基于LangChain构建高效RAG问答系统:向量检索与LLM集成实战
基于LangChain构建高效RAG问答系统:向量检索与LLM集成实战
在本文中,我将详细介绍如何使用LangChain框架构建一个完整的RAG(检索增强生成)问答系统。通过向量检索获取相关上下文,并结合大语言模型,我们能够构建出一个能够基于特定知识库回答问题的智能系统。
1. 基础设置与向量检索准备
首先,我们需要导入必要的库并设置向量存储访问:
import os
from dotenv import load_dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore# 加载环境变量
load_dotenv()# 定义查询问题
query = "我的生日是几月几日?"# 初始化阿里云百炼平台的向量模型
embedding = DashScopeEmbeddings(model="text-embedding-v3", dashscope_api_key=os.getenv("ALY_EMBADING_KEY"))
redis_url = "redis://localhost:6379" # Redis数据库的连接地址# 配置Redis向量存储
config = RedisConfig(index_name="my_index2", # 索引名称redis_url=redis_url, # Redis数据库的连接地址
)# 创建向量存储实例和检索器
vector_store = RedisVectorStore(embedding, config=config)
retriever = vector_store.as_retriever()
这部分代码完成了以下工作:
- 加载环境变量以安全地使用API密钥
- 初始化阿里云文本嵌入模型
- 配置Redis向量数据库连接
- 创建检索器(retriever),用于执行向量相似度检索
2. 执行向量检索
接下来,我们使用检索器从向量库中获取与查询相关的文本段落:
# 执行检索,获取相关文本段落
retriever_segments = retriever.invoke(query, k=5)
print(retriever_segments)# 将检索结果整合
text = []
for segment in retriever_segments:text.append(segment.page_content)
在这段代码中:
retriever.invoke(query, k=5)检索与查询语义最相关的5个文本段落- 我们将检索到的每个段落的文本内容提取并整合到一个列表中
3. 构建Prompt模板
我们需要设计一个提示模板,将检索到的相关信息和用户问题一起传递给大语言模型:
from langchain_core.prompts import ChatPromptTemplateprompt_template = ChatPromptTemplate.from_messages([("system", """你是一个问答机器人,你的任务是根据下述给定的已知信息回答用户的问题已知信息:{context}用户问题:{query}如果已知问题不包含用户问题的答案,或者已知信息不足以回答用户的问题,请回答"抱歉,我无法回答这个问题。"请不要输出已知信息中不包含的信息或者答案。用中文回答用户问题"""),]
)# 格式化prompt
prompt = prompt_template.invoke({"context": text, "query": query})
print(prompt.to_messages()[0].content)
这个提示模板:
- 明确定义了AI助手的角色和任务
- 设置了两个变量:
{context}用于传入检索结果,{query}用于传入用户问题 - 提供了清晰的回答指令,包括当信息不足时如何响应
4. 调用大语言模型获取回答
现在,我们使用LLM来生成基于上下文的回答:
from langchain_openai import ChatOpenAI# 结果解析器,直接获取纯文本回复
parser = StrOutputParser()# 初始化LLM模型接口
model = ChatOpenAI(base_url="https://openrouter.ai/api/v1", api_key=os.getenv("OPENAI_KEY"),model="qwen/qwq-32b:free")# 调用模型获取回答
result = model.invoke(prompt)
print(result)
这里我们:
- 使用了OpenRouter平台上的通义千问模型
- 通过
model.invoke(prompt)将格式化后的提示发送给模型 - 获取模型的文本响应
5. 构建完整的RAG链
最后,我们将把所有步骤整合成一个完整的LangChain处理链,实现端到端的RAG问答:
from operator import itemgetter# 辅助函数:收集文档内容
def collect_documents(segments):text = []for segment in segments:text.append(segment.page_content)return text# 构建完整的处理链
chain = ({"context": itemgetter("query") | retriever | collect_documents,"query": itemgetter("query")
} | prompt_template | model | parser)# 设置新的查询并执行链
query = "你能帮助史可轩处理日常事务吗"
response = chain.invoke({"query": query})
print(response)
这个链式处理流程:
- 接收用户查询
- 执行向量检索获取相关上下文
- 将上下文和查询组合到提示模板中
- 调用LLM生成回答
- 解析并返回最终的文本响应
详细解析链式处理
让我们解析一下这个链式处理的构建方式:
chain = ({"context": itemgetter("query") | retriever | collect_documents,"query": itemgetter("query")
} | prompt_template | model | parser)
这个链式结构使用了LangChain的管道操作符 |,实现了以下流程:
itemgetter("query")从输入字典中提取查询文本- 将查询传递给
retriever执行向量检索 collect_documents函数处理检索结果,提取文本内容- 将处理后的上下文和原始查询分别作为
context和query传递给提示模板 - 提示模板格式化后的内容发送给LLM模型处理
- 最后通过
parser解析LLM的响应,获取纯文本结果
总结
本文介绍了如何使用LangChain框架构建一个完整的RAG问答系统,主要包含以下步骤:
- 向量检索:从Redis向量数据库中检索与用户问题语义相似的文本段落
- 提示工程:设计合适的提示模板,将检索结果作为上下文与用户问题一起发送给模型
- 模型调用:利用LangChain的接口调用大语言模型生成答案
- 链式处理:使用LangChain的管道操作将各个组件整合成一个端到端的工作流
这种RAG架构具有很好的可解释性和可靠性,能够基于特定的知识库回答问题,避免了大语言模型"幻觉"问题,特别适合构建企业级知识问答系统、客服助手等应用。
通过向量检索提供相关上下文,我们可以让大语言模型更准确地回答特定领域的问题,同时也能降低知识更新的成本(只需更新向量库而无需重新训练模型)。这种方案在实际应用中具有很高的灵活性和可扩展性。
相关文章:

