机器学习与深度学习10-支持向量机02
目录
- 前文回顾
- 6.如何构建SVM
- 7.SVM与多分类问题
- 8.SVM与逻辑回归
- 9.SVM的可扩展性
- 10.SVM的适用性和局限性
前文回顾
上一篇文章链接:地址
6.如何构建SVM
选择合适的核函数和超参数来构建支持向量机(SVM)模型通常需要一定的经验和实验。以下是一般的步骤和一些Python示例代码
- 数据准备:
- 首先,需要准备好数据集,包括特征和标签
- 划分数据集:
- 将数据集分为训练集和测试集,以便评估模型的性能
- 选择核函数:
- SVM的性能与核函数的选择密切相关。常见的核函数包括线性核、多项式核和径向基函数(RBF)核。选择核函数的一种方法是尝试不同的核函数,并比较它们的性能
以下是一个示例:
from sklearn import svm
# 使用线性核
linear_svm = svm.SVC(kernel='linear')
# 使用多项式核
poly_svm = svm.SVC(kernel='poly', degree=3) # 可以调整多项式的阶数
# 使用RBF核
rbf_svm = svm.SVC(kernel='rbf')
- 选择超参数:
- SVM还有一些超参数需要调整,例如正则化参数C、多项式核的阶数、RBF核的γ等。通常使用交叉验证来选择合适的超参数。以下是一个示例:
from sklearn.model_selection import GridSearchCV
# 定义超参数搜索范围
param_grid = {'C': [0.1, 1, 10],'gamma': [0.001, 0.01, 0.1, 1]}
# 创建SVM模型
svm_model = svm.SVC(kernel='rbf')
# 使用网格搜索来选择最佳超参数
grid_search = GridSearchCV(svm_model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 输出最佳超参数
best_params = grid_search.best_params_
print("Best Hyperparameters:", best_params)
- 模型评估:
- 在测试集上评估模型的性能,可以使用准确度、精确度、召回率等指标来评估模型
- 可视化决策边界:
- 对于二维数据,可以绘制决策边界来可视化模型的分类结果
以下是一个完整的Python示例代码,演示了上述步骤:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.model_selection import GridSearchCV
# 生成示例数据
X, y = datasets.make_classification(n_samples=100, n_features=2, n_classes=2,n_clusters_per_class=1, n_redundant=0, random_state=42)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义超参数搜索范围
param_grid = {'C': [0.1, 1, 10],'gamma': [0.001, 0.01, 0.1, 1]}
# 创建SVM模型
svm_model = svm.SVC(kernel='rbf')
# 使用网格搜索来选择最佳超参数
grid_search = GridSearchCV(svm_model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 输出最佳超参数
best_params = grid_search.best_params_
print("Best Hyperparameters:", best_params)
# 训练最佳模型
best_svm_model = svm.SVC(kernel='rbf', C=best_params['C'], gamma=best_params['gamma'])
best_svm_model.fit(X_train, y_train)
# 在测试集上评估模型性能
accuracy = best_svm_model.score(X_test, y_test)
print("Accuracy:", accuracy)
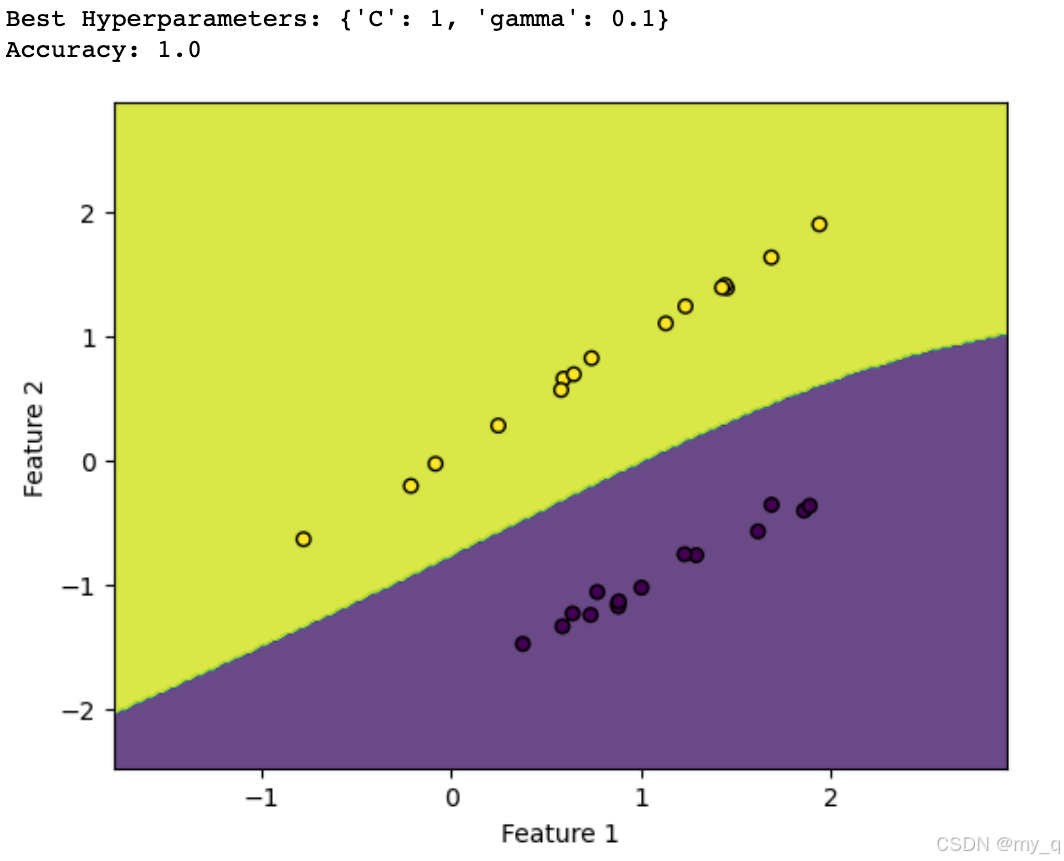
# 绘制决策边界
def plot_decision_boundary(model, X, y):h = 0.02 # 步长x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8)plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', s=30)plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.show()
