Redisson单机模式
redisson调用unlock的过程
Redisson 是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid)框架,提供了分布式和可扩展的数据结构和服务。Redisson 的 unlock 方法用于释放锁。下面是 unlock 方法的调用过程:
-
获取锁的状态:首先,Redisson 会检查当前线程是否持有锁。如果当前线程没有持有锁,则会抛出
IllegalMonitorStateException异常。
-
尝试释放锁:如果当前线程持有锁,Redisson 会尝试释放锁。它会调用 Redis 的
eval命令执行 Lua 脚本,以确保释放锁的操作是原子性的。Lua 脚本会检查锁的持有者是否是当前线程,如果是,则释放锁。
-
处理锁的计数:Redisson 支持可重入锁,因此在释放锁时需要处理锁的计数。如果当前线程持有的锁计数大于 1,则只减少计数而不真正释放锁;如果计数为 1,则真正释放锁。
-
通知等待的线程:如果锁被成功释放,Redisson 会通知等待的线程,以便它们可以尝试获取锁。
下面是一个简化的 unlock 方法的伪代码示例:
public void unlock() {// 获取当前线程的IDlong threadId = Thread.currentThread().getId();// 检查当前线程是否持有锁if (!isHeldByCurrentThread()) {throw new IllegalMonitorStateException("Current thread does not hold the lock");}// 尝试释放锁RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(),RedisCommands.EVAL_BOOLEAN,"if (redis.call('hexists', KEYS[1], ARGV[2]) == 0) then " +"return nil; " +"end; " +"local counter = redis.call('hincrby', KEYS[1], ARGV[2], -1); " +"if (counter > 0) then " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return 0; " +"else " +"redis.call('del', KEYS[1]); " +"return 1; " +"end; " +"return nil;",Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));// 处理释放锁的结果future.onComplete((res, e) -> {if (e != null) {// 处理异常} else if (res) {// 通知等待的线程signal();}});
}这个伪代码展示了 unlock 方法的核心逻辑,包括检查锁的持有者、尝试释放锁、处理锁的计数以及通知等待的线程。实际的实现可能会更加复杂,包含更多的错误处理和边界情况处理。
在分布式环境中,Redisson 使用 Redis 的发布/订阅(Pub/Sub)机制来通知等待的线程。具体来说,当一个线程成功释放锁时,它会向一个特定的 Redis 频道发布消息,通知其他等待的线程锁已经被释放。其他等待的线程会订阅这个频道,并在收到消息后尝试获取锁。
以下是一个简化的过程描述:
-
订阅频道:当一个线程尝试获取锁但未成功时,它会订阅一个特定的 Redis 频道。这个频道通常与锁的名称相关联。
-
发布消息:当持有锁的线程成功释放锁时,它会向这个频道发布一条消息,通知其他等待的线程锁已经被释放。
-
接收通知:其他等待的线程会接收到这个消息,并尝试重新获取锁。
下面是一个简化的伪代码示例,展示了如何使用 Redis 的发布/订阅机制来通知等待的线程:
public void unlock() {long threadId = Thread.currentThread().getId();if (!isHeldByCurrentThread()) {throw new IllegalMonitorStateException("Current thread does not hold the lock");}RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), RedisCommands.EVAL_BOOLEAN,"if (redis.call('hexists', KEYS[1], ARGV[2]) == 0) then " +"return nil; " +"end; " +"local counter = redis.call('hincrby', KEYS[1], ARGV[2], -1); " +"if (counter > 0) then " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return 0; " +"else " +"redis.call('del', KEYS[1]); " +"redis.call('publish', KEYS[2], ARGV[3]); " + // 发布消息"return 1; " +"end; " +"return nil;",Arrays.<Object>asList(getName(), getChannelName()), internalLockLeaseTime, getLockName(threadId), "UNLOCKED");future.onComplete((res, e) -> {if (e != null) {// 处理异常} else if (res) {// 锁已成功释放}});
}public void lock() {long threadId = Thread.currentThread().getId();while (true) {RFuture<Boolean> future = tryAcquireLockAsync(threadId);future.onComplete((res, e) -> {if (e != null) {// 处理异常} else if (res) {// 成功获取锁return;}});// 订阅频道,等待通知RFuture<Void> subscribeFuture = commandExecutor.subscribe(getChannelName(), message -> {// 收到通知,尝试重新获取锁lock();});subscribeFuture.onComplete((res, e) -> {if (e != null) {// 处理异常}});// 等待一段时间后再尝试获取锁Thread.sleep(100);}
}在这个伪代码示例中:
-
unlock方法在成功释放锁后,通过redis.call('publish', KEYS[2], ARGV[3])向频道发布消息。 -
lock方法在尝试获取锁失败后,订阅频道并等待通知。当收到通知时,它会再次尝试获取锁。
通过这种方式,Redisson 可以在分布式环境中通知等待的线程锁已经被释放,从而实现分布式锁的协调。
Redis 的发布/订阅(Pub/Sub)是一种消息传递模式,发送者(发布者)将消息发送到频道,接收者(订阅者)订阅这些频道以接收消息。发布者和订阅者之间没有直接的联系,消息通过 Redis 服务器进行传递。
在Redisson中,锁的释放有两种方式:手动释放和自动超时释放。无论是哪种方式,都会涉及到发布事件到频道的机制。
-
手动释放锁:当你调用
unlock方法手动释放锁时,Redisson 会发布一个解锁事件到相应的频道。其他订阅了该频道的线程会收到这个事件,并尝试获取锁。
-
锁超时释放:当锁的持有时间超过了设定的超时时间,Redisson 会自动释放锁。此时,Redisson 同样会发布一个解锁事件到相应的频道。其他订阅了该频道的线程会收到这个事件,并尝试获取锁。
因此,无论是手动释放锁还是锁超时释放,Redisson 都会发布解锁事件到频道,通知其他线程锁已经被释放。其他线程通过订阅该频道,接收到解锁事件后,会尝试重新获取锁。
总结:
-
手动释放锁:调用
unlock方法,发布解锁事件到频道。 -
锁超时释放:锁超时自动释放,发布解锁事件到频道。
在这两种情况下,其他线程都能通过订阅频道接收到解锁事件,并尝试获取锁。
在Redisson中,锁的获取可以是公平锁也可以是非公平锁,具体取决于你使用的锁类型。
-
非公平锁(默认):Redisson 默认提供的锁是非公平锁。非公平锁的特点是,锁的获取顺序不一定按照线程请求的顺序来,任何线程都有可能在锁释放时立即获取到锁。
-
公平锁:Redisson 也提供了公平锁。公平锁的特点是,锁的获取顺序是按照线程请求的顺序来进行的,先请求锁的线程会先获取到锁。Redisson 的公平锁是通过
RLock接口的fairLock方法来实现的。
以下是如何使用这两种锁的示例:
-
非公平锁(默认):
RLock lock = redisson.getLock("myLock"); lock.lock(); try {// 业务逻辑 } finally {lock.unlock(); }
-
公平锁:
RLock fairLock = redisson.getFairLock("myFairLock"); fairLock.lock(); try {// 业务逻辑 } finally {fairLock.unlock(); }
总结:
-
非公平锁:默认情况下,Redisson 提供的是非公平锁。
-
公平锁:可以通过
getFairLock方法获取公平锁,确保锁的获取顺序按照线程请求的顺序进行。
RLock 是 Redisson 提供的分布式锁接口,它是基于 Redis 实现的。RLock 提供了类似于 Java 标准库中的 ReentrantLock 的功能,但它是分布式的,可以在多个 JVM 实例之间共享。
RLock 和 ReentrantLock 的关系
-
相似点:
-
接口和方法:
RLock提供的接口和方法与ReentrantLock类似,包括lock(),unlock(),tryLock(),lockInterruptibly()等方法。 -
可重入性:
RLock和ReentrantLock都是可重入锁,这意味着同一个线程可以多次获取同一把锁,而不会发生死锁。
-
-
不同点:
-
分布式特性:
ReentrantLock是本地锁,只能在单个 JVM 实例中使用。而RLock是分布式锁,可以在多个 JVM 实例之间共享,适用于分布式系统。 -
实现机制:
ReentrantLock是基于 Java 内部的同步机制实现的,而RLock是基于 Redis 实现的,通过 Redis 的原子操作来保证分布式锁的正确性。
-
使用示例
-
ReentrantLock** 示例**:ReentrantLock lock = new ReentrantLock(); lock.lock(); try {// 业务逻辑 } finally {lock.unlock(); }
-
RLock** 示例**:RLock lock = redisson.getLock("myLock"); lock.lock(); try {// 业务逻辑 } finally {lock.unlock(); }
RLock 的其他功能
除了基本的锁功能,RLock 还提供了一些高级功能:
-
公平锁:通过
getFairLock方法获取公平锁。 -
读写锁:通过
getReadWriteLock方法获取读写锁。 -
联锁:通过
getMultiLock方法获取联锁,可以同时锁定多个RLock实例。 -
红锁:通过
getRedLock方法获取红锁,适用于 Redis 集群环境。
总结
-
ReentrantLock:本地锁,只能在单个 JVM 实例中使用。 -
RLock:分布式锁,可以在多个 JVM 实例之间共享,适用于分布式系统。提供了类似ReentrantLock的接口和方法,但基于 Redis 实现。
发布/订阅的基本操作
-
订阅频道:使用
SUBSCRIBE命令订阅一个或多个频道。 -
发布消息:使用
PUBLISH命令向一个频道发布消息。 -
接收消息:订阅者会自动接收并处理发布到它所订阅频道的消息。
示例
以下是一个简单的示例,展示了如何使用 Redis 的发布/订阅功能。
订阅频道
假设我们有一个 Redis 客户端订阅了频道 my_channel:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPubSub;public class Subscriber {public static void main(String[] args) {Jedis jedis = new Jedis("localhost");jedis.subscribe(new JedisPubSub() {@Overridepublic void onMessage(String channel, String message) {System.out.println("Received message: " + message + " from channel: " + channel);}}, "my_channel");}
}在这个示例中,JedisPubSub 类的 onMessage 方法会在接收到消息时被调用。
发布消息
另一个 Redis 客户端可以向 my_channel 发布消息:
import redis.clients.jedis.Jedis;public class Publisher {public static void main(String[] args) {Jedis jedis = new Jedis("localhost");jedis.publish("my_channel", "Hello, Redis!");}
}当发布者发布消息后,订阅者会接收到并处理该消息。
使用场景
Redis 的发布/订阅功能适用于以下场景:
-
实时消息传递:如聊天室、实时通知等。
-
事件驱动架构:如微服务之间的事件通知。
-
数据更新通知:如缓存失效通知。
注意事项
-
消息丢失:如果订阅者在消息发布时未连接到 Redis 服务器,则会错过该消息。
-
消息顺序:Redis 保证消息按发布顺序传递给订阅者。
-
性能:发布/订阅模式适用于低延迟、高吞吐量的场景,但在大量消息和订阅者的情况下,可能会影响 Redis 的性能。
通过 Redis 的发布/订阅功能,可以实现简单而高效的消息传递机制,适用于多种实时通信场景。
Redis Lua 是指在 Redis 中使用 Lua 脚本进行编程。Redis 是一个高性能的键值存储数据库,而 Lua 是一种轻量级的脚本语言。通过在 Redis 中使用 Lua 脚本,可以实现一些复杂的操作和逻辑,从而提高性能和灵活性。
使用 Redis Lua 脚本的主要优点包括:
-
原子性:Lua 脚本在 Redis 中是原子执行的,这意味着在脚本执行期间不会有其他命令插入,从而保证了操作的原子性。
-
性能:将多个 Redis 命令组合成一个 Lua 脚本,可以减少客户端与服务器之间的通信开销,从而提高性能。
-
灵活性:Lua 脚本可以实现一些复杂的逻辑和操作,这些操作可能无法通过单个 Redis 命令实现。
在 Redis 中使用 Lua 脚本的基本步骤如下:
-
编写 Lua 脚本。
-
使用
EVAL命令将 Lua 脚本发送到 Redis 服务器执行。
例如,以下是一个简单的 Lua 脚本示例,该脚本将两个键的值相加并返回结果:
