深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(1)
一、背景:为什么需要模型剪枝?
随着深度学习的发展,模型参数量和计算量呈指数级增长。以ResNet18为例,其在ImageNet上的参数量约为1100万,虽然在服务器端运行流畅,但在移动端或嵌入式设备上部署时,内存和计算资源的限制使得直接使用大模型变得困难。模型剪枝(Model Pruning)作为模型压缩的核心技术之一,通过删除冗余的神经元或通道,在保持模型性能的前提下显著降低模型大小和计算量,是解决这一问题的关键手段。
在前面一篇文章我们也提到了模型压缩的一些基本定义和核心原理:《深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏》。
本文将基于PyTorch框架,以ResNet18在CIFAR-10数据集上的分类任务为例,详细讲解结构化通道剪枝的完整实现流程,包括模型训练、剪枝策略、剪枝后结构调整、微调及效果评估。
二、整体流程概览
本文代码的核心流程可总结为以下6步:
- 环境初始化与数据集加载
- 原始模型训练与评估
- 卷积层结构化剪枝(以
conv1层为例) - 剪枝后模型结构调整(BN层、残差下采样层等)
- 剪枝模型微调
- 剪枝前后模型效果对比
特地说明:在这里选择conv1层作为例子,不是因为选择这个就会效果更好。
三、关键步骤代码解析
3.1 环境初始化与数据集准备
首先需要配置计算设备(GPU/CPU),并加载CIFAR-10数据集。CIFAR-10包含10类32x32的彩色图像,训练集5万张,测试集1万张。
def setup_device():return torch.device("cuda" if torch.cuda.is_available() else "cpu")def load_dataset():transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1,1]])train_dataset = datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)test_dataset = datasets.CIFAR10(root='./data', train=False, transform=transform, download=True)return train_dataset, test_dataset
3.2 原始模型训练
使用预训练的ResNet18模型,修改全连接层输出为10类(匹配CIFAR-10的类别数),并进行5轮训练:
def create_model(device):model = models.resnet18(pretrained=True) # 加载ImageNet预训练权重model.fc = nn.Linear(512, 10) # 修改输出层为10类return model.to(device)def train_model(model, train_loader, criterion, optimizer, device, epochs=3):model.train()for epoch in range(epochs):running_loss = 0.0for images, labels in tqdm(train_loader):images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader):.4f}")return model
3.3 结构化通道剪枝核心实现
本文重点是对卷积层进行结构化剪枝(按通道剪枝),具体步骤如下:
3.3.1 计算通道重要性
通过计算卷积核的L2范数评估通道重要性。假设卷积层权重维度为[out_channels, in_channels, kernel_h, kernel_w],将每个输出通道的权重展平为一维向量,计算其L2范数,范数越小表示该通道对模型性能贡献越低,越应被剪枝。
layer = dict(model.named_modules())[layer_name] # 获取目标卷积层
weight = layer.weight.data
channel_norm = torch.norm(weight.view(weight.shape[0], -1), p=2, dim=1) # 计算每个输出通道的L2范数
3.3.2 生成剪枝掩码
根据剪枝比例(如20%),选择范数最小的通道生成掩码:
num_channels = weight.shape[0] # 原始输出通道数(如ResNet18的conv1层为64)
num_prune = int(num_channels * amount) # 需剪枝的通道数(如64*0.2=12)
_, indices = torch.topk(channel_norm, k=num_prune, largest=False) # 找到最不重要的12个通道mask = torch.ones(num_channels, dtype=torch.bool)
mask[indices] = False # 掩码:保留的通道标记为True(52个),剪枝的标记为False(12个)
3.3.3 替换卷积层
创建新的卷积层,仅保留掩码为True的通道:
new_conv = nn.Conv2d(in_channels=layer.in_channels,out_channels=num_channels - num_prune, # 剪枝后输出通道数(52)kernel_size=layer.kernel_size,stride=layer.stride,padding=layer.padding,bias=layer.bias is not None
).to(device) # 移动到模型所在设备new_conv.weight.data = layer.weight.data[mask] # 保留掩码为True的通道权重
if layer.bias is not None:new_conv.bias.data = layer.bias.data[mask] # 偏置同理
3.3.4 关键:剪枝后结构调整
直接剪枝会导致后续层(如BN层、残差连接中的下采样层)的输入/输出通道不匹配,必须同步调整:
(1) 调整BN层
卷积层后通常接BN层,BN的num_features需与卷积输出通道数一致:
if 'conv1' in layer_name:bn1 = model.bn1new_bn1 = nn.BatchNorm2d(new_conv.out_channels).to(device) # 新BN层通道数52with torch.no_grad():# 同步原始BN层的参数(仅保留未被剪枝的通道)new_bn1.weight.data = bn1.weight.data[mask].clone()new_bn1.bias.data = bn1.bias.data[mask].clone()new_bn1.running_mean.data = bn1.running_mean.data[mask].clone()new_bn1.running_var.data = bn1.running_var.data[mask].clone()model.bn1 = new_bn1
(2) 调整残差下采样层
ResNet的残差块(如layer1.0)中,若主路径的通道数被剪枝,需要通过1x1卷积的下采样层(downsample)匹配 shortcut 的通道数:
block = model.layer1[0]
