Scrapy爬虫框架Spiders爬虫脚本使用技巧
我们都知道Scrapy是一个用于爬取网站数据、提取结构化数据的Python框架。在Scrapy中,Spiders是用户自定义的类,用于定义如何爬取某个(或某些)网站,包括如何执行爬取(即跟踪链接)以及如何从页面中提取结构化数据(即爬取项)。至于如何定义Spiders爬虫逻辑和规则可以看看我下面总结的经验。

Scrapy 是一个强大的 Python 爬虫框架,其核心组件 Spiders 用于定义爬取逻辑和数据提取规则。下面是一个详细的结构解析和示例:
一、Scrapy Spider 核心组件
- 类定义:继承
scrapy.Spider或其子类 - 必要属性:
name:爬虫唯一标识符start_urls:初始爬取 URL 列表
- 核心方法:
parse(self, response):默认回调函数,处理响应并提取数据
- 可选扩展:
- 自定义设置(
custom_settings) - 链接跟踪规则(
CrawlSpider)
- 自定义设置(
二、基础 Spider 示例
import scrapyclass BookSpider(scrapy.Spider):name = "book_spider"start_urls = ["http://books.toscrape.com/"]def parse(self, response):# 提取书籍列表页数据for book in response.css("article.product_pod"):yield {"title": book.css("h3 a::attr(title)").get(),"price": book.css("p.price_color::text").get(),"rating": book.css("p.star-rating::attr(class)").get().split()[-1]}# 跟踪下一页next_page = response.css("li.next a::attr(href)").get()if next_page:yield response.follow(next_page, callback=self.parse)
三、进阶 CrawlSpider 示例(自动链接跟踪)
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractorclass AdvancedSpider(CrawlSpider):name = "crawl_spider"allowed_domains = ["example.com"]start_urls = ["http://www.example.com/catalog"]# 定义链接提取规则rules = (# 匹配商品详情页(回调函数处理)Rule(LinkExtractor(restrict_css=".product-item"), callback="parse_item"),# 匹配分页链接(无回调默认跟随)Rule(LinkExtractor(restrict_css=".pagination")))def parse_item(self, response):yield {"product_name": response.css("h1::text").get(),"sku": response.xpath("//div[@class='sku']/text()").get(),"description": response.css(".product-description ::text").getall()}
四、关键功能解析
| 组件 | 作用 |
|---|---|
response.css() | 用 CSS 选择器提取数据(推荐 ::text/::attr(xxx)) |
response.xpath() | XPath 选择器,处理复杂结构 |
response.follow() | 自动处理相对 URL 的请求生成 |
LinkExtractor | 自动发现并跟踪链接,支持正则/CSS/XPath 过滤 |
custom_settings | 覆盖全局配置(如:DOWNLOAD_DELAY, USER_AGENT) |
五、最佳实践
-
数据管道:
- 在
pipelines.py中定义数据清洗/存储逻辑 - 在
settings.py启用管道:ITEM_PIPELINES
- 在
-
中间件:
-
下载中间件处理请求头/代理/IP轮换
-
示例代理中间件:
class ProxyMiddleware:def process_request(self, request, spider):request.meta["proxy"] = "http://proxy_ip:port"
-
-
防反爬策略:
- 随机 User-Agent:
scrapy-fake-useragent库 - 自动限速:
AUTOTHROTTLE_ENABLED = True
- 随机 User-Agent:
六、运行与调试
-
启动爬虫:
scrapy crawl book_spider -o books.json -
Shell 调试:
scrapy shell "http://books.toscrape.com" >>> response.css('h1::text').get()
七、常见问题解决
- 403 禁止访问:添加合法
USER_AGENT - 数据缺失:检查目标页面动态加载(需启用
scrapy-splash或selenium中间件) - 重复 URL:启用去重中间件
DUPEFILTER_CLASS
如果掌握上面这些核心模式后,大体上就可以灵活应对各类网站爬取需求。但是也要建议多结合Scrapy 官方文档多多学习。
相关文章:
Scrapy爬虫框架Spiders爬虫脚本使用技巧
我们都知道Scrapy是一个用于爬取网站数据、提取结构化数据的Python框架。在Scrapy中,Spiders是用户自定义的类,用于定义如何爬取某个(或某些)网站,包括如何执行爬取(即跟踪链接)以及如何从页面中…...
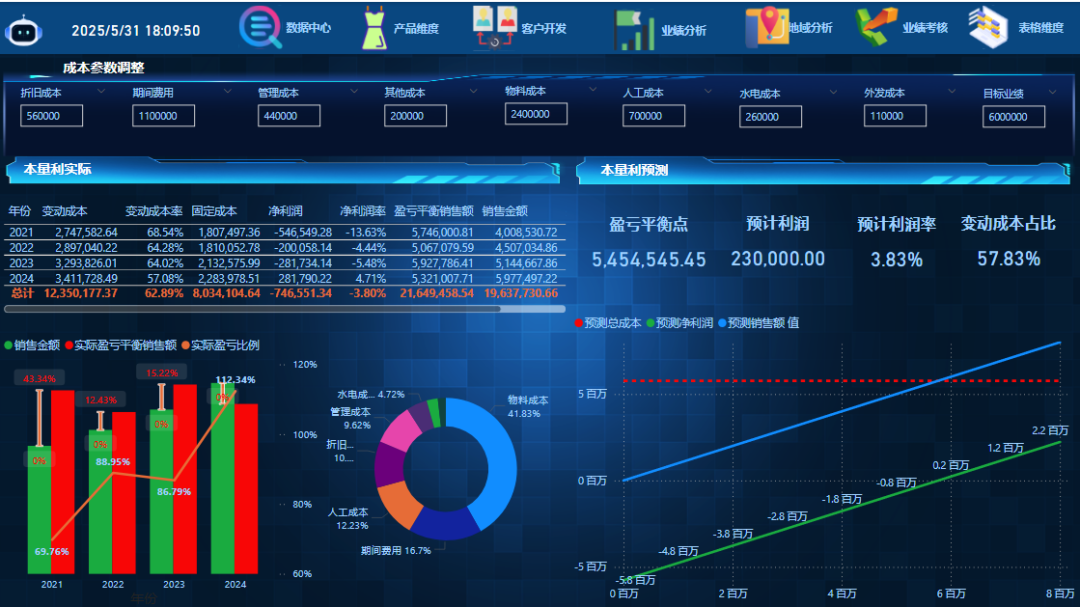
PowerBI企业运营分析—全动态盈亏平衡分析
PowerBI企业运营分析—全动态盈亏平衡分析 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 该平台通过整合多源数据,实现关键指标的实时监控,从而迅速洞察业务动态,精准…...