local value1 = redis.call('GET', KEYS[1])
local value2 = redis.call('GET', KEYS[2])
return tonumber(value1) + tonumber(value2)可以使用以下命令在 Redis 中执行该脚本:
EVAL "local value1 = redis.call('GET', KEYS[1]); local value2 = redis.call('GET', KEYS[2]); return tonumber(value1) + tonumber(value2)" 2 key1 key2在这个命令中,2 表示有两个键作为参数,key1 和 key2 是传递给脚本的键名。
Redis 的 NIO(Non-blocking I/O,非阻塞 I/O)是指 Redis 使用了一种非阻塞的网络 I/O 模型来处理客户端请求。非阻塞 I/O 模型使得 Redis 能够高效地处理大量并发连接,从而提高性能和吞吐量。
在传统的阻塞 I/O 模型中,每个客户端连接都会占用一个线程,当线程等待 I/O 操作完成时(例如读取数据或写入数据),该线程会被阻塞,无法执行其他任务。这种模型在处理大量并发连接时会导致线程资源耗尽,性能下降。
而在非阻塞 I/O 模型中,I/O 操作不会阻塞线程。当一个 I/O 操作无法立即完成时,线程可以继续执行其他任务,而不是等待 I/O 操作完成。Redis 使用了基于事件驱动的非阻塞 I/O 模型,通过单线程事件循环来处理所有客户端连接和请求。
Redis 的非阻塞 I/O 模型的实现主要依赖于以下几个关键组件:
-
事件循环:Redis 使用一个单线程事件循环来处理所有的 I/O 事件。事件循环会不断地检查是否有新的 I/O 事件(例如新的客户端连接、可读或可写的套接字等),并调用相应的事件处理器来处理这些事件。
-
多路复用:Redis 使用多路复用技术(如
select、poll、epoll等)来同时监视多个文件描述符(套接字)。多路复用允许 Redis 在一个线程中高效地处理多个客户端连接。
-
事件处理器:Redis 为不同类型的 I/O 事件(如读事件、写事件、连接事件等)注册了相应的事件处理器。当事件循环检测到某个事件发生时,会调用相应的事件处理器来处理该事件。
通过使用非阻塞 I/O 模型,Redis 能够在单线程中高效地处理大量并发连接,从而实现高性能和高吞吐量。这也是 Redis 能够在实际应用中表现出色的一个重要原因。
在Redis中,select、poll 和 epoll 是三种不同的I/O多路复用机制,用于处理多个网络连接。它们的主要作用是提高Redis在高并发场景下的性能。下面是对这三种机制的简要介绍:
-
select:
-
select是最早的I/O多路复用机制之一。 -
它使用一个固定大小的数组来存储文件描述符(file descriptors)。
-
每次调用
select时,内核会遍历整个数组,检查每个文件描述符的状态。 -
由于需要遍历整个数组,
select的性能在文件描述符数量较多时会显著下降。 -
select的文件描述符数量受限于FD_SETSIZE,通常是1024。
-
-
poll:
-
poll是select的改进版本。 -
它使用一个链表来存储文件描述符,因此没有
select的文件描述符数量限制。 -
每次调用
poll时,内核仍然需要遍历整个链表,检查每个文件描述符的状态。 -
虽然
poll在文件描述符数量上没有限制,但在高并发场景下,性能仍然会受到影响。
-
-
epoll:
-
epoll是Linux特有的I/O多路复用机制,专为高并发场景设计。 -
它使用一个事件驱动的机制,只在文件描述符状态发生变化时通知应用程序。
-
epoll使用一个红黑树来管理文件描述符,并通过一个双向链表来存储就绪的文件描述符。 -
由于
epoll只在状态变化时通知,因此在高并发场景下性能非常高。 -
epoll没有文件描述符数量的限制,适用于大规模并发连接。
-
Redis默认使用 epoll(在Linux系统上),因为它在高并发场景下性能最佳。如果 epoll 不可用,Redis 会退而使用 poll 或 select。
通俗来说,**Redis 的 epoll** 就像是一个“高效的门卫”,专门用来管理成千上万个客户端的网络请求。举个例子:
假设你开了一家餐厅,只有一个服务员(单线程的 Redis)。传统方式是服务员挨个问每桌客人:“要点菜吗?”(类似轮询),效率很低。而 epoll 的作用是:
-
不用挨个问:服务员(Redis)只需要坐在门口,拿一个“监控屏幕”(epoll 实例)。
-
谁准备好就通知谁:当某桌客人主动举手(数据到达)时,屏幕会立刻提示服务员去处理这一桌。
-
省时省力:服务员不用浪费时间在“空等”或“反复询问”上,可以专注处理真正需要服务的客人。
为什么 Redis 要用 epoll?
-
单线程也能高并发:Redis 核心逻辑是单线程的,但通过 **epoll 多路复用技术**,它能同时监控大量网络连接,只处理“有数据到达”的请求,避免阻塞。
-
性能优势:相比传统的
select/poll,epoll 使用红黑树管理连接,事件触发更高效,尤其适合连接数多但活跃请求少的场景(比如 Redis 的高并发读取)。
举个实际场景:
当 1 万个客户端同时连接 Redis 时,epoll 会快速识别哪些客户端发送了命令(比如读取缓存),并通知 Redis 依次处理这些命令,而不会让其他客户端“干等着”。这就是 Redis 单线程却能支持高吞吐量 的关键设计之一。
简单总结:**epoll 是 Redis 高效处理海量网络请求的“智能调度器”**,让它用最少的资源,快速响应最多的客户端。
Redis 是线程安全的。Redis 是一个单线程的服务器,这意味着它在任何给定时间只会处理一个命令。通过这种方式,Redis 避免了多线程编程中常见的竞争条件和死锁问题,从而保证了线程安全性。
不过,虽然 Redis 本身是单线程的,但它的客户端库通常是多线程的。因此,在使用 Redis 客户端时,仍然需要注意线程安全问题,确保在多线程环境中正确使用客户端库。
在 Redis 中,实现原子操作并不一定必须使用 Lua 脚本。Redis 提供了多种方式来实现原子操作,以下是几种常见的方法:
-
单个命令的原子性:
-
Redis 的大多数单个命令都是原子操作。例如,
INCR、DECR、LPUSH、RPOP等命令都是原子操作。
-
事务(Transactions):
-
Redis 提供了事务功能,可以使用
MULTI、EXEC、DISCARD和WATCH命令来实现一组命令的原子执行。事务中的命令会按顺序执行,直到执行EXEC命令时,所有命令会被一次性执行。
MULTI
INCR key1
INCR key2
EXEC-
乐观锁(Optimistic Locking):
-
使用
WATCH命令可以实现乐观锁。WATCH命令会监视一个或多个键,在执行EXEC命令之前,如果任何一个被监视的键发生了变化,事务会被中止。
WATCH key1 key2
MULTI
INCR key1
INCR key2
EXEC-
Lua 脚本:
-
Lua 脚本可以将多个操作封装在一个脚本中,保证这些操作的原子性。Redis 会在执行 Lua 脚本时锁住所有涉及的键,确保脚本中的所有命令作为一个原子操作执行。
local value1 = redis.call('INCR', 'key1')
local value2 = redis.call('INCR', 'key2')
return {value1, value2}综上所述,虽然 Lua 脚本是实现复杂原子操作的强大工具,但在 Redis 中实现原子操作并不一定必须使用 Lua 脚本。根据具体需求,可以选择合适的方法来实现原子操作。
Redisson 是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid)框架,它提供了许多分布式的数据结构和服务。Redisson 的看门狗机制(Watchdog)是其分布式锁实现中的一个重要特性,用于自动续期锁的过期时间,防止锁在持有期间意外过期。
在分布式系统中,分布式锁通常是通过设置一个带有过期时间的键来实现的。这样可以防止在持有锁的客户端崩溃或网络分区的情况下,锁永远不会被释放。然而,如果锁的持有时间超过了预设的过期时间,锁可能会被意外释放,从而导致并发问题。
Redisson 的看门狗机制通过以下方式解决了这个问题:
-
自动续期:当一个客户端成功获取到锁后,Redisson 会启动一个看门狗线程,该线程会定期检查锁的状态,并在锁即将过期时自动续期锁的过期时间。这样可以确保锁在持有期间不会意外过期。
-
可配置的过期时间:看门狗机制的默认锁过期时间是 30 秒,但可以通过配置进行调整。用户可以根据具体需求设置合适的过期时间。
-
锁的释放:当客户端显式释放锁时,看门狗线程会停止续期操作,锁会被正常释放。
以下是一个使用 Redisson 分布式锁的示例代码:
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonLockExample {public static void main(String[] args) {// 创建配置Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");// 创建 Redisson 客户端RedissonClient redisson = Redisson.create(config);// 获取分布式锁RLock lock = redisson.getLock("myLock");// 尝试获取锁lock.lock();try {// 执行需要加锁的操作System.out.println("Lock acquired, executing protected code...");// 模拟长时间操作Thread.sleep(60000);} catch (InterruptedException e) {e.printStackTrace();} finally {// 释放锁lock.unlock();System.out.println("Lock released.");}// 关闭 Redisson 客户端redisson.shutdown();}
}在这个示例中,lock.lock() 方法会启动看门狗线程,确保锁在持有期间不会过期。即使 Thread.sleep(60000) 模拟的操作时间超过了默认的锁过期时间(30 秒),看门狗机制也会自动续期锁的过期时间,确保锁不会被意外释放。
Redisson 是一个在 Redis 上实现的分布式 Java 数据结构和服务的客户端。Redisson 提供了许多高级功能,其中之一就是看门狗机制(Watchdog Mechanism)。
看门狗机制主要用于分布式锁的自动续期。具体来说,当一个线程获取到锁之后,如果在锁的持有期间内没有主动释放锁,看门狗机制会自动延长锁的有效期,防止锁过期被其他线程获取。
看门狗机制的工作原理
-
获取锁:当一个线程获取到锁时,Redisson 会默认设置一个锁的有效期(例如 30 秒)。
-
启动看门狗:获取锁后,Redisson 会启动一个看门狗定时任务,这个任务会在锁的有效期到期之前(例如 10 秒前)自动延长锁的有效期。
-
自动续期:看门狗定时任务会不断地延长锁的有效期,直到线程主动释放锁或者程序结束。
代码示例
以下是一个使用 Redisson 分布式锁的简单示例:
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonWatchdogExample {public static void main(String[] args) {// 配置 RedissonConfig config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");RedissonClient redisson = Redisson.create(config);// 获取锁RLock lock = redisson.getLock("myLock");try {// 尝试加锁lock.lock();// 执行业务逻辑System.out.println("Lock acquired, executing business logic...");// 模拟长时间的业务处理Thread.sleep(60000); // 60 秒} catch (InterruptedException e) {e.printStackTrace();} finally {// 释放锁lock.unlock();System.out.println("Lock released.");}// 关闭 Redisson 客户端redisson.shutdown();}
}在这个示例中,线程获取到锁后会执行一个长时间的业务逻辑(模拟 60 秒)。由于看门狗机制的存在,锁会在业务逻辑执行期间不断续期,防止锁过期。
配置看门狗
Redisson 的看门狗机制默认是开启的,并且默认的锁续期时间是 30 秒。如果需要自定义看门狗的行为,可以在配置中进行调整:
config.setLockWatchdogTimeout(45000); // 设置看门狗超时时间为 45 秒通过这种方式,可以根据具体的业务需求调整看门狗的超时时间。
总结
Redisson 的看门狗机制通过自动续期锁的有效期,确保了分布式锁在长时间业务处理中的可靠性,避免了锁过期导致的并发问题。
Redisson的看门狗(WatchDog)机制通过以下规则决定是否续期:
-
触发条件当使用
lock()方法获取锁且**未显式指定锁超时时间(leaseTime)**时,看门狗会自动生效。若手动设置leaseTime,则需自行处理续期逻辑。
-
续期判断逻辑
-
看门狗默认每 10秒(超时时间的1/3) 检查一次锁状态。
-
通过Lua脚本验证当前线程是否仍持有锁,若持有则**重置锁超时时间为30秒**(默认值,可通过
lockWatchdogTimeout配置修改)。 -
若锁已被释放或业务完成,看门狗会停止续期(通过移除
EXPIRATION_RENEWAL_MAP中的记录)。
-
-
终止续期的场景
-
业务代码执行完毕,显式调用
unlock()释放锁。 -
持有锁的线程异常退出或进程终止,看门狗线程随之停止,锁超时后自动释放。
-
核心设计目标:在避免死锁的同时,确保业务执行期间锁的持有权,防止因超时导致并发问题。
如果业务完成,但是忘记手动释放锁,看门狗会续期吗
如果业务代码执行完成但**忘记手动释放锁(unlock())**,看门狗会**持续为锁续期**,直到以下条件满足之一:
-
进程或线程终止:若持有锁的线程或进程崩溃、被终止(如服务器宕机),看门狗线程随之停止,锁最终会在**默认30秒超时**后自动释放。
-
锁被其他方式强制释放:例如管理员手动介入删除锁,或Redis触发了数据过期策略。
潜在风险与建议:
-
风险:忘记释放锁 + 看门狗续期会导致锁长期占用,可能引发**死锁假象**(其他线程无法获取锁)。
-
解决方案:
-
使用
tryLock()或lock()时,**务必在finally块中调用****unlock()**(即使业务异常)。 -
若需避免手动释放,可设置锁超时时间(
leaseTime参数),但需确保业务在超时前完成。 -
监控锁持有时间,通过
RedissonClient.getLock("lockName").remainTimeToLive()检查锁剩余存活时间。
-
核心结论:看门狗仅依赖锁持有状态续期,**不感知业务逻辑是否完成**。**开发者必须主动释放锁**,否则锁会因续期机制长期存在。
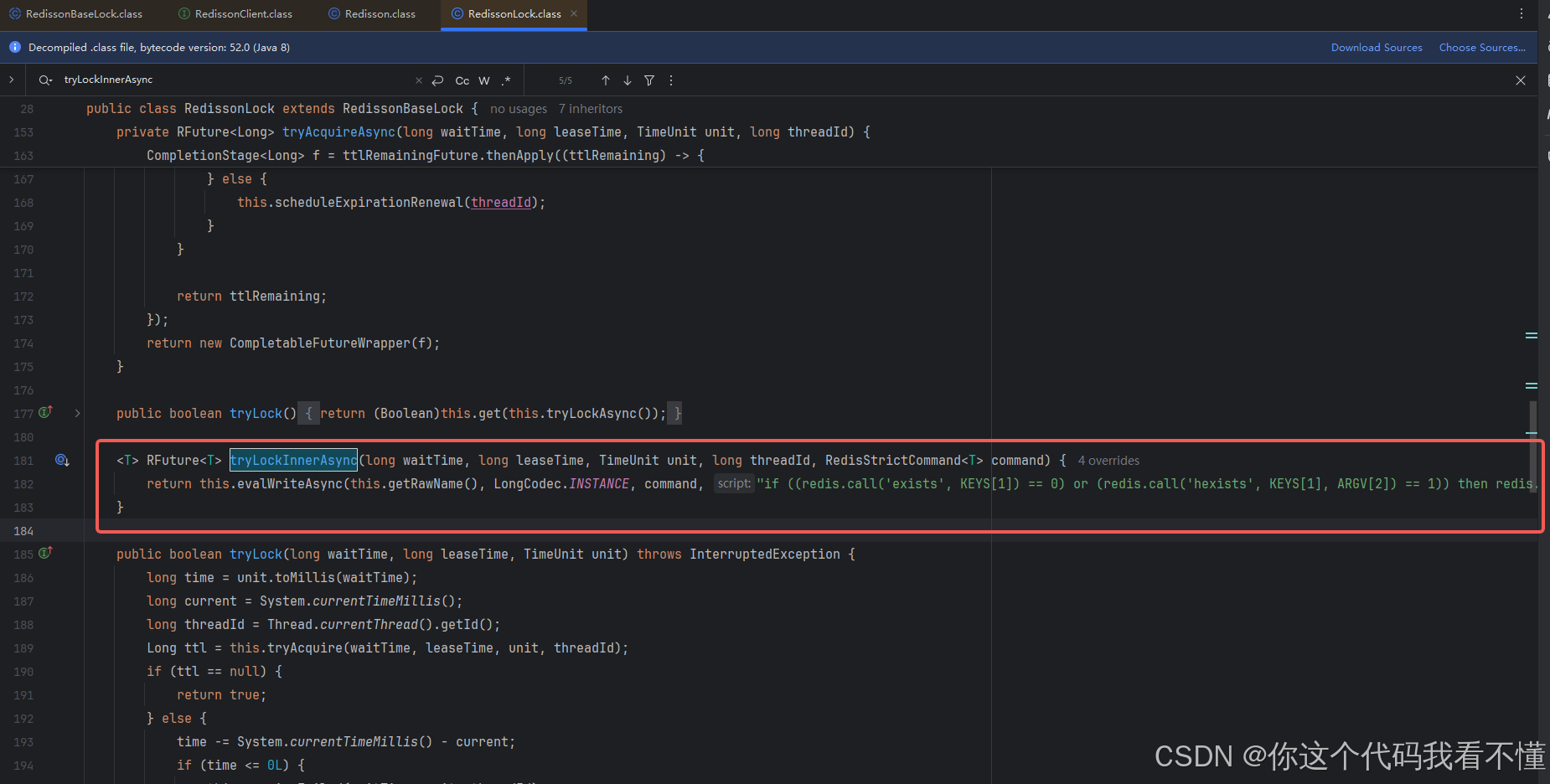
