【Redis】zset 类型
zset
- 一. zset 类型介绍
- 二. zset 命令
- zadd
- zcard、zcount
- zrange、zrevrange、zrangebyscore
- zpopmax、zpopmin
- zrank、zrevrank、zscore
- zrem、zremrangebyrank、zremrangebyscore
- zincrby
- 阻塞版本命令:bzpopmax、bzpopmin
- 集合间操作:zinterstore、zunionstore
- 三. zset 命令小结
- 四. zset 内部编码方式
- 五. zset 使用场景
- 排行榜系统
一. zset 类型介绍
- zset (有序集合):相对于字符串、列表、哈希、集合来说会有一些陌生。它保留了集合不能有重复成员的特点,但与集合不同的是,有序集合中的每个元素都有一个唯一的浮点类型的分数 (score) 与之关联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个分数。
如下图所示,该有序集合显示了三国中的武将的武力。
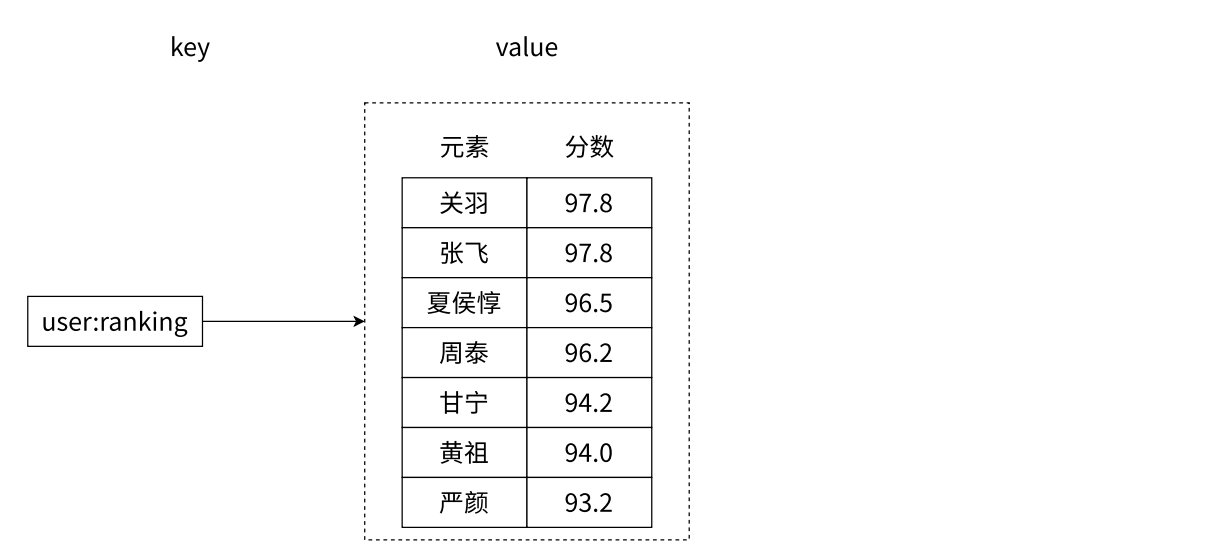
- 有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能,合理地利用有序集合,可以帮助我们在实际开发中解决很多问题。
- 有序集合中的元素是不能重复的,但分数允许重复。类比于一次考试之后,每个人一定有一个唯一的分数,但分数允许相同
- 排序规则:分数不同时按照分数进行排序,分数相同时按照字典序进行排序,实际上 zset 内部就是按照升序方式来进行排序的。
列表、集合、有序集合三者的异同点,如下:
| 数据结构 | 是否允许重复元素 | 是否有序 | 有序依据 | 应用场景 |
|---|---|---|---|---|
| list | 是 | 是 | 索引下标 | 时间轴、消息队列等 |
| set | 否 | 否 | 标签、社交等 | |
| zset | 否 | 是 | 分数 | 排行榜系统、社交等 |
注意:list 的有序指的是按照某种顺序,而 zset 的有序指的是升序/降序。
二. zset 命令
zadd
- zadd:添加或者更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负极限也是合法的。
- 添加的时候:既要添加元素,又要添加分数;member 和 score 称为一个 “pair”,不要把 member 和 score 理解成 “键值对” (key-value pair)
- 键值对中存在明确的角色区分,谁是键谁是值是明确的,一定是根据键找对应的值。
- 对于 zset 来说,既可以通过 member 找到对应的 score;又可以通过 score 找到匹配的 member;
- 语法:
zadd key [NX|XX] [CH] [INCR] score member [score member ...]- 不加 XX | NX:如果当前 member 不存在,此时就会达到添加新 member 的效果;如果当前 member 已经存在,此时就会达到更新 member 对应 score 的效果。
- 加上 XX:仅仅用于更新已经存在的 member 对应 score 的效果,不会添加新 member
- 加上 NX:仅仅用于添加 member 的效果,不会更新已经存在的 member 对应的 score
- CH:默认情况下,zadd 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。
- INCR:此时命令类似 zincrby 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和分数。
- 不加 XX | NX:如果当前 member 不存在,此时就会达到添加新 member 的效果;如果当前 member 已经存在,此时就会达到更新 member 对应 score 的效果。
- 时间复杂度:O(logN),N 是有序集合中元素的个数。
- 之前 hash、list、set 添加一个元素,都是 O(1)
- 由于 zset 是有序结构,要求新增的元素放在合适的位置,之所以是 O(logN),就是充分利用了有序这样的特点 (zset 内部的数据结构主要是跳表)
- 返回值:本次添加成功的元素个数。
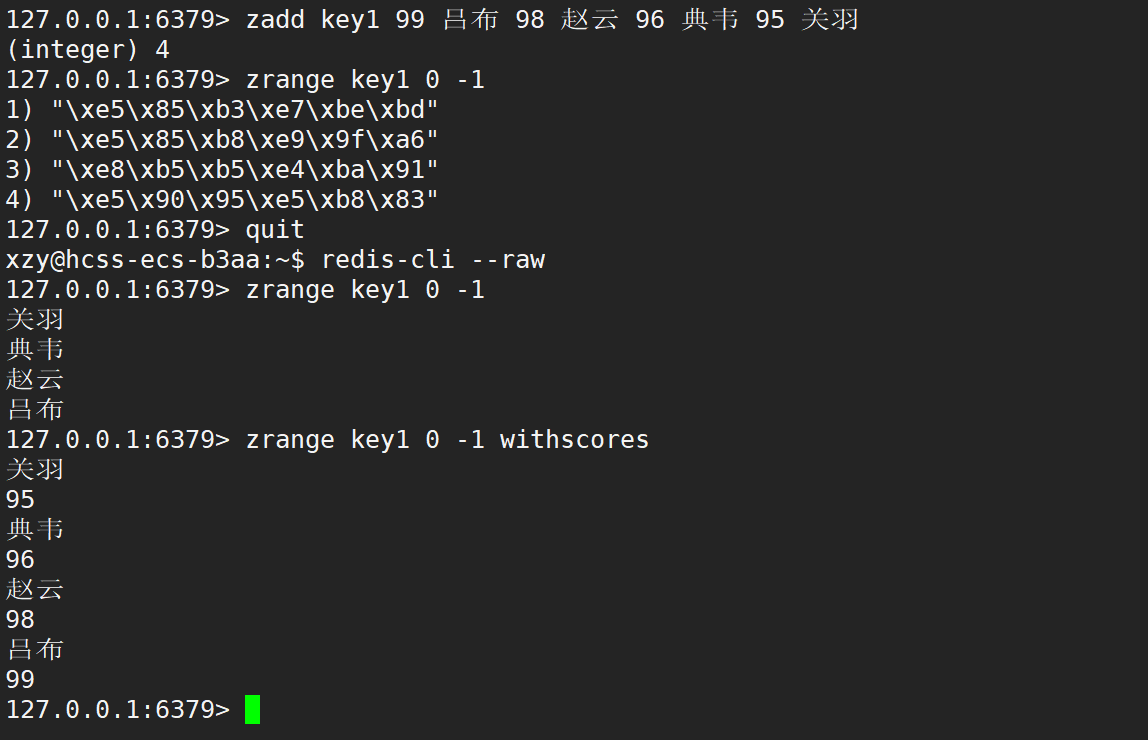
Redis 内部存储数据的时候,是按照二进制的方式来存储的,这就意味着,Redis 服务器不负责 “字符编码” 的,要把二进制字节转回到汉字,还需要客户端来支持,登入 Redis 客户端时的命令 redis-cli --raw
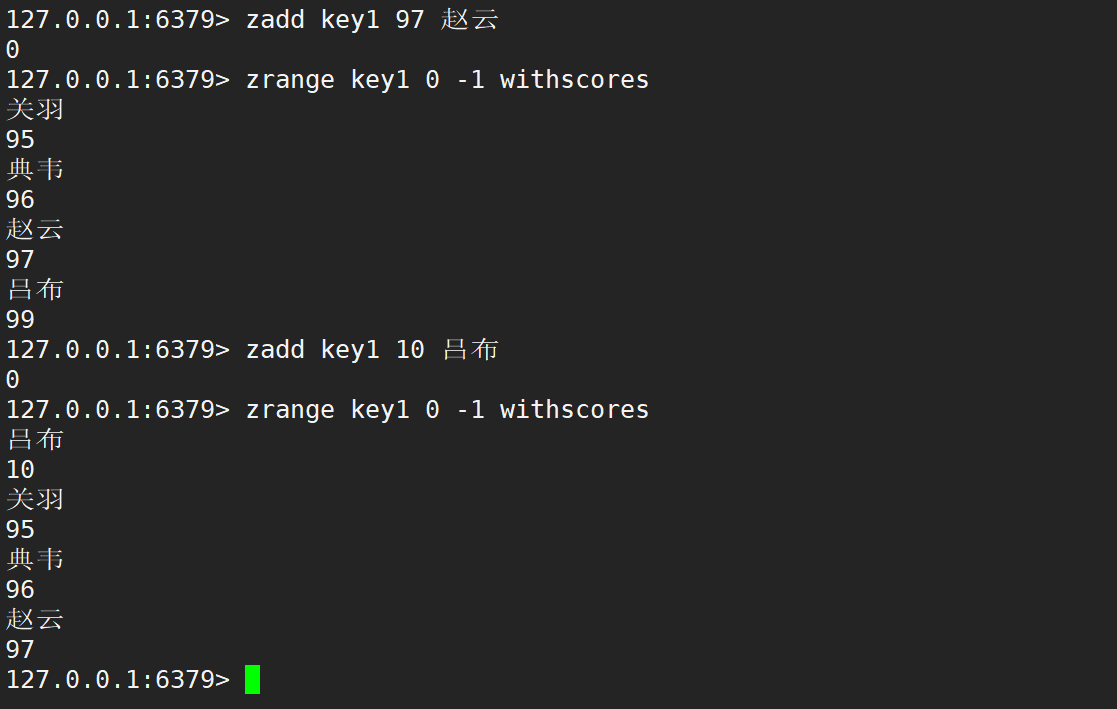
如果修改的分数,影响到了之前的顺序,就会自动移动元素的位置,保持原有的升序顺序不变。
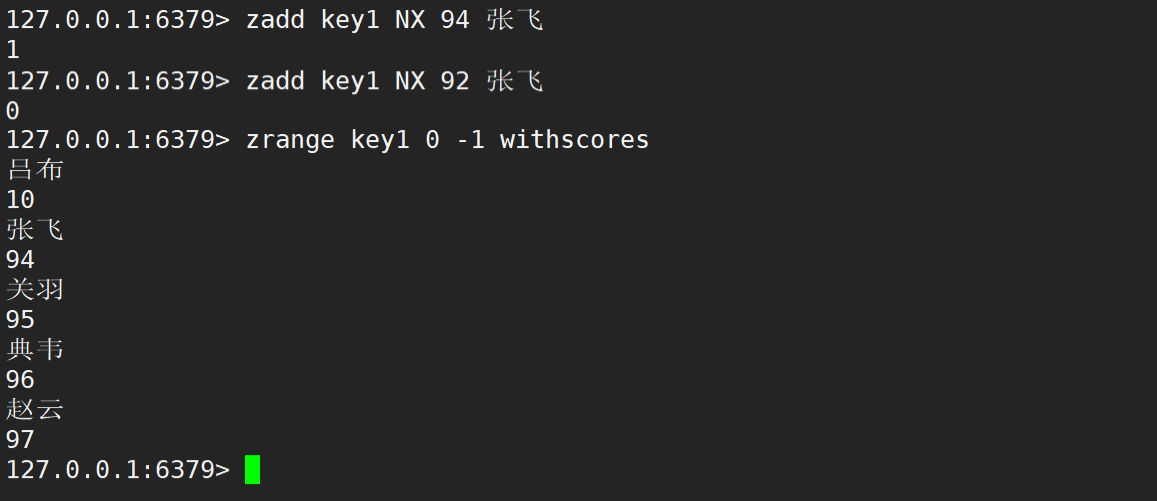
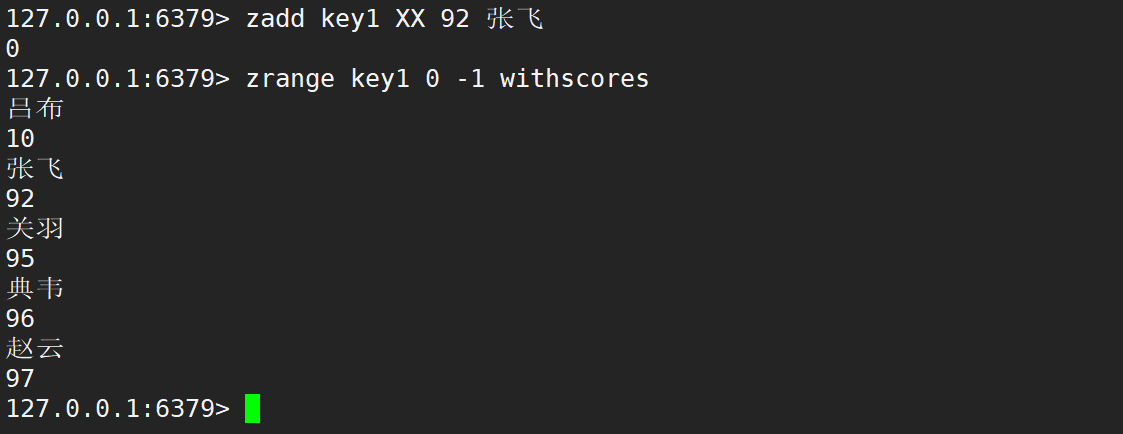
