Python训练营打卡Day43
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
config.py
import os# 基础配置类
class Config:def __init__(self):# Kaggle配置self.kaggle_username = "" # Kaggle用户名self.kaggle_key = "" # Kaggle API密钥# 数据集配置self.dataset_name = "chest-xray-pneumonia" # 默认使用胸部X光数据集self.data_dir = "data"self.train_dir = os.path.join(self.data_dir, "train")self.val_dir = os.path.join(self.data_dir, "val")self.test_dir = os.path.join(self.data_dir, "test")# 模型配置self.model_save_path = "models/cnn_model.h5"self.img_width, self.img_height = 224, 224self.batch_size = 32self.epochs = 10self.learning_rate = 0.001# Grad-CAM配置self.gradcam_output_dir = "gradcam_output"self.target_layer = "block5_conv3" # VGG16最后一个卷积层,根据模型调整 data_loader.py
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from config import Configclass DataLoader:def __init__(self, config: Config):self.config = configself.train_generator = Noneself.val_generator = Noneself.test_generator = Noneself.class_indices = Nonedef setup_data_generators(self):# 数据增强配置train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=20,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')test_datagen = ImageDataGenerator(rescale=1./255)# 创建数据生成器self.train_generator = train_datagen.flow_from_directory(self.config.train_dir,target_size=(self.config.img_width, self.config.img_height),batch_size=self.config.batch_size,class_mode='categorical')self.val_generator = test_datagen.flow_from_directory(self.config.val_dir,target_size=(self.config.img_width, self.config.img_height),batch_size=self.config.batch_size,class_mode='categorical')self.test_generator = test_datagen.flow_from_directory(self.config.test_dir,target_size=(self.config.img_width, self.config.img_height),batch_size=self.config.batch_size,class_mode='categorical',shuffle=False)self.class_indices = self.train_generator.class_indicesreturn self.train_generator, self.val_generator, self.test_generatordef get_class_names(self):if self.class_indices is None:self.setup_data_generators()return list(self.class_indices.keys()) grad_cam.py
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import cv2
from tensorflow.keras.models import Model
from config import Configclass GradCAM:def __init__(self, model, class_names, config: Config):self.model = modelself.class_names = class_namesself.config = configos.makedirs(self.config.gradcam_output_dir, exist_ok=True)def generate_heatmap(self, img_array, layer_name=None):if layer_name is None:layer_name = self.config.target_layer# 创建一个用于获取输出的模型grad_model = Model(inputs=[self.model.inputs],outputs=[self.model.get_layer(layer_name).output, self.model.output])# 计算梯度with tf.GradientTape() as tape:conv_outputs, predictions = grad_model(img_array)class_idx = np.argmax(predictions[0])class_name = self.class_names[class_idx]loss = predictions[:, class_idx]# 获取梯度grads = tape.gradient(loss, conv_outputs)# 平均梯度pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))# 权重激活映射conv_outputs = conv_outputs[0]heatmap = tf.reduce_mean(tf.multiply(pooled_grads, conv_outputs), axis=-1)# 归一化热图heatmap = np.maximum(heatmap, 0) / np.max(heatmap)return heatmap, class_name, predictions[0][class_idx]def overlay_heatmap(self, heatmap, img_path, alpha=0.4):# 加载原始图像img = cv2.imread(img_path)img = cv2.resize(img, (self.config.img_width, self.config.img_height))# 调整热图大小heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))# 将热图转换为RGBheatmap = np.uint8(255 * heatmap)heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)# 将热图叠加到原图superimposed_img = heatmap * alpha + imgsuperimposed_img = np.uint8(superimposed_img)return img, heatmap, superimposed_imgdef process_image(self, img_path, layer_name=None):# 加载和预处理图像img = tf.keras.preprocessing.image.load_img(img_path, target_size=(self.config.img_width, self.config.img_height))img_array = tf.keras.preprocessing.image.img_to_array(img)img_array = np.expand_dims(img_array, axis=0)img_array = img_array / 255.0# 生成热图heatmap, class_name, confidence = self.generate_heatmap(img_array, layer_name)# 叠加热图original_img, heatmap_img, superimposed_img = self.overlay_heatmap(heatmap, img_path)# 保存结果filename = os.path.basename(img_path)output_path = os.path.join(self.config.gradcam_output_dir, f"gradcam_{filename}")# 创建可视化fig, axes = plt.subplots(1, 3, figsize=(15, 5))axes[0].imshow(cv2.cvtColor(original_img, cv2.COLOR_BGR2RGB))axes[0].set_title('原始图像')axes[0].axis('off')axes[1].imshow(heatmap)axes[1].set_title('Grad-CAM热图')axes[1].axis('off')axes[2].imshow(cv2.cvtColor(superimposed_img, cv2.COLOR_BGR2RGB))axes[2].set_title(f'叠加图像 - {class_name} ({confidence:.2%})')axes[2].axis('off')plt.tight_layout()plt.savefig(output_path)plt.close()return output_path, class_name, confidence kaggle_downloader.py
import os
import json
import kaggle
from kaggle.api.kaggle_api_extended import KaggleApi
from config import Config
import zipfileclass KaggleDownloader:def __init__(self, config: Config):self.config = configself.api = Nonedef authenticate(self):# 设置Kaggle API凭证os.environ['KAGGLE_USERNAME'] = self.config.kaggle_usernameos.environ['KAGGLE_KEY'] = self.config.kaggle_key# 初始化API客户端self.api = KaggleApi()self.api.authenticate()def download_dataset(self):if not self.api:self.authenticate()# 创建数据目录os.makedirs(self.config.data_dir, exist_ok=True)# 下载数据集print(f"正在下载数据集: {self.config.dataset_name}")self.api.dataset_download_files(self.config.dataset_name, path=self.config.data_dir, unzip=True)print(f"数据集下载完成,保存路径: {self.config.data_dir}")# 解压文件(如果需要)for file in os.listdir(self.config.data_dir):if file.endswith('.zip'):zip_path = os.path.join(self.config.data_dir, file)with zipfile.ZipFile(zip_path, 'r') as zip_ref:zip_ref.extractall(self.config.data_dir)os.remove(zip_path) main.py
import argparse
from config import Config
from kaggle_downloader import KaggleDownloader
from data_loader import DataLoader
from model_builder import ModelBuilder
from trainer import Trainer
from grad_cam import GradCAM
import tensorflow as tf
import osdef main():# 解析命令行参数parser = argparse.ArgumentParser(description='Kaggle图像数据CNN训练与Grad-CAM可视化')parser.add_argument('--download', action='store_true', help='下载Kaggle数据集')parser.add_argument('--train', action='store_true', help='训练模型')parser.add_argument('--evaluate', action='store_true', help='评估模型')parser.add_argument('--visualize', action='store_true', help='运行Grad-CAM可视化')parser.add_argument('--dataset', type=str, help='Kaggle数据集名称')parser.add_argument('--model_type', type=str, default='vgg16', choices=['simple', 'vgg16'], help='模型类型')parser.add_argument('--img_path', type=str, help='用于Grad-CAM可视化的图像路径')args = parser.parse_args()# 配置config = Config()# 更新配置if args.dataset:config.dataset_name = args.dataset# 1. 下载Kaggle数据集if args.download:downloader = KaggleDownloader(config)downloader.download_dataset()# 2. 加载数据data_loader = DataLoader(config)train_generator, val_generator, test_generator = data_loader.setup_data_generators()class_names = data_loader.get_class_names()print(f"分类类别: {class_names}")# 3. 构建模型model_builder = ModelBuilder(config, len(class_names))if args.model_type == 'simple':model = model_builder.build_simple_cnn()else:model = model_builder.build_vgg16_model()# 4. 训练模型if args.train:trainer = Trainer(config)history = trainer.train(model, train_generator, val_generator)print("模型训练完成")# 5. 评估模型if args.evaluate:if os.path.exists(config.model_save_path):model = tf.keras.models.load_model(config.model_save_path)print("加载已保存的模型")test_loss, test_acc = model.evaluate(test_generator)print(f"测试集准确率: {test_acc:.2%}")# 6. Grad-CAM可视化if args.visualize:if os.path.exists(config.model_save_path):model = tf.keras.models.load_model(config.model_save_path)print("加载已保存的模型用于可视化")if args.img_path and os.path.exists(args.img_path):grad_cam = GradCAM(model, class_names, config)output_path, class_name, confidence = grad_cam.process_image(args.img_path)print(f"可视化完成,结果保存在: {output_path}")print(f"预测类别: {class_name}, 置信度: {confidence:.2%}")else:print("请提供有效的图像路径")if __name__ == "__main__":main() model_builder.py
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.applications import VGG16
from tensorflow.keras.optimizers import Adam
from config import Configclass ModelBuilder:def __init__(self, config: Config, num_classes: int):self.config = configself.num_classes = num_classesdef build_simple_cnn(self):# 构建简单的CNN模型model = Sequential([Conv2D(32, (3, 3), activation='relu', input_shape=(self.config.img_width, self.config.img_height, 3)),MaxPooling2D((2, 2)),Conv2D(64, (3, 3), activation='relu'),MaxPooling2D((2, 2)),Conv2D(128, (3, 3), activation='relu'),MaxPooling2D((2, 2)),Flatten(),Dense(128, activation='relu'),Dropout(0.5),Dense(self.num_classes, activation='softmax')])model.compile(optimizer=Adam(learning_rate=self.config.learning_rate),loss='categorical_crossentropy',metrics=['accuracy'])return modeldef build_vgg16_model(self, fine_tune=False):# 构建基于VGG16的预训练模型base_model = VGG16(weights='imagenet',include_top=False,input_shape=(self.config.img_width, self.config.img_height, 3))# 是否微调预训练模型if not fine_tune:for layer in base_model.layers:layer.trainable = False# 添加自定义层x = base_model.outputx = Flatten()(x)x = Dense(256, activation='relu')(x)x = Dropout(0.5)(x)predictions = Dense(self.num_classes, activation='softmax')(x)model = Model(inputs=base_model.input, outputs=predictions)model.compile(optimizer=Adam(learning_rate=self.config.learning_rate),loss='categorical_crossentropy',metrics=['accuracy'])return model trainer.py
import os
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
from config import Configclass Trainer:def __init__(self, config: Config):self.config = configdef train(self, model, train_generator, val_generator):# 创建模型保存目录os.makedirs(os.path.dirname(self.config.model_save_path), exist_ok=True)# 定义回调函数callbacks = [ModelCheckpoint(self.config.model_save_path, monitor='val_accuracy', save_best_only=True, mode='max',verbose=1),EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True,verbose=1),ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=3, min_lr=0.00001,verbose=1)]# 训练模型history = model.fit(train_generator,steps_per_epoch=train_generator.samples // self.config.batch_size,validation_data=val_generator,validation_steps=val_generator.samples // self.config.batch_size,epochs=self.config.epochs,callbacks=callbacks)return history @浙大疏锦行
相关文章:

