NLP学习路线图(十七):主题模型(LDA)
在浩瀚的文本海洋中航行,人类大脑天然具备发现主题的能力——翻阅几份报纸,我们迅速辨别出"政治"、"体育"、"科技"等板块;浏览社交媒体,我们下意识区分出美食分享、旅行见闻或科技测评。但机器如何理解文本背后隐藏的主题结构? 这正是主题模型要解决的核心问题。在深度学习浪潮席卷NLP之前,潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)作为主题模型的代表,为我们打开了无监督探索文本语义结构的窗口。
想象《红楼梦》中黛玉的一句"早知他来,我就不来了"。在"情感分析"主题下,这句话透露出幽怨;在"社交礼仪"主题下,它可能只是客套;而在"家族关系"主题下,又隐含贾府复杂的人际网络。LDA的核心能力,正是揭示这种一词多义背后的主题分布。
一、主题模型:文本挖掘的基石
1.1 从词袋到主题
传统文本表示如词袋模型(Bag-of-Words, BoW)和TF-IDF虽能转换文本为向量,却面临两大困境:
-
高维稀疏性:万级词汇表导致特征空间巨大,单个文档仅激活少量维度
-
语义鸿沟:无法捕捉"手机"与"智能手机"的关联,或"苹果"的水果与品牌歧义
主题模型应运而生,其核心思想是:文档是主题的混合,而主题是词语的概率分布。LDA作为生成式概率图模型,通过引入隐变量(主题),在文档-词语矩阵之上构建了一层抽象表示。
1.2 LDA之前的探索
-
LSI/LSA:利用SVD分解词-文档矩阵,但缺乏概率解释
-
pLSI:提出文档-主题分布概念,但无法泛化到新文档
-
LDA突破:引入狄利克雷先验,实现完全生成式建模,支持新文档推理
二、LDA原理解析:三层贝叶斯网络的魅力
2.1 生成过程:文本如何"诞生"
LDA的核心是一个优雅的文本生成模拟:
For each document d in corpus D:1. 从狄利克雷分布中采样文档主题分布 θ_d ~ Dir(α)2. For each word w_{d,n} in document d:a. 从主题分布采样一个主题 z_{d,n} ~ Multinomial(θ_d)b. 从该主题的词语分布采样词语 w_{d,n} ~ Multinomial(φ_z)示例:生成一篇"人工智能"相关的文档:
-
步骤1:确定主题混合比,如[科技:0.6, 伦理:0.3, 教育:0.1]
-
步骤2a:对第一个词,按比例随机选中"科技"主题
-
步骤2b:从科技主题的词语分布中采样出"算法"
-
重复直至生成所有词语
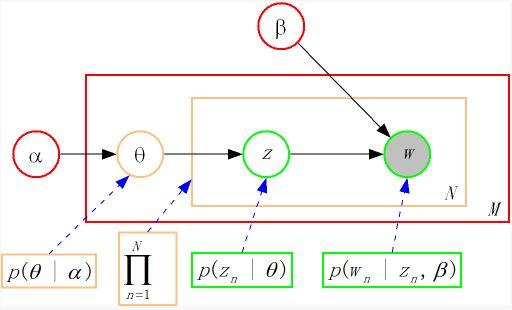
2.2 概率图模型表示
LDA的贝叶斯网络结构清晰表达了变量依赖关系:
α β│ │▼ ▼θ_d ──► z_{d,n} ──► w_{d,n}▲ ▲ ▲│ │ │
Dirichlet Multinomial Multinomial-
α, β:超参数,控制主题分布的稀疏性
-
θ_d:文档d的主题分布(文档级变量)
-
φ_k:主题k的词语分布(语料级变量)
-
z_{d,n}:词语w_{d,n]的隐主题(词语级变量)
2.3 Dirichlet分布:关键的先验选择
狄利克雷分布作为多项式分布的共轭先验,其概率密度函数为:
Dir(p|α) = (1/B(α)) * ∏_{i=1}^K p_i^{α_i-1}-
α<1:偏好稀疏分布(少数主题主导)
-
α>1:偏好均匀分布(主题混合均匀)
-
实践意义:通过调整α控制文档主题集中度,调整β控制主题内词语集中度
可视化实验:当α=0.1时,采样点靠近单纯形顶点;当α=2.0时,采样点向中心聚集。
三、LDA求解:从吉布斯采样到变分推断
3.1 吉布斯采样(Gibbs Sampling)
通过迭代更新每个词语的主题分配进行近似推断:
P(z_i=k | z_{-i}, w) ∝ (n_{d,k}^{-i} + α_k) * (n_{k,w_i}^{-i} + β_{w_i}) / (n_k^{-i} + β_sum)-
n_{d,k}:文档d中主题k出现的次数
-
n_{k,w}:主题k下词语w出现的次数
-
^{-i}:排除当前词语的计数
Python伪代码实现:
# 初始化:随机分配每个词的主题
for iter in range(num_iterations):for d in documents:for i in word_position:# 排除当前词统计decrement_counts(z[d][i], w[d][i], d)# 按概率采样新主题p_z = compute_topic_prob(d, w[d][i])new_z = sample_from(p_z)# 更新统计z[d][i] = new_zincrement_counts(new_z, w[d][i], d)3.2 变分推断(Variational Inference)
通过优化变分分布q(θ,z|γ,φ)逼近真实后验:
最大化 ELBO(γ,φ; α,β) = E_q[log p(θ,z,w|α,β)] - E_q[log q(θ,z|γ,φ)]-
γ_d:文档d的主题分布的变分参数
-
λ_k:主题k的词语分布的变分参数
对比:
-
吉布斯采样:结果更精确,但内存消耗大,适合小型语料
-
变分推断:速度更快,适合大规模数据,但可能低估方差
四、LDA实战:从数据到洞察
4.1 预处理流程

4.2 模型训练(Python示例)
from gensim.models import LdaModel
from gensim.corpora import Dictionary# 构建词典和语料
dictionary = Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]# 训练LDA模型
model = LdaModel(corpus=corpus,id2word=dictionary,num_topics=10,alpha='auto',eta='auto',iterations=50