# 绘制决策边界
plot_decision_boundary(best_svm_model, X_test, y_test)
这个示例代码涵盖了选择核函数和超参数以及模型评估的基本步骤,并通过决策边界可视化模型的分类结果。可以根据自己的数据和问题来调整这些步骤以获得最佳的SVM模型
7.SVM与多分类问题
多类别分类问题是指需要将数据分成多个不同类别或标签的问题,而不仅仅是两个类别(二分类问题),支持向量机(SVM)通常是用于二分类问题的,但可以通过不同的策略来处理多类别分类问题。一种常用的方法是一对一(One - vs - One)和一对多(One - vs - Rest或One - vs - All)策略
- 一对一策略:在这种策略下,对于有K个类别的问题,我们构建K(K - 1)/2个二分类SVM模型,每个模型解决两个类别之间的问题。然后,通过投票或其他组合方法将这些二分类器的结果合并成一个多类别分类器
- 一对多策略:在这种策略下,对于有K个类别的问题,我们构建K个二分类SVM模型,每个模型将一个类别与其他所有类别进行区分。然后,通过选择具有最高置信度的分类器来决定样本的最终类别
以下的Python示例,演示如何使用一对一策略和一对多策略来处理多类别分类问题,并可视化决策边界:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
#生成示例数据
X, y = datasets.make_classification(n_samples=100, n_features=2, n_classes=3,n_clusters_per_class=1, n_redundant=0, random_state=42)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用一对一策略
from sklearn.multiclass import OneVsOneClassifier
ovo_svm = OneVsOneClassifier(svm.SVC(kernel='linear'))
ovo_svm.fit(X_train, y_train)
accuracy_ovo = ovo_svm.score(X_test, y_test)
print("Accuracy (One-vs-One):", accuracy_ovo)
# 使用一对多策略
from sklearn.multiclass import OneVsRestClassifier
ova_svm = OneVsRestClassifier(svm.SVC(kernel='linear'))
ova_svm.fit(X_train, y_train)
accuracy_ova = ova_svm.score(X_test, y_test)
print("Accuracy (One-vs-Rest):", accuracy_ova)
# 绘制决策边界
def plot_decision_boundary(model, X, y):h = 0.02 # 步长x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8)plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', s=30)plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.title("Decision Boundary")plt.show()
# 绘制决策边界(One-vs-one)
plot_decision_boundary(ovo_svm, X_test, y_test)
# 绘制决策边界(One-vs-Rest)
plot_decision_boundary(ova_svm, X_test, y_test)
代码演示了使用一对一和一对多策略来处理多类别分类问题,并通过可视化决策边界展示了两种策略的效果
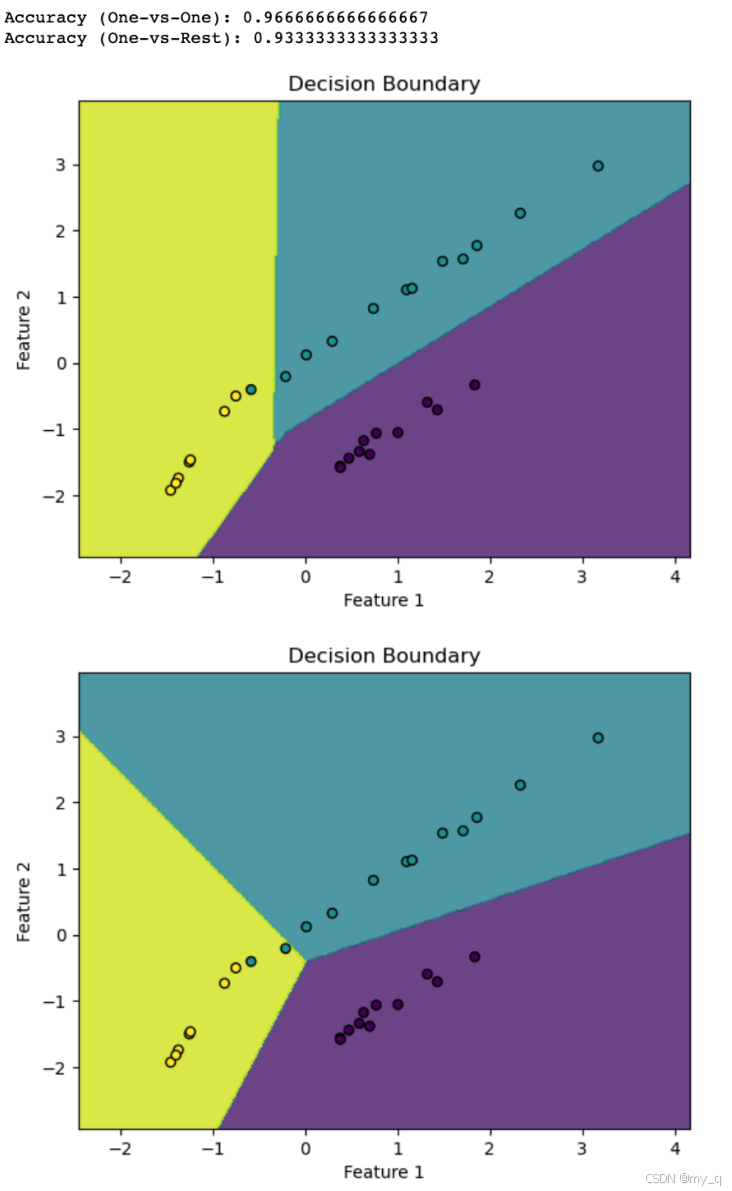
在实际应用中,可以根据数据和问题选择合适的策略来解决多分类问题
8.SVM与逻辑回归
支持向量机和逻辑回归(Logistic Regression)是两种不同的机器学习算法,用于分类和回归任务。
它们有一些相似之处,也有一些显著的差异。下面是它们之间的相似之处和差异:
相似之处
- 用途:SVM和逻辑回归都可以用于二元分类问题,也可以扩展到多类别分类
- 线性模型:SVM和逻辑回归都是线性模型,它们尝试在特征空间中找到一个线性决策边界来分离不同类别的数据点
差异
- 损失函数:逻辑回归使用对数损失函数,而SVM使用合页损失函数(Hinge Loss)。这导致了它们在优化和预测时的不同行为
