Opencl
**OpenCL(Open Computing Language)**是一种用于异构平台(包括CPU、GPU、FPGA、DSP等)上的并行计算框架和编程标准。它由Khronos Group制定,旨在提供一种跨平台、统一的编程接口,使开发者可以利用不同硬件设备进行高性能并行计算。
OpenCL的核心概念
- 平台(Platform):代表不同厂商的计算平台,如NVIDIA CUDA、AMD GPU、Intel CPU等。
- 设备(Device):平台下的具体计算硬件,比如GPU、CPU核。
- 上下文(Context):管理设备和资源的环境。
- 命令队列(Command Queue):提交任务(如内核执行、内存操作)到设备。
- 内核(Kernel):在设备上运行的计算函数。
- 程序对象(Program):包含编译后的内核代码。
OpenCL的使用流程
- 获取平台和设备
- 创建上下文和命令队列
- 编译内核程序(Kernel)代码
- 创建缓冲区(Buffer)
- 设置内核参数
- 运行(Enqueue)内核
- 读取结果
- 清理释放资源
OpenCL的代码结构通常由两部分组成:主程序代码(Host Program) 和 内核代码(Kernel Code)。它们可以用C或C++编写,取决于你的编译环境和API的使用。
- OpenCL API本身是基于C的,所以在“主程序”中,通常用C或C++都可以调用。
- 可以用C++,比如用STL容器、更复杂的封装,也可以用
cl.hpp(C++封装版的OpenCL头文件),提供更面向对象的接口。 - 内核代码通常用C语言风格,代码在
.cl文件中。
1. 文件后缀
-
Host程序(主代码):一般用
.c(纯C)或.cpp(C++)文件编写。例如:main.cpphost.c
-
内核代码(Device端代码):用特殊的源文件,常用后缀包括:
.cl(主要文件扩展名)- 也可以用
.cpp或其他扩展,不过标准和习惯是用.cl
总结:
.cl文件:存放OpenCL内核程序(GPU、CPU上的设备程序)- 主程序文件(C或C++):调用OpenCL API,负责加载、编译内核、管理数据等
2. 代码结构
例:典型的OpenCL程序结构(包括两个文件)
a. kernel.cl (内核代码)(在GPU上运行)
// kernel function 向量加法
__kernel void vector_add(__global const float* A, __global const float* B, __global float* C, int N) {int i = get_global_id(0);if (i < N) {C[i] = A[i] + B[i];}
}b. 主程序用C++调用OpenCL API(在CPU上执行)】
- 包含OpenCL API调用:
- 选择平台和设备
- 创建上下文和命令队列
- 加载内核代码(读入
kernel.cl文件内容) - 编译程序
- 设置参数、分配缓冲区
- 启动核函数
- 读出和处理结果
方法1:
#include <iostream>
#include <vector>
#include <fstream>
#include <streambuf>
#include <CL/cl.h> const char* kernel_file = "kernel.cl"; int main() { // 1. 读取内核源码文件 std::ifstream kernel_stream(kernel_file); if (!kernel_stream.is_open()) { std::cerr << "Failed to open kernel file." << std::endl; return -1; } std::string kernel_code((std::istreambuf_iterator<char>(kernel_stream)), std::istreambuf_iterator<char>()); const char* kernel_source = kernel_code.c_str(); // 2. 获取平台 cl_platform_id platform; clGetPlatformIDs(1, &platform, NULL); // 3. 获取设备(GPU或CPU) cl_device_id device; clGetDeviceIDs(platform, CL_DEVICE_TYPE_DEFAULT, 1, &device, NULL); // 4. 创建上下文 cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL); // 5. 创建命令队列 cl_command_queue queue = clCreateCommandQueue(context, device, 0, NULL); // 6. 编译内核程序 const size_t source_size = kernel_code.size(); cl_program program = clCreateProgramWithSource(context, 1, &kernel_source, &source_size, NULL); if (clBuildProgram(program, 1, &device, NULL, NULL, NULL) != CL_SUCCESS) { // 输出编译错误信息 size_t log_size; clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size); std::vector<char> build_log(log_size); clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, build_log.data(), NULL); std::cerr << "Error in kernel:\n" << build_log.data() << std::endl; clReleaseProgram(program); clReleaseContext(context); return -1; } // 7. 创建内核 cl_kernel kernel = clCreateKernel(program, "vector_add", NULL); // 8. 创建向量数据 const int N = 1024; std::vector<float> A(N, 1.0f); std::vector<float> B(N, 2.0f); std::vector<float> C(N, 0); // 9. 创建缓冲区 cl_mem bufA = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * N, A.data(), NULL); cl_mem bufB = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * N, B.data(), NULL); cl_mem bufC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * N, NULL, NULL); // 10. 设置内核参数 clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufA); clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufB); clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufC); clSetKernelArg(kernel, 3, sizeof(int), &N); // 11. 定义全局与本地工作项数 size_t global_size = ((N + 255) / 256) * 256; // 以256为块大小的倍数 size_t local_size = 256; // 12. 执行内核 clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &global_size, &local_size, 0, NULL, NULL); // 13. 读取结果 clEnqueueReadBuffer(queue, bufC, CL_TRUE, 0, sizeof(float) * N, C.data(), 0, NULL, NULL); // 14. 输出前几个结果验证 std::cout << "C[0] = " << C;// 释放资源clReleaseMemObject(bufA);clReleaseMemObject(bufB);clReleaseMemObject(bufC);clReleaseKernel(kernel);clReleaseProgram(program);clReleaseCommandQueue(queue);clReleaseContext(context);
