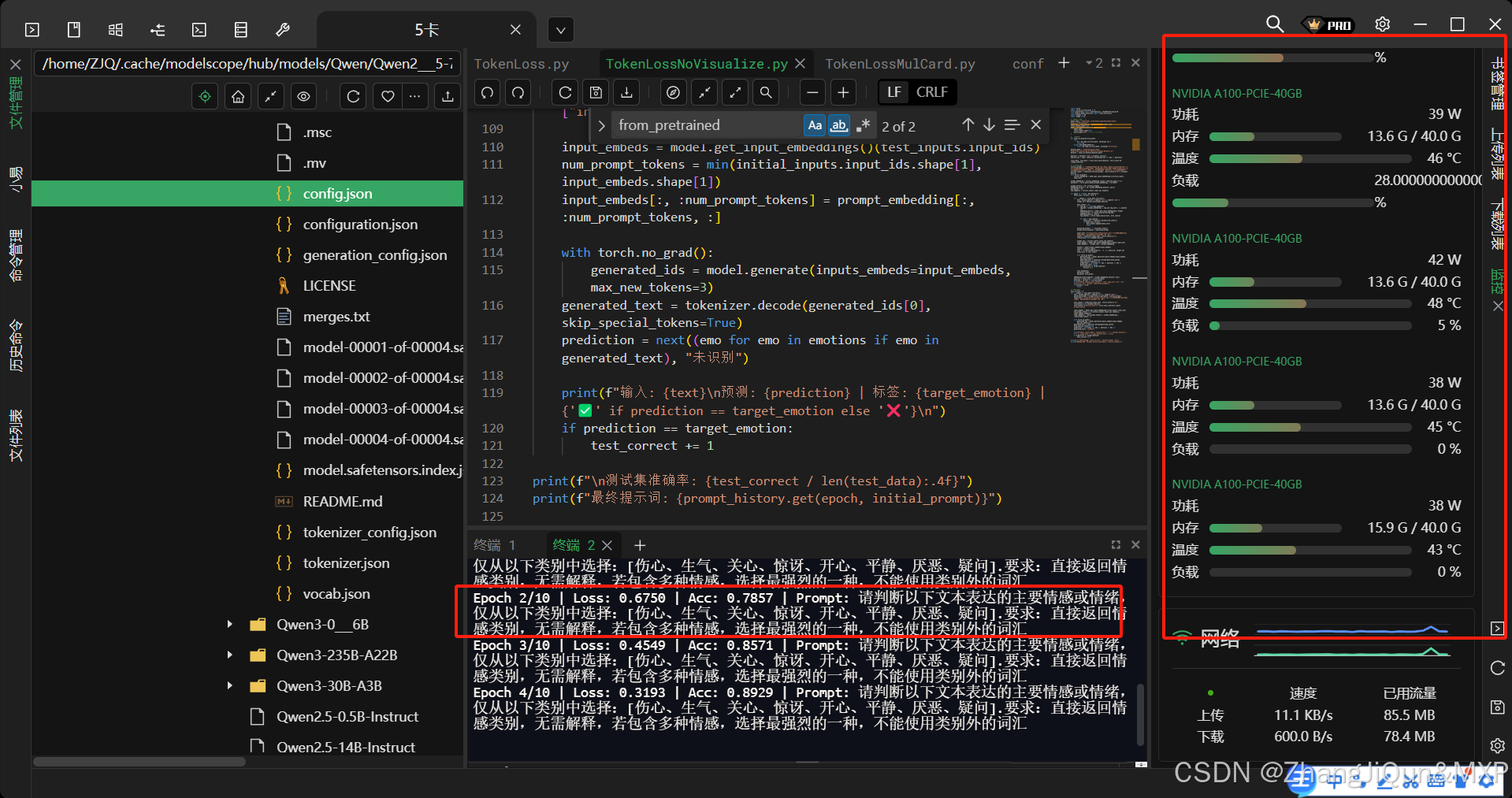
qwen 2.5 并行计算机制:依靠 PyTorch 和 Transformers 库的分布式能力
qwen 2.5 并行计算机制:依靠 PyTorch 和 Transformers 库的分布式能力 完整可运行代码: import torch import torch.nn.functional as F from transformers...

