IBM DB2分布式数据库架构
一、什么是分布式数据库架构
分布式数据库架构是现代数据库系统的重要发展方向,特别适合处理大规模数据、高并发访问和高可用性需求的应用场景。下面我们从原理、架构模式、关键技术、实现方式和常见产品几个方面来系统讲
1、分布式数据库的基本概念与原理
1. 什么是分布式数据库?
分布式数据库(Distributed Database)是指:
-
数据分布在多个物理节点上;
-
通过网络协调访问;
-
对外表现为一个整体、统一的数据库系统。
它的目标是:高性能、高可用、高扩展、容错性强,并保持与传统数据库相近的数据一致性。
2、分布式数据库的核心架构模式
1. Shared-Nothing 架构(无共享架构)✅主流
-
每个节点有独立的存储、计算资源;
-
节点间通过网络通信;
-
易扩展、故障隔离好;
-
举例:CockroachDB、TiDB、MongoDB、Elasticsearch。
2. Shared-Disk 架构(共享存储)
-
多个计算节点共享一套存储系统;
-
存储性能高、管理统一;
-
适合事务强一致性需求;
-
举例:Oracle RAC。
3. Shared-Memory 架构(共享内存)
-
多个进程/线程共享内存空间;
-
通常用于同一物理服务器的并发优化;
-
用于传统单机数据库中。
3、核心原理与关键技术
1. 数据分片(Sharding)
将大表水平或垂直拆分成多个分片,分别存储在不同节点。
-
水平分片:按行拆分(例如按用户ID取模)
-
垂直分片:按列拆分(例如将基础信息和交易信息分开)
2. 数据副本(Replication)
提高可用性,数据有多个副本。
-
主从复制(Master-Slave)
-
多主复制(Multi-Master)
-
Raft/Paxos一致性协议支持强一致性
3. 分布式事务
实现跨节点的数据一致性。
-
两阶段提交(2PC)
-
三阶段提交(3PC)
-
基于Paxos/Raft等强一致协议的分布式共识机制
4. 数据一致性模型
-
强一致性(Linearizability)
-
最终一致性(Eventual Consistency)
-
可调一致性(如 Cassandra 的 Consistency Level)
5. 全局查询优化器 & 执行引擎
在多个节点执行 SQL,需要:
-
全局查询解析 ➜ 分发子任务
-
子查询在各节点并行执行
-
合并汇总结果
4、实现方式
1. 基于中间件的分布式数据库(“分布式网关”)
-
中间件分片 SQL、转发到后端数据库节点
-
常用产品:
-
ShardingSphere
-
MyCat
-
Vitess
-
优点:使用现有数据库,无需改动底层
缺点:事务支持弱,运维复杂
2. 原生分布式数据库(从底层设计为分布式)
-
底层支持分片、副本、分布式事务
-
更强的一致性与高可用支持
典型产品:
-
TiDB(兼容 MySQL,HTAP)
-
CockroachDB(兼容 PostgreSQL,强一致性)
-
YugabyteDB(支持 PostgreSQL 接口)
-
Google Spanner(全球同步、全球唯一主键)
3. 分布式 NoSQL 数据库
-
强调可扩展性和最终一致性
-
通常放弃事务支持
-
如:Cassandra、MongoDB、HBase
5、一个简化的实现思路(以 TiDB 为例)
-
TiDB Server(SQL 层):接收 SQL 请求,解析优化,生成执行计划
-
Placement Driver(PD):集群管理、调度器,负责分片元数据管理
-
TiKV(KV 存储层):分片存储数据,每个分片有多个副本
-
Raft 共识协议:用于副本之间的一致性同步
-
TiFlash(列存):支持分析型查询(OLAP)
6、实际使用中的关键考量
| 关键点 | 说明 |
|---|---|
| CAP 原则 | 分布式系统在一致性、可用性、分区容错性三者不可兼得 |
| 扩展性 | 节点数量能否线性扩展,是否存在瓶颈 |
| 容灾能力 | 异地多活、灾难恢复、数据备份机制 |
| 运维复杂度 | 数据迁移、扩容缩容、监控告警等工具是否健全 |
| SQL 支持 | 是否完全兼容标准 SQL,是否支持事务 |
7、常见分布式数据库产品对比
| 产品 | 架构类型 | 是否强一致性 | 兼容接口 | 特点 |
|---|---|---|---|---|
| TiDB | 原生分布式 | ✅ 强一致性 | MySQL | HTAP 混合负载,国产化支持 |
| CockroachDB | 原生分布式 | ✅ 强一致性 | PostgreSQL | 全球部署方便,强事务一致性 |
| YugabyteDB | 原生分布式 | ✅ 强一致性 | PostgreSQL | 多数据中心支持,容器化部署好 |
| MongoDB | NoSQL | ❌ 最终一致性 | 自有接口 | 文档存储,开发友好 |
| Cassandra | NoSQL | ❌ 最终一致性 | 自有接口 | 超强写入能力,大规模可扩展性 |
二、IBM DB2的分布式支持能力
IBM Db2 支持一定程度上的分布式数据库架构,但它的设计理念与那些“原生为分布式而生”的数据库(如 TiDB、CockroachDB)不同。我们需要区分几个关键概念来正确理解 Db2 在“分布式”方面的能力。
1、Db2 的分布式支持能力概述
| 分布式特性 | Db2 是否支持 | 说明 |
|---|---|---|
| 跨节点查询(联邦查询) | ✅ 支持 | 通过 Db2 Federation 功能实现 |
| 数据分片(分布式表) | ❌ 非原生 | 不支持像 TiDB 那样自动分片的原生架构 |
| 复制(主从、多活) | ✅ 支持 | 通过 HADR、Q Replication 等 |
| 分布式事务 | ✅ 支持 | 通过两阶段提交(2PC)协议支持 |
| 分布式高可用 | ✅ 强 | HADR + TSA 实现 HA 和灾难恢复 |
| 原生无共享多节点分布式存储 | ❌ 不支持 | 不是 Shared-Nothing 架构 |
| 并行处理(MPP) | ✅ 支持 | 通过 Db2 Warehouse(MPP 引擎) 支持大数据分析 |
2、Db2 的主要“分布式能力”详解
1. 联邦数据库功能(Db2 Federation)
-
Db2 可以作为查询协调器(coordinator),访问多个异构数据源(包括其他 Db2、Oracle、SQL Server、甚至 MongoDB)。
-
通过
nickname创建远程表的别名,实现跨库联合查询。 -
支持 SQL 查询优化,智能路由到远程源。
用途:适用于数据整合场景,但性能取决于网络与远程源。
2. 分布式事务(2PC 支持)
-
Db2 支持两阶段提交协议(Two-Phase Commit,2PC),用于处理跨多个数据库节点的事务一致性。
-
常用于与 MQ、其他数据库系统的集成(如 WebSphere 中的 JTA 管理的事务)。
3. 高可用和灾难恢复(HADR)
-
HADR(High Availability Disaster Recovery) 提供主备机制,适用于高可用部署。
-
可搭配 TSA(Tivoli System Automation) 实现自动故障切换。
-
支持异地容灾、读写分离(备库可用于只读)。
4. Db2 Warehouse 与 MPP 架构(适用于大数据)
-
IBM 推出的 Db2 Warehouse on Cloud / on Premise 是基于 MPP(Massively Parallel Processing) 的架构,属于“类分布式”的数据仓库引擎。
-
多个处理节点共享存储,并在执行层面进行并行处理。
-
更接近于 Snowflake、Amazon Redshift 那种大数据分析架构。
3、Db2 的“分布式程度”总结
| 类型 | 说明 | 分布式级别 |
|---|---|---|
| Db2 LUW (Linux/Unix/Windows) | 企业级传统数据库,支持 HADR + 联邦查询 | ✅“逻辑分布式”支持,但非原生分布式数据库 |
| Db2 z/OS(大型机版) | 强事务保障,可与 LUW 联邦整合 | ✅ 支持 |
| Db2 Warehouse | MPP 架构,适合分析型大数据场景 | ✅ 接近原生分布式分析系统 |
| 原生分布式数据库(如 TiDB) | 从架构底层就为分布式设计(分片、副本、协调器) | ✅ 全分布式,架构本身就是 Shared-Nothing |
4、使用IBM BAW+DB的建议
如果使用 IBM BAW + DB2,当前场景大多是事务型工作流系统,Db2 的 HADR 和联邦功能就足够使用。但如果未来考虑:
-
更大规模的数据增长、
-
多地区分布式部署、
-
读写压力过大、
那可以评估:
-
使用 Db2 Warehouse 做分析型数据支持;
-
或将冷数据分布式迁移到支持 HTAP 的 TiDB / ClickHouse;
-
或通过 Federation 与云数据库集成。
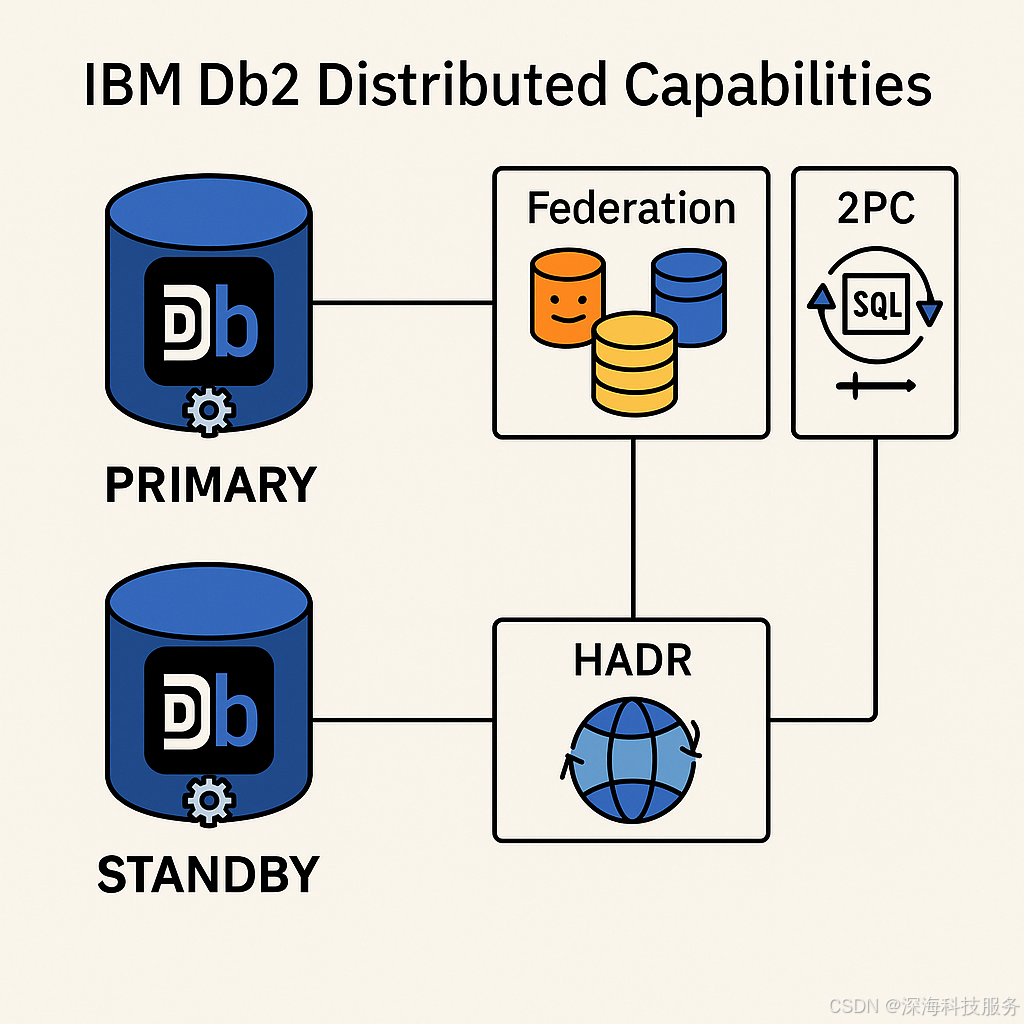
-
主备(HADR)
-
联邦查询(Federation)
-
分布式事务(2PC)
-
与 BAW、MQ 的整合
三、IBM Db2 pureScale
IBM Db2 pureScale 是 IBM 专门为实现高可用、高并发和分布式数据库架构而设计的组件,适用于 OLTP(在线事务处理)系统,可以理解为 Db2 实现“类分布式架构”的核心方案之一。
1、什么是 Db2 pureScale?
Db2 pureScale 是基于 共享磁盘 + 集群 架构(Shared-Disk Architecture)的一种高可用并行数据库集群方案,其核心目标是:
实现单一数据库实例的并行扩展、事务一致性、高可用性,适用于大规模 OLTP 工作负载。
它最接近于 Oracle RAC(Real Application Clusters)架构。
2、pureScale 架构概览
✅ 关键组件:
| 组件 | 功能 |
|---|---|
| 成员节点(Members) | 负责处理 SQL、事务执行(相当于并发数据库实例) |
| CF(Cluster Caching Facility) | 管理全局缓存、锁定和一致性协调,保持全局事务一致 |
| 共享存储(SAN、GPFS) | 所有成员共享访问数据 |
| TSA(Tivoli System Automation) | 故障检测与自动故障转移 |
所有节点访问同一个共享数据文件系统,CF 协调缓存一致性,确保数据完整性。
3、与“原生分布式数据库”的区别
| 特性 | Db2 pureScale | 原生分布式数据库(如 TiDB) |
|---|---|---|
| 架构类型 | Shared-Disk + 全局缓存 | Shared-Nothing(无共享架构) |
| 数据存储 | 所有节点共享底层数据文件 | 每个节点持有部分数据(分片) |
| 扩展方式 | 增加成员节点 + CF | 增加分片节点 + 复制节点 |
| 一致性支持 | 强一致性,事务原生支持 | Raft/Paxos 实现强一致性或最终一致性 |
| 部署复杂度 | 较高,需要共享存储、CF 组件等配置 | 相对灵活,支持云原生部署 |
✅ 总结:
-
pureScale 适合对 高一致性、高事务安全性 要求极高的银行、电信、保险等场景;
-
它不是为互联网量级数据扩展而设计的,不具备自动分片和多地分布式部署能力。
4、pureScale 的典型场景
-
银行核心交易系统
-
金融结算平台
-
电信计费系统
-
对 ACID 强一致性要求高的大型 OLTP 应用
5、简要部署结构图(文字描述)
+------------------+| Application |+--------+---------+|+--v--+ +--v--+ +--v--+| DB1 | ... | DB2 | ... | DBn | ← 多个 pureScale 成员节点+--+--+ +--+--+ +--+--+| | |+--v-----------v-----------v--+| Cluster Caching Facility (CF) |+-----------------------------+|+-----------------------------+| Shared Storage (GPFS) |+-----------------------------+
6、总结
| 是否分布式 | ✅ 是(一种 Shared-Disk 分布式集群) |
|---|---|
| 是否自动分片 | ❌ 否 |
| 事务支持 | ✅ 强事务一致性 |
| 扩展能力 | ✅ 并发处理扩展强,但横向扩展受限 |
| 部署复杂度 | 较高,需要共享存储 + CF + TSA 配合 |
四、pureScale 如何与 BAW 结合使用实现高可用性
IBM Db2 pureScale 与 IBM Business Automation Workflow (BAW) 结合使用时,可以为 BAW 系统提供高可用性和故障恢复能力,确保在遇到硬件故障、网络中断或其他系统故障时,系统依然能够持续运行,并保证数据一致性和事务可靠性。
以下是 Db2 pureScale 与 BAW 集成实现高可用性的主要机制和步骤:
1、Db2 pureScale 与 BAW 集成概述
1. Db2 pureScale 的高可用性架构
Db2 pureScale 采用共享磁盘架构,所有数据库节点共享一个统一的存储系统(如 GPFS、SAN)。通过 Cluster Caching Facility (CF) 实现全局一致性和缓存同步,确保多个数据库节点上的数据一致性。
2. BAW 的高可用性需求
BAW(IBM Business Automation Workflow)要求数据库具有高可用性、事务一致性、容错性。通过 Db2 pureScale 提供的高可用性特性,BAW 系统在数据库级别实现容错。
3. 结合方式
当 BAW 的数据库使用 Db2 pureScale 时:
-
BAW 与 Db2 pureScale 的数据库节点直接通信,保证事务的高可用性。
-
BAW 通过与 Db2 的连接池(如 Db2 JDBC、ODBC)进行交互,支持应用层面自动切换到备用节点(Failover)。
-
结合 Tivoli System Automation (TSA) 实现自动化故障转移(Failover),确保 BAW 系统可以在 Db2 节点故障时平滑迁移到备用节点。
2、关键技术与工作原理
1. 高可用性架构
在 pureScale 集群中,多个数据库节点(Members)与 Cluster Caching Facility (CF) 组件共同工作,保证数据一致性和容错能力。CF 确保各节点的数据缓存保持同步,并处理全局锁和事务一致性。
-
节点故障恢复:如果某个数据库节点发生故障,系统会通过 TSA(Tivoli System Automation)自动将负载转移到其他健康节点。
-
应用自动恢复:应用(如 BAW)在与数据库的连接池交互时,可以配置多个节点进行容错。即使某个节点不可用,应用可以无缝地切换到其他节点。
2. 自动故障转移
Db2 pureScale 与 TSA 配合使用,提供自动故障检测与自动故障切换功能:
-