}方法2:
#include <CL/cl.h>
#include <iostream>
#include <vector> const char* kernel_source = R"(
__kernel void vector_add(__global const float* A, __global const float* B, __global float* C, int N) { int i = get_global_id(0); if (i < N) { C[i] = A[i] + B[i]; }
}
)"; int main() { // 1. 获取平台和设备 cl_platform_id platform; cl_device_id device; clGetPlatformIDs(1, &platform, NULL); clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL); // 2. 创建上下文和命令队列 cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL); cl_command_queue queue = clCreateCommandQueue(context, device, 0, NULL); int N = 1024; std::vector<float> A(N, 1.0f), B(N, 2.0f), C(N); // 3. 创建缓冲区 cl_mem bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * N, A.data(), NULL); cl_mem bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * N, B.data(), NULL); cl_mem bufferC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * N, NULL, NULL); // 4. 编译程序 cl_program program = clCreateProgramWithSource(context, 1, &kernel_source, NULL, NULL); clBuildProgram(program, 0, NULL, NULL, NULL, NULL); cl_kernel kernel = clCreateKernel(program, "vector_add", NULL); // 5. 设置内核参数 clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA); clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB); clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC); clSetKernelArg(kernel, 3, sizeof(int), &N); // 6. 运行内核 size_t global_size = N; clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &global_size, NULL, 0, NULL, NULL); // 7. 读取结果 clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, sizeof(float) * N, C.data(), 0, NULL, NULL); // 8. 输出和清理 std::cout << "C[0] = " << C[0] << std::endl; clReleaseMemObject(bufferA); clReleaseMemObject(bufferB); clReleaseMemObject(bufferC); clReleaseKernel(kernel); clReleaseProgram(program); clReleaseCommandQueue(queue); clReleaseContext(context); return 0; cmake 编译opencl代码
用CMake管理OpenCL项目,包括编译.cl内核文件和保护源代码,主要涉及以下几个方面:
1. 在CMake中如何处理.cl文件
方案一:将.cl文件作为资源文件(非源代码)打包到项目中
- 将内核代码存放在项目目录内,比如
kernels/vector_add.cl。 - 使用
configure_file()或file()命令,将内核文件复制到输出目录。 - 在运行时,主程序用文件IO加载
vector_add.cl的内容。
示例:CMakeLists.txt
cmake_minimum_required(VERSION 3.14)
project(OpenCLExample)# 添加可执行文件
add_executable(opencl_example main.cpp)# 包含OpenCL头文件路径(根据你的环境调整)
target_include_directories(opencl_example PRIVATE /path/to/OpenCL/headers)# 安装内核源码文件
install(FILES kernels/vector_add.cl DESTINATION ${CMAKE_BINARY_DIR}/kernels)# 在配置阶段复制内核文件到输出目录
configure_file(kernels/vector_add.cl ${CMAKE_BINARY_DIR}/kernels/vector_add.cl COPYONLY)在代码中加载内核
// 在运行时加载内核文件内容
std::ifstream kernel_file("path/to/kernels/vector_add.cl");
std::string kernel_source((std::istreambuf_iterator<char>(kernel_file)), std::istreambuf_iterator<char>());或使用与configure_file()相配合的路径。
2. 编译内核文件到二进制(.bin)以保护源代码
- 可以在CMake中调用
clCreateProgramWithBinary(),预编译内核成二进制(.bin文件),避免暴露源码。
步骤:
- 先用
clBuildProgram()生成内核二进制(用OpenCL工具或程序) - 将
.bin文件存放在项目中 - 使用
clCreateProgramWithBinary()加载预编译的二进制
示例(伪代码):
// 读取内核的二进制文件
std::ifstream bin_file("vector_add.bin", std::ios::binary);
std::vector<unsigned char> binary((std::istreambuf_iterator<char>(bin_file)), std::istreambuf_iterator<char>());
// 传入clCreateProgramWithBinary
cl_program program = clCreateProgramWithBinary(context, 1, &device, &binary.size(), (const unsigned char**)&binary[0], &binary_status, &err);3. 如何保护代码不泄露?
- 预编译成二进制(pocl,SPIR-V、OpenCL二进制):
- 编译内核为二进制文件,这样源代码不会被直接暴露。
- 代码混淆:
- 不常用,难以实现,效果有限。
- 硬件保护方案(如GPU的安全特性):
- 一些GPU厂商提供程序保护,但难以完全防止逆向。
4. 总结
| 操作 | 说明 |
|---|---|
.cl源文件处理 | 在CMake中复制到可访问路径,运行时加载,保护较弱 |
| 预编译成二进制文件 | 用OpenCL工具或程序编译成.bin文件,运行时用clCreateProgramWithBinary()加载,增强保护 |
| 保护源码 | 最好只发行二进制,或者使用硬件/软件级别的保护方案 |
5.示例
一、项目结构示范
OpenCLProject/
├── CMakeLists.txt
├── src/
│ └── main.cpp
└── kernels/└── vector_add.cl二、操作流程和示例
1. 准备OpenCL内核源代码