Python训练营打卡Day43
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 config.py import os# 基础配置类 class Config:def __init__(self):# Kaggle配置self.kaggle_username "" # Kaggle用户名self.kaggle_key &quo…...
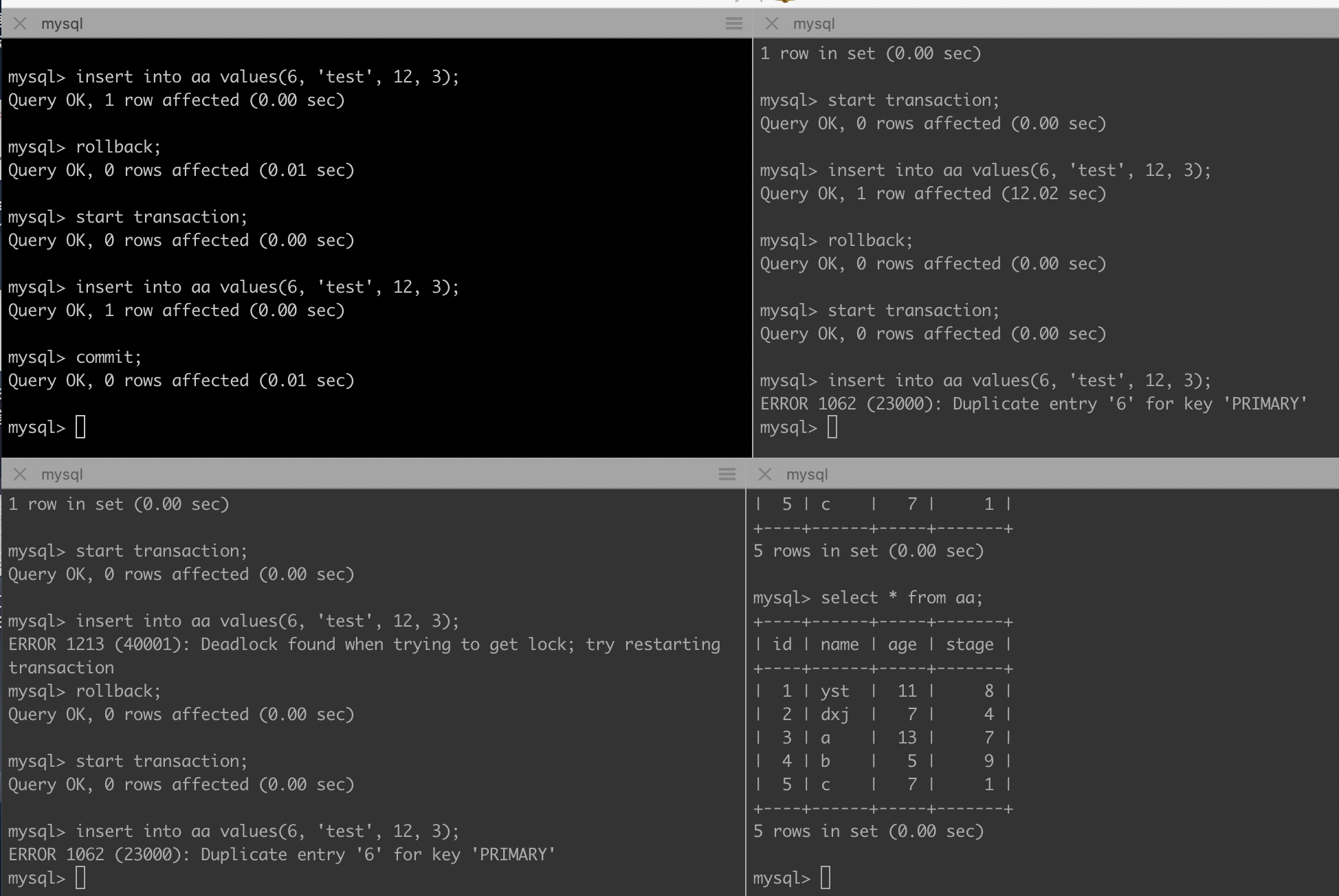
Mysql锁及其分类
目录 InnoDb锁Shared locks(读锁) 和 Exclusive locks(写锁)Exclusive locksShared locks Intention Locks(意向锁)为什么要有意向锁? Record Locks(行锁)Gap Locks(间隙锁)Next-Key LocksInsert Intention Locks(插入…...