当某个节点发生故障时,TSA 会立即通知 BAW 系统切换到备用节点。
-
BAW 不需要手动干预,即可恢复正常运行。
3. 数据库连接池与负载均衡
BAW 系统的数据库连接池配置可以支持多个 Db2 节点的连接。当 BAW 进行数据库操作时,连接池会根据负载均衡策略选择一个可用节点。如果当前节点不可用,连接池会自动切换到另一个健康节点。
4. 事务一致性和高并发
通过 Db2 pureScale 的强一致性保障,BAW 系统能够确保跨多个节点执行的事务能够保持一致。无论是跨多个工作流实例还是多个用户的事务,都会在 Db2 pureScale 中实现强一致性和高并发处理。
5. 灾备与备份支持
-
Db2 pureScale 支持多活部署和灾难恢复,BPM 系统(BAW)可以通过自动化备份和恢复机制确保在灾难发生时尽可能短的恢复时间。
-
可以将纯数据(如任务历史记录、附件等)存储在分布式环境中,保证业务流程的连续性。
3、Db2 pureScale 与 BAW 集成的典型部署架构
1.BAW 应用服务器(部署在多台服务器上,负载均衡)
-
提供与用户的交互,处理流程和任务。
2.Db2 pureScale 集群(包含多个数据库节点)
-
提供高可用性数据库支持。
-
通过 Cluster Caching Facility (CF) 和 Tivoli System Automation (TSA) 进行故障转移和容错。
3.Tivoli System Automation (TSA)
-
监控数据库节点,自动发现故障并将负载转移到其他健康节点。
-
确保数据库故障时,BAW 系统仍可保持业务连续性。
4.负载均衡器
-
在 BAW 应用与数据库之间提供负载均衡,确保请求均匀分布。
-
支持数据库节点的自动切换,避免单点故障。
4、总结:Db2 pureScale 提供的高可用性与 BAW 的协作
| 特性 | 描述 |
|---|---|
| 高可用性 | 通过 Db2 pureScale 的 Cluster Caching Facility 和 TSA 实现自动故障转移和容错 |
| 事务一致性 | 保证 BAW 中跨节点的事务一致性,避免数据丢失或不一致 |
| 负载均衡 | 使用数据库连接池与负载均衡器,自动切换到备用节点 |
| 自动恢复 | 在数据库节点故障时,BAW 系统能够自动切换到其他健康节点,保证系统无缝恢复 |
| 灾备支持 | BAW 数据库部署可以通过 Db2 pureScale 的灾备机制实现多活和数据备份,保证灾难恢复能力 |
这个架构可以确保你的 BAW 系统在面对数据库节点故障时依然能正常运行,并且实现了零停机和最小恢复时间。
五、如何将 IBM Db2 pureScale 与 IBM Business Automation Workflow (BAW) 集成
下面的操作指南将说明如何将 IBM Db2 pureScale 与 IBM Business Automation Workflow (BAW) 集成,以实现高可用性和自动故障转移。
1、架构需求与前提条件
-
IBM Db2 pureScale 集群已经搭建完成,至少有两个数据库节点和一个 Cluster Caching Facility (CF) 节点。
-
IBM BAW 已经安装并运行,且使用 IBM Db2 作为数据库。
2、Db2 pureScale 与 BAW 集成步骤
1. 安装和配置 Db2 pureScale 集群
a. 安装 Db2 pureScale 软件
-
按照 IBM Db2 的官方安装指南来安装 Db2。在安装时,确保选择安装 Db2 pureScale 版本。
-
在安装过程中,你需要配置 Db2 集群的共享存储(如 GPFS 或 SAN)。
b. 配置 Db2 pureScale 集群
-
创建 pureScale 实例:
你需要在多个节点上启动 Db2 实例,并配置集群。db2start -
设置 Cluster Caching Facility (CF):
配置 CF 节点用于管理全局缓存和协调各个数据库节点的一致性。db2cluster -create -
配置 Db2 数据库:
在每个节点上配置数据库,使其能够在共享存储上进行读写。 -
配置故障转移和恢复策略:
使用 TSA(Tivoli System Automation) 来监控和管理节点的故障切换。-
在每个节点上启用 TSA,并配置相应的故障转移策略。
-
c. 配置数据库连接池与负载均衡
为确保 BAW 与 Db2 的高可用性,可以使用 负载均衡器 和 数据库连接池 来均匀分配请求。
-
配置数据库连接池,支持多个 Db2 节点。以下是一个基于 JDBC 的连接池配置示例:
<datasource><name>Db2DataSource</name><jdbcUrl>jdbc:db2://db2node1:50000,db2node2:50000/mydb</jdbcUrl><driverClassName>com.ibm.db2.jcc.DB2Driver</driverClassName><username>db2admin</username><password>password</password><maxActive>100</maxActive><maxIdle>20</maxIdle> </datasource>
2. 配置 BAW 连接到 Db2 pureScale
a. 配置 BAW 数据源
在 BAW 中,你需要配置数据库的数据源,以便 BAW 能够与 Db2 pureScale 进行通信。通过 BAW 的管理控制台,创建并配置连接到 Db2 的数据源。
-
登录到 BAW 管理控制台。
-
导航到 System Admin > Data Sources。
-
在 Data Source 页面,点击 New Data Source。
-
填写以下信息:
-
JDBC URL:
jdbc:db2://db2node1:50000,db2node2:50000/mydb -
JDBC Driver:选择
DB2驱动。 -
Username 和 Password:数据库的用户名和密码。
-
b. 配置自动故障转移(Failover)
在 BAW 中配置 数据库连接池,使其在数据库节点发生故障时能够自动切换。
-
如果 BAW 的数据库连接池使用 JDBC,可以设置多个节点(例如 db2node1, db2node2)并启用 failover。
在配置数据库连接时,确保开启 failover 功能,例如:
<jdbcUrl>jdbc:db2://db2node1:50000,db2node2:50000/mydb;failover=true</jdbcUrl>
3. 配置高可用性与灾难恢复
使用 Tivoli System Automation (TSA) 来实现故障自动切换。
1.安装 TSA:
-
在所有节点上安装 Tivoli System Automation。
-
配置 TSA 来监控 Db2 节点的健康状态。
2.设置自动故障转移:
配置 TSA,让它能够监控 Db2 的健康状态,并在节点发生故障时进行自动恢复。
/usr/sbin/tsahosts -add node1 node2 node3
这将定义一个包含三个节点的集群,TSA 会监控这些节点并在故障发生时执行自动故障转移。
-
使用
TSA命令行工具配置故障转移策略。例如,使用TSA配置文件定义节点故障时的切换行为。
3.测试高可用性:
手动关闭某个 Db2 节点,验证系统是否能够成功切换到备用节点,并且 BAW 系统能够继续正常工作。
4. 监控与维护
使用 IBM Monitoring(如 Db2 Monitoring、Tivoli Monitoring)来监控 Db2 集群的状态和 BAW 系统的性能。
-
监控 Db2 pureScale 节点的健康状态。
-
监控数据库连接池的负载均衡状态。
你可以定期检查系统的运行状态,确保数据库的高可用性特性正常工作。
3、总结
集成流程:
-
部署 Db2 pureScale 集群,包括多个节点和 CF,设置故障转移和负载均衡。
-
在 BAW 系统中配置 JDBC 数据源,使用多个数据库节点。
-
配置 TSA 实现 Db2 集群的自动故障转移,确保高可用性。
-
配置数据库连接池,启用 failover 功能,确保 BAW 在数据库节点故障时自动切换。
配置检查:
-
确保数据库连接池的故障转移和负载均衡策略正确配置。
-
测试故障转移机制,验证在数据库节点发生故障时,BAW 系统是否能够继续运行。
-
监控集群的运行状态,确保系统始终保持高可用性。
六、数据联邦(Data Federation) 和 Db2 pureScale
数据联邦(Data Federation) 和 Db2 pureScale 都是 IBM 提供的技术,但它们的目标和应用场景不同。它们解决的问题、实现的方式以及适用的场景各有差异。以下是这两者的对比与区别:
1、定义与核心目标
1. 数据联邦(Data Federation)
数据联邦 是一种技术架构,它允许来自不同数据库系统的数据在应用程序层进行整合和查询,而不需要将数据物理地移动或复制到单一存储位置。数据联邦使得应用程序可以跨多个数据库、文件系统和外部数据源查询,实现虚拟化数据访问。
-
目标:整合异构数据库,提供统一的数据查询接口,而无需数据物理整合。
-
技术组件:包括数据库连接、数据映射、查询解析器等,用于跨多个数据源查询和合并结果。
-
常见场景:当数据分散在多个异构系统中(例如 Db2、Oracle、SQL Server、NoSQL 数据库等),而你不希望或者不能将数据合并到单一系统中时,数据联邦是一种有效的方案。
2. Db2 pureScale
Db2 pureScale 是 IBM 提供的一个高可用、可扩展的数据库集群架构,旨在为企业级应用提供强一致性、高可用性和高并发的数据库支持。它基于 共享磁盘架构,所有节点共享同一个存储系统,通过 Cluster Caching Facility (CF) 实现全局一致性和高并发事务处理。
-
目标:提供一个高可用、强一致性和高并发的分布式数据库架构,支持 OLTP(在线事务处理)工作负载。
-
技术组件:Db2 节点、Cluster Caching Facility (CF)、Tivoli System Automation (TSA) 等。
-
常见场景:高事务一致性要求的应用,适合金融、电信等对数据一致性和可用性要求极高的场景。
2、核心区别与对比
| 特性/维度 | 数据联邦(Data Federation) | Db2 pureScale |
|---|---|---|
| 架构 | 虚拟化层架构,多个数据源联合查询 | 高可用、高并发的分布式数据库集群架构 |
| 数据存储 | 不需要物理存储合并,数据源分散在各个数据库中 | 所有节点共享底层存储,数据在物理层进行存储和访问 |
| 一致性 | 基于查询层面的联邦查询,不提供强一致性保障 | 强一致性,使用 Cluster Caching Facility (CF) 实现数据一致性 |
| 扩展性 | 查询扩展,但不支持数据存储扩展,数据源无法自动分片 | 支持数据库节点横向扩展,通过共享存储扩展处理能力 |
| 使用场景 | 跨多个异构数据库进行查询整合,适用于数据整合、虚拟化查询 | 高事务负载、高并发数据库应用,适用于 OLTP 系统 |
| 故障恢复 | 没有原生的故障恢复机制,取决于各数据源的容错能力 | 支持自动故障转移和高可用性,容错能力强 |
| 性能优化 | 数据查询优化依赖于各个数据源的性能,性能瓶颈可能出现在数据源之间的网络延迟 | 高并发处理能力,优化事务性能,支持大规模在线事务 |
| 数据迁移 | 不涉及数据的迁移或复制,仅通过查询接口访问不同数据源 | 支持数据在多个节点间共享与同步,具备强一致性 |
3、实际应用场景对比
数据联邦的应用场景:
1.异构数据库整合:
-
企业可能使用多种数据库(如 Db2、Oracle、MySQL、NoSQL 等),需要在应用中统一查询这些不同的数据源,避免将所有数据迁移到同一数据库系统。
-
例如,一个数据分析平台可能需要从多个业务系统(如 Oracle 和 Db2)中获取数据,并进行联合查询。
2.数据虚拟化:
-
当数据源非常分散,且不适合物理迁移时,数据联邦可以为应用程序提供虚拟化的数据访问。
-
例如,某些应用需要实时访问多个数据库中的最新数据,但不希望使用传统 ETL 工具将数据迁移到同一数据库。
Db2 pureScale 的应用场景:
1.高可用性和高并发事务系统:
-
适用于需要高事务一致性、高并发的应用,如金融系统、电信计费系统等。
-
例如,一个在线银行系统可能需要在多个节点之间处理大量并发事务,确保在发生故障时能够自动恢复。
2.大规模 OLTP 系统:
-
对数据库的性能和可用性有极高要求,尤其是对于需要保持数据一致性的大规模在线事务处理(OLTP)系统。
-
例如,大型电商平台、在线支付平台等。
4、总结
| 特性 | 数据联邦 | Db2 pureScale |
|---|---|---|
| 主要功能 | 数据源的虚拟化查询与整合 | 高可用、高并发、强一致性数据库集群 |
| 目标应用场景 | 多数据源联合查询、数据虚拟化 | 高事务一致性要求的高并发事务系统 |
| 数据存储 | 数据存储分散在不同的数据源 | 数据在所有节点间共享,存储统一 |
| 一致性 | 查询层面的最终一致性 | 强一致性,确保跨节点事务一致性 |
| 扩展性 | 不支持数据存储扩展,仅查询层扩展 | 支持节点横向扩展,适用于大规模应用 |
| 故障恢复 | 依赖于各数据源的故障恢复 | 自动故障转移,高可用性 |
总结:
-
数据联邦 适合异构系统数据整合,通过虚拟化查询访问多个数据源,而不涉及数据物理存储合并。
-
Db2 pureScale 适合对高可用、高并发和强一致性要求高的事务型应用,提供了一个分布式的数据库集群架构。
相关文章:
IBM DB2分布式数据库架构
一、什么是分布式数据库架构 分布式数据库架构是现代数据库系统的重要发展方向,特别适合处理大规模数据、高并发访问和高可用性需求的应用场景。下面我们从原理、架构模式、关键技术、实现方式和常见产品几个方面来系统讲 1、分布式数据库的基本概念与原理 1. 什…...
)
初始化已有项目仓库,推送远程(Git)
初始化Git仓库(如果还没初始化) git init 添加并提交文件 git add . ("."表示当前项目所有文件) git commit -m “first commit” 关联远程仓库(如果还没关联) git remote add origin http://xxxxxxxx 推送代码 …...
Android Studio 向模拟器手机添加照片、视频、音乐
Android Studio 向模拟器手机添加照片、视频、音乐(其实都是一样的,只是添加到不同的文件夹),例如我们在很多程序中功能例如:选择头像,跳转到手机相册选择头像,此时相册为空,即模拟器没有图片资…...
数据结构-算法学习C++(入门)
目录 03二进制和位运算04 选择、冒泡、插入排序05 对数器06 二分搜索07 时间复杂度和空间复杂度08 算法和数据结构09 单双链表09.1单双链表及反转09.2合并链表09.2两数相加09.2分隔链表 013队列、栈、环形队列013.1队列013.2栈013.3循环队列 014栈-队列的相互转换014.1用栈实现…...