docker的基本命令
容器的三大组成 镜像image 一个静态文件,特点:分层结构,不可更改 容器container 镜像运行的结果,容器可以修改,运行完后直接停止 仓库registry 用来存放镜像文件的地方 容器的常用命令介绍 关于镜像的命令 docker …...
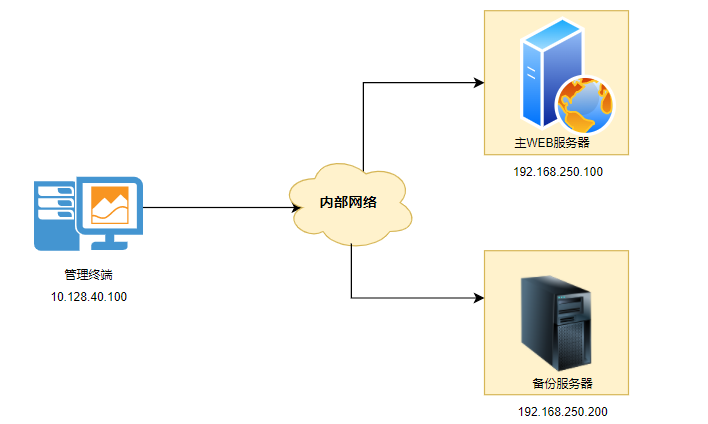
【运维实战】Rsync将一台主Web服务器上的文件和目录同步到另一台备份服务器!
在管理 Web 服务器时,确保数据安全且在发生故障时能够快速恢复至关重要,备份和镜像 Web 服务器数据最可靠的方法之一是使用 rsync。 Rsync 工具可以帮助在两台服务器之间同步文件和目录,非常适合用于创建 Web 服务器数据的备份和镜像。 下面…...

实时通信RTC与传统直播的异同
实时通信(RTC)与直播虽然在音视频传输领域密切相关,但设计目标和实现原理是存在显著差异的。 一、核心联系 共同目标:均需实现音视频数据的采集、编码、传输与播放。技术重叠:使用相似的编码标准(如H.264/…...
)
Python-正则表达式(re 模块)
目录 一、re 模块的使用过程二、正则表达式的字符匹配1. 匹配开头结尾2. 匹配单个字符3. 匹配多个字符4. 匹配分组5. Python 代码示例 三、re 模块的函数1. 函数一览表2. Python 代码示例1)search 与 finditer2)findall3)sub4)spl…...
AgenticSeek 本地部署教程(Windows 系统)
#工作记录 Fosowl/agenticSeek:完全本地的 Manus AI。 部署排错参考资料在文末 或查找往期笔记。 AgenticSeek 本地部署教程(Windows 系统) 一、环境准备 1. 安装必备工具 Docker Desktop 下载地址:Docker Desktop 官网 安装后启…...
基于 qiankun + vite + vue3 构建微前端应用实践
核心内容摘要 技术栈组合 采用 Vite Vue3 Qiankun 构建微前端架构主应用和子应用独立开发部署,通过 Qiankun 集成 2. 主应用关键配置通过 registerMicroApps 注册子应用,配置路由匹配规则(activeRule)使用…...

