高性能MCU的MPU与Cache优化详解
概述
在现代高性能单片机(如ARM Cortex-M7、Cortex-A系列在MCU中的应用)中,Memory Protection Unit (MPU) 和Cache系统的协同工作对系统性能有着决定性影响。本文将深入分析MPU配置如何影响Cache命中率,多主设备对RAM访问的竞争问题,以及Cache一致性维护策略。
高性能MCU的存储子系统架构
典型的多主设备架构
现代高性能MCU通常具有复杂的总线架构,支持多个主设备同时访问存储器:
STM32H7系列存储器映射
以STM32H7为例的详细存储器布局:
// STM32H7存储器映射定义
#define ITCM_BASE 0x00000000UL // 指令TCM,64KB
#define FLASH_BASE 0x08000000UL // Flash存储器,2MB
#define DTCM_BASE 0x20000000UL // 数据TCM,128KB
#define SRAM1_BASE 0x20020000UL // SRAM1,128KB
#define SRAM2_BASE 0x20040000UL // SRAM2,128KB
#define SRAM3_BASE 0x20060000UL // SRAM3,32KB
#define SRAM4_BASE 0x38000000UL // SRAM4,64KB
#define BACKUP_SRAM_BASE 0x38800000UL // 备份SRAM,4KB
#define SDRAM_BASE 0xC0000000UL // 外部SDRAM// 各存储器的访问特性
typedef struct {uint32_t base_addr;uint32_t size;uint8_t wait_states; // 等待周期uint8_t cache_policy; // 缓存策略uint8_t shareable; // 是否可共享uint8_t dma_coherent; // DMA一致性
} memory_region_info_t;static const memory_region_info_t memory_map[] = {{ITCM_BASE, 64*1024, 0, CACHE_WRITEBACK, 0, 1}, // ITCM - 零等待{DTCM_BASE, 128*1024, 0, CACHE_WRITEBACK, 0, 1}, // DTCM - 零等待{SRAM1_BASE, 128*1024, 1, CACHE_WRITEBACK, 1, 1}, // SRAM1 - 1等待周期{SRAM2_BASE, 128*1024, 1, CACHE_WRITEBACK, 1, 1}, // SRAM2 - 1等待周期{SRAM3_BASE, 32*1024, 1, CACHE_WRITEBACK, 1, 1}, // SRAM3 - 1等待周期{SRAM4_BASE, 64*1024, 2, CACHE_WRITETHROUGH, 1, 1}, // SRAM4 - 2等待周期{SDRAM_BASE, 32*1024*1024, 4, CACHE_WRITETHROUGH, 1, 1}, // SDRAM - 4等待周期
};
MPU配置对Cache性能的深度影响
1. 缓存策略的性能对比
不同的MPU缓存策略对性能有显著影响:
// 缓存策略性能测试
typedef enum {TEST_POLICY_NOCACHE = 0, // 不缓存TEST_POLICY_WRITETHROUGH, // 写通TEST_POLICY_WRITEBACK, // 写回TEST_POLICY_WRITE_ALLOCATE // 写分配
} cache_test_policy_t;// 性能测试结果结构
typedef struct {uint32_t read_cycles;uint32_t write_cycles;uint32_t cache_hits;uint32_t cache_misses;float hit_ratio;
} performance_result_t;// 配置MPU区域的详细函数
void configure_mpu_detailed(uint8_t region, uint32_t base_addr, uint32_t size_code,uint8_t cache_policy, uint8_t access_perm) {// 禁用MPU进行配置MPU->CTRL = 0;__DSB();__ISB();// 选择区域MPU->RNR = region;// 设置基地址和有效位MPU->RBAR = base_addr | MPU_RBAR_VALID_Msk | region;// 构造RASR寄存器值uint32_t rasr = 0;rasr |= MPU_RASR_ENABLE_Msk; // 启用区域rasr |= (size_code << MPU_RASR_SIZE_Pos); // 区域大小rasr |= (access_perm << MPU_RASR_AP_Pos); // 访问权限// 根据缓存策略设置TEX、C、B位switch (cache_policy) {case TEST_POLICY_NOCACHE:// TEX=001, C=0, B=0 - 共享设备rasr |= (1 << MPU_RASR_TEX_Pos);rasr |= MPU_RASR_S_Msk; // 共享break;case TEST_POLICY_WRITETHROUGH:// TEX=000, C=1, B=0 - 正常内存,写通,无写分配rasr |= MPU_RASR_C_Msk;break;case TEST_POLICY_WRITEBACK:// TEX=001, C=1, B=1 - 正常内存,写回,写分配rasr |= (1 << MPU_RASR_TEX_Pos);rasr |= MPU_RASR_C_Msk | MPU_RASR_B_Msk;break;case TEST_POLICY_WRITE_ALLOCATE:// TEX=001, C=1, B=1 - 正常内存,写回,读写分配rasr |= (1 << MPU_RASR_TEX_Pos);rasr |= MPU_RASR_C_Msk | MPU_RASR_B_Msk;break;}MPU->RASR = rasr;// 启用MPUMPU->CTRL = MPU_CTRL_ENABLE_Msk | MPU_CTRL_PRIVDEFENA_Msk;__DSB();__ISB();
}// 综合性能测试
performance_result_t test_cache_performance(void *test_buffer, size_t buffer_size,cache_test_policy_t policy) {performance_result_t result = {0};// 配置测试区域的MPUuint32_t region_size_code = 0;size_t size = buffer_size;while (size > 1) {size >>= 1;region_size_code++;}region_size_code--; // MPU size encodingconfigure_mpu_detailed(7, (uint32_t)test_buffer, region_size_code, policy, MPU_REGION_FULL_ACCESS);// 清空Cache统计reset_cache_counters();// 读取性能测试uint32_t start_cycles = DWT->CYCCNT;volatile uint32_t *buffer = (volatile uint32_t*)test_buffer;for (int i = 0; i < buffer_size/4; i++) {volatile uint32_t data = buffer[i]; // 防止编译器优化(void)data;}result.read_cycles = DWT->CYCCNT - start_cycles;// 写入性能测试start_cycles = DWT->CYCCNT;for (int i = 0; i < buffer_size/4; i++) {buffer[i] = 0x12345678 + i;}result.write_cycles = DWT->CYCCNT - start_cycles;// 获取Cache统计get_cache_statistics(&result.cache_hits, &result.cache_misses);result.hit_ratio = (float)result.cache_hits / (result.cache_hits + result.cache_misses) * 100.0f;return result;
}
2. Cache行为分析与优化
// Cache行为分析工具