访谈 | 吴恩达全景解读 AI Agents 发展现状:多智能体、工具生态、评估体系、语音栈、Vibe Coding 及创业建议一文尽览
在最新的 LangChain Interrupt 大会上(2025),LangChain 联合创始人 & CEO Harrison Chase 与吴恩达(Andrew Ng)就 AI Agnets 的发展现状,进行了一场炉边谈话。 吴恩达回顾了与 LangChain 的渊源&#…...
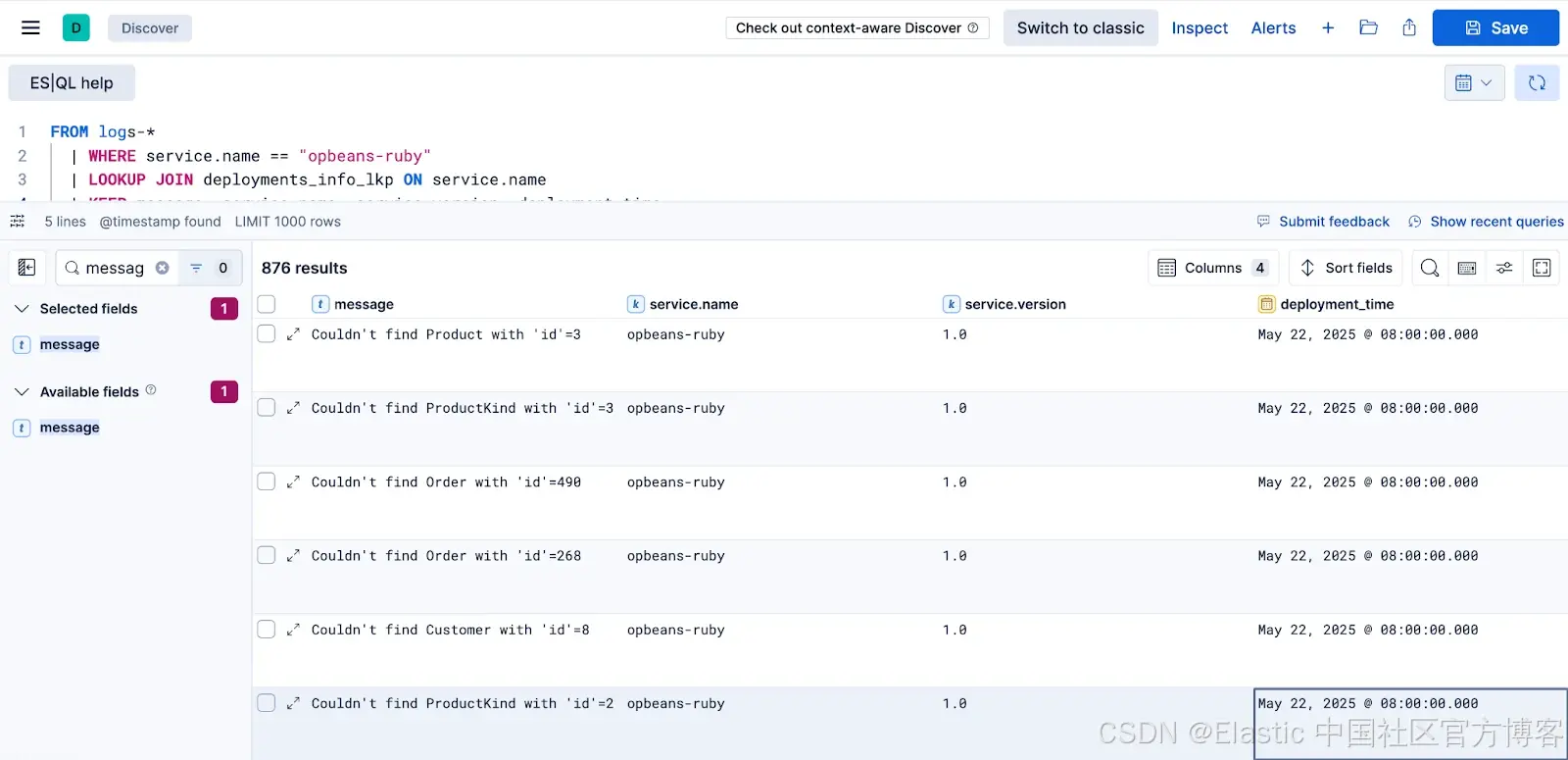
连接关键点:使用 ES|QL 联接实现更丰富的可观测性洞察
作者:来自 Elastic Luca Wintergerst ES|QL 的 LOOKUP JOIN 现已进入技术预览阶段,它允许你在查询时对日志、指标和追踪进行丰富处理,无需在摄取时进行非规范化。动态添加部署、基础设施或业务上下文,减少存储占用,加速…...