VR教育:开启教育新时代的钥匙
VR 教育,即虚拟现实教育,是将虚拟现实技术(Virtual Reality,简称 VR)应用于教育领域的一种创新教育模式。它借助计算机技术、图形图像技术、传感器技术等,创建出高度逼真的虚拟学习环境,让学生通过头戴式显示设备、手柄…...
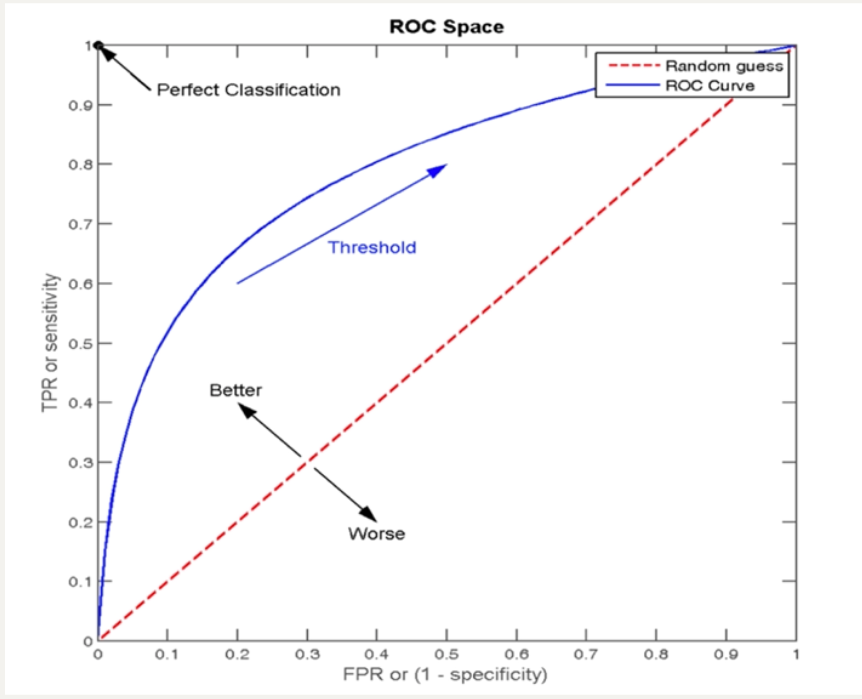
机器学习:逻辑回归与混淆矩阵
本文目录: 一、逻辑回归Logistic Regression二、混淆矩阵(一)精确率precision(二)召回率recall(三)F1-score:了解评估方向的综合预测能力(四)Roc曲线…...

20250602在荣品的PRO-RK3566开发板的Android13下打开HDMI显示
20250602在荣品的PRO-RK3566开发板的Android13下打开HDMI显示 2025/6/2 16:20 缘起:貌似荣品的PRO-RK3566开发板的Android13默认关闭了HDMI显示。 据说:荣品确认RK3566的GPU比较弱,同时开【MIPI接口的】LCD屏显示和HDMI显示容易出现异常。 更…...

【学习记录】快速上手 PyQt6:设置 Qt Designer、PyUIC 和 PyRCC 在 PyCharm中的应用
文章目录 📌 前言✅ 第一步:安装 PyQt6 及其工具包🔧 第二步:找到相关工具路径🧰 第三步:在 PyCharm 中配置外部工具打开设置🛠️ 配置 Qt Designer🛠️ 配置 PyUIC6(UI转…...
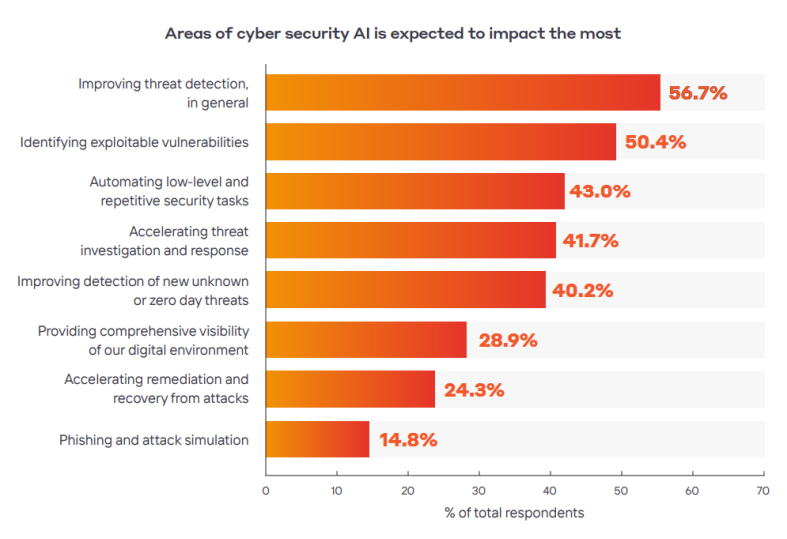
AI在网络安全领域的应用现状和实践
当前,人工智能技术已深度融入网络安全产品,推动传统防御模式向智能化、自适应方向加速演进。各安全厂商通过机器学习、深度学习与知识图谱等技术的融合应用,提高安全产品在威胁检测、攻击溯源、风险评估等场景的能力跃迁,突破传统…...

DrissionPage 异常处理实战指南:构建稳健的网页自动化防线
在网页自动化领域,异常处理能力直接决定了系统的健壮性。作为融合Selenium与Requests特性的创新工具,DrissionPage提供了多层次的异常处理机制。本文将深入剖析其异常体系,结合真实场景案例,为您构建一套完善的自动化容错方案。 …...

鸿蒙任务项设置案例实战
目录 案例效果 资源文件与初始化 string.json color.json CommonConstant 添加任务 首页组件 任务列表初始化 任务列表视图 任务编辑页 添加跳转 任务目标设置模型(formatParams) 编辑页面 详情页 任务编辑列表项 目标设置展示 引入目标…...

TDengine 的 AI 应用实战——运维异常检测
作者: derekchen Demo数据集准备 我们使用公开的 NAB数据集 里亚马逊 AWS 东海岸数据中心一次 API 网关故障中,某个服务器上的 CPU 使用率数据。数据的频率为 5min,单位为占用率。由于 API 网关的故障,会导致服务器上的相关应用…...

