DAY 36神经网络加速器easy
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。
●作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。
●探索性作业(随意完成):尝试进入nn.Module中,查看他的方法
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as pltclass CreditNet(nn.Module):def __init__(self, input_size):super(CreditNet, self).__init__()# 定义网络结构self.layer1 = nn.Sequential(nn.Linear(input_size, 64),nn.BatchNorm1d(64), # 批归一化nn.ReLU(),nn.Dropout(0.3) # dropout防止过拟合)self.layer2 = nn.Sequential(nn.Linear(64, 32),nn.BatchNorm1d(32),nn.ReLU(),nn.Dropout(0.2))self.layer3 = nn.Sequential(nn.Linear(32, 16),nn.BatchNorm1d(16),nn.ReLU(),nn.Dropout(0.1))self.output = nn.Linear(16, 2) # 二分类问题def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.output(x)return xclass CreditClassifier:def __init__(self, input_size, learning_rate=0.001, device='cuda' if torch.cuda.is_available() else 'cpu'):self.device = deviceself.model = CreditNet(input_size).to(device)self.criterion = nn.CrossEntropyLoss()self.optimizer = optim.Adam(self.model.parameters(), lr=learning_rate)self.scaler = StandardScaler()def prepare_data(self, X_train, X_test):# 标准化数据X_train_scaled = self.scaler.fit_transform(X_train)X_test_scaled = self.scaler.transform(X_test)# 转换为张量X_train_tensor = torch.FloatTensor(X_train_scaled).to(self.device)X_test_tensor = torch.FloatTensor(X_test_scaled).to(self.device)return X_train_tensor, X_test_tensordef train(self, X_train, y_train, X_test, y_test, epochs=2000, batch_size=32):# 准备数据X_train_tensor, X_test_tensor = self.prepare_data(X_train, X_test)y_train_tensor = torch.LongTensor(y_train.values).to(self.device)y_test_tensor = torch.LongTensor(y_test.values).to(self.device)# 创建数据加载器train_dataset = torch.utils.data.TensorDataset(X_train_tensor, y_train_tensor)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)# 记录训练过程train_losses = []train_accs = []test_accs = []for epoch in range(epochs):self.model.train()total_loss = 0correct = 0total = 0for batch_X, batch_y in train_loader:self.optimizer.zero_grad()outputs = self.model(batch_X)loss = self.criterion(outputs, batch_y)loss.backward()self.optimizer.step()total_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += batch_y.size(0)correct += (predicted == batch_y).sum().item()# 计算训练指标avg_loss = total_loss / len(train_loader)train_acc = 100 * correct / total# 评估测试集test_acc = self.evaluate(X_test_tensor, y_test_tensor)# 记录指标train_losses.append(avg_loss)train_accs.append(train_acc)test_accs.append(test_acc)if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {avg_loss:.4f}, 'f'Train Acc: {train_acc:.2f}%, Test Acc: {test_acc:.2f}%')# 绘制训练过程self.plot_training_process(train_losses, train_accs, test_accs)def evaluate(self, X, y):self.model.eval()with torch.no_grad():outputs = self.model(X)_, predicted = torch.max(outputs.data, 1)total = y.size(0)correct = (predicted == y).sum().item()return 100 * correct / totaldef predict(self, X):X_tensor = torch.FloatTensor(self.scaler.transform(X)).to(self.device)self.model.eval()with torch.no_grad():outputs = self.model(X_tensor)_, predicted = torch.max(outputs.data, 1)return predicted.cpu().numpy()def plot_training_process(self, losses, train_accs, test_accs):plt.figure(figsize=(12, 4))# 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(losses)plt.title('Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')# 绘制准确率曲线plt.subplot(1, 2, 2)plt.plot(train_accs, label='Train Accuracy')plt.plot(test_accs, label='Test Accuracy')plt.title('Model Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.legend()plt.tight_layout()plt.show()
好的,我们来整理一下你的项目文件,并详细解释神经网络模型和训练脚本。
文件组织
根据你提供的文件和常见的项目结构,我建议如下安排:
DAY36/(主目录)data.csv: 你的原始数据文件。credit_nn_model.py: 包含神经网络模型 (CreditNet) 和分类器包装类 (CreditClassifier) 的定义。train_credit_model.py: 包含数据预处理、模型训练和评估的脚本。day36复习.ipynb: 你的 Jupyter Notebook,可以在这里进行实验、调用train_credit_model.py中的函数或直接使用CreditClassifier。
重要: 为了确保 train_credit_model.py 能够正确导入 credit_nn_model.py,它们需要位于同一个目录 (DAY36/) 中。同时,train_credit_model.py 中的导入语句需要做一点小调整。
