【学习笔记】On the Biology of a Large Language Model
On the Biology of a Large Language Model
1 Introduction
目标是对这些模型的内部工作机制进行逆向工程,从而更好地理解它们,并评估它们是否适合特定用途。
正如细胞是生物系统的基本构建单元,我们假设特征是模型内部计算的基本单位。仅仅识别出这些构建单元还不足以理解模型;还需要知道它们之间是如何相互作用的。
本文主要依赖一种称为“归因图(attribution graphs)”的工具,它可以部分追踪模型将特定输入提示转化为输出响应所经历的中间计算步骤。归因图可以生成关于模型使用机制的假设,随后通过干预实验来验证并改进这些假设。
本文专注于使用归因图来研究一个特定的语言模型 —— Claude 3.5 Haiku。我们研究了各种各样的现象,其中许多在之前已有相关研究(见第16节“相关工作”),但我们的方法能够在前沿模型的背景下提供额外的洞见:
- 入门示例:多步推理。 展示了一个简单示例,模型在“脑中”执行“两跳”推理,以识别出“包含达拉斯的州的首府”是“奥斯汀”。能够观察并操控模型在内部表示“德克萨斯”的那一步。
- 诗歌中的计划行为。 在写诗句时,模型会提前规划输出内容。在开始写每一行之前,它会先挑选出可能出现在句末的押韵词。这些预选的押韵选项随后会影响整行的构造方式。
- 多语言电路。 模型同时使用语言特定和抽象的、与语言无关的路径。在 Claude 3.5 Haiku 中,语言无关的路径比在更小、能力更弱的模型中更为突出。
- 加法运算。 展示了多个案例,其中相同的加法路径能够在非常不同的上下文中泛化使用。
- 医学诊断。 展示了一个示例,模型基于报告的症状识别出候选诊断结果,并据此提出针对额外症状的后续问题,以帮助验证诊断 —— 所有这些都发生在模型“内部”,并没有将推理过程显式写出。
- 实体识别与幻觉。 揭示了模型用于区分熟悉与不熟悉实体的路径机制,这些机制决定模型是选择回答一个事实性问题,还是表示不知道。该机制的“失误”可能导致幻觉现象。
- 拒绝有害请求。 模型在微调过程中构建了一个通用的“有害请求”特征,该特征是从预训练中学到的具体有害请求特征中整合出来的。
- 越狱攻击分析。 分析了一种攻击方式,它首先诱使模型在“未意识到”的情况下开始给出危险指令,随后由于语法和句法一致性的压力,模型继续生成这类内容。
- 思维链条的真实性。 思维链条推理是否真实反映了模型的实际内部机制。能够区分出几种情况:模型确实执行了它所声称的推理步骤、模型虚构了推理过程不顾真伪、以及模型从人类提供的提示中反推过程,使其“推理”最终能导出人类建议的答案。
- 一个隐藏目标的模型。 应用于一个变体模型,该模型被微调为追求一个隐藏目标:利用其训练过程中的“漏洞”。尽管模型在被直接询问时会避免暴露其目标,我们的方法仍能识别出参与追求该目标的内部机制。有趣的是,这些机制嵌入在模型的“助手”人格表示中。
本文的研究结果揭示了模型采用的多种复杂策略。例如,Claude 3.5 Haiku 经常在“脑中”使用多个中间推理步骤来决定其输出。它表现出前瞻性规划的迹象,会在很早之前就考虑将要说的多种可能性;它也会进行逆向规划,从目标状态反推以构建回答的前半部分。
一些原始的“元认知”路径,使模型能够了解自身知识的范围。从更广义上看,模型的内部计算非常抽象,能够在不同的上下文中泛化应用。本文分析方法有时还能审计模型的内部推理步骤,识别出那些从模型表面回答中看不出的、令人担忧的“思维过程”。
2 Method Overview
本研究所分析的模型是基于 Transformer 架构的语言模型,这类模型以一系列的 token作为输入,并逐个生成新的 token 作为输出。此类模型主要由两个基本组件构成:MLP层,用于在每个 token 位置内部处理信息,依靠的是由多个神经元组成的网络;以及注意力层,用于在不同的 token 位置之间传递信息。
这些模型之所以难以解释,其中一个原因是它们的神经元通常具有多义性——也就是说,每个神经元可能在不同情况下执行看似无关的多种功能。为了解决这一问题,我们构建了一个替代模型,用更具可解释性的组件来近似还原原始模型的激活情况。本文的替代模型基于一种跨层转码器(cross-layer transcoder, CLT)架构,该架构被训练用于将原模型中的 MLP 神经元替换为稀疏激活的“替代神经元”,这些替代神经元往往对应可解释的概念。
在本文中,CLT 替代模型在所有层中共包含约三千万个特征。
![![[Pasted image 20250601180753.png]]](https://i-blog.csdnimg.cn/direct/6bd97df654254928975f001d972a3345.png)
图1:替代模型是通过将原始模型的神经元替换为transcoder中稀疏激活的特征而获得的。
特征通常代表人类可理解的概念,涵盖从低层级(如特定的词或短语)到高层级(如情感、计划和推理步骤)等多个层面。通过查看特征可视化图——即该特征激活时出现的不同文本示例——可以为每个特征赋予一个人类可理解的标签。
本文中的文本示例均来自开源数据集。
替代模型无法完美重建原始模型的激活。在特定的提示词下,两个模型之间会存在差异。可以通过引入误差节点来填补这些差异,这些误差节点表示两个模型之间的偏差。与特征不同,误差节点是无法解释的。 但引入它们可以让我们更准确地感知解释的缺失程度。
替代模型也不会尝试替换原始模型的注意力层。在任意一个提示词上,直接使用原始模型的注意力模式,并将其视为固定组件。
最终得到的模型——包含误差节点,并继承原始模型的注意力模式——称之为“局部替代模型”。之所以称为“局部”,是因为误差节点和注意力模式在不同提示词下会有所变化。但这个模型仍然尽可能多地用(相对)可解释的特征来重现原始模型的计算过程。
![![[Pasted image 20250601181047.png]]](https://i-blog.csdnimg.cn/direct/7259cd4f18c44769adc647f69f407b50.png)
图2:局部替代模型是在替代模型的基础上,通过添加误差项和固定的注意力模式,以在特定提示词上精确复现原始模型的行为而得到的。
通过研究局部替代模型中各特征之间的相互作用,可以追踪模型在生成响应时的中间步骤。更具体地说,生成“归因图”(attribution graphs),一种用于图示模型为特定输入生成输出时所执行计算步骤的图形表示形式,其中节点表示特征,边表示它们之间的因果关系。
由于归因图可能非常复杂,通过移除对模型输出影响不大的节点和边,将其修剪为最重要的组成部分。
在得到修剪后的归因图后,我们常常能观察到一组语义相关、在图中起相似作用的特征。通过将这些相关的图节点手动分组成“超级节点”(supernodes),可以得到模型所执行计算步骤的简化表示。
![![[Pasted image 20250601181932.png]]](https://i-blog.csdnimg.cn/direct/7f1b28f93bd04e97a7dab2d270bd28f5.png)
图 3:将相关的图节点分组成超级节点,可以得到一个更简洁的图。
![![[Pasted image 20250601182300.png]]](https://i-blog.csdnimg.cn/direct/c56bb00ae6dc4b84a69e0011f165159e.png)
图4:为了验证归因图所揭示的关于底层模型机制的假设,进行了干预实验。