- 决策边界:SVM的目标是找到离决策边界最近的数据点(支持向量),而逻辑回归的目标是找到最大似然估计下的决策边界。因此,SVM更加关注支持向量,而逻辑回归更加关注整体数据点的概率分布
- 鲁棒性:SVM通常对异常值更加鲁棒,因为它最大化了离决策边界最近的数据点的间隔。逻辑回归对异常值更加敏感,因为它使用了对数损失函数
- 参数调整:SVM的性能高度依赖于核函数的选择,而逻辑回归相对较少需要参数调整
下面是一个示意图,用于说明SVM和逻辑回归在二元分类问题上的决策边界和支持向量的不同行为:
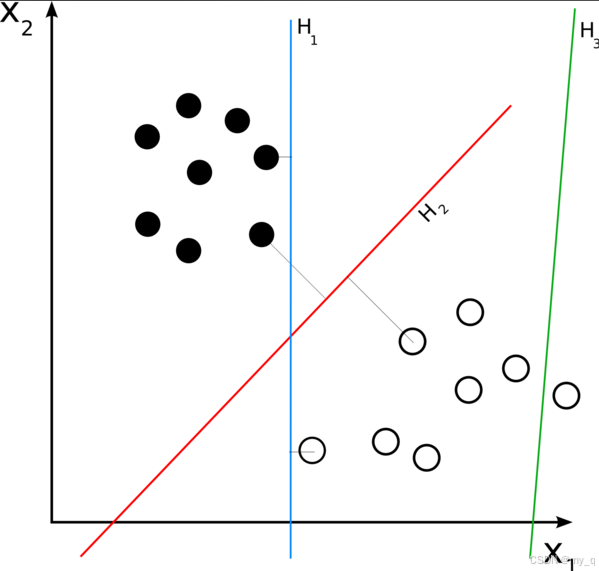
比如上图中,左边是SVM的决策边界,右边是逻辑回归的决策边界。SVM的决策边界受支持向量的影响,这些支持向量是距离决策边界最近的数据点。逻辑回归的决策边界受所有数据点的影响,并且以概率分布方式建模。这个示意图突出了它们之间的差异,以及SVM更关注离决策边界最近的数据点,而逻辑回归更关注整体数据点的概率分布
9.SVM的可扩展性
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,可以用于分类和回归任务。在大规模数据集上训练SVM模型可能会变得非常耗时,但有一些方法可以加速其训练过程并提高可扩展性:
- 特征选择和降维:在大规模数据集上,可以通过选择最重要的特征或者使用降维技术(如主成分分析)来减小数据的维度。减小特征空间可以大幅降低模型的复杂性,从而提高训练速度
- 随机子样本:可以考虑使用随机子样本來代替整个数据集进行训练。这种方法被称为随机梯度下降(Stochastic Gradient Descent,SGD),它在每个训练迭代中仅使用部分数据,从而加速了训练过程。这对于大规模数据集通常效果很好
- 核技巧的近似方法:SVM中的核技巧(kernel trick)可以将低维特征映射到高维空间,但计算复杂度高。可以使用近似方法,如随机四元数化(Random Fourier Features)或Nystrom方法,来加速核矩阵的计算,从而减少训练时间
- 并行化和分布式计算:在大规模数据集上,可以利用并行计算或分布式计算框架来加速SVM的训练。这允许多个计算单元同时处理不同的数据批次或模型参数
- 缩放到更小的问题:将大规模数据集分成多个较小的子问题进行训练,然后将它们组合起来。这种方法通常用于分布式SVM训练
- 使用线性SVM或线性核:如果问题允许,考虑使用线性SVM或线性核,因为它们的训练速度通常比非线性SVM更快
- 软件工具和库:使用经过优化的SVM库和工具,如LIBSVM、Scikit-learn等,它们通常已经实现了一些优化策略来提高可扩展性和训练速度
支持向量机的可扩展性受到多个因素的影响,包括数据集的大小、特征维度、核函数的复杂性以及计算硬件的性能。上述提到的方法可以帮助提高SVM在大规模数据集上的可扩展性,但在某些极端情况下,仍然可能面临性能问题。因此,在实际应用中,需要综合考虑问题的复杂性和可用资源来选择合适的方法以加速SVM的训练过程
10.SVM的适用性和局限性
支持向量机(SVM)一些常见的局限性和适用性条件:
- 高维问题:在高维空间中,SVM的性能可能会下降,因为数据在高维空间中更容易出现过拟合问题,而且计算复杂度也会增加。在高维问题中,选择适当的核函数和正则化参数非常重要
- 大规模数据集:在大规模数据集上,SVM的训练时间可能会很长,特别是对于非线性SVM或具有复杂核函数的SVM。针对大规模数据集的训练方法需要特别注意
- 选择适当的核函数:选择合适的核函数是关键,但并不总是容易。核函数的选择可能需要领域知识或者交叉验证等技术来进行调优。错误的核函数选择可能导致模型性能下降
- 不适用于大量噪声数据:SVM对噪声数据敏感,特别是在训练数据中存在大量噪声或异常值时。需要在数据预处理中处理噪声或异常值
- 不适用于非平衡数据集:当类别不平衡且一个类别的样本数量远远超过另一个类别时,SVM可能会倾向于支持样本数量更多的类别,而忽略样本数量较少的类别。在这种情况下,需要采取类别平衡的策略,如过采样或欠采样
- 需要调整超参数:SVM的性能高度依赖于正则化参数和核函数的选择,这些超参数需要仔细调整。通常需要进行交叉验证来找到最佳的超参数设置
- 不适用于大规模多类别分类问题:SVM在处理大规模多类别分类问题时可能变得非常复杂。针对此类问题通常有更适合的算法,如深度学习模型
SVM 适用于许多分类和回归问题,尤其在中小规模数据集上表现出色
相关文章:
机器学习与深度学习10-支持向量机02
目录 前文回顾6.如何构建SVM7.SVM与多分类问题8.SVM与逻辑回归9.SVM的可扩展性10.SVM的适用性和局限性 前文回顾 上一篇文章链接:地址 6.如何构建SVM 选择合适的核函数和超参数来构建支持向量机(SVM)模型通常需要一定的经验和实验。以下是…...

