量化Quantization初步之--带量化(QAT)的XOR异或pyTorch版250501
量化(Quantization)这词儿听着玄,经常和量化交易Quantitative Trading (量化交易)混淆。
其实机器学习(深度学习)领域的量化Quantization是和节约内存、提高运算效率相关的概念(因大模型的普及,这个量化问题尤为迫切)。
揭秘机器学习“量化”:不止省钱,更让AI高效跑起来!
“量化(Quantization)”这个词,在机器学习领域,常常让人联想到复杂的数学或是与金融交易相关的“量化交易”,从而感到困惑。但实际上,它与我们日常生活中的数字转换概念更为接近,而在AI世界里,它扮演的角色是节约内存、提高运算效率的“幕后英雄”(现在已经显露到“幕布之前”),尤其在大模型时代,其重要性日益凸显。
那么,机器学习中的“量化”究竟是啥?咱为啥用它?
什么是机器学习中的“量化”(Quantization)?
简单讲,机器学习中的“量化”就是将模型中原本采用高精度浮点数(如32位浮点数,即FP32)表示的权重(weights)和激活值(activations),转换成低精度表示(如8位整数,即INT8)的过程。
你可以把它想象成“数字的压缩”。在计算机中,浮点数就像是拥有无限小数位的精确数字,而整数则像只有整数部分的数字。从高精度浮点数到低精度整数的转换,必然会损失一些信息,但与此同时,它也带来了显著的优势:
- 内存占用大幅减少: 8位整数比32位浮点数少占用4倍的内存空间。这意味着更大的模型可以被部署到内存有限的设备上(如手机、IoT设备),或者在相同内存下可以运行更大的模型。
- 计算速度显著提升: 整数运算通常比浮点数运算更快、功耗更低。这使得模型在推理(Inference)阶段能以更高的效率运行,减少延迟。
为何需要“量化”?
随着深度学习模型变得越来越大,越来越复杂,它们对计算资源的需求也呈爆炸式增长。一个动辄几十亿甚至上百亿参数的大模型,如果全部使用FP32存储和计算,将对硬件资源提出极高的要求。
- 部署到边缘设备: 手机、自动驾驶汽车、智能音箱等边缘设备通常算力有限,内存紧张。量化是让大模型“瘦身”后成功“登陆”这些设备的必经之路。
- 降低运行成本: 在云端部署大模型时,更低的内存占用和更快的计算速度意味着更低的服务器成本和能耗。
- 提升用户体验: 实时响应的AI应用,如语音助手、图像识别等,对推理速度有极高要求。量化可以有效缩短响应时间。
量化策略:后训练量化 vs. 量化感知训练(QAT)
量化并非只有一种方式。根据量化发生的时间点,主要可以分为两大类:
-
后训练量化(Post-Training Quantization, PTQ): 顾名思义,PTQ 是在模型训练完成之后,对已经训练好的FP32模型进行量化。它操作简单,不需要重新训练,是实现量化的最快途径。然而,由于量化过程中会损失精度,PTQ 可能会导致模型性能(如准确率)的下降。对于对精度要求不那么苛刻的应用,PTQ 是一个不错的选择。
-
量化感知训练*(这是本文重点推介的:Quantization Aware Training, QAT): 这正是我们今天着重讲解的明星策略!QAT 的核心思想是——在模型训练过程中,就“感知”到未来的量化操作。
在QAT中,量化误差被集成到模型的训练循环中。这意味着,模型在训练时就“知道”它最终会被量化成低精度,并会努力学习如何在这种低精度下保持最优性能。
具体来说,QAT通常通过在模型中插入“伪量化”(Fake Quantization)节点来实现。这些节点在训练过程中模拟量化和反量化操作,使得模型在FP32环境下进行前向传播和反向传播时,能够学习到量化对模型参数和激活值的影响。当训练完成后,这些伪量化节点会被真正的量化操作所取代,从而得到一个高性能的量化模型。
为什么QAT是量化策略的“王牌”?
相较于PTQ……QAT 的优势显而易见:
- 精度损失最小: 这是QAT最大的亮点。通过在训练过程中模拟量化,模型能够自我调整以适应量化带来的精度损失,从而在量化后依然保持接近FP32模型的性能。
- 适用于更苛刻的场景: 对于那些对模型精度要求极高,不能容忍明显性能下降的应用(如自动驾驶、医疗影像分析),QAT几乎是唯一的选择。
- 更好的泛化能力: 在训练阶段就考虑量化,使得模型在量化后对各种输入数据具有更好的鲁棒性。
PyTorch中的QAT实践
在PyTorch中实现QAT,通常需要以下几个关键步骤:
- 准备量化配置: 定义量化类型(如INT8)、量化方法(如对称量化、非对称量化)以及需要量化的模块。
- 模型转换: 使用PyTorch提供的
torch.quantization模块,将普通的FP32模型转换为QAT模型。这个过程会在模型中插入伪量化模块。 - 重新训练/微调: 在新的数据集上对转换后的模型进行短时间的微调(Fine-tuning),或者在原有训练基础上继续训练。这个阶段,模型会学习如何适应伪量化带来的精度损失。
- 模型融合(可选但推荐): 将一些连续的层(如Conv-BN-ReLU)融合为一个操作,可以进一步提高量化后的推理效率。
- 模型量化和保存: 训练完成后,将微调好的QAT模型转换为真正的量化模型,并保存。
总结
量化(Quantization)是深度学习模型优化不可或缺的一环,它通过降低模型精度来换取内存和计算效率的大幅提升。而量化感知训练(QAT)作为一种高级量化策略,通过在训练阶段就考虑量化对模型的影响,极大地减小了量化带来的精度损失,使得在各种设备上部署高性能AI模型成为可能。
随着大模型和边缘AI的普及,掌握量化尤其是QAT的原理和实践,将成为每一位AI工程师和研究人员的必备技能。让我们一起,让AI跑得更快、更高效!
import torch
import torch.nn as nn
import torch.optim as optim
import torch.quantization
import numpy as np
import os# ===== 1. XOR数据集 =====
X = torch.tensor([[0., 0.],[0., 1.],[1., 0.],[1., 1.]
