NLP学习路线图(十八):Word2Vec (CBOW Skip-gram)
自然语言处理(NLP)的核心挑战在于让机器“理解”人类语言。传统方法依赖独热编码(One-hot Encoding) 表示单词,但它存在严重缺陷:每个单词被视为孤立的符号,无法捕捉词义关联(如“国王”与“王后”的关系),且维度灾难使计算效率低下。
词向量(Word Embedding) 革命性地解决了这些问题。它将单词映射为稠密、低维的实数向量(如50-300维),其核心思想是:具有相似上下文(Context)的单词,其向量表示在向量空间中也应彼此接近。Word2Vec正是实现这一思想的里程碑式模型。
一、Word2Vec:分布式表示的引擎
Word2Vec由Tomas Mikolov等人于2013年在谷歌提出,包含两种高效架构:
-
CBOW(Continuous Bag-of-Words):通过上下文预测中心词
-
Skip-gram:通过中心词预测上下文
两者共享核心目标:优化词向量,使模型能根据上下文/中心词准确预测目标词的概率。
🔍 核心概念:分布式假设
“一个词的意义由其周围经常出现的词所决定。” —— J.R. Firth
Word2Vec完美实践了这一假设。例如:
句子:“猫在沙发上睡觉”
上下文窗口(size=2): [“在”, “沙发”, “上”, “睡觉”] → 中心词“猫”模型通过上下文学习“猫”的向量表示。
二、CBOW模型详解:上下文预测中心词
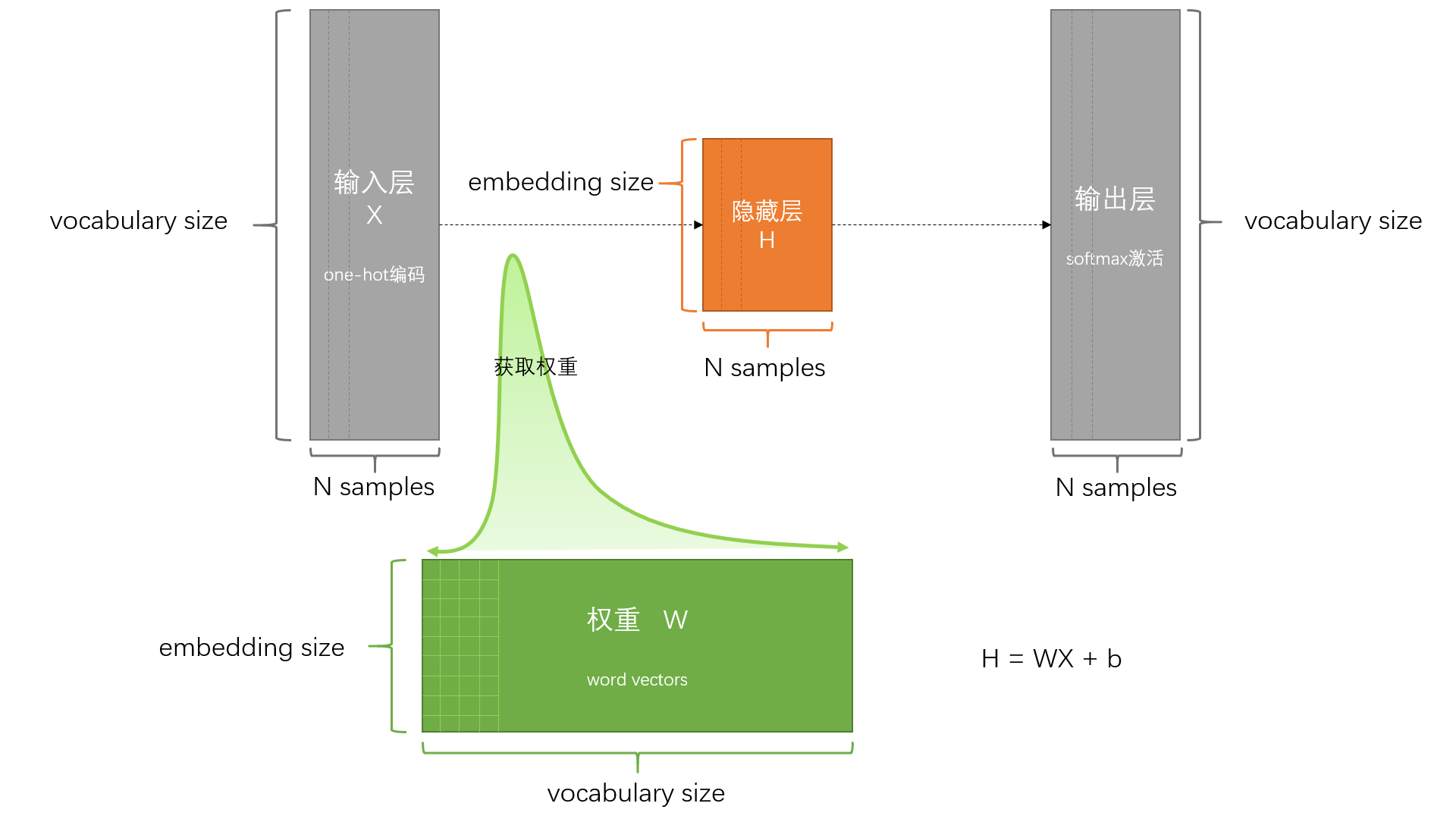
1. 模型架构
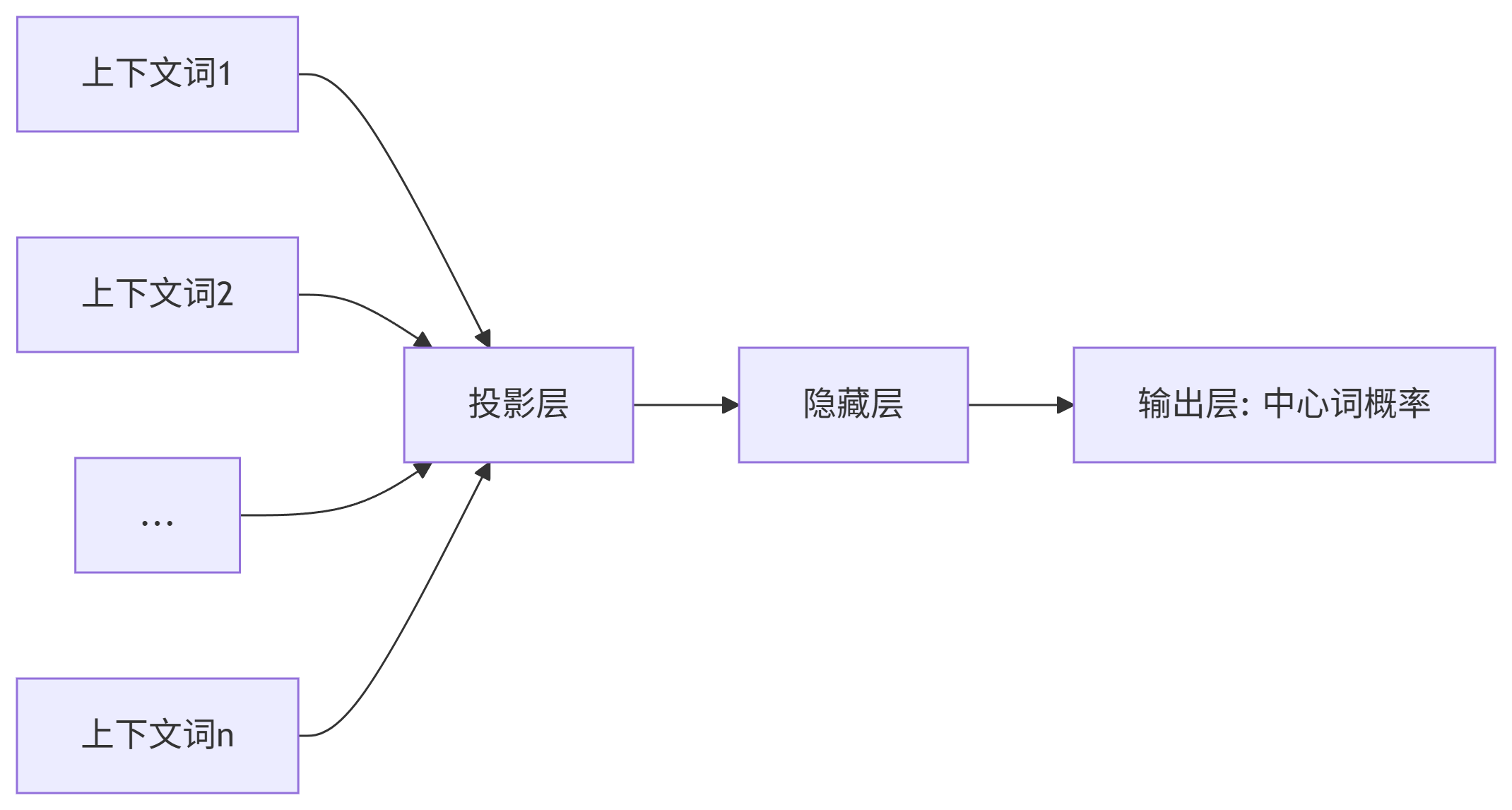
-
输入层:上下文窗口内所有单词的独热向量(
1×V,V=词汇表大小) -
投影层:上下文词向量求平均(或求和),形成固定长度向量
-
隐藏层:无激活函数的全连接层(本质是词向量查找)
-
输出层:Softmax计算中心词概率分布
2. 数学过程
设上下文词为 c₁, c₂, ..., cₘ,中心词为 w:
-
输入:
one_hot(c₁), ..., one_hot(cₘ) -
查词向量:
v_{c₁} = W_input · one_hot(c₁)(W_input为输入矩阵) -
计算上下文平均向量:
h = (v_{c₁} + ... + v_{cₘ}) / m -
预测中心词概率:
P(w|context) = softmax(W_output · h)
(W_output为输出矩阵)
3. 损失函数:交叉熵
Loss = -log(P(w_true | context))通过反向传播更新 W_input 和 W_output。
✅ 优点:
-
对小规模数据更鲁棒
-
训练速度快(尤其高频词)
-
对中心词预测更平滑
❌ 缺点:
-
上下文词平等对待(忽略位置信息)
-
对低频词学习效果较差
