python学习打卡day43
DAY 43 复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
@浙大疏锦行
数据集使用猫狗数据集,训练集中包含猫图像4000张、狗图像4005张。测试集包含猫图像1012张,狗图像1013张。以下是数据集的下载地址。
猫和狗 --- Cat and Dog
1.数据集加载与数据预处理
我这里对数据集文件路径做了改变
C:\Users\vijay\Desktop\1\
├── train\
│ ├── cats\
│ └── dogs\
└── test\
├── cats\
└── dags\
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as F# 设置随机种子确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 新增:调整图像大小为统一尺寸transforms.Resize((32, 32)), # 确保所有图像都是32x32像素transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])# 测试集:仅进行必要的标准化,保持数据原始特性
test_transform = transforms.Compose([# 新增:调整图像大小为统一尺寸transforms.Resize((32, 32)), # 确保所有图像都是32x32像素transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])# 定义数据集根目录
root = r'C:\Users\vijay\Desktop\1'train_dataset = datasets.ImageFolder(root=root + '/train', # 指向 train 子文件夹transform=train_transform
)
test_dataset = datasets.ImageFolder(root=root + '/test', # 指向 test 子文件夹transform=test_transform
)# 打印类别信息,确认数据加载正确
print(f"训练集类别: {train_dataset.classes}")
print(f"测试集类别: {test_dataset.classes}")# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.模型训练与评估
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 第一个卷积层,输入通道为3(彩色图像),输出通道为32,卷积核大小为3x3,填充为1以保持图像尺寸不变self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)# 第二个卷积层,输入通道为32,输出通道为64,卷积核大小为3x3,填充为1self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 第三个卷积层,输入通道为64,输出通道为128,卷积核大小为3x3,填充为1self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 最大池化层,池化核大小为2x2,步长为2,用于下采样,减少数据量并提取主要特征self.pool = nn.MaxPool2d(2, 2)# 第一个全连接层,输入特征数为128 * 4 * 4(经过前面卷积和池化后的特征维度),输出为512self.fc1 = nn.Linear(128 * 4 * 4, 512)# 第二个全连接层,输入为512,输出为2(对应猫和非猫两个类别)self.fc2 = nn.Linear(512, 2)def forward(self, x):# 第一个卷积层后接ReLU激活函数和最大池化操作,经过池化后图像尺寸变为原来的一半,这里输出尺寸变为16x16x = self.pool(F.relu(self.conv1(x)))# 第二个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为8x8x = self.pool(F.relu(self.conv2(x)))# 第三个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为4x4x = self.pool(F.relu(self.conv3(x)))# 将特征图展平为一维向量,以便输入到全连接层x = x.view(-1, 128 * 4 * 4)# 第一个全连接层后接ReLU激活函数x = F.relu(self.fc1(x))# 第二个全连接层输出分类结果x = self.fc2(x)return x# 初始化模型
model = SimpleCNN()
print("模型已创建")# 如果有GPU则使用GPU,将模型转移到对应的设备上
model = model.to(device)# 训练模型
