【C++】string类的模拟实现(详解)
文章目录
- 上文链接
- 一、整体框架
- 二、构造函数
- 1. default
- 2. copy
- 3. range
- 三、析构函数
- 四、拷贝构造
- (1) 传统写法
- (2) 现代写法
- 五、赋值重载
- (1) 传统写法
- (2) 现代写法
- 六、获取元素
- 1. operator[ ]
- 七、迭代器
- 1. begin
- 2. end
- 八、容量相关
- 1. size
- 2. reserve
- 3. clear
- 九、修改操作
- 1. push_back
- 2. append
- 3. operator+=(常用)
- 4. insert
- 5. erase
- 6. swap
- 十、字符串的其他操作
- 1. c_str
- 2. find
- 3. substr
- 4. 字符串的比较
- (1) operator<
- (2) operator==
- (3) operator<=
- (4) operator>
- (5) operator>=
- (6) operator!=
- 十一、非成员函数
- 1. operator<<
- 2. operator>>
- 十二、引用计数的写时拷贝
- 十三、完整代码
- 1. string.h
- 2. string.cpp
上文链接
- 【C++】string类的使用(万字详解)
一、整体框架
我们模拟 C++ 库中的 string 类来实现一个自己的 string 类,因此为了避免使用时与库中的 string 重名,所以我们将其定义在一个叫 mine 的命名空间中。私有成员变量中包含三个值 _str、_size、_capacity,分别对应指向字符串数组的指针、实际存储的字符串的大小以及开辟的总空间大小。
注意:
_size和_capacity在==计算大小时均不计算结尾的\0==。
namespace mine
{class string{public:// 成员函数的实现private:// 可以把缺省值给上char* _str = nullptr;size_t _size = 0;size_t _capacity = 0;}
}
二、构造函数
1. default
我们可以创建一个空的字符串,由于没有存储任何有效字符,所以我们的字符串只包含一个 \0(注意 _str 不是 nullptr)。
// 像构造函数这些函数属于高频常用的函数,考虑放在类中作为内联函数
// string.h
string():_str(new char('\0')),_size(0),_capacity(0)
{}
2. copy
我们也可以用一个常量字符串来初始化我们的 string 对象,即把常量字符串的内容拷贝给我们的 _str。
注意我们实际开空间的时候是开这个常量字符串的长度 + 1个长度,因为末尾还有一个 \0。只不过我们的 _size 和 _capacity 在计算大小的时候不包含这个末尾的 \0。
string(const char* str):_str(new char[strlen(str)] + 1) ,_size(strlen(str)),_capacity(strlen(str))
{}
上面这种写法从语法上是没问题的,但是我们调用了三次 strlen 函数,它的时间复杂度为 O ( n ) O(n) O(n),效率非常低。所以我们为了避免重复调用该函数,我们可以选择用已经初始化好的变量去初始化另外的变量。
下面的写法是否可行?
string(const char* str): _size(strlen(str)), _str(new char[_size] + 1), _capacity(_size)
{}
不行!因为==初始化列表的初始化顺序是按照成员变量声明的顺序进行初始化的==。而我们在成员变量的声明处的顺序是 _str、_size、_capacity,因此这里初始化列表会先初始化 _str,但是此时 _size 并没有被初始化为正确的值,就会出问题。
因此,我们可以选择将 _str 和 _capacity 放在函数体中,这样就不存在顺序的问题了(尽量不去改变声明的顺序)。另外,为了更完善,我们可以给参数列表一个缺省值,const char* str = "",注意不是 nullptr,因为 strlen 会进行解引用操作。
// string.h
string(const char* str = "") :_size(strlen(str))
{_capacity = _size;_str = new char[_size + 1]; // strcpy(_str, str);memcpy(_str, str, _size + 1);
}
这里用 strcpy 不行是因为==常量字符串内部有可能包含 \0==,比如 hello\0world\0。如果用 strcpy 的话遇到第一个 \0 就结束拷贝了,因此我们需要使用 memcpy。
3. range
我们也可以采用迭代器区间的方式来构造一个对象。
template <class InputIterator>
string(InputIterator first, InputIterator last)
{while (first != last){push_back(*first);++first;}
}
三、析构函数
析构就比较简单:释放空间,置空指针,清空数据。
// string.h
~string()
{if(_str) // 如果 _str 为空,那么就不需要析构了{delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}
}
注意到我们这里的 delete 后是有方括号 [] 的,所以为了保持一致,我们最开始的构造一个空串的构造函数的 new 最好与其保持一致,也使用方括号 []。
// string.h
string()//:_str(new char('\0')):_str(new char[1]{ '\0' }),_size(0),_capacity(0)
{}
四、拷贝构造
把一个 string 对象拷贝给另一个 string 对象。注意拷贝构造我们要自己实现,因为系统默认的拷贝构造是一个浅拷贝,会导致拷贝出来的对象和原对象指向同一块空间。所以我们需要自己实现一个深拷贝。即开辟一块不同的一样大小的空间,然后进行赋值。
(1) 传统写法
在传统写法中,我们自己开空间,自己去拷贝数据。
// string.h
string(const string& s);// string.cpp
string::string(const string& s)
{_str = new char[s._capacity + 1];memcpy(_str, s._str, s._size + 1);_size = s._size;_capacity = s._capacity;
}
(2) 现代写法
现代写法就是让编译器帮我们拷贝,等一切就绪之后,我们再来一波移花接木。本质是复用构造函数。
// 现代写法
string::string(const string& s)
{// 先通过构造函数构造出一个对象string tmp(s._str);// this 原本指向空,然后让tmp和它交换swap(tmp);
}
但是上面的写法还有一点缺陷,就是当字符串内部有 \0 时会出现少拷贝的情况,因为这里构造函数的内部逻辑是构造 strlen 个长度,而 strlen 遇到 \0 就终止了。
所以我们可以考虑采用迭代区间构造的方式。
// string.cpp
string::string(const string& s)
{string tmp(s.begin(), s.end());swap(tmp);
}
五、赋值重载
(1) 传统写法
// string.h
string& operator=(string tmp);// string.cpp
string& string::operator=(const string& s)
{// 防止自己给自己赋值// 自己给自己赋值,下面的写法不会有问题,但是会做无用功// 如果最开始就先释放旧空间就会出错// 所以综上,我们判断一下if (this != &s) {char* tmp = new char[s._capacity + 1];memcpy(tmp, s._str, s._size + 1);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;}return *this; // 有返回值是为了支持连续的赋值
}
(2) 现代写法
// string.cpp
string& string::operator=(const string& s)
{if (this != &s){string tmp(s); // 复用拷贝构造swap(tmp);}return *this;
}
更简洁的写法:
string& string::operator=(string tmp) // 直接在传参的时候就用 s 拷贝出这个 tmp
{swap(tmp);return *this;
}
六、获取元素
1. operator[ ]
重载运算符 [] 通过下标访问元素。该函数分为两个版本:普通的可读可写的版本,const 修饰的只可读的版本。
// string.cpp
char& string::operator[](size_t i)
{assert(i < _size); // 注意判断 i 位置是否合法return _str[i];
}const char& string::operator[](size_t i) const
{assert(i < _size);return _str[i];
}
- 测试
// test.cpp
void test_string_1()
{string s1;cout << s1.c_str() << endl; // c_str 就是获取成员变量 _strstring s2("hello world");cout << s2.c_str() << endl;s2[0]++;for (size_t i = 0; i < s2.size(); i++){cout << s2[i] << " ";}cout << endl;const string s3("hello C++");// s3[0]++; // 会报错,因为调用的是 const 版本,不能修改
}int main()
{test_string_1();return 0;
}
- 输出
hello world
i e l l o w o r l d
七、迭代器
迭代器是类中的一个类型,它的功能类似于指针,在模拟实现上也可以用指针来实现。
typedef char* iterator;
1. begin
获取字符串第一个字符的迭代器。该函数分为两个版本,一种是普通的 iterator,另一种是 const 版本的 const_iterator。const 版本的迭代器所==“指向”的内容不可修改==。
// string.h
// 定义在类内部
typedef char* iterator;
typedef const char* const_iterator;
iterator begin();
const_iterator begin() const;// string.cpp
iterator string::begin()
{return _str;
}const_iterator string::begin() const
{return _str;
}
2. end
获取字符出最后一个字符下一个位置的迭代器。
iterator string::end()
{return _str + _size;
}const_iterator string::end() const
{return _str + _size;
}
- 测试
// test.cpp
void test_string_2()
{string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;// 只要有迭代器,就有了范围for,因为范围for相当于替换为了迭代器for (auto ch : s1){cout << ch << " ";}cout << endl;
}int main()
{test_string_2();return 0;
}
- 输出
h e l l o w o r l d
h e l l o w o r l d
八、容量相关
1. size
获取字符串的长度。由于我们不会去修改任何数据,所以考虑将其设计为 const 成员函数。
// string.cpp
size_t string::size() const
{return _size;
}
2. reserve
传入一个参数 n,该函数会将字符串的总容量(capacity)修改至 n。一般用于扩容。
- n > capacity:扩容至 n。
- n < capacity:编译器会视情况看要不要缩容,不同平台对于是否缩容的有不同的规则,在 VS 下是坚决不会缩容的。
