利用 Scrapy 构建高效网页爬虫:框架解析与实战流程
目录
- 前言
- 1 Scrapy 框架概述
- 1.1 Scrapy 的核心优势
- 1.2 Scrapy 的典型应用场景
- 2 Scrapy 工作原理解析
- 2.1 框架结构图
- 2.2 Spider:定义数据采集策略
- 2.3 Scheduler:调度请求与去重
- 2.4 Downloader:网页下载器
- 2.5 Item:结构化数据容器
- 2.6 Pipeline:数据清洗与存储
- 2.7 Middleware:请求与响应的拦截器
- 3 Scrapy 爬虫开发流程详解
- 3.1 创建项目
- 3.2 编写 Item 类
- 3.3 编写爬虫逻辑
- 3.4 配置 settings 参数
- 3.5 启动爬虫
- 3.6 数据持久化
- 4 实战案例:抓取豆瓣电影 Top250
- 4.1 页面分析
- 4.2 编写 Spider
- 5 结语
前言
在大数据时代,信息的获取能力在很大程度上决定了一个人或组织的竞争力。而网页数据爬取正是快速收集海量信息的重要手段。作为 Python 生态中最著名的爬虫框架之一,Scrapy 以其高效、模块化、易拓展的特点,成为众多开发者和数据工程师的首选工具。
本文将从 Scrapy 框架的整体结构出发,逐步解析它的核心组件与工作机制,并结合一个简单的实例,演示从网页抓取到数据处理的完整流程,帮助你系统地掌握 Scrapy 的使用方法。
1 Scrapy 框架概述
Scrapy 是一个基于 Python 编写的开源网页抓取框架,最初由 scrapinghub 公司开发。它最显著的特点是基于异步网络框架 Twisted 构建,天然支持高并发请求,使得在爬取大规模网站数据时依然具备优秀的性能。
与传统的脚本式爬虫不同,Scrapy 提供了一套完整的“抓取—处理—保存”流程,所有模块高度解耦,便于开发者灵活替换和配置。
1.1 Scrapy 的核心优势
Scrapy 能在实际项目中胜出的原因包括:
- 高效异步处理能力,支持上千并发请求;
- 清晰的工程结构,适合构建大型爬虫项目;
- 可插拔的中间件和管道机制,方便进行反爬处理和数据清洗;
- 强大的请求调度器与去重机制,自动避免重复请求;
- 支持多种数据导出格式,如 CSV、JSON、XML,甚至直接写入数据库。
1.2 Scrapy 的典型应用场景
Scrapy 广泛应用于以下领域:
- 电商网站商品信息抓取;
- 新闻聚合与内容监控;
- 房产、招聘等信息平台的数据采集;
- 舆情监控、竞品分析、价格跟踪等商业用途。
接下来我们将逐步分析 Scrapy 的内部架构和数据处理流程。
2 Scrapy 工作原理解析
Scrapy 的爬虫流程可以抽象为“请求 - 响应 - 解析 - 存储”的闭环。这一过程由多个模块协同完成,每个模块各司其职、相互衔接。
2.1 框架结构图
简化后的 Scrapy 执行流程如下:
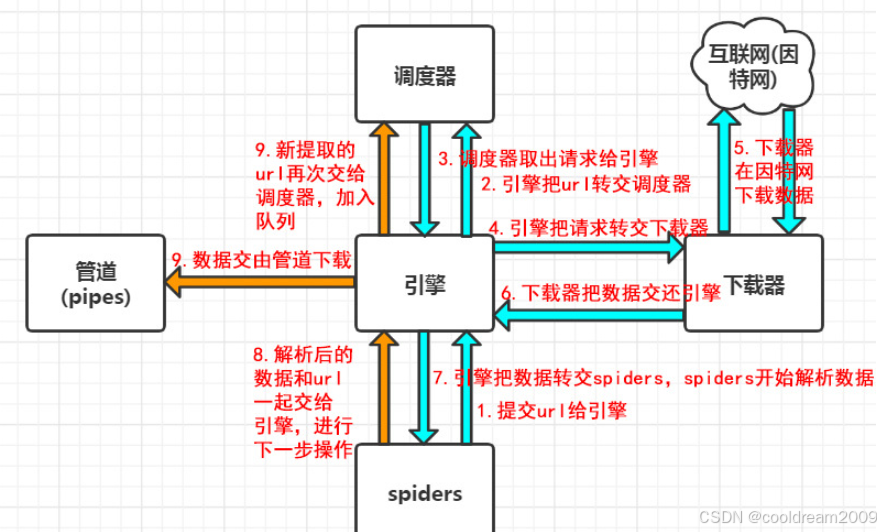
Spider → Scheduler → Downloader → Middleware → Response↓ ↑Item ← Pipeline ← [清洗/校验/存储]
下面我们从开发者视角,逐一介绍各模块的功能和作用。
2.2 Spider:定义数据采集策略
Spider 是 Scrapy 中的核心组件之一,用户主要通过它来定义抓取逻辑。每个 Spider 通常对应一个站点或抓取任务,指定起始 URL,并通过 parse 方法解析响应数据。
class MySpider(scrapy.Spider):name = "example"start_urls = ['http://example.com']def parse(self, response):yield {'title': response.xpath('//title/text()').get(),'url': response.url}
Spider 接收到响应后,负责提取页面中的关键信息,并将其封装成 Item 对象,交由后续 Pipeline 处理。同时,也可以返回新的请求,形成递归抓取。
2.3 Scheduler:调度请求与去重
调度器(Scheduler)用于管理所有待请求的 URL,并决定下一个要发送的请求。Scrapy 内置了请求去重机制,避免多次抓取同一页面。
当 Spider 返回一个新的 Request 对象时,Scheduler 会先判断该请求是否已被抓取过,若没有则加入队列等待 Downloader 执行。
2.4 Downloader:网页下载器
Downloader 负责将请求发送至互联网,获取对应的响应结果。它是一个异步处理器,基于 Twisted 网络引擎运行,效率极高。
Scrapy 的 Downloader 可通过中间件自定义行为,例如设置 User-Agent、使用代理池、处理 Cookie 或实现验证码识别等。
2.5 Item:结构化数据容器
Item 类似于一个轻量级的数据模型,用于描述需要提取和保存的字段。它通常定义在 items.py 文件中:
import scrapyclass ArticleItem(scrapy.Item):title = scrapy.Field()url = scrapy.Field()content = scrapy.Field()
Spider 会将页面中提取的数据填入 Item 中,交由 Pipeline 进一步处理。