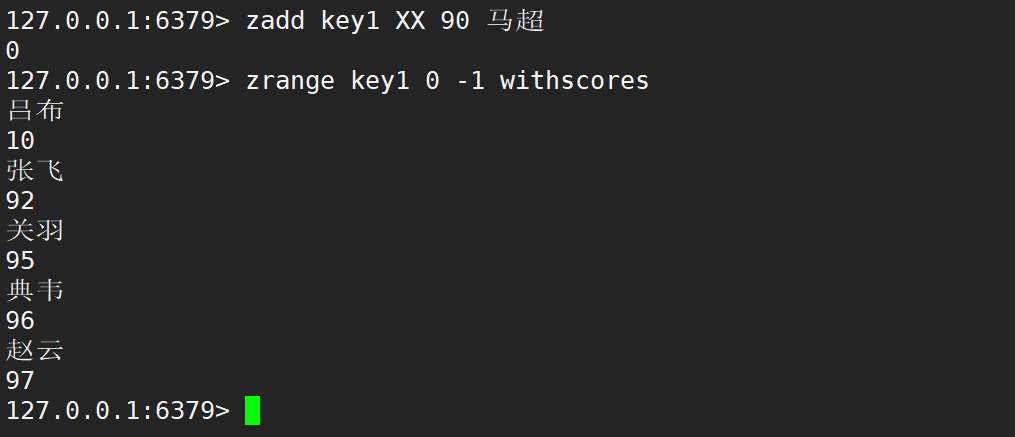
zadd 在默认情况下,返回值就是新增成功的元素个数。若更新时不存在元素,则更新失败。
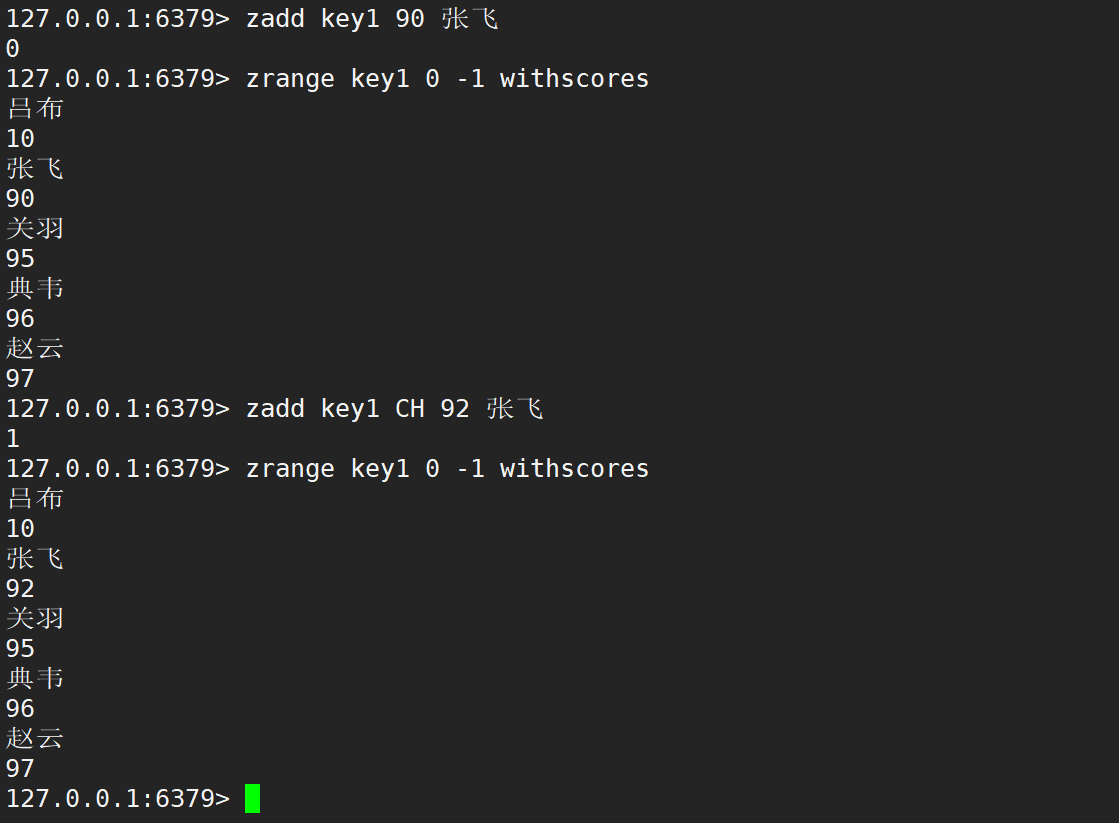
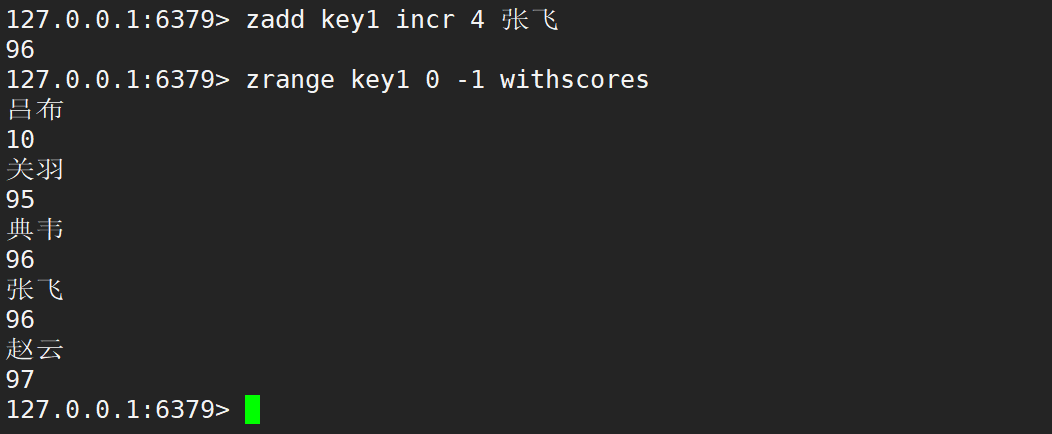
添加 incr 修改 member 的 score 时,后面只能跟一个 member,且返回值是 member 之后的 score
- C++ 中 std::set 存储的元素 (key-value) 的 key 是有序的,但是这里的 key 是不能修改的。
- Redis 中 zset 的 member 是可以修改的,修改之后 score 仍然要排序,满足有序。
zcard、zcount
- zcard:获取⼀个 zset 的基数 (cardinality),即 zset 中的元素 member 的个数。
- 语法:
zcard key - 时间复杂度:O(1)
- 返回值:zset 内的元素个数。
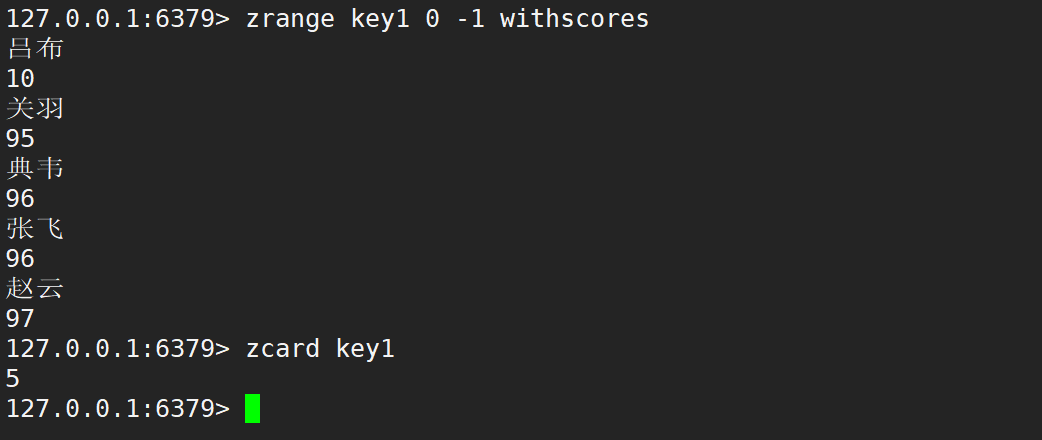
- zcount:返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的。但是可以通过 ( 进行排除。
- 语法:
zcount key min max - 时间复杂度:O(logN)
- 先根据 min 找到对应的元素,再根据 max 找到对应的元素,是 O(logN)
- 如果区间中元素比较多,此时就需要进行遍历,时间复杂度:O(logN + M),N 是 zset 中元素的个数,M 是区间中元素的个数。
- 实际 zset 内部,会记录每个元素当前 “排行”/“次序”,查询到元素,就直接知道了元素所在的 “次序” (下标),就可以直接把 max 对应的元素次序和 min 对应的元素次序,做差即可得出结果。
- 返回值:满足条件的元素列表个数。
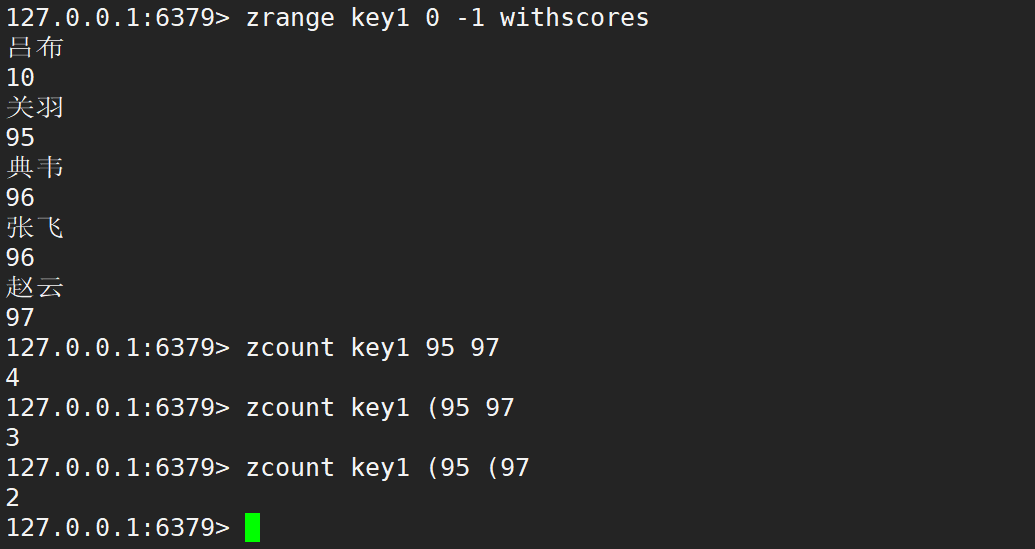
- 使用 ( 表示开区间,[ 表示闭区间,默认是一个闭区间,但是此处的写法比较奇葩。
- 一个好的设计,是符合直觉的,越符合直觉,学习成本就越低,既然已经这么设定了,只能遵循这样的规则。后面想要修改很难,需要考虑兼容性。
- 广泛使用的软件,一但在新版本中,引入和之前不兼容的特性,成本是非常高的。
- 考虑兼容性的案例:C++ 兼容 C 语言。
- 不考虑兼容性的案例:IPV6 不兼容 IPV4
- 一般来说,确实需要做出这种不兼容的修改,可以先把这个要修改的内容,标记成 “弃用”,给程序员打个预防针,同时推出新版本的方案。
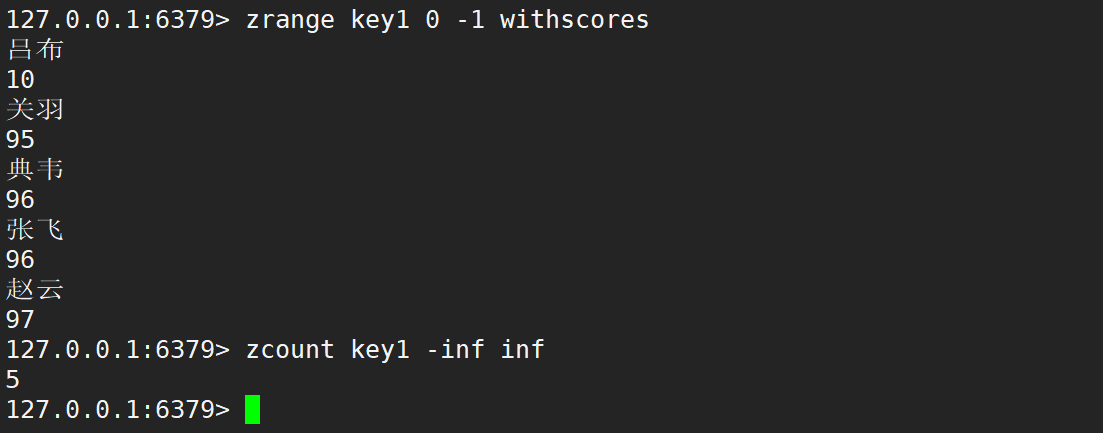
- min 和 max 是可以写成浮点数 (zset 分数本身就是浮点数),在浮点数中,存在两个特殊的数值:-inf 负无穷大,inf 无穷大,zset 分数也是支持使用 -inf 和 inf 作为 min 和 max 的。
- 注意:负无穷大不是无穷小,而无穷小指的是无限趋近于 0 的数。
zrange、zrevrange、zrangebyscore
- zrange:返回指定区间里的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
- 语法:
zrange key start stop [WITHSCORES] - 时间复杂度:O(logN + M),N 是 zset 中元素的个数,M 是区间中元素的个数。
- 返回值:区间内的元素列表。
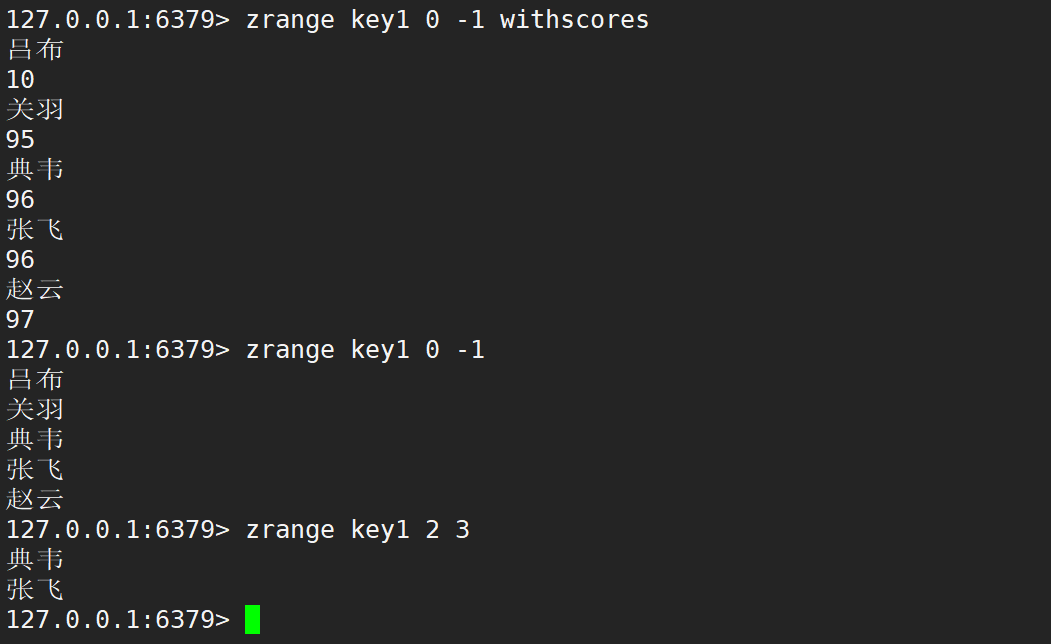
- zrevrange:返回指定区间里的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。
- 语法:
zrevrange key start stop [WITHSCORES] - 时间复杂度:O(logN + M),N 是 zset 中元素的个数,M 是区间中元素的个数。
- 返回值:区间内的元素列表。
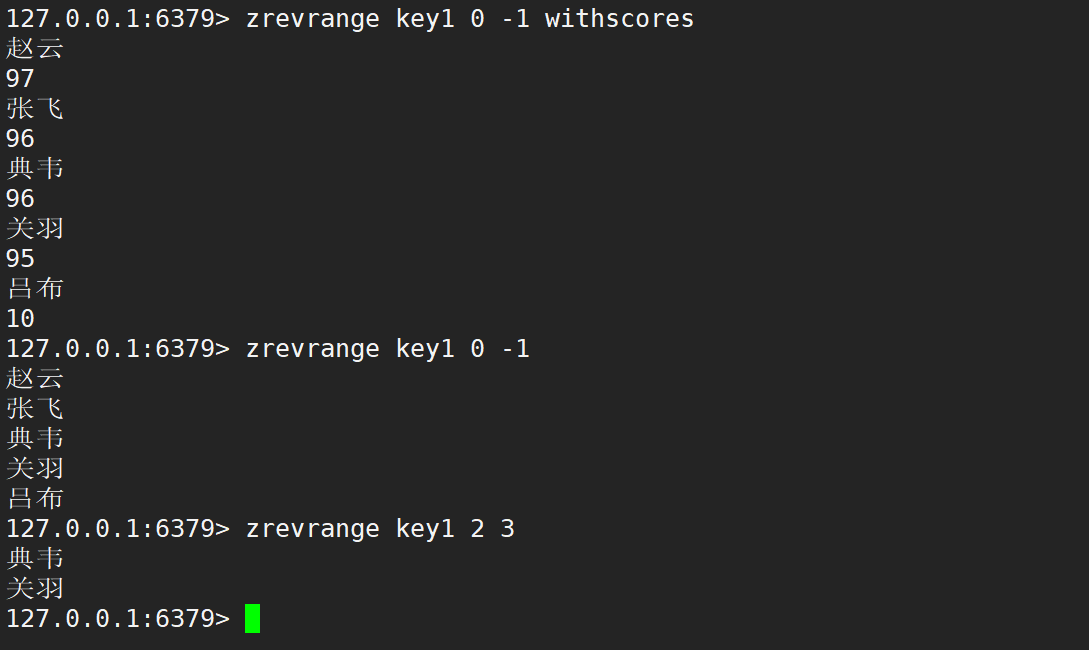
注意:第一个元素的下标是 0,最后一个元素的下标是 len - 1,也可以使用 -1 代替,且 zrevrange 的区间和 zrange 的区间两个参数的顺序是一样的,即二者区间的使用是一样的,只不过得出结果的顺序不一样。
- zrangebyscore:返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的。但是可以通过 ( 进行排除。和 zcount 类似。
- 语法:
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]- WITHSCORES:将分数也返回。
- LIMIT offset count:从偏移量 offset 开始,返回 count 个元素。
- 时间复杂度:O(logN + M),N 是 zset 中元素的个数,M 是区间中元素的个数。
- 返回值:区间内的元素列表。
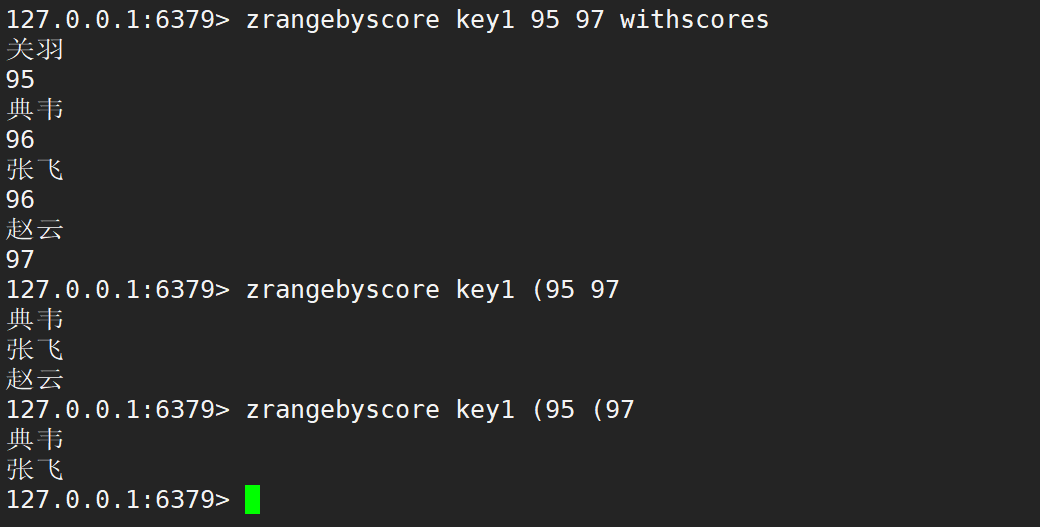

