连接关键点:使用 ES|QL 联接实现更丰富的可观测性洞察
作者:来自 Elastic Luca Wintergerst

ES|QL 的 LOOKUP JOIN 现已进入技术预览阶段,它允许你在查询时对日志、指标和追踪进行丰富处理,无需在摄取时进行非规范化。动态添加部署、基础设施或业务上下文,减少存储占用,加速 Elastic Observability 中的根本原因分析。
连接关键点:使用 ES|QL 联接实现更丰富的可观测性洞察
你可能已经看到我们最近发布的关于 Elasticsearch 中引入 SQL 风格联接的公告,也就是 ES|QL 的 LOOKUP JOIN 命令(目前处于技术预览阶段!)。虽然那篇文章介绍了基础内容,但现在我们将从可观测性的角度更深入地探讨这一功能。这项新的联接能力,如何帮助工程师和 SRE 更好地理解日志、指标和追踪数据,同时通过减少数据反规范化来提升 Elasticsearch 的存储效率?
注意:在深入细节之前,需要再次强调,这项功能目前依赖一个特殊的查找索引(lookup index)。目前 还无法 对任意索引进行 JOIN 操作。
可观测性不只是收集数据,更重要的是理解数据。很多时候,原始遥测数据 —— 例如一条日志、一项指标或一个追踪片段——缺乏快速诊断或影响评估所需的完整上下文。我们需要关联数据、使用业务或基础设施上下文对其进行丰富,并提出更高级的问题。
传统上,在 Elasticsearch 中实现这些能力的方法包括在摄取时对数据进行非规范化(例如通过使用 enrich processor 的 ingest pipeline),或在客户端执行联接。
通过在数据流入时添加必要的上下文(如主机详情或用户属性),每个文档在进入索引时就已准备好用于查询和分析,无需后续额外处理。这种方法在很多场景下运行良好,特别是当引用数据变化缓慢或丰富字段对几乎每次查询都至关重要时。
但随着环境变得越来越动态和多样化,频繁更新引用数据(或避免在每个文档中重复存储字段)的需求也暴露了一些权衡和限制。
在 Elasticsearch 8.18 和 9.0 中引入的 ES|QL LOOKUP JOIN 提供了另一种更加灵活的选择,适用于那些需要实时查找和最小重复数据的场景。这两种方法 —— 摄取时丰富与查询时 LOOKUP JOIN —— 根据更新频率、查询性能和存储考量等不同用例需求,可以互为补充并同时有效。
为什么在可观测性中使用 Lookup Join
Lookup join 保持了灵活性。你可以在查询时根据需要动态决定是否查找额外信息来辅助调查。
以下是一些示例:
-
部署信息:是哪个版本的代码在产生这些错误?
-
基础设施映射:是哪个 Kubernetes 集群或云区域延迟较高?使用了什么硬件?
-
业务上下文:这个性能下降是否影响到了关键客户?
-
团队归属:哪个团队负责这个抛出异常的服务?
要把这类信息完美地反规范化到每一条日志或指标数据中,既困难又低效。而且像部署列表、服务器清单、客户等级或服务归属这类查找数据集,通常和遥测数据是独立变化的。
LOOKUP JOIN 在这里非常适用,原因如下:
-
查找索引可写:更新你的部署列表、CMDB 导出或值班表到查找索引中,下一次的 ES|QL 查询会立即使用这些最新数据。无需重新执行复杂的 enrich 策略或重新索引数据。
-
灵活性:你可以在查询时决定需要联接哪个上下文。也许你今天关注的是部署版本,明天关注的则是云区域。
-
更简单的设置:如之前的文章所说,不需要维护任何 enrich 策略。只需创建一个带有
index.mode: lookup的索引并加载你的数据——每个查找索引最多支持 20 亿条文档。
可观测性使用场景与 ES|QL 示例
现在让我们看一些示例,了解 Lookup Join 如何提供帮助。
使用部署上下文丰富错误日志
假设你发现 checkout-service 的错误突然增加。你的日志已经流入数据流中,但它们只包含服务名称。这些文档本身没有任何与部署活动相关的信息。
FROM logs-*| WHERE log.level == "error"| WHERE service.name == "opbeans-ruby"
你需要知道这些错误是否与最近的部署有关。为此,我们可以维护一个名为 deployments_info_lkp 的索引(设置为 index.mode: lookup),它将服务名称映射到其部署时间。这个索引可以在每次部署发生时由我们的 CI/CD 流水线自动更新。