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {return this.evalWriteAsync(this.getRawName(), LongCodec.INSTANCE, command, "if ((redis.call('exists', KEYS[1]) == 0) or (redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);", Collections.singletonList(this.getRawName()), new Object[]{unit.toMillis(leaseTime), this.getLockName(threadId)});
}这段代码是一个用于尝试获取分布式锁的异步方法。它使用了Redis作为分布式锁的存储介质。下面是对这段代码的详细解释:
方法签名
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command)-
<T>:泛型类型参数,表示返回值的类型。 -
RFuture<T>:表示一个异步操作的结果,类似于Java的Future,但用于异步操作。 -
tryLockInnerAsync:方法名称,表示尝试异步获取锁。 -
参数:
-
waitTime:等待时间。 -
leaseTime:租约时间,即锁的有效期。 -
unit:时间单位,表示waitTime和leaseTime的单位。 -
threadId:线程ID,用于标识请求锁的线程。 -
command:Redis命令,表示要执行的具体Redis操作。
-
方法体
return this.evalWriteAsync(this.getRawName(), LongCodec.INSTANCE, command, "if ((redis.call('exists', KEYS[1]) == 0) or (redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then " +"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +"return redis.call('pttl', KEYS[1]);", Collections.singletonList(this.getRawName()), new Object[]{unit.toMillis(leaseTime), this.getLockName(threadId)}
);-
this.evalWriteAsync(...):调用异步执行Redis写操作的方法。-
this.getRawName():获取锁的名称。 -
LongCodec.INSTANCE:用于编码和解码数据的编解码器。 -
command:传入的Redis命令。 -
Lua脚本:
if ((redis.call('exists', KEYS[1]) == 0) or (redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);-
if ((redis.call('exists', KEYS[1]) == 0) or (redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then:如果键不存在,或者键中已经存在当前线程的锁,则执行以下操作:-
redis.call('hincrby', KEYS[1], ARGV[2], 1):将当前线程的锁计数加1。 -
redis.call('pexpire', KEYS[1], ARGV[1]):设置键的过期时间。 -
return nil:返回nil,表示成功获取锁。
-
-
end:结束if语句。 -
return redis.call('pttl', KEYS[1]):返回键的剩余生存时间(TTL)。
-
-
Collections.singletonList(this.getRawName()):将锁的名称作为键传入Lua脚本。 -
new Object[]{unit.toMillis(leaseTime), this.getLockName(threadId)}:将租约时间(毫秒)和锁的名称(包含线程ID)作为参数传入Lua脚本。
-
总结
这段代码的主要功能是尝试获取一个分布式锁。如果锁不存在或者当前线程已经持有锁,则增加锁的计数并设置锁的过期时间;否则,返回锁的剩余生存时间。通过异步方式执行,可以避免阻塞线程,提高性能。
在Redis中使用Lua脚本时,可以通过redis.call或redis.pcall来执行Redis命令,并且可以通过KEYS和ARGV来传递参数。以下是详细的说明和示例:
传递参数的方式
-
KEYS:用于传递键名。KEYS是一个数组,包含所有传递的键名。 -
ARGV:用于传递其他参数。ARGV是一个数组,包含所有传递的非键名参数。
示例
假设我们有一个Lua脚本,需要传递两个键名和两个参数:
local key1 = KEYS[1]
local key2 = KEYS[2]
local arg1 = ARGV[1]
local arg2 = ARGV[2]-- 示例操作:将arg1的值设置到key1,将arg2的值设置到key2
redis.call('set', key1, arg1)
redis.call('set', key2, arg2)-- 返回结果
return {key1, key2, arg1, arg2}在Java中调用Lua脚本
假设我们使用Jedis库来调用上述Lua脚本:
import redis.clients.jedis.Jedis;public class RedisLuaExample {public static void main(String[] args) {// 连接到Redis服务器Jedis jedis = new Jedis("localhost", 6379);// Lua脚本String luaScript = "local key1 = KEYS[1] " +"local key2 = KEYS[2] " +"local arg1 = ARGV[1] " +"local arg2 = ARGV[2] " +"redis.call('set', key1, arg1) " +"redis.call('set', key2, arg2) " +"return {key1, key2, arg1, arg2}";// 定义键名和参数List<String> keys = Arrays.asList("key1", "key2");List<String> args = Arrays.asList("value1", "value2");// 执行Lua脚本Object result = jedis.eval(luaScript, keys, args);// 打印结果System.out.println(result);}
}解释
-
Lua脚本:
-
local key1 = KEYS[1]:获取第一个键名。 -
local key2 = KEYS[2]:获取第二个键名。 -
local arg1 = ARGV[1]:获取第一个参数。 -
local arg2 = ARGV[2]:获取第二个参数。 -
redis.call('set', key1, arg1):将第一个参数的值设置到第一个键。 -
redis.call('set', key2, arg2):将第二个参数的值设置到第二个键。 -
return {key1, key2, arg1, arg2}:返回键名和参数。
-
-
Java代码:
-
连接到Redis服务器。
-
定义Lua脚本。
-
定义键名和参数。
-
使用
jedis.eval方法执行Lua脚本,传入脚本、键名列表和参数列表。 -
打印结果。
-
通过这种方式,可以在Lua脚本中使用传入的键名和参数,执行相应的Redis命令。
Lua脚本存在的原因主要有以下几个方面:
-
轻量级和高效:Lua是一种轻量级的脚本语言,设计之初就考虑了嵌入式系统的需求。它的解释器非常小巧,运行速度快,适合在资源受限的环境中使用。
-
嵌入性强:Lua可以很容易地嵌入到其他编程语言(如C、C++)中,作为一种嵌入式脚本语言使用。这使得开发者可以在主程序中调用Lua脚本,实现灵活的扩展和动态配置。
-
易于学习和使用:Lua的语法简单明了,学习曲线平缓,开发者可以快速上手并编写脚本。
-
跨平台:Lua是跨平台的,可以在多种操作系统和硬件平台上运行,这使得它在游戏开发、嵌入式系统、网络应用等领域得到了广泛应用。
-
强大的扩展性:Lua提供了丰富的标准库和强大的扩展机制,开发者可以根据需要扩展Lua的功能,满足各种应用场景的需求。
-
社区支持:Lua有一个活跃的社区,提供了大量的文档、教程和第三方库,帮助开发者解决问题并提高开发效率。
综上所述,Lua脚本的存在为开发者提供了一种高效、灵活、易用的解决方案,广泛应用于游戏开发、嵌入式系统、网络应用等领域。
Redis 的发布/订阅(Pub/Sub)和 Kafka 都是消息传递系统,但它们在设计目标、架构和使用场景上有显著的区别。以下是它们的主要区别:
1. 设计目标和使用场景
-
Redis Pub/Sub:
-
设计目标:Redis 的 Pub/Sub 机制主要用于实时消息传递,适用于需要低延迟、实时性高的场景。
-
使用场景:适用于实时聊天、通知系统、实时数据流等需要快速响应的场景。
-
消息持久化:Redis Pub/Sub 不提供消息持久化功能,消息一旦发布,如果没有订阅者接收,消息就会丢失。
-
-
Kafka:
-
设计目标:Kafka 是一个分布式流处理平台,设计用于高吞吐量、持久化和分布式的消息传递。
-
使用场景:适用于日志收集、事件追踪、数据流处理、消息队列等需要高吞吐量和持久化的场景。
-
消息持久化:Kafka 提供消息持久化功能,消息会被存储在磁盘上,消费者可以在任何时候读取消息。
-
2. 架构
-
Redis Pub/Sub:
-
架构:Redis 的 Pub/Sub 是基于内存的,消息发布者将消息发布到频道,所有订阅该频道的订阅者都会接收到消息。
-
消息传递:消息是实时传递的,没有持久化,订阅者必须在线才能接收到消息。
-
-
Kafka:
-
架构:Kafka 是一个分布式系统,由多个 Broker 组成,消息被发布到主题(Topic),每个主题可以有多个分区(Partition)。
-
消息传递:消息被持久化到磁盘,消费者可以在任何时候读取消息,支持消息的回溯和重放。
-
3. 消息模型
-
Redis Pub/Sub:
-
消息模型:发布/订阅模型,发布者将消息发布到频道,所有订阅该频道的订阅者都会接收到消息。
-
消息顺序:消息是按发布顺序传递的,但没有持久化,无法保证消息的可靠性。
-
-
Kafka:
-
消息模型:发布/订阅模型,消息被发布到主题,消费者从主题的分区中读取消息,同一个groupId只有一个消费者获取到消息。
-
消息顺序:在同一个分区内,消息是按发布顺序存储和传递的,Kafka 提供了消息的持久化和可靠性保证。
-
4. 性能和扩展性
-
Redis Pub/Sub:
-
性能:Redis Pub/Sub 的性能非常高,适用于低延迟的实时消息传递。
-
扩展性:Redis 是单线程的,扩展性有限,适用于中小规模的实时消息传递。
-
-
Kafka:
-
性能:Kafka 设计用于高吞吐量的消息传递,能够处理大量的消息。
-
扩展性:Kafka 是分布式系统,具有很好的扩展性,可以通过增加 Broker 来扩展系统的处理能力。
-
总结
-
Redis Pub/Sub:适用于低延迟、实时性高的场景,不提供消息持久化,适用于中小规模的实时消息传递。
-
Kafka:适用于高吞吐量、持久化和分布式的消息传递,适用于日志收集、事件追踪、数据流处理等需要高可靠性和扩展性的场景。
Redisson 作为 Redis 的 Java 客户端,在分布式场景中表现突出,以下是其核心优缺点分析:
优点
-
分布式特性丰富提供分布式锁、集合、队列等高级数据结构,支持可重入锁、公平锁、联锁等机制,并解决**锁续期(看门狗机制)**和主从一致性等问题。
-
线程安全与高可用基于 Netty 实现异步非阻塞通信,支持多线程安全操作,且天然适配 Redis 集群和哨兵模式。
-
与 Spring 生态无缝集成提供 Spring Cache、Session 管理等模块化支持,简化分布式场景下的开发。
-
复杂场景优化支持数据序列化、自动重试、限流策略,并兼容多种编码协议(如 JSON、Avro)。
缺点
-
学习成本较高抽象层级较高,API 设计复杂,需熟悉分布式概念(如锁的续期、RedLock 算法)。
-
部分 Redis 特性不支持对字符串操作、排序、事务、管道等原生 Redis 功能的支持较弱。
-
性能开销依赖 Netty 框架和复杂逻辑(如锁续期),在简单场景下可能不如轻量级客户端(如 Jedis)高效。
-
依赖稳定性风险强依赖 Redis 可用性,若 Redis 集群故障,分布式锁等机制可能失效。
| 维度 | 优势 | 局限 |
| 功能特性 | 支持分布式锁、集合、队列等高级功能,解决锁续期、主从一致性 | 不支持原生 Redis 的字符串操作、事务、管道等特性 |
| 开发体验 | 与 Spring 深度集成,提供线程安全和易用的 API | API 抽象度高,学习曲线陡峭 |
| 性能与扩展性 | 基于 Netty 实现高并发,适配集群/哨兵模式 | 复杂逻辑(如锁续期)可能增加延迟,轻量级场景性能不如 Jedis |
| 适用场景 | 适合分布式系统(如微服务锁控制、分布式集合操作) | 简单 KV 存储或高频字符串操作场景建议选择其他客户端(如 Lettuce/Jedis) |
总结:Redisson 是构建分布式系统的利器,尤其在需要**复杂锁控制**或**分布式数据结构**时优势明显,但需权衡其学习成本和性能开销。对于简单查询或字符串操作,可搭配轻量级客户端使用。
乐观锁和悲观锁是数据库和并发编程中常用的两种锁机制,它们各有优缺点,适用于不同的场景。
乐观锁
优点:
-
高并发性能:乐观锁不使用数据库锁机制,而是通过版本号或时间戳等机制来实现,减少了锁的开销,适合读多写少的场景。
-
无死锁:由于不使用数据库锁机制,避免了死锁的发生。
-
适合分布式系统:在分布式系统中,乐观锁可以减少锁的粒度,提高系统的整体性能。
缺点:
-
冲突处理复杂:在高并发写操作的场景下,冲突的概率较高,需要处理冲突的逻辑较为复杂。
-
重试成本高:当发生冲突时,需要进行重试操作,可能会导致性能下降。
悲观锁
优点:
-
数据一致性高:悲观锁通过锁定数据来保证数据的一致性,适合写多读少的场景。
-
简单易用:悲观锁的实现相对简单,适合对数据一致性要求较高的场景。
缺点:
-
性能开销大:悲观锁需要频繁地加锁和解锁操作,增加了系统的开销,降低了并发性能。
-
容易产生死锁:在复杂的并发场景下,容易产生死锁问题,需要额外的机制来检测和处理死锁。
-
不适合分布式系统:在分布式系统中,悲观锁的实现较为复杂,性能也不如乐观锁。
适用场景
-
乐观锁:适用于读多写少的场景,如大部分查询操作较多的系统。
-
悲观锁:适用于写多读少的场景,如银行转账等对数据一致性要求较高的系统。
通过了解乐观锁和悲观锁的优缺点,可以根据具体的业务需求选择合适的锁机制,以提高系统的性能和数据一致性。
相关文章:
Redisson单机模式
redisson调用unlock的过程 Redisson 是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid)框架,提供了分布式和可扩展的数据结构和服务。Redisson 的 unlock 方法用于释放锁。下面是 unlock 方法的调用过程: 获取锁的状…...