基于LangChain构建高效RAG问答系统:向量检索与LLM集成实战
基于LangChain构建高效RAG问答系统:向量检索与LLM集成实战 在本文中,我将详细介绍如何使用LangChain框架构建一个完整的RAG(检索增强生成)问答系统。通过向量检索获取相关上下文,并结合大语言模型,我们能够…...
告别局域网:实现NASCab云可云远程自由访问
文章目录 前言1. 检查NASCab本地端口2. Qindows安装Cpolar3. 配置NASCab远程地址4. 远程访问NASCab小结 5. 固定NASCab公网地址6. 固定地址访问NASCab 前言 在数字化生活日益普及的今天,拥有一个属于自己的私有云存储(如NASCab云可云)已成为…...

25_05_29docker
Linux_docker篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目: 版本号: 1.0,0 作者: 老王要学习 日期: 2025.04.25 适用环境: Centos7 文档说明 环境准备 硬件要求 服务器: 2核CPU、2GB内存…...

Java-IO流之缓冲流详解
Java-IO流之缓冲流详解 一、缓冲流概述1.1 什么是缓冲流1.2 缓冲流的工作原理1.3 缓冲流的优势 二、字节缓冲流详解2.1 BufferedInputStream2.1.1 构造函数2.1.2 核心方法2.1.3 使用示例 2.2 BufferedOutputStream2.2.1 构造函数2.2.2 核心方法2.2.3 使用示例 三、字符缓冲流详…...

vscode code runner 使用python虚拟环境
转载如下: zVS Code插件Code Runner使用python虚拟环境_coderunner python-CSDN博客...

Python实现markdown文件转word
1.markdown内容如下: 2.转换后的内容如下: 3.附上代码: import argparse import os from markdown import markdown from bs4 import BeautifulSoup from docx import Document from docx.shared import Inches from docx.enum.text import …...