2.6 Pipeline:数据清洗与存储
数据管道(Pipeline)主要处理来自 Spider 的数据,负责数据的验证、清洗、转换或保存到数据库等持久化操作。
class MyPipeline:def process_item(self, item, spider):item['title'] = item['title'].strip()return item
Pipeline 可通过配置启用多个,每个数据项会按顺序通过各个 Pipeline 组件。
2.7 Middleware:请求与响应的拦截器
Downloader Middleware 和 Spider Middleware 是两个钩子点,用于拦截请求或响应进行修改。开发者可利用它实现诸如:
- 动态设置请求头;
- 自动切换 IP 代理;
- 实现断点续爬或重试机制;
- 模拟浏览器行为绕过反爬机制。
3 Scrapy 爬虫开发流程详解
Scrapy 项目开发结构清晰、流程规范。一个标准的 Scrapy 项目包含以下步骤:
3.1 创建项目
使用 Scrapy 提供的命令行工具初始化项目结构:
scrapy startproject myproject
生成的目录包含 spiders/、items.py、pipelines.py、settings.py 等模块,便于模块化开发。
3.2 编写 Item 类
在 items.py 中定义所需的数据字段,便于统一管理与导出格式。
3.3 编写爬虫逻辑
在 spiders/ 目录下创建爬虫文件,并继承 scrapy.Spider 或 CrawlSpider 类,定义初始 URL 和解析逻辑。
3.4 配置 settings 参数
在 settings.py 文件中配置项目参数,包括:
USER_AGENT:设置请求头标识;DOWNLOAD_DELAY:请求延时,防止被封;ITEM_PIPELINES:启用数据处理管道;DOWNLOADER_MIDDLEWARES:启用中间件。
例如:
USER_AGENT = 'Mozilla/5.0'
DOWNLOAD_DELAY = 1.0
ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
3.5 启动爬虫
使用以下命令运行爬虫:
scrapy crawl example
如果需要将数据导出为 CSV 文件:
scrapy crawl example -o output.csv
3.6 数据持久化
Scrapy 支持多种数据输出方式,如 CSV、JSON、MongoDB、MySQL 等。Pipeline 中可以根据需求将 Item 写入数据库或上传至云端。
4 实战案例:抓取豆瓣电影 Top250
下面以豆瓣 Top250 为例,展示 Scrapy 的完整应用流程。
4.1 页面分析
目标站点:https://movie.douban.com/top250
每页包含 25 部电影,通过翻页参数 ?start=0, 25, 50... 控制页码。
电影信息包含:标题、评分、详情页链接。
4.2 编写 Spider
class DoubanSpider(scrapy.Spider):name = 'douban'start_urls = ['https://movie.douban.com/top250']def parse(self, response):for movie in response.css('div.item'):yield {'title': movie.css('span.title::text').get(),'score': movie.css('span.rating_num::text').get(),'link': movie.css('a::attr(href)').get(),}next_page = response.css('span.next a::attr(href)').get()if next_page:yield response.follow(next_page, callback=self.parse)
运行爬虫即可获取所有 Top250 电影信息。
5 结语
Scrapy 是一个功能完备、设计优雅的爬虫框架,适用于各种规模的数据抓取项目。通过本文的介绍,相信你已经对 Scrapy 的核心原理、模块结构以及使用流程有了较为深入的理解。
在实际开发中,Scrapy 不仅能高效完成爬虫任务,还能通过中间件机制和管道处理打造出灵活、健壮的数据采集系统。掌握它,将极大提升你在数据采集和信息处理方面的能力。
相关文章:
利用 Scrapy 构建高效网页爬虫:框架解析与实战流程
目录 前言1 Scrapy 框架概述1.1 Scrapy 的核心优势1.2 Scrapy 的典型应用场景 2 Scrapy 工作原理解析2.1 框架结构图2.2 Spider:定义数据采集策略2.3 Scheduler:调度请求与去重2.4 Downloader:网页下载器2.5 Item:结构化数据容器2…...
RPG20.创建敌人的初始能力和加载武器
1. 基于StartUpAbilitiy基类创建专门用于敌人数据的DAStartUpABility,然后再基于新创建的DA再创建一个蓝图 2.打开 DataAsset_EnemyStartUpData.h // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "Cor…...

