Hive自定义函数案例(UDF、UDAF、UDTF)
目录
前提条件
背景
概念及适用场景
UDF(User-Defined Function)
概念
适用场景
UDAF(User-Defined Aggregate Function)
概念
适用场景
UDTF(User-Defined Table-Generating Function)
概念
适用场景
案例
UDF案例
UDTF案例
UDAF案例
前提条件
- 安装好Hive,可参考:openEuler24.03 LTS下安装Hive3
- 具备Java开发环境:JDK8、Maven3、IDEA
背景
Hive 作为大数据领域常用的数据仓库工具,提供了丰富的内置函数,但在实际业务场景中,内置函数往往无法满足复杂的计算需求。这时,Hive 的自定义函数就显得尤为重要。Hive 支持三种类型的自定义函数:UDF、UDAF 和 UDTF,本文分别介绍它们的概念和适用场景,并给出典型案例。
概念及适用场景
UDF(User-Defined Function)
概念
UDF 是最基本的自定义函数类型,用于实现 "单行进,单行出" 的处理逻辑,即对每行数据中的一个或多个输入值进行计算,返回一个结果值。
适用场景
- 字符串处理(如格式转换、编码转换)
- 数学计算(如自定义计算公式)
- 日期处理(如自定义日期格式解析)
UDAF(User-Defined Aggregate Function)
概念
UDAF 即用户定义的聚合函数,用于实现 "多行进,一行出" 的处理逻辑,将一组数据经过计算后返回一个汇总结果,类似于 SQL 中的 SUM、COUNT 等内置聚合函数。
适用场景
- 自定义统计指标(如计算中位数、众数)
- 复杂数据聚合(如分组拼接字符串)
- 多阶段聚合计算
UDTF(User-Defined Table-Generating Function)
概念
UDTF 是用户定义的表生成函数,实现 "单行进,多行出" 的处理逻辑,将一行数据扩展为多行或多列数据。
适用场景
- 字符串拆分(如将逗号分隔的字符串拆分为多行)
- 数组或集合展开(如将 JSON 数组展开为多行记录)
- 复杂数据结构解析(如解析嵌套 JSON)
案例
UDF案例
需求:
自定义一个UDF实现计算给定基本数据类型的长度,效果如下:
hive(default)> select my_len("abcd");41)使用IDEA创建一个Maven工程Hive,工程名称例如:udf
2)添加依赖
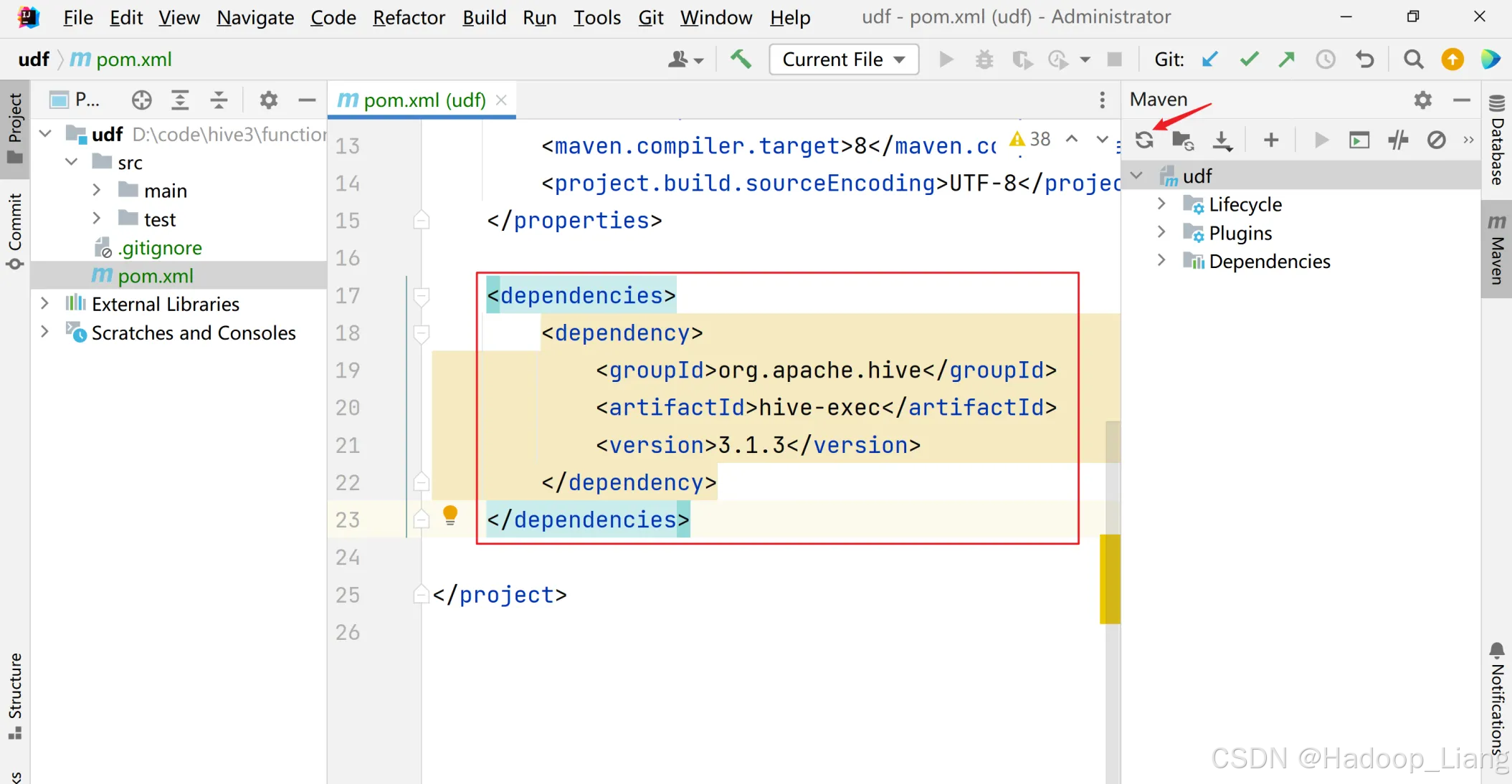
<dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version></dependency>
</dependencies>添加依赖后,刷新依赖,如下
3)创建包、创建类
创建包:在src/main/java下创建org.exapmle.hive.udf包
创建类:MyUDF.java