注意 reserve 是不会改变字符串原本的数据和 size 的大小的。这里我们就简单实现一种情况,即 n > capacity 时的扩容操作,不实现缩容。
// string.cpp
void string::reserve(size_t n)
{if (n > _capacity){char* tmp = new char[n + 1]; // 开空间多开一个给\0if (_str) // 旧空间有可能为空,那就不拷贝了{// 这里不能用 strcmp,因为极端情况字符串内部会有很多\0memcpy(tmp, _str, _size + 1); // +1 是因为有\0delete[] _str;}_str = tmp;_capacity = n;}
}
3. clear
清空字符串(注意留一个 \0)。
由于 _size 记录的是有效字符的数量,所以我们并不需要对原先存在的字符串进行处理,只需要将 _size 置为 0 即可。
void string::clear()
{_str[0] = '\0';_size = 0;
}
九、修改操作
1. push_back
尾插一个字符,同时字符串的长度 (size) + 1。注意不能尾插字符串或者 string 类,只能是一个字符。
// string.cpp
void string::push_back(char ch)
{// 如果空间满了要扩容if (_size == _capacity){// 原本空间可能为空,需要单独考虑reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size++] = ch; // 把 \0 位置覆盖掉了_str[_size] = '\0'; // 注意结尾补上 \0
}
2. append
这里我们就实现一个最常用的:尾部追加一个常量字符串。
// string.cpp
void string::append(const char* str)
{size_t len = strlen(str);// 如果满了需要扩容if (_size + len > _capacity){// 直接开_size + len可能会导致频繁扩容// 直接开 2 倍也可能频繁扩// 所以我们折中对比一下size_t newcapacity = _size + len > 2 * _capacity ? _size + len : 2 * _capacity;reserve(newcapacity);}memcpy(_str + _size, str, len + 1);_size += len;
}
- 测试
// test.cpp
void test_string_3()
{string(s1);s1.push_back('x');s1.push_back('x');s1.push_back('x');s1.push_back('x');s1.push_back('x');for (auto ch : s1) cout << ch;cout << endl;s1.append("hello world");for (auto ch : s1) cout << ch;cout << endl;
}
- 输出
xxxxx
xxxxxhello world
3. operator+=(常用)
在字符串尾部追加一个字符或字符串。
// string.cpp
// 追加一个字符
string& string::operator+=(char ch)
{push_back(ch);return *this; // 有返回值是为了支持连续加等的情况
}// 追加一个字符串
string& string::operator+=(const char* str)
{append(str);return *this;
}
4. insert
在指定的 pos 位置插入一个字符 ch 或一个字符串 str。
实现思路:
- 判断 pos 位置是否合法。
- 判断是否需要扩容。
- 挪动数据。
- 插入数据并更新
_size。
观察下面的代码是否正确。
// string.cpp
void string::insert(size_t pos, char ch)
{// 判断 pos 位置是否合法assert(pos <= _size);// 如果满了需要扩容if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}size_t end = _size;// 挪动数据while (end >= pos) // end 位置往后挪{_str[end + 1] = _str[end];--end;}_str[pos] = ch; // 插入数据++_size;
}
上面的代码是不对的,因为它可能会陷入死循环。当我们需要头插一个字符的时候,即 pos == 0 时,while 循环的结束条件是 end 比 pos 小,也就是 end 至少要到 -1 才行。但是 end 是一个无符号整型,到了 -1 之后会变成整型的最大值。所以当头插的时候循环永远不会结束!
那么我们把它们的类型都改成 int 是否可行?可行是可行,但是标准库中的 insert 函数参数列表的 pos 就是 size_t,这里最好不要修改。那么我们只把 end 修改成 int 呢?
int end = _size;
// 挪动数据
while (end >= pos)
{_str[end + 1] = _str[end];--end;
}
也是不可行的。此时头插的循环终止条件依然是 end 至少到达 -1 才行,但是==当一个 int 类型和一个 size_t 类型作比较的时候,范围小的类型会提升成为范围大的类型,即 int 类型会提升称为 size_t,这种现象称为类型提升==。所以这样又回到了最开始的问题——死循环。
解决这个问题,有两种方案。
- 既然不能改参数中的
size_t,那么我可以在循环比较的时候把pos强转成int类型。
int end = _size;
while (end >= (int)pos) // 这是一种方式
{_str[end + 1] = _str[end];--end;
}
- 另外一个种方式就是改变挪动数据的逻辑。
size_t end = _size + 1;
while (end > pos) // 另一种方式: 前一个位置往 end 挪
{_str[end] = _str[end - 1];--end;
}
这样就不存在 end 变成 -1 的情况了。
// string.cpp
// insert 完成代码
void string::insert(size_t pos, char ch)
{assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}size_t end = _size + 1;while (end > pos) // 前一个位置往 end 挪{_str[end] = _str[end - 1];--end;}_str[pos] = ch;++_size;
}// 插入一个字符串同理,但是注意挪动字符时的细节
void string::insert(size_t pos, const char* str)
{assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){size_t newcapacity = _size + len > 2 * _capacity ? _size + len : 2 * _capacity;reserve(newcapacity);}// 挪动字符,注意细节size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];--end;}for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;
}
5. erase
在指定的 pos 位置处删除 len 个字符,如果不指定 len 那么 len 就用缺省值 npos。或者指定的 len 过大,那么就把 pos 位置后的字符删完。
npos是无符号整型的最大值,它需要单独在类中声明,定义在类外(其他文件)。
// sting.h
class string
{// ...
public:static const size_t npos; // 声明
};// string.cpp
const size_t string::npos = -1; // 定义
注:在 C++ 中,对 const 的静态整型变量有一个特殊处理,它可以将声明和定义写在一起。
// sting.h
class string
{// ...
public:static const size_t npos = -1; // 注意这里不是初始化列表的逻辑,他就是一种特殊处理,相当于初始化了
};// 上面的写法写了之后就不用再在其他文件定义了
// string.h
void erase(size_t pos, size_t len = npos);// string.cpp
void string::erase(size_t pos, size_t len) // 声明与定义分离时定义处不加缺省值
{assert(pos < _size);if (len == npos || len >= _size - pos) // 删完{_str[pos] = '\0';_size = pos;}else // 删部分{memmove(_str + pos, _str + pos + len, _size + 1 - (pos + len));_size -= len;}
}
- 测试
// test.cpp
void test_string_4()
{string s1("hello world");s1 += ' ';s1 += "hello C++";cout << s1.c_str() << endl;string s2("hello world");s2.insert(6, 'x');cout << s2.c_str() << endl;string s3("hello world");s3.erase(6);cout << s3.c_str() << endl;string s4("hello world");s4.erase(6, 3);cout << s4.c_str() << endl;
}
- 输出
hello world hello C++
hello xworld
hello
hello ld
6. swap
交换两个字符串。
在 C++ 的算法库中,有一个通用的 swap 函数,那么为什么 string 类还要自己实现一个 swap 作为成员函数呢?这就需要了解它们的底层原理了。下面是模拟的算法库中的 swap 函数:
template <class T>
void swap(T& a, T& b)
{T c(a); a = b; b = c;
}
不难发现,如果两个 string 对象直接使用算法库中的 swap 的函数的话会发生 3 次深拷贝!代价是非常大的。所以为了达到同样的效果,我们可以转为交换两个 string 对象内部的指针、_size 和 _capacity 即可。
// string.cpp
void string::swap(string& s)
{// 内置类型用库中的 swap 消耗就比较小了std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);
}
但是,有一些人不管底层的实现如何,就直接用算法库中的 swap,不会去用 string 类内部的 swap 函数。考虑到这一点,设计 C++ 的那些大佬们想出了一个解决方案:他们在库中又写了一个全局的 swap 函数。
// 有些人不管底层,所以为了照顾这些人,库里面又重新写了一个全局的 swap
void swap(string& x, string& y) // 普通函数可以和模板同时存在
{x.swap(y); // 转为调用 string 类中的 swap,减少消耗
}
有了这样一个全局的 swap 函数,当调用两个 string 对象的 swap 函数时,会优先调用上面这一个 swap 而不是模板的 swap。
十、字符串的其他操作
1. c_str
返回 C 语言形式下的字符串,相当于把一个 string 类型转换成了 const char* 类型,并且最后一个位置加上一个 \0。
实现起来非常简单,就返回成员变量 _str 即可。
// string.h
// 可能需要频繁调用,所以我们把它放在类内部作为内联函数
const char* c_str() const
{return _str;
}
2. find
从 pos 位置开始找一个目标字符或字符串,找到了返回第一个匹配项的起始下标,没找到返回 npos。如果不指定 pos 则默认从第一个位置开始找。
查找一个字符非常简单,直接从 pos 位置开始遍历字符串即可。由于我们不需要修改任何数据,因此我们将其设置为 const 成员函数。
// string.h
size_t find(char ch, size_t pos = 0) const;// string.cpp
size_t string::find(char ch, size_t pos) const