RabbitMQ实用技巧
RabbitMQ是一个流行的开源消息中间件,广泛用于实现消息传递、任务分发和负载均衡。通过合理使用RabbitMQ的功能,可以显著提升系统的性能、可靠性和可维护性。本文将介绍一些RabbitMQ的实用技巧,包括基础配置、高级功能及常见问题的解决方案。…...
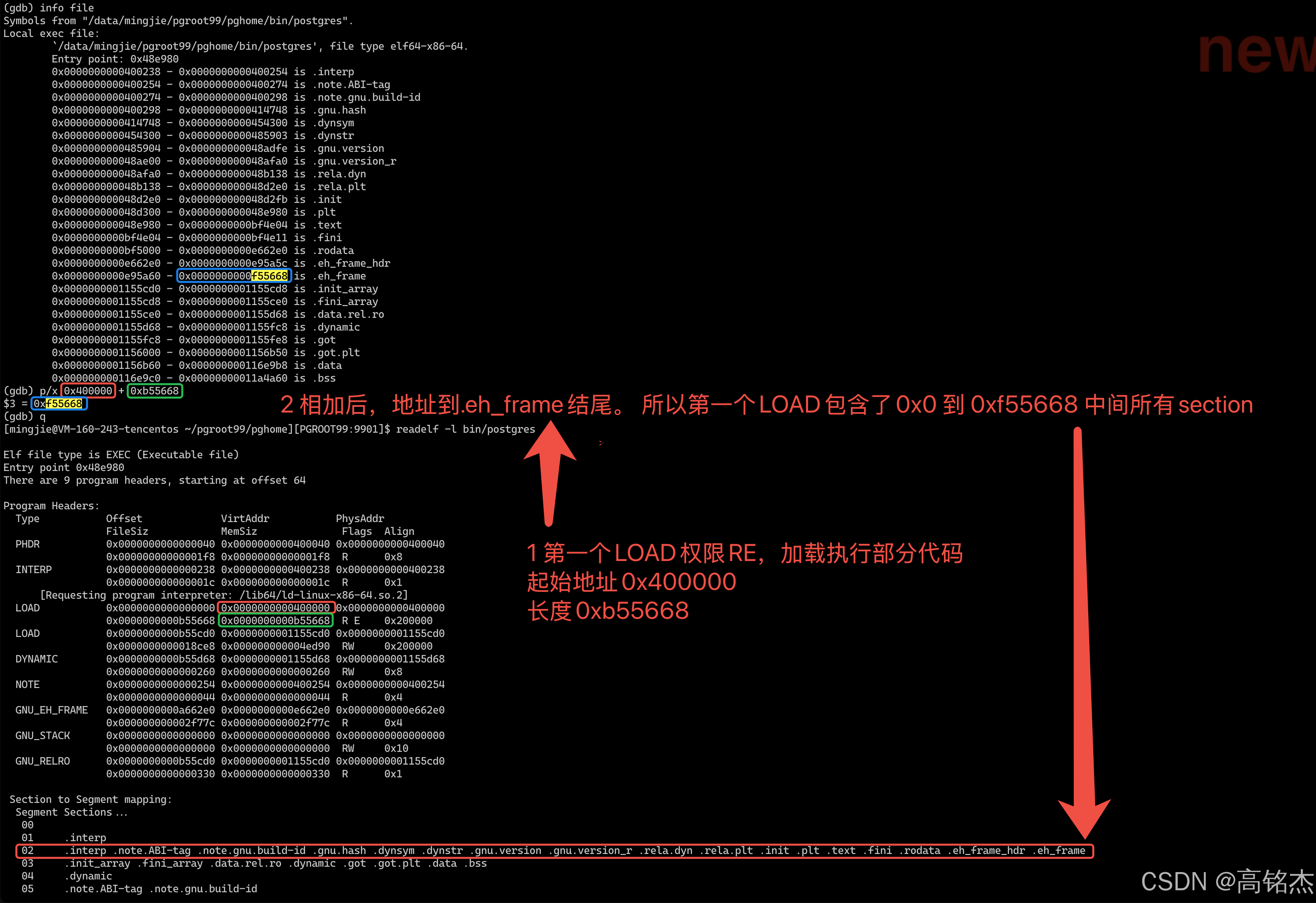
Postgresql源码(146)二进制文件格式分析
相关 Linux函数调用栈的实现原理(X86) 速查 # 查看elf头 readelf -h bin/postgres# 查看Section readelf -S bin/postgres (gdb) info file (gdb) maint info sections# 查看代码段汇编 disassemble 0x48e980 , 0x48e9b0 disassemble main# 查看代码段某…...

