大模型分布式训练笔记(基于accelerate+deepspeed分布式训练解决方案)
文章目录
- 一、分布式训练基础与环境配置
- (1)分布式训练简介
- (2)如何进行分布式训练
- (3)分布式训练环境配置
- 二、数据并行-原理与实战(pytorch框架的nn.DataParallel)
- 1)data parallel-数据并行 原理及流程
- 2)data parallel-数据并行 训练实战
- 3)data parallel-数据并行 推理对比
- 三、分布式数据并行Distributed DataParallel-原理与实战(俗称ddp)
- 1)distributed data parrallel并行原理
- 2)分布式训练中的一些基本概念
- 3)分布式训练中的通信基本概念
- 4)distributed data parallel 训练实战(DDP)
- 四、Accelerate基础入门
- 1)Accelerate基本介绍
- 2)基于AccelerateDDP代码介绍
- 3)Accelerate启动命令介绍
- 五、Accelerate使用进阶
- 1)Accelerate混合精度训练
- 2)Accelerate梯度累积功能
- 3)Accelerate实验记录功能
- 4)Accelerate模型保存功能
- 5)Accelerate断点续训练功能
- 6)前五个功能后的总代码
- 六、Accelerate集成Deepspeed
- 1)Deepspeed介绍
- 2)Accelerate + Deepspeed代码实战
一、分布式训练基础与环境配置
(1)分布式训练简介
- 背景介绍
海量的训练数据给大模型训练带来了海量的计算需求,主要体现在变大的模型对显存的依赖逐渐加剧 - 单卡场景如何解决显存问题
1)可训练参数量降低
①参数高效微调--PEFT
②prompt-Tuning、Prefix-Tuning、Lora等
2)参数精度降低
①低精度模型训练--Bitsandbytes
②半精度、INT8、NF4
- 分布式训练简介
指的是系统或计算任务被分布到多个独立的节点或计算资源上进行处理,而不是集中在单个节点或计算机上
(2)如何进行分布式训练
-
分布式训练方法
1)数据并行:Data Parrallel,DP
原理:每个GPU上都复制一份完整模型,但是每个GPU上训练的数据不同。要求每张卡内都可以完整执行训练过程
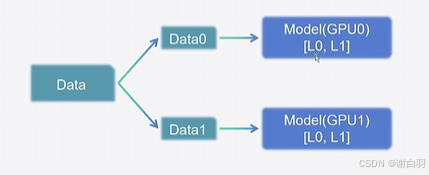
2)流水并行:Pipeline Parrallel,PP
原理:将模型按层拆开,每个GPU上包含部分的层,保证能够正常训练。不要求每张卡内都能完整执行训练过程
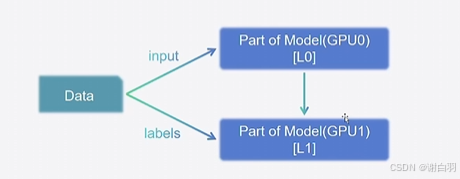
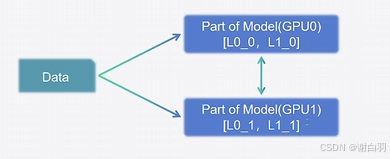
3)张量并行:Tensor Parrallel,TP
原理:将模型每层的权重拆开,对于一份权重,每个GPU上各包含一部分,保证能够正常训练。不要求每张卡内都可以完整执行训练过程
-
分布式训练方式选择
①单卡可以完成训练流程的模型:
做法:每个GPU上都复制一份完整模型,但是每个GPU上训练的数据不同
组合:数据并行
②单卡无法完成训练流程的模型
做法:
1)做法一:流水并行,将模型按层拆开训练,每个GPU包含一部分层
2)做法二:张量并行,将模型权重拆开,每个GPU包含一部分权重
③混合策略
做法:数据并行+流水并行+张量并行 -
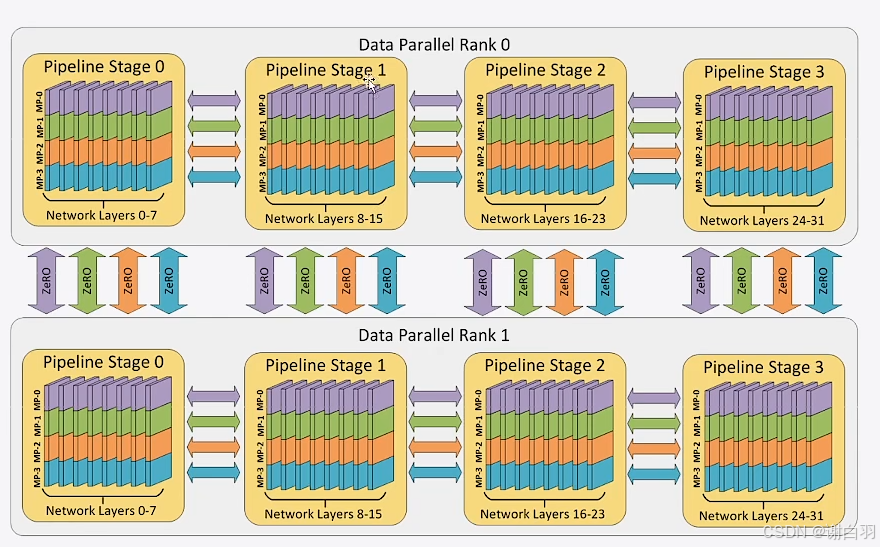
3D并行举例
2路数据并行,上下各一路
4路流水并行(0-7层的权重每个方块都被拆成了4份分开训练)
4路张量并行(0~7、8~15、16~23、24~31)
(3)分布式训练环境配置
1)服务器显卡租赁平台:趋动云、AutoDL
2)环境安装:
①设置pypi源:
进入下图的路径修改源

http://mirrors.aliyun.com/pypi/simple/
修改后如图下

安装aacelerate库
pip install transformers==4.36.2 accelerate==0.26.1 evaluate datasets
- 以下是趋动云的环境配置举例
①选择pytorch2.1.1作为环境的docker镜像
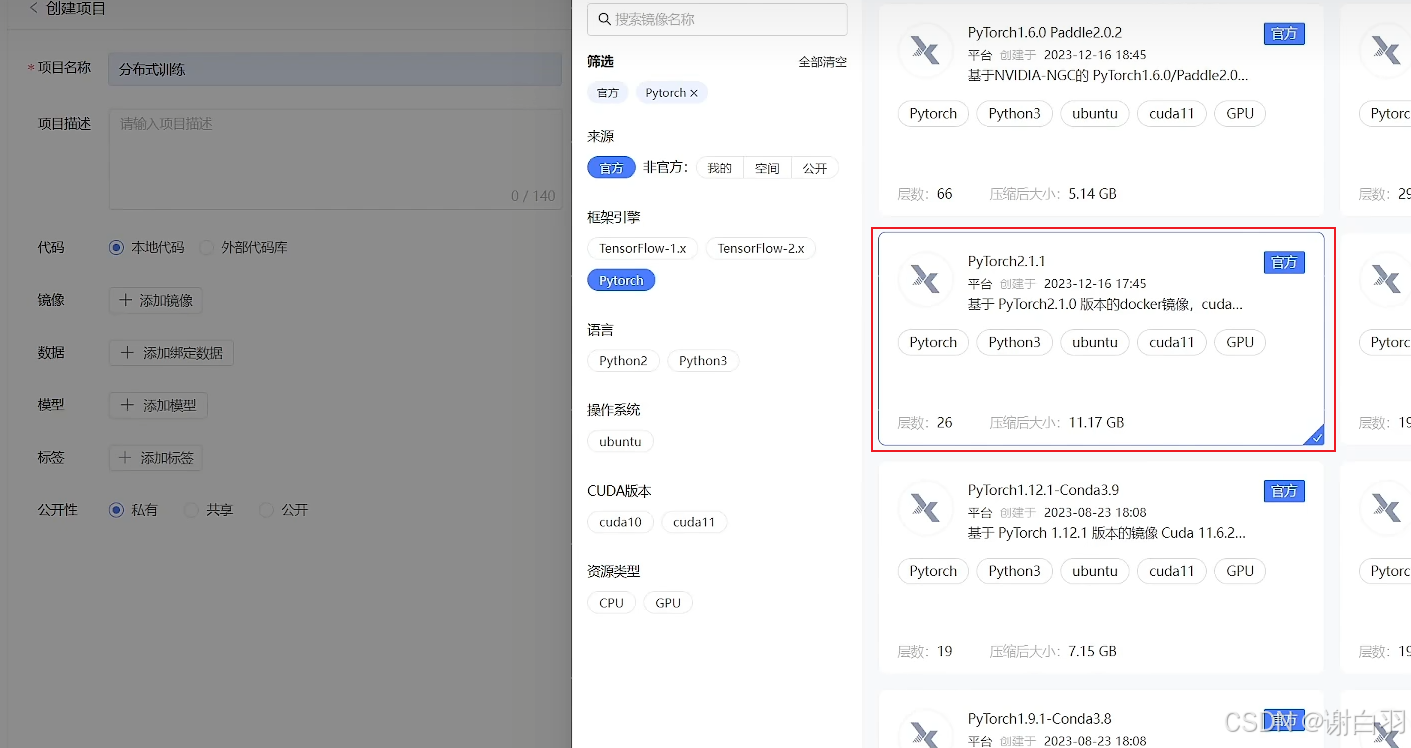
②任选公开模型,这里举例选择的bert
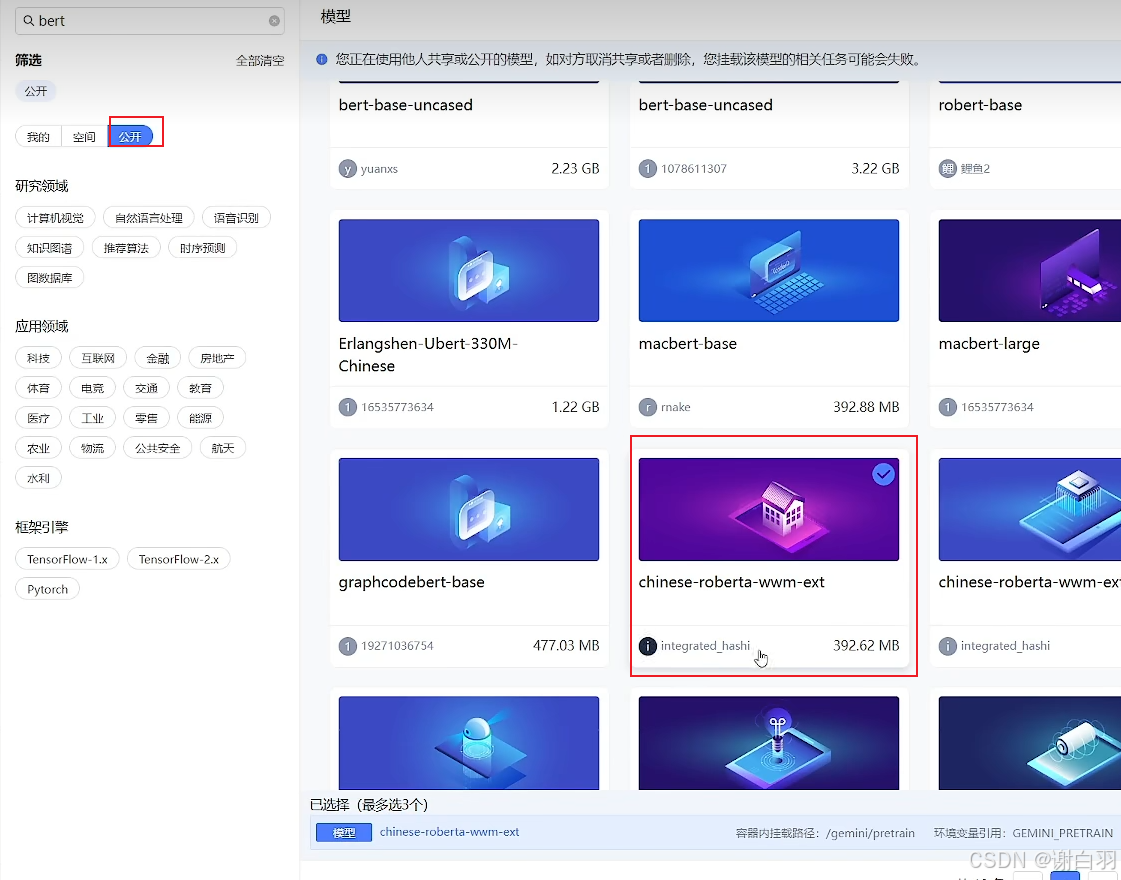
可以看到代码、数据集、结果集在云平台的存放位置
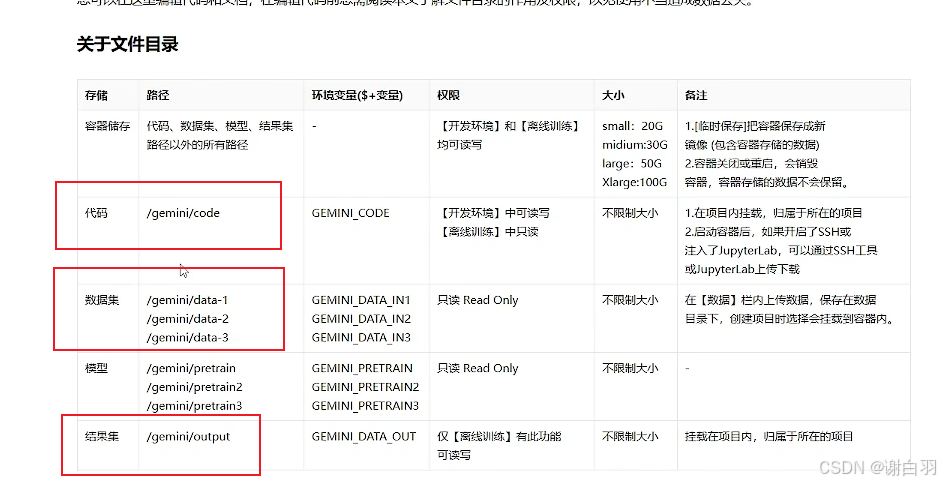
③开发上传代码要选择不同显卡资源配置,这里选择2张显卡的B1款
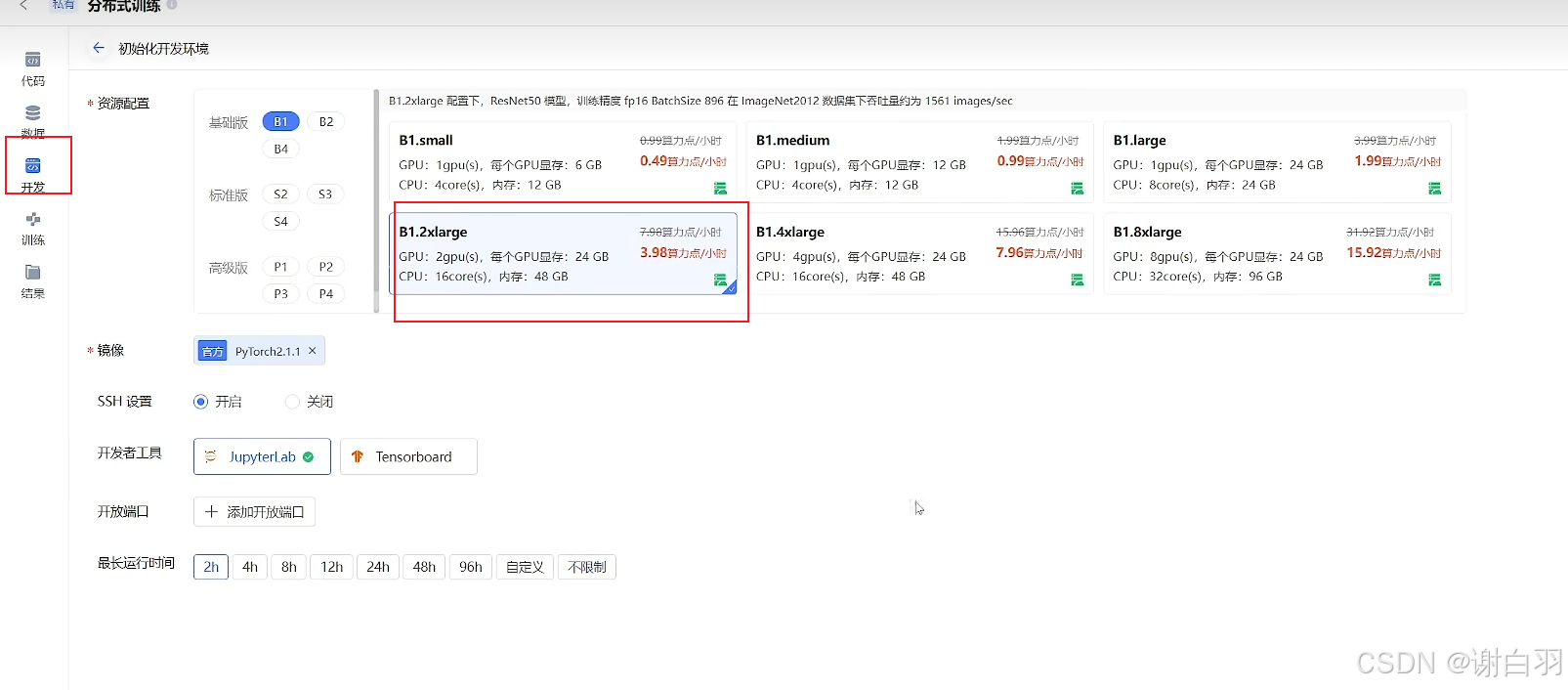
-
测试代码运行
1)报错解决:import apex报错
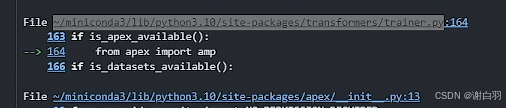
解决方法:
①进入路径