由于归因图是基于替代模型构建的,因此无法通过它们对底层模型(即 Claude 3.5 Haiku)得出确定性的结论。
因此,归因图提供的是关于底层模型中运行机制的假设。关于这些假设何时以及为何可能不完整或具有误导性,请参见第14节“局限性”。
为了增强对所描述机制的真实性和重要性的信心,可以在原始模型上进行干预实验,例如抑制特征组并观察其对其他特征以及模型输出的影响(上图最后一幅图——百分比表示原始激活值的保留比例)。如果这些影响与归因图的预测一致,就可以更有信心地认为该图反映了模型中真实存在(尽管可能不完整)的机制。
3 Introductory Example: Multi-step Reasoning
本文方法旨在揭示模型在生成回答过程中所采用的中间推理步骤。
本节将通过一个简单的多步推理示例,尝试识别出模型完成任务所经历的每一个步骤。此过程强调一些将在其他案例研究中反复出现的关键概念。
让我们来看这个提示语:“Fact: the capital of the state containing Dallas is”,Claude 3.5 Haiku 成功补全为 “Austin”。直观来看,这一回答需要两个步骤——首先,推断出包含达拉斯的州是德克萨斯州;其次,得出德克萨斯州的首都是奥斯汀。
Claude 是否真的在内部执行了这两个推理步骤?还是它使用了一种“捷径”,比如可能在训练数据中见过类似句子,并直接记住了答案?以往的研究显示,在不同语境中,模型确实会表现出真实的多跳推理能力(尽管程度不一)。
本节将提供证据,表明在这个例子中,模型确实在内部进行了真实的两步推理,这种推理过程与“捷径式”推理共存。
我们可以通过计算该提示的归因图来研究这个问题,该归因图描述了模型用于生成答案的特征以及它们之间的相互作用。首先,检查这些特征的可视化图,以便理解它们的含义,并将它们归类为不同的类别(“超级节点”)。例如:
- 发现了几个与“首都”一词和/或这一概念相关的特征,比如有四个特征在词语 “capital” 上激活最强。我们还发现了一些特征以更通用的方式表示“首都”这一概念。比如,有一个特征在“capitals”一词上激活,同时也在关于州首都的问题中激活,还包括中文问题“广东省的省会是?”中“省会”的第二个字。另一个特征则是多语言特征,在多个词组上激活最强,比如 “başkenti”(土耳其语)、“राजधानी”(印地语)、“ibu kota”(印尼语)和 “Hauptstadt”(德语)——这些词在不同语言中都大致表示“首都”这一概念。虽然这些特征所代表的具体概念略有不同,但在当前这个提示的语境下,它们的共同功能似乎就是表达“首都”的概念。因此将它们(以及其他几个相似特征)归入同一个“超级节点”。
- 识别出一些“输出特征”,会稳定地推动模型输出某些特定的 token,即使它们本身所激活的词或短语并不具有明显规律。这可以通过特征可视化图中的 “Top Outputs” 部分看到,该部分列出了该特征最直接强化的输出 token。例如,有一个特征在德州中部的地标名称上激活,但在本提示中,它最关键的作用是强烈推动模型输出“Austin”这个词。因此,我们将此特征归为“输出奥斯汀”(say Austin)超级节点。需要注意的是,“Top Outputs”信息并不总是有用,早期层的特征往往是通过影响其他特征间接作用于输出的,其直接输出的重要性不大。
- 发现了一些更广义地推动模型输出“某个首都名称”的特征,我们通过结合上述两类信号来识别和标注它们。例如,有一个特征推动模型输出多种美国州的首都名;另一个特征更强烈地推动输出世界各国的首都,而不是美国的,但它又在包含美国州与对应首都的列表中激活最强;还有一个特征,其直接输出是一组看似无关的 token,但它经常在输出某个国家首都(如巴黎、华沙或堪培拉)之前激活。将这些特征归为“输出某个首都”say a capital“超级节点。
- 一些特征表示与“德克萨斯州”相关的多种语境,但并不特指某个城市(尤其不是“达拉斯”或“奥斯汀”)。虽然每个特征都代表与德州相关但不同的具体概念,但在这个提示中,它们的主要功能似乎是共同表达“德州”这一整体概念。因此将这些特征归入“德州”(Texas)超级节点。
在形成这些超级节点之后,可以在归因图界面中看到,例如,“首都”(capital)超级节点会促进“输出某个首都”(say a capital)超级节点,而后者又会进一步促进“输出奥斯汀”(say Austin)超级节点,如下图片段所示:
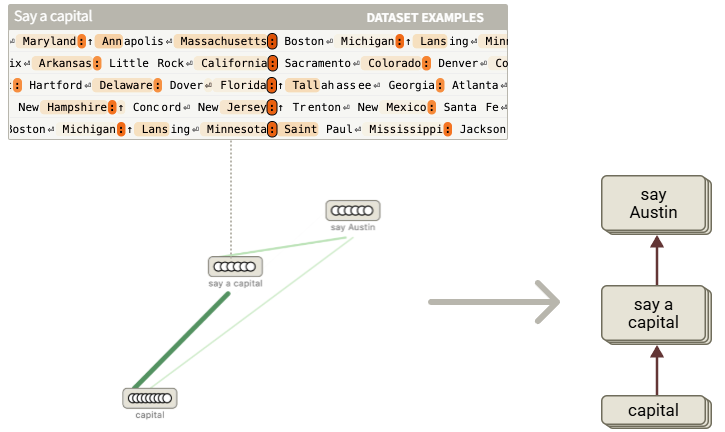
图5:在通过可视化分析和标注特征后,将反映提示中相同方面的特征手动归类为“超级节点”。图形界面会聚合超级节点中各特征之间的归因关系。在归因图的示意图中,用棕色箭头连接归因关系较强的超级节点。
在标注了更多特征并构建了更多超级节点之后,用下图总结了它们之间的相互作用。
![![[Pasted image 20250601221818.png]]](https://i-blog.csdnimg.cn/direct/4a364194d63c4a388496b1477d6a60d1.png)
图6:Haiku 通过一个“多步骤”图完成句子,从 Dallas → Texas → Austin。请注意,这是简化后的版本。
归因图中包含多个有趣的路径,简要总结如下:
- Dallas 相关特征(以及一些州相关特征的贡献)激活了一组表示德克萨斯州相关概念的特征。
- 与此同时,单词 “capital” 激活的特征会激活另一组输出特征,这些特征促使模型说出一个首府的名称(上文已展示了其中一个特征的例子)。
- Texas 特征与 say a capital 特征共同提升了模型输出 “Austin” 的概率。这种提升通过两条路径实现:
- 直接影响 Austin 输出;
- 间接地,通过激活一组 say Austin 输出特征。
- 此外,还存在一条从 Dallas 直接通向 say Austin 的“捷径”边。
3.1 Validation with Inhibition Experiments
上图所示的图谱描述的是可解释替代模型所使用的机制。
为了验证这些机制是否能够代表实际模型的行为,本节对上述特征组进行了干预实验:通过抑制它们,并测量这种干预对其他特征簇中激活值的影响,以及对模型输出的影响。
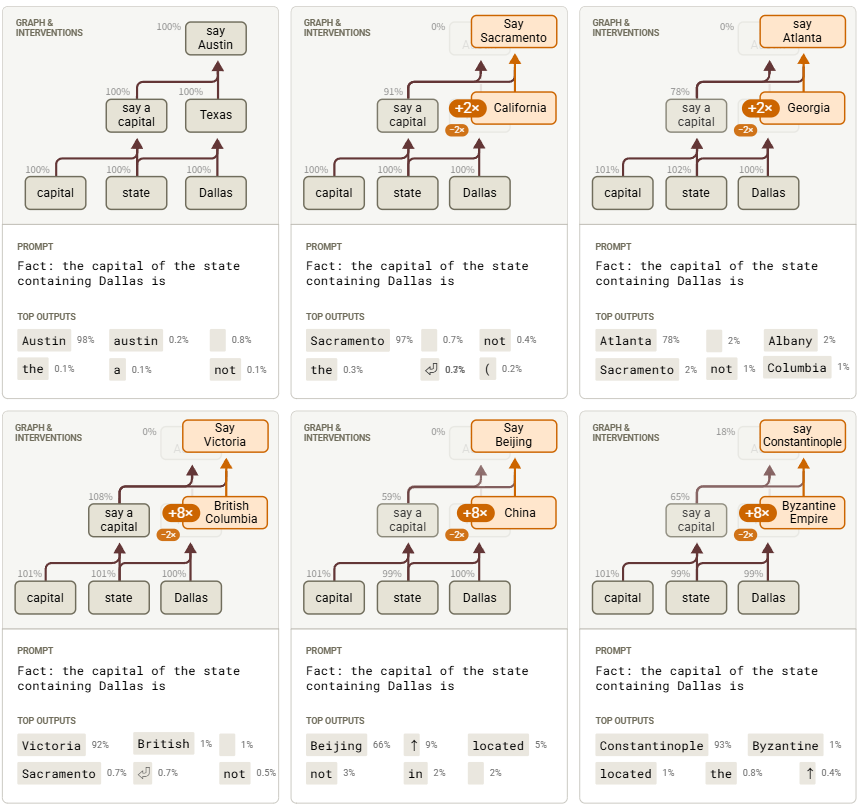
图9:对“达拉斯的首都是?”这个提示语进行干预实验,将“德克萨斯”替换为其他州、省或国家。节点激活值是相对于baseline激活值进行测量的。
在某些情况下,注入那些为了改变模型输出所需的特征的幅度更大(见底部一行)。有趣的是,这些情况对应的注入特征并不属于美国的某个州,这表明这些特征可能与原始提示语中所激活的路径机制“契合度”较低。
8 Entity Recognition and Hallucinations
语言模型有时会产生“幻觉”,即在回答问题时编造虚假信息。当模型被问及较为冷僻的事实或话题时,幻觉现象尤为常见。这主要源于语言模型的预训练目标,该目标促使模型去猜测文本块的合理补全。
例如,考虑下面由 Haiku 3.5(作为基础模型,即没有“人类/助手”格式化)给出的幻觉续写:
Prompt: Michael Batkin plays the sport of
Completion: Pickleball, which is a paddle sport that combines elements of tennis, badminton, and table tennis.