typedef struct {uint32_t line_size; // Cache行大小uint32_t associativity; // 组相联度uint32_t total_size; // 总Cache大小uint32_t sets; // 组数
} cache_info_t;// 获取Cache信息(ARM Cortex-M7)
cache_info_t get_cache_info(void) {cache_info_t info = {0};// 读取Cache类型寄存器uint32_t ctr = __get_CTR();// L1数据Cache信息uint32_t dminline = (ctr >> 16) & 0xF;info.line_size = 4 << dminline; // Cache行大小// 对于Cortex-M7,通常是4KB,4路组相联,32字节行info.total_size = 4096;info.associativity = 4;info.sets = info.total_size / (info.associativity * info.line_size);return info;
}// Cache友好的数据结构设计
#define CACHE_LINE_SIZE 32// 避免伪共享的结构设计
typedef struct {// 频繁访问的数据放在一起uint32_t hot_data[7]; // 28字节uint8_t flag; // 1字节uint8_t padding[3]; // 填充到32字节边界
} __attribute__((aligned(CACHE_LINE_SIZE))) cache_optimized_struct_t;// 多线程/多DMA场景下避免伪共享
typedef struct {volatile uint32_t cpu_counter;uint8_t cpu_padding[CACHE_LINE_SIZE - sizeof(uint32_t)];volatile uint32_t dma_counter;uint8_t dma_padding[CACHE_LINE_SIZE - sizeof(uint32_t)];
} __attribute__((aligned(CACHE_LINE_SIZE))) separated_counters_t;// Cache预热和数据预取
void cache_warmup_and_prefetch(void *data, size_t size) {cache_info_t info = get_cache_info();volatile uint8_t *ptr = (uint8_t*)data;// 按Cache行进行预热for (size_t i = 0; i < size; i += info.line_size) {// 读取每个Cache行的第一个字节volatile uint8_t dummy = ptr[i];(void)dummy;// 使用ARM的预取指令(如果支持)#ifdef __ARM_FEATURE_UNALIGNED__PLD(ptr + i + info.line_size); // 预取下一个Cache行#endif}
}
多主设备RAM访问冲突与优化
1. 总线仲裁和优先级配置
// STM32H7总线矩阵配置
typedef enum {BUS_MASTER_CPU = 0,BUS_MASTER_DMA1,BUS_MASTER_DMA2,BUS_MASTER_MDMA,BUS_MASTER_ETH,BUS_MASTER_USB,BUS_MASTER_GPU,BUS_MASTER_COUNT
} bus_master_t;typedef struct {uint8_t priority; // 0-15, 15最高优先级uint8_t round_robin; // 是否启用轮询uint8_t fixed_priority; // 固定优先级模式
} bus_arbitration_config_t;// 配置总线仲裁优先级
void configure_bus_arbitration(void) {// 配置AHB总线矩阵寄存器 (具体地址依芯片而定)// 以下为概念性代码,实际地址需查阅参考手册// CPU获得最高优先级用于实时任务*((volatile uint32_t*)0x52005400) = 0x0F; // CPU master priority// DMA获得中等优先级*((volatile uint32_t*)0x52005404) = 0x08; // DMA1 priority*((volatile uint32_t*)0x52005408) = 0x08; // DMA2 priority// 大容量传输设备获得较低优先级*((volatile uint32_t*)0x5200540C) = 0x04; // ETH priority*((volatile uint32_t*)0x52005410) = 0x04; // USB priority// 启用轮询仲裁减少饥饿*((volatile uint32_t*)0x52005420) = 0x01; // Round-robin enable
}// 内存带宽监控
typedef struct {uint32_t cpu_accesses;uint32_t dma_accesses;uint32_t conflicts;uint32_t wait_cycles;float bandwidth_utilization;
} memory_bandwidth_stats_t;memory_bandwidth_stats_t monitor_memory_bandwidth(uint32_t duration_ms) {memory_bandwidth_stats_t stats = {0};// 启用性能计数器enable_bus_performance_counters();uint32_t start_time = HAL_GetTick();uint32_t start_cycles = DWT->CYCCNT;// 重置计数器reset_bus_counters();// 监控期间while (HAL_GetTick() - start_time < duration_ms) {// 继续正常操作}uint32_t total_cycles = DWT->CYCCNT - start_cycles;// 读取性能计数器stats.cpu_accesses = read_cpu_access_counter();stats.dma_accesses = read_dma_access_counter();stats.conflicts = read_conflict_counter();stats.wait_cycles = read_wait_cycle_counter();// 计算带宽利用率uint32_t total_accesses = stats.cpu_accesses + stats.dma_accesses;stats.bandwidth_utilization = (float)total_accesses / total_cycles * 100.0f;return stats;
}
2. DMA与CPU的Cache一致性管理
// DMA操作的Cache管理策略
typedef enum {DMA_CACHE_NONE = 0, // 无Cache操作DMA_CACHE_CLEAN, // 清理CacheDMA_CACHE_INVALIDATE, // 使Cache无效DMA_CACHE_CLEAN_INVALIDATE // 清理并使无效
} dma_cache_operation_t;// DMA传输前的Cache管理
void dma_transfer_prepare(void *buffer, size_t size, DMA_HandleTypeDef *hdma, dma_cache_operation_t cache_op) {// 确保地址Cache行对齐uint32_t addr = (uint32_t)buffer;uint32_t aligned_addr = addr & ~(CACHE_LINE_SIZE - 1);uint32_t aligned_size = ((addr + size + CACHE_LINE_SIZE - 1) & ~(CACHE_LINE_SIZE - 1)) - aligned_addr;// 根据传输方向执行Cache操作switch (cache_op) {case DMA_CACHE_CLEAN:// DMA从内存读取数据前,清理CPU Cache到内存SCB_CleanDCache_by_Addr((uint32_t*)aligned_addr, aligned_size);break;case DMA_CACHE_INVALIDATE:// DMA向内存写入数据前,使CPU Cache无效SCB_InvalidateDCache_by_Addr((uint32_t*)aligned_addr, aligned_size);break;case DMA_CACHE_CLEAN_INVALIDATE:// 双向传输,先清理再无效SCB_CleanInvalidateDCache_by_Addr((uint32_t*)aligned_addr, aligned_size);break;default:break;}// 确保操作完成__DSB();__ISB();