数据结构第6章 图(竟成)
第 6 章 图 【考纲内容】 1.图的基本概念 2.图的存储及基本操作:(1) 邻接矩阵法;(2) 邻接表法;(3) 邻接多重表、十字链表 3.图的遍历:(1) 深度优先搜索;(2) 广度优先搜索 4.图的基本应用:(1) 最小 (代价) 生…...

机器人现可完全破解验证码:未来安全技术何去何从?
引言 随着计算机视觉技术的飞速发展,机器学习模型现已能够100%可靠地解决Google的视觉reCAPTCHAv2验证码。这标志着一个时代的结束——自2000年代初以来,CAPTCHA("全自动区分计算机与人类的图灵测试"的缩写)一直是区分…...

CppCon 2014 学习:(Costless)Software Abstractions for Parallel Architectures
硬件和科学计算的演变关系: 几十年来的硬件进步:计算机硬件不断快速发展,从提升单核速度,到多核并行。科学计算的驱动力:科学计算需求推动硬件创新,比如需要更多计算能力、更高性能。当前的解决方案是并行…...
网络爬虫 - App爬虫及代理的使用(十一)
App爬虫及代理的使用 一、App抓包1. App爬虫原理2. reqable的安装与配置1. reqable安装教程2. reqable的配置3. 模拟器的安装与配置1. 夜神模拟器的安装2. 夜神模拟器的配置4. 内联调试及注意事项1. 软件启动顺序2. 开启抓包功能3. reqable面板功能4. 夜神模拟器设置项5. 注意事…...
SASL认证(zookeeper))
Kafka集群部署(docker容器方式)SASL认证(zookeeper)
一、服务器环境 序号 部署版本 版本 1 操作系统 CentOS Linux release 7.9.2009 (Core) 2 docker Docker version 20.10.6 3 docker-compose docker-compose version 1.28.2 二、服务规划 序号 服务 名称 端口 1 zookeeper zookeeper 2181,2888,3888 2 ka…...

