【深度学习优化算法】02:凸性

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、定义
- (一)凸集
- (二)凸函数
- (三)詹森不等式
- 二、性质
- (一)局部极小值是全局极小值
- (二)凸函数的下水平集是凸的
- (三)凸性和二阶导数
- 三、约束
- (一)拉格朗日函数
- (二)惩罚
- (三)投影
- 小结
凸性(convexity)在优化算法的设计中起到至关重要的作用,这主要是由于在这种情况下对算法进行分析和测试要容易。换言之,如果算法在凸性条件设定下的效果很差,那通常我们很难在其他条件下看到好的结果。此外,即使深度学习中的优化问题通常是非凸的,它们也经常在局部极小值附近表现出一些凸性。这可能会产生一些比较有意思的新优化变体。
%matplotlib inline
import numpy as np
import torch
from mpl_toolkits import mplot3d
from d2l import torch as d2l
一、定义
在进行凸分析之前,我们需要定义凸集(convex sets)和凸函数(convex functions)。
(一)凸集
凸集(convex set)是凸性的基础。简单地说,如果对于任何 a , b ∈ X a, b \in \mathcal{X} a,b∈X,连接 a a a和 b b b的线段也位于 X \mathcal{X} X中,则向量空间中的一个集合 X \mathcal{X} X是凸(convex)的。在数学术语上,这意味着对于所有 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1],我们得到
λ a + ( 1 − λ ) b ∈ X 当 a , b ∈ X (1) \lambda a + (1-\lambda) b \in \mathcal{X} \text{ 当 } a, b \in \mathcal{X} \tag{1} λa+(1−λ)b∈X 当 a,b∈X(1)
这听起来有点抽象,那我们来看一下图1里的例子。第一组存在不包含在集合内部的线段,所以该集合是非凸的,而另外两组则没有这样的问题。

接下来来看一下图2所示的交集。假设 X \mathcal{X} X和 Y \mathcal{Y} Y是凸集,那么 X ∩ Y \mathcal {X} \cap \mathcal{Y} X∩Y也是凸集的。现在考虑任意 a , b ∈ X ∩ Y a, b \in \mathcal{X} \cap \mathcal{Y} a,b∈X∩Y,因为 X \mathcal{X} X和 Y \mathcal{Y} Y是凸集,所以连接 a a a和 b b b的线段包含在 X \mathcal{X} X和 Y \mathcal{Y} Y中。鉴于此,它们也需要包含在 X ∩ Y \mathcal {X} \cap \mathcal{Y} X∩Y中,从而证明我们的定理。

我们可以毫不费力地进一步得到这样的结果:给定凸集 X i \mathcal{X}_i Xi,它们的交集 ∩ i X i \cap_{i} \mathcal{X}_i ∩iXi是凸的,但是反向是不正确的。
考虑两个不相交的集合 X ∩ Y = ∅ \mathcal{X} \cap \mathcal{Y} = \emptyset X∩Y=∅,取 a ∈ X a \in \mathcal{X} a∈X和 b ∈ Y b \in \mathcal{Y} b∈Y。因为我们假设 X ∩ Y = ∅ \mathcal{X} \cap \mathcal{Y} = \emptyset X∩Y=∅,在图3中连接 a a a和 b b b的线段需要包含一部分既不在 X \mathcal{X} X也不在 Y \mathcal{Y} Y中。因此线段也不在 X ∪ Y \mathcal{X} \cup \mathcal{Y} X∪Y中,因此证明了凸集的并集不一定是凸的,即非凸(nonconvex)的。