package org.example.hive.udf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;/*** 我们需计算一个要给定基本数据类型的长度*/
public class MyUDF extends GenericUDF {/*** 判断传进来的参数的类型和长度* 约定返回的数据类型*/@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {if (arguments.length !=1) {throw new UDFArgumentLengthException("please give me only one arg");}if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){throw new UDFArgumentTypeException(1, "i need primitive type arg");}return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}/*** 解决具体逻辑的*/@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {Object o = arguments[0].get();if(o==null){return 0;}return o.toString().length();}/*** 用于获取解释的字符串*/@Overridepublic String getDisplayString(String[] children) {return "";}
}4)创建临时函数
1)打成jar包上传到Linux /opt/module/hive/datas/myudf.jar
点击右侧的Maven,点开Lifecycle,按Ctrl键不放,同时选中clean和package,点击箭头指向的三角形图标运行
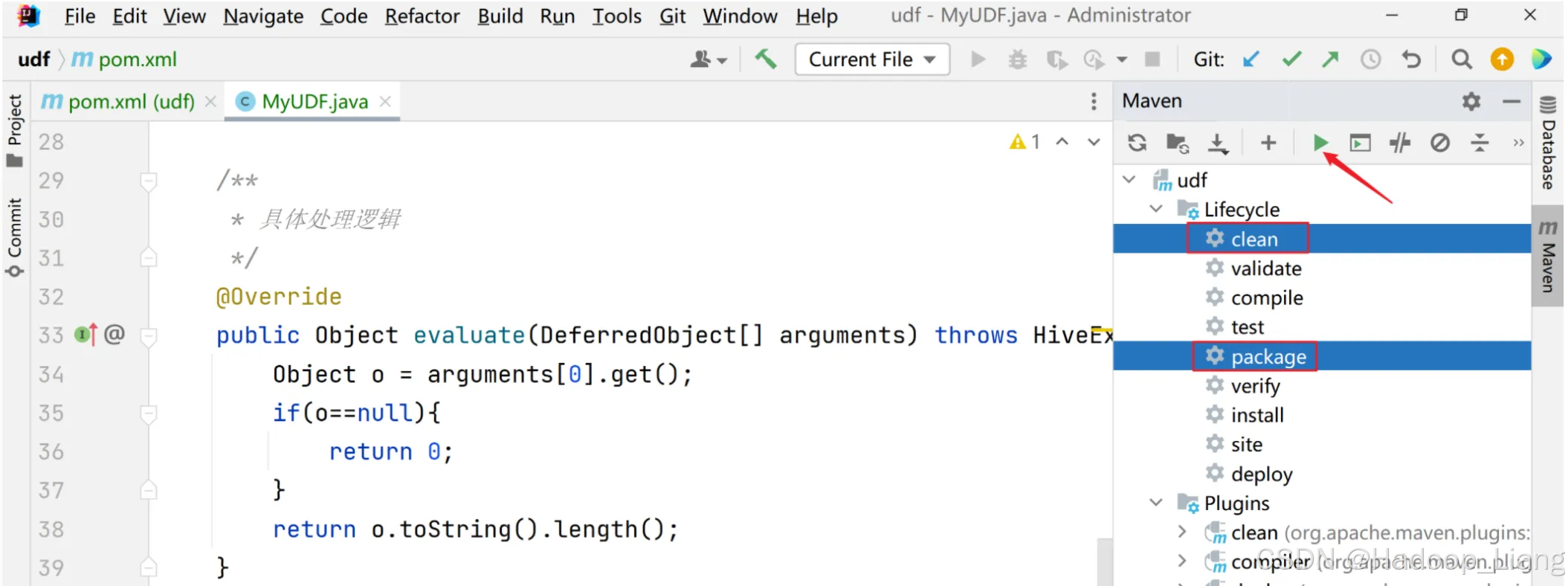
看到BUILD SUCCESS说明打包成功,同时看到jar包所在路径,如下
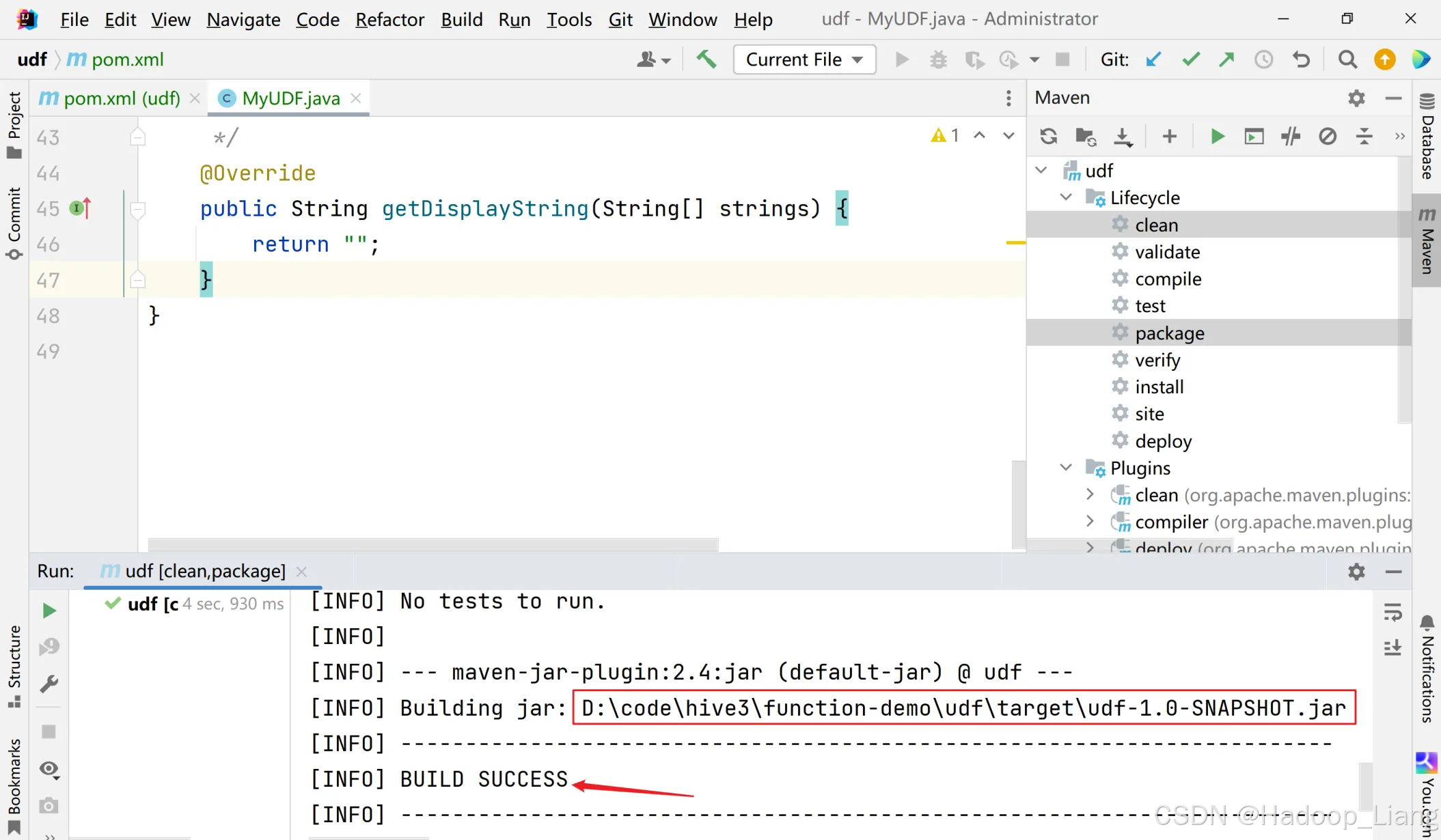
将jar包上传到Linux合适目录下,例如:/home/liang/testjar
[liang@node2 testjar]$ ls
udf-1.0-SNAPSHOT.jar(2)将jar包添加到hive的classpath,临时生效
hive (default)> add jar /home/liang/testjar/udf-1.0-SNAPSHOT.jar;(3)创建临时函数与开发好的java class关联
hive (default)> create temporary function my_len as "org.exapmle.hive.udf.MyUDF";注意:创建临时函数,此时只是在当前会话生效,关闭会话,临时函数被删除。如果需要能在其他会话能看到,且关闭会话后,不删除自定义函数,则需要创建永久函数。