def train_model(model, train_loader, test_loader, epochs=10):# 定义损失函数为交叉熵损失,用于分类任务criterion = nn.CrossEntropyLoss()# 定义优化器为Adam,用于更新模型参数,学习率设置为0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)for epoch in range(epochs):# 训练阶段model.train()running_loss = 0.0correct = 0total = 0for i, data in enumerate(train_loader, 0):# 从数据加载器中获取图像和标签inputs, labels = data# 将图像和标签转移到对应的设备(GPU或CPU)上inputs, labels = inputs.to(device), labels.to(device)# 清空梯度,避免梯度累加optimizer.zero_grad()# 模型前向传播得到输出outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()if i % 100 == 99:# 每100个批次打印一次平均损失和准确率print(f'[{epoch + 1}, {i + 1}] 损失: {running_loss / 100:.3f} | 准确率: {100.*correct/total:.2f}%')running_loss = 0.0# 测试阶段model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)test_loss += criterion(outputs, labels).item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()print(f'测试集 [{epoch + 1}] 损失: {test_loss/len(test_loader):.3f} | 准确率: {100.*correct/total:.2f}%')print("训练完成")return model# 训练模型
try:# 尝试加载预训练模型(如果存在)model.load_state_dict(torch.load('cat_classifier.pth'))print("已加载预训练模型")
except:print("无法加载预训练模型,训练新模型")model = train_model(model, train_loader, test_loader, epochs=10)# 保存训练后的模型参数torch.save(model.state_dict(), 'cat_classifier.pth')# 设置模型为评估模式
model.eval()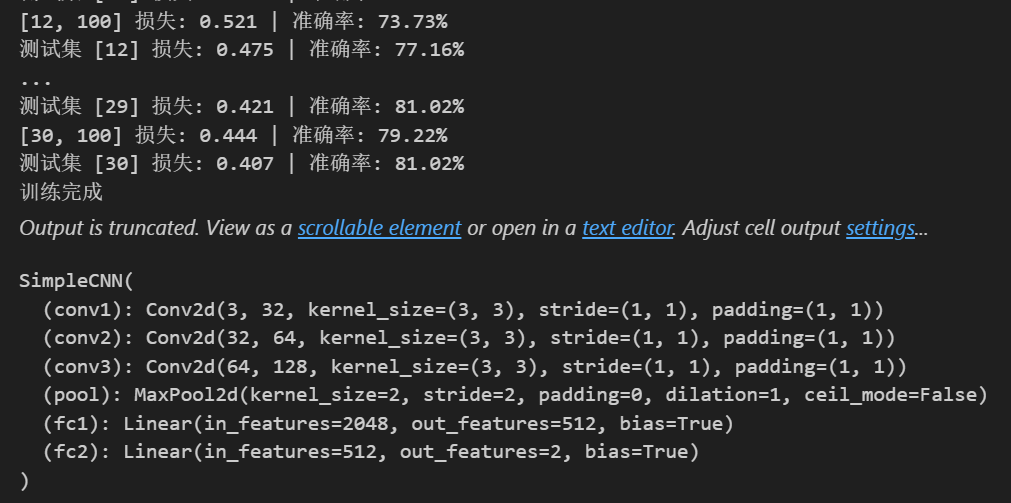
3. Grad-CAM实现
# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(32x32),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_class# 可视化Grad-CAM结果的函数
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 选择一个随机图像
# idx = np.random.randint(len(test_dataset))
idx = 102 # 选择测试集中的第101张图片 (索引从0开始)
image, label = test_dataset[idx]
print(f"选择的图像类别: {test_dataset.classes[label]}")# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv3)# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可视化
plt.figure(figsize=(12, 4))# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像: {test_dataset.classes[label]}")
plt.axis('off')# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图: {test_dataset.classes[pred_class]}")
plt.axis('off')# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("叠加热力图")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()print("Grad-CAM可视化完成。已保存为grad_cam_result.png")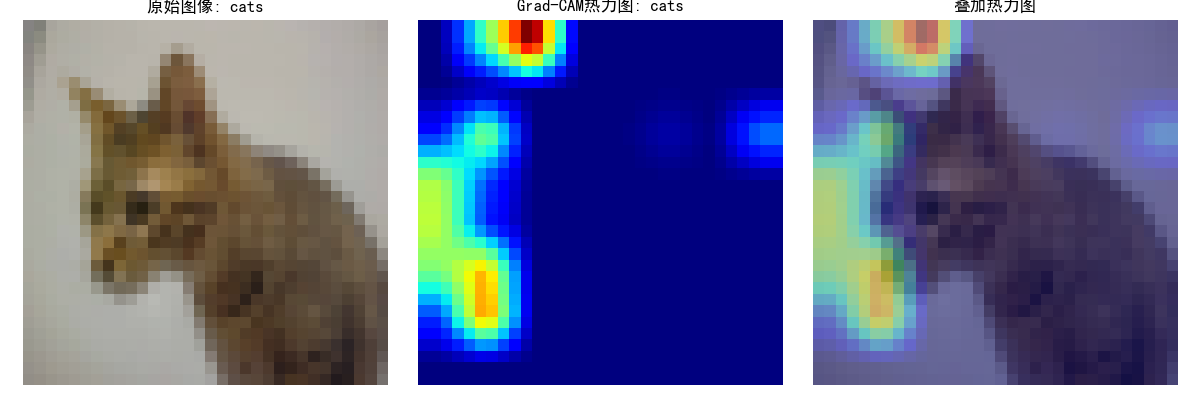
相关文章:
python学习打卡day43
DAY 43 复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 浙大疏锦行 数据集使用猫狗数据集,训练集中包含猫图像4000张、狗图像4005张。测试集包含猫图像1012张,狗图像1013张。以下是数据集的下…...

