deepseek问答:torch.full() 函数详解
torch.full() 是 PyTorch 中用于创建指定形状、所有元素值都相同的新张量的核心函数。它在深度学习中有广泛应用,尤其是在初始化张量和创建特殊数据结构时。
函数签名
torch.full(size, fill_value, *, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False, memory_format=torch.contiguous_format)
参数说明
| 参数 | 类型 | 描述 |
|---|---|---|
| size | tuple of ints | 定义张量形状的整数元组(如 (3, 4) 表示 3行4列) |
| fill_value | scalar | 填充张量的值(整型或浮点型) |
| dtype | torch.dtype (可选) | 张量的数据类型(默认根据 fill_value 类型推断) |
| device | torch.device (可选) | 张量所在设备(CPU/GPU)(默认使用当前设备) |
| requires_grad | bool (可选) | 是否需要计算梯度(默认 False) |
| layout | torch.layout (可选) | 张量布局(默认 strided) |
| pin_memory | bool (可选) | 是否使用锁页内存(默认 False) |
| memory_format | torch.memory_format (可选) | 内存格式(默认 contiguous_format) |
核心功能
创建满足以下条件的张量:
- 指定形状:由 size 参数确定
- 全相同值:所有元素值都等于 fill_value
- 完全控制:可自定义数据类型、设备、内存格式等属性
使用示例
#基础用法
import torch#创建 2x3 的张量,所有元素值为 5
= torch.full((2, 3), 5)print(a)
tensor([[5, 5, 5],[5, 5, 5]])创建 3x3 的浮点数张量,所有元素值为 3.14
= torch.full((3, 3), 3.14)print(b)
tensor([[3.1400, 3.1400, 3.1400],[3.1400, 3.1400, 3.1400],[3.1400, 3.1400, 3.1400]])高级用法
指定数据类型
= torch.full((2, 2), 1.5, dtype=torch.float16)print(c)
tensor([[1.5000, 1.5000],[1.5000, 1.5000]], dtype=torch.float16)创建在GPU上的张量
= torch.full((3,), 10, device='cuda')print(d)
tensor([10, 10, 10], device='cuda:0')创建需要梯度的张量
= torch.full((2, 3), 0.1, requires_grad=True)print(e.requires_grad) # True创建4维张量(如批量大小×通道×高度×宽度)
= torch.full((2, 3, 4, 4), 0) # 创建全零掩码print(f.shape) # torch.Size([2, 3, 4, 4])
与相似函数的对比
| 函数 | 描述 | 主要区别 |
|---|---|---|
| torch.full() | 直接指定形状填充 | 基本版本,灵活 |
| torch.full_like() | 参考其他张量形状填充 | 复制其他张量的形状和属性 |
| torch.ones() | 创建全1张量 | 固定值=1 |
| torch.zeros() | 创建全0张量 | 固定值=0 |
| torch.empty() | 创建未初始化张量 | 元素值随机 |
| torch.tensor() | 从数据创建张量 | 可包含不同值 |
应用场景
1)张量初始化
#初始化偏置项为0.1bias = torch.full((128,), 0.1)#初始化掩码为1mask = torch.full((64, 64), 1)
2)特定值容器
#创建注意力掩码(1表示有效位置)
attn_mask = torch.full((batch_size, seq_len), 1.0)
#创建特殊值矩阵(如填充无效值)
invalid_mask = torch.full(data.shape, float('-inf'))
3)设备优化
#直接在GPU上创建用于计算的张量
gpu_tensor = torch.full((100, 100), 0.5, device='cuda')
4)数值敏感操作
#创建需要高精度的常数张量
high_precision = torch.full((10,), 0.123456789, dtype=torch.float64)
常见问题与注意事项
1)数据类型推断:
当未指定 dtype 时:
- 整数 fill_value → torch.int64
- 浮点数 fill_value → torch.float32
2)值类型转换:
# 整数4会被转换为浮点数4.0tensor = torch.full((3,), 4, dtype=torch.float32)print(tensor) # tensor([4., 4., 4.])
3)内存优化:
当需要复制同样值时,使用 torch.full() 比使用 Python 列表更高效:
# 不推荐:低效bad_tensor = torch.tensor([[5]100]100)# 推荐:高效good_tensor = torch.full((100, 100), 5)
4)梯度处理:
在模型中作为参数使用时需要设置 requires_grad=True:
trainable_scalar = torch.full((1,), 0.5, requires_grad=True)
与 numpy.full() 的对比
PyTorch 的 torch.full() 与 NumPy 的 np.full() 功能相似,但针对深度学习进行了优化:
import numpy as np
import torch#NumPy 版本np_array = np.full((3, 3), 5)
print(type(np_array)) # <class 'numpy.ndarray'>#PyTorch 版本torch_tensor = torch.full((3, 3), 5)
print(type(torch_tensor)) # <class 'torch.Tensor'>
主要区别:
- PyTorch 版本支持 GPU 加速和自动微分
- PyTorch 默认使用32位浮点数而非64位
- PyTorch 提供更灵活的设备控制选项
总结
torch.full() 是一个功能强大且高效的工具,用于创建全相同值的张量:
- 形状灵活 - 支持任意维度的张量创建
- 值自由定义 - 可填充任意标量值
- 完全可控 - 可精确指定数据类型、设备等属性
- 高效内存 - 比类似Python结构更高效
- 梯度支持 - 可直接用于可训练参数
它在神经网络开发中常用于初始化张量、创建掩码、设置特殊值和建立模型参数,是PyTorch张量操作工具箱中不可缺少的一部分。
相关文章:
 函数详解)
deepseek问答:torch.full() 函数详解
torch.full() 是 PyTorch 中用于创建指定形状、所有元素值都相同的新张量的核心函数。它在深度学习中有广泛应用,尤其是在初始化张量和创建特殊数据结构时。 函数签名 torch.full(size, fill_value, *, dtypeNone, layouttorch.strided, deviceNone, requires_gra…...