{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch) return i;}return npos;
}
查找一个子串的方式有很多,最直接的是 BF 算法,也就是暴力匹配算法,每个位置都去匹配一遍,在库中的 strstr 函数就是采用的这样的逻辑。
还有一个知名度比较高的字符串匹配算法是 KMP 算法,这个算法较复杂,这里不展开。当然还有其他的比如说 BM 算法等等。
这里我们就直接用库中的 strstr 函数来实现。
// string.h
size_t find(const char* sub, size_t pos = 0) const;// string.cpp
size_t string::find(const char* sub, size_t pos) const
{assert(pos < _size);const char* p = strstr(_str, sub); // 没有匹配项返回空指针return p == nullptr ? npos : p - _str;
}
3. substr
从 pos 位置开始截取一个字符串的 len 个字符作为一个子串然后返回。如果 len 过大或者不指定 len 则截取到尾。
// string.h
string substr(size_t pos = 0, size_t len = npos) const;// string.cpp
string string::substr(size_t pos, size_t len) const
{assert(pos < _size);if (len > _size - pos){len = _size - pos;}string ret;ret.reserve(len); // 开 len 个空间for (size_t i = 0; i < len; i++){ret += _str[pos + i]; // 复用 += 运算符重载}return ret;
}
4. 字符串的比较
(1) operator<
两个字符串的比较,从左往右按每一位的字典序进行比较。
这里我们需要手动实现比较逻辑,用库中的 strcmp 和 memcmp 都比较不出来。因为 strcmp 遇到 \0 就终止,而我们的字符串可能存在中间有 \0 的情况。而 memcmp 虽然不会受 \0 的影响,但是它需要传入一个需要进行比较的长度,也就是说两个字符串不一样长的话,其中一个字符串结束了那么整个比较就结束了。例如 hello 和 helloworld 两个字符串,用 memcmp 的话比较出来结果是相等,但是实际上应该是 hello < helloworld。
// string.cpp
bool string::operator<(const string& s) const
{// 如果直接用 strcmp 的话比不出来中间有\0的情况// 用 memcmp 的话需要指定一个固定的长度,也比较不出来size_t len1 = _size;size_t len2 = s._size;size_t i1 = 0, i2 = 0;while (i1 < len1 && i2 < len2){if (_str[i1] < s._str[i2]){return true;}else if(_str[i1] > s._str[i2]){return false;}else{++i1;++i2;}}//if (i1 == len1 && i2 <= len2)// return true;//else// return false;return i1 == len1 && i2 < len2;
}
(2) operator==
// string.cpp
bool string::operator==(const string& s) const
{size_t len1 = _size;size_t len2 = s._size;size_t i1 = 0, i2 = 0;while (i1 < len1 && i2 < len2){if (_str[i1] != s._str[i2]){return false;}else{++i1;++i2;}}//if (i1 == len1 && i2 <= len2)// return true;//else// return false;return i1 == len2 && i2 < len2;
}
(3) operator<=
剩下的比较逻辑就直接复用 < 和 == 即可。
// string.cpp
bool string::operator<=(const string& s) const
{return *this < s || *this == s;
}
(4) operator>
// string.cpp
bool string::operator>(const string& s) const
{return !(*this <= s);
}
(5) operator>=
// string.cpp
bool string::operator>=(const string& s) const
{return !(*this < s);
}
(6) operator!=
// string.cpp
bool string::operator!=(const string& s) const
{return !(*this == s);
}
十一、非成员函数
1. operator<<
重载流插入运算符 << 对一个 string 对象的字符串内容进行输出。便可以支持 cout << s 这样的写法了。(s 为 string 对象)
// string.cpp
std::ostream& operator<<(std::ostream& os, const string& s) // 这里没有必要写成友元
{for (size_t i = 0; i < s.size(); i++){os << s[i];}return os;
}
一般情况下用 cout << 和 c_str 打印字符串没有区别,但是当字符串内部有 \0 时就会有差别。因为 c_str 遇到 \0 就终止,而 cout << 能够把除了结尾 \0 之外的其他字符全部打印出来。
2. operator>>
重载流提取用于输入一个字符串并赋值给一个 string 对象。
我们需要将输入的内容放在一个临时的空间中,然后再把这个空间中的字符串赋值给指定的 string 对象。但是我们输入的字符串可以很小,也可以很大。那么如果这个临时空间开得很小,那么可能会面临扩容很多次的问题;而如果开得很大,又可能会导致空间浪费的问题。所以有一种方案就是开 256 个大小的空间,这样是一种这种的方案,不会导致扩容过多次,也不会浪费过多空间。
并且我们开的这个空间不需要是自己 new 出来的一块空间,可以直接定义一个临时的字符串数组,存储在栈上,它是在编译的时候就会开好的,并且函数结束之后自动销毁,能提高效率。
// string.cpp
std::istream& operator>>(std::istream& is, string& s)
{s.clear();char tmp[256]; // 用于存储输入的字符串size_t i = 0;// cin 是读不到空格和换行符的,会忽略掉,导致死循环char ch = is.get(); // get 可以读取任意一个字符while (ch != ' ' && ch != '\n'){tmp[i++] = ch;ch = is.get();// 不需要写扩容的逻辑,只需要重复利用 tmp 这个数组即可if (i == 255) // 满了就让下标 i 重置为 0{tmp[255] = '\0';s += tmp;i = 0;}}// 如果 tmp 中还有内容,需要判断然后补上去if (i > 0){tmp[i] = '\0';s += tmp;}return is;
}
十二、引用计数的写时拷贝
在老版本的 Linux 环境中,采用 string s2(s1) 这样的拷贝构造构造出来的 s2 对象,它所存储的字符串 _str 的地址与 s1 的存储的字符串 _str 地址相同,相当于它们都指向同一块空间,是一种浅拷贝。
那么这样的话弊端很明显,其中一点就是当 s1 和 s2 析构的时候这块空间会被析构两次。此时在某些环境下就采用了一种技术叫做==引用计数。它可以用来记录一块空间被多少个对象所“指向”,比如上面的例子中,s1 和 s2 所指向的空间就会有一个引用计数,它的值为 2。当析构这块空间的时候它不会直接先去释放空间,而是转为去让引用计数减一。每析构一次,引用计数减一,当引用计数为 0 时,释放空间==。这种方案在一定程度上可以减少拷贝次数。
除了析构时会有弊端之外,还有一个问题是当其中一个对象要修改内容的时候,那么另外一个对象也要被迫修改,因为它们都指向同一块空间。这时又采用了一种技术叫做==写时拷贝,也就是说只有当要修改内容的时候才进行拷贝(深拷贝)==。
十三、完整代码
1. string.h
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<cstring>
#include<cassert>
#include<iostream>namespace mine
{class string{public:typedef char* iterator; // 迭代器可以用指针来实现typedef const char* const_iterator;//string()// // :_str(nullptr)// :_str(new char[1] { '\0' })// ,_size(0)// ,_capacity(0)//{}//string(const char* str)// :_str(new char[strlen(str)] + 1)// ,_size(strlen(str))// ,_capacity(strlen(str))//{}//string(const char* str)// : _size(strlen(str))// , _str(new char[_size] + 1)// , _capacity(_size)//{}string(const char* str = "")// 我们可以把它们都放在初始化列表// 但是注意保持初始化顺序与声明顺序一致// 但是都放初始化列表不好,会受顺序影响,所以我们把一部分放在函数体中:_size(strlen(str)){_capacity = _size;_str = new char[_size + 1];// strcpy(_str, str);memcpy(_str, str, _size + 1);}template <class InputIterator>string(InputIterator first, InputIterator last){while (first != last){push_back(*first);++first;}}const char* c_str() const{return _str;}~string(){delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}string(const string& s);//string& operator=(const string & s);string& operator=(string tmp);size_t size() const;char& operator[](size_t i);const char& operator[](size_t i) const;iterator begin();iterator end();const_iterator begin() const;const_iterator end() const;void reserve(size_t n);void push_back(char ch);void append(const char* str);string& operator+=(char ch);string& operator+=(const char* str);void insert(size_t pos, char ch);void insert(size_t pos, const char* str);void erase(size_t pos, size_t len = npos);size_t find(char ch, size_t pos = 0) const;size_t find(const char* sub, size_t pos = 0) const;string substr(size_t pos = 0, size_t len = npos) const;void clear();void swap(string& s);bool operator<(const string& s) const;bool operator<=(const string& s) const;bool operator>(const string& s) const;bool operator>=(const string& s) const;bool operator==(const string& s) const;bool operator!=(const string& s) const;private:char* _str = nullptr;// 计算时都不包含结尾的 '\0'size_t _size = 0;size_t _capacity = 0;public:static const size_t npos;// 特殊处理: const 的整型静态成员变量可以给初始值,就是初始化// static const size_t npos = -1;};std::ostream& operator<<(std::ostream& os, const string& s);std::istream& operator>>(std::istream& is, string& s);
