60天python训练计划----day44
DAY 44 预训练模型
知识点回顾:
- 预训练的概念
- 常见的分类预训练模型
- 图像预训练模型的发展史
- 预训练的策略
- 预训练代码实战:resnet18
一、预训练的概念
我们之前在训练中发现,准确率最开始随着epoch的增加而增加。随着循环的更新,参数在不断发生更新。
所以参数的初始值对训练结果有很大的影响:
1. 如果最开始的初始值比较好,后续训练轮数就会少很多
2. 很有可能陷入局部最优值,不同的初始值可能导致陷入不同的局部最优值
所以很自然的想到,如果最开始能有比较好的参数,即可能导致未来训练次数少,也可能导致未来训练避免陷入局部最优解的问题。这就引入了一个概念,即预训练模型。如果别人在某些和我们目标数据类似的大规模数据集上做过训练,我们可以用他的训练参数来初始化我们的模型,这样我们的模型就比较容易收敛。
为了帮助你们理解,这里提出几个自问自答的问题。
1. 那为什么要选择类似任务的数据集预训练的模型参数呢?
因为任务差不多,他提取特征的能力才有用,如果任务相差太大,他的特征提取能力就没那么好。所以本质预训练就是拿别人已经具备的通用特征提取能力来接着强化能力使之更加适应我们的数据集和任务。
2. 为什么要求预训练模型是在大规模数据集上训练的,小规模不行么?
因为提取的是通用特征,所以如果数据集数据少、尺寸小,就很难支撑复杂任务学习通用的数据特征。比如你是一个物理的博士,让你去做小学数学题,很快就能上手;但是你是一个小学数学速算高手,让你做物理博士的课题,就很困难。所以预训练模型一般就挺强的。
我们把用预训练模型的参数,然后接着在自己数据集上训练来调整该参数的过程叫做微调,这种思想叫做迁移学习。把预训练的过程叫做上游任务,把微调的过程叫做下游任务。
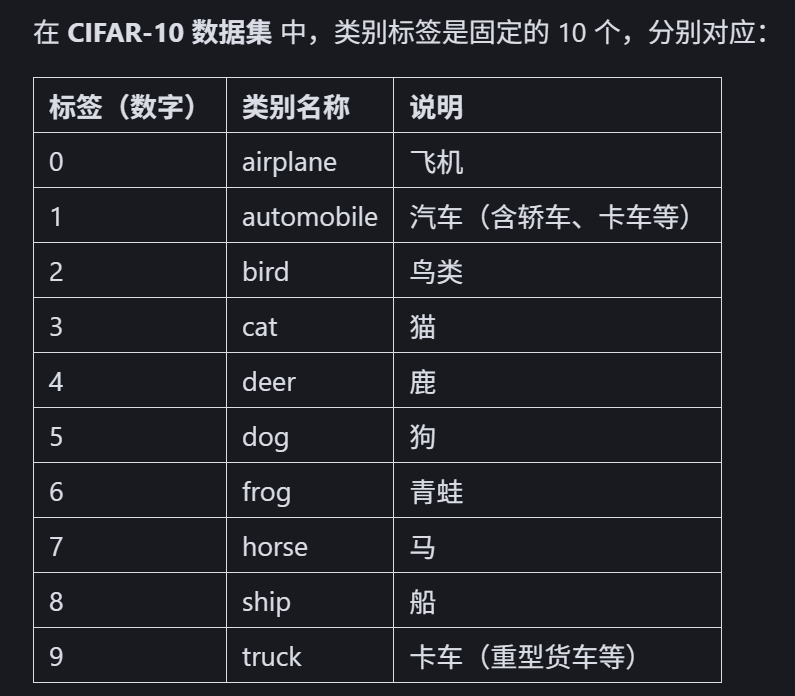
现在再来看下之前一直用的cifar10数据集,他是不是就很明显不适合作为预训练数据集?
1. 规模过小:仅 10 万张图像,且尺寸小(32x32),无法支撑复杂模型学习通用视觉特征;
2. 类别单一:仅 10 类(飞机、汽车等),泛化能力有限;
二、 经典的预训练模型
2.1 CNN架构预训练模型

