逐步检索增强推理的跨知识库路由学习
摘要
多模态检索增强生成(MRAG)在多模态大语言模型(MLLM)中通过在生成过程中结合外部知识来减轻幻觉的发生,已经显示出了良好的前景。现有的MRAG方法通常采用静态检索流水线,该流水线从多个知识库(KB)中获取相关信息,然后是精化步骤。然而,这些方法忽略了MLLM在推理过程中动态确定如何与不同KB交互的推理和规划能力。为了解决这一问题,提出了一种新的MRAG框架R1-Router,该框架能够根据推理状态的演化来学习决定何时何地进行知识检索.具体地说,R1-Router可以根据当前推理步骤生成后续查询,将这些中间查询路由到最合适的KB,并将外部知识整合成连贯的推理轨迹来回答原始查询。在此基础上,我们引入了一种定制的强化学习算法Step-GRPO(Step-wise Group Relative Policy Optimization),它通过分配特定于步骤的奖励来优化MLLM的推理行为。在多个开放域QA基准测试平台上的实验结果表明,R1-Router的性能优于基准模型7%以上。进一步的分析表明,R1-Router能够自适应地有效利用不同的知识库,减少不必要的检索,提高效率和准确率。所有代码均可在https://github.1引言com/OpenBMB/R1-Router上获得
一、简介
检索增强生成(RAG)方法[2,28,44]使大型语言模型(LLM)能够从维基百科,研究论文和网页等文本来源访问外部知识[6,61,27]。这种外部信息作为一种形式的“记忆”,模型可以在推理过程中参考[4,15,62],有助于减轻幻觉并提高许多知识密集型任务的性能[10,18,29]。然而,在现实世界的场景中,这样的外部“记忆”通常来自不同的知识库,例如图像-标题对、文本文档和表格数据。这些在支持模型获取用于回答查询的各种知识方面发挥着独特的作用。现有的多模态RAG(MRAG)方法[1,54,60]通常从预定义的知识库中执行一次性检索,并旨在细化检索到的知识以增强生成过程[34]。这种设计限制了多模式LLM(MLLM)与不同的知识库(KB)动态交互的能力,,并且在推理过程中无法完全满足MLLM的信息需求[41,46,59,22]。
为了解决这一限制,现有的研究已经探索了迭代检索策略,以引出更多的相关信息,满足MLLM回答查询的知识要求[37,41,48]。这些方法通常提示MLLM分解输入查询,检索每个子查询的外部知识,并将检索到的证据合并到输入上下文中以生成最终答案。虽然有效,但这些方法通常依赖于预定义的检索管道,优先考虑单一的主导模态,从而限制了它们从不同知识库获取信息的灵活性[32,59]。为了减轻这种刚性,最近的工作提出了模块化框架,该框架利用规划器来动态调整基于当前子查询的检索动作,并将查询路由到特定的知识库[32,57,59]。然而,这些框架主要依赖于MLLM的查询路由能力,而没有充分利用它们的推理能力[53]。这种依赖性限制了MLLM在查询不同知识库时的动态和自适应潜力,因为在复杂RAG任务的解决方案中信息需求不断发展[8,19]。
此外,最近的研究探索了利用大型推理模型(LRM)[20,33,47,55]作为骨干模型来增强RAG框架的规划和推理能力[12,30]。这些方法允许LRM在推理过程中调用检索器,从而在遇到不确定或不完整的信息时实现知识的动态检索[30]。此外,最近的进展已经采用强化学习(RL)方法来优化LLM,以学习在推理过程中何时触发检索动作[11,45,63,23]。尽管取得了这些成功,但现有的基于LRM的方法主要关注文本模态,缺乏多模态感知能力[38,55],使得它们无法处理不同模态的查询并确定最合适的检索知识源。
在本文中,我们提出了R1路由器,一种新的框架,使MLLM动态地确定何时何地获取外部知识,通过选择下一个动作的基础上的推理过程的当前状态。如图1所示,R1-Router允许MLLM在需要额外知识时生成查询,将其路由到适当的知识库,并根据先前的推理结果继续推理。这个迭代过程一直持续到推理步骤达到最大数量,或者模型确定已经收集了足够的信息来产生最终答案。为了有效地训练R1-Router,我们引入了逐步组相对策略优化(Step-GRPO),它提供了特定于步骤的奖励来指导整个推理轨迹的优化。不同的QA任务的实验证明了R1-Router的有效性,表现出实质性的改善不同的RAG模型。R1-Router由Step-GRPO提供支持,能够进行更深入的逐步推理,并对各种QA场景具有很强的泛化能力。此外,R1-Router在访问不同的知识库方面表现出高度的灵活性,从而大大减少了在视觉QA和表格QA任务中产生准确答案所需的检索步骤数量。
二、相关工作
具有多个知识库(KB)的RAG方法[36,43,62]通过从各种来源检索知识来扩展RAG方法[28,44,40],从而增强其解决更复杂和多样化的现实世界应用的能力[1,5,58,26]。这些方法通常将查询路由到预定义的知识库(如表或图像配置),然后进行单次检索以寻求知识,以在生成过程中支持MLLM [13,52]。然而,这种固定和刚性的检索策略限制了RAG解决需要来自不同领域的知识的用户查询的能力。
为了解决这个问题,最近的研究进一步探索训练或提示多模态LLM(MLLM)作为代理自适应地规划检索策略,以动态选择用于检索的语料库的适当模态,以帮助MLLM生成准确的响应[59,32,57]。一些方法[57]提出了一种统一的检索器-控制器架构,该架构根据查询类型和上下文选择特定于模态的检索器,从而为不同的任务提供路由查询。OmniSearch [32]引入了一个模块化管道,可以分解复杂的查询并将子查询分配给模态适当的检索器,从而有效地集成了不同的知识源。CogPlanner [59]利用基于LLM的代理来执行推理驱动的分解和检索计划,协调何时何地跨多个模态检索外部信息,以支持迭代RAG建模。然而,这些方法依赖于提示或监督微调来引导MLLM将查询路由到不同的KB,而不是利用MLLM的内在推理能力,从而限制了它们的泛化能力[17,56]。
为了更好地将检索纳入推理过程,最近的方法利用强化学习(RL)[24]来优化基于文本的RAG模型,包括DPO [39]和GRPO [42]等方法。DeepRAG [19]采用二叉决策树并应用DPO来训练模型,以根据用户偏好信号决定是直接响应还是在回答之前进行检索。ReSearch [11]在GRPO框架内统一了检索和推理,使用来自最终答案准确性的反馈来指导训练过程并提高复杂查询的性能。R1-R2 [45]采用两阶段和结果驱动的RL训练策略来提高LLM的搜索能力,使它们能够在推理过程中自主调用外部搜索工具来访问特定的知识库。然而,这些基于结果的优化方法依赖于粗粒度的训练信号,并且缺乏对中间决策的细粒度监督,这使得难以避免可能对最终答案产生负面影响的不必要或次优的检索步骤。
三、方法论
这一部分介绍了我们提出的R1-Router方法,该方法使MLLM能够在推理过程中自主地从多个知识源中检索知识。我们首先概述了R1-Router如何自适应地决定在推理过程中何时何地检索相关信息(第第3.1段)。然后,我们将描述R1-Router如何通过逐步组相对策略优化(Step-GRPO)算法来优化MLLM以搜索知识(第3.2段)。
3.1 R1路由器的总体框架
给定初始查询q 0和混合知识库(KB)D,R1-Router执行逐步推理以检索相关信息并生成最终答案a:
 其中输入查询Q 0来自不同的模态,例如文本或图像。知识库D包括异构源,包括图像-字幕对、文本文档和表格数据,使得MLLM能够集成来自不同KB的知识以用于查询应答。
其中输入查询Q 0来自不同的模态,例如文本或图像。知识库D包括异构源,包括图像-字幕对、文本文档和表格数据,使得MLLM能够集成来自不同KB的知识以用于查询应答。
R1-Router执行的推理过程R由n + 1个步骤组成:
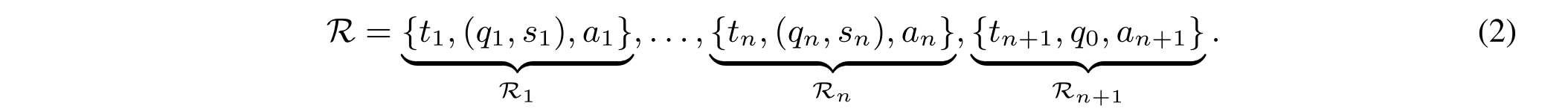 前n个步骤R1:n侧重于从不同的知识库检索相关证据。在最后的步骤n + 1中,R1-Router将所收集的知识{a1,...,an}在先前的推理期间和初始查询q0融合以生成最终答案AN+1。然后详细描述了R1-Router的知识积累R1:n和最终答案生成Rn+1的推理步骤。
前n个步骤R1:n侧重于从不同的知识库检索相关证据。在最后的步骤n + 1中,R1-Router将所收集的知识{a1,...,an}在先前的推理期间和初始查询q0融合以生成最终答案AN+1。然后详细描述了R1-Router的知识积累R1:n和最终答案生成Rn+1的推理步骤。
逐步收集知识
在每个推理步骤Ri(1 ≤ i ≤ n),R1-Router首先产生中间推理输出ti,以评估迄今为止收集的信息是否足以回答初始查询q 0:
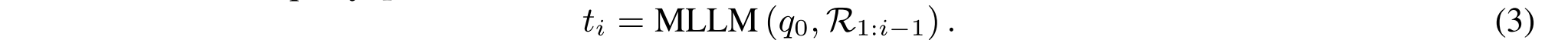
基于q 0、推理历史R1:i-1和当前推理输出ti,R1-Router生成后续查询qi并选择检索器标识符si:
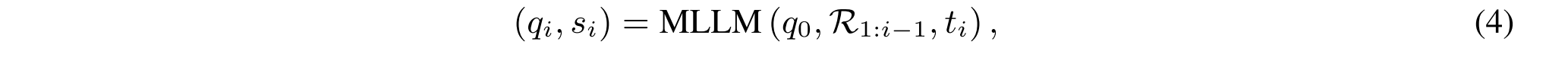
其中si是用于确定从哪个KB进行搜索的检索器标识符。检索器标识符si可以是“文本检索器”、“文本图像检索器”或“表格检索器”,每个检索器对应于查询混合知识库D的子集的特定检索器。使用所选择的检索器si,R1-Router用中间查询qi查询对应的子KB D(si)以检索相关证据di:
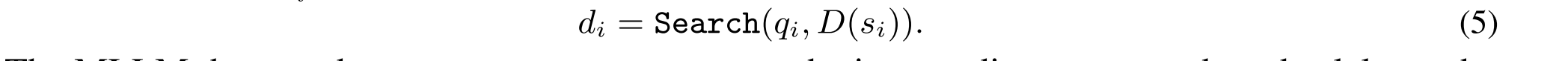
MLLM然后仅基于当前上下文元组(ti,qi,di)产生响应ai以回答中间查询qi:
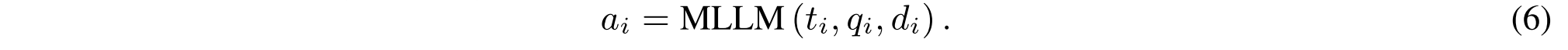
最终答案生成在完成前n步推理R1:n之后,R1-Router继续生成最终答案。在第n + 1步,MLLM确定不需要额外的证据,并将后续查询设置为“无”或n达到最大推理步骤。因此,我们将“None”替换为初始查询q 0以获得最终答案:
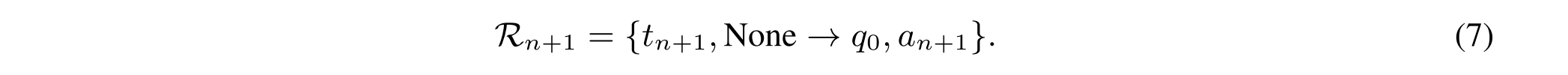
在该最后步骤中,MLLM根据初始查询q0、完整推理轨迹R1:n和推理结果tn+1的整合来生成答案an+1:
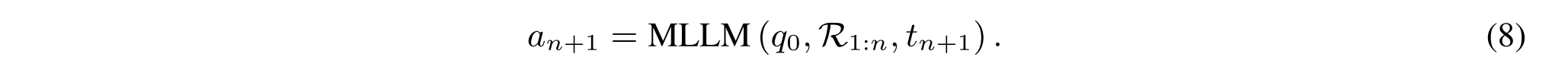
3.2使用Step-GRPO优化MLLM跨KB路由
R1-路由器首先收集地面实况推理轨迹R = R 1,...,R * n,R * n+1,可以帮助生成初始查询q 0的正确答案。然后,它介绍了Step-GRPO,这是一种扩展组相对策略优化(GRPO)[42]的方法,以优化MLLM,用于跨不同的KB D检索信息并执行逐步推理。具体地,在每个推理步骤Ri处,模型以先前的基本事实推理步骤R 1:i-1为条件,并被训练以生成下一步骤推理结果Ri。
R1-Router中的分步奖励模型
为了优化每个推理步骤Ri,R1-Router定义了两种类型的奖励r(1)和r(2),以指导模型(1)获取适当的信息di和(2)在探索轨迹内产生更准确的答案ai。
首先,r(1)鼓励模型在推理步骤Ri(1 ≤ i ≤ n)期间询问更有针对性的查询并将它们正确地路由到相关的KB。这涉及两个组成部分:(i)查询奖励rask(qi),其使用BGE-M3嵌入模型[9]来测量生成的查询qi与R_i中对应的黄金查询之间的语义相似度;以及(ii)路由奖励rroute(si),其评估模型是否正确地选择了适当的检索来从KB的相关子集中搜索。总回报r(1)定义为:
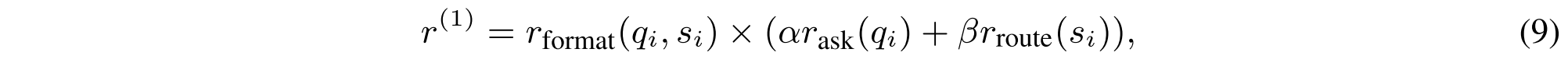
其中α和β是平衡查询相关性和正确路由的重要性的超参数。格式化奖励rformat(qi,si)确保查询和检索器标识符分别包含在特殊的令牌中。
其次,为了在每个步骤Ri优化答案ai,我们定义以下奖励:
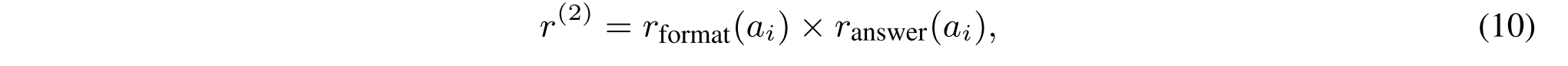
其中,Ranswer(ai)评估所生成的答案ai是否正确。我们通过使用准确性和F1-召回来评估答案质量[32]。F1-Recall应用于中间答案ai(1 ≤ i ≤ n),这通常对应于长且复杂的LLM生成的引用。并且,对于最终答案an+1,由于黄金参考较短,我们使用准确度进行评估。格式化奖励rformat(ai)强制答案包含在特殊令牌中。附录A.3提供了关于细粒度奖励设计的更多细节。