PUT /deployments_info_lkp
{"settings": {"index.mode": "lookup"},"mappings": {"properties": {"service": {"properties": {"name": {"type": "keyword"},"deployment_time": {"type": "date"},"version": {"type": "keyword"}}}}}
}# Bulk index the deployment documents
POST /_bulk
{ "index" : { "_index" : "deployments_info_lkp" } }
{ "service.name": "opbeans-ruby", "service.version": "1.0", "deployment_time": "2025-05-22T06:00:00Z" }
{ "index" : { "_index" : "deployments_info_lkp" } }
{ "service.name": "opbeans-go", "service.version": "1.1.0", "deployment_time": "2025-05-22T06:00:00Z" }
利用这些信息,你现在可以编写一个将这两个数据源连接起来的查询。
ES|QL 查询:
FROM logs-* | WHERE log.level == "error"| WHERE service.name == "opbeans-ruby"| LOOKUP JOIN deployments_info_lkp ON service.name
这本身就是排查问题的重要一步。现在每条错误日志中都包含了 deployment_time 列。接下来的最后一步是利用这个字段进行进一步筛选。
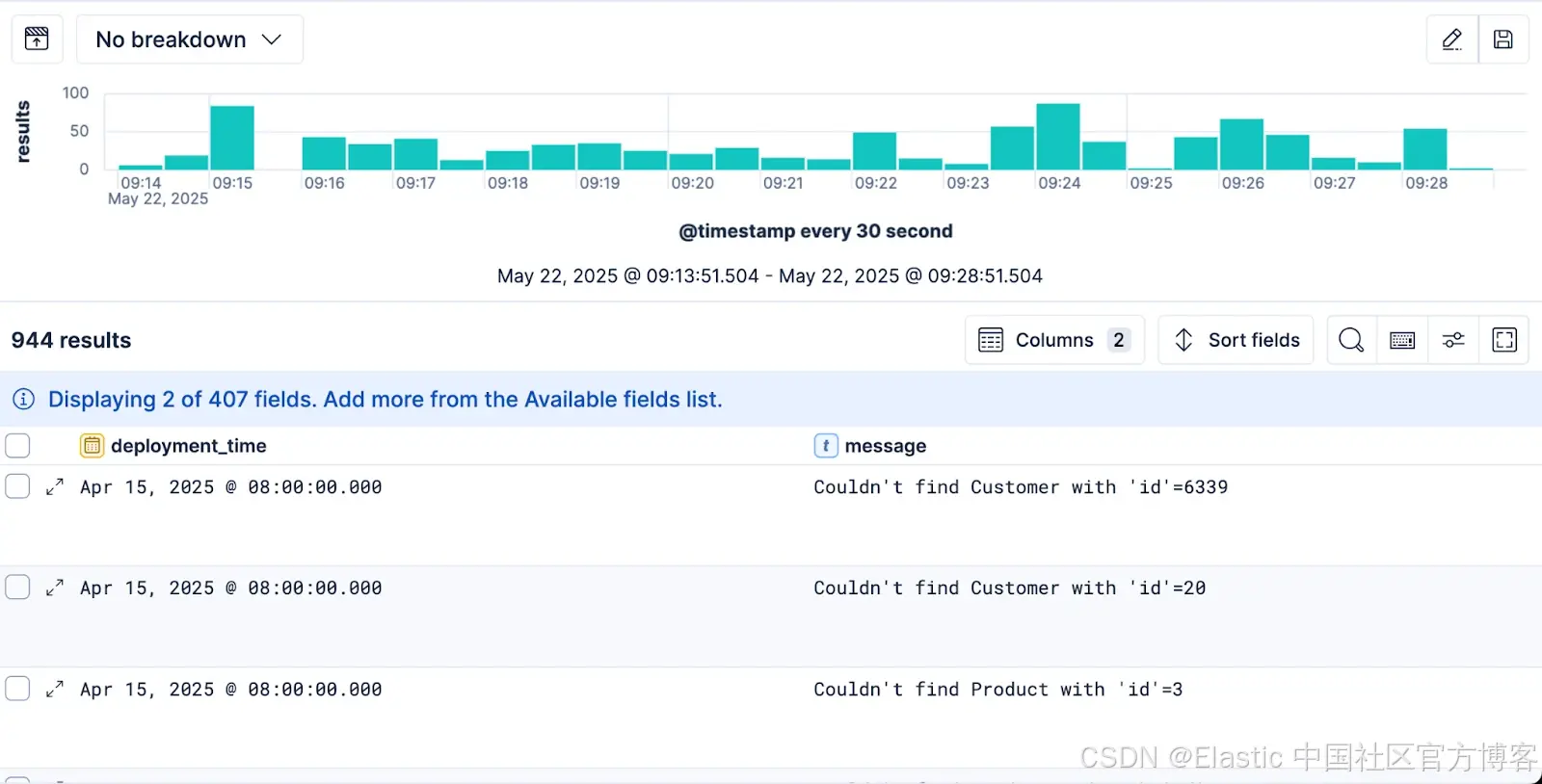
我们从 lookup 索引中连接到的任何数据,都可以像 ES|QL 查询中其他常规可用数据一样处理。这意味着我们可以基于它进行过滤,并检查是否有最近的部署。
FROM logs-*| WHERE log.level == "error"| WHERE service.name == "opbeans-ruby"| LOOKUP JOIN deployments_info_lkp ON service.name | KEEP message, service.name, service.version, deployment_time | WHERE deployment_time > NOW() - 2h
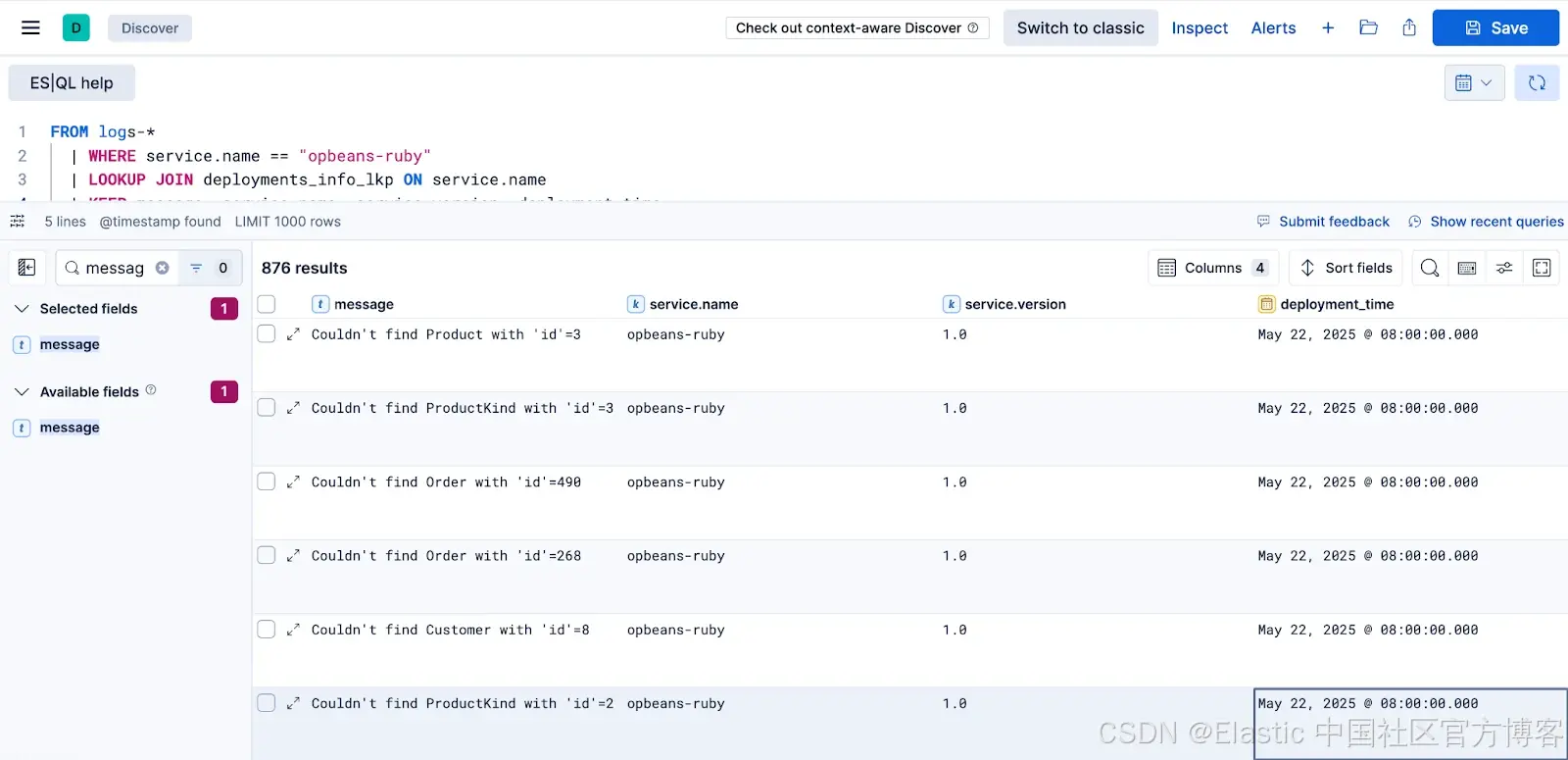
使用 JOIN 节省磁盘空间
通过在每条日志事件中直接包含主机操作系统或云服务商等上下文信息来反规范化数据,虽然查询方便,但会增加存储消耗,尤其是在高流量数据流中。与其重复存储这些经常冗余的信息,不如利用 join 按需获取,从而节省宝贵的磁盘空间。虽然压缩通常能很好地处理重复数据,但完全移除这些字段仍能显著减少存储。
在这个示例中,我们使用了 1,000,000 条 Kubernetes 容器日志数据,采用 Kubernetes 集成的默认映射,启用了 logsdb 索引模式。该索引的初始大小为 35.5MB。
GET _cat/indices/k8s-logs-default?h=index,pri.store.size
###
k8s-logs-default 35.5mb
通过磁盘使用情况 API(disk usage API),我们观察到像 host.os 和 cloud.* 这样的字段大约占据了磁盘上索引总大小(35.5MB)的 5%。这些字段在某些情况下有用,但像 os.name 这样的信息很少被查询。
// Example host.os structure
"os": {"codename": "Plow", "family": "redhat", "kernel": "6.6.56+","name": "Red Hat Enterprise Linux", "platform": "rhel", "type": "linux", "version": "9.5 (Plow)"
}// Example cloud structure