我将修改 DAY36/train_credit_model.py 中的导入语句。
模型逻辑流程图
代码解释
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as pltclass CreditNet(nn.Module):def __init__(self, input_size):super(CreditNet, self).__init__()# 定义网络结构self.layer1 = nn.Sequential(nn.Linear(input_size, 64),nn.BatchNorm1d(64), # 批归一化nn.ReLU(),nn.Dropout(0.3) # dropout防止过拟合)self.layer2 = nn.Sequential(nn.Linear(64, 32),nn.BatchNorm1d(32),nn.ReLU(),nn.Dropout(0.2))self.layer3 = nn.Sequential(nn.Linear(32, 16),nn.BatchNorm1d(16),nn.ReLU(),nn.Dropout(0.1))self.output = nn.Linear(16, 2) # 二分类问题def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.output(x)return xclass CreditClassifier:def __init__(self, input_size, learning_rate=0.001, device='cuda' if torch.cuda.is_available() else 'cpu'):self.device = deviceself.model = CreditNet(input_size).to(device)self.criterion = nn.CrossEntropyLoss()self.optimizer = optim.Adam(self.model.parameters(), lr=learning_rate)self.scaler = StandardScaler()def prepare_data(self, X_train, X_test):# 标准化数据X_train_scaled = self.scaler.fit_transform(X_train)X_test_scaled = self.scaler.transform(X_test)# 转换为张量X_train_tensor = torch.FloatTensor(X_train_scaled).to(self.device)X_test_tensor = torch.FloatTensor(X_test_scaled).to(self.device)return X_train_tensor, X_test_tensordef train(self, X_train, y_train, X_test, y_test, epochs=2000, batch_size=32):# 准备数据X_train_tensor, X_test_tensor = self.prepare_data(X_train, X_test)y_train_tensor = torch.LongTensor(y_train.values).to(self.device)y_test_tensor = torch.LongTensor(y_test.values).to(self.device)# 创建数据加载器train_dataset = torch.utils.data.TensorDataset(X_train_tensor, y_train_tensor)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)# 记录训练过程train_losses = []train_accs = []test_accs = []for epoch in range(epochs):self.model.train()total_loss = 0correct = 0total = 0for batch_X, batch_y in train_loader:self.optimizer.zero_grad()outputs = self.model(batch_X)loss = self.criterion(outputs, batch_y)loss.backward()self.optimizer.step()total_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += batch_y.size(0)correct += (predicted == batch_y).sum().item()# 计算训练指标avg_loss = total_loss / len(train_loader)train_acc = 100 * correct / total# 评估测试集test_acc = self.evaluate(X_test_tensor, y_test_tensor)# 记录指标train_losses.append(avg_loss)train_accs.append(train_acc)test_accs.append(test_acc)if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {avg_loss:.4f}, 'f'Train Acc: {train_acc:.2f}%, Test Acc: {test_acc:.2f}%')# 绘制训练过程self.plot_training_process(train_losses, train_accs, test_accs)def evaluate(self, X, y):self.model.eval()with torch.no_grad():outputs = self.model(X)_, predicted = torch.max(outputs.data, 1)total = y.size(0)correct = (predicted == y).sum().item()return 100 * correct / totaldef predict(self, X):X_tensor = torch.FloatTensor(self.scaler.transform(X)).to(self.device)self.model.eval()with torch.no_grad():outputs = self.model(X_tensor)_, predicted = torch.max(outputs.data, 1)return predicted.cpu().numpy()def plot_training_process(self, losses, train_accs, test_accs):plt.figure(figsize=(12, 4))# 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(losses)plt.title('Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')# 绘制准确率曲线plt.subplot(1, 2, 2)plt.plot(train_accs, label='Train Accuracy')plt.plot(test_accs, label='Test Accuracy')plt.title('Model Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.legend()plt.tight_layout()plt.show()
1. credit_nn_model.py
这个文件定义了神经网络的核心结构和训练、评估的辅助类。
-
CreditNet(nn.Module)类:__init__(self, input_size):- 初始化函数,继承自
torch.nn.Module。 input_size: 输入特征的数量,由训练数据动态确定。- 网络层定义:
self.layer1,self.layer2,self.layer3: 定义了三个全连接层(nn.Linear)。- 每个层包含:线性变换 -> 批归一化 (
nn.BatchNorm1d) -> ReLU激活函数 (nn.ReLU) -> Dropout (nn.Dropout)。 - 批归一化 (BatchNorm): 加速训练,提高模型稳定性,减少对初始化参数的敏感度。
- ReLU: 常用的激活函数,引入非线性。
- Dropout: 在训练过程中随机失活一部分神经元,防止过拟合。
- 每个层包含:线性变换 -> 批归一化 (
self.output: 最后的输出层,将特征映射到2个输出单元(因为是二分类问题:违约或不违约)。
- 初始化函数,继承自
forward(self, x):- 定义数据在网络中的前向传播路径。
- 输入