**kernels/vector_add.cl**内容:
__kernel void vector_add(__global const float* A, __global const float* B, __global float* C, int N) {int i = get_global_id(0);if (i < N) {C[i] = A[i] + B[i];}
}2. 预编译内核,生成二进制(二进制保护)
方法:
- 使用官方OpenCL SDK提供的工具(如
clBuildProgram后用clGetProgramInfo()的CL_PROGRAM_BINARY_SIZES和CL_PROGRAM_BINARIES)在程序运行时生成 - 或者用OpenCL API在代码运行时将源编译为二进制文件(
clCompileProgram)简便方案:
- 用OpenCL程序在第一次运行时,将
clBuildProgram的二进制保存到文件
示例:在main.cpp中添加代码(仅做提示,实际在项目中编写)
// 省略初始化(平台、设备、上下文)...
cl_program program = clCreateProgramWithSource(context, 1, &kernel_source, &source_size, &err);
clBuildProgram(program, 1, &device, NULL, NULL, NULL);// 获取二进制
size_t binary_size;
clGetProgramInfo(program, CL_PROGRAM_BINARY_SIZES, sizeof(size_t), &binary_size, NULL);
unsigned char* binary = new unsigned char[binary_size];
unsigned char* binaries[] = {binary};
clGetProgramInfo(program, CL_PROGRAM_BINARIES, sizeof(unsigned char*), &binaries, NULL);// 保存二进制到文件
std::ofstream bin_file("vector_add.bin", std::ios::binary);
bin_file.write((char*)binary, binary_size);
bin_file.close();delete[] binary;
clReleaseProgram(program);此文件vector_add.bin可以在部署时分发,用于替换源代码,避免泄露。
3. 在正式运行时用二进制程序
用二进制加载(示例代码片段):
// 加载二进制文件
std::ifstream bin_file("vector_add.bin", std::ios::binary);
size_t bin_size;
bin_file.seekg(0, std::ios::end);
bin_size = bin_file.tellg();
bin_file.seekg(0, std::ios::beg);
unsigned char* binary_data = new unsigned char[bin_size];
bin_file.read((char*)binary_data, bin_size);
bin_file.close();cl_int binary_status;
cl_program bin_program = clCreateProgramWithBinary(context, 1, &device, &bin_size, (const unsigned char**)&binary_data, &binary_status, &err);
delete[] binary_data;clBuildProgram(bin_program, 0, NULL, NULL, NULL, NULL);
cl_kernel kernel_bin = clCreateKernel(bin_program, "vector_add", NULL);完整main.cpp
支持两种方式:一次性加载内核源码执行,以及加载预编译的二进制文件(保护源码)。
#include <CL/cl.h>
#include <iostream>
#include <vector>
#include <fstream>
#include <string> // 选择使用源码或二进制
const bool USE_BINARY = true; // 设置为true加载二进制,为false加载源码 const std::string kernel_source_file = "kernels/vector_add.cl";
const std::string kernel_binary_file = "vector_add.bin"; int main() { cl_int err; // 1. 获取平台 cl_platform_id platform; clGetPlatformIDs(1, &platform, NULL); // 2. 获取设备 cl_device_id device; clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL); // 3. 创建上下文 cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, &err); // 4. 创建命令队列 cl_command_queue queue = clCreateCommandQueue(context, device, 0, &err); // 5. 加载内核程序 cl_program program; if (USE_BINARY) { // 载入二进制 std::ifstream bin_file(kernel_binary_file, std::ios::binary); if (!bin_file.is_open()) { std::cerr << "Failed to open kernel binary: " << kernel_binary_file << std::endl; return -1; } size_t bin_size; bin_file.seekg(0, std::ios::end); bin_size = bin_file.tellg(); bin_file.seekg(0, std::ios::beg); std::vector<unsigned char> binary_data(bin_size); bin_file.read((char*)binary_data.data(), bin_size); bin_file.close(); const unsigned char* binaries[] = { binary_data.data() }; program = clCreateProgramWithBinary(context, 1, &device, &bin_size, binaries, NULL, &err); if (err != CL_SUCCESS) { std::cerr << "Failed to create program with binary" << std::endl; return -1; } // 编译二进制(某些平台可能不需要) err = clBuildProgram(program, 1, &device, NULL, NULL, NULL); if (err != CL_SUCCESS) { size_t log_size; clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size); std::vector<char> log(log_size); clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, log.data(), NULL); std::cerr << "Build log:\n" << log.data() << std::endl; return -1; } } else { // 载入源码 std::ifstream kernel_file(kernel_source_file); if (!kernel_file.is_open()) { std::cerr << "Failed to open kernel file" << std::endl; return -1; } std::string kernel_code((std::istreambuf_iterator<char>(kernel_file)), std::istreambuf_iterator<char>()); const char* kernel_source = kernel_code.c_str(); program = clCreateProgramWithSource(context, 1, &kernel_source, NULL, &err); if (err != CL_SUCCESS) { std::cerr << "Failed to create program with source" << std::endl; return -1; } // 编译程序 if (clBuildProgram(program, 1, &device, NULL, NULL, NULL) != CL_SUCCESS) { size_t log_size; clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size); std::vector<char> log(log_size); clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, log.data(), NULL); std::cerr << "Build log:\n" << log.data() << std::endl; return -1; } } // 6. 