【动手学MCP从0到1】2.1 SDK介绍和第一个MCP创建的步骤详解
SDK介绍和第一个MCP
- 1. 安装SDK
- 2. MCP通信协议
- 3. 基于stdio通信
- 3.1 服务段脚本代码
- 3.2 客户端执行代码
- 3.2.1 客户端的初始化设置
- 3.2.2 创建执行进行的函数
- 3.2.3 代码优化
- 4. 基于SSE协议通信
1. 安装SDK
开发mcp项目,既可以使用Anthropic官方提供的SDK,也可以直接通过实现MCP协议的方式来实现。毫无疑问,通过SDK使用MCP是最方便和最节省时间的。安装命令如下:
pip install mcp[cli]
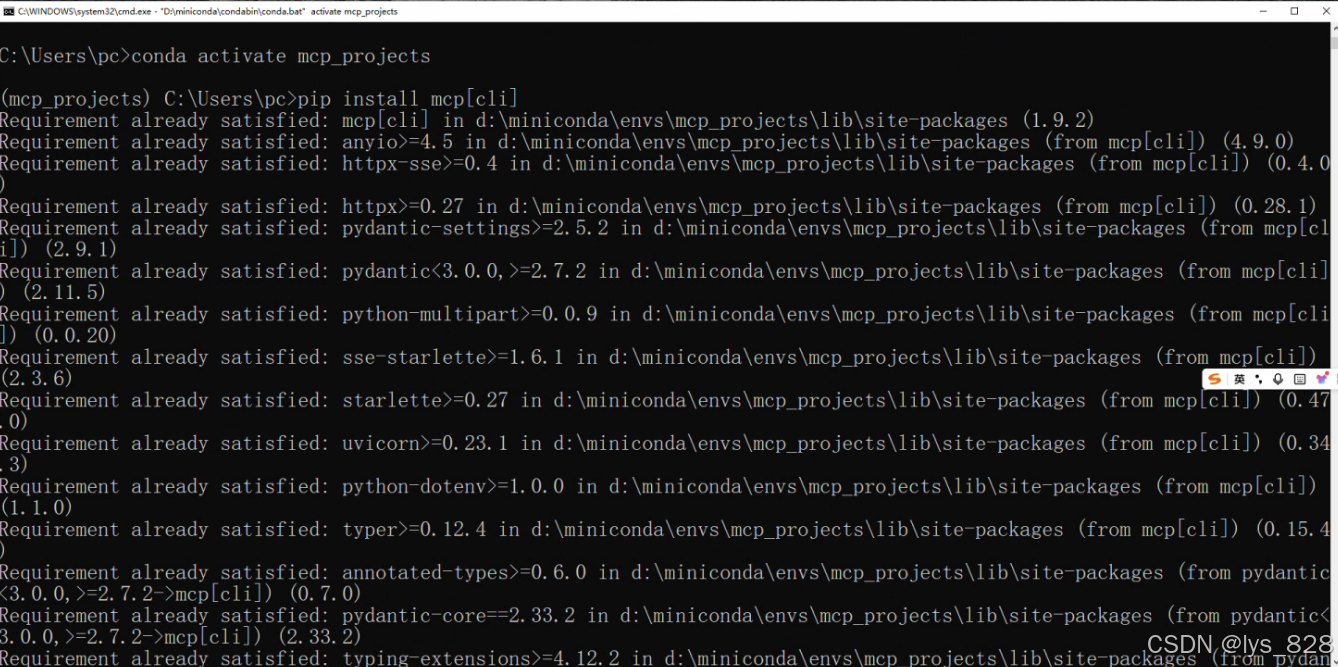
执行结果如下:(为保证版本之间互不干涉,可以新建一个虚拟环境进行安装,此处的mcp_projects就是新建的虚拟环境)
2. MCP通信协议
MCP是服务器和客户端架构的,服务器和客户端之间的通信协议包括两种:
- stdio :本地的标准输入与输出,基于进程间通信。客户端将服务端脚本放到子进程中执行。
- SSE:Server-Sent Event协议,底层基于Http协议。
不管是stdio还是SSE,他们都是采用JSON-RPC协议进行交互
3. 基于stdio通信
我们首先基于stdio来实现一个最简单的mcp应用。stdio是客户端代码中使用一个子进程来运行服务端脚本代码。这里我们实现一个计算两个数之和为例来演示开发过程
3.1 服务段脚本代码
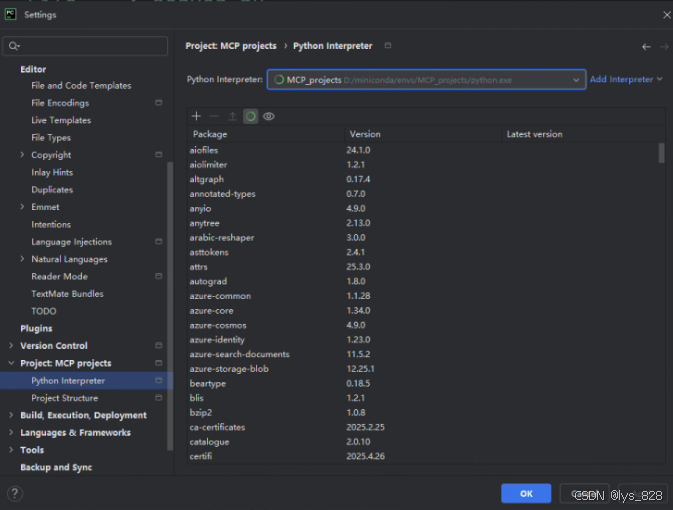
新建一个项目,名为MCP projects,然后添加好python环境,比如虚拟环境是基于Python 3.12版本创建的MCP_projects名称,如下
然后再项目中命名文件夹名称为server.py,然后输入以下代码
from mcp.server.fastmcp import FastMCPapp = FastMCP("start mcp")@app.tool()
def plus_tool(a:float, b:float) -> float:'''计算两个浮点数相加的结果:param a: 第一个浮点数:param b: 第二个浮点数:return: 浮点数'''return a + bif __name__ == '__main__':app.run(transport="stdio")
代码中:函数中的介绍(description)十分重要,后面大模型调用函数(工具)时候需要按照介绍执行,因此需要尽可能的对函数功能和参数介绍清楚(具体的数据类型和解释)。
以上就是一个简单的server程序,执行一个加法运算。
3.2 客户端执行代码
完成服务端的功能代码编写后,接着就是创建一个客户端来运行服务端脚本代码。
接着在项目文件夹中,创建一个client_stdio.py文件。在编写代码之前需要先安装openai库
pip install openai
这里不是说要使用openai里面的ChatGPT的大模型来执行,而是使用openai提供的流程来加载国内的大模型,比如deepseek。其作为一个标准的大模型引入方式可以进行通用。
3.2.1 客户端的初始化设置
client_stdio.py文件中内容如下:(包括两个内容:①服务端的执行路径和②大模型引入)
from openai import OpenAI# stdio: 在客户端中,启动一个新的子进程来执行服务端的脚本代码
class MCPClient(OpenAI):def __init__(self,server_path):self.server_path = server_pathself.deepseek = OpenAI(api_key="<KEY>", #需要填入自己的keybase_url="https://api.openai.com/v1",)
记住使用stdio进行执行服务端的任务是通过创建一个进程来实现的。为了方便后续操作,首先要有一个服务器路径server_path,也就是后面要执行的依据。然后就是把大模型框架加载进来,这里需要打开的deepseek官网的api使用的网址,如下
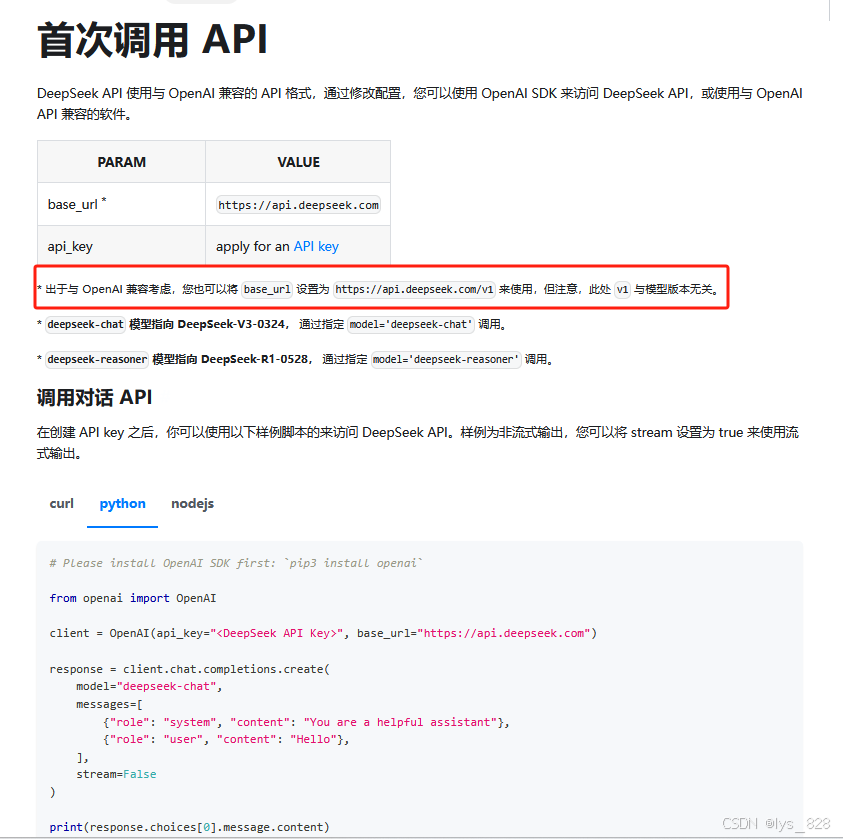
对于首次调用大模型的同学,注意看到上面红色框框的提醒,有时候我们会看到有人把base_url的赋值为:https://api.deepseek.com,也有人使用:https://api.deepseek.com/v1。这两种方式都是一样的效果。
在国内,如果使用base_url=https://api.openai.com/v1,运行结果显示下面报错,可以考虑将其赋值变为另外一种使用方式

然后,我们可以看到,里面如何创建一个客户端client,就是通过引入openai库中的OpenAI函数来实现的,里面有两个需要传递的参数,一个是大模型执行的base_url,就是上面介绍的两种方式都可以,然后另外一个就是api_key,该参数就是使用大模型的秘钥(需要付费),可以直接在官网左侧API keys导航栏创建,然后再充值导航栏中进行充值即可(首次使用可充值少量金额)。