x依次通过layer1,layer2,layer3, 和output层。 - 返回最终的原始输出(logits),之后会送入损失函数(
CrossEntropyLoss通常内置了Softmax)。
-
CreditClassifier类:__init__(self, input_size, learning_rate=0.001, device='cuda' if torch.cuda.is_available() else 'cpu'):input_size: 传递给CreditNet。learning_rate: 优化器的学习率。device: 自动检测是否有可用的CUDA GPU,否则使用CPU。self.model: 实例化CreditNet并将其移动到指定设备 (.to(device))。self.criterion: 定义损失函数为交叉熵损失 (nn.CrossEntropyLoss),适用于多分类(包括二分类)问题。self.optimizer: 定义优化器为 Adam (optim.Adam),一种常用的自适应学习率优化算法。self.scaler: 实例化StandardScaler用于后续数据标准化。
prepare_data(self, X_train, X_test):- 接收训练和测试集的特征数据 (
X_train,X_test)。 - 使用
self.scaler.fit_transform(X_train)对训练数据进行标准化(计算均值和标准差并应用转换)。 - 使用
self.scaler.transform(X_test)对测试数据进行标准化(使用训练集计算得到的均值和标准差)。 - 将标准化后的数据转换为 PyTorch 的
FloatTensor并移动到指定设备。
- 接收训练和测试集的特征数据 (
train(self, X_train, y_train, X_test, y_test, epochs=100, batch_size=32):- 主要的训练逻辑。
X_train,y_train,X_test,y_test: 训练和测试数据。epochs: 训练的总轮数。batch_size: 每个批次处理的样本数量。- 数据准备: 调用
prepare_data,并将标签y_train,y_test转换为LongTensor。 DataLoader: 创建TensorDataset和DataLoader来实现小批量训练,shuffle=True表示每个epoch开始前打乱训练数据。- 训练循环 (
for epoch in range(epochs)):self.model.train(): 将模型设置为训练模式(这对Dropout和BatchNorm等层很重要)。- 批量循环 (
for batch_X, batch_y in train_loader):self.optimizer.zero_grad(): 清除上一轮的梯度。outputs = self.model(batch_X): 前向传播,得到预测结果。loss = self.criterion(outputs, batch_y): 计算损失。loss.backward(): 反向传播,计算梯度。self.optimizer.step(): 更新模型参数。- 累积
total_loss,计算correct和total样本数以监控训练准确率。
- 计算平均损失
avg_loss和训练准确率train_acc。 - 调用
self.evaluate在测试集上评估当前模型的准确率test_acc。 - 记录每个epoch的损失和准确率。
- 每10个epoch打印一次训练信息。
- 训练结束后,调用
self.plot_training_process绘制损失和准确率曲线。
evaluate(self, X, y):- 评估模型在给定数据上的准确率。
self.model.eval(): 将模型设置为评估模式。with torch.no_grad(): 在评估时禁用梯度计算,节省内存和计算。- 计算预测正确的样本比例。
predict(self, X):- 用训练好的模型进行预测。
- 对输入数据
X进行标准化和Tensor转换。 self.model.eval()和torch.no_grad()。torch.max(outputs.data, 1): 获取最可能的类别(概率最高的那个)。- 返回预测结果的NumPy数组。
plot_training_process(self, losses, train_accs, test_accs):- 使用
matplotlib绘制训练过程中的损失曲线和训练/测试准确率曲线。
- 使用
2. train_credit_model.py
这个脚本负责将所有部分串联起来,执行完整的模型训练流程。
- 导入必要的库:
CreditClassifier从自定义模块导入,以及pandas,train_test_split,warnings,torch。 torch.manual_seed(42): 设置随机种子以保证结果的可复现性。preprocess_data()函数:- 与你之前在
day19.ipynb中的预处理逻辑基本一致:- 读取
data.csv。 - 对
Home Ownership和Years in current job进行标签编码。 - 对
Purpose进行独热编码。 - 对
Term进行映射并重命名。 - 对数值列使用众数填充缺失值。
- 读取
- 返回预处理后的
DataFrame。
- 与你之前在
main()函数:data = preprocess_data(): 调用数据预处理函数。- 特征与目标分离:
X为特征,y为目标变量Credit Default。 - 划分数据集: 使用
train_test_split将数据按80:20的比例划分为训练集和测试集,random_state=42保证划分的一致性。 - 创建模型:
input_size = X_train.shape[1]: 获取训练数据的特征数量作为神经网络的输入大小。- 实例化
CreditClassifier。
- 训练模型: 调用
model.train()方法,传入训练集和测试集数据以及训练参数。 - 预测与评估:
y_pred = model.predict(X_test): 在测试集上进行预测。- 使用
sklearn.metrics中的classification_report和confusion_matrix打印详细的分类性能报告和混淆矩阵。
if __name__ == "__main__": main(): 确保main()函数只在直接运行此脚本时执行。
训练效果解释 (预期)
当运行 train_credit_model.py 后,你将会看到:
-
训练过程打印输出:
- 每10个epoch,会打印当前的Epoch数、平均训练损失 (Loss)、训练集准确率 (Train Acc)、测试集准确率 (Test Acc)。
- 损失 (Loss): 应该随着训练的进行逐渐下降。如果损失不下降或震荡剧烈,可能需要调整学习率、模型复杂度或数据预处理。
- 训练准确率 (Train Acc): 通常会比测试准确率高。如果训练准确率很高但测试准确率很低,说明模型可能过拟合了。
- 测试准确率 (Test Acc): 这是衡量模型泛化能力的关键指标。我们希望它尽可能高且接近训练准确率。
-
训练过程图表:
- 损失曲线: 直观展示训练损失随epoch的变化,理想情况下应平滑下降并趋于稳定。
- 准确率曲线: 同时展示训练准确率和测试准确率随epoch的变化。
- 两条曲线都上升并最终趋于稳定是理想状态。
- 如果训练准确率持续上升而测试准确率在某个点开始下降或停滞不前,这是过拟合的典型迹象。
- 如果两条曲线之间的差距很大,也可能表示过拟合。
-
最终评估报告:
- 分类报告 (
classification_report):- Precision (精确率): 对于每个类别,模型预测为该类别的样本中,有多少是真正属于该类别的。 ( \text{Precision} = \frac{TP}{TP + FP} )
- Recall (召回率/查全率): 对于每个类别,真正属于该类别的样本中,有多少被模型成功预测出来了。 ( \text{Recall} = \frac{TP}{TP + FN} )
- F1-score: 精确率和召回率的调和平均数,综合衡量指标。 ( F1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} )
- Support: 每个类别的真实样本数量。
- Accuracy (准确率): 模型正确分类的样本占总样本的比例。
- 混淆矩阵 (
confusion_matrix):- 一个N x N的矩阵(N为类别数),显示了模型预测的详细情况。
- 例如,对于二分类:
[[True Negative (TN), False Positive (FP)],[False Negative (FN), True Positive (TP)]] - 可以帮助你分析模型在哪些类别上表现好,在哪些类别上容易混淆。
- 分类报告 (
通过分析这些输出和图表,你可以判断模型的训练情况,是否达到预期效果,以及可能需要进行的调整(如调整模型结构、超参数、数据增强等)。
浙大疏锦行-CSDN博客
相关文章:

DAY 36神经网络加速器easy
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 ●作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。 ●探索性作业(随意完成):尝试进入…...
STM32 单片机启动过程全解析:从上电到主函数的旅程
一、为什么要理解启动过程? STM32 的启动过程就像一台精密仪器的开机自检,它确保所有系统部件按既定方式初始化,才能顺利运行我们的应用代码。对初学者而言,理解启动过程能帮助解决常见“程序跑飞”“不进 main”“下载后无反应”…...
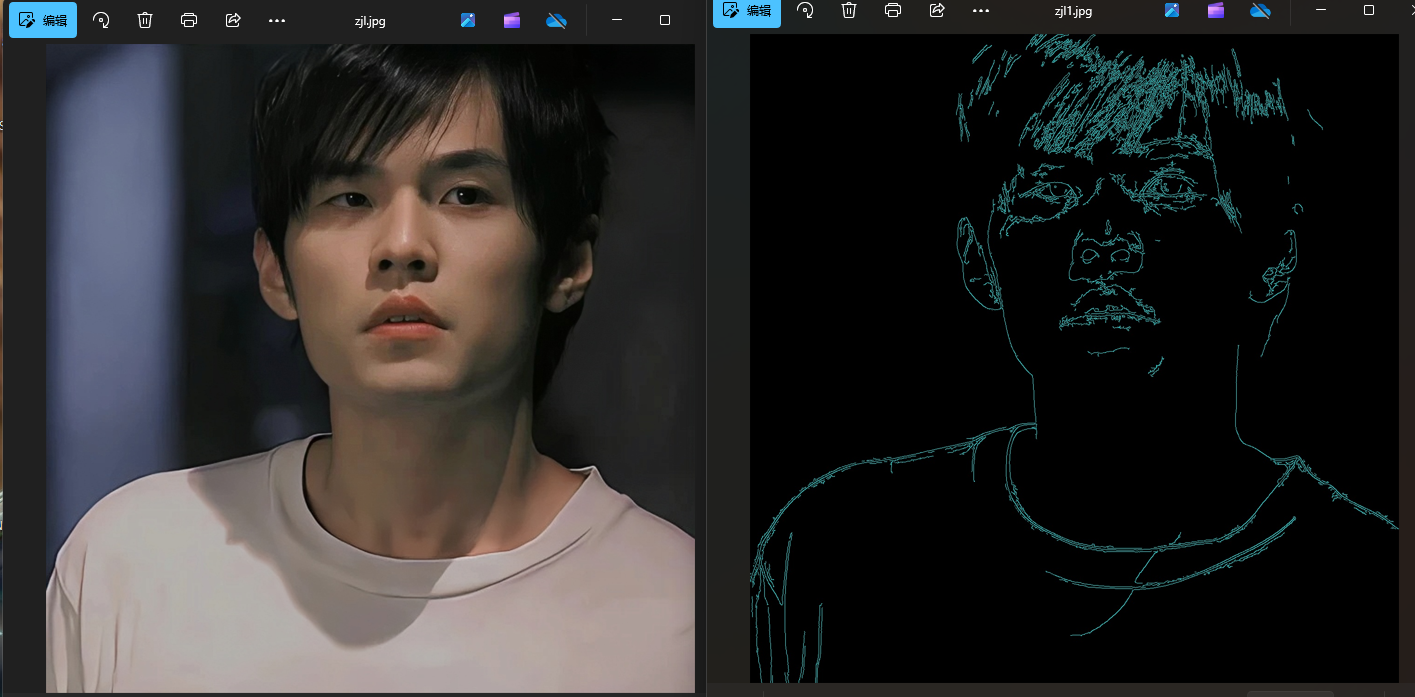
4.RV1126-OPENCV 图像轮廓识别
一.图像识别API 1.图像识别作用 它常用于视觉任务、目标检测、图像分割等等。在 OPENCV 中通常使用 Canny 函数、findContours 函数、drawContours 函数结合在一起去做轮廓的形检测。 2.常用的API findContours 函数:用于寻找图片的轮廓,并把所有的数…...
WEB3——开发者怎么查看自己的合约日志记录
在区块链中查看合约的日志信息(也叫事件 logs),主要有以下几种方式,具体方法依赖于你使用的区块链平台(如 Ethereum、BSC、Polygon 等)和工具(如 Etherscan、web3.js、ethers.js、Hardhat 等&am…...