}// DMA传输完成后的Cache管理
void dma_transfer_complete(void *buffer, size_t size, DMA_HandleTypeDef *hdma,dma_cache_operation_t cache_op) {uint32_t addr = (uint32_t)buffer;uint32_t aligned_addr = addr & ~(CACHE_LINE_SIZE - 1);uint32_t aligned_size = ((addr + size + CACHE_LINE_SIZE - 1) & ~(CACHE_LINE_SIZE - 1)) - aligned_addr;// DMA写入完成后,使相关Cache无效if (cache_op == DMA_CACHE_INVALIDATE || cache_op == DMA_CACHE_CLEAN_INVALIDATE) {SCB_InvalidateDCache_by_Addr((uint32_t*)aligned_addr, aligned_size);}__DSB();__ISB();
}// 高性能DMA配置示例
void configure_high_performance_dma(DMA_HandleTypeDef *hdma) {// DMA优先级设置hdma->Init.Priority = DMA_PRIORITY_VERY_HIGH;// 使用双缓冲模式减少Cache冲突hdma->Init.Mode = DMA_DOUBLE_BUFFER_MODE;// 配置突发传输减少总线占用hdma->Init.PeriphBurst = DMA_PBURST_INC4; // 4-word bursthdma->Init.MemBurst = DMA_MBURST_INC4; // 4-word burst// FIFO模式优化传输效率hdma->Init.FIFOMode = DMA_FIFOMODE_ENABLE;hdma->Init.FIFOThreshold = DMA_FIFO_THRESHOLD_FULL;HAL_DMA_Init(hdma);
}
3. 多主设备内存分配策略
// 基于访问模式的内存分配策略
typedef enum {MEMORY_USAGE_CPU_ONLY = 0, // 仅CPU访问MEMORY_USAGE_DMA_ONLY, // 仅DMA访问MEMORY_USAGE_SHARED, // CPU和DMA共享MEMORY_USAGE_REALTIME // 实时访问
} memory_usage_pattern_t;typedef struct {void *base_addr;size_t size;memory_usage_pattern_t usage;uint8_t cache_policy;uint8_t mpu_region;
} memory_pool_t;// 定义专用内存池
static memory_pool_t memory_pools[] = {// CPU密集型数据放在DTCM,零等待周期{(void*)DTCM_BASE, 128*1024, MEMORY_USAGE_CPU_ONLY, CACHE_WRITEBACK, 0},// DMA缓冲区放在SRAM1,使用写通Cache减少一致性开销{(void*)SRAM1_BASE, 128*1024, MEMORY_USAGE_DMA_ONLY, CACHE_WRITETHROUGH, 1},// 共享数据放在SRAM2,仔细管理Cache一致性{(void*)SRAM2_BASE, 128*1024, MEMORY_USAGE_SHARED, CACHE_WRITETHROUGH, 2},// 实时数据放在SRAM3,关闭Cache确保确定性延迟{(void*)SRAM3_BASE, 32*1024, MEMORY_USAGE_REALTIME, CACHE_DISABLE, 3}
};// 智能内存分配器
void* allocate_optimized_memory(size_t size, memory_usage_pattern_t usage) {for (int i = 0; i < sizeof(memory_pools)/sizeof(memory_pools[0]); i++) {if (memory_pools[i].usage == usage && memory_pools[i].size >= size) {// 找到匹配的内存池memory_pool_t *pool = &memory_pools[i];// 配置对应的MPU区域configure_mpu_detailed(pool->mpu_region, (uint32_t)pool->base_addr,get_mpu_size_code(pool->size),pool->cache_policy,MPU_REGION_FULL_ACCESS);// 从内存池分配// 这里简化处理,实际需要实现内存池管理return pool->base_addr;}}return NULL; // 分配失败
}// Cache感知的数据搬移函数
void cache_aware_memcpy(void *dest, const void *src, size_t size) {cache_info_t cache_info = get_cache_info();// 小数据量直接复制if (size <= cache_info.line_size) {memcpy(dest, src, size);return;}// 大数据量使用Cache优化策略const uint8_t *src_ptr = (const uint8_t*)src;uint8_t *dest_ptr = (uint8_t*)dest;// 处理非对齐的开头部分uint32_t src_align = (uint32_t)src_ptr & (cache_info.line_size - 1);if (src_align != 0) {uint32_t head_size = cache_info.line_size - src_align;head_size = (head_size > size) ? size : head_size;memcpy(dest_ptr, src_ptr, head_size);src_ptr += head_size;dest_ptr += head_size;size -= head_size;}// 按Cache行处理主体部分while (size >= cache_info.line_size) {// 预取下一个Cache行__PLD(src_ptr + cache_info.line_size);// 复制当前Cache行memcpy(dest_ptr, src_ptr, cache_info.line_size);src_ptr += cache_info.line_size;dest_ptr += cache_info.line_size;size -= cache_info.line_size;}// 处理剩余部分if (size > 0) {memcpy(dest_ptr, src_ptr, size);}
}
4. 实时性能监控和调优
// 实时性能监控结构
typedef struct {uint32_t timestamp;uint32_t cpu_cycles;uint32_t memory_stalls;uint32_t cache_misses;uint32_t dma_conflicts;float cpu_utilization;float memory_bandwidth;
} performance_snapshot_t;#define PERF_HISTORY_SIZE 100
static performance_snapshot_t perf_history[PERF_HISTORY_SIZE];
static uint32_t perf_history_index = 0;// 性能快照采集