2.2 Transformer类预训练模型

2.3 自监督预训练模型

三、常见的分类预训练模型介绍
3.1 预训练模型的发展史
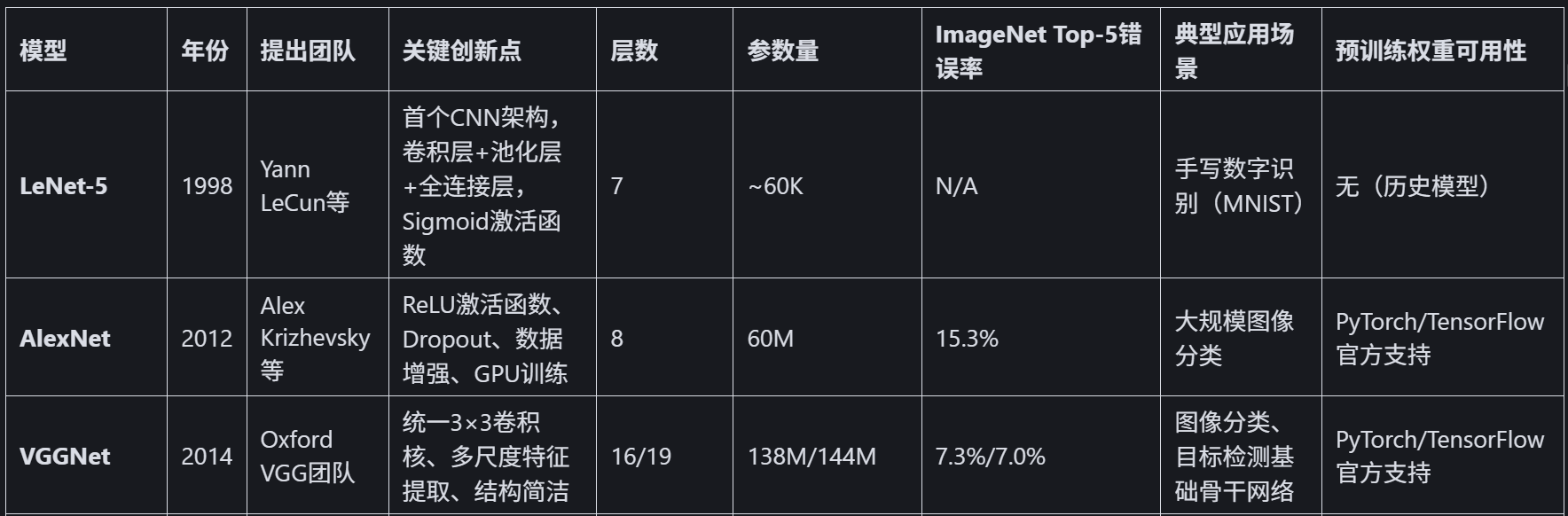


上图的层数,代表该模型不同的版本resnet有resnet18、resnet50、resnet152;efficientnet有efficientnet-b0、efficientnet-b1、efficientnet-b2、efficientnet-b3、efficientnet-b4等
其中ImageNet Top - 5 准确率是图像分类任务里的一种评估指标 ,用于衡量模型在 ImageNet 数据集上的分类性能,模型对图像进行分类预测,输出所有类别(共 1000 类 )的概率,取概率排名前五的类别,只要这五个类别里包含人工标注的正确类别,就算预测正确。
模型架构演进关键点总结
1. 深度突破:从LeNet的7层到ResNet152的152层,残差连接解决了深度网络的训练难题。 ----没上过我复试班cv部分的自行去了解下什么叫做残差连接,很重要!
2. 计算效率:GoogLeNet(Inception)和MobileNet通过结构优化,在保持精度的同时大幅降低参数量。
3.特征复用:DenseNet的密集连接设计使模型能更好地利用浅层特征,适合小数据集。
4. 自动化设计:EfficientNet使用神经架构搜索(NAS)自动寻找最优网络配置,开创了AutoML在CNN中的应用。
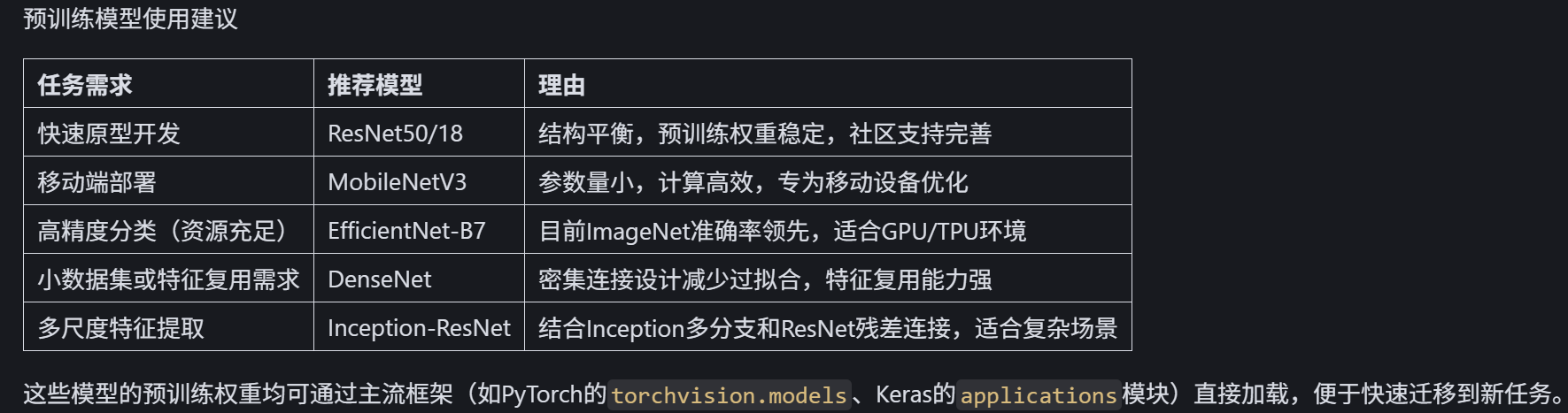
总结:CNN 架构发展脉络
1. 早期探索(1990s-2010s):LeNet 验证 CNN 可行性,但受限于计算和数据。
2. 深度学习复兴(2012-2015):AlexNet、VGGNet、GoogLeNet 通过加深网络和结构创新突破性能。
3. 超深网络时代(2015 年后):ResNet 解决退化问题,开启残差连接范式,后续模型围绕效率(MobileNet)、特征复用(DenseNet)、多分支结构(Inception)等方向优化。
3.2 预训练模型的训练策略
那么什么模型会被选为预训练模型呢?比如一些调参后表现很好的cnn神经网络(固定的神经元个数+固定的层数等)。
所以调用预训练模型做微调,本质就是 用这些固定的结构+之前训练好的参数 接着训练
所以需要找到预训练的模型结构并且加载模型参数
相较于之前用自己定义的模型有以下几个注意点:
1. 需要调用预训练模型和加载权重
2. 需要resize 图片让其可以适配模型
3. 需要修改最后的全连接层以适应数据集
其中,训练过程中,为了不破坏最开始的特征提取器的参数,最开始往往先冻结住特征提取器的参数,然后训练全连接层,大约在5-10个epoch后解冻训练。
主要做特征提取的部分叫做backbone骨干网络;负责融合提取的特征的部分叫做Featue Pyramid Network(FPN);负责输出的预测部分的叫做Head。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器(可调整batch_size)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 训练函数(支持学习率调度器)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []for epoch in range(epochs):running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 5. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('训练过程中的Iteration损失变化')plt.grid(True)plt.show()# 6. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('准确率随Epoch变化')plt.legend()plt.grid(True)# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('损失值随Epoch变化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()