(4)查询函数
hive (default)> show functions;
...
months_between
murmur_hash
my_len
named_struct
negative
...
Time taken: 0.024 seconds, Fetched: 291 row(s)看到my_len函数,说明可以使用自定义函数了。
(5)使用自定义的临时函数
hive (default)> select my_len("abcd");结果为
4(6)删除临时函数
使用如下语句或者关闭会话(退出Hive命令行)删除临时函数。
hive (default)> drop temporary function my_len;5)创建永久函数
(1)创建永久函数
把jar包上传到hdfs
[liang@node2 ~]$ hdfs dfs -put /home/liang/testjar/udf-1.0-SNAPSHOT.jar /创建永久函数
hive (default)>
create function my_len2 as "org.exapmle.hive.udf.MyUDF" using jar "hdfs://node2:8020/udf-1.0-SNAPSHOT.jar";操作过程
hive (default)> create function my_len2 as "org.exapmle.hive.udf.MyUDF" using jar "hdfs://node2:8020/udf-1.0-SNAPSHOT.jar";
Added [/tmp/944c050b-e360-48f1-b7b6-93f8fd7e2644_resources/udf-1.0-SNAPSHOT.jar] to class path
Added resources: [hdfs://node2:8020/udf-1.0-SNAPSHOT.jar]
OK
Time taken: 0.212 seconds查看函数
hive (default)> show functions;
...
dayofweek
decode
default.my_len2
degrees
dense_rank
...
Time taken: 0.019 seconds, Fetched: 291 row(s)看到永久函数名为库名.函数名。
注意:永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
退出hive命令行会话,重新进入hive命令行,再次查看函数,还可以看到default.my_len2
hive (default)> show functions;
...
dayofweek
decode
default.my_len2
degrees
dense_rank
...