dvwa4——File Inclusion
LOW: 先随便点开一个文件,可以观察到url栏变成这样,说明?page是dvwa当前关卡用来加载文件的参数 http://10.24.8.35/DVWA/vulnerabilities/fi/?pagefile1.php 我们查看源码 ,没有什么过滤,直接尝试访问其他文件 在url栏的pag…...

MYSQL 高级 SQL 技巧
高级 SQL 技巧 以下是一些高级 SQL 技巧,可以帮助优化查询、提高性能并解决复杂的数据处理问题。 使用窗口函数 窗口函数允许在查询结果的行上进行计算,而不会减少行数。常见的窗口函数包括 ROW_NUMBER()、RANK()、DENSE_RANK() 和聚合函数如 SUM() 与…...
Spring Boot养老院管理系统源码分享
概述 基于Spring Boot开发的养老院管理系统,该系统通过智能化管理模块,为养老机构提供高效运营解决方案。 主要内容 后台管理功能 系统后台功能完善,左侧导航栏涵盖首页、安全巡查管理、设备管理等模块。设备管理界面以表格形式清晰展示设…...
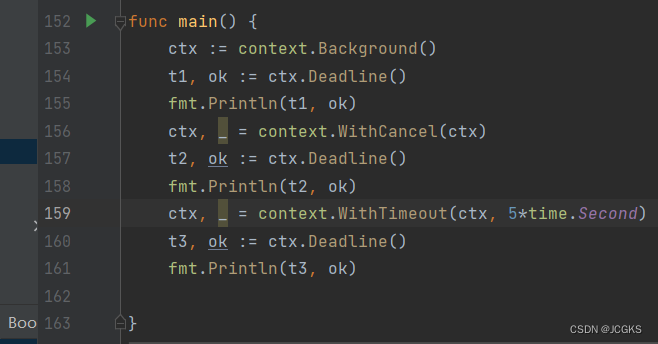
go|context源码解析
文章目录 Context接口Deadline()Done()Err()Value() canceler接口ctxemptyCtxcancelCtxtimerCtxvalueCtx 基本使用cancelCtxvalueCtx 首先看一下源码对“context”的描述, When a Context is canceled, all Contexts derived from it are also canceled. 当一个Cont…...
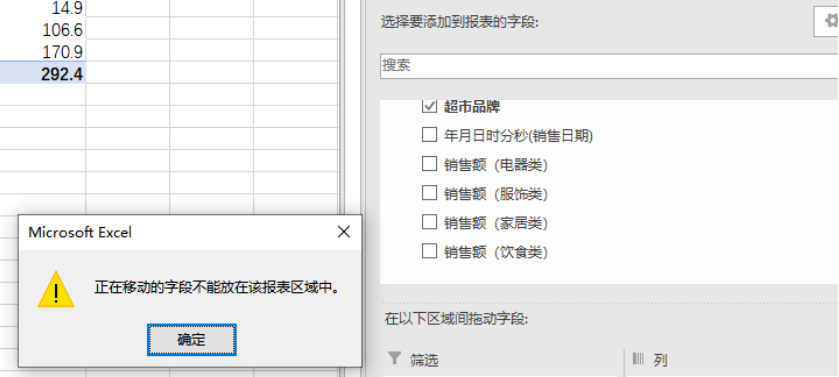
如何在PowerBI中使用Analyze in Excel
如何在PowerBI中使用Analyze in Excel 之前分享过如何使用DAXStudio将PowerBI与Excel连接 ,今天介绍另外一个工具,也可以实现同样的功能,Analyze in Excel。 使用Analyze in Excel 第一步: 首先准备好一个PBIX文件,…...