NLP学习路线图(十七):主题模型(LDA)
在浩瀚的文本海洋中航行,人类大脑天然具备发现主题的能力——翻阅几份报纸,我们迅速辨别出"政治"、"体育"、"科技"等板块;浏览社交媒体,我们下意识区分出美食分享、旅行见闻或科技测评。但机器如何…...
)
深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(2)
前言 《深度学习之模型压缩三驾马车:基于ResNet18的模型剪枝实战(1)》里面我只是提到了对conv1层进行剪枝,只是为了验证这个剪枝的整个过程,但是后面也有提到:仅裁剪 conv1层的影响极大,原因如…...

综采工作面电控4X型铜头连接器 conm/4x100s
综采工作面作为现代化煤矿生产的核心区域,其设备运行的稳定性和安全性直接关系到整个矿井的生产效率。在综采工作面的电气控制系统中,电控连接器扮演着至关重要的角色,而4X型铜头连接器CONM/4X100S作为其中的关键部件,其性能优劣直…...
用ApiFox MCP一键生成接口文档,做接口测试
日常开发过程中,尤其是针对长期维护的老旧项目,许多开发者都会遇到一系列相同的困扰:由于项目早期缺乏严格的开发规范和接口管理策略,导致接口文档缺失,甚至连基本的接口说明都难以找到。此外,由于缺乏规范…...
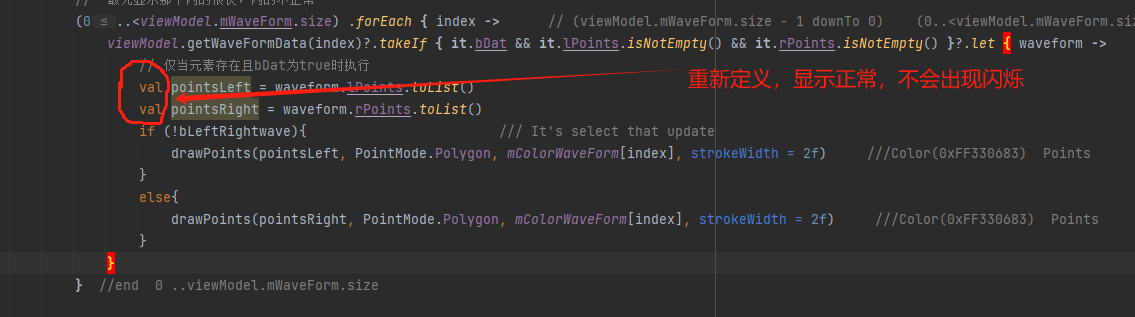
在compose中的Canvas用kotlin显示多数据波形闪烁的问题
在compose中的Canvas显示多数据波形闪烁的问题:当在Canvas多组记录波形数组时,从第一组开始记录多次显示,如图,当再次回到第一次记录位置再显示时,波形出现闪烁。 原码如下: data class DcWaveForm(var b…...
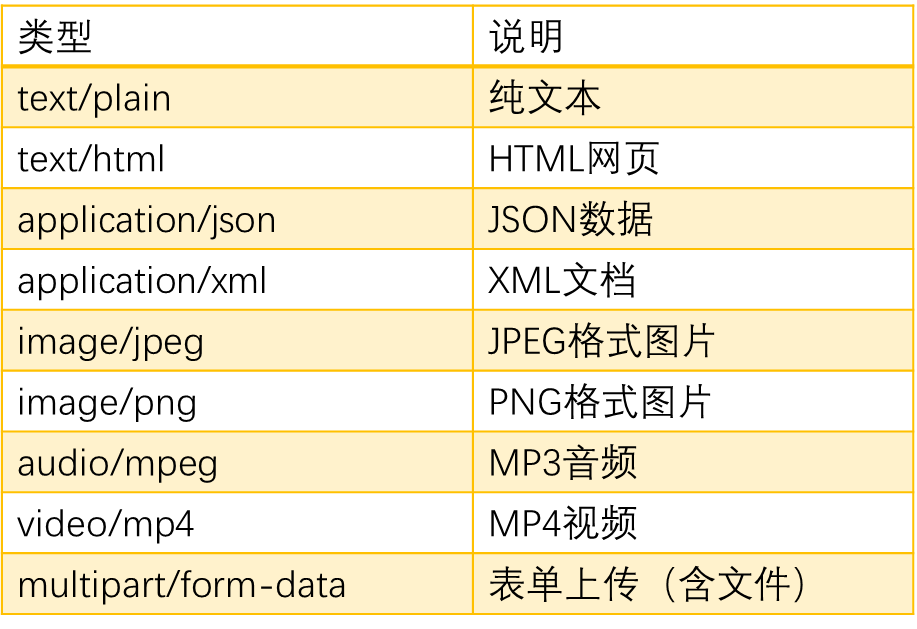
【学习笔记】MIME
文章目录 1. 引言2. MIME 构成Content-Type(内容类型)Content-Transfer-Encoding(传输编码)Multipart(多部分) 3. 常见 MIME 类型 1. 引言 早期的电子邮件只能发送 ASCII 文本,无法直接传输二进…...