Time taken: 0.019 seconds, Fetched: 291 row(s)使用永久函数
hive (default)> select my_len2("abcd");结果为
4(3)删除永久函数
hive (default)> drop function my_len2;注意:永久函数使用的时候,在其他库里面使用的话加上,库名.函数名。
UDTF案例
需求:
将字符串按分隔符分割为多行,例如:将a,b,c按照,进行分隔,得到三行
a
b
c代码
package org.exapmle.hive.udtf;import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableStringObjectInspector;
import org.apache.hadoop.io.Text;import java.util.Arrays;
import java.util.List;@Description(name = "explode_string",value = "将字符串按分隔符分割为多行",extended = "SELECT explode_string('a,b,c', ',') FROM table_name;"
)
public class ExplodeWordsUDTF extends GenericUDTF {private WritableStringObjectInspector inputOI;private WritableStringObjectInspector separatorOI;private final Object[] forwardObj = new Object[1];private final Text outputText = new Text();@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {// 获取输入参数的ObjectInspectorList<? extends StructField> inputFields = argOIs.getAllStructFieldRefs();// 检查参数数量if (inputFields.size() != 2) {throw new UDFArgumentLengthException("explode_string需要两个参数: 字符串和分隔符");}// 检查参数类型ObjectInspector firstOI = inputFields.get(0).getFieldObjectInspector();ObjectInspector secondOI = inputFields.get(1).getFieldObjectInspector();if (!(firstOI instanceof WritableStringObjectInspector) || !(secondOI instanceof WritableStringObjectInspector)) {throw new UDFArgumentLengthException("参数必须是字符串类型");}inputOI = (WritableStringObjectInspector) firstOI;separatorOI = (WritableStringObjectInspector) secondOI;// 定义输出结构List<String> fieldNames = Arrays.asList("element");List<ObjectInspector> fieldOIs = Arrays.asList(PrimitiveObjectInspectorFactory.writableStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);}@Overridepublic void process(Object[] args) throws HiveException {if (args[0] == null) {return;}Text input = inputOI.getPrimitiveWritableObject(args[0]);Text sep = separatorOI.getPrimitiveWritableObject(args[1]);String separator = sep != null ? sep.toString() : ",";String inputStr = input.toString();// 处理空字符串if (inputStr.isEmpty()) {outputText.set("");forwardObj[0] = outputText;forward(forwardObj);return;}// 使用正则表达式分隔字符串String[] elements = inputStr.split(separator, -1);for (String element : elements) {outputText.set(element);forwardObj[0] = outputText;forward(forwardObj);}}@Overridepublic void close() throws HiveException {}
}
打jar包,上传到Linux
注册与使用
hive (default)> ADD JAR /home/liang/testjar/udf-1.0-SNAPSHOT.jar;
Added [/home/liang/testjar/udf-1.0-SNAPSHOT.jar] to class path
Added resources: [/home/liang/testjar/udf-1.0-SNAPSHOT.jar]hive (default)> CREATE TEMPORARY FUNCTION explode_string AS 'org.exapmle.hive.udtf.ExplodeStringUDTF';
OK
Time taken: 0.362 secondshive (default)> SELECT explode_string('a,b,c', ',');
OK
element
a
b
c
Time taken: 2.844 seconds, Fetched: 3 row(s)hive (default)> SELECT explode_string('hello,world', ',');
OK
element
hello
world
Time taken: 0.209 seconds, Fetched: 2 row(s)UDAF案例
需求:
计算加权平均值,加权平均数=(Σ(数值×权重))/Σ权重
例如:
计算学生综合成绩时,若数学(学分4分,成绩90)和语文(学分3分,成绩80),其中数值为成绩,权重为学分,则加权平均成绩为 (4×90+3×80)/(4+3)≈85.71(4×90+3×80)/(4+3)≈85.71分。
代码
package org.exapmle.hive.udaf;import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;@Description(name = "weighted_avg",value = "计算加权平均值",extended = "SELECT weighted_avg(score, credit) FROM grades GROUP BY student_id;"
)
public class WeightedAverageUDAF extends UDAF {public static class WeightedAverageEvaluator implements UDAFEvaluator {// 存储中间结果private double sumWeightedValues;private double sumWeights;private boolean empty;@Overridepublic void init() {sumWeightedValues = 0;sumWeights = 0;empty = true;}// 处理输入行public boolean iterate(DoubleWritable value, DoubleWritable weight) {if (value == null || weight == null || weight.get() <= 0) {return true;}sumWeightedValues += value.get() * weight.get();sumWeights += weight.get();empty = false;return true;}// 存储部分结果的类public static class PartialResult implements Writable {double sumWeightedValues;double sumWeights;@Overridepublic void write(DataOutput out) throws IOException {out.writeDouble(sumWeightedValues);out.writeDouble(sumWeights);}@Overridepublic void readFields(DataInput in) throws IOException {sumWeightedValues = in.readDouble();sumWeights = in.readDouble();}}// 返回部分结果public PartialResult terminatePartial() {if (empty) {return null;}PartialResult result = new PartialResult();result.sumWeightedValues = sumWeightedValues;result.sumWeights = sumWeights;return result;}// 合并部分结果public boolean merge(PartialResult other) {if (other == null) {return true;}sumWeightedValues += other.sumWeightedValues;sumWeights += other.sumWeights;empty = false;return true;}// 返回最终结果public DoubleWritable terminate() {if (empty || sumWeights <= 0) {return null;}return new DoubleWritable(sumWeightedValues / sumWeights);}}
}打jar包,上传到Linux
注册
hive (default)> ADD JAR /home/liang/testjar/udf-1.0-SNAPSHOT.jar;
Added [/home/liang/testjar/udf-1.0-SNAPSHOT.jar] to class path
Added resources: [/home/liang/testjar/udf-1.0-SNAPSHOT.jar]hive (default)> CREATE TEMPORARY FUNCTION weighted_avg AS 'org.exapmle.hive.udaf.WeightedAverageUDAF';
OK
Time taken: 0.043 seconds使用
WITH grades AS (SELECT 1 AS student_id, 'Math' AS course, 90 AS score, 4 AS creditUNION ALLSELECT 1, 'English', 85, 3UNION ALLSELECT 2, 'Math', 88, 4UNION ALLSELECT 2, 'English', 92, 3
)
SELECT student_id,weighted_avg(score, credit) AS gpa
FROM grades
GROUP BY student_id;操作过程
hive (default)> WITH grades AS (> SELECT 1 AS student_id, 'Math' AS course, 90 AS score, 4 AS credit> UNION ALL> SELECT 1, 'English', 85, 3> UNION ALL> SELECT 2, 'Math', 88, 4> UNION ALL> SELECT 2, 'English', 92, 3> )> SELECT> student_id,> weighted_avg(score, credit) AS gpa> FROM grades> GROUP BY student_id;
Query ID = liang_20250521165046_6335eb21-2d92-4ae1-b30c-511bcb9a98ab
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:set mapreduce.job.reduces=<number>
Starting Job = job_1747808931389_0001, Tracking URL = http://node3:8088/proxy/application_1747808931389_0001/
Kill Command = /opt/module/hadoop-3.3.4/bin/mapred job -kill job_1747808931389_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2025-05-21 16:51:04,388 Stage-1 map = 0%, reduce = 0%
2025-05-21 16:51:12,756 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.89 sec
2025-05-21 16:51:28,486 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.36 sec
MapReduce Total cumulative CPU time: 11 seconds 360 msec
Ended Job = job_1747808931389_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 11.36 sec HDFS Read: 12918 HDFS Write: 151 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 360 msec
OK
student_id gpa
1 87.85714285714286
2 89.71428571428571
Time taken: 43.272 seconds, Fetched: 2 row(s)更多Hive自定义函数用法,请参考:Hive官方文档
完成!enjoy it!