通常,深度学习中的问题是在凸集上定义的。例如, R d \mathbb{R}^d Rd,即实数的 d d d-维向量的集合是凸集(毕竟 R d \mathbb{R}^d Rd中任意两点之间的线存在 R d \mathbb{R}^d Rd)中。在某些情况下,我们使用有界长度的变量,例如球的半径定义为 { x ∣ x ∈ R d 且 ∥ x ∥ ≤ r } \{\mathbf{x} | \mathbf{x} \in \mathbb{R}^d \text{ 且 } \| \mathbf{x} \| \leq r\} {x∣x∈Rd 且 ∥x∥≤r}。
(二)凸函数
现在我们有了凸集,我们可以引入凸函数(convex function) f f f。给定一个凸集 X \mathcal{X} X,如果对于所有 x , x ′ ∈ X x, x' \in \mathcal{X} x,x′∈X和所有 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1],函数 f : X → R f: \mathcal{X} \to \mathbb{R} f:X→R是凸的,我们可以得到
λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≥ f ( λ x + ( 1 − λ ) x ′ ) (2) \lambda f(x) + (1-\lambda) f(x') \geq f(\lambda x + (1-\lambda) x') \tag{2} λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)(2)
为了说明这一点,让我们绘制一些函数并检查哪些函数满足要求。下面我们定义一些函数,包括凸函数和非凸函数。
f = lambda x: 0.5 * x**2 # 凸函数
g = lambda x: torch.cos(np.pi * x) # 非凸函数
h = lambda x: torch.exp(0.5 * x) # 凸函数x, segment = torch.arange(-2, 2, 0.01), torch.tensor([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3))
for ax, func in zip(axes, [f, g, h]):d2l.plot([x, segment], [func(x), func(segment)], axes=ax)
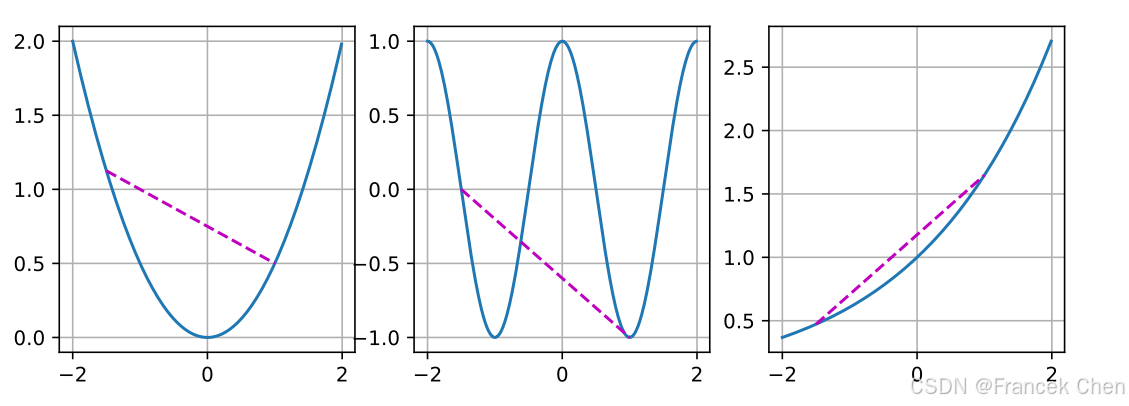
不出所料,余弦函数为非凸的,而抛物线函数和指数函数为凸的。请注意,为使该条件有意义, X \mathcal{X} X是凸集的要求是必要的。否则可能无法很好地界定 f ( λ x + ( 1 − λ ) x ′ ) f(\lambda x + (1-\lambda) x') f(λx+(1−λ)x′)的结果。
(三)詹森不等式
给定一个凸函数 f f f,最有用的数学工具之一就是詹森不等式(Jensen’s inequality)。它是凸性定义的一种推广:
∑ i α i f ( x i ) ≥ f ( ∑ i α i x i ) 且 E X [ f ( X ) ] ≥ f ( E X [ X ] ) (3) \sum_i \alpha_i f(x_i) \geq f\left(\sum_i \alpha_i x_i\right) \text{ 且 } E_X[f(X)] \geq f\left(E_X[X]\right) \tag{3} i∑αif(xi)≥f(i∑αixi) 且 EX[f(X)]≥f(EX[X])(3) 其中, α i \alpha_i αi是满足 ∑ i α i = 1 \sum_i \alpha_i = 1 ∑iαi=1的非负实数, X X X是随机变量。换句话说,凸函数的期望不小于期望的凸函数,其中后者通常是一个更简单的表达式。为了证明第一个不等式,我们多次将凸性的定义应用于一次求和中的一项。
詹森不等式的一个常见应用:用一个较简单的表达式约束一个较复杂的表达式。例如,它可以应用于部分观察到的随机变量的对数似然。具体地说,由于 ∫ P ( Y ) P ( X ∣ Y ) d Y = P ( X ) \int P(Y) P(X \mid Y) dY = P(X) ∫P(Y)P(X∣Y)dY=P(X),所以
E Y ∼ P ( Y ) [ − log P ( X ∣ Y ) ] ≥ − log P ( X ) (4) E_{Y \sim P(Y)}[-\log P(X \mid Y)] \geq -\log P(X) \tag{4} EY∼P(Y)[−logP(X∣Y)]≥−logP(X)(4) 其中, Y Y Y是典型的未观察到的随机变量, P ( Y ) P(Y) P(Y)是它可能如何分布的最佳猜测, P ( X ) P(X) P(X)是将 Y Y Y积分后的分布。例如,在聚类中 Y Y Y可能是簇标签,而在应用簇标签时, P ( X ∣ Y ) P(X \mid Y) P(X∣Y)是生成模型。
二、性质
下面我们来看一下凸函数一些有趣的性质。
(一)局部极小值是全局极小值
首先凸函数的局部极小值也是全局极小值。下面我们用反证法给出证明。
假设 x ∗ ∈ X x^{\ast} \in \mathcal{X} x∗∈X是一个局部最小值,则存在一个很小的正值 p p p,使得当 x ∈ X x \in \mathcal{X} x∈X满足 0 < ∣ x − x ∗ ∣ ≤ p 0 < |x - x^{\ast}| \leq p 0<∣x−x∗∣≤p时,有 f ( x ∗ ) < f ( x ) f(x^{\ast}) < f(x) f(x∗)<f(x)。
现在假设局部极小值 x ∗ x^{\ast} x∗不是 f f f的全局极小值:存在 x ′ ∈ X x' \in \mathcal{X} x′∈X使得 f ( x ′ ) < f ( x ∗ ) f(x') < f(x^{\ast}) f(x′)<f(x∗)。则存在 λ ∈ [ 0 , 1 ) \lambda \in [0, 1) λ∈[0,1),比如 λ = 1 − p / ( x ∗ − x ′ ) \lambda = 1 - p/(x^{\ast} - x') λ=1−p/(x∗−x′),使得 0 < ∣ λ x ∗ + ( 1 − λ ) x ′ − x ∗ ∣ ≤ p 0 < |\lambda x^{\ast} + (1-\lambda) x' - x^{\ast}| \leq p 0<∣λx∗+(1−λ)x′−x∗∣≤p。
然而,根据凸性的性质,有
f ( λ x ∗ + ( 1 − λ ) x ′ ) ≤ λ f ( x ∗ ) + ( 1 − λ ) f ( x ′ ) < λ f ( x ∗ ) + ( 1 − λ ) f ( x ∗ ) = f ( x ∗ ) , (5) \begin{aligned} f(\lambda x^{\ast} + (1-\lambda) x') &\leq \lambda f(x^{\ast}) + (1-\lambda) f(x') \\ &< \lambda f(x^{\ast}) + (1-\lambda) f(x^{\ast}) \\ &= f(x^{\ast}), \\ \end{aligned} \tag{5} f(λx∗+(1−λ)x′)≤λf(x∗)+(1−λ)f(x′)<λf(x∗)+(1−λ)f(x∗)=f(x∗),(5) 这与 x ∗ x^{\ast} x∗是局部最小值相矛盾。因此,不存在 x ′ ∈ X x' \in \mathcal{X} x′∈X满足 f ( x ′ ) < f ( x ∗ ) f(x') < f(x^{\ast}) f(x′)<f(x∗)。
综上所述,局部最小值 x ∗ x^{\ast} x∗也是全局最小值。
例如,对于凸函数 f ( x ) = ( x − 1 ) 2 f(x) = (x-1)^2 f(x)=(x−1)2,有一个局部最小值 x = 1 x=1 x=1,它也是全局最小值。
f = lambda x: (x - 1) ** 2
d2l.set_figsize()
d2l.plot([x, segment], [f(x), f(segment)], 'x', 'f(x)')
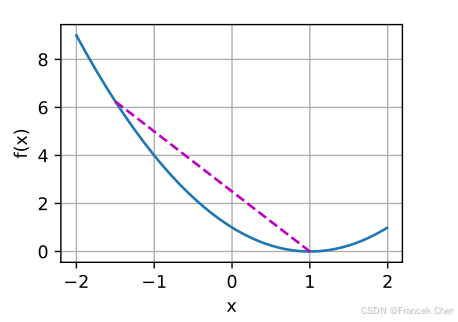
凸函数的局部极小值同时也是全局极小值这一性质是很方便的。这意味着如果我们最小化函数,我们就不会“卡住”。但是请注意,这并不意味着不能有多个全局最小值,或者可能不存在一个全局最小值。例如,函数 f ( x ) = m a x ( ∣ x ∣ − 1 , 0 ) f(x) = \mathrm{max}(|x|-1, 0) f(x)=max(∣x∣−1,0)在 [ − 1 , 1 ] [-1,1] [−1,1]区间上都是最小值。相反,函数 f ( x ) = exp ( x ) f(x) = \exp(x) f(x)=exp(x)在 R \mathbb{R} R上没有取得最小值。对于 x → − ∞ x \to -\infty x→−∞,它趋近于 0 0 0,但是没有 f ( x ) = 0 f(x) = 0 f(x)=0的 x x x。
(二)凸函数的下水平集是凸的
我们可以方便地通过凸函数的下水平集(below sets)定义凸集。具体来说,给定一个定义在凸集 X \mathcal{X} X上的凸函数 f f f,其任意一个下水平集
