第四十天打卡
知识点回顾:
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
道图片的规范写法
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率彩色图片的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")@浙大疏锦行
相关文章:

第四十天打卡
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...

【请关注】ELK集群部署真实案例分享
ELK集群部署 1,准备es配置 es.yml: -------------------------------------------------------------- #集群名称 cluster.name: elasticsearch-cluster #节点名称 node.name: es-node1 #设置绑定的ip地址,可以使ipv4或者ipv6 #绑定这台机器的任何一个ip network.bind_hos…...

odoo17 windows server布署错误分析
odoo17 windows server布署错误分析 错误代码: File "C:\od172406\odoo\sql_db.py", line 681, in borrow result psycopg2.connect( ^^^^^^^^^^^^^^^^^ File "C:\od172406\venv\Lib\site-packages\psycopg2\__init__.py"…...

PyTorch 入门学习笔记
一、简介 PyTorch 是由 Meta(原 Facebook) 开源的深度学习框架。其前身 Torch 是一个基于 LuaJIT 的科学计算框架,核心功能是提供高效的张量(Tensor)操作和神经网络支持。由于 Lua 语言的生态限制,Torch 逐…...

【 Samba】Windows 用户访问Docker服务器上当前A用户的 ~/aaa目录
要让 Windows 用户访问 ~/aaa目录,需要在 Linux 系统上配置 Samba 共享服务,并设置合适的权限。以下是具体步骤: 1. 安装 Samba bash sudo apt update sudo apt install samba 2. 创建 Samba 用户(可选) 如果你希望 …...
pycharm生成图片
文章目录 图片例子生成图片并储存,设置中文字体支持两条线绘制散点图和直方图绘制条形图(bar)绘制条形图(横着的)(plt.barh)分组的条形图 颜色和线条风格1. **颜色字符 (color)**其他颜色指定方…...
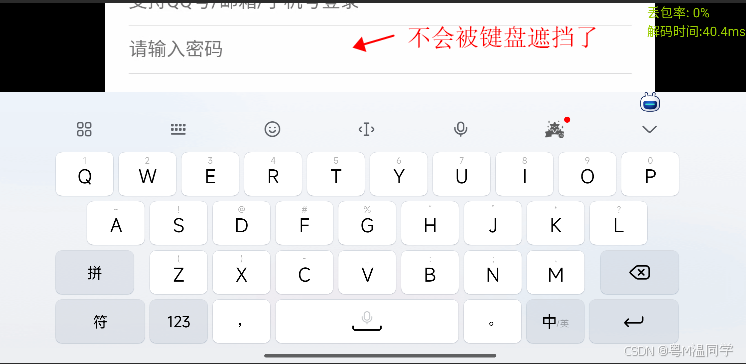
Android 云手机横屏模式下真机键盘遮挡输入框问题处理
一、背景 打开横屏应用,点击云机EditText输入框,输入框被键盘遮挡,如下图: 未打开键盘状态: 点击第二个输入框,键盘遮挡了输入框: 二、解决方案(推荐第三中方案,博主采用的也是第三种方案) 博主这里整理了三种方案:…...

Redis 中的 5 种数据类型和示例场景
Redis 作为一款高性能的键值对数据库,凭借其丰富的数据类型,在缓存、消息队列、排行榜等众多场景中发挥着重要作用。本文将详细介绍 Redis 的 5 种核心数据类型,并结合示例场景和代码,让你快速掌握它们的使用方法。 一、String&am…...
Axure设计案例——科技感对比柱状图
想让数据对比展示摆脱平淡无奇,瞬间抓住观众的眼球吗?那就来看看这个Axure设计的科技感对比柱状图案例!科技感设计风格运用独特元素打破传统对比柱状图的常规,营造出一种极具冲击力的视觉氛围。每一组柱状体都仿佛是科技战场上的士…...

SpringBoot项目搭建指南
SpringBoot项目搭建指南 文章目录 SpringBoot项目搭建指南一、SpringBoot项目搭建1.1 SpringBoot 版本选择1.2 SpringBoot 框架引入方式1.2.1 继承 Starter Parent POM1.2.2 不使用 Parent POM 来使用 Spring Boot 1.3 SpringBoot 打包插件 二、日志框架引入2.1 引入SpringBoot…...

分布式锁剖析
一、分布式锁 1. 为什么需要分布式锁? 在单体应用中,通过synchronized或ReentrantLock等进程内锁即可解决多线程资源竞争问题。但在分布式系统中,多个服务实例运行在不同进程中,传统进程内锁失效,此时需要一种跨进程…...