Microsoft Word使用技巧分享(本科毕业论文版)
小铃铛最近终于完成了毕业答辩后空闲下来了,但是由于学校没有给出准确地参考模板,相信诸位朋友们也在调整排版时感到头疼,接下来小铃铛就自己使用到的一些排版技巧分享给大家。 注:以下某些设置是根据哈尔滨工业大学(威…...
windows安装多个版本composer
一、需求场景 公司存在多个项目,有的项目比较老,需要composer 1.X版本才能使用 新的项目又需要composer 2.X版本才能使用 所以需要同时安装多个版本的composer二、下载多个版本composer #composer官网 https://getcomposer.org/download/三、放到指定目…...
【办公类-22-05】20250601Python模拟点击鼠标上传CSDN12篇
、 背景需求: 每周为了获取流量券,每天上传2篇,获得1500流量券,每周共上传12篇,才能获得3000和500的券。之前我用UIBOT模拟上传12篇。 【办公类-22-04】20240418 UIBOT模拟上传每天两篇,获取流量券,并删除内容_csdn 每日任务流量券-CSDN博客文章浏览阅读863次,点赞18…...

贪心算法应用:边着色问题详解
贪心算法应用:边着色问题详解 贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而希望导致结果是全局最优的算法策略。边着色问题是图论中的一个经典问题,贪心算法可以有效地解决它。下面我将从基础概念到具体实现,全…...

【蓝桥杯】包子凑数
包子凑数 题目描述 小明几乎每天早晨都会在一家包子铺吃早餐。他发现这家包子铺有 NN 种蒸笼,其中第 ii 种蒸笼恰好能放 AiAi 个包子。每种蒸笼都有非常多笼,可以认为是无限笼。 每当有顾客想买 XX 个包子,卖包子的大叔就会迅速选出若干…...

ck-editor5的研究 (2):对 CKEditor5 进行设计,并封装成一个可用的 vue 组件
前言 在上一篇文章中—— ck-editor5的研究(1):快速把 CKEditor5 集成到 nuxt 中 ,我仅仅是把 ckeditor5 引入到了 nuxt 中,功能还不算通用。 这一篇内容将会对其进行设计,并封装成可复用的 vue 组件&…...
Java-redis实现限时在线秒杀功能
1.使用redisson pom文件添加redisson <!--redisson--><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.23.4</version></dependency> 2.mysql数据库表设…...

simulink mask、sfunction和tlc的联动、接口
这里全部是讲的level2 sfunction(用m语言编写),基于matlab 2020a。 1.mask的参数操作 1)mask通过set_param和get_param这2个函数接口对mask里面定义的Parameters&Dialog的参数的大部分属性进行读写,一般是Value值…...
VMWare安装常见问题
如果之前安装过VMWare软件,只要是 15/16 版本的,可以正常使用的,不用卸载!!! 如果之前安装过,卸载了,一定要保证通过正常的渠道去卸载(通过控制面板卸载软件)…...