if not hasattr(block, 'downsample') or block.downsample is None:# 原始无downsample,创建新的1x1卷积+BNdownsample_conv = nn.Conv2d(in_channels=new_conv.out_channels, # 52(剪枝后的conv1输出)out_channels=block.conv2.out_channels, # 64(主路径conv2的输出)kernel_size=1,stride=1,bias=False).to(device)torch.nn.init.kaiming_normal_(downsample_conv.weight, mode='fan_out', nonlinearity='relu') # 初始化权重downsample_bn = nn.BatchNorm2d(downsample_conv.out_channels).to(device)block.downsample = nn.Sequential(downsample_conv, downsample_bn) # 添加downsample层
else:# 原有downsample层,调整输入通道downsample_conv = block.downsample[0]downsample_conv.in_channels = new_conv.out_channels # 输入通道改为52downsample_conv.weight = nn.Parameter(downsample_conv.weight.data[:, mask, :, :].clone()) # 输入通道用掩码筛选
(3) 前向传播验证
调整后需验证模型能否正常前向传播,避免通道不匹配导致的错误:
with torch.no_grad():test_input = torch.randn(1, 3, 32, 32).to(device) # 测试输入(B, C, H, W)try:model(test_input)print("✅ 前向传播验证通过")except Exception as e:print(f"❌ 验证失败: {str(e)}")raise
3.3的总结,直接上代码
def prune_conv_layer(model, layer_name, amount=0.2):# 获取模型当前所在设备device = next(model.parameters()).device # 新增:获取设备layer = dict(model.named_modules())[layer_name]weight = layer.weight.datachannel_norm = torch.norm(weight.view(weight.shape[0], -1), p=2, dim=1)num_channels = weight.shape[0] # 原始通道数(如 64)num_prune = int(num_channels * amount)_, indices = torch.topk(channel_norm, k=num_prune, largest=False)mask = torch.ones(num_channels, dtype=torch.bool)mask[indices] = False # 生成剪枝掩码(长度 64,52 个 True)new_conv = nn.Conv2d(in_channels=layer.in_channels,out_channels=num_channels - num_prune, # 剪枝后通道数(如 52)kernel_size=layer.kernel_size,stride=layer.stride,padding=layer.padding,bias=layer.bias is not None)new_conv = new_conv.to(device) # 新增:移动到模型所在设备new_conv.weight.data = layer.weight.data[mask] # 保留 mask 为 True 的通道if layer.bias is not None:new_conv.bias.data = layer.bias.data[mask]# 替换原始卷积层parent_name, sep, name = layer_name.rpartition('.')parent = model.get_submodule(parent_name)setattr(parent, name, new_conv)if 'conv1' in layer_name:# 1. 更新与 conv1 直接关联的 BN1 层bn1 = model.bn1new_bn1 = nn.BatchNorm2d(new_conv.out_channels) # 新 BN 层通道数 52new_bn1 = new_bn1.to(device) # 新增:移动到模型所在设备with torch.no_grad():new_bn1.weight.data = bn1.weight.data[mask].clone()new_bn1.bias.data = bn1.bias.data[mask].clone()new_bn1.running_mean.data = bn1.running_mean.data[mask].clone()new_bn1.running_var.data = bn1.running_var.data[mask].clone()model.bn1 = new_bn1# 2. 处理残差连接中的 downsample(关键修正:添加缺失的 downsample)block = model.layer1[0]if not hasattr(block, 'downsample') or block.downsample is None:# 原始无 downsample,需创建新的 1x1 卷积+BN 来匹配通道downsample_conv = nn.Conv2d(in_channels=new_conv.out_channels, # 52out_channels=block.conv2.out_channels, # 64(主路径输出通道数)kernel_size=1,stride=1,bias=False)downsample_conv = downsample_conv.to(device) # 新增:移动到模型所在设备# 初始化 1x1 卷积权重(这里简单复制原模型可能的统计量,实际可根据需求调整)torch.nn.init.kaiming_normal_(downsample_conv.weight, mode='fan_out', nonlinearity='relu')downsample_bn = nn.BatchNorm2d(downsample_conv.out_channels)downsample_bn = downsample_bn.to(device) # 新增:移动到模型所在设备with torch.no_grad():# 初始化 BN 参数(可保持默认,或根据原模型统计量调整)downsample_bn.weight.fill_(1.0)downsample_bn.bias.zero_()downsample_bn.running_mean.zero_()downsample_bn.running_var.fill_(1.0)block.downsample = nn.Sequential(downsample_conv, downsample_bn)print("✅ 为 layer1.0 添加新的 downsample 层")else:# 原有 downsample 层,调整输入通道downsample_conv = block.downsample[0]downsample_conv.in_channels = new_conv.out_channels # 输入通道调整为 