相关文章:
Hive自定义函数案例(UDF、UDAF、UDTF)
目录 前提条件 背景 概念及适用场景 UDF(User-Defined Function) 概念 适用场景 UDAF(User-Defined Aggregate Function) 概念 适用场景 UDTF(User-Defined Table-Generating Function) 概念 适…...
【学习笔记】Circuit Tracing: Revealing Computational Graphs in Language Models
Circuit Tracing: Revealing Computational Graphs in Language Models 替代模型(Replacement Model):用更多的可解释的特征来替代transformer模型的神经元。 归因图(Attribution Graph):展示特征之间的相互影响,能够追踪模型生成输出时所采用…...

3D视觉重构工业智造:解码迁移科技如何用“硬核之眼“重塑生产节拍
一、工业视觉的进化论:从CCD到3D相机的范式革命 在汽车冲压车间里,传统CCD相机正面临四大检测困局: 平面感知局限:二维视觉无法捕捉曲面工件形变环境适应性差:反光板件导致误检率超12%动态捕捉延迟:传送带…...
和刷新间隔介绍)
Elasticsearch中的刷新(Refresh)和刷新间隔介绍
在 Elasticsearch 中,刷新(Refresh) 是控制索引数据何时对搜索可见的机制,而 刷新间隔(Refresh Interval) 则是配置该机制执行频率的参数。理解这两个概念对于平衡搜索实时性与写入性能至关重要。 一、刷新(Refresh)的本质 Lucene 索引结构与搜索可见性Elasticsearch …...
STM32标准库-TIM定时器
文章目录 一、TIM定时器1.1定时器1.2定时器类型1.1.1 高级定时器1.1.2通用定时器1.1.3基本定时器 二、定时中断基本结构预分频器时器计时器时序计数器无预装时序计数器有预装时序RCC时钟树 三、定时器定时中断3.1 接线图3.2代码3.3效果: 四、定时器外部中断4.1接线图…...

【算法训练营Day05】哈希表part1
文章目录 哈希表理论基础有效的字母异位词两个数组的交集快乐数两数之和 哈希表理论基础 几个值得关注的知识点: hash表用于快速的判断元素是否存在(空间换时间)其原理就是将数据通过散列函数映射到bucket中,如果发生hash碰撞&a…...

CMap应用场景和例子
CMap 详解 CMap 是 MFC (Microsoft Foundation Classes) 库中的一个模板类,用于实现键值对的映射关系(类似哈希表或字典)。它提供了高效的数据存储和检索功能,适用于需要通过键快速查找值的场景。 基本模板参数 cpp 运行 tem…...