set_property LOC约束
##下列指令是用于清除自带GT CELL相关的LOC约束,或者覆盖 ##你需要把IP中自带的GT cell相关的LOC约束清除掉,或者覆盖掉 ##以下命令可以用来覆盖GT_CHANNEL的LOC约束, 在这条命令之后执行你自己的physical constraint: ##GT的channel的相关管脚有两种设计…...
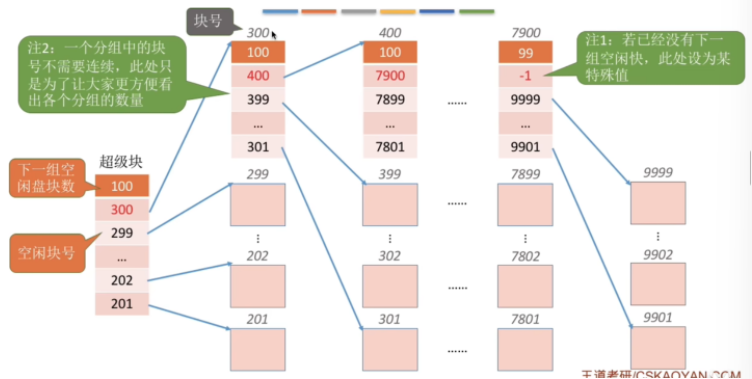
【北邮 操作系统】第十二章 文件系统实现
一、文件的物理结构 1.1 文件块、磁盘块 类似于内存分页,磁盘中的存储单元也会被分为一个个“块/磁盘块/物理块”。很多操作系统中,磁盘块的大小与内存块、页面的大小相同 内存与磁盘之间的数据交换(即读/写操作、磁盘I/0)都是以“块”为单位进行的。即…...
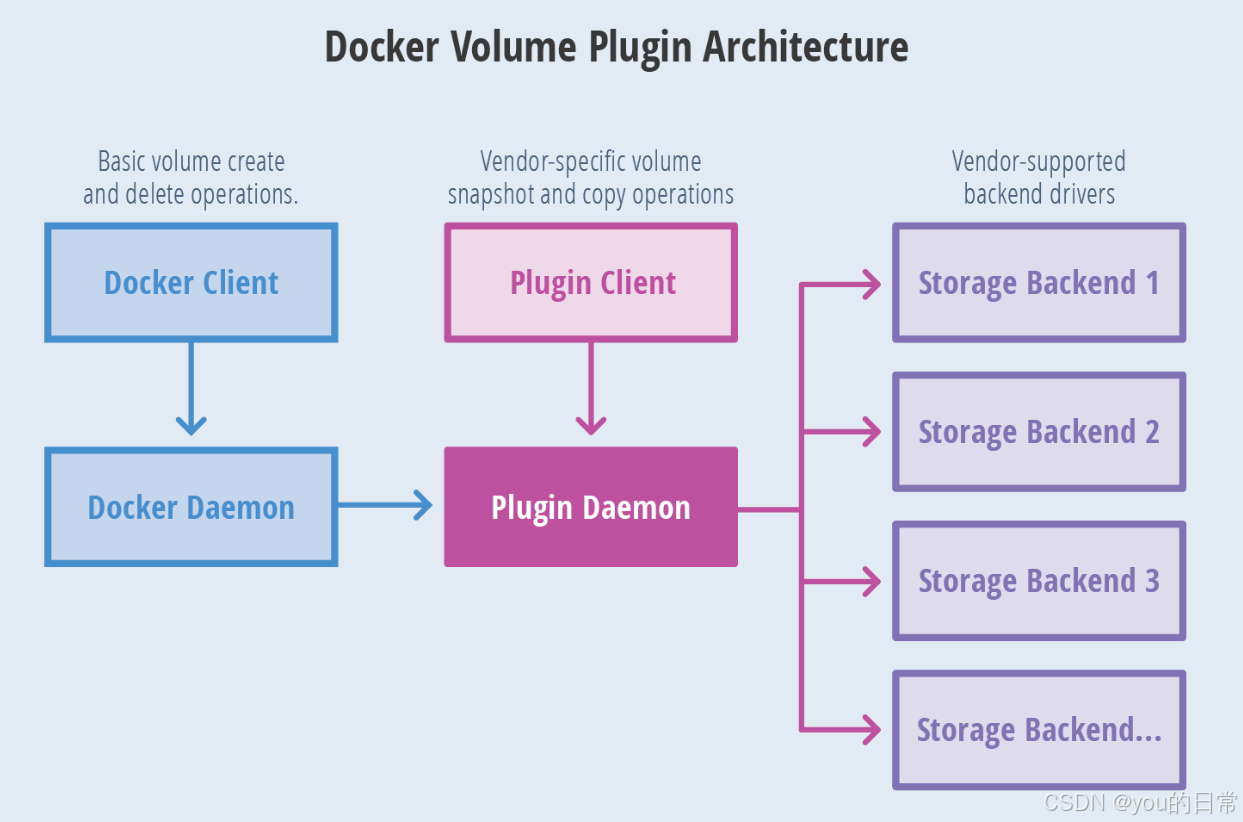
Docker 插件生态:从网络插件到存储插件的扩展能力解析
Docker 容器技术以其轻量、快速、可移植的特性,迅速成为构建和部署现代应用的核心工具。然而,尽管 Docker Engine 自身功能强大,但在面对多样化的生产环境和复杂业务需求时,仅靠核心功能往往无法满足所有场景。 例如,跨主机的容器网络通信、异构存储系统的持久化数据管理…...