这种行为是合理的,因为在模型的训练数据中,这样的句子很可能以某种运动名称作为补全。由于没有关于“Michael Batkin”是谁的更多信息,模型只能随机猜测一个合理的运动名称。
然而,在微调过程中,模型被训练以避免在扮演助手角色时出现这种行为。因此会产生如下回答:
Human: Which sport does Michael Batkin play? Answer in one word.
Assistant: I apologize, but I cannot find a definitive record of a sports figure named Michael Batkin. Without additional context or information, I cannot confidently state which sport, if any, he plays.
鉴于幻觉在某种意义上是一种“自然”行为,但通过微调得以缓解,因此寻找能够防止模型产生幻觉的机制是合理的。
本节中我们提供以下证据:
- 模型包含“默认”路径,使其在某些情况下拒绝回答问题。
- 当模型被问及它知道的问题时,它会激活一组特征,这些特征抑制该默认回路,从而使模型能够回答问题。
- 至少部分幻觉可归因于这种抑制回路的“误触发”。例如,当询问模型某位作者写过哪些论文时,即使模型不了解该作者的具体论文,它仍可能激活一些“已知答案”特征。
![![[Pasted image 20250601231952.png]]](https://i-blog.csdnimg.cn/direct/5a048cc4c9c1469cb23e488f2a20a969.png)
图32:关键实体识别机制的总结如下,详细内容将在下文中展开说明。图中带有“T”形末端的蓝色连接表示抑制性输入(即具有负号的归因图边)。
8.1 Default Refusal Circuits
Human/Assistant 提示中,Assistant 道歉第一词上的归因图。一组与体育相关的特征被激活,推动模型说出某种运动的名称。然而,这条线路路径被另一条并行线路“压制”,后者促使模型开始以“I apologize(我很抱歉)”作为回应的开头。
这个线路的关键在于一组“无法回答”的特征,它们在 Assistant 纠正或质疑用户问题的前提,或声明自己缺乏足够信息无法回答时被激活。
这些特征是由一类广泛响应 Human/Assistant 提示的特征直接激活的。这种结构表明,“无法回答”特征在所有 Human/Assistant 提示中是默认被激活的!换句话说,模型默认对用户请求持怀疑态度。
此外,这些“无法回答”特征还会受到一组“陌生姓名”特征的推动,而这些特征又是由“Michael Batkin”这个名字的单个词元和一个通用的“名字”特征激活的。这表明,只要出现人名,这些“陌生姓名”特征也会被“默认”激活。
8.2 An Inhibitory “Known Answer” Circuit
如果模型默认会激活促进拒答的“无法回答”和“未知姓名”特征,那它又是如何给出有信息量的回答的呢?
假设这些特征会被代表模型熟悉的实体或话题的特征所抑制。对于未知实体 Michael Batkin,这些拒答特征未被抑制;但我们可以设想,像 Michael Jordan 这样的已知实体相关特征可以成功地抑制它们。
为了验证这一假设,计算了以下提示的归因图:
Human:Which sport does Michael Jordan play? Answer in one word.
Assistant:Basketball
我们重点关注了“无法回答”特征。我们确认,正如预期的那样,这些特征在该提示中的激活程度相比于 Michael Batkin 提示要么是未激活,要么明显更弱。
我们还在归因图中观察到,这些“无法回答”特征受到以下特征的抑制:
- 与 Michael Jordan 相关的特征;
- 一组“已知答案”和“已知实体”特征,当 Assistant 被问及其可能了解的人物或事物时,它们会被激活。
而这些“已知答案”和“已知实体”特征,又是由一组与 Michael Jordan 相关的特征所激活的。
结合我们对两个提示的分析,其机制总结如下:
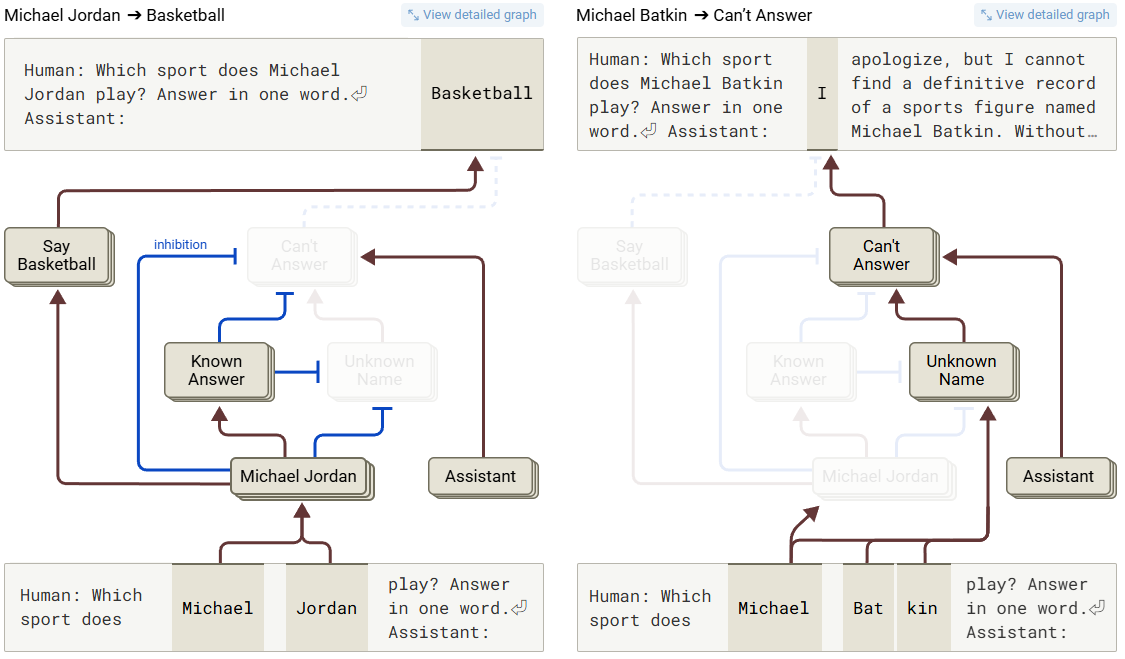
图33:分别展示了 Michael Jordan 和虚构人物 “Michael Batkin” 的两个简化归因路径组。Haiku 被询问他们从事的运动。对于 Jordan,Haiku 能正确回答,是因为激活了“已知答案”路径,并抑制了“未知姓名”路径;而对于 Batkin,情况正好相反。图中带“T”形端点的蓝色连线表示抑制性输入(即负边权)。本图为交互式图表,可将鼠标悬停在节点上查看详细的特征可视化内容。
这个路径与假设一致:已知的实体或话题会抑制那些原本会被激活的“无法回答”特征。如果这一假设成立,应该可以在 Michael Batkin 的提示中通过激活“已知答案/实体”特征来抑制“无法回答”特征,从而诱导模型产生幻觉。
相反,在 Jordan 的提示中抑制“已知答案”特征,会使模型有时给出表示不确定的回答,例如“假设的”(Hypothetical)、“信息不足的”(Underspecified)等词语。
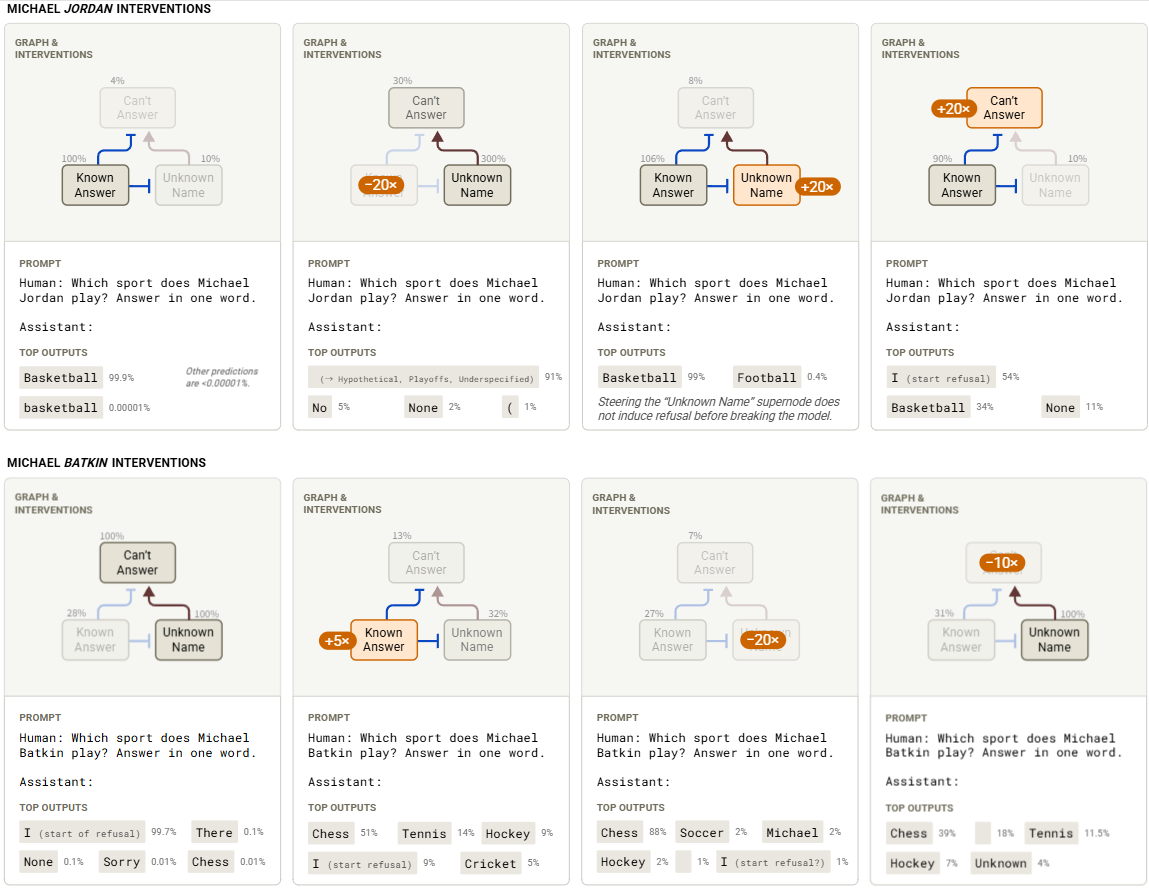
图34:对 Michael Jordan 和 Batkin 图进行干预测试。节点激活值是相对于最大基线激活值进行测量的。
本文还对“无法回答”和“未知姓名”特征进行了干预测试,大多数结果支持的路径假设。然而,也出现了一些出人意料的结果。例如,在 Michael Jordan 提示中,仅激活“未知姓名”特征似乎不足以诱发模型拒答。更普遍地说,要产生显著效果所需的干预强度相对于原始提示中的特征激活值来说相当高。这表明所识别的特征和连接仅捕捉到了部分机制。
相关文章:
【学习笔记】On the Biology of a Large Language Model
On the Biology of a Large Language Model 1 Introduction 目标是对这些模型的内部工作机制进行逆向工程,从而更好地理解它们,并评估它们是否适合特定用途。 正如细胞是生物系统的基本构建单元,我们假设特征是模型内部计算的基本单位。仅仅…...
飞腾D2000,麒麟系统V10,docker,ubuntu1804,小白入门喂饭级教程
#下载docker Index of linux/static/stable/ 根据电脑的CPU类型选择: Intel和AMD选x86_64飞腾D2000选aarch64 #选择较新的版本 #在包含下载的docker-XX.X.X.tgz的文件夹中右键->打开终端 # 解压安装包(根据实际下载的文件) tar -zxvf …...
星野录(博客系统)测试报告
目录 一. 项目背景 二、项目功能 三、测试计划 1. 功能测试 1.1 测试用例 1.2 执行测试部分操作截图 2. 使用selenium进行自动化测试 2.1 添加相关依赖 2.2 登录页面测试 3.3 注册页面测试 3.4 博客列表页面测试 3.5 博客详情页测试 3.6 博客编辑页面测试 3.7 个人…...
使用 Java 实现一个简单且高效的任务调度框架
目录 一、任务调度系统概述 (一)任务调度的目标 (二)任务调度框架的关键组成 二、任务状态设计 (一)任务状态流转设计 (二)任务表设计(SQL) 三、单机任务调度实现 (一)获取待处理任务 (二)执行任务 代码实现(单线程版本) (三)多线程提高吞吐量 四…...