"cloud": {"account": { "id": "elastic-observability" },"availability_zone": "us-central1-c","instance": { "id": "5799032384800802653", "name": "gke-edge-oblt-edge-oblt-pool-46262cd0-w905" },"machine": { "type": "e2-standard-4" },"project": { "id": "elastic-observability" },"provider": "gcp", "region": "us-central1", "service": { "name": "GCE" }
}
与其在每个文档中存储这些信息,不如在 ingest pipeline 中去除这些字段:
PUT _ingest/pipeline/drop-host-os-cloud
{"processors": [{ "remove": { "field": "host.os" } },{ "set": { "field": "tmp1", "value": "{{cloud.instance.id}}" } }, // Temporarily store the ID{ "remove": { "field": "cloud" } }, // Remove the entire cloud object{ "set": { "field": "cloud.instance.id", "value": "{{tmp1}}" } }, // Restore just the cloud instance ID{ "remove": { "field": "tmp1", "ignore_missing": true } } // Clean up temporary field]
}
重新索引(并强制合并为一个段)后,索引大小如下,节省了大约 5% 的空间。
GET _cat/indices/k8s-logs-*?h=index,pri.store.size
###
k8s-logs-default 33.7mb
k8s-logs-drop-cloud-os 35.5mb
现在,为了在分析时重新获得被移除的 host.os 和 cloud.* 信息,而不必存储在每条日志中,我们可以创建一个 lookup 索引。该索引将存储完整的主机和云元数据,使用我们在日志中保留的 cloud.instance.id 作为键。这个 instance_metadata_lkp 索引会比节省的空间小得多,因为它只需为每个唯一实例存储一条文档。
# Create the lookup index for instance metadata
PUT /instance_metadata_lkp
{"settings": {"index.mode": "lookup"},"mappings": {"properties": {"cloud.instance.id": { # The join key we kept in the logs"type": "keyword"},"host.os": { # The full host.os object we removed"type": "object","enabled": false # Often don't need to search sub-fields here},"cloud": { # The full cloud object we removed (mostly)"type": "object","enabled": false # Often don't need to search sub-fields here}}}
}# Bulk index sample instance metadata (keyed by cloud.instance.id)
# This data might come from your cloud provider API or CMDB
POST /_bulk
{ "index" : { "_index" : "instance_metadata_lkp", "_id": "5799032384800802653" } }