P5684 [CSP-J2019 江西] 非回文串 题解
https://www.luogu.com.cn/problem/P5684 /* 比较简单的组合计数 题目没有以文字去描述,而是用下标来形式化题意,给我们一个关键信息:判定两个串是否相同不是看字符是否相同,而是看下标 换言之就是相同的字符,如果下标…...
自适应移动平均(Adaptive Moving Average, AMA)
文章目录 1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现2. 对 (KAMA)算法参数进行优化及实现 自适应移动平均(Adaptive Moving Average, AMA)由Perry Kaufman在其著作《Trading Systems and Methods》中提出,它通过动态调整平滑系数来…...

Java密码加密存储算法,SpringBoot 实现密码安全存储
文章目录 一、写在前面二、密码加密存储方式1、基于MD5加盐方式2、SHA-256 Salt(不需要第三方依赖包)3、使用 BCrypt 进行哈希4、使用 PBKDF2 进行哈希5、使用 Argon2 进行哈希6、SCrypt 一、写在前面 日常开发中,用户密码存储是严禁明文存…...
)
使用 Version Catalogs统一配置版本 (Gradle 7.0+ 特性)
1.在 gradle/libs.versions.toml 文件中定义: [versions] compileSdk "34" minSdk "21" targetSdk "34" 2. 在 build.gradle 中使用: android {compileSdkVersion libs.versions.compileSdk.get().toInteger()defaul…...