WordPress搜索引擎优化的最佳重定向插件:进阶指南
在管理网站时,我们经常需要调整网页地址或修复错误链接。这时,通过重定向不仅能有效解决这些问题,还能显著提升网站在搜索引擎中的排名。对于熟悉基础重定向插件的用户来说,一些功能更强大的工具可以帮助你更全面地管理网站&#…...
org.junit.runners.model.InvalidTestClassError:此类问题的解决
不知道大家是否遇见过以上这种情况,我也是今天被这个错误搞得很烦,后来通过网上查找资料终于找到了问题所在————就是简单的Test注解的错误使用 Test注解的注意情况 :1 权限必须是public 2 不能有参数 3 返回值类型是void 4 本类的其他的…...
用户管理页面(解决toggleRowSelection在dialog用不了的隐患,包含el-table的plus版本的组件)
新增/编辑/删除/分配角色,图片上传在此文章分类下另一个文章 1.重点分配角色: <template><!-- 客户资料 --><div class"pageBox"><elPlusTable :tableData"tableData" :tablePage"tablePage" onSi…...

打卡第35天:GPU训练以及类的Call方法
知识点回归: 1.CPU性能的查看:看架构代际、核心数、线程数 2.GPU性能的查看:看显存、看级别、看架构代际 3.GPU训练的方法:数据和模型移动到GPU device上 4.类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)…...

Linux-GCC、makefile、GDB
GCC gcc -E test.c -o test.i预处理(-o指定文件名) gcc -S test.i -o test.s编译gcc -c test.s -o test.o汇编gcc test.o -o test链接(生成一个可执行程序的软连接) gcc test.c -o test一条指令可以完成以上所有内容 gcc *.c -I(大写的i) include由于在main.c中找不到当前文件…...

[MySQL初阶]MySQL(7) 表的内外连接
标题:[MySQL初阶]MySQL(7)表的内外连接 水墨不写bug 文章目录 一. 内连接 (INNER JOIN)二. 外连接 (OUTER JOIN)关键区别总结 三、 如何选择 在 MySQL 中,连接(JOIN)用于根据两个或多个表之间的相关列组合行。内连接(I…...