Tiktok App 登录账号、密码、验证码 XOR 加密算法
抖音 App 登录账号、密码、验证码 XOR 加密算法% E9 n z, \& R1 a4 b. ^ 流程分析 登录 Tiktok APP 时,通过抓包发现账号密码是非明文传输的。 <?php// http://xxx.xx.x.x.x/tiktok/$tiktok new TikTokClient();$userId 7212597544604484614; $secUid …...
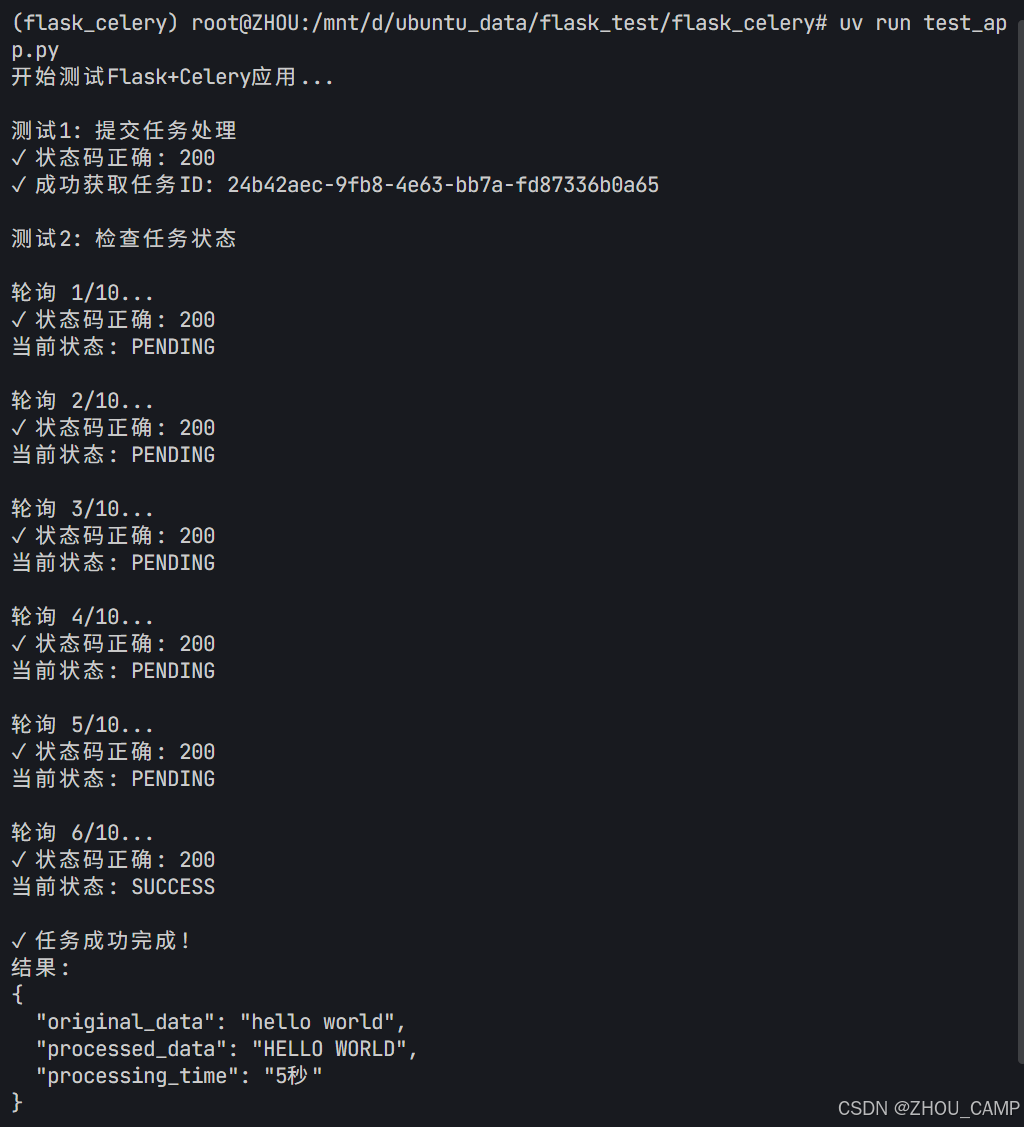
Flask + Celery 应用
目录 Flask Celery 应用项目结构1. 创建app.py2. 创建tasks.py3. 创建celery_worker.py4. 创建templates目录和index.html运行应用测试文件 Flask Celery 应用 对于Flask与Celery结合的例子,需要创建几个文件。首先安装必要的依赖: pip install flas…...