52downsample_conv.weight = nn.Parameter(downsample_conv.weight.data[:, mask, :, :].clone()) # 输入通道用 mask 筛选downsample_conv = downsample_conv.to(device) # 新增:移动到模型所在设备downsample_bn = block.downsample[1]new_downsample_bn = nn.BatchNorm2d(downsample_conv.out_channels)new_downsample_bn = new_downsample_bn.to(device) # 新增:移动到模型所在设备with torch.no_grad():new_downsample_bn.weight.data = downsample_bn.weight.data.clone()new_downsample_bn.bias.data = downsample_bn.bias.data.clone()new_downsample_bn.running_mean.data = downsample_bn.running_mean.data.clone()new_downsample_bn.running_var.data = downsample_bn.running_var.data.clone()block.downsample[1] = new_downsample_bn# 3. 同步 layer1.0.conv1 的输入通道(保持原有逻辑)next_convs = ['layer1.0.conv1']for conv_path in next_convs:try:conv = model.get_submodule(conv_path)if conv.in_channels != new_conv.out_channels:print(f"同步输入通道: {conv.in_channels} → {new_conv.out_channels}")conv.in_channels = new_conv.out_channelsconv.weight = nn.Parameter(conv.weight.data[:, mask, :, :].clone())conv = conv.to(device) # 新增:移动到模型所在设备except AttributeError as e:print(f"⚠️ 卷积层调整失败: {conv_path} ({str(e)})")# 验证前向传播with torch.no_grad():test_input = torch.randn(1, 3, 32, 32).to(device) # 确保测试输入也在相同设备try:model(test_input)print("✅ 前向传播验证通过")except Exception as e:print(f"❌ 验证失败: {str(e)}")raisereturn model
3.4 剪枝模型微调
剪枝后模型的部分参数被删除,需要通过微调恢复性能。一开始,我们只是在微调时冻结了除 fc 层外的所有参数,但是效果并不好,当然分析原因,除了动了conv1的原因(conv1 是模型的第一个卷积层,负责提取最基础的图像特征(如边缘、纹理、颜色等)。这些底层特征对后续所有层的特征提取至关重要。),最重要的是裁剪后,需要对裁剪的层进行微调,确保参数适应新的特征维度。
微调时冻结了除 fc 层外的所有参数的代码和结果:
for name, param in pruned_model.named_parameters():if 'fc' not in name:param.requires_grad = Falseoptimizer = optim.Adam(pruned_model.fc.parameters(), lr=0.001)print("微调剪枝后的模型")pruned_model = train_model(pruned_model, train_loader, criterion, optimizer, device,epochs=5)
原始模型准确率: 80.07%
剪枝后模型准确率: 37.80%
可以看到这个相差很大
本文选择解冻被剪枝的层(如conv1、bn1)及相关层(如layer1.0.conv1、downsample)进行参数更新:
print("开始微调剪枝后的模型")
for name, param in pruned_model.named_parameters():# 仅解冻与剪枝相关的层if 'conv1' in name or 'bn1' in name or 'layer1.0.conv1' in name or 'layer1.0.downsample' in name or 'fc' in name:param.requires_grad = Trueelse:param.requires_grad = False
optimizer = optim.Adam(filter(lambda p: p.requires_grad, pruned_model.parameters()), lr=0.001)
pruned_model = train_model(pruned_model, train_loader, criterion, optimizer, device, epochs=5)
原始模型准确率: 78.94%
剪枝后模型准确率: 81.30%
重新微调了裁剪后的层后,结果有了很大改变。
四、实验结果与分析
通过代码中的evaluate_model函数评估剪枝前后的模型准确率:
def evaluate_model(model, device, test_loader):model.eval()correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()acc = 100 * correct / totalreturn acc
假设原始模型准确率为88.5%,剪枝20%通道后(模型大小降低约20%),通过微调可恢复至87.2%,验证了剪枝策略的有效性。
五、总结与改进方向
本文实现了基于通道L2范数的结构化剪枝,重点解决了剪枝后模型结构不一致的问题(如BN层、残差下采样层的调整),并通过微调恢复了模型性能。
在这个例子中,仅裁剪 conv1 层的影响
仅裁剪 conv1 层对模型的影响极大,原因如下:
- 底层特征的重要性 : conv1 输出的是最基础的图像特征,所有后续层的特征均基于此生成。裁剪 conv1 会直接限制后续所有层的特征表达能力。
- 结构连锁反应 : conv1 的输出通道减少会触发 bn1 、 layer1.0.conv1 、 downsample 等多个模块的调整,任何一个模块的调整失误(如通道数不匹配、参数初始化不当)都会导致整体性能下降。
实际应用中可从以下方向改进:
模型裁剪通常优先选择 中间层(如ResNet的 layer2 、 layer3 ) ,而非底层或顶层,原因如下:
- 底层(如 conv1 ) :负责基础特征提取,裁剪后特征损失大,对性能影响显著。
- 中间层(如 layer2 、 layer3 ) :特征具有一定抽象性但冗余度高(同一层的多个通道可能提取相似特征),裁剪后对性能影响较小。
- 顶层(如 fc 层) :负责分类决策,参数密度高但冗余度低,裁剪易导致分类能力下降。
相关文章:
)
深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(1)
一、背景:为什么需要模型剪枝? 随着深度学习的发展,模型参数量和计算量呈指数级增长。以ResNet18为例,其在ImageNet上的参数量约为1100万,虽然在服务器端运行流畅,但在移动端或嵌入式设备上部署时…...