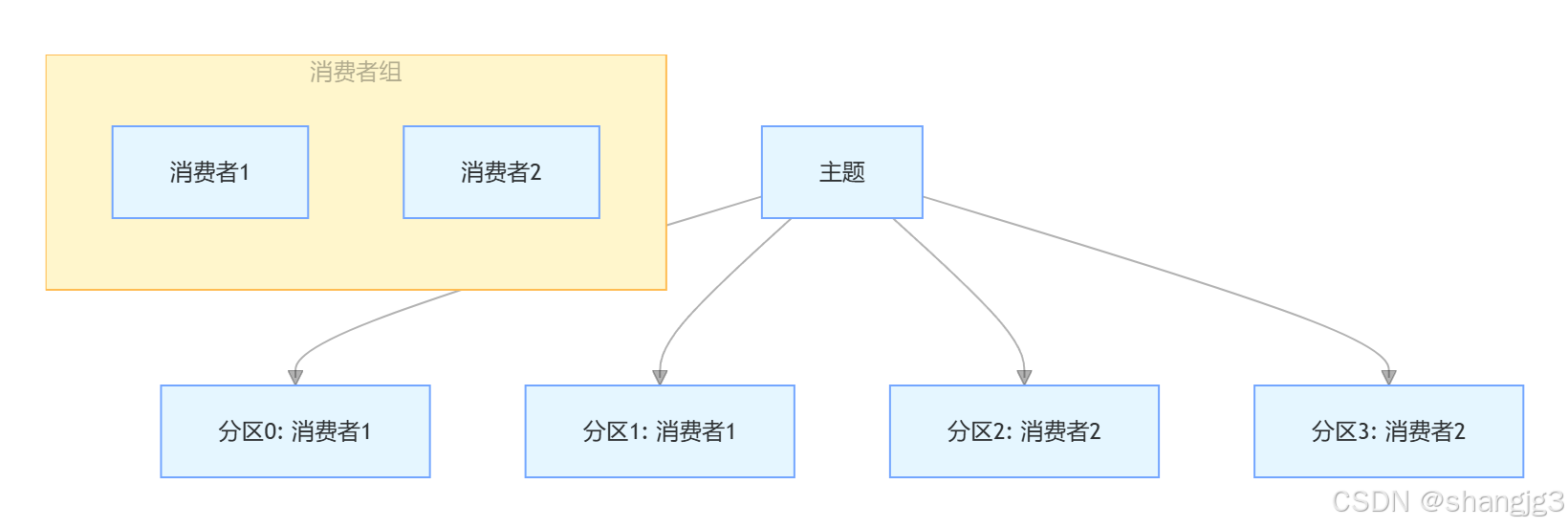
Kafka 如何保证顺序消费
在消息队列的应用场景中,保证消息的顺序消费对于一些业务至关重要,例如金融交易中的订单处理、电商系统的库存变更等。Kafka 作为高性能的分布式消息队列系统,通过巧妙的设计和配置,能够实现消息的顺序消费。接下来,我…...
【算法题】算法一本通
每周更新至完结,建议关注收藏点赞。 目录 待整理文章已整理的文章方法论思想总结模版工具总结排序 数组与哈希表栈双指针(滑动窗口、二分查找、链表)树前缀树堆 优先队列(区间/间隔问题、贪心 )回溯图一维DP位操作数学…...

Modbus转Ethernet IP赋能挤出吹塑机智能监控
在现代工业自动化领域,小疆智控Modbus转Ethernet IP网关GW-EIP-001与挤出吹塑机的应用越来越广泛。这篇文章将为您详细解读这两者的结合是如何提高生产效率,降低维护成本的。首先了解什么是Modbus和Ethernet IP。Modbus是一种串行通信协议,它…...

C++中如何遍历map?
文章目录 1. 使用范围for循环(C11及以上)2. 使用迭代器3. 使用反向迭代器注意事项 在C中, std::map 是一种关联容器,它存储的是键值对(key-value pairs),并且按键的顺序进行排序。遍历 std::m…...

什么是终端安全管理系统(终端安全管理软件2024科普)
在当今数字化迅速发展的时代,企业面临着越来越多的信息安全威胁。为了应对这些挑战,保障公司数据的安全性和完整性,终端安全管理系统(Endpoint Security Management System)应运而生。 本文将为您深入浅出地科普2024年…...
0604)
书籍转圈打印矩阵(8)0604
题目 给定一个整型矩阵matrix,请按照转圈的方式打印它。 例如: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 打印结果为:1,2,3ÿ…...
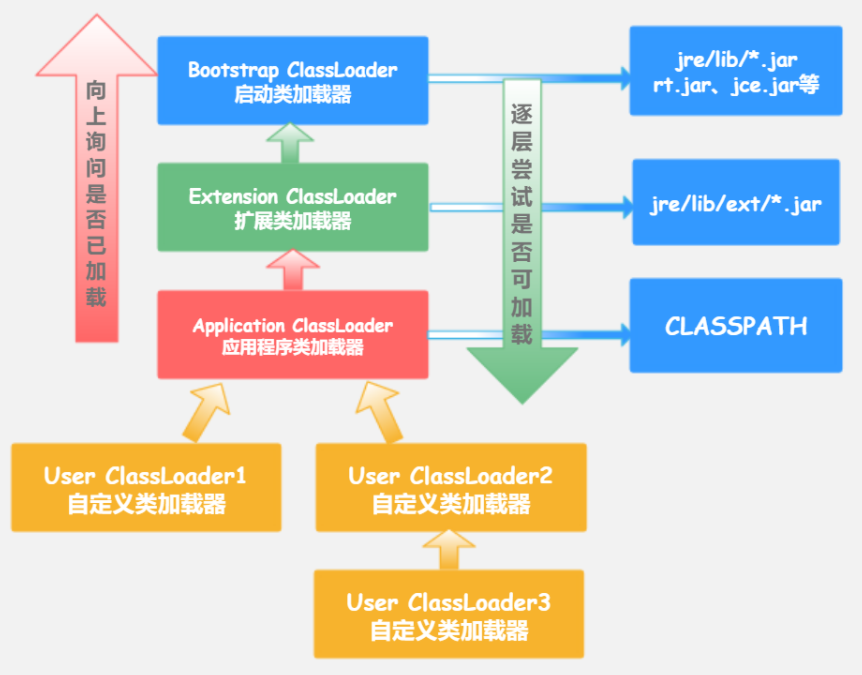
【JVM】Java类加载机制
【JVM】Java类加载机制 什么是类加载? 在 Java 的世界里,每一个类或接口在经过编译后,都会生成对应的 .class 字节码文件。 所谓类加载机制,就是 JVM 将这些 .class 文件中的二进制数据加载到内存中,并对其进行校验…...
介绍)
Elasticsearch中的自定义分析器(Custom Analyzer)介绍
在 Elasticsearch 中,自定义分析器(Custom Analyzer) 是一种可配置的文本处理组件,允许用户通过组合分词器(Tokenizer)、过滤器(Token Filter)和字符过滤器(Character Filter)来定义特定的文本分析逻辑。这使得 Elasticsearch 能够针对不同语言、业务场景或特殊需求,…...

