统信 UOS 服务器版离线部署 DeepSeek 攻略
日前,DeepSeek 系列模型因拥有“更低的成本、更强的性能、更好的体验”三大核心优势,在全球范围内备受瞩目。
本次,我们为大家提供了在统信 UOS 服务器版 V20(AMD64 或 ARM64 架构)上本地离线部署 DeepSeek-R1 模型的攻略,以帮助您顺利完成 DeepSeek-R1 模型部署。
注:(1)部署前,请保证 BaseOS、AppStream、PowerTools、Plus、os 和 everything 源均可用。
(2)部署时,若找不到对应的安装包或对操作步骤有疑问,请联系我们。
单机部署 Ollama+DeepSeek+OpenWebUI
Step 1:防火墙放行端口
执行如下命令,在防火墙中开放 11434 和 3000 端口。
firewall-cmd --add-port=11434/tcp --permanentfirewall-cmd --add-port=3000/tcp --permanentfirewall-cmd --reload
注:11434 端口将用于 Ollama 服务,3000 端口将用于 OpenWebUI 服务。
Step 2:部署 Ollama
1、执行 dnf install -y ollama 命令,安装 Ollama 软件包。
2、在/usr/lib/systemd/system/ollama.service服务配置文件中的 [Service] 下新增如下两行内容,分别用于配置远程访问和跨域请求:
Environment="OLLAMA_HOST=0.0.0.0"Environment="OLLAMA_ORIGINS=*"
3、执行 systemctl daemon-reload 命令,更新服务配置。
4、执行 systemctl enable --now ollama 命令,启动 Ollama 服务。
Step 3:拉取 DeepSeek-R1 模型
执行 ollama pull deepseek-r1:1.5b 命令,拉取 DeepSeek-R1 模型。