三、Skip-gram模型详解:中心词预测上下文
1. 模型架构
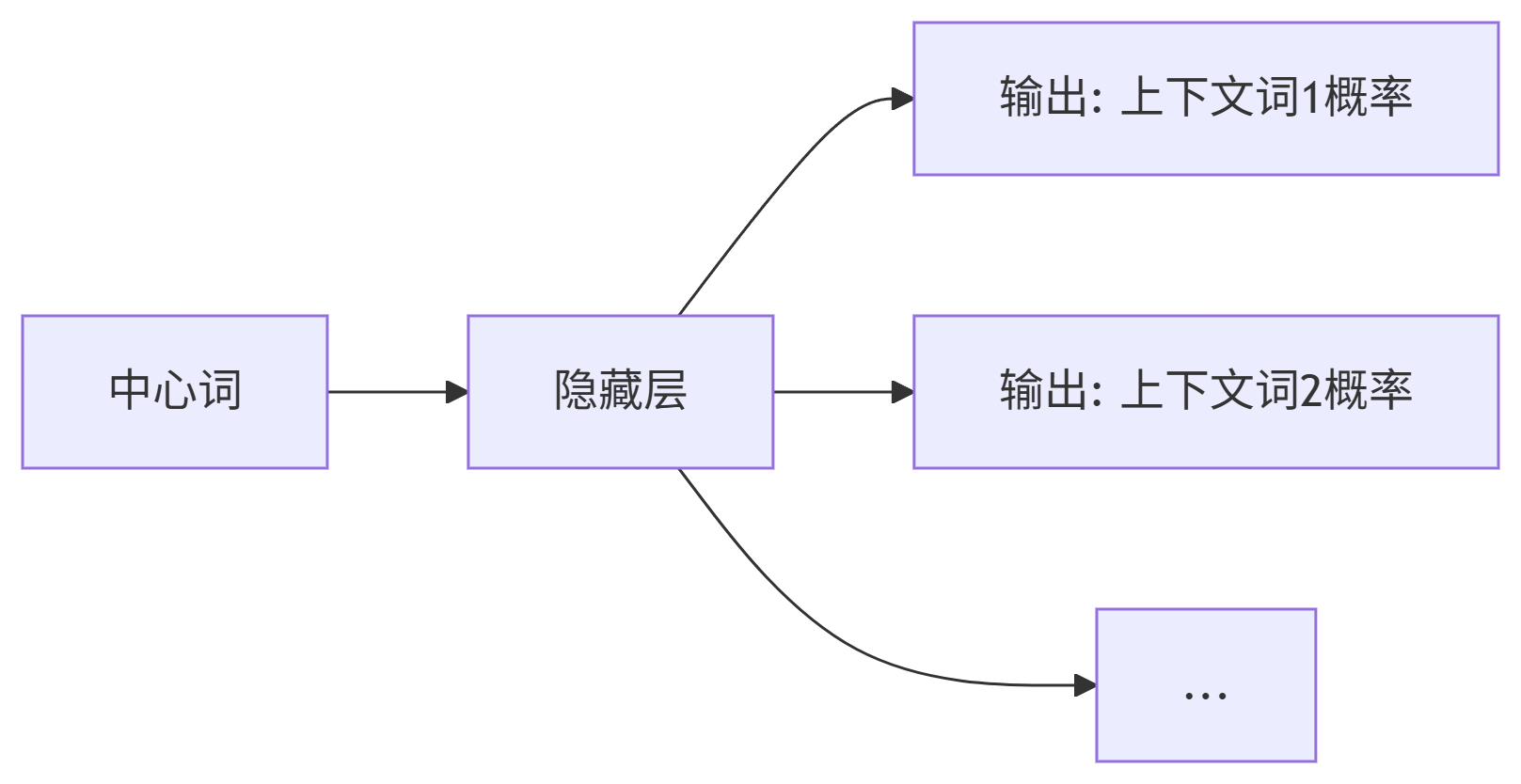
-
输入层:中心词的独热向量
-
隐藏层:直接映射为中心词向量
-
输出层:为每个上下文位置独立预测概率
2. 数学过程
设中心词为 w,上下文词为 c₁, c₂, ..., cₘ:
-
输入:
one_hot(w) -
查中心词向量:
v_w = W_input · one_hot(w) -
对每个上下文位置
j:
P(c_j | w) = softmax(W_output · v_w) -
目标:最大化所有上下文词的概率乘积
3. 损失函数:负对数似然
Loss = -Σ log(P(c_j | w)) (j=1 to m)✅ 优点:
-
在大型语料库上表现优异
-
能有效学习低频词表示
-
生成高质量的词向量(尤其在复杂任务中)
❌ 缺点:
-
训练速度较慢(需预测多个目标)
-
小数据集易过拟合
四、关键技术:优化训练效率
原始Softmax计算成本高昂(O(V)复杂度)。Word2Vec采用两种加速技术:
1. 层次Softmax(Hierarchical Softmax)
-
使用哈夫曼树(Huffman Tree) 组织词汇表(高频词路径短)
-
将V分类问题转化为约
log₂(V)次二分类 -
每个节点有参数向量,概率计算沿路径进行:
P(word=w | context) = ∏ P(branch_decision at node)
2. 负采样(Negative Sampling)
-
核心思想:仅更新少数权重
-
对每个正样本(中心词, 真实上下文词),随机采样K个负样本(中心词, 非上下文词)
-
优化目标变为:
Loss = -log(σ(u_o^T · v_c)) - Σ_{k=1}^K log(σ(-u_k^T · v_c)) -
其中:
-
σ为sigmoid函数 -
u_o是正样本词向量 -
u_k是负样本词向量
-
-
K通常取5~20,大幅减少计算量
⚡ 经验:Skip-gram + 负采样是最常用组合,在语义任务中表现最佳。
五、Word2Vec特性与局限
✨ 核心特性:
-
语义相似性:相似词向量距离小
cosine(v("国王"), v("王后")) ≈ 0.8 -
线性关系:词类比任务表现惊艳
v("国王") - v("男人") + v("女人") ≈ v("王后") -
上下文依赖:一词多义有不同向量(需结合上下文扩展)
⚠️ 重要局限:
-
静态表示:每个词仅一个向量,无法处理一词多义
(如“苹果”在公司和水果语境中含义不同) -
未考虑全局统计:仅依赖局部窗口,忽略文档级共现
-
未建模词序:CBOW/Skip-gram均忽略词位置信息
-
OOV问题:无法处理未登录词
六、实战:训练与评估
🛠️ 训练步骤(Python示例):