{ "cloud.instance.id": "5799032384800802653", "host.os": { "codename": "Plow", "family": "redhat", "kernel": "6.6.56+", "name": "Red Hat Enterprise Linux", "platform": "rhel", "type": "linux", "version": "9.5 (Plow)" }, "cloud": { "account": { "id": "elastic-observability" }, "availability_zone": "us-central1-c", "instance": { "id": "5799032384800802653", "name": "gke-edge-oblt-edge-oblt-pool-46262cd0-w905" }, "machine": { "type": "e2-standard-4" }, "project": { "id": "elastic-observability" }, "provider": "gcp", "region": "us-central1", "service": { "name": "GCE" } } }
通过这种设置,当你需要日志的完整主机或云上下文时,只需在 ES|QL 查询中使用 LOOKUP JOIN,并继续基于 lookup 索引中的数据进行过滤。
FROM logs-* | LOOKUP JOIN instance_metadata_lkp ON cloud.instance.id | WHERE cloud.region == "us-central1"
这种方法允许我们在需要时查询完整上下文(例如,按 host.os.name 或 cloud.region 过滤日志),同时通过避免冗余数据的反规范化,显著减少高流量日志索引的存储占用。
需要注意的是,低基数的元数据字段通常压缩效果很好,这里大部分存储节省来自 host.os.name 和 cloud.instance.name 字段的 “text” 映射。请务必使用 disk usage API 来评估这种方法是否适合你的具体用例。
开始使用 Observability 的 Lookup
创建必要的 lookup 索引很简单。正如我们最初的博客文章所述,你可以使用 Kibana 的索引管理界面、Create Index API 或文件上传工具,关键是在索引设置中将 "index.mode" 设置为 "lookup"。
对于 Observability,可以考虑自动填充这些 lookup 索引:
-
定期从你的 CMDB、CRM 或 HR 系统导出数据。
-
让你的 CI/CD 流水线在成功部署后更新 deployments_lkp 索引。
-
使用 Logstash 等工具,配置 elasticsearch 输出写入你的 lookup 索引。
性能和替代方案说明
虽然功能强大,但 joins 并非免费。每个 LOOKUP JOIN 都会增加查询的处理开销。对于非常静态的上下文数据(例如主机永久所在的云区域)且几乎每次查询都需要时,传统的在 ingest 时丰富数据的方法,可能在特定查询上性能更优,前期处理和存储开销换取查询速度。
但是,对于 Observability 中常见的动态、灵活和有针对性的丰富场景,比如映射不断变化的部署、用户分组或团队结构,LOOKUP JOIN 提供了一个高效且更易管理的解决方案。
结论
ES|QL 的 LOOKUP JOIN 让你能在查询时轻松关联并丰富日志、指标和跟踪数据,结合最新的外部信息;你可以更快地从发现问题到理解其范围、影响和根本原因。
该功能目前在 Elasticsearch 8.18 和 Serverless 中处于技术预览阶段,现已在 Elastic Cloud 上可用。我们鼓励你用自己的 Observability 数据试用,并通过 Discover 中 ES|QL 编辑器的“Submit feedback”按钮分享反馈。期待看到你如何用它来连接系统中的点!
原文:Connecting the Dots: ES|QL Joins for Richer Observability Insights — Elastic Observability Labs
相关文章:
连接关键点:使用 ES|QL 联接实现更丰富的可观测性洞察
作者:来自 Elastic Luca Wintergerst ES|QL 的 LOOKUP JOIN 现已进入技术预览阶段,它允许你在查询时对日志、指标和追踪进行丰富处理,无需在摄取时进行非规范化。动态添加部署、基础设施或业务上下文,减少存储占用,加速…...