)# 可视化主题
import pyLDAvis.gensim_models
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(model, corpus, dictionary)
pyLDAvis.display(vis)4.3 结果解释与优化
-
主题一致性评估:
from gensim.models import CoherenceModel coherence = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v') coherence_score = coherence.get_coherence() -
参数调优技巧:
-
使用
alpha='auto'自动学习非对称α -
通过网格搜索选择最佳主题数k
-
结合UMAP降维可视化主题分布
-
4.4 主题演化分析(动态LDA)
from gensim.models import LdaSeqModel# 按时间切片语料
time_slice = [len(corpus_2019), len(corpus_2020), len(corpus_2021)]# 训练动态主题模型
dyn_model = LdaSeqModel(corpus=all_corpus,time_slice=time_slice,num_topics=10,chunksize=1000
)# 获取主题演化路径
dyn_model.print_topics(time=1) # 查看第二时间段的主题五、LDA应用场景:超越文本挖掘
5.1 推荐系统
-
用户画像构建:将用户历史行为文档化,提取兴趣主题
-
跨域推荐:通过共享主题空间连接不同内容类型
Netflix案例:将影片描述、用户评论转化为主题混合,计算主题相似度提升推荐多样性。
5.2 舆情监控
# 情感-主题联合分析
def sentiment_aware_lda(docs):# Step1: 情感词典标注doc_sentiments = [get_sentiment(doc) for doc in docs]# Step2: 扩展词典dictionary.add_documents([["POS_"+w, "NEG_"+w] for w in sentiment_words])# Step3: 训练联合模型model = LdaModel(corpus, num_topics=20, ...)# Step4: 分析主题-情感关联return model, doc_sentiments5.3 生物信息学
-
基因功能分析:将文献作为文档,基因为"词语",发现功能主题
-
药物重定位:通过疾病-药物主题关联寻找潜在治疗组合
六、LDA的局限与新时代发展
6.1 固有局限性
-
词序忽略:无法建模"算法优秀"与"优秀算法"的差异
-
短文本失效:推文等短文本因数据稀疏难以提取可靠主题
-
主题一致性:自动化评估指标与人工判断常存在差距
6.2 融合深度学习
-
Neural LDA:用神经网络参数化主题分布
class NeuralLDA(nn.Module):def __init__(self, num_topics, vocab_size):super().__init__()self.encoder = nn.Sequential(nn.Linear(vocab_size, 256),nn.ReLU(),nn.Linear(256, num_topics))self.topic_emb = nn.Embedding(num_topics, vocab_size)def forward(self, x):# 输出文档主题分布theta = F.softmax(self.encoder(x), dim=-1)# 重建词频分布word_dist = torch.matmul(theta, self.topic_emb.weight)return word_dist, theta -
结合词向量:用Word2Vec代替词袋提升语义敏感度
-
BERTopic:利用BERT嵌入聚类实现上下文感知的主题建模
结语:主题模型的时代价值
尽管深度学习模型在诸多NLP任务上超越了传统方法,LDA依然在特定场景闪耀独特价值:
-
可解释性:相比深度模型的"黑箱",LDA的主题词列表直观可理解
-
无监督优势:无需标注数据即可探索海量文本的隐藏结构
-
计算效率:在资源受限环境下仍具实用性
相关文章:
NLP学习路线图(十七):主题模型(LDA)
在浩瀚的文本海洋中航行,人类大脑天然具备发现主题的能力——翻阅几份报纸,我们迅速辨别出"政治"、"体育"、"科技"等板块;浏览社交媒体,我们下意识区分出美食分享、旅行见闻或科技测评。但机器如何…...
)
深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(2)
前言 《深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(1)》里面我只是提到了对conv1层进行剪枝,只是为了验证这个剪枝的整个过程,但是后面也有提到:仅裁剪 conv1层的影响极大,原因如…...

综采工作面电控4X型铜头连接器 conm/4x100s
综采工作面作为现代化煤矿生产的核心区域,其设备运行的稳定性和安全性直接关系到整个矿井的生产效率。在综采工作面的电气控制系统中,电控连接器扮演着至关重要的角色,而4X型铜头连接器CONM/4X100S作为其中的关键部件,其性能优劣直…...
用ApiFox MCP一键生成接口文档,做接口测试
日常开发过程中,尤其是针对长期维护的老旧项目,许多开发者都会遇到一系列相同的困扰:由于项目早期缺乏严格的开发规范和接口管理策略,导致接口文档缺失,甚至连基本的接口说明都难以找到。此外,由于缺乏规范…...