奥威BI+AI数据分析:企业数智化转型的加速器
在当今数据驱动的时代,企业对于数据分析的需求日益增长。奥威BIAI数据分析的组合,正成为众多企业数智化转型的加速器。 奥威BI以其强大的数据处理和可视化能力著称。它能够轻松接入多种数据源,实现数据的快速整合与清洗。通过内置的ETL工具&…...
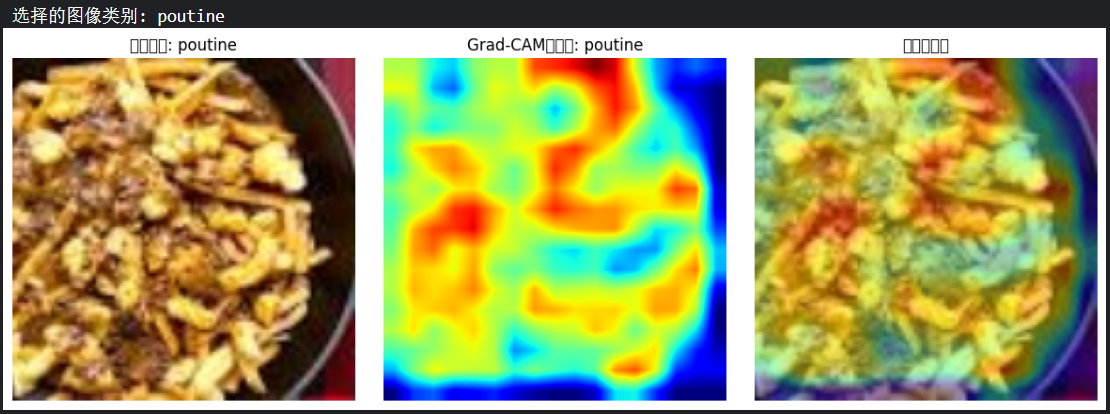
python打卡day43
复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 找了个街头食物图像分类的数据集Popular Street Foods(其实写代码的时候就开始后悔了),原因在于&…...