3.2.2 创建执行进行的函数
创建run函数进行执行。函数中具体包含的步骤归纳如下:
- 1.创建连接服务端的参数
- 2.创建读、写通道
- 3.创建客户端和服务端通信的session对象
- 4.初始化通信
- 5.获取服务端的所有工具(函数)
- 6.将工具封装为Function Calling能识别的对象
- 7.发送消息给大模型,让大模型选择调用哪个工具(大模型不会自己调用)
- 8.重新把消息发给大模型,让大模型生成最终响应
(1)创建连接服务端的参数
这部分代码是指定客服端如何来执行服务端的脚本代码,需要指定具体的类型和文件路径。在mcp库中封装好了StdioServerParameters这个类。在PyCharm编辑器中,通过点击这个类名进入到具体介绍的文件中,如下
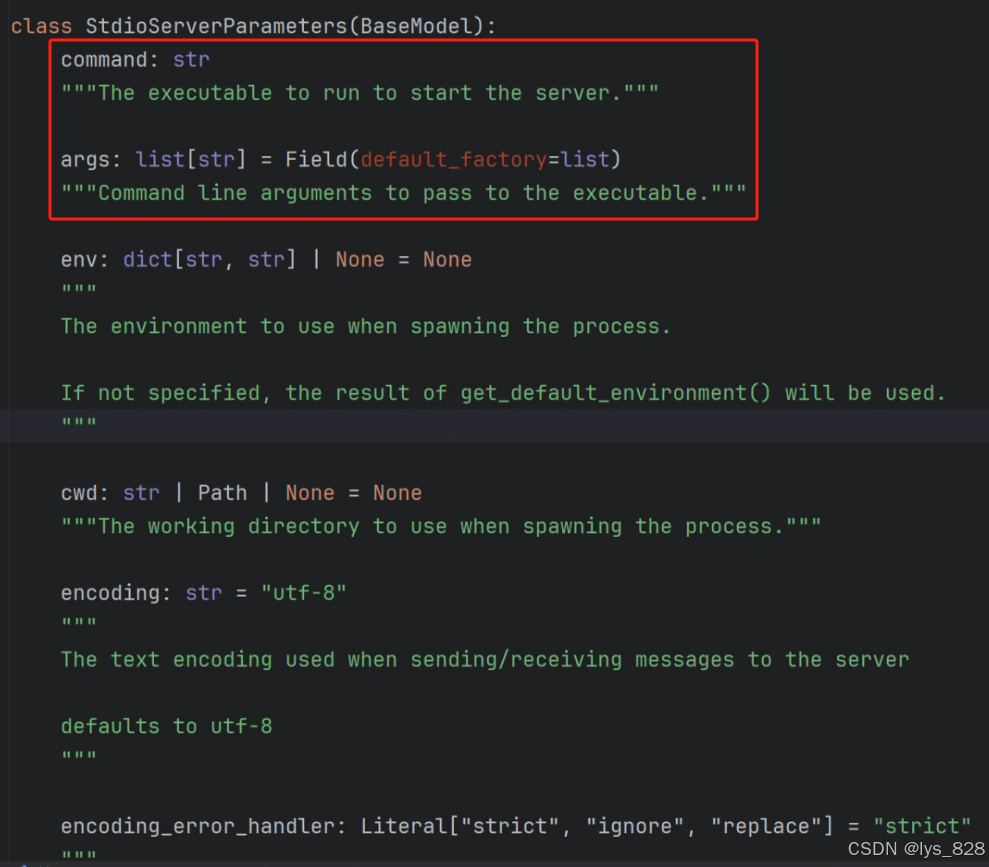
引入这个类,主要是两个重要参数command和args,如下
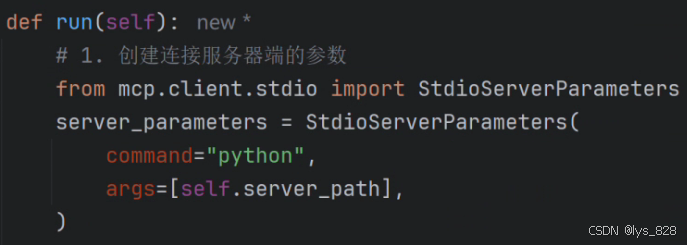
def run(self):# 1. 创建连接服务器端的参数from mcp.client.stdio import StdioServerParametersserver_parameters = StdioServerParameters(command="python",args=[self.server_path],)
pycharm中代码如下,引入StdioServerParameters这个类的代码为了显示方便放在截图中,实际在编写代码时按照书写习惯会放置在文件的最上方。
(2)创建读、写通道
(3)创建客户端和服务端通信的session对象
这两个步骤实际上是一步,就是在创建进程时候的输出格式要求。创建进程的过程,在mcp中也封装了对应的类,这个类是stdio_client,其和StdioServerParameters引入方式一致。点击这个类的代码解释文件的内容如下
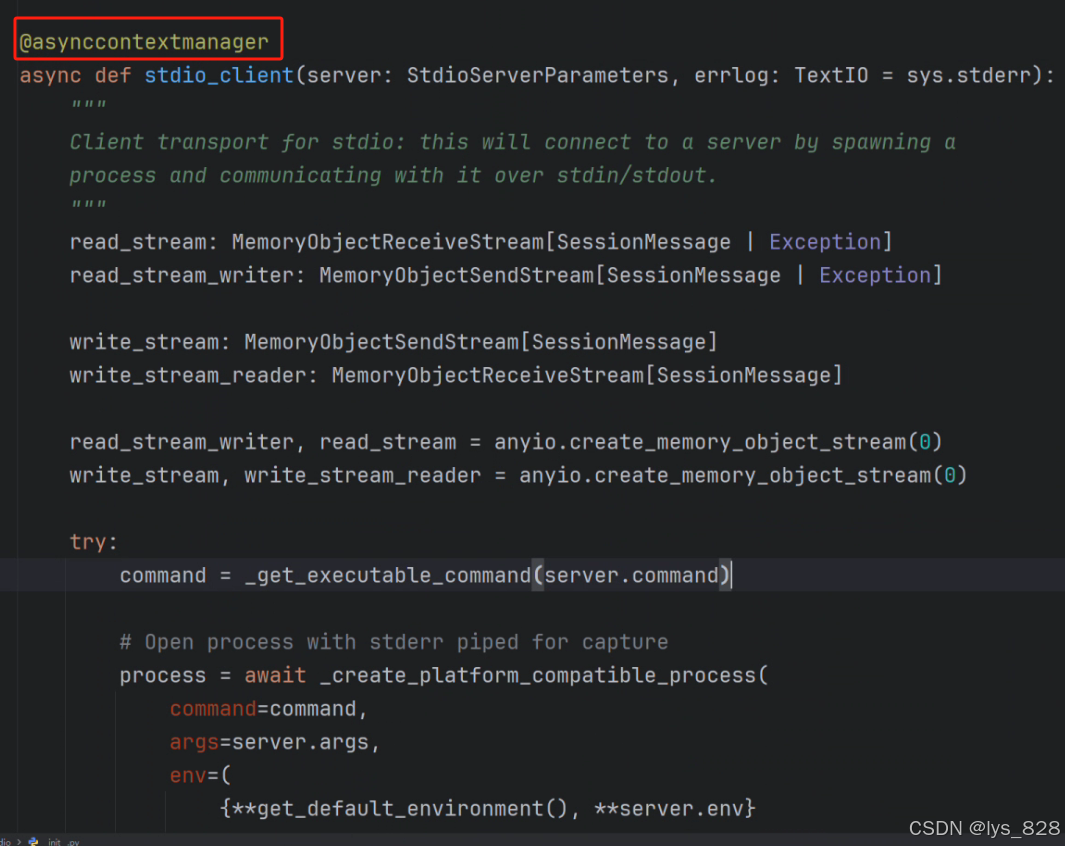
可以看出封装的这个函数是基于asynccontextmanager这个装饰器函数,因此在创建进程之前,需要搞清楚这个装饰器函数到底是起到什么作用,进一步点击装饰器函数名称,跳转到对应的解释文档,如下
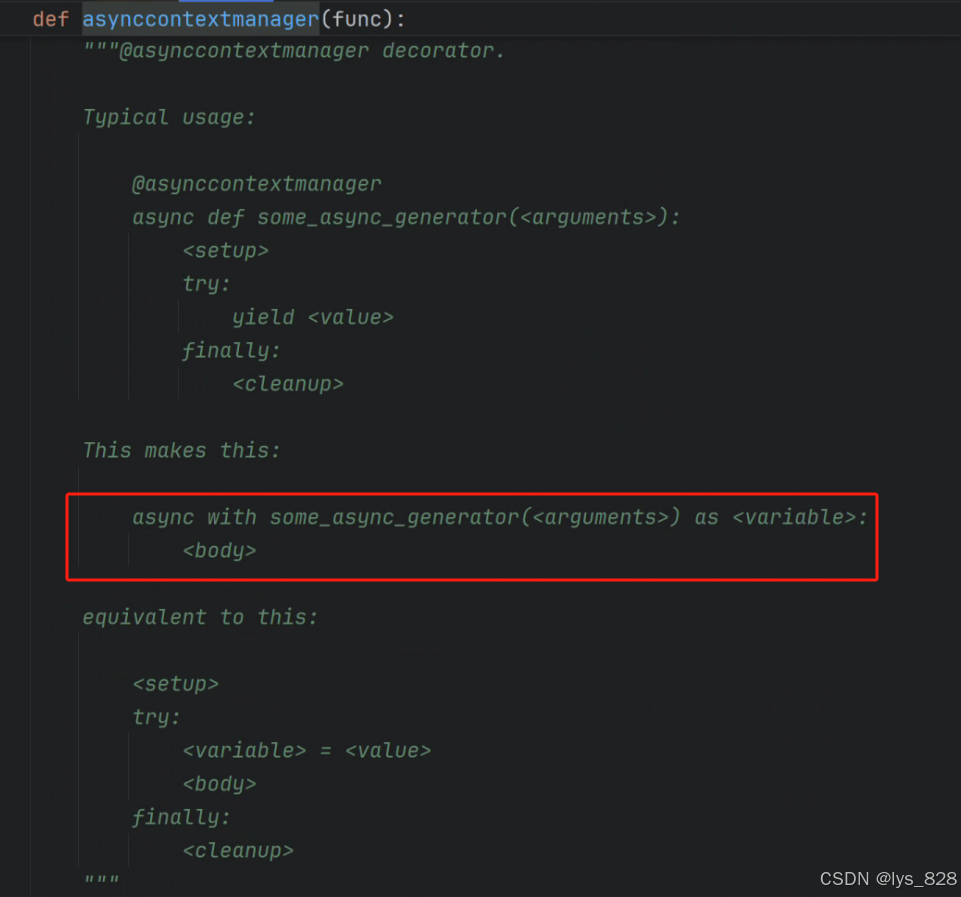
函数解释中,详细介绍了这个上下文管理装饰器函数的使用方式,根据上面的介绍,在使用这个装饰器时候,函数会yield一个值出来,然后等价于后续使用with 函数名称 as 变量的方法,其中最后面的变量就是指引到yield后的那个值。
那么回到我们创建进程函数的这个代码文件中,可以找寻一下,是不是函数内部有一个yield的操作,如下
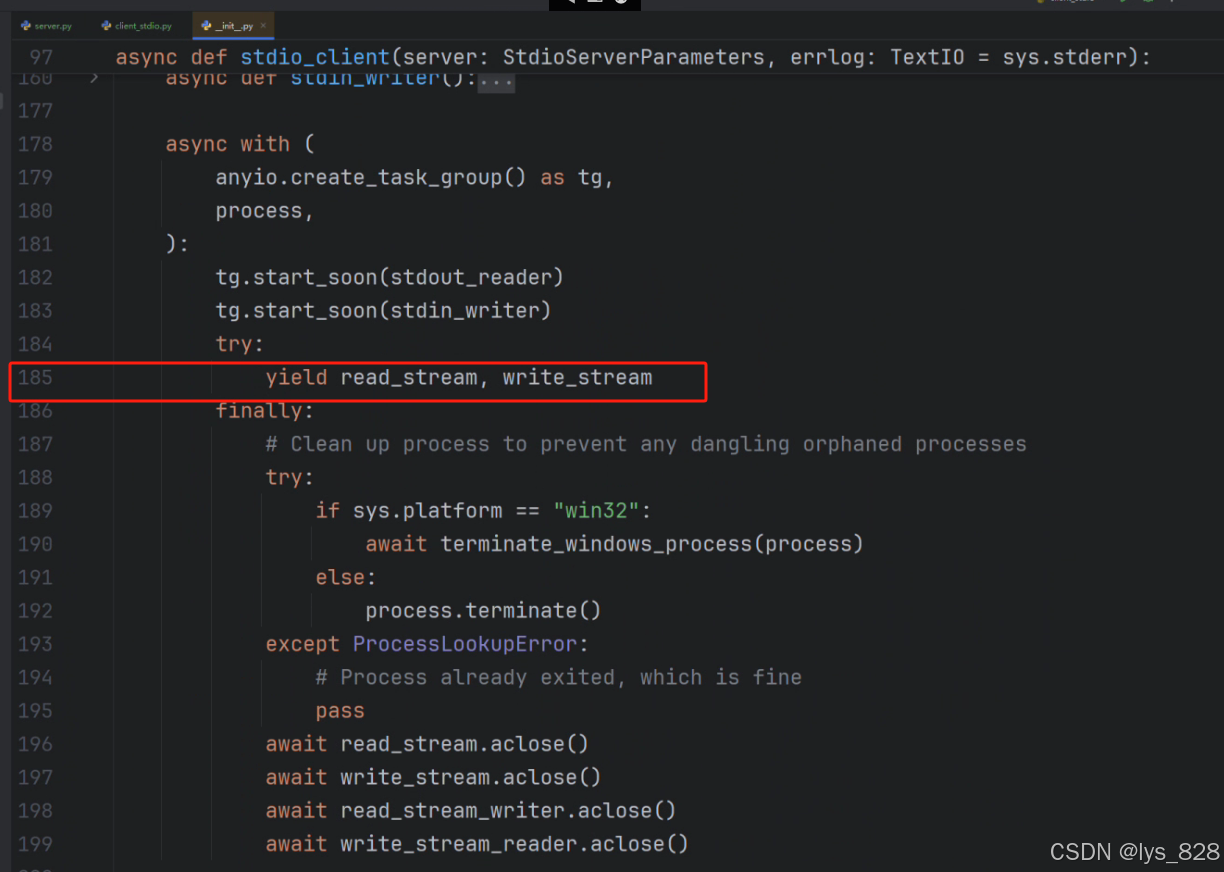
通过往下拉,可以发现在文件的185行中就出现了yield的现象。注意,这里不是yield出来了两个数据,而是一个元祖数据类型(可以省略括号),如下