Spring Boot中Excel处理完全指南:从基础到高级实践
Excel处理基础知识 1.1 为什么需要在应用中处理Excel文件? 在企业应用开发中,Excel文件处理是一个非常常见的需求,主要用于以下场景: 数据导入:允许用户通过Excel上传批量数据到系统 数据导出:将系统数据…...

Windows下NVM的安装与使用
本文将介绍windows下nvm相关知识。 在不同的项目中可能会使用不同版本的Node.js,例如A项目中需要node>18;B项目中需要node>20。这时候就需要使用NVM切换不同的node版本。进而可以在同一台设备上使用多个node版本。 一、NVM是什么? n…...

Ubuntu挂起和休眠
Ubuntu挂起和休眠 1. 挂起(Suspend)2. 休眠(Hibernate)3. 混合挂起(Hybrid-Sleep)注意事项图形界面操作 在 Ubuntu 系统中,挂起(Suspend)和休眠(Hibernate&am…...

【R语言编程绘图-mlbench】
mlbench库简介 mlbench是一个用于机器学习的R语言扩展包,主要用于提供经典的基准数据集和工具,常用于算法测试、教学演示或研究场景。该库包含多个知名数据集,涵盖分类、回归、聚类等任务。 包含的主要数据集 BostonHousing 波士顿房价数据…...

云服务器部署Gin+gorm 项目 demo
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

MySQL数据一致性守护者:pt-table-checksum原理与实战全解析
MySQL数据一致性守护者:pt-table-checksum原理与实战全解析 在MySQL主从复制环境中,数据一致性是DBA和运维人员最关心的问题之一。主从数据不一致可能导致业务逻辑错误、报表数据失真甚至系统故障。Percona Toolkit中的pt-table-checksum工具正是为解决这一痛点而生,它能够…...
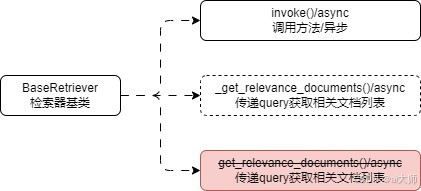
检索器组件深入学习与使用技巧 BaseRetriever 检索器基类
1. BaseRetriever 检索器基类 在 LangChain 中,传递一段 query 并返回与这段文本相关联文档的组件被称为 检索器,并且 LangChain 为所有检索器设计了一个基类——BaseRetriever,该类继承了 RunnableSerializable,所以该类是一个 …...

Unity——QFramework工具 AciontKit时序动作执行系统
AciontKit 是一个时序动作执行系统。 游戏中,动画的播放、延时、资源的异步加载、网络请求等,这些全部都是时序任务,而 ActionKit,可以把这些任务全部整合在一起,使用统一的 API,来对他们的执行进行计划。…...
【Doris基础】Doris中的Replica详解:Replica原理、架构
目录 1 Replica基础概念 1.1 什么是Replica 1.2 Doris中的副本类型 2 Doris副本架构设计 2.1 副本分布机制 2.2 副本一致性模型 3 副本生命周期管理 3.1 副本创建流程 3.2 副本恢复机制 4 副本读写流程详解 4.1 写入流程与副本同步 4.2 查询流程与副本选择 5 副本…...

【中国·广州】第三届信号处理与智能计算国际学术会议 (SPIC2025) 即将开启
第三届信号处理与智能计算国际学术会议 (SPIC2025) 即将开启 在信息技术飞速发展的当下,信号处理与智能计算作为前沿科技领域,正深刻改变着我们的生活与产业格局。为汇聚全球顶尖智慧,推动该领域进一步突破,第三届信号处理与智能…...
Android12 Launcher3显示所有应用列表
Android12 Launcher3显示所有应用列表 1.前言: 最近在Android12Rom定制时需要显示所有桌面应用的图标,并且不能去掉抽屉,在手机上面抽屉和所有应该列表是两种不同模式,用户基可以自行选择,但是在自定义的launcher中这…...