注:1.5b 代表模型具备 15 亿参数,您可以根据部署机器的性能将其按需修改为 7b、8b、14b 和 32b 等。
Step 4:部署 OpenWebUI
1、执行 dnf install -y docker 命令,安装 docker。
2、执行 systemctl enable --now docker 命令,启动 docker 服务。
3、执行如下命令,运行 OpenWebUI。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data--name open-webui --restart always ghcr.io/open-webui/open-webui:mainStep 5:通过浏览器访问交互界面
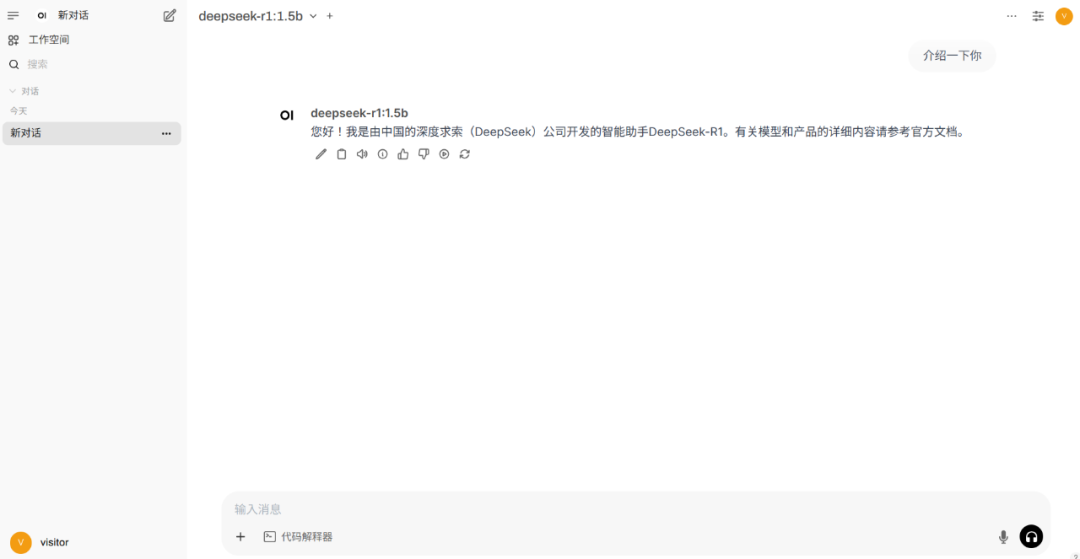
1、打开浏览器,访问 http://IP:3000。其中,您需将 IP 替换为部署机器的实际 IP 地址。
2、登录交互界面。请注意,首次访问交互界面时,需要先注册一个账号。
3、在界面左上角,选择 deepseek-r1:1.5b 模型后,输入消息即可开始对话。
集群部署Kubernetes + KubeRay + vLLM + FastAPI
Step 1:创建 Kubernetes 集群
1、使用 kubeadm 工具,并将 containerd 作为容器运行时,创建Kubernetes 集群。
注:下文以创建一个包含 1 个控制平面节点、1 个 CPU 工作节点(8 vCPUs + 32GB memory)和 2 个 GPU 工作节点(4 vCPUs + 32 GB memory + 1 GPU + 16GB GPU memory)的 Kubernetes 集群为例进行介绍。
2、安装 NVIDIA 设备驱动 nvidia-driver、NVIDIA 容器工具集 nvidia-container-toolkit。
dnf install -y nvidia-driver nvidia-container-toolkit3、配置 nvidia-container-runtime 作为 containerd 底层使用的低层级容器运行时。
nvidia-ctk runtime configure --runtime=containerdsystemctl restart containerd
4、在 Kubernetes 上部署 GPU 设备插件。
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.0/deployments/static/nvidia-device-plugin.yml5、执行 kubectl get nodes 命令,获取 2 个 GPU 工作节点的节点名字,并为 GPU 节点设置污点。
kubectl taint nodes <gpu节点1名字> gpu=true:NoSchedulekubectl taint nodes <gpu节点2名字> gpu=true:NoSchedule
Step 2:编写Ray Serve应用示例(vLLM 模型推理服务应用)
请基于 ray-ml 官方镜像,添加 vLLM,并配置 Ray 和 vLLM。
应用程序将使用 vLLM 提供模型推理服务,通过 Hugging Face 下载模型文件,并通过 FastAPI 提供兼容 OpenAI API 的 API 服务。
注:下文中提到的 registry.uniontech.com/uos-app/vllm-0.6.5-ray-2.40.0.22541c-py310-cu121-serve:latest 为打包好的 Ray Serve 示例应用的容器镜像。
Step 3:在 Kubernetes 上创建 Ray 集群
1、安装 KubeRay。
#安装Helm工具dnf install -y helm#配置Kuberay官方Helm仓库helm repo add kuberay https://ray-project.github.io/kuberay-helm/ #安装kuberay-operator helm install kuberay-operator kuberay/kuberay-operator --version 1.2.2#安装kuberay-apiserverhelm install kuberay-apiserver kuberay/kuberay-apiserver --version 1.2.2
2、执行 kubectl get pods 命令,获取 kuberay-apiserver 的 pod 名字,例如 kuberay-apiserver-857869f665-b94px,并配置 KubeRay API Server 的端口转发。
kubectl port-forward <kubeary-apiserver的Pod名> 8888:88883、创建一个名字空间,用于驻留与 Ray 集群相关的资源。
kubectl create ray-blog4、向http://localhost:8888/apis/v1/namespaces/ray-blog/compute_templates
分别发送带有如下两个请求体的 POST 请求。
注:每个 Ray 集群由一个头节点 Pod 和一组工作节点 Pod 组成。
Ray 头节点 Pod:
{"name": "ray-head-cm","namespace": "ray-blog","cpu": 5,"memory": 20}
Ray 工作节点 Pod:
{"name": "ray-worker-cm","namespace": "ray-blog","cpu": 3,"memory": 20,"gpu": 1,"tolerations": [{"key": "gpu","operator": "Equal","value": "true","effect": "NoSchedule"}]}
可借助系统里的 curl 命令发送请求:
curl -X POST "http://localhost:8888/apis/v1/namespaces/ray-blog/compute_templates" \-H "Content-Type: application/json" \-d '{"name": "ray-head-cm","namespace": "ray-blog","cpu": 5,"memory": 20}'
curl -X POST "http://localhost:8888/apis/v1/namespaces/ray-blog/compute_templates" \-H "Content-Type: application/json" \-d '{"name": "ray-worker-cm","namespace": "ray-blog","cpu": 3,"memory": 20,"gpu": 1,"tolerations": [{"key": "gpu","operator": "Equal","value": "true","effect": "NoSchedule"}]}'
5、向http://localhost:8888/apis/v1/namespaces/ray-blog/clusters 发送带有如下请求体的 POST 请求。
{"name":"ray-vllm-cluster","namespace":"ray-blog","user":"ishan","version":"v1","clusterSpec":{"headGroupSpec":{"computeTemplate":"ray-head-cm","rayStartParams":{"dashboard-host":"0.0.0.0","num-cpus":"0","metrics-export-port":"8080"},"image":"registry.uniontech.com/uos-app/vllm-0.6.5-ray-2.40.0.22541c-py310-cu121-serve:latest","imagePullPolicy":"Always","serviceType":"ClusterIP"},"workerGroupSpec":[{"groupName":"ray-vllm-worker-group","computeTemplate":"ray-worker-cm","replicas":2,"minReplicas":2,"maxReplicas":2,"rayStartParams":{"node-ip-address":"$MY_POD_IP"},"image":"registry.uniontech.com/uos-app/vllm-0.6.5-ray-2.40.0.22541c-py310-cu121-serve:latest","imagePullPolicy":"Always","environment":{"values":{"HUGGING_FACE_HUB_TOKEN":"<your_token>"}}}]},"annotations":{"ray.io/enable-serve-service":"true"}}
可借助系统里的 curl 命令发送请求:
curl -X POST "http://localhost:8888/apis/v1/namespaces/ray-blog/clusters" \-H "Content-Type: application/json" \-d '{"name": "ray-vllm-cluster","namespace": "ray-blog","user": "ishan","version": "v1","clusterSpec": {"headGroupSpec": {"computeTemplate": "ray-head-cm","rayStartParams": {"dashboard-host": "0.0.0.0","num-cpus": "0","metrics-export-port": "8080"},"image": "registry.uniontech.com/uos-app/vllm-0.6.5-ray-2.40.0.22541c-py310-cu121-serve:latest","imagePullPolicy": "Always","serviceType": "ClusterIP"},"workerGroupSpec": [{"groupName": "ray-vllm-worker-group","computeTemplate": "ray-worker-cm","replicas": 2,"minReplicas": 2,"maxReplicas": 2,"rayStartParams": {"node-ip-address": "$MY_POD_IP"},"image": "registry.uniontech.com/uos-app/vllm-0.6.5-ray-2.40.0.22541c-py310-cu121-serve:latest","imagePullPolicy": "Always","environment": {"values": {"HUGGING_FACE_HUB_TOKEN": "<your_token>"}}}]},"annotations": {"ray.io/enable-serve-service": "true"}}'
Step4:部署 Ray Serve 应用
1、执行 kubectl get services -n ray-blog 命令,获取 head-svc 服务的名字,例如 kuberay-head-svc,并配置端口转发。
kubectl port-forward service/<head-svc服务名> 8265:8265 -n ray-blog2、向 http://localhost:8265/api/serve/applications/ 发送带有如下请求体的 PUT 请求。
{
"applications":[ { "import_path":"serve:model", "name":"deepseek-r1", "route_prefix":"/", "autoscaling_config":{ "min_replicas":1, "initial_replicas":1, "max_replicas":1 }, "deployments":[ { "name":"VLLMDeployment", "num_replicas":1, "ray_actor_options":{ } } ], "runtime_env":{ "working_dir":"file:///home/ray/serve.zip", "env_vars":{ "MODEL_ID":"deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B", "TENSOR_PARALLELISM":"1", "PIPELINE_PARALLELISM":"2", "MODEL_NAME":"deepseek_r1" } } } ]}
可借助系统里的 curl 命令发送请求:
curl -X PUT "http://localhost:8265/api/serve/applications/" \-H "Content-Type: application/json" \-d '{"applications": [{"import_path": "serve:model","name": "deepseek-r1","route_prefix": "/","autoscaling_config": {"min_replicas": 1,"initial_replicas": 1,"max_replicas": 1},"deployments": [{"name": "VLLMDeployment","num_replicas": 1,"ray_actor_options": {}}],"runtime_env": {"working_dir": "file:///home/ray/serve.zip","env_vars": {"MODEL_ID": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B","TENSOR_PARALLELISM": "1","PIPELINE_PARALLELISM": "2","MODEL_NAME": "deepseek_r1"}}}]}'
发送请求后,需要一定的时间等待部署完成,应用达到 healthy 状态。
Step 5:访问模型进行推理
1、执行 kubectl get services -n ray-blog 命令,获取 head-svc 服务的名字,例如 kuberay-head-svc,并配置端口转发。
2、向http://localhost:8000/v1/chat/completions 发送带有如下请求体的 POST 请求。
{"model": "deepseek_r1","messages": [{"role": "user","content": "介绍一下你"}]}
可借助系统里的 curl 命令发送请求:
curl -X POST "http://localhost:8000/v1/chat/completions" \-H "Content-Type: application/json" \-d '{"model": "deepseek_r1","messages": [{"role": "user","content": "介绍一下你"}]}'
性能调优GPU内核级优化
# 锁定GPU频率至最高性能sudo nvidia-smi -lgc 1780,1780 # 3060卡默认峰值频率# 启用持久化模式sudo nvidia-smi -pm 1# 启用MPS(多进程服务)sudo nvidia-cuda-mps-control -d
内存与通信优化
# 在模型代码中添加(减少内存碎片)torch.cuda.set_per_process_memory_fraction(0.9)# 启用激活检查点(Activation Checkpointing)from torch.utils.checkpoint import checkpointdef forward(self, x):return checkpoint(self._forward_impl, x)
内核参数调优
#调整swappiness参数,控制着系统将内存数据交换到磁盘交换空间的倾向,取值范围 0 - 100。echo "vm.swappiness = 10" | sudo tee -a /etc/sysctl.conf# 调整网络参数echo "net.core.rmem_max = 134217728" | sudo tee -a /etc/sysctl.confecho "net.core.wmem_max = 134217728" | sudo tee -a /etc/sysctl.confecho "net.core.somaxconn = 65535" | sudo tee -a /etc/sysctl.conf# 然后执行以下命令使修改生效sudo sysctl -p
核心概念
DeepSeek
DeepSeek 模型是由中国 AI 公司深度求索开发的一款大型语言模型,拥有高效的架构和创新的训练策略。DeepSeek 模型在数学推理、代码生成和知识理解等方面表现突出,可广泛应用于教育培训、内容创作、科研探索等领域。
Ollama
Ollama 是一个基于 Go 语言开发的开源框架,旨在简化大型语言模型的安装、运行和管理过程。它支持多种大型语言模型,如 LLaMA、DeepSeek等,并提供与 OpenAI 兼容的 API 接口,方便开发者和企业快速搭建私有化 AI 服务。
OpenWebUI
OpenWebUI 是一个可扩展的、功能丰富且界面友好的大模型对话平台。它支持多种大型语言模型运行器,包括与 Ollama 和 OpenAI 兼容的 API。
Kubernetes
Kubernetes(简称 K8s)是一个容器编排平台,旨在自动化部署、扩展和管理容器化的应用程序。通过其丰富的 API 和可扩展性设计,K8s 能够支持公有云、私有云、混合云等多种环境,广泛应用于微服务架构、大数据处理、DevOps 及云原生应用等领域。
kubeRay
Ray 是一个通用的分布式计算编程框架,可用于扩展和并行化 AI 应用程序,实现并行化和分布式地处理跨多节点、多 GPU 的 AI 工作负载。KubeRay 是Kubernetes 上托管 Ray 集群和部署 Ray 分布式应用的集成工具集。
vLLM
vLLM 是一个快速且易于使用的库,专为大型语言模型的推理和部署而设计。vLLM 无缝集成 HuggingFace,提供 OpenAI API 兼容的 HTTP 服务,支持 NVIDIA GPU、AMD CPU 和 GPU、Intel CPU 和 GPU、PowerPC CPU、TPU 以及 AWS Neuron 等硬件,支持张量并行和流水线并行的分布式推理。
FastAPI
FastAPI 是一个现代、高性能的 Web API 框架,用于部署提供本地模型的 API 服务。
相关文章:
统信 UOS 服务器版离线部署 DeepSeek 攻略
日前,DeepSeek 系列模型因拥有“更低的成本、更强的性能、更好的体验”三大核心优势,在全球范围内备受瞩目。 本次,我们为大家提供了在统信 UOS 服务器版 V20(AMD64 或 ARM64 架构)上本地离线部署 DeepSeek-R1 模型的…...