MySQL 如何判断某个表中是否存在某个字段
在MySQL中,判断某个表中是否存在某个字段,可以通过查询系统数据库 INFORMATION_SCHEMA.COLUMNS 实现。以下是详细步骤和示例: 方法:使用 INFORMATION_SCHEMA.COLUMNS 通过查询系统元数据表 COLUMNS,检查目标字段是否存…...

Linux --进程优先级
概念 什么是进程优先级,为什么需要进程优先级,怎么做到进程优先级这是本文需要解释清楚的。 优先级的本质其实就是排队,为了去争夺有限的资源,比如cpu的调度。cpu资源分配的先后性就是指进程的优先级。优先级高的进程有优先执行的…...
安装和配置 Nginx 和 Mysql —— 一步一步配置 Ubuntu Server 的 NodeJS 服务器详细实录6
前言 昨天更新了四篇博客,我们顺利的 安装了 ubuntu server 服务器,并且配置好了 ssh 免密登录服务器,安装好了 服务器常用软件安装, 配置好了 zsh 和 vim 以及 通过 NVM 安装好Nodejs,还有PNPM包管理工具 。 作为服务器的运行…...

Linux 测试本机与192.168.1.130 主机161/udp端口连通性
Linux 测试本机与 192.168.1.130 主机 161/UDP 端口连通性 161/UDP 端口是 SNMP(简单网络管理协议)的标准端口。以下是多种测试方法: 🛠️ 1. 使用 nmap 进行专业测试(推荐) sudo nmap -sU -p 161 -Pn 1…...