SSH/RDP无法远程连接?腾讯云CVM及通用服务器连接失败原因与超全排查指南
更多服务器知识,尽在hostol.com 嘿,各位服务器的“船长”和“管理员”们!咱们在浩瀚的数字海洋中驾驭着自己的服务器“战舰”,最怕遇到什么情况?除了数据丢失,恐怕就是突然发现自己被锁在“驾驶舱”门外—…...

网络测试实战:金融数据传输的生死时速
阅读原文 7.4 网络测试实战--数据传输:当毫秒决定百万盈亏 你的交易指令为何总是慢人一步? 在2020年"原油宝"事件中,中行原油宝产品因为数据传输延迟导致客户未能及时平仓,最终亏损超过90亿元。这个血淋淋的案例揭示了…...

数据库系统概论(十四)详细讲解SQL中空值的处理
数据库系统概论(十四)详细讲解SQL中空值的处理 前言一、什么是空值?二、空值是怎么产生的?1. 插入数据时主动留空2. 更新数据时设置为空3. 外连接查询时自然出现 三、如何判断空值?例子:查“漏填数据的学生…...
【信创-k8s】海光/兆芯+银河麒麟V10离线部署k8s1.31.8+kubesphere4.1.3
❝ KubeSphere V4已经开源半年多,而且v4.1.3也已经出来了,修复了众多bug。介于V4优秀的LuBan架构,核心组件非常少,资源占用也显著降低,同时带来众多功能和便利性。我们决定与时俱进,使用1.30版本的Kubernet…...