], dtype=torch.float32)
y = torch.tensor([[0.],[1.],[1.],[0.]
], dtype=torch.float32)# ===== 2. 神经网络模型 (标准FP32) =====
class XORNet(nn.Module):def __init__(self):super(XORNet, self).__init__()self.fc1 = nn.Linear(2, 3)self.relu = nn.ReLU()self.fc2 = nn.Linear(3, 1)# QAT阶段不用Sigmoid,直接用BCEWithLogitsLoss# self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)# return self.sigmoid(x)return x# ===== 3. 初始化模型/优化器 =====
model = XORNet()
# He初始化,适合ReLU
for m in model.modules():if isinstance(m, nn.Linear):nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.05)# ===== 4. 训练(标准模型) =====
print("--- 开始标准模型训练 ---")
epochs = 900#1000#500 #1500
for epoch in range(epochs):outputs = model(X)loss = criterion(outputs, y)optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 300 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')with torch.no_grad():probs = torch.sigmoid(model(X))predictions = (probs > 0.5).float()accuracy = (predictions == y).sum().item() / y.numel()print(f"\n标准模型训练后精度: {accuracy*100:.2f}%")print(f"标准模型预测结果:\n{predictions}")# ===== 5. 构建QAT模型 =====
class XORNetQAT(nn.Module):def __init__(self):super(XORNetQAT, self).__init__()# 量化Stubself.quant = torch.quantization.QuantStub()self.fc1 = nn.Linear(2, 3)self.relu = nn.ReLU()self.fc2 = nn.Linear(3, 1)self.dequant = torch.quantization.DeQuantStub()def forward(self, x):x = self.quant(x)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)x = self.dequant(x)return xdef fuse_model(self):torch.quantization.fuse_modules(self, [['fc1', 'relu']], inplace=True)# ===== 6. QAT前权重迁移、模型融合 =====
model_qat = XORNetQAT()
# 迁移参数
model_qat.load_state_dict(model.state_dict())
# 融合(此步必须!)
model_qat.fuse_model()# 配置QAT
model_qat.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm') # CPU
torch.quantization.prepare_qat(model_qat, inplace=True)optimizer_qat = optim.Adam(model_qat.parameters(), lr=0.01)# ===== 7. QAT训练 =====
qat_epochs = 700
print("\n--- QAT训练 ---")
for epoch in range(qat_epochs):model_qat.train()outputs_qat = model_qat(X)loss_qat = criterion(outputs_qat, y)optimizer_qat.zero_grad()loss_qat.backward()optimizer_qat.step()if (epoch + 1) % 150 == 0:print(f'QAT Epoch [{epoch+1}/{qat_epochs}], Loss: {loss_qat.item():.4f}')# ===== 8. 转换到量化模型/评估精度 =====
print("\n--- 转换为量化模型 ---")
model_qat.eval()
model_quantized = torch.quantization.convert(model_qat.eval(), inplace=False)with torch.no_grad():probs_quantized = torch.sigmoid(model_quantized(X))predictions_quantized = (probs_quantized > 0.5).float()accuracy_quantized = (predictions_quantized == y).sum().item() / y.numel()print(f"量化模型精度: {accuracy_quantized*100:.2f}%")print(f"量化模型预测:\n{predictions_quantized}")# ===== 9. 模型大小对比 =====
torch.save(model.state_dict(), 'xor_fp32.pth')
torch.save(model_quantized.state_dict(), 'xor_int8.pth')
fp32_size = os.path.getsize('xor_fp32.pth') / (1024 * 1024)
int8_size = os.path.getsize('xor_int8.pth') / (1024 * 1024)
print(f"\nFP32模型大小: {fp32_size:.6f} MB")
print(f"INT8模型大小: {int8_size:.6f} MB")
print(f"模型缩减比例: {fp32_size/int8_size:.2f} 倍")
运行结果:
====================== RESTART: F:/qatXorPytorch250501.py
--- 开始标准模型训练 ---
Epoch [300/900], Loss: 0.0033
Epoch [600/900], Loss: 0.0011
Epoch [900/900], Loss: 0.0005
标准模型训练后精度: 100.00%
标准模型预测结果:
tensor([[0.],
[1.],
[1.],
[0.]])
--- QAT训练 ---
QAT Epoch [150/700], Loss: 0.0005
QAT Epoch [300/700], Loss: 0.0004
QAT Epoch [450/700], Loss: 0.0004
QAT Epoch [600/700], Loss: 0.0003
--- 转换为量化模型 ---
量化模型精度: 100.00%
量化模型预测:
tensor([[0.],
[1.],
[1.],
[0.]])
FP32模型大小: 0.001976 MB
INT8模型大小: 0.004759 MB
模型缩减比例: 0.42 倍
最后:
其实,这次量化
量化后的模型是量化前的 4.2倍(咦?不是说好了压缩吗?咋变大了?)