from gensim.models import Word2Vecsentences = [["猫", "坐", "在", "沙发"], ...] # 分词后的语料# 训练Skip-gram模型
model = Word2Vec(sentences,vector_size=100, # 向量维度window=5, # 上下文窗口sg=1, # 1=Skip-gram; 0=CBOWnegative=5, # 负采样数min_count=5, # 忽略低频词workers=4 # 并行线程
)# 保存与加载
model.save("word2vec.model")
model = Word2Vec.load("word2vec.model")# 应用示例
print(model.wv.most_similar("人工智能", topn=5))
# 输出: [('机器学习', 0.88), ('深度学习', 0.85), ...]result = model.wv.evaluate_word_analogies("analogy-questions.txt")
print("词类比准确率:", result["correct"] / result["total"])📊 评估方法:
-
内部任务:
-
词相似度(如计算与人类判断的相关性)
-
词类比(如
man:woman :: king:?)
-
-
下游任务:
-
文本分类(作为特征输入)
-
命名实体识别(增强上下文表示)
-
情感分析(捕捉情感语义)
-
研究显示:在词类比任务中,Skip-gram比CBOW平均高5-10%准确率。
七、超越Word2Vec:现代嵌入技术
尽管Word2Vec影响深远,后续技术已解决其关键短板:
-
FastText:引入子词(subword)信息,能生成未登录词向量
向量("深度学习") ≈ 向量("深") + 向量("度") + 向量("学习") -
GloVe:结合全局统计与局部窗口,优化共现矩阵分解
-
上下文嵌入(ELMo/BERT):动态生成词向量,解决一词多义
BERT("苹果股价") vs BERT("吃苹果")→ 不同向量表示 -
大规模预训练模型(GPT, T5):基于Transformer架构,生成任务感知嵌入
八、总结:为什么Word2Vec仍是基石?
Word2Vec的成功在于其简洁性与高效性的完美平衡:
-
首次证明浅层神经网络可学习高质量语义表示
-
负采样/层次Softmax 大幅提升训练效率
-
开创了词类比评估范式,直观展示语义关系
-
启发了后续嵌入技术的爆炸性发展
相关文章:
NLP学习路线图(十八):Word2Vec (CBOW Skip-gram)
自然语言处理(NLP)的核心挑战在于让机器“理解”人类语言。传统方法依赖独热编码(One-hot Encoding) 表示单词,但它存在严重缺陷:每个单词被视为孤立的符号,无法捕捉词义关联(如“国…...