涨薪技术|0到1学会性能测试第95课-全链路脚本开发实例
至此关于系统资源监控、apache监控调优、Tomcat监控调优、JVM调优、Mysql调优、前端监控调优、接口性能监控调优的知识已分享完,今天学习全链路脚本开发知识。后续文章都会系统分享干货,带大家从0到1学会性能测试。 前面章节介绍了如何封装.h头文件,现在通过一个实例来介绍…...

C++文件和流基础
C文件和流基础 1. C文件和流基础1.1 文件和流的概念1.2 标准库支持1.3 常用文件流类ifstream 类ofstream 类fstream 类 2.1 打开文件使用构造函数打开文件使用 open() 成员函数打开文件打开文件的模式标志 2.2 关闭文件使用 close() 成员函数关闭文件关闭文件的重要性 3.1 写入…...
Spring AI Alibaba + Nacos 动态 MCP Server 代理方案
作者:刘宏宇,Spring AI Alibaba Contributor 文章概览 Spring AI Alibaba MCP 可基于 Nacos 提供的 MCP server registry 信息,建立一个中间代理层 Java 应用,将 Nacos 中注册的服务信息转换成 MCP 协议的服务器信息,…...
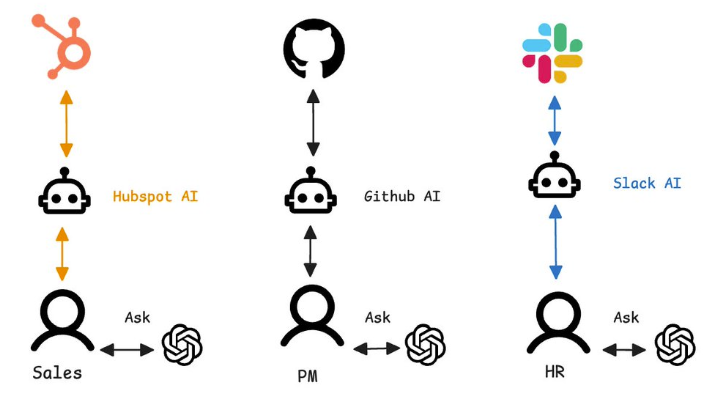
MCP:让AI工具协作变得像聊天一样简单 [特殊字符]
想象一下,你正在处理一个项目,需要从A平台查看团队讨论,从B平台获取客户信息,还要在GitHub上检查代码进度。传统做法是什么?打开三个不同的网页,在各个平台间来回切换,复制粘贴数据,最后还可能因为信息分散而遗漏重要细节。 听起来很熟悉?这正是当前工作流程的痛点所…...

C++ Learning string类模拟实现
string类模拟实现 std::string 类作为 C 标准库中非常重要的一个类型,它封装了字符串的动态分配、内存管理以及其他字符串操作。 基本构思与设计 一个简化版的 string 类需要满足以下基本功能: 存储一个字符数组(char*)。记录…...