调整数据集的方法
我们对worldquant中的数据, 对数据频率怎么算 在 WorldQuant 平台中,数据更新频率是影响量化策略有效性、回测准确性和实盘交易表现的核心因素之一。它决定了数据的时效性和连续性,直接关系到策略能否捕捉市场动态、应对突发事件或适应不同…...

TCP 四次挥手
引言:优雅的告别 在网络通信中,建立连接需要三次握手,而终止连接则需要四次挥手。这种设计体现了 TCP 协议的可靠性和完整性原则。本文将用通俗易懂的方式,深入解析四次挥手的原理、状态转换和实际应用,帮助您掌握这一…...
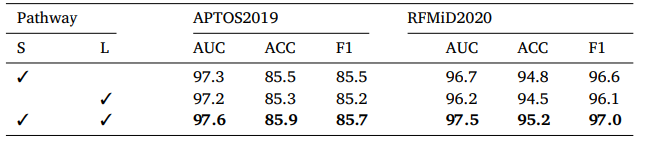
MSTNet:用于糖尿病视网膜病变分类的多尺度空间感知 Transformer 与多实例学习方法|文献速递-深度学习医疗AI最新文献
Title 题目 MSTNet: Multi-scale spatial-aware transformer with multi-instance learning for diabetic retinopathy classification MSTNet:用于糖尿病视网膜病变分类的多尺度空间感知 Transformer 与多实例学习方法 01 文献速递介绍 糖尿病视网膜病变&#…...
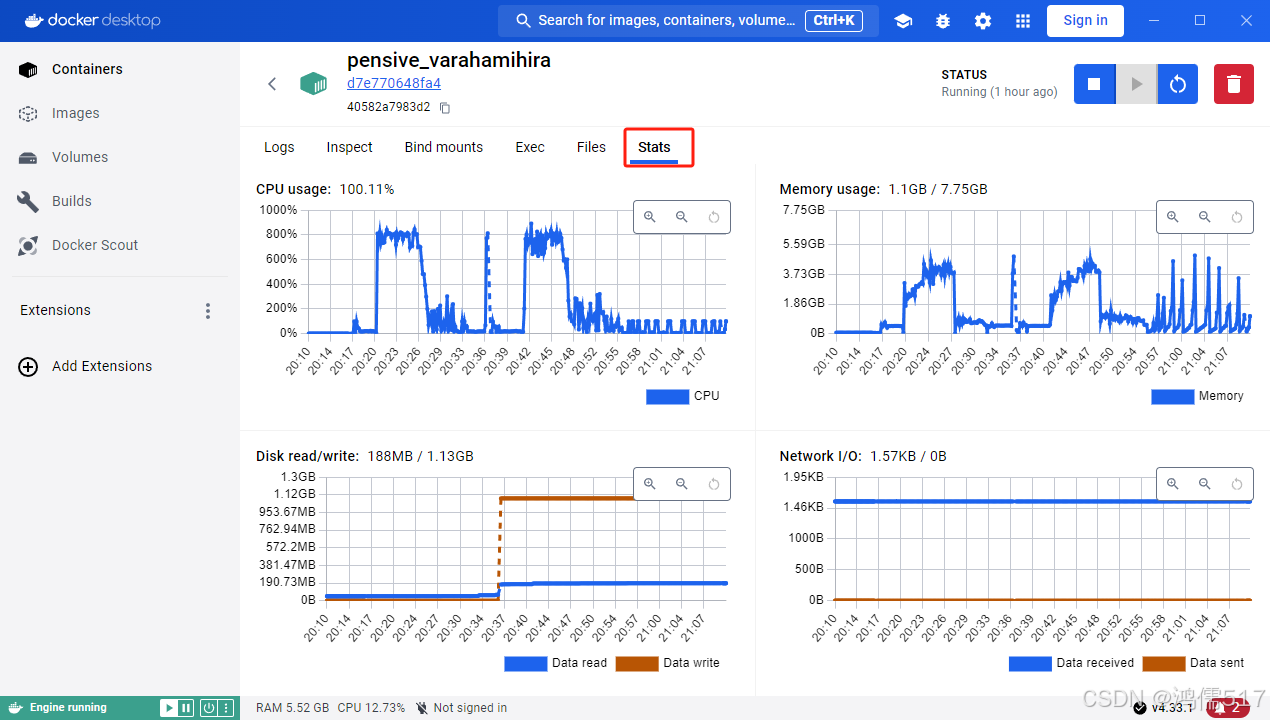
docker运行程序Killed异常排查
问题描述 我最近开发了一个C 多线程程序,测试没有问题,封装docker测试也没有问题,然后提交给客户了,然后在他那边测试有问题,不定时、不定位置异常中断,以前一直认为只要封装了docker就万事大吉࿰…...