魔鬼藏在细节:
咱们看看 量化 之前的 (基线的)模型 参数+权重等等:
===== Model Architecture =====
XORNet(
(fc1): Linear(in_features=2, out_features=3, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=3, out_features=1, bias=True)
)
===== Layer Parameters =====
[fc1.weight] shape: (3, 2)
[[ 1.723932, 1.551827],
[ 2.106917, 1.681809],
[-0.299378, -0.444912]]
[fc1.bias] shape: (3,)
[-1.725313, -2.509506, 0. ]
[fc2.weight] shape: (1, 3)
[[-2.492318, -3.94821 , 0.911841]]
[fc2.bias] shape: (1,)
[0.692789]
===== Extra Info (Hyperparameters) =====
Optimizer: Adam
Learning Rate: 0.05
Epochs: 900
Loss: BCEWithLogitsLoss
Activation: ReLU
量化之后的模型参数等:
超参数部分:
===== Model Architecture =====
XORNetQAT(
(quant): Quantize(scale=tensor([0.0079]), zero_point=tensor([0]), dtype=torch.quint8)
(fc1): QuantizedLinearReLU(in_features=2, out_features=3, scale=0.0678500160574913, zero_point=0, qscheme=torch.per_channel_affine)
(relu): Identity()
(fc2): QuantizedLinear(in_features=3, out_features=1, scale=0.1376650333404541, zero_point=65, qscheme=torch.per_channel_affine)
(dequant): DeQuantize()
)
===== Layer Parameters =====
===== Extra Info (Hyperparameters) =====
Optimizer: Adam
Learning Rate: 0.01
QAT Epochs: 700
Loss: BCEWithLogitsLoss
QConfig: QConfig(activation=functools.partial(<class 'torch.ao.quantization.fake_quantize.FusedMovingAvgObsFakeQuantize'>, observer=<class 'torch.ao.quantization.observer.MovingAverageMinMaxObserver'>, quant_min=0, quant_max=255, reduce_range=True){'factory_kwargs': <function _add_module_to_qconfig_obs_ctr.<locals>.get_factory_kwargs_based_on_module_device at 0x00000164FDB16160>}, weight=functools.partial(<class 'torch.ao.quantization.fake_quantize.FusedMovingAvgObsFakeQuantize'>, observer=<class 'torch.ao.quantization.observer.MovingAveragePerChannelMinMaxObserver'>, quant_min=-128, quant_max=127, dtype=torch.qint8, qscheme=torch.per_channel_symmetric){'factory_kwargs': <function _add_module_to_qconfig_obs_ctr.<locals>.get_factory_kwargs_based_on_module_device at 0x00000164FDB16160>})
看到吗?
量化后, 参数 变多了哈哈!
那量化的意义到底在哪里呢??
在下面的 参数(非超参)的 权重的部分:
===== 量化 (Quantization) 后参数 =====
[fc1] (QuantizedLinearReLU)
[weight] shape: torch.Size([3, 2]), dtype: torch.qint8
weight (quantized):
[[ 3.97 3.98]
[ 3.95 3.96]
[-0.56 -1.05]]
weight (raw int):
[[127 127]
[127 127]
[-18 -33]]
scale: 0.06785
zero_point: 0
[bias] shape: torch.Size([3]), dtype: torch.float
bias:
[-3.049073e-04 -3.960315e+00 0.000000e+00]
[fc2] (QuantizedLinear)
[weight] shape: torch.Size([1, 3]), dtype: torch.qint8
weight (quantized):
[[ 3.77 -7.79 0.41]]
weight (raw int):
[[ 27 -57 3]]
scale: 0.13766
zero_point: 65
[bias] shape: torch.Size([1]), dtype: torch.float
bias:
[-7.147094]
再看看量化前:
===== Layer Parameters =====
[fc1.weight] shape: (3, 2)
[[ 1.723932, 1.551827],
[ 2.106917, 1.681809],
[-0.299378, -0.444912]]
[fc1.bias] shape: (3,)
[-1.725313, -2.509506, 0. ]
[fc2.weight] shape: (1, 3)
[[-2.492318, -3.94821 , 0.911841]]
[fc2.bias] shape: (1,)
[0.692789]
最后看看 量化 后:
===== 量化 (Quantization) 后参数 =====
[fc1] (QuantizedLinearReLU)
[weight] shape: torch.Size([3, 2]), dtype: torch.qint8
weight (quantized):
[[ 3.97 3.98]
[ 3.95 3.96]
[-0.56 -1.05]]
weight (raw int):
[[127 127]
[127 127]
[-18 -33]]
scale: 0.06785
zero_point: 0
[bias] shape: torch.Size([3]), dtype: torch.float
bias:
看出区别了吗?
So:
量化操作 只 适用于 大、中型号的模型……道理就在此:
量化前 的 Weights 的权重 全部都是: Float32浮点型 ……很占内存的!
量化后 是所谓INT8(即一个字节、8bits)……至少(在权重部分)节省了 3/4 的内存!
So: 大模型 必须 要 量化 才 节省内存。
当然前提 是 你的 GPU 硬件 要 支持 INT8(8bits)的 运算哦……(这是后话,下次再聊)。
(over)完!
相关文章:
的XOR异或pyTorch版250501)
量化Quantization初步之--带量化(QAT)的XOR异或pyTorch版250501
量化(Quantization)这词儿听着玄,经常和量化交易Quantitative Trading (量化交易)混淆。 其实机器学习(深度学习)领域的量化Quantization是和节约内存、提高运算效率相关的概念(因大模型的普及,这个量化问题尤为迫切)。 揭秘机器…...

Linux Maven Install
在 CentOS(例如 CentOS 7 或 CentOS 8)中安装 Maven(Apache Maven)的方法主要有两种:使用包管理器(简单但可能版本较旧),或者手动安装(推荐,可获得最新版&…...

#Java篇:学习node后端之sql常用操作
学习路线 1、javascript基础; 2、nodejs核心模块 fs: 文件系统操作 path: 路径处理 http / https: 创建服务器或发起请求 events: 事件机制(EventEmitter) stream: 流式数据处理 buffer: 处理二进制数据 os: 获取操作系统信息 util: 工具方…...