【学习记录】Element UI导入报错 * element-ui/lib/theme-chalk/index.css in ./src/main.js
文章目录 📌 摘要⚠️ 问题描述🔍 原因分析✅ 正常情况下的依赖结构❗ 问题根源 ✅ 解决方案✅ 方法一:使用 cnpm 安装 Element UI(推荐)步骤 1:全局安装 cnpm(使用淘宝镜像)步骤 2&…...

大模型分布式训练笔记(基于accelerate+deepspeed分布式训练解决方案)
文章目录 一、分布式训练基础与环境配置(1)分布式训练简介(2)如何进行分布式训练(3)分布式训练环境配置 二、数据并行-原理与实战(pytorch框架的nn.DataParallel)1)data …...
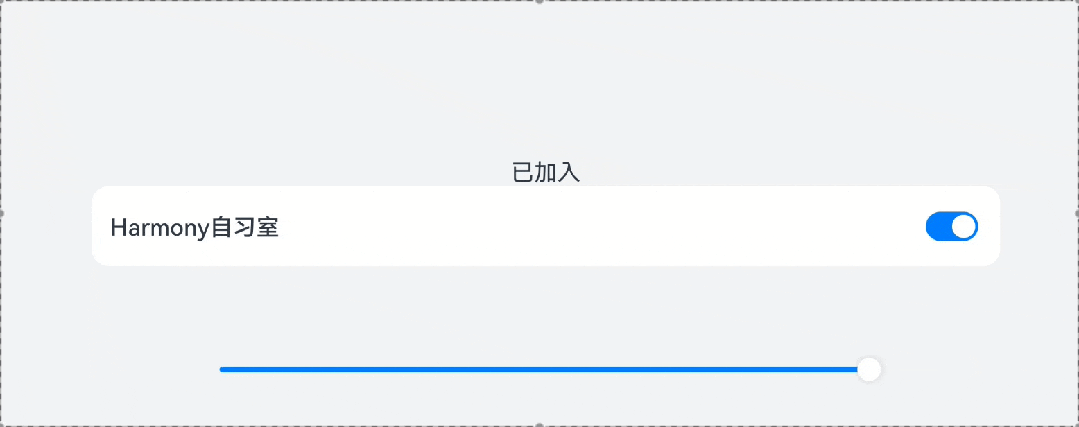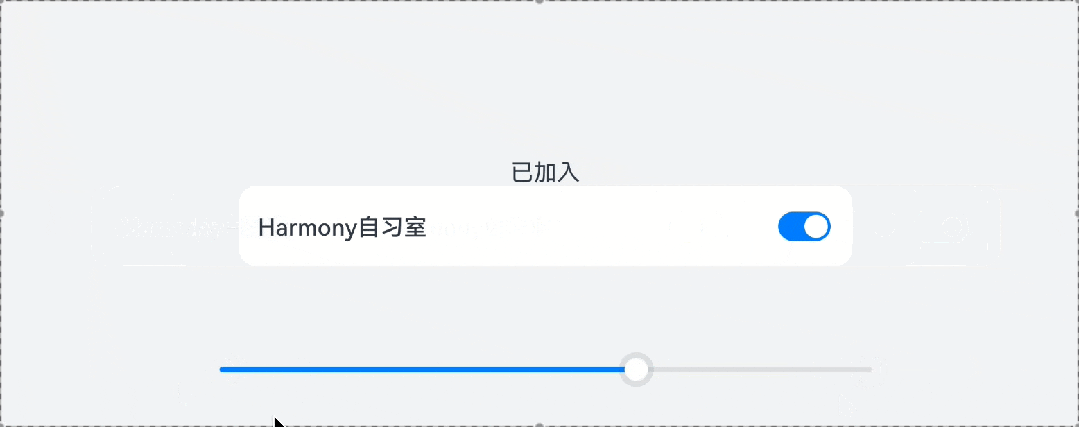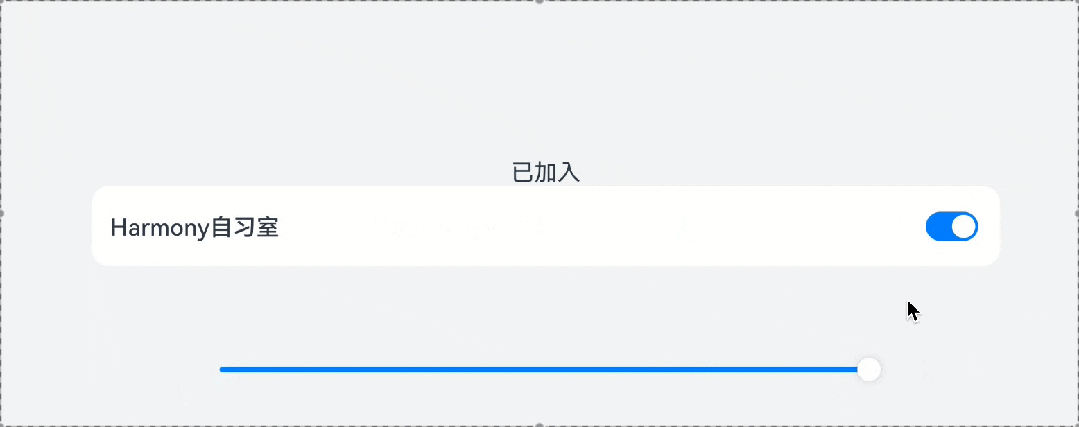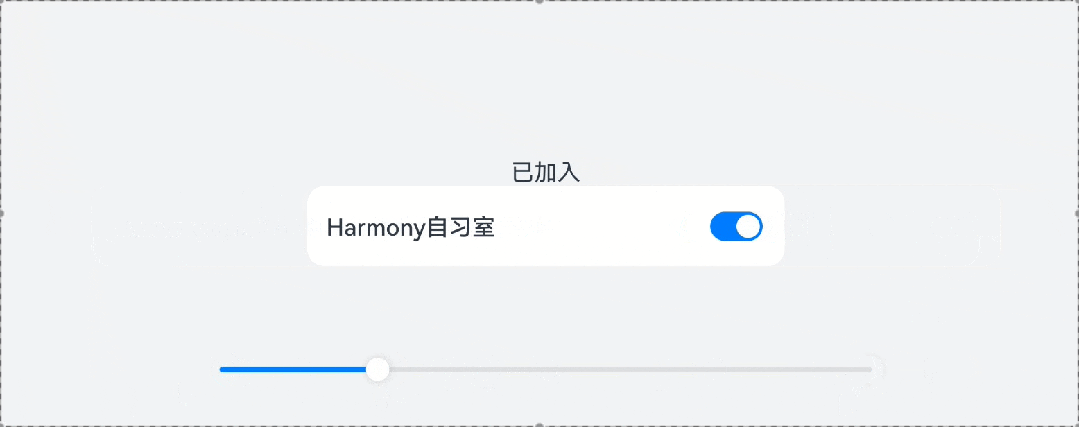
鸿蒙UI开发——组件的自适应拉伸
1、概 述 针对常见的开发场景,ArkUI开发框架提供了非常多的自适应布局能力,这些布局可以独立使用,也可多种布局叠加使用。本文针对ArkUI提供的拉伸能力做简单讨论。 拉伸能力是指容器组件尺寸发生变化时,增加或减小的空间全部分…...