void capture_performance_snapshot(void) {performance_snapshot_t *snapshot = &perf_history[perf_history_index];snapshot->timestamp = HAL_GetTick();snapshot->cpu_cycles = DWT->CYCCNT;// 读取性能计数器(需要事先配置)snapshot->memory_stalls = read_performance_counter(PERF_CNT_MEMORY_STALL);snapshot->cache_misses = read_performance_counter(PERF_CNT_CACHE_MISS);snapshot->dma_conflicts = read_bus_conflict_counter();// 计算利用率static uint32_t last_cycles = 0;static uint32_t last_timestamp = 0;if (last_timestamp != 0) {uint32_t time_diff = snapshot->timestamp - last_timestamp;uint32_t cycle_diff = snapshot->cpu_cycles - last_cycles;// CPU利用率 = 实际执行周期 / 可用周期snapshot->cpu_utilization = (float)cycle_diff / (SystemCoreClock * time_diff / 1000) * 100.0f;}last_cycles = snapshot->cpu_cycles;last_timestamp = snapshot->timestamp;// 更新环形缓冲区索引perf_history_index = (perf_history_index + 1) % PERF_HISTORY_SIZE;
}// 性能趋势分析
typedef struct {float avg_cpu_utilization;float avg_cache_hit_ratio;uint32_t peak_memory_stalls;uint32_t total_dma_conflicts;uint8_t performance_grade; // 0-100分
} performance_analysis_t;performance_analysis_t analyze_performance_trend(void) {performance_analysis_t analysis = {0};uint32_t valid_samples = 0;// 分析最近的性能数据for (int i = 0; i < PERF_HISTORY_SIZE; i++) {performance_snapshot_t *snapshot = &perf_history[i];if (snapshot->timestamp != 0) {analysis.avg_cpu_utilization += snapshot->cpu_utilization;// Cache命中率计算uint32_t total_accesses = snapshot->cache_misses + estimate_cache_hits(snapshot);if (total_accesses > 0) {float hit_ratio = (float)(total_accesses - snapshot->cache_misses) /total_accesses * 100.0f;analysis.avg_cache_hit_ratio += hit_ratio;}// 峰值统计if (snapshot->memory_stalls > analysis.peak_memory_stalls) {analysis.peak_memory_stalls = snapshot->memory_stalls;}analysis.total_dma_conflicts += snapshot->dma_conflicts;valid_samples++;}}// 计算平均值if (valid_samples > 0) {analysis.avg_cpu_utilization /= valid_samples;analysis.avg_cache_hit_ratio /= valid_samples;}// 性能评分算法uint8_t cpu_score = (analysis.avg_cpu_utilization < 80) ? (100 - analysis.avg_cpu_utilization) : 20;uint8_t cache_score = analysis.avg_cache_hit_ratio;uint8_t stall_score = (analysis.peak_memory_stalls < 1000) ? 100 : (2000 - analysis.peak_memory_stalls) / 10;uint8_t conflict_score = (analysis.total_dma_conflicts < 100) ? 100 : (200 - analysis.total_dma_conflicts);analysis.performance_grade = (cpu_score + cache_score + stall_score + conflict_score) / 4;return analysis;
}// 自适应优化策略
void adaptive_performance_optimization(void) {performance_analysis_t analysis = analyze_performance_trend();// 根据分析结果调整系统配置if (analysis.avg_cache_hit_ratio < 85.0f) {// Cache命中率低,调整MPU配置puts("调整Cache策略以提高命中率");// 增加更多区域使用写回策略for (int i = 0; i < 4; i++) {if (memory_pools[i].cache_policy != CACHE_WRITEBACK) {configure_mpu_detailed(memory_pools[i].mpu_region,(uint32_t)memory_pools[i].base_addr,get_mpu_size_code(memory_pools[i].size),CACHE_WRITEBACK,MPU_REGION_FULL_ACCESS);}}}if (analysis.total_dma_conflicts > 50) {// DMA冲突较多,调整总线优先级puts("调整DMA优先级以减少总线冲突");configure_bus_arbitration();}if (analysis.avg_cpu_utilization > 90.0f) {// CPU利用率过高,启用更激进的预取puts("启用激进预取策略");// 启用硬件预取器(如果支持)enable_aggressive_prefetch();}// 打印优化建议printf("性能评分: %d/100\n", analysis.performance_grade);printf("CPU利用率: %.1f%%\n", analysis.avg_cpu_utilization);printf("Cache命中率: %.1f%%\n", analysis.avg_cache_hit_ratio);printf("最大内存停顿: %u周期\n", analysis.peak_memory_stalls);printf("DMA冲突总数: %u\n", analysis.total_dma_conflicts);
}
最佳实践总结
1. MPU配置原则
- 分层优化: 根据访问频率和模式配置不同的Cache策略
- 一致性权衡: 在性能和一致性之间找到平衡点
- 实时性考虑: 关键实时路径禁用Cache确保确定性
- 动态调整: 根据运行时性能监控结果调整配置
2. 多主设备协调策略
- 优先级配置: 为不同类型的访问设置合适的总线优先级
- 时间分割: 使用时间片轮转避免某个主设备长期占用总线
- 专用通道: 为高带宽设备提供专用的内存通道
- 缓冲策略: 使用FIFO和双缓冲减少实时冲突
3. 性能调优方法
- 监控驱动: 基于实际性能数据进行优化决策
- 渐进调整: 逐步调整配置,避免引入新的性能瓶颈
- 场景测试: 在典型工作负载下验证优化效果
- 文档记录: 记录优化过程和效果,便于后续维护
通过系统性的MPU配置、Cache管理和多主设备协调,可以显著提升高性能MCU系统的整体性能,实现更高的吞吐量和更低的延迟。
相关文章:

高性能MCU的MPU与Cache优化详解
概述 在现代高性能单片机(如ARM Cortex-M7、Cortex-A系列在MCU中的应用)中,Memory Protection Unit (MPU) 和Cache系统的协同工作对系统性能有着决定性影响。本文将深入分析MPU配置如何影响Cache命中率,多主设备对RAM访问的竞争问…...
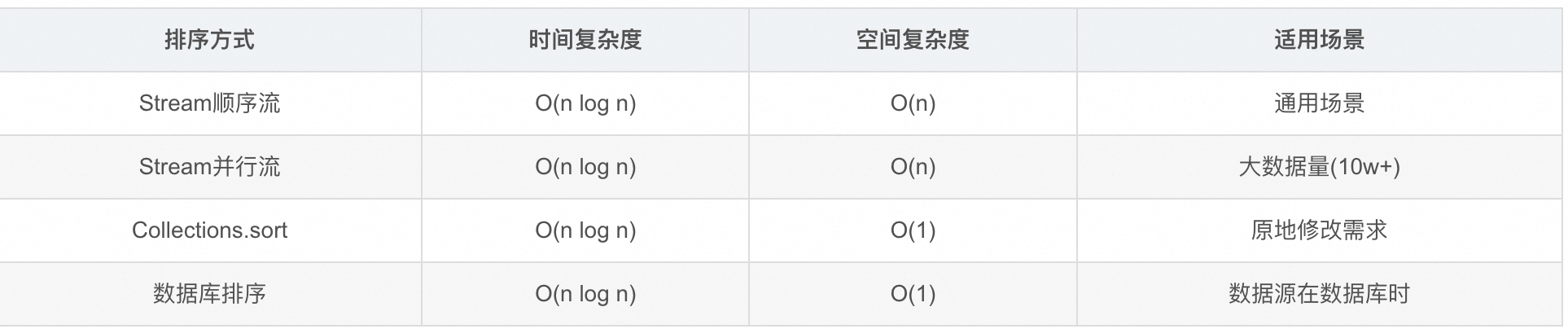
关于list集合排序的常见方法
目录 1、list.sort() 2、Collections.sort() 3、Stream.sorted() 4、进阶排序技巧 4.1 空值安全处理 4.2 多字段组合排序 4.3. 逆序 5、性能优化建议 5.1 并行流加速 5.2 原地排序 6、最佳实践 7、注意事项 前言 Java中对于集合的排序操作,分别为list.s…...