步骤-GRPO目标
为了有效地优化多步推理任务的策略模型,R1-Router采用了Step-GRPO目标,该目标显式地计算每个中间推理步骤的策略优势。给定一个需要n个推理步骤R的查询q 0,Step-GRPO在每个中间步骤i对一组输出进行采样,并最小化以下目标:
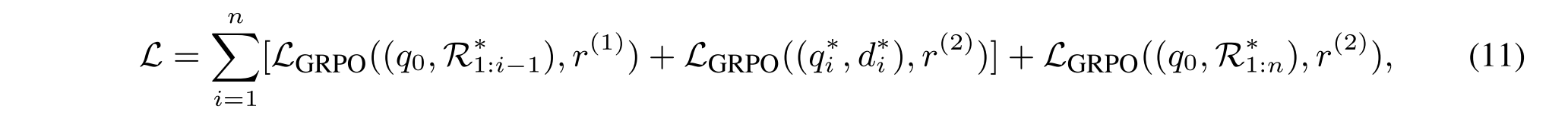
·其中,q i和d i表示黄金查询和从第i个黄金推理步骤R i检索到的文档。最后一项LGRPO((q0,R 1:n),r(2))对应于第(n + 1)步,该步骤仅关注于基于初始查询q0和完整推理轨迹R1:n生成最终答案a。每个GRPO损失项LGRPO(x,r)是在给定输入x和奖励r的情况下,在来自旧策略模型πθold的一批采样轨迹上计算的:
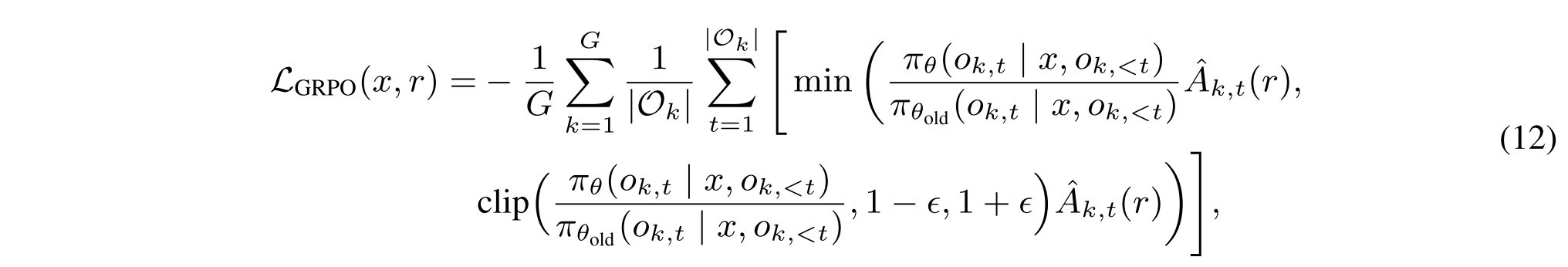
其中,ε是剪裁超参数,πθ是当前政策模型。每个Ok表示来自πθold的采样令牌序列,并且Ok,t表示第k个采样轨迹Ok中的第t个令牌。对于输入x,我们对一组响应{O 1,O2,...,OG},以及它们的奖励{r1,r2,...,rG}是通过奖励函数r(1)或r(2)获得的。每个令牌的标准化优势估计得分A * k,t(r)计算为:
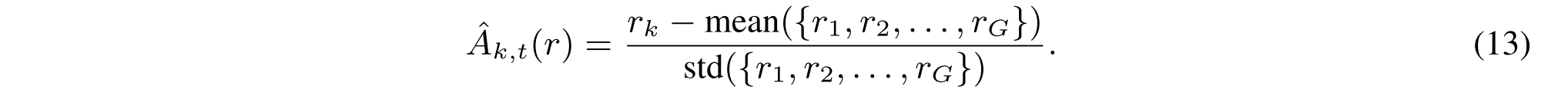
四、实验方法
数据集
本文首先介绍了实验中使用的数据集,然后介绍了黄金推理轨迹构建的数据统计方法
我们的实验包含了三种QA场景:文本QA(2 WikiMultihopQA [21])、可视化QA(InfoSeek [16]、Dyn-VQA [32]和WebQA [6])和表格QA(Open-WikiTable [25]和TabFact [14])。具体来说,我们使用2 WikiMultihopQA,InfoSeek和Open-WikiTable进行训练和评估,而Dyn-VQA,TabFact和WebQA用于评估R1-Router的泛化能力。我们采用针对每种模态量身定制的专用检索器,以支持不同的QA任务。对于文本检索,我们利用BGE-M3 [9]从维基百科转储3中检索相关段落。对于多模态场景,我们采用UniIR [50]作为统一的文本图像检索器,从M-BEIR语料库[50]中检索相关图像,并使用相应的图像描述进行增强。对于表检索,我们遵循Open-WikiTable [25]的设置,使用相同的密集检索器和表语料库。更多详情见附录A.1。
为了构建用于训练R1-Router的黄金推理轨迹,我们使用R1-Distill-Qwen 32 B [20]和Qwen2.5-VL-7 B [3]来生成候选推理路径。然后,我们通过验证它们是否导致正确的答案来过滤这些推理轨迹。经过处理,我们得到了441条用于训练的推理轨迹(包含2,686步)和119条用于开发的轨迹(758步)。有关数据构建过程的更多详细信息,请参见附录A.2。
评估指标
我们使用F1-召回作为所有任务的评估指标,该指标根据先前的工作[32]计算模型响应和真实之间的标准标记比率。
基准
我们将R1-Router与几种基本方法进行了比较,包括vanilla(M)LLM、vanilla RAG模型、迭代RAG模型以及带有知识库(KB)路由的RAG模型。
对于vanilla(M)LLM建模,模型直接接收查询沿着图像并生成答案,而无需任何检索过程。相比之下,对于没有多模态功能的LLM,输入图像首先通过MLLM提供的图像字幕转换为详细的文本描述。香草RAG模型将检索到的证据作为额外的上下文,以帮助MLLM回答查询[43,40]。我们还评估了三个代表性的迭代RAG模型:IRCoT [48],IterRetGen [41]和Search-O 1 [30]。IRCoT和IterRetGen都进行固定次数的检索迭代,以逐步从知识库中收集相关知识。关键的区别在于它们的查询生成策略:IRCoT生成一个思想链(CoT)[51]作为后续查询,而IterRetGen依赖于MLLM基于当前状态生成潜在的查询。Search-O 1进一步为QA任务进行自适应检索[22],将检索操作集成到LLM的深度推理过程中[20]。此外,我们比较了三种设计用于检索的KB路由机制的RAG模型:CogPlanner [59],UniversalRAG [57]和OmniSearch [32]。UniversalRAG实现了一个路由模块,将查询分发到适当的知识库,并进行单步检索。CogPlanner通过启用迭代检索扩展了这一点:MLLM在每一步之后都被提示生成子查询并选择合适的KB。与CogPlanner不同,OmniSearch使用合成数据和InfoSeek数据集[16]微调MLLM,使它们能够充当自主选择相关知识源的规划者。附录A.5提供了基线方法的更多实施细节。
实现详细数据
我们采用Qwen2.5-VL-7 B [3]作为我们提出的R1路由器的主干模型。R1-Router在8× NVIDIA A100- 80 GB GPU上训练,超参数= 0.2,α = 0.5,β = 0.5,学习速率为1 e −6,组采样数为8,共15个时期。为了避免无限的检索循环,我们将检索迭代次数限制为至多3次(n ≤ 3)。在知识积累之后,初始查询q 0被重新馈送到模型中,以通过第n + 1个推理步骤Rn+1产生最终答案。
五、评价结果
在本节中,我们首先介绍R1-Router在各种QA任务中的性能,包括文本QA、视觉QA和表格QA。然后,我们进行消融研究,以检查不同的训练策略。接下来,我们分析了R1-Router如何在推理过程中执行自适应检索。最后,我们提供了案例研究来分析R1路由器的行为。
5.1整体性能
R1-路由器和基线方法的总体性能如表1所示。对于普通和迭代RAG模型,我们评估了两种检索设置:(1)从每个特定于模态的KB(文本、图像或表格)中单独检索5个文档,以及(2)聚合从这些KB中检索到的所有15个文档。
表1:R1-路由器和基线的总体性能(突出显示最佳和第二名)。除Search-O 1(R1-Distill-Qwen-7 B)外,所有基线RAG方法均使用Qwen2.5-VL-7 B作为骨架。
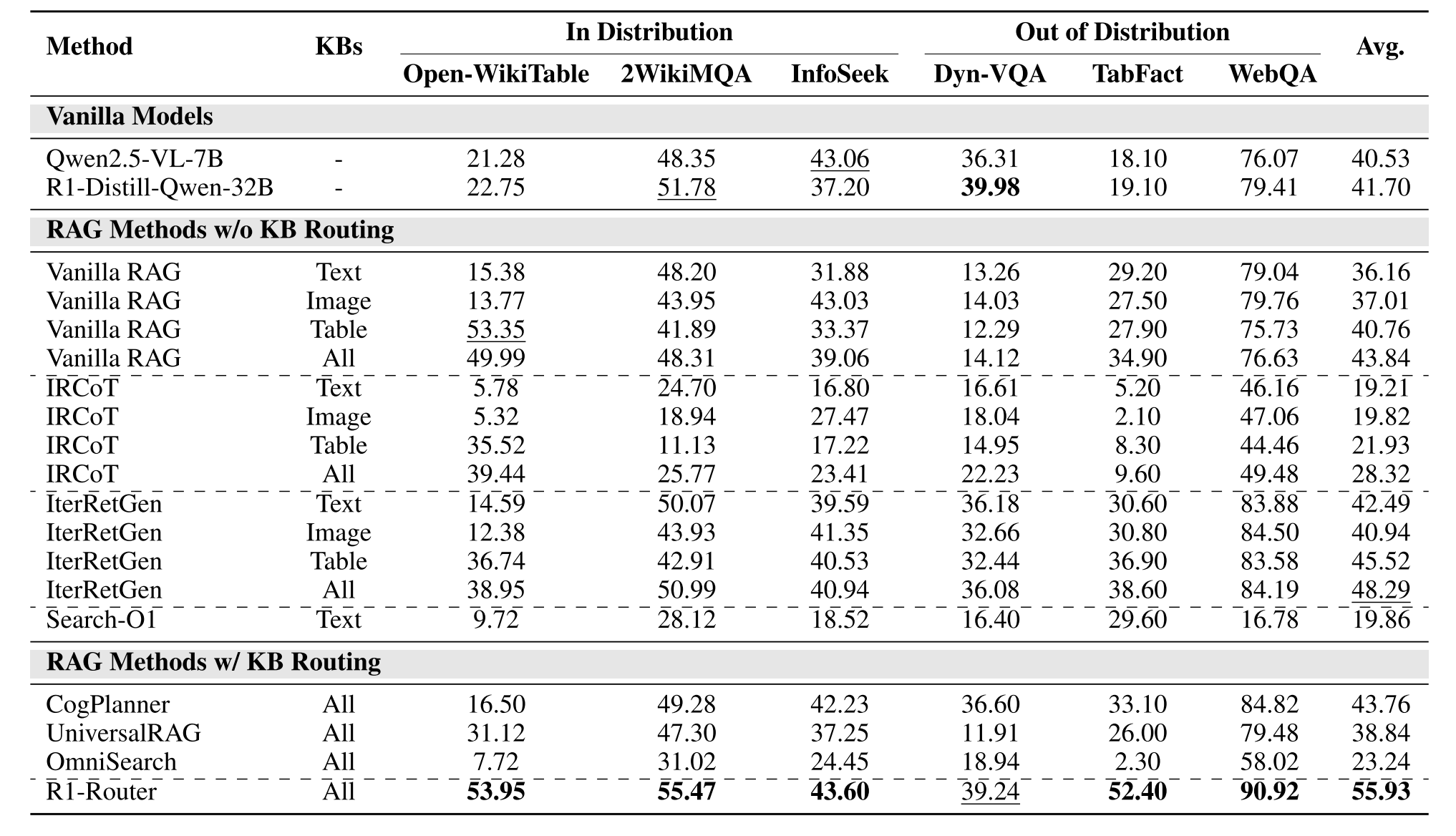
总体而言,R1-Router始终优于所有基准型号,实现了约7%的平均性能提升。值得注意的是,R1-Router通过自适应地将查询路由到不同的KB来收集信息,显示出一致的改进,突出了其强大的泛化能力和作为处理不同QA任务的通用解决方案的潜力。与没有KB路由的RAG模型相比,R1路由器通过动态地将查询路由到不同的知识库进行信息检索,具有明显的优势。在缺乏知识库路由的RAG基线组中,合并从多个知识库检索的证据导致QA性能的显著改善,表明不同的知识库提供了支持MLLM回答查询的补充信息,此外,IterRetGen实现了比普通RAG模型更好的性能,说明迭代检索可以帮助积累更多相关和足够的信息来回答这些复杂的查询。虽然Search-O 1鼓励大型推理模型(LRM)在推理过程中执行自适应检索,但它的性能比其他模型差。这可能归因于基于检索的方法在有效引导LRM利用检索工具方面的局限性,这是一种在预训练期间可能没有充分学习的能力[23]。此外,R1-Router优于配备基于KB的路由的RAG方法,突出了其在扩展MLLM的QA任务的深度推理能力方面的有效性。在我们的Step-GRPO策略的基础上,R1-Router联合改进了MLLM的路由和推理能力,从而形成了一个更有效和适应性更强的RAG框架。
5.2消融研究
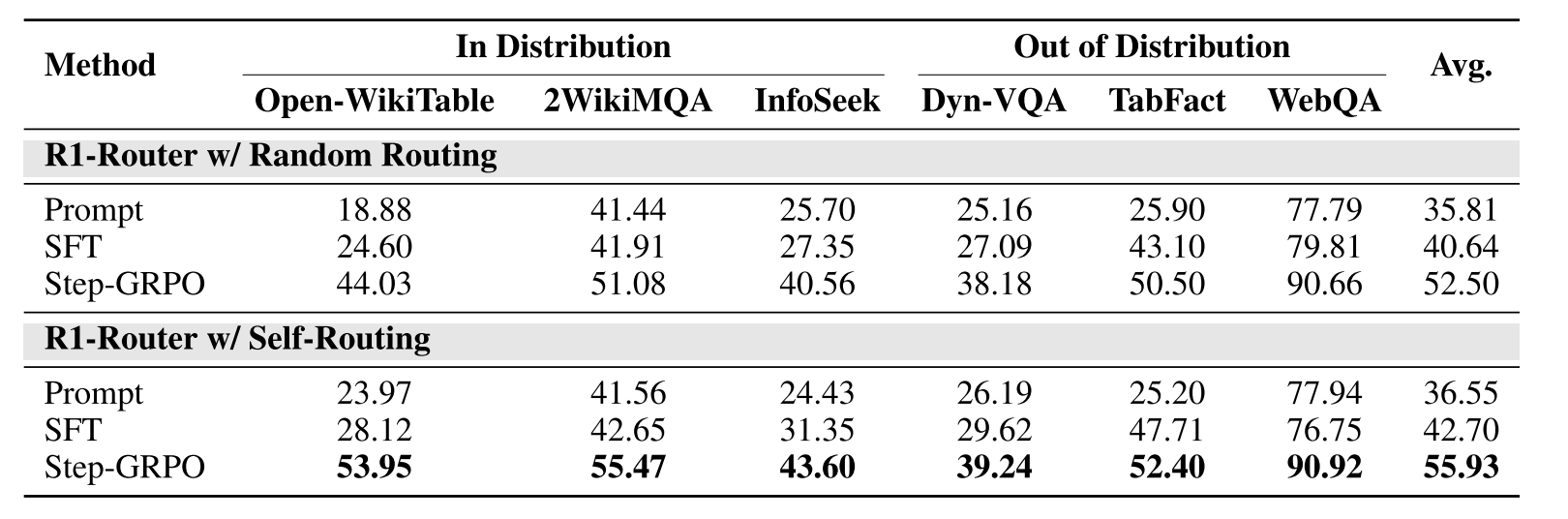
本节进行消融研究,以评估不同训练策略的有效性,包括Prompt、SFT和Step-GRPO。为了评估KB路由的贡献,我们进一步比较了两种评估设置:(1)随机路由,其中为每个中间查询随机选择KB,以及(2)自路由,其中MLLM本身确定最相关的KB。
如表2所示,R1-Router(Step-GRPO)的性能始终优于所有基线,在所有任务中均获得了超过10%的改进。该结果突出了Step-GRPO在以下方面的有效性:这一结果突出了Step-GRPO通过多步推理和结构化知识获取指导MLLM的有效性。虽然R1-Router(SFT)在数据集上的性能略优于2 WikiMultihopQA,InfoSeek和WebQA等基于数据集的方法,但这表明仅使用SFT进行模型优化使得R1-Router在各种QA场景中缺乏泛化能力。相比之下,R1-Router(Step-GRPO)在所有任务中产生更一致和显著的改进,通过RL优化展示了其上级推理和知识积累能力。值得注意的是,即使与随机路由结合使用,R1-Router(Step-GRPO)也能保持比Prompt和SFT方法更强大的性能增益,这表明它的好处不仅源于路由精度,但也从更有效的推理和中间查询生成。通过进一步整合自路由,R1-Router(Step-GRPO)实现了额外3%的改进。这证实了R1-Router在动态选择相关KB方面的有效性,从而产生更准确的答案。
表2:消融研究
5.3 R1-Router在自适应检索和推理中的行为分析
在本节中,我们首先检查Step-GRPO在使MLLM能够执行自适应推理和检索方面的有效性。然后,我们分析了不同模型的知识库路由行为,以更好地了解他们的知识寻求策略。
Step-GRPO的有效性
如图2所示,我们评估了Step-GRPO训练方法对提高MLLM推理能力的影响。在图2a和2b中,我们分别显示了训练期间奖励分数和反应长度的进展。随着训练的进行,奖励分数稳步增加并最终达到平台,这表明生成的响应质量有所提高。与此同时,响应长度最初减少,然后增加,这表明Step-GRPO帮助MLLM逐步探索推理策略,并最终生成更长,更完整的推理轨迹。图2c显示了正确回答查询所需的平均推理步骤数。我们将所有测试数据分为三种类型-表QA,视觉QA(VQA)和文本QA-基于所需的知识。在TextQA场景中,Step-GRPO在平均推理步骤方面执行了其他训练策略,这表明单独进行更深层次的推理可能不会降低纯文本查询的检索复杂性。相比之下,在VQA和Table QA场景中,R1-Router显着减少了推理步骤的数量,证明了其在指导MLLM更有效地跨不同知识库路由查询以进行更有效的知识使用方面的有效性。
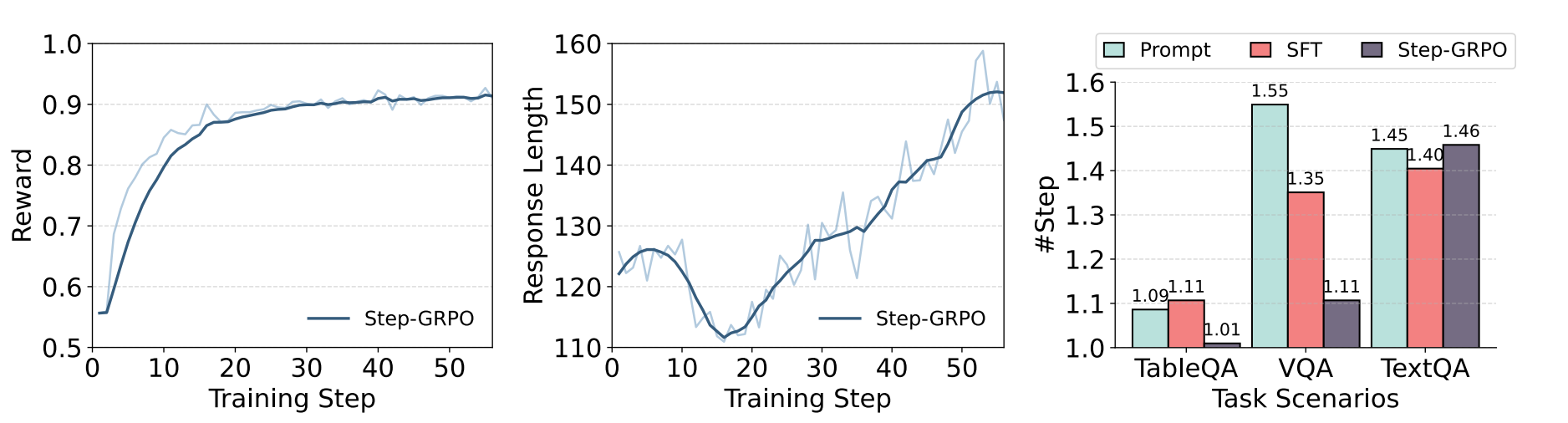
(a)逐步GRPO训练期间奖励分数的演变 (b)Step-GRPO训练期间的响应长度轨迹。(c)正确回答问题所需的推理步骤。
图2:Step-GRPO训练方法的性能
推理期间R1路由器的路由偏好
我们进一步研究如何步GRPO减少推理步骤,通过分析路由偏好的演变在整个推理过程中的R1路由器。如图3所示,我们在VQA任务的每个推理步骤中计算选定KB的比例。与R1-Router(Prompt)相比,R1-Router(SFT)模型表现出一种严格的检索模式,主要继承自特定的偏好。它首先倾向于使用文本图像检索器从预定义的特定于任务的知识库中获取相关的视觉描述。然后,它在文本图像检索器和文本检索器之间交替搜索多个KB。相比之下,Step-GRPO鼓励更具适应性和灵活性的路由行为。具体地,R1-Router(Step-GRPO)越来越多地将其检索偏好从文本图像检索器转移到文本检索器,这表明文本知识(例如,来自Wikipedia)在回答视觉查询时通常起着更重要的作用。此外,它选择性地采用表检索器在适当的时候,证明了它的能力,利用多模态知识库的基础上的信息需求自适应。这种自适应的知识寻求行为突出了Step-GRPO的潜力,使更多的通用和灵活的RAG系统的多模态QA任务。
5.4样例研究
为了进一步证明R1-Router的有效性,我们从InfoSeek数据集上展示了一个VQA任务的案例研究。如图4所示,我们展示了R1-Router针对一个查询的逐步推理过程,该查询要求获得图中所示鸟类的最接近父分类。