鸿蒙仓颉语言开发教程:自定义弹窗
假期第一天,祝大家端午节快乐。昨天观看了时代旗舰尊界S800的发布,不得不感慨这车真好啊~ 放假闲来无事,继续跟大家分享仓颉语言的开发教程,今天介绍一下自定义弹窗。 仓颉语言中的自定义弹窗和ArkTs类似,…...

meilisearch docker 简单安装
ElasticSearch平替 docker run -it -d -p 7700:7700 -v /home/dev/melisearch/meili_data:/meili_data -e MEILI_MASTER_KEYRhTX1pLPSKSn7KW9yf9u_MNKC0v1YKkmx2Sc6qSwbLQ getmeili/meilisearch:v1.13 MEILI_MASTER_KEYRhTX1pLPSKSn7KW9yf9u_MNKC0v1YKkmx2Sc6qSwbLQ …...

Python 数据分析与可视化实战:从数据清洗到图表呈现
目录 一、数据采集与初步探索 二、数据清洗的七种武器 1. 缺失值处理策略 2. 异常值检测与修正 3. 数据类型转换技巧 三、数据转换的魔法工坊 1. 透视表与交叉表 2. 窗口函数实战 3. 文本数据处理 四、可视化呈现的艺术 1. 基础图表进阶用法 2. 高级可视化方案 3.…...