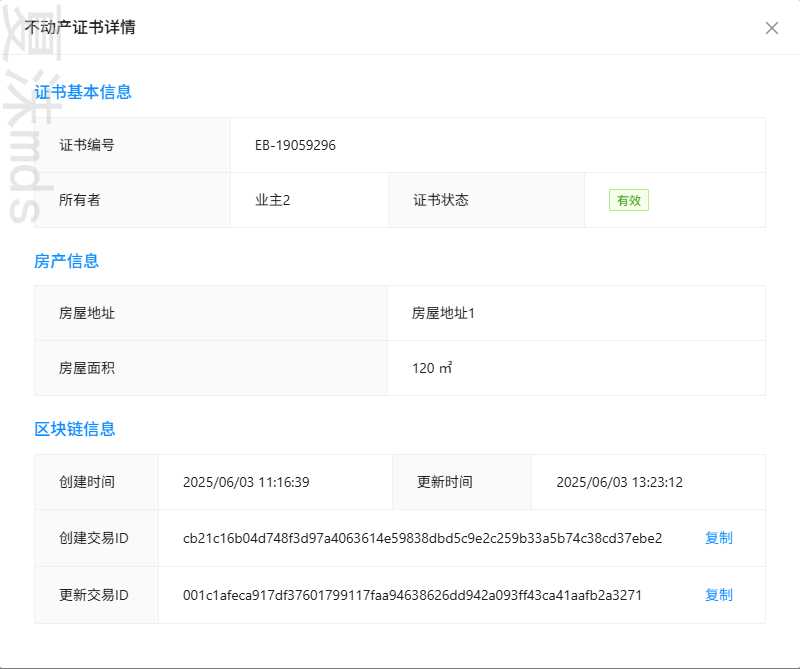
不动产登记区块链系统(Vue3 + Go + Gin + Hyperledger Fabric)
好久没有介绍过新项目的制作了,之前做的一直都是Fisco Bcos的项目,没有介绍过Hyperledger Fabric的项目,这次来给大家分享下。 系统概述 不动产登记与交易平台是一个基于Hyperledger Fabric的综合性管理系统,旨在实现不动产登记…...
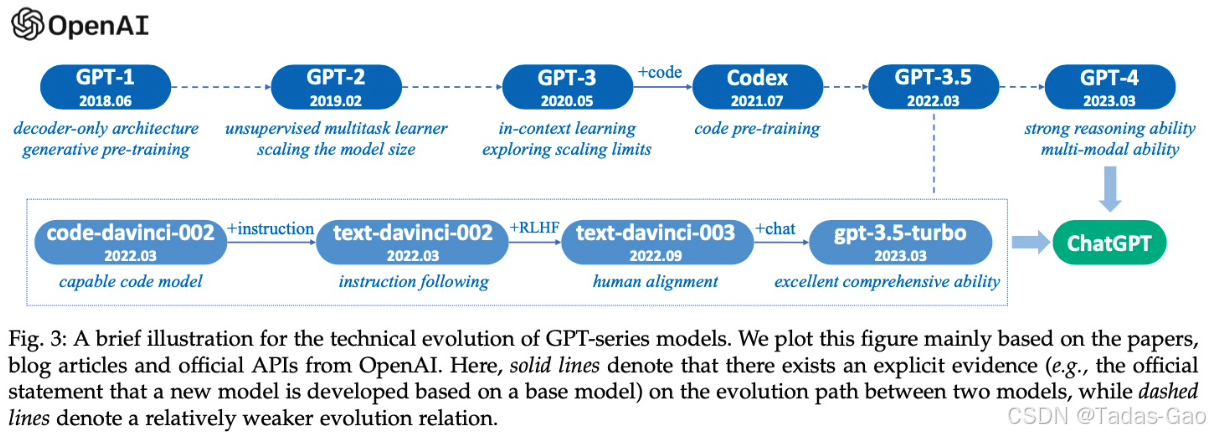
从 GPT 的发展看大模型的演进
这是一个技术爆炸的时代。一起来看看 GPT 诞生后,与BERT 的角逐。 BERT 和 GPT 是基于 Transformer 模型架构的两种不同类型的预训练语言模型。它们之间的角逐可以从 Transformer 的编码解码结构角度来分析。 BERT(Bidirectional Encoder Representatio…...
全流程预测与诊疗辅助系统详细技术方案)
基于大模型的短暂性脑缺血发作(TIA)全流程预测与诊疗辅助系统详细技术方案
目录 系统整体架构系统部署拓扑图核心模块详细技术方案1. 术前风险预测模块算法实现伪代码:数据处理流程:2. 手术方案智能生成系统手术方案决策伪代码:手术方案生成流程:3. 麻醉智能决策系统麻醉方案伪代码:4. 术后监护与复发预测实时监测流程:5. 并发症预测系统双通道风…...

JSCH使用SFTP详细教程
文章目录 1. JSCH和SFTP基础概念1.1 什么是JSCH?1.2 SFTP协议特点1.3 JSCH的优势1.4 常用场景 2. 环境配置和依赖管理2.1 Maven依赖配置2.2 Gradle依赖配置2.3 基础配置类2.4 配置文件示例 3. SFTP连接管理3.1 基础连接类3.2 连接池管理3.3 连接测试工具 4. 文件上传…...

Trae CN IDE 中 PHP 开发的具体流程和配置指南
以下是 Trae CN IDE 中 PHP 开发的具体流程和配置指南,结合知识库内容和实际开发需求整理,并附实例说明: 一、安装与初始配置 下载与安装 Trae IDE 访问 Trae 官网 下载 macOS 或 Windows 版本。安装完成后,启动 Trae,首次运行会进入初始化向导。初始设置 主题与语言:选择…...