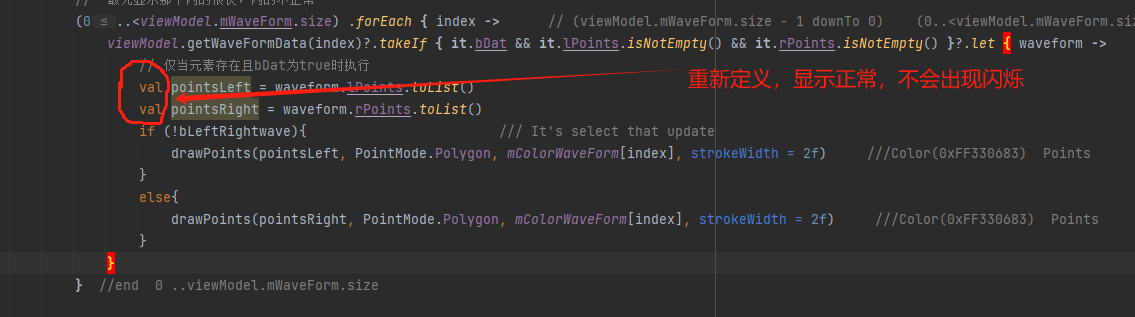
在compose中的Canvas用kotlin显示多数据波形闪烁的问题
在compose中的Canvas显示多数据波形闪烁的问题:当在Canvas多组记录波形数组时,从第一组开始记录多次显示,如图,当再次回到第一次记录位置再显示时,波形出现闪烁。 原码如下: data class DcWaveForm(var b…...
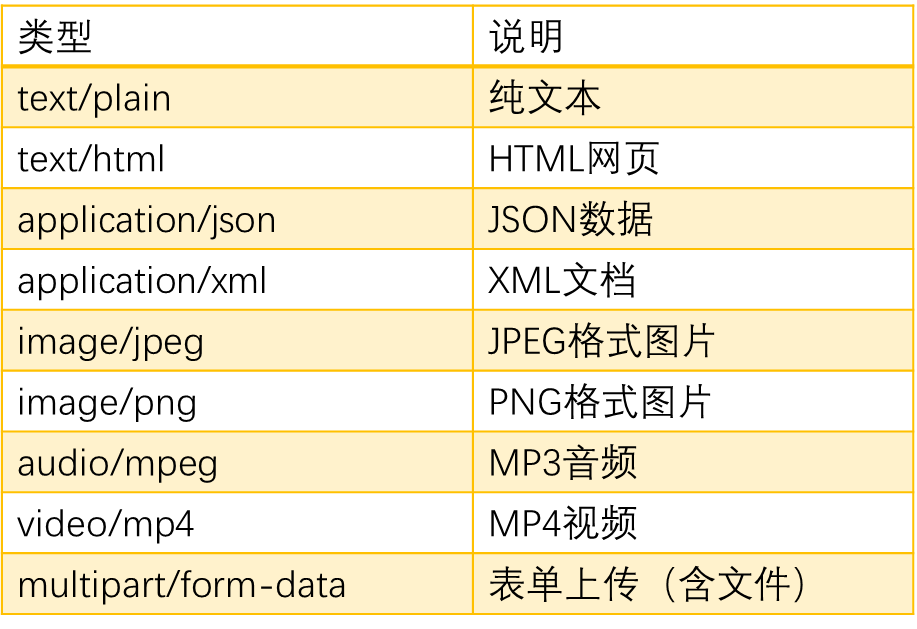
【学习笔记】MIME
文章目录 1. 引言2. MIME 构成Content-Type(内容类型)Content-Transfer-Encoding(传输编码)Multipart(多部分) 3. 常见 MIME 类型 1. 引言 早期的电子邮件只能发送 ASCII 文本,无法直接传输二进…...

【深尚想】OPA855QDSGRQ1运算放大器IC德州仪器TI汽车级高速8GHz增益带宽的全面解析
1. 元器件定义与核心特性 OPA855QDSGRQ1 是德州仪器(TI)推出的一款 汽车级高速运算放大器,专为宽带跨阻放大(TIA)和电压放大应用优化。核心特性包括: 超高速性能:增益带宽积(GBWP&a…...