机器学习数据降维方法
1.数据类型 2.如何选择降维方法进行数据降维 3.线性降维:主成分分析(PCA)、线性判别分析(LDA) 4.非线性降维 5.基于特征选择的降维 6.基于神经网络的降维 数据降维是将高维数据转换为低维表示的过程,旨在保…...
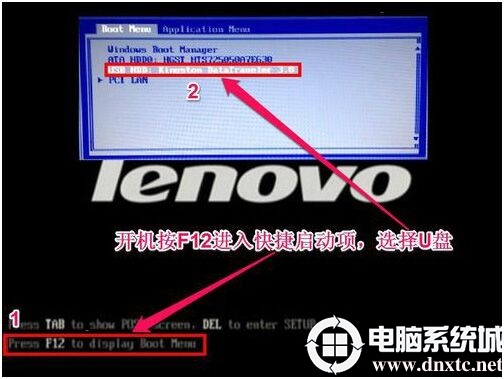
uefi和legacy有什么区别_从几方面分析uefi和legacy的区别
uefi和legacy是两种不同的引导方式,uefi是新式的BIOS,legacy是传统BIOS。你在UEFI模式下安装的系统,只能用UEFI模式引导;同理,如果你是在Legacy模式下安装的系统,也只能在legacy模式下进系统。uefi只支持64为系统且磁盘…...

Spring @Autowired自动装配的实现机制
Spring Autowired自动装配的实现机制 Autowired 注解实现原理详解一、Autowired 注解定义二、Qualifier 注解辅助指定 Bean 名称三、BeanFactory:按类型获取 Bean四、注入逻辑实现五、小结 源码见:mini-spring Autowired 注解实现原理详解 Autowired 的…...