S b : = { x ∣ x ∈ X and f ( x ) ≤ b } (6) \mathcal{S}_b := \{x | x \in \mathcal{X} \text{ and } f(x) \leq b\} \tag{6} Sb:={x∣x∈X and f(x)≤b}(6) 是凸的。
让我们快速证明一下。对于任何 x , x ′ ∈ S b x, x' \in \mathcal{S}_b x,x′∈Sb,我们需要证明:当 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1]时, λ x + ( 1 − λ ) x ′ ∈ S b \lambda x + (1-\lambda) x' \in \mathcal{S}_b λx+(1−λ)x′∈Sb。因为 f ( x ) ≤ b f(x) \leq b f(x)≤b且 f ( x ′ ) ≤ b f(x') \leq b f(x′)≤b,所以
f ( λ x + ( 1 − λ ) x ′ ) ≤ λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≤ b (7) f(\lambda x + (1-\lambda) x') \leq \lambda f(x) + (1-\lambda) f(x') \leq b \tag{7} f(λx+(1−λ)x′)≤λf(x)+(1−λ)f(x′)≤b(7)
(三)凸性和二阶导数
当一个函数的二阶导数 f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R存在时,我们很容易检查这个函数的凸性。我们需要做的就是检查 ∇ 2 f ≥ 0 \nabla^2f \geq 0 ∇2f≥0,即对于所有 x ∈ R n \mathbf{x} \in \mathbb{R}^n x∈Rn, x ⊤ H x ≥ 0 \mathbf{x}^\top \mathbf{H} \mathbf{x} \geq 0 x⊤Hx≥0。例如,函数 f ( x ) = 1 2 ∥ x ∥ 2 f(\mathbf{x}) = \frac{1}{2} \|\mathbf{x}\|^2 f(x)=21∥x∥2是凸的,因为 ∇ 2 f ≥ 1 \nabla^2 f \geq \mathbf{1} ∇2f≥1,即其导数是单位矩阵。
更正式地讲, f f f为凸函数,当且仅当任意二次可微一维函数 f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R是凸的。对于任意二次可微多维函数 f : R n → R f: \mathbb{R}^{n} \rightarrow \mathbb{R} f:Rn→R,它是凸的当且仅当它的黑塞矩阵 ∇ 2 f ≥ 0 \nabla^2f \geq 0 ∇2f≥0。
首先,我们来证明一下一维情况。为了证明凸函数的 f ′ ′ ( x ) ≥ 0 f''(x) \geq 0 f′′(x)≥0,我们使用:
1 2 f ( x + ϵ ) + 1 2 f ( x − ϵ ) ≥ f ( x + ϵ 2 + x − ϵ 2 ) = f ( x ) (8) \frac{1}{2} f(x + \epsilon) + \frac{1}{2} f(x - \epsilon) \geq f\left(\frac{x + \epsilon}{2} + \frac{x - \epsilon}{2}\right) = f(x) \tag{8} 21f(x+ϵ)+21f(x−ϵ)≥f(2x+ϵ+2x−ϵ)=f(x)(8) 因为二阶导数是由有限差分的极限给出的,所以遵循
f ′ ′ ( x ) = lim ϵ → 0 f ( x + ϵ ) + f ( x − ϵ ) − 2 f ( x ) ϵ 2 ≥ 0 (9) f''(x) = \lim_{\epsilon \to 0} \frac{f(x+\epsilon) + f(x - \epsilon) - 2f(x)}{\epsilon^2} \geq 0 \tag{9} f′′(x)=ϵ→0limϵ2f(x+ϵ)+f(x−ϵ)−2f(x)≥0(9) 为了证明 f ′ ′ ≥ 0 f'' \geq 0 f′′≥0可以推导 f f f是凸的,我们使用这样一个事实: f ′ ′ ≥ 0 f'' \geq 0 f′′≥0意味着 f ′ f' f′是一个单调的非递减函数。假设 a < x < b a < x < b a<x<b是 R \mathbb{R} R中的三个点,其中, x = ( 1 − λ ) a + λ b x = (1-\lambda)a + \lambda b x=(1−λ)a+λb且 λ ∈ ( 0 , 1 ) \lambda \in (0, 1) λ∈(0,1).根据中值定理,存在 α ∈ [ a , x ] \alpha \in [a, x] α∈[a,x], β ∈ [ x , b ] \beta \in [x, b] β∈[x,b],使得
f ′ ( α ) = f ( x ) − f ( a ) x − a 且 f ′ ( β ) = f ( b ) − f ( x ) b − x (10) f'(\alpha) = \frac{f(x) - f(a)}{x-a} \text{ 且 } f'(\beta) = \frac{f(b) - f(x)}{b-x} \tag{10} f′(α)=x−af(x)−f(a) 且 f′(β)=b−xf(b)−f(x)(10) 由于单调性 f ′ ( β ) ≥ f ′ ( α ) f'(\beta) \geq f'(\alpha) f′(β)≥f′(α),因此
x − a b − a f ( b ) + b − x b − a f ( a ) ≥ f ( x ) (11) \frac{x-a}{b-a}f(b) + \frac{b-x}{b-a}f(a) \geq f(x) \tag{11} b−ax−af(b)+b−ab−xf(a)≥f(x)(11) 由于 x = ( 1 − λ ) a + λ b x = (1-\lambda)a + \lambda b x=(1−λ)a+λb,所以
λ f ( b ) + ( 1 − λ ) f ( a ) ≥ f ( ( 1 − λ ) a + λ b ) (12) \lambda f(b) + (1-\lambda)f(a) \geq f((1-\lambda)a + \lambda b) \tag{12} λf(b)+(1−λ)f(a)≥f((1−λ)a+λb)(12) 从而证明了凸性。
其次,我们需要一个引理证明多维情况: f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R是凸的当且仅当对于所有 x , y ∈ R n \mathbf{x}, \mathbf{y} \in \mathbb{R}^n x,y∈Rn,
g ( z ) = d e f f ( z x + ( 1 − z ) y ) ,其中 z ∈ [ 0 , 1 ] (13) g(z) \stackrel{\mathrm{def}}{=} f(z \mathbf{x} + (1-z) \mathbf{y}) ,其中 z \in [0,1] \tag{13} g(z)=deff(zx+(1−z)y),其中z∈[0,1](13) 是凸的。
为了证明 f f f的凸性意味着 g g g是凸的,我们可以证明,对于所有的 a , b , λ ∈ [ 0 , 1 ] a,b,\lambda \in[0,1] a,b,λ∈[0,1](这样有 0 ≤ λ a + ( 1 − λ ) b ≤ 1 0 \leq \lambda a + (1-\lambda) b \leq 1 0≤λa+(1−λ)b≤1),
g ( λ a + ( 1 − λ ) b ) = f ( ( λ a + ( 1 − λ ) b ) x + ( 1 − λ a − ( 1 − λ ) b ) y ) = f ( λ ( a x + ( 1 − a ) y ) + ( 1 − λ ) ( b x + ( 1 − b ) y ) ) ≤ λ f ( a x + ( 1 − a ) y ) + ( 1 − λ ) f ( b x + ( 1 − b ) y ) = λ g ( a ) + ( 1 − λ ) g ( b ) (14) \begin{aligned} &g(\lambda a + (1-\lambda) b)\\ =&f\left(\left(\lambda a + (1-\lambda) b\right)\mathbf{x} + \left(1-\lambda a - (1-\lambda) b\right)\mathbf{y} \right)\\ =&f\left(\lambda \left(a \mathbf{x} + (1-a) \mathbf{y}\right) + (1-\lambda) \left(b \mathbf{x} + (1-b) \mathbf{y}\right) \right)\\ \leq& \lambda f\left(a \mathbf{x} + (1-a) \mathbf{y}\right) + (1-\lambda) f\left(b \mathbf{x} + (1-b) \mathbf{y}\right) \\ =& \lambda g(a) + (1-\lambda) g(b) \end{aligned} \tag{14} ==≤=g(λa+(1−λ)b)f((λa+(1−λ)b)x+(1−λa−(1−λ)b)y)f(λ(ax+(1−a)y)+(1−λ)(bx+(1−b)y))λf(ax+(1−a)y)+(1−λ)f(bx+(1−b)y)λg(a)+(1−λ)g(b)(14) 为了证明这一点,我们可以证明对 [ 0 , 1 ] [0,1] [0,1]中所有的 λ \lambda λ,