P1438 无聊的数列/P1253 扶苏的问题
因为这两天在写线性代数的作业,没怎么写题…… P1438 无聊的数列 题目背景 无聊的 YYB 总喜欢搞出一些正常人无法搞出的东西。有一天,无聊的 YYB 想出了一道无聊的题:无聊的数列。。。 题目描述 维护一个数列 ai,支持两种操…...
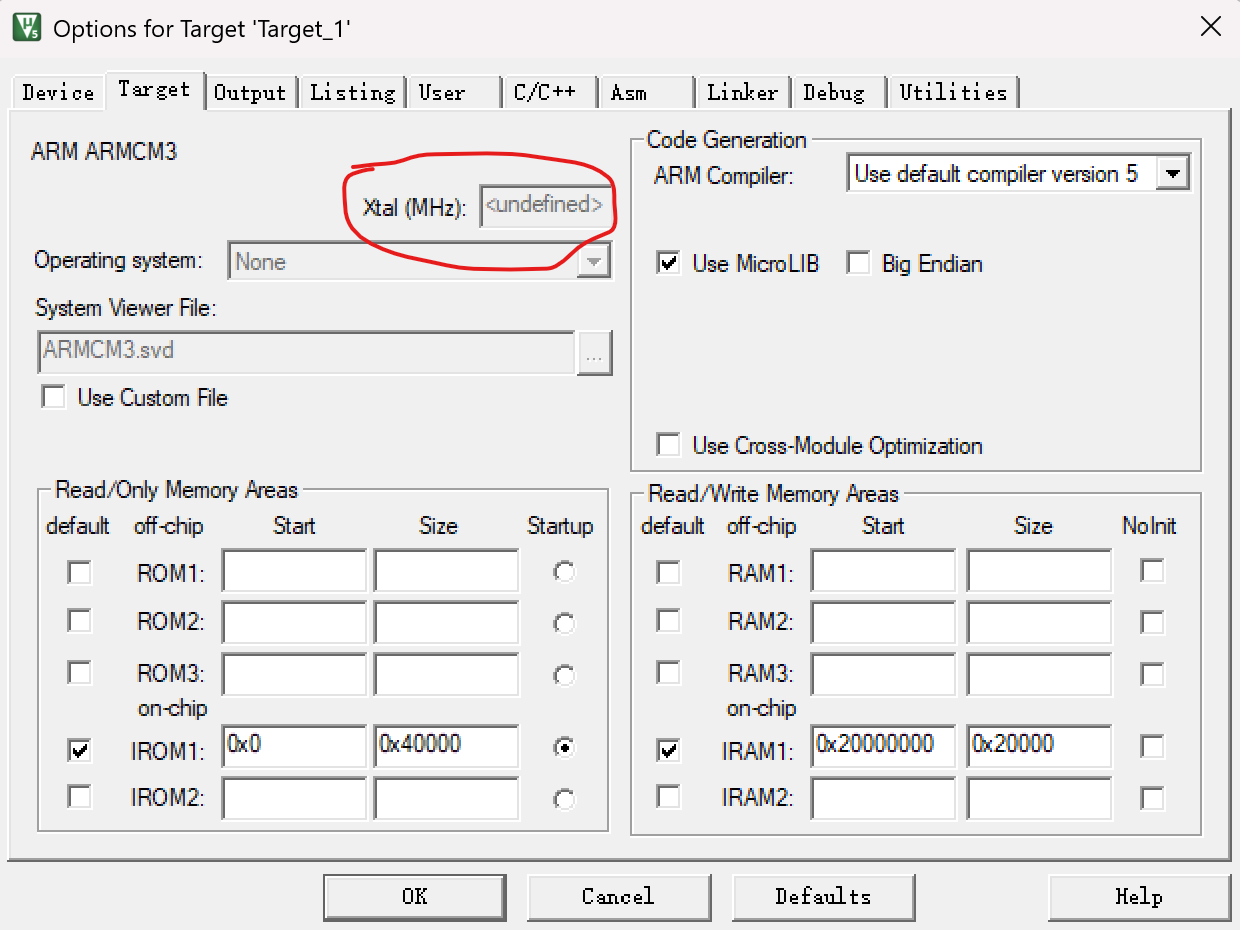
嵌入式学习笔记 - 新版Keil软件模拟时钟Xtal灰色不可更改的问题
在新版Keil软件中,模拟时钟无法修改XTAL频率,默认只能使用12MHz时钟。这是因为Keil MDK从5.36版本开始,参数配置界面不再支持修改系统XTAL频率,XTAL选项变为灰色,无法修改。这会导致在软件仿真时出现时间错误的问题&…...