图4:演示R1-Router性能的可视化QA任务示例。
在第一个推理步骤中,R1-Router启动了一个审议过程,并将任务分解为一个子目标:进行视觉分析。它制定了一个中间查询-“图像中显示的鸟的名字是什么?”- 并选择文本图像检索器以获取相关的视觉信息。通过利用该检索器,R1-Router从知识库中检索语义相似图像的图像描述,其中包括描述给定图像中的鸟的关键实体,例如“Bay-breasted Warbler”。值得注意的是,R1-Router执行反射步骤,以基于独特的视觉特征(例如,胸部模式)检索到的证据中提到。这证明了R1风格的深度推理在基于RAG的建模中的有效性。在第二步中,R1-Router制定了一个后续查询-“湾胸莺最接近的父分类是什么?”- 并选择文本检索器来收集事实知识。使用检索到的内容,R1-Router将湾胸柳莺的属识别为“Setophaga”,并最终输出正确的最终答案。该案例研究展示了R1-Router在解决问题过程中动态决定何时以及从哪个知识源检索信息的能力,展示了其强大的推理和检索规划能力。
六、结语
本文提出了R1路由器,设计的方法来动态地确定何时何地检索相关的知识在推理过程中。具体来说,R1-Router引入了逐步组相对策略优化(Step-GRPO)。该优化算法在中间推理步骤中计算特定于步骤的奖励,以指导MLLM学习如何在推理过程中从不同的知识库中检索信息。实验结果表明,R1-Router可以跨多个知识库进行实际的检索操作,并在当前问题求解上下文的条件下进行迭代推理。这使它能够有效地处理需要多步推理和异构信息源的复杂查询。此外,R1-Router通过使MLLM能够有效地管理不同的知识源并处理广泛的查询类型,为构建可推广的RAG系统迈出了有希望的一步。
A 附录
A.1 R1-Router中使用的知识库的更多实验细节
检索器
当R1路由器将查询路由到文本知识库时,我们使用BGE-M3 [9]作为我们的文本检索器。它利用文本查询从文本知识库中检索事实知识,帮助MLLM生成更准确的答案。UniIR [50]被用作我们的文本-图像检索器,以基于查询文本和图像获得视觉描述。具体地说,UniIR独立地对查询文本和图像进行编码,将它们的特征融合成统一的多模态表示,并从语料库中检索最相关的文本-图像对。然后,这些对的文本成分被用作我们检索的证据。对于表知识库,我们遵循Open-WikiTable [25],并使用相同的表检索器根据查询搜索相关表。不同检索器的检索样例如图5所示。