【深尚想】OPA855QDSGRQ1运算放大器IC德州仪器TI汽车级高速8GHz增益带宽的全面解析
1. 元器件定义与核心特性 OPA855QDSGRQ1 是德州仪器(TI)推出的一款 汽车级高速运算放大器,专为宽带跨阻放大(TIA)和电压放大应用优化。核心特性包括: 超高速性能:增益带宽积(GBWP&a…...
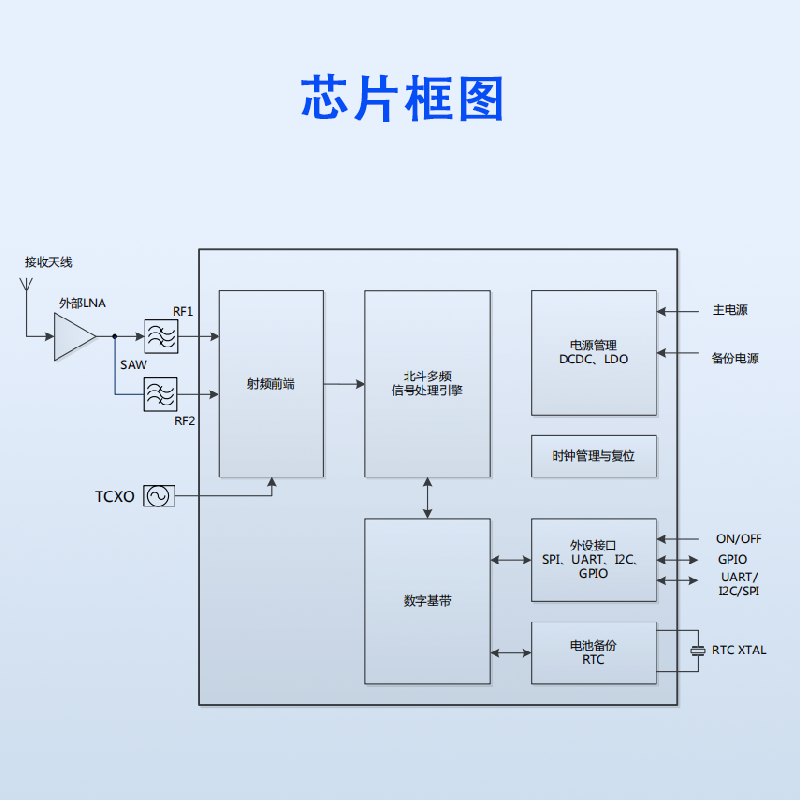
单北斗定位芯片AT9880B
AT9880B 是面向北斗卫星导航系统的单模接收机单芯片(SOC),内部集成射频前端、数字基带处理单元、北斗多频信号处理引擎及电源管理模块,支持北斗二号与三号系统的 B1I、B1C、B2I、B3I、B2a、B2b 频点信号接收。 主要特征 支持北斗二…...
旅游微信小程序制作指南
想创建旅游微信小程序吗?知道旅游业企业怎么打造自己的小程序吗?这里有零基础小白也能学会的教程,教你快速制作旅游类微信小程序! 旅游行业能不能开发微信小程序呢?答案是肯定的。微信小程序对旅游企业来说可是个宝&am…...
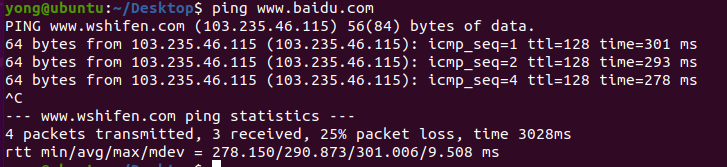
Ubuntu ifconfig 查不到ens33网卡
BUG:ifconfig查看网络配置信息: 终端输入以下命令: sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service network-manager start - service network - manager stop :停止…...