Tiktok App 登录账号、密码、验证码 XOR 加密算法
抖音 App 登录账号、密码、验证码 XOR 加密算法% E9 n z, \& R1 a4 b. ^ 流程分析 登录 Tiktok APP 时,通过抓包发现账号密码是非明文传输的。 <?php// http://xxx.xx.x.x.x/tiktok/$tiktok new TikTokClient();$userId 7212597544604484614; $secUid …...
Flask + Celery 应用
目录 Flask Celery 应用项目结构1. 创建app.py2. 创建tasks.py3. 创建celery_worker.py4. 创建templates目录和index.html运行应用测试文件 Flask Celery 应用 对于Flask与Celery结合的例子,需要创建几个文件。首先安装必要的依赖: pip install flas…...

奥威BI+AI数据分析:企业数智化转型的加速器
在当今数据驱动的时代,企业对于数据分析的需求日益增长。奥威BIAI数据分析的组合,正成为众多企业数智化转型的加速器。 奥威BI以其强大的数据处理和可视化能力著称。它能够轻松接入多种数据源,实现数据的快速整合与清洗。通过内置的ETL工具&…...
python打卡day43
复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 找了个街头食物图像分类的数据集Popular Street Foods(其实写代码的时候就开始后悔了),原因在于&…...

MySQL 如何判断某个表中是否存在某个字段
在MySQL中,判断某个表中是否存在某个字段,可以通过查询系统数据库 INFORMATION_SCHEMA.COLUMNS 实现。以下是详细步骤和示例: 方法:使用 INFORMATION_SCHEMA.COLUMNS 通过查询系统元数据表 COLUMNS,检查目标字段是否存…...

Linux --进程优先级
概念 什么是进程优先级,为什么需要进程优先级,怎么做到进程优先级这是本文需要解释清楚的。 优先级的本质其实就是排队,为了去争夺有限的资源,比如cpu的调度。cpu资源分配的先后性就是指进程的优先级。优先级高的进程有优先执行的…...
安装和配置 Nginx 和 Mysql —— 一步一步配置 Ubuntu Server 的 NodeJS 服务器详细实录6
前言 昨天更新了四篇博客,我们顺利的 安装了 ubuntu server 服务器,并且配置好了 ssh 免密登录服务器,安装好了 服务器常用软件安装, 配置好了 zsh 和 vim 以及 通过 NVM 安装好Nodejs,还有PNPM包管理工具 。 作为服务器的运行…...

Linux 测试本机与192.168.1.130 主机161/udp端口连通性
Linux 测试本机与 192.168.1.130 主机 161/UDP 端口连通性 161/UDP 端口是 SNMP(简单网络管理协议)的标准端口。以下是多种测试方法: 🛠️ 1. 使用 nmap 进行专业测试(推荐) sudo nmap -sU -p 161 -Pn 1…...

OpenCV 滑动条调整图像亮度
一、知识点 1、int createTrackbar(const String & trackbarname, const String & winname, int * value, int count, TrackbarCallback onChange 0, void * userdata 0); (1)、创建一个滑动条并将其附在指定窗口上。 (2)、参数说明: trackbarname: 创建的…...
图解gpt之注意力机制原理与应用
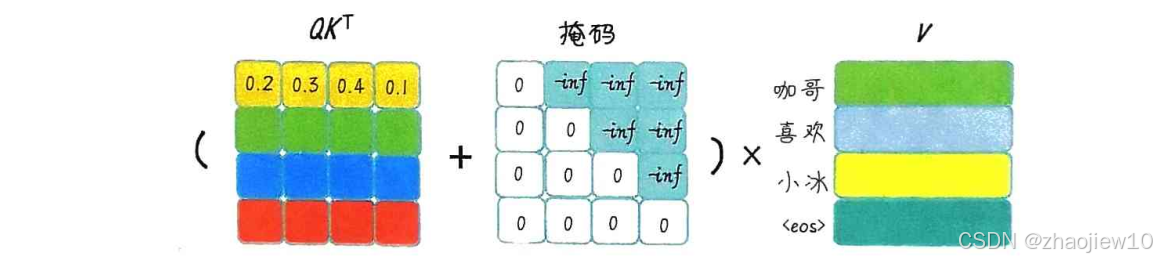
大家有没有注意到,当序列变长时,比如翻译一篇长文章,或者处理一个长句子,RNN这种编码器就有点力不从心了。它把整个序列信息压缩到一个固定大小的向量里,信息丢失严重,而且很难记住前面的细节,特…...

硬件学习笔记--65 MCU的RAM及FLash简介
MCU(微控制器单元)内部的 RAM 和 Flash 是最关键的两种存储器,它们直接影响MCU的性能、功耗和编程方式。以下是它们的详细讲解及作用: 1. RAM(随机存取存储器) 1.1 特性 1)易失性:…...

【Oracle】视图
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 视图基础概述1.1 视图的概念与特点1.2 视图的工作原理1.3 视图的分类 2. 简单视图2.1 创建简单视图2.1.1 基本简单视图2.1.2 带计算列的简单视图 2.2 简单视图的DML操作2.2.1 通过视图进行INSERT操作2.2.2 通…...
 与 MySQL (SQL) 的写法对比)
数据库 MongoDB (NoSQL) 与 MySQL (SQL) 的写法对比
MongoDB (NoSQL) 与 MySQL (SQL) 的写法对比及优劣势分析 基本概念差异 MySQL/SQL:关系型数据库,使用结构化查询语言(SQL),数据以表格形式存储,有预定义的模式(schema)MongoDB/NoSQL:文档型数据库,无固定…...

基于粒子滤波的PSK信号解调实现
基于粒子滤波的PSK信号解调实现 一、引言 相移键控(PSK)是数字通信中广泛应用的调制技术。在非高斯噪声和动态相位偏移环境下,传统锁相环(PLL)性能受限。粒子滤波(Particle Filter)作为一种序列蒙特卡洛方法,能有效处理非线性/非高斯系统的状态估计问题。本文将详细阐…...

更强劲,更高效:智源研究院开源轻量级超长视频理解模型Video-XL-2
长视频理解是多模态大模型关键能力之一。尽管OpenAI GPT-4o、Google Gemini等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。近日,智源研究院联合上海交通大学等机构,正式发布新一代超长视…...