f ( λ x + ( 1 − λ ) y ) = g ( λ ⋅ 1 + ( 1 − λ ) ⋅ 0 ) ≤ λ g ( 1 ) + ( 1 − λ ) g ( 0 ) = λ f ( x ) + ( 1 − λ ) f ( y ) (15) \begin{aligned} &f(\lambda \mathbf{x} + (1-\lambda) \mathbf{y})\\ =&g(\lambda \cdot 1 + (1-\lambda) \cdot 0)\\ \leq& \lambda g(1) + (1-\lambda) g(0) \\ =& \lambda f(\mathbf{x}) + (1-\lambda) f(\mathbf{y}) \end{aligned} \tag{15} =≤=f(λx+(1−λ)y)g(λ⋅1+(1−λ)⋅0)λg(1)+(1−λ)g(0)λf(x)+(1−λ)f(y)(15)
最后,利用上面的引理和一维情况的结果,我们可以证明多维情况:多维函数 f : R n → R f:\mathbb{R}^n\rightarrow\mathbb{R} f:Rn→R是凸函数,当且仅当 g ( z ) = d e f f ( z x + ( 1 − z ) y ) g(z) \stackrel{\mathrm{def}}{=} f(z \mathbf{x} + (1-z) \mathbf{y}) g(z)=deff(zx+(1−z)y)是凸的,这里 z ∈ [ 0 , 1 ] z \in [0,1] z∈[0,1], x , y ∈ R n \mathbf{x}, \mathbf{y} \in \mathbb{R}^n x,y∈Rn。根据一维情况,此条成立的条件为,当且仅当对于所有 x , y ∈ R n \mathbf{x}, \mathbf{y} \in \mathbb{R}^n x,y∈Rn, g ′ ′ = ( x − y ) ⊤ H ( x − y ) ≥ 0 g'' = (\mathbf{x} - \mathbf{y})^\top \mathbf{H}(\mathbf{x} - \mathbf{y}) \geq 0 g′′=(x−y)⊤H(x−y)≥0( H = d e f ∇ 2 f \mathbf{H} \stackrel{\mathrm{def}}{=} \nabla^2f H=def∇2f)。这相当于根据半正定矩阵的定义, H ≥ 0 \mathbf{H} \geq 0 H≥0。
三、约束
凸优化的一个很好的特性是能够让我们有效地处理约束(constraints)。即它使我们能够解决以下形式的约束优化(constrained optimization)问题:
m i n i m i z e x f ( x ) 使得所有 i ∈ { 1 , … , N } , 满足 c i ( x ) ≤ 0 (16) \begin{aligned} &\mathop{\mathrm{minimize~}}\limits_{\mathbf{x}} f(\mathbf{x}) \\ &\text{ 使得所有 } i \in \{1, \ldots, N\} , \text{ 满足 } c_i(\mathbf{x}) \leq 0 \end{aligned} \tag{16} xminimize f(x) 使得所有 i∈{1,…,N}, 满足 ci(x)≤0(16)
这里 f f f是目标函数, c i c_i ci是约束函数。例如第一个约束 c 1 ( x ) = ∥ x ∥ 2 − 1 c_1(\mathbf{x}) = \|\mathbf{x}\|_2 - 1 c1(x)=∥x∥2−1,则参数 x \mathbf{x} x被限制为单位球。如果第二个约束 c 2 ( x ) = v ⊤ x + b c_2(\mathbf{x}) = \mathbf{v}^\top \mathbf{x} + b c2(x)=v⊤x+b,那么这对应于半空间上所有的 x \mathbf{x} x。同时满足这两个约束等于选择一个球的切片作为约束集。
(一)拉格朗日函数
通常,求解一个有约束的优化问题是困难的,解决这个问题的一种方法来自物理中相当简单的直觉。想象一个球在一个盒子里,球会滚到最低的地方,重力将与盒子两侧对球施加的力平衡。简而言之,目标函数(即重力)的梯度将被约束函数的梯度所抵消(由于墙壁的“推回”作用,需要保持在盒子内)。请注意,任何不起作用的约束(即球不接触壁)都将无法对球施加任何力。
这里我们简略拉格朗日函数 L L L的推导,上述推理可以通过以下鞍点优化问题来表示:
L ( x , α 1 , … , α n ) = f ( x ) + ∑ i = 1 n α i c i ( x ) , 其中 α i ≥ 0 (17) L(\mathbf{x}, \alpha_1, \ldots, \alpha_n) = f(\mathbf{x}) + \sum_{i=1}^n \alpha_i c_i(\mathbf{x}) ,\text{ 其中 } \alpha_i \geq 0 \tag{17} L(x,α1,…,αn)=f(x)+i=1∑nαici(x), 其中 αi≥0(17)
这里的变量 α i \alpha_i αi( i = 1 , … , n i=1,\ldots,n i=1,…,n)是所谓的拉格朗日乘数(Lagrange multipliers),它确保约束被正确地执行。选择它们的大小足以确保所有 i i i的 c i ( x ) ≤ 0 c_i(\mathbf{x}) \leq 0 ci(x)≤0。例如,对于 c i ( x ) < 0 c_i(\mathbf{x}) < 0 ci(x)<0中任意 x \mathbf{x} x,我们最终会选择 α i = 0 \alpha_i = 0 αi=0。此外,这是一个鞍点(saddlepoint)优化问题。在这个问题中,我们想要使 L L L相对于 α i \alpha_i αi最大化(maximize),同时使它相对于 x \mathbf{x} x最小化(minimize)。有大量的文献解释如何得出函数 L ( x , α 1 , … , α n ) L(\mathbf{x}, \alpha_1, \ldots, \alpha_n) L(x,α1,…,αn)。我们这里只需要知道 L L L的鞍点是原始约束优化问题的最优解就足够了。
(二)惩罚
一种至少近似地满足约束优化问题的方法是采用拉格朗日函数 L L L。除了满足 c i ( x ) ≤ 0 c_i(\mathbf{x}) \leq 0 ci(x)≤0之外,我们只需将 α i c i ( x ) \alpha_i c_i(\mathbf{x}) αici(x)添加到目标函数 f ( x ) f(x) f(x)。这样可以确保不会严重违反约束。
事实上,我们一直在使用这个技巧。比如权重衰减,在目标函数中加入 λ 2 ∣ w ∣ 2 \frac{\lambda}{2} |\mathbf{w}|^2 2λ∣w∣2,以确保 w \mathbf{w} w不会增长太大。使用约束优化的观点,我们可以看到,对于若干半径 r r r,这将确保 ∣ w ∣ 2 − r 2 ≤ 0 |\mathbf{w}|^2 - r^2 \leq 0 ∣w∣2−r2≤0。通过调整 λ \lambda λ的值,我们可以改变 w \mathbf{w} w的大小。
通常,添加惩罚是确保近似满足约束的一种好方法。在实践中,这被证明比精确的满意度更可靠。此外,对于非凸问题,许多使精确方法在凸情况下的性质(例如,可求最优解)不再成立。
(三)投影
满足约束条件的另一种策略是投影(projections)。同样,我们之前也遇到过,例如在循环神经网络的从零开始实现中处理梯度截断时,我们通过
g ← g ⋅ m i n ( 1 , θ / ∥ g ∥ ) (18) \mathbf{g} \leftarrow \mathbf{g} \cdot \mathrm{min}(1, \theta/\|\mathbf{g}\|) \tag{18} g←g⋅min(1,θ/∥g∥)(18) 确保梯度的长度以 θ \theta θ为界限。
这就是 g \mathbf{g} g在半径为 θ \theta θ的球上的投影(projection)。更泛化地说,在凸集 X \mathcal{X} X上的投影被定义为
P r o j X ( x ) = a r g m i n x ′ ∈ X ∥ x − x ′ ∥ (19) \mathrm{Proj}_\mathcal{X}(\mathbf{x}) = \mathop{\mathrm{argmin}}\limits_{\mathbf{x}' \in \mathcal{X}} \|\mathbf{x} - \mathbf{x}'\| \tag{19} ProjX(x)=x′∈Xargmin∥x−x′∥(19) 它是 X \mathcal{X} X中离 X \mathbf{X} X最近的点。