图5:不同检索器的案例研究
检索语料库
对于文本语料库,我们使用英文维基百科转储20241020作为源。根据先前的工作[7,49],我们从转储中提取文本内容,并将每篇文章分割成多个不相交的文本块,每个文本块100个单词,这些文本块用作基本检索单元。为了确保文本KB的质量,我们丢弃了包含少于7个单词的所有文本块,最终收集了52,493,415个段落。每个段落前面都有维基百科文章的标题。对于文本-图像语料库,我们遵循UniIR [50]的设置,并采用M-BEIR作为我们的图像描述语料库,该语料库包含超过560万个候选项。对于表格语料库,我们遵循Open-WikiTable [25],并利用他们的语料库作为我们的表格语料库,其中包括24,680个表格。
A.2黄金推理轨迹的数据构建
为了有效地训练和开发R1-Router,我们构建了一个QA数据集,该数据集具有跨不同任务场景的黄金推理轨迹。本节详细介绍了施工过程。
数据源
我们从现有的QA数据集收集样本,跨越不同的任务场景,构建了问答对。具体来说,我们使用2 WikiMultihopQA [21]进行文本QA,InfoSeek [16]用于视觉QA(VQA),Open-WikiTable [25]用于表格QA。这些数据集包含复杂的查询,通常需要多个步骤才能准确回答。
数据综合
我们建立了一个自动化的数据流水线来合成黄金推理轨迹R #,用于训练R1-Router。具体来说,我们提示LRM或MLLM迭代地生成一步一步的推理轨迹,应用拒绝采样来过滤和保留高质量的例子。中间查询生成和检索器标识符选择的过程可以表示为:
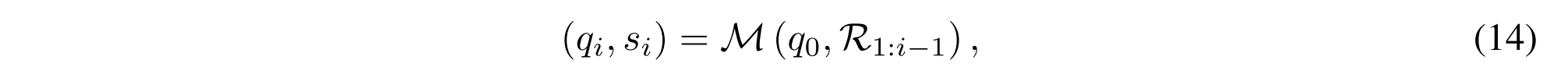
其中,q 0表示初始查询,R1:i-1表示先前的推理轨迹,qi和si表示中间查询和推理步骤i中选择的检索器标识符。M表示在我们的流水线中使用的LRM或MLLM。对于VQA任务,我们采用Qwen2.5-VL-7 B [3]作为基础模型,而对于表格QA和文本QA任务,我们采用R1-Distill-Qwen-32 B [20]。然后,中间答案生成步骤可以表示为:
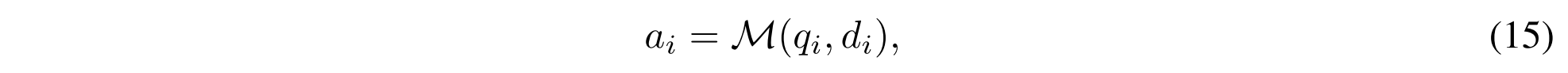
其中di表示检索到的内容,ai表示相应的中间答案。最终答案生成步骤的格式为:
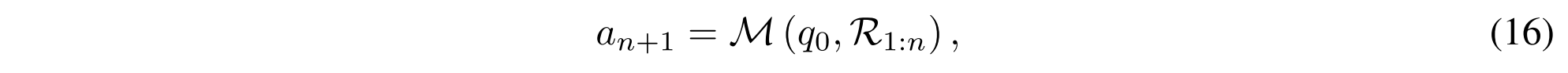
其中an+1是生成的最终答案。为了确保训练数据的质量,我们应用拒绝采样来过滤数据,仅保留其答案相对于地面真实答案a n+1的准确度为1的推理路径作为地面真实推理步骤R n,其格式为:
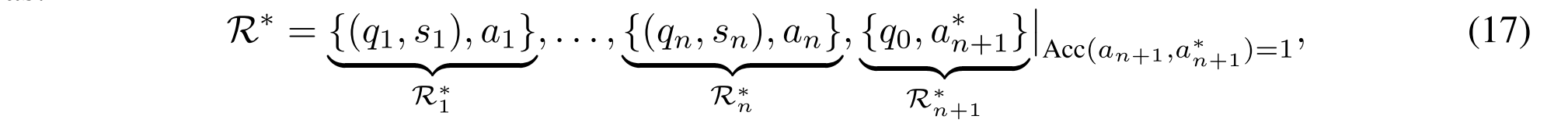
从而为R1-Router提供高质量的逐步训练数据集。
数据统计
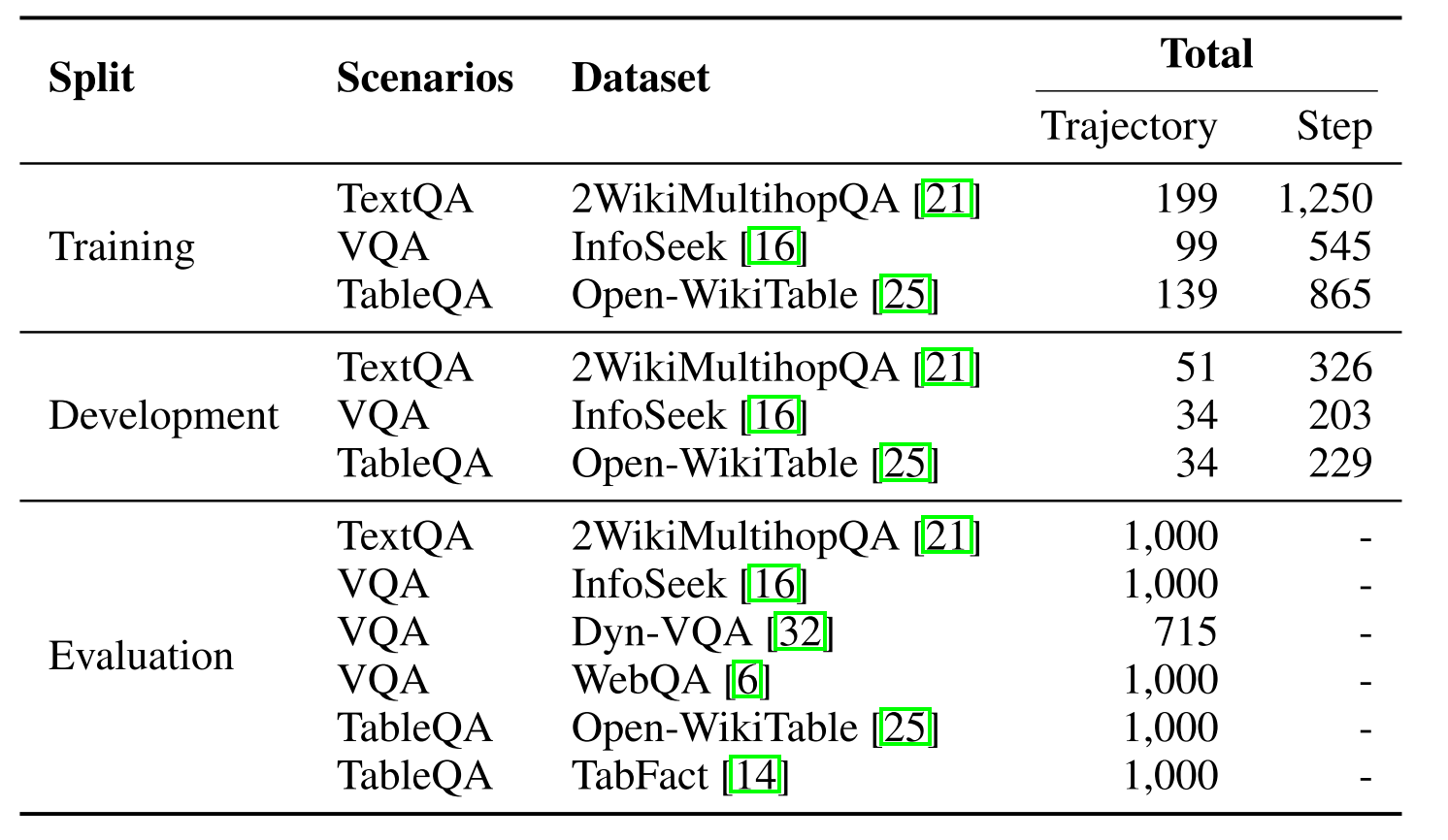
我们在表3中显示了训练、开发和评估的数据统计。我们用199条推理轨迹训练R1-Router进行文本QA(总共1,250个推理步骤),99VQA的推理轨迹(总共545个推理步骤)和Table QA的139个推理轨迹(总共865个推理步骤)。此外,我们利用了一个开发集,包括119个推理轨迹,其中包括总共758个推理步骤。为了进行评估,我们从每个数据集中随机选择了1,000个样本,Dyn-VQA数据集除外,该数据集仅包含715个样本-这些样本都用于测试。
表3:数据统计
A.3关于细粒度奖励的更多细节
设置奖励格式
我们设置奖励的格式,以确保生成的内容包含在特殊的令牌中。具体地说,R1-Router的推理过程、中间查询和被调用的检索器都应该包含在<think>...</think>,<sub-question>...</sub-question>而且<ret>...</ret>标签。根据以上格式要求,本步骤中的格式奖励可定义为:

其中qi和si是中间查询和在第i个推理步骤中所选择的检索器的标识符。在生成中间答案和最终答案时,我们定义了推理过程的正确格式,答案应包含在<think>...</think>而且<answer>...</answer>标签,分别。根据上述格式要求,本步骤中的格式奖励可以定义为:

其中ai是在第i个推理步骤生成的答案。
查询奖励
查询奖励。我们将查询奖励定义为所生成的中间查询与地面实况中间查询之间的文本相似度。具体地,我们采用BGE-M3-embedding [9]模型作为编码器E(·),将它们投影到高维嵌入空间中,并计算它们的相似度,其可表示为:

其中qi是在第i个推理步骤处生成的查询,并且qi是基础事实查询。sim表示相似度函数,其中我们使用点积来计算qi和q i之间的相似度。
路由奖励
我们利用知识库路由的准确性作为我们的路由奖励,计算如下: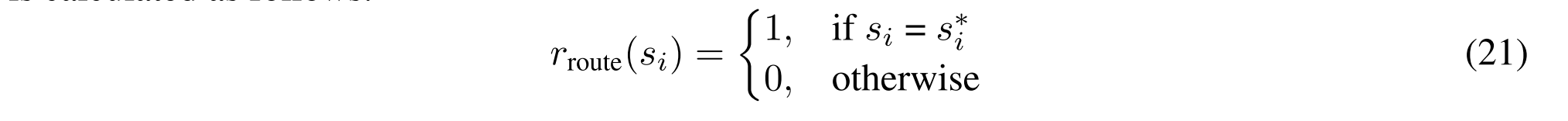
其中si是在第i个推理步骤中选择的检索器标识符,并且si_i是基本事实检索器标识符。
回答奖励
我们采用F1-Recall [32]来计算第i个推理步骤的中间答案ai(1 ≤ i ≤ n)的答案奖励,并评估最终答案an+1的准确性。具体地,中间答案ai(1 ≤ i ≤ n)的答案奖励可以表示为:
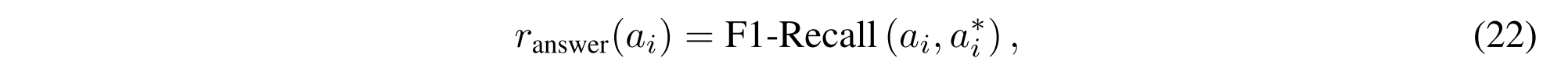
其中a * i代表第i个推理步骤中的真实中间答案。F1-召回可以计算为:
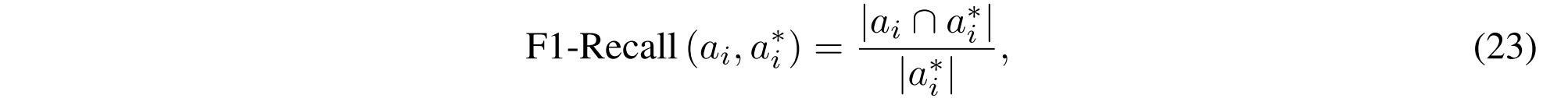
其中表示预测答案ai和地面实况答案a i之间的交集中的单词数量。对于预测的最终答案an+1,答案奖励可以使用准确度分数计算:
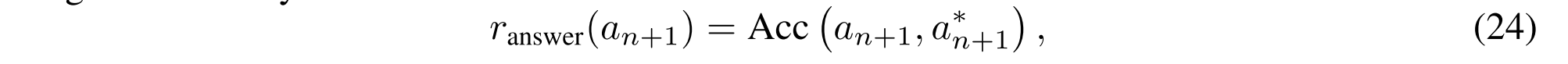
其中,a = n+1表示最终答案的真实值。准确度分数通常用于评估现有工程中QA系统的性能[2,31]。
A.4 R1路由器中使用的提示模板
R1-Router(Prompt)和R1-Router(SFT)方法使用的8次提示模板用于跨三个任务场景生成中间查询和选择检索器,如图6、图7和图8所示。在数据构建期间应用相同的提示模板,随后过滤掉包含不正确最终答案的样本。我们在图9中展示了R1 Router(Step-GRPO)用于查询生成和路由的提示模板。图10和图11分别显示了所有R1-Router模型用于生成中间和最终答案的提示模板。
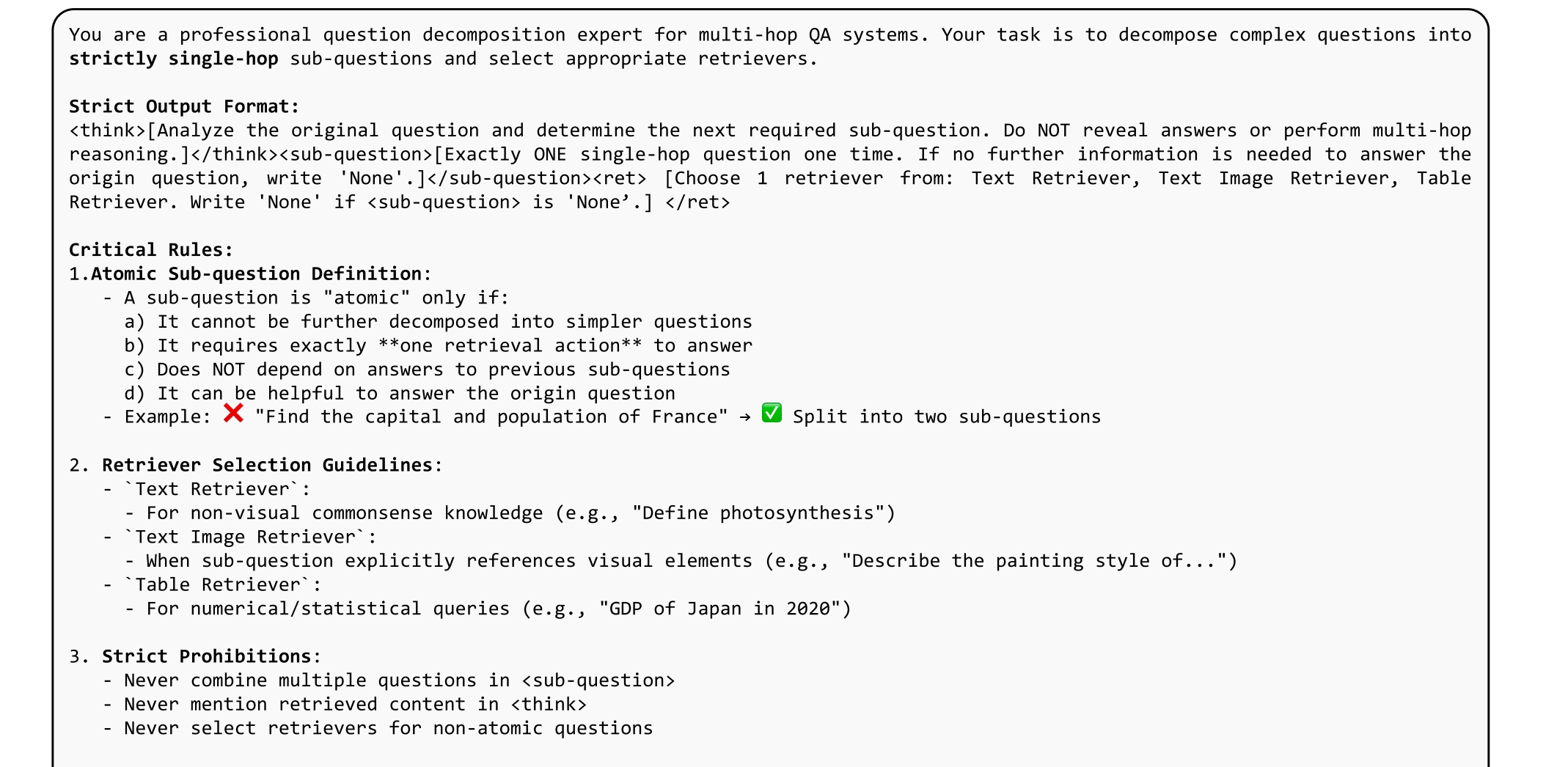


图6:R1-Router(SFT)和R1-Router(Prompt)的提示模板,用于TextQA任务中的查询生成和检索器选择。我们还使用这些提示模板进行数据构建。
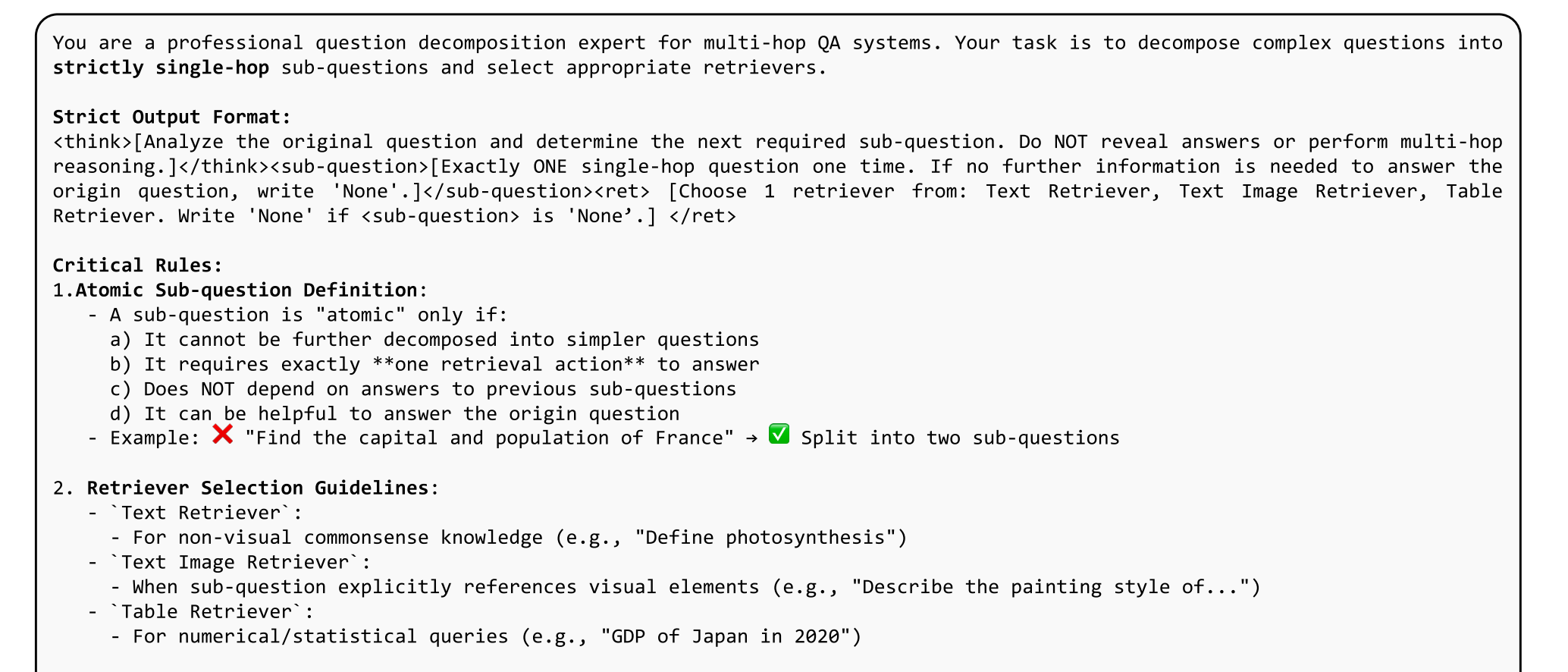