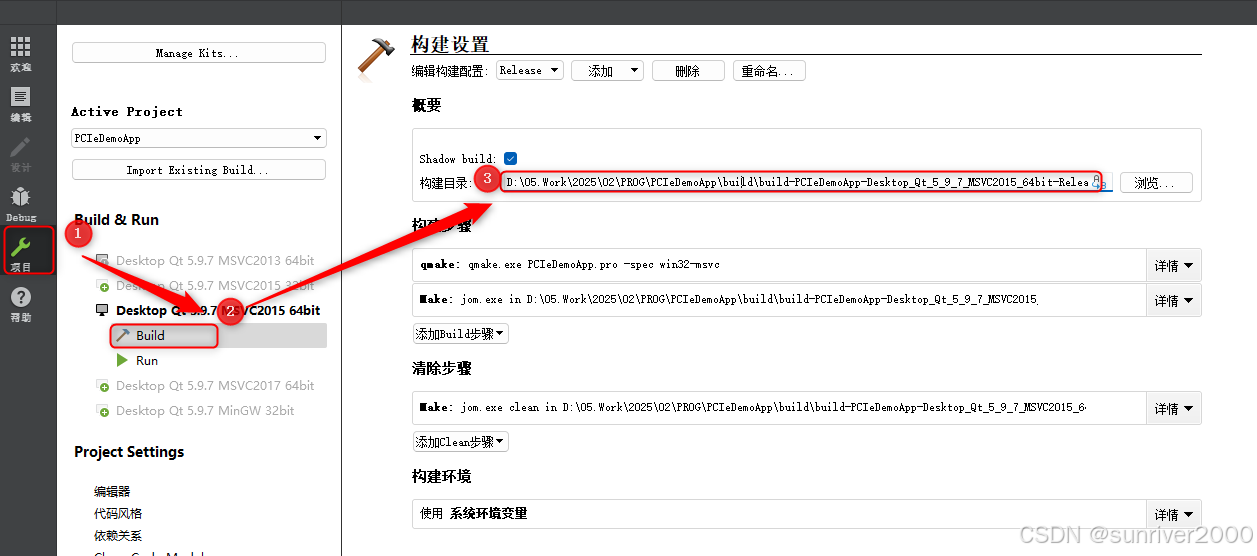
【Qt】构建目录设置
问题 ProjectRoot/├── src/ # 源代码│ ├── project1│ └── project2├── build/ # 构建目录│ ├── build-PCIeDemoApp-Desktop_Qt_5_9_7_MSVC2015_64bit-Debug/│ └── build-PCIeDemoApp-Desktop_Qt_5_9_7_MSVC2015_64bit-Rele…...

【仿生机器人】极具前瞻性的架构——认知-情感-记忆“三位一体的仿生机器人系统架构
基于您的深度需求分析,我将为您设计一个全新的"认知-情感-记忆"三位一体的仿生机器人系统架构。以下是经过深度优化的解决方案: 一、核心架构升级(三体认知架构) 采用量子纠缠式架构设计: 认知三角…...

Web后端快速入门(Maven)
Maven是apche旗下的一个开源项目,是一款用于管理和构建java项目的工具。 开源项目:Welcome to The Apache Software Foundation. Maven的作用: 依赖管理(方便快捷的管理项目依赖的资源,避免版本冲突问题)…...

机器学习算法:逻辑回归
1. 基础概念 定义: 逻辑回归(Logistic Regression)是一种用于解决二分类问题的监督学习算法,通过概率预测样本属于某一类别的可能性。 核心特点:输出是概率值(0~1),通过阈值&#…...

企业展示型网站模板HTML5网站模板下载指南
在当今数字化浪潮中,企业网站已成为企业展示形象、推广产品和服务的重要窗口。一个设计精美、功能完善的企业展示型网站,不仅能提升企业的品牌形象,还能吸引潜在客户,促进业务增长。而HTML5网站模板,凭借其跨平台兼容性…...
)
ArrayList和LinkedList(深入源码加扩展)
ArrayList 和 LinkedList 是 Java 集合框架中两种常用的列表实现,它们在底层数据结构、性能特点和适用场景上有显著的区别。以下是它们的详细对比以及 ArrayList 的扩容机制。 1. ArrayList 和 LinkedList 的底层区别 (1) 底层数据结构 ArrayList: 基于动态数组(Dynamic Ar…...
Unity UI 性能优化--Sprite 篇
🎯 Unity UI 性能优化终极指南 — Sprite篇 🧩 Sprite 是什么?—— 渲染的基石与性能的源头 在Unity的2D渲染管线中,Sprite 扮演着至关重要的角色。它不仅仅是2D图像资源本身,更是GPU进行渲染批处理(Batch…...

AI健康小屋+微高压氧舱:科技如何重构我们的健康防线?
目前,随着科技和社会的不断发展,人们的生活水平和方式有了翻天覆地的变化。 从吃饱穿暖到吃好喝好再到健康生活,观念也在逐渐发生改变。 尤其是在21世纪,大家对健康越来越重视,这就不得不提AI健康小屋和氧舱。 一、A…...
:颜色空间转换、数值类型转换、图像混合、图像缩放)
OpenCV C++ 学习笔记(五):颜色空间转换、数值类型转换、图像混合、图像缩放
文章目录 颜色空间转换cvtColor通道分离split通道合并merge数值类型转换convertTo图片混合addWeighted图片缩放resize 颜色空间转换cvtColor cvtColor 是 OpenCV 中用于将图像从一种色彩空间转换为另一种色彩空间的函数。它非常适用于各种图像处理任务,如灰度化、颜…...

如何做接口测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 01、通用的项目架构 02、什么是接口 接口:服务端程序对外提供的一种统一的访问方式,通常采用HTTP协议,通过不同的urlÿ…...

【JMeter】性能测试知识和工具
目录 何为系统性能 何为性能测试 性能测试分类 性能测试指标 性能测试流程 性能测试工具:JMeter(主测web应用) jmeter文件目录 启动方式 基本元件:元件内有很多组件 jmeter参数化 jmeter关联 自动录制脚本 直连数据库…...
SOC-ESP32S3部分:25-HTTP请求
飞书文档https://x509p6c8to.feishu.cn/wiki/KL4RwxUQdipzCSkpB2lcBd03nvK HTTP(Hyper Text Transfer Protocol) 超文本传输协议,是一种建立在 TCP 上的无状态连接,整个基本的工作流程是客户端发送一个 HTTP 请求,说明…...
字符编码全解析:ASCII、GBK、Unicode、UTF-8与ANSI
UTF - 8(全球字符能被唯一标识)、GBK、Unicode、ANSI 区别与关联 qwen模型分词器文件 1. ASCII(基础铺垫,理解编码起源) 作用:最早期为处理英文文本设计,是字符编码的基础,后演变成其他编码兼容的一部分 。范围:共 128 个字符(0 - 127),包含英文大小写字母、数字…...

《前端面试题:HTML5、CSS3、ES6新特性》
现代前端开发中,HTML5、CSS3和JavaScript ES6共同构成了三大核心技术支柱。这些技术不仅显著提升了用户体验和性能表现,更大幅提高了开发效率。本文将从技术演进、核心特性到最佳实践,系统性地介绍这三大技术的应用之道。 我们将首先探讨HTM…...