投影的数学定义听起来可能有点抽象,为了解释得更清楚一些,请看图4。图中有两个凸集,一个圆和一个菱形。两个集合内的点(黄色)在投影期间保持不变。两个集合(黑色)之外的点投影到集合中接近原始点(黑色)的点(红色)。虽然对 L 2 L_2 L2的球面来说,方向保持不变,但一般情况下不需要这样。
凸投影的一个用途是计算稀疏权重向量。在本例中,我们将权重向量投影到一个 L 1 L_1 L1的球上,这是图4中菱形例子的一个广义版本。
小结
在深度学习的背景下,凸函数的主要目的是帮助我们详细了解优化算法。我们由此得出梯度下降法和随机梯度下降法是如何相应推导出来的。
- 凸集的交点是凸的,并集不是。
- 根据詹森不等式,“一个多变量凸函数的总期望值”大于或等于“用每个变量的期望值计算这个函数的总值“。
- 一个二次可微函数是凸函数,当且仅当其Hessian(二阶导数矩阵)是半正定的。
- 凸约束可以通过拉格朗日函数来添加。在实践中,只需在目标函数中加上一个惩罚就可以了。
- 投影映射到凸集中最接近原始点的点。
相关文章:
【深度学习优化算法】02:凸性
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

JAVA国际版一对一视频交友视频聊天系统源码支持H5+APP
全球畅连无界社交:JAVA国际版一对一视频交友系统源码(H5APP双端覆盖) 在全球化社交需求激增的今天,构建一个支持多语言、适配国际支付且功能丰富的视频交友平台,成为出海创业者和企业的核心诉求。JAVA国际版一对一视频…...
策略公开了:年化494%,夏普比率5.86,最大回撤7% | 大模型查询akshare,附代码
原创内容第907篇,专注智能量化投资、个人成长与财富自由。 这位兄弟的策略公开了,年化494%,夏普比率5.86,最大回撤7%,欢迎大家前往围观: http://www.ailabx.com/strategy/683ed10bdabe146c4c0b2293 系统代…...
)
【C++】string类的模拟实现(详解)
文章目录 上文链接一、整体框架二、构造函数1. default2. copy3. range 三、析构函数四、拷贝构造(1) 传统写法(2) 现代写法 五、赋值重载(1) 传统写法(2) 现代写法 六、获取元素1. operator[ ] 七、迭代器1. begin2. end 八、容量相关1. size2. reserve3. clear 九、修改操作1…...