TDengine 集群容错与灾备
简介 为了防止数据丢失、误删操作,TDengine 提供全面的数据备份、恢复、容错、异地数据实时同步等功能,以保证数据存储的安全。本节简要说明 TDengine 中的容错与灾备。 容错 TDengine 支持 WAL 机制,实现数据的容错能力,保证数…...
MG影视登录解锁永久VIP会员 v8.0 支持手机电视TV版影视直播软件
MG影视登录解锁永久VIP会员 v8.0 支持手机电视TV版影视直播软件 MG影视App电视版是一款资源丰富、免费便捷、且专为大屏优化的影视聚合应用,聚合海量资源,畅享电视直播,是您电视盒子和…...
)
如何成为一名优秀的产品经理(自动驾驶)
一、 夯实核心基础 深入理解智能驾驶技术栈: 感知: 摄像头、雷达(毫米波、激光雷达)、超声波传感器的工作原理、优缺点、融合策略。了解目标检测、跟踪、SLAM等基础算法概念。 定位: GNSS、IMU、高精地图、轮速计等定…...

BAT脚本编写详细教程
目录 第一部分:BAT脚本简介第二部分:创建和运行BAT脚本第三部分:基本命令和语法第四部分:变量使用第五部分:流程控制第六部分:函数和子程序第七部分:高级技巧第八部分:实用示例第一部分:BAT脚本简介 BAT脚本(批处理脚本)是Windows操作系统中的一种脚本文件,扩展名…...