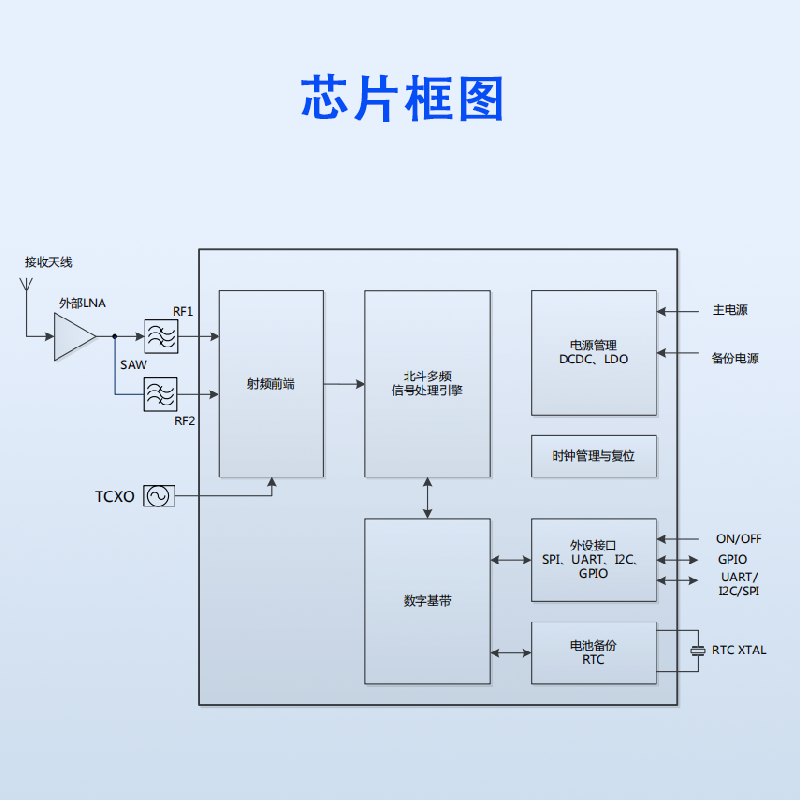
单北斗定位芯片AT9880B
AT9880B 是面向北斗卫星导航系统的单模接收机单芯片(SOC),内部集成射频前端、数字基带处理单元、北斗多频信号处理引擎及电源管理模块,支持北斗二号与三号系统的 B1I、B1C、B2I、B3I、B2a、B2b 频点信号接收。 主要特征 支持北斗二…...
旅游微信小程序制作指南
想创建旅游微信小程序吗?知道旅游业企业怎么打造自己的小程序吗?这里有零基础小白也能学会的教程,教你快速制作旅游类微信小程序! 旅游行业能不能开发微信小程序呢?答案是肯定的。微信小程序对旅游企业来说可是个宝&am…...
Ubuntu ifconfig 查不到ens33网卡
BUG:ifconfig查看网络配置信息: 终端输入以下命令: sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service network-manager start - service network - manager stop :停止…...

zookeeper 学习
Zookeeper 简介 github:https://github.com/apache/zookeeper 官网:https://zookeeper.apache.org/ 什么是 Zookeeper Zookeeper 是一个开源的分布式协调服务,用于管理分布式应用程序的配置、命名服务、分布式同步和组服务。其核心是通过…...
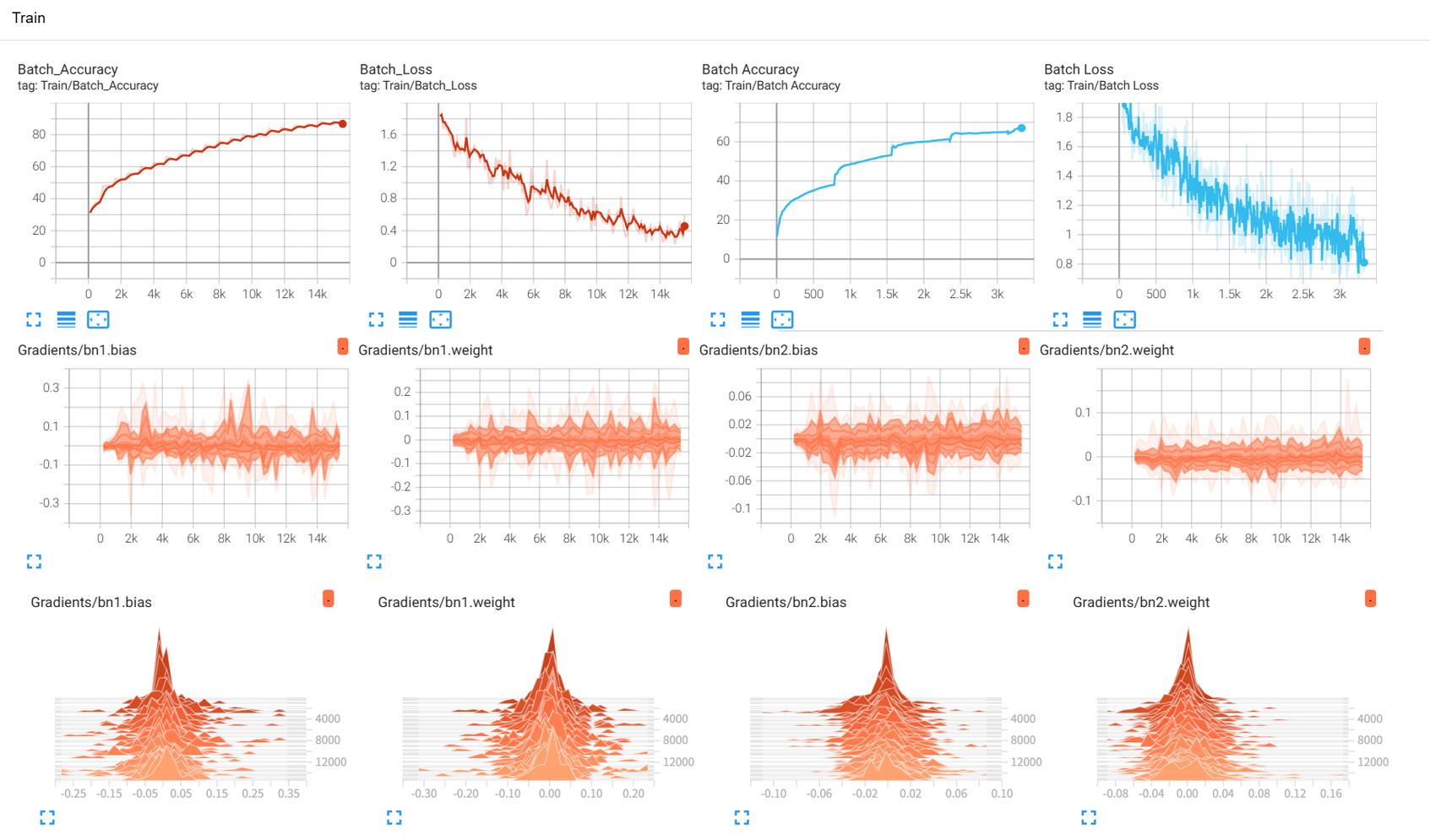
【python深度学习】Day 45 Tensorboard使用介绍
知识点: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorboard监…...