DHCP与DNS的配置
在网络管理中,DHCP(动态主机配置协议)和DNS(域名系统)是两个关键组件。DHCP用于自动分配IP地址,而DNS用于将域名解析为IP地址。本文将详细介绍如何在Linux环境下配置DHCP和DNS服务。 一、DHCP配置 1. 安装…...
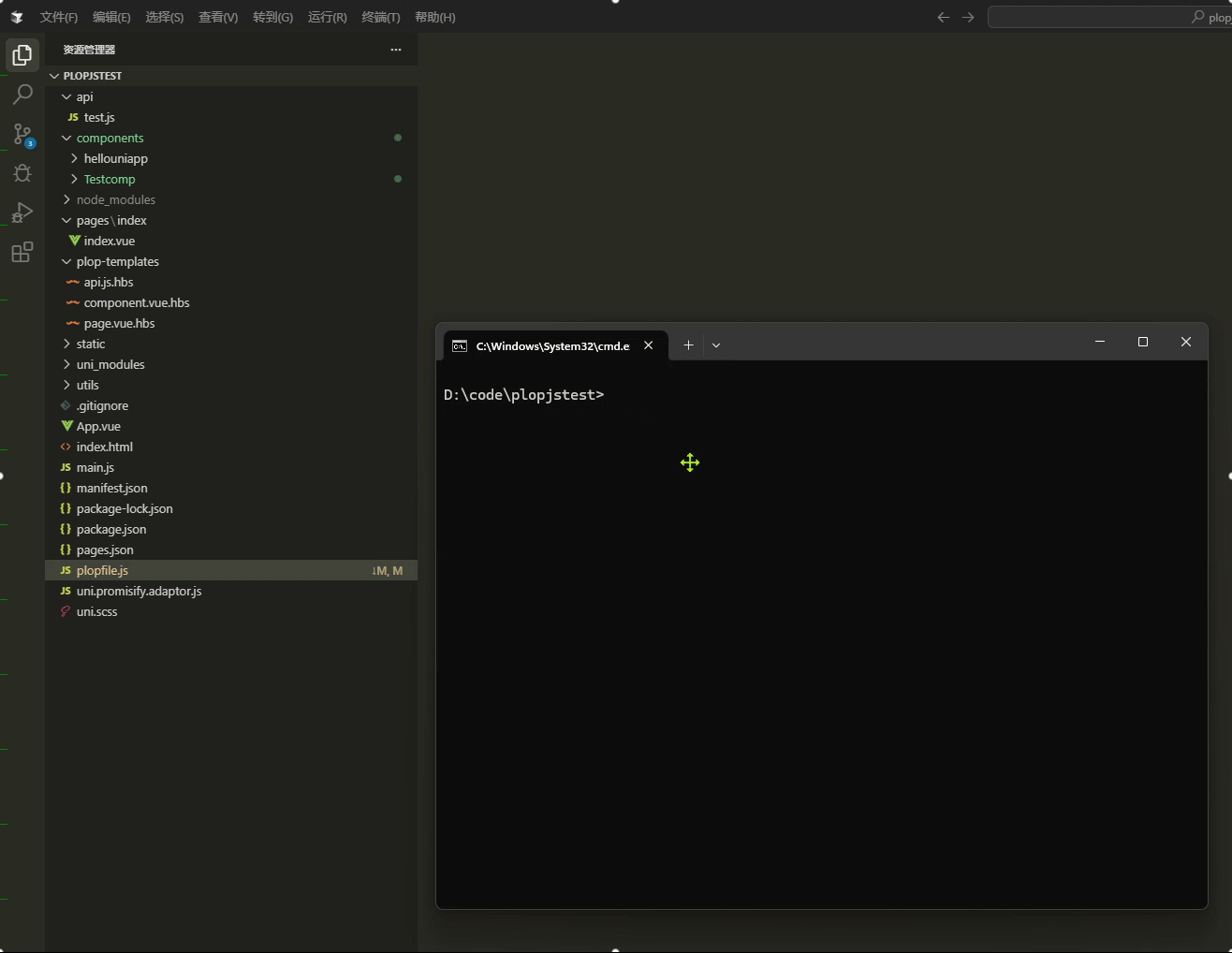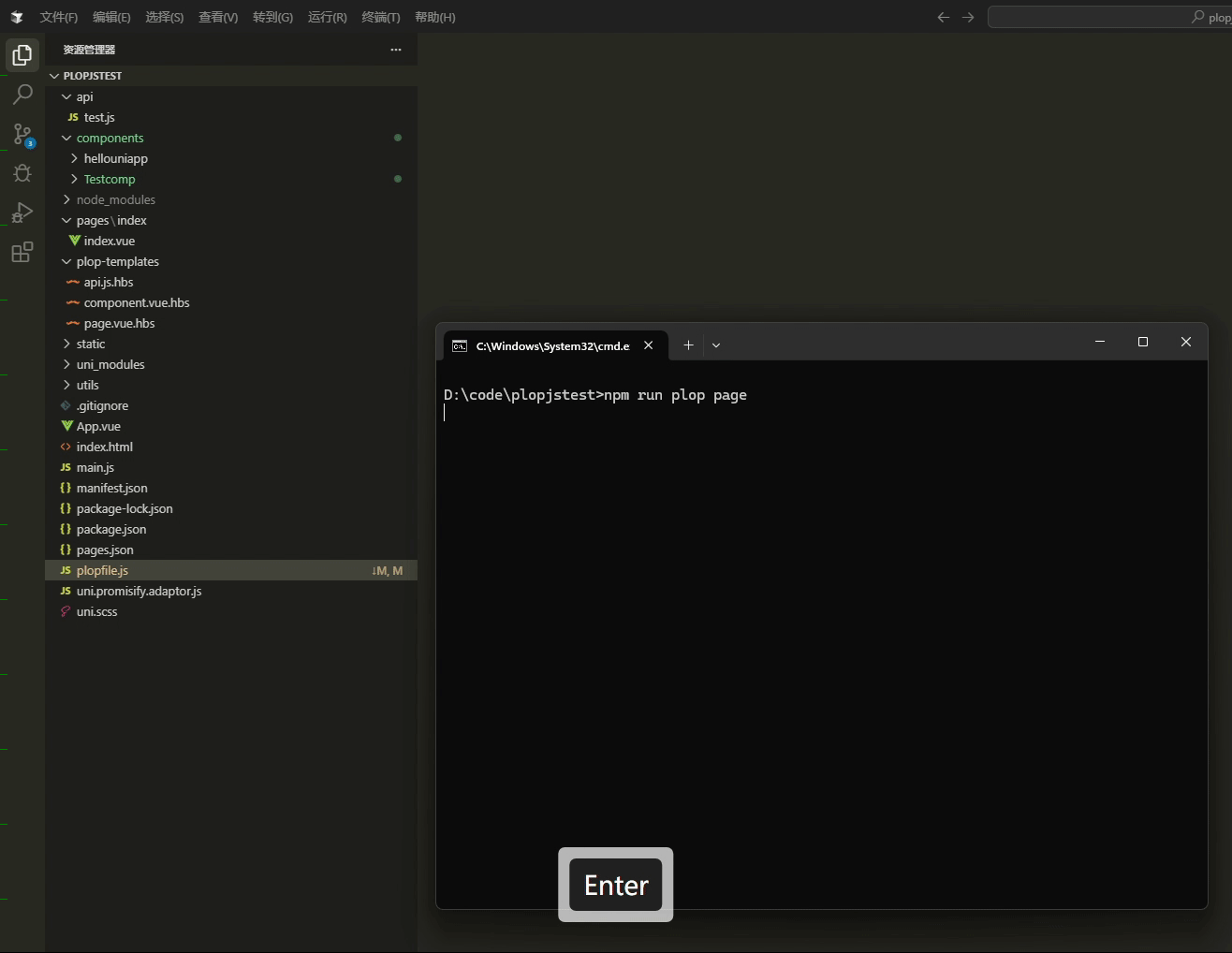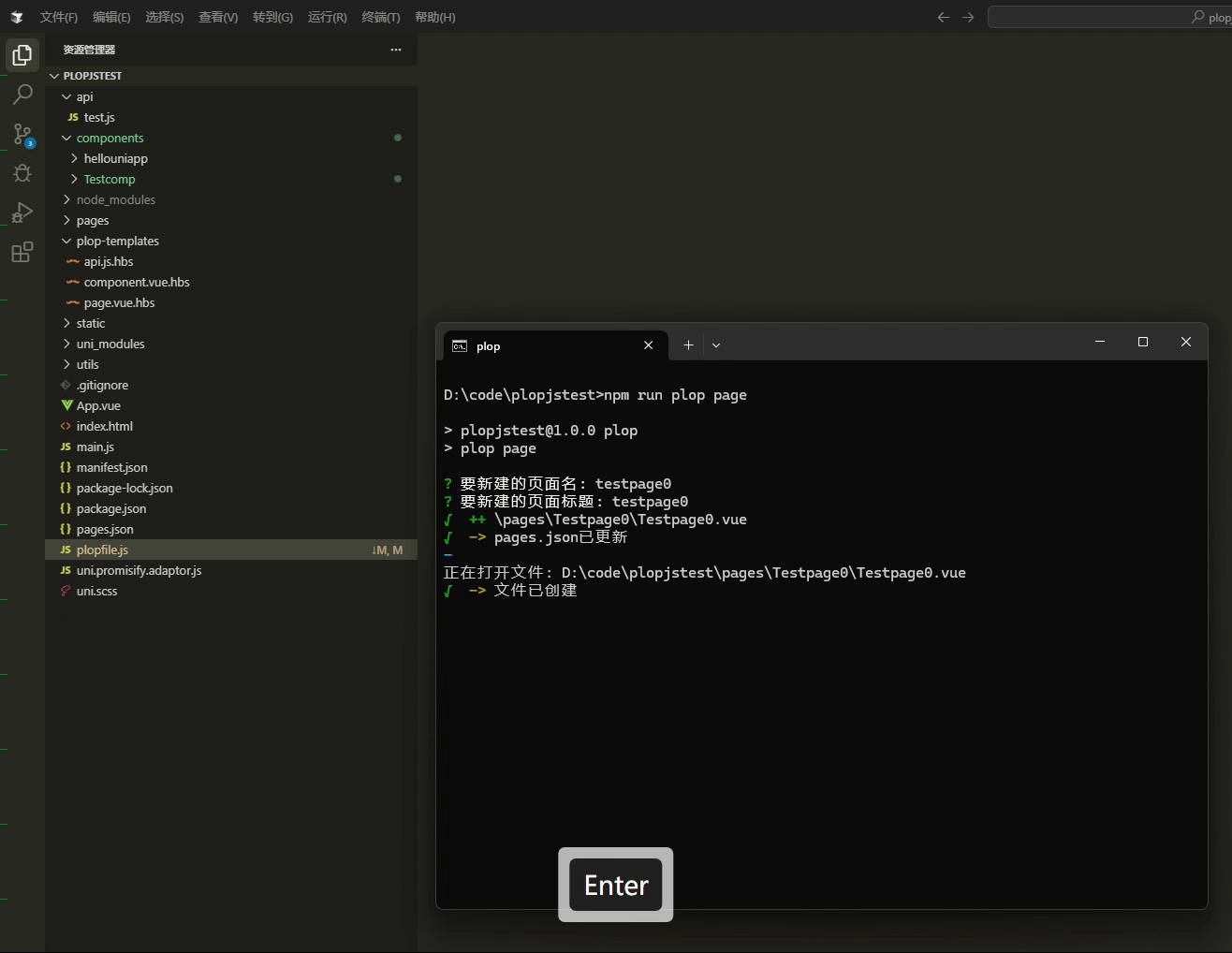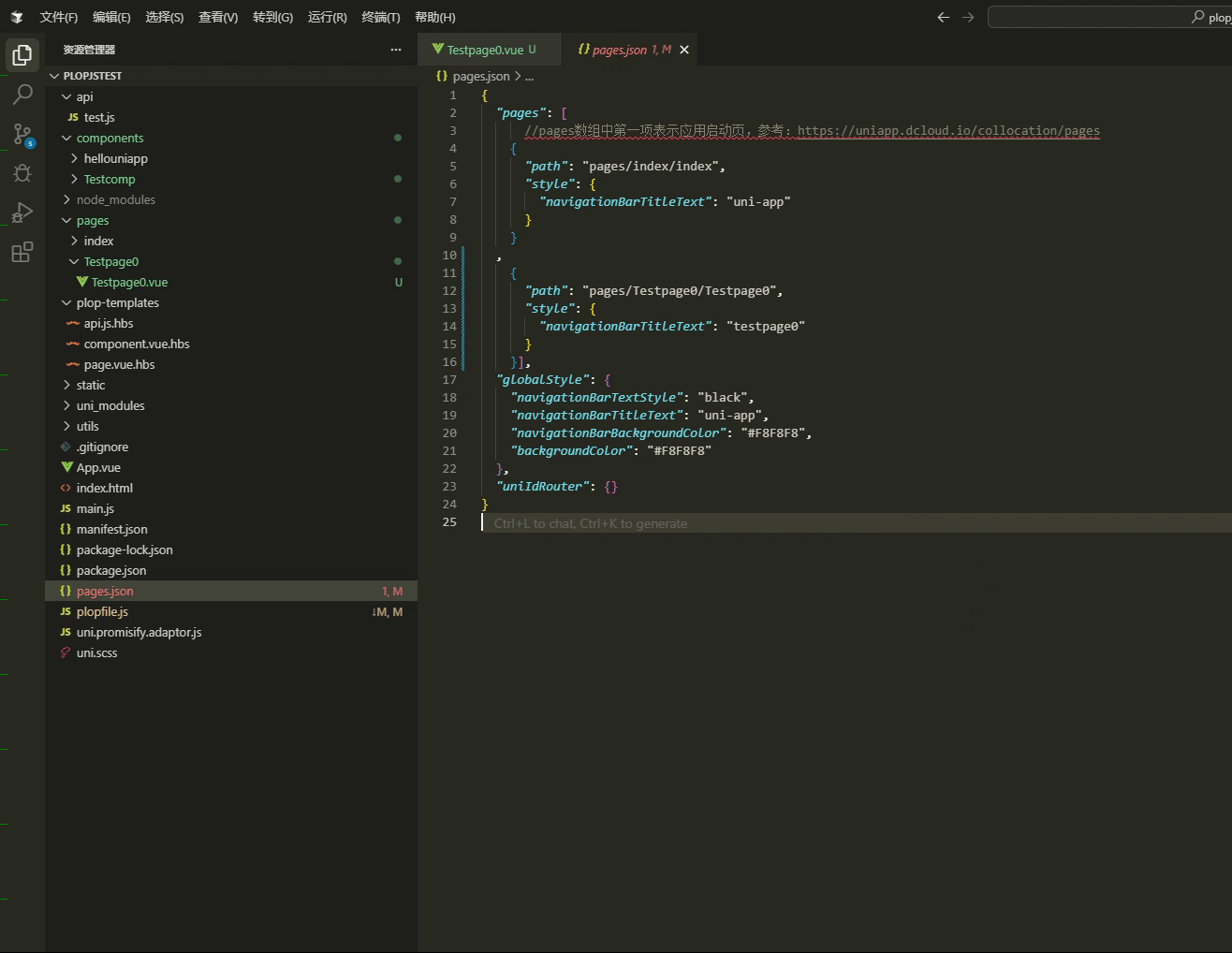
使用Plop.js高效生成模板文件