}
2. string.cpp
#include"string.h"namespace mine
{const size_t string::npos = -1;typedef char* iterator; typedef const char* const_iterator;/* 传统写法string::string(const string& s){_str = new char[s._capacity + 1];memcpy(_str, s._str, s._size + 1);_size = s._size;_capacity = s._capacity;}*/// 现代写法// 但是有一个缺陷: 中间有\0就会少拷贝,所以我们采用迭代区间构造string::string(const string& s){//string tmp(s._str);string tmp(s.begin(), s.end());// this 原本指向空,然后让tmp和它交换swap(tmp);}//string& string::operator=(const string& s)//{// if (this != &s) // 防止自己给自己赋值// {// char* tmp = new char[s._capacity + 1];// memcpy(tmp, s._str, s._size + 1);// delete[] _str;//// _str = tmp;// _size = s._size;// _capacity = s._capacity;// }// // return *this;//}/*string& string::operator=(const string& s){if (this != &s){string tmp(s);swap(tmp);}return *this;}*/// 更简洁的写法string& string::operator=(string tmp){swap(tmp);return *this;}size_t string::size() const{return _size;}char& string::operator[](size_t i){assert(i < _size);return _str[i];}const char& string::operator[](size_t i) const{assert(i < _size);return _str[i];}iterator string::begin(){return _str;}iterator string::end(){return _str + _size;}const_iterator string::begin() const{return _str;}const_iterator string::end() const{return _str + _size;}void string::reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];if (_str) // 旧空间有可能为空,那就不拷贝了{// 这里不能用 strcmp,因为极端情况字符串内部会有很多\0memcpy(tmp, _str, _size + 1); // +1 是因为有\0delete[] _str;}_str = tmp;_capacity = n;}}void string::push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size++] = ch;_str[_size] = '\0';} void string::append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){// 直接开_size + len会导致频繁扩容// 直接开 2 倍也可能频繁扩// 所以我们折中对比一下size_t newcapacity = _size + len > 2 * _capacity ? _size + len : 2 * _capacity;reserve(newcapacity);}memcpy(_str + _size, str, len + 1);_size += len;}string& string::operator+=(char ch){push_back(ch);return *this;}string& string::operator+=(const char* str){append(str);return *this;}void string::insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}// 下面这种写法头插会出问题,因为 end 是无符号整型,永远不会小于 0//size_t end = _size;//while (end >= pos) // end 位置往后挪//{// _str[end + 1] = _str[end];// --end;//}// 把 end 改成 int 也不行,因为 pos 是 size_t,比较时会发生类型提升,从而 end 变成 size_t//size_t end = _size;//while (end >= (int)pos) // 这是一种方式//{// _str[end + 1] = _str[end];// --end;//}size_t end = _size + 1;while (end > pos) // 另一种方式: 前一个位置往 end 挪{_str[end] = _str[end - 1];--end;}_str[pos] = ch;++_size;}void string::insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){size_t newcapacity = _size + len > 2 * _capacity ? _size + len : 2 * _capacity;reserve(newcapacity);}// 挪动字符,注意细节size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];--end;}for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;}void string::erase(size_t pos, size_t len) // 声明与定义分离时不加缺省值{assert(pos < _size);if (len == npos || len >= _size - pos) // 删完{_str[pos] = '\0';_size = pos;}else // 删部分{memmove(_str + pos, _str + pos + len, _size + 1 - (pos + len));_size -= len;}}size_t string::find(char ch, size_t pos) const{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch) return i;}return npos;}size_t string::find(const char* sub, size_t pos) const{assert(pos < _size);const char* p = strstr(_str, sub);return p == nullptr ? npos : p - _str;}string string::substr(size_t pos, size_t len) const{assert(pos < _size);if (len > _size - pos){len = _size - pos;}string ret;ret.reserve(len);for (size_t i = 0; i < len; i++){ret += _str[pos + i];}return ret;}void string::clear(){_str[0] = '\0';_size = 0;}void string::swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}bool string::operator<(const string& s) const{// 如果直接用 strcmp 的话比不出来中间有\0的情况// 用 memcmp 的话需要指定长度,也比较不出来size_t len1 = _size;size_t len2 = s._size;size_t i1 = 0, i2 = 0;while (i1 < len1 && i2 < len2){if (_str[i1] < s._str[i2]){return true;}else if(_str[i1] > s._str[i2]){return false;}else{++i1;++i2;}}//if (i1 == len1 && i2 <= len2)// return true;//else// return false;return i1 == len1 && i2 < len2;}bool string::operator<=(const string& s) const{return *this < s || *this == s;}bool string::operator>(const string& s) const{return !(*this <= s);}bool string::operator>=(const string& s) const{return !(*this < s);}bool string::operator==(const string& s) const{// 如果直接用 strcmp 的话比不出来中间有\0的情况size_t len1 = _size;size_t len2 = s._size;size_t i1 = 0, i2 = 0;while (i1 < len1 && i2 < len2){if (_str[i1] != s._str[i2]){return false;}else{++i1;++i2;}}//if (i1 == len1 && i2 <= len2)// return true;//else// return false;return i1 == len2 && i2 < len2;}bool string::operator!=(const string& s) const{return !(*this == s);}std::ostream& operator<<(std::ostream& os, const string& s) // 这里没有必要写成友元{for (size_t i = 0; i < s.size(); i++){os << s[i];}return os;}std::istream& operator>>(std::istream& is, string& s){s.clear();char tmp[256];size_t i = 0;// cin 是读不到空格和换行符的,会忽略掉,导致死循环char ch = is.get(); // 读取任意一个字符while (ch != ' ' && ch != '\n'){tmp[i++] = ch;ch = is.get();if (i == 255){tmp[255] = '\0';s += tmp;i = 0;}}if (i > 0){tmp[i] = '\0';s += tmp;}return is;}
}
相关文章:
)
【C++】string类的模拟实现(详解)
文章目录 上文链接一、整体框架二、构造函数1. default2. copy3. range 三、析构函数四、拷贝构造(1) 传统写法(2) 现代写法 五、赋值重载(1) 传统写法(2) 现代写法 六、获取元素1. operator[ ] 七、迭代器1. begin2. end 八、容量相关1. size2. reserve3. clear 九、修改操作1…...