2022—2025年:申博之路及硕士阶段总结
文章目录 1 前景概要2 打造神兵利器2.1 夺天地之精2.2 锻兵魂之形2.3 契人兵之命 3 潜心闭关修炼3.1 第一阶段:苦心智3.2 第二阶段:劳筋骨3.3 第三阶段:摧意志 4 突破晋级4.1 突破失败4.2 聚气凝神4.3 心魔再现4.4 新起点 5 回顾及深思 1 前景…...
项目执行中缺乏灵活应对机制,如何增强适应性?
项目执行中缺乏灵活应对机制可以通过建立风险预警机制、培养团队快速响应能力、制定动态调整方案、加强团队沟通协作、引入敏捷管理理念来增强适应性。 其中,培养团队快速响应能力尤为重要。这种能力意味着当项目遇到突发状况时,团队能迅速评估问题、确定…...

Agentic Workflow是什么?Agentic Workflow会成为下一个AI风口吗?
无论是想要学习人工智能当做主业营收,还是像我一样作为开发工程师但依然要运用这个颠覆开发的时代宠儿,都有必要了解、学习一下人工智能。 近期发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,入行门槛低&#x…...

大模型模型推理的成本过高,如何进行量化或蒸馏优化
在人工智能的浪潮中,大模型已经成为推动技术革新的核心引擎。从自然语言处理到图像生成,再到复杂的多模态任务,像GPT、BERT、T5这样的庞大模型展现出了惊人的能力。它们在翻译、对话系统、内容生成等领域大放异彩,甚至在医疗、金融等行业中也开始扮演重要角色。可以说,这些…...
BUUCTF[极客大挑战 2019]EasySQL 1题解
[极客大挑战 2019]EasySQL题解 分析解题过程漏洞原理分析明确注入点:尝试万能密码法法一法二 总结 分析 从题目分析,这道题应该与SQL注入有关,启动靶机之后,访问url是一个登录界面,随便输入用户名密码之后࿰…...