注意:zrevrange、zrangebyscore 这两个命令在 Redis 6.2.0 之后废弃,并且功能合并到 zrange 中。
zpopmax、zpopmin
- zpopmax:删除并返回分数最高的 count 个元素。
- 语法:
zpopmax key [count] - 时间复杂度:O(logN * M),N 是 zset 的元素个数,M 是要删除的元素个数。
- 此处在有序集合删除最大值,就相当于最后一个元素 (尾删),既然是尾删,为什么我们不把这个最后一个元素的位置特殊记录下来,后续删除不就可以做到 O(1) 了嘛?省去了查找过程,但是 Redis 并没有这么做。
- 事实上 Redis 源码中,针对有序集合,确实记录了尾部这样的特点位置,但是实际删除的时候,并没有用上这个特性,而是直接调用了一个 “通用的删除函数”,给点一个 member 的值,进行查找,找到位置之后再删除。
- 虽然存在这样的优化空间,但是未来真的会这么优化,也不好说。优化这种活,要优化到刀刃上,优化一般是要先找到性能瓶颈,再针对性的进行优化。
- 因为当前的这个 logN 的速度其实是不慢的,如果 N 不是非常夸张的大,基本可以近似看作 O(1) 的。
- 返回值:分数和元素列表。
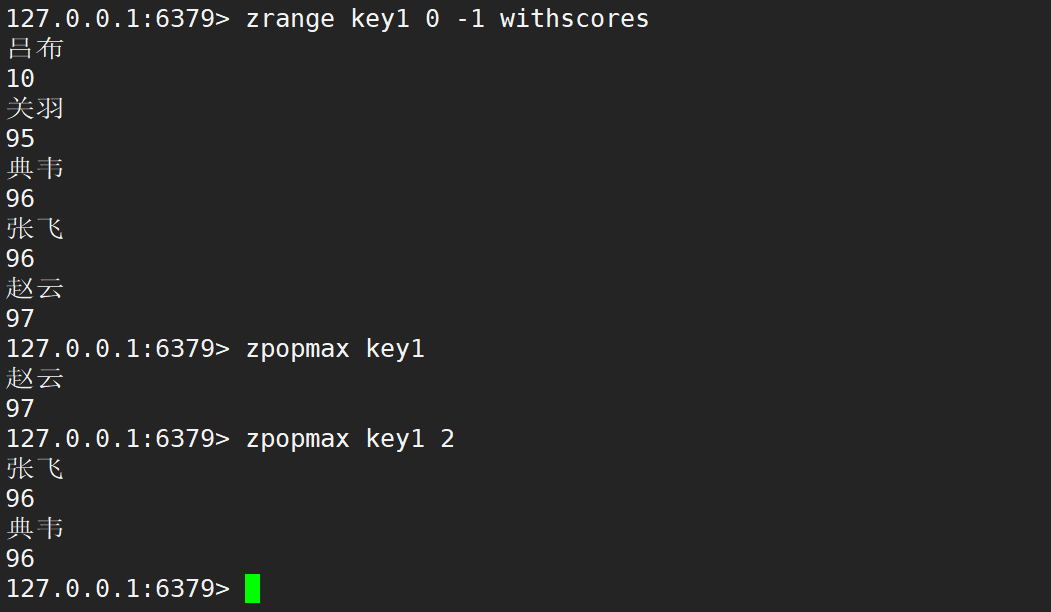
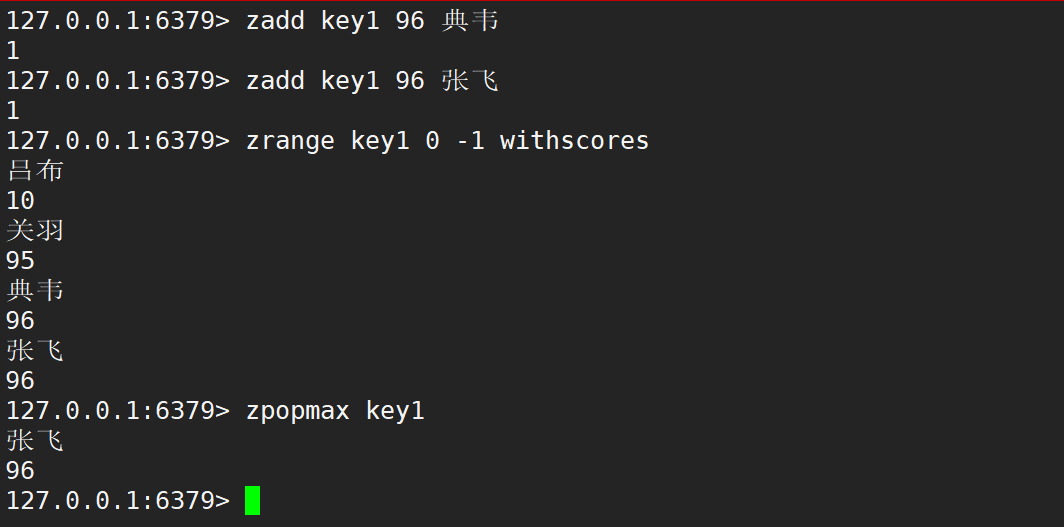
如果存在多个元素的分数相同,同时为最大值时,zpopmax 删除的时候,仍然值删除其中一个元素,会按照 member 字符串的字典序决定删除的先后顺序。
- zpopmin:删除并返回分数最低的 count 个元素。
- 语法:
zpopmin key [count] - 时间复杂度:O(logN * M),N 是 zset 的元素个数,M 是要删除的元素个数。
- 此处的 zpopmin 和 zpopmax 的逻辑是一样的 (同一个函数实现的),虽然 Redis 的有序集合记录了开头的元素,但是删除的时候,使用的是通用的删除函数,导致出现了重新查找的过程。
- 返回值:分数和元素列表。
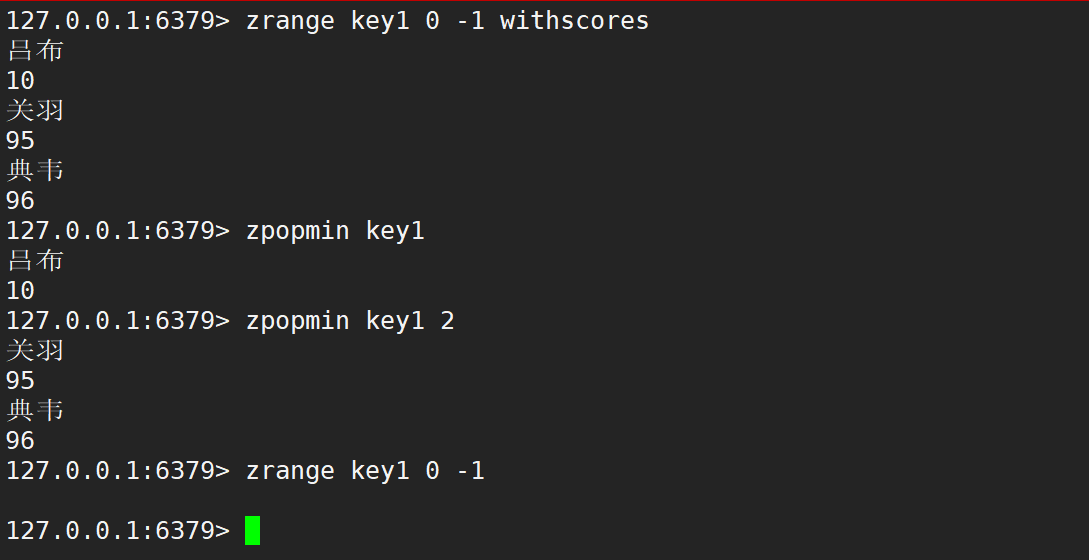
zrank、zrevrank、zscore
- zrank:返回指定元素的排名 (类似下标),升序。
- 语法:
zrank key member - 时间复杂度:O(logN)
- 返回值:排名。
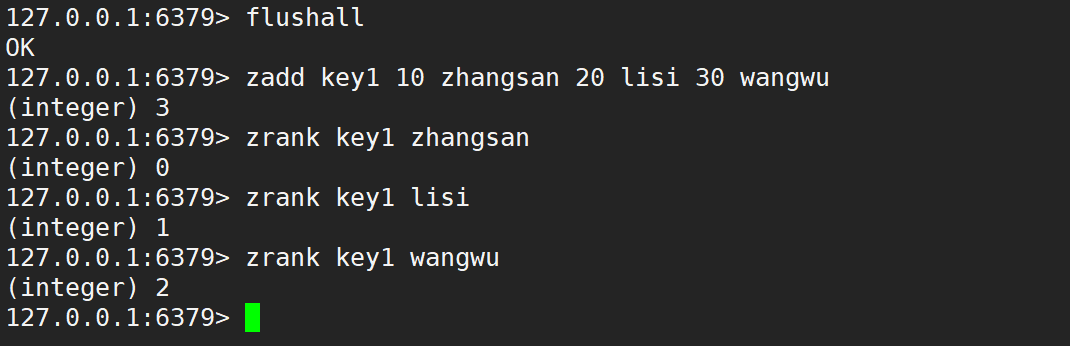
在 zcount 计算的时候,就是先根据分数找到元素,再根据元素获取到排名,最后把排名相减,就可以得到区间中元素的个数。
- zrevrank:返回指定元素的排名 (类似下标),降序。
- 语法:
zrevrank key member - 时间复杂度:O(logN)
- 返回值:排名。
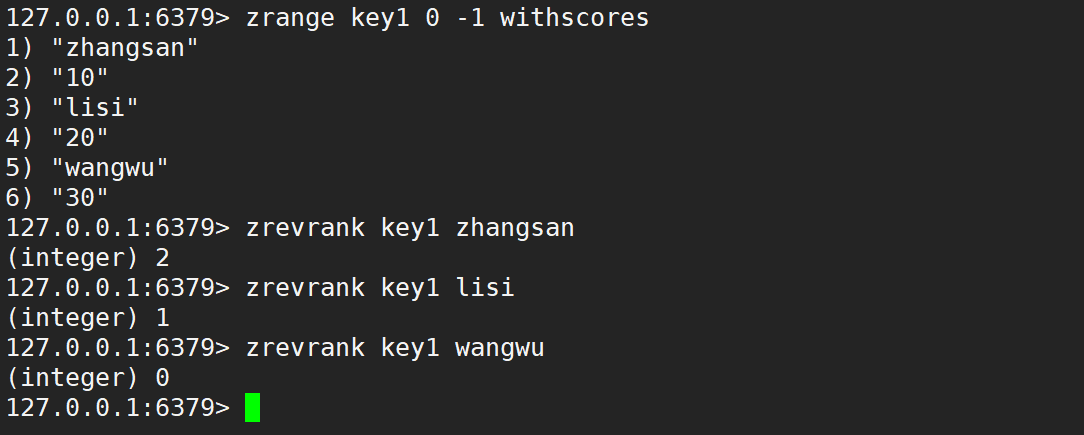
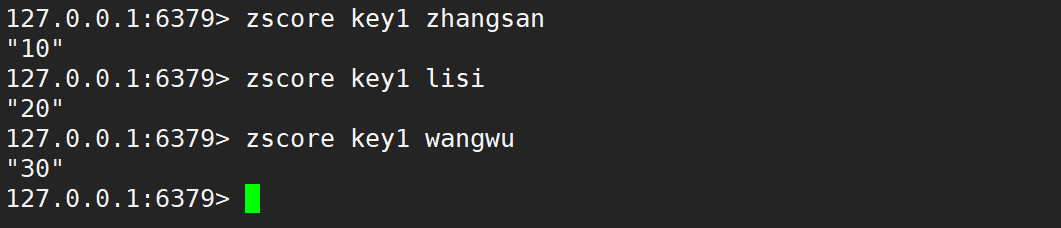
- zscore:查询指定元素的分数。
- 语法:
zscore key member - 时间复杂度:O(1)
- 前面根据 member 找元素,都是 O(logN),这里也是先要找元素,为什么是 O(1)?此处相当于 Redis 对应这样的查询操作做了特殊优化,付出了额外的空间代价。
- 返回值:分数。
zrem、zremrangebyrank、zremrangebyscore
- zrem:删除指定的元素。
- 语法:
zrem key member [member ...] - 时间复杂度:O(logN * M),N 是 zset 的元素个数,M 是要删除的元素个数。
- 返回值:本次操作删除的元素个数。
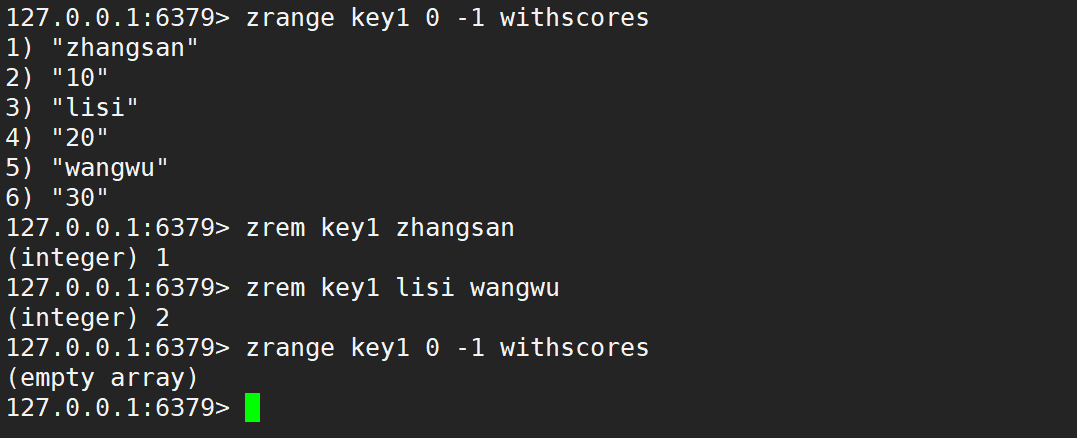
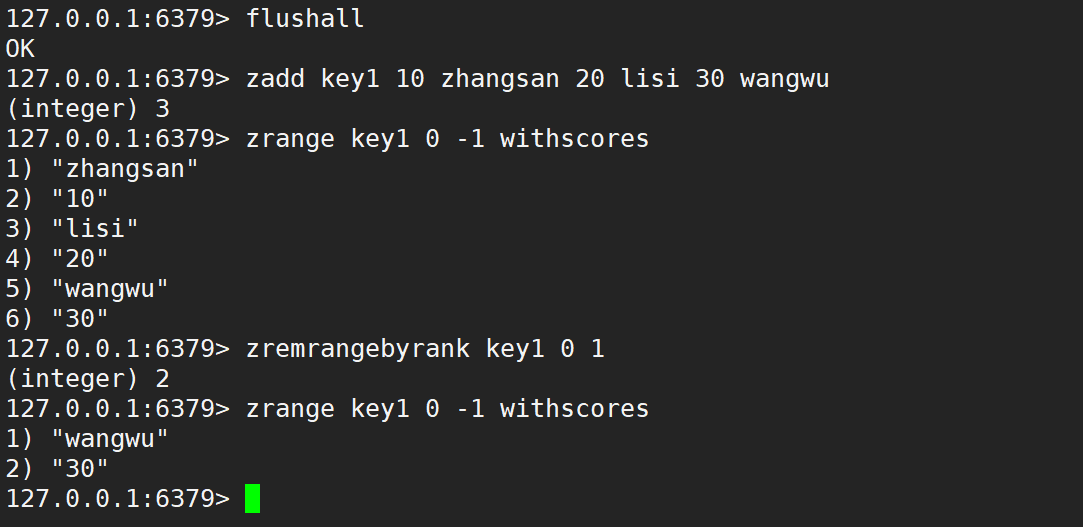
- zremrangebyrank:按照排序,升序删除指定范围的元素,左闭右闭。
- 语法:
zremrangebyrank key start stop - 时间复杂度:O(logN + M),N 是 zset 的元素个数,M 是要删除的区间中元素个数。
- 此处的查找只需要进行一次,不需要重复进行,之后的元素是紧紧挨着的。
- 返回值:本次操作删除的元素个数。
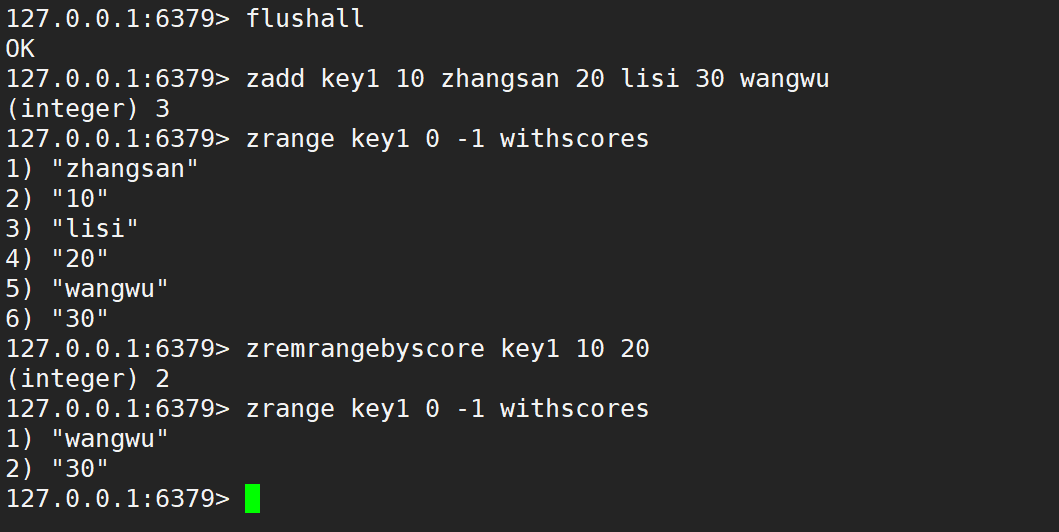
- zremrangebyscore:按照分数删除指定范围的元素,左闭右闭。
- 语法:
zremrangebyscore key min max - 时间复杂度:O(logN + M),N 是 zset 的元素个数,M 是要删除的区间中元素个数。
- 返回值:本次操作删除的元素个数。
zincrby
- zincrby:为指定的元素的关联分数添加指定的分数值。
- 语法:
zincrby key increment member - 时间复杂度:O(logN)
- 返回值:增加后元素的分数。
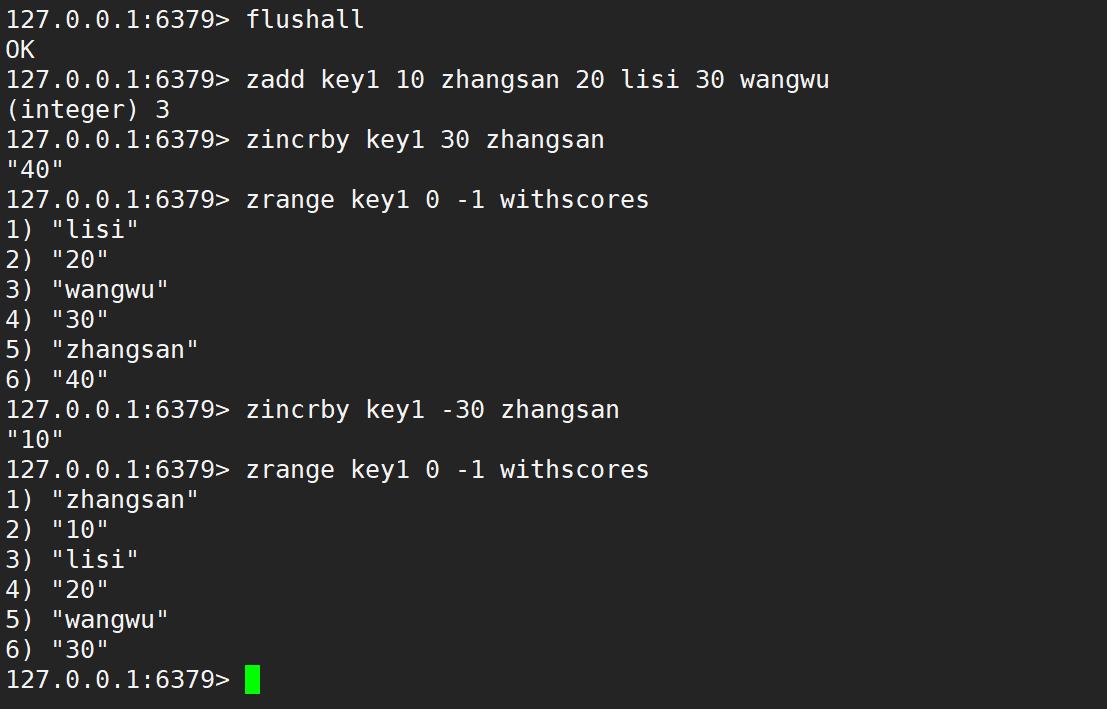
注意:不光会修改分数内容,也能同时移动位置,保持整个有序集合仍然是升序的。
阻塞版本命令:bzpopmax、bzpopmin
针对 list 的 blpop、brpop 命令,实现类似阻塞队列的效果,我们这里的 “有序集合” 也可以视为是一个 “优先级队列”,有的时候,也需要一个带有 “阻塞功能” 的优先级队列。
- bzpopmax:zpopmax 的阻塞版本。
- 阻塞是在有序集合为空的时候触发的,阻塞直到有其他客户端插入元素。
- 语法:
bzpopmax key [key ...] timeout- key:都是一个有序集合 zset
- timeout:超时时间,单位是秒,且支持小数。
- 时间复杂度:O(logN),N 是 zset 的元素个数。
- 返回值:哪个 zset、member 和 score