业界宽松内存模型的不统一而导致的软件问题, gcc, linux kernel, JVM
当不同CPU厂商未能就统一的宽松内存模型(Relaxed Memory Model)达成一致,很多软件的可移植性会收到限制或损害,主要体现在以下几个方面: 1. 可能的理论限制 1.1. 并发程序的行为不一致 现象上,同一段多线程…...

多模态大语言模型arxiv论文略读(101)
ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2 ➡️ 论文标题:ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2 ➡️ 论文作者:Wenjun Huang, Jiakai Pan, Jiahao Tang, Yanyu Ding, Yifei Xing, …...
的XOR异或pyTorch版250501)
量化Quantization初步之--带量化(QAT)的XOR异或pyTorch版250501
量化(Quantization)这词儿听着玄,经常和量化交易Quantitative Trading (量化交易)混淆。 其实机器学习(深度学习)领域的量化Quantization是和节约内存、提高运算效率相关的概念(因大模型的普及,这个量化问题尤为迫切)。 揭秘机器…...

Linux Maven Install
在 CentOS(例如 CentOS 7 或 CentOS 8)中安装 Maven(Apache Maven)的方法主要有两种:使用包管理器(简单但可能版本较旧),或者手动安装(推荐,可获得最新版&…...

#Java篇:学习node后端之sql常用操作
学习路线 1、javascript基础; 2、nodejs核心模块 fs: 文件系统操作 path: 路径处理 http / https: 创建服务器或发起请求 events: 事件机制(EventEmitter) stream: 流式数据处理 buffer: 处理二进制数据 os: 获取操作系统信息 util: 工具方…...
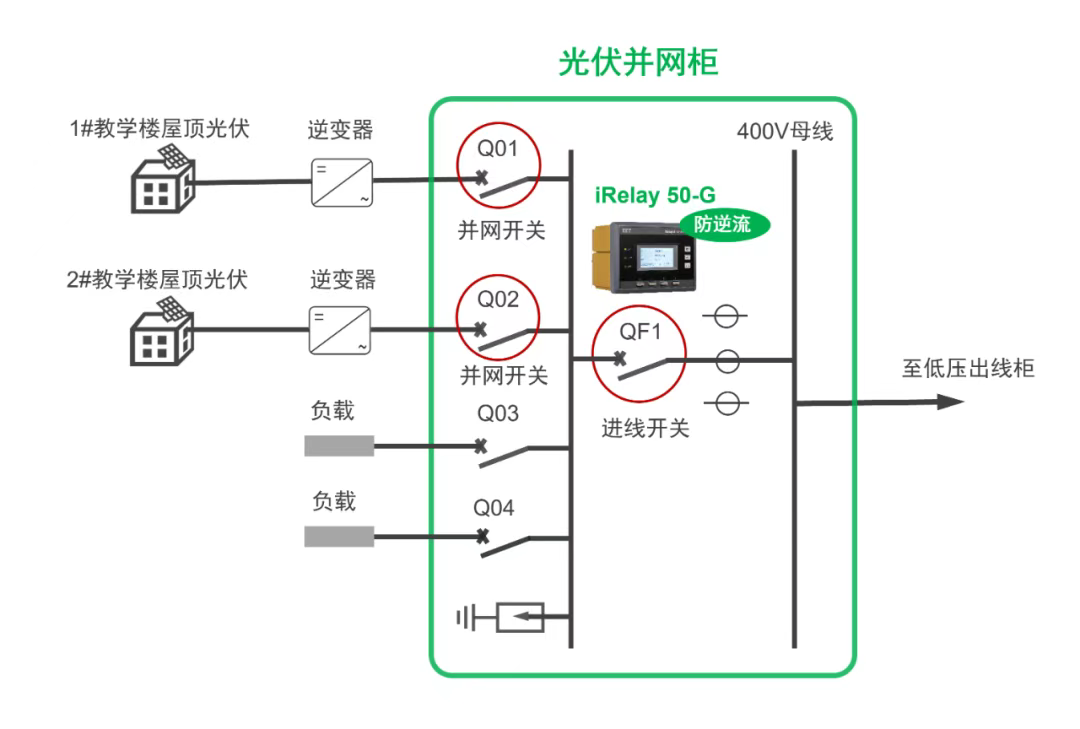
电网“逆流”怎么办?如何实现分布式光伏发电全部自发自用?
2024年10月9日,国家能源局综合司发布了《分布式光伏发电开发建设管理办法(征求意见稿)》,意见稿规定了户用分布式光伏、一般工商业分布式光伏以及大型工商业分布式光伏的发电上网模式,当选择全部自发自用模式时&#x…...
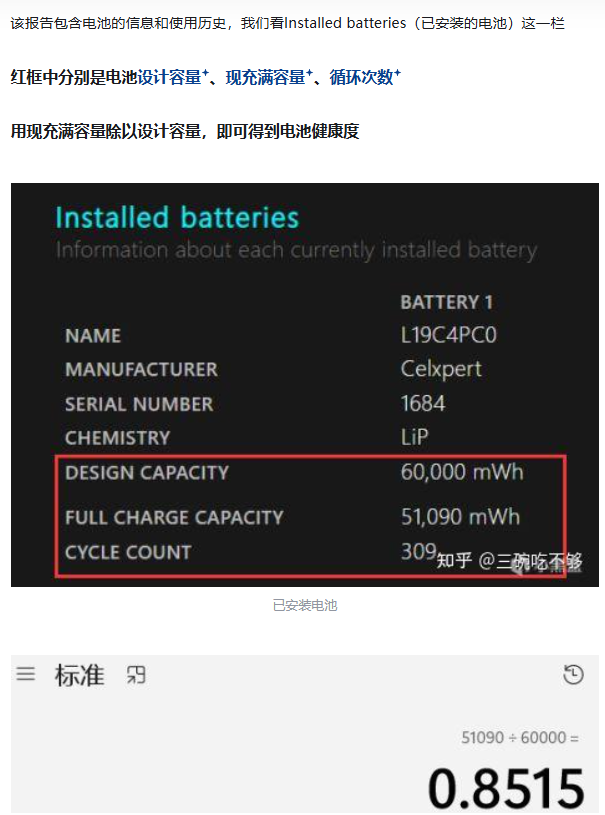
如何查看电脑电池性能
检查电脑电池性能的方法如下: 按下winR键,输入cmd回车,进入命令行窗口 在命令行窗口输入powercfg /batteryreport 桌面双击此电脑,把刚刚复制的路径粘贴到文件路径栏,然后回车 回车后会自动用浏览器打开该报告 红…...
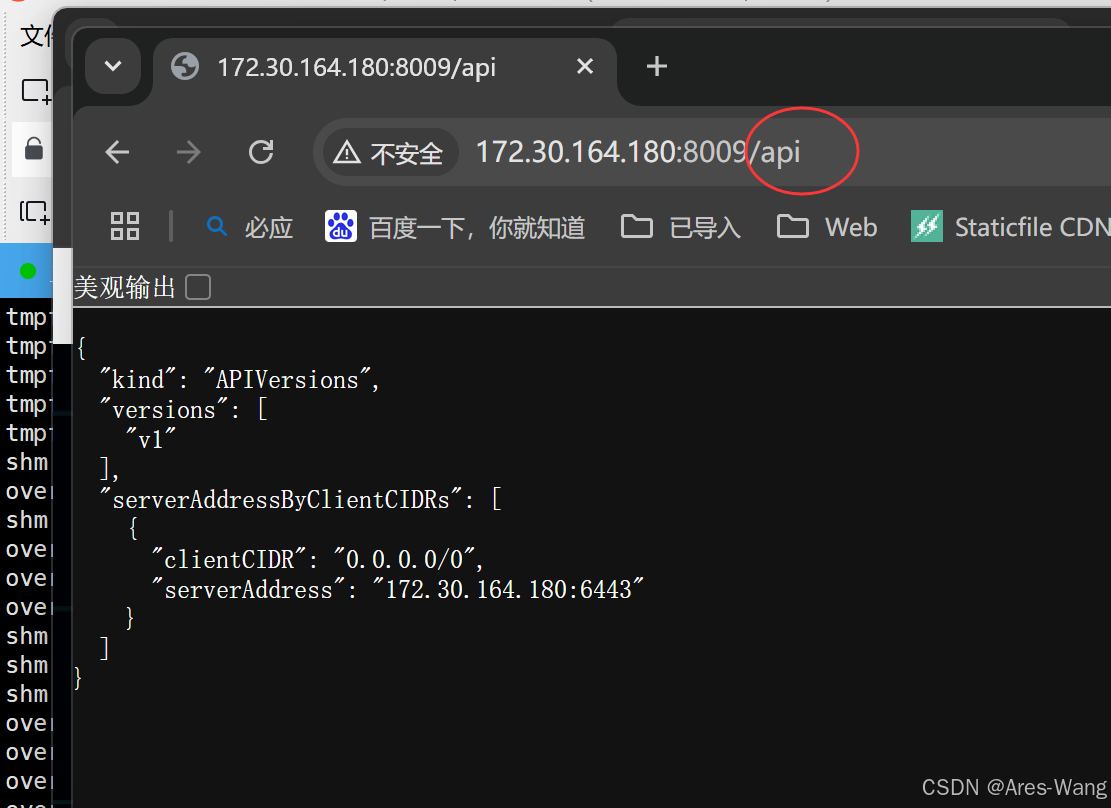
kubernetes》》k8s》》kubectl proxy 命令后面加一个
命令后面加一个& 在Linux终端中,如果在命令的末尾加上一个&符号,这表示将这个任务放到后台去执行 kubectl proxy 官网资料 是 Kubernetes 提供的一个命令行工具,用于在本地和 Kubernetes API Server 之间创建一个安全的代理通道。…...