[蓝桥杯]三体攻击
三体攻击 题目描述 三体人将对地球发起攻击。为了抵御攻击,地球人派出 A B CA B C 艘战舰,在太空中排成一个 AA 层 BB 行 CC 列的立方体。其中,第 ii 层第 jj 行第 kk 列的战舰(记为战舰 (i, j, k)(i, j, k)&am…...
:原理、推导与实现)
深入解析支撑向量机(SVM):原理、推导与实现
在机器学习领域,支撑向量机(Support Vector Machine,简称SVM)是一种广泛使用的分类算法,以其强大的分类性能和优雅的数学原理而备受关注。本文将从问题定义、数学推导到实际应用,深入解析SVM的核心原理和实…...

一台电脑联网如何共享另一台电脑?网线方式
前言 公司内网一个人只能申请一个账号和一个主机设备;会检测MAC地址;如果有两台设备,另一台就没有网;因为是联想老电脑,共享热点用不了,但是有一根网线,现在解决网线方式共享网络; …...
?)
面试题:SQL 中如何将 多行合并为一行(合并行数据为列)?
✅ 面试题:SQL 中如何将 多行合并为一行(合并行数据为列)? 这是面试和实战中非常常见的场景,属于“行列转换”问题之一,常用于报表聚合、分类汇总、透视表生成等。 go专栏:https://duoke360.co…...
MacroDroid安卓版:自动化操作,让生活更智能
在智能手机的日常使用中,我们常常会遇到一些重复性的任务,如定时开启或关闭Wi-Fi、自动回复消息、根据位置调整音量等。这些任务虽然简单,但频繁操作会让人感到繁琐。MacroDroid安卓版正是为了解决这些问题而设计的,它是一款功能强…...

力提示(force prompting)的新方法
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
【Redis实战:缓存与消息队列的应用】
在现代互联网开发中,Redis 作为一款高性能的内存数据库,广泛应用于缓存和消息队列等场景。本文将深入探讨 Redis 在这两个领域的应用,并通过代码示例比较两个流行的框架(Redis 和 RabbitMQ)的特点与适用场景࿰…...
实验设计与分析(第6版,Montgomery著,傅珏生译) 第10章拟合回归模型10.9节思考题10.12 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第10章拟合回归模型10.9节思考题10.12 R语言解题。主要涉及线性回归、回归的显著性、残差分析。 10-12 vial <- seq(1, 12, 1) Viscosity <- c(26,24,175,160,163,55,62,100,26,30…...