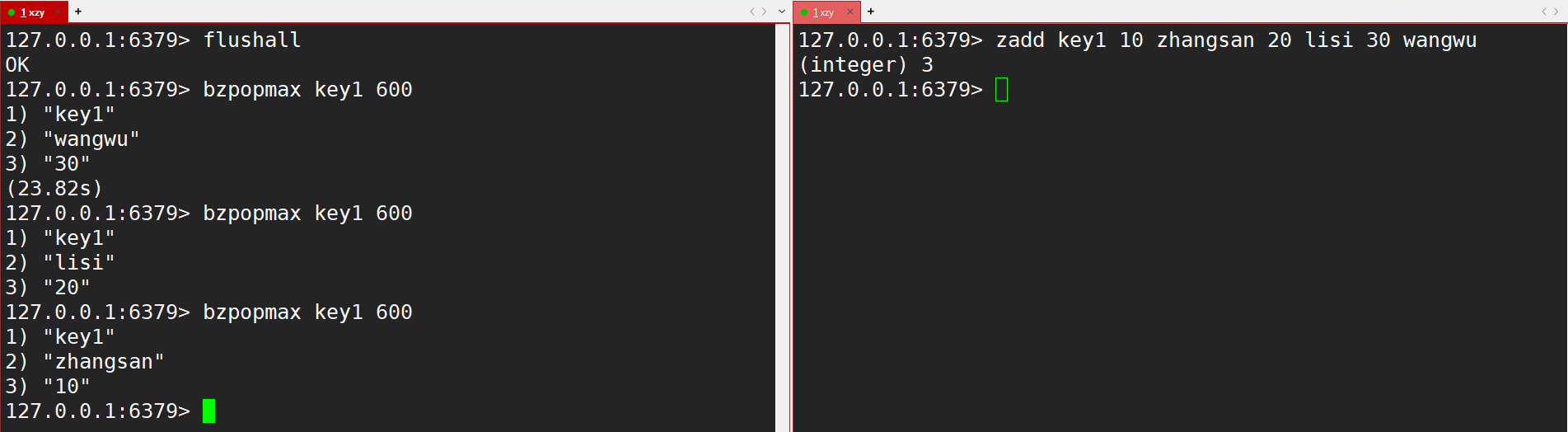
如果有序集合中已经存在元素了,直接就能返回了,就不会阻塞了。
- bzpopmin:zpopmin 的阻塞版本。
- 语法:
bzpopmin key [key ...] timeout - 时间复杂度:O(logN),N 是 zset 的元素个数。
- 返回值:哪个 zset、member 和 score
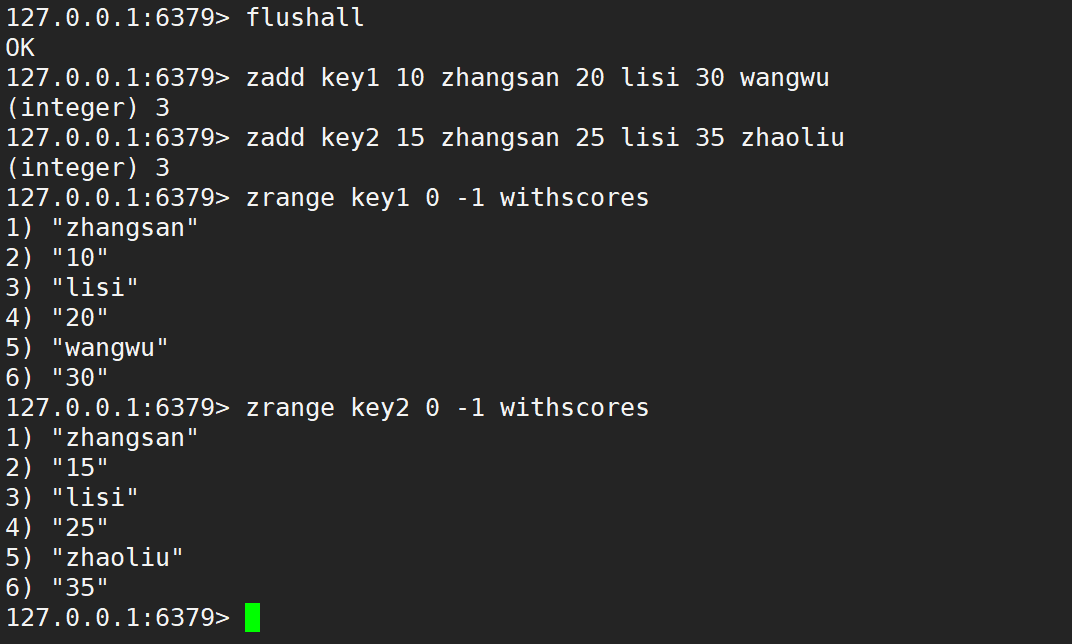
集合间操作:zinterstore、zunionstore
在 set 中,存在 sinter、sunion、sdiff 这些命令求交集、并集、差集操作。而在 zset 中的 zinter、zunion、zdiff 这些命令是从 Redis 6.2 开始支持的,这里使用的是 Redis 5 版本,此处不涉及,但是 Redis 提供了 zinterstore、zunionstore 命令求交集和并集。
有序集合的交集操作