《深入解析UART协议及其硬件实现》-- 第二篇:UART硬件架构设计与FPGA实现
第二篇:UART硬件架构设计与FPGA实现 1. 模块化架构设计 1.1 系统级框图与时钟域划分 核心模块划分 : 发送模块(TX) :负责数据帧组装与串行输出。 接收模块(RX) :负责串行数据采样与…...

java swing 晃动鼠标改变背景颜色
import java.awt.Color; import java.awt.Component; import java.awt.event.MouseEvent; import java.awt.event.MouseMotionListener;import javax.swing.*; public class testA extends JFrame {testA(){super("晃动鼠标改变背景颜色");setBounds(600, 200, 600, …...
HikariCP 可观测性最佳实践
HikariCP 介绍 HikariCP 是一个高性能、轻量级的 JDBC 连接池,由 Brett Wooldridge 开发。它以“光”命名,象征快速高效。它支持多种数据库,配置简单,通过字节码优化和智能管理,实现低延迟和高并发处理。它还具备自动…...
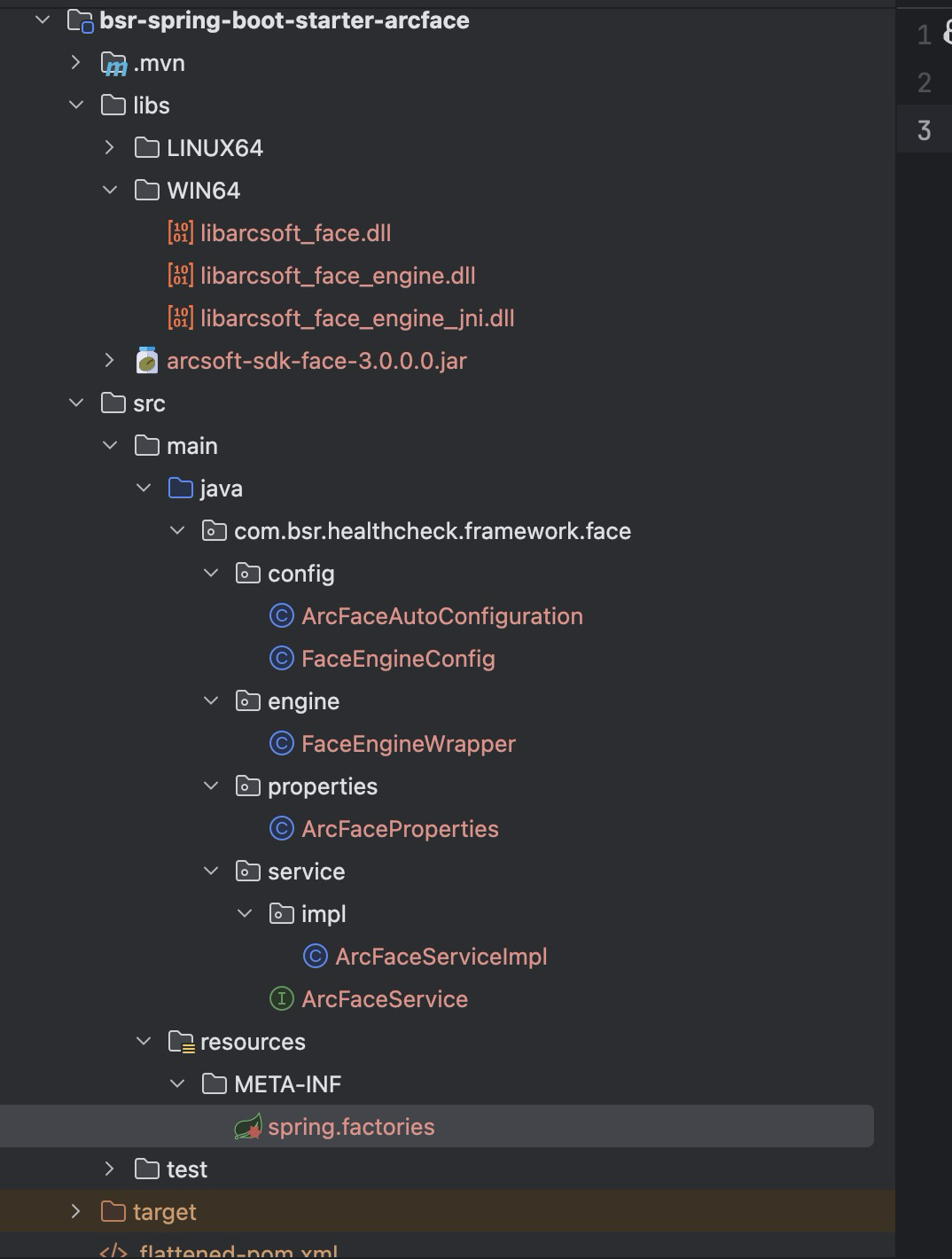
简简单单探讨下starter