spring ai mcp 和现有业务逻辑如何结合,现有项目用的是spring4.3.7
将 Spring AI 的 MCP(Model Context Protocol)协议集成到基于 Spring 4.3.7 的现有项目中, 需解决版本兼容性和架构适配问题。 有两种方式:1 mcp tool 封装, 2:如果是微服务,可以用spring ai a…...

【设计模式-4.11】行为型——解释器模式
说明:本文介绍行为型设计模式之一的解释器模式 定义 解释器模式(Interpreter Pattern)指给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。解释器模式是一种…...
【已解决】MACOS M4 芯片使用 Docker Desktop 工具安装 MICROSOFT SQL SERVER
1. 环境准备 确认 Docker Desktop 配置 确保已安装 Docker Desktop for Mac (Apple Silicon)(版本 ≥ 4.15.0)。开启 Rosetta(默认开启): 打开 Docker Desktop → Settings → General → Virtual Machine Options …...
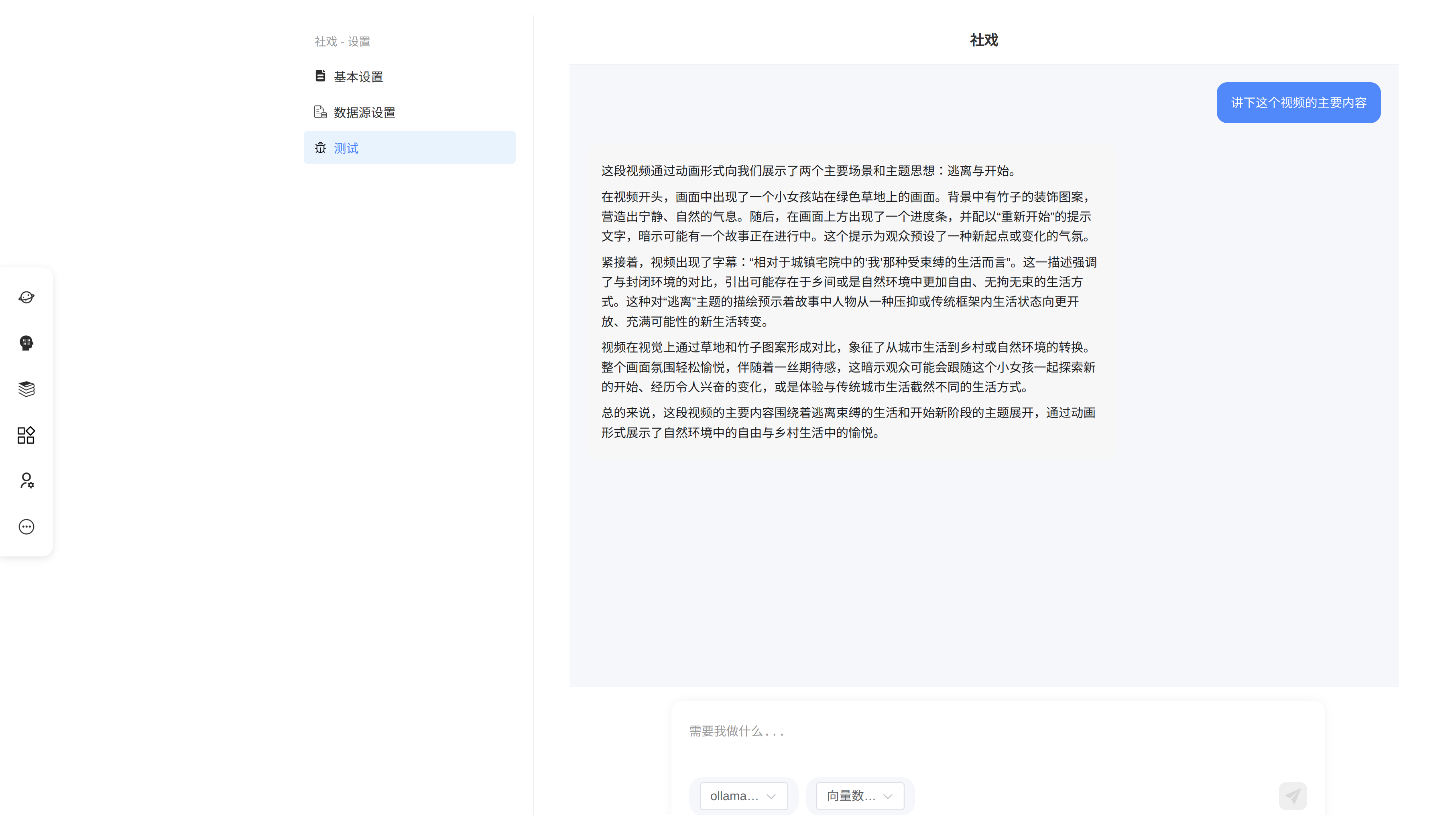
Quipus系统的视频知识库的构建原理及使用
1 原理 VideoRag在LightRag基础上增加了对视频的处理,详细的分析参考LightRag的兄弟项目VideoRag系统分析-CSDN博客。 Quipus的底层的知识库的构建的核心流程与LightRag类似,但在技术栈的选择和处理有所不同。Quipus对于视频的处理实现,与Vi…...
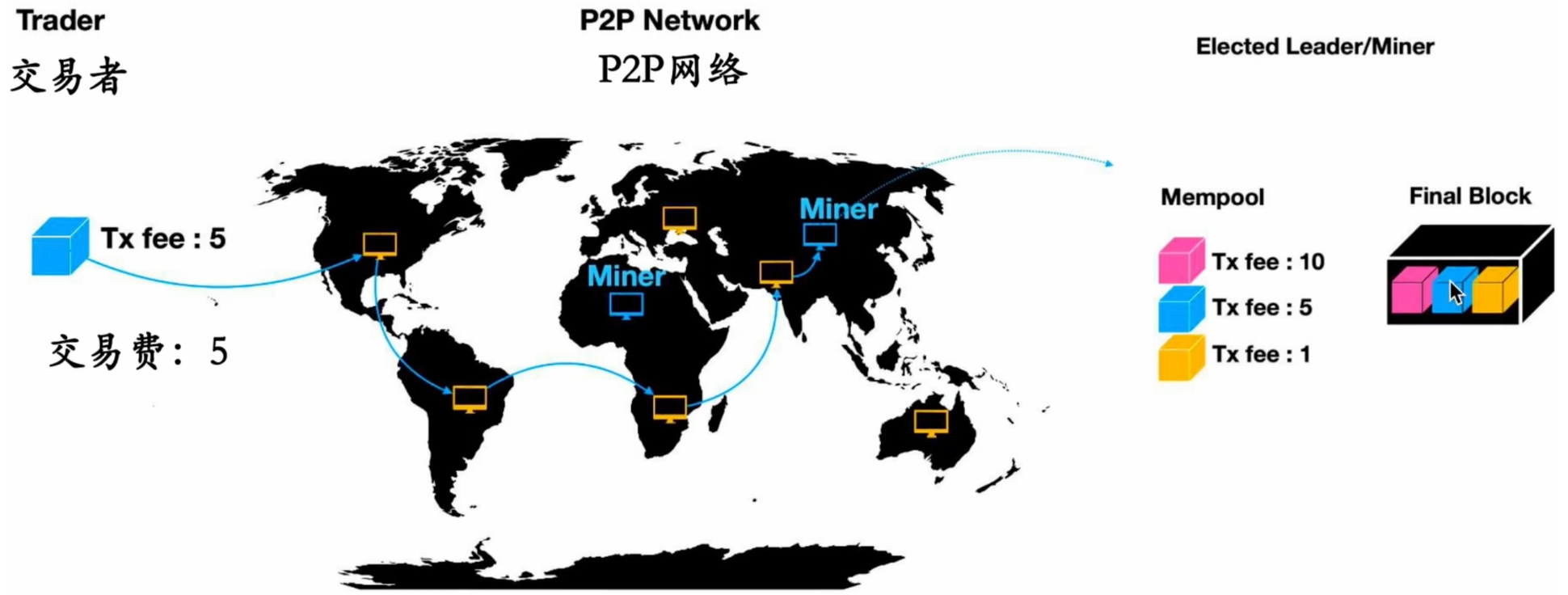
web3-去中心化金融深度剖析:DEX、AMM及兑换交易传播如何改变世界
web3-去中心化金融深度剖析:DEX、AMM及兑换交易传播如何改变世界 金融问题 1.个人投资:在不同的时间和可能的情况(状态)下积累财富 2.商业投资:为企业家和企业提供投资生产性活动的资源 目标:跨越时间和…...