【图像处理入门】5. 形态学处理:腐蚀、膨胀与图像的形状雕琢
摘要 形态学处理是基于图像形状特征的处理技术,在图像分析中扮演着关键角色。本文将深入讲解腐蚀、膨胀、开闭运算等形态学操作的原理,结合OpenCV代码展示其在去除噪声、提取边缘、分割图像等场景的应用,带你掌握通过结构元素雕琢图像形状的核心技巧。 一、形态学处理:基…...
并行智算MaaS云平台:打造你的专属AI助手,开启智能生活新纪元
目录 引言:AI助手,未来生活的必备伙伴 并行智算云:大模型API的卓越平台 实战指南:调用并行智算云API打造个人AI助手 3.1 准备工作 3.2 API调用示例 3.3 本地智能AI系统搭建 3.4 高级功能实现 并行智算云的优势 4.1 性能卓越…...

在 SpringBoot+Tomcat 环境中 线程安全问题的根本原因以及哪些变量会存在线程安全的问题。
文章目录 前言Tomcat SpringBoot单例加载结果分析多例加载:结果分析: 哪些变量存在线程安全的问题?线程不安全线程安全 总结 前言 本文带你去深入理解为什么在web环境中(Tomcat SpringBoot)会存在多线程的问题以及哪些变量会存在线程安全的…...
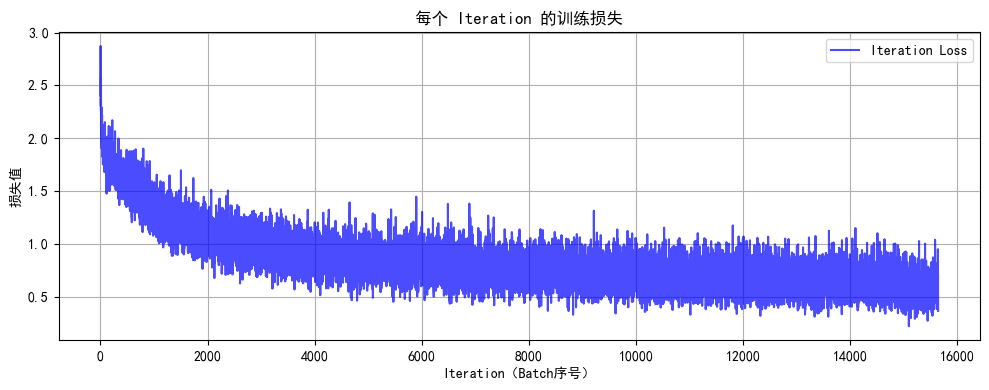
Day45 Python打卡训练营
知识点回顾: 1. tensorboard的发展历史和原理 2. tensorboard的常见操作 3. tensorboard在cifar上的实战:MLP和CNN模型 一、tensorboard的基本操作 1.1 发展历史 TensorBoard 是 TensorFlow 生态中的官方可视化工具(也可无缝集成 PyTorch&…...