按照StdioServerParameters文档中的介绍,创建进程的代码编写如下
from mcp.client.stdio import stdio_client
async with stdio_client(server=server_parameters) as (read_stream,write_stream):from mcp import ClientSessionsession = ClientSession()
Pycharm中的代码如下:(关于客户端对象的创建按照文档的格式可以完成,然后为了保障服务端和客服端之间的通信,也就是session的构建,mcp中封装了一个ClientSession的类,用于交互链接)

进一步,点击ClientSession的类的解释文件,详细看一下,里面有哪些参数和使用说明,如下
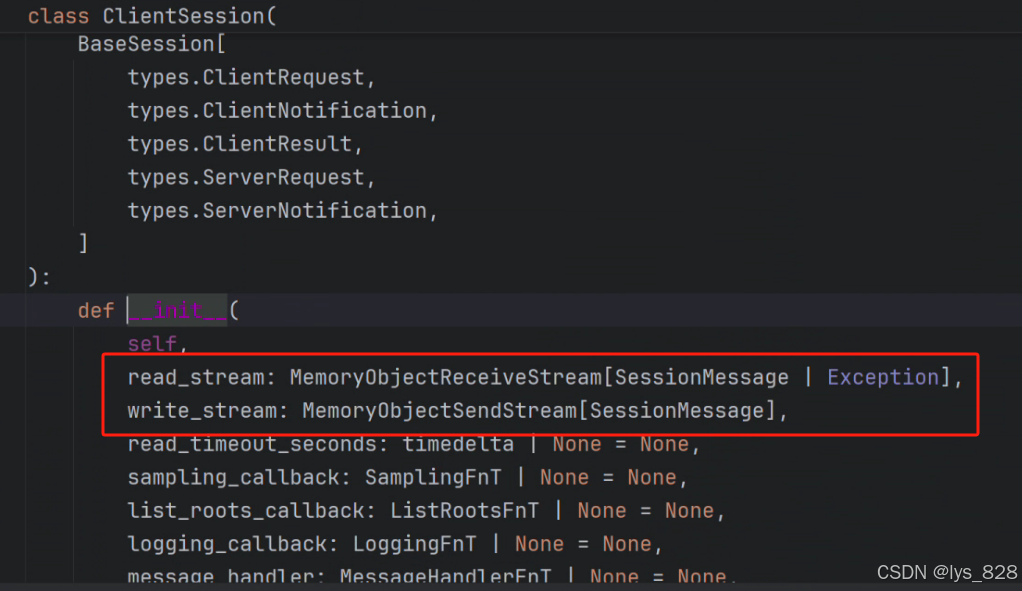
可以看出,前两个参数就是必须参数,为读、写通道(或者称为读、写流)。此外,需要考虑的是,涉及到I/O(读写,输入和输出)控制,需要考虑资源的管理,比如在读取文件使用,我们使用open函数就可以直接进行读取,但是往往使用with进行上下文管理,为了保证资源释放,避免泄漏。这里创建进程也是同理,为了保证资源利用,也是使用with进行处理。
完善后的代码如下
from mcp.client.stdio import stdio_client
async with stdio_client(server=server_parameters) as (read_stream,write_stream):from mcp import ClientSessionasync with ClientSession(read_stream, write_stream) as session:session.initialize()
Pycharm中的示意代码