# 导入ResNet模型
from torchvision.models import resnet18# 定义ResNet18模型(支持预训练权重加载)
def create_resnet18(pretrained=True, num_classes=10):# 加载预训练模型(ImageNet权重)model = resnet18(pretrained=pretrained)# 修改最后一层全连接层,适配CIFAR-10的10分类任务in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)# 将模型转移到指定设备(CPU/GPU)model = model.to(device)return model
# 创建ResNet18模型(加载ImageNet预训练权重,不进行微调)
model = create_resnet18(pretrained=True, num_classes=10)
model.eval() # 设置为推理模式# 测试单张图片(示例)
from torchvision import utils# 从测试数据集中获取一张图片
dataiter = iter(test_loader)
images, labels = dataiter.next()
images = images[:1].to(device) # 取第1张图片# 前向传播
with torch.no_grad():outputs = model(images)_, predicted = torch.max(outputs.data, 1)# 显示图片和预测结果
plt.imshow(utils.make_grid(images.cpu(), normalize=True).permute(1, 2, 0))
plt.title(f"预测类别: {predicted.item()}")
plt.axis('off')
plt.show()
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义ResNet18模型
def create_resnet18(pretrained=True, num_classes=10):model = models.resnet18(pretrained=pretrained)# 修改最后一层全连接层in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)return model.to(device)# 5. 冻结/解冻模型层的函数
def freeze_model(model, freeze=True):"""冻结或解冻模型的卷积层参数"""# 冻结/解冻除fc层外的所有参数for name, param in model.named_parameters():if 'fc' not in name:param.requires_grad = not freeze# 打印冻结状态frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)total_params = sum(p.numel() for p in model.parameters())if freeze:print(f"已冻结模型卷积层参数 ({frozen_params}/{total_params} 参数)")else:print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")return model# 6. 训练函数(支持阶段式训练)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []# 初始冻结卷积层if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解冻控制:在指定轮次后解冻所有层if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解冻后调整优化器(可选)optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合model.train() # 设置为训练模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 7. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('训练过程中的Iteration损失变化')plt.grid(True)plt.show()# 8. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('准确率随Epoch变化')plt.legend()plt.grid(True)# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('损失值随Epoch变化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 主函数:训练模型
def main():# 参数设置epochs = 40 # 总训练轮次freeze_epochs = 5 # 冻结卷积层的轮次learning_rate = 1e-3 # 初始学习率weight_decay = 1e-4 # 权重衰减# 创建ResNet18模型(加载预训练权重)model = create_resnet18(pretrained=True, num_classes=10)# 定义优化器和损失函数optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)criterion = nn.CrossEntropyLoss()# 定义学习率调度器scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)# 开始训练(前5轮冻结卷积层,之后解冻)final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')# print("模型已保存至: resnet18_cifar10_finetuned.pth")if __name__ == "__main__":main() 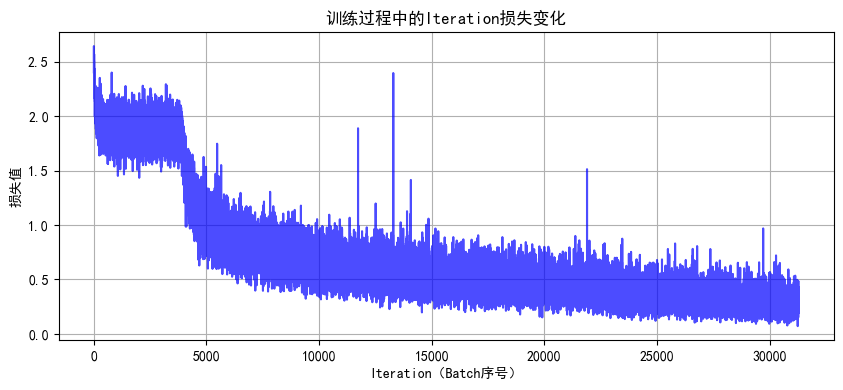
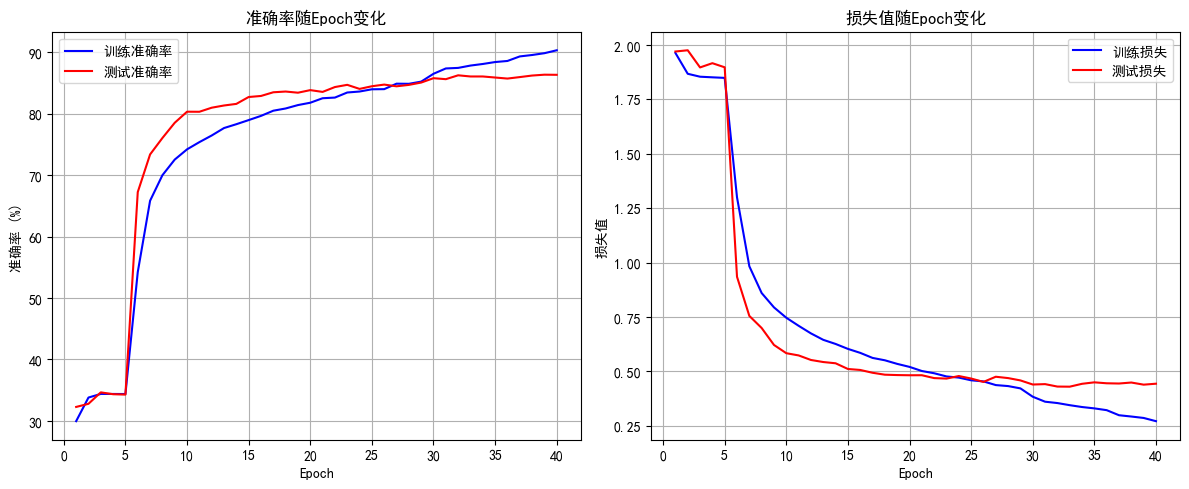
几个明显的现象
1. 解冻后几个epoch即可达到之前cnn训练20轮的效果,这是预训练的优势
2. 由于训练集用了 RandomCrop(随机裁剪)、RandomHorizontalFlip(随机水平翻转)、ColorJitter(颜色抖动)等数据增强操作,这会让训练时模型看到的图片有更多 “干扰” 或变形。比如一张汽车图片,训练时可能被裁剪成只显示局部、颜色也有变化,模型学习难度更高;而测试集是标准的、没增强的图片,模型预测相对轻松,就可能出现训练集准确率暂时低于测试集的情况,尤其在训练前期增强对模型影响更明显。随着训练推进,模型适应增强后会缓解。
3. 最后收敛后的效果超过非预训练模型的80%,大幅提升
@浙大疏锦行
相关文章:
60天python训练计划----day44
DAY 44 预训练模型 知识点回顾: 预训练的概念常见的分类预训练模型图像预训练模型的发展史预训练的策略预训练代码实战:resnet18 一、预训练的概念 我们之前在训练中发现,准确率最开始随着epoch的增加而增加。随着循环的更新,参数…...
【JAVA版】意象CRM客户关系管理系统+uniapp全开源
一.介绍 CRM意象客户关系管理系统,是一个综合性的客户管理平台,旨在帮助企业高效地管理客户信息、商机、合同以及员工业绩。系统通过首页、系统管理、工作流程、审批中心、线索管理、客户管理、商机管理、合同管理、CRM系统、数据统计和系统配置等模块&…...
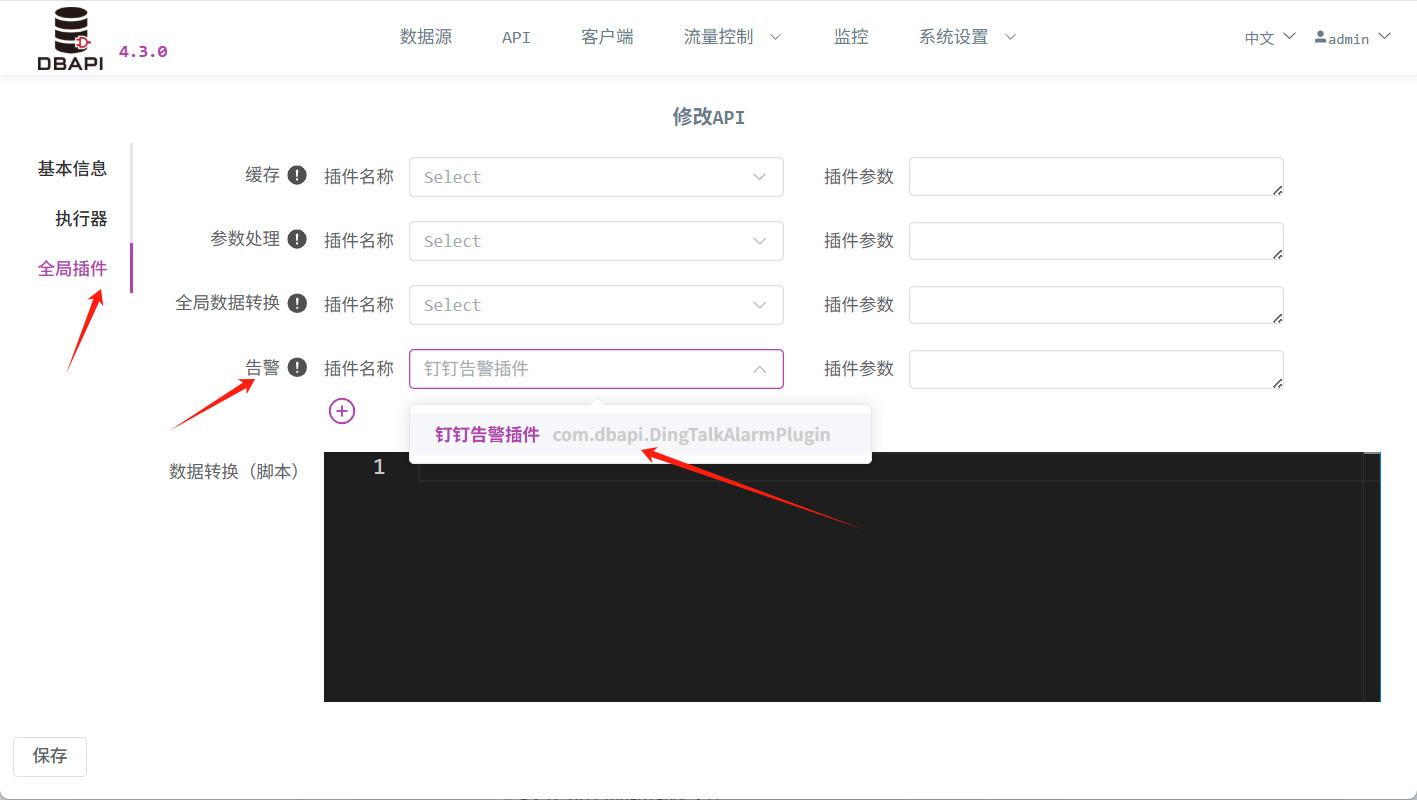
API异常信息如何实时发送到钉钉
#背景 对于一些重要的API,开发人员会非常关注API有没有报错,为了方便开发人员第一时间获取错误信息,我们可以使用插件来将API报错实时发送到钉钉群。 接下来我们就来实操如何实现 #准备工作 #创建钉钉群 如果已有钉钉群,可以跳…...
Python爬虫(48)基于Scrapy-Redis与深度强化学习的智能分布式爬虫架构设计与实践
目录 一、背景与行业痛点二、核心技术架构设计2.1 分布式爬虫基础架构2.2 深度强化学习模块 三、生产环境实践案例3.1 电商价格监控系统3.2 学术文献采集系统 四、高级优化技术4.1 联邦学习增强4.2 神经架构搜索(NAS) 五、总结🌈Python爬虫相…...