快速了解 GO之接口解耦
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

【多线程初阶】内存可见性问题 volatile
文章目录 再谈线程安全问题内存可见性问题可见性问题案例编译器优化 volatileJava内存模型(JMM) 再谈线程安全问题 如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该有的结果,则说这个程序是线程安全的,反之,多线程环境中,并发执行后,产生bug就是线程不安全…...

C++ 类模板三参数深度解析:从链表迭代器看类型推导与实例化(为什么迭代器类模版使用三参数?实例化又会是怎样?)
本篇主要续上一篇的list模拟实现遇到的问题详细讲解:<传送门> 一、引言:模板参数的 "三角锁钥" 在 C 双向链表实现中,__list_iterator类模板的三个参数(T、Ref、Ptr)如同精密仪器的调节旋钮&#x…...

MySQL强化关键_018_MySQL 优化手段及性能分析工具
目 录 一、优化手段 二、SQL 性能分析工具 1.查看数据库整体情况 (1)语法格式 (2)说明 2.慢查询日志 (1)说明 (2)开启慢查询日志功能 (3)实例 3.s…...

ASP.NET MVC添加模型示例
ASP.NET MVC高效构建Web应用ASP.NET MVC 我们总在谈“模型”,那到底什么是模型?简单说来,模型就是当我们使用软件去解决真实世界中各种实际问题的时候,对那些我们关心的实际事物的抽象和简化。比如,我们在软件系统中设…...
【Part 3 Unity VR眼镜端播放器开发与优化】第二节|VR眼镜端的开发适配与交互设计
文章目录 《VR 360全景视频开发》专栏Part 3|Unity VR眼镜端播放器开发与优化第一节|基于Unity的360全景视频播放实现方案第二节|VR眼镜端的开发适配与交互设计一、Unity XR开发环境与设备适配1.1 启用XR Plugin Management1.2 配置OpenXR与平…...

第1天:认识RNN及RNN初步实验(预测下一个数字)
RNN(循环神经网络) 是一种专门设计用来处理序列数据的人工神经网络。它的核心思想是能够“记住”之前处理过的信息,并将其用于当前的计算,这使得它非常适合处理具有时间顺序或上下文依赖关系的数据。 核心概念:循环连…...

全文索引详解及适用场景分析
全文索引详解及适用场景分析 1. 全文索引基本概念 1.1 定义与核心原理 全文索引(Full-Text Index)是一种特殊的数据库索引类型,专门设计用于高效处理文本数据的搜索需求。与传统的B树索引不同,全文索引不是基于精确匹配,而是通过建立倒排索引(Inverted Index)结构来实现对…...

利用DeepSeek编写能在DuckDB中读PostgreSQL表的表函数
前文实现了UDF和UDAF,还有一类函数是表函数,它放在From 子句中,返回一个集合。DuckDB中已有PostgreSQL插件,但我们可以用pqxx库实现一个简易的只读read_pg()表函数。 提示词如下: 请将libpqxx库集成到我们的程序&#…...
树莓派安装openwrt搭建软路由(ImmortalWrt固件方案)
🤣👉我这里准备了两个版本的openwrt安装方案给大家参考使用,分别是原版的OpenWrt固件以及在原版基础上进行改进的ImmortalWrt固件。推荐使用ImmortalWrt固件,当然如果想直接在原版上进行开发也可以,看个人选择。 &…...