Neo4j 数据可视化与洞察获取:原理、技术与实践指南
在关系密集型数据的分析领域,Neo4j 凭借其强大的图数据模型脱颖而出。然而,将复杂的连接关系转化为直观见解,需要专业的数据可视化技术和分析方法。本文将深入探讨 Neo4j 数据可视化的核心原理、关键技术、实用技巧以及结合图数据科学库&…...
一种基于性能建模的HADOOP配置调优策略
1.摘要 作为分布式系统基础架构的Hadoop为应用程序提供了一组稳定可靠的接口。该文作者提出了一种基于集成学习建模的Hadoop配置参数调优的方法。实验结果表明,该性能模型可以准确预测MapReduce应用程序的运行时间。采用提出的Hadoop配置参数方法调优后,…...
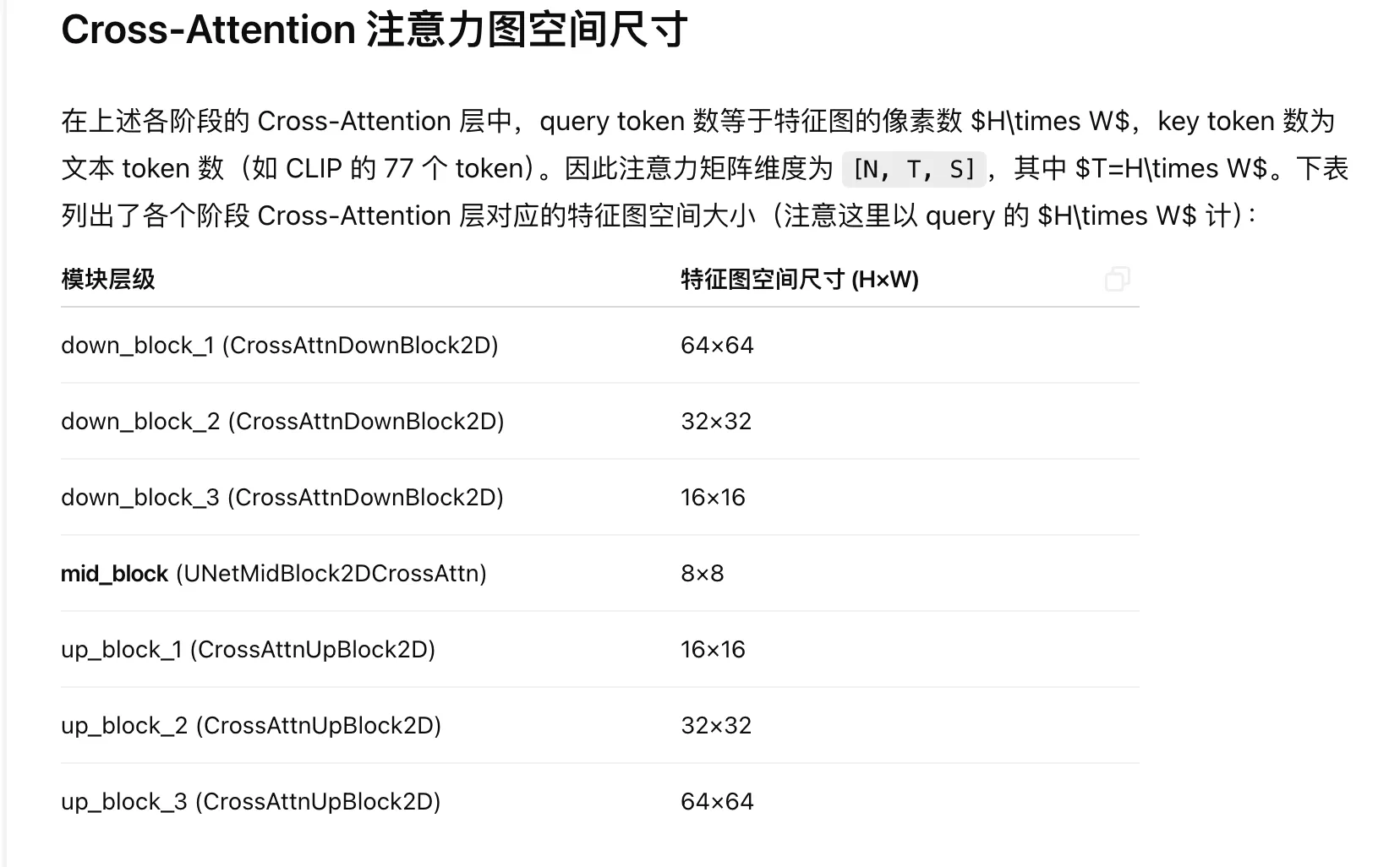
【Stable Diffusion 1.5 】在 Unet 中每个 Cross Attention 块中的张量变化过程
系列文章目录 文章目录 系列文章目录前言特征图和注意力图的尺寸差异原因在Break-a-Scene中的具体实现总结 前言 特征图 (Latent) 尺寸和注意力图(attention map)尺寸在扩散模型中有差异,是由于模型架构和注意力机制的特性决定的。 特征图和注意力图的尺寸差异原…...
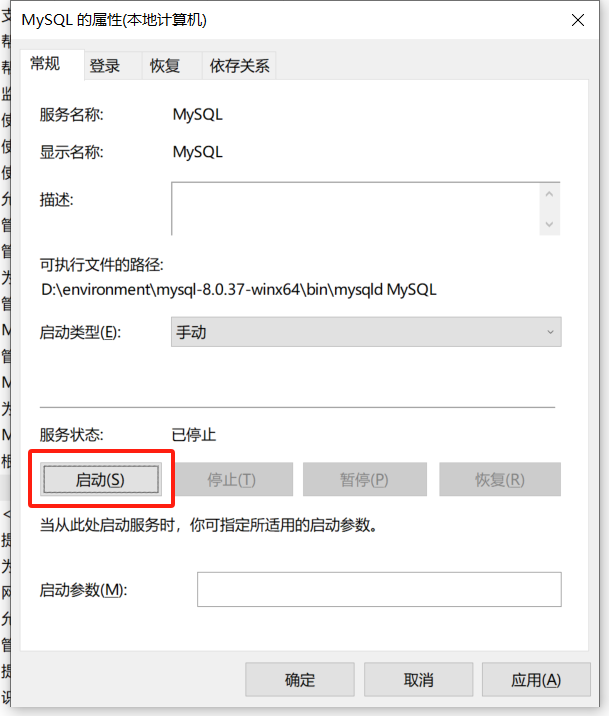
MySQL - Windows 中 MySQL 禁用开机自启,并在需要时手动启动
Windows 中 MySQL 禁用开机自启,并在需要时手动启动 打开服务管理器:在底部搜索栏输入【services.msc】 -> 点击【服务】 打开 MySQL 服务的属性管理:找到并右击 MySQL 服务 -> 点击【属性】 此时的 MySQL 服务:正在运行&a…...

前端下载文件,文件打不开的问题记录
需求: 下载是很常见的接口,但是经常存在下载的文件异常的问题。此处记录一个常见的错误。 分析: 1、接口请求需要配置{responseType: ‘blob’},此时要求返回的格式为blob,进而进行下载。 const res await axios.…...