前情 开发是个创造型的职业,也是枯燥的职业,因为开发绝大多数都是每天在业务的代码中无法自拨,说到开发工作,就永远都逃不开新建文件的步骤,特别现在组件化开发胜行,每天都是在新建新建组件的道路上一去不…...
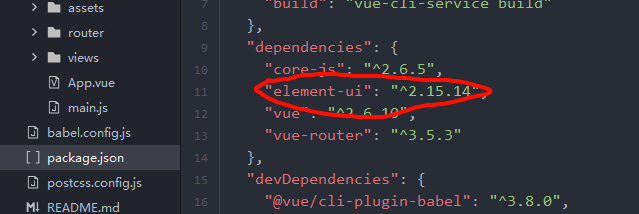
Vue框架2(vue搭建方式2:利用脚手架,ElementUI)
一.引入vue第二种搭建方式 在以前的前端项目中,一个项目需要多个html文件实现页面之前的切换,如果页面中需要依赖js或者css文件,那么我们就需要在多个html文件中都需要导入vue.js文件,太过繁琐. 现在前端开发都采用单页面结果,一个项目中只有一个html文件 其他不同的内容都写…...
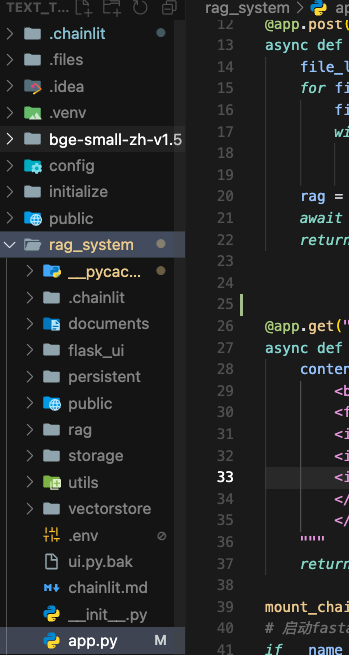
mac 设置cursor (像PyCharm一样展示效果)