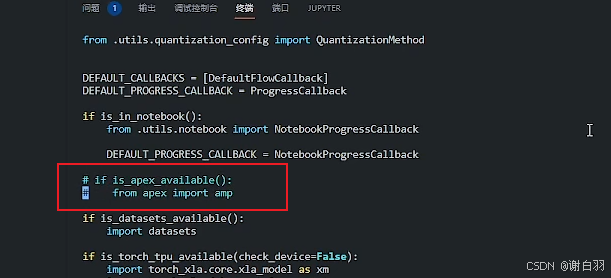
②修改源码,注释掉这两行
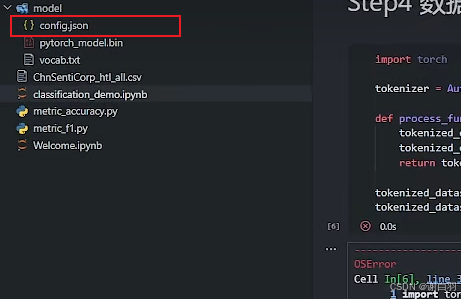
2)json文件报错,因为老版文件是config.json,新版本是bert_config.json,为了兼容老版本需要换成新的tokenlizer,又因为是只读路径,不支持修改,所以复制到另外个目录去修改

修改名字为config.json
-
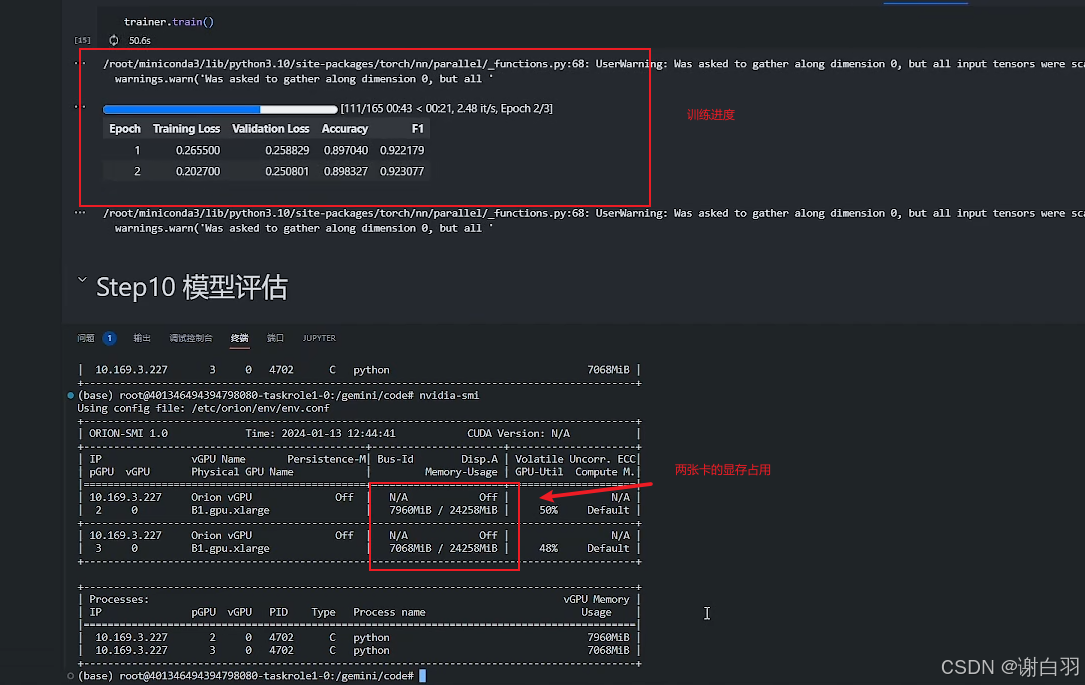
训练代码
检测显卡可以看到两张显卡都占用了显存
from transformers import DataCollatorWithPadding,Trainer,TrainingArguments,BertForSequenceClassification,BertTokenizer
from datasets import load_dataset
import torch
import evaluate#1、load dataset
dataset = load_dataset("csv", data_files="./ChnSetiCorp_htl_all.csv",split="train")
dataset = dataset.filter(lambda x:x["review"] is not None)#2、split dataset
datasets = dataset.train_test_split(test_size=0.1)#4、dataset preprocess
tokenizer = BertTokenizer.from_pretrained("/gemini/pretrain/")
def process_function(examples):tokenized_examples = tokenizer(examples["review"], truncation=True, padding="max_length", max_length=32)tokenized_examples["labels"] = examples["label"]return tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True,remove_columns=datasets["train"].column_names)#5、create model 创建模型
model = BertForSequenceClassification.from_pretrained("/model/")#6、create evaluation function 创建评估函数
acc_metric = evaluate.load("./metric_acuracy.py")
f1_metric = evaluate.load("./metric_f1.py")
def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = predictions.argmax(axis=-1)acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metric.compute(predictions=predictions, references=labels)acc.update(f1)return acc#7、create training args 创建训练参数
training_args = TrainingArguments(output_dir="./checkpoint", #输出文件目录per_device_train_batch_size=64, #训练批次大小per_device_eval_batch_size=128, #评估批次大小logging_steps=10, #日志打印频率 evaluation_strategy="epoch", #评估策略save_strategy="epoch", #保存策略save_total_limit=3, #保存的最大检查点数量learning_rate=2e-5, #学习率weight_decay=0.01, #权重衰减metric_for_best_model="f1", #最佳模型评估指标load_best_model_at_end=True, #在训练结束时加载最佳模型
)#8、create trainer 创建训练器
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=eval_metric,
)#9、start training 开始训练
trainer.train()二、数据并行-原理与实战(pytorch框架的nn.DataParallel)
- 特点
改动代码改动小,但是效率提升不明显
1)data parallel-数据并行 原理及流程
-
介绍

-
训练流程
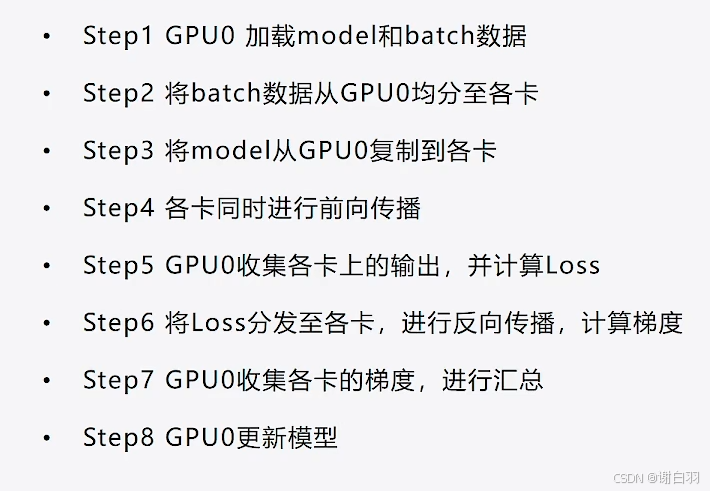
-
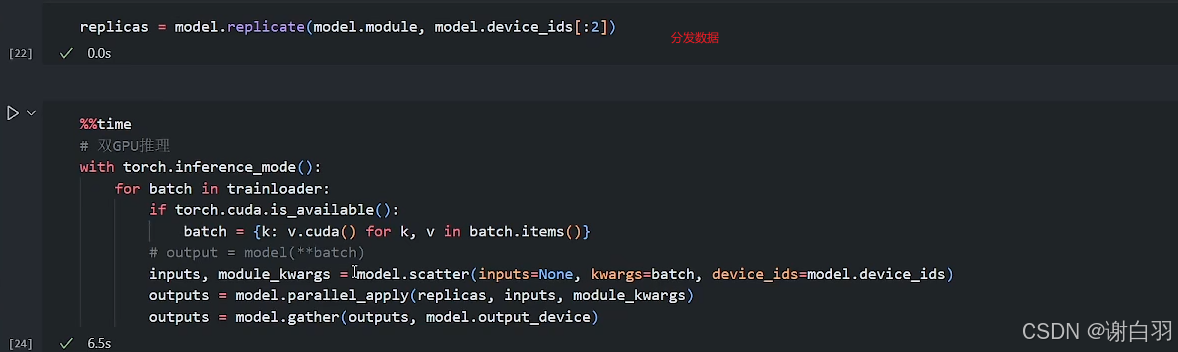
nn.DataParallel源码实现.
代码讲解:
①将batch数据分发到各个显卡
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
②将model分发到各个显卡
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
③收集各个显卡的梯度
self.gather(outputs, self.output_device)
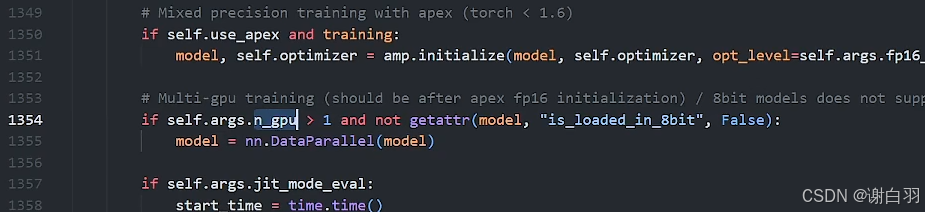
def forward(self, *inputs, **kwargs):with torch.autograd.profiler.record_function("DataParallel.forward"):if not self.device_ids:return self.module(*inputs, **kwargs)for t in chain(self.module.parameters(), self.module.buffers()):if t.device != self.src_device_obj:raise RuntimeError("module must have its parameters and buffers ""on device {} (device_ids[0]) but found one of ""them on device: {}".format(self.src_device_obj, t.device))inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)# for forward function without any inputs, empty list and dict will be created# so the module can be executed on one device which is the first one in device_idsif not inputs and not kwargs:inputs = ((),)kwargs = ({},)if len(self.device_ids) == 1:return self.module(*inputs[0], **kwargs[0])replicas = self.replicate(self.module, self.device_ids[:len(inputs)])outputs = self.parallel_apply(replicas, inputs, kwargs)return self.gather(outputs, self.output_device)2)data parallel-数据并行 训练实战
- 备注
①huggingface的train源码自带数据并行
参数设置在TrainingArguments函数的默认参数


-
环境配置

-
训练代码(文本分类)
from transformers import DataCollatorWithPadding,Trainer,TrainingArguments,BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch#1、load dataset 加载数据集
data = pd.read_csv("./ChnSetiCorp_htl_all.csv")
data = data.dropna() # 删除review列中为None的行#2、创建dataset
class MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]dataset = MyDataset()#3、split dataset 划分数据集
train_set, validset = random_split(dataset, [0.9, 0.1])#4、创建dataloader
tokenizer = BertTokenizer.from_pretrained("./model/")
def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
trainloader = DataLoader(train_set, batch_size=32, shuffle=True, collate_fn=collate_fn)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_fn)# Note: The following line is for demonstration purposes and may not produce meaningful output without the actual dataset.
# It attempts to print the second element (data) of the first enumerated item from the validloader.#5、创建模型及优化器
model = BertForSequenceClassification.from_pretrained("./model")if torch.cuda.is_available():model = model.cuda()
#新加(当 device_ids=None 时,DataParallel 会默认使用所有可用的 GPU 设备)
model=torch.nn.DataParallel(model,device_ids=None)optimizer = Adam(model.parameters(), lr=2e-5)#6、训练和验证
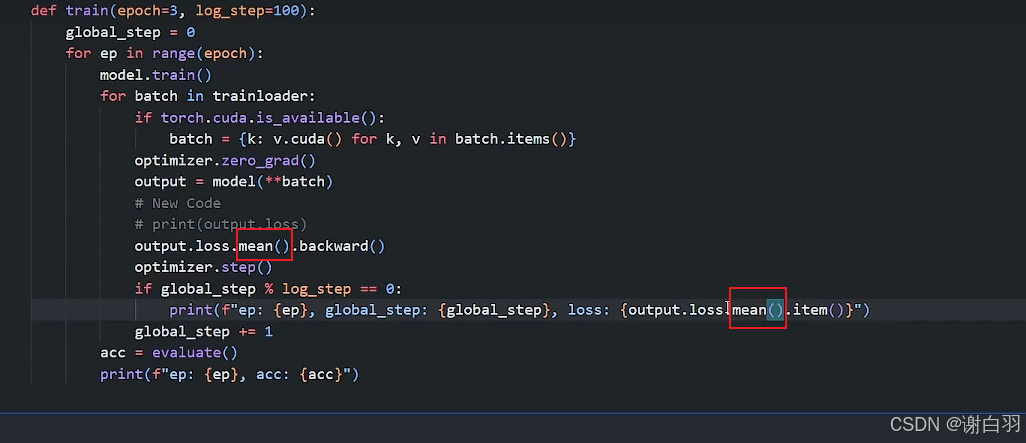
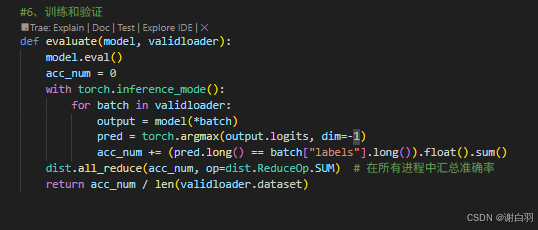
def evaluate():model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}output = model(*batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validset)def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()for batch in trainloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}optimizer.zero_grad()output = model(**batch)output.loss.mean().backward()optimizer.step()if global_step % log_step == 0:print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.mean().item()}")global_step += 1acc = evaluate()print(f"ep:{ep} ,Validation accuracy: {acc.item() * 100:.2f}%")train()#7、模型预测- 遇到的问题点
loss是标量值才进行反向传播,loss使用mean方法转化为变量才能反向转播
- 数据并行训练耗时总结
1)单GPU batch32 1min42.3s
2)双GPU batch 2*16 1min33.6s总batchsize提升64
2)双GPU batch 2*32 1min9.5s
- data parallel问题点
每次前向传播都得主卡去同步给副卡一遍

GIL锁:

3)data parallel-数据并行 推理对比
1)单GPU推理:共花了13s,batchsize=32
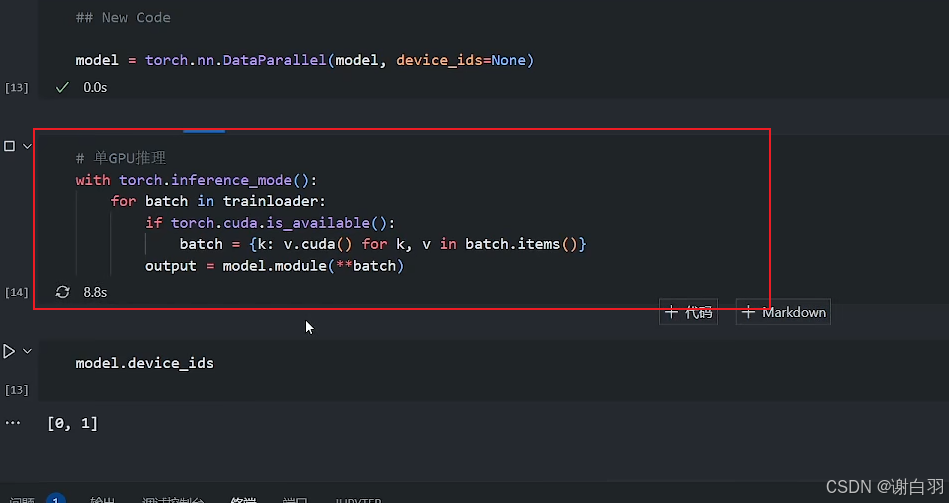
2)双GPU:21.1s,batchsize=32
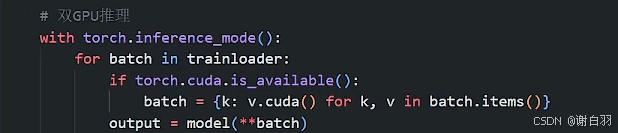
3)batchsize=64
单GPU:10.5s
双GPU:8.8s
4)batchsize=128
单GPU:10.4s
双GPU:7.0s
5)每次训练的时候都会同步模型,将这部分去掉,推理的时候使用自己的train函数,双显卡只耗时6.6s
三、分布式数据并行Distributed DataParallel-原理与实战(俗称ddp)
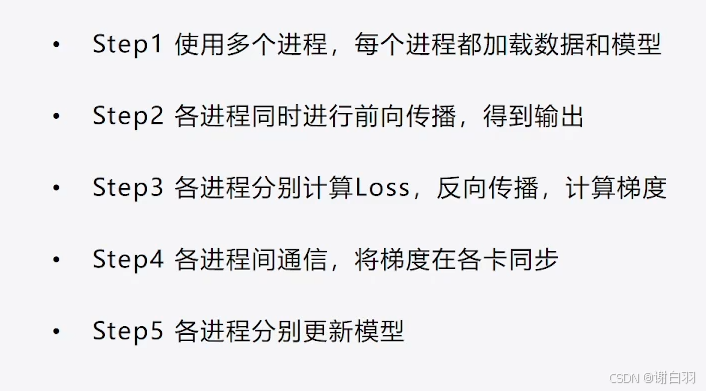
1)distributed data parrallel并行原理
2)分布式训练中的一些基本概念

3)分布式训练中的通信基本概念
-
图来示例
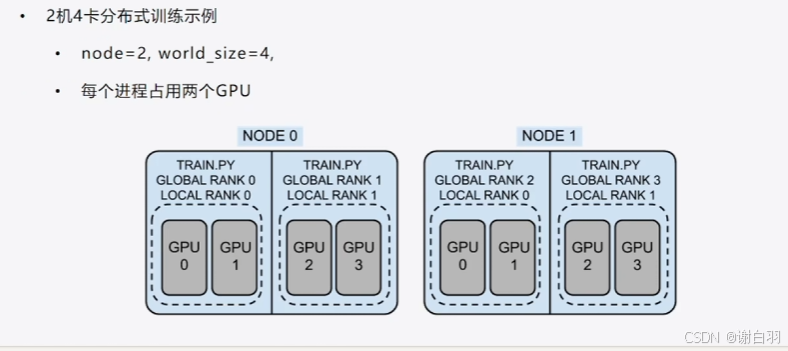
-
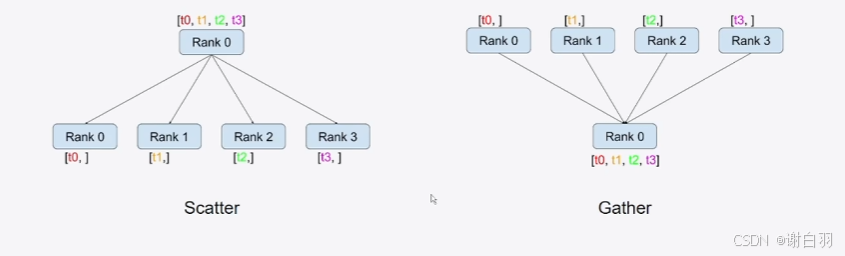
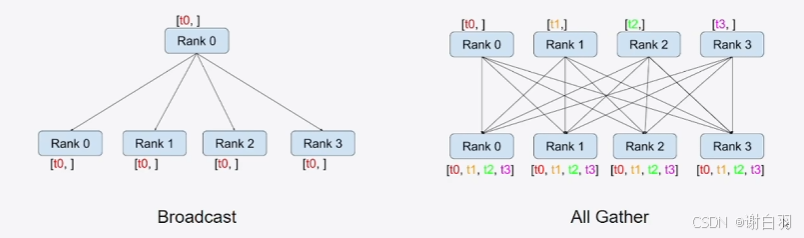
通信类型

①scatter和Gather
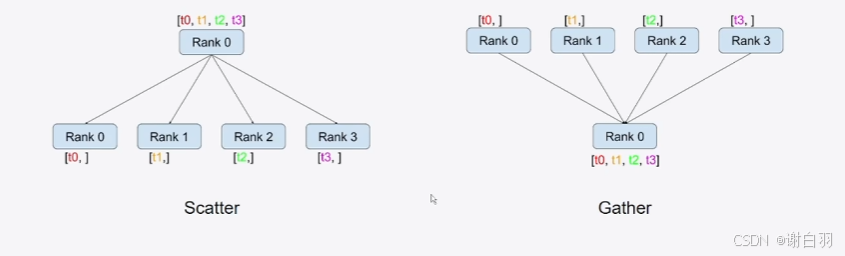
reduce:将各显卡的信息集中并做额外的处理,例如图中的加法
4)distributed data parallel 训练实战(DDP)
- 环境配置
- 代码相关
①加载distribute库
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器#1)初始化进程组
dist.init_process_group(backend='nccl')
②去掉DataLoader的shuffle为true的参数,传sample参数为DistributedSampler
trainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,sampler=DistributedSampler(train_set))
validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,sampler=DistributedSampler(validset))
③用local_rank区别同一显卡内的不同进程
#5、创建模型及优化器
from torch.nn.parallel import DistributedDataParallel as DDP
import os
model = BertForSequenceClassification.from_pretrained("./model")
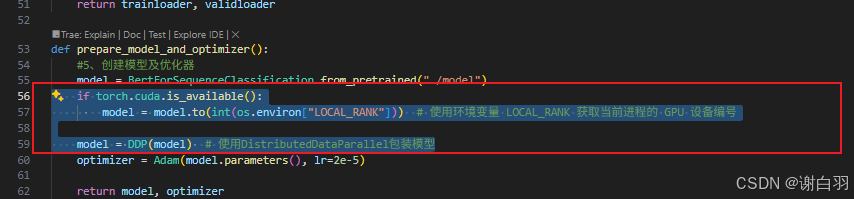
if torch.cuda.is_available():model = model.to(int(os.environ["LOCAL_RANK"])) # 使用环境变量 LOCAL_RANK 获取当前进程的 GPU 设备编号model = DDP(model) # 使用DistributedDataParallel包装模型
optimizer = Adam(model.parameters(), lr=2e-5)
继续把train函数的地方把.cuda改成local_rank
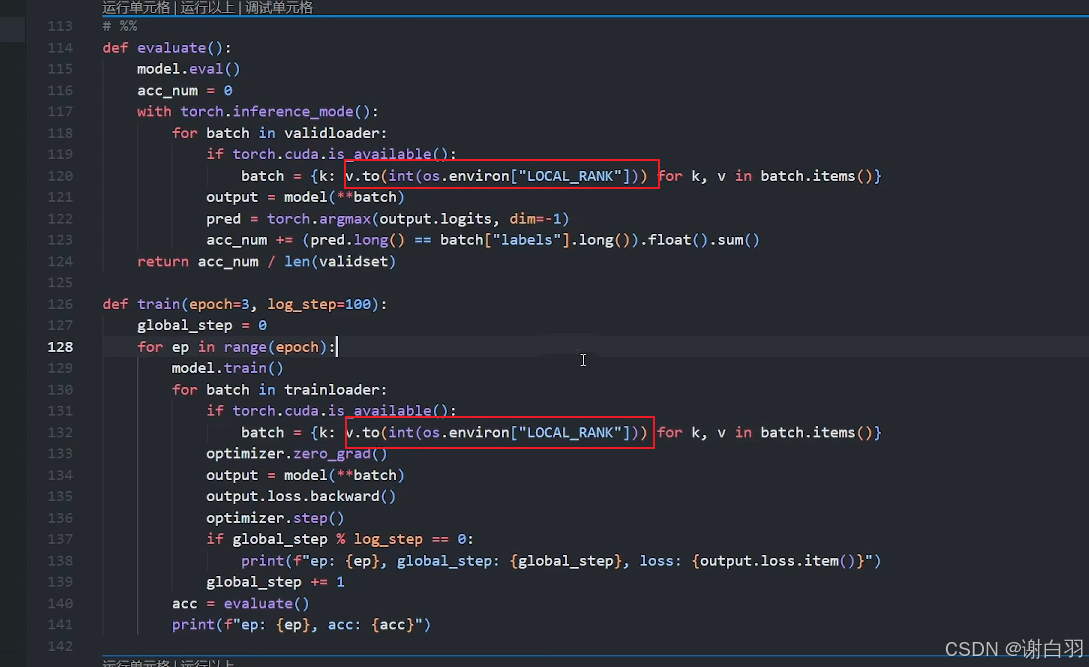
④运行命令
torchrun --nproc_per_node 2 ddp.py #这里nproc_per_node表示一张显卡的进程数
⑤优化一:由于结果打印的是各个GPU显卡的损失值loss,而不是总体的平均值,需要各显卡通信打印平均值loss
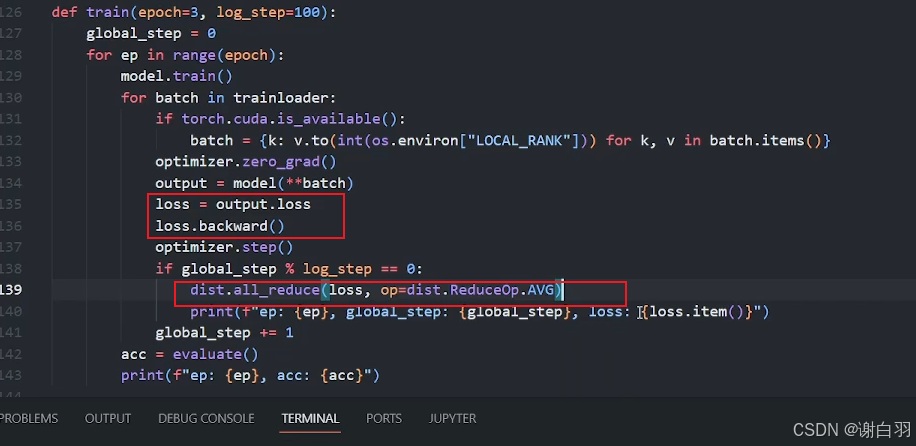
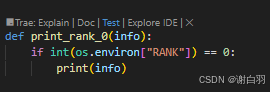
⑥优化二:
由于一张卡有全体唯一的global_rank,而现在一张卡用了两条线程去做,会打印两次,现在需求是根据global_rank只打印一次
把打印都替换一下
def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)
⑦优化三:现在准确率是除以了全部的数据,现在单个local rank只需要除以自己处理部分的数据来计算准确率
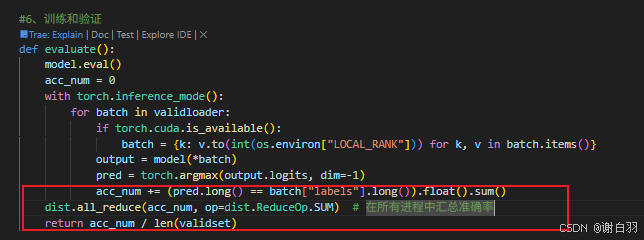
⑧优化四:
数据集两个进程之间划分容易有重叠,准确率会虚高
#3、split dataset 划分数据集
train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))
⑨优化五:让训练数据不重复,随机打断
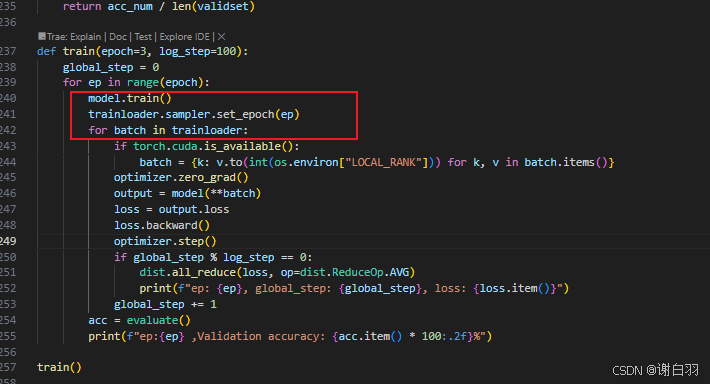
istributedSampler 的 set_epoch 方法会依据传入的轮次编号(ep)更新采样器的随机种子,这样在不同的训练轮次中,采样器会以不同的随机顺序对数据进行采样。这意味着每个进程在不同轮次会处理不同的数据子集,有助于模型接触到更多的数据变化,提高模型的泛化能力和训练效果。
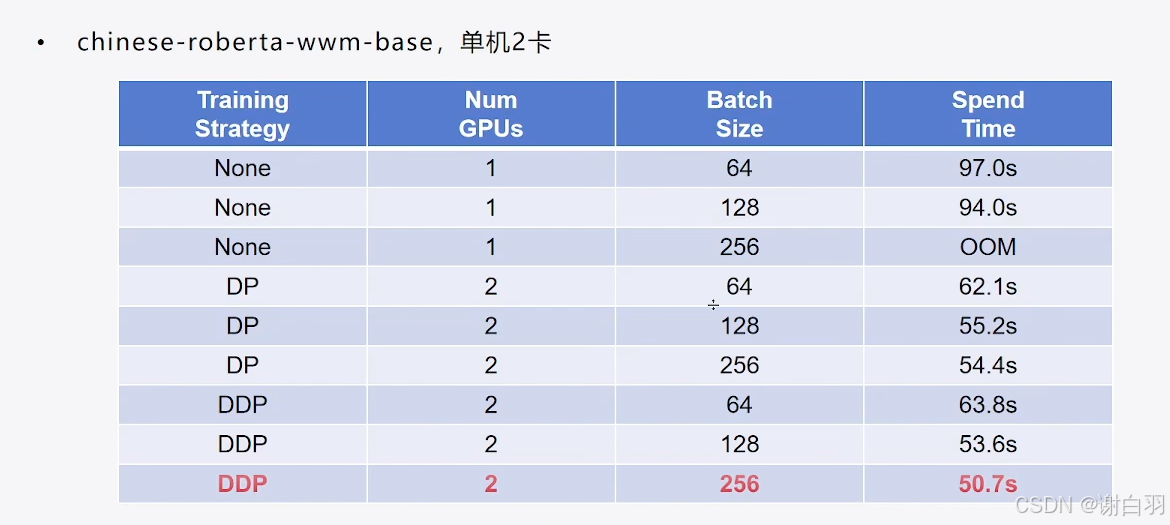
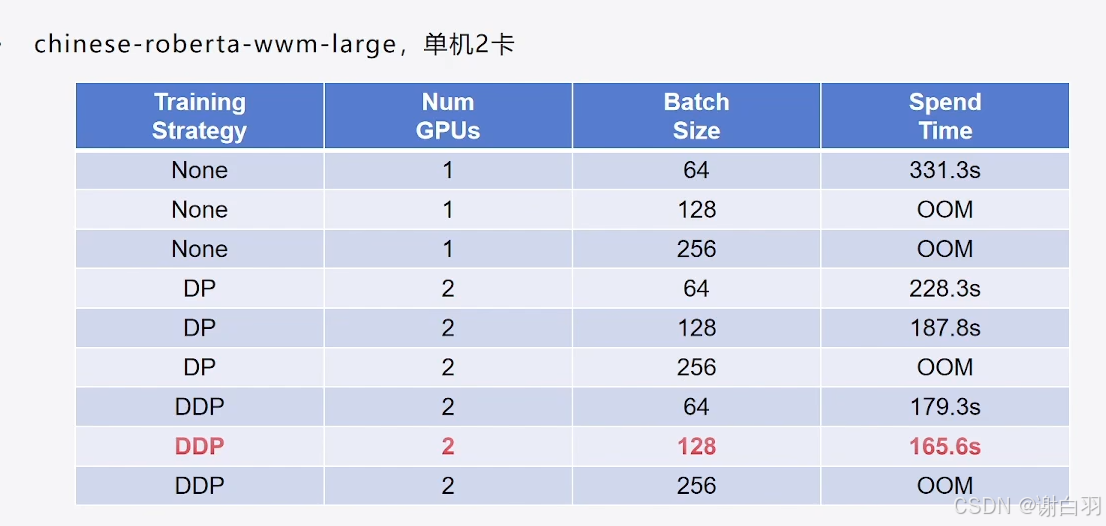
- DDP和DP效率对比(基本上batchsize越高ddp效率越好过于DP)
- 代码
from transformers import DataCollatorWithPadding,Trainer,TrainingArguments,BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器
import os#1)初始化进程组
dist.init_process_group(backend='nccl')def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)#2、创建dataset
class MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]dataset = MyDataset()#3、split dataset 划分数据集
train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))#4、创建dataloader
tokenizer = BertTokenizer.from_pretrained("./model/")
def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
trainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,sampler=DistributedSampler(train_set))
validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,sampler=DistributedSampler(validset))# Note: The following line is for demonstration purposes and may not produce meaningful output without the actual dataset.
# It attempts to print the second element (data) of the first enumerated item from the validloader.#5、创建模型及优化器
from torch.nn.parallel import DistributedDataParallel as DDP
model = BertForSequenceClassification.from_pretrained("./model")
if torch.cuda.is_available():model = model.to(int(os.environ["LOCAL_RANK"])) # 使用环境变量 LOCAL_RANK 获取当前进程的 GPU 设备编号model = DDP(model) # 使用DistributedDataParallel包装模型
optimizer = Adam(model.parameters(), lr=2e-5)#6、训练和验证
def evaluate():model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.to(int(os.environ["LOCAL_RANK"])) for k, v in batch.items()}output = model(*batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()dist.all_reduce(acc_num, op=dist.ReduceOp.SUM) # 在所有进程中汇总准确率return acc_num / len(validset)def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()trainloader.sampler.set_epoch(ep)for batch in trainloader:if torch.cuda.is_available():batch = {k: v.to(int(os.environ["LOCAL_RANK"])) for k, v in batch.items()}optimizer.zero_grad()output = model(**batch)loss = output.lossloss.backward()optimizer.step()if global_step % log_step == 0:dist.all_reduce(loss, op=dist.ReduceOp.AVG)print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")global_step += 1acc = evaluate()print(f"ep:{ep} ,Validation accuracy: {acc.item() * 100:.2f}%")train()
四、Accelerate基础入门
1)Accelerate基本介绍