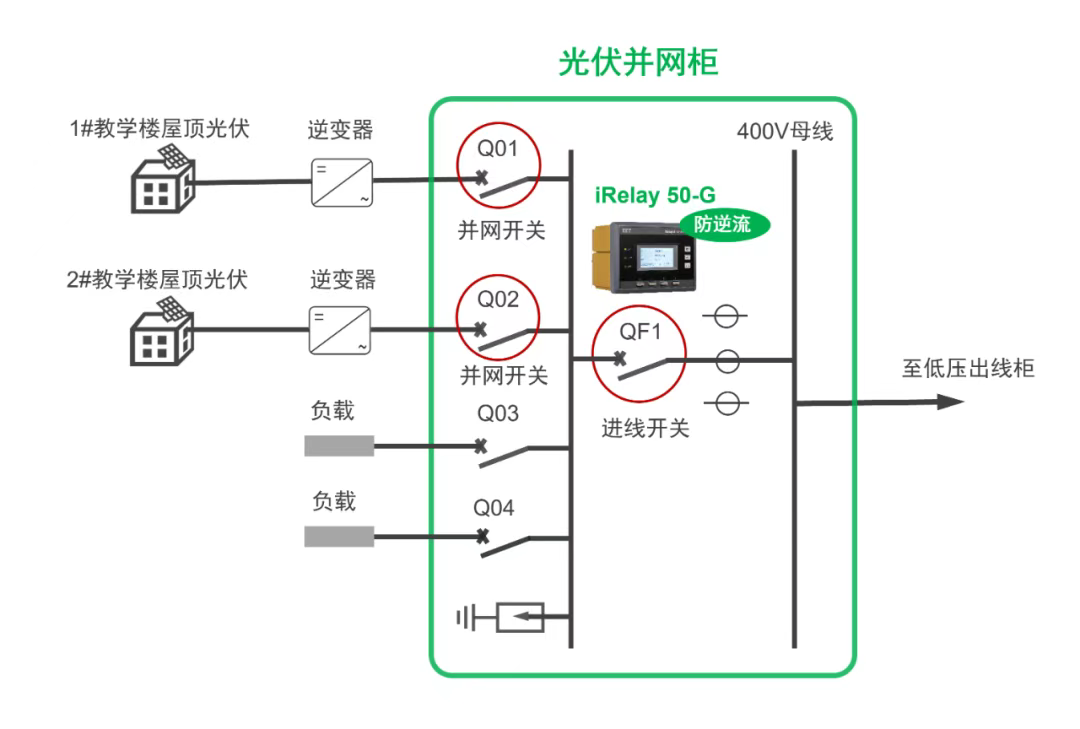
电网“逆流”怎么办?如何实现分布式光伏发电全部自发自用?
2024年10月9日,国家能源局综合司发布了《分布式光伏发电开发建设管理办法(征求意见稿)》,意见稿规定了户用分布式光伏、一般工商业分布式光伏以及大型工商业分布式光伏的发电上网模式,当选择全部自发自用模式时&#x…...
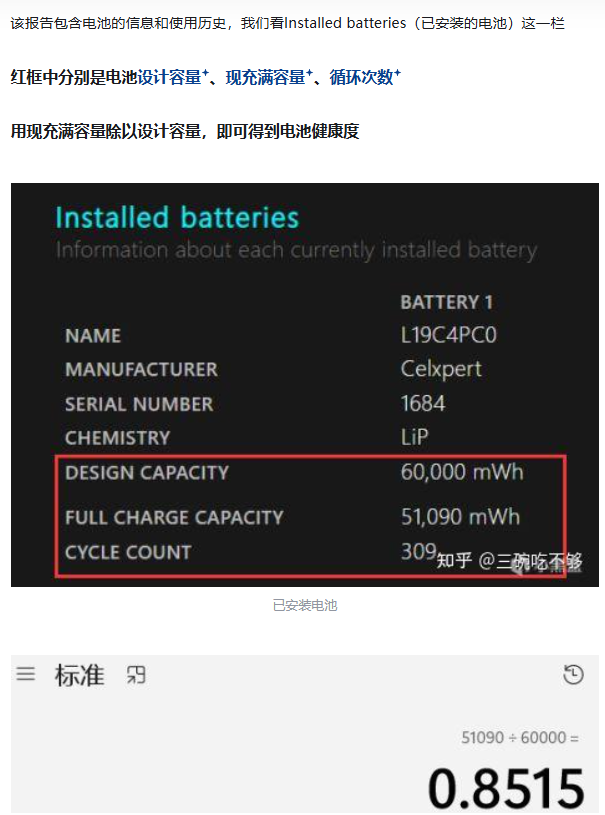
如何查看电脑电池性能
检查电脑电池性能的方法如下: 按下winR键,输入cmd回车,进入命令行窗口 在命令行窗口输入powercfg /batteryreport 桌面双击此电脑,把刚刚复制的路径粘贴到文件路径栏,然后回车 回车后会自动用浏览器打开该报告 红…...