国芯思辰|SCS5501/5502芯片组打破技术壁垒,重构车载视频传输链路,兼容MAX9295A/MAX96717
在新能源汽车产业高速发展的背景下,电机控制、智能驾驶等系统对高精度信号处理与高速数据传输的需求持续攀升。 针对车载多摄像头与自动驾驶辅助系统对长距离、低误码率、高抗干扰性数据传输的需求,SCS5501串行器与SCS5502解串器芯片组充分利用了MIPI A…...

【图像处理3D】:点云图是怎么生成的
点云图是怎么生成的 **一、点云数据的采集方式****1. 激光雷达(LiDAR)****2. 结构光(Structured Light)****3. 双目视觉(Stereo Vision)****4. 飞行时间相机(ToF Camera)****5. 其他…...

压敏电阻的选型都要考虑哪些因素?同时注意事项都有哪些?
压敏电阻,英文名简称VDR,电子元器件中重要的成员之一,是一种非线性伏安特性的电阻器件,有电阻特性的同时,也拥有其他自身的特性,广泛应用于众多领域。在电源系统、安防系统、浪涌抑制器、电动机保护、汽车电…...

用WPDRRC模型,构建企业安全防线
文章目录 前言什么是 WPDRRC 模型预警(Warning)保护(Protection)检测(Detection)响应(Response)恢复(Recovery)反击(Counterattack) W…...

使用 Amazon Q Developer CLI 快速搭建各种场景的 Flink 数据同步管道
在 AI 和大数据时代,企业通常需要构建各种数据同步管道。例如,实时数仓实现从数据库到数据仓库或者数据湖的实时复制,为业务部门和决策团队分析提供数据结果和见解;再比如,NoSQL 游戏玩家数据,需要转换为 S…...

Java应用服务在Kubernetes集群中的改造与配置
哈喽,大家好,我是左手python! 微服务架构与容器化 微服务架构的优势 微服务架构是一种将应用程序构建为一组小型独立服务的方法。每个服务负责完成特定的业务功能,并且可以独立地进行开发、部署和扩展。这种架构在Kubernetes环境…...

Linux 里 su 和 sudo 命令这两个有什么不一样?
《小菜狗 Linux 操作系统快速入门笔记》目录: 《小菜狗 Linux 操作系统快速入门笔记》(01.0)文章导航目录【实时更新】 Linux 是一个多用户的操作系统。在 Linux 中,理论上来说,我们可以创建无数个用户,但…...