创建核函数 cl_kernel kernel = clCreateKernel(program, "vector_add", &err); if (err != CL_SUCCESS) { std::cerr << "Failed to create kernel" << std::endl; return -1; } // 7. 准备数据 const int N = 1024; std::vector<float> A(N, 1.0f); 三、CMakeLists.txt配置示例
cmake_minimum_required(VERSION 3.14)
project(OpenCLExample)# 查找OpenCL
find_package(OpenCL REQUIRED)# 添加可执行文件
add_executable(opencl_example src/main.cpp)# 添加源码路径(要根据实际路径调整)
target_include_directories(opencl_example PRIVATE ${OPENCL_INCLUDE_DIRS})
target_link_libraries(opencl_example PRIVATE ${OPENCL_LIBRARIES})# 复制kernel文件到构建目录(可选)
configure_file(kernels/vector_add.cl ${CMAKE_BINARY_DIR}/kernels/vector_add.cl COPYONLY)四、总结
- 开发时:用
.cl源码工程方便调试。 - 发布时:用OpenCL API在程序中生成二进制文件,存为
.bin,并加载二进制,避免源码泄露。 - CMake主要负责布局和资源管理,不涉及二进制生成的细节,但可以利用
configure_file()复制资源。
OPENCL编译模式
在编译OpenCL程序时,特别是在使用CMake或其他构建工具,对OpenCL内核进行预编译或处理时,通常会涉及一些标志或参数。这些缩写(IL、BC、CL、CLS)代表不同的概念,主要与OpenCL内核的中间表示和二进制格式有关:
1. IL(Intermediate Language,中间语言)
- 定义:OpenCL的内核可以被编译成一种中间表示(Intermediate Language),类似于LLVM IR或SPIR-V,方便在不同硬件和驱动之间进行移植和优化。
- 作用:IL是一种平台无关的“中间码”,可以被存储和传输,然后再在目标设备上被编译成硬件特定的机器码。
- 使用场景:通常在预编译、特定平台支持或多通用硬件环境中使用。
2. BC(Binary Code,二进制代码)
- 定义:这是OpenCL内核被编译后生成的二进制格式,比如为特定GPU/CPU生成的专用机器代码。
- 区别:比中间语言更接近设备底层,可以直接加载到设备上执行。
- 用途:减少运行时编译时间,保护内核源码。
3. CL(OpenCL C代码)
- 定义:这是OpenCL标准定义的C语言风格的内核源代码(
.cl文件)。 - 处理方式:需要在运行时由OpenCL驱动或API(如
clBuildProgram())编译成设备可执行二进制或中间格式。 - 扩展:当你用“CL”作为参数或标志,通常指操作的目标是OpenCL的源代码或相关操作。
4. CLS(OpenCL C Source)
- 定义:即OpenCL的C源代码,也就是
.cl文件,纯文本的源代码形式。 - 作用:这是最原始的代码形式,用于开发和调试。
总结区别与用途:
表格
| 缩写 | 全名 | 类型 | 描述 |
|---|---|---|---|
| IL | Intermediate Language | 中间语言(中间表示) | 跨平台、中立的中间码,方便后续优化和转换 |
| BC | Binary Code | 二进制代码 | 设备专用、编译后生成的二进制形式,直接加载执行 |
| CL | OpenCL C Source | 源代码(.cl) | 开发时的源代码,需要在运行时编译成可执行形式 |
| CLS | OpenCL C Source | 与CL类似,纯文本源代码 | 通常指源代码文件,也可以理解为直接的好理解的源码文本 |
怎么在CMake或者编译流程中使用?
- 源代码(
.cl,CLS):用clCreateProgramWithSource加载,然后运行clBuildProgram编译成二进制。 - 预编译二进制(
.bc,.bin, IL):用clCreateProgramWithBinary,直接加载预先编译好的二进制(推荐保护代码,提升加载速度) - 生成IL或BC:可以在不同平台用工具链(如XLA、SPIR-V工具)或在运行时由API自动生成。
- 如果你的目标是保护源码,建议预编译成二进制(BC/IL),在加载时用
clCreateProgramWithBinary()。
RK系列芯片上怎么使用opencl
在RK(Rockchip)系列芯片上使用OpenCL,通常需要满足以下几个条件和步骤:
一、确认支持情况
- 硬件支持:
RK系列芯片(如RK3399、RK3566等)多配备ARM Mali GPU或Mali兼容的OpenCL驱动支持。 - 软件支持:
需要安装支持的OpenCL平台驱动(通常是Mali的OpenCL SDK或Rockchip的专用驱动包)。
二、获取和安装OpenCL驱动
- 获取官方驱动:
- 你可以从Rockchip官网或者芯片供应商那里获取专用的OpenCL SDK或驱动包,通常包含动态库(libOpenCL.so)、头文件和示例。
- 实现或集成驱动:
- 使用来自Rockchip的预编译OpenCL库,或者自己编译Mali的OpenCL实现(如果你拥有源代码和编译环境)。
- 配置环境:
- 将驱动库(
libOpenCL.so)放在系统库路径(如/usr/lib/或/usr/local/lib/)。 - 可能需要设置环境变量,比如
LD_LIBRARY_PATH=/usr/local/lib。
- 将驱动库(
三、使用OpenCL开发
-
编写应用程序:
- 你可以用标准OpenCL API(和之前讲解的一样)进行开发。
-
运行时环境:
- 确保运行环境中有匹配的
libOpenCL.so库,应用程序在启动时会识别到GPU的OpenCL平台。
- 确保运行环境中有匹配的
-
验证支持:
- 运行简单的OpenCL程序(如列出平台和设备)确认支持。
// 简单示例:列出平台和设备
cl_platform_id platform;
clGetPlatformIDs(1, &platform, NULL);cl_device_id device;
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);// 打印设备信息
char buffer[256];
clGetDeviceInfo(device, CL_DEVICE_NAME, sizeof(buffer), buffer, NULL);
printf("Device: %s\n", buffer);四、特定驱动可能的注意事项
-
驱动版本兼容:
需要确保OpenCL驱动版本与你的硬件和软件环境匹配,否则可能无法正确加载或运行。 -
硬件优化:
利用Mali GPU的特性优化内核代码,以获得更好的性能。 -
调试和调优:
使用厂商提供的工具或OpenCL调试工具监测性能。
五、总结
表格
| 步骤 | 说明 |
|---|---|
| 获取驱动 | 从Rockchip或Mali提供商下载官方OpenCL SDK或驱动包 |
| 安装驱动 | 将库文件放到系统路径,配置好环境变量 |
| 开发应用 | 使用OpenCL API(如前述代码示例)编写程序 |
| 运行测试 | 运行示例程序确认支持,开始GPU加速 |
相关文章:

Opencl
**OpenCL(Open Computing Language)**是一种用于异构平台(包括CPU、GPU、FPGA、DSP等)上的并行计算框架和编程标准。它由Khronos Group制定,旨在提供一种跨平台、统一的编程接口,使开发者可以利用不同硬件设…...
如何在 HTML 中添加按钮
原文:如何在 HTML 中添加按钮 | w3cschool笔记 (请勿将文章标记为付费!!!!) 在网页开发中,按钮是用户界面中不可或缺的元素之一。无论是用于提交表单、触发动作还是导航࿰…...

【优秀三方库研读】quill 开源库中的命名空间为什么要用宏封装
将命名空间封装成宏的作用与优势 QUILL_BEGIN_NAMESPACE 和 QUILL_END_NAMESPACE 这种宏封装是 C++ 库开发中的常见技巧,主要解决以下问题并提供显著优势: 1. 解决核心问题:命名空间嵌套与版本控制 问题场景: 库需要支持多版本共存(如 quill::v1, quill::v2),但希望默认…...
)
AlphaFold3运行错误及解决方法(1)
1. chemical_component_sets.pickle 运行alphafold3遇到下面的问题: FileNotFoundError: [Errno 2] No such file or directory: /xxx/xxx/anaconda3/envs/alphafold3/lib/python3.11/site-packages/alphafold3/constants/converters/chemical_component_sets.pickle搜索你的系…...
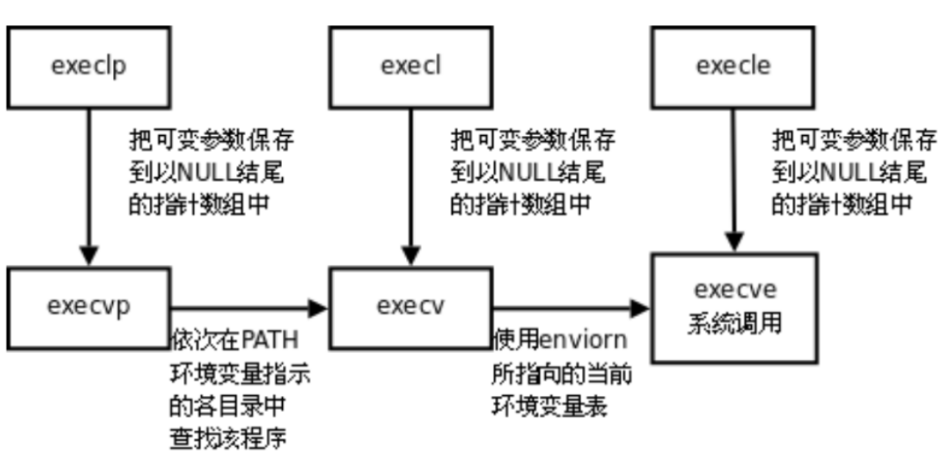
Linux--进程的程序替换
问题导入: 前面我们知道了,fork之后,子进程会继承父进程的代码和“数据”(写实拷贝)。 那么如果我们需要子进程完全去完成一个自己的程序怎么办呢? 进程的程序替换来完成这个功能! 1.替换原理…...
调教 DeepSeek - 输出精致的 HTML MARKDOWN
【序言】 不知道是不是我闲的蛋疼,对百度AI 和 DeepSeek 的回答都不太满意。 DeepSeek 回答句子的引用链接,始终无法准确定位。有时链接只是一个域名,有时它给的链接是搜索串如: baidu.com/?q"搜索内容"。 百度AI 回答句子的引用…...
【笔记】Windows系统部署suna基于 MSYS2的Poetry 虚拟环境backedn后端包编译失败处理
基于 MSYS2(MINGW64)中 Python 的 Poetry 虚拟环境包编译失败处理笔记 一、背景 在基于 MSYS2(MINGW64)中 Python 创建的 Poetry 虚拟环境里,安装 Suna 开源项目相关包时编译失败,阻碍项目正常部署。 后端…...
:分组注意力机制的原理与实践《一》)
GQA(Grouped Query Attention):分组注意力机制的原理与实践《一》
GQA(Grouped Query Attention)是近年来在大语言模型中广泛应用的一种注意力机制优化方法,最初由 Google 在 2023 年提出。它是对 Multi-Query Attention (MQA) 的扩展,旨在平衡模型性能与计算效率。 🌟 GQA 是什么&…...