Css样式中设置gap: 12px以后左右出现距离问题解析
原因核心: 虽然写的是: display: flex; gap: 12px;但在实际 DOM 中,这段结构: <div class"el-form-item__content"><div class"el-input"><input type"text" class"el-inpu…...
与count(1)有什么区别)
MySQL问题:count(*)与count(1)有什么区别
Count(1)查询过程 如果表里只有主键索引,没有二级索引时,InnoDB循环遍历主键索引,将读取到的记录返回给Server层,但是不会读取记录中的任何字段的值,因为count函数的参数是1,不是字…...

大模型 提示模板 设计
大模型 提示模板 设计 论文介绍:LangGPT - 从编程语言视角重构大语言模型结构化可复用提示设计框架 核心问题: 现有提示工程缺乏结构化设计模板,依赖经验优化,学习成本高且复用性低,难以支持提示的迭代更新。 创新思路: 受编程语言的结构化和可复用性启发,提出LangGP…...

excel表格记账 : 操作单元格进行加减乘除 | Excel中Evaluate函数
文章目录 引用I 基础求和∑II Excel中Evaluate函数基于字符串表达式进行计算用法案例 :基于Evaluate实现汇率计算利润知识扩展在单元格内的换行选择整列单元格引用 需求: 基于汇率计算利润,调整金额以及进汇率和出汇率自动算出利润,已经统计总利润。 基于Evaluate实现汇率计…...
20250602在荣品的PRO-RK3566开发板的Android13下的uboot启动阶段配置BOOTDELAY为10s
20250602在荣品的PRO-RK3566开发板的Android13下的uboot启动阶段配置BOOTDELAY为10s 2025/6/2 18:15 缘起:有些时候,需要在uboot阶段做一些事情。 于是,希望在荣品的PRO-RK3566开发板的Android13下的uboot启动停下。 1、【原始的LOGÿ…...

如何合理设计缓存 Key的命名规范,以避免在共享 Redis 或跨服务场景下的冲突?
设计合理的缓存 Key 命名规范对于避免冲突、提高可维护性和可读性至关重要,尤其是在共享 Redis 实例或跨服务调用的场景下。 以下是一个推荐的缓存 Key 命名规范和设计思路: 一、核心原则 唯一性 (Uniqueness): 这是最重要的原则,确保不同…...

Trae CN IDE自动生成注释功能测试与效率提升全解析
Trae CN IDE 的自动注释功能可以通过 AI 驱动的代码分析生成自然语言注释,以下是具体测试方法和优势总结: 一、Python 代码注释生成测试 1. 测试环境 IDE:Trae CN IDE(需确认支持 Python)代码示例: def …...

让AI弹琴作曲不再是梦:Python+深度学习玩转自动化音乐创作
让AI弹琴作曲不再是梦:Python+深度学习玩转自动化音乐创作 一、AI也能谱出动人的旋律?真不是科幻! 还记得小时候学钢琴时老师的那句经典:“感觉不到情绪的乐句,是没灵魂的。” 当时我一边练琴一边想:要是有个机器能帮我写谱、调性又不跑调就好了! 结果几年后,真被我碰…...

C++概率论算法详解:理论基础与实践应用
清言神力,创作奇迹。接受福利,做篇笔记。 参考资料 [0] 概率论中均值、方差、标准差介绍及C/OpenCV/Eigen的三种实现. https://blog.csdn.net/fengbingchun/article/details/73323475. [4] C中的随机数及其在算法竞赛中的使用 - 博客园. https://www.…...
ssh登录wsl2
1. ssh服务重新安装 Ubuntu20.04子系统自带的ssh服务无法连接,需卸载后重新安装。 sudo apt-get remove openssh-server sudo apt-get install openssh-server2. 修改配置信息 sudo vim /etc/ssh/sshd_config修改内容: # 最好一模一样 Port 33 # 这…...