前言 今天其实首先想跟大家探讨下:微服务架构,分业务线了,接入第三方服务、包啥的是否自己定义一个stater更好? 一、starter是什么? 在 Spring Boot 中,Starter 是一种特殊的依赖模块,用于快速…...
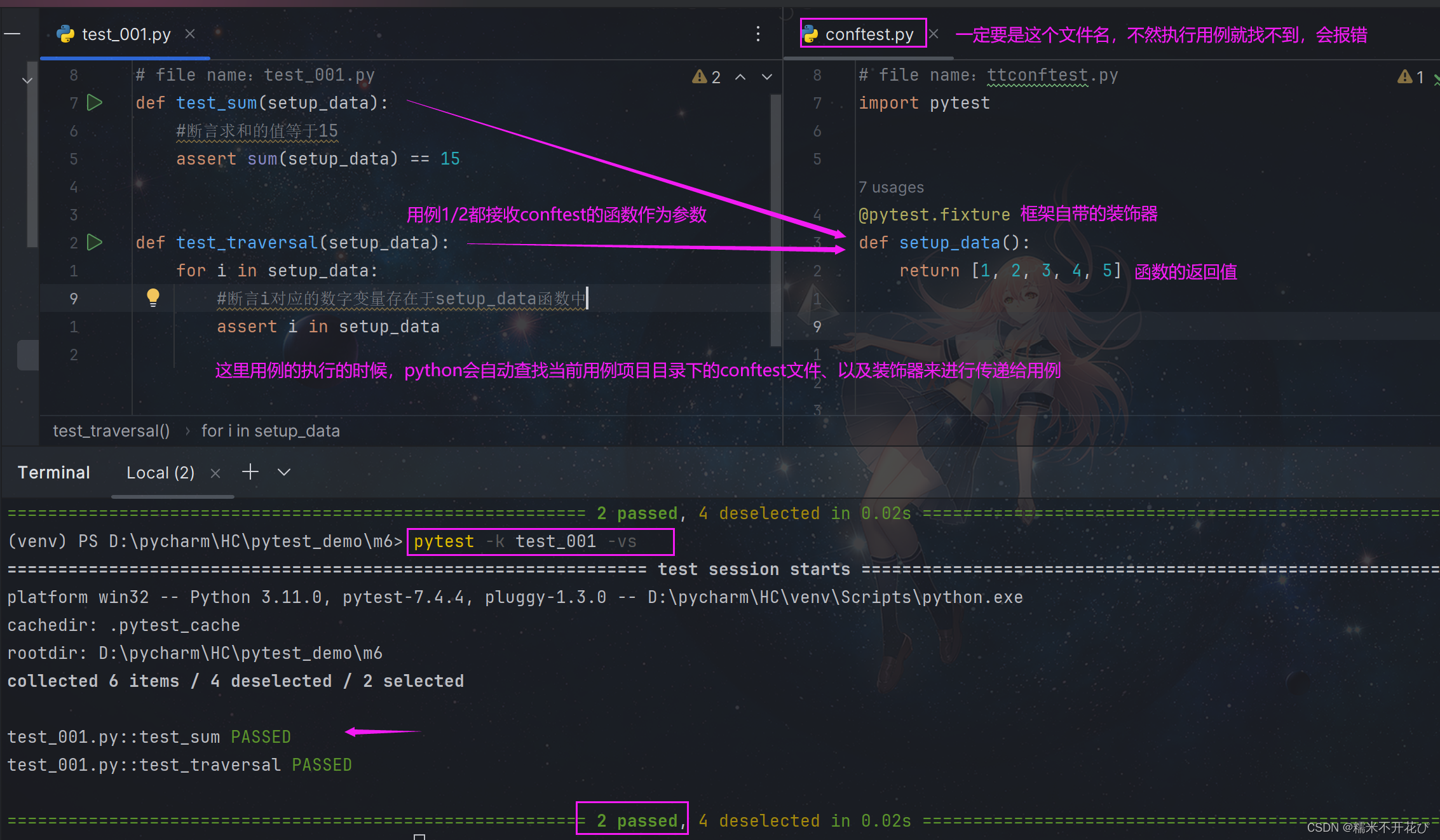
PyTest框架学习
0. 优先查看学习教程 超棒的学习教程 1. yield 语句 yield ptc_udp_clientyield:在 Pytest fixture 中,yield 用于分隔设置和清理代码。yield 之前的代码在测试用例执行前运行,yield 之后的代码在测试用例执行后运行。ptc_udp_client&…...
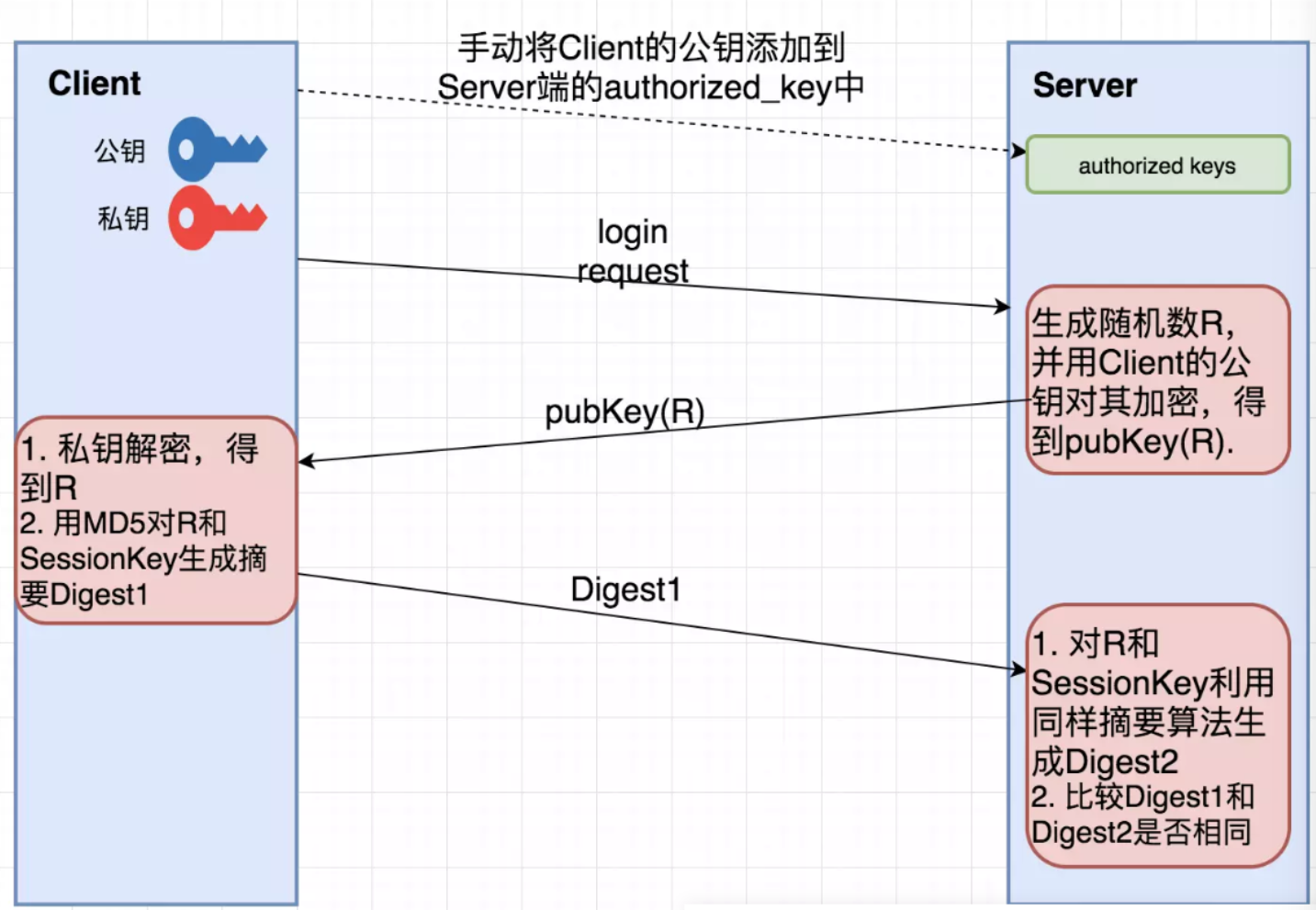
SIP、SAP、SDP、mDNS、SSH、PTP
🌈 一、SIP 会话初始协议 会话初始协议 SIP 是一个在 IP 网络上进行多媒体通信的应用层控制协议,它被用来创建、修改和终结 1 / n 个参加者参加的会话进程。SIP 不能单独完成呼叫功能,需要和 RTP、SDP 和 DNS 配合来完成。 1. SIP 协议的功…...
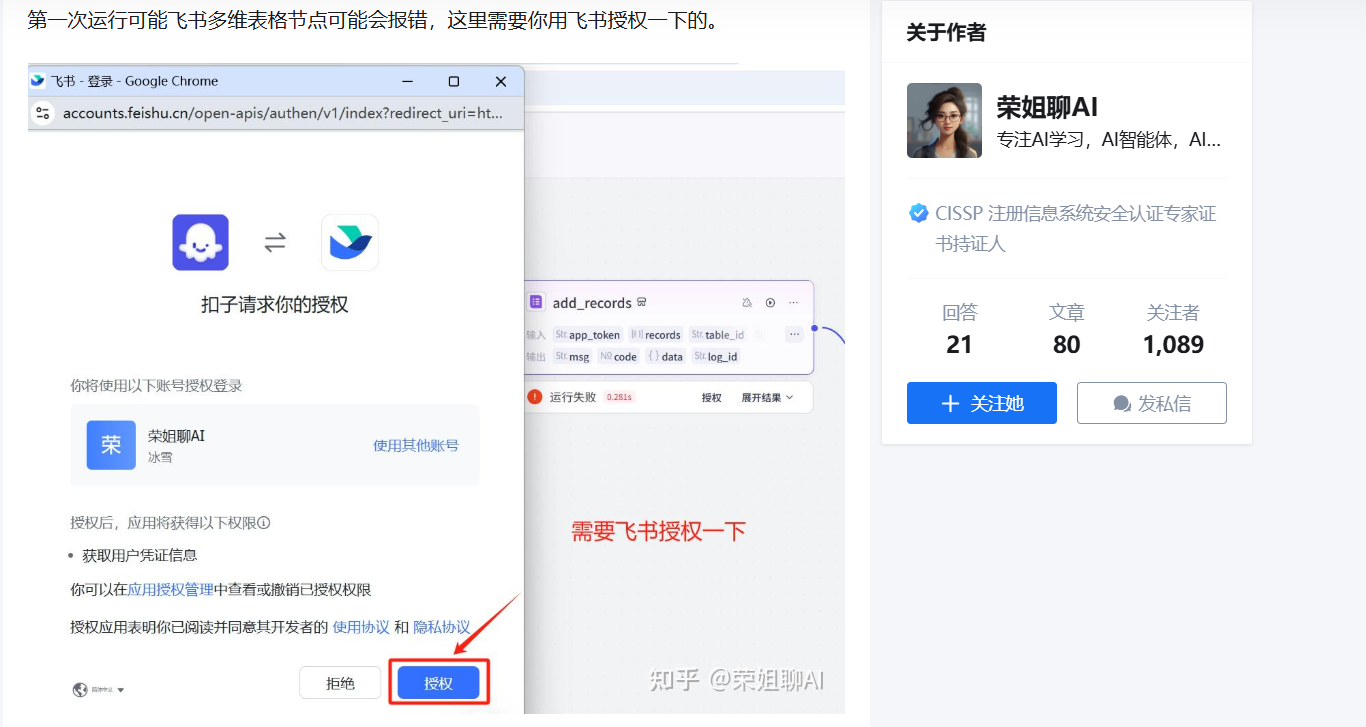
【AI学习笔记】Coze工作流写入飞书多维表格(即:多维表格飞书官方插件使用教程)
背景前摇: 今天遇到一个需求,需要把Coze平台大模型和用户的对话记录保存进飞书表格,这个思路其实不难,因为官方提供了写入飞书表格和多维表格的插件,但是因为平台教程和案例的资料匮乏,依据现有的官方文档…...