美尔斯通携手北京康复辅具技术中心开展公益活动,科技赋能助力银龄健康管理
2025 年 5 月 30 日,北京美尔斯通科技发展股份有限公司携手北京市康复辅具技术中心,在朝阳区核桃园社区开展 “全国助残日公益服务” 系列活动。活动通过科普讲座、健康检测与科技体验,将听力保健与心脏健康服务送至居民家门口,助…...

《前端面试题:前端响应式介绍》
前端响应式设计完全指南:从理论到实战 掌握响应式设计是构建现代网站的核心能力,也是前端面试的必考内容 一、响应式设计:移动优先时代的必备技能 在当今多设备时代,用户通过手机、平板、笔记本、桌面显示器等多种设备访问网站。…...
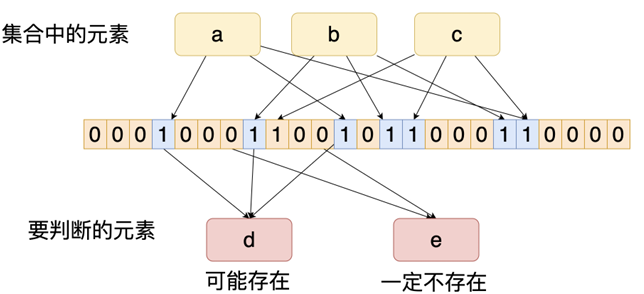
Redis Stack常见拓展
Redis JSON RedisJSON 是 Redis Stack 提供的模块之一,允许你以 原生 JSON 格式 存储、检索和修改数据。相比传统 Redis Hash,它更适合结构化文档型数据,并支持嵌套结构、高效查询和部分更新。 #设置⼀个JSON数据,其中$表示JSON数据的根节点…...