C语言中函数指针和指针函数的定义及用法
在C/C中,函数指针和指针函数是两个容易混淆但完全不同的概念。以下是它们的详细对比和学习指南,结合代码示例帮助你彻底掌握。 1. 函数指针(Function Pointer) 本质:一个指向函数的指针变量,用于动态调用…...

Spring Boot DevTools 热部署
在Spring Boot项目中加入 spring-boot-devtools 热部署依赖启动器后,通常不需要手动重启项目即可让更改生效。spring-boot-devtools 的核心特性之一就是自动重启或热加载。 Spring Boot DevTools 热部署关键知识点 🔥 目的:spring-boot-devt…...

unix/linux source 命令,其基本属性、语法、操作、api
现在像解剖精密仪器一样,来细致地审视 source (或 .) 命令的各个方面:它的属性、语法、操作方式,以及可以称之为“API”的交互接口。这种细致的分析有助于我们精确地理解和使用它。 让我们深入细节: 一、基本属性 (Core Attributes) 命令类型 (Command Type): Shell 内置…...
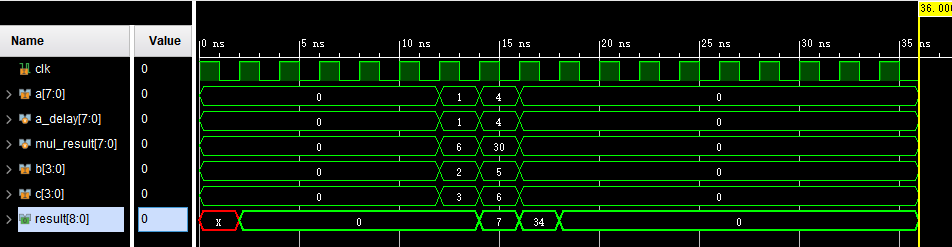
FPGA仿真中阻塞赋值(=)和非阻塞赋值(<=)区别
FPGA仿真中阻塞赋值和非阻塞赋值的区别 单独仿真小模块对但将小模块加入整个工程仿真不对就有可能是没有注意到仿真中阻塞赋值和非阻塞赋值的区别 目录 前言 一、简介 二、设计实例 三、仿真实例 1、仿真用非阻塞赋值 2、仿真用阻塞赋值 总结 前言 网上很多人介绍verilo…...
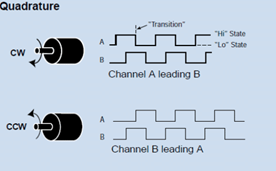
LabVIEW轴角编码器自动检测
LabVIEW 开发轴角编码器自动检测系统,针对指控系统中高故障率的轴角编码器性能检测需求,通过模块化硬件架构与软件设计,实现编码器运转状态模拟、扭矩 / 转速实时监测、19 位并行编码采集译码、数据自动分析及报告生成等功能,解决…...

MySQL数据库从0到1
目录 数据库概述 基本命令 查询命令 函数 表的操作 增删改数据和表结构 约束 事务 索引 视图 触发器 存储过程和函数 三范式 数据库概述 SQL语句的分类: DQL:查询语句,凡是select语句都是DQL。 DML:insert,delete,up…...
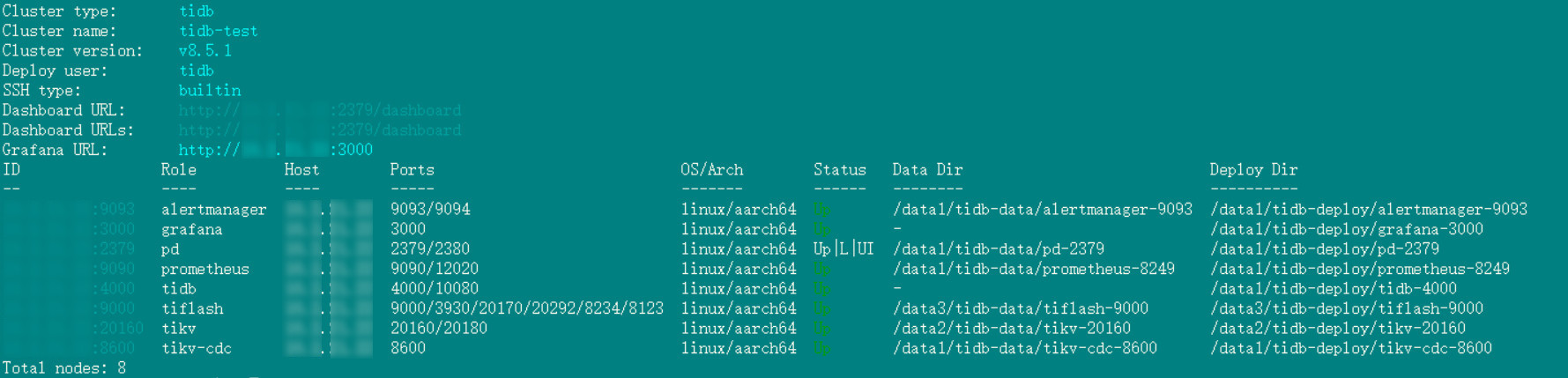
WiFi万能钥匙鲲鹏服务器部署 TiDB 集群实战指南
作者: TiDBer_yangxi 原文来源: https://tidb.net/blog/15a234d0 一、环境准备 1. 硬件要求 服务器架构 :鲲鹏服务器(ARM架构),TiDB 官方明确支持 ARM 架构服务器部署 推荐配置 (生产环…...