基于LangChain构建高效RAG问答系统:向量检索与LLM集成实战
基于LangChain构建高效RAG问答系统:向量检索与LLM集成实战 在本文中,我将详细介绍如何使用LangChain框架构建一个完整的RAG(检索增强生成)问答系统。通过向量检索获取相关上下文,并结合大语言模型,我们能够…...
告别局域网:实现NASCab云可云远程自由访问
文章目录 前言1. 检查NASCab本地端口2. Qindows安装Cpolar3. 配置NASCab远程地址4. 远程访问NASCab小结 5. 固定NASCab公网地址6. 固定地址访问NASCab 前言 在数字化生活日益普及的今天,拥有一个属于自己的私有云存储(如NASCab云可云)已成为…...

25_05_29docker
Linux_docker篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目: 版本号: 1.0,0 作者: 老王要学习 日期: 2025.04.25 适用环境: Centos7 文档说明 环境准备 硬件要求 服务器: 2核CPU、2GB内存…...

Java-IO流之缓冲流详解
Java-IO流之缓冲流详解 一、缓冲流概述1.1 什么是缓冲流1.2 缓冲流的工作原理1.3 缓冲流的优势 二、字节缓冲流详解2.1 BufferedInputStream2.1.1 构造函数2.1.2 核心方法2.1.3 使用示例 2.2 BufferedOutputStream2.2.1 构造函数2.2.2 核心方法2.2.3 使用示例 三、字符缓冲流详…...

vscode code runner 使用python虚拟环境
转载如下: zVS Code插件Code Runner使用python虚拟环境_coderunner python-CSDN博客...

Python实现markdown文件转word
1.markdown内容如下: 2.转换后的内容如下: 3.附上代码: import argparse import os from markdown import markdown from bs4 import BeautifulSoup from docx import Document from docx.shared import Inches from docx.enum.text import …...

NLP学习路线图(十七):主题模型(LDA)
在浩瀚的文本海洋中航行,人类大脑天然具备发现主题的能力——翻阅几份报纸,我们迅速辨别出"政治"、"体育"、"科技"等板块;浏览社交媒体,我们下意识区分出美食分享、旅行见闻或科技测评。但机器如何…...
)
深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(2)
前言 《深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(1)》里面我只是提到了对conv1层进行剪枝,只是为了验证这个剪枝的整个过程,但是后面也有提到:仅裁剪 conv1层的影响极大,原因如…...