Linux 驱动之设备树
Linux 驱动之设备树 参考视频地址 【北京迅为】嵌入式学习之Linux驱动(第七期_设备树_全新升级)_基于RK3568_哔哩哔哩_bilibili 本章总领 1.设备树基本知识 什么是设备树? Linux之父Linus Torvalds在2011年3月17日的ARM Linux邮件列表…...
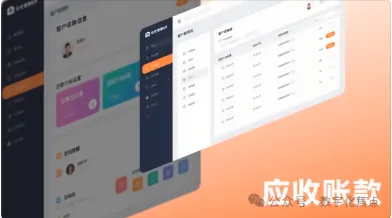
12、企业应收账款(AR)全流程解析:从发票开具到回款完成
在商业活动中,现金流如同企业的命脉,而应收管理则是维系这条命脉正常运转的重要保障。许多企业由于对应收账款缺乏有效管理,常常面临资金周转困难的问题。实践证明,建立科学的应收管理体系能够显著提升资金回笼效率,为…...

php 各版本下载
https://windows.php.net/downloads/releases/archives/ 参考资料:php5.6.40 在 win10下安装全过程 ( 图文教程、附官方下载链接 )...
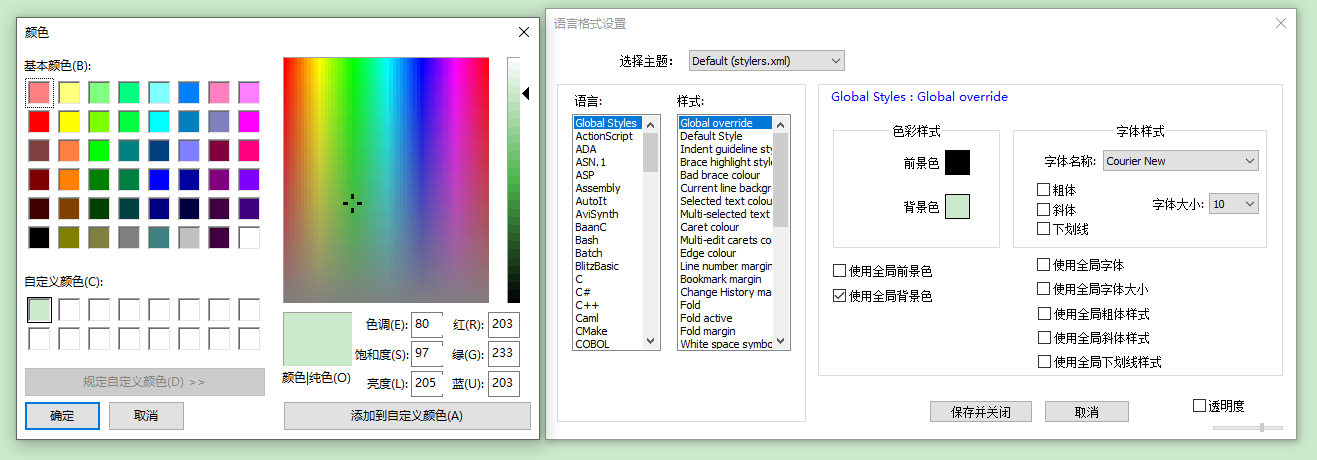
【notepad++】如何设置notepad++背景颜色?
如何设置notepad背景颜色? 设置--语言格式设置 勾选使用全局背景色 例如选择护眼色---80,97,205;...