业界宽松内存模型的不统一而导致的软件问题, gcc, linux kernel, JVM
当不同CPU厂商未能就统一的宽松内存模型(Relaxed Memory Model)达成一致,很多软件的可移植性会收到限制或损害,主要体现在以下几个方面: 1. 可能的理论限制 1.1. 并发程序的行为不一致 现象上,同一段多线程…...

多模态大语言模型arxiv论文略读(101)
ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2 ➡️ 论文标题:ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2 ➡️ 论文作者:Wenjun Huang, Jiakai Pan, Jiahao Tang, Yanyu Ding, Yifei Xing, …...
的XOR异或pyTorch版250501)
量化Quantization初步之--带量化(QAT)的XOR异或pyTorch版250501
量化(Quantization)这词儿听着玄,经常和量化交易Quantitative Trading (量化交易)混淆。 其实机器学习(深度学习)领域的量化Quantization是和节约内存、提高运算效率相关的概念(因大模型的普及,这个量化问题尤为迫切)。 揭秘机器…...

Linux Maven Install
在 CentOS(例如 CentOS 7 或 CentOS 8)中安装 Maven(Apache Maven)的方法主要有两种:使用包管理器(简单但可能版本较旧),或者手动安装(推荐,可获得最新版&…...

#Java篇:学习node后端之sql常用操作
学习路线 1、javascript基础; 2、nodejs核心模块 fs: 文件系统操作 path: 路径处理 http / https: 创建服务器或发起请求 events: 事件机制(EventEmitter) stream: 流式数据处理 buffer: 处理二进制数据 os: 获取操作系统信息 util: 工具方…...
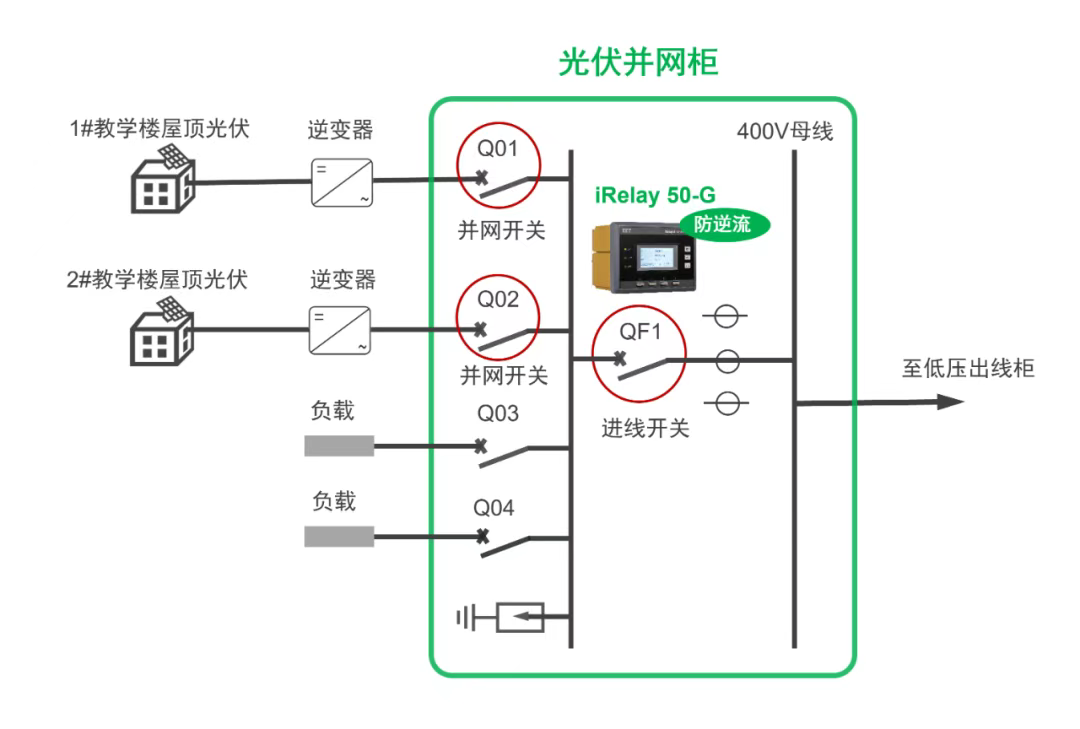
电网“逆流”怎么办?如何实现分布式光伏发电全部自发自用?
2024年10月9日,国家能源局综合司发布了《分布式光伏发电开发建设管理办法(征求意见稿)》,意见稿规定了户用分布式光伏、一般工商业分布式光伏以及大型工商业分布式光伏的发电上网模式,当选择全部自发自用模式时&#x…...
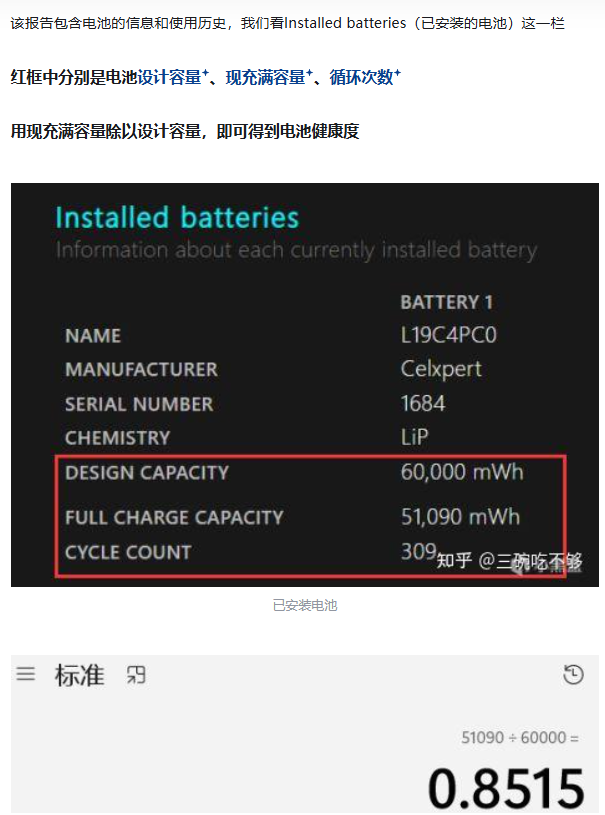
如何查看电脑电池性能
检查电脑电池性能的方法如下: 按下winR键,输入cmd回车,进入命令行窗口 在命令行窗口输入powercfg /batteryreport 桌面双击此电脑,把刚刚复制的路径粘贴到文件路径栏,然后回车 回车后会自动用浏览器打开该报告 红…...
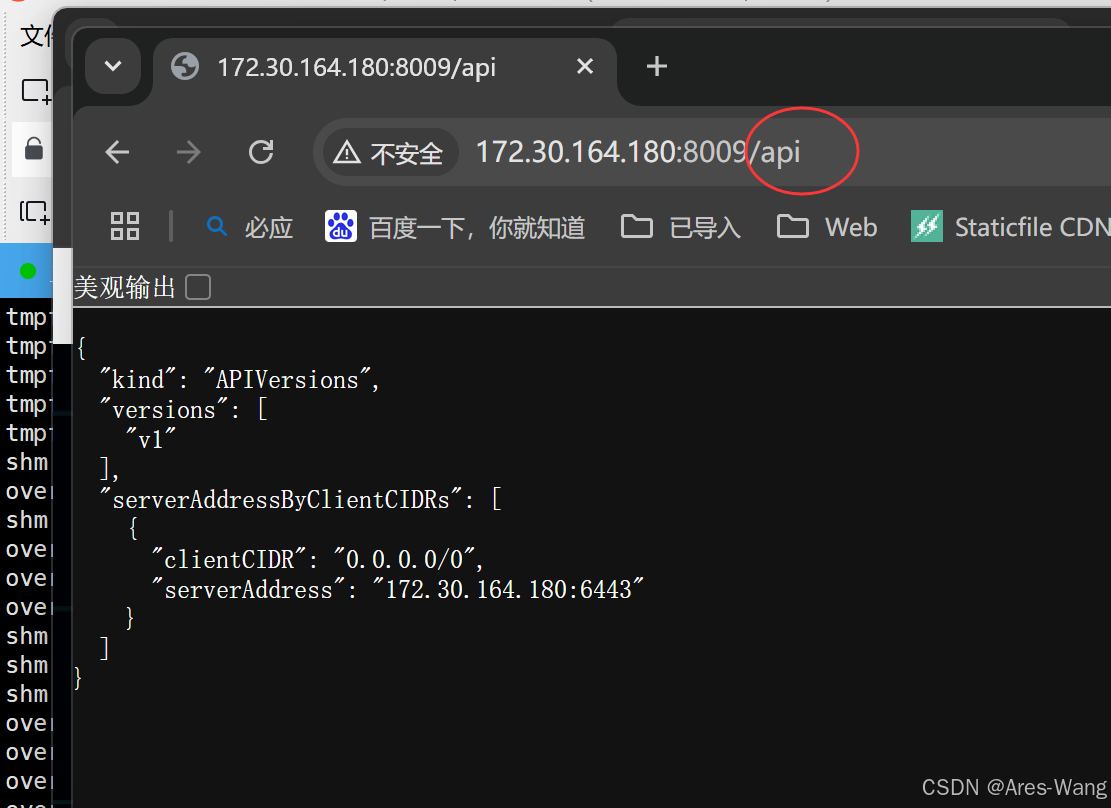
kubernetes》》k8s》》kubectl proxy 命令后面加一个
命令后面加一个& 在Linux终端中,如果在命令的末尾加上一个&符号,这表示将这个任务放到后台去执行 kubectl proxy 官网资料 是 Kubernetes 提供的一个命令行工具,用于在本地和 Kubernetes API Server 之间创建一个安全的代理通道。…...

深入理解Linux系统进程切换
目录 引言 一、什么是进程切换? 二、进程切换的触发条件 三、进程切换的详细步骤 1、保存当前进程上下文: 2、更新进程控制块(PCB): 3、选择下一个进程: 4、恢复新进程上下文: 5、切换地址空间: 6…...

网络安全运维实训室建设方案
一、网络安全运维人才需求与实训困境 在数字化时代,网络安全已成为国家安全、社会稳定和经济发展的重要基石。随着信息技术的飞速发展,网络安全威胁日益复杂多样,从个人隐私泄露到企业商业机密被盗,从关键基础设施遭受攻击到社会…...
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required 一、必须要看这个 >> :参考文献 二、补充 2.1 说明 MySQL5、6这些版本比较老,而DBeaver默认下载的是MySQL8的连接库,所以连接旧版本mysql报错:CLIEN…...

联通专线赋能,亿林网络裸金属服务器:中小企业 IT 架构升级优选方案
在当今数字化飞速发展的时代,中小企业面临着日益增长的业务需求与复杂多变的市场竞争环境。如何构建高效、稳定且具性价比的 IT 架构,成为众多企业突破发展瓶颈的关键所在。而亿林网络推出的 24 核 32G 裸金属服务器,搭配联通专线的千兆共享带…...

Web3时代的数据保护挑战与应对策略
随着互联网技术的飞速发展,我们正步入Web3时代,这是一个以去中心化、用户主权和数据隐私为核心的新时代。然而,Web3时代也带来了前所未有的数据保护挑战。本文将探讨这些挑战,并提出相应的应对策略。 数据隐私挑战 在Web3时代&a…...

Qwen3与MCP协议:重塑大气科学的智能研究范式
在气象研究领域,从海量数据的解析到复杂气候模型的构建,科研人员长期面临效率低、门槛高、易出错的挑战。而阿里云推出的Qwen3大模型与MCP协议的结合,正通过混合推理模式与标准化协同机制,为大气科学注入全新活力。本文将深入解析…...

CppCon 2015 学习:Benchmarking C++ Code
关于性能问题与调试传统 bug(如段错误)之间差异的分析。以下是对这一页内容的详细解释: 主题:传统问题(如段错误)调试流程清晰 问题类型:段错误(Segmentation Fault) …...
的认识)
URL 结构说明+路由(接口)的认识
一、URL 结构说明 以这个为例:http://127.0.0.1:5000/zhouleifeng 1.组成部分: http://:协议 127.0.0.1:主机(本地地址) :5000:端口号(Flask 默认 5000) /zhouleifeng:…...