【python爬虫】利用代理IP爬取filckr网站数据
亮数据官网链接:亮数据官网...
群晖 NAS 如何帮助培训学校解决文件管理难题
在现代教育环境中,数据管理和协同办公的效率直接影响到教学质量和工作流畅性。某培训学校通过引入群晖 NAS,显著提升了部门的协同办公效率。借助群晖的在线协作、自动备份和快照功能,该校不仅解决了数据散乱和丢失的问题,还大幅节…...
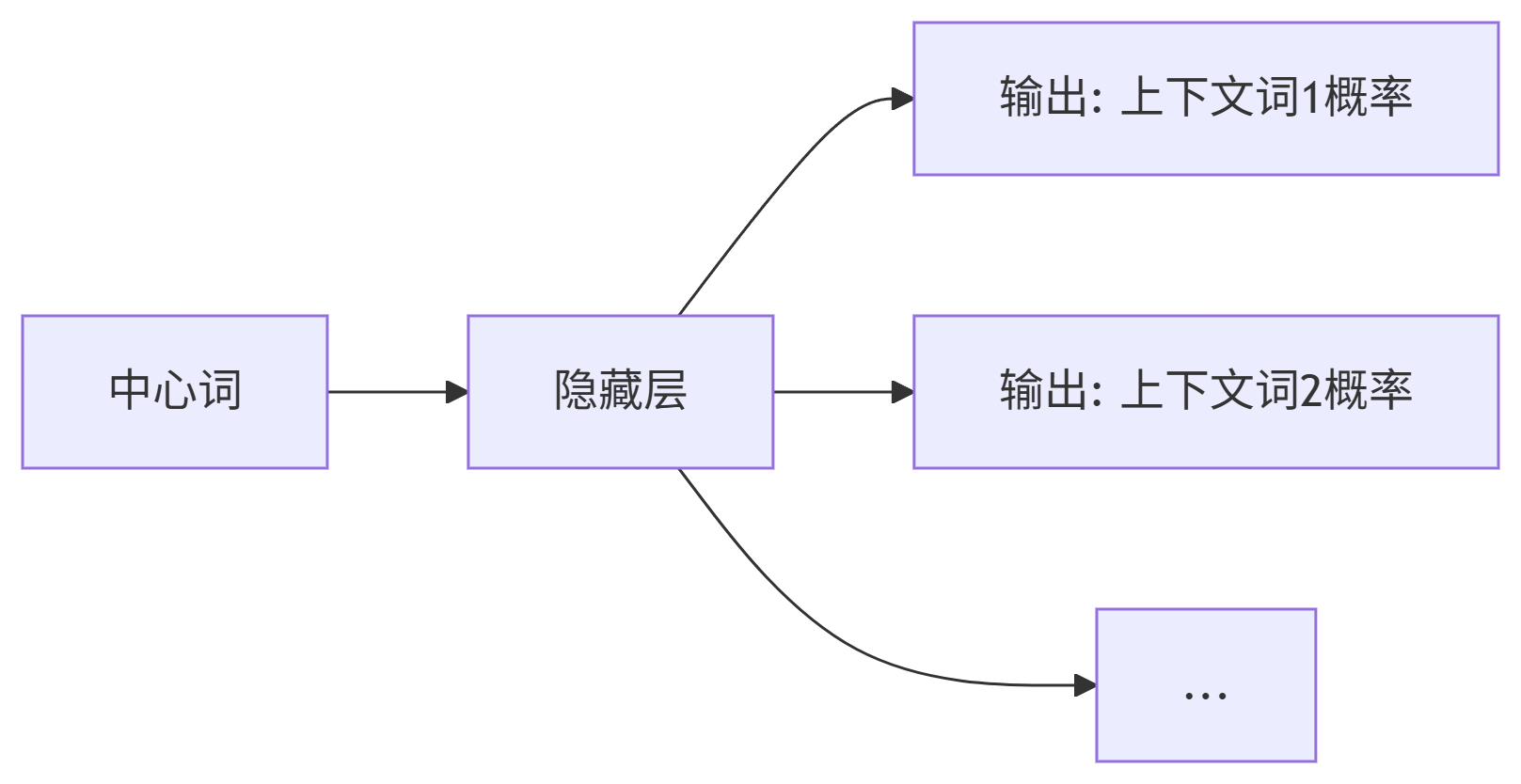
NLP学习路线图(十八):Word2Vec (CBOW Skip-gram)
自然语言处理(NLP)的核心挑战在于让机器“理解”人类语言。传统方法依赖独热编码(One-hot Encoding) 表示单词,但它存在严重缺陷:每个单词被视为孤立的符号,无法捕捉词义关联(如“国…...