深入理解Linux系统进程切换
目录 引言 一、什么是进程切换? 二、进程切换的触发条件 三、进程切换的详细步骤 1、保存当前进程上下文: 2、更新进程控制块(PCB): 3、选择下一个进程: 4、恢复新进程上下文: 5、切换地址空间: 6…...

网络安全运维实训室建设方案
一、网络安全运维人才需求与实训困境 在数字化时代,网络安全已成为国家安全、社会稳定和经济发展的重要基石。随着信息技术的飞速发展,网络安全威胁日益复杂多样,从个人隐私泄露到企业商业机密被盗,从关键基础设施遭受攻击到社会…...
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required 一、必须要看这个 >> :参考文献 二、补充 2.1 说明 MySQL5、6这些版本比较老,而DBeaver默认下载的是MySQL8的连接库,所以连接旧版本mysql报错:CLIEN…...

联通专线赋能,亿林网络裸金属服务器:中小企业 IT 架构升级优选方案
在当今数字化飞速发展的时代,中小企业面临着日益增长的业务需求与复杂多变的市场竞争环境。如何构建高效、稳定且具性价比的 IT 架构,成为众多企业突破发展瓶颈的关键所在。而亿林网络推出的 24 核 32G 裸金属服务器,搭配联通专线的千兆共享带…...

Web3时代的数据保护挑战与应对策略
随着互联网技术的飞速发展,我们正步入Web3时代,这是一个以去中心化、用户主权和数据隐私为核心的新时代。然而,Web3时代也带来了前所未有的数据保护挑战。本文将探讨这些挑战,并提出相应的应对策略。 数据隐私挑战 在Web3时代&a…...

Qwen3与MCP协议:重塑大气科学的智能研究范式
在气象研究领域,从海量数据的解析到复杂气候模型的构建,科研人员长期面临效率低、门槛高、易出错的挑战。而阿里云推出的Qwen3大模型与MCP协议的结合,正通过混合推理模式与标准化协同机制,为大气科学注入全新活力。本文将深入解析…...

CppCon 2015 学习:Benchmarking C++ Code
关于性能问题与调试传统 bug(如段错误)之间差异的分析。以下是对这一页内容的详细解释: 主题:传统问题(如段错误)调试流程清晰 问题类型:段错误(Segmentation Fault) …...
的认识)
URL 结构说明+路由(接口)的认识
一、URL 结构说明 以这个为例:http://127.0.0.1:5000/zhouleifeng 1.组成部分: http://:协议 127.0.0.1:主机(本地地址) :5000:端口号(Flask 默认 5000) /zhouleifeng:…...