System.Threading.Timer 和 System.Timers.Timer
在 .NET 中,System.Threading.Timer 和 System.Timers.Timer 都是用于定时任务的类,但它们的实现方式、使用场景和特性有所不同。以下是它们的 核心区别 和 使用示例: 1. System.Threading.Timer 特点 轻量级,基于线程池…...

在 Windows 系统下配置 VSCode + CMake + Ninja 进行 C++ 或 Qt 开发
在 Windows 系统下配置 VSCode CMake Ninja 进行 C 或 Qt 开发,是一个轻量级但功能强大的开发环境。下面我将分步骤详细说明如何搭建这个开发环境,支持纯 C 和 Qt 项目。 🧰 所需工具安装 1. 安装 Visual Studio Code(VSCode&…...

`tokenizer.decode` 出现乱码或异常输出,怎么处理
tokenizer.decode 出现乱码或异常输出,怎么处理 在使用 Hugging Face Transformers 库进行大语言模型(LLM)开发时,tokenizer.decode 出现乱码或异常输出,通常和模型输出的 token 序列、分词器对齐逻辑、特殊 token 处理有关。以下从模型侧、分词器侧、后处理环节给出解决…...

几何绘图与三角函数计算应用
几何绘图与三角函数计算应用 设计思路 左侧为绘图控制面板,右侧为绘图区域支持绘制点、线、矩形、圆、多边形等基本几何图形实现三角函数计算器(正弦、余弦、正切等)包含角度/弧度切换和常用数学常数历史记录功能保存用户绘图 完整实现代码…...

leetcode 二叉搜索树中第k小的元素 java
中序遍历 定义一个栈,用于存取二叉树中的元素 Deque<TreeNode> stack new ArrayDeque<TreeNode>();进入while循环while(! stack.isEmpty()|| root ! null){}将root的左节点入栈,直到rootnull while(rootnull){stack.push(root);root ro…...