2025.6.3学习日记 Nginx 基本概念 配置 指令 文件
1.初始nginx Nginx(发音为 “engine x”)是一款高性能的开源 Web 服务器软件,同时也具备反向代理、负载均衡、邮件代理等功能。它由俄罗斯工程师 Igor Sysoev 开发,最初用于解决高并发场景下的性能问题,因其轻量级、高…...
【连接器专题】案例:产品测试顺序表解读与应用
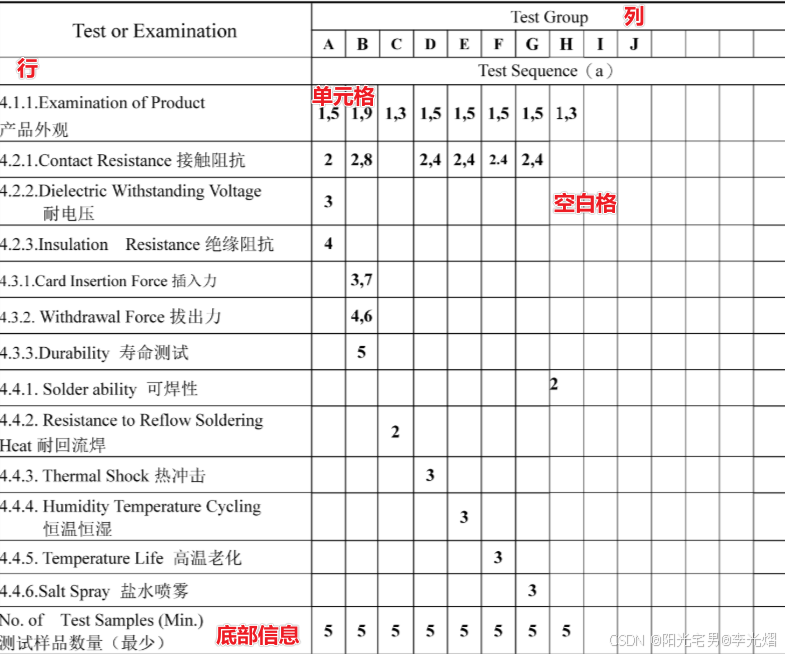
在查看SD卡座连接器的规格书,一些测试报告时,你可能会看到如下一张产品测试顺序表。为什么会出现一张测试顺序表呢? 测试顺序表的使用其实定义测试环节的验证的“路线图”和“游戏规则”,本文就以我人个经验带领大家一起看懂这张表并理解其设计逻辑。 测试顺序表结构 测试…...

星动纪元的机器人大模型 VPP,泛化能力效果如何?与 VLA 技术的区别是什么?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 VPP 利用了大量互联网视频数据进行训练,直接学习人类动作,减轻了对于高质量机器人真机数据的依赖,且可在不同人形机器人本体之间自如切换,这有望…...

4000万日订单背后,饿了么再掀即时零售的“效率革命”
当即时零售转向价值深耕,赢面就是综合实力的强弱。 文|郭梦仪 编|王一粟 在硝烟弥漫的外卖行业“三国杀”中,饿了么与淘宝闪购的日订单量竟然突破了4000万单。 而距淘宝闪购正式上线,还不到一个月。 在大额福利优惠…...
入门AJAX——XMLHttpRequest(Get)
一、什么是 AJAX AJAX Asynchronous JavaScript And XML(异步的 JavaScript 和 XML)。 1、XML与异步JS XML: 是一种比较老的前后端数据传输格式(已经几乎被 JSON 代替)。它的格式与HTML类似,通过严格的闭合自定义标…...