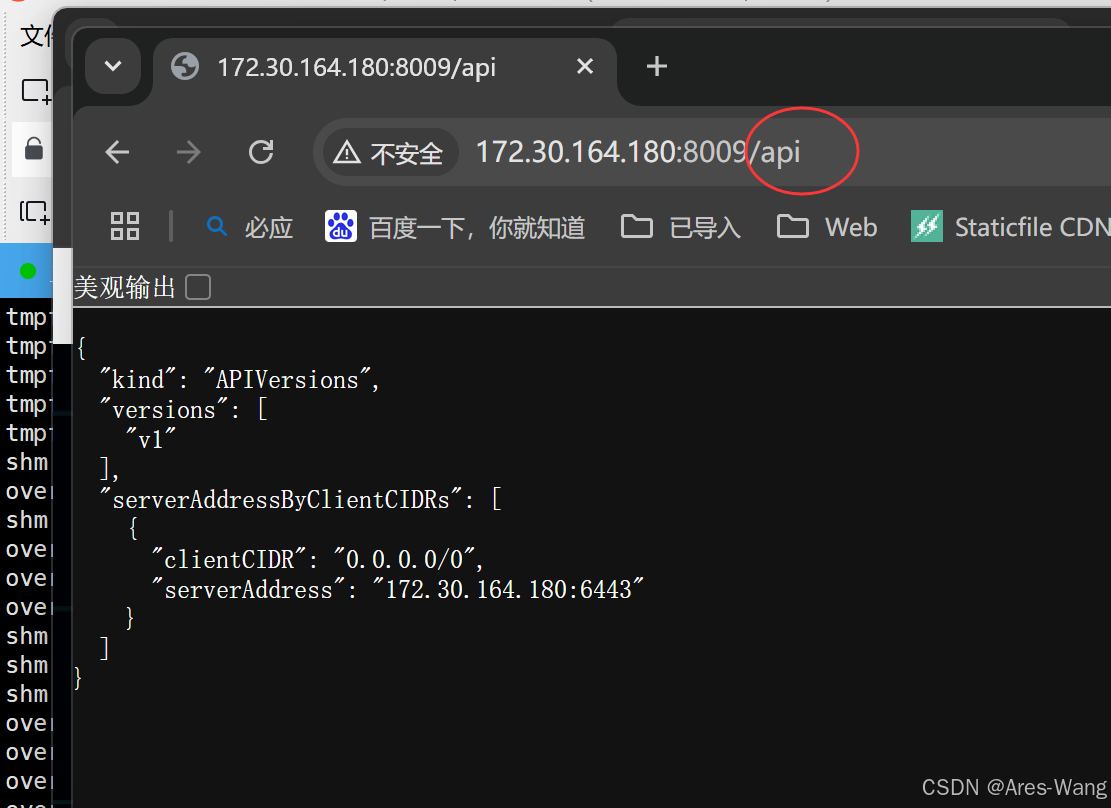
kubernetes》》k8s》》kubectl proxy 命令后面加一个
命令后面加一个& 在Linux终端中,如果在命令的末尾加上一个&符号,这表示将这个任务放到后台去执行 kubectl proxy 官网资料 是 Kubernetes 提供的一个命令行工具,用于在本地和 Kubernetes API Server 之间创建一个安全的代理通道。…...

深入理解Linux系统进程切换
目录 引言 一、什么是进程切换? 二、进程切换的触发条件 三、进程切换的详细步骤 1、保存当前进程上下文: 2、更新进程控制块(PCB): 3、选择下一个进程: 4、恢复新进程上下文: 5、切换地址空间: 6…...

网络安全运维实训室建设方案
一、网络安全运维人才需求与实训困境 在数字化时代,网络安全已成为国家安全、社会稳定和经济发展的重要基石。随着信息技术的飞速发展,网络安全威胁日益复杂多样,从个人隐私泄露到企业商业机密被盗,从关键基础设施遭受攻击到社会…...
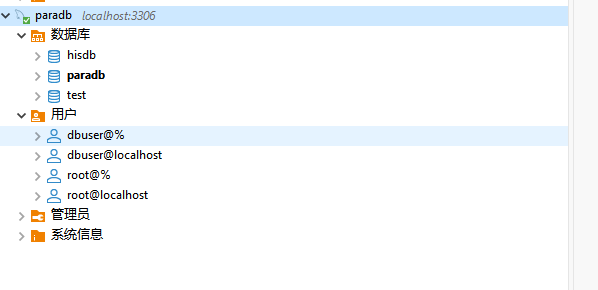
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required 一、必须要看这个 >> :参考文献 二、补充 2.1 说明 MySQL5、6这些版本比较老,而DBeaver默认下载的是MySQL8的连接库,所以连接旧版本mysql报错:CLIEN…...

联通专线赋能,亿林网络裸金属服务器:中小企业 IT 架构升级优选方案
在当今数字化飞速发展的时代,中小企业面临着日益增长的业务需求与复杂多变的市场竞争环境。如何构建高效、稳定且具性价比的 IT 架构,成为众多企业突破发展瓶颈的关键所在。而亿林网络推出的 24 核 32G 裸金属服务器,搭配联通专线的千兆共享带…...

Web3时代的数据保护挑战与应对策略
随着互联网技术的飞速发展,我们正步入Web3时代,这是一个以去中心化、用户主权和数据隐私为核心的新时代。然而,Web3时代也带来了前所未有的数据保护挑战。本文将探讨这些挑战,并提出相应的应对策略。 数据隐私挑战 在Web3时代&a…...

Qwen3与MCP协议:重塑大气科学的智能研究范式
在气象研究领域,从海量数据的解析到复杂气候模型的构建,科研人员长期面临效率低、门槛高、易出错的挑战。而阿里云推出的Qwen3大模型与MCP协议的结合,正通过混合推理模式与标准化协同机制,为大气科学注入全新活力。本文将深入解析…...

CppCon 2015 学习:Benchmarking C++ Code
关于性能问题与调试传统 bug(如段错误)之间差异的分析。以下是对这一页内容的详细解释: 主题:传统问题(如段错误)调试流程清晰 问题类型:段错误(Segmentation Fault) …...
的认识)
URL 结构说明+路由(接口)的认识
一、URL 结构说明 以这个为例:http://127.0.0.1:5000/zhouleifeng 1.组成部分: http://:协议 127.0.0.1:主机(本地地址) :5000:端口号(Flask 默认 5000) /zhouleifeng:…...

省赛中药检测模型调优
目录 一、baseline性能二、baseline DETR head三、baseline RepC3K2四、baseline RepC3K2 SimSPPF五、baseline RepC3K2 SimSPPF LK-C2PSA界面1.引入库2.读入数据 总结 一、baseline性能 Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size120/120 …...