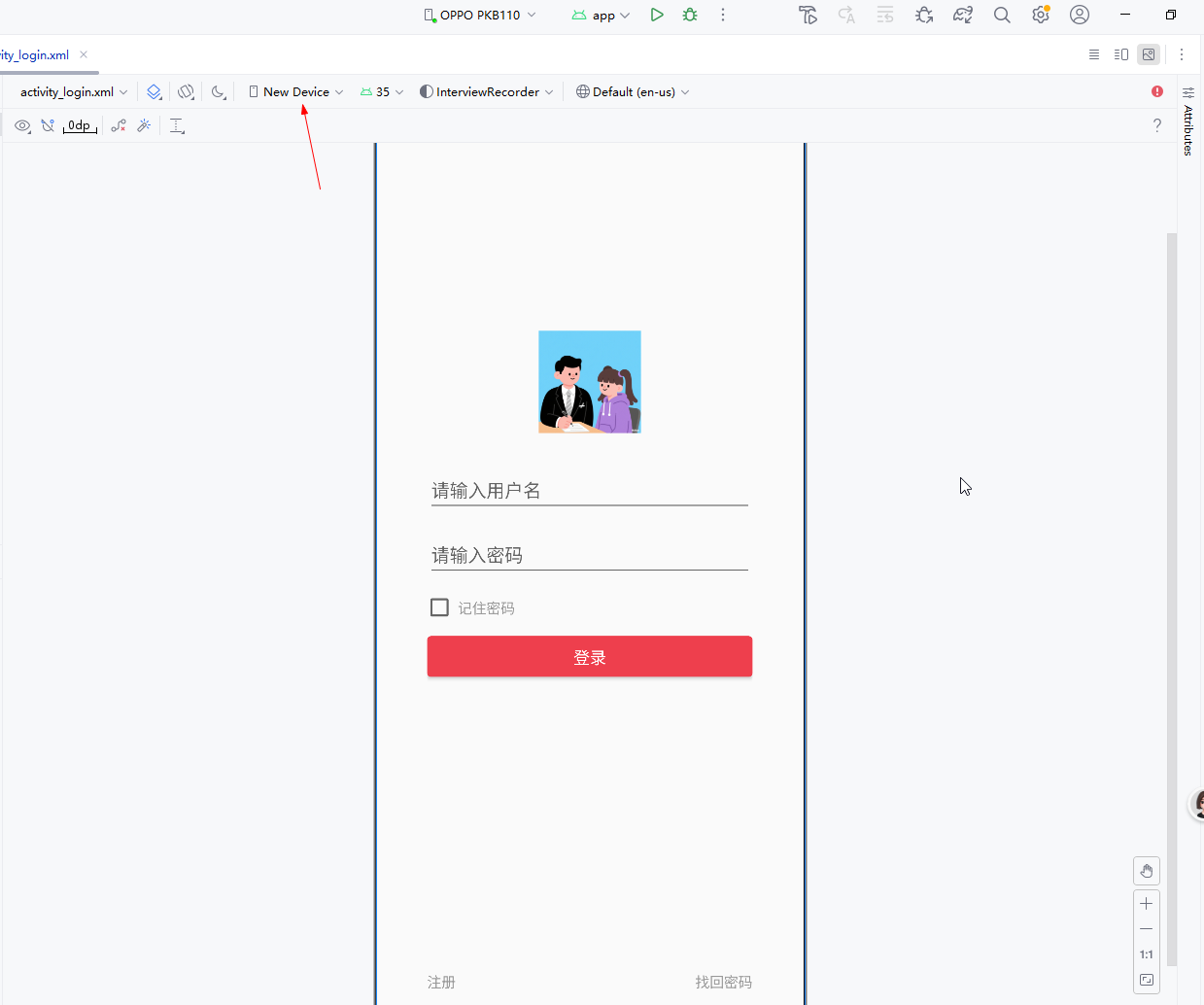
2025年目前最新版本Android Studio自定义xml预览的屏幕分辨率
一、前言 在实际开发项目当中,我们的设备的分辨率可能会比较特殊,AS并没有自带这种屏幕分辨率的设备,但是我们又想一边编写XML界面,一边实时看到较为真实的预览效果,该怎么办呢?在早期的AS版本中ÿ…...
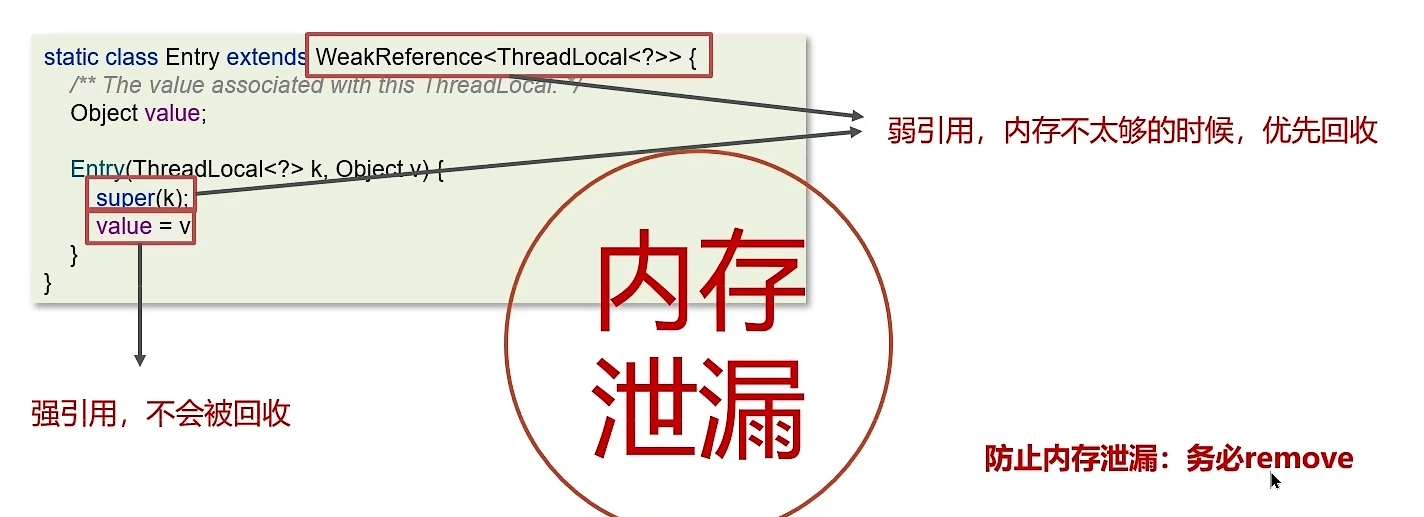
黑马Java面试笔记之 并发编程篇(线程池+使用场景)
一. 线程池的核心参数(线程池的执行原理) 线程池核心参数主要参考ThreadPoolExecutor这个类的7个参数的构造函数 corePoolSize 核心线程数目 maximumPoolSize 最大线程数目 (核心线程救急线程的最大数目) keepAliveTime 生存时间 - 救急线程的生存时…...