(4)初始化通信
上面的初始化代码是利用Pycharn中AI自动补全的,通过查找ClientSession类中的初始化函数,可以发现,初始化的函数是异步的,也就是前面添加了async关键字,因此在代码中我们在调用异步函数执行时候,前面对应的要加上await关键字
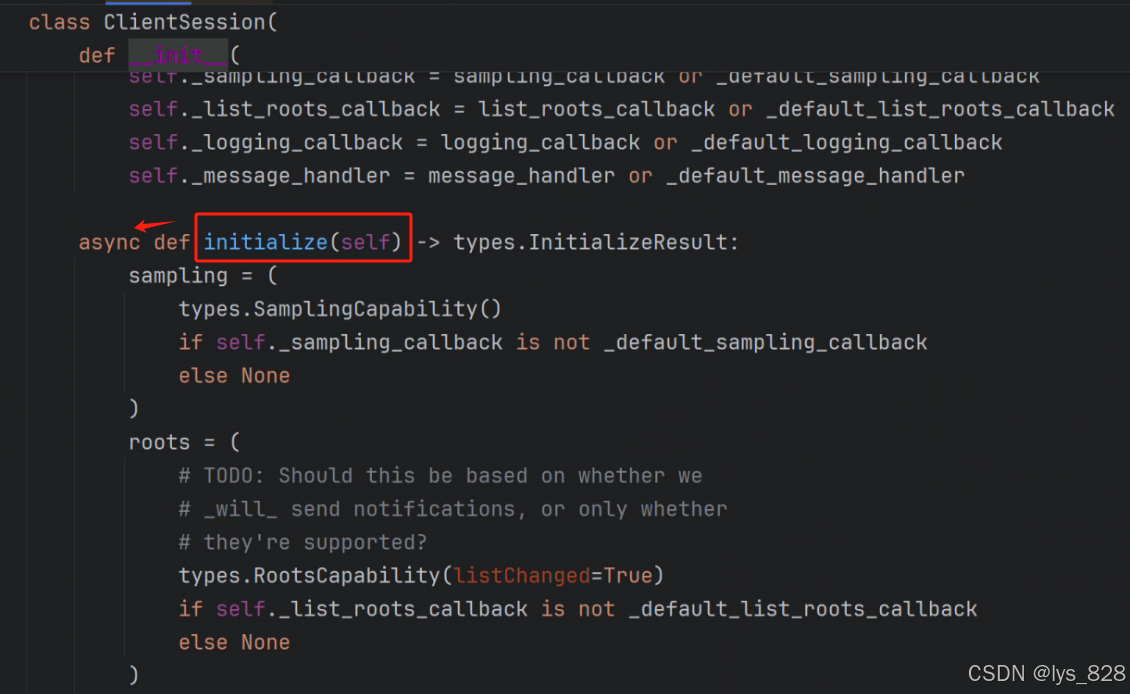
此时定义run函数前也就需要添加异步函数的关键字,不然一个函数中不能同时存在异步和同步两种方法。此时前四步的完整代码如下
async def run(self):# 1. 创建连接服务器端的参数server_parameters = StdioServerParameters(command="python",args=[self.server_path],)# 2. 创建读写流async with stdio_client(server=server_parameters) as (read_stream,write_stream):# 3. 创建客户端与服务端的进程通话async with ClientSession(read_stream, write_stream) as session:# 4. 初始化请求await session.initialize()
以上的4步操作就是标准化的书写方式,可认为就是规定的流程。往后的流程会随着不同的工具而代码不同。
(5)获取服务端的所有工具(函数)
直接获取session中的所有的工具列表,借助list_tools()函数即可。然后此时可以打印出当前客户端可以获取服务端的具体的工具信息,如下
"""
-------------------------------------------------------------------------------
@Project : MCP projects
File : client_stdio.py
Time : 2025-06-03 9:40
author : musen
Email : xianl828@163.com
-------------------------------------------------------------------------------
"""
import asynciofrom openai import OpenAI
from mcp.client.stdio import StdioServerParameters,stdio_client
from mcp import ClientSession# stdio: 在客户端中,启动一个新的子进程来执行服务端的脚本代码
class MCPClient(OpenAI):def __init__(self,server_path):self.server_path = server_pathself.deepseek = OpenAI(api_key="<KEY>",base_url="https://api.openai.com/v1",)async def run(self):# 1. 创建连接服务器端的参数server_parameters = StdioServerParameters(command="python",args=[self.server_path],)# 2. 创建读写流async with stdio_client(server=server_parameters) as (read_stream,write_stream):# 3. 创建客户端与服务端的进程通话async with ClientSession(read_stream, write_stream) as session:# 4. 初始化请求await session.initialize()# 5. 获取服务端的所有的toolsresponse = await session.list_tools()print(response)if __name__ == "__main__":client = MCPClient('./server.py')asyncio.run(client.run())
为了方便核对代码及流程,对于第一次打印输出结果的代码给出完整版。最后面是通过初始化客户端类对象,然后进行运行,考虑到属于异步函数,需要再引入异步执行函数包装一下,最后输出的结果如下
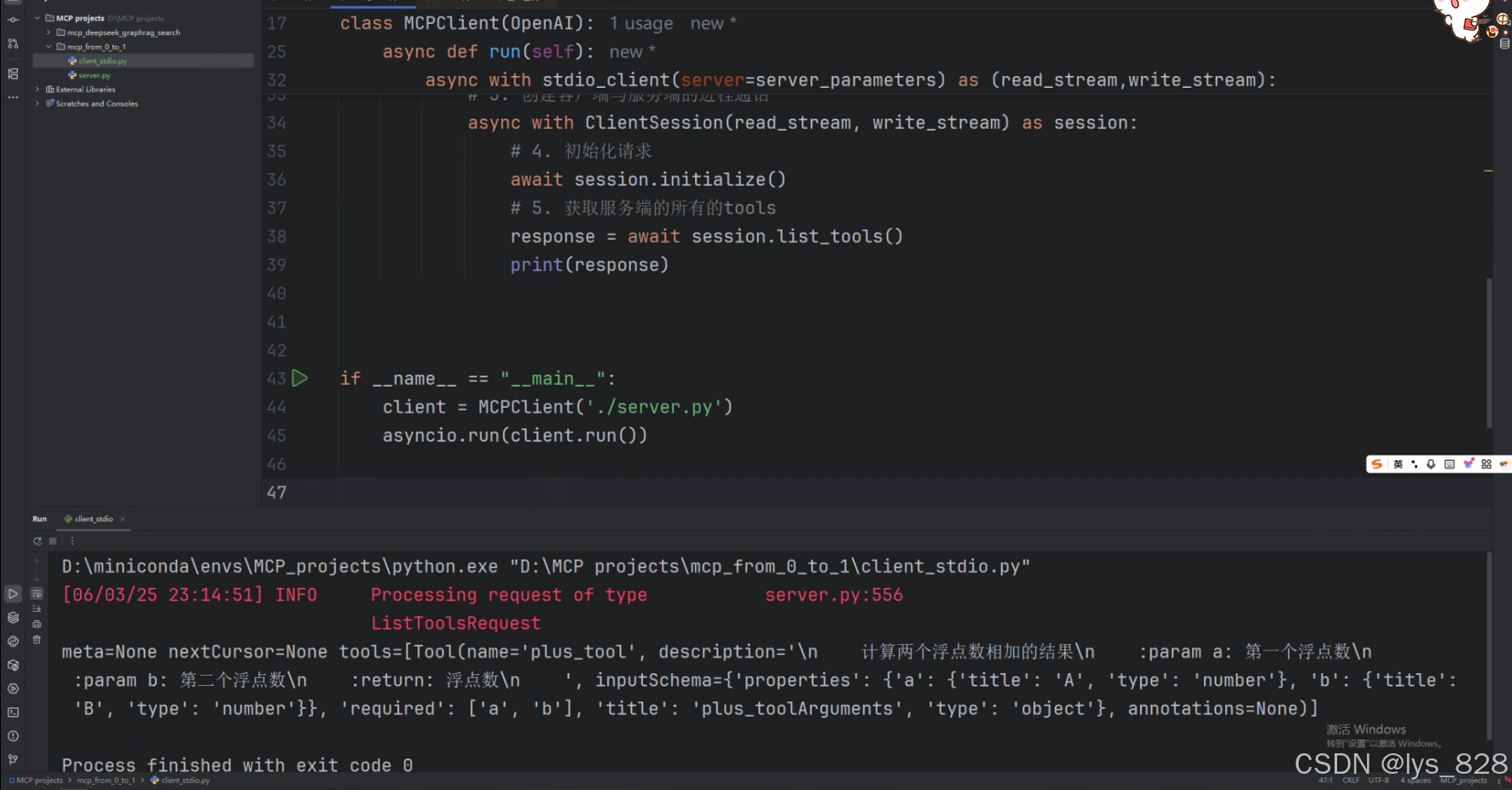
通过输出结果,可以发现工具是在tools中,其是一个列表结构,里面有一些参数,后续会用到。
(6) 将工具封装为Function Calling能识别的对象
对于大模型来说,我们给与让其使用(选择)的工具,前提是其可以正常识别,因此,在让大模型调用工具之前,需要将工具转换为大模型可以识别的对象。
# 6. 将工具封装成Function Calling能识别的对象
# tools = [Tool(name='plus_tool',
# description='\n 计算两个浮点数相加的结果\n :param a: 第一个浮点数\n :param b: 第二个浮点数\n :return: 浮点数\n ',
# inputSchema={'properties': {'a': {'title': 'A', 'type': 'number'},
# 'b': {'title': 'B', 'type': 'number'}},
# 'required': ['a', 'b'], 'title': 'plus_toolArguments', 'type': 'object'},
# annotations=None)]
tools = []
for tool in response.tools:name = tool.namedescription = tool.descriptioninput_schema = tool.inputSchematools.append({"type":"function","function":{"name":name,"description":description,"input_schema":input_schema,}})
print(tools)
代码中,按照输出的格式来构建Function Calling能识别的对象,其中tools是一个列表套字典的形式,原来的是列表里面套一个Tool类对象。输出结果如下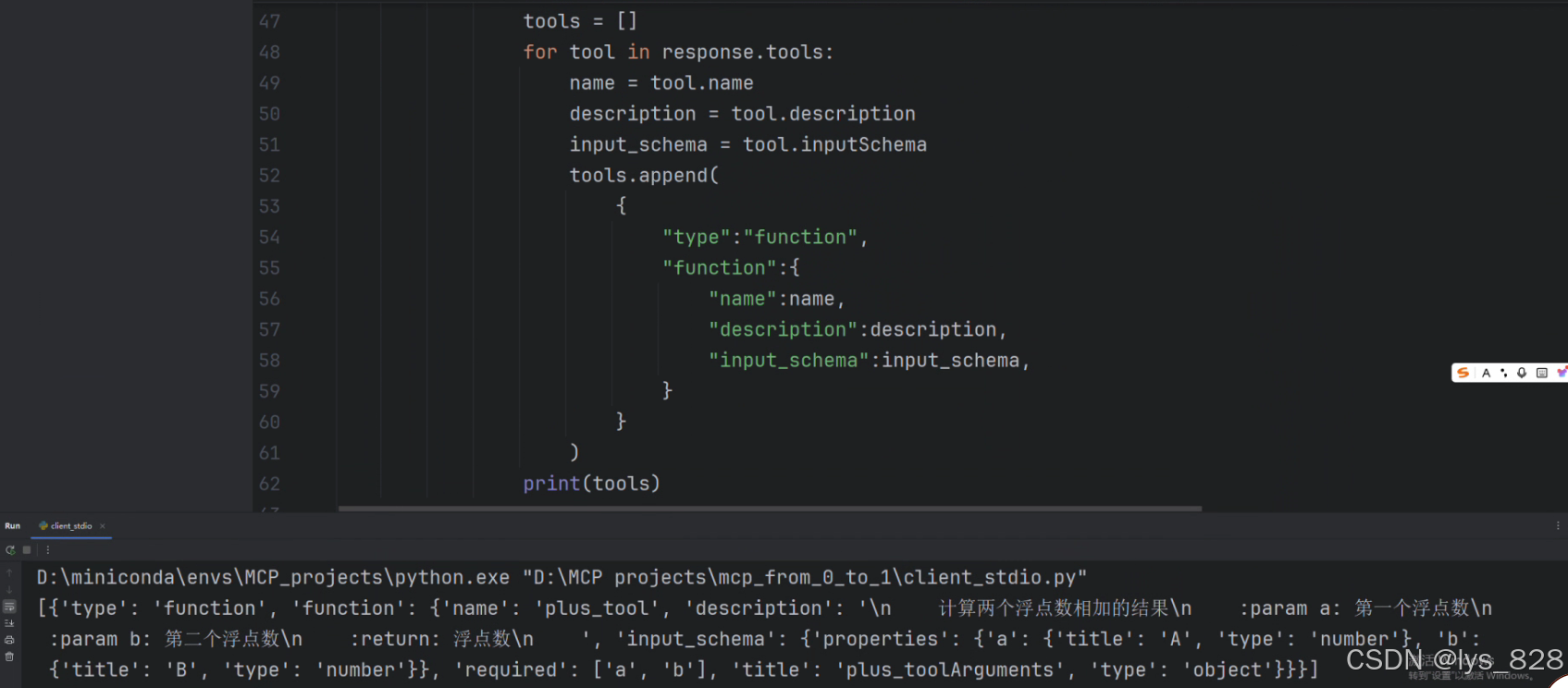
(7)发送消息给大模型,让大模型选择调用哪个工具(大模型不会自己调用)
关于首次接触大模型开发的新手,有必要梳理一下有关于大模型中角色role的作用和说明,如下
# 7. 发送消息给大模型,让大模型选择调用哪个工具(大模型不会自己调用)
# role:
# 1. user:用户发送给大模型的消息
# 2. assistant:大模型发给用户的消息
# 3. system:给大模型的系统提示词
# 4. tool:函数执行完后返回的信息
messages = [{"role":"user","content":query
}]
deepseek_response = self.deepseek.chat.completions.create(messages=messages,model="deepseek-chat",tools=tools,
)print(deepseek_response)
此时,运行后输出结果如下:(由输出结果可知,这个大模型返回的内容角色是assistant,代表内容是大模型返回给我们的,然后choice参数,代表大模型做的选择,其可以识别出我们问的问题:就是2+3为多少,例如a为3,b为2。大模型选择的工具是plus_tool)
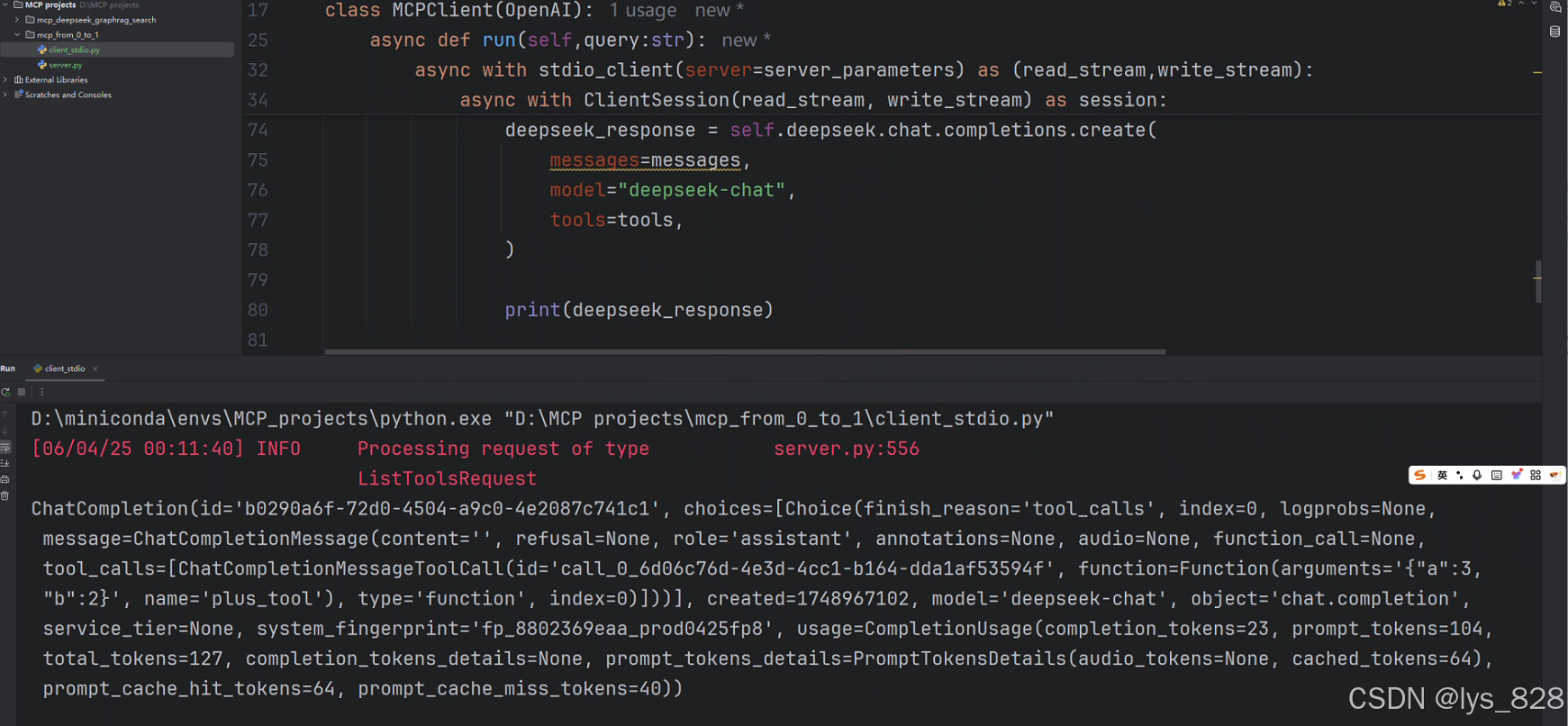
注意上面返回的结果中,finish_reason=tool_call,证明了大模型可以调用工具(选择了一个工具),为了让回复的结果更精准,可以考虑将大模型选择工具的message的信息添加到messages中
(8)重新把消息发给大模型,让大模型生成最终响应
上面的输出结果中,可以获取大模型的选择choice,获取具体的参数也很简单。需要判断一下大模型是不是选择了一个模型,也就是这里的finish_reason是不是等于tool_call。将信息添加到messages中,使用到model_dump()函数。tool_calls是一个列表,有时候会有多个工具,因此需要进行遍历循环。
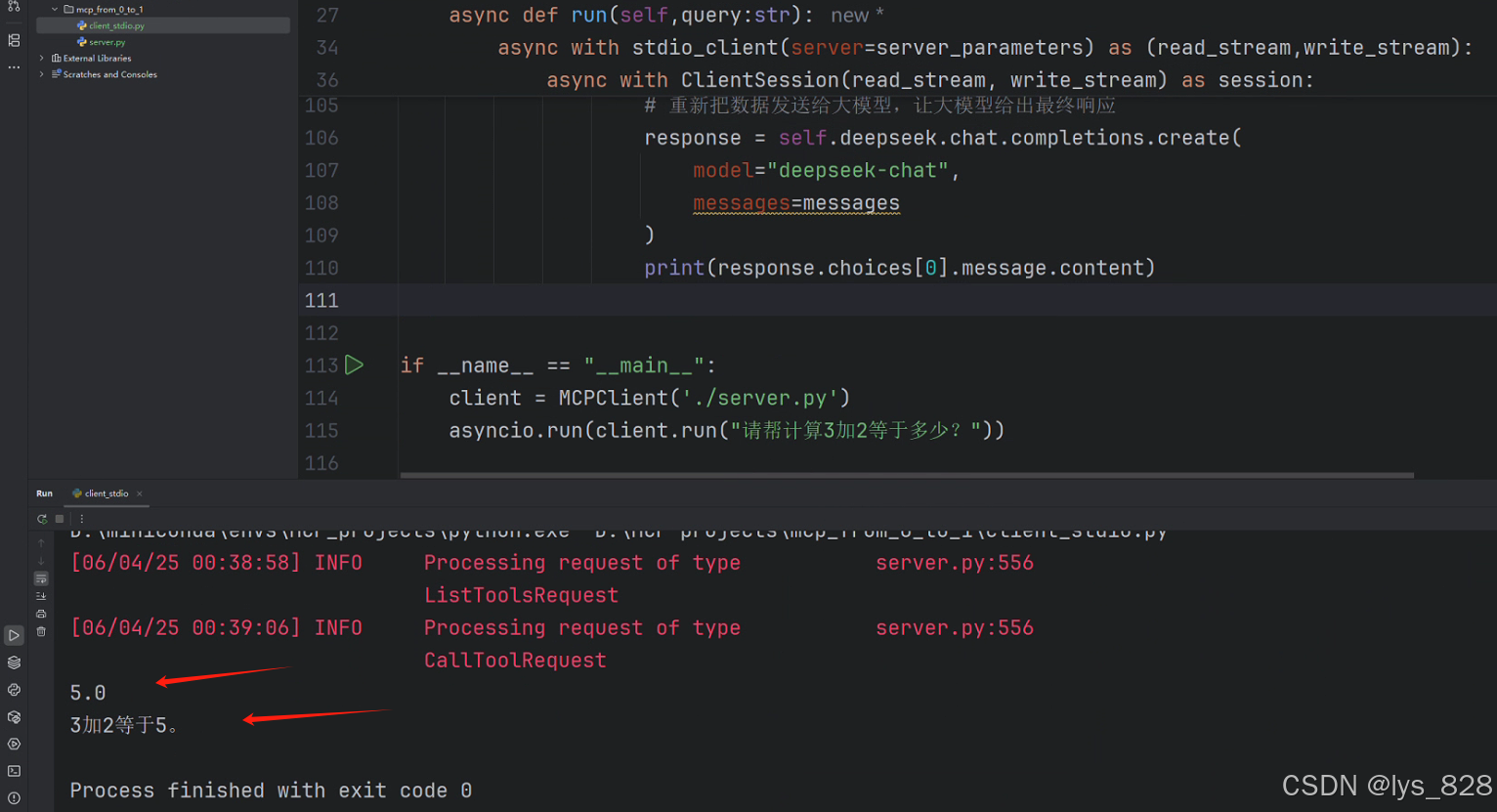
注意遍历循环中,获取对应属性的值,可按照上面的输出结果进行理解,不要写错单词。主要是对于function信息的添加。信息收集完毕后,使用进程调用一下工具,得到第一次大模型调用服务端计算工具返回的结果。打印出来后,此时输出结果为5.0。