省赛中药检测模型调优
目录 一、baseline性能二、baseline DETR head三、baseline RepC3K2四、baseline RepC3K2 SimSPPF五、baseline RepC3K2 SimSPPF LK-C2PSA界面1.引入库2.读入数据 总结 一、baseline性能 Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size120/120 …...
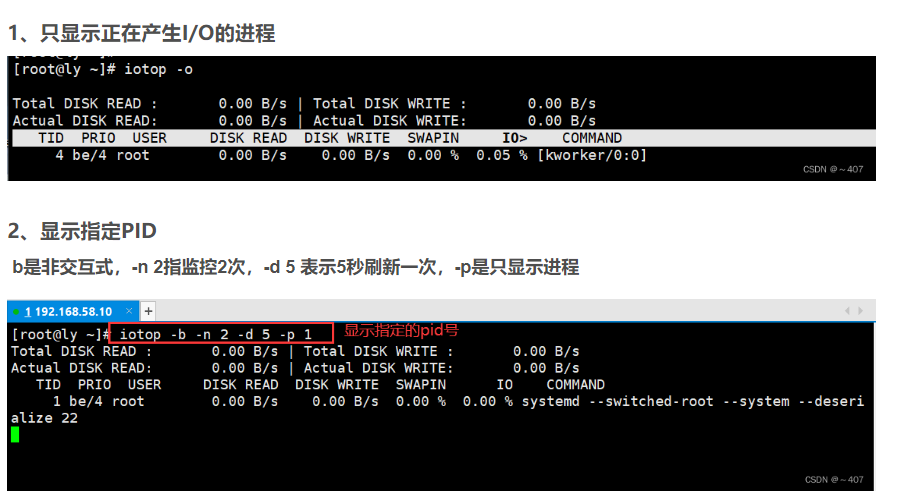
linux 故障处置通用流程-36计+1计
通用标准处置快速索引 编号 通 用 标 准 处 置 索 引 001 Linux操作系统标准关闭 002 Linux操作系统标准重启 003 Linux操作系统强行关闭 004 Linux操作系统强行重启 005 检查Linux操作系统CPU负载 006 查询占用CPU资源最多的进程 007 检查Linux操…...
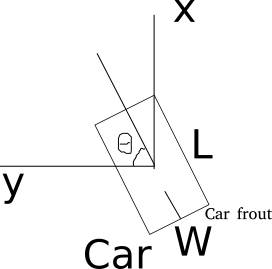
BEV和OCC学习-3:mmdet3d 坐标系
目录 坐标系 转向角 (yaw) 的定义 框尺寸的定义 与支持的数据集的原始坐标系的关系 KITTI Waymo NuScenes Lyft ScanNet SUN RGB-D S3DIS 坐标系 坐标系 — MMDetection3D 1.4.0 文档https://mmdetection3d.readthedocs.io/zh-cn/latest/user_guides/coord_sys_tuto…...
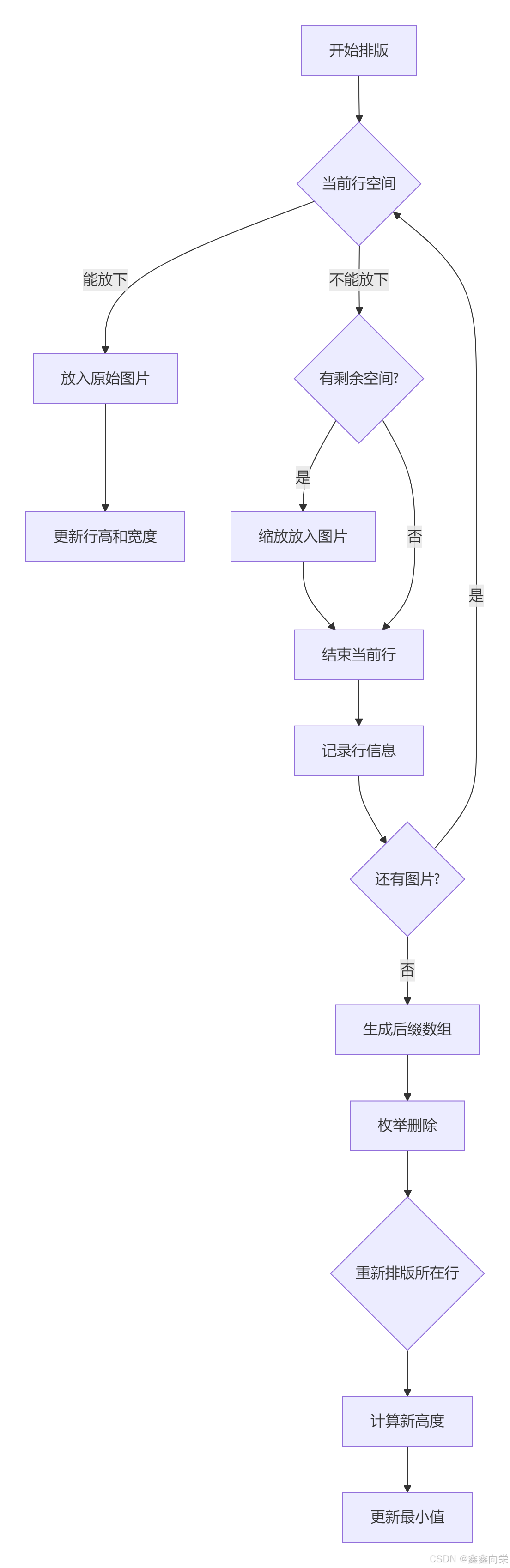
[蓝桥杯]图形排版
图形排版 题目描述 小明需要在一篇文档中加入 NN 张图片,其中第 ii 张图片的宽度是 WiWi,高度是 HiHi。 假设纸张的宽度是 MM,小明使用的文档编辑工具会用以下方式对图片进行自动排版: 1. 该工具会按照图片顺序࿰…...