正则表达式的前世今生
当你熟练地用正则表达式查找替换代码时,这个工具的历史可以追溯到1943年。那时候还没有计算机,更别说编程语言了。 从神经网络到文本匹配 故事要从两个神经生理学家说起。1943年,Warren McCulloch和Walter Pitts发表了一篇论文《A logical ca…...
Vue 核心技术与实战智慧商城项目Day08-10
温馨提示:这个黑马的视频在b占可以找到,里面有完整的教学过程 然后这个项目有完整的代码,我已经上传了,如果审核成功大家就可以看了,但是需要审核多久我也不是很确定 1.项目演示 2. 项目收获 3. 创建项目 4. 调整初始化…...

TCP/IP协议精华总结pdf分享
hi ,大家好,应小伙伴们的要求,上次分享了个人的一些学习和职场经验,其中网络协议PDF文档是我之前学习协议的时候总结一些精华知识,网络属于基本功,是互联网必备知识,我深信掌握好核心20%知识&am…...

组件化:软件工程化的基础
在现代软件系统中,**组件化(Componentization)**不仅是一种设计技术,更是推动软件工程走向工业化、体系化的关键基础。随着业务复杂度、团队规模与生命周期成本的持续上升,软件开发从“写代码”演变为“构建系统”。而…...

⚡️ Linux grep 命令参数详解
⚡️ Linux grep 用法及参数详解 📘 1. grep 简介 grep 是 Linux/Unix 系统中用于文本搜索的命令,其全称为 Global Regular Expression Print,意为全局正则表达式打印器。 它根据给定的 模式(pattern) 对文件或标准…...