choice = deepseek_response.choices[0]# 如果finish_reason=tool_calls,那么说明大模型选择了一个工具if choice.finish_reason == 'tool_calls':# 为了后期,大模型能够更加精准的回复,把大模型选择的工具的message,重新添加到messagesmessages.append(choice.message.model_dump())# 获取工具tool_calls = choice.message.tool_calls# 依次调用for tool_call in tool_calls:tool_call_id = tool_call.idfunction = tool_call.functionfunction_name = function.namefunction_arguments = json.loads(function.arguments)result = await session.call_tool(name=function_name,arguments=function_arguments)content = result.content[0].textprint(content)messages.append({"role":"tool","content":content,"tool_call_id": tool_call_id})# 重新把数据发送给大模型,让大模型给出最终响应response = self.deepseek.chat.completions.create(model="deepseek-chat",messages=messages)print(response.choices[0].message.content)
程序输出结果如下:(大模型总共被调用2次,第一次返回的结果是5.0 ,第二次返回结果是把第一次返回的结果重新添加到信息中,再次调用返回的结果更加精确。注意:工具调用,此时的role为tool,需要指定tool_call_id)
至此,关于stdio进行通信的客户端执行服务端的工具的代码就梳理完毕了,最后全部的代码如下:
"""
-------------------------------------------------------------------------------
@Project : MCP projects
File : client_stdio.py
Time : 2025-06-03 9:40
author : musen
Email : xianl828@163.com
-------------------------------------------------------------------------------
"""
import asyncio
import jsonfrom openai import OpenAI
from mcp.client.stdio import StdioServerParameters,stdio_client
from mcp import ClientSession# stdio: 在客户端中,启动一个新的子进程来执行服务端的脚本代码
class MCPClient(OpenAI):def __init__(self,server_path):self.server_path = server_pathself.deepseek = OpenAI(api_key="sk-5d307e0a45xxxxxce4575ff9",base_url="https://api.deepseek.com",)async def run(self,query:str):# 1. 创建连接服务器端的参数server_parameters = StdioServerParameters(command="python",args=[self.server_path],)# 2. 创建读写流async with stdio_client(server=server_parameters) as (read_stream,write_stream):# 3. 创建客户端与服务端的进程通话async with ClientSession(read_stream, write_stream) as session:# 4. 初始化请求await session.initialize()# 5. 获取服务端的所有的toolsresponse = await session.list_tools()# print(response)# 6. 将工具封装成Function Calling能识别的对象# tools = [Tool(name='plus_tool',# description='\n 计算两个浮点数相加的结果\n :param a: 第一个浮点数\n :param b: 第二个浮点数\n :return: 浮点数\n ',# inputSchema={'properties': {'a': {'title': 'A', 'type': 'number'},# 'b': {'title': 'B', 'type': 'number'}},# 'required': ['a', 'b'], 'title': 'plus_toolArguments', 'type': 'object'},# annotations=None)]tools = []for tool in response.tools:name = tool.namedescription = tool.descriptioninput_schema = tool.inputSchematools.append({"type":"function","function":{"name":name,"description":description,"input_schema":input_schema,}})# print(tools)# 7. 发送消息给大模型,让大模型选择调用哪个工具(大模型不会自己调用)# role:# 1. user:用户发送给大模型的消息# 2. assistant:大模型发给用户的消息# 3. system:给大模型的系统提示词# 4. tool:函数执行完后返回的信息messages = [{"role":"user","content":query}]deepseek_response = self.deepseek.chat.completions.create(messages=messages,model="deepseek-chat",tools=tools,)# print(deepseek_response)choice = deepseek_response.choices[0]# 如果finish_reason=tool_calls,那么说明大模型选择了一个工具if choice.finish_reason == 'tool_calls':# 为了后期,大模型能够更加精准的回复,把大模型选择的工具的message,重新添加到messagesmessages.append(choice.message.model_dump())# 获取工具tool_calls = choice.message.tool_calls# 依次调用for tool_call in tool_calls:tool_call_id = tool_call.idfunction = tool_call.functionfunction_name = function.namefunction_arguments = json.loads(function.arguments)result = await session.call_tool(name=function_name,arguments=function_arguments)content = result.content[0].textprint(content)messages.append({"role":"tool","content":content,"tool_call_id": tool_call_id})# 8. 重新把数据发送给大模型,让大模型给出最终响应response = self.deepseek.chat.completions.create(model="deepseek-chat",messages=messages)print("AI回复:",response.choices[0].message.content)else:print("执行出错")if __name__ == "__main__":client = MCPClient('./server.py')asyncio.run(client.run("请帮计算3加2等于多少?"))
3.2.3 代码优化
关于async with 与 AsyncExitStack的区别:(借助大模型回复的内容,都是属于资源管理的方式)