图7:VQA任务中用于查询生成和检索器选择的R1-Router(SFT)和R1-Router(Prompt)的提示模板。我们也使用这个提示模板进行数据构建。



图8:用于TableQA任务中查询生成和检索器选择的R1-Router(SFT)和R1-Router(Prompt)的提示模板。我们也使用这个提示模板进行数据构建。
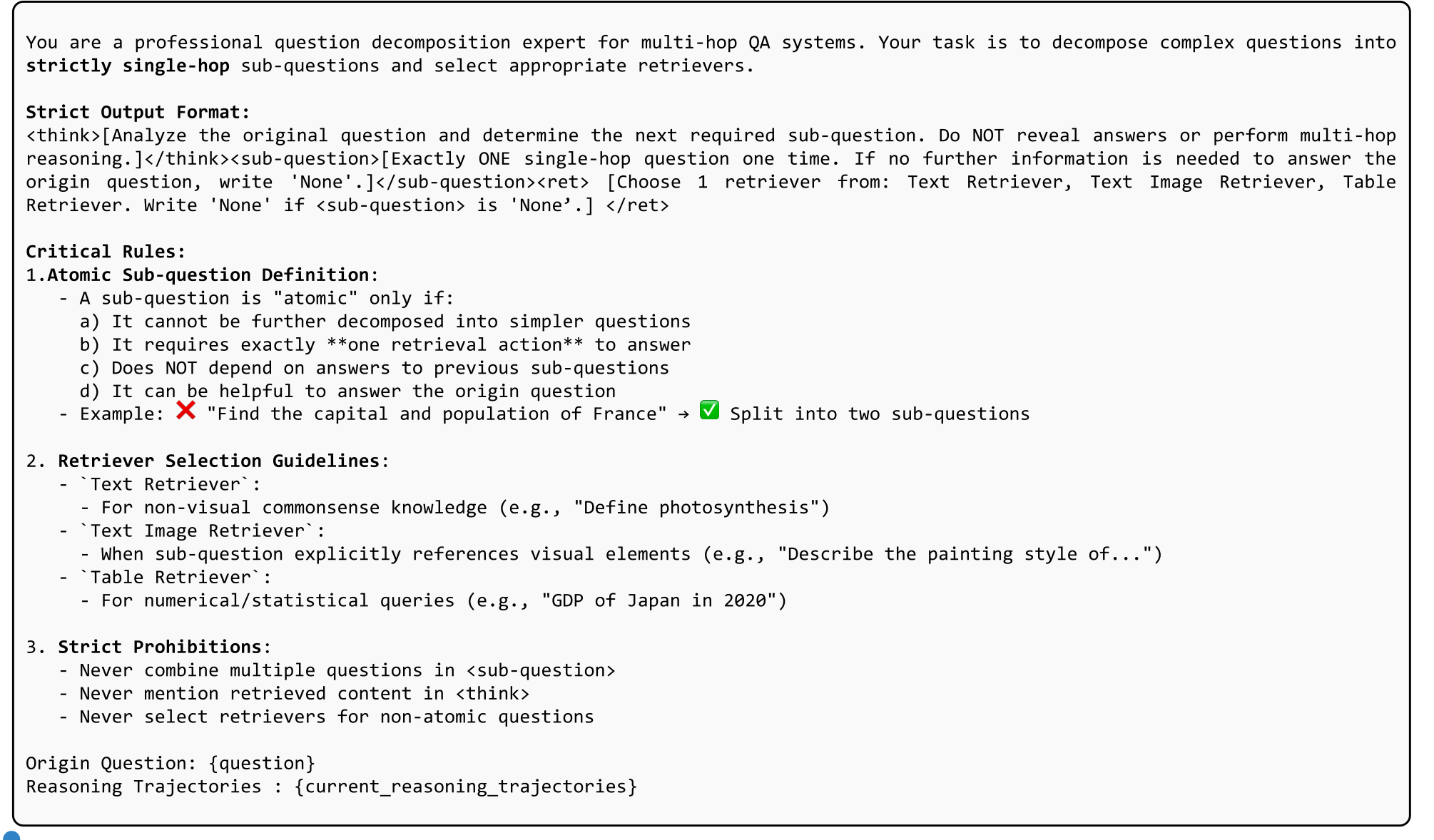
图9:R1-Router(Step-GRPO)用于查询生成和检索器选择的提示模板。

图10:R1-Router生成中间应答的提示模板。我们将此提示模板用于所有R1-Router型号,包括R1-Router(SFT)、R1-Router(Prompt)和R1-Router(Step-GRPO)。

图11:R1-Router生成最终应答的提示模板。我们将此提示模板用于所有R1-Router型号,包括R1-Router(SFT)、R1-Router(Prompt)和R1-Router(Step-GRPO)。
A.5基准方法的更多实施细节
在本节中,我们将介绍在实验中使用的基线方法的实现细节。
Vanilla模型
我们提示Qwen2.5-VL-7 B和R1-Distill-Qwen-32 B直接回答初始查询。对于R1-Distill-Qwen-32 B,我们利用Qwen2.5-VL-7 B来生成图像的详细文本描述,并将其合并到输入上下文中以便于生成答案。所使用的提示模板如图12所示。

图12:Vanilla模型和Vanilla RAG模型的提示模板
VanillaRAG
我们使用Qwen 2. 5-VL-7 B作为基础模型来实现Vanilla RAG方法,并从特定知识库中检索相关知识,将检索到的前5个证据片段合并到输入上下文中。我们进一步将从多个知识库中检索到的这些证据片段连接起来,以扩展输入上下文,并评估模型利用来自不同知识库的信息的能力。Vanilla RAG使用的提示模板如图12所示。
IRCoT.
我们按照论文[48]将IRCoT作为我们的基线方法。IRCoT迭代地引导模型在每个检索步骤后生成一个思维链(CoT)[51],使用CoT的最后一句话作为下一轮检索的查询,直到CoT包含“答案是”或达到检索迭代的最大次数。然后,CoT的最后一句话被视为最终答案。图13显示了我们用于实施IRCoT的8次激发即时建模方法。最大迭代次数设置为3。


图13:IRCoT方法的提示模板
CogonPlanner
CogPlanner [59]提示Qwen2.5-VL-7 B迭代生成中间查询,决定是否需要检索,并选择适当的知识库进行检索。当模型确定累积的信息足够全面并且当前查询足够清楚时,迭代过程终止。随后,该模型整合所有检索到的证据,以产生最终答案。CogPlanner使用的提示模板如图14和图15所示。

图14:CogPlanner的检索器选择提示模板
迭代RetGen
我们采用迭代检索和生成(IterRetGen)[41]框架作为我们的基线。IterRetGen在迭代检索和生成之间交替进行,并使用检索到的证据和当前查询来为下一次迭代生成新的中间查询。此迭代过程将继续,直到模型输出“None”作为中间查询或达到最大迭代次数。用于中间查询生成的提示模板如图15所示。我们使用Qwen2.5-VL-7 B作为基础模型。用于中间答案生成和最终答案生成的提示模板如图16和图17所示。最大迭代次数设置为3。


图15:IterRetGen的查询分解提示模板

图16:用于生成中间答案的IterRetGen提示模板

图17:IterRetGen的提示模板,用于生成最终答案
Search-O 1
我们基于Search-O 1 [30]的官方代码库4实现了Search-O 1 [30],并采用R1-DistillQwen-7 B [20]作为主干推理模型。当模型生成特殊令牌<|开始搜寻查询|>和<|搜索查询结束|>,则Search-O 1使用所生成的查询从文本知识库执行检索。然后,使用标记对检索到的前5个证据进行提炼并将其合并到推理链中。|开始搜索结果|>和<|搜索结果结束|>.此迭代检索和推理过程继续进行,直到模型产生最终答案或达到推理步骤的最大数目(设置为3)。
UniversalRAG
我们使用他们论文中的8-shot提示符来实现UniversalRAG [57],指导Qwen2.5-VL-7 B直接回答查询或路由到适当的知识库进行检索。一旦选择了知识库,它将制定一个搜索查询来检索前5个相关文档,并使用它们来生成最终答案。取数设置与R1-Router一致,UniversalRAG的提示模板如图18所示。全方位搜索。我们使用他们的官方检查点5和他们论文中提供的提示模板来实现

图18:UniversalRAG的检索器选择提示模板。
OmniSearch
该模型基于Qwen-VL-Chat通过对GPT-4V生成的合成数据的监督微调(SFT)进行训练,以使MLLM能够迭代地生成中间查询并选择适当的知识库进行检索。迭代过程将继续,直到模型输出“最终答案”或达到最大迭代次数。OmniSearch使用的提示符如图19所示。

图19:OmniSearch的提示模板
A.6 R1路由器的其他案例研究
在本小节中,我们将提供其他案例研究,以进一步证明R1-Router的有效性。具体地说,我们展示了各种任务场景中的示例,以说明R1 Router如何自适应地规划中间查询,选择合适的知识库进行检索,并集成检索到的信息以构建连贯的推理轨迹。
我们开始以图20中所示的情况为例,它取自Table QA任务下的Open-WikiTable QA数据集。该示例查询戴尔咖喱在多伦多猛龙队历史上的C名单上的任期长度。R1-Router确定不需要中间查询,并直接使用Table Retriever获取相关信息。这突出了R1-Router动态决定何时停止中间查询生成并生成最终答案的能力。此外,在第二步中,R1-Router通过验证Dell咖喱的任期持续了四年(1999-2002)来准确执行反映机制,确保子问题和相应答案的一致性。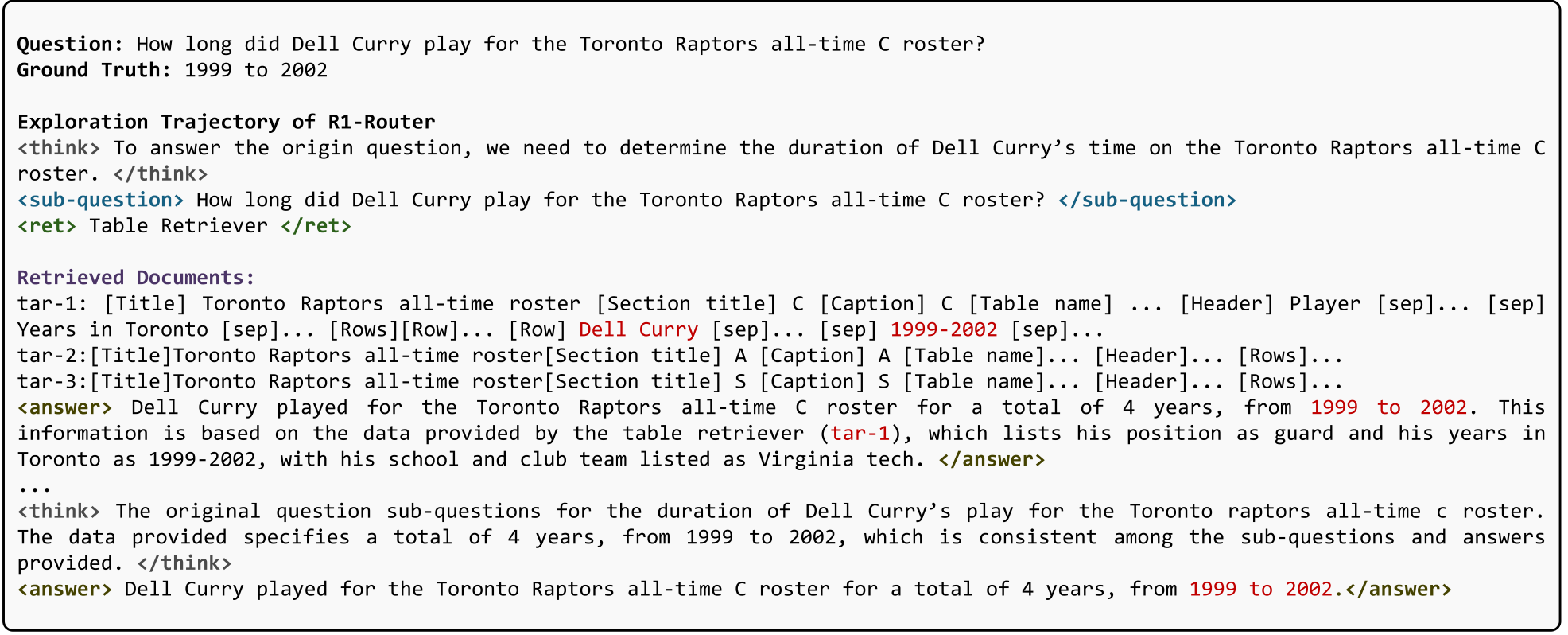
图20:Open-WikiTable QA上R1-Router的案例研究。
接下来我们分析图21中所示的案例,该案例来自Dyn-VQA数据集,属于VQA任务。该案例的初始查询是:“她出生在哪个城市?",伴随着相应的图像。R1-路由器使用文本图像检索器获取图像描述,以识别图像中的人物是“艾米丽·迪金森”。然后,它制定了后续查询“艾米丽狄金森出生在哪里?",并使用文本知识库来补充用于解决问题的事实知识。根据检索到的内容,R1-Router识别出艾米丽·狄金森的出生城市是马萨诸塞州的阿默斯特。值得注意的是,R1-Router一旦可以用积累的知识回答原始问题,就停止生成进一步的中间查询,这表明它有能力自适应地确定何时收集了足够的信息进行有效推理。