k8s的出现解决了java并发编程胡问题了
Kubernetes(K8s)作为一种开源的容器编排平台,极大地简化了应用程序的部署、管理和扩展。这不仅解决了很多基础设施方面的问题,也间接解决了Java并发编程中的一些复杂问题。本文将详细探讨Kubernetes是如何帮助解决Java并发编程中的…...

如何利用大语言模型生成特定格式文风的报告类文章
在这个算法渗透万物的时代,我们不再仅仅满足于大语言模型(LLM)能“写”,更追求它能“写出精髓,写出风格”。尤其在专业且高度格式化的报告类文章领域,仅仅是内容正确已远远不够,文风的精准复刻才是决定报告是否“对味儿”、能否被目标受众有效接受的关键。这不再是简单的…...

黑马Java面试笔记之 集合篇(算法复杂度+ArrayList+)
一. 算法复杂度分析 1.1 时间复杂度 时间复杂度分析:来评估代码的执行耗时的 常见的复杂度表示形式 常见复杂度 1.2 空间复杂度 空间复杂度全称是渐进空间复杂度,表示算法占用的额外存储空间与数据规模之间的增长关系 二. 数组 数组(Array&a…...

【从0-1的HTML】第2篇:HTML标签
文章目录 1.标题标签2.段落标签3.文本标签brbstrongsubsup 4.超链接标签5.图片标签6.表格标签7.列表标签有序列表ol无序列表ul定义列表dl 8.表单标签9.音频标签10.视频标签11.HTML元素分类块级元素内联元素 12.HTML布局13.内联框架13.内联框架 1.标题标签 标题标签:…...

从“Bucharest”谈起:词语翻译的音译与意译之路
在翻译中,面对地名、人名或新兴术语时,我们常常会遇到一个抉择:到底是“音译”,保留其原发音风貌,还是“意译”,让它意义通达? 今天我们以“Bucharest”为例,展开一次语言与文化的微…...

Nginx+Tomcat负载均衡
目录 Tomcat简介 Tomcat 的核心功能 Tomcat架构 Tomcat 的特点 Tomact配置 关闭防火墙及系统内核 Tomcar 主要文件信息 配置文件说明 案例一:Java的Web站点 案例二:NginxTomcat负载均衡、动静分离 Tomcat简介 Tomcat 是由 Apache 软件基金会&am…...

JVM——JVM中的字节码:解码Java跨平台的核心引擎
引入 在Java的技术版图中,字节码(Bytecode)是连接源代码与机器世界的黄金桥梁。当开发者写下第一行public class HelloWorld时,编译器便开始了一场精密的翻译工程——将人类可读的Java代码转化为JVM能够理解的字节码指令。这些由…...