AtCoder Beginner Contest 407 E - Most Valuable Parentheses
AtCoder Beginner Contest 407 E - Most Valuable Parentheses E - Most Valuable Parentheses 反悔贪心算法 性质: 假设长度为 n n n, n ≡ 0 ( m o d 2 ) n \equiv 0 \pmod{2} n≡0(mod2) 的括号序列是合法的,那么有 n 2 \frac{n}{2}…...

(1-6-3)Java 多线程
目录 0.知识拓扑 1. 多线程相关概念 1.1 进程 1.2 线程 1.3 java 中的进程 与 线程概述 1.4 CPU、进程 与 线程的关系 2.多线程的创建方式 2.1 继承Thread类 2.2 实现Runnable接口 2.3 实现Callable接口 2.4 三种创建方式对比 3.线程同步 3.1 线程同步机制概述 …...

java31
1.网络编程 三要素: 网址实质上就是ip InetAddress: UDP通信程序: 多个接收端的地址都要加入同一个组播地址,这样发送端发信息,全部接收端都能接受到数据 广播的代码差不多,就是地址不一样而已 TCP通信程序…...

多模态之智能数字人
多模态下智能数字人的开发是一个复杂且系统性的工程,它融合了人工智能(AI)、计算机图形学、自然语言处理(NLP)、语音技术、计算机视觉(CV)等多个前沿领域。 多模态下智能数字人的开发流程规范 目标: 构建一个能够理解并生成多模态信息(文本、语音、视觉等),具备智…...
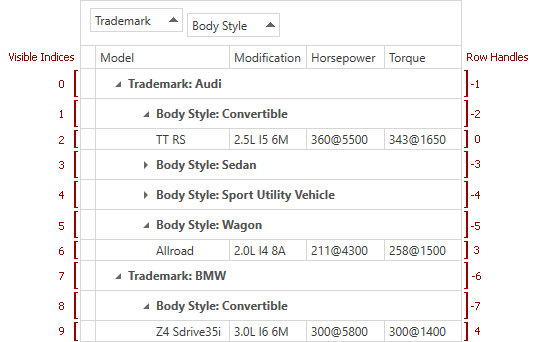
界面组件DevExpress WPF中文教程:Grid - 如何识别行和卡片?
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...
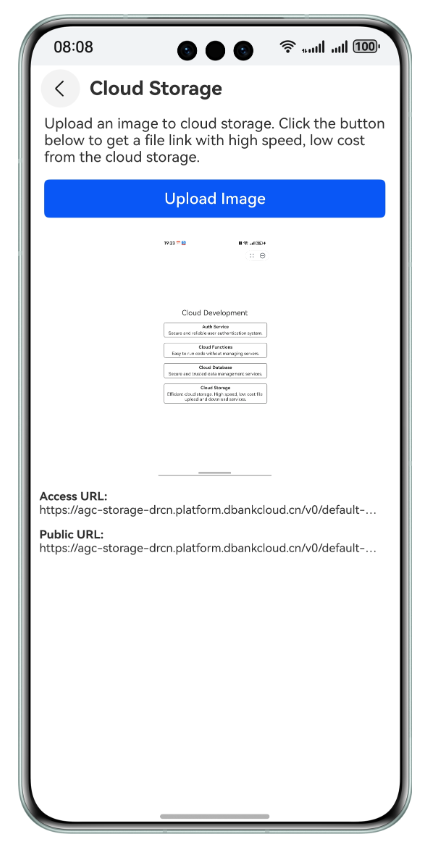
【HarmonyOS Next之旅】DevEco Studio使用指南(三十)
目录 1 -> 部署云侧工程 2 -> 通过CloudDev面板获取云开发资源支持 3 -> 通用云开发模板 3.1 -> 适用范围 3.2 -> 效果图 4 -> 总结 1 -> 部署云侧工程 可以选择在云函数和云数据库全部开发完成后,将整个云工程资源统一部署到AGC云端。…...
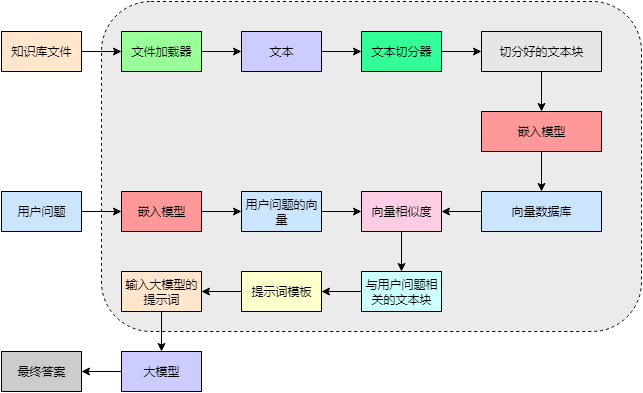
AI基础知识(LLM、prompt、rag、embedding、rerank、mcp、agent、多模态)
AI基础知识(LLM、prompt、rag、embedding、rerank、mcp、agent、多模态) 1、LLM大语言模型 --基于深度学习技术,通过海量文本数据训练而成的超大规模人工智能模型,能够理解、生成和推理自然语言文本 --产品&…...
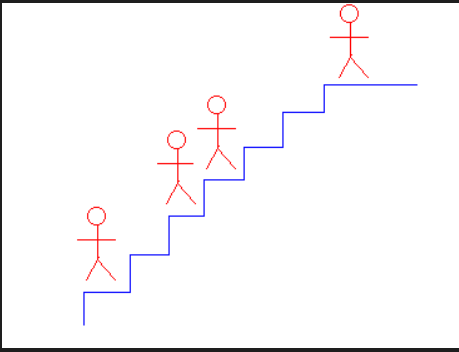
[蓝桥杯]高僧斗法
高僧斗法 题目描述 古时丧葬活动中经常请高僧做法事。仪式结束后,有时会有"高僧斗法"的趣味节目,以舒缓压抑的气氛。 节目大略步骤为:先用粮食(一般是稻米)在地上"画"出若干级台阶(…...

pycharm F2 修改文件名 修改快捷键
菜单:File-> Setting, Keymap中搜索 Rename, 其中,有 Refactor-> Rename,右键添加快捷键,F2,删除原有快捷键就可以了。...
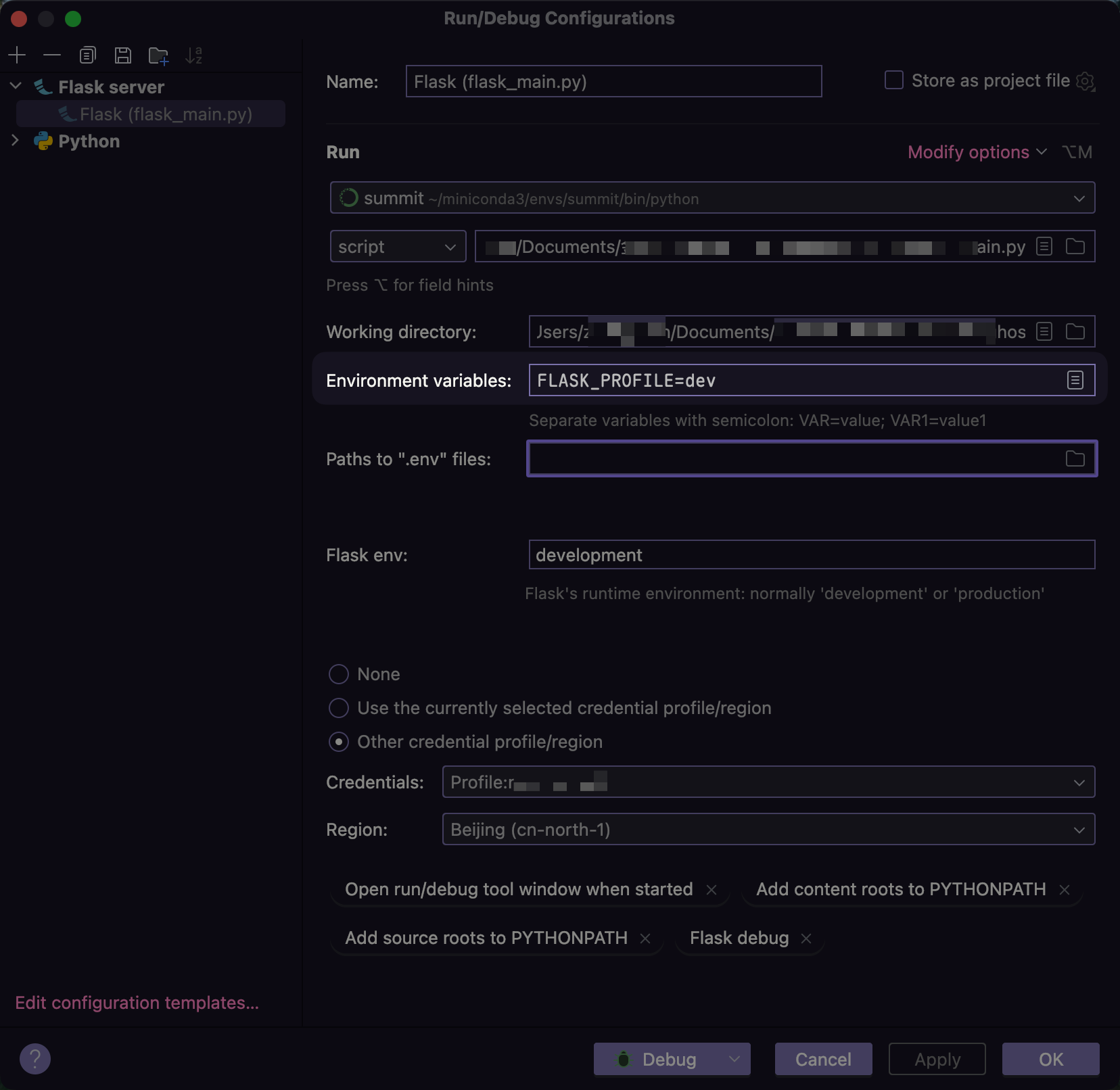
Python Flask中启用AWS Secrets Manager+AWS Parameter Store配置中心
问题 最近需要改造一个Python的Flask项目。需要在这个项目中添加AWS Secrets Manager作为配置中心,主要是数据库相关配置。 前提 得预先在Amazon RDS里面新建好数据库用户和数据库,以AWS Aurora为例子,建库和建用户语句类似如下࿱…...
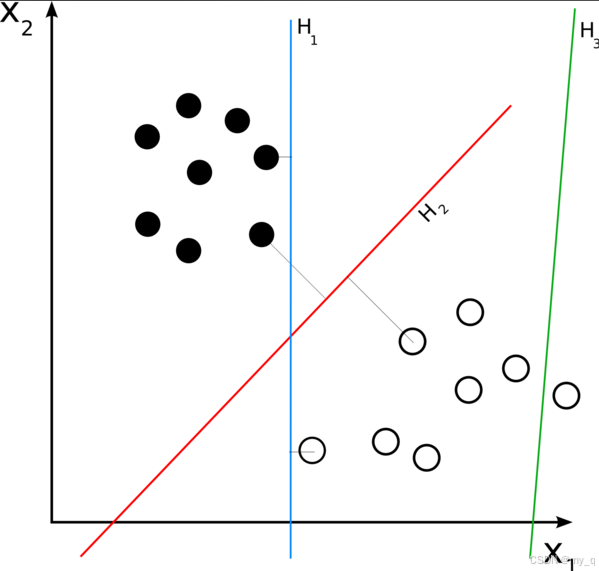
机器学习与深度学习10-支持向量机02
目录 前文回顾6.如何构建SVM7.SVM与多分类问题8.SVM与逻辑回归9.SVM的可扩展性10.SVM的适用性和局限性 前文回顾 上一篇文章链接:地址 6.如何构建SVM 选择合适的核函数和超参数来构建支持向量机(SVM)模型通常需要一定的经验和实验。以下是…...