省赛中药检测模型调优
目录 一、baseline性能二、baseline DETR head三、baseline RepC3K2四、baseline RepC3K2 SimSPPF五、baseline RepC3K2 SimSPPF LK-C2PSA界面1.引入库2.读入数据 总结 一、baseline性能 Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size120/120 …...
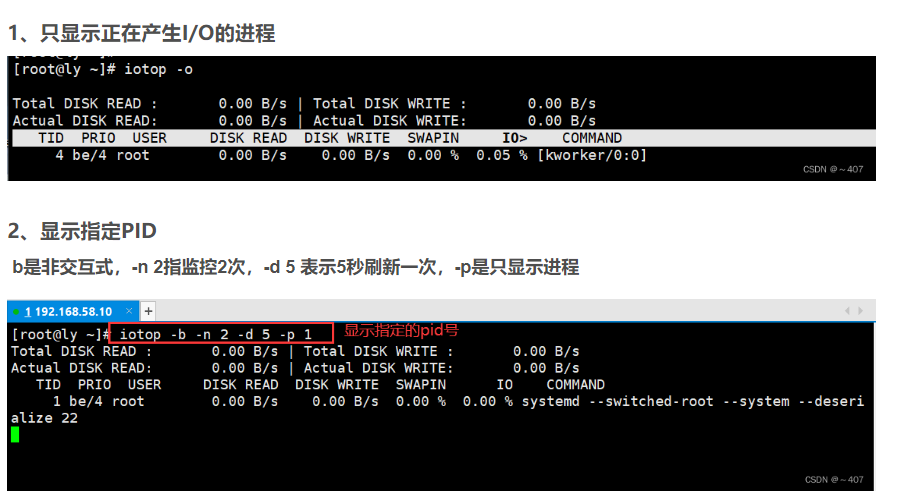
linux 故障处置通用流程-36计+1计
通用标准处置快速索引 编号 通 用 标 准 处 置 索 引 001 Linux操作系统标准关闭 002 Linux操作系统标准重启 003 Linux操作系统强行关闭 004 Linux操作系统强行重启 005 检查Linux操作系统CPU负载 006 查询占用CPU资源最多的进程 007 检查Linux操…...
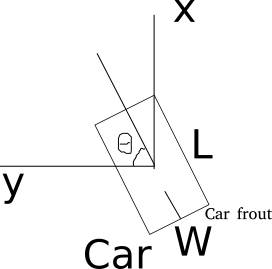
BEV和OCC学习-3:mmdet3d 坐标系
目录 坐标系 转向角 (yaw) 的定义 框尺寸的定义 与支持的数据集的原始坐标系的关系 KITTI Waymo NuScenes Lyft ScanNet SUN RGB-D S3DIS 坐标系 坐标系 — MMDetection3D 1.4.0 文档https://mmdetection3d.readthedocs.io/zh-cn/latest/user_guides/coord_sys_tuto…...
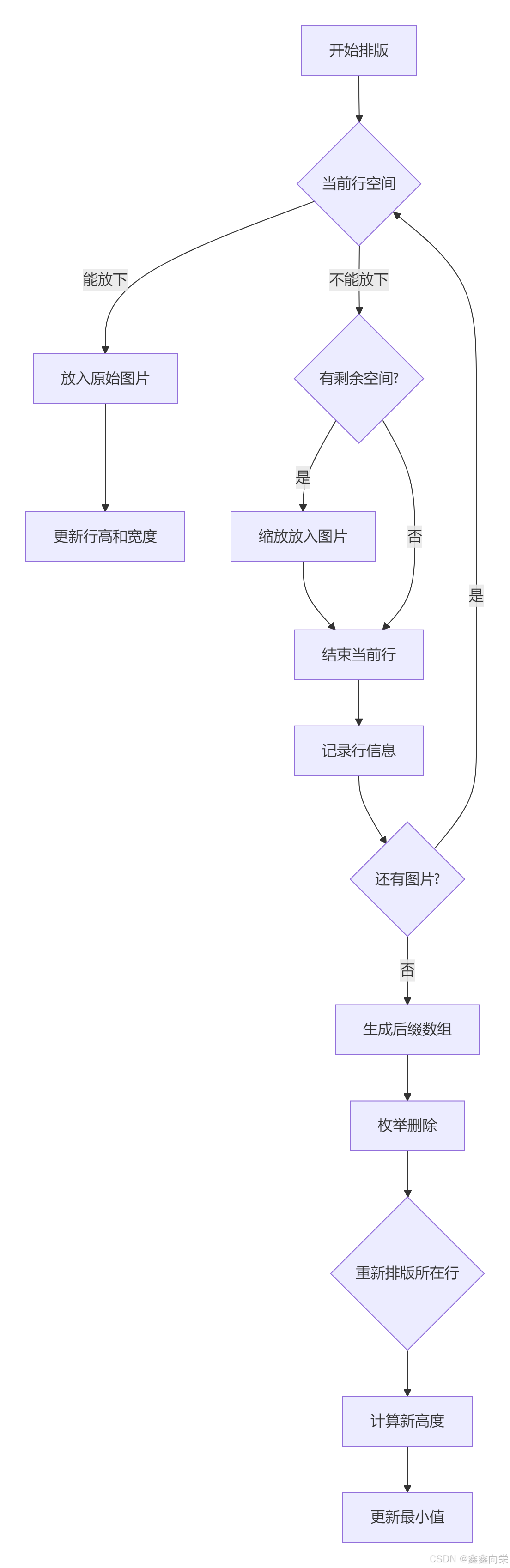
[蓝桥杯]图形排版
图形排版 题目描述 小明需要在一篇文档中加入 NN 张图片,其中第 ii 张图片的宽度是 WiWi,高度是 HiHi。 假设纸张的宽度是 MM,小明使用的文档编辑工具会用以下方式对图片进行自动排版: 1. 该工具会按照图片顺序࿰…...

【Linux仓库】冯诺依曼体系结构与操作系统【进程·壹】
🌟 各位看官好,我是! 🌍 Linux Linux is not Unix ! 🚀 今天来学习冯诺依曼体系结构与操作系统。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦࿰…...
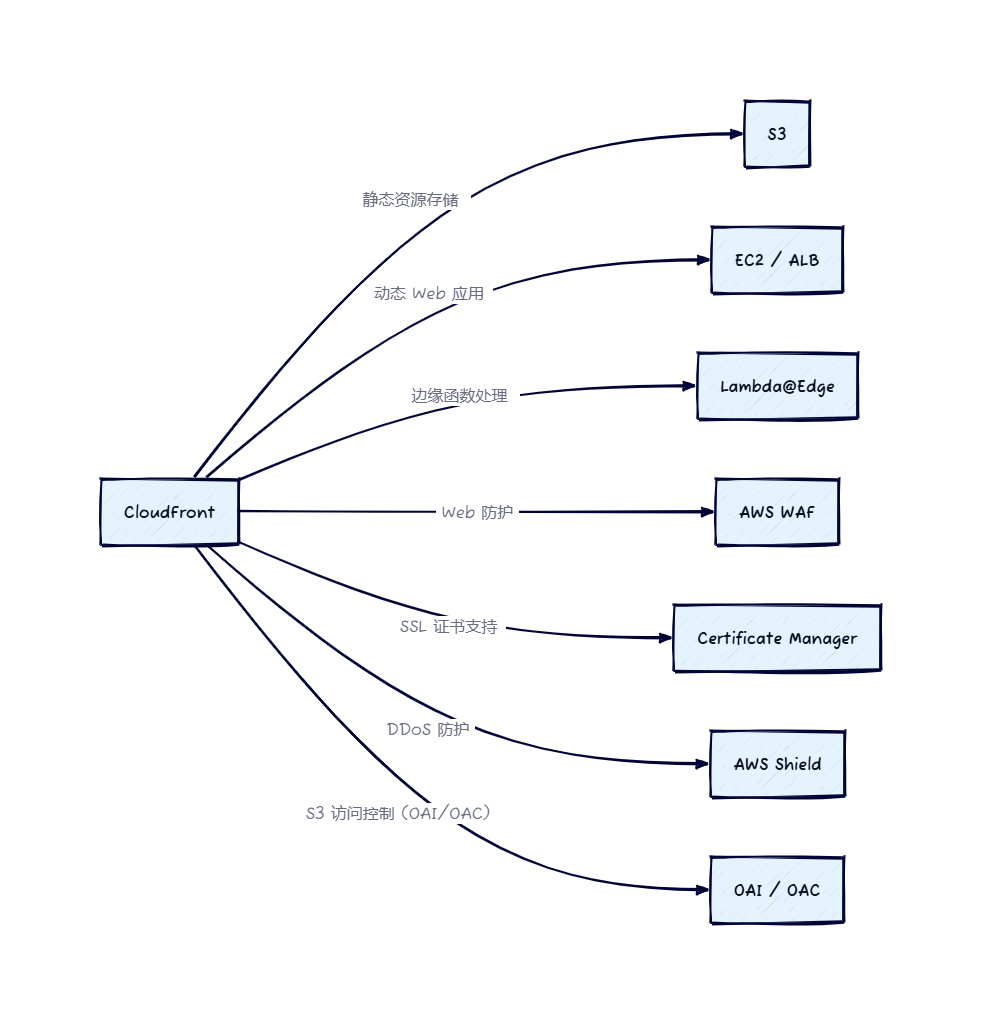
CloudFront 加速详解:AWS CDN 怎么用?
让全球访问更快速稳定,深入解读 AWS 的内容分发网络 在上一篇中,我们介绍了 Amazon S3 对象存储,它非常适合托管静态资源,比如图片、视频、网页等。但你可能遇到过这样的问题: “我把网站静态文件部署到了 S3…...