Message=“HalconDotNet.HHandleBase”的类型初始值设定项引发异常
该异常通常与HalconDotNet库的版本冲突或环境配置问题有关,以下是常见解决方案: 版本冲突处理 检查项目中是否同时存在多个HalconDotNet引用(如NuGet安装和本地引用混用),需删除所有冲突引用并统一版本2确保工具…...
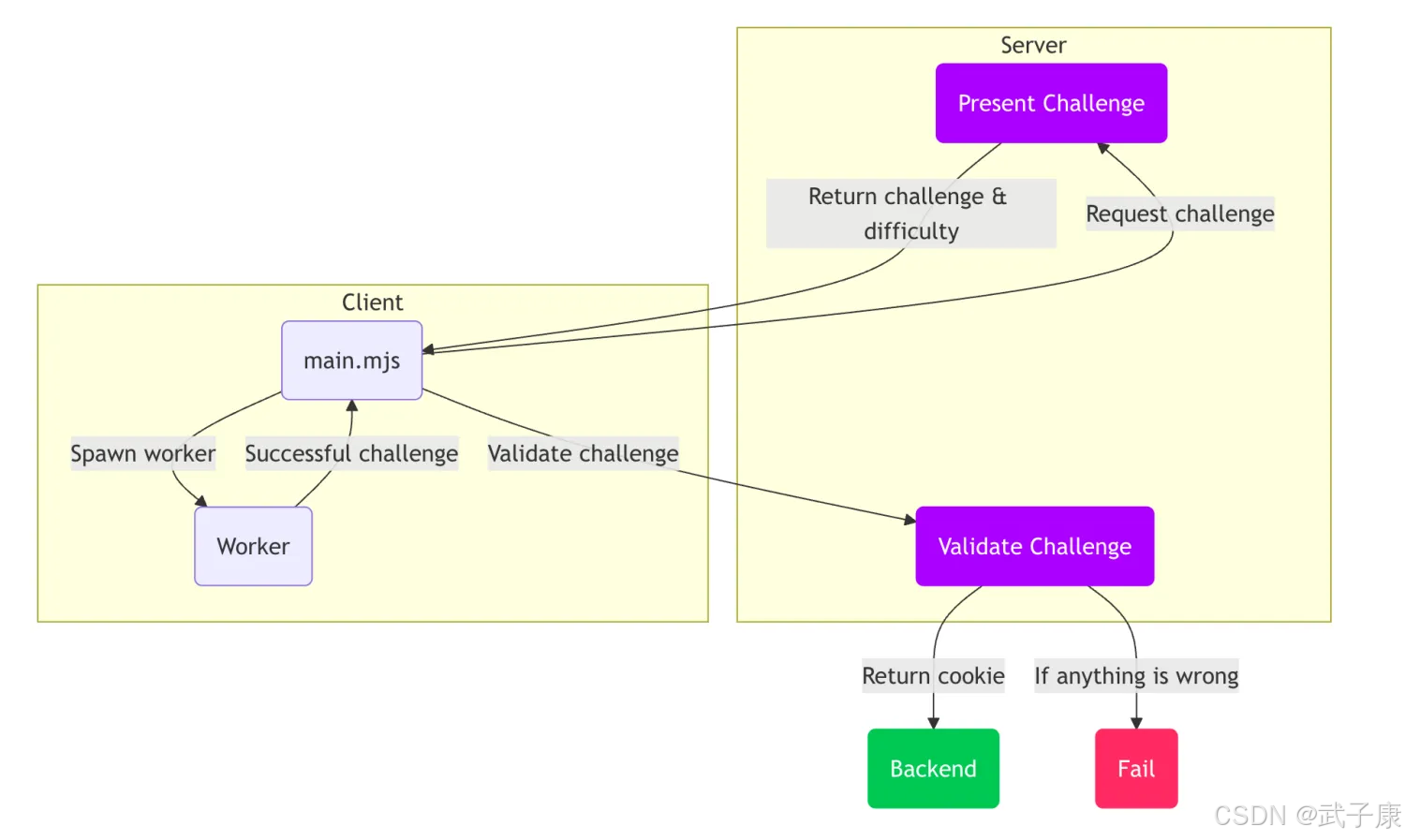
AI炼丹日志-27 - Anubis 通过 PoW工作量证明的反爬虫组件 上手指南 原理解析
点一下关注吧!!!非常感谢!!持续更新!!! Java篇: MyBatis 更新完毕目前开始更新 Spring,一起深入浅出! 大数据篇 300: Hadoop&…...