5分钟申请edu邮箱【方案本周有效】
这篇文章主要展示的是成果。如果你是第1次看见我的内容,具体的步骤请翻看往期的两篇作品。先看更正补全,再看下一个。 建议你边看边操作。 【更正补全】edu教育申请通过方案 本周 edu教育邮箱注册可行方案 #edu邮箱 伟大无需多言 我已经验证了四个了…...
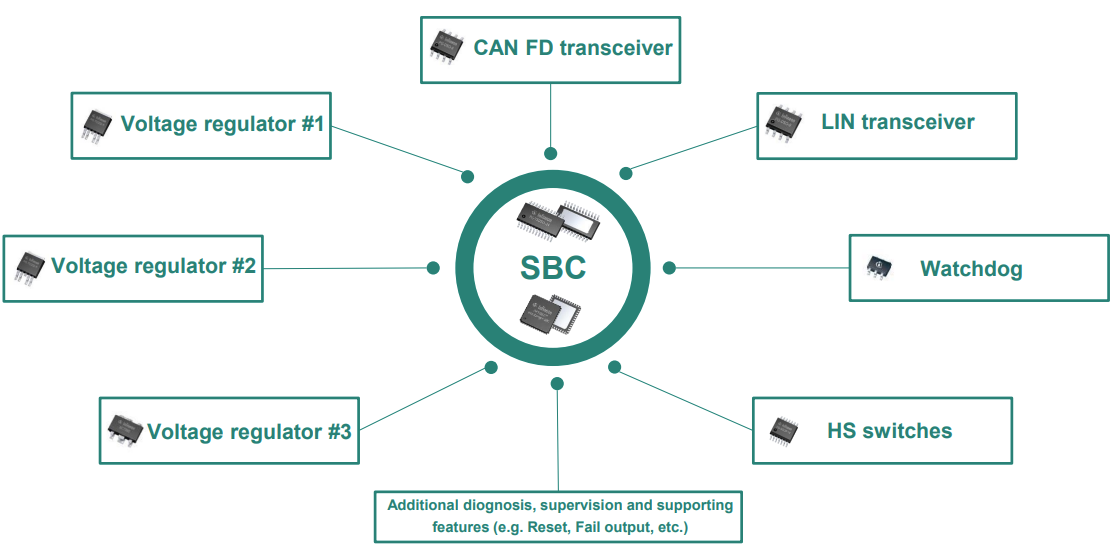
闲谈PMIC和SBC
今天不卷,简单写点。 在ECU设计里,供电芯片选型是逃不开的话题,所以聊聊PMIC或者SBC的各自特点,小小总结下。 PMIC,全称Power Management Intergrated Circuits,听名字就很专业:电源管理&…...
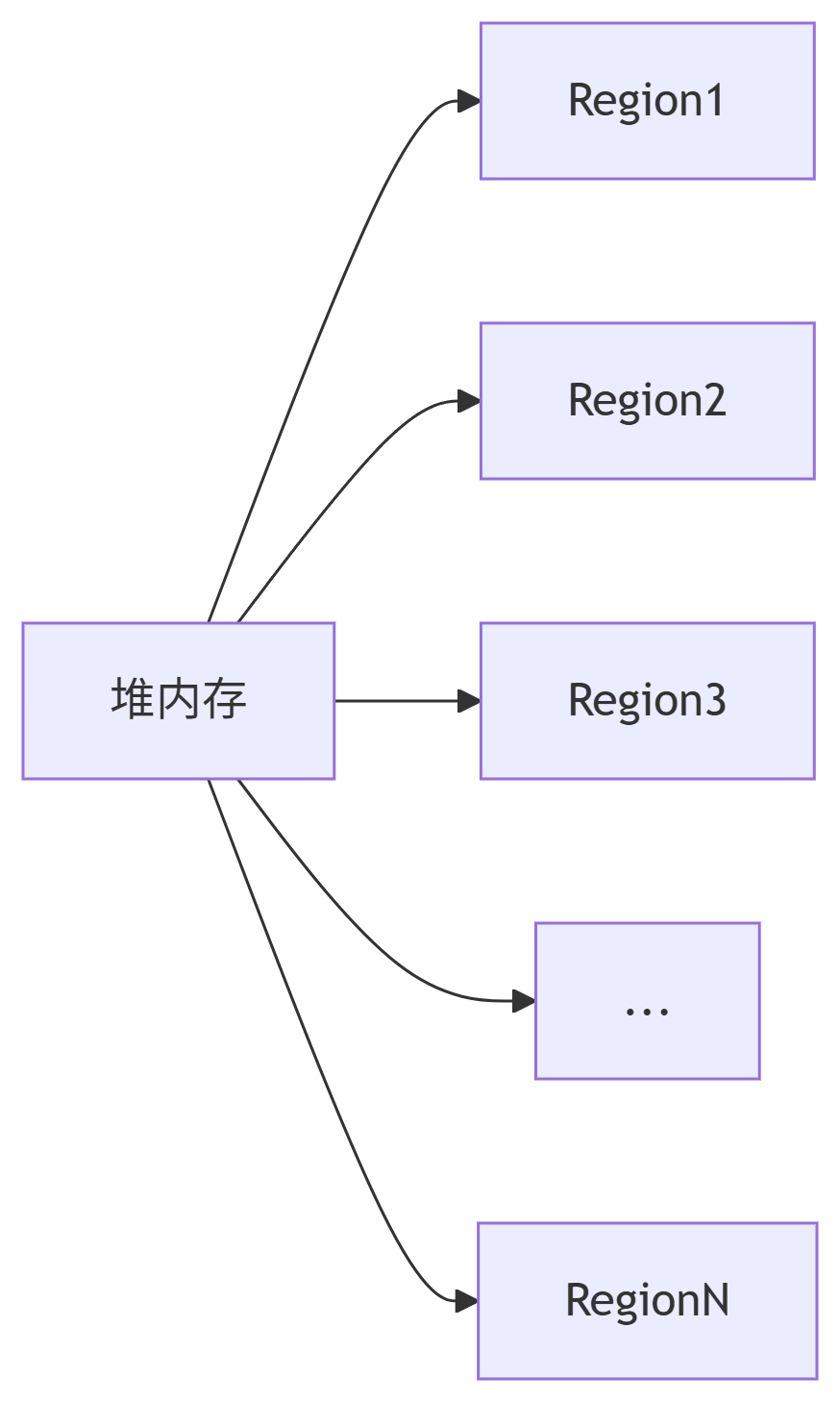
Java垃圾回收机制深度解析:从理论到实践的全方位指南
Java垃圾回收(GC)是Java虚拟机(JVM)的核心功能,它自动管理内存分配与回收,避免了C/C中常见的内存泄漏问题。本文将深入剖析Java垃圾回收的工作原理、算法实现、收集器类型及调优策略,助你全面掌握JVM内存管理的精髓。 一、垃圾回收基础概念 …...