- accelerate 四行代码导入训练

2)基于AccelerateDDP代码介绍
- 实战环境准备

- 代码
上篇章节DPP的代码 - 修改点
①去掉框中代码:在没有使用 accelerate 库时,这段代码的作用是把数据批次中的每个张量都移动到对应的 GPU 设备上。os.environ[“LOCAL_RANK”] 表示当前进程所在的本地 GPU 设备编号,v.to(int(os.environ[“LOCAL_RANK”])) 会将张量 v 移动到该编号对应的 GPU 上。
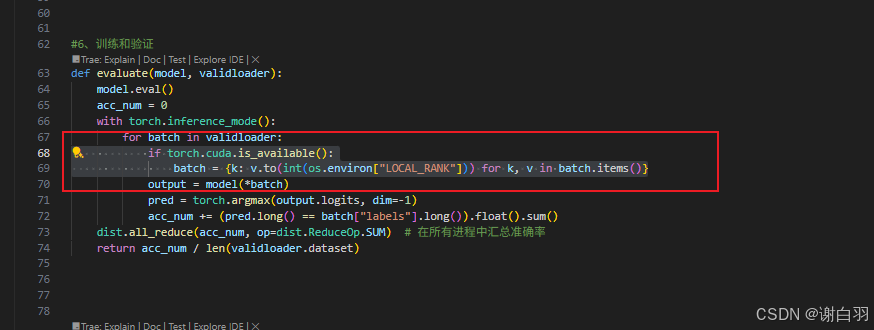
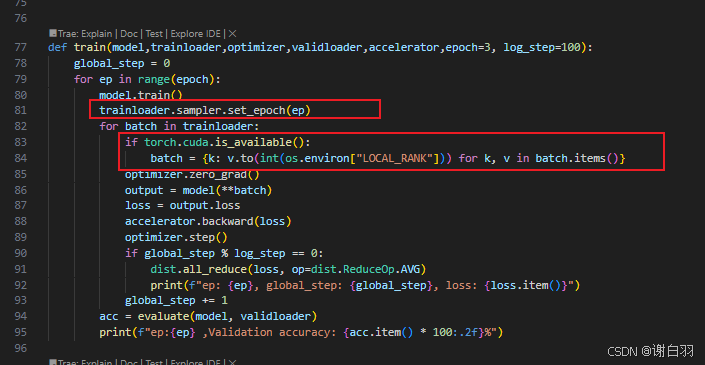
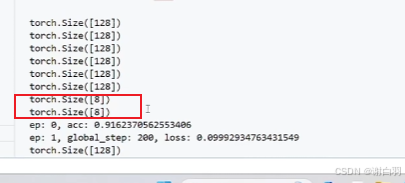
②出现问题一:准确率高于100%、
原因:数据集按照64作为batchsize训练的时候,不够一次训练就填充了数据
变更前:
变更后:
可以看到最后几次就不会把验证集填充到128次
③ddp的all_reduce可以替换成accelerate的接口
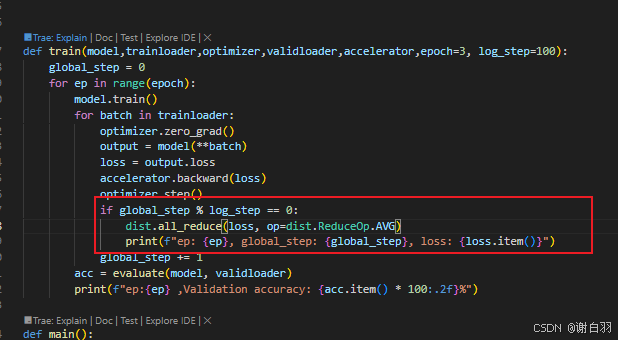
改成:
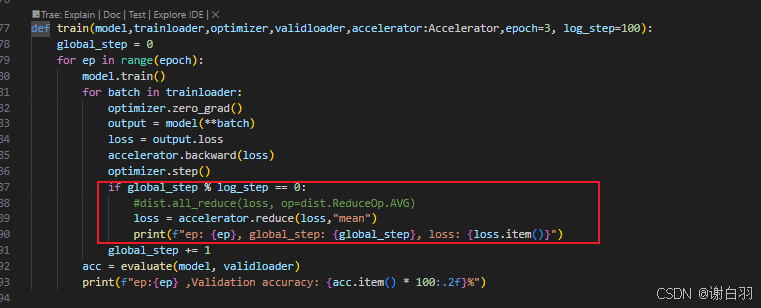
④打印日志接口可以用accelerate接口:
原先:
现在:
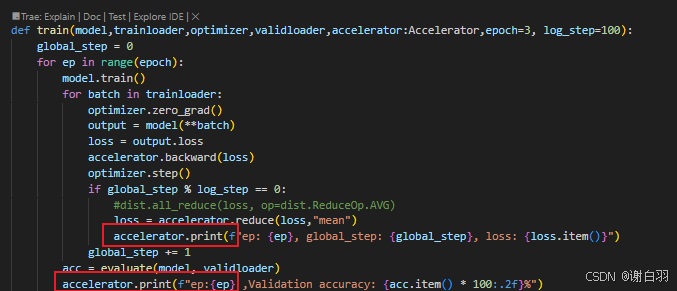
⑤启动该监本命令:
accelerate launch ddp_accelerate.py
第一次执行会询问生成配置
- 代码
from transformers import BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器
from torch.nn.parallel import DistributedDataParallel as DDP
import os
import torch
from accelerate import Acceleratorclass MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)def prepare_dataloader():#2、创建datasetdataset = MyDataset()#3、split dataset 划分数据集train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))#4、创建dataloadertokenizer = BertTokenizer.from_pretrained("./model/")def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputstrainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,shuffle=True)validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,shuffle=False)return trainloader, validloaderdef prepare_model_and_optimizer():#5、创建模型及优化器model = BertForSequenceClassification.from_pretrained("./model")optimizer = Adam(model.parameters(), lr=2e-5)return model, optimizer#6、训练和验证
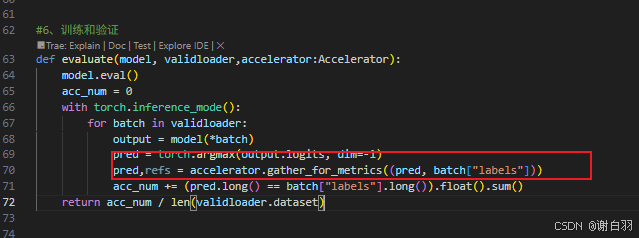
def evaluate(model, validloader,accelerator:Accelerator):model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:output = model(*batch)pred = torch.argmax(output.logits, dim=-1)pred,refs = accelerator.gather_for_metrics((pred, batch["labels"]))acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validloader.dataset)def train(model,trainloader,optimizer,validloader,accelerator:Accelerator,epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train()for batch in trainloader:optimizer.zero_grad()output = model(**batch)loss = output.lossaccelerator.backward(loss)optimizer.step()if global_step % log_step == 0:#dist.all_reduce(loss, op=dist.ReduceOp.AVG)loss = accelerator.reduce(loss,"mean")accelerator.print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")global_step += 1acc = evaluate(model, validloader)accelerator.print(f"ep:{ep} ,Validation accuracy: {acc.item() * 100:.2f}%")def main():accelerator = Accelerator()trainloader, validloader = prepare_dataloader()model, optimizer = prepare_model_and_optimizer()model, optimizer, trainloader, validloader = accelerator.prepare(model, optimizer, trainloader, validloader)train(model, trainloader, optimizer, validloader,accelerator)if __name__ == "__main__":main()3)Accelerate启动命令介绍

五、Accelerate使用进阶
1)Accelerate混合精度训练
- 概念讲解
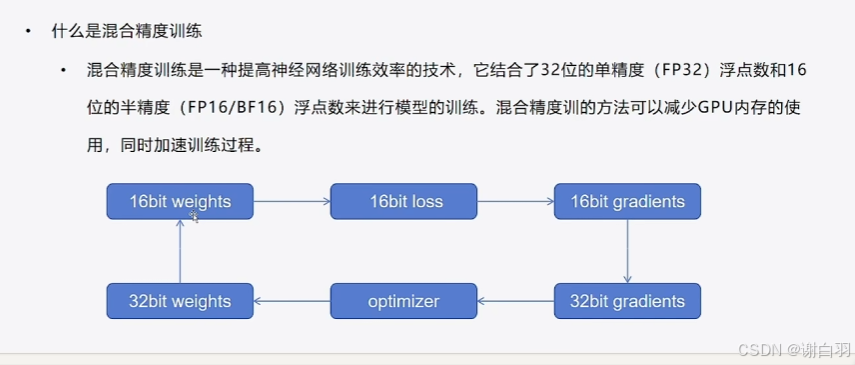
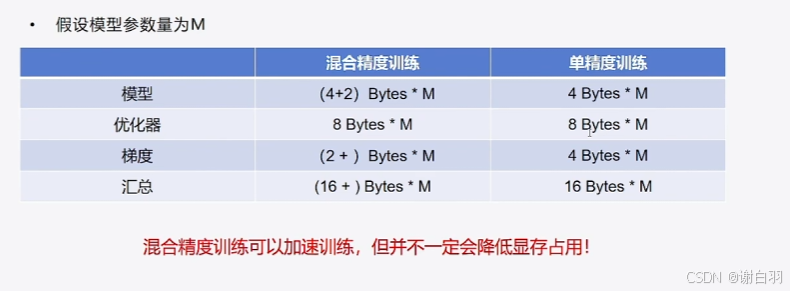
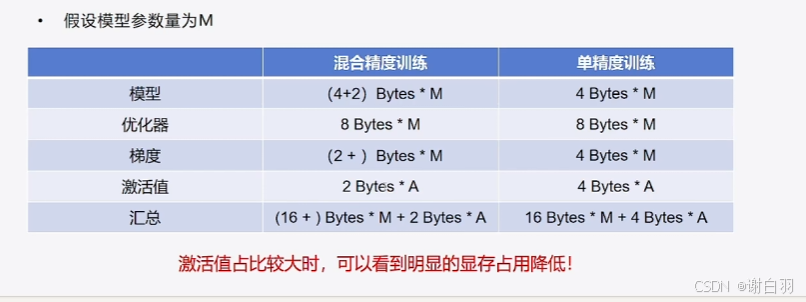
- 混合精度训练方式

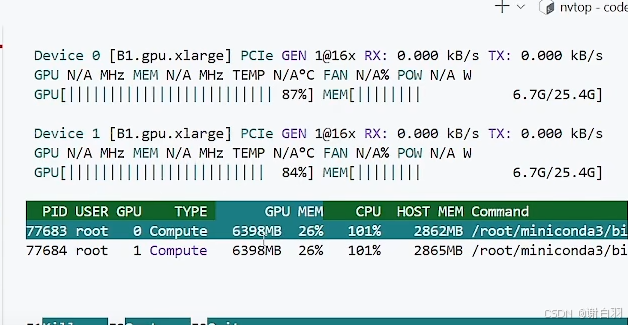
方式一:batchsize=32,bf16,最后测得59s,单卡占用5500MB显存
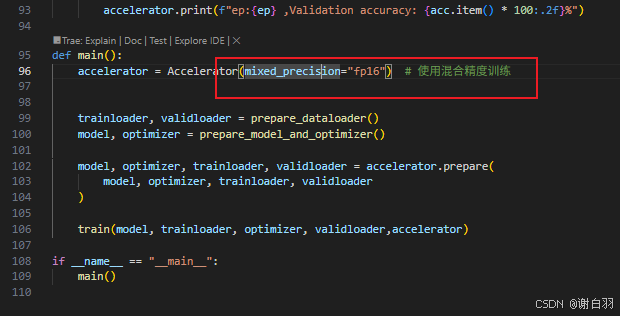
启动
accelerate launch ddp_accelerate.py
用nvtop检测显存占用
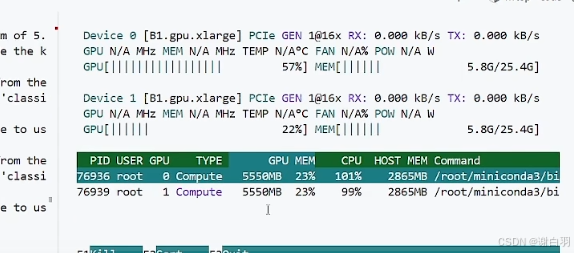
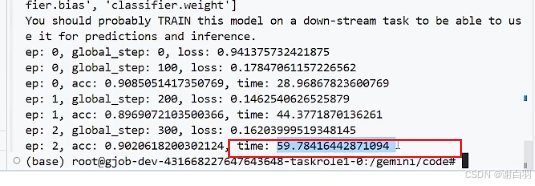
对比普通不用accelerate的情况,batchsize=32,正常跑,最后测得83s,单卡占用6400MB显存
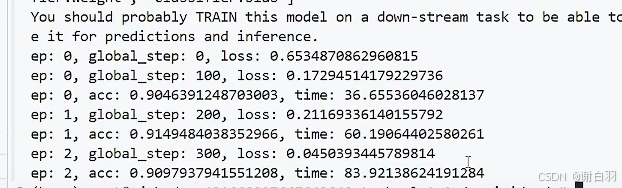
方式二:配置选择bf16
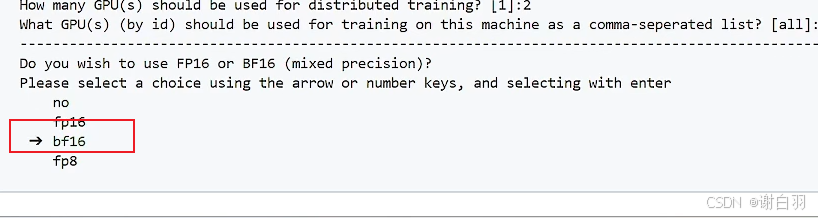
方式三:命令行指示精度