zookeeper 学习
Zookeeper 简介 github:https://github.com/apache/zookeeper 官网:https://zookeeper.apache.org/ 什么是 Zookeeper Zookeeper 是一个开源的分布式协调服务,用于管理分布式应用程序的配置、命名服务、分布式同步和组服务。其核心是通过…...
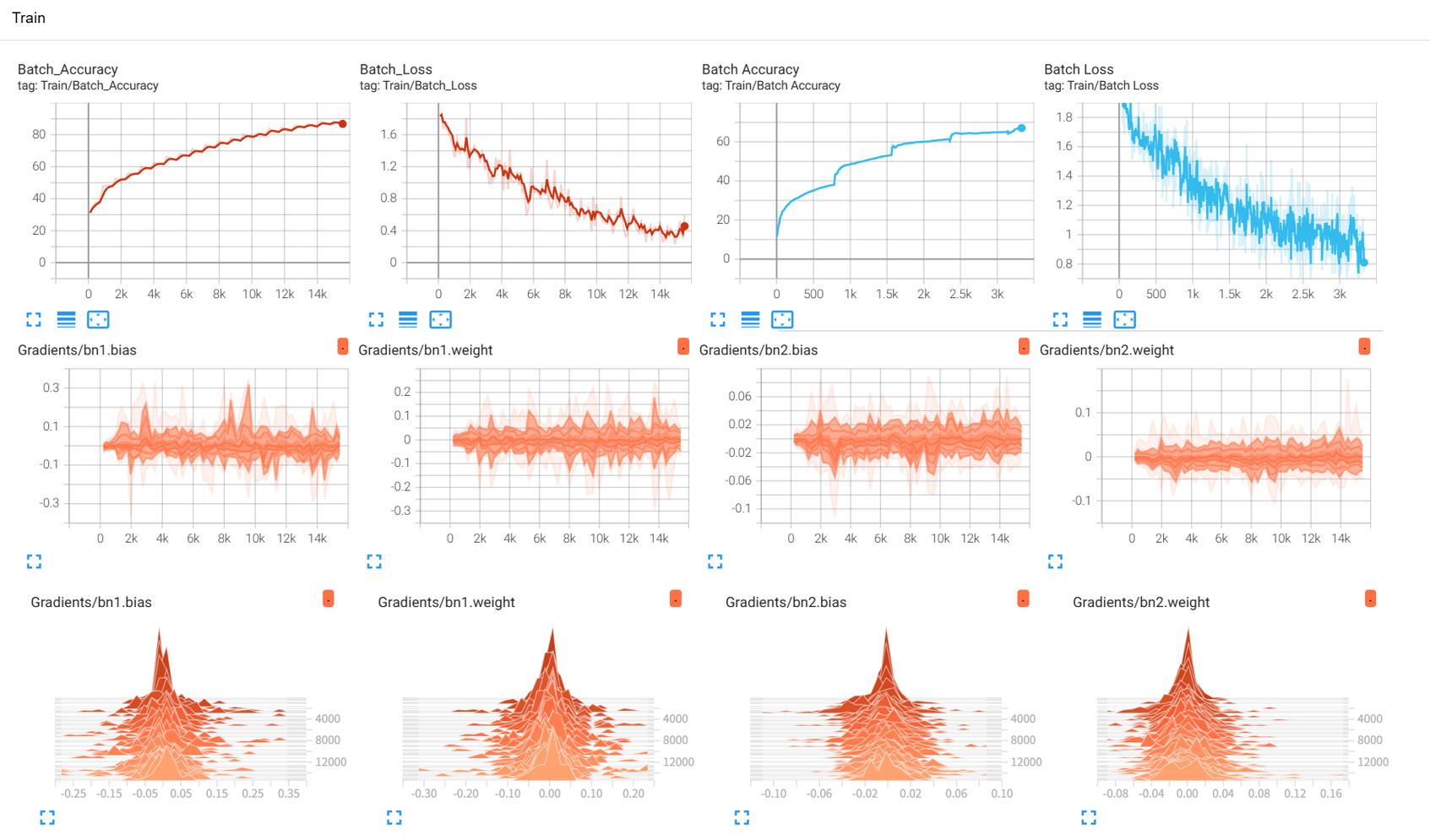
【python深度学习】Day 45 Tensorboard使用介绍
知识点: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorboard监…...