OpenCV 滑动条调整图像亮度
一、知识点 1、int createTrackbar(const String & trackbarname, const String & winname, int * value, int count, TrackbarCallback onChange 0, void * userdata 0); (1)、创建一个滑动条并将其附在指定窗口上。 (2)、参数说明: trackbarname: 创建的…...
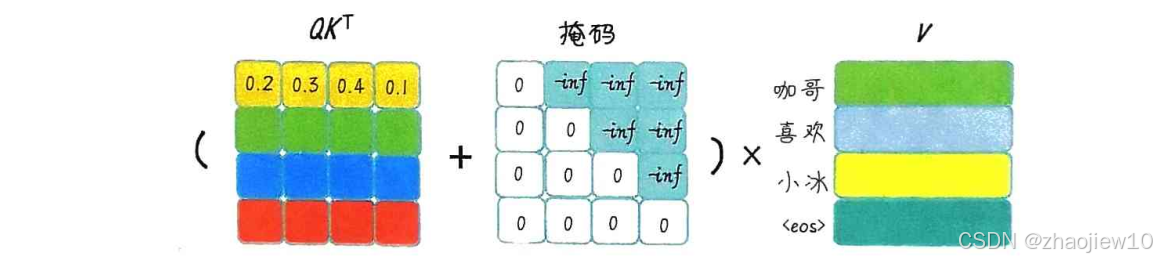
图解gpt之注意力机制原理与应用
大家有没有注意到,当序列变长时,比如翻译一篇长文章,或者处理一个长句子,RNN这种编码器就有点力不从心了。它把整个序列信息压缩到一个固定大小的向量里,信息丢失严重,而且很难记住前面的细节,特…...

硬件学习笔记--65 MCU的RAM及FLash简介
MCU(微控制器单元)内部的 RAM 和 Flash 是最关键的两种存储器,它们直接影响MCU的性能、功耗和编程方式。以下是它们的详细讲解及作用: 1. RAM(随机存取存储器) 1.1 特性 1)易失性:…...

【Oracle】视图
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 视图基础概述1.1 视图的概念与特点1.2 视图的工作原理1.3 视图的分类 2. 简单视图2.1 创建简单视图2.1.1 基本简单视图2.1.2 带计算列的简单视图 2.2 简单视图的DML操作2.2.1 通过视图进行INSERT操作2.2.2 通…...
 与 MySQL (SQL) 的写法对比)
数据库 MongoDB (NoSQL) 与 MySQL (SQL) 的写法对比
MongoDB (NoSQL) 与 MySQL (SQL) 的写法对比及优劣势分析 基本概念差异 MySQL/SQL:关系型数据库,使用结构化查询语言(SQL),数据以表格形式存储,有预定义的模式(schema)MongoDB/NoSQL:文档型数据库,无固定…...

基于粒子滤波的PSK信号解调实现
基于粒子滤波的PSK信号解调实现 一、引言 相移键控(PSK)是数字通信中广泛应用的调制技术。在非高斯噪声和动态相位偏移环境下,传统锁相环(PLL)性能受限。粒子滤波(Particle Filter)作为一种序列蒙特卡洛方法,能有效处理非线性/非高斯系统的状态估计问题。本文将详细阐…...

更强劲,更高效:智源研究院开源轻量级超长视频理解模型Video-XL-2
长视频理解是多模态大模型关键能力之一。尽管OpenAI GPT-4o、Google Gemini等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。近日,智源研究院联合上海交通大学等机构,正式发布新一代超长视…...

2025.6.3学习日记 Nginx 基本概念 配置 指令 文件
1.初始nginx Nginx(发音为 “engine x”)是一款高性能的开源 Web 服务器软件,同时也具备反向代理、负载均衡、邮件代理等功能。它由俄罗斯工程师 Igor Sysoev 开发,最初用于解决高并发场景下的性能问题,因其轻量级、高…...
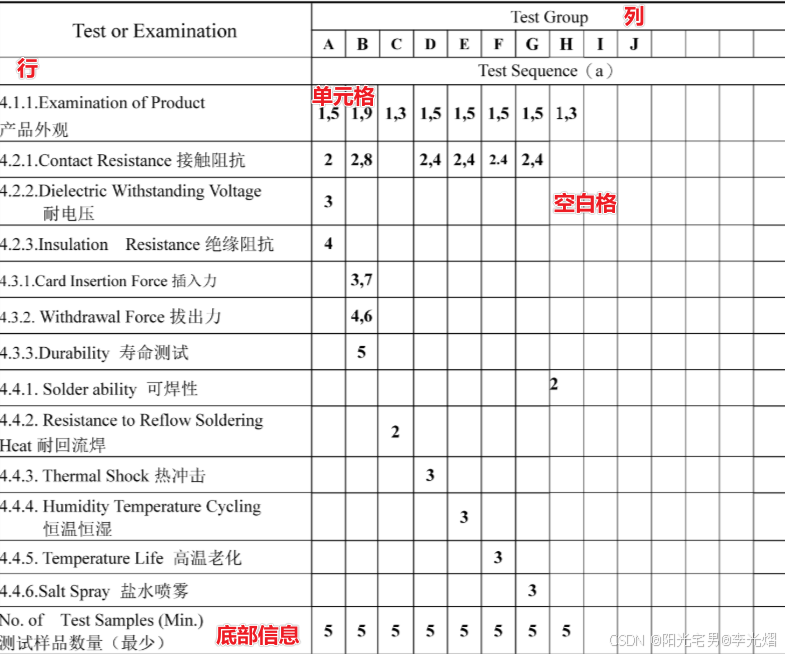
【连接器专题】案例:产品测试顺序表解读与应用
在查看SD卡座连接器的规格书,一些测试报告时,你可能会看到如下一张产品测试顺序表。为什么会出现一张测试顺序表呢? 测试顺序表的使用其实定义测试环节的验证的“路线图”和“游戏规则”,本文就以我人个经验带领大家一起看懂这张表并理解其设计逻辑。 测试顺序表结构 测试…...

星动纪元的机器人大模型 VPP,泛化能力效果如何?与 VLA 技术的区别是什么?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 VPP 利用了大量互联网视频数据进行训练,直接学习人类动作,减轻了对于高质量机器人真机数据的依赖,且可在不同人形机器人本体之间自如切换,这有望…...

4000万日订单背后,饿了么再掀即时零售的“效率革命”
当即时零售转向价值深耕,赢面就是综合实力的强弱。 文|郭梦仪 编|王一粟 在硝烟弥漫的外卖行业“三国杀”中,饿了么与淘宝闪购的日订单量竟然突破了4000万单。 而距淘宝闪购正式上线,还不到一个月。 在大额福利优惠…...
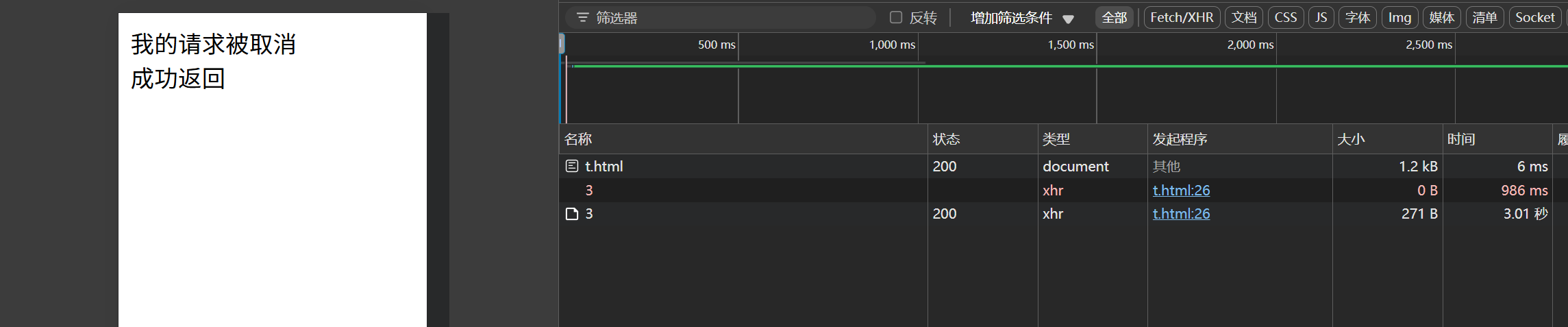
入门AJAX——XMLHttpRequest(Get)
一、什么是 AJAX AJAX Asynchronous JavaScript And XML(异步的 JavaScript 和 XML)。 1、XML与异步JS XML: 是一种比较老的前后端数据传输格式(已经几乎被 JSON 代替)。它的格式与HTML类似,通过严格的闭合自定义标…...