float和float32有什么区别
这是一个非常重要但容易混淆的问题。我们来一步一步讲清楚: ✅ 简答:float 和 float32 的区别 项目float(通用名称)float32(精确定义)含义通常指“浮点数”,具体精度由语言/平台决定明确指 32 …...
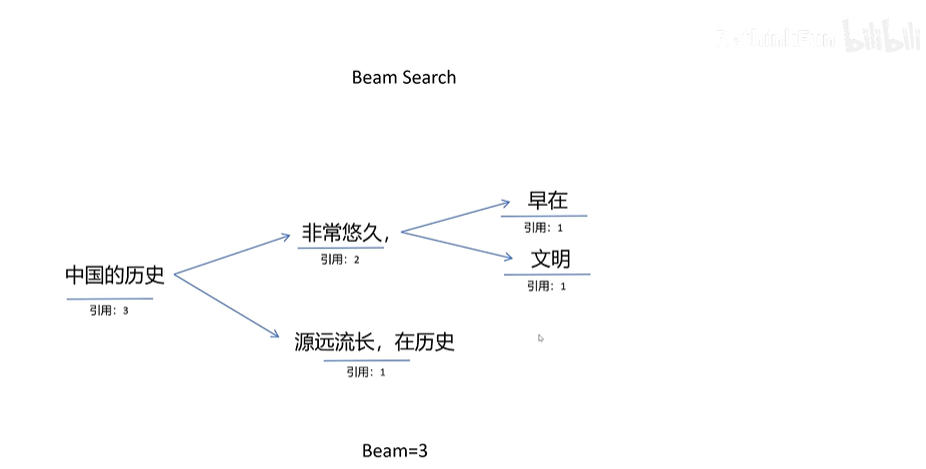
【AI学习】KV-cache和page attention
目录 带着问题学AI KV-cache KV-cache是什么? 之前每个token生成的K V矩阵给缓存起来有什么用? 为啥缓存K、V,没有缓存Q? KV-cache为啥在训练阶段不需要,只在推理阶段需要? KV cache的过程图解 阶段一:KV cac…...
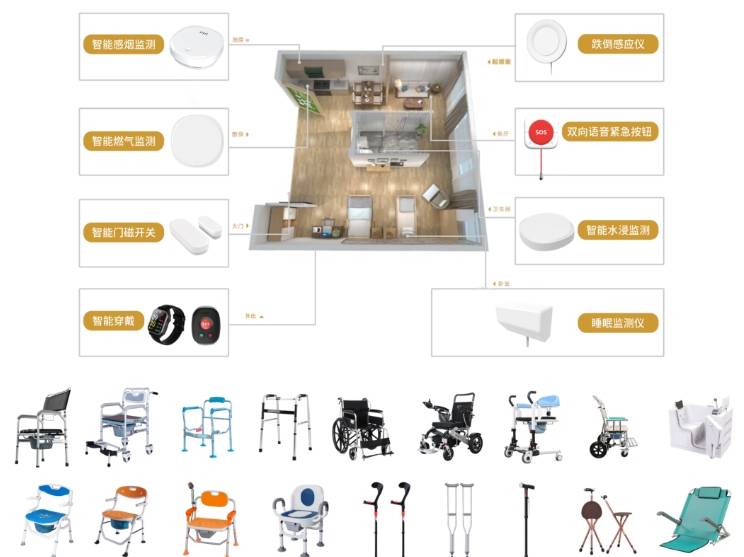
七彩喜智慧养老平台:科技赋能下的市场蓝海,满足多样化养老服务需求
在人口老龄化加速与科技快速发展的双重驱动下,七彩喜智慧养老平台正成为破解养老服务供需矛盾、激活银发经济的核心引擎。 这一领域依托物联网、人工智能、大数据等技术,构建起覆盖居家、社区、机构的多层次服务体系。 既满足老年人多样化需求…...
《Pytorch深度学习实践》ch8-多分类
------B站《刘二大人》 1.Softmax Layer 在多分类问题中,输出的是每类的概率: 计算公式:保证了每类概率大于 0 ,又由保证了概率之和为 1; 举例如下: 2.Cross Entropy 计算损失: y np.array…...

国产录播一体机:科技赋能智慧教育信息化
在数字化时代,教育正经历着前所未有的变革。国产工控机作为信息化教育的核心载体,正在重新定义学习方式,赋能教师与学生,打造高效、互动、智能的教学环境,让我们一起感受科技与教育的深度融合!高能计算机推…...