「数据分析 - Pandas 函数」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 105 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 Pandas 核心功能详解与示例 文章目录 Pandas 核心功能详解与示例1. 数据结构基础1.1 Series 创建与操作1.2 DataFrame 创建与操作 2. 数据选择与过滤2.1 基本选择方法2.2 布尔索引 3. 数据处理与清洗3.1 缺失值处理3.…...
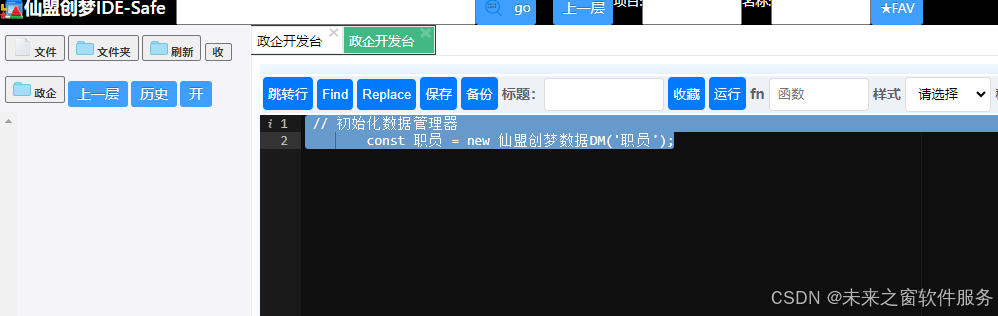
JAVASCRIPT 简化版数据库--智能编程——仙盟创梦IDE
// 数据模型class 仙盟创梦数据DM {constructor(key) {this.key ${STORAGE_PREFIX}${key};this.data this.加载数据();}加载数据() {return JSON.parse(localStorage.getItem(this.key)) || [];}保存() {localStorage.setItem(this.key, JSON.stringify(this.data));}新增(it…...

YAML在自动化测试中的三大核心作用
YAML在自动化测试中的三大核心作用 配置中心:管理测试环境/参数 # config.yaml environments:dev: url: "http://dev.api.com"timeout: 5prod:url: "https://api.com"timeout: 10数据驱动:分离测试数据与脚本 # test_data.yaml lo…...
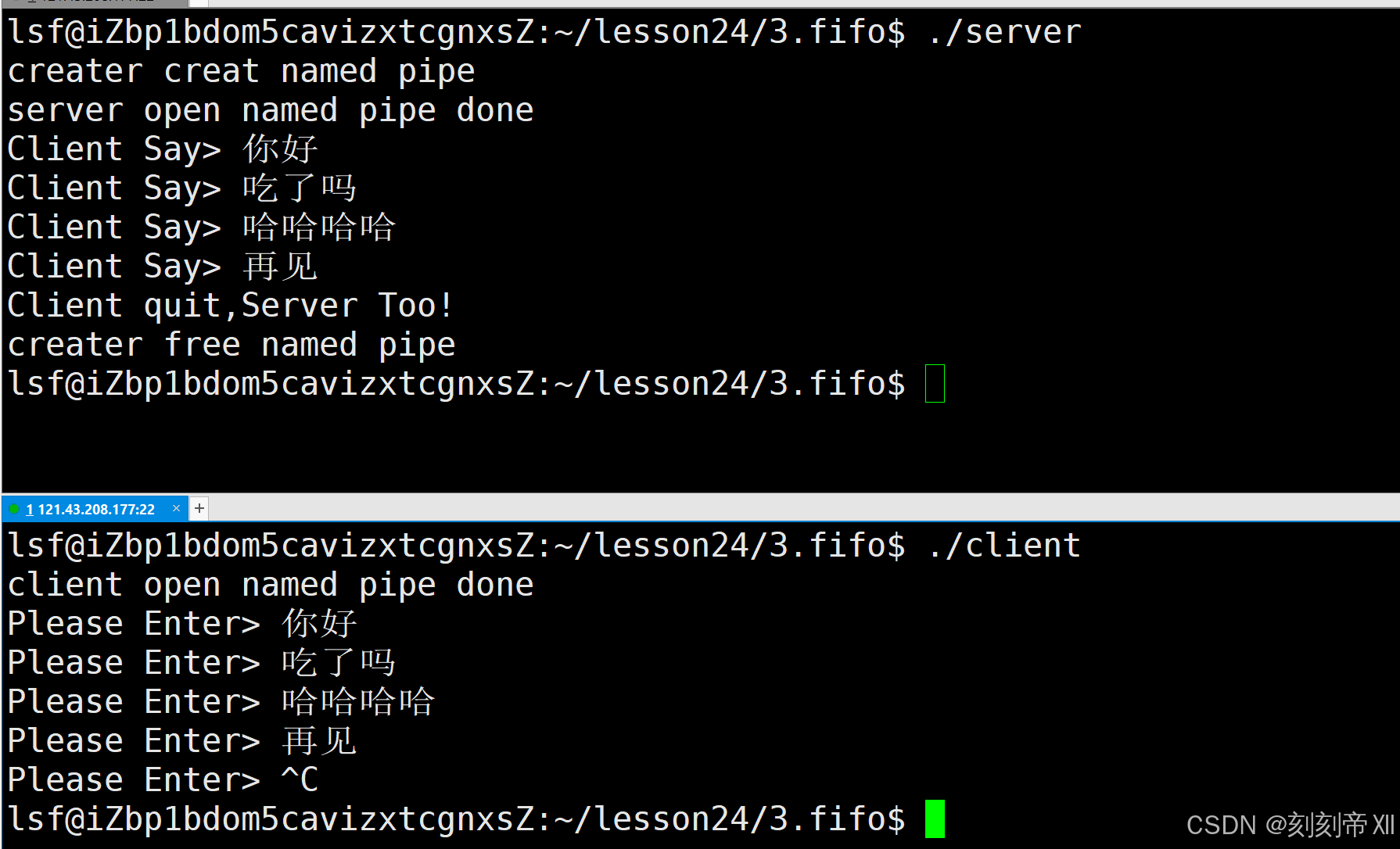
命名管道实现本地通信
目录 命名管道实现通信 命名管道通信头文件 创建命名管道mkfifo 删除命名管道unlink 构造函数 以读方式打开命名管道 以写方式打开命名管道 读操作 写操作 析构函数 服务端 客户端 运行结果 命名管道实现通信 命名管道通信头文件 #pragma#include <iostream> #include &l…...
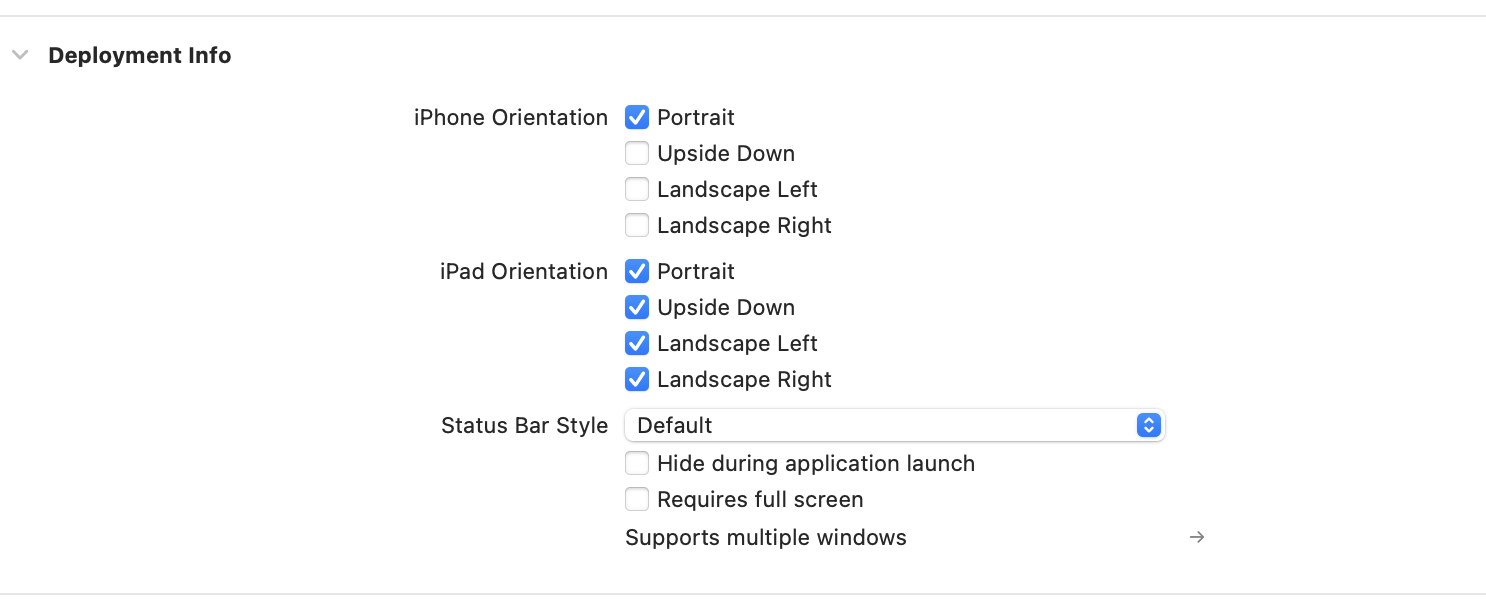
iOS上传应用包错误问题 “Invalid bundle. The “UIInterfaceOrientationPortrait”“
引言 在开发 iOS 应用的整个生命周期中,打包上传到 App Store 是一个至关重要的步骤。每一次提交,Xcode 都会在后台执行一系列严格的校验流程,包括对 Info.plist 配置的检查、架构兼容性的验证、资源完整性的审查等。如果某些关键项配置不当…...
)
【LeetCode】1061. 按字典序排列最小的等效字符串(并查集)
LeetCode 1061. 按字典序排列最小的等效字符串 (中等) 题目链接:LeetCode 1061. 按字典序排列最小的等效字符串 (中等) 题目描述 给出长度相同的两个字符串s1 和 s2 ,还有一个字符串 baseStr 。 其中 s1[i] 和 s2[i] 是一组等价字符。 举个例子&#…...