5.1 初探大数据流式处理
在本节中,我们深入探讨了大数据流式处理的基础知识和关键技术。首先,我们区分了批式处理和流式处理两种大数据处理方式,了解了它们各自的适用场景和特点。流式处理以其低延迟和高实时性适用于需要快速响应的场景,而批式处理则适用…...

基于 Android 和 JBox2D 的简单小游戏
以下是一个基于 Android 和 JBox2D 的简单小游戏开发示例,实现一个小球在屏幕上弹跳的效果: 1. 添加 JBox2D 依赖 在项目的 build.gradle 文件中添加 JBox2D 的依赖: dependencies {implementation org.jbox2d:jbox2d-library:2.3.1 } 2.…...
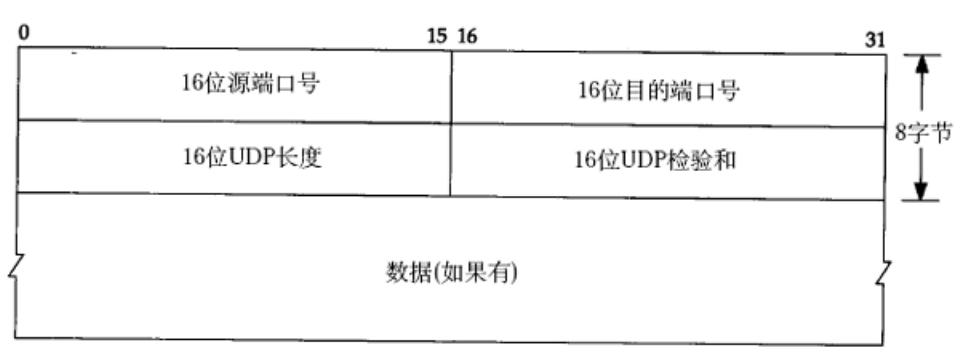
传输层协议 UDP 介绍 -- UDP 协议格式,UDP 的特点,UDP 的缓冲区
目录 1. 再识的端口号 1.1 端口号范围划分 1.2 知名端口号(Well-Know Port Number) 2. UDP 协议 2.1 UDP 协议格式 2.2 UDP 的特点 2.3 UDP 的缓冲区 2.4 一些基于 UDP 的应用层协议 传输层(Transport Layer)是计算机网络…...

Python try-except-else 语句详解
try-except-else 是 Python 中用于异常处理的重要结构,它允许你优雅地处理可能出现的错误,并在没有错误发生时执行特定代码。下面我将详细解释这个结构及其用法。 基本语法 try:# 可能引发异常的代码块 except [ExceptionType]:# 异常处理代码块 else:…...
ApacheSuperset CVE-2023-27524
前言:CVE-2023-27524 是一种远程代码执行漏洞,攻击者通过该漏洞可在受影响系统上执行任意代码,从而获得未授权访问权 CVE-2023-27524 GitHubhttps://github.com/horizon3ai/CVE-2023-27524 任务一 代理 | 拉取镜像 vi /etc/proxychains4.conf //最下面修…...

Windows Server部署Vue3+Spring Boot项目
在Windows Server 上部署Vue3 Spring Boot前后端分离项目的详细步骤如下: 一、环境准备 安装JDK 17 下载JDK MSI安装包(如Oracle JDK 或 OpenJDK) 双击安装,配置环境变量: JAVA_HOME:JDK安装路径…...

malloc 是如何分配内存的?——C 语言内存分配详解
文章目录 malloc是如何分配内存的?——C语言内存分配详解一、引言二、内存分配的基本概念1. 虚拟内存与物理内存2. 进程内存布局 三、malloc函数详解1. 函数原型与功能2. 关键特性 四、malloc的底层实现机制1. 内存分配器的角色2. 分配策略3. 内存碎片问题 五、glib…...

Opencl
**OpenCL(Open Computing Language)**是一种用于异构平台(包括CPU、GPU、FPGA、DSP等)上的并行计算框架和编程标准。它由Khronos Group制定,旨在提供一种跨平台、统一的编程接口,使开发者可以利用不同硬件设…...
如何在 HTML 中添加按钮
原文:如何在 HTML 中添加按钮 | w3cschool笔记 (请勿将文章标记为付费!!!!) 在网页开发中,按钮是用户界面中不可或缺的元素之一。无论是用于提交表单、触发动作还是导航࿰…...