- zinterstore:求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数。
- 语法:
zinterstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]- numkeys:整数,描述了后续有几个 key 参与交集运算。
- 前面 set 介绍的命令,不涉及到类似于此处的设定,主要是因为 numkeys 描述出 key 的个数之后,就可以明确的知道,后面的 “选项” 是从哪里开始的,避免选项和 key 混淆。
- 例如:HTTP 协议的请求报头中的 Content-Length 描述了正文的长度,防止数据产生的黏包问题,HTTP 协议在传输层是基于 TCP 实现的,而 TCP 是面向字节流的,黏包问题是面向字节流这种 IO 方式中的一个普遍存在的问题。
- 同理文件读写也是面向字节流的,解决黏包问题的关键在于明确包的长度/边界。对于有正文的 HTTP 请求,Content-Length 就是包的长度;而对于没有正文的 HTTP 请求,空行就是包的边界。
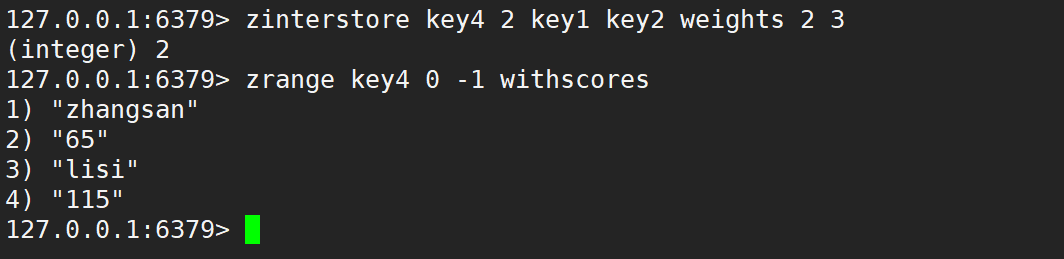
- weights:权重,合并生成的有序集合是带有分数的,此处指定的权重,相当于一个系数,会乘以当前的分数。
- aggregate:总计最终 score 的方式。
- 有序集合中,member 才是元素的本体,score 只是辅助排序的工具人,因此,在进行比较 “相同” 的时候,只要 member 相同即可,score 不一样不影响。
- 如果 member 相同,score 不同,进行交集合并之后,最终的 score,就是根据这里的 aggregate 来计算 (求和/取最大/取最小)
- numkeys:整数,描述了后续有几个 key 参与交集运算。
- 时间复杂度:O(N * K) + O(M * logM),N 是输入的有序集合中,最小的有序集合的元素个数;K 是输入的个有序集合个数;M 是最终结果的有序集合的元素个数。
- 这个东西取决于 Redis 源码如何实现的,这里的 K 一般不会很多,可以近似看作 1,化简一下,认为 N 和 M 是接近的 (同一个数量级,假设不严谨,只是近似看来),最终就是 O(M) + O(M * logM) 近似 O(M * logM),
- 返回值:目标集合中的元素个数。
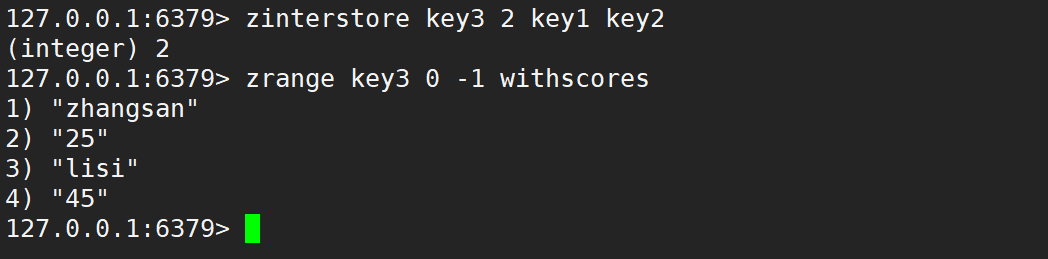
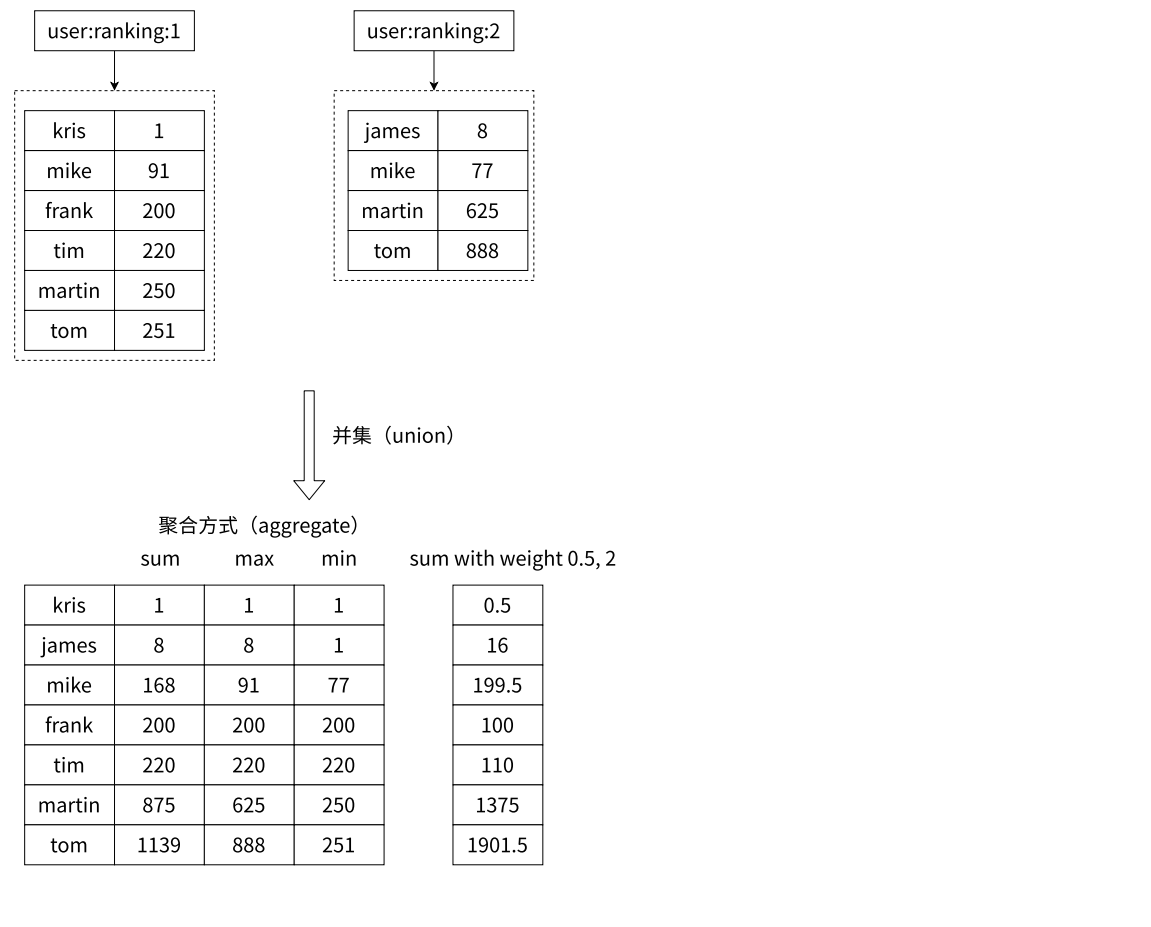
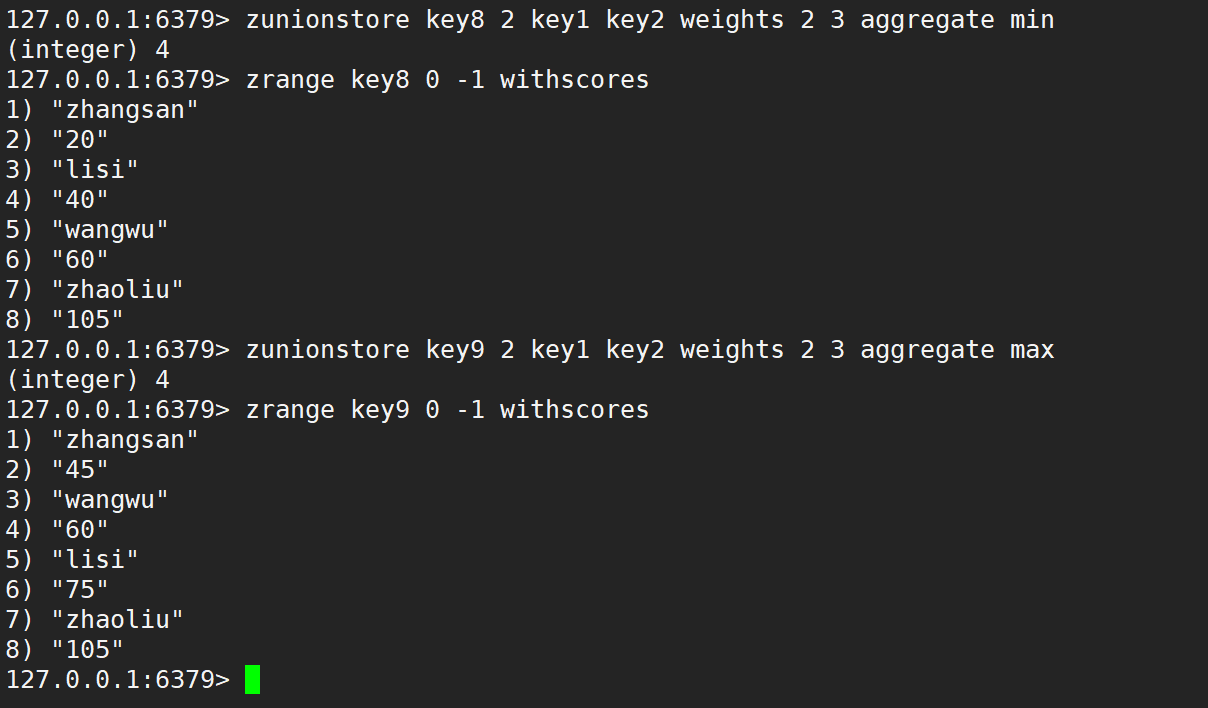
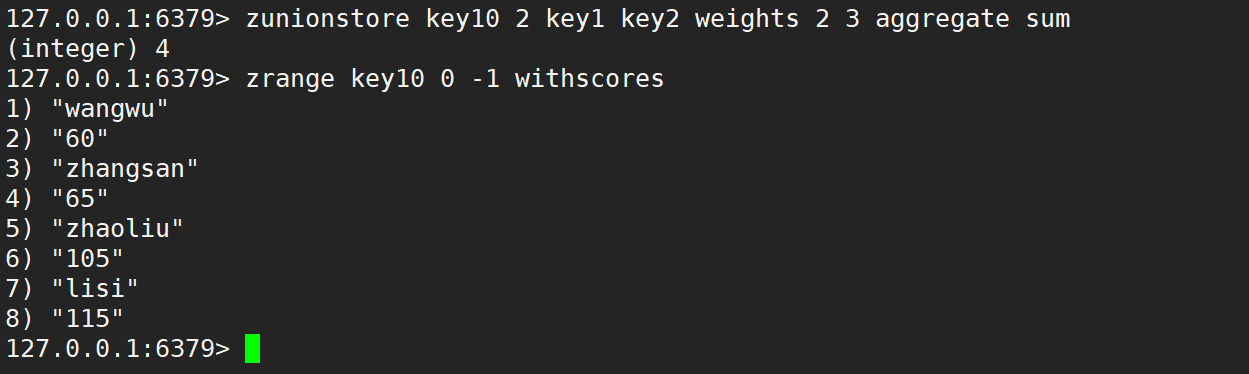
默认情况是相加,如下:
只使用 weights,默认情况是先乘权重系数,再相加,如下:
只使用 aggregate 取最小、取最大、求和,如下:
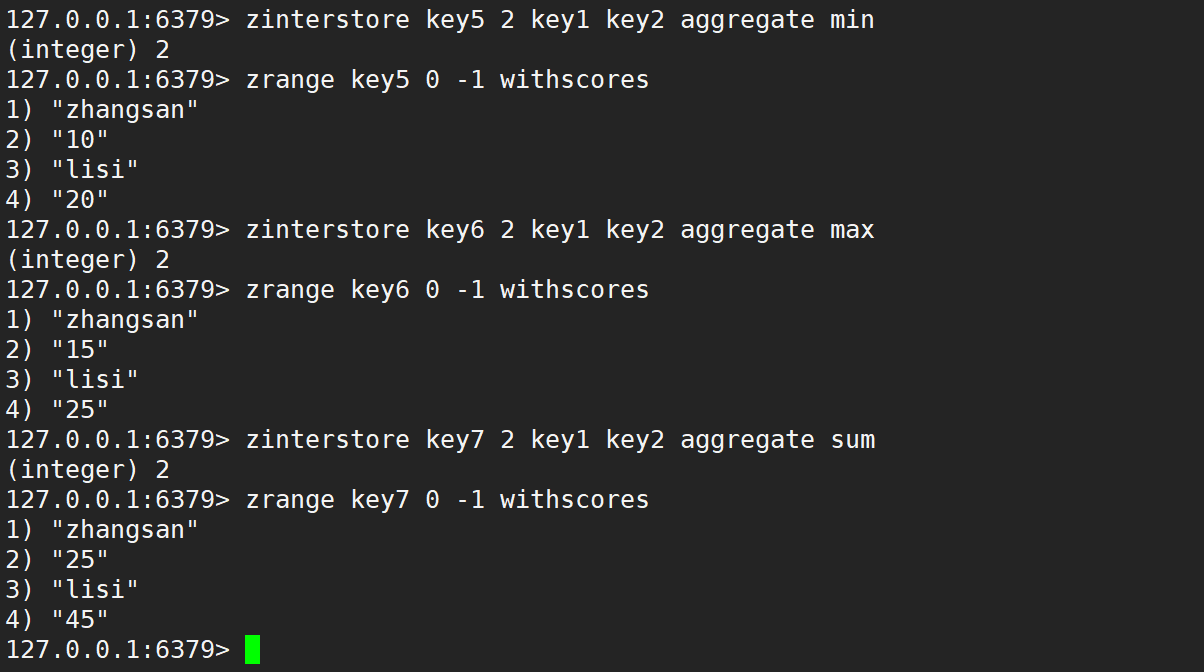
同时使用 weight 和 aggregate 取最小、取最大、求和,如下:
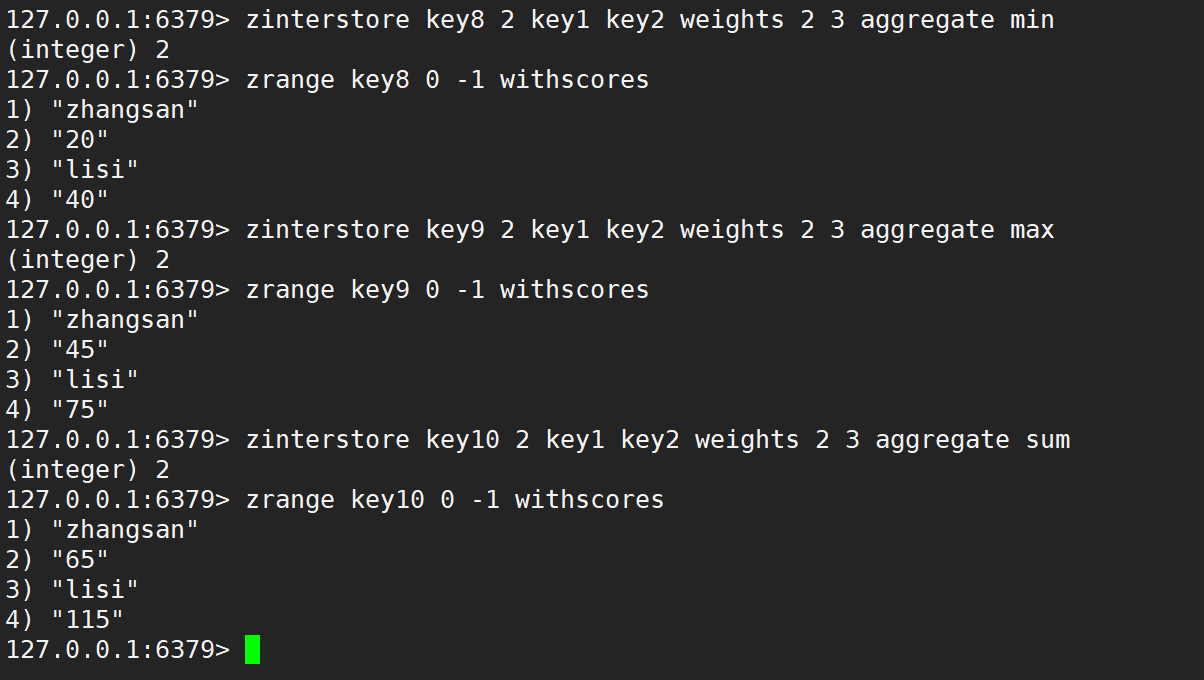
有序集合的并集操作
- zunionstore:求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数。
- 语法:
zunionstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] - 时间复杂度:O(N) + O(M * logM),N 是输入的有序集合总的元素个数;M 是最终结果的有序集合的元素个数。
- 返回值:目标集合中的元素个数
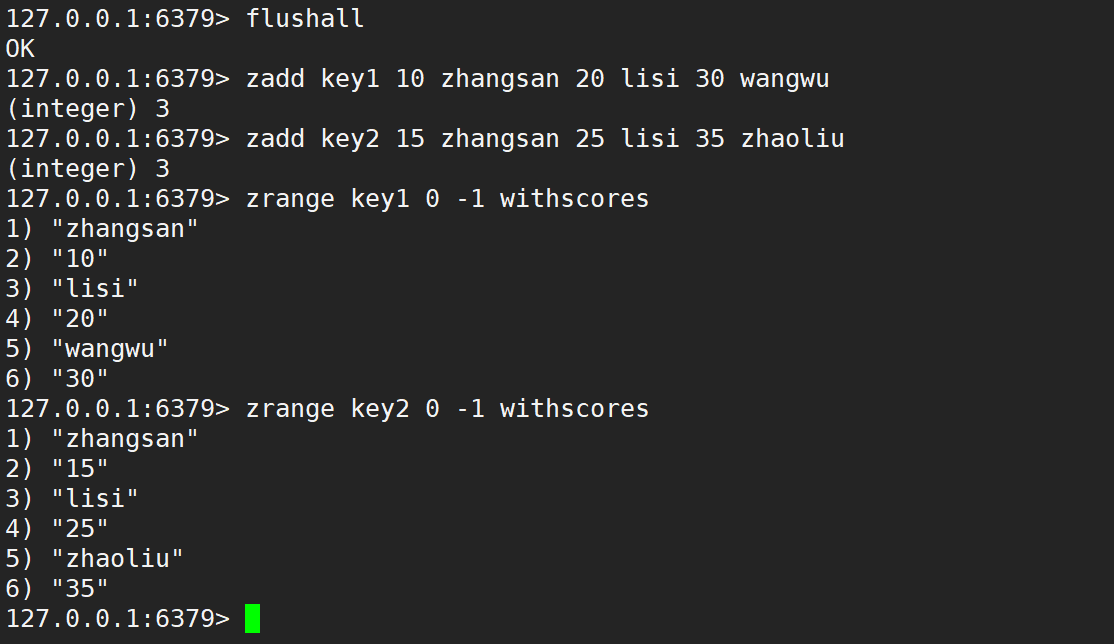
默认情况是相加,如下:
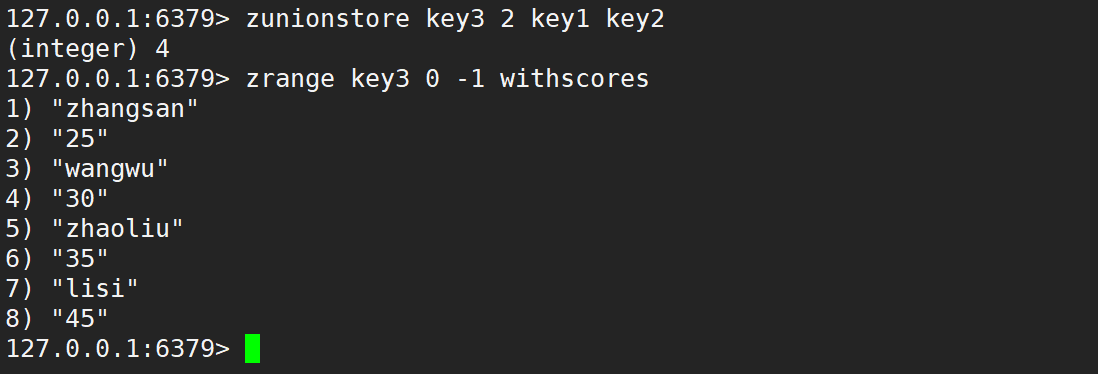
只使用 weights,默认情况是先乘权重系数,再相加,如下:
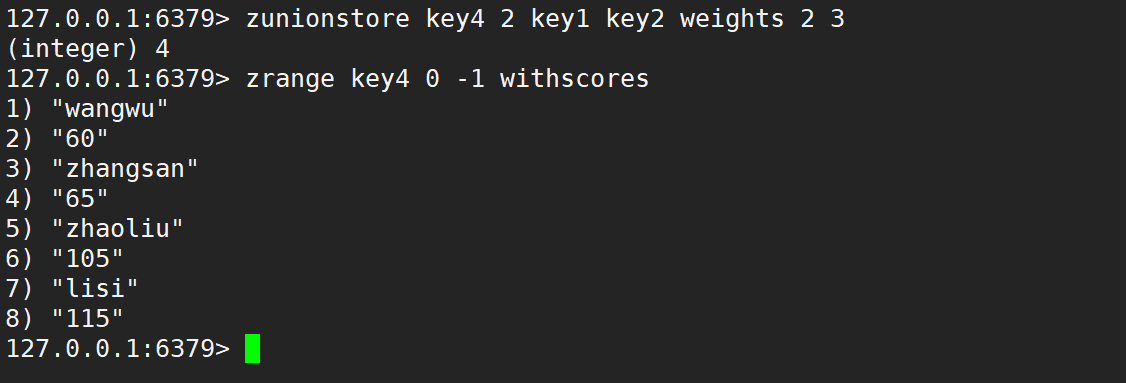
只使用 aggregate 取最小、取最大、求和,如下:
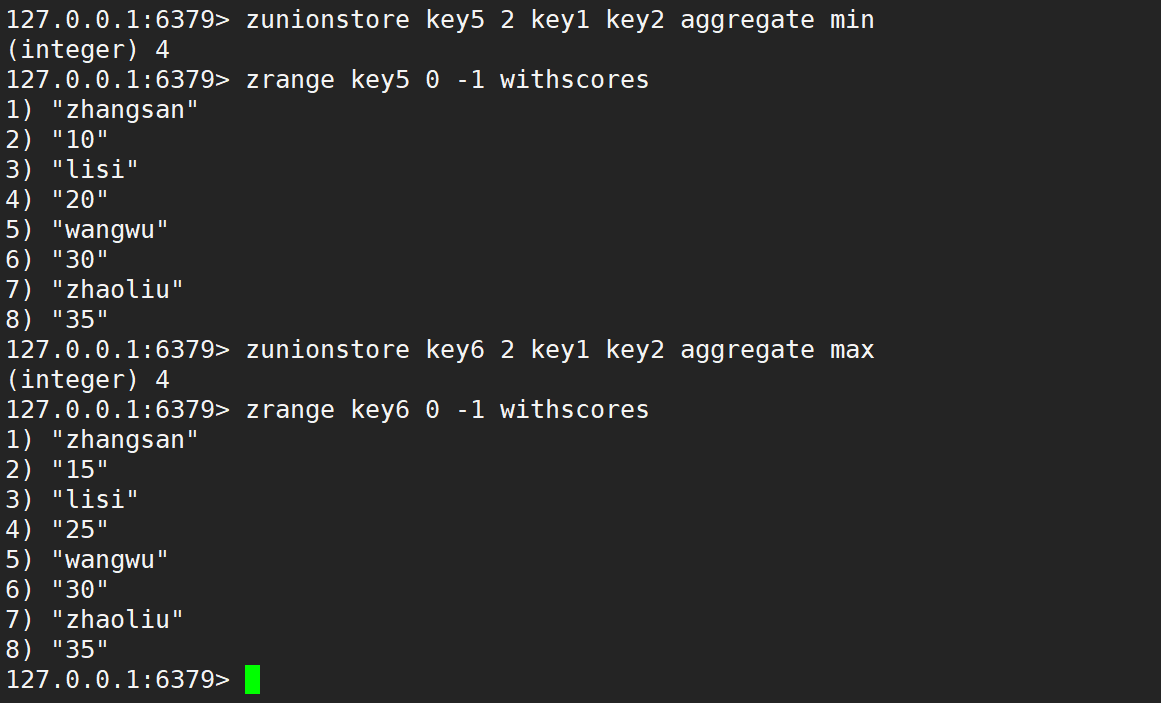
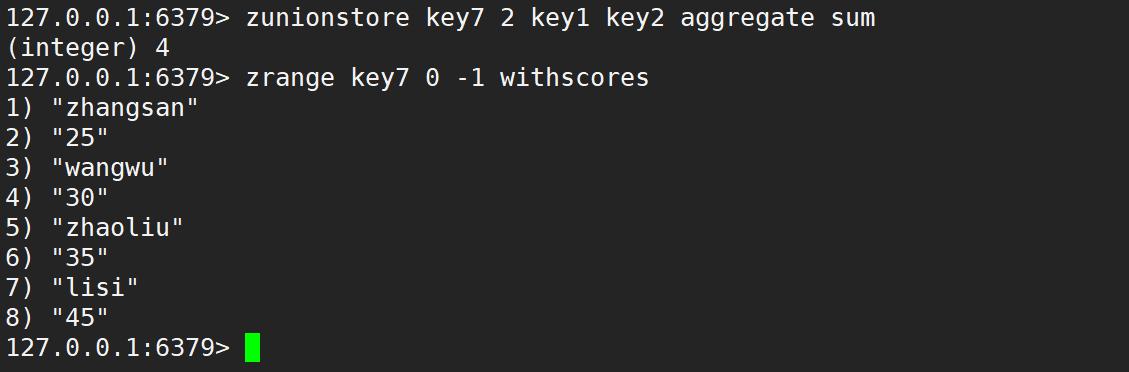
同时使用 weight 和 aggregate 取最小、取最大、求和,如下:
三. zset 命令小结
| 命令 | 执行效果 | 时间复杂度 |
|---|---|---|
| zadd key [NX/XX] [CH] [INCR] score member [score member …] | 向有序集合中添加元素 | O(K * logN) |
| zcard key | 获取有序集合中元素的个数 | O(1) |
| zcount key min max | 获取有序集合 [min, max] 区间内的元素 | logN |
| zrange key start stop [WITHSCORES] | 获取有序集合中的元素,升序 | O(logN + M) |
| zrevrange key start stop [WITHSCORES] | 获取有序集合中的元素,降序 | O(logN + M) |
| zrangebyscore key min max [WITHSCORES] [LIMIT offset count] | 按照分数获取有序集合 [min, max] 区间内的元素 | O(logN + M) |
| zpopmax key [count] | 删除并返回分数最高的 count 个元素 | O(logN + M) |
| zpopmin key [count] | 删除并返回分数最低的 count 个元素 | O(logN + M) |
| zrank key member | 返回有序集合中元素的排名,升序 | O(logN) |
| zrevrank key member | 返回有序集合中元素的排名,降序 | O(logN) |
| zscore key member | 查询指定元素的分数 | O(1) |
| zrem key member [member …] | 删除指定的元素 | O(logN + M) |
| zremrangebyrank key start stop | 按照排序,升序删除指定范围的元素 | O(logN + M) |
| zremrangebyscore key min max | 按照分数删除指定范围的元素 | O(logN + M) |
| zincrby key increment member | 为指定的元素的关联分数添加指定的分数值 | O(logN) |
| bzpopmax key [key …] timeout | zpopmax 的阻塞版本 | O(logN) |
| bzpopmin key [key …] timeout | zpopmin 的阻塞版本 | O(logN) |