图21:Dyn-VQA上R1路由器的案例研究。
最后一个案例(如图22所示)来自2 WikiMultihopQA数据集,该数据集属于文本QA任务。问题是关于塞尔维亚的丈夫阿纳斯塔西娅的死亡地点。R1-Router最初决定澄清“谁是塞尔维亚的阿纳斯塔西娅的丈夫?”并选择文本检索器以获得相关信息。在确认塞尔维亚的阿纳斯塔西娅的丈夫是Stefan Nemanja,R1-路由器继续进行后续查询,“Stefan Nemanja死在哪里?",并再次利用文本检索器来收集必要的知识。然后,R1-Router通过积累的信息得到了最终答案“Hilandar Monastery”。这个案例表明,R1-Router能够生成高质量的子问题,有效地分解原始查询,并指导推理过程。
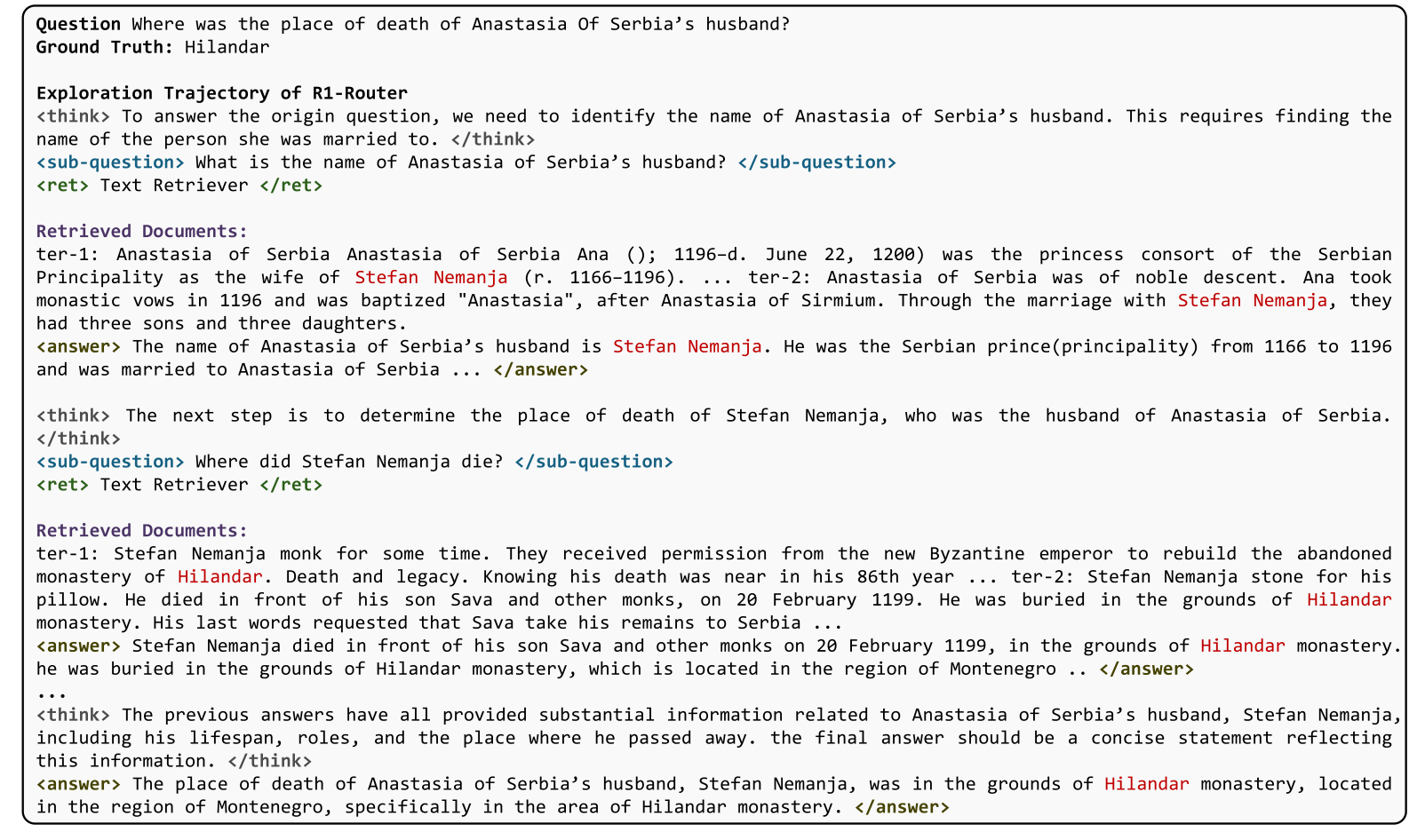
图22:2WikiMultihop QA上R1路由器的案例研究
B 限制和社会影响
局限性
虽然R1-Router通过生成中间查询和选择合适的知识库来实现强大的性能,但其多步推理引入了额外的推理开销。此外,Step-GRPO训练过程依赖于小规模合成数据集,即使在过滤之后,该数据集也可能包含不正确的推理轨迹。这会导致模型获得次优推理模式。尽管存在这些限制,R1-Router的性能始终优于所有基准,这表明其整体推理能力仍然很强。
社会影响
R1-Router的有效性通过支持分布在异构源上的外部知识的自适应获取、管理和利用,为推进多模式RAG方法提供了一个新的视角。这种能力为构建一个能够处理真实世界QA任务的通用RAG系统奠定了坚实的基础,其中的知识通常来自不同的模态和领域。在这样的系统中,MLLM充当中央代理,其动态地协调对各种知识库的访问,并在推理期间集成检索到的信息。这种范式支持与外部知识环境进行目标驱动和上下文感知的交互,与类人问题解决过程紧密结合。
相关文章:
逐步检索增强推理的跨知识库路由学习
摘要 多模态检索增强生成(MRAG)在多模态大语言模型(MLLM)中通过在生成过程中结合外部知识来减轻幻觉的发生,已经显示出了良好的前景。现有的MRAG方法通常采用静态检索流水线,该流水线从多个知识库ÿ…...

用Git管理你的服务器配置文件与自动化脚本:版本控制、变更追溯、团队协作与安全回滚的运维之道
更多服务器知识,尽在hostol.com 咱们在和服务器打交道的日子里,是不是经常要和各种各样的配置文件(Nginx的、Apache的、PHP的、防火墙的……)还有自己辛辛苦苦写下的自动化脚本打交道?那你有没有遇到过这样的“抓狂”…...
【数据库】关系数据库标准语言-SQL(金仓)下
4、数据查询 语法: SELECT [ALL | DISTINCT] <目标列表达式> [,<目标列表达式>] … FROM <表名或视图名>[, <表名或视图名> ] … [ WHERE <条件表达式> ] [ GROUP BY <列名1> [ HAVING <条件表达式> ] ] [ ORDER BY <…...
Vue3+SpringBoot全栈开发:从零实现增删改查与分页功能
前言 在现代化Web应用开发中,前后端分离架构已成为主流。本文将详细介绍如何使用Vue3作为前端框架,SpringBoot作为后端框架,实现一套完整的增删改查(CRUD)功能,包含分页查询、条件筛选等企业级特性。 技术栈介绍 前端࿱…...

小黑大语言模型应用探索:langchain智能体构造源码demo搭建1(初步流程)
导入工具包 rom langchain_core.tools import BaseTool from typing import Sequence, Optional, List from langchain_core.prompts import BasePromptTemplate import re from langchain_core.tools import tool from langchain_core.prompts.chat import (ChatPromptTempla…...

极客时间:用 FAISS、LangChain 和 Google Colab 模拟 LLM 的短期与长期记忆
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

leetcode hot100刷题日记——35.子集
解答: 方法一:选or不选的dfs(输入视角) 思路:[1,2,3]的全部子集可以看成是对数组的每一位数字做选择。 eg.空集就是一个数字都不选,[1,2]就是1,2选,3不选。 class Solution { pub…...
MybatisPlus(含自定义SQL、@RequiredArgsConstructor、静态工具类Db)
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。 因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是…...

React 组件异常捕获机制详解
1. 错误边界(Error Boundaries)基础 在React应用开发中,组件异常的有效捕获对于保证应用稳定性至关重要。React提供了一种称为"错误边界"的机制,专门用于捕获和处理组件树中的JavaScript错误。 错误边界是React的一种…...
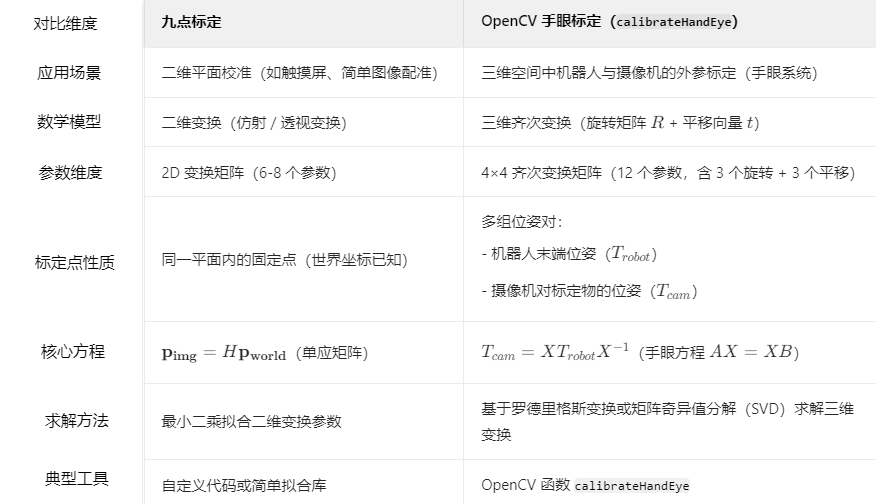
手眼标定:九点标定、十二点标定、OpenCV 手眼标定
因为一直使用6轴协作机器人,且主要应用是三维视觉,平常的手眼标定基本都是基于OpenCV来计算的,听说有九点标定和十二点标定,顺便了解下。 目录 1.九点标定1.1 基本原理1.2 关于最小二乘法1.3 具体示例 2.十二点标定3.OpenCV 手眼标…...