【优秀三方库研读】quill 开源库中的命名空间为什么要用宏封装
将命名空间封装成宏的作用与优势 QUILL_BEGIN_NAMESPACE 和 QUILL_END_NAMESPACE 这种宏封装是 C++ 库开发中的常见技巧,主要解决以下问题并提供显著优势: 1. 解决核心问题:命名空间嵌套与版本控制 问题场景: 库需要支持多版本共存(如 quill::v1, quill::v2),但希望默认…...
)
AlphaFold3运行错误及解决方法(1)
1. chemical_component_sets.pickle 运行alphafold3遇到下面的问题: FileNotFoundError: [Errno 2] No such file or directory: /xxx/xxx/anaconda3/envs/alphafold3/lib/python3.11/site-packages/alphafold3/constants/converters/chemical_component_sets.pickle搜索你的系…...
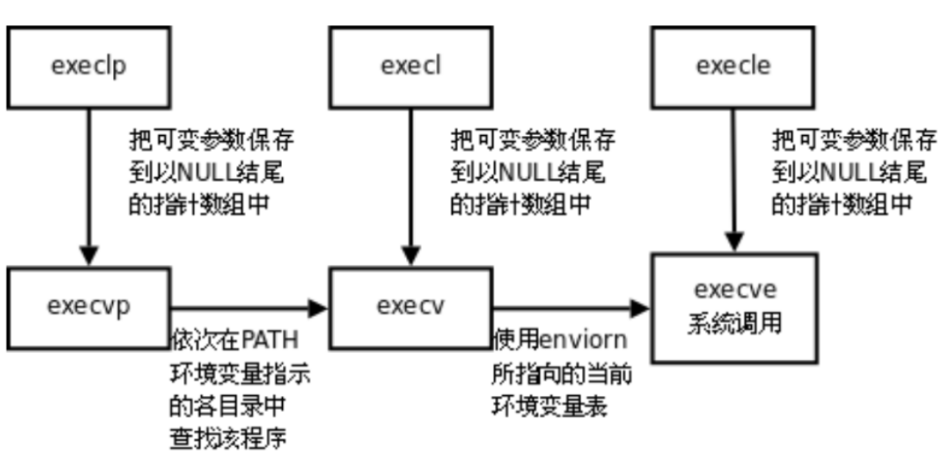
Linux--进程的程序替换
问题导入: 前面我们知道了,fork之后,子进程会继承父进程的代码和“数据”(写实拷贝)。 那么如果我们需要子进程完全去完成一个自己的程序怎么办呢? 进程的程序替换来完成这个功能! 1.替换原理…...
调教 DeepSeek - 输出精致的 HTML MARKDOWN
【序言】 不知道是不是我闲的蛋疼,对百度AI 和 DeepSeek 的回答都不太满意。 DeepSeek 回答句子的引用链接,始终无法准确定位。有时链接只是一个域名,有时它给的链接是搜索串如: baidu.com/?q"搜索内容"。 百度AI 回答句子的引用…...
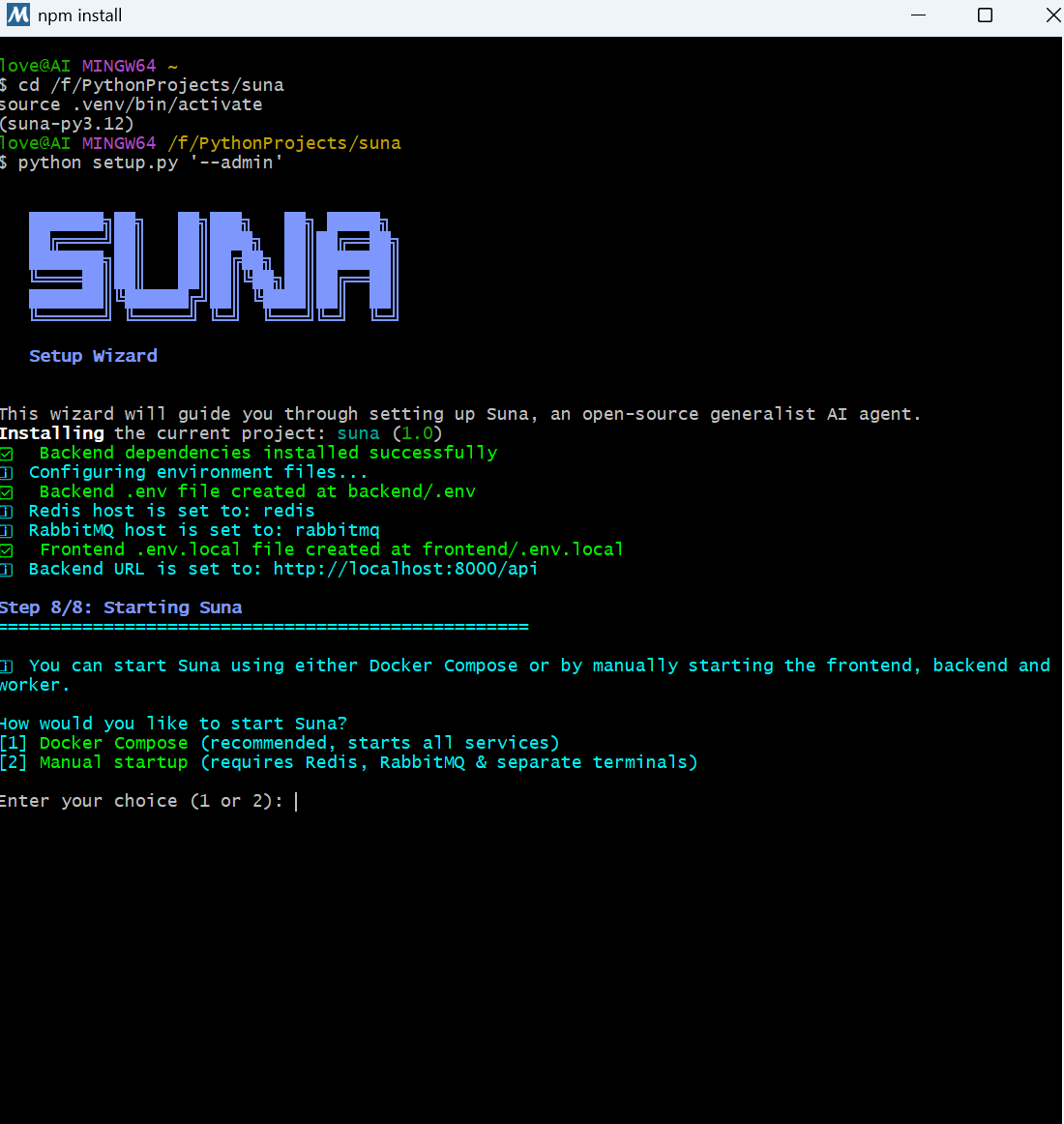
【笔记】Windows系统部署suna基于 MSYS2的Poetry 虚拟环境backedn后端包编译失败处理
基于 MSYS2(MINGW64)中 Python 的 Poetry 虚拟环境包编译失败处理笔记 一、背景 在基于 MSYS2(MINGW64)中 Python 创建的 Poetry 虚拟环境里,安装 Suna 开源项目相关包时编译失败,阻碍项目正常部署。 后端…...
:分组注意力机制的原理与实践《一》)
GQA(Grouped Query Attention):分组注意力机制的原理与实践《一》
GQA(Grouped Query Attention)是近年来在大语言模型中广泛应用的一种注意力机制优化方法,最初由 Google 在 2023 年提出。它是对 Multi-Query Attention (MQA) 的扩展,旨在平衡模型性能与计算效率。 🌟 GQA 是什么&…...

【深度学习优化算法】02:凸性
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

JAVA国际版一对一视频交友视频聊天系统源码支持H5+APP
全球畅连无界社交:JAVA国际版一对一视频交友系统源码(H5APP双端覆盖) 在全球化社交需求激增的今天,构建一个支持多语言、适配国际支付且功能丰富的视频交友平台,成为出海创业者和企业的核心诉求。JAVA国际版一对一视频…...