阿姆达尔定律的演进:古斯塔夫森定律
前言 在上一篇文章《使用阿姆达尔定律来提升效率》中提到的阿姆达尔定律前提是假设问题的规模保持不变,并且给定一台速度更快的机器,目标是更快地解决问题。然而,在大多数情况下,这并不完全正确。当有一台更快的机器时࿰…...

JavaScript极致性能优化全攻略
JavaScript性能优化深度指南 1 引言 JavaScript性能优化在现代Web开发中至关重要。随着Web应用日益复杂,性能直接影响用户体验、搜索引擎排名和业务转化率。研究表明,页面加载时间每增加1秒,转化率下降7%,跳出率增加32%。通过优化JavaScript性能,开发者可以: 提升用户满…...
)
批量大数据并发处理中的内存安全与高效调度设计(以Qt为例)
背景 在批量处理大型文件(如高分辨率图片、视频片段、科学数据块)时,开发者通常希望利用多核CPU并行计算以提升处理效率。然而,如果每个任务对象的数据量很大,直接批量并发处理极易导致系统内存被迅速耗尽,出现程序假死、崩溃,甚至系统级“死机”。 Qt自带的线程池(Q…...
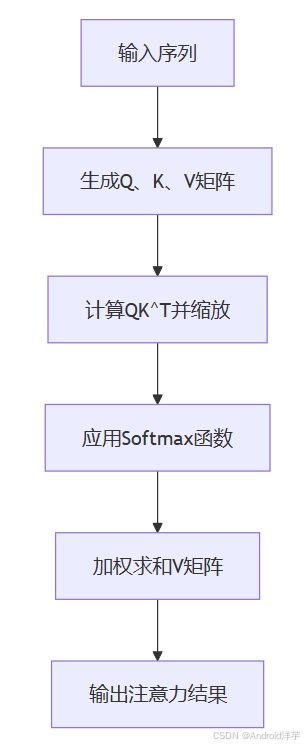
Transformer核心原理
简介 在人工智能技术飞速发展的今天,Transformer模型凭借其强大的序列处理能力和自注意力机制,成为自然语言处理、计算机视觉、语音识别等领域的核心技术。本文将从基础理论出发,结合企业级开发实践,深入解析Transformer模型的原…...

Grafana-State timeline状态时间线
显示随时间推移的状态变化 状态区域:即状态时间线上的状态显示的条或带,区域长度表示状态持续时间或频率 数据格式要求(可视化效果最佳): 时间戳实体名称(即:正在监控的目标对应名称…...
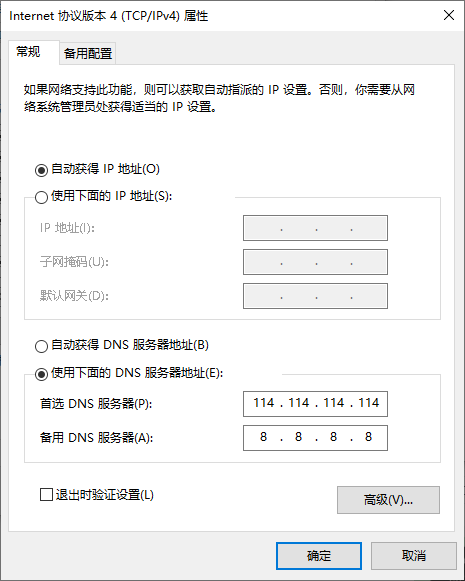
解决CSDN等网站访问不了的问题
原文网址:解决CSDN等网站访问不了的问题-CSDN博客 简介 本文介绍解决CSDN等网站访问不了的方法。 问题描述 CSDN访问不了了,页面是空的。 问题解决 方案1:修改DNS 可能是dns的问题,需要重新配置。 国内常用的dns是&#x…...
)
【华为云Astro Zero】组装设备管理页面开发(图形拖拽 + 脚本绑定)
目录 🧠 一、核心原理概览(类比说明) 🛠 二、完整操作步骤(详细图形拖拽流程) 1. 创建项目页面骨架 2. 定义设备信息的数据模型 equipmentInstance 3. 定义服务模型(接口绑定机器人搬运逻辑) 4. 拖拽组件搭建界面结构 4.1 表格: 4.2 工具栏按钮(新增) 4.…...