《深入解析UART协议及其硬件实现》-- 第二篇:UART硬件架构设计与FPGA实现
第二篇:UART硬件架构设计与FPGA实现 1. 模块化架构设计 1.1 系统级框图与时钟域划分 核心模块划分 : 发送模块(TX) :负责数据帧组装与串行输出。 接收模块(RX) :负责串行数据采样与…...

java swing 晃动鼠标改变背景颜色
import java.awt.Color; import java.awt.Component; import java.awt.event.MouseEvent; import java.awt.event.MouseMotionListener;import javax.swing.*; public class testA extends JFrame {testA(){super("晃动鼠标改变背景颜色");setBounds(600, 200, 600, …...
HikariCP 可观测性最佳实践
HikariCP 介绍 HikariCP 是一个高性能、轻量级的 JDBC 连接池,由 Brett Wooldridge 开发。它以“光”命名,象征快速高效。它支持多种数据库,配置简单,通过字节码优化和智能管理,实现低延迟和高并发处理。它还具备自动…...
简简单单探讨下starter
前言 今天其实首先想跟大家探讨下:微服务架构,分业务线了,接入第三方服务、包啥的是否自己定义一个stater更好? 一、starter是什么? 在 Spring Boot 中,Starter 是一种特殊的依赖模块,用于快速…...