猎板厚铜PCB工艺能力如何?
在电子产业向高功率、高集成化狂奔的今天,电路板早已不是沉默的配角。当5G基站、新能源汽车、工业电源等领域对电流承载、散热效率提出严苛要求时,一块能够“扛得住大电流、耐得住高温”的厚铜PCB,正成为决定产品性能的关键拼图。而在这条赛道…...
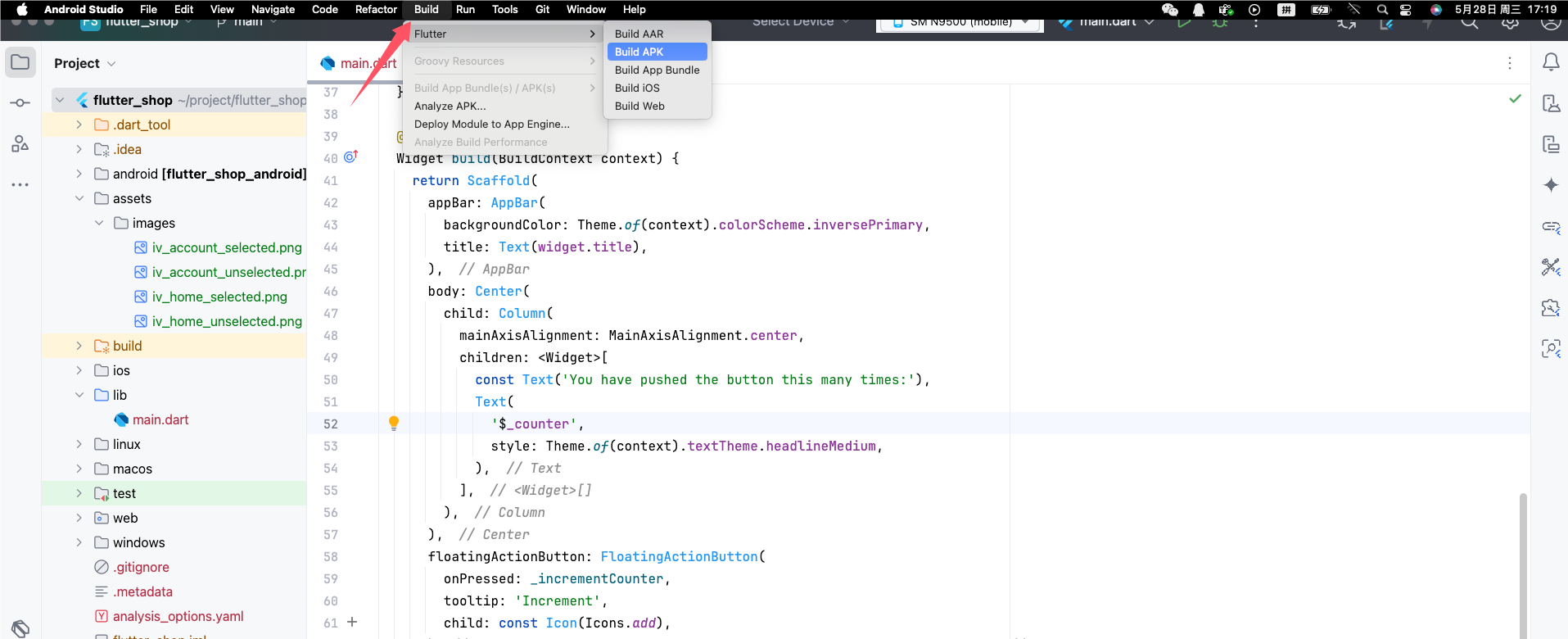
Flutter快速上手,入门教程
目录 一、参考文档 二、准备工作 下载Flutter SDK: 配置环境 解决环境报错 zsh:command not found:flutter 执行【flutter doctor】测试效果 安装Xcode IOS环境 需要安装brew,通过brew安装CocoaPods. 复制命令行,打开终端 分别执行…...