P1438 无聊的数列/P1253 扶苏的问题
因为这两天在写线性代数的作业,没怎么写题…… P1438 无聊的数列 题目背景 无聊的 YYB 总喜欢搞出一些正常人无法搞出的东西。有一天,无聊的 YYB 想出了一道无聊的题:无聊的数列。。。 题目描述 维护一个数列 ai,支持两种操…...
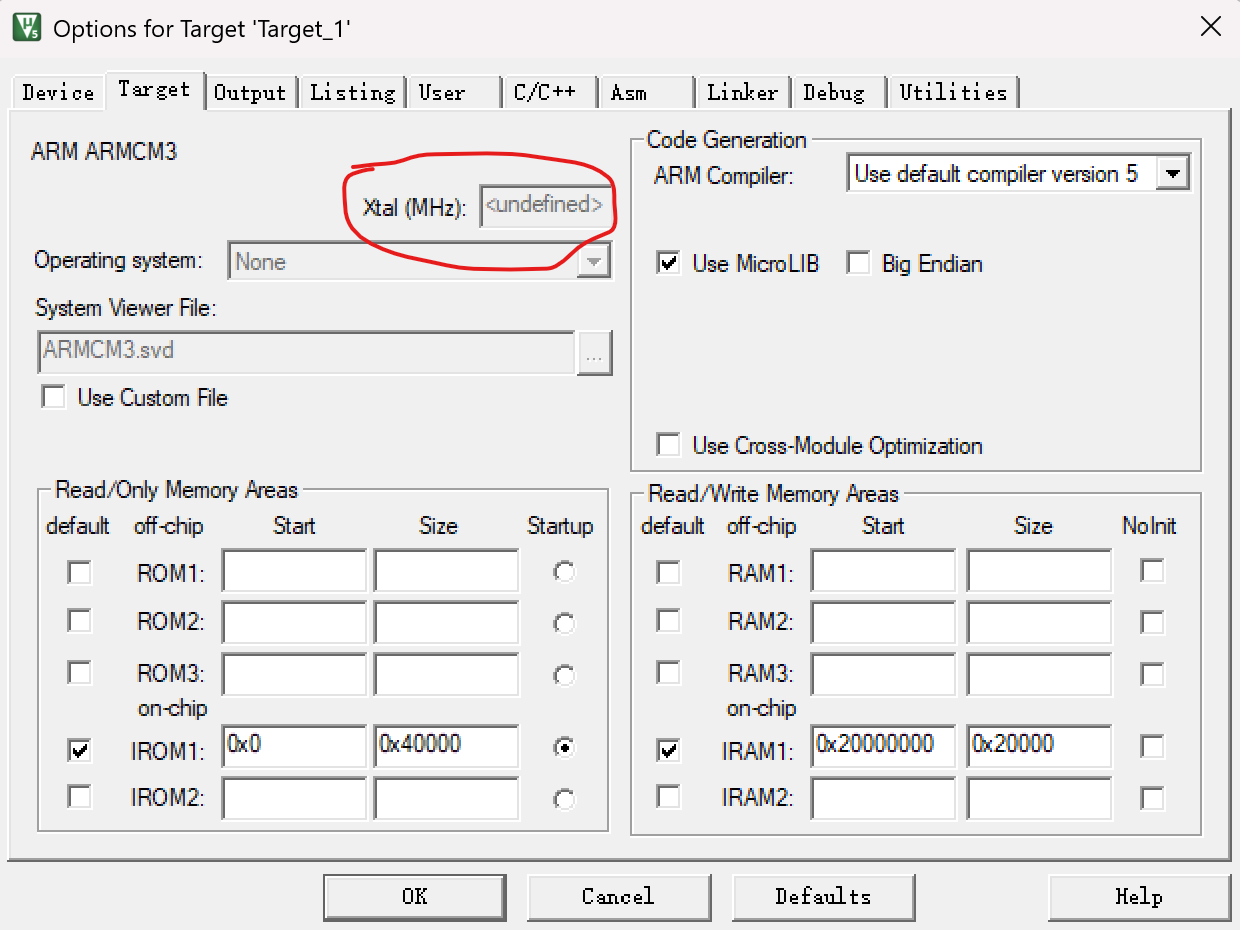
嵌入式学习笔记 - 新版Keil软件模拟时钟Xtal灰色不可更改的问题
在新版Keil软件中,模拟时钟无法修改XTAL频率,默认只能使用12MHz时钟。这是因为Keil MDK从5.36版本开始,参数配置界面不再支持修改系统XTAL频率,XTAL选项变为灰色,无法修改。这会导致在软件仿真时出现时间错误的问题&…...