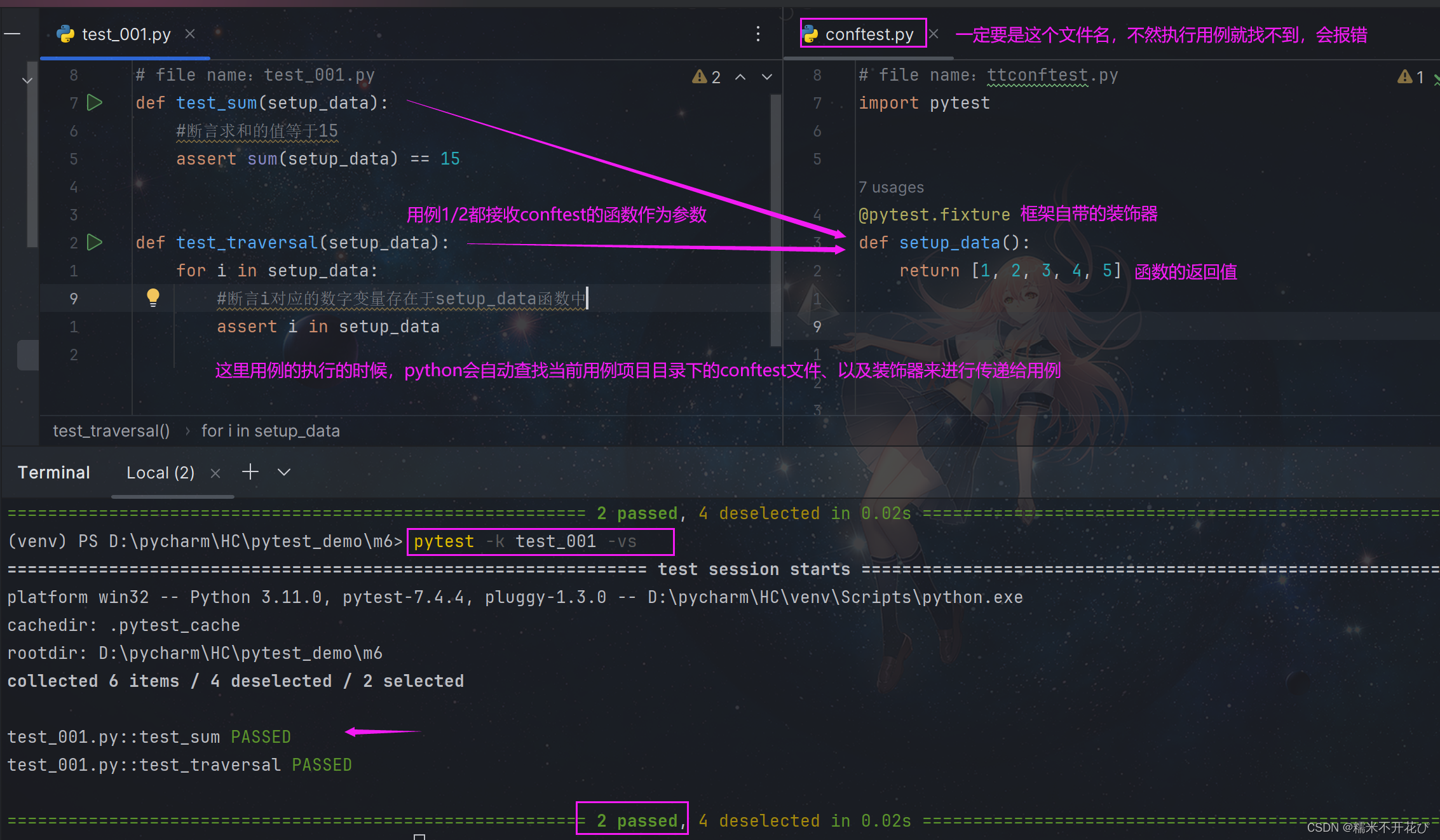
PyTest框架学习
0. 优先查看学习教程 超棒的学习教程 1. yield 语句 yield ptc_udp_clientyield:在 Pytest fixture 中,yield 用于分隔设置和清理代码。yield 之前的代码在测试用例执行前运行,yield 之后的代码在测试用例执行后运行。ptc_udp_client&…...
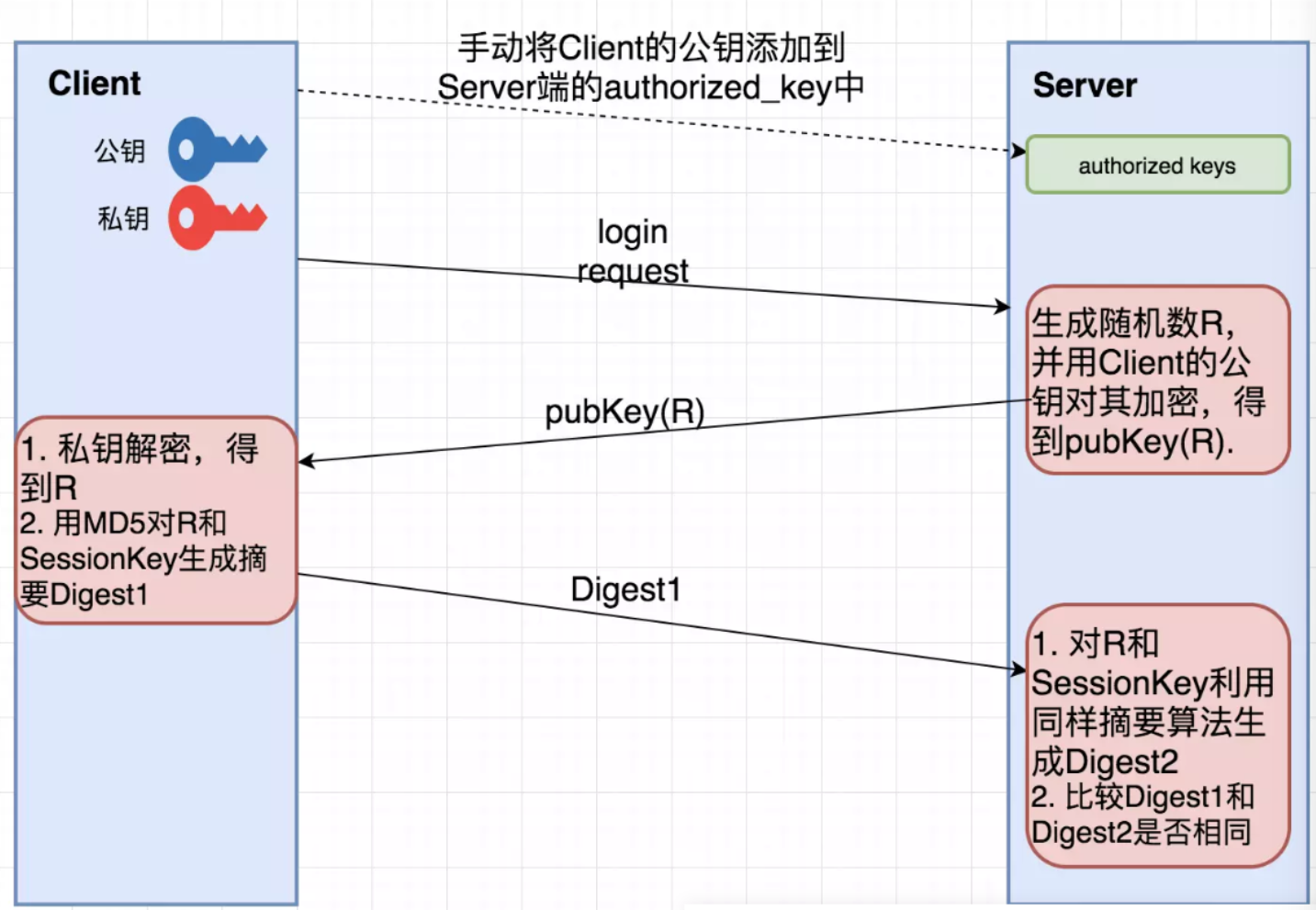
SIP、SAP、SDP、mDNS、SSH、PTP
🌈 一、SIP 会话初始协议 会话初始协议 SIP 是一个在 IP 网络上进行多媒体通信的应用层控制协议,它被用来创建、修改和终结 1 / n 个参加者参加的会话进程。SIP 不能单独完成呼叫功能,需要和 RTP、SDP 和 DNS 配合来完成。 1. SIP 协议的功…...
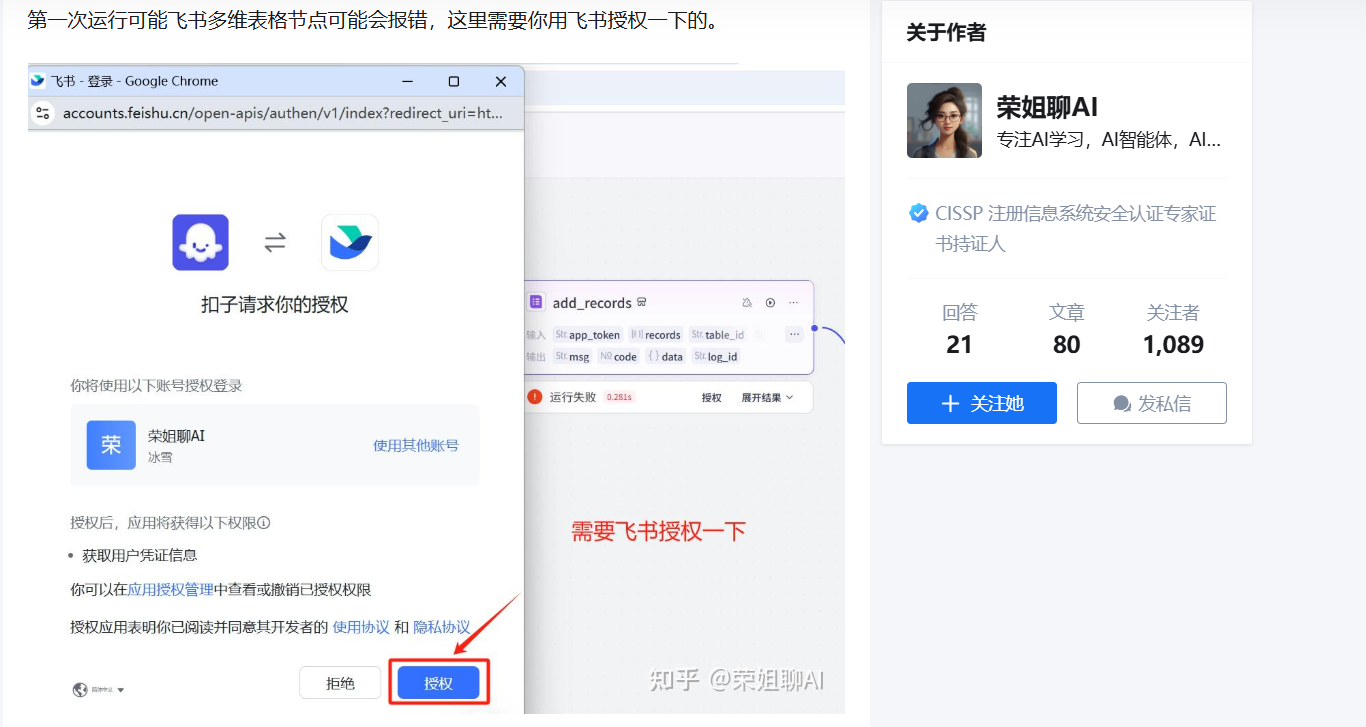
【AI学习笔记】Coze工作流写入飞书多维表格(即:多维表格飞书官方插件使用教程)
背景前摇: 今天遇到一个需求,需要把Coze平台大模型和用户的对话记录保存进飞书表格,这个思路其实不难,因为官方提供了写入飞书表格和多维表格的插件,但是因为平台教程和案例的资料匮乏,依据现有的官方文档…...