| zinterstore destination numkeys key [key …] [WE/GHTS weight] [AGGREGATE SUM/MIN/MAX] | 将交集存储在目标有序集合中 | O(N * K) + O(M * logM) |
| zunionstore destination numkeys key [key …] [WE/GHTS weight] [AGGREGATE SUM/MIN/MAX] | 将并集存储在目标有序集合中 | O(N) + O(M * logM) |
其中 N 是有序集合中元素的个数,M 是区间中元素的个数/要删除的元素的个数。
四. zset 内部编码方式
有序集合类型的内部编码有两种:
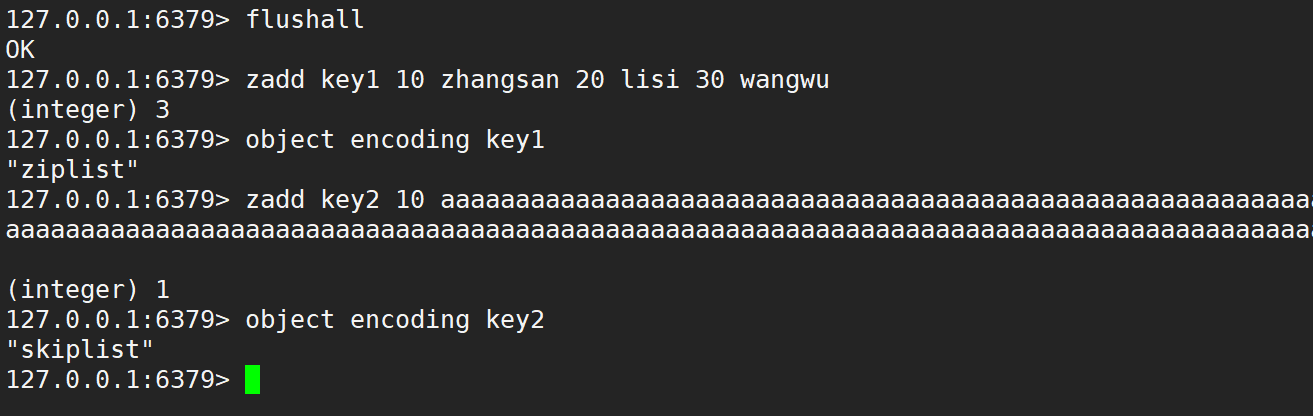
- ziplist (压缩列表):当有序集合的元素个数小于 zset-max-ziplist-entries 配置 (默认 128 个),同时每个元素的值都小于 zset-max-ziplist-value 配置 (默认 64 字节) 时,Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。
- 如果有序列表中的元素个数比较少,或者单个元素体积较小,使用 ziplist 来存储,做到节省空间,但是效率会下降。
- skiplist (跳表):当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时 ziplist 的操作效率会下降。
- 如果有序列表中的元素个数比较多,或者单个元素体积较大,使用 skiplist 来存储,做到提高效率。
- 简单来说,跳表是一个 “复杂链表”,查询一个元素的时间复杂度是 logN,相比于树形结构 (平衡二叉搜索树),更适合按照范围获取元素,功能类似于 MySQL 数据库低层的 B+ 树。
可以使用 object encoding 命令,来查看当前有序集合的内部编码方式,如下:
五. zset 使用场景
排行榜系统
- 有序集合比较典型的使用场景就是排行榜系统,例如:微博热搜、游戏天梯排行、成绩排行。
- 榜单的维度可能是多方面的:按照时间、按照阅读量、按照点赞量。用来排行的 “分数” 是实时变化的,使用 zset 来完成上述操作,就非常的简单、高效的更新排行。
- 比如:游戏天梯排行,只需要把玩家信息和对应的分数给放到有序集合中即可,自动就形成了一个排行榜,随着可以按照排行 (下标)、按照分数,进行范围查找,随着分数发生改变,也可以比较方便的使用 zincrby 修改分数,排行顺序也能自动调整。
- 但是游戏玩家这么多,此时都用 zset 来在内存中存储,能存的下嘛?假设 userId 按照 4 个字节计算,score 按照 8 个字节计算,表示一个玩家就是 12 个字节,若存在 1 亿个玩家就是 12 亿字节,约等于 1.2 GB,即便是家用电脑都能够存下,更何况公司的服务器。
- 对于游戏排行榜,这里的先后顺序非常容易确定,但是有的排行榜就要复杂一些,比如:微博热点,是一些综合的体现 (浏览量、点赞量、转发量、评论量),使用权重 weight 分配,具体有多少个维度,每个维度权重该怎么分配,以及怎么设定是最优的,公司团队通过人工智能的方式来进行计算,根据每个维度,计算得到的综合得分,就是热度。
- 此时就可以借助 zinterstore / zunionstore 按照加权方式处理,把上述每个维度的数值都放到一个有序集合中,member 就是微博的 id,score 就是某个维度的数值,按照约定好的权重,进行集合间运算即可,得到的结果集合的分数就是热度,此时排行榜也就出来了。
- 实现排行榜,zset 是一个选择,但不是说非得用 Redis 中的 zset,有些场景确实可以用到有序集合,但不方便使用 Redis,此时可以考虑使用其他方式的有序集合 (第三方库、自己基于跳表实现有序集合)
本例中我们使用点赞数这个维度,维护每天的热榜:
- 添加用户赞数:用户 james 发布了一篇文章,并获得 3 个赞,可以使用有序集合的 zadd 和 zincrby 功能。之后如果再获得赞,可以使用 zincrby:
zadd user:ranking:2022-03-15 3 james
zincrby user:ranking:2022-03-15 1 james
- 取消用户赞数:由于各种原因 (例如用户注销、用户作弊等) 需要将用户删除,此时需要将用户从榜单中删除掉,可以使用 zrem。例如删除成员 tom:
zrem user:ranking:2022-03-15 tom
- 展示获取赞数最多的 10 个用户:此功能使用 zrevrange 命令实现:
zrevrangebyrank user:ranking:2022-03-15 0 9
- 展示用户信息以及用户分数:次功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户的分数和排名可以使用 zscore 和 zrank 来实现:
hgetall user:info:tom
zscore user:ranking:2022-03-15 mike
zrank user:ranking:2022-03-15 mike
相关文章:
【Redis】zset 类型
zset 一. zset 类型介绍二. zset 命令zaddzcard、zcountzrange、zrevrange、zrangebyscorezpopmax、zpopminzrank、zrevrank、zscorezrem、zremrangebyrank、zremrangebyscorezincrby阻塞版本命令:bzpopmax、bzpopmin集合间操作:zinterstore、zunionstor…...
从Gartner报告看Atlassian在生成式AI领域的创新路径与实践价值
本文来源atlassian.com,由Atlassian全球白金合作伙伴——龙智翻译整理。 二十余年来,Atlassian始终是创新领域的领军者。凭借对团队协作本质的深刻理解,Atlassian在AI时代仍持续引领协作方式的革新。如今,这一领先地位再次获得权威…...
Kafka 安装教程(支持 Windows / Linux / macOS)
一、下载 1、kafka官网下载地址:https://kafka.apache.org/downloads 根据实际情况下载对应的版本 2、JDK的版本最好是17+ JDK下载地址:https://www.oracle.com/java/technologies/javase/jdk17-0-13-later-archive-downloads.html 二、安装 前置条件 安装 Java(至少 Jav…...
OpenCV种的cv::Mat与Qt种的QImage类型相互转换
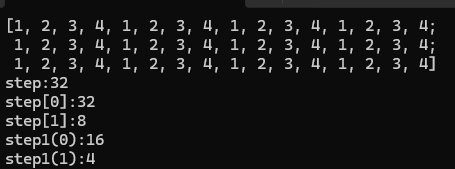
一、首先了解cv::Mat结构体 cv::Mat::step与QImage转换有着较大的关系。 step的几个类别区分: step:矩阵第一行元素的字节数step[0]:矩阵第一行元素的字节数step[1]:矩阵中一个元素的字节数step1(0):矩阵中一行有几个通道数step1(1):一个元素有几个通道数(channel()) cv::Ma…...