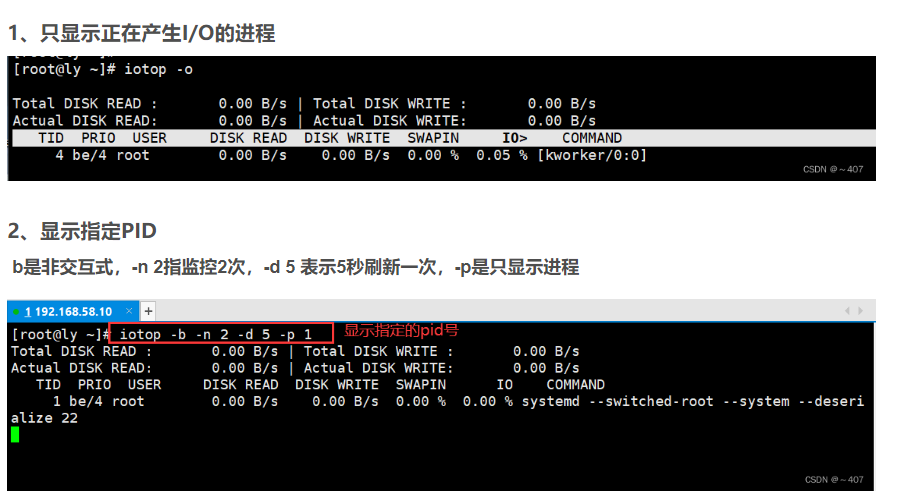
linux 故障处置通用流程-36计+1计
通用标准处置快速索引 编号 通 用 标 准 处 置 索 引 001 Linux操作系统标准关闭 002 Linux操作系统标准重启 003 Linux操作系统强行关闭 004 Linux操作系统强行重启 005 检查Linux操作系统CPU负载 006 查询占用CPU资源最多的进程 007 检查Linux操…...
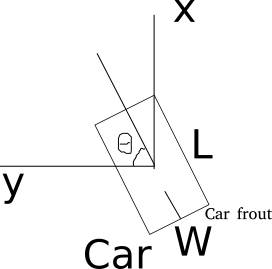
BEV和OCC学习-3:mmdet3d 坐标系
目录 坐标系 转向角 (yaw) 的定义 框尺寸的定义 与支持的数据集的原始坐标系的关系 KITTI Waymo NuScenes Lyft ScanNet SUN RGB-D S3DIS 坐标系 坐标系 — MMDetection3D 1.4.0 文档https://mmdetection3d.readthedocs.io/zh-cn/latest/user_guides/coord_sys_tuto…...
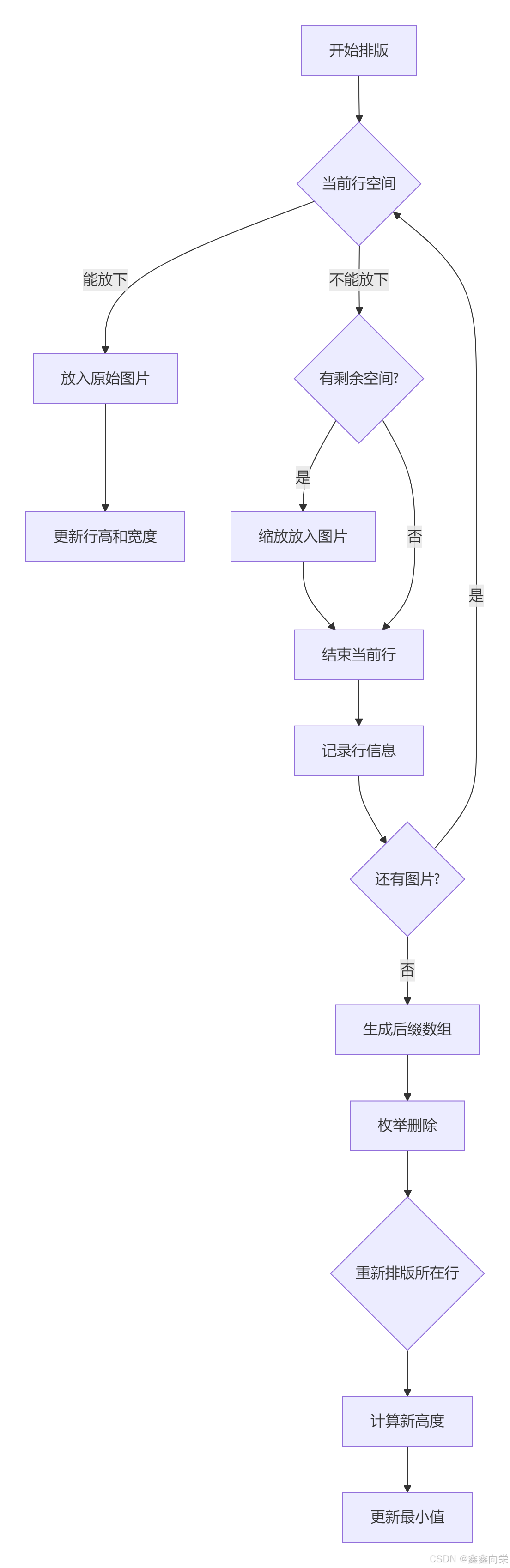
[蓝桥杯]图形排版
图形排版 题目描述 小明需要在一篇文档中加入 NN 张图片,其中第 ii 张图片的宽度是 WiWi,高度是 HiHi。 假设纸张的宽度是 MM,小明使用的文档编辑工具会用以下方式对图片进行自动排版: 1. 该工具会按照图片顺序࿰…...

【Linux仓库】冯诺依曼体系结构与操作系统【进程·壹】
🌟 各位看官好,我是! 🌍 Linux Linux is not Unix ! 🚀 今天来学习冯诺依曼体系结构与操作系统。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦࿰…...