【论文解读】ReAct:从思考脱离行动, 到行动反馈思考
认识从实践开始,经过实践得到了理论的认识,还须再回到实践去。 ——《实践论》,毛泽东 1st author: About – Shunyu Yao – 姚顺雨 paper [2210.03629] ReAct: Synergizing Reasoning and Acting in Language ModelsReAct: Synergizing Reasoning and…...
)
数据解析:一文掌握Python库 lxml 的详细使用(处理XML和HTML的高性能库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、lxml 概述1.1 lxml 介绍1.2 安装和第一个案例1.3 性能优化技巧二、XML处理2.1 解析XML2.2 访问元素2.3 遍历XML树2.4 修改XML2.5 写入XML三、HTML处理3.1 解析HTML3.2 XPath查询3.3 CSS选择器四、高级功能4.1 使用命…...

react native webview加载本地HTML,解决iOS无法加载成功问题
在react native中使用 “react-native-webview”: “^13.13.5”,加载HTML文件 Android: 将HTML文件放置到android/src/main/assets目录,访问 {uri: file:///android_asset/markmap/index.html}ios: 在IOS中可以直接可以直接放在react native项目下,访问…...
简单配置RHEL9.X
切换默认运行级别 将系统默认启动模式从多用户的图形界面调整为多用户的文本界面,适用于优化系统资源占用或进行远程服务器管理的场景。 注意:安装选择“带GUI的服务器”部分常用命令默认安装;如果选择“最小安装”时,部分常用命…...
)
默认网关 -- 负责转发数据包到其他网络的设备(通常是路由器)
✅ 默认网关概括说明: 默认网关(Default Gateway)是网络中一台负责转发数据包到其他网络的设备(通常是路由器)。当一台主机要访问不在本地子网内的设备时,会将数据包发给默认网关,由它继续转发…...

python调用硅基流动的视觉语言模型
参考: https://docs.siliconflow.cn/cn/userguide/capabilities/vision import base64 import json from openai import OpenAI from PIL import Image import io# 初始化OpenAI客户端 client OpenAI(api_key"sk-**********", # 替换为实际API密钥b…...
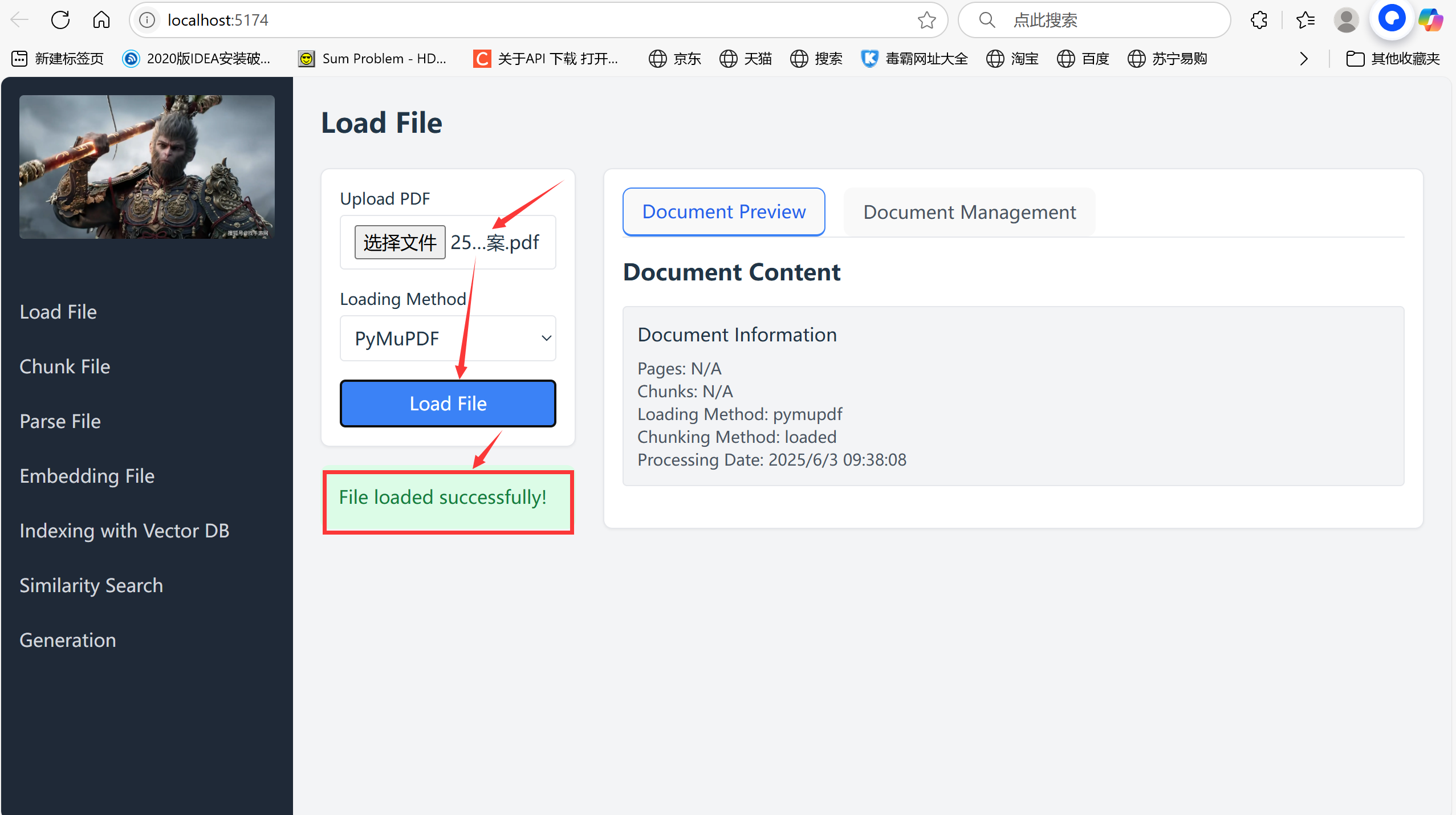
下载并运行自制RAG框架
项目部署 https://github.com/huangjia2019/rag-project01-framework git clone https://github.com/huangjia2019/rag-project01-framework.git 一 、 前端分部分部署 在 Ubuntu 系统 上安装 Node.js 和 npm(Node Package Manager),并初始…...
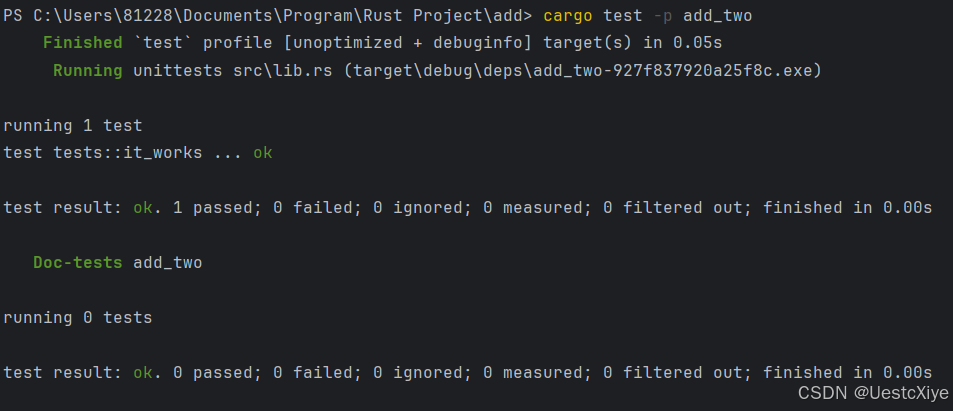
Rust 学习笔记:Cargo 工作区
Rust 学习笔记:Cargo 工作区 Rust 学习笔记:Cargo 工作区创建工作区在工作区中创建第二个包依赖于工作区中的外部包向工作区添加测试将工作区中的 crate 发布到 crates.io添加 add_two crate 到工作区总结 Rust 学习笔记:Cargo 工作区 随着项…...
颈部的 “异常坚持”
生活中,有些人的颈部会突然变得 “异常坚持”—— 头部不受控制地偏向一侧,或是不自主地旋转、后仰,仿佛被无形的力量牵引着。这种情况不仅影响外观,还会带来强烈的不适感,颈部肌肉紧绷、酸痛,像被一根绳索…...