【数学 逆序对 构造】P12386 [蓝桥杯 2023 省 Python B] 混乱的数组|普及+
本文涉及知识点 数学 构造 P12386 [蓝桥杯 2023 省 Python B] 混乱的数组 题目描述 给定一个正整数 x x x,请找出一个尽可能短的仅含正整数的数组 A A A 使得 A A A 中恰好有 x x x 对 i , j i, j i,j 满足 i < j i < j i<j 且 A i > A j A_…...
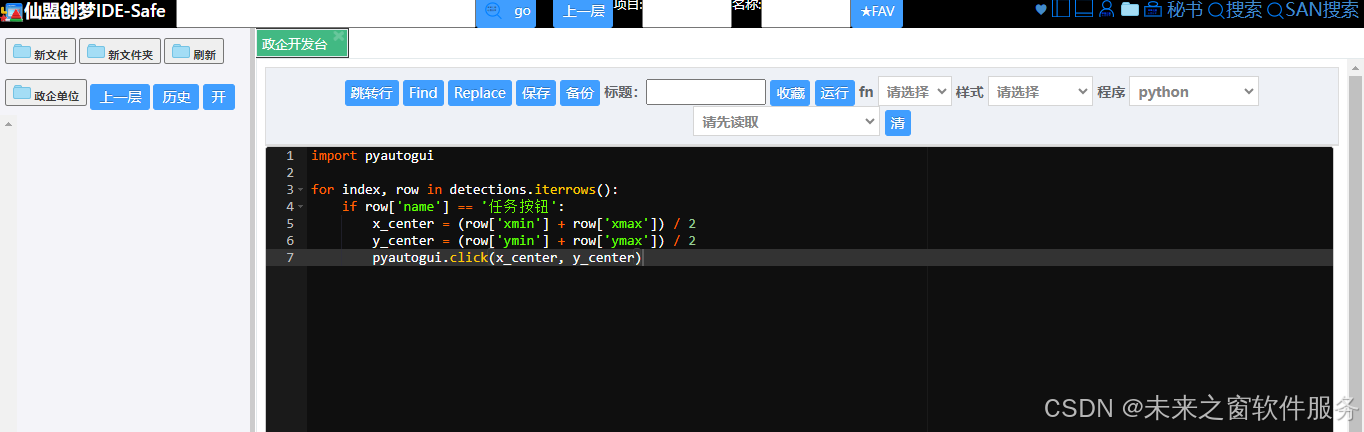
Excel 批量下载PDF、批量下载考勤图片——仙盟创梦IDE
在办公场景中,借助应用软件实现 Excel 批量处理考勤图片、电子文档与 PDF,具有诸多显著优势。 从考勤图片处理来看,通过 Excel 批量操作,能快速提取图片中的考勤信息,如员工打卡时间、面部识别数据等,节省…...