PopupImageMenuItem 无响应
Popup Menu | GNOME JavaScript let menuItem new PopupMenu.PopupImageMenuItem(设置, settings, {}); 第三个参数 params (Object) — Additional item properties 写了个 {},我就以为是 function,我还改成了 () > {} ! 正常是通过 connect 响…...

C++ Vector算法精讲与底层探秘:从经典例题到性能优化全解析
前引:在C标准模板库(STL)中,vector作为动态数组的实现,既是算法题解的基石,也是性能优化的关键战场。其连续内存布局、动态扩容机制和丰富的成员函数,使其在面试高频题(如LeetCode、…...

Flowith,有一种Agent叫无限
大家好,我是羊仔,专注AI工具、智能体、编程。 今天羊仔要和大家聊聊一个最近发现的超级实用的Agent平台,名字叫Flowith。 这篇文章会带你从零了解到实战体验,搞清楚Flowith是如何让工作效率飙升好几倍,甚至重新定义未…...

系统思考:短期利益与长期系统影响
一个决策难题:一家公司接到了一个大订单,客户提出了10%的降价要求,而企业的产能还无法满足客户的需求。你会选择增加产能,接受这个订单,还是拒绝?从系统思考的角度来看,这个决策不仅仅是一个简单…...

大数据 ETL 工具 Sqoop 深度解析与实战指南
一、Sqoop 核心理论与应用场景 1.1 设计思想与技术定位 Sqoop 是 Apache 旗下的开源数据传输工具,核心设计基于MapReduce 分布式计算框架,通过并行化的 Map 任务实现高效的数据批量迁移。其特点包括: 批处理特性:基于 MapReduc…...