【Linux仓库】冯诺依曼体系结构与操作系统【进程·壹】
🌟 各位看官好,我是! 🌍 Linux Linux is not Unix ! 🚀 今天来学习冯诺依曼体系结构与操作系统。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦࿰…...
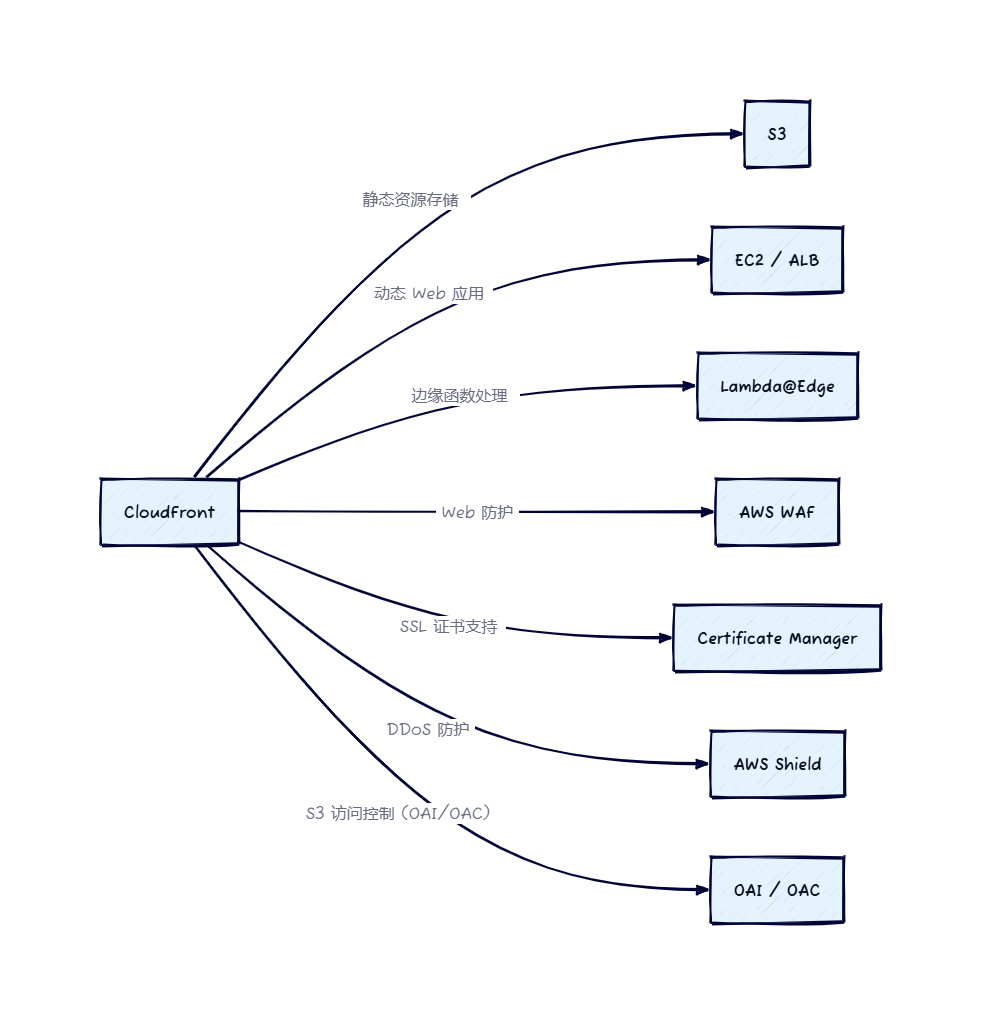
CloudFront 加速详解:AWS CDN 怎么用?
让全球访问更快速稳定,深入解读 AWS 的内容分发网络 在上一篇中,我们介绍了 Amazon S3 对象存储,它非常适合托管静态资源,比如图片、视频、网页等。但你可能遇到过这样的问题: “我把网站静态文件部署到了 S3…...

《高级架构师》------- 考后感想
笔者来聊一下架构师考后的感想 复习备考 考前过了很多知识点,只是蜻蜓点水,没有起到复习的作用,即使考出来也不会,下次复习注意这个,复习到了,就记住,或者画出来,或者文件总结&…...
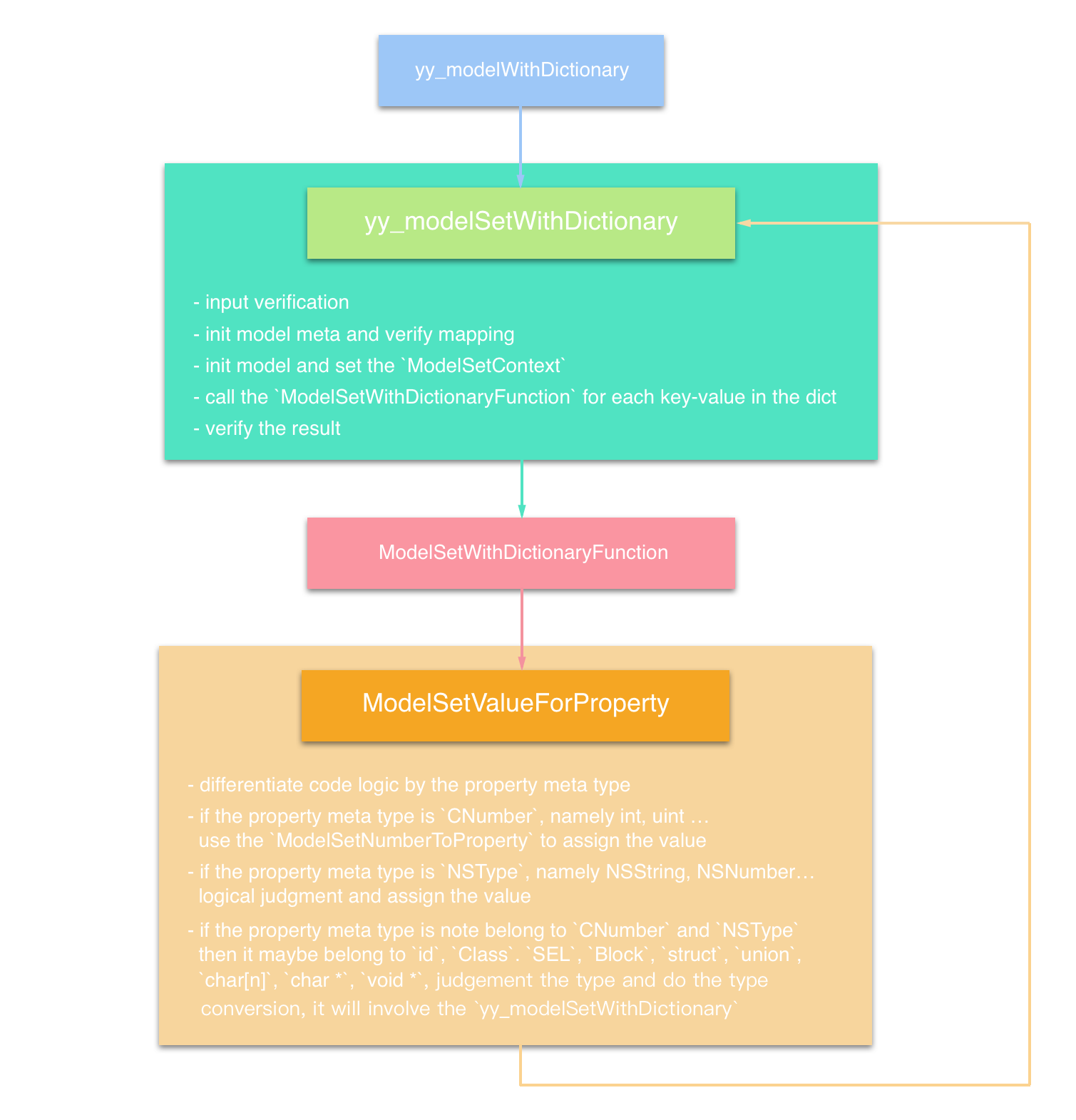
【iOS】YYModel源码解析
YYModel源码解析 文章目录 YYModel源码解析前言YYModel性能优势YYModel简介YYClassInfo解析YYClassIvarInfo && objc_ivarYYClassMethodInfo && objc_methodYYClassPropertyInfo && property_tYYClassInfo && objc_class YYClassInfo的初始化细…...

C++算法训练营 Day6 哈希表(1)
1.有效的字母异位词 LeetCode:242.有效的字母异位词 给定两个字符串s和t ,编写一个函数来判断t是否是s的字母异位词。 示例 1: 输入: s “anagram”, t “nagaram” 输出: true 示例 2: 输入: s “rat”, t “car” 输出: false 解题思路ÿ…...
【C语言编译与链接】--翻译环境和运行环境,预处理,编译,汇编,链接
目录 一.翻译环境和运行环境 二.翻译环境 2.1--预处理(预编译) 2.2--编译 2.2.1--词法分析 2.2.2--语法分析 2.2.3--语义分析 2.3--汇编 2.4--链接 三.运行环境 🔥个人主页:草莓熊Lotso的个人主页 🎬作者简介:C研发…...