Ubuntu22.04安装MinkowskiEngine
MinkowskiEngine简介 Minkowski引擎是一个用于稀疏张量的自动微分库。它支持所有标准神经网络层,例如对稀疏张量的卷积、池化和广播操作。 MinkowskiEngine安装 官方源码链接:GitHub - NVIDIA/MinkowskiEngine: Minkowski Engine is an auto-diff neu…...

【计算机网络】第2章:应用层—应用层协议原理
目录 1. 网络应用的体系结构 2. 客户-服务器(C/S)体系结构 3. 对等体(P2P)体系结构 4. C/S 和 P2P 体系结构的混合体 Napster 即时通信 5. 进程通信 6. 分布式进程通信需要解决的问题 7. 问题1:对进程进行编址…...
【Zephyr 系列 6】使用 Zephyr + BLE 打造蓝牙广播与连接系统(STEVAL-IDB011V1 实战)
🧠关键词:Zephyr、BLE、广播、连接、GATT、低功耗蓝牙、STEVAL-IDB011V1 📌适合人群:希望基于 Zephyr 实现 BLE 通信的嵌入式工程师、蓝牙产品开发人员 🧭 前言:为什么选择 Zephyr 开发 BLE? 在传统 BLE 开发中,我们大多依赖于厂商 SDK(如 Nordic SDK、BlueNRG SD…...
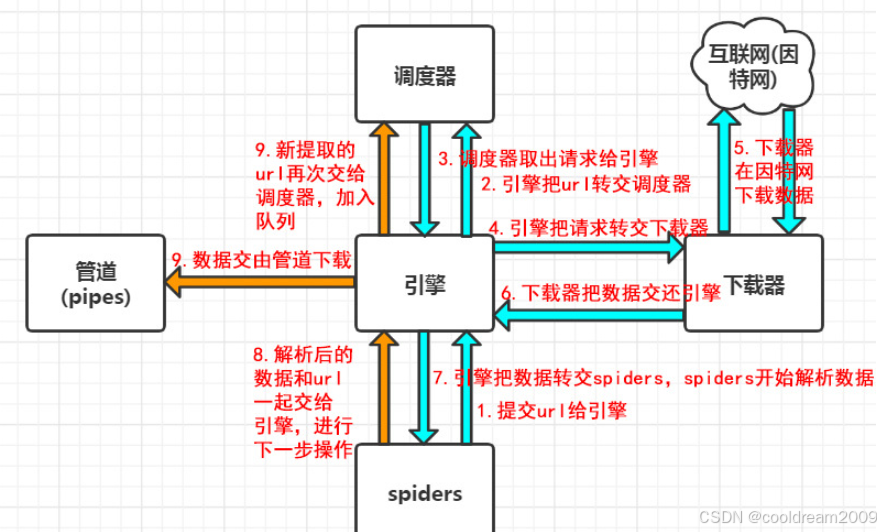
利用 Scrapy 构建高效网页爬虫:框架解析与实战流程
目录 前言1 Scrapy 框架概述1.1 Scrapy 的核心优势1.2 Scrapy 的典型应用场景 2 Scrapy 工作原理解析2.1 框架结构图2.2 Spider:定义数据采集策略2.3 Scheduler:调度请求与去重2.4 Downloader:网页下载器2.5 Item:结构化数据容器2…...
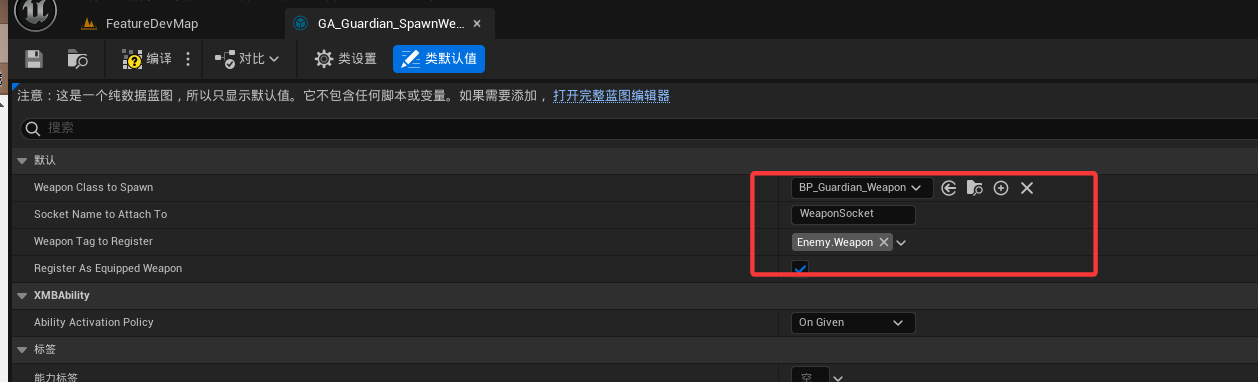
RPG20.创建敌人的初始能力和加载武器
1. 基于StartUpAbilitiy基类创建专门用于敌人数据的DAStartUpABility,然后再基于新创建的DA再创建一个蓝图 2.打开 DataAsset_EnemyStartUpData.h // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "Cor…...