使用 C++/OpenCV 制作跳动的爱心动画
使用 C/OpenCV 制作跳动的爱心动画 本文将引导你如何使用 C 和 OpenCV 库创建一个简单但有趣的跳动爱心动画。我们将通过绘制参数方程定义的爱心形状,并利用正弦函数来模拟心跳的缩放效果。 目录 简介先决条件核心概念 参数方程绘制爱心动画循环模拟心跳效果 代码…...

Go Modules 详解 -《Go语言实战指南》
Go Modules(简称 go mod)是 Go 官方推出的包依赖管理系统,自 Go 1.11 起引入,Go 1.16 起成为默认方式,取代了旧的 GOPATH 模式。 本章将全面讲解 Go Modules 的基本原理、使用方法以及常见问题处理。 一、Go Modules 简…...
在Oxygen编辑器中使用DeepSeek
罗马尼亚公司研制开发的Oxygen编辑器怎样与国产大模型结合,这是今年我在tcworld大会上给大家的分享,需要ppt的朋友请私信联系 - 1 - Oxygen编辑器中的人工智能助手 Oxygen编辑器是罗马尼亚的Syncro Soft公司开发的一款结构化文档编辑器。 它是用来编写…...
(Go语言版))
【LeetCode 热题100】BFS/DFS 实战:岛屿数量 腐烂的橘子(力扣200 / 994 )(Go语言版)
🌊 BFS/DFS 实战:岛屿数量 & 腐烂的橘子(LeetCode 200 & 994) 两道图论基础题,涉及 BFS 与 DFS 的应用,主要用于掌握二维网格中遍历与标记访问的技巧: 🏝️ 200. 岛屿数量…...

一、基础环境配置
一、虚拟机 主:192.168.200.200 从:192.168.200.201 从:192.168.200.202 二、docker docker基础搭建,有不会的自行百度。 1.目录结构 /opt/software:软件包/opt/module:解压包,自定义脚本…...

论文阅读笔记——FLOW MATCHING FOR GENERATIVE MODELING
Flow Matching 论文 扩散模型:根据中心极限定理,对原始图像不断加高斯噪声,最终将原始信号破坏为近似的标准正态分布。这其中每一步都构造为条件高斯分布,形成离散的马尔科夫链。再通过逐步去噪得到原始图像。 Flow matching 采取…...

SQL Views(视图)
目录 Views Declaring Views Example: View Definition Example: Accessing a View Advantages of Views Triggers on Views Interpreting a View Insertion(视图插入操作的解释) The Trigger Views A view is a relation defined in terms of…...
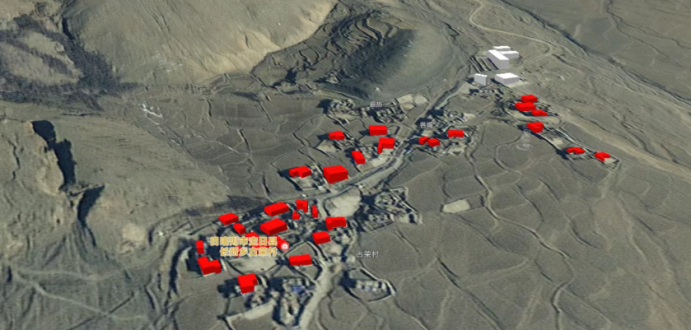
「卫星百科」“绿色守卫”高分六号
高分六号(GF-6)是中国高分辨率对地观测系统(高分专项)的重要组成卫星,于2018年6月2日成功发射。高分六号卫星凭借其高时空分辨率、红边波段、宽覆盖能力,在农业、生态、灾害等领域提供了重要的数据支撑。本…...

秋招Day12 - 计算机网络 - IP
IP协议的定义和作用? IP协议用于在计算机网络中传递数据包,定义了数据包的格式和处理规则,确保数据能够从一个设备传递到另一个设备,中间可能经过多个不同的设备(路由器)。 IP协议有哪些作用?…...

Servlet 快速入门
文章目录 概念SpringBoot 测试案例执行原理传统 Servlet在 SpringBoot (嵌入式 Tomcat Spring MVC) 中请求从浏览器到业务代码的完整步骤关键点流程图 参考 概念 运行在服务器端的小程序, Servlet 就是一个接口,定义 Java 类被浏…...

【前端】CSS面试八股
网上现有资料已经很丰富了,我挑了些自己押面试题时总结过的来写。 Q:回流和重绘 A: 回流reflow:计算元素的几何,引发layout重绘repaint:更新元素可见样式,引发paint 回流的成本比重绘高得多&…...