小白的进阶之路系列之十一----人工智能从初步到精通pytorch综合运用的讲解第四部分
本文将介绍如何用PyTorch构建模型 torch.nn.Module和torch.nn.Parameter 除了Parameter之外,本视频中讨论的所有类都是torch.nn.Module的子类。这是PyTorch基类,用于封装PyTorch模型及其组件的特定行为。 torch.nn.Module的一个重要行为是注册参数。如果特定的Module子类具…...
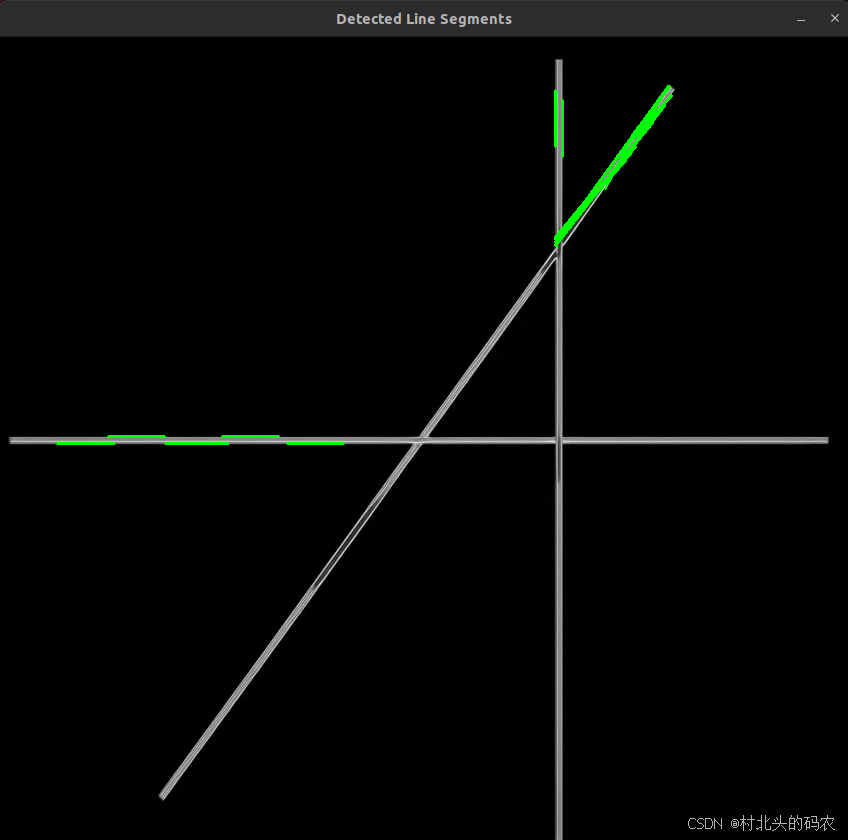
OpenCV CUDA模块霍夫变换------在 GPU 上执行概率霍夫变换检测图像中的线段端点类cv::cuda::HoughSegmentDetector
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::HoughSegmentDetector 是 OpenCV 的 CUDA 模块中一个非常重要的类,它用于在 GPU 上执行 概率霍夫变换(Probabi…...

详解一下RabbitMQ中的channel.Publish
函数定义(来自 github.com/streadway/amqp) func (ch *Channel) Publish(exchange string,key string,mandatory bool,immediate bool,msg Publishing, ) error这个方法的作用是:向指定的交换机 exchange 发送一条消息 msg,带上路…...

硬件学习笔记--62 MCU的ECC功能简介
1. 基本概念 ECC(Error Correction Code,错误校正码)是MCU(微控制器)中用于检测和纠正存储器数据错误的硬件功能,主要应用于Flash、RAM、Cache等存储单元,确保数据在传输或存储过程中的可靠性。…...

Uiverse.io:免费UI组件库
Uiverse.io 完整使用指南:免费UI组件库的终极教程 🌟 什么是 Uiverse.io? Uiverse.io 是一个开源的UI组件库平台,为开发者和设计师提供了大量精美的、可直接使用的HTML/CSS组件。这个平台的特色在于所有组件都是由社区贡献的,完全免费,并且可以直接复制代码使用。 �…...
)
普中STM32F103ZET6开发攻略(四)
接续上文:普中STM32F103ZET6开发攻略(三)-CSDN博客 点关注不迷路哟。你的点赞、收藏,一键三连,是我持续更新的动力哟!!! 目录 接续上文:普中STM32F103ZET6开发攻略&am…...

ck-editor5的研究 (5):优化-页面离开时提醒保存,顺便了解一下 Editor的生命周期 和 6大编辑器类型
前言 经过前面的 4 篇内容,我们已经慢慢对 CKEditor5 熟悉起来了。这篇文章,我们就来做一个优化,顺便再补几个知识点: 当用户离开时页面时,提醒他保存数据了解一下 CKEditor5 的 六大编辑器类型了解一下 editor 实例对…...