一、注册 Cursor - The AI Code Editor 二、配置Python环境 我之前使用pycharm创建的python项目,以及创建了虚拟环境,现在要使用cursor继续开发。 2.1 选择Python 虚拟环境 PyCharm 通常将虚拟环境存储在项目目录下的 venv 或 .venv 文件夹中…...
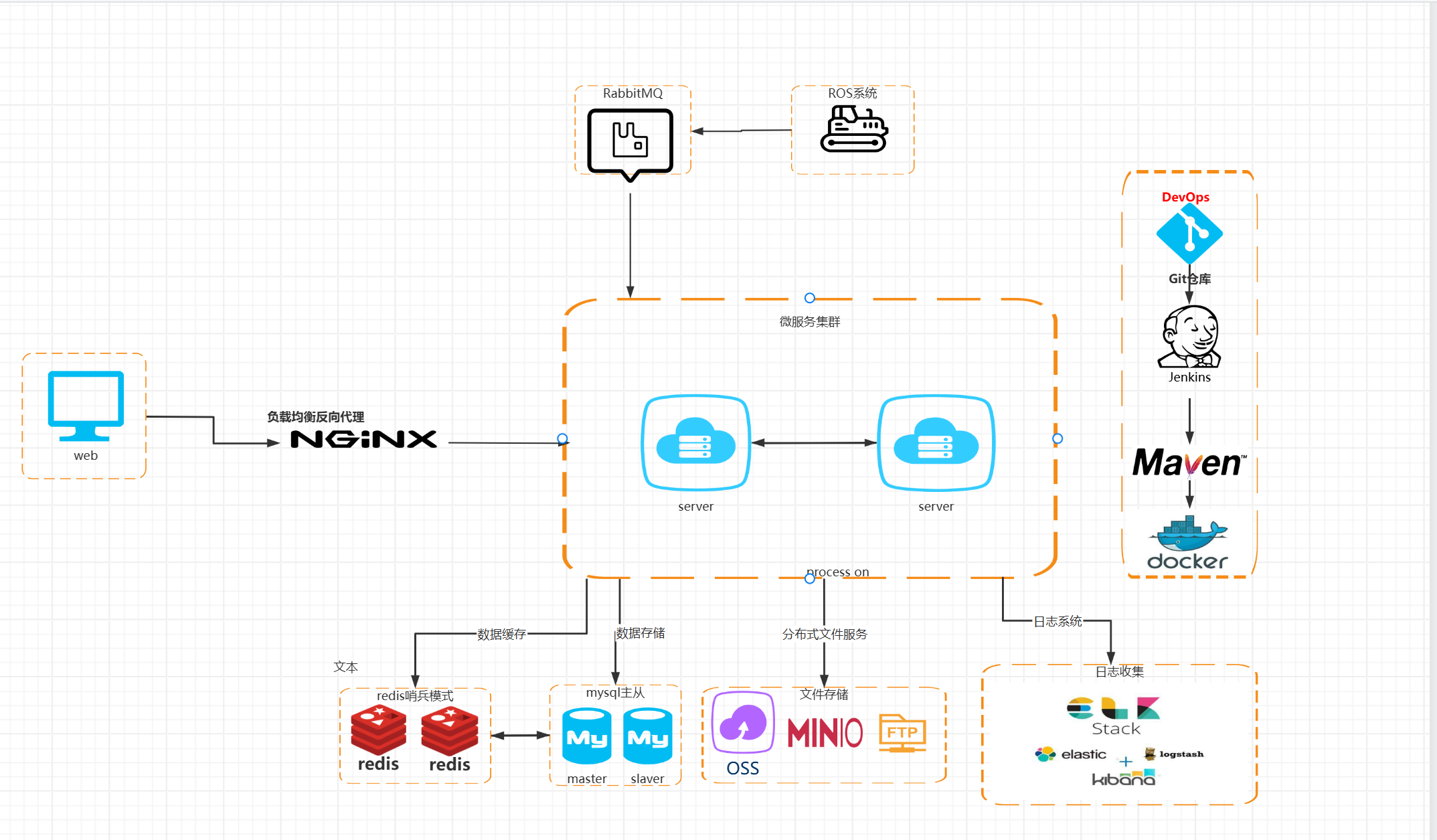
SpringCloudAlibaba微服务架构
技术架构图 SpringCloudAlibaba微服务架构 说明: 1.1、采用SpringCloudAlibaba分布式微服务架构,使用Nginx做代理,服务治理使用Nacos组件,Gateway网关做权限验证、路由、过滤。 1.2、Redis做消息缓存,包括数据大屏、数…...