黑马Java面试笔记之 消息中间件篇(Kafka)
一. Kafka保证消息不丢失 Kafka如何保证消息不丢失 使用Kafka在消息的收发过程中都会出现消息丢失,Kafka分别给出了解决方案 生产者发送消息到Brocker丢失消息在Brocker中存储丢失消费者从Brocker接收消息丢失 1.1 生产者发送消息到Brocker丢失 设置异步发送 消息…...

LeetCode - 234. 回文链表
目录 题目 快慢双指针步骤 读者可能的错误写法 正确的写法 题目 234. 回文链表 - 力扣(LeetCode) 快慢双指针步骤 找到链表的中点(find_mid函数): 使用快慢指针,慢指针每次走一步,快指针…...
PYTHON通过VOSK实现离线听写支持WINDOWSLinux_X86架构
在当今人工智能快速发展的时代,语音识别技术已经成为人机交互的重要方式之一。本文将介绍如何使用Python结合Vosk和PyAudio库实现一个离线语音识别系统,无需依赖网络连接即可完成语音转文字的功能。 技术栈概述 1. Vosk语音识别引擎 Vosk是一个开源的…...

nginx+tomcat动静分离、负载均衡
一、理论 nginx用于处理静态页面以及做调度器,tomcat用于处理动态页面 lvs(四层) 轮询(rr) 加权轮询(wrr) 最小连接(lc) 加权最小连接(wlc) ngi…...

SQL进阶之旅 Day 13:CTE与递归查询技术
【SQL进阶之旅 Day 13】CTE与递归查询技术 引言 欢迎来到“SQL进阶之旅”的第13天!今天我们重点探讨的是CTE(公用表表达式)与递归查询技术。CTE是现代SQL中的一个重要特性,能够极大地提高复杂查询的可读性与维护性。而递归CTE则…...

【PmHub面试篇】Gateway全局过滤器统计接口调用耗时面试要点解析
你好,欢迎来到本次关于Gateway全局过滤器统计接口调用耗时的面试系列分享。在这篇文章中,我们将深入探讨这一技术领域的相关面试题预测。若想对相关内容有更透彻的理解,强烈推荐参考之前发布的博文:【PmHub后端篇】PmHub Gateway全…...
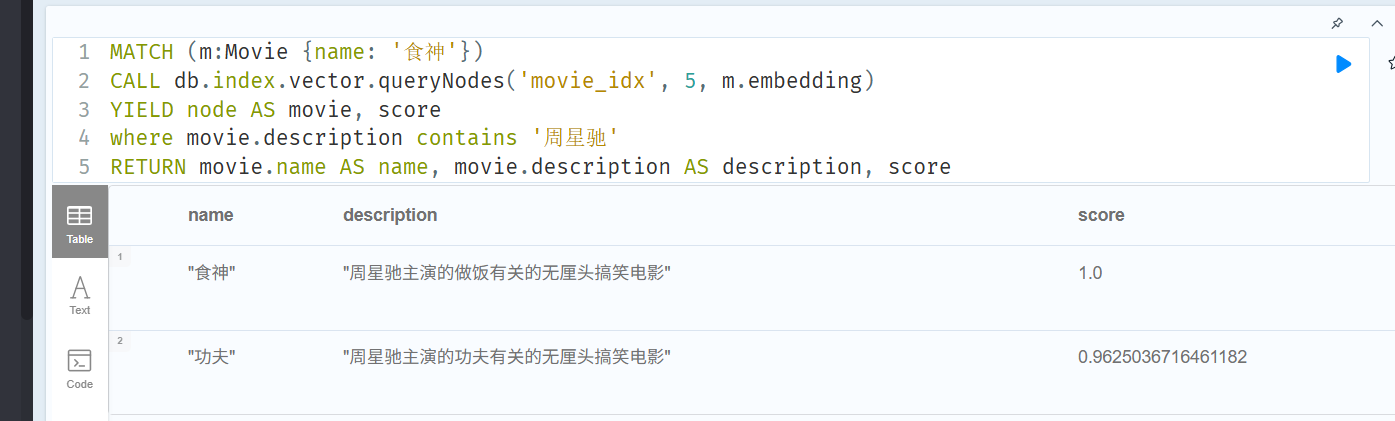
neo4j 5.19.0两种基于向量进行相似度查询的方式
介绍 主要讲的是两种相似度查询 一种是创建向量索引,然后直接从索引的所有数据中进行相似度搜索,这种不支持基于自己查询的结果中进行相似度匹配另一种是自己调用向量方法生产相似度进行相似度搜索,这种可以基于自己的查询结果中进行相似度…...