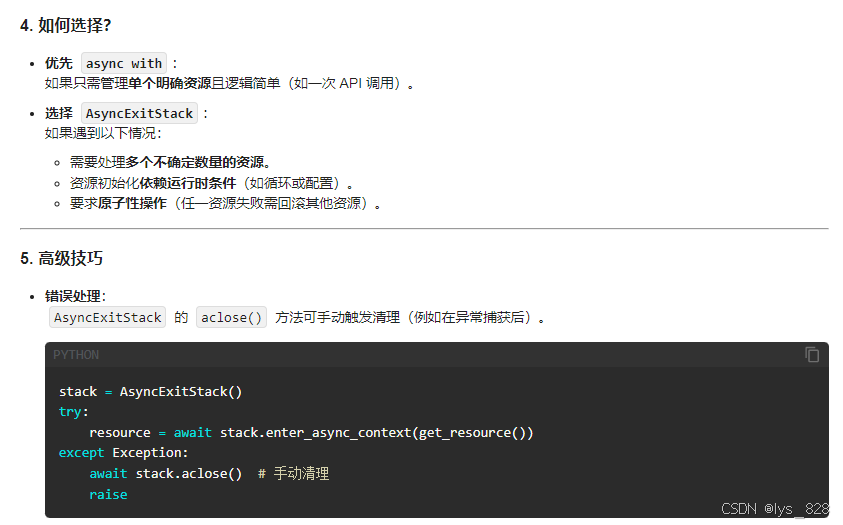
根据官网,提示的开发实例: For Client Developers。如下:
首先在类中添加AsyncExitStack函数,
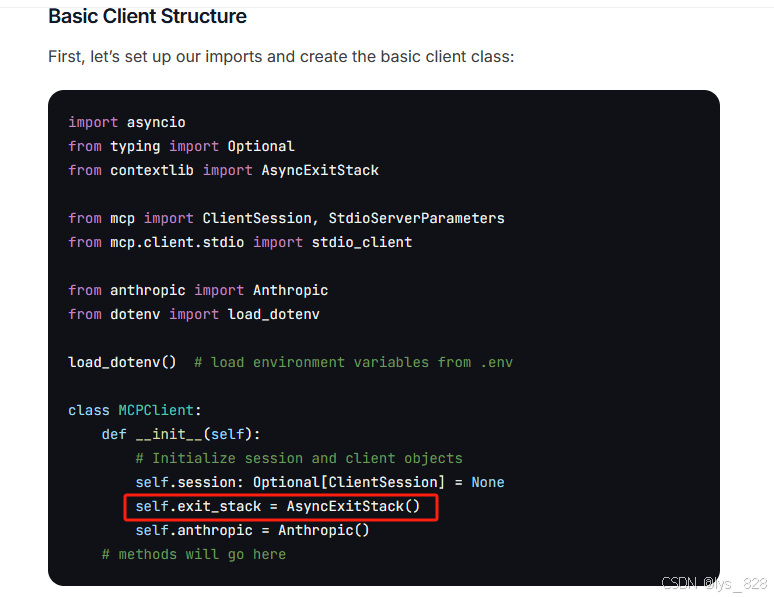
然后再正文中处理时候,将async with替换成为了AsyncExitStack的使用方式。
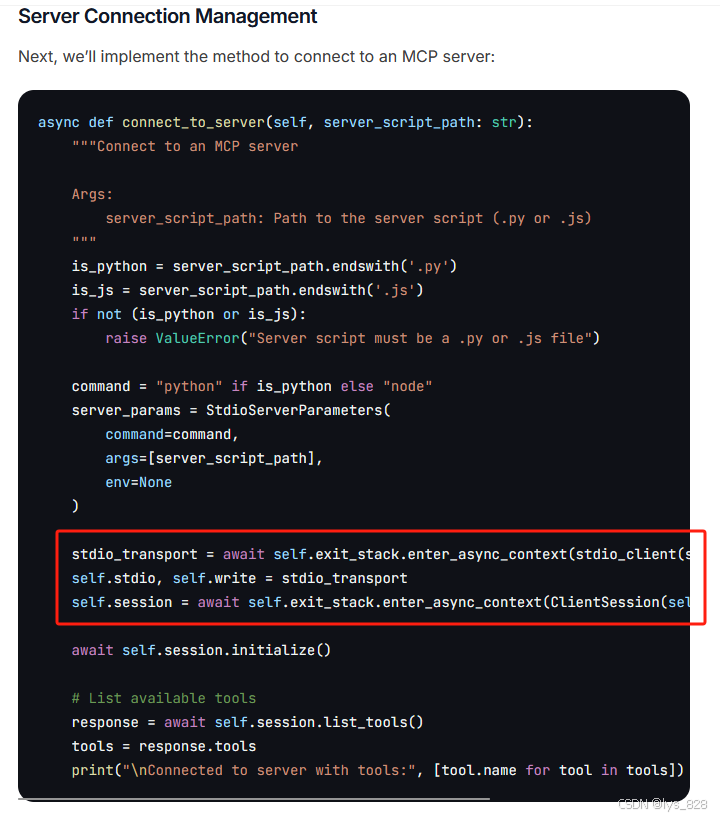
最后,手动设置了清理函数,如下
最后优化后的全部代码如下:
from openai import OpenAI
from mcp.client.stdio import StdioServerParameters, stdio_client
from mcp import ClientSession
import asyncio
import json
from contextlib import AsyncExitStack# stdio:在客户端中,启一个新的子进程来执行服务端的脚本代码class MCPClient:def __init__(self, server_path: str):self.server_path = server_pathself.deepseek = OpenAI(api_key="sk-e2bec0ab4xxxxxaad44b849",base_url="https://api.deepseek.com")self.exit_stack = AsyncExitStack()async def run(self, query: str):# 1. 创建连接服务端的参数server_parameters = StdioServerParameters(command="python",args=[self.server_path])# 改成用异步上下文堆栈来处理read_stream, write_stream = await self.exit_stack.enter_async_context(stdio_client(server=server_parameters))session = await self.exit_stack.enter_async_context(ClientSession(read_stream=read_stream, write_stream=write_stream))# 4. 初始化通信await session.initialize()# 5. 获取服务端有的toolsresponse = await session.list_tools()# 6. 将工具封装成Function Calling格式的对象tools = []for tool in response.tools:name = tool.namedescription = tool.descriptioninput_schema = tool.inputSchematools.append({"type": "function","function": {"name": name,"description": description,"input_schema": input_schema,}})# 7. 发送消息给大模型,让大模型自主选择哪个工具(大模型不会自己调用)# role:# 1. user:用户发送给大模型的消息# 2. assistant:大模型发送给用户的消息# 3. system:给大模型的系统提示词# 4. tool:函数执行完后返回的信息messages = [{"role": "user","content": query}]deepseek_response = self.deepseek.chat.completions.create(messages=messages,model="deepseek-chat",tools=tools)choice = deepseek_response.choices[0]# 如果finish_reason=tool_calls,那么说明大模型选择了一个工具if choice.finish_reason == 'tool_calls':# 为了后期,大模型能够更加精准的回复。把大模型选择的工具的message,重新添加到messages中messages.append(choice.message.model_dump())# 获取工具tool_calls = choice.message.tool_calls# 依次调用工具for tool_call in tool_calls:tool_call_id = tool_call.idfunction = tool_call.functionfunction_name = function.namefunction_arguments = json.loads(function.arguments)result = await session.call_tool(name=function_name, arguments=function_arguments)content = result.content[0].textmessages.append({"role": "tool","content": content,"tool_call_id": tool_call_id})# 重新把消息发送给大模型,让大模型生成最终的回应response = self.deepseek.chat.completions.create(model="deepseek-chat",messages=messages)print(f"AI:{response.choices[0].message.content}")else:print('回复错误!')async def aclose(self):await self.exit_stack.aclose()async def main():client = MCPClient(server_path="./server.py")try:await client.run('请帮我计算2加3等于多少')finally:# 不管上面代码是否出现异常,都要执行关闭操作await client.aclose()if __name__ == '__main__':# client = MCPClient(server_path="./server.py")# asyncio.run(client.run("请帮我计算2加3等于多少"))asyncio.run(main())
4. 基于SSE协议通信
基于SSE协议,则服务端代码和客户端代码是分开来运行的。由于服务端代码是单独运行,因此可以非常方便的采用这种方式来调试服务端代码。
新建一个python文件,命名为:client_sse.py,全部代码如下
from openai import OpenAI
from mcp.client.sse import sse_client # 修改1
from mcp import ClientSession
import asyncio
import json
from contextlib import AsyncExitStack# stdio:在客户端中,启一个新的子进程来执行服务端的脚本代码class MCPClient:def __init__(self, server_path: str):self.server_path = server_pathself.deepseek = OpenAI(api_key="sk-e2bec0ab4cxxxxxx44b849",base_url="https://api.deepseek.com")self.exit_stack = AsyncExitStack()async def run(self, query: str):# 改成用异步上下文堆栈来处理read_stream, write_stream = await # 修改2self.exit_stack.enter_async_context(sse_client("http://127.0.0.1:8000/sse")) session = await self.exit_stack.enter_async_context(ClientSession(read_stream=read_stream, write_stream=write_stream))# 4. 初始化通信await session.initialize()# 5. 获取服务端有的toolsresponse = await session.list_tools()# 6. 将工具封装成Function Calling格式的对象tools = []for tool in response.tools:name = tool.namedescription = tool.descriptioninput_schema = tool.inputSchematools.append({"type": "function","function": {"name": name,"description": description,"input_schema": input_schema,}})# 7. 发送消息给大模型,让大模型自主选择哪个工具(大模型不会自己调用)# role:# 1. user:用户发送给大模型的消息# 2. assistant:大模型发送给用户的消息# 3. system:给大模型的系统提示词# 4. tool:函数执行完后返回的信息messages = [{"role": "user","content": query}]deepseek_response = self.deepseek.chat.completions.create(messages=messages,model="deepseek-chat",tools=tools)choice = deepseek_response.choices[0]# 如果finish_reason=tool_calls,那么说明大模型选择了一个工具if choice.finish_reason == 'tool_calls':# 为了后期,大模型能够更加精准的回复。把大模型选择的工具的message,重新添加到messages中messages.append(choice.message.model_dump())# 获取工具tool_calls = choice.message.tool_calls# 依次调用工具for tool_call in tool_calls:tool_call_id = tool_call.idfunction = tool_call.functionfunction_name = function.namefunction_arguments = json.loads(function.arguments)result = await session.call_tool(name=function_name, arguments=function_arguments)content = result.content[0].textmessages.append({"role": "tool","content": content,"tool_call_id": tool_call_id})# 重新把消息发送给大模型,让大模型生成最终的回应response = self.deepseek.chat.completions.create(model="deepseek-chat",messages=messages)print(f"AI:{response.choices[0].message.content}")else:print('回复错误!')async def aclose(self):await self.exit_stack.aclose()async def main():client = MCPClient(server_path="./server.py")try:await client.run('请帮我计算2加3等于多少')finally:# 不管上面代码是否出现异常,都要执行关闭操作await client.aclose()if __name__ == '__main__':# client = MCPClient(server_path="./server.py")# asyncio.run(client.run("请帮我计算2加3等于多少"))asyncio.run(main())
对于客户端的代码只需要修改2处,就是把原来导入stdio_cientr更换为sse_client。然后服务端中需要修改1处,如下
from mcp.server.fastmcp import FastMCPapp = FastMCP("start mcp")@app.tool()
def plus_tool(a: float, b: float) -> float:"""计算两数相加的工具:param a: 第一个相加的数:param b: 第二个相加的数:return: 返回两数相加后的结果"""return a + bif __name__ == '__main__':# app.run(transport="stdio")app.run(transport="sse")
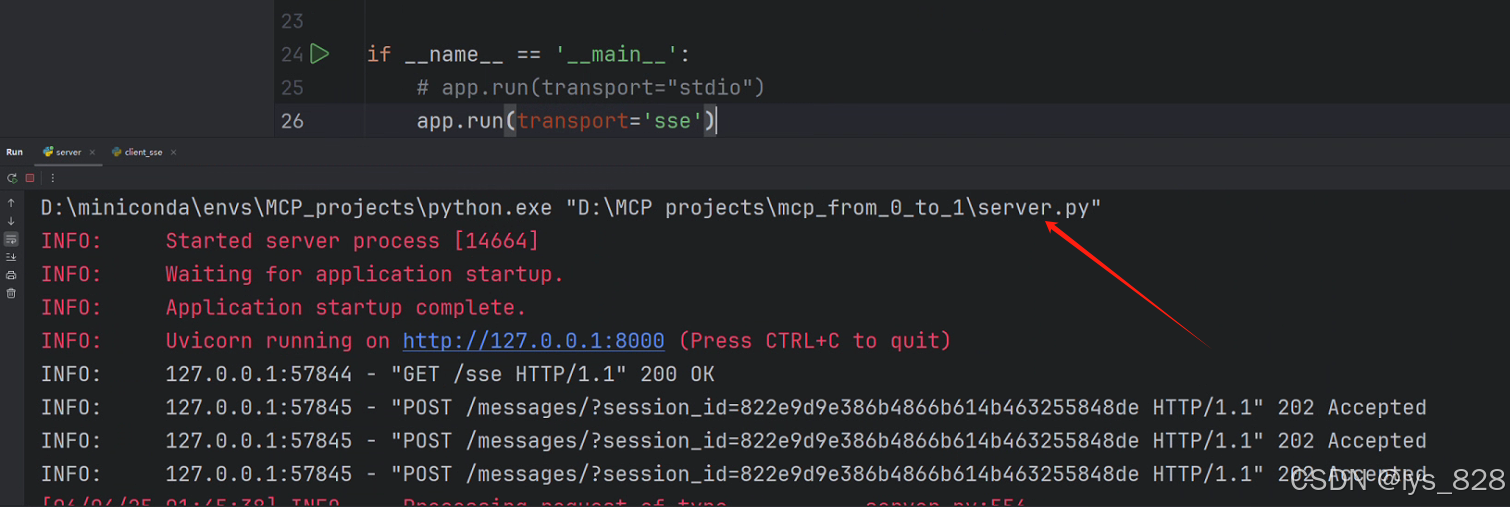
将通信模型修改一下,然后再运行客户端之前,服务端需要先执行,根据输出的url进行配置客户端中的sse_client中的网址。
服务端运行输出结果如下:
客户端执行输出结果如下:
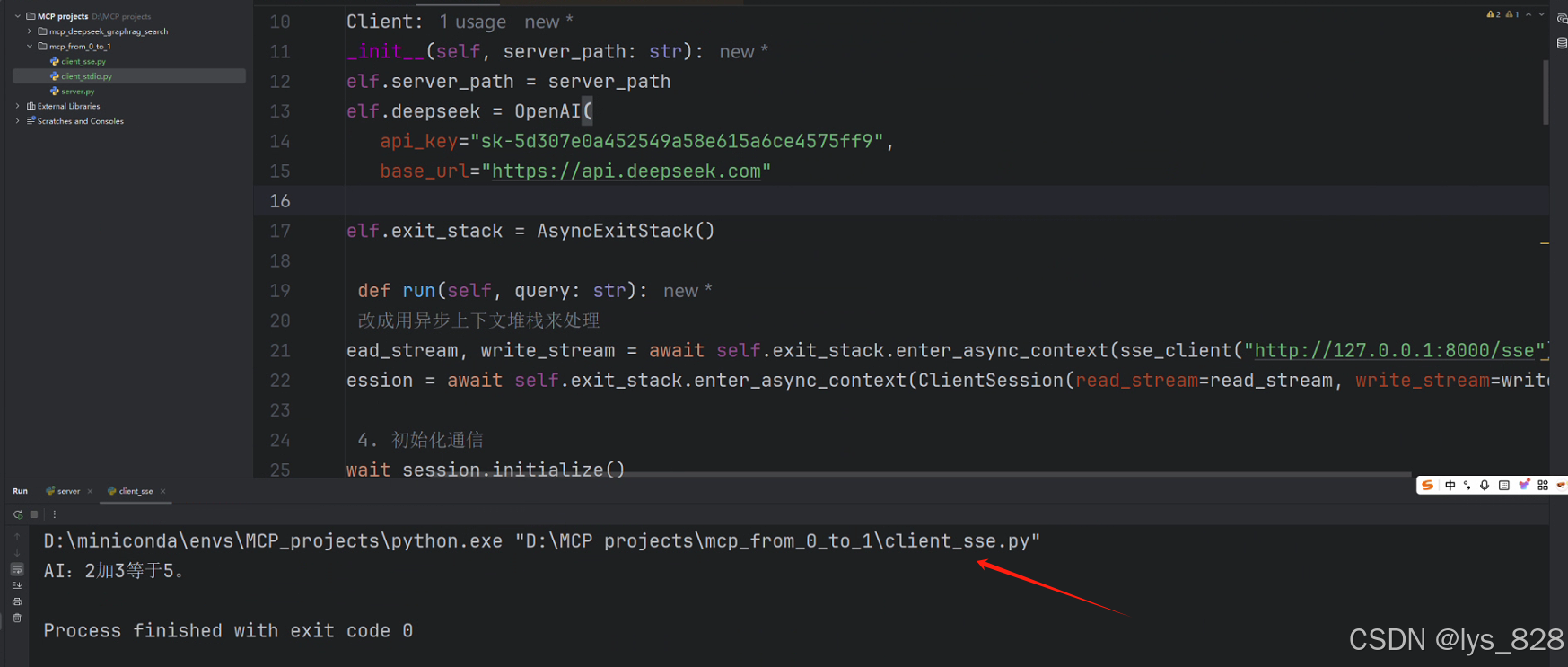
至此,第一个MCP项目的开发步骤详细梳理就完结,撒花✿✿ヽ(°▽°)ノ✿。
相关文章:
【动手学MCP从0到1】2.1 SDK介绍和第一个MCP创建的步骤详解
SDK介绍和第一个MCP 1. 安装SDK2. MCP通信协议3. 基于stdio通信3.1 服务段脚本代码3.2 客户端执行代码3.2.1 客户端的初始化设置3.2.2 创建执行进行的函数3.2.3 代码优化 4. 基于SSE协议通信 1. 安装SDK 开发mcp项目,既可以使用Anthropic官方提供的SDK,…...