Java高级 | 【实验三】Springboot 静态资源访问
隶属文章: Java高级 | (二十二)Java常用类库-CSDN博客 系列文章: Java高级 | 【实验一】Spring Boot安装及测试 最新-CSDN博客 Java高级 | 【实验二】Springboot 控制器类相关注解知识-CSDN博客 目录 一、Thymeleaf 1.1 是什么&…...

C语言_预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 1 __FILE__ //进行编译的源文件 2 __LINE__//文件当前的行号 3 __DATE__ //文件被编译的日期 4 __TIME__//文件被编译的时间 5 __STDC__//如果编译器遵循ANSI…...

将前后端分离版的前端vue打包成EXE的完整解决方案
将若依前后端分离版的前端打包成EXE的完整解决方案 将若依前后端分离版的Vue前端打包成Windows可执行文件(.exe),同时保持与后端API的通信,需要使用Electron框架来实现。下面是详细的步骤和解决方案。 一、准备工作 1. 环境要求 Node.js (推荐v16+)npm 或 yarn若依前后端分…...
基础概念和设备)
物联网协议之MQTT(一)基础概念和设备
前言: 本文内容均以实战出发,像MQTT概念这种基础内容建议大家自行百度。 推荐资料: mica-mqtt文档 一、MQTT简单介绍 作为当今物联网的主流协议,MQTT的使用范围非常广,如果你想了解甚至是从事物联网行业,…...
「Java教案」Java程序的构成
课程目标 1.知识目标 能够按照Java标识符的命名规则,规范变量的命名。能够区分Java中的关键字与保留字。能够对注释进行分类,根据注释的用途合理的选择注释方式。 2.能力目标 能编写符合规范的标识符。能识别Java中的关键字和…...