Ubuntu系统 | 本地部署ollama+deepseek
1、Ollama介绍 Ollama是由Llama开发团队推出的开源项目,旨在为用户提供高效、灵活的本地化大型语言模型(LLM)运行环境。作为Llama系列模型的重要配套工具,Ollama解决了传统云服务对计算资源和网络连接的依赖问题,让用户能够在个人电脑或私有服务器上部署和运行如Llama 3等…...
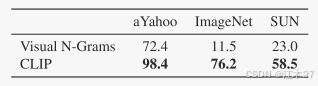
论文阅读:CLIP:Learning Transferable Visual Models From Natural Language Supervision
从自然语言监督中学习可迁移的视觉模型 虽然有点data/gpu is all you need的味道,但是整体实验和谈论丰富度上还是很多的,也是一篇让我多次想放弃的文章,因为真的是非常长的原文和超级多的实验讨论,隔着屏幕感受到了实验的工作量之…...
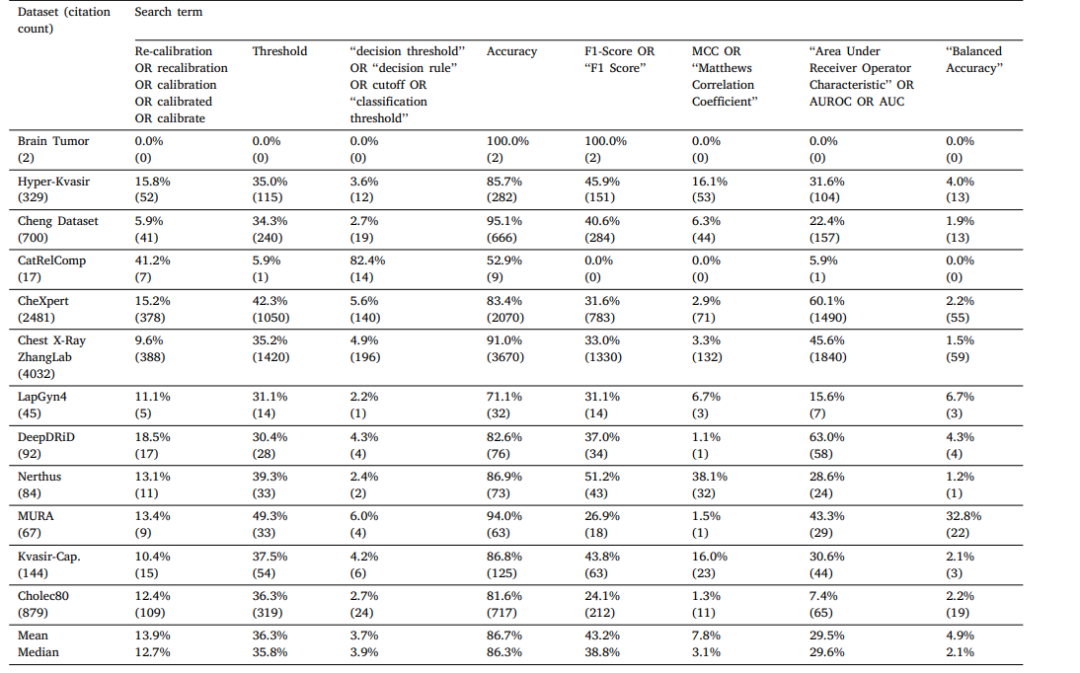
在图像分析算法部署中应对流行趋势的变化|文献速递-深度学习医疗AI最新文献
Title 题目 Navigating prevalence shifts in image analysis algorithm deployment 在图像分析算法部署中应对流行趋势的变化 01 文献速递介绍 机器学习(ML)已开始革新成像研究与实践的诸多领域。然而,医学图像分析领域存在显著的转化鸿…...
CAMEL-AI开源自动化任务执行助手OWL一键整合包下载
OWL 是由 CAMEL-AI 团队开发的开源多智能体协作框架,旨在通过动态智能体交互实现复杂任务的自动化处理,在 GAIA 基准测试中以 69.09 分位列开源框架榜首,被誉为“Manus 的开源平替”。我基于当前最新版本制作了免安装一键启动整合包。 CAMEL-…...

Selenium 中 JavaScript 点击的优势及使用场景
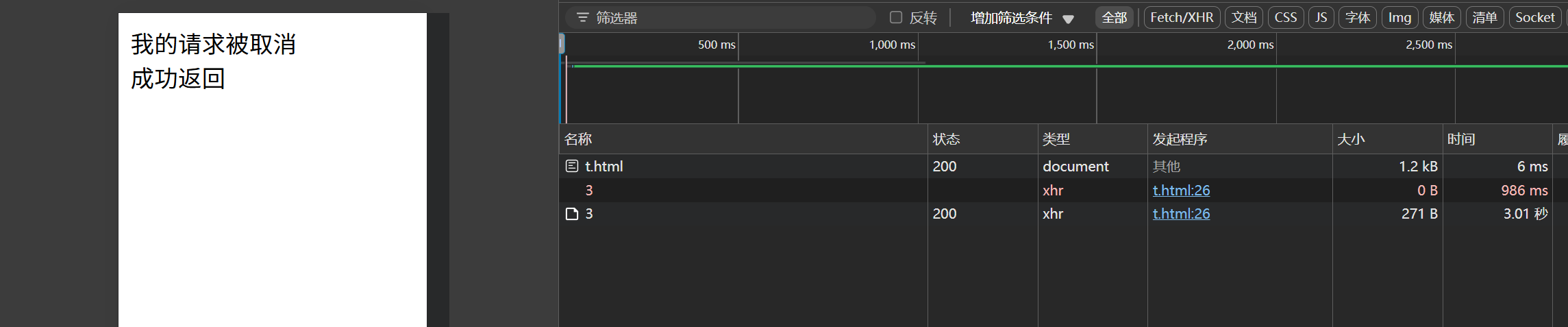
*在 Selenium 自动化测试中,使用 JavaScript 执行点击操作(如driver.execute_script("arguments[0].click();", element))相比直接调用element.click()有以下几个主要优势: 1. 绕过元素不可点击的限制 问题场景&#x…...
Linux系统-基本指令(5)
文章目录 mv 指令cat 指令(查看小文件)知识点(简单阐述日志)more 和 less 指令(查看大文件)head 和 tail 指令(跟查看文件有关)知识点(管道)时间相关的指令&a…...