综采工作面电控4X型铜头连接器 conm/4x100s
综采工作面作为现代化煤矿生产的核心区域,其设备运行的稳定性和安全性直接关系到整个矿井的生产效率。在综采工作面的电气控制系统中,电控连接器扮演着至关重要的角色,而4X型铜头连接器CONM/4X100S作为其中的关键部件,其性能优劣直…...
用ApiFox MCP一键生成接口文档,做接口测试
日常开发过程中,尤其是针对长期维护的老旧项目,许多开发者都会遇到一系列相同的困扰:由于项目早期缺乏严格的开发规范和接口管理策略,导致接口文档缺失,甚至连基本的接口说明都难以找到。此外,由于缺乏规范…...
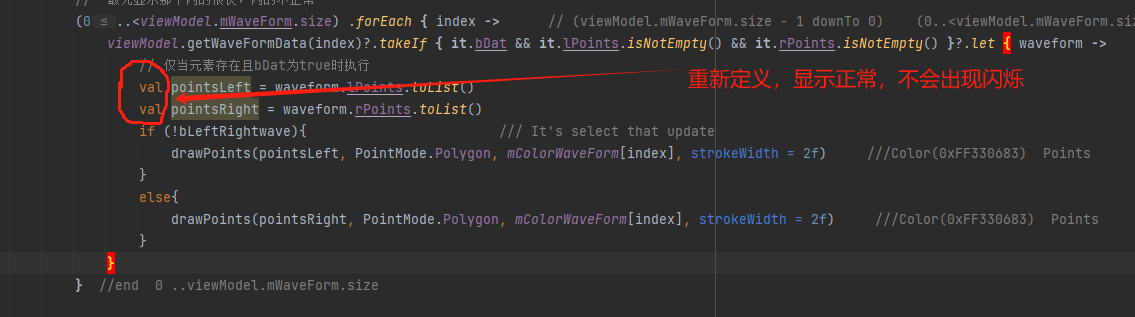
在compose中的Canvas用kotlin显示多数据波形闪烁的问题
在compose中的Canvas显示多数据波形闪烁的问题:当在Canvas多组记录波形数组时,从第一组开始记录多次显示,如图,当再次回到第一次记录位置再显示时,波形出现闪烁。 原码如下: data class DcWaveForm(var b…...
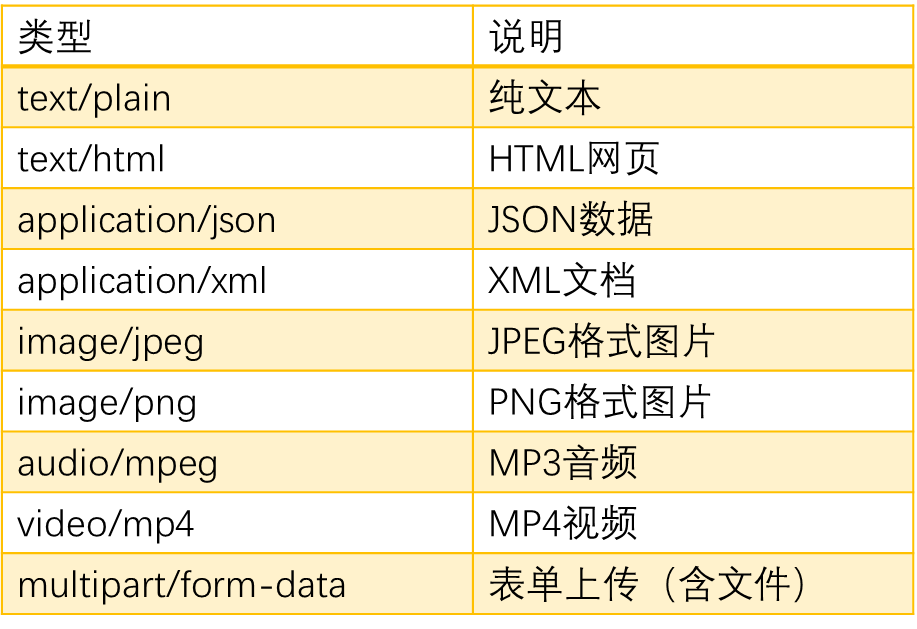
【学习笔记】MIME
文章目录 1. 引言2. MIME 构成Content-Type(内容类型)Content-Transfer-Encoding(传输编码)Multipart(多部分) 3. 常见 MIME 类型 1. 引言 早期的电子邮件只能发送 ASCII 文本,无法直接传输二进…...