P5684 [CSP-J2019 江西] 非回文串 题解
https://www.luogu.com.cn/problem/P5684 /* 比较简单的组合计数 题目没有以文字去描述,而是用下标来形式化题意,给我们一个关键信息:判定两个串是否相同不是看字符是否相同,而是看下标 换言之就是相同的字符,如果下标…...
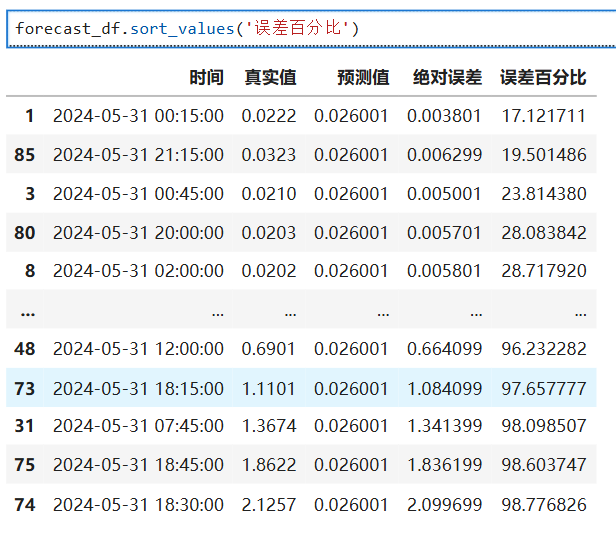
自适应移动平均(Adaptive Moving Average, AMA)
文章目录 1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现2. 对 (KAMA)算法参数进行优化及实现 自适应移动平均(Adaptive Moving Average, AMA)由Perry Kaufman在其著作《Trading Systems and Methods》中提出,它通过动态调整平滑系数来…...

Java密码加密存储算法,SpringBoot 实现密码安全存储
文章目录 一、写在前面二、密码加密存储方式1、基于MD5加盐方式2、SHA-256 Salt(不需要第三方依赖包)3、使用 BCrypt 进行哈希4、使用 PBKDF2 进行哈希5、使用 Argon2 进行哈希6、SCrypt 一、写在前面 日常开发中,用户密码存储是严禁明文存…...
)
使用 Version Catalogs统一配置版本 (Gradle 7.0+ 特性)
1.在 gradle/libs.versions.toml 文件中定义: [versions] compileSdk "34" minSdk "21" targetSdk "34" 2. 在 build.gradle 中使用: android {compileSdkVersion libs.versions.compileSdk.get().toInteger()defaul…...

涨薪技术|0到1学会性能测试第95课-全链路脚本开发实例
至此关于系统资源监控、apache监控调优、Tomcat监控调优、JVM调优、Mysql调优、前端监控调优、接口性能监控调优的知识已分享完,今天学习全链路脚本开发知识。后续文章都会系统分享干货,带大家从0到1学会性能测试。 前面章节介绍了如何封装.h头文件,现在通过一个实例来介绍…...

C++文件和流基础
C文件和流基础 1. C文件和流基础1.1 文件和流的概念1.2 标准库支持1.3 常用文件流类ifstream 类ofstream 类fstream 类 2.1 打开文件使用构造函数打开文件使用 open() 成员函数打开文件打开文件的模式标志 2.2 关闭文件使用 close() 成员函数关闭文件关闭文件的重要性 3.1 写入…...