2)Accelerate梯度累积功能
-
介绍

-
代码实现

-
实现步骤

-
代码更改部分
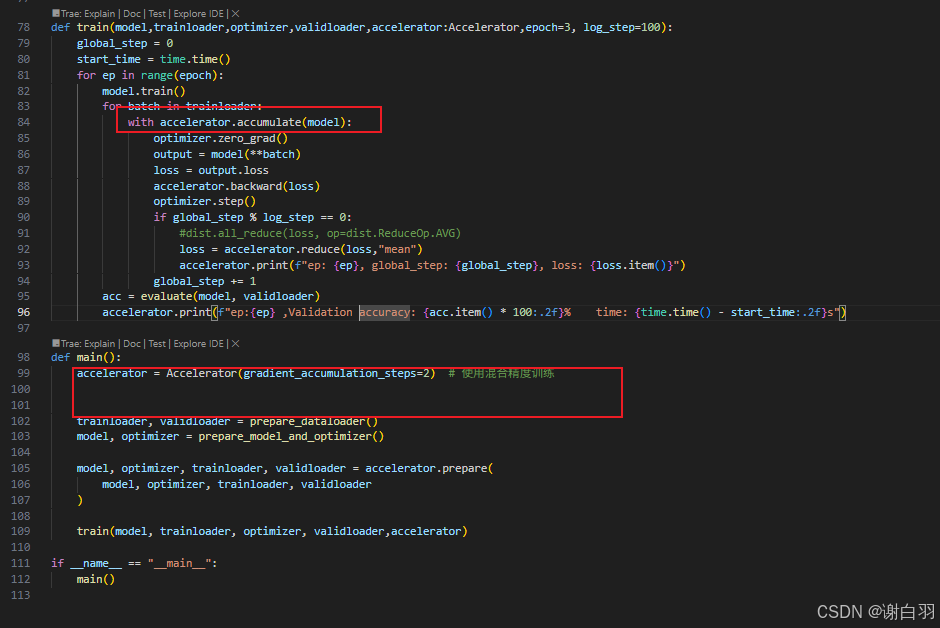
-
问题点
global_step功能可以由梯度累积实现
global_step的作用:让单张显卡多个进程只打印一次更新模型梯度时的信息
改进前:
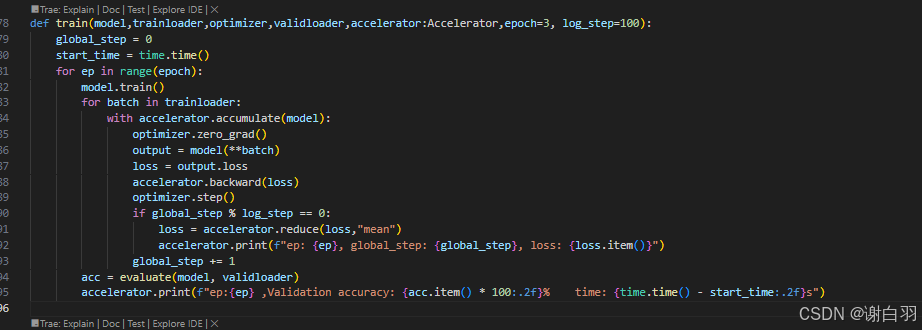
改进后:
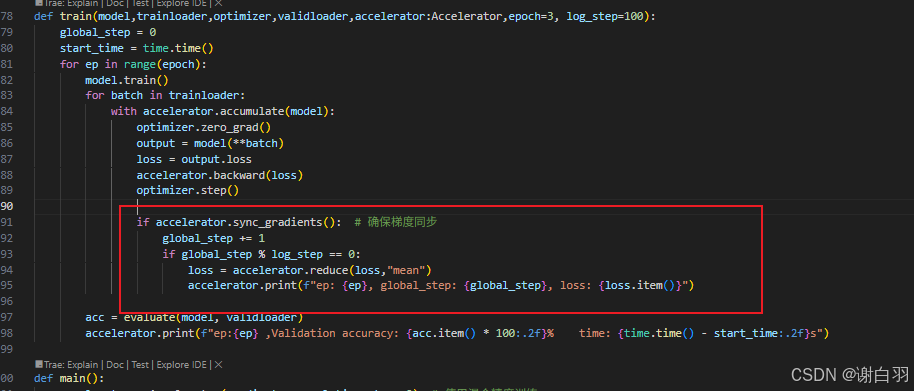
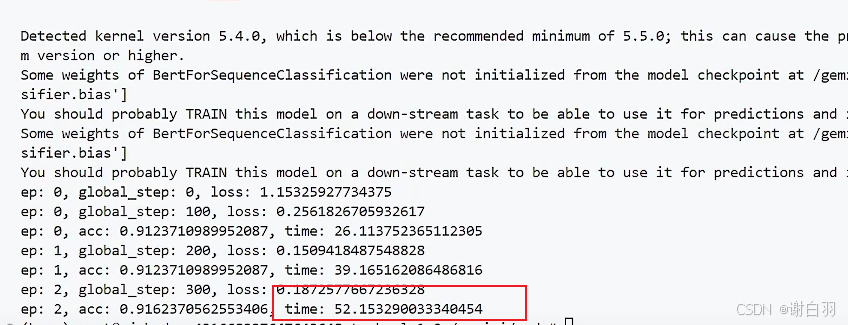
- 结果打印(因为2张显卡,参数更新步数少了一半)耗时52s
3)Accelerate实验记录功能
-
实验记录工具

-
记录方法

-
代码实现(记录损失值和正确率)
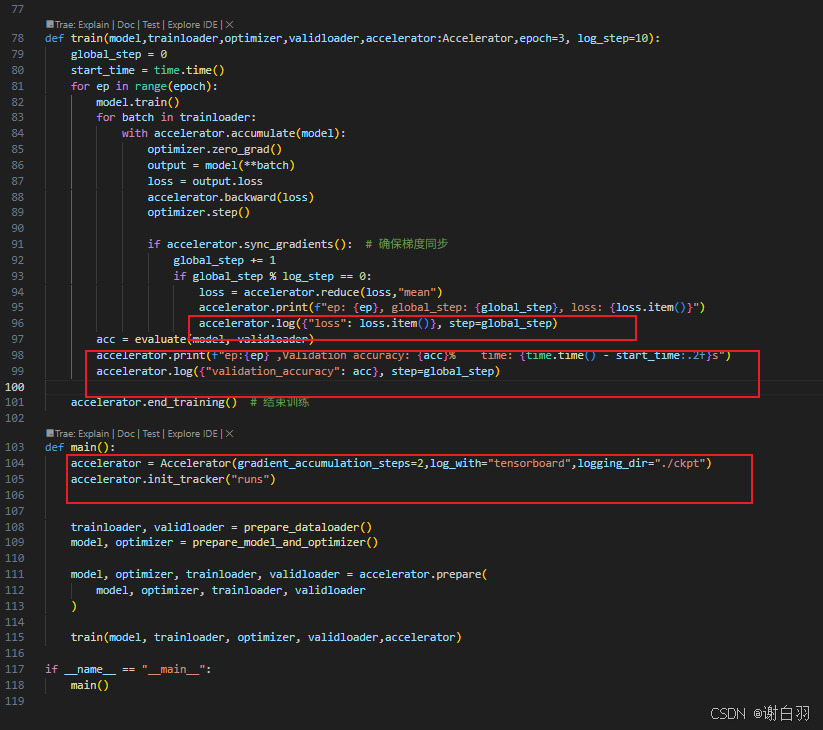
-
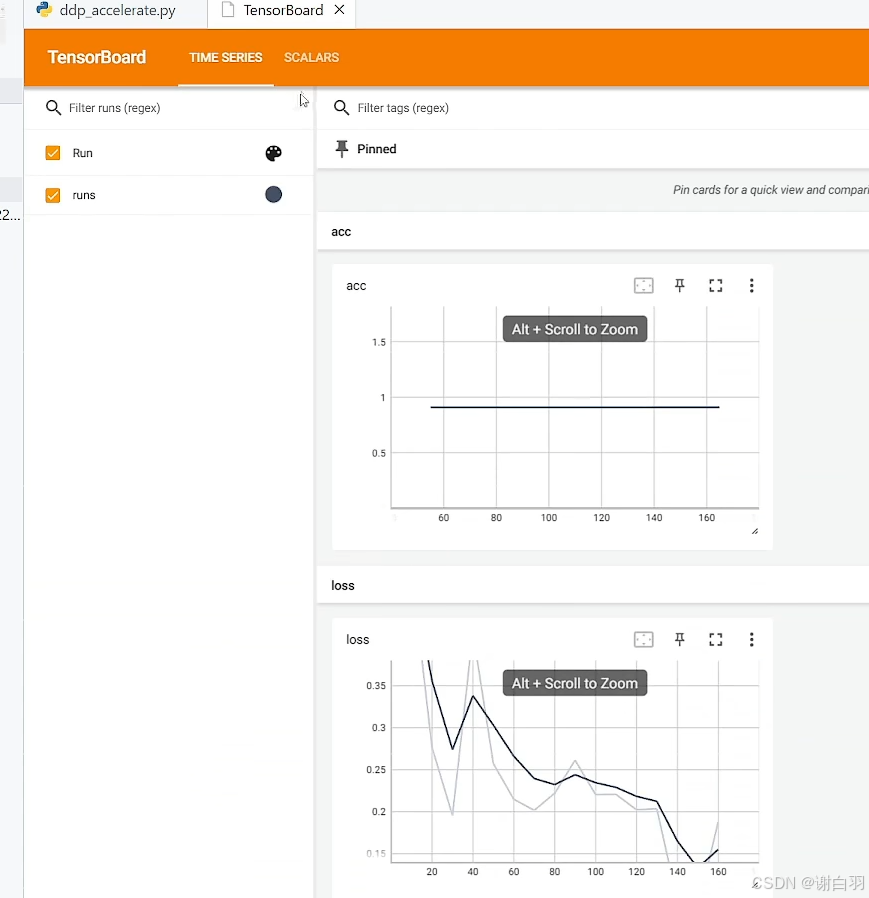
产出文件

用tensorboard打开
vscode界面,control+shift+p打开tensorboard命令

并选择文件目录

4)Accelerate模型保存功能
- 介绍

- 保存方式(方式一应该是save_model)

- 方式一实现
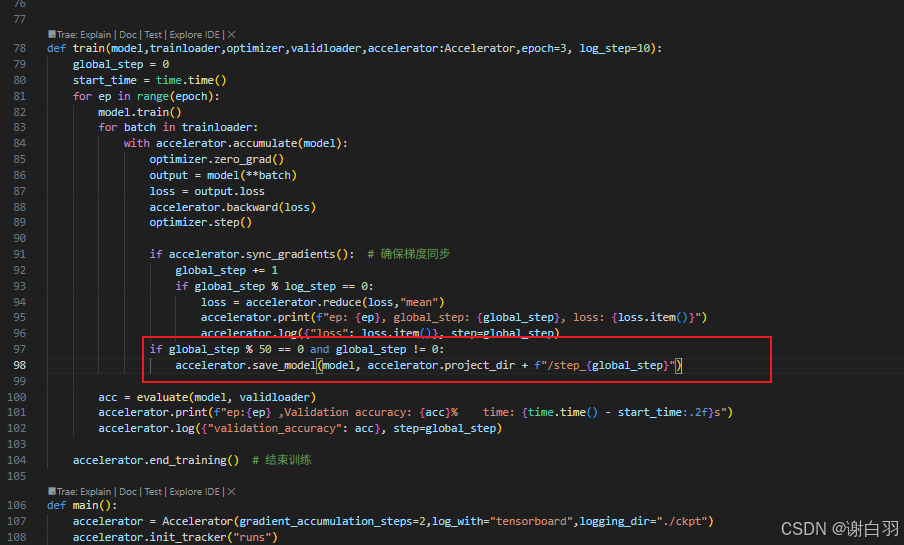
问题:没有模型配置文件
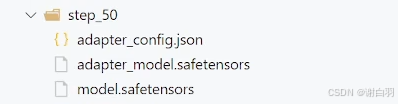
还有就是对peft不能只得到lora的那一部分

方式二:

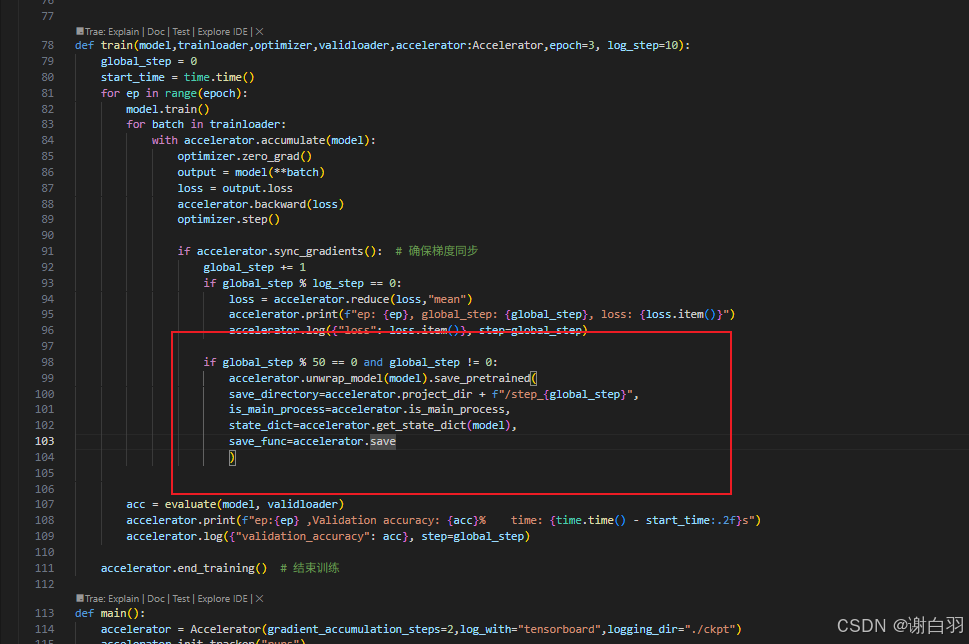
结果展示
5)Accelerate断点续训练功能
- 介绍

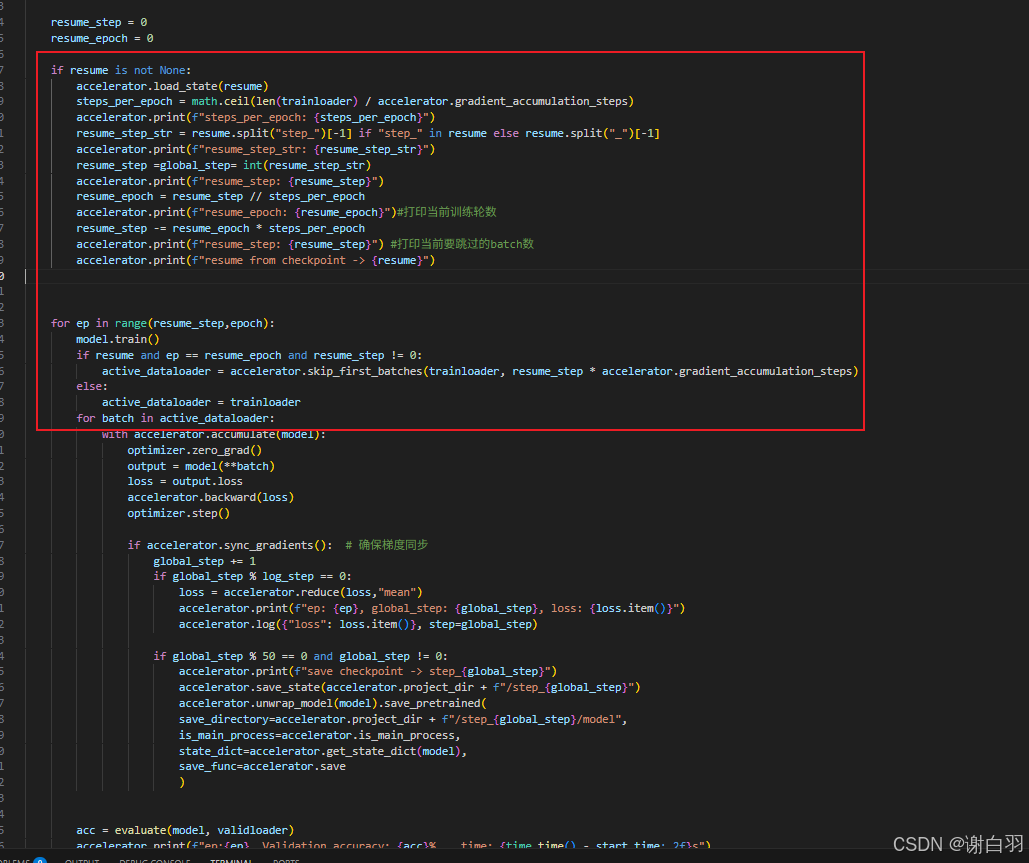
- 步骤

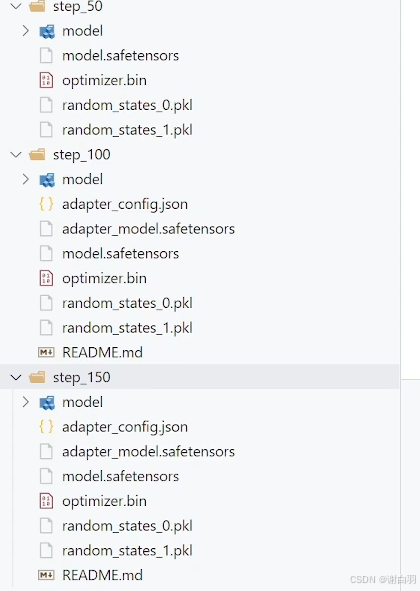
保存检查点,模型放到model下一级目录
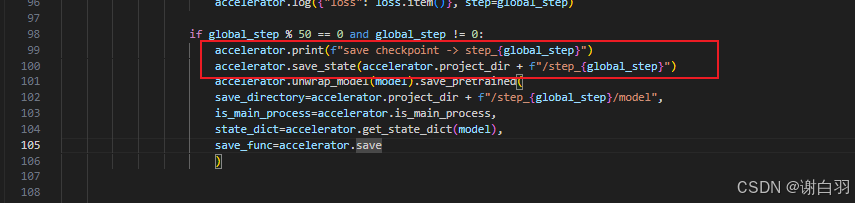
计算跳过步数
保存结果展示
续训代码

6)前五个功能后的总代码
- 代码
from transformers import BertForSequenceClassification,BertTokenizer
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler #采样器,在不同的GPU中间取得不同的采样器
from torch.nn.parallel import DistributedDataParallel as DDP
import os
import torch
import time
import math
from accelerate import Acceleratorclass MyDataset(Dataset):def __init__(self, data)->None:super().__init__()self.data = pd.read_csv("./ChnSetiCorp_htl_all.csv")self.data = data.dropna() # 删除review列中为None的行def __len__(self):return len(self.data)def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def print_rank_0(info):if int(os.environ["RANK"]) == 0:print(info)def prepare_dataloader():#2、创建datasetdataset = MyDataset()#3、split dataset 划分数据集train_set, validset = random_split(dataset, [0.9, 0.1], generator=torch.Generator().manual_seed(42))#4、创建dataloadertokenizer = BertTokenizer.from_pretrained("./model/")def collate_fn(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputstrainloader = DataLoader(train_set, batch_size=32, collate_fn=collate_fn,shuffle=True)validloader = DataLoader(validset, batch_size=64, collate_fn=collate_fn,shuffle=False)return trainloader, validloaderdef prepare_model_and_optimizer():#5、创建模型及优化器model = BertForSequenceClassification.from_pretrained("./model")optimizer = Adam(model.parameters(), lr=2e-5)return model, optimizer#6、训练和验证
def evaluate(model, validloader,accelerator:Accelerator):model.eval()acc_num = 0with torch.inference_mode():for batch in validloader:output = model(*batch)pred = torch.argmax(output.logits, dim=-1)pred,refs = accelerator.gather_for_metrics((pred, batch["labels"]))acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validloader.dataset)def train(model,trainloader,optimizer,validloader,accelerator:Accelerator,resume,epoch=3, log_step=10):global_step = 0start_time = time.time()resume_step = 0resume_epoch = 0if resume is not None:accelerator.load_state(resume)steps_per_epoch = math.ceil(len(trainloader) / accelerator.gradient_accumulation_steps)accelerator.print(f"steps_per_epoch: {steps_per_epoch}")resume_step_str = resume.split("step_")[-1] if "step_" in resume else resume.split("_")[-1]accelerator.print(f"resume_step_str: {resume_step_str}")resume_step =global_step= int(resume_step_str)accelerator.print(f"resume_step: {resume_step}")resume_epoch = resume_step // steps_per_epochaccelerator.print(f"resume_epoch: {resume_epoch}")#打印当前训练轮数resume_step -= resume_epoch * steps_per_epochaccelerator.print(f"resume_step: {resume_step}") #打印当前要跳过的batch数accelerator.print(f"resume from checkpoint -> {resume}")for ep in range(resume_step,epoch):model.train()if resume and ep == resume_epoch and resume_step != 0:active_dataloader = accelerator.skip_first_batches(trainloader, resume_step * accelerator.gradient_accumulation_steps)else:active_dataloader = trainloaderfor batch in active_dataloader:with accelerator.accumulate(model):optimizer.zero_grad()output = model(**batch)loss = output.lossaccelerator.backward(loss)optimizer.step()if accelerator.sync_gradients(): # 确保梯度同步global_step += 1if global_step % log_step == 0:loss = accelerator.reduce(loss,"mean")accelerator.print(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")accelerator.log({"loss": loss.item()}, step=global_step)if global_step % 50 == 0 and global_step != 0:accelerator.print(f"save checkpoint -> step_{global_step}")accelerator.save_state(accelerator.project_dir + f"/step_{global_step}")accelerator.unwrap_model(model).save_pretrained(save_directory=accelerator.project_dir + f"/step_{global_step}/model",is_main_process=accelerator.is_main_process,state_dict=accelerator.get_state_dict(model),save_func=accelerator.save)acc = evaluate(model, validloader)accelerator.print(f"ep:{ep} ,Validation accuracy: {acc}% time: {time.time() - start_time:.2f}s")accelerator.log({"validation_accuracy": acc}, step=global_step)accelerator.end_training() # 结束训练def main():accelerator = Accelerator(gradient_accumulation_steps=2,log_with="tensorboard",logging_dir="./ckpt") accelerator.init_tracker("runs")trainloader, validloader = prepare_dataloader()model, optimizer = prepare_model_and_optimizer()model, optimizer, trainloader, validloader = accelerator.prepare(model, optimizer, trainloader, validloader)train(model, trainloader, optimizer, validloader,accelerator,resume="/gemini/code/ckpts/step_150")if __name__ == "__main__":main()六、Accelerate集成Deepspeed
1)Deepspeed介绍
- DDP存在的问题

零冗余:优化每个GPU显卡上存在以下三个冗余的情况
①梯度 gradient
②优化器 optimizer,每张卡只加载优化器的一部分
③模型参数 model param
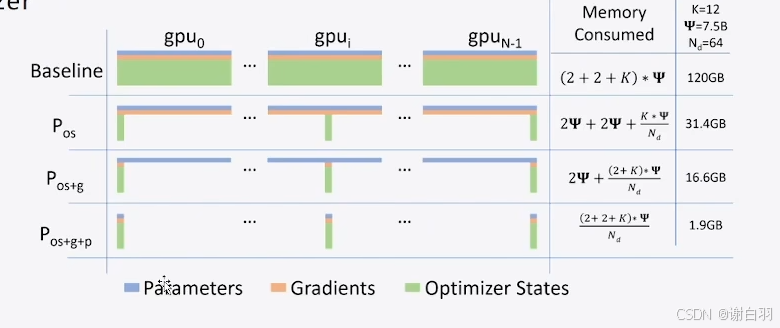
- 通信量分析

- 额外功能介绍

2)Accelerate + Deepspeed代码实战
- Accelerate + Deepspeed集合
方式一:

使用之前记得安装deepspeed
pip install deepspeed
使用accelerate config配置文件,一般选择zero2策略即可,速度比zero要快一些,然后指定目录下配置文件启动
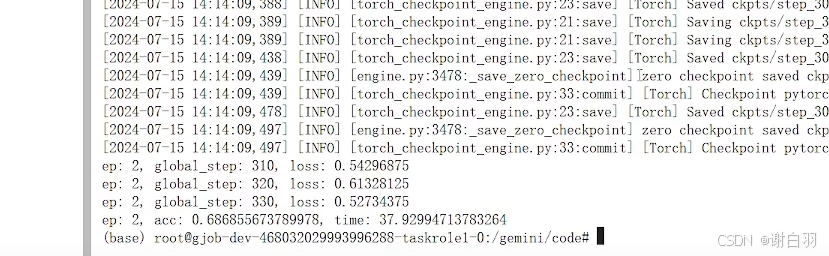
训练结果:37秒完成训练
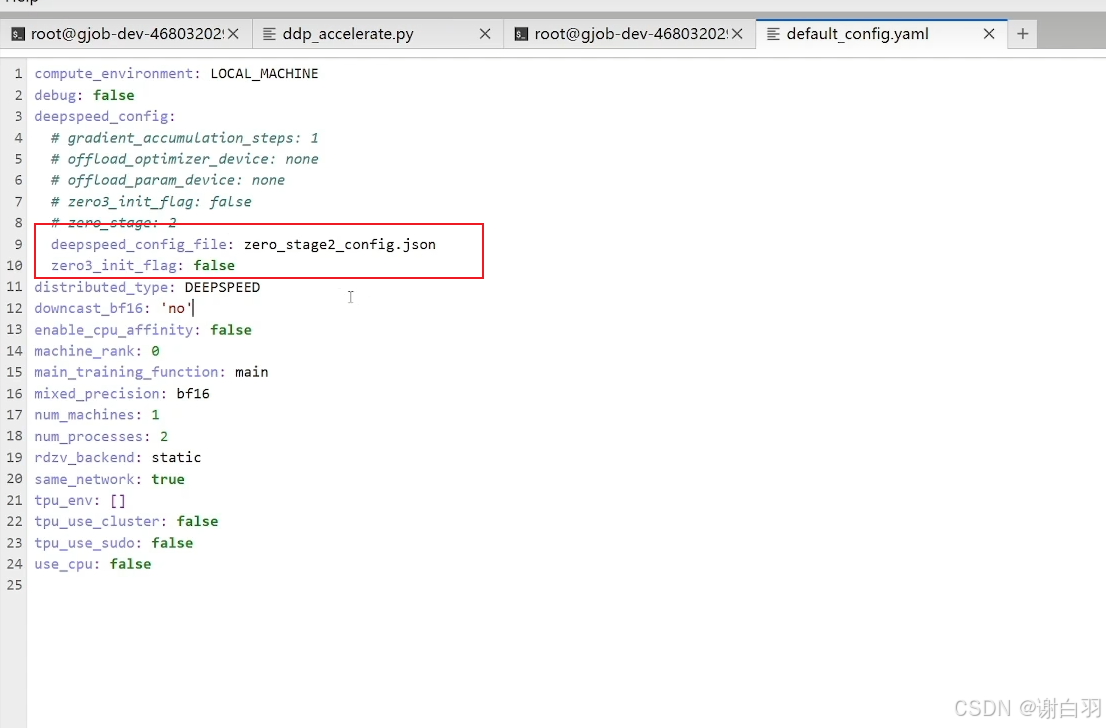
方式二:

accelerate配置文件增加deepspeed配置文件名字
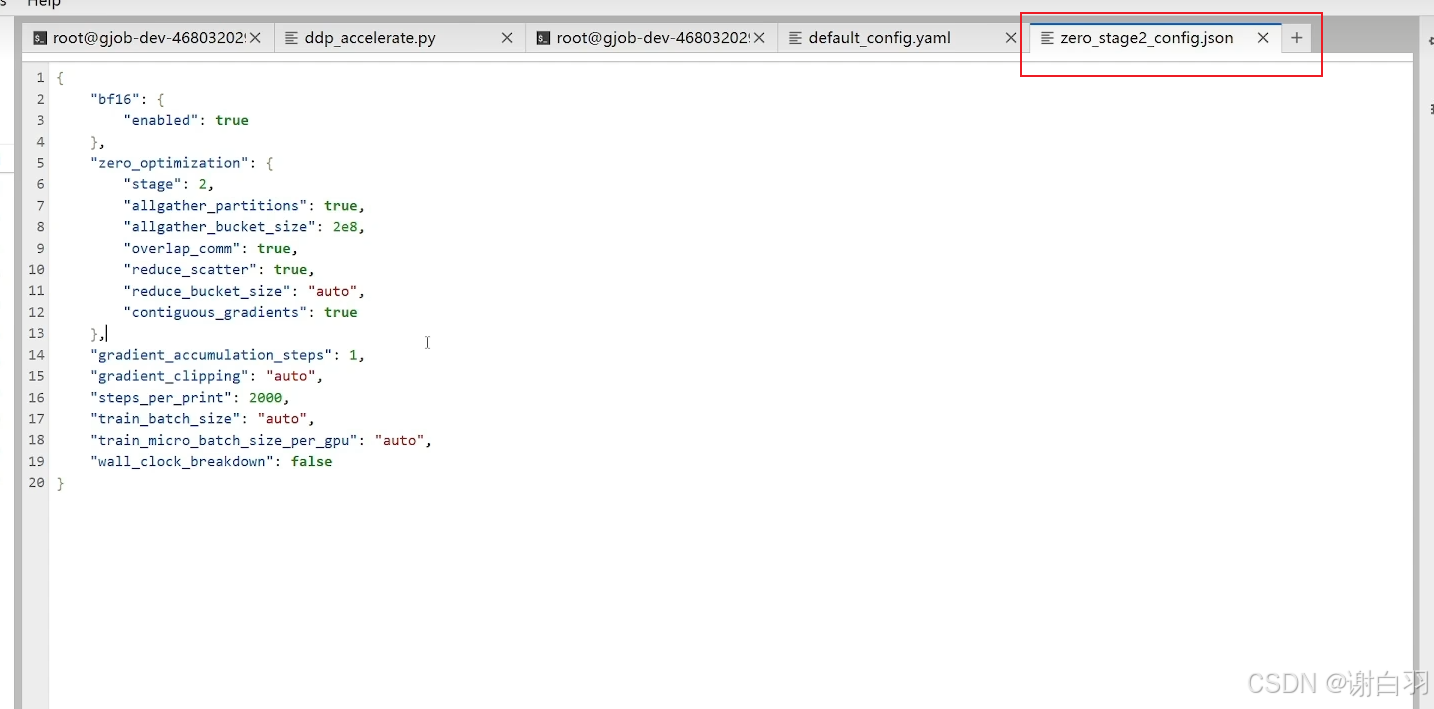
新增deepspeed配置文件
- 遇到的问题:
①由于accelerate配置指定zero3的时候,会有模型参数保存补全报错
解决:要加一行配置
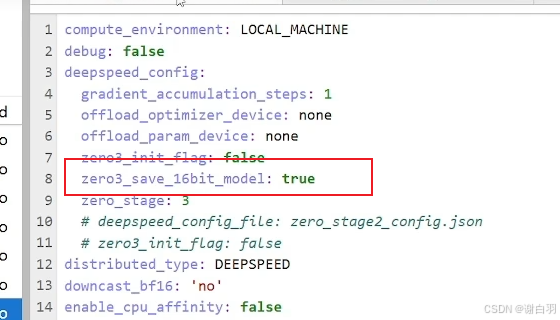
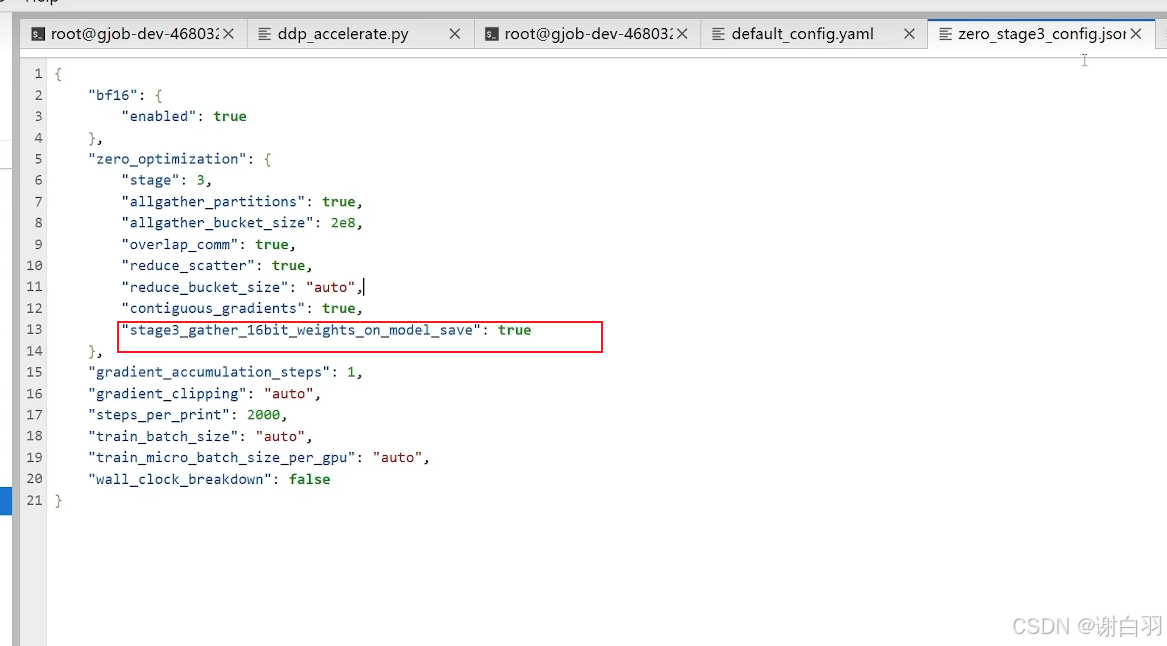
相当于deepspeed配置的这个:
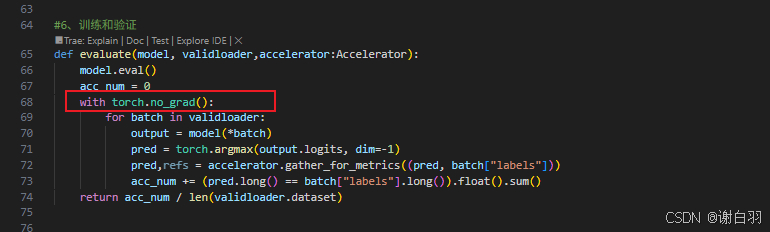
②由于zero3会计算提低更新模型,但是梯度已经分散出去,这时候要在推理过程中禁止梯度计算
原因:
将 torch.inference_mode 替换为 torch.no_grad() 主要作用是在推理过程中禁止梯度计算。在验证阶段,我们只需要模型前向传播得到预测结果,无需计算梯度来更新模型参数,因此禁用梯度计算能节省内存和计算资源
- 注意事项


相关文章:
大模型分布式训练笔记(基于accelerate+deepspeed分布式训练解决方案)
文章目录 一、分布式训练基础与环境配置(1)分布式训练简介(2)如何进行分布式训练(3)分布式训练环境配置 二、数据并行-原理与实战(pytorch框架的nn.DataParallel)1)data …...
鸿蒙UI开发——组件的自适应拉伸
1、概 述 针对常见的开发场景,ArkUI开发框架提供了非常多的自适应布局能力,这些布局可以独立使用,也可多种布局叠加使用。本文针对ArkUI提供的拉伸能力做简单讨论。 拉伸能力是指容器组件尺寸发生变化时,增加或减小的空间全部分…...

鸿蒙仓颉语言开发教程:自定义弹窗
假期第一天,祝大家端午节快乐。昨天观看了时代旗舰尊界S800的发布,不得不感慨这车真好啊~ 放假闲来无事,继续跟大家分享仓颉语言的开发教程,今天介绍一下自定义弹窗。 仓颉语言中的自定义弹窗和ArkTs类似,…...

meilisearch docker 简单安装
ElasticSearch平替 docker run -it -d -p 7700:7700 -v /home/dev/melisearch/meili_data:/meili_data -e MEILI_MASTER_KEYRhTX1pLPSKSn7KW9yf9u_MNKC0v1YKkmx2Sc6qSwbLQ getmeili/meilisearch:v1.13 MEILI_MASTER_KEYRhTX1pLPSKSn7KW9yf9u_MNKC0v1YKkmx2Sc6qSwbLQ …...

Python 数据分析与可视化实战:从数据清洗到图表呈现
目录 一、数据采集与初步探索 二、数据清洗的七种武器 1. 缺失值处理策略 2. 异常值检测与修正 3. 数据类型转换技巧 三、数据转换的魔法工坊 1. 透视表与交叉表 2. 窗口函数实战 3. 文本数据处理 四、可视化呈现的艺术 1. 基础图表进阶用法 2. 高级可视化方案 3.…...

机器学习数据降维方法
1.数据类型 2.如何选择降维方法进行数据降维 3.线性降维:主成分分析(PCA)、线性判别分析(LDA) 4.非线性降维 5.基于特征选择的降维 6.基于神经网络的降维 数据降维是将高维数据转换为低维表示的过程,旨在保…...
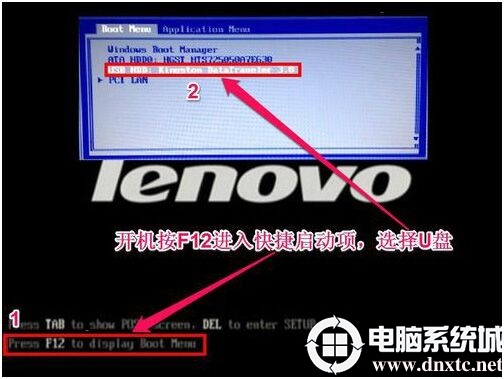
uefi和legacy有什么区别_从几方面分析uefi和legacy的区别
uefi和legacy是两种不同的引导方式,uefi是新式的BIOS,legacy是传统BIOS。你在UEFI模式下安装的系统,只能用UEFI模式引导;同理,如果你是在Legacy模式下安装的系统,也只能在legacy模式下进系统。uefi只支持64为系统且磁盘…...

Spring @Autowired自动装配的实现机制
Spring Autowired自动装配的实现机制 Autowired 注解实现原理详解一、Autowired 注解定义二、Qualifier 注解辅助指定 Bean 名称三、BeanFactory:按类型获取 Bean四、注入逻辑实现五、小结 源码见:mini-spring Autowired 注解实现原理详解 Autowired 的…...

Neo4j 数据可视化与洞察获取:原理、技术与实践指南
在关系密集型数据的分析领域,Neo4j 凭借其强大的图数据模型脱颖而出。然而,将复杂的连接关系转化为直观见解,需要专业的数据可视化技术和分析方法。本文将深入探讨 Neo4j 数据可视化的核心原理、关键技术、实用技巧以及结合图数据科学库&…...
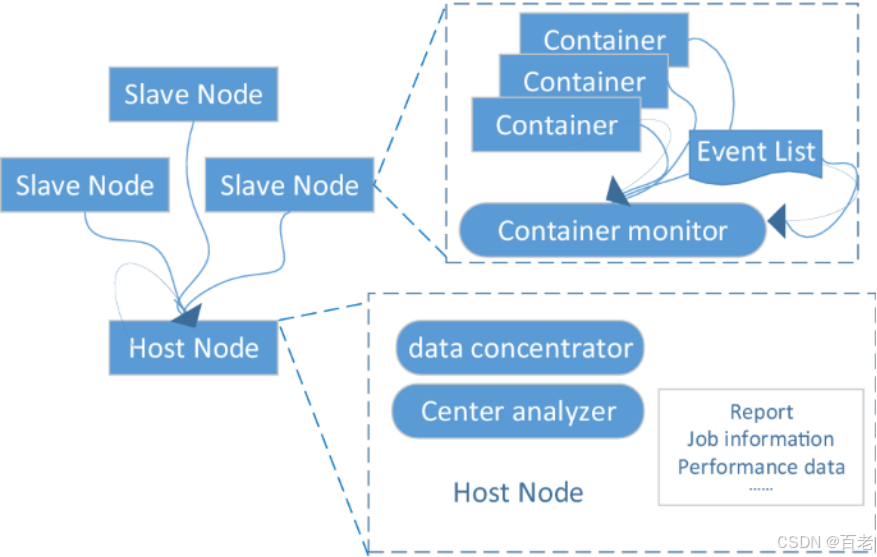
一种基于性能建模的HADOOP配置调优策略
1.摘要 作为分布式系统基础架构的Hadoop为应用程序提供了一组稳定可靠的接口。该文作者提出了一种基于集成学习建模的Hadoop配置参数调优的方法。实验结果表明,该性能模型可以准确预测MapReduce应用程序的运行时间。采用提出的Hadoop配置参数方法调优后,…...
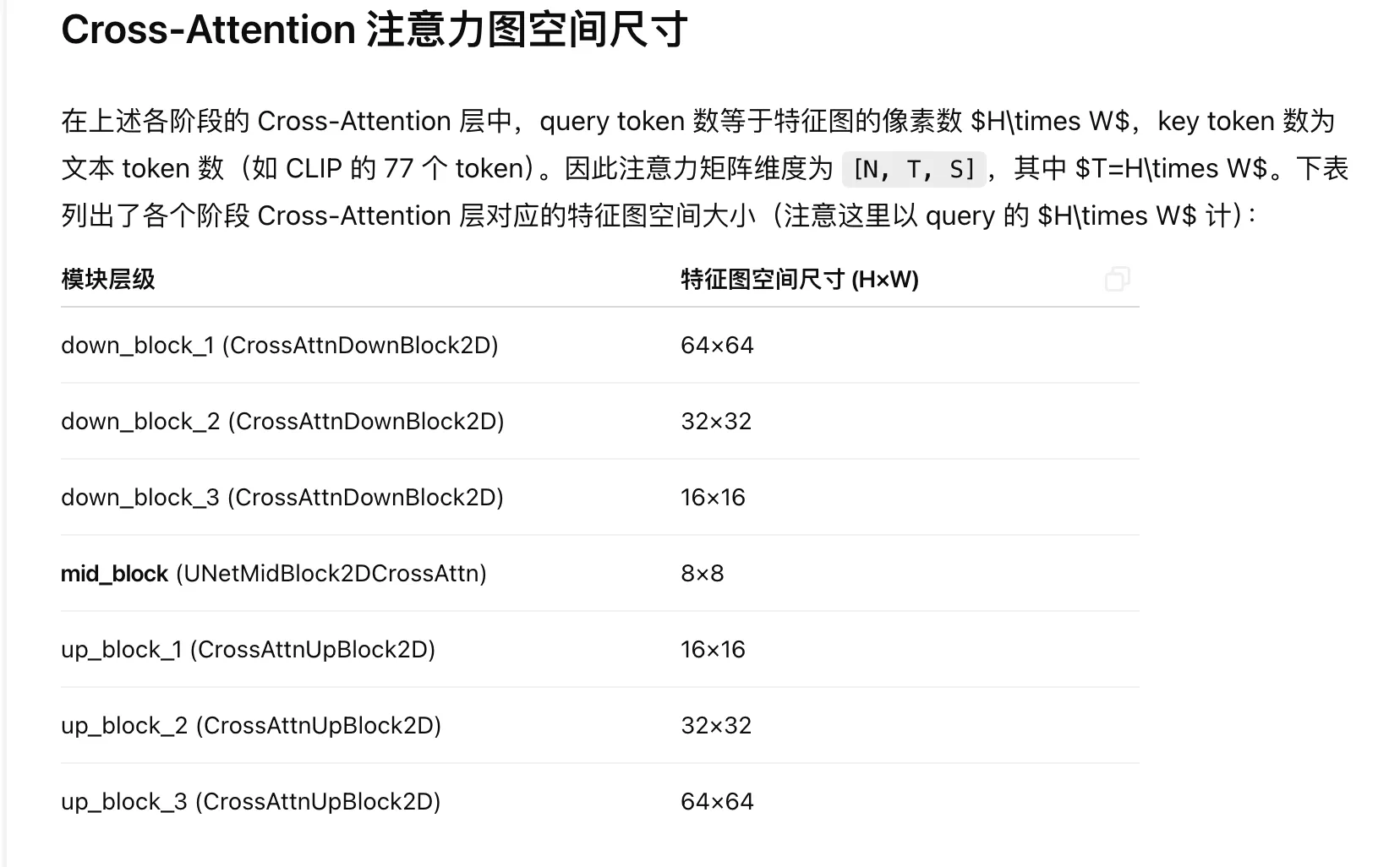
【Stable Diffusion 1.5 】在 Unet 中每个 Cross Attention 块中的张量变化过程
系列文章目录 文章目录 系列文章目录前言特征图和注意力图的尺寸差异原因在Break-a-Scene中的具体实现总结 前言 特征图 (Latent) 尺寸和注意力图(attention map)尺寸在扩散模型中有差异,是由于模型架构和注意力机制的特性决定的。 特征图和注意力图的尺寸差异原…...
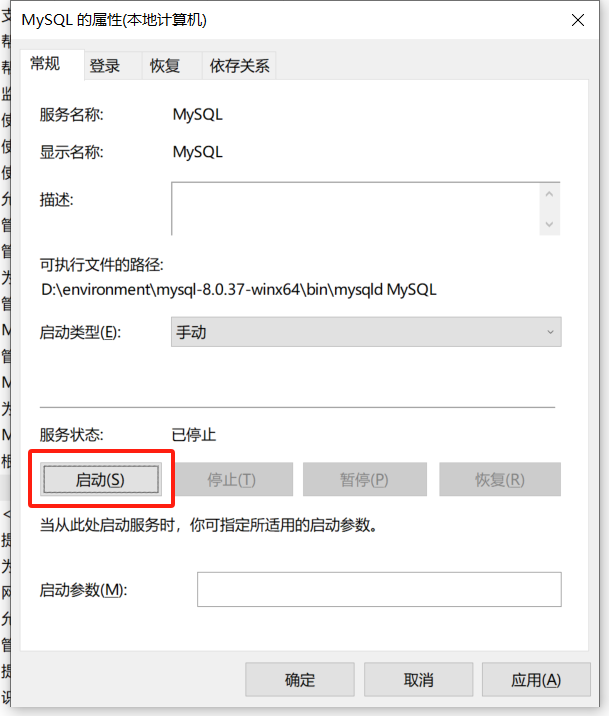
MySQL - Windows 中 MySQL 禁用开机自启,并在需要时手动启动
Windows 中 MySQL 禁用开机自启,并在需要时手动启动 打开服务管理器:在底部搜索栏输入【services.msc】 -> 点击【服务】 打开 MySQL 服务的属性管理:找到并右击 MySQL 服务 -> 点击【属性】 此时的 MySQL 服务:正在运行&a…...