5分钟申请edu邮箱【方案本周有效】
这篇文章主要展示的是成果。如果你是第1次看见我的内容,具体的步骤请翻看往期的两篇作品。先看更正补全,再看下一个。 建议你边看边操作。 【更正补全】edu教育申请通过方案 本周 edu教育邮箱注册可行方案 #edu邮箱 伟大无需多言 我已经验证了四个了…...
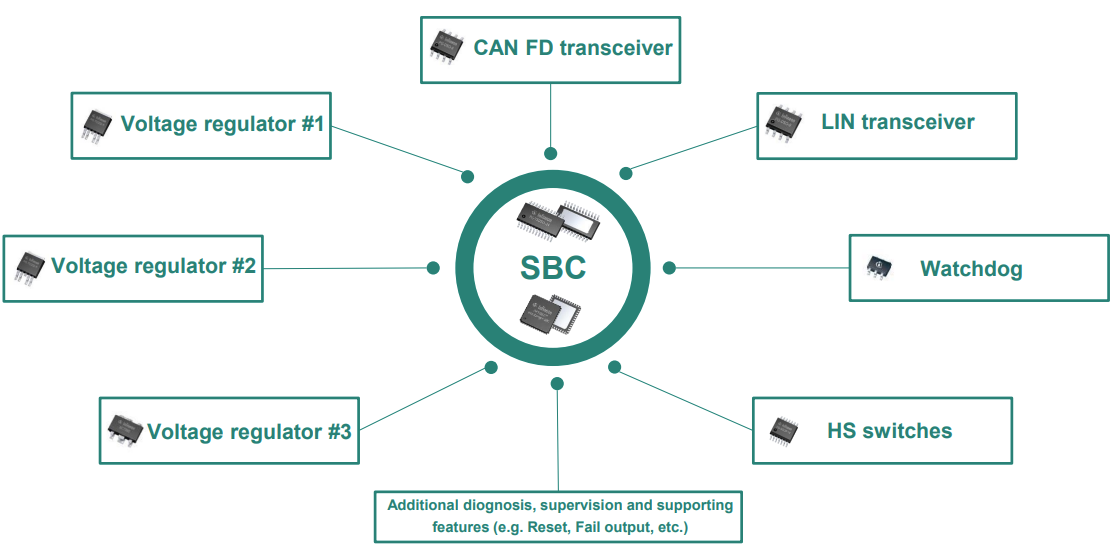
闲谈PMIC和SBC
今天不卷,简单写点。 在ECU设计里,供电芯片选型是逃不开的话题,所以聊聊PMIC或者SBC的各自特点,小小总结下。 PMIC,全称Power Management Intergrated Circuits,听名字就很专业:电源管理&…...
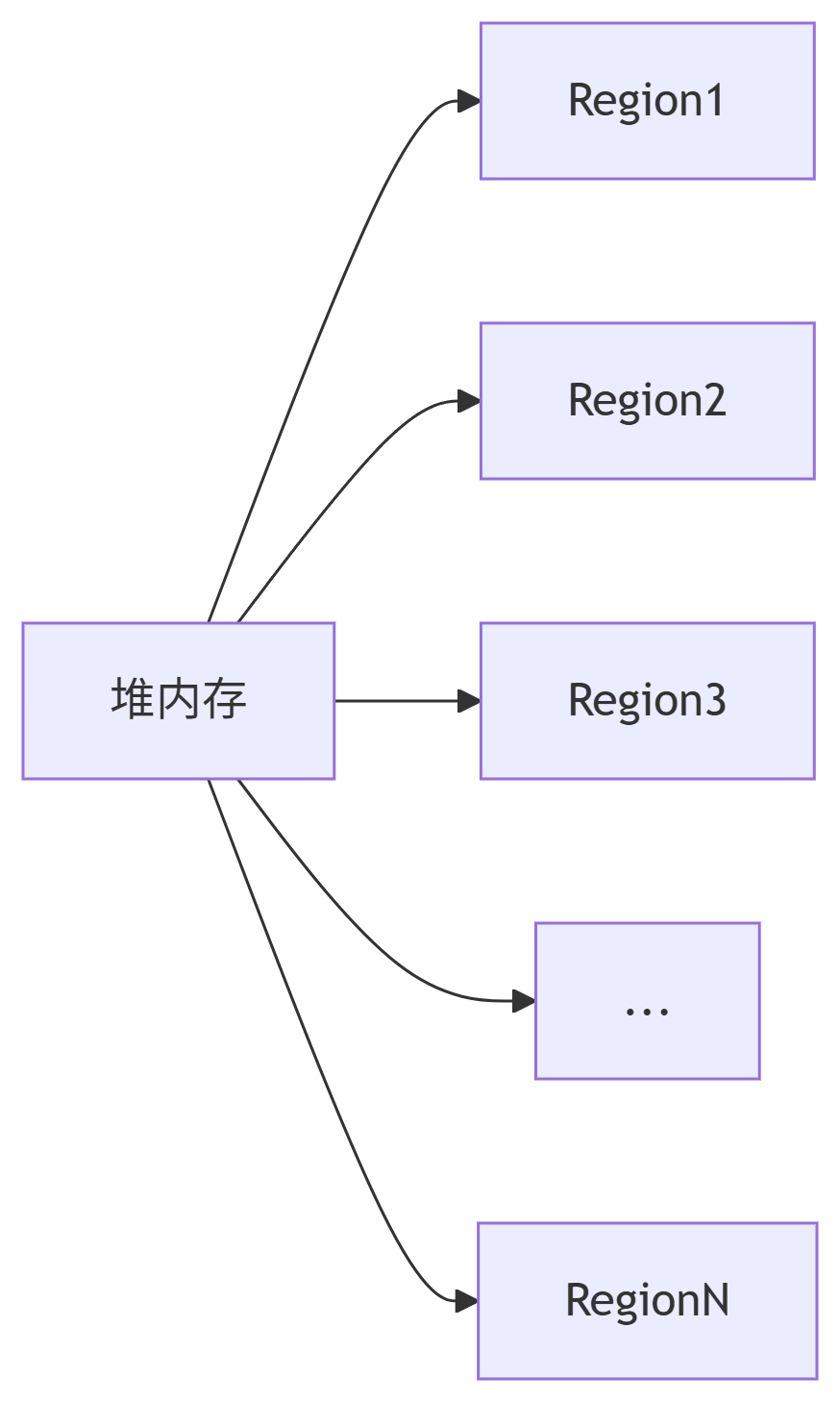
Java垃圾回收机制深度解析:从理论到实践的全方位指南
Java垃圾回收(GC)是Java虚拟机(JVM)的核心功能,它自动管理内存分配与回收,避免了C/C中常见的内存泄漏问题。本文将深入剖析Java垃圾回收的工作原理、算法实现、收集器类型及调优策略,助你全面掌握JVM内存管理的精髓。 一、垃圾回收基础概念 …...

Ubuntu系统 | 本地部署ollama+deepseek
1、Ollama介绍 Ollama是由Llama开发团队推出的开源项目,旨在为用户提供高效、灵活的本地化大型语言模型(LLM)运行环境。作为Llama系列模型的重要配套工具,Ollama解决了传统云服务对计算资源和网络连接的依赖问题,让用户能够在个人电脑或私有服务器上部署和运行如Llama 3等…...