k8s的出现解决了java并发编程胡问题了
Kubernetes(K8s)作为一种开源的容器编排平台,极大地简化了应用程序的部署、管理和扩展。这不仅解决了很多基础设施方面的问题,也间接解决了Java并发编程中的一些复杂问题。本文将详细探讨Kubernetes是如何帮助解决Java并发编程中的…...

如何利用大语言模型生成特定格式文风的报告类文章
在这个算法渗透万物的时代,我们不再仅仅满足于大语言模型(LLM)能“写”,更追求它能“写出精髓,写出风格”。尤其在专业且高度格式化的报告类文章领域,仅仅是内容正确已远远不够,文风的精准复刻才是决定报告是否“对味儿”、能否被目标受众有效接受的关键。这不再是简单的…...

黑马Java面试笔记之 集合篇(算法复杂度+ArrayList+)
一. 算法复杂度分析 1.1 时间复杂度 时间复杂度分析:来评估代码的执行耗时的 常见的复杂度表示形式 常见复杂度 1.2 空间复杂度 空间复杂度全称是渐进空间复杂度,表示算法占用的额外存储空间与数据规模之间的增长关系 二. 数组 数组(Array&a…...

【从0-1的HTML】第2篇:HTML标签
文章目录 1.标题标签2.段落标签3.文本标签brbstrongsubsup 4.超链接标签5.图片标签6.表格标签7.列表标签有序列表ol无序列表ul定义列表dl 8.表单标签9.音频标签10.视频标签11.HTML元素分类块级元素内联元素 12.HTML布局13.内联框架13.内联框架 1.标题标签 标题标签:…...

从“Bucharest”谈起:词语翻译的音译与意译之路
在翻译中,面对地名、人名或新兴术语时,我们常常会遇到一个抉择:到底是“音译”,保留其原发音风貌,还是“意译”,让它意义通达? 今天我们以“Bucharest”为例,展开一次语言与文化的微…...

Nginx+Tomcat负载均衡
目录 Tomcat简介 Tomcat 的核心功能 Tomcat架构 Tomcat 的特点 Tomact配置 关闭防火墙及系统内核 Tomcar 主要文件信息 配置文件说明 案例一:Java的Web站点 案例二:NginxTomcat负载均衡、动静分离 Tomcat简介 Tomcat 是由 Apache 软件基金会&am…...

JVM——JVM中的字节码:解码Java跨平台的核心引擎
引入 在Java的技术版图中,字节码(Bytecode)是连接源代码与机器世界的黄金桥梁。当开发者写下第一行public class HelloWorld时,编译器便开始了一场精密的翻译工程——将人类可读的Java代码转化为JVM能够理解的字节码指令。这些由…...