【学习记录】Django Channels + WebSocket 异步推流开发常用命令汇总
文章目录 📌 摘要🧰 虚拟环境管理✅ 创建虚拟环境✅ 删除虚拟环境✅ 激活/切换虚拟环境 🛠️ Django 项目管理✅ 查看 Django 版本✅ 创建 Django 项目✅ 创建 Django App 💬 Channels 常用操作✅ 查看 Channels 版本 ὐ…...
动手实现多层感知机:深度学习中的非线性建模实战)
(四)动手实现多层感知机:深度学习中的非线性建模实战
1 多层感知机(MLP) 多层感知机(Multilayer Perceptron, MLP)是一种前馈神经网络,包含一个或多个隐藏层。它能够学习数据中的非线性关系,广泛应用于分类和回归任务。MLP的每个神经元对输入信号进行加权求和…...
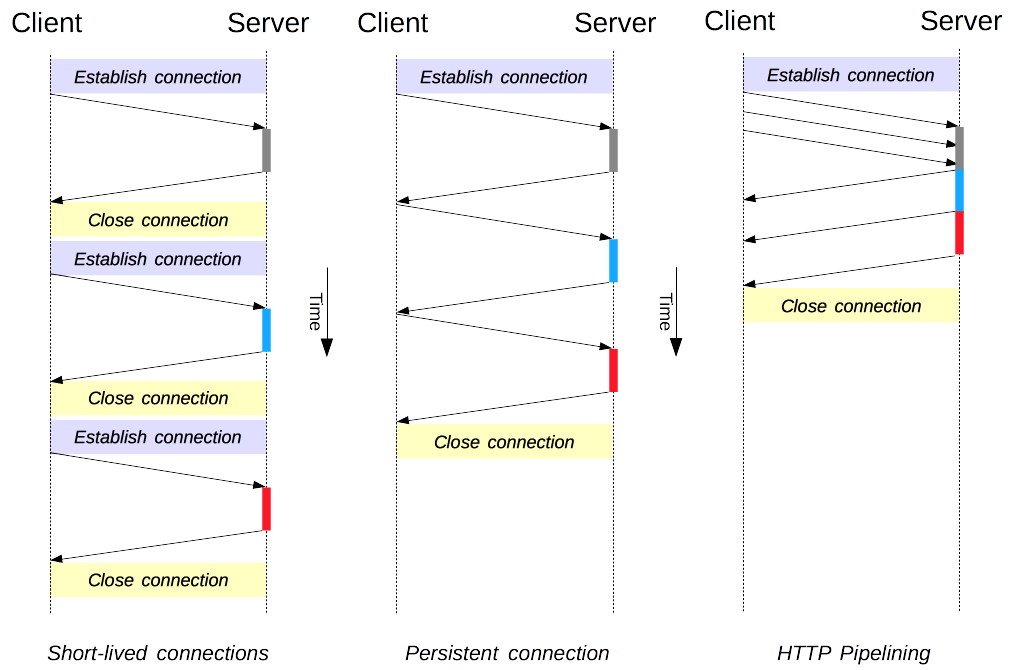
HTTP连接管理——短连接,长连接,HTTP 流水线
连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有多种模型:短连接、_长连接_和 HTTP 流水线。 下面分别来详细解释 短连接 HTTP 协议最初(0.9/1.0)是个非常简单的…...
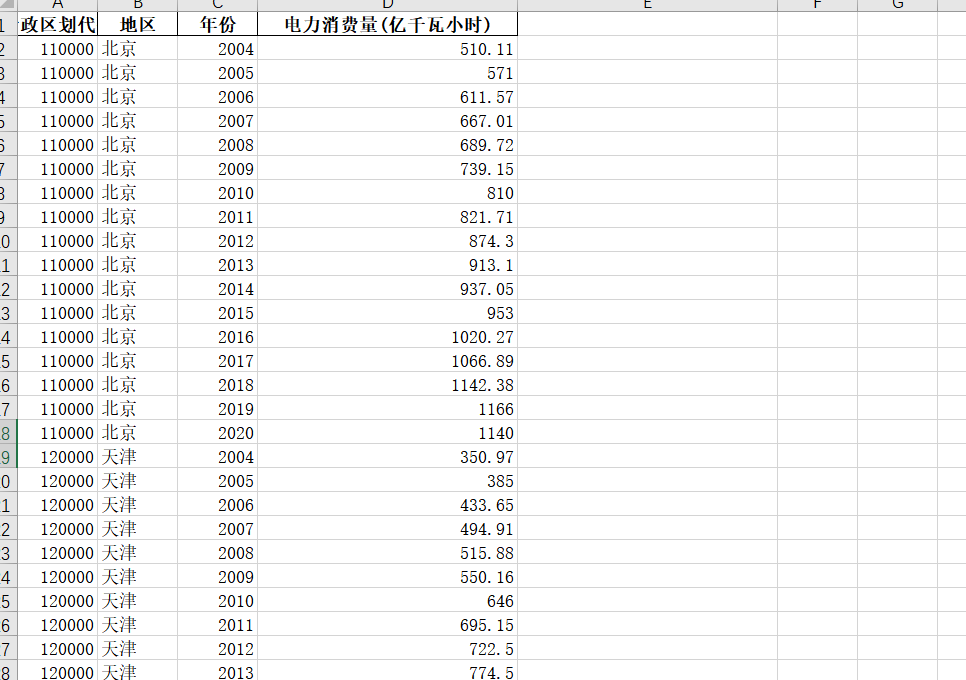
【免费】2004-2020年各省电力消费量数据
2004-2020年各省电力消费量数据 1、时间:2004-2020年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、电力消费量(亿千瓦小时) 4、范围:31省 5、指标说明:电力消费量是指在一定时期内ÿ…...
 | if语句)
Python编程基础(四) | if语句
引言:很久没有写 Python 了,有一点生疏。这是学习《Python 编程:从入门到实践(第3版)》的课后练习记录,主要目的是快速回顾基础知识。 练习1:条件测试 编写一系列条件测试,将每个条…...