[蓝桥杯]找到给定字符串中的不同字符
题目描述 在不考虑字符排列的条件下,对于相差只有一个字符的两个字符串,实现一个算法来识别相差的那个字符。要求如下: 当传入的字符串为 aad 和 ad 时,结果为 a。 当传入的字符串为 aaabccdd 和 abdcacade 时,结果为…...
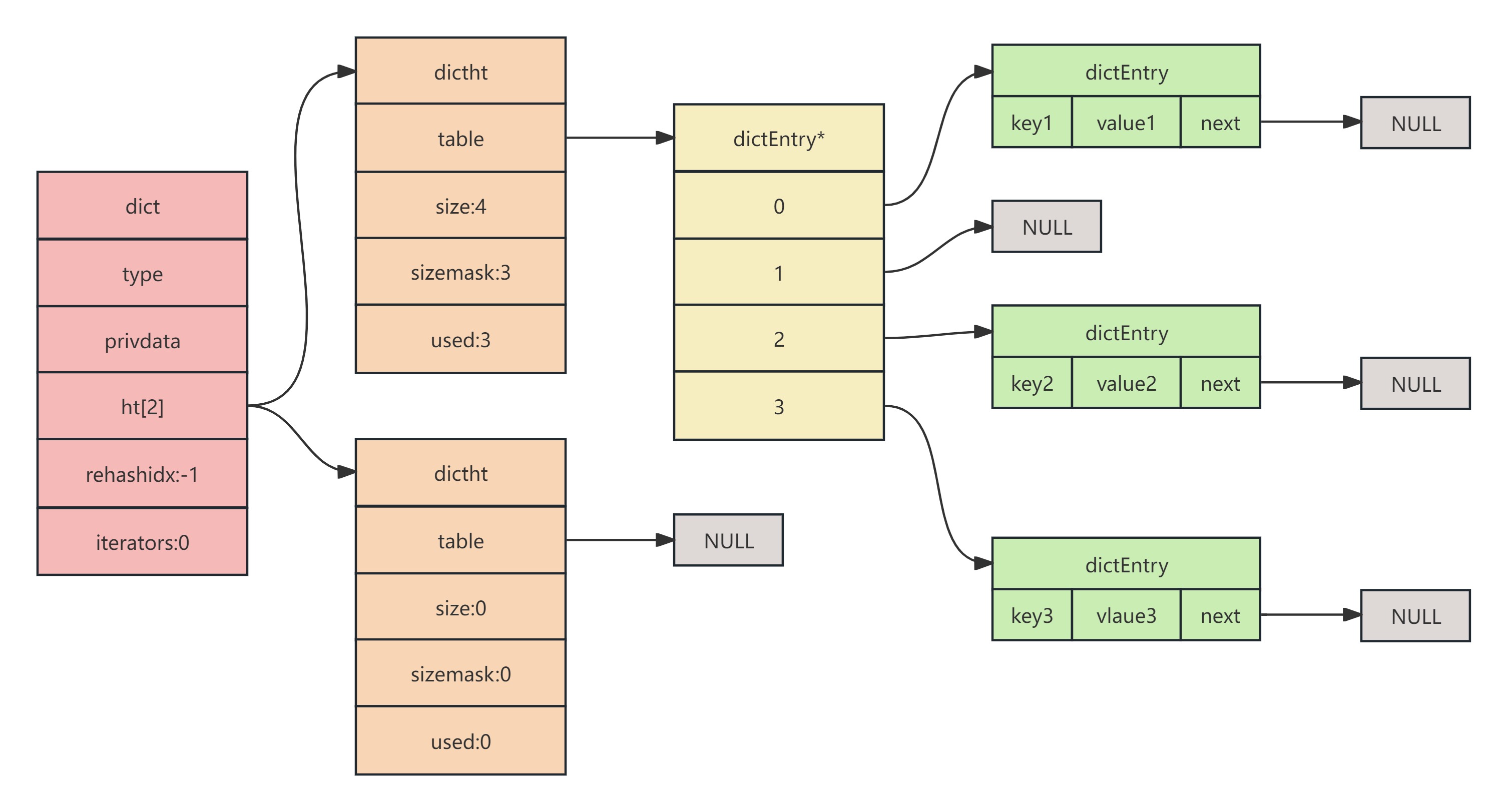
Redis底层数据结构之字典(Dict)
Dict基本结构 Dict我们可以想象成目录,要翻看什么内容,直接通过目录能找到页数,翻过去看。如果没有目录,我们需要一页一页往后翻,这样时间复杂度就与遍历的O(n)一样了,而用了Dict我们就可以在O(1)的时间复杂…...