《C++初阶之入门基础》【C++的前世今生】
【C的前世今生】目录 前言:---------------起源---------------一、历史背景二、横空出世---------------发展---------------三、标准立世C98:首个国际标准版本C03:小修订版本 四、现代进化C11:现代C的开端C14:对C11的…...
Apache APISIX
目录 Apache APISIX是什么? Lua Lua 的主要特点: Lua 的常见应用: CVE-2020-13945(Apache APISIX默认API Token导致远程Lua代码执行) 编辑Lua脚本解析 CVE-2021-45232(Apache APISIX Dashboard API权限绕过导致RCE) Apache …...
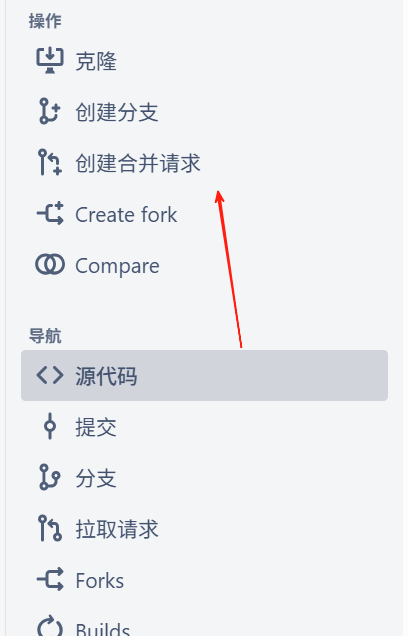
如何在 git dev 中创建合并请求
先将 自己的代码 推到 自己的远程的 分支上 在 创建 合并请求 根据提示 将 自己的远程的 源码 合并到 对应的分支上 然后 创建 合并请求 等待 对应的 人 来 进行合并就行...
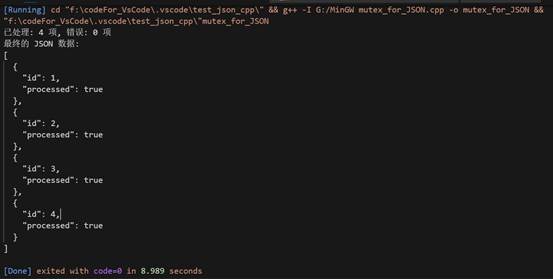
基于nlohmann/json 实现 从C++对象转换成JSON数据格式
C对象的JSON序列化与反序列化 基于JsonCpp库实现C对象序列化与反序列化 JSON 介绍 JSON作为一种轻量级的数据交换格式,在Web服务和应用程序中广泛使用。 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读…...

Java枚举类映射MySQL的深度解析与实践指南
Java枚举类映射MySQL的深度解析与实践指南 一、枚举类型映射的四大核心策略 1. 序数映射法(ordinal映射) 实现原理:存储枚举值的下标顺序 public enum OrderStatus {PENDING, // 存储为0PROCESSING, // 存储为1SHIPPED, //…...
跳跃游戏2)
代码训练LeetCode(21)跳跃游戏2
代码训练(21)LeetCode之跳跃游戏2 Author: Once Day Date: 2025年6月4日 漫漫长路,才刚刚开始… 全系列文章可参考专栏: 十年代码训练_Once-Day的博客-CSDN博客 参考文章: 45. 跳跃游戏 II - 力扣(LeetCode)力扣 (LeetCode) 全球极客挚爱…...

【HarmonyOS 5】鸿蒙APP使用【团结引擎Unity】开发的案例教程
以下是基于团结引擎开发鸿蒙Unity应用的详细案例教程,整合环境配置、工程适配、跨语言通信等核心环节 一、环境配置(关键前置步骤) 1. 工具安装 工具版本要求作用团结引擎Hub≥1.2.3Unity鸿蒙项目构建管理DevEco Studio≥…...

《T/CI 404-2024 医疗大数据智能采集及管理技术规范》全面解读与实施分析
规范背景与详细信息 《T/CI 404-2024 医疗大数据智能采集及管理技术规范》是由中国国际科技促进会联合河南科技大学、河南科技大学第一附属医院、深圳市人民医院等十余家医疗机构与企业共同制定的团体标准,于2024年5月正式发布实施。该规范是我国医疗大数据领域的重要技术标准…...
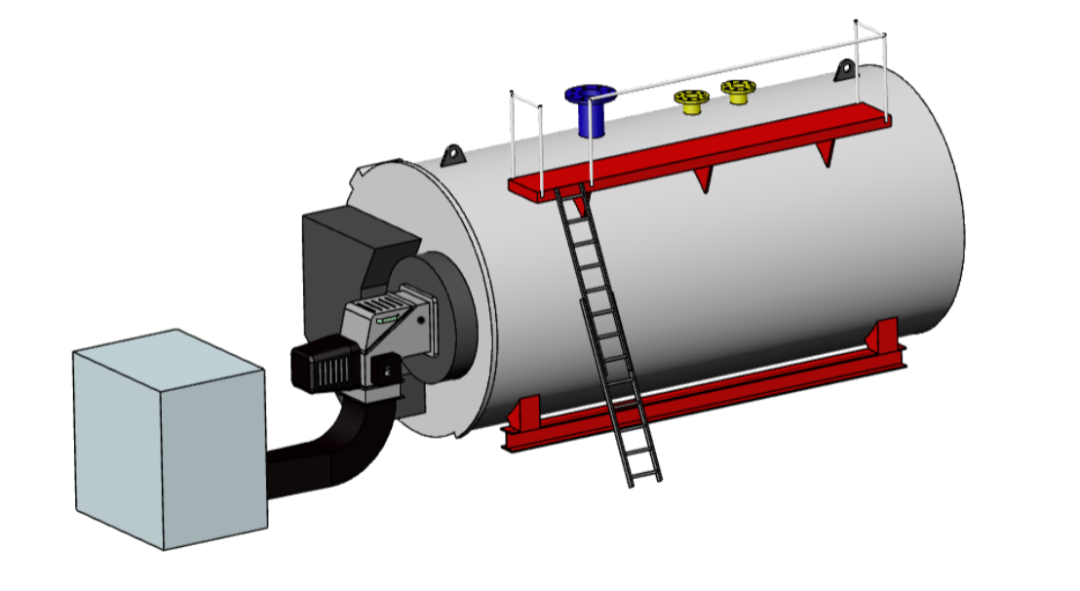
国产三维CAD皇冠CAD在「金属压力容器制造」建模教程:蒸汽锅炉
面对蒸汽锅炉设计中复杂的曲面封头、密集的管板开孔、多变的支撑结构以及严格的强度与安全规范(如GB150、ASME等),传统二维设计手段往往捉襟见肘,易出错、效率低、协同难。国产三维CAD皇冠CAD(CrownCAD)凭借…...