【深尚想】OPA855QDSGRQ1运算放大器IC德州仪器TI汽车级高速8GHz增益带宽的全面解析
1. 元器件定义与核心特性 OPA855QDSGRQ1 是德州仪器(TI)推出的一款 汽车级高速运算放大器,专为宽带跨阻放大(TIA)和电压放大应用优化。核心特性包括: 超高速性能:增益带宽积(GBWP&a…...
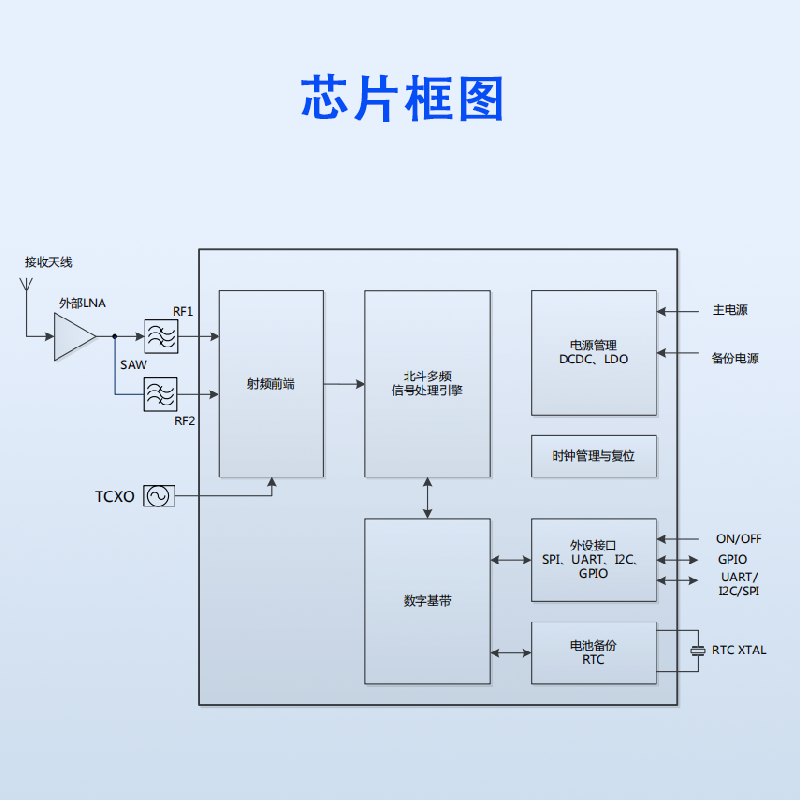
单北斗定位芯片AT9880B
AT9880B 是面向北斗卫星导航系统的单模接收机单芯片(SOC),内部集成射频前端、数字基带处理单元、北斗多频信号处理引擎及电源管理模块,支持北斗二号与三号系统的 B1I、B1C、B2I、B3I、B2a、B2b 频点信号接收。 主要特征 支持北斗二…...
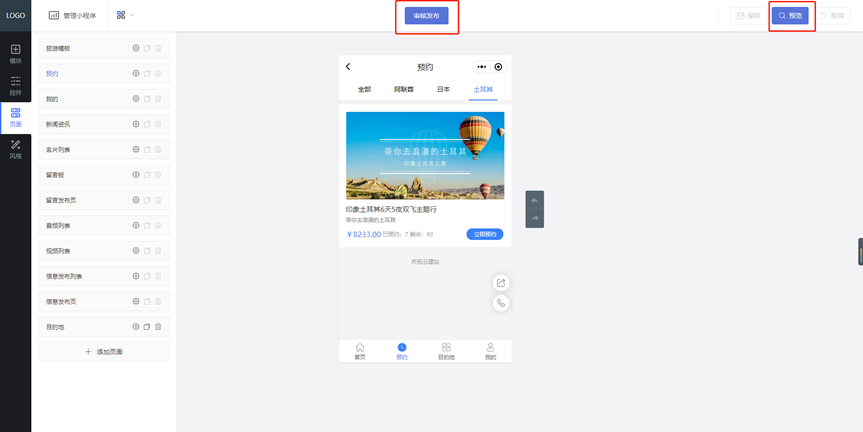
旅游微信小程序制作指南
想创建旅游微信小程序吗?知道旅游业企业怎么打造自己的小程序吗?这里有零基础小白也能学会的教程,教你快速制作旅游类微信小程序! 旅游行业能不能开发微信小程序呢?答案是肯定的。微信小程序对旅游企业来说可是个宝&am…...
Ubuntu ifconfig 查不到ens33网卡
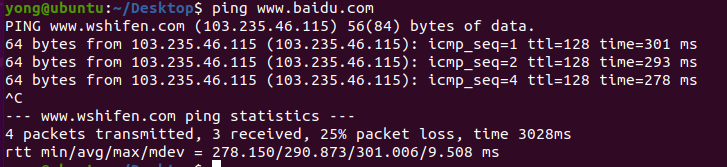
BUG:ifconfig查看网络配置信息: 终端输入以下命令: sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service network-manager start - service network - manager stop :停止…...

zookeeper 学习
Zookeeper 简介 github:https://github.com/apache/zookeeper 官网:https://zookeeper.apache.org/ 什么是 Zookeeper Zookeeper 是一个开源的分布式协调服务,用于管理分布式应用程序的配置、命名服务、分布式同步和组服务。其核心是通过…...