基于MyBatis插件实现动态表名解决多环境单一数据库问题
业务场景 在为某新能源汽车厂商进行我司系统私有化部署时,在预演环境和生产环境中,客户仅提供了一个 MySQL 数据库实例。为了确保数据隔离并避免不同环境之间的数据冲突,常规做法是为每个环境创建独立的表(如通过添加环境前缀或后…...
测试面试题总结一
目录 列表、元组、字典的区别 nvicat连接出现问题如何排查 mysql性能调优 python连接mysql数据库方法 参数化 pytest.mark.parametrize 装饰器 list1 [1,7,4,5,5,6] for i in range(len(list1): assert list1[i] < list1[i1] 这段程序有问题嘛? pytest.i…...

Spring Boot应用多环境打包与Shell自动化部署实践
一、多环境配置管理(Profile方案) 推荐方案:通过Maven Profiles实现环境隔离 在pom.xml中定义不同环境配置,避免硬编码在application.yml中: <profiles><!-- 默认环境 --><profile><id>node…...
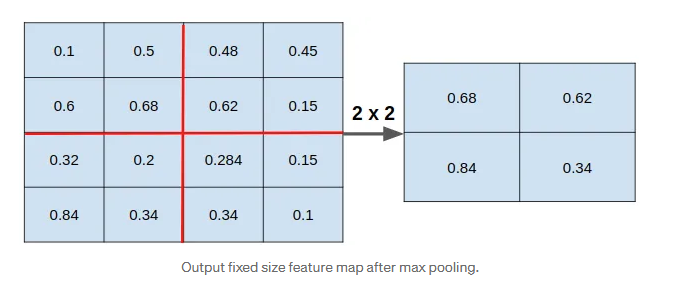
【深度学习】14. DL在CV中的应用章:目标检测: R-CNN, Fast R-CNN, Faster R-CNN, MASK R-CNN
深度学习在计算机视觉中的应用介绍 深度卷积神经网络(Deep convolutional neural network, DCNN)是将深度学习引入计算机视觉发展的关键概念。通过模仿生物神经系统,深度神经网络可以提供前所未有的能力来解释复杂的数据模式&…...

grpc的二进制序列化与http的文本协议对比
grpc的二进制序列化与http的文本协议对比 1. 二进制格式 vs 文本格式2. 编码机制:Varint 与固定长度3. 没有字段名与标点4. 较少的元信息开销4.1 HTTP/1.1 请求的元信息组成与开销4.1.1 各部分字节数示例 4.2 HTTP/2 帧结构与 HPACK 头部压缩4.2.1 HEADERS 开销对比…...

Linux 环境下 PPP 拨号的嵌入式开发实现
一、PPP 协议基础与嵌入式应用场景 PPP (Point-to-Point Protocol) 是一种在串行线路上传输多协议数据包的通信协议,广泛应用于拨号上网、VPN 和嵌入式系统的远程通信场景。在嵌入式开发中,PPP 常用于 GPRS/3G/4G 模块、工业路由器和物联网设备的网络连接…...
UE 材质基础第三天
飘动的旗帜 错乱的贴图排序,创建一个材质函数 可以用在地面材质 体积云材质制作 通过网盘分享的文件:虚幻引擎材质宝典.rar 链接: https://pan.baidu.com/s/1AYRz2V5zQFaitNPA5_JbJw 提取码: cz1q --来自百度网盘超级会员v6的分享...

【Github/Gitee Webhook触发自动部署-Jenkins】
Github/Gitee Webhook触发自动部署-Jenkins #mermaid-svg-hRyAcESlyk5R2rDn {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-hRyAcESlyk5R2rDn .error-icon{fill:#552222;}#mermaid-svg-hRyAcESlyk5R2rDn .error-tex…...

软件工程专业本科毕业论文模板
以下是软件工程专业本科毕业论文的通用模板框架,结合学术规范与工程实践要求,涵盖从需求分析到测试验证的全流程结构,并附格式说明与写作建议: 一、前置部分 1. 封面 - 包含论文标题(简明反映研究核心,如“…...
新松机械臂 2001端口服务的客户端例程
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...
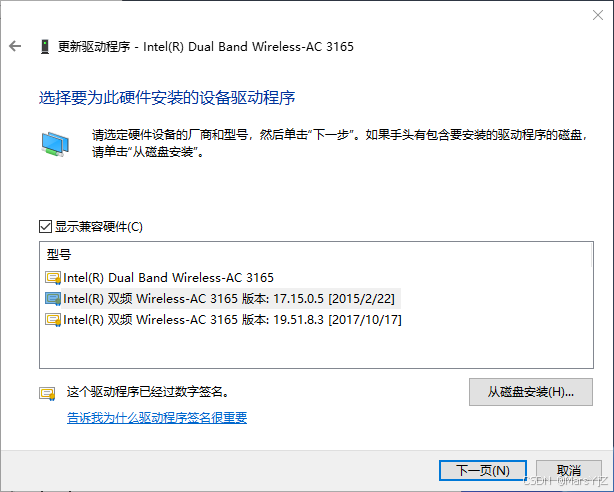
电脑网络重置,找不到原先自家的WIFI,手机还能正常连接并上网
问题排查:1、电脑感觉网络太慢,因此打算点击了网络重置 2、点击提示会删除网络,在五分钟后关机重启 3、从设备管理器设备的无线wifi属性-事件中发现删除记录 4、选择更新驱动程序 5、从列表中选取 6、更改回老驱动版本 备选方案&#…...

期末复习(学习)之机器学习入门基础
上课没听过报道。欢迎补充交流! 前言:老师画的重点其实可以完全不用看,我这里只是看了一眼书顺着书本敲一遍。 比较干货的部分,直接看学习通的内容就好。最重要的是把学习通的内容记好。 目录 老师划的重点:P50 结构…...
网络各类型(BMA,NBMA,P2P)
网络类型—基于二层(数据链路层)使用的协议不同从而导致数据包封装方式不同,工作方式也有所区别,从而对网络本身进行分类 一、网络类型分类 2. 关键差异对比 1. HDLC(高级数据链路控制协议) 协议特点&…...

Linux 库文件的查看和管理
Linux 库文件说明1、库文件的类型2、库文件存储路径3、库文件查找顺序 Linux 库文件管理1、查看动态库相关信息2、添加动态库查找路径 Linux 库文件说明 1、库文件的类型 Linux 中的库文件本质上就是封装好的功能模块,某个应用程序如果要实现某个功能,…...

Java设计模式深度解析:策略模式的核心原理与实战应用
目录 策略模式基础解析策略模式实现指南策略模式典型应用场景Java生态中的策略模式实践策略模式进阶技巧策略模式最佳实践总结与展望1. 策略模式基础解析 1.1 核心概念与定义 策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法族,将每个算法封装成独立…...

【计算机网络】第3章:传输层—概述、多路复用与解复用、UDP
目录 一、概述和传输层服务 二、多路复用与解复用 三、无连接传输:UDP 四、总结 (一)多路复用与解复用 (二)UDP 一、概述和传输层服务 二、多路复用与解复用 三、无连接传输:UDP 四、总结 (…...
服务的步骤)
6、在树莓派上安装 NTP(Network Time Protocol )服务的步骤
在树莓派上安装 NTP(Network Time Protocol )服务的步骤: 1. 安装 NTP 服务 打开树莓派终端,输入以下命令更新软件包列表: sudo apt-get update然后安装 NTP 服务: sudo apt-get install ntp2. 配置 NT…...
神经符号AI的企业应用:结合符号推理与深度学习的混合智能
💡 技术前沿: 神经符号AI代表了人工智能发展的新阶段,它将深度学习的模式识别能力与符号推理的逻辑分析能力有机结合,创造出更加智能、可解释且可靠的AI系统。这种混合智能技术正在重塑企业的智能化应用,从自动化决策到…...
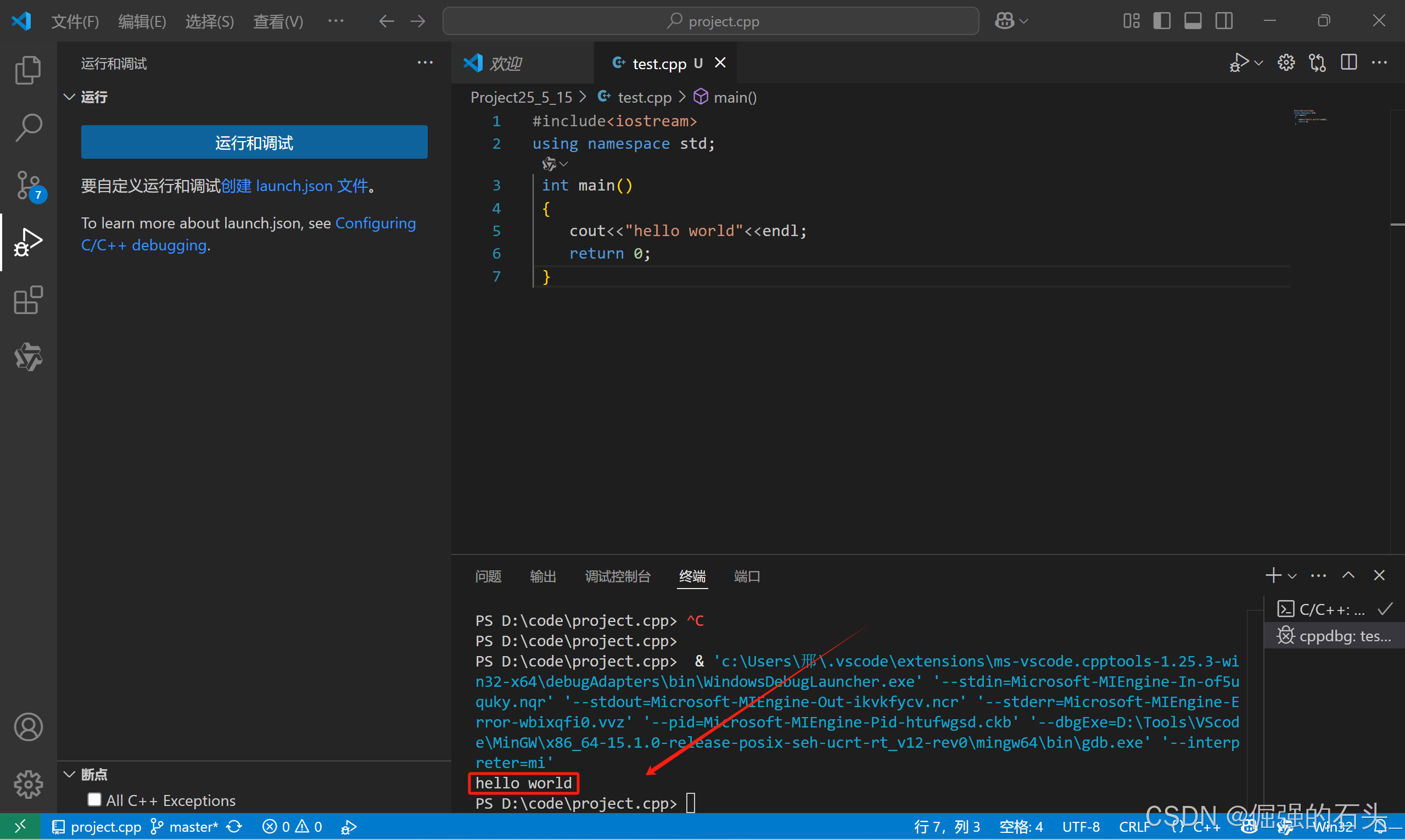
VSCode 中 C/C++ 安装、配置、使用全攻略:小白入门指南
引言 本文为Windows系统下安装配置与使用VSCode编写C/C代码的完整攻略,示例机器为Windows11。 通过本文的指导,你可以成功在Windows 机器上上使用VSCode进行C/C开发。 在文章开始之前,你可以先阅读下面这段话,以便于对步骤有个大…...