关于逻辑回归的见解
逻辑回归通过将线性回归的输出映射到 [ 0 , 1 ] \left[0,1\right] [0,1]区间,来表示某个类别的概率。也就是其本质是先通过线性回归的预测值 y \boldsymbol{y} y输入到映射函数,既将线性回归的输出通过映射函数映射到 [ 0 , 1 ] \left[0,1\right] [0,1].常用的映射函数是sigm…...
Amazon Augmented AI:人类智慧与AI协作,破解机器学习审核难题
在人工智能日益渗透业务核心的今天,你是否遭遇过这样的困境:自动化AI处理海量数据时,面对模糊、复杂或高风险的场景频频“卡壳”?人工审核团队则被低效、重复的任务压得喘不过气?Amazon Augmented AI (A2I) 的诞生&…...

CMake入门:3、变量操作 set 和 list
在 CMake 中,set 和 list 是两个核心命令,用于变量管理和列表操作。理解它们的用法对于编写高效的 CMakeLists.txt 文件至关重要。下面详细介绍这两个命令的功能和常见用法: 一、set 命令:变量定义与赋值 set 命令用于创建、修改…...

聊聊FlaUI:让Windows UI自动化测试优雅起飞!
你还在为手动点点点测试Windows应用而感到膝盖疼?更愁于自动化测试工具价格贵得让钱包瑟瑟发抖?今天,我要给你安利一款“野路子有余,正经事儿也能干”的.NET UI自动化神器——FlaUI!别眨眼,看完你能少加三个…...
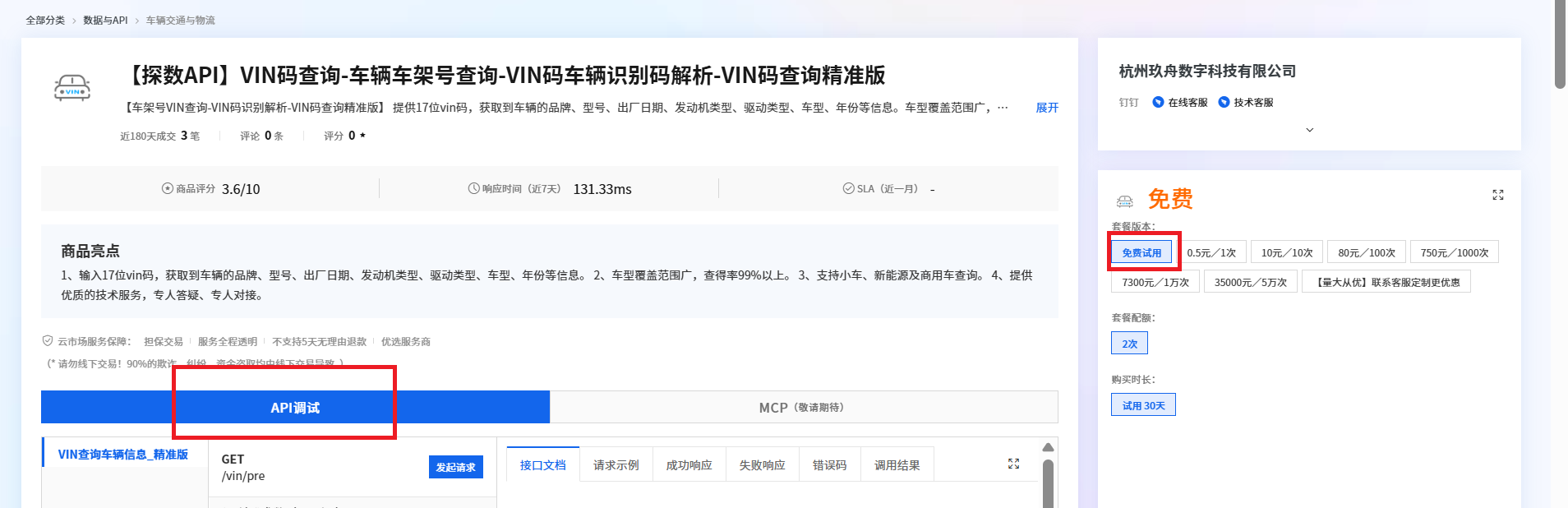
VIN码车辆识别码解析接口如何用C#进行调用?
一、什么是VIN码车辆识别码解析接口 输入17位vin码,获取到车辆的品牌、型号、出厂日期、发动机类型、驱动类型、车型、年份等信息。无论是汽车电商平台、二手车商、维修厂,还是保险公司、金融机构,都能通过接入该API实现信息自动化、决策智能…...

[论文阅读] 人工智能 | 用大语言模型解决软件元数据“身份谜题”:科研软件的“认脸”新方案
用大语言模型解决软件元数据“身份谜题”:科研软件的“认脸”新方案 论文信息 作者: Eva Martn del Pico, Josep Llus Gelp, Salvador Capella-Gutirrez 标题: Identity resolution of software metadata using Large Language Models 年份: 2025 来源: arX…...

gorm多租户插件的使用
一、关于gorm多租户插件的使用 1、安装依赖 go get -u github.com/kuangshp/gorm-tenant2、创建一个mysql数据表 DROP TABLE IF EXISTS user; CREATE TABLE user (id int(11) NOT NULL AUTO_INCREMENT primary key COMMENT 主键id,name varchar(50) not null comment 名称,ten…...