【深度学习优化算法】02:凸性
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

JAVA国际版一对一视频交友视频聊天系统源码支持H5+APP
全球畅连无界社交:JAVA国际版一对一视频交友系统源码(H5APP双端覆盖) 在全球化社交需求激增的今天,构建一个支持多语言、适配国际支付且功能丰富的视频交友平台,成为出海创业者和企业的核心诉求。JAVA国际版一对一视频…...
策略公开了:年化494%,夏普比率5.86,最大回撤7% | 大模型查询akshare,附代码
原创内容第907篇,专注智能量化投资、个人成长与财富自由。 这位兄弟的策略公开了,年化494%,夏普比率5.86,最大回撤7%,欢迎大家前往围观: http://www.ailabx.com/strategy/683ed10bdabe146c4c0b2293 系统代…...
)
【C++】string类的模拟实现(详解)
文章目录 上文链接一、整体框架二、构造函数1. default2. copy3. range 三、析构函数四、拷贝构造(1) 传统写法(2) 现代写法 五、赋值重载(1) 传统写法(2) 现代写法 六、获取元素1. operator[ ] 七、迭代器1. begin2. end 八、容量相关1. size2. reserve3. clear 九、修改操作1…...

业界宽松内存模型的不统一而导致的软件问题, gcc, linux kernel, JVM
当不同CPU厂商未能就统一的宽松内存模型(Relaxed Memory Model)达成一致,很多软件的可移植性会收到限制或损害,主要体现在以下几个方面: 1. 可能的理论限制 1.1. 并发程序的行为不一致 现象上,同一段多线程…...

多模态大语言模型arxiv论文略读(101)
ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2 ➡️ 论文标题:ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2 ➡️ 论文作者:Wenjun Huang, Jiakai Pan, Jiahao Tang, Yanyu Ding, Yifei Xing, …...
的XOR异或pyTorch版250501)
量化Quantization初步之--带量化(QAT)的XOR异或pyTorch版250501
量化(Quantization)这词儿听着玄,经常和量化交易Quantitative Trading (量化交易)混淆。 其实机器学习(深度学习)领域的量化Quantization是和节约内存、提高运算效率相关的概念(因大模型的普及,这个量化问题尤为迫切)。 揭秘机器…...

Linux Maven Install
在 CentOS(例如 CentOS 7 或 CentOS 8)中安装 Maven(Apache Maven)的方法主要有两种:使用包管理器(简单但可能版本较旧),或者手动安装(推荐,可获得最新版&…...