[总结]前端性能指标分析、性能监控与分析、Lighthouse性能评分分析
前端性能分析大全 前端性能优化 LightHouse性能评分 性能指标监控分析 浏览器加载资源的全过程性能指标分析 性能指标 在实现性能监控前,先了解Web Vitals涉及的常见的性能指标 Web Vitals 是由 Google 推出的网页用户体验衡量指标体系,旨在帮助开发者量…...

React-native的新架构
本文总结: 文章主要介绍了 React Native 的新架构,包括以下几个方面的内容:📱✨ 如何抹平 iOS 和 Android 样式差异,提升跨平台一致性; 分析了旧架构中存在的问题,如通信瓶颈、启动慢、维护复杂等&#x…...

【Android】MT6835 + MT6631 WiFi进入Meta模式出现WiFi_HQA_OpenAdapter failed
问题描述 WiFi进入Meta异常,出现WiFi_HQA_OpenAdapter failed [ 12.694501] mtk_wmtd_worker: [name:wlan_drv_gen4m_6835&][wlan][710]wlanProbeSuccessForLowLatency:(INIT INFO) LowLatency(ProbeOn) [ 12.699854] ccci_fsm: [name:ccci_md_all&][ccci1/fsm]M…...
Git 全平台安装指南:从 Linux 到 Windows 的详细教程
目录 一、Git 简介 二、Linux 系统安装指南 1、CentOS/RHEL 系统安装 2、Ubuntu/Debian 系统安装 3、Windows 系统安装 四、安装后配置(后面会详细讲解,现在了解即可) 五、视频教程参考 一、Git 简介 Git 是一个开源的分布式版本控制系…...
Tree 树形组件封装
整体思路 数据结构设计 使用递归的数据结构(TreeNode)表示树形数据每个节点包含id、name、可选的children数组和selected状态 状态管理 使用useState在组件内部维护树状态的副本通过deepCopyTreeData函数进行深拷贝,避免直接修改原始数据 核…...
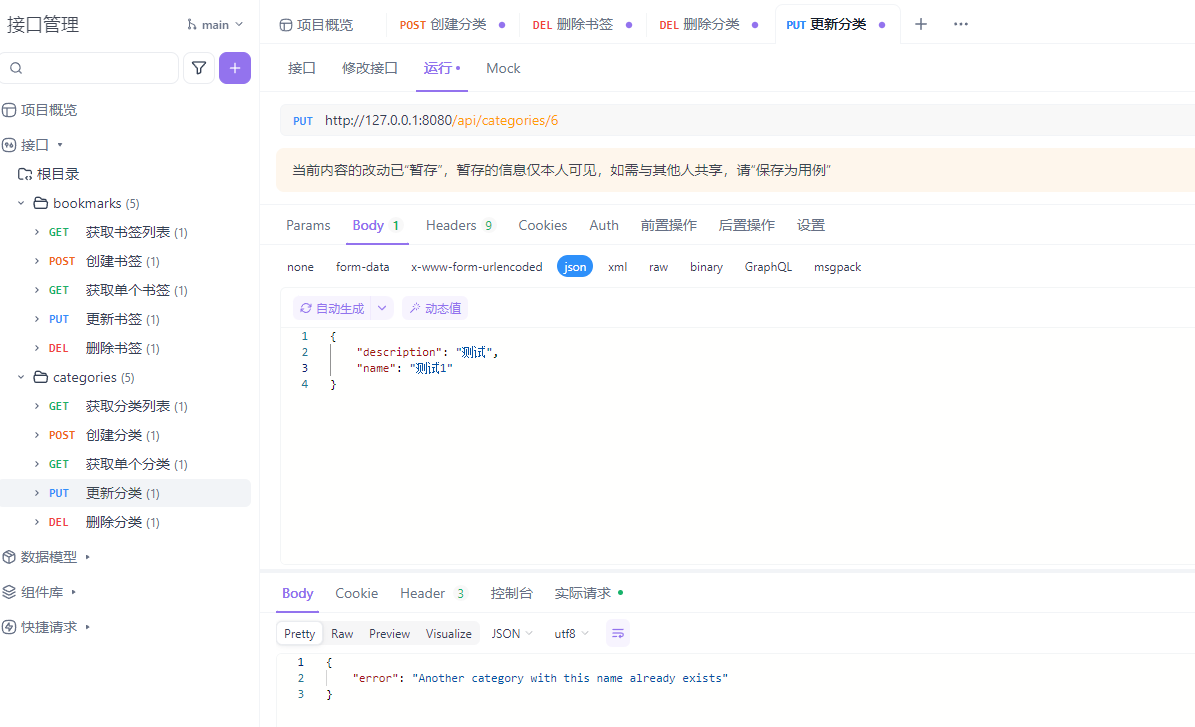
AI书签管理工具开发全记录(五):后端服务搭建与API实现
文章目录 AI书签管理工具开发全记录(四):后端服务搭建与API实现前言 📝1. 后端框架选型 🛠️2. 项目结构优化 📁3. API路由设计 🧭分类管理书签管理 4. 数据模型定义 💾分类模型&…...

netTAP 100:在机器人技术中将 POWERLINK 转换为 EtherNet/IP
工业机器人服务专家 年轻的 More Robots 公司成立仅一年多,但其在许多应用领域的专业技术已受到广泛欢迎。这是因为More Robots提供 360 度全方位服务,包括从高品质工业机器人和协作机器人到咨询和培训。这包括推荐适合特定任务或应用的机器人࿰…...

多模态大语言模型arxiv论文略读(九十八)
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight ➡️ 论文标题:Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight ➡️ 论文作者:Ziyuan Huang, Kaixiang Ji, Biao Gong, Zhiwu Qing, Qinglong Zhang, Kecheng Zhe…...
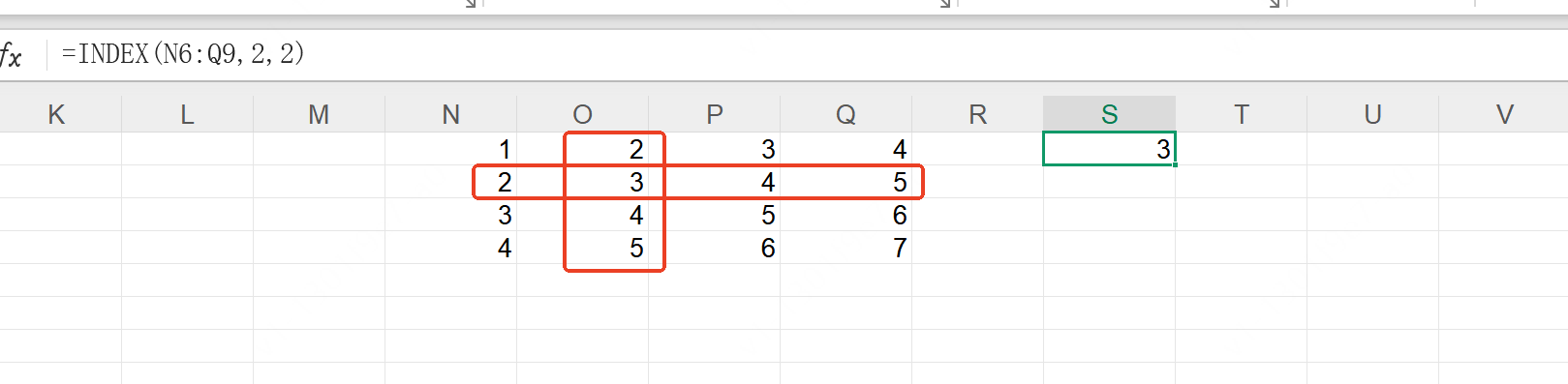
EXCEL--累加,获取大于某个值的第一个数
一、函数 LET(data,A1:A5,cumSum,SCAN(0,data,LAMBDA(a,b,ab)),idx,MATCH(TRUE,cumSum>C1,0),INDEX(data,idx)) 二、函数拆解 1、LET函数:LET(name1, value1, [name2, value2, ...], calculation) name1, name2...:自定义的变量名(需以字…...

【vscode】切换英文字母大小写快捷键如何配置
按 ⌘(Command) Shift P 打开命令面板搜索 "Transform to Uppercase" 或 "Transform to Lowercase" 点击Transform to Uppercase 命令后的齿轮图标 进入设置页面 然后就可以进行配置了 比如我是mac电脑, 切换大写可以配置为 shift alt…...

vue笔记-路由
文章目录 createWebHistory的使用router-linkrouter-link颜色是黑色,正常应该是蓝色router-link 跳转了但是不展示 其他 vue这个题目还是太大,路由单独拆出来。 createWebHistory的使用 推荐在vue-router4中使用。 1、导入。 import { createRouter, c…...
本地部署 DeepSeek R1(最新)【从下载、安装、使用和调用一条龙服务】
文章目录 一、安装 Ollama1.1 下载1.2 安装 二、下载 DeepSeek 模型三、使用 DeepSeek3.1 在命令行环境中使用3.2 在第三方软件中使用 一、安装 Ollama 1.1 下载 官方网址:Ollama 官网下载很慢,甚至出现了下载完显示 无法下载,需要授权 目…...

域名解析怎么查询?有哪些域名解析查询方式?
在互联网的世界里,域名就像是我们日常生活中的门牌号,帮助我们快速定位到想要访问的网站。而域名解析则是将这个易记的域名转换为计算机能够识别的IP地址的关键过程。当我们想要了解一个网站的域名解析情况,或者排查网络问题时,掌…...
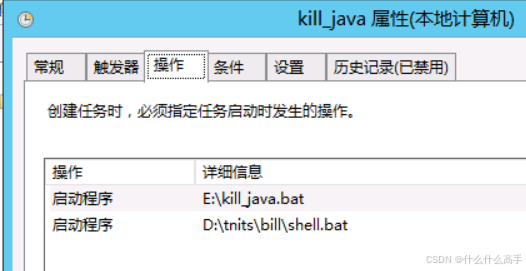
win主机如何结束正在执行的任务进程并重启
最近遇到一个问题,一个java入库程序经常在运行了几个小时之后消息无法入库,由于已经没有研发人员来维护这个程序了,故此只能每隔一段时间来重启这个程序以保证一直有消息入库。 但是谁也不能保证一直有人去看这个程序,并且晚上也不…...

maven中的maven-resources-plugin插件详解
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 一、插件定位与核心功能 maven-resources-plugin是Maven构建工具的核心插件之一,主要用于处理项目中的资源文件(如…...

ROS云课基础篇-01-Linux-250529
ROS云课基础篇收到了很多反馈,正面评价比例高,还有很多朋友反馈需要写更具体一点。 ROS云课基础篇极简复习-C、工具、导航、巡逻一次走完-CSDN博客 于是,有了这篇以及之后的案例,案例均已经测试过8年,但没有在博客公…...

通俗易懂解析:@ComponentScan 与 @MapperScan 的异同与用法
在 Spring 和 MyBatis 集成开发中,ComponentScan 和 MapperScan 是两个核心注解,但它们的用途和工作机制截然不同。本文将通过通俗的语言和示例代码,带您轻松掌握它们的区别和使用方法。 一、基础概念 ComponentScan:Spring 的“通…...
深入了解 C# 异步编程库 AsyncEx
在现代应用程序开发中,异步编程已经成为提升性能和响应能力的关键,尤其在处理网络请求、I/O 操作和其他耗时任务时,异步编程可以有效避免阻塞主线程,提升程序的响应速度和并发处理能力。C# 提供了内建的异步编程支持(通…...

NodeJS全栈开发面试题讲解——P1Node.js 基础与核心机制
✅ 1.1 Node.js 的事件循环原理?如何处理异步操作? 面试官您好,我理解事件循环是 Node.js 的异步非阻塞编程核心。 Node.js 构建在 V8 引擎与 libuv 库之上。虽然 Node.js 是单线程模型,但它通过事件循环(event loop&a…...
Vulhub靶场搭建(Ubuntu)
前言:Vulhub 是一个开源的漏洞靶场平台,全称是 Vulhub: Vulnerable Web Application Environments,主要用于学习和复现各类 Web 安全漏洞。它的核心特征是通过 Docker 环境快速搭建出带有特定漏洞的靶场系统,适合渗透测试学习者、…...