《高级架构师》------- 考后感想
笔者来聊一下架构师考后的感想 复习备考 考前过了很多知识点,只是蜻蜓点水,没有起到复习的作用,即使考出来也不会,下次复习注意这个,复习到了,就记住,或者画出来,或者文件总结&…...
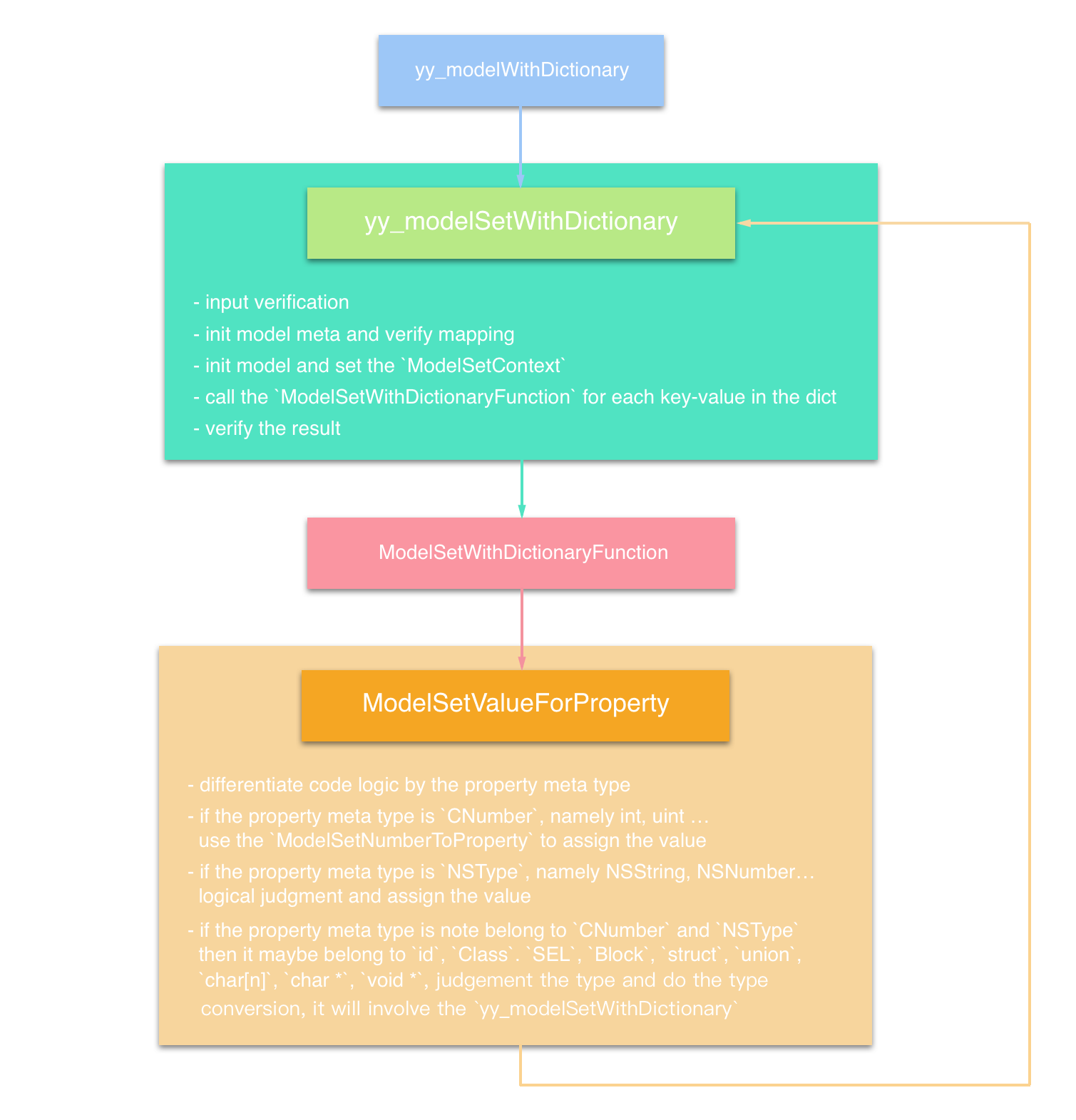
【iOS】YYModel源码解析
YYModel源码解析 文章目录 YYModel源码解析前言YYModel性能优势YYModel简介YYClassInfo解析YYClassIvarInfo && objc_ivarYYClassMethodInfo && objc_methodYYClassPropertyInfo && property_tYYClassInfo && objc_class YYClassInfo的初始化细…...

C++算法训练营 Day6 哈希表(1)
1.有效的字母异位词 LeetCode:242.有效的字母异位词 给定两个字符串s和t ,编写一个函数来判断t是否是s的字母异位词。 示例 1: 输入: s “anagram”, t “nagaram” 输出: true 示例 2: 输入: s “rat”, t “car” 输出: false 解题思路ÿ…...
【C语言编译与链接】--翻译环境和运行环境,预处理,编译,汇编,链接
目录 一.翻译环境和运行环境 二.翻译环境 2.1--预处理(预编译) 2.2--编译 2.2.1--词法分析 2.2.2--语法分析 2.2.3--语义分析 2.3--汇编 2.4--链接 三.运行环境 🔥个人主页:草莓熊Lotso的个人主页 🎬作者简介:C研发…...
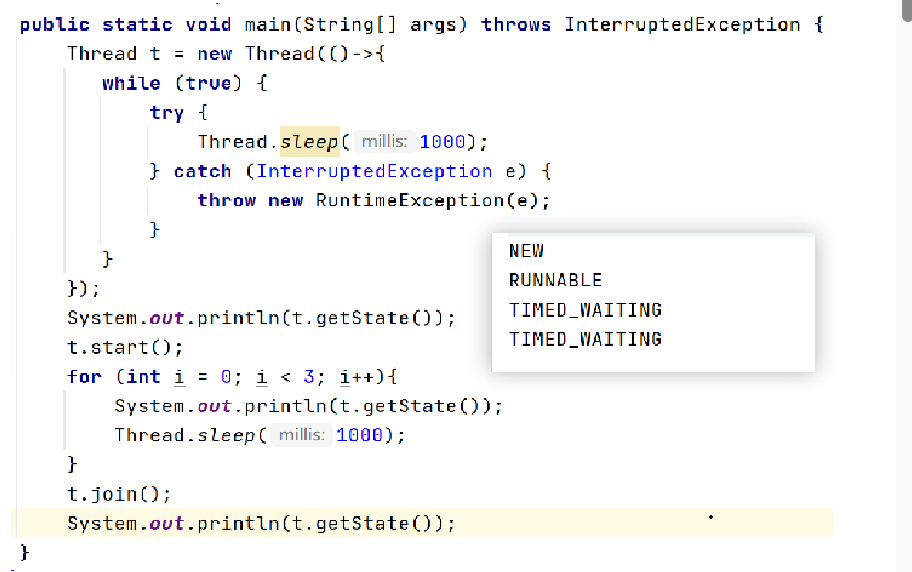
【JavaEE】多线程
8.线程状态 根据 Java 的Thread.state包,线程一共有六种状态: NEWRUNNABLEBLOCKEDWAITINGTIMED_WAITINGTERMINATED 二、每种状态的含义 1. NEW(新建) 当使用new 关键字创建一个线程对象,但尚未调用其start() 方法时…...
【项目】在线OJ(负载均衡式)
目录 一、项目目标 二、开发环境 1.技术栈 2.开发环境 三、项目树 目录结构 功能逻辑 编写思路 四、编码 1.complie_server 服务功能 代码蓝图 开发编译功能 日志功能 编辑 测试编译模块 开发运行功能 设置运行限制 jsoncpp 编写CR 如何生成唯一文件名 …...

贪心算法应用:在线租赁问题详解
贪心算法应用:在线租赁问题详解 贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而希望导致结果是全局最优的算法策略。在线租赁问题(Greedy Algorithm for Online Rentals)是一个经典的贪心算法应用场景,下面我将从多个维度全面…...