佰力博科技与您探讨低温介电温谱测试仪的应用领域
低温介电温谱测试应用领域有如下: 一、电子材料: 低温介电温谱测试仪广泛应用于电子材料的性能测试,如陶瓷材料、半导体材料、压电材料等。通过该设备,可以评估材料在高温或低温环境下的介电性能,为材料的优化和应用提…...

ubuntu之开机自启frpc
在 Ubuntu 系统中为 frpc 设置开机自启(以 frpc -c frpc.toml 命令为例),可以通过 systemd 服务实现。以下是详细步骤: 创建 systemd 服务文件 sudo vim /etc/systemd/system/frpc.service 写入以下内容(根据你的路…...
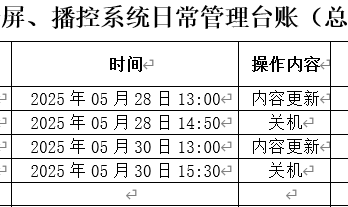
【办公类-48-04】202506每月电子屏台账汇总成docx-5(问卷星下载5月范围内容,自动获取excel文件名,并转移处理)
背景需求: 1-4月电子屏表格,都是用这个代码将EXCEL数据整理成分类成3个WORD表格。 【办公类-48-04】20250118每月电子屏台账汇总成docx-4(提取EXCLE里面1月份的内容,自制月份文件夹)-CSDN博客文章浏览阅读1.2k次&…...

对 `llamafactory-cli api -h` 输出的详细解读
llamafactory-cli 是 LlamaFactory 项目提供的命令行接口工具,它允许用户通过命令行参数来配置和运行大型语言模型的各种任务,如预训练(PT)、有监督微调(SFT)、奖励模型训练(RM)、基…...

基于 ZYNQ UltraScale+ OV5640的高速图像传输系统设计,支持国产替代
引 言 随着电子信息技术的不断进步,人工智能、医 疗器械、机器视觉等领域都在高速发展 [1] ,工业相机 是机器视觉系统中的一部分 [2] ,对工业相机而言,传 输图像的速率、传输过程的抗干扰能力是其关键, 工业相…...

demo_win10配置WSL、DockerDesktop环境,本地部署Dify,ngrok公网测试
win10配置WSL、DockerDesktop环境,本地部署Dify,ngrok分享测试 一、配置WSL 1.1 开启Hyper-V 安装WSL2首先要保证操作系统可以开启hyper-v功能,默认支持开启hyper-v的版本为:Windows11企业版、专业版或教育版,而家庭版是不支持…...

TablePlus:一个跨平台的数据库管理工具
TablePlus 是一款现代化的跨平台(Window、Linux、macOS、iOS)数据库管理工具,提供直观的界面和强大的功能,可以帮助用户轻松管理和操作数据库。 TablePlus 免费版可以永久使用,但是只能同时打开 2 个连接窗口ÿ…...
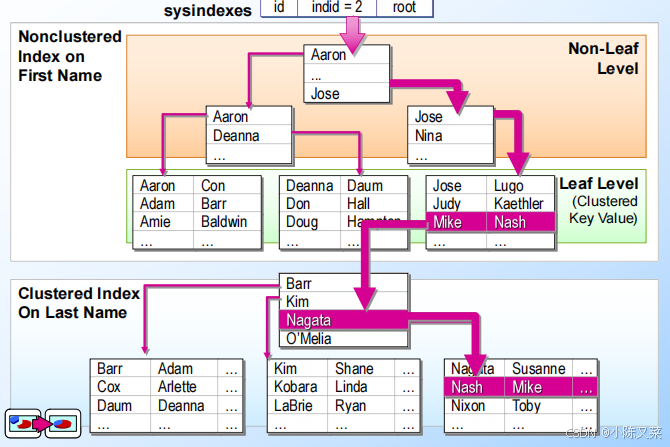
SQL Indexes(索引)
目录 Indexes Using Clustered Indexes Using Nonclustered Indexes Declaring Indexes Using Indexes Finding Rows Without Indexes Finding Rows in a Heap with a Nonclustered Index Finding Rows in a Clustered Index Finding Rows in a Clustered Index with …...
Axure 基础入门
目录 认识产品经理 项目团队* 基本概述 认识产品经理 A公司产品经理 B公司产品经理 C公司产品经理 D公司产品经理 产品经理工作范围 产品经理工作流程* 产品经理的职责 产品经理的分类 产品经理能力要求 产品工具 产品体验报告 原型设计介绍 原型设计概述 为…...