【论文解读】ReAct:从思考脱离行动, 到行动反馈思考
认识从实践开始,经过实践得到了理论的认识,还须再回到实践去。 ——《实践论》,毛泽东 1st author: About – Shunyu Yao – 姚顺雨 paper [2210.03629] ReAct: Synergizing Reasoning and Acting in Language ModelsReAct: Synergizing Reasoning and…...
)
数据解析:一文掌握Python库 lxml 的详细使用(处理XML和HTML的高性能库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、lxml 概述1.1 lxml 介绍1.2 安装和第一个案例1.3 性能优化技巧二、XML处理2.1 解析XML2.2 访问元素2.3 遍历XML树2.4 修改XML2.5 写入XML三、HTML处理3.1 解析HTML3.2 XPath查询3.3 CSS选择器四、高级功能4.1 使用命…...

react native webview加载本地HTML,解决iOS无法加载成功问题
在react native中使用 “react-native-webview”: “^13.13.5”,加载HTML文件 Android: 将HTML文件放置到android/src/main/assets目录,访问 {uri: file:///android_asset/markmap/index.html}ios: 在IOS中可以直接可以直接放在react native项目下,访问…...
简单配置RHEL9.X
切换默认运行级别 将系统默认启动模式从多用户的图形界面调整为多用户的文本界面,适用于优化系统资源占用或进行远程服务器管理的场景。 注意:安装选择“带GUI的服务器”部分常用命令默认安装;如果选择“最小安装”时,部分常用命…...
)
默认网关 -- 负责转发数据包到其他网络的设备(通常是路由器)
✅ 默认网关概括说明: 默认网关(Default Gateway)是网络中一台负责转发数据包到其他网络的设备(通常是路由器)。当一台主机要访问不在本地子网内的设备时,会将数据包发给默认网关,由它继续转发…...

python调用硅基流动的视觉语言模型
参考: https://docs.siliconflow.cn/cn/userguide/capabilities/vision import base64 import json from openai import OpenAI from PIL import Image import io# 初始化OpenAI客户端 client OpenAI(api_key"sk-**********", # 替换为实际API密钥b…...
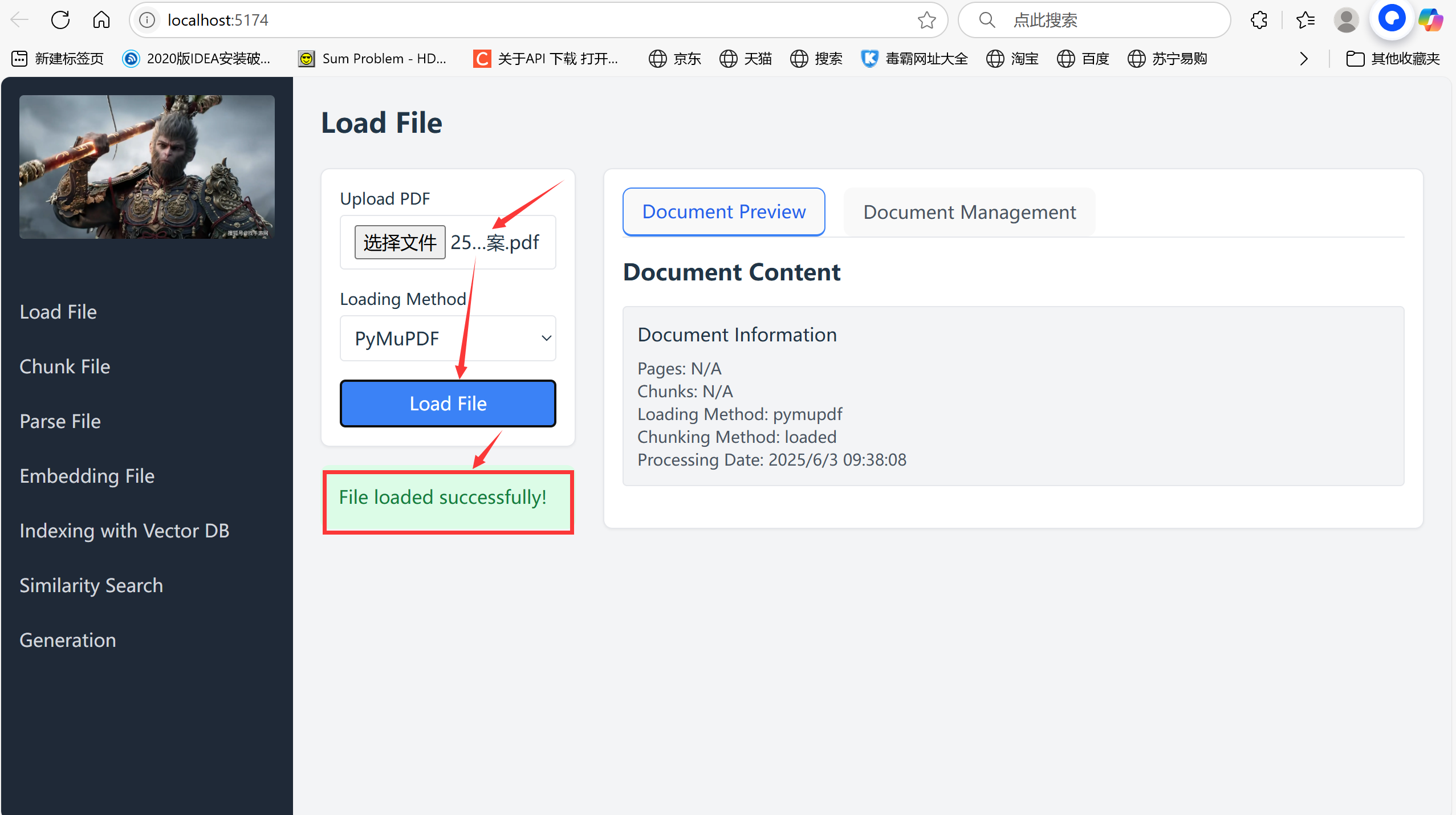
下载并运行自制RAG框架
项目部署 https://github.com/huangjia2019/rag-project01-framework git clone https://github.com/huangjia2019/rag-project01-framework.git 一 、 前端分部分部署 在 Ubuntu 系统 上安装 Node.js 和 npm(Node Package Manager),并初始…...
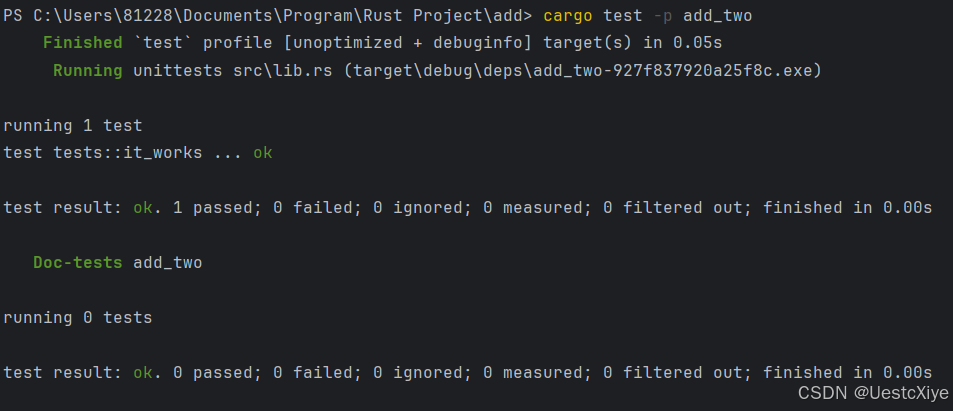
Rust 学习笔记:Cargo 工作区
Rust 学习笔记:Cargo 工作区 Rust 学习笔记:Cargo 工作区创建工作区在工作区中创建第二个包依赖于工作区中的外部包向工作区添加测试将工作区中的 crate 发布到 crates.io添加 add_two crate 到工作区总结 Rust 学习笔记:Cargo 工作区 随着项…...
颈部的 “异常坚持”
生活中,有些人的颈部会突然变得 “异常坚持”—— 头部不受控制地偏向一侧,或是不自主地旋转、后仰,仿佛被无形的力量牵引着。这种情况不仅影响外观,还会带来强烈的不适感,颈部肌肉紧绷、酸痛,像被一根绳索…...

Ubuntu22.04安装MinkowskiEngine
MinkowskiEngine简介 Minkowski引擎是一个用于稀疏张量的自动微分库。它支持所有标准神经网络层,例如对稀疏张量的卷积、池化和广播操作。 MinkowskiEngine安装 官方源码链接:GitHub - NVIDIA/MinkowskiEngine: Minkowski Engine is an auto-diff neu…...

【计算机网络】第2章:应用层—应用层协议原理
目录 1. 网络应用的体系结构 2. 客户-服务器(C/S)体系结构 3. 对等体(P2P)体系结构 4. C/S 和 P2P 体系结构的混合体 Napster 即时通信 5. 进程通信 6. 分布式进程通信需要解决的问题 7. 问题1:对进程进行编址…...
【Zephyr 系列 6】使用 Zephyr + BLE 打造蓝牙广播与连接系统(STEVAL-IDB011V1 实战)
🧠关键词:Zephyr、BLE、广播、连接、GATT、低功耗蓝牙、STEVAL-IDB011V1 📌适合人群:希望基于 Zephyr 实现 BLE 通信的嵌入式工程师、蓝牙产品开发人员 🧭 前言:为什么选择 Zephyr 开发 BLE? 在传统 BLE 开发中,我们大多依赖于厂商 SDK(如 Nordic SDK、BlueNRG SD…...