机器学习——什么时候使用决策树
无论是决策树,包括集成树还是神经网络都是非常强大、有效的学习方法。 下面是各自的优缺点: 决策树和集成树通常在表格数据上表现良好,也称为结构化数据,这意味着如果你的数据集看起来像一个巨大的电子表格,那么决策…...

llm-d:面向Kubernetes的高性能分布式LLM推理框架
在生成式AI(GenAI)浪潮中,高效、经济地部署和扩展大型语言模型(LLM)推理服务是企业面临的核心挑战。传统基于Kubernetes的横向扩展(Scale-out)和负载均衡策略在处理独特的LLM推理工作负载时往往…...
前端没有“秦始皇“,但可以做跨端的王[特殊字符]
前端各领域的 “百家争鸣” 框架之争:有 React、Vue、Angular 等多种框架。它们各有优缺点,开发者之间还存在鄙视链,比如 Vue 嫌 React 难用,React 嫌 Vue 不够灵活。样式处理: CSS 预处理器:像 Sass、Les…...

Flutter如何支持原生View
在 Flutter 中集成原生 View(如 Android 的 SurfaceView、iOS 的 WKWebView)是通过 平台视图(Platform View) 实现的。这一机制允许在 Flutter UI 中嵌入原生组件,解决了某些场景下 Flutter 自身渲染能力的不足&#x…...