还原Windows防火墙
还原Windows防火墙 1. 背景2. 为何“还原”完胜“关闭”?三大核心优势3. 还原防火墙默认值操作步骤4. 还原防火墙时,系统背后的工作5. 需要还原防火墙场景一招拯救混乱网络!还原Windows防火墙,找回你的“安全速度”1. 背景 你是否曾因一时误操作关闭了Windows防火墙?是…...

区块链可投会议CCF B--EDBT 2026 截止10.8 附录用率
Conference:EDBT: 29th International Conference on Extending Database Technology CCF level:CCF B Categories:数据库/数据挖掘/内容检索 Year:2026 Conference time:24th March - 27th…...
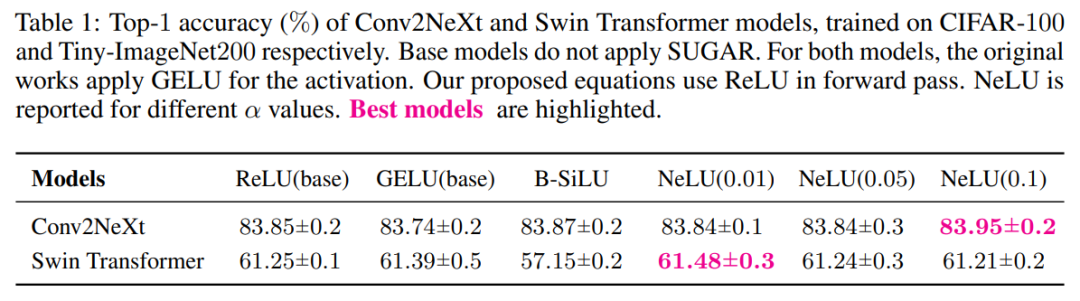
经典ReLU回归!重大缺陷「死亡ReLU问题」已被解决
来源 | 机器之心 在深度学习领域中,对激活函数的探讨已成为一个独立的研究方向。例如 GELU、SELU 和 SiLU 等函数凭借其平滑梯度与卓越的收敛特性,已成为热门选择。 尽管这一趋势盛行,经典 ReLU 函数仍因其简洁性、固有稀疏性及…...

在VSCode中开发一个uni-app项目
创建项目 使用命令行工具(例如 vue-cli)来创建一个新的 uni-app 项目。 创建以JavaScript开发的工程 npx degit dcloudio/uni-preset-vue#vite my-vue3-project //或者 npx degit dcloudio/uni-preset-vue#vite-alpha my-vue3-project创建以TypeScript…...