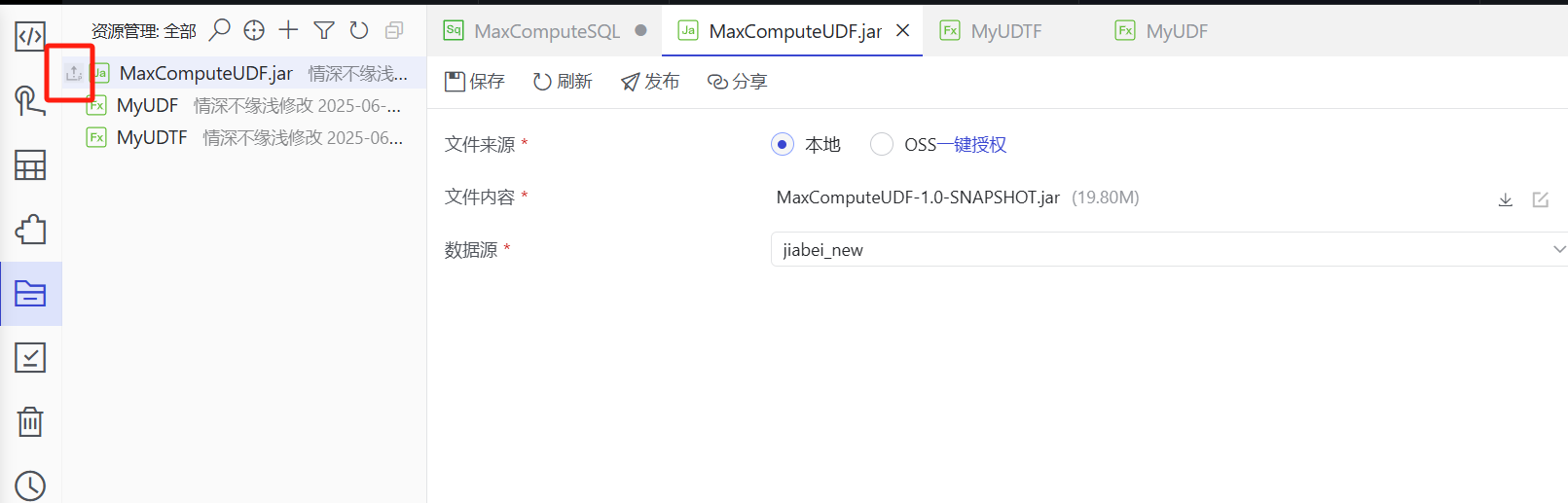
MaxCompute开发UDF和UDTF案例
文章目录 一、Java开发UDF1、创建Maven项目2、创建UDF类3、打包上传资源4、创建函数MyUDF5、SQL验证 二、Java开发UDTF1、创建Maven项目2、创建UDTF类3、打包上传更新资源4、创建函数MyUDTF5、SQL验证 三、常见问题1、发布函数报错 一、Java开发UDF 1、创建Maven项目 创建Mav…...

49套夏日小清新计划总结日系卡通ppt模板
绿色小清新PPT模版,日系小清新PPT模版,粉红色PPT模版,蓝色PPT模版,草青色PPT模版,日系卡通PPT模版 49套夏日小清新计划总结日系卡通ppt模板:夏日小清新日系卡通PPT模版https://pan.quark.cn/s/9e4270d390fa…...
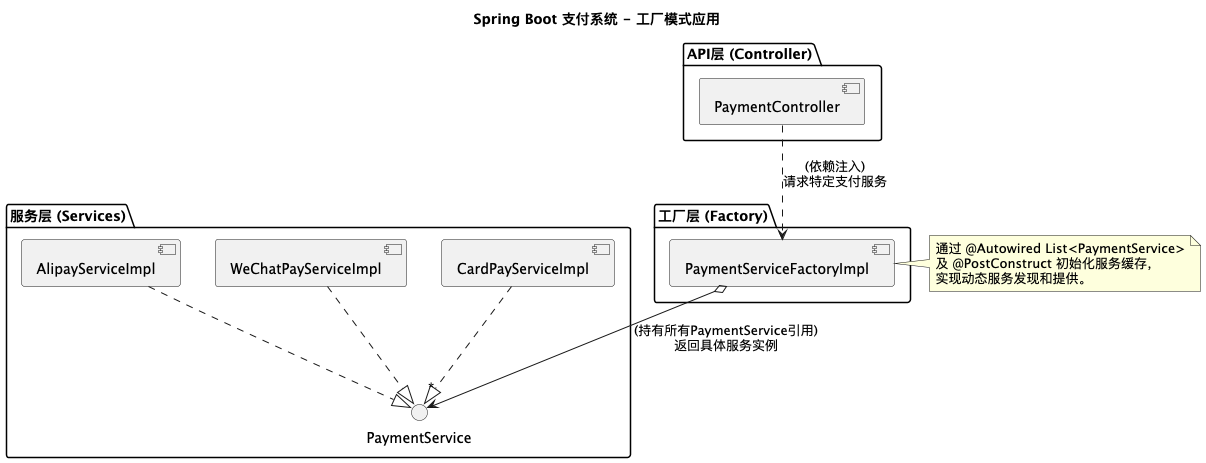
告别硬编码!用工厂模式优雅构建可扩展的 Spring Boot 应用 [特殊字符]
嗨,各位技术伙伴们!👋 在日常的软件开发中,我们经常面临需求变更的挑战。如何构建一个既能满足当前需求,又能轻松应对未来变化的系统呢?答案往往藏在那些经典的设计模式中。 今天,我们就来聊聊…...
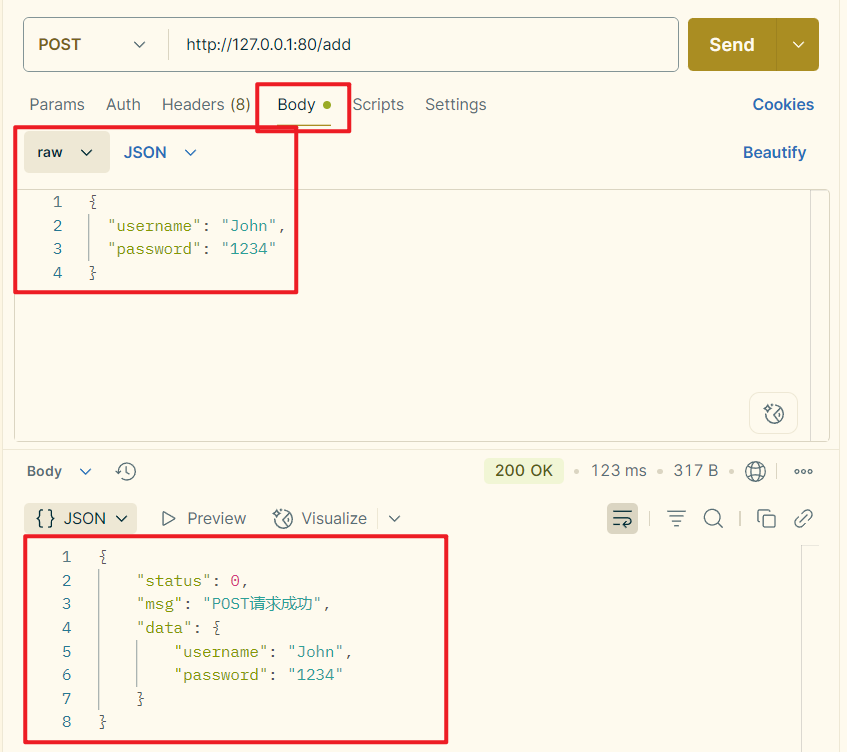
Express教程【006】:使用Express写接口
文章目录 8、使用Express写接口8.1 创建API路由模块8.2 编写GET接口8.3 编写POST接口 8、使用Express写接口 8.1 创建API路由模块 1️⃣新建routes/apiRouter.js路由模块: /*** 路由模块*/ // 1-导入express const express require(express); // 2-创建路由对象…...