mongodb源码分析session异步接受asyncSourceMessage()客户端流变Message对象
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制,ASIOSession和connection是循环接受客户端命令,状态转变流程是:State::Created 》 State::Source 》State::…...
【数据分析】什么是鲁棒性?
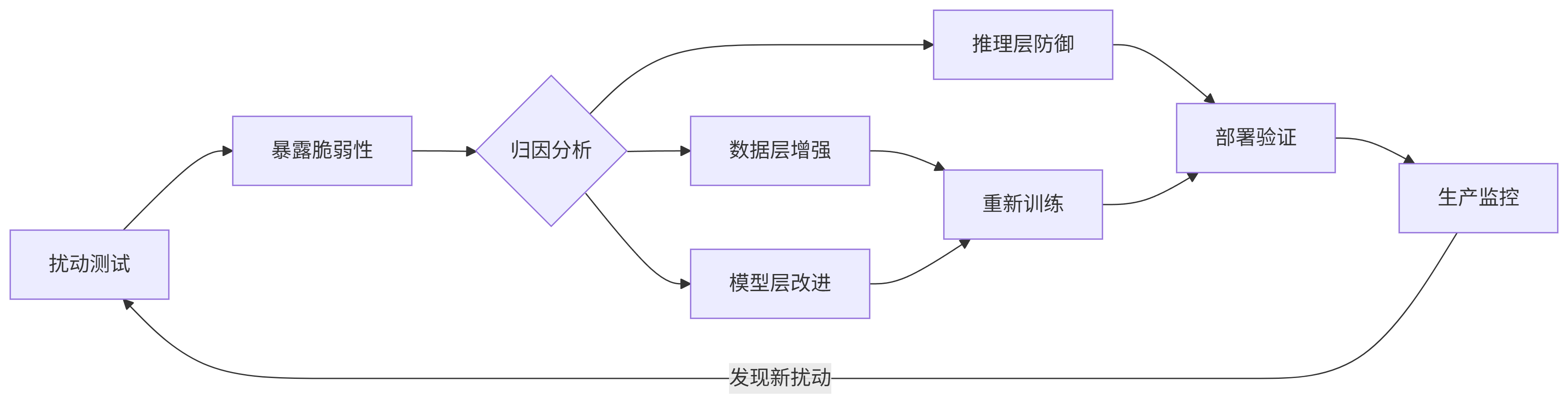
引言 —— 为什么我们需要“抗折腾”的系统? 当你乘坐的飞机穿越雷暴区时机体剧烈颠簸,自动驾驶汽车在暴雨中稳稳避开障碍物,或是手机从口袋摔落后依然流畅运行——这些场景背后,都藏着一个工程领域的“隐形守护者”:…...

适老化场景重构:现代家政老年照护虚拟仿真实训室建设方案
随着老龄化社会的深度发展,老年照护服务的专业化需求对人才培养提出了更高要求。 凯禾瑞华以现代家政管理理念为核心,推出老年照护虚拟仿真实训室建设方案,通过虚拟仿真技术重构适老化生活场景,融合数字课程、产教融合及搭载智能…...
Qt/C++学习系列之QGroupBox控件的简单使用
Qt/C学习系列之QGroupBox控件的简单使用 前言样式使用代码层面初始化控件事件过滤器点击事件处理 总结 前言 最近在练手一个项目,项目中有不同功能的划分,为了功能分区一目了然,我使用到QGroupBox控件,也是在界面排版布局中最常用…...

Ubuntu设置之初始化
安装SSH服务 # 安装 OpenSSH Server sudo apt update sudo apt install -y openssh-server# 检查 SSH 服务状态 sudo systemctl status ssh # Active: active (running) since Sat 2025-05-31 17:13:07 CST; 6s ago# 重启服务 sudo systemctl restart ssh自定义分辨率 新…...

如何轻松地将数据从 iPhone传输到iPhone 16
对升级到 iPhone 16 感到兴奋吗?恭喜!然而,除了兴奋之外,学习如何将数据从 iPhone 传输到 iPhone 16 也很重要。毕竟,那些重要的联系人、笔记等都是不可或缺的。为了实现轻松的iPhone 到 iPhone 传输,我们总…...
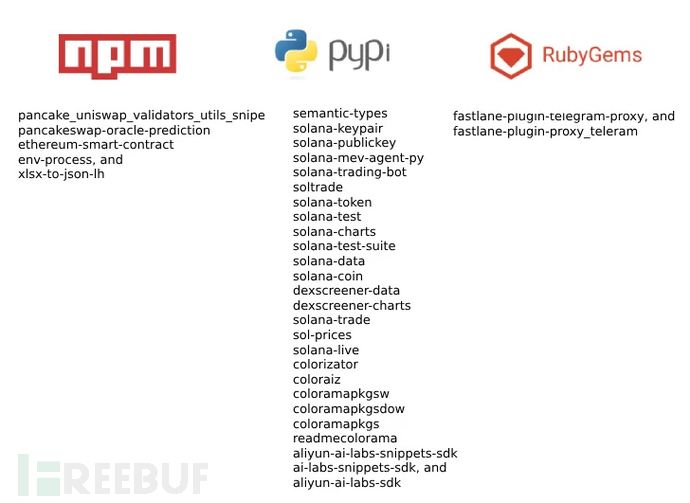
开源供应链攻击持续发酵,多个软件包仓库惊现恶意组件
近期在npm、Python和Ruby软件包仓库中相继发现多组恶意组件,这些组件能够清空加密货币钱包资金、安装后删除整个代码库并窃取Telegram API令牌,再次印证了开源生态系统中潜伏的多样化供应链威胁。 多平台恶意组件集中曝光 Checkmarx、ReversingLabs、S…...

Docker Compose 备忘
1。docker-compose.yml services:air-web:build: .ports:- "1027:1027"volumes:- .:/codedepends_on:- air-redisair-redis:image: "redis:alpine" 2. DockerfileFROM python:3.12-slim-bookworm #设置工作目录 WORKDIR /code #将当前目录内容拷贝到容器…...

量子计算+AI:特征选择与神经网络优化创新应用
在由玻色量子协办的第二届APMCM“五岳杯”量子计算挑战赛中,来自北京理工大学的Q-Masterminds团队摘取了银奖。该团队由北京理工大学张玉利教授指导,依托玻色量子550计算量子比特的相干光量子计算机,将量子计算技术集成到特征选择和神经网络剪…...

算法分析与设计-动态规划、贪心算法
目录 第三章——动态规划 第四章——贪心算法 第三章——动态规划 /*【问题描述】 使用动态规划算法解矩阵连乘问题,具体来说就是,依据其递归式自底向上的方式进行计算,在计算过程中,保存子问题答案,每个子问题只解…...
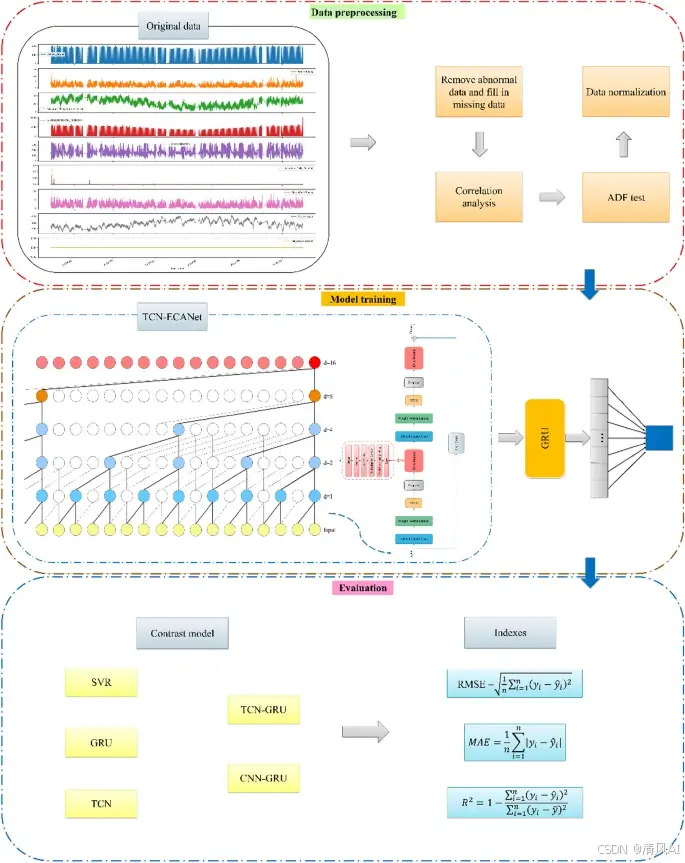
光伏功率预测新突破:TCN-ECANet-GRU混合模型详解与复现
研究背景 背景与挑战 光伏发电受天气非线性影响,传统方法(统计模型、机器学习)难以处理高维时序数据,预测误差大。创新模型提出 融合时序卷积网络(TCN)、高效通道注意力(ECANet)和门控循环单元(GRU)的混合架构。方法论细节 TCN:膨胀因果卷积提取长时序特…...

React组件基础
组件是什么? 概念:一个组件就是用户界面的一部分,它可以有自己的逻辑和外观,组件之间可以相互嵌套,也可以多次复用 组件化开发,可以让开发者像搭积木一样构建一个完整庞大的应用 react组件 在react中&a…...

2025年5月24日系统架构设计师考试题目回顾
当前仅仅是个人用于记录,还未做详细分析,待更新… 综合知识 设 x,y 满足约束条件:x-1>0, x-y<0, x-y-x<0, 则 y/x 的最大值是()。 A. 3 B. 2 C. 4 D. 1 申请软件著作权登记时应当向中国版本保护中心提交软件的鉴别材料ÿ…...

ABP 框架集成 EasyAbp.Abp.GraphQL 构建高性能 GraphQL API
🚀 ABP 框架集成 EasyAbp.Abp.GraphQL 构建高性能 GraphQL API 📚 目录 🚀 ABP 框架集成 EasyAbp.Abp.GraphQL 构建高性能 GraphQL API🧭 背景与目标🛠 安装与依赖📦 模块注册与启动MyProjectHttpApiHostMo…...

C# 用户控件(User Control)详解:创建、使用与最佳实践
在C#应用程序开发中,用户控件(User Control)是一种强大的工具,它允许开发者将多个标准控件组合成一个可复用的自定义组件。无论是Windows Forms还是WPF,用户控件都能显著提高UI开发的效率,减少重复代码&…...
OpenWrt 搭建 samba 服务器的方法并解决 Windows 不允许访问匿名服务器(0x80004005的错误)的方法
文章目录 一、安装所需要的软件二、配置自动挂载三、配置 Samba 服务器四、配置 Samba 访问用户和密码(可选)新建 Samba 专门的用户添加无密码的 Samba 账户使用root账户 五、解决 Windows 无法匿名访问Samba方案一 配置无密码的Samba账户并启用匿名访问…...

【 Redis | 完结篇 缓存优化 】
前言:本节包含常见redis缓存问题,包含缓存一致性问题,缓存雪崩,缓存穿透,缓存击穿问题及其解决方案 1. 缓存一致性 我们先看下目前企业用的最多的缓存模型。缓存的通用模型有三种: 缓存模型解释Cache Asi…...
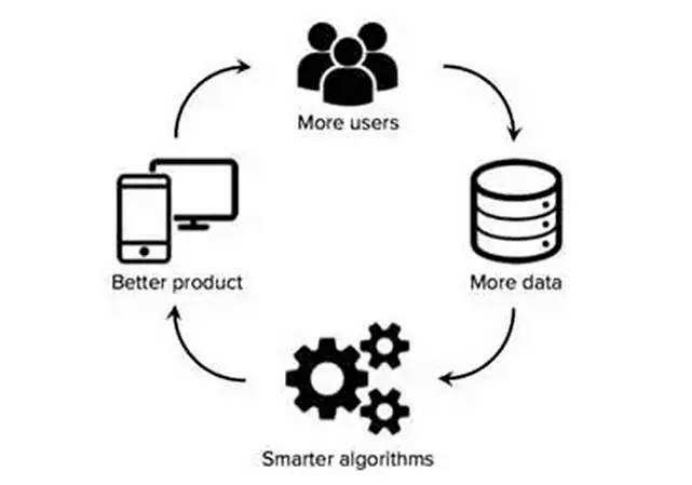
AI数据集构建:从爬虫到标注的全流程指南
AI数据集构建:从爬虫到标注的全流程指南 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 AI数据集构建:从爬虫到标注的全流程指南摘要引言流程图:数据集构建全生命周期一、数据采…...

Android 颜色百分比对照
本文就是简单写个demo,打印下颜色百分比的数值.方便以后使用. 1: 获取透明色 具体的代码如下: /*** 获取透明色* param percent* param red* param green* param blue* return*/public static int getTransparentColor(int percent, int red, int green, int blue) {int alp…...
AI破局:饿了么如何搅动即时零售江湖
最近,即时零售赛道打的火热,对我们的生活也产生了不少的影响。 美女同事小张就没少吐槽“他们咋样了我不知道,奶茶那么便宜,胖了五六斤不说,钱包也空了,在淘宝买奶茶的时候,换了个手机还买了不少…...
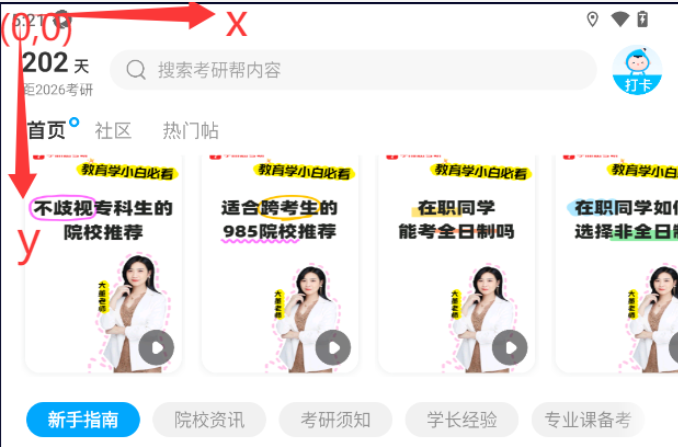
04 APP 自动化- Appium toast 元素定位列表滑动
文章目录 一、toast 元素的定位二、滑屏操作 一、toast 元素的定位 toast 元素就是简易的消息提示框,toast 显示窗口显示的时间有限,一般3秒左右 # -*- codingutf-8 -*- from time import sleep from appium import webdriver from appium.options.an…...

判断它是否引用了外部库
在一个 C# 项目中,要系统性地判断它是否引用了外部库(包括 NuGet 包、引用的 DLL、项目间依赖等),你应从以下几个关键维度入手进行检查和分析: 1. 检查 .csproj 项目文件 C# 项目使用 .csproj 文件(MSBuil…...