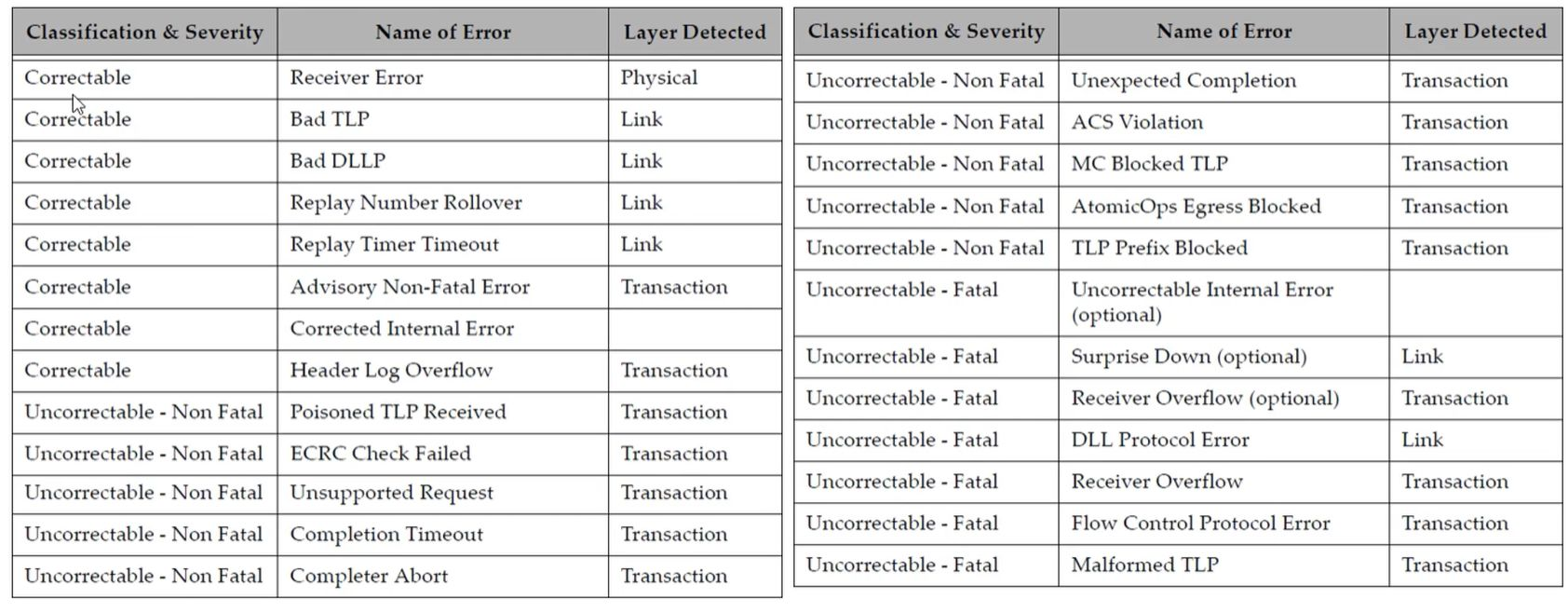
PCIe-Error Detection(一)
下表为PCIe协议中给出的错误: 一、可纠正错误(Correctable Errors,8种) 检错机制 错误名称检测层级触发条件Receiver ErrorPhysical接收端均衡器(EQ)监测到…...
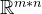
向量空间的练习题目
1.考虑 中的向量x1 和x2 求每一向量的长度 令x3x1x2,求x3的长度,它的长度与x1和x2的和有什么关系? 2.重复练习1,取向量 3.令C为复数集合,定义C上的加法为 (abi)(cdi)(ac)(bd)i 并定义标量乘法为对所有实数a (abi) a bi 证明&…...
Leetcode 2123. 使矩阵中的 1 互不相邻的最小操作数
1.题目基本信息 1.1.题目描述 给你一个 下标从 0 开始 的矩阵 grid。每次操作,你可以把 grid 中的 一个 1 变成 0 。 如果一个矩阵中,没有 1 与其它的 1 四连通(也就是说所有 1 在上下左右四个方向上不能与其他 1 相邻)&#x…...