前端下载文件,文件打不开的问题记录
需求: 下载是很常见的接口,但是经常存在下载的文件异常的问题。此处记录一个常见的错误。 分析: 1、接口请求需要配置{responseType: ‘blob’},此时要求返回的格式为blob,进而进行下载。 const res await axios.…...

小白的进阶之路系列之十一----人工智能从初步到精通pytorch综合运用的讲解第四部分
本文将介绍如何用PyTorch构建模型 torch.nn.Module和torch.nn.Parameter 除了Parameter之外,本视频中讨论的所有类都是torch.nn.Module的子类。这是PyTorch基类,用于封装PyTorch模型及其组件的特定行为。 torch.nn.Module的一个重要行为是注册参数。如果特定的Module子类具…...
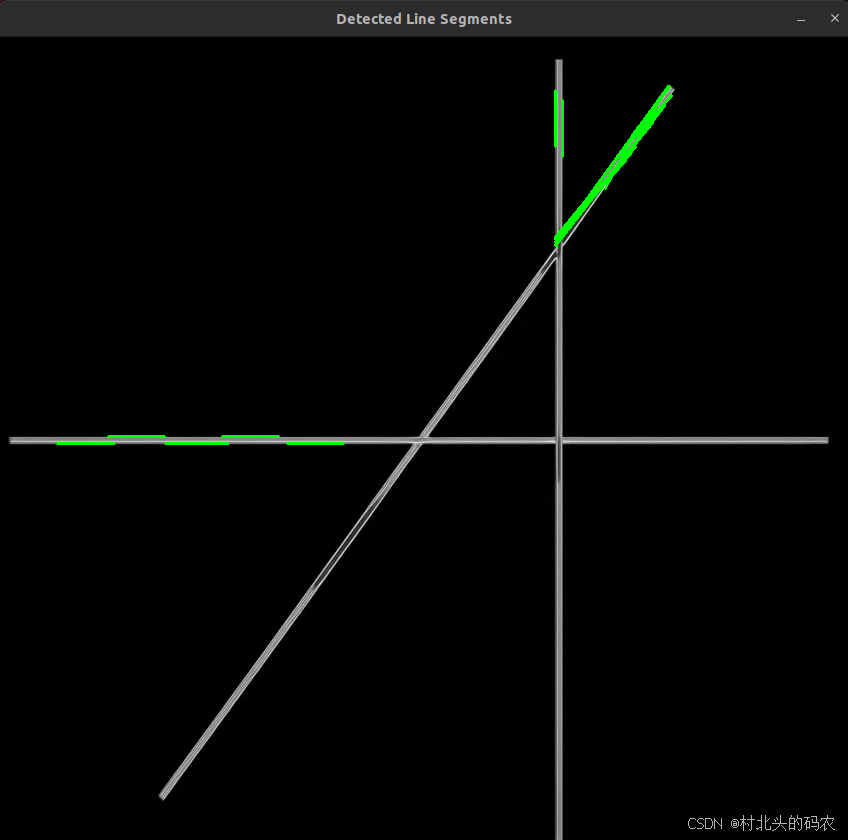
OpenCV CUDA模块霍夫变换------在 GPU 上执行概率霍夫变换检测图像中的线段端点类cv::cuda::HoughSegmentDetector
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::HoughSegmentDetector 是 OpenCV 的 CUDA 模块中一个非常重要的类,它用于在 GPU 上执行 概率霍夫变换(Probabi…...

详解一下RabbitMQ中的channel.Publish
函数定义(来自 github.com/streadway/amqp) func (ch *Channel) Publish(exchange string,key string,mandatory bool,immediate bool,msg Publishing, ) error这个方法的作用是:向指定的交换机 exchange 发送一条消息 msg,带上路…...

硬件学习笔记--62 MCU的ECC功能简介
1. 基本概念 ECC(Error Correction Code,错误校正码)是MCU(微控制器)中用于检测和纠正存储器数据错误的硬件功能,主要应用于Flash、RAM、Cache等存储单元,确保数据在传输或存储过程中的可靠性。…...

Uiverse.io:免费UI组件库
Uiverse.io 完整使用指南:免费UI组件库的终极教程 🌟 什么是 Uiverse.io? Uiverse.io 是一个开源的UI组件库平台,为开发者和设计师提供了大量精美的、可直接使用的HTML/CSS组件。这个平台的特色在于所有组件都是由社区贡献的,完全免费,并且可以直接复制代码使用。 �…...
)
普中STM32F103ZET6开发攻略(四)
接续上文:普中STM32F103ZET6开发攻略(三)-CSDN博客 点关注不迷路哟。你的点赞、收藏,一键三连,是我持续更新的动力哟!!! 目录 接续上文:普中STM32F103ZET6开发攻略&am…...

ck-editor5的研究 (5):优化-页面离开时提醒保存,顺便了解一下 Editor的生命周期 和 6大编辑器类型
前言 经过前面的 4 篇内容,我们已经慢慢对 CKEditor5 熟悉起来了。这篇文章,我们就来做一个优化,顺便再补几个知识点: 当用户离开时页面时,提醒他保存数据了解一下 CKEditor5 的 六大编辑器类型了解一下 editor 实例对…...

[3D GISMesh]三角网格模型中的孔洞修补算法
📐 三维网格模型空洞修复技术详解 三维网格模型在扫描、重建或传输过程中常因遮挡、噪声或数据丢失产生空洞(即边界非闭合区域),影响模型的完整性与可用性。空洞修复(Hole Filling)是计算机图形学和几何处…...

11.2 java语言执行浅析3美团面试追魂七连问
美团面试追魂七连问:关于Object o New Object() ,1请解释一下对象的创建过程(半初始化) 2,加问DCL要不要volatile 问题(指令重排) 3.对象在内存中的存储布局(对象与数组的存储不同),4.对象头具体包括什么.5.对象怎么定位.6.对象怎么分配(栈-线程本地-Eden-Old)7.在…...
MySQL 全量、增量备份与恢复
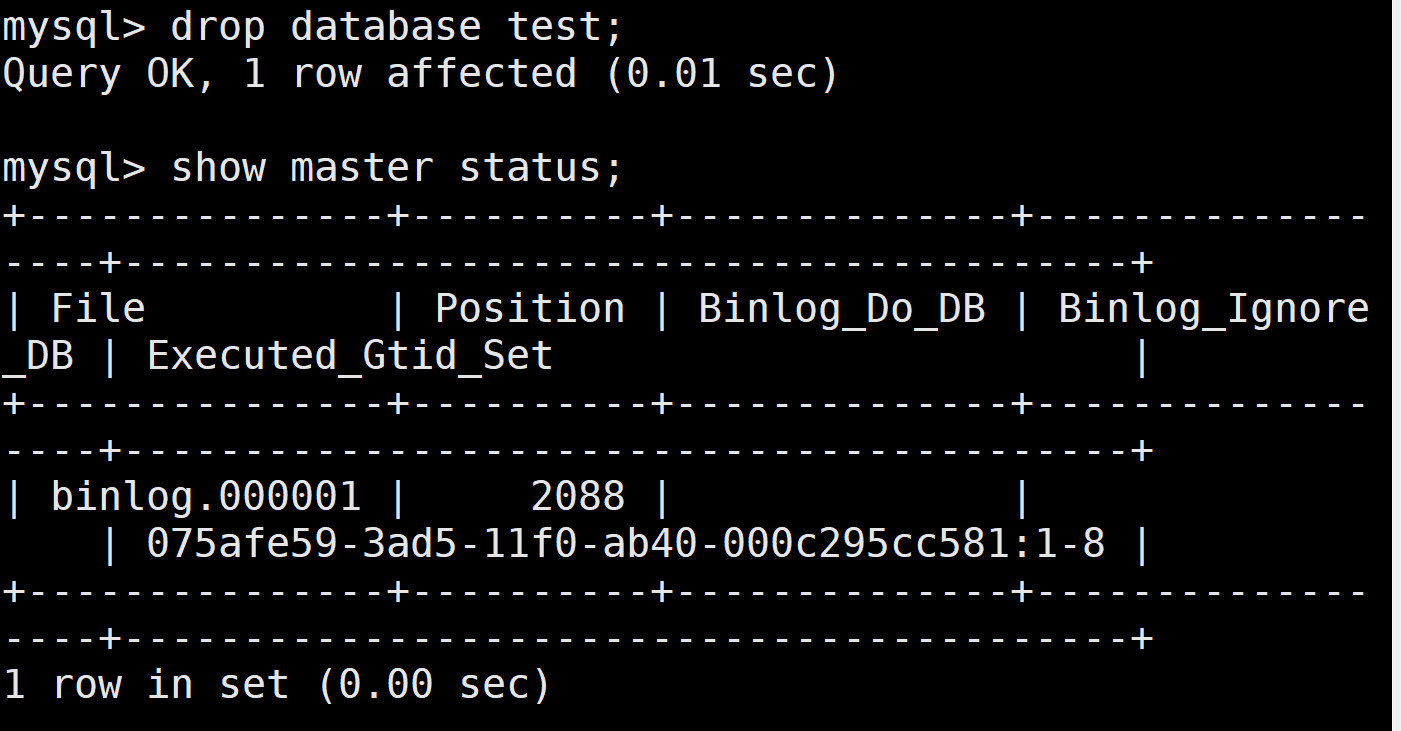
一.MySQL 数据库备份概述 备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。之前已经学习过如何安装 MySQL,本小节将从生产运维的角度了解备份恢复的分类与方法。 1 数据备份的重要性 在企业中数据的价值至关…...

【25.06】FISCOBCOS使用caliper自定义测试 通过webase 单机四节点 helloworld等进行测试
前置条件 安装一个Ubuntu20+的镜像 基础环境安装 Git cURL vim jq sudo apt install -y git curl vim jq Docker和Docker-compose 这个命令会自动安装docker sudo apt install docker-compose sudo chmod +x /usr/bin/docker-compose docker versiondocker-compose vers…...
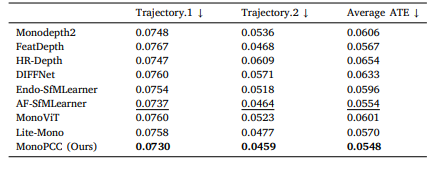
MonoPCC:用于内窥镜图像单目深度估计的光度不变循环约束|文献速递-深度学习医疗AI最新文献
Title 题目 MonoPCC: Photometric-invariant cycle constraint for monocular depth estimation of endoscopic images MonoPCC:用于内窥镜图像单目深度估计的光度不变循环约束 01 文献速递介绍 单目内窥镜是胃肠诊断和手术的关键医学成像工具,但其…...

如何计算H5页面加载时的白屏时间
计算 H5 页面加载时的 白屏时间(First Paint Time)是前端性能优化的重要指标,通常指从用户发起页面请求到浏览器首次渲染像素(如背景色、文字等)的时间。以下是几种常用的计算方法: 1. 使用 Performance AP…...
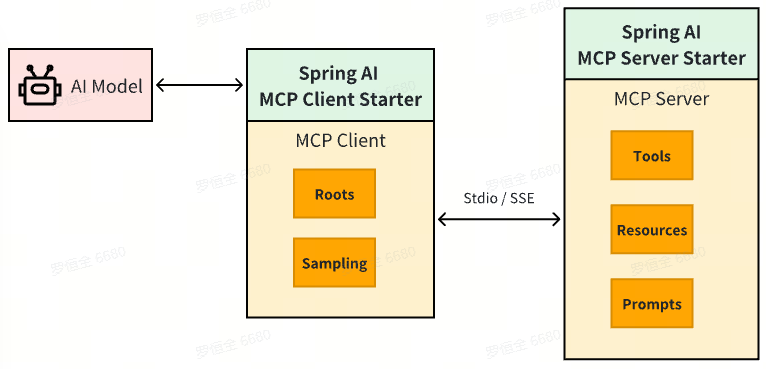
SpringAI系列 - MCP篇(三) - MCP Client Boot Starter
目录 一、Spring AI Mcp集成二、Spring AI MCP Client Stater三、spring-ai-starter-mcp-client-webflux集成示例3.1 maven依赖3.2 配置说明3.3 集成Tools四、通过SSE连接MCP Server五、通过STDIO连接MCP Server六、通过JSON文件配置STDIO连接一、Spring AI Mcp集成 Spring AI…...

【深度学习新浪潮】以Dify为例的大模型平台的对比分析
我们从核心功能、适用群体、易用性、可扩展性和安全性五个维度展开对比分析: 一、核心功能对比 平台核心功能多模型支持插件与工具链Dify低代码开发、RAG增强、Agent自律执行、企业级安全支持GPT-4/5、Claude、Llama3、Gemini及开源模型(如Qwen-VL-72B),支持混合模型组合可…...
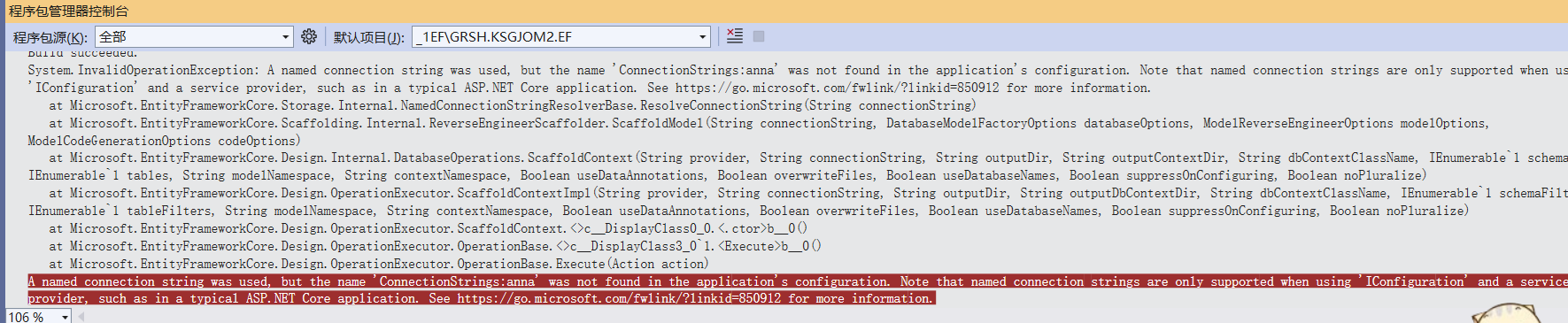
Asp.net core 使用EntityFrame Work
安装以下Nuget 包 Microsoft.EntityFrameworkCore.Tools Microsoft.EntityFrameworkCore.Design Microsoft.AspNetCore.Diagnostics.EntityFrameworkCore Microsoft.EntityFrameworkCore.SqlServer或者Npgsql.EntityFrameworkCore.PostgreSQL 安装完上述Nuget包之后,在appset…...

isp中的 ISO代表什么意思
isp中的 ISO代表什么意思 在摄影和图像信号处理(ISP,Image Signal Processor)领域,ISO是一个用于衡量相机图像传感器对光线敏感度的标准参数。它最初源于胶片摄影时代的 “国际标准化组织(International Organization …...