算法:前缀和
1.【模版】前缀和 【模板】前缀和_牛客题霸_牛客网 这道题如果使用暴力解法时间复杂度为O(n*m),会超时,所以要使用前缀和算法。 前缀和->快速求出数组中某一个连续区间的和。 第一步:预处理出一个前缀和数组 dp。 dp[i]表示[1, i] 区间…...
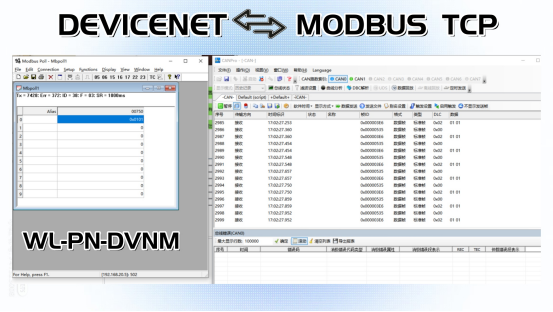
DEVICENET转MODBUS TCP网关与AB数据输出模块的高效融合方案研究
在工业自动化领域,多样化的设备通常采用不同的通信协议,这为系统集成带来了显著的挑战。特别是在需要将遵循DeviceNet协议的设备与基于MODBUS TCP协议的系统进行互连时,这一挑战尤为突出。AB数据输出作为一种功能卓越的DeviceNet分布式输入/输…...
牛客小白月赛113
前言:这场的E题补的我头皮都发麻了。 A. 2025 题目大意:一个仅有‘-’‘*’组成的字符串,初始有一个sum 1, 从左到右依次遍历字符串,遇到-就让sum--;遇到*就让sum* 2,问sum有没有可能大于等于…...
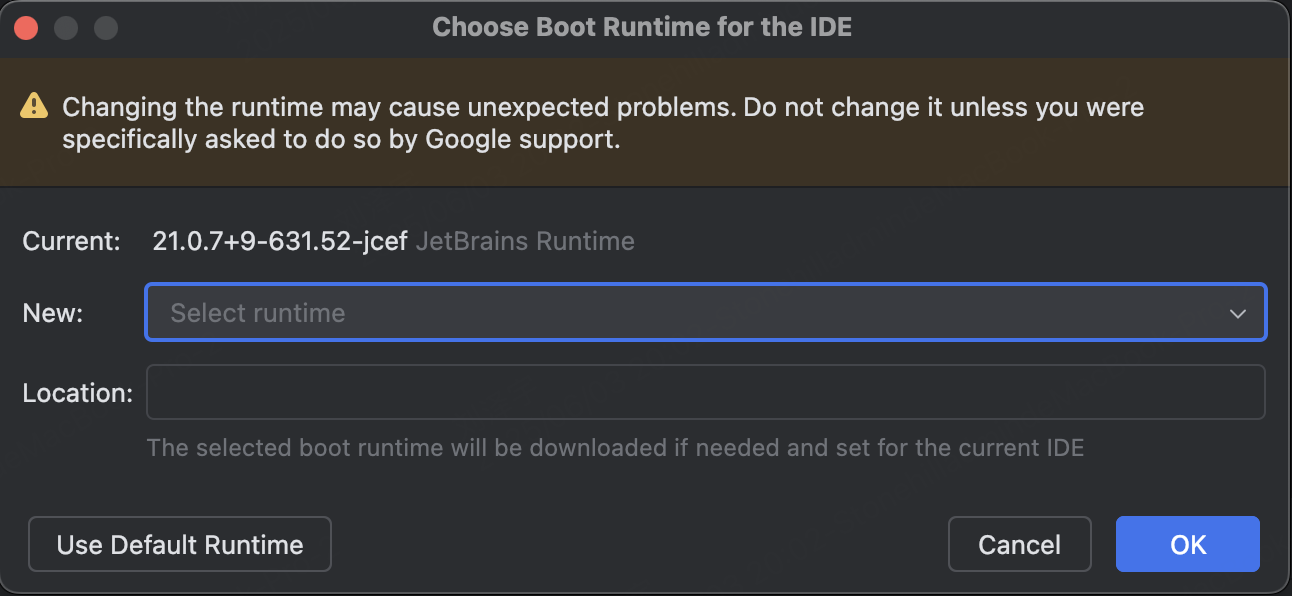
Mac版本Android Studio配置LeetCode插件
第一步:Android Studio里面找到Settings,找到Plugins,在Marketplace里面搜索LeetCode Editor。 第二步:安装对应插件,并在Tools->LeetCode Plugin页面输入帐号和密码。 理论上,应该就可以使用了。但是&a…...

电子电路基础1(杂乱)
电路基础知识 注意:电压源与电流源的表现形式 注意:在同一根导线上电势相等 电阻电路的等效变换 电子元器件基础 电阻...

rocketmq延迟消息的底层原理浅析
rocketmq延迟消息的底层原理 消息实体 延时消息是指允许消息在指定延迟时间后才被消费者消费 Apache RocketMQ 中,消息的核心实体类是 org.apache.rocketmq.common.message.Message public class Message implements Serializable {private String topic; …...