重温经典算法——希尔排序
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 基本原理 希尔排序是插入排序的改进版,通过按增量分组并逐步缩小增量实现排序。时间复杂度取决于增量序列,平均约为 O(n log n) 到 O(n^(3/2))&…...
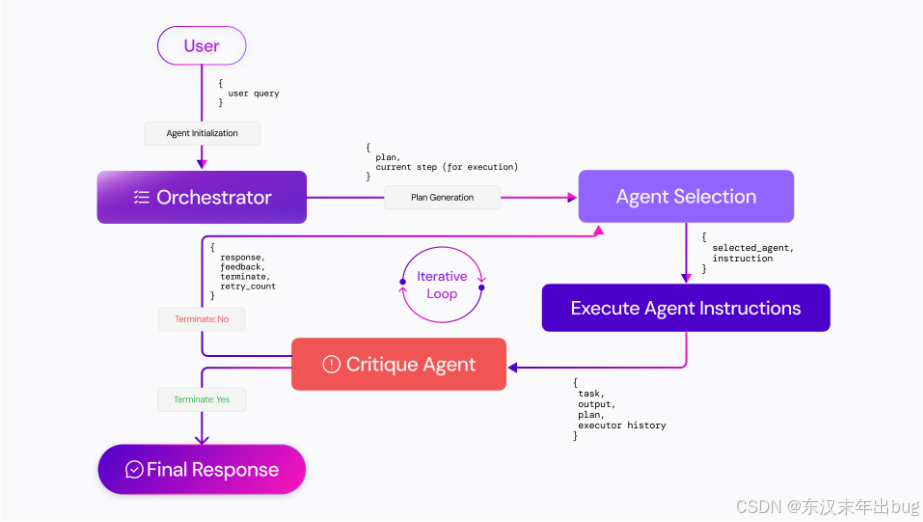
CortexON:开源的多代理AI系统无缝自动化和简化日常任务
简介 CortexON是一个开源的多代理AI系统,灵感来自Manus和OpenAI DeepResearch等高级代理平台。CortexON旨在无缝自动化和简化日常任务,擅长执行复杂的工作流程,包括全面的研究任务、技术操作和复杂的业务流程自动化。 技术架构 CortexON的技…...
海信IP810N-海思MV320芯片-安卓9-2+16G-免拆优盘卡刷固件包
海信IP810N-海思MV320芯片-安卓9-216G-免拆优盘卡刷固件包 线刷方法:(新手参考借鉴一下) 1.准备一个优盘,最佳是4G,卡刷强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化…...

【Golang】使用gin框架导出excel和csv文件
目录 1、背景2、go库【1】excel库下载【2】csv标准库 3、代码示例4、使用方法 1、背景 项目中可能会遇到导入导出一批数据的功能,对于批量大数据可能用表格的方式直观性更好,所以本篇文件来讲一下go中导出excel和csv文件的方式。 2、go库 【1】excel库…...
和AssetBundleBrowser的使用介绍)
【unity游戏开发入门到精通——通用篇】AssetBundle(AB包)和AssetBundleBrowser的使用介绍
文章目录 前言1、什么是AssetBundle?2、AB包与Resources系统对比3、AB包核心价值一、AB包打包工具Asset Bundle Browser1、下载安装AssetBundles-Browser2、打开Asset Bundle Browser窗口3、如何让资源关联AB包二、AssetBundleBrowser参数相关1、Configure 配置页签2、Build 构…...
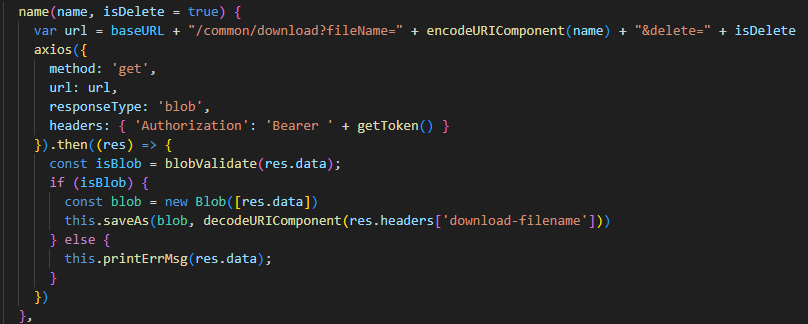
2025年6月4日收获
Authorization Authorization是一种通用的、标准化的权限控制和认证的通用框架,它能够使跨系统和跨域的身份验证和授权管理更容易,使不同应用程序之间能够更轻松地实现单点登录(SSO)、用户身份验证和授权控制等。 在前端使用 axi…...
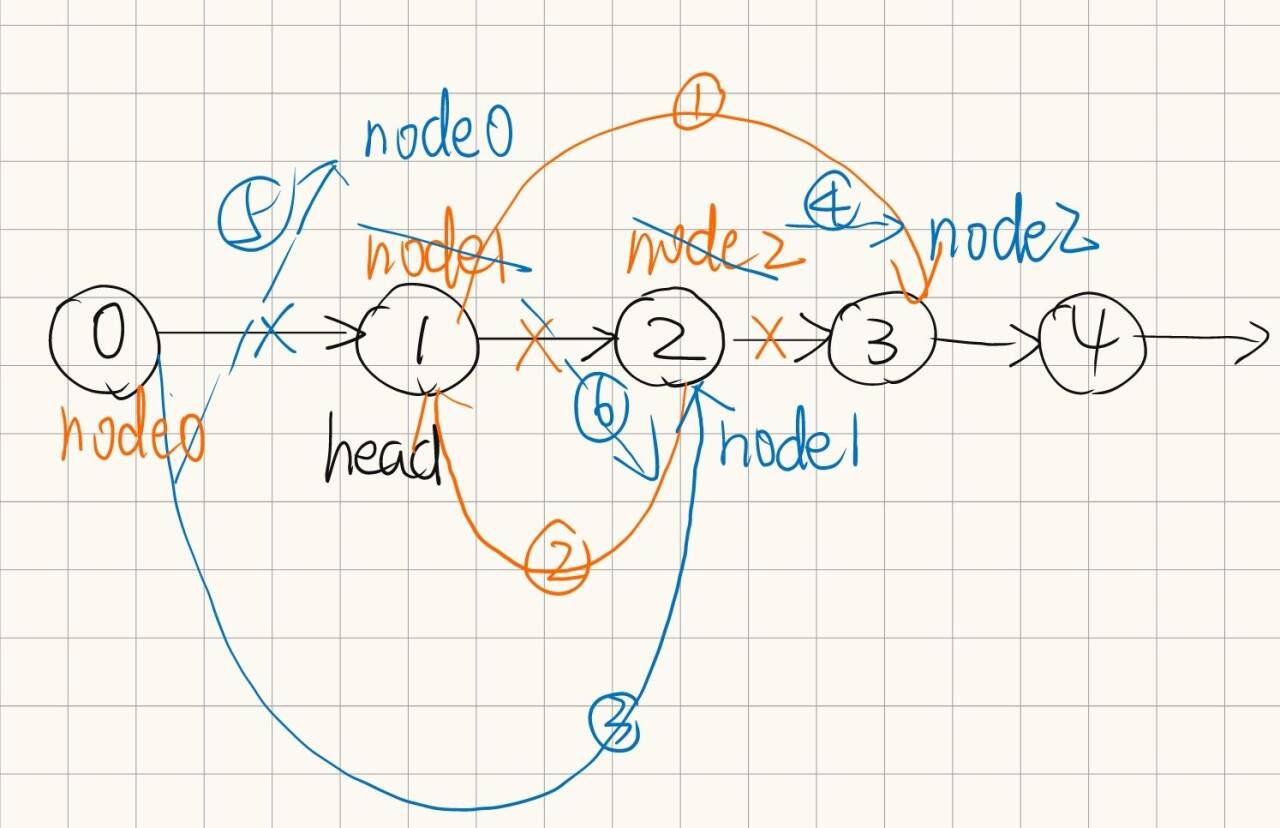
leetcode hot100 链表(二)
书接上回: leetcode hot100 链表(一)-CSDN博客 8.删除链表的倒数第N个结点 class Solution { public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode* currhead;int len0;while(curr){currcurr->next;len;}int poslen-n…...
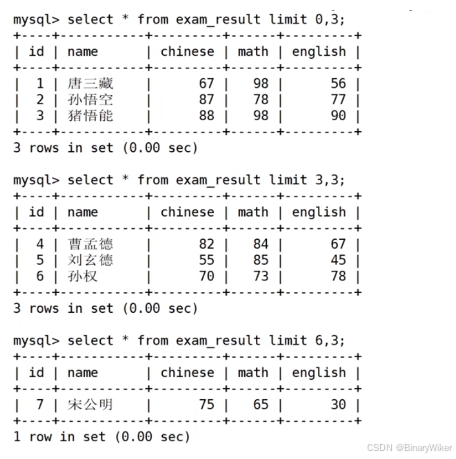
6. MySQL基本查询
1. 表的增删改查 Create(创建), Retrieve(读取), Update(更新), Delete(删除) 2. Create & Insert 语法: insert [info] table_name () values () 2.1. 案例: 创建一个学生表 指定列单行插入, 如果values前省略, 则默认是全属性插入多行指定列插入, 中间分隔符为, 3. 插入替…...

JavaWeb简介
目录 1.1 JavaWeb 简介 1.2 JavaWeb 技术栈 1.3 JavaWeb 交互模式 1.4 JavaWeb 的 C/S 和 B/S 模式 C/S 模式 (Client-Server / 客户端-服务器模式) B/S 模式 (Browser-Server / 浏览器-服务器模式) 1.5 JavaWeb 实现前…...
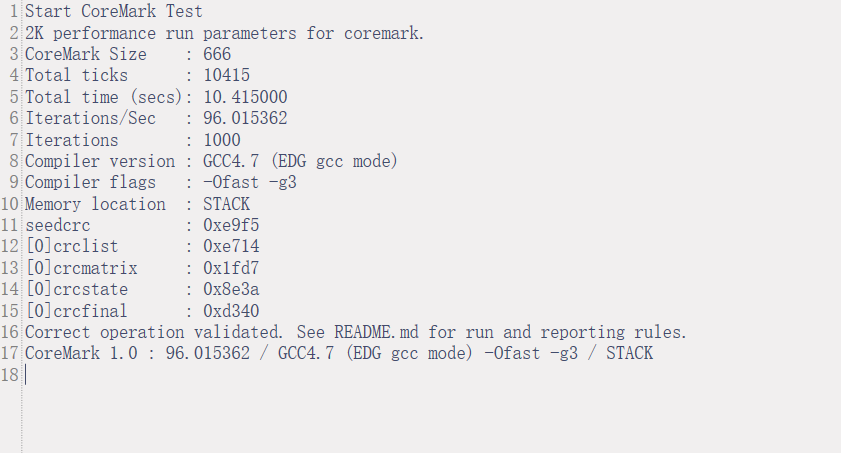
CMS32M65xx/67xx系列CoreMark跑分测试
CMS32M65xx/67xx系列CoreMark跑分测试 1、参考资料准备 1.1、STM32官方跑分链接 1.2、官网链接 官方移植文档,如下所示,点击红框处-移植文档: A new whitepaper and video explain how to port CoreMark-Pro to bare-metal 1.3、测试软件git下载链接 …...