[3D GISMesh]三角网格模型中的孔洞修补算法
📐 三维网格模型空洞修复技术详解 三维网格模型在扫描、重建或传输过程中常因遮挡、噪声或数据丢失产生空洞(即边界非闭合区域),影响模型的完整性与可用性。空洞修复(Hole Filling)是计算机图形学和几何处…...

11.2 java语言执行浅析3美团面试追魂七连问
美团面试追魂七连问:关于Object o New Object() ,1请解释一下对象的创建过程(半初始化) 2,加问DCL要不要volatile 问题(指令重排) 3.对象在内存中的存储布局(对象与数组的存储不同),4.对象头具体包括什么.5.对象怎么定位.6.对象怎么分配(栈-线程本地-Eden-Old)7.在…...
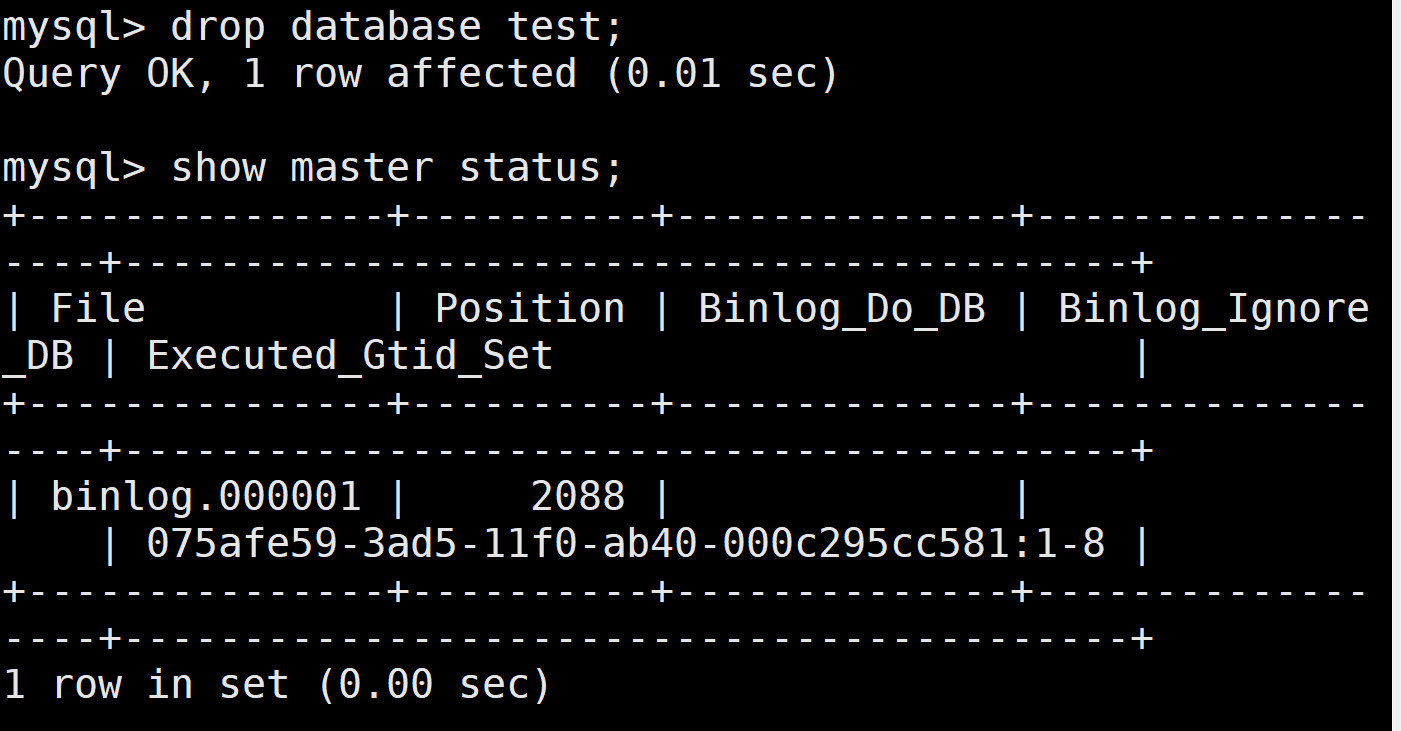
MySQL 全量、增量备份与恢复
一.MySQL 数据库备份概述 备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。之前已经学习过如何安装 MySQL,本小节将从生产运维的角度了解备份恢复的分类与方法。 1 数据备份的重要性 在企业中数据的价值至关…...