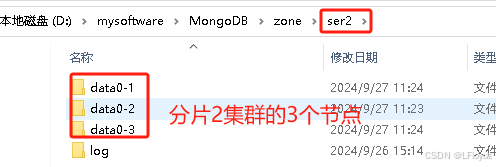
mongodb集群之分片集群
目录 1. 适用场景2. 集群搭建如何搭建搭建实例Linux搭建实例(待定)Windows搭建实例1.资源规划2. 配置conf文件3. 按顺序启动不同角色的mongodb实例4. 初始化config、shard集群信息5. 通过router进行分片配置 1. 适用场景 数据量大影响性能 数据量大概达到千万级或亿级的时候&…...
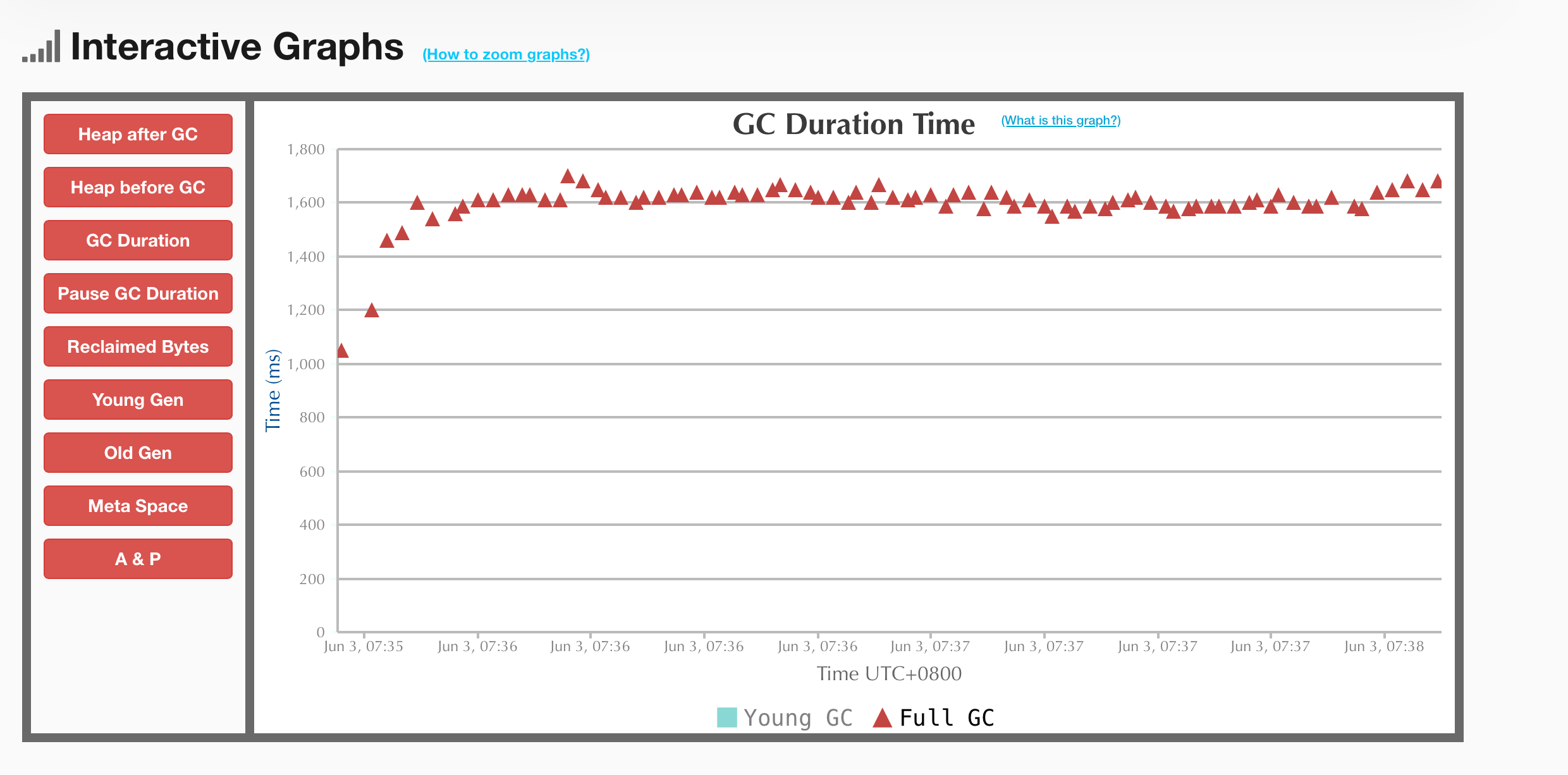
Starrocks Full GC日志分析
GC日志样例: [2025-06-03T07:36:06.1770800] GC(227) Pause Full (G1 Evacuation Pause) [2025-06-03T07:36:06.1960800] GC(227) Phase 1: Mark live objects [2025-06-03T07:36:06.9480800] GC(227) Cleaned string and symbol table, strings: 47009 processed,…...
飞算 JavaAI 赋能老项目重构:破旧立新的高效利器
许多企业的 Java 老项目面临着代码陈旧、架构落后、维护困难等问题。老项目重构势在必行,却又因庞大的代码量、复杂的业务逻辑让开发团队望而却步。 老项目重构困境重重 传统的 Java 老项目往往在长期的迭代和维护中积累了诸多问题。一方面,代码质量堪…...

RockyLinux9安装Docker
如何在RockyLinux9下安装Docker RockyLinux采用了全新的dnf来进行包管理,dnf支持yum别名,还没习惯的可以将dnf替换为yum 确保dnf最新 sudo dnf update -y安装dnf-plugins-core包 sudo dnf install -y dnf-plugins-core yum-utils添加Docker的官方仓库…...

RequestRateLimiterGatewayFilterFactory
一、功能说明 RequestRateLimiterGatewayFilterFactory 是 Spring Cloud Gateway 的流量控制组件,用于实现 API 请求速率限制,核心功能包括: 限制单位时间内的请求数量(如每秒10次)防止服务被突发流量击垮࿰…...