2025年第三届CCF·夜莺开源创新论坛通知
点击蓝字 关注我们 CCF Opensource Development Committee 01 大会简介 由中国计算机学会主办、CCF开源发展委员会及夜莺开源社区承办的第三届CCF夜莺开源创新论坛拟于2025年7月4日在北京召开。本次论坛以“AI 加速可观测”为主题,汇聚了开源夜莺核心开发团队&#…...
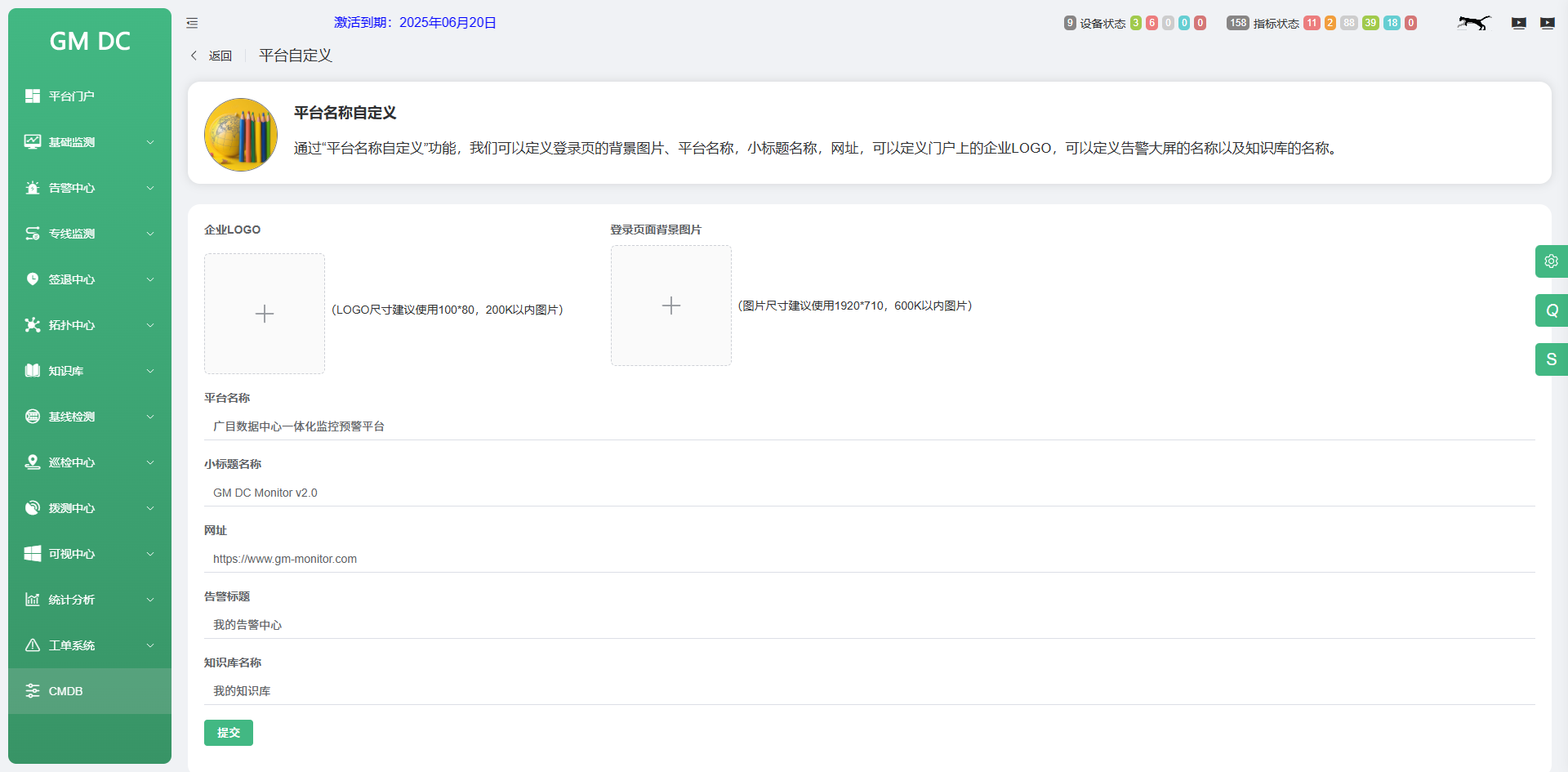
GMDCMonitor企业版功能分享0602
企业版包含了拓扑中心、签退中心、知识库、通知渠道配置、平台自定义,这5个功能 1)拓扑中心 拓扑中心绘制的时候需要注意2点: 1)要先选择 “矩形区域” 或 “圆形区域” 来添加各个背景区域,同时录入区域尺寸&#x…...