Mysql避免索引失效
1. 在索引列上使用函数或表达式 问题描述 SELECT * FROM users WHERE YEAR(create_time) 2023; 如果create_time列上有索引,上述查询会导致索引失效,因为MySQL无法直接利用索引的B树结构。 解决方法 将函数应用于条件值,而不是列&#…...
)
python爬虫:Ruia的详细使用(一个基于asyncio和aiohttp的异步爬虫框架)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Ruia概述1.1 Ruia介绍1.2 Ruia特点1.3 安装Ruia1.4 使用案例二、基本使用2.1 Request 请求2.2 Response - 响应2.3 Item - 数据提取2.4 Field 提取数据2.5 Spider - 爬虫类2.6 Middleware - 中间件三、高级功能3.1 …...
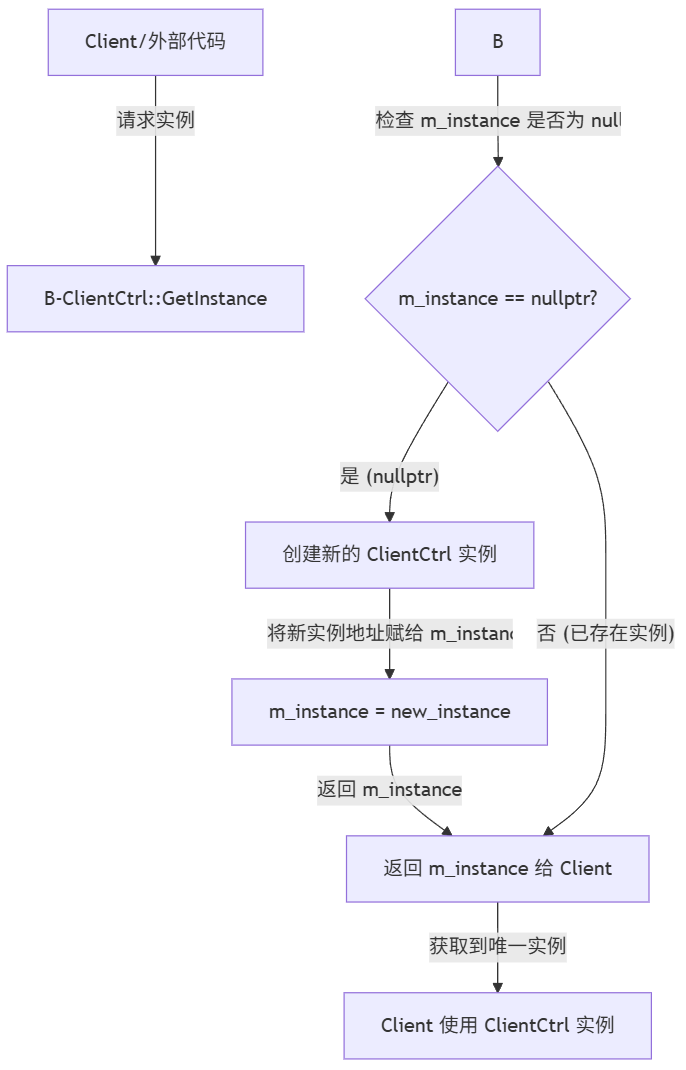
C++中单例模式详解
在C中,单例模式 (Singleton Pattern) 确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。这在需要一个全局对象来协调整个系统行为的场景中非常有用。 为什么要有单例模式? 在许多项目中,某些类从逻辑上讲只需要一个实…...

舆情监控系统爬虫技术解析
之前我已经详细解释过爬虫在系统中的角色和技术要点,这次需要更聚焦“如何实现”这个动作。 我注意到上次回复偏重架构设计,这次应该拆解为更具体的操作步骤:从目标定义到数据落地的完整流水线。尤其要强调动态调度这个容易被忽视的环节——…...

Windows上用FFmpeg采集摄像头推流 → MediaMTX服务器转发流 → WSL2上拉流播放
1. Windows上 FFmpeg 推流(摄像头采集) 设备名称可用 ffmpeg -list_devices true -f dshow -i dummy 查询,假设为Integrated Camera 采集推流示例(推RTMP到MediaMTX): ffmpeg -rtbufsize 100M -f dshow …...

cpp多线程学习
1.thread std::thread是 C11 引入的跨平台线程管理类,封装了操作系统的线程 API(如 pthread、Windows 线程),提供统一的线程操作接口。线程的生命周期由join()和detach()控制。 thread在创建时就开始执行 join():阻…...