#Java篇:学习node后端之sql常用操作
学习路线 1、javascript基础; 2、nodejs核心模块 fs: 文件系统操作 path: 路径处理 http / https: 创建服务器或发起请求 events: 事件机制(EventEmitter) stream: 流式数据处理 buffer: 处理二进制数据 os: 获取操作系统信息 util: 工具方…...
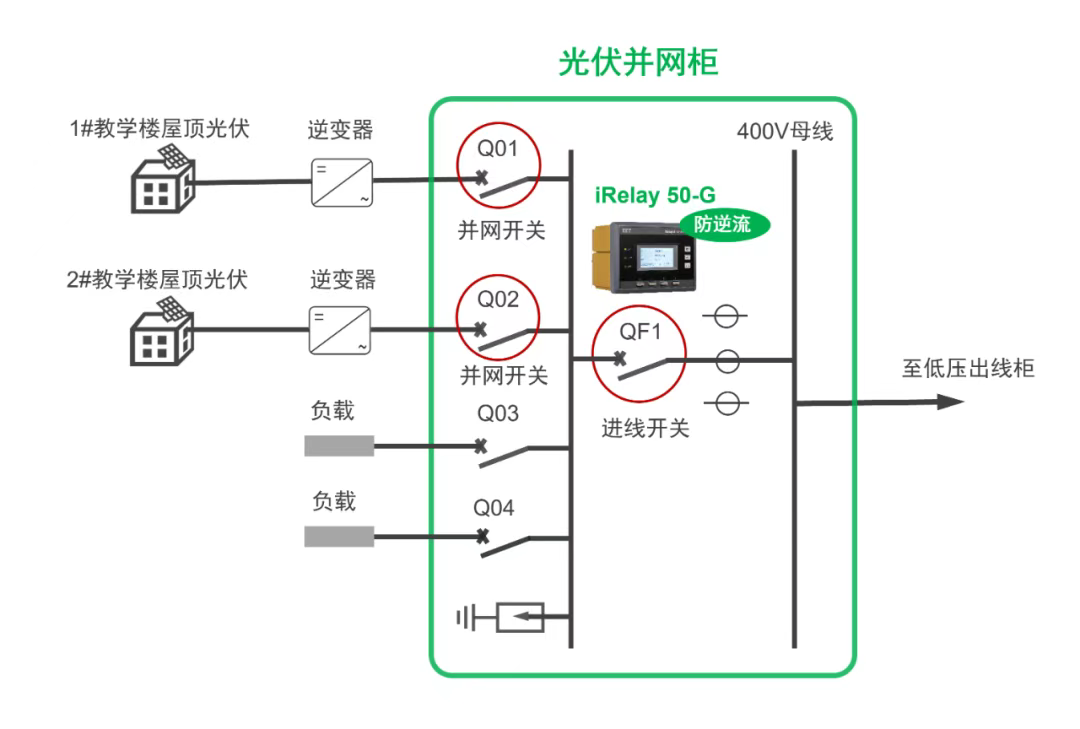
电网“逆流”怎么办?如何实现分布式光伏发电全部自发自用?
2024年10月9日,国家能源局综合司发布了《分布式光伏发电开发建设管理办法(征求意见稿)》,意见稿规定了户用分布式光伏、一般工商业分布式光伏以及大型工商业分布式光伏的发电上网模式,当选择全部自发自用模式时&#x…...
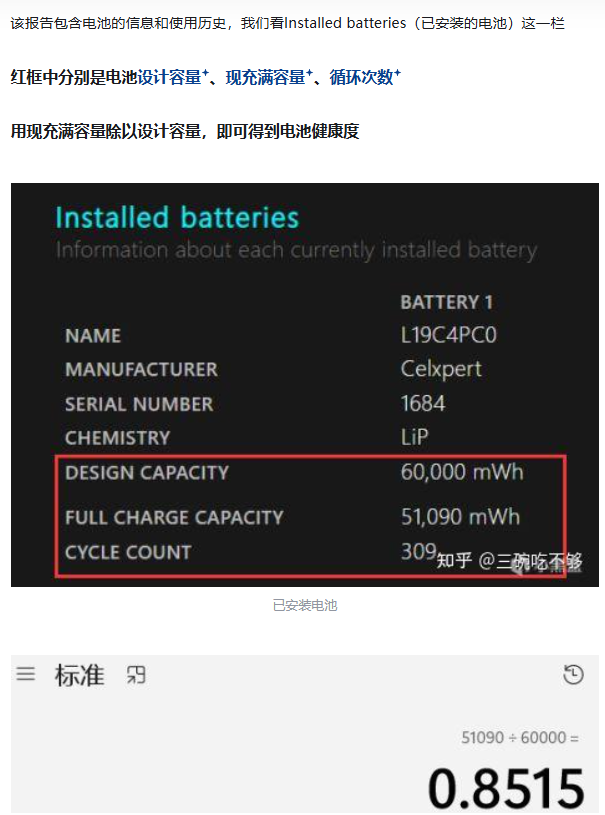
如何查看电脑电池性能
检查电脑电池性能的方法如下: 按下winR键,输入cmd回车,进入命令行窗口 在命令行窗口输入powercfg /batteryreport 桌面双击此电脑,把刚刚复制的路径粘贴到文件路径栏,然后回车 回车后会自动用浏览器打开该报告 红…...
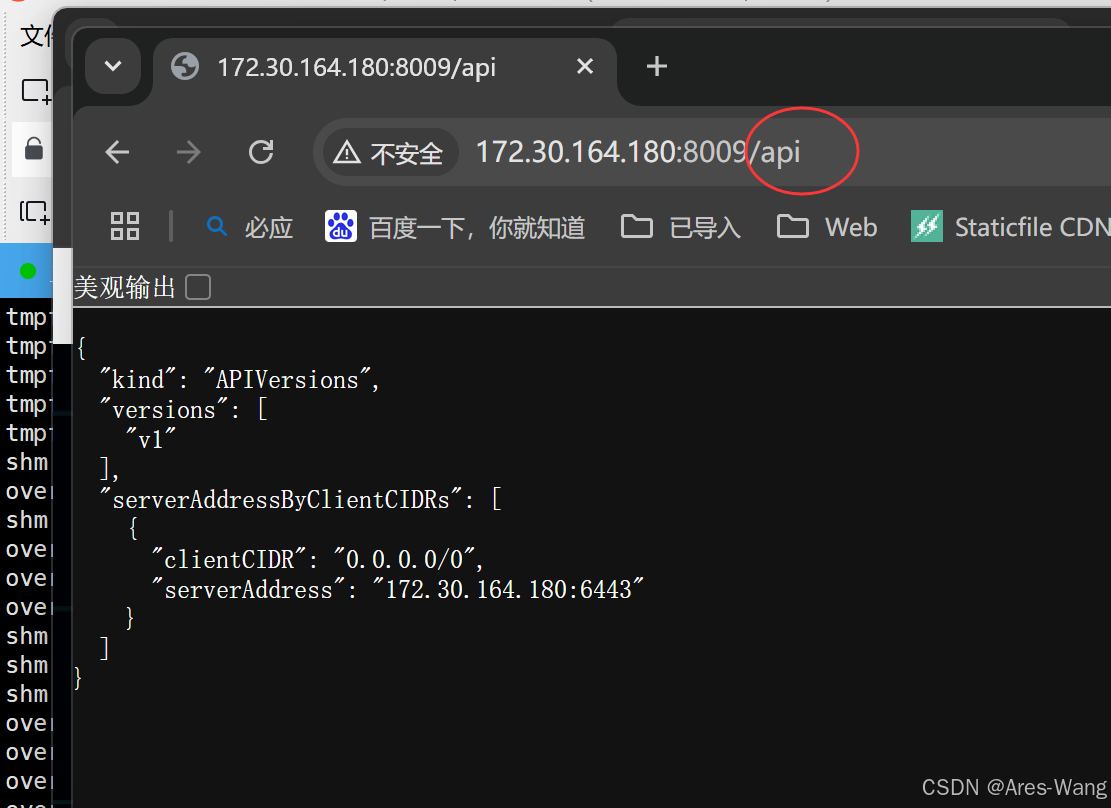
kubernetes》》k8s》》kubectl proxy 命令后面加一个
命令后面加一个& 在Linux终端中,如果在命令的末尾加上一个&符号,这表示将这个任务放到后台去执行 kubectl proxy 官网资料 是 Kubernetes 提供的一个命令行工具,用于在本地和 Kubernetes API Server 之间创建一个安全的代理通道。…...