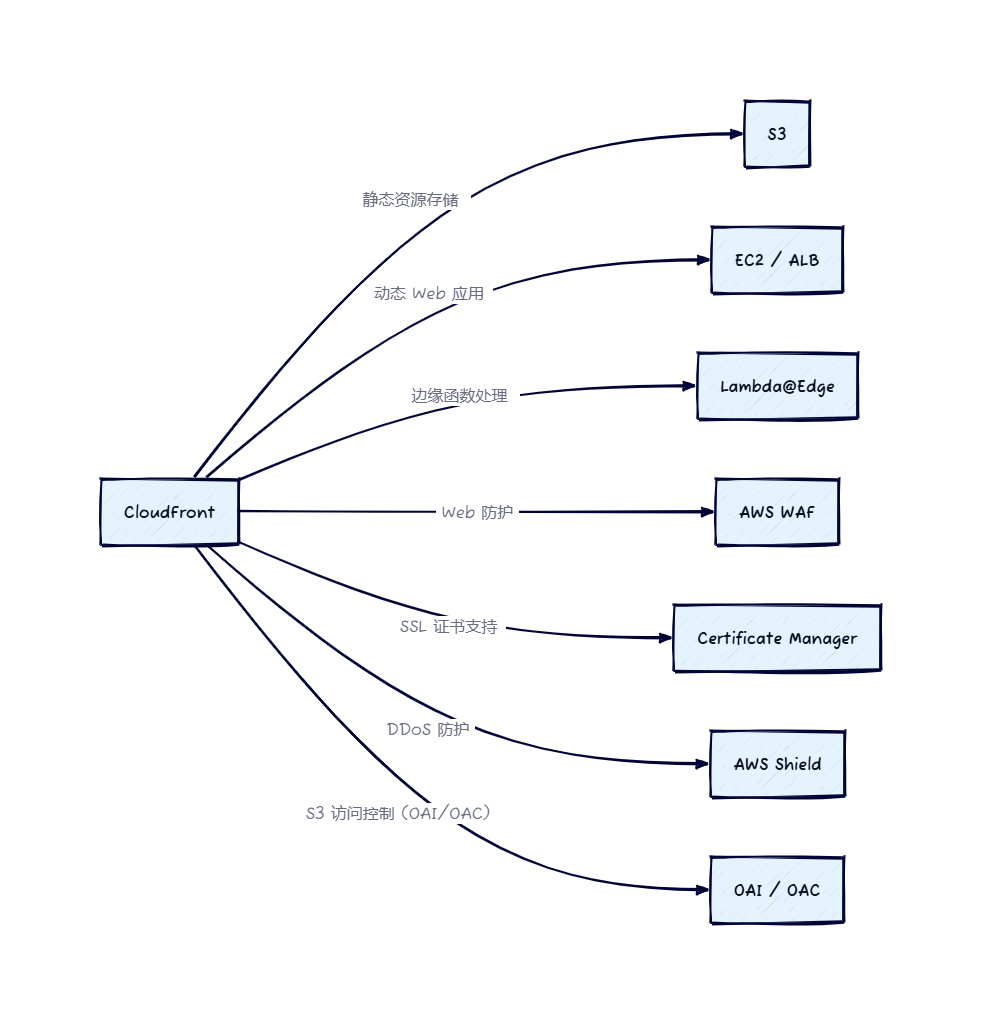
CloudFront 加速详解:AWS CDN 怎么用?
让全球访问更快速稳定,深入解读 AWS 的内容分发网络 在上一篇中,我们介绍了 Amazon S3 对象存储,它非常适合托管静态资源,比如图片、视频、网页等。但你可能遇到过这样的问题: “我把网站静态文件部署到了 S3…...

《高级架构师》------- 考后感想
笔者来聊一下架构师考后的感想 复习备考 考前过了很多知识点,只是蜻蜓点水,没有起到复习的作用,即使考出来也不会,下次复习注意这个,复习到了,就记住,或者画出来,或者文件总结&…...
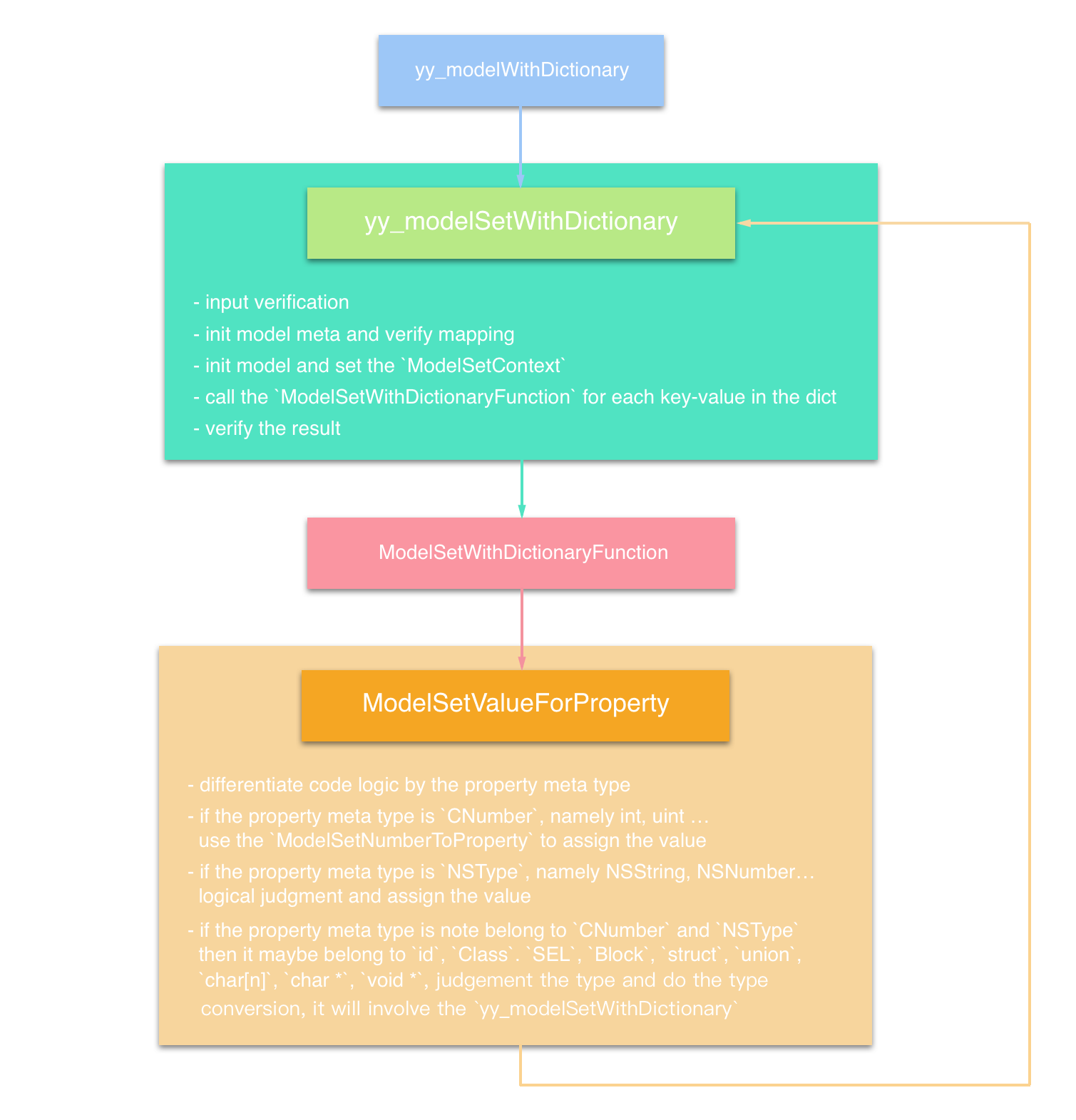
【iOS】YYModel源码解析
YYModel源码解析 文章目录 YYModel源码解析前言YYModel性能优势YYModel简介YYClassInfo解析YYClassIvarInfo && objc_ivarYYClassMethodInfo && objc_methodYYClassPropertyInfo && property_tYYClassInfo && objc_class YYClassInfo的初始化细…...