automa
网页版插件 https://extension.automa.site/(可能插件下架了) https://github.com/AutomaApp/automa/releases/tag/v1.29.9(可以直接在git上下载) automa官网地址: https://www.automa.site/ 官方的文档 https://docs.automa.si…...
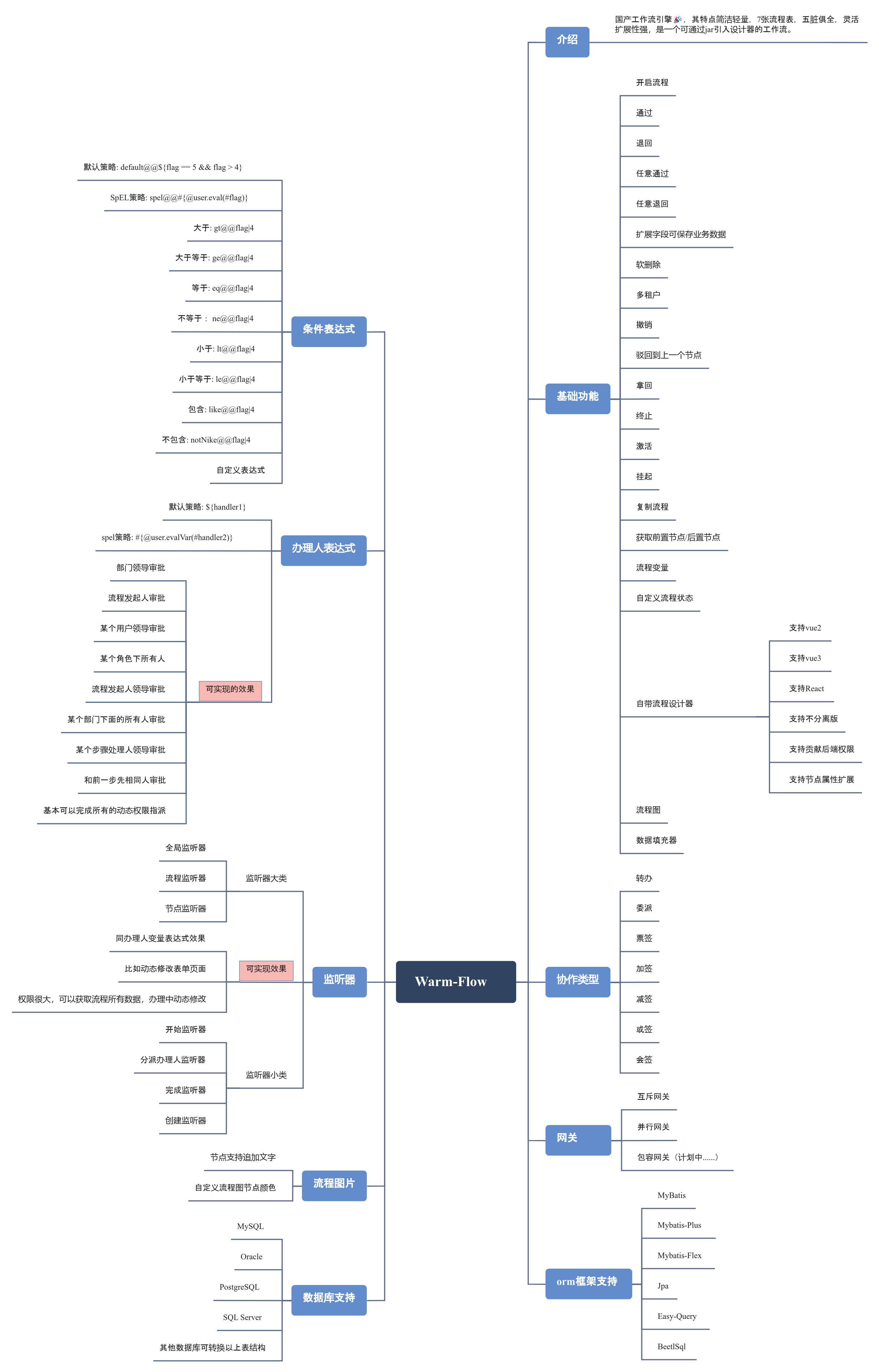
Warm-Flow发布1.7.3 端午节(设计器流和流程图大升级)
Warm-Flow发布1.7.3 端午节(设计器流和流程图大升级) 更新内容项目介绍功能思维导图演示地址官网Warm-Flow视频 更新内容 [feat] 新版流程图通过前端渲染[perf] 美化流程设计器ui[feat] 办理人权限处理器,新增办理人转换接口,比如…...

【存储基础】SAN存储基础知识
文章目录 1. 什么是SAN存储?2. SAN存储组网架构3. SAN存储的主要协议SCSI光纤通道(FC)协议iSCSIFCoENVMe-oFIB 4. SAN存储的关键技术Thin Provision:LUN空间按需分配Tier:分级存储Cache:缓存机制QoS&#x…...
2025年ESWA SCI1区TOP,改进成吉思汗鲨鱼算法MGKSO+肝癌疾病预测,深度解析+性能实测
1.摘要 本文针对肝癌(HCC)早期诊断难题,提出了一种基于改进成吉思汗鲨鱼优化算法(MGKSO)的计算机辅助诊断系统。由于HCC在早期症状不明显且涉及高维复杂数据,传统机器学习方法易受噪声和冗余特征干扰。为提…...
:增长率的真相——从数据基准到科学增长策略)
精益数据分析(93/126):增长率的真相——从数据基准到科学增长策略
精益数据分析(93/126):增长率的真相——从数据基准到科学增长策略 在创业领域,增长率常被视为企业成功的核心指标,但多少才算“足够好”?如何避免陷入“盲目增长陷阱”?今天,我们将…...