项目课题——基于ESP32的智能插座
一、功能需求 1.1 基础功能 ✅ 远程控制 通过Wi-Fi实现手机APP/小程序远程开关支持定时任务(如定时开启热水器) 🔌 用电监测 实时显示电压/电流/功率电能统计(日/月/年用电量报表) 🔋多接口支持 220V三线…...
华为云Flexus+DeepSeek征文|利用华为云 Flexus 云服务一键部署 Dify 平台开发文本转语音助手全流程实践
目录 前言 1 华为云 Flexus 与 Dify 平台简介 1.1 Flexus:为AI而生的轻量级云服务 1.2 Dify:开源的LLM应用开发平台 2 一键部署Dify平台至Flexus环境 3 构建文本转语音助手应用 3.1 创建ChatFlow类型应用 3.2 配置语音合成API的HTTP请求 3.3 设…...
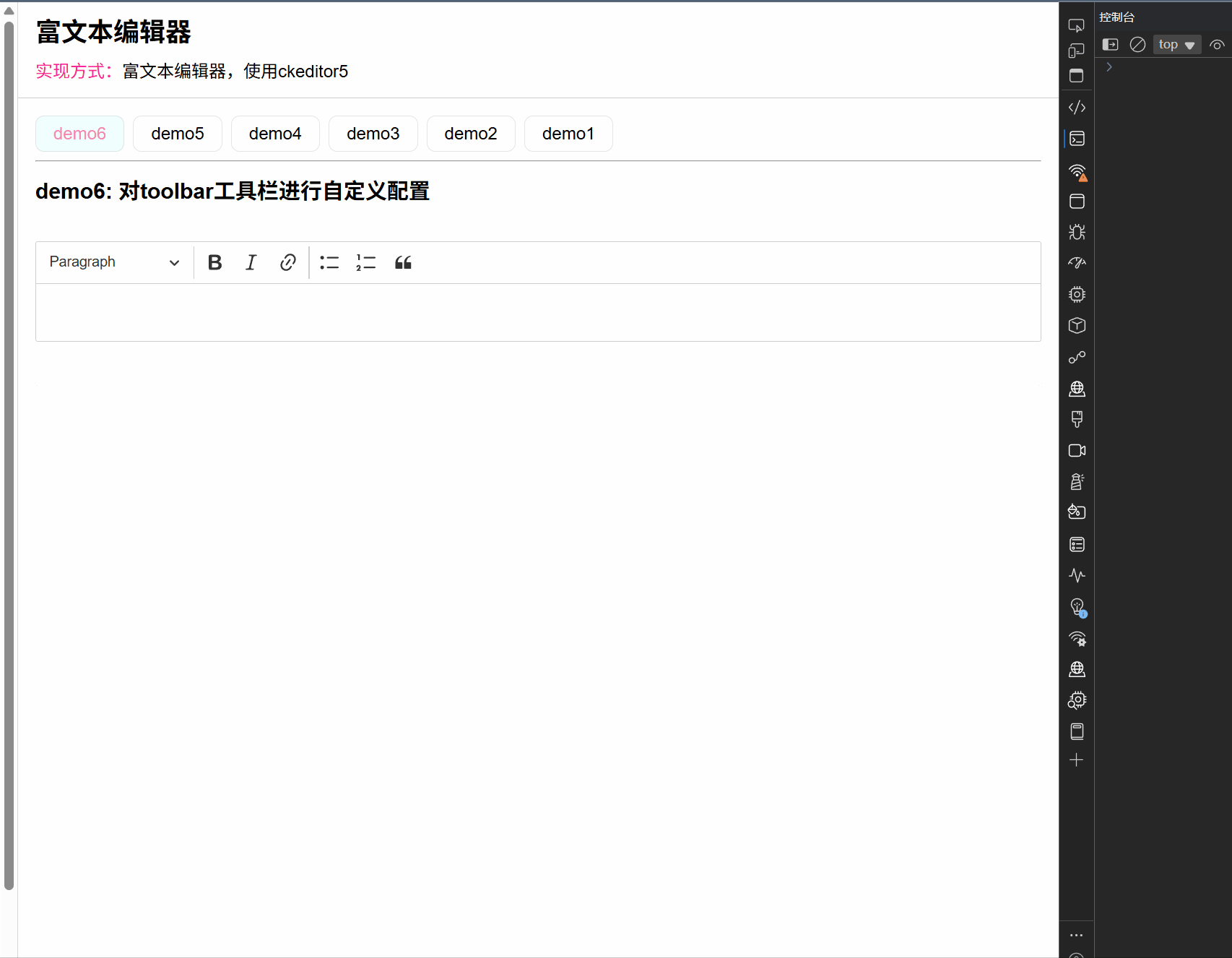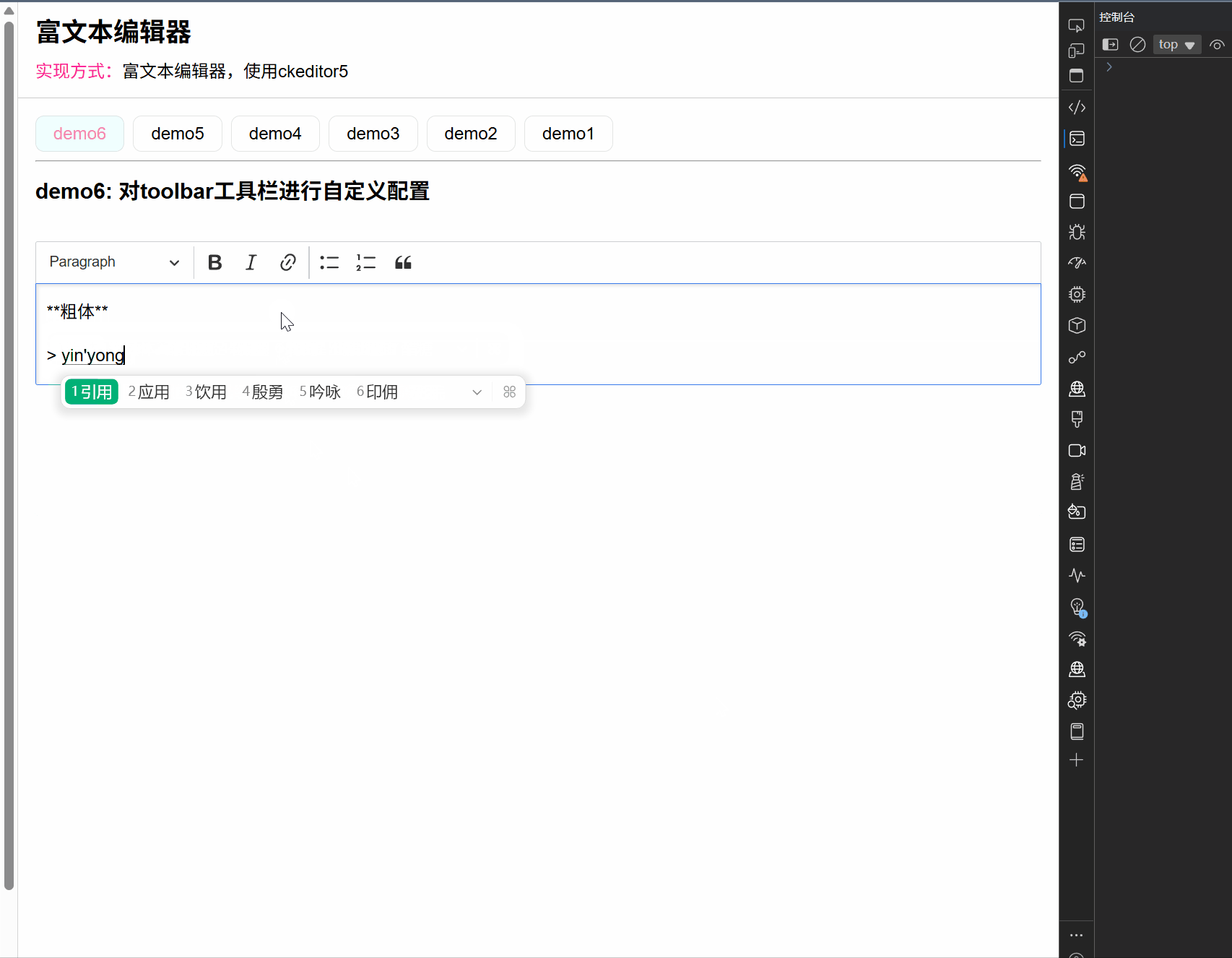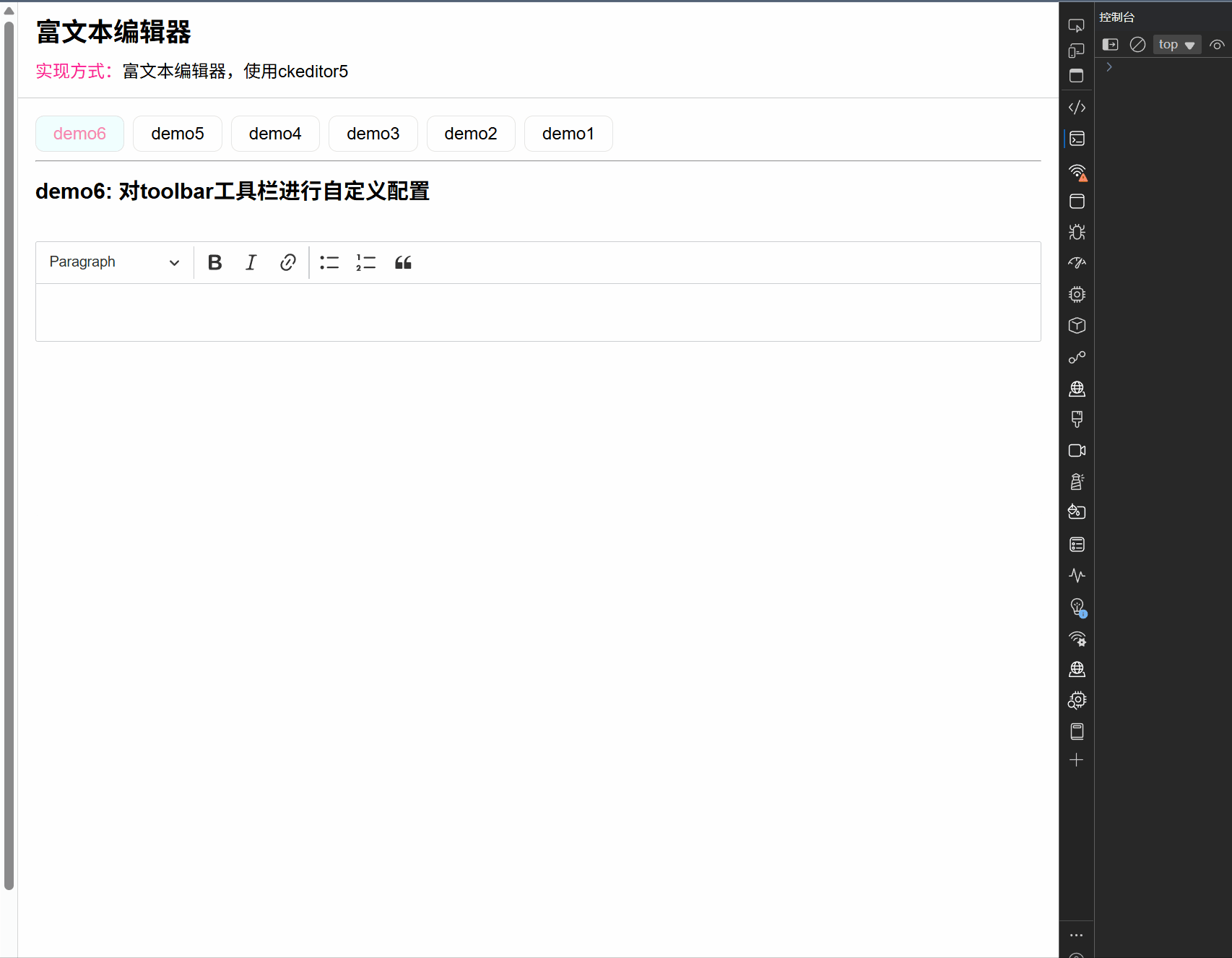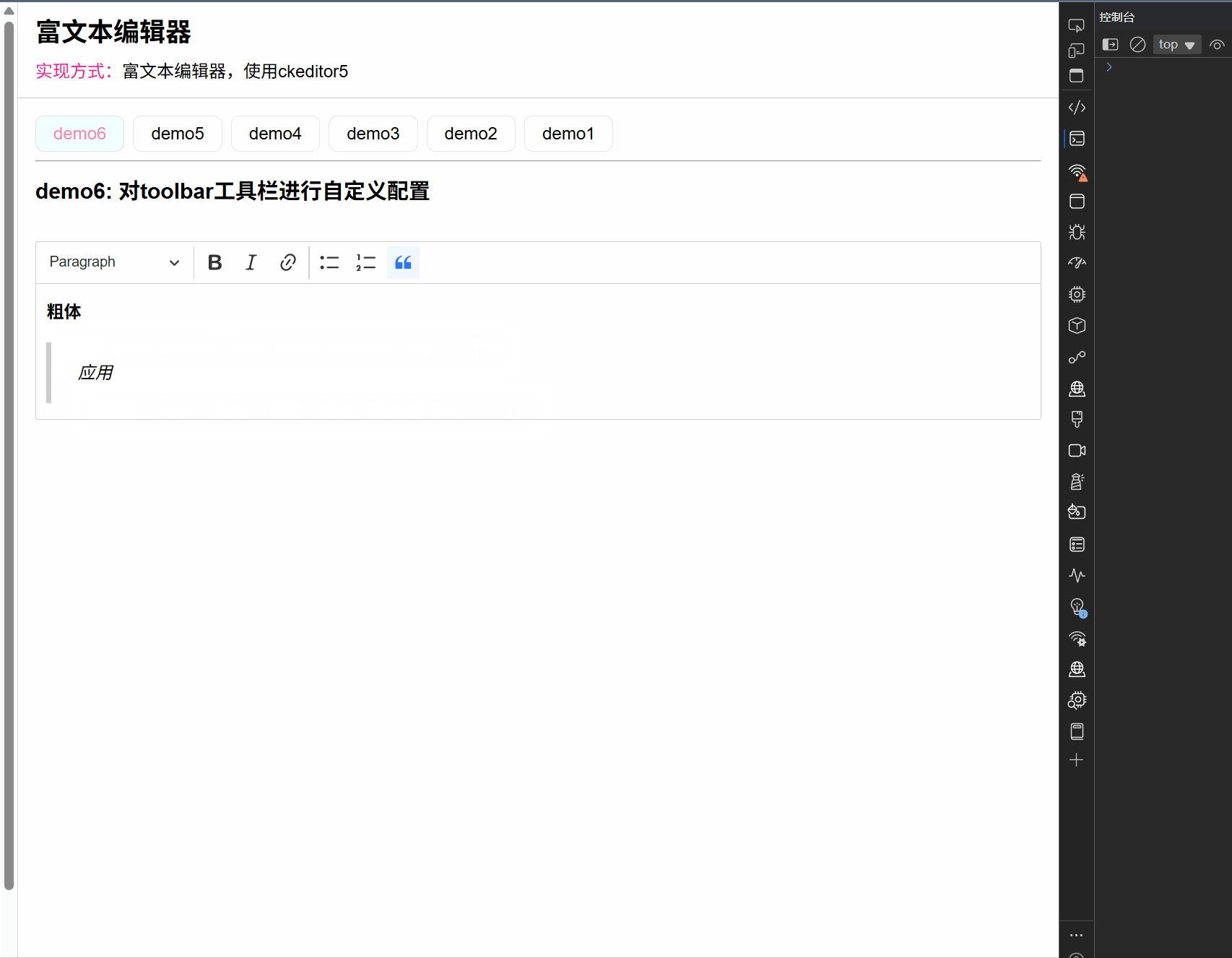
ck-editor5的研究 (7):自定义配置 CKeditor5 的 toolbar 工具栏
文章目录 一、前言二、实现步骤1. 第一步: 搭建目录结构2. 第二步:配置toolbar工具栏的步骤(2-1). 配置粗体和斜体(2-2). 配置链接和标题+正文(2-3). 配置列表和引用(2-4). 配置自动格式化3. 第三步:更多工具三、测试效果和细节四、总结一、前言 在前面的文章中,我们已经对…...

MPLS-EVPN笔记详述
目录 EVPN简介: EVPN路由: 基本四种EVPN路由 扩展: EVPN工作流程: 1.启动阶段: 2.流量转发: 路由次序整理: 总结: EVPN基本术语: EVPN表项: EVPN支持的多种服务模式: 简介: 1.Port Based: 简介: 配置实现: 2.VLAN Based: 简介: 配置实现: 3.VLAN Bundle: 简…...