排序算法——详解
排序算法 (冒泡、选择、插入、快排、归并、堆排、计数、桶、基数) 稳定性 (Stability): 如果排序算法能保证,当待排序序列中存在值相等的元素时,排序后这些元素的相对次序保持不变,那么该算法就是稳定的。 例如&#…...

Go整合Redis2.0发布订阅
Go整合Redis2.0发布订阅 Redis goredis-cli --version redis-cli 5.0.14.1 (git:ec77f72d)Go go get github.com/go-redis/redis/v8package redisimport ("MyKindom-Server-v2.0/com/xzm/core/config/yaml""MyKindom-Server-v2.0/com/xzm/core/config/yaml/po…...
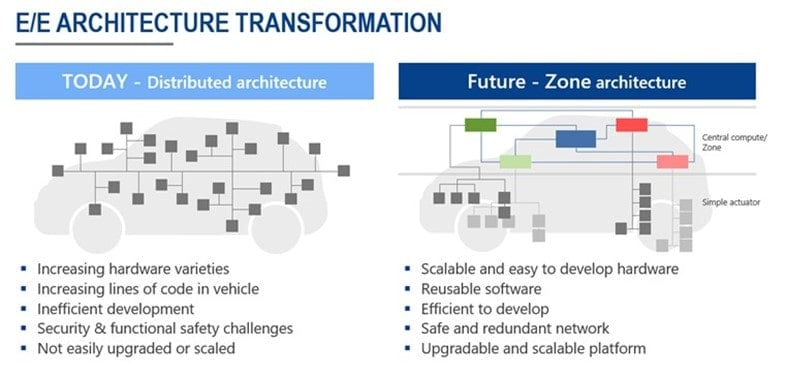
电子电气架构 --- 如何应对未来区域式电子电气(E/E)架构的挑战?
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

鸿蒙OS基于UniApp的区块链钱包开发实践:打造支持鸿蒙生态的Web3应用#三方框架 #Uniapp
基于UniApp的区块链钱包开发实践:打造支持鸿蒙生态的Web3应用 前言 最近在带领团队开发一个支持多链的区块链钱包项目时,我们选择了UniApp作为开发框架。这个选择让我们不仅实现了传统移动平台的覆盖,还成功将应用引入了快速发展的鸿蒙生态…...
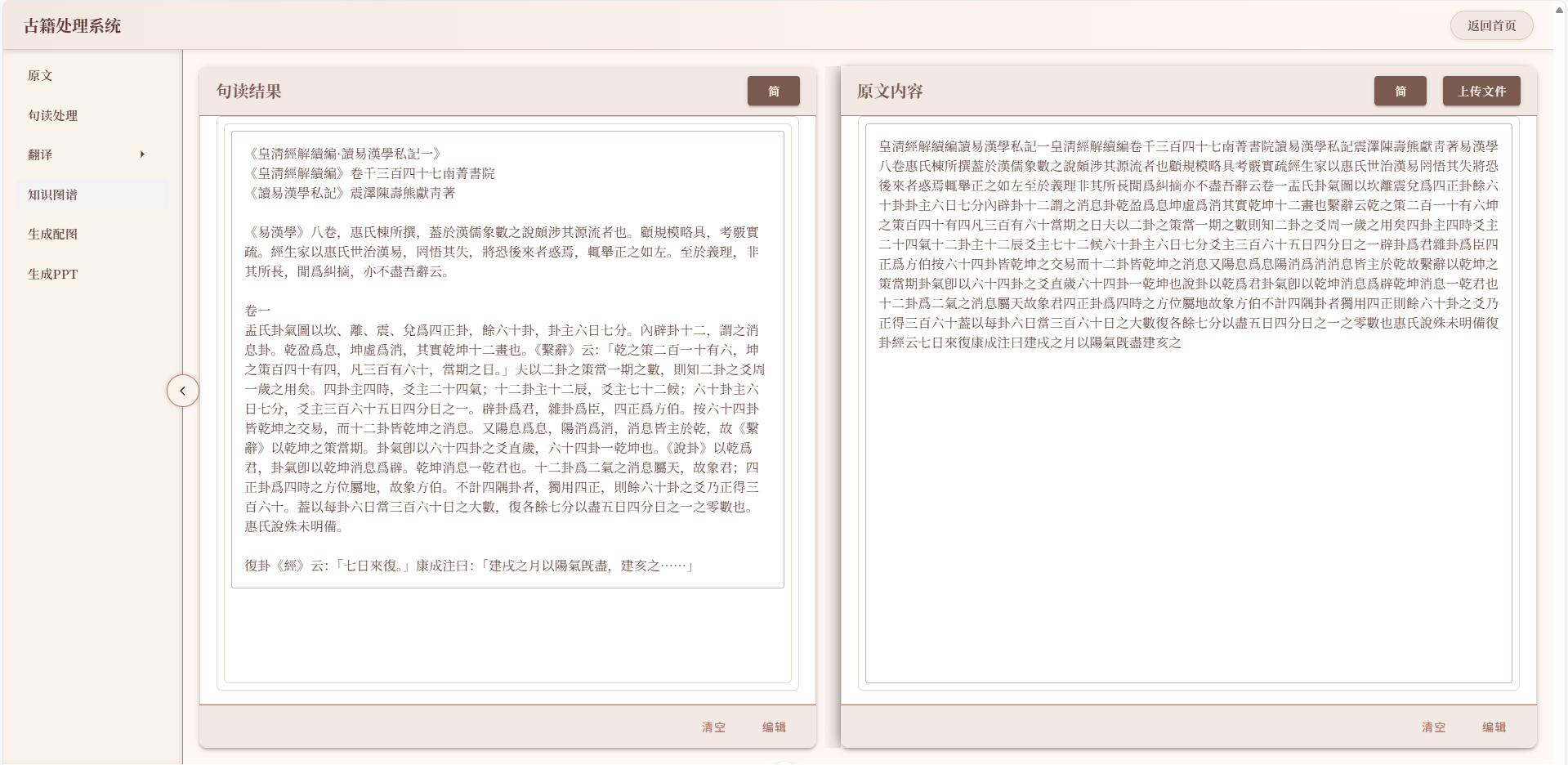
易学探索助手-个人记录(十二)
近期我完成了古籍处理板块页面升级,补充完成原文、句读、翻译的清空、保存和编辑(其中句读仅可修改标点)功能,新增原文和句读的繁简体切换功能 一、古籍处理板块整体页面升级 将原来一整个页面呈现的布局改为分栏呈现࿰…...