深入理解Linux系统进程切换
目录 引言 一、什么是进程切换? 二、进程切换的触发条件 三、进程切换的详细步骤 1、保存当前进程上下文: 2、更新进程控制块(PCB): 3、选择下一个进程: 4、恢复新进程上下文: 5、切换地址空间: 6…...

网络安全运维实训室建设方案
一、网络安全运维人才需求与实训困境 在数字化时代,网络安全已成为国家安全、社会稳定和经济发展的重要基石。随着信息技术的飞速发展,网络安全威胁日益复杂多样,从个人隐私泄露到企业商业机密被盗,从关键基础设施遭受攻击到社会…...
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required
DBeaver 连接mysql报错:CLIENT_PLUGIN_AUTH is required 一、必须要看这个 >> :参考文献 二、补充 2.1 说明 MySQL5、6这些版本比较老,而DBeaver默认下载的是MySQL8的连接库,所以连接旧版本mysql报错:CLIEN…...

联通专线赋能,亿林网络裸金属服务器:中小企业 IT 架构升级优选方案
在当今数字化飞速发展的时代,中小企业面临着日益增长的业务需求与复杂多变的市场竞争环境。如何构建高效、稳定且具性价比的 IT 架构,成为众多企业突破发展瓶颈的关键所在。而亿林网络推出的 24 核 32G 裸金属服务器,搭配联通专线的千兆共享带…...

Web3时代的数据保护挑战与应对策略
随着互联网技术的飞速发展,我们正步入Web3时代,这是一个以去中心化、用户主权和数据隐私为核心的新时代。然而,Web3时代也带来了前所未有的数据保护挑战。本文将探讨这些挑战,并提出相应的应对策略。 数据隐私挑战 在Web3时代&a…...

Qwen3与MCP协议:重塑大气科学的智能研究范式
在气象研究领域,从海量数据的解析到复杂气候模型的构建,科研人员长期面临效率低、门槛高、易出错的挑战。而阿里云推出的Qwen3大模型与MCP协议的结合,正通过混合推理模式与标准化协同机制,为大气科学注入全新活力。本文将深入解析…...

CppCon 2015 学习:Benchmarking C++ Code
关于性能问题与调试传统 bug(如段错误)之间差异的分析。以下是对这一页内容的详细解释: 主题:传统问题(如段错误)调试流程清晰 问题类型:段错误(Segmentation Fault) …...
的认识)
URL 结构说明+路由(接口)的认识
一、URL 结构说明 以这个为例:http://127.0.0.1:5000/zhouleifeng 1.组成部分: http://:协议 127.0.0.1:主机(本地地址) :5000:端口号(Flask 默认 5000) /zhouleifeng:…...

省赛中药检测模型调优
目录 一、baseline性能二、baseline DETR head三、baseline RepC3K2四、baseline RepC3K2 SimSPPF五、baseline RepC3K2 SimSPPF LK-C2PSA界面1.引入库2.读入数据 总结 一、baseline性能 Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size120/120 …...
linux 故障处置通用流程-36计+1计
通用标准处置快速索引 编号 通 用 标 准 处 置 索 引 001 Linux操作系统标准关闭 002 Linux操作系统标准重启 003 Linux操作系统强行关闭 004 Linux操作系统强行重启 005 检查Linux操作系统CPU负载 006 查询占用CPU资源最多的进程 007 检查Linux操…...