System.Threading.Timer 和 System.Timers.Timer
在 .NET 中,System.Threading.Timer 和 System.Timers.Timer 都是用于定时任务的类,但它们的实现方式、使用场景和特性有所不同。以下是它们的 核心区别 和 使用示例: 1. System.Threading.Timer 特点 轻量级,基于线程池…...

在 Windows 系统下配置 VSCode + CMake + Ninja 进行 C++ 或 Qt 开发
在 Windows 系统下配置 VSCode CMake Ninja 进行 C 或 Qt 开发,是一个轻量级但功能强大的开发环境。下面我将分步骤详细说明如何搭建这个开发环境,支持纯 C 和 Qt 项目。 🧰 所需工具安装 1. 安装 Visual Studio Code(VSCode&…...

`tokenizer.decode` 出现乱码或异常输出,怎么处理
tokenizer.decode 出现乱码或异常输出,怎么处理 在使用 Hugging Face Transformers 库进行大语言模型(LLM)开发时,tokenizer.decode 出现乱码或异常输出,通常和模型输出的 token 序列、分词器对齐逻辑、特殊 token 处理有关。以下从模型侧、分词器侧、后处理环节给出解决…...

几何绘图与三角函数计算应用
几何绘图与三角函数计算应用 设计思路 左侧为绘图控制面板,右侧为绘图区域支持绘制点、线、矩形、圆、多边形等基本几何图形实现三角函数计算器(正弦、余弦、正切等)包含角度/弧度切换和常用数学常数历史记录功能保存用户绘图 完整实现代码…...

leetcode 二叉搜索树中第k小的元素 java
中序遍历 定义一个栈,用于存取二叉树中的元素 Deque<TreeNode> stack new ArrayDeque<TreeNode>();进入while循环while(! stack.isEmpty()|| root ! null){}将root的左节点入栈,直到rootnull while(rootnull){stack.push(root);root ro…...

5.1 初探大数据流式处理
在本节中,我们深入探讨了大数据流式处理的基础知识和关键技术。首先,我们区分了批式处理和流式处理两种大数据处理方式,了解了它们各自的适用场景和特点。流式处理以其低延迟和高实时性适用于需要快速响应的场景,而批式处理则适用…...

基于 Android 和 JBox2D 的简单小游戏
以下是一个基于 Android 和 JBox2D 的简单小游戏开发示例,实现一个小球在屏幕上弹跳的效果: 1. 添加 JBox2D 依赖 在项目的 build.gradle 文件中添加 JBox2D 的依赖: dependencies {implementation org.jbox2d:jbox2d-library:2.3.1 } 2.…...
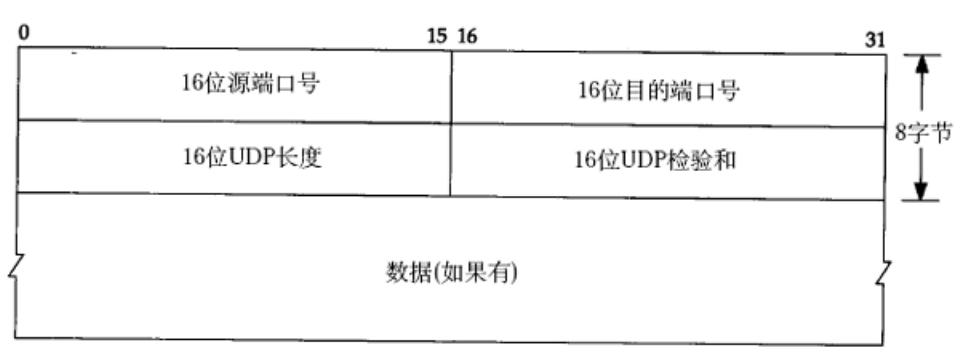
传输层协议 UDP 介绍 -- UDP 协议格式,UDP 的特点,UDP 的缓冲区
目录 1. 再识的端口号 1.1 端口号范围划分 1.2 知名端口号(Well-Know Port Number) 2. UDP 协议 2.1 UDP 协议格式 2.2 UDP 的特点 2.3 UDP 的缓冲区 2.4 一些基于 UDP 的应用层协议 传输层(Transport Layer)是计算机网络…...