C++算法训练营 Day6 哈希表(1)
1.有效的字母异位词 LeetCode:242.有效的字母异位词 给定两个字符串s和t ,编写一个函数来判断t是否是s的字母异位词。 示例 1: 输入: s “anagram”, t “nagaram” 输出: true 示例 2: 输入: s “rat”, t “car” 输出: false 解题思路ÿ…...
【C语言编译与链接】--翻译环境和运行环境,预处理,编译,汇编,链接
目录 一.翻译环境和运行环境 二.翻译环境 2.1--预处理(预编译) 2.2--编译 2.2.1--词法分析 2.2.2--语法分析 2.2.3--语义分析 2.3--汇编 2.4--链接 三.运行环境 🔥个人主页:草莓熊Lotso的个人主页 🎬作者简介:C研发…...
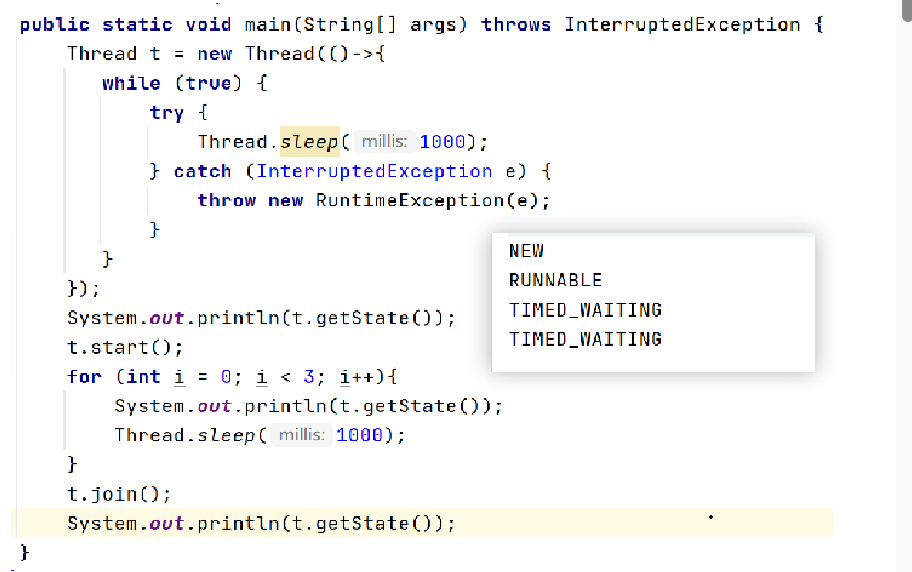
【JavaEE】多线程
8.线程状态 根据 Java 的Thread.state包,线程一共有六种状态: NEWRUNNABLEBLOCKEDWAITINGTIMED_WAITINGTERMINATED 二、每种状态的含义 1. NEW(新建) 当使用new 关键字创建一个线程对象,但尚未调用其start() 方法时…...
【项目】在线OJ(负载均衡式)
目录 一、项目目标 二、开发环境 1.技术栈 2.开发环境 三、项目树 目录结构 功能逻辑 编写思路 四、编码 1.complie_server 服务功能 代码蓝图 开发编译功能 日志功能 编辑 测试编译模块 开发运行功能 设置运行限制 jsoncpp 编写CR 如何生成唯一文件名 …...

贪心算法应用:在线租赁问题详解
贪心算法应用:在线租赁问题详解 贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而希望导致结果是全局最优的算法策略。在线租赁问题(Greedy Algorithm for Online Rentals)是一个经典的贪心算法应用场景,下面我将从多个维度全面…...
用法简介)
torch.zeros()用法简介
torch.zeros()是PyTorch中用于创建全零张量的核心函数,其功能和使用方法如下: 1. 基本语法 torch.zeros(*size, outNone, dtypeNone, layouttorch.strided, deviceNone, requires_gradFalse)参数说明: *size:定义张量形状的…...
Prj10--8088单板机C语言8259测试(1)
1.原理图 2.Deepseek示例代码 #include <dos.h> #include <conio.h> #include <stdio.h>#define PIC1_CMD 0x400 // 命令端口 (A00) #define PIC1_DATA 0x401 // 数据端口 (A01)volatile int int_count 0; // 中断计数器 void interrupt (*old_isr)(…...

3步在小米13手机跑DeepSeek R1
大家好!我是羊仔,专注AI工具、智能体、编程。 一、从性能旗舰到AI主机 春节大扫除时,翻出尘封的小米13,这台曾以骁龙8 Gen2著称的性能小钢炮,如今正在执行更科幻的使命——本地运行DeepSeek R1。 想起两年前用它连续肝…...