Windows 账号管理与安全指南
Windows 账号管理与安全指南 概述 Windows 账号管理是系统安全的基础,了解如何正确创建、管理和保护用户账户对于系统管理员和安全专业人员至关重要。本文详细介绍 Windows 系统中的账户管理命令、隐藏账户创建方法以及安全防护措施。 基础账户管理命令 net use…...
Python窗体编程技术详解
文章目录 1. Tkinter简介示例代码优势劣势 2. PyQt/PySide简介示例代码(PyQt5)优势劣势 3. wxPython简介示例代码优势劣势 4. Kivy简介示例代码优势劣势 5. PySimpleGUI简介示例代码优势劣势 技术对比总结选择建议 Python提供了多种实现图形用户界面(GUI)编程的技术,…...

思维链提示:激发大语言模型推理能力的突破性方法
论文出处: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 作者: Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou 机构: Google Research, B…...

NVMe协议简介之AXI总线更新
更新AXI4总线知识 AXI4总线协议 AXI4总线协议是由ARM公司提出的一种片内总线协议 ,旨在实现SOC中各模块之间的高效可靠的数据传输和管理。AXI4协议具有高性能、高吞吐量和低延迟等优点,在SOC设计中被广泛应用 。随着时间的推移,AXI4的影响不…...
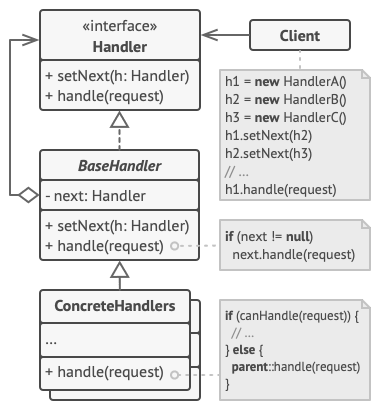
设计模式——责任链设计模式(行为型)
摘要 责任链设计模式是一种行为型设计模式,旨在将请求的发送者与接收者解耦,通过多个处理器对象按链式结构依次处理请求,直到某个处理器处理为止。它包含抽象处理者、具体处理者和客户端等核心角色。该模式适用于多个对象可能处理请求的场景…...
基于Android的医院陪诊预约系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...
基于Spring Boot 电商书城平台系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...