【图像处理入门】5. 形态学处理:腐蚀、膨胀与图像的形状雕琢
摘要 形态学处理是基于图像形状特征的处理技术,在图像分析中扮演着关键角色。本文将深入讲解腐蚀、膨胀、开闭运算等形态学操作的原理,结合OpenCV代码展示其在去除噪声、提取边缘、分割图像等场景的应用,带你掌握通过结构元素雕琢图像形状的核心技巧。 一、形态学处理:基…...
并行智算MaaS云平台:打造你的专属AI助手,开启智能生活新纪元
目录 引言:AI助手,未来生活的必备伙伴 并行智算云:大模型API的卓越平台 实战指南:调用并行智算云API打造个人AI助手 3.1 准备工作 3.2 API调用示例 3.3 本地智能AI系统搭建 3.4 高级功能实现 并行智算云的优势 4.1 性能卓越…...

在 SpringBoot+Tomcat 环境中 线程安全问题的根本原因以及哪些变量会存在线程安全的问题。
文章目录 前言Tomcat SpringBoot单例加载结果分析多例加载:结果分析: 哪些变量存在线程安全的问题?线程不安全线程安全 总结 前言 本文带你去深入理解为什么在web环境中(Tomcat SpringBoot)会存在多线程的问题以及哪些变量会存在线程安全的…...
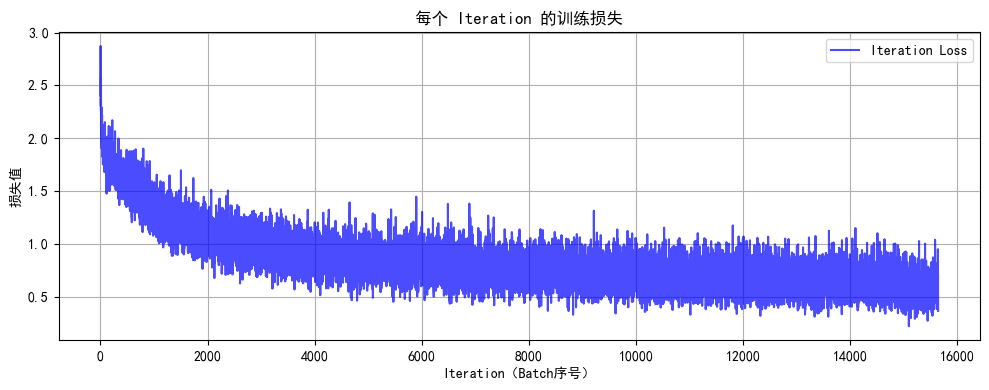
Day45 Python打卡训练营
知识点回顾: 1. tensorboard的发展历史和原理 2. tensorboard的常见操作 3. tensorboard在cifar上的实战:MLP和CNN模型 一、tensorboard的基本操作 1.1 发展历史 TensorBoard 是 TensorFlow 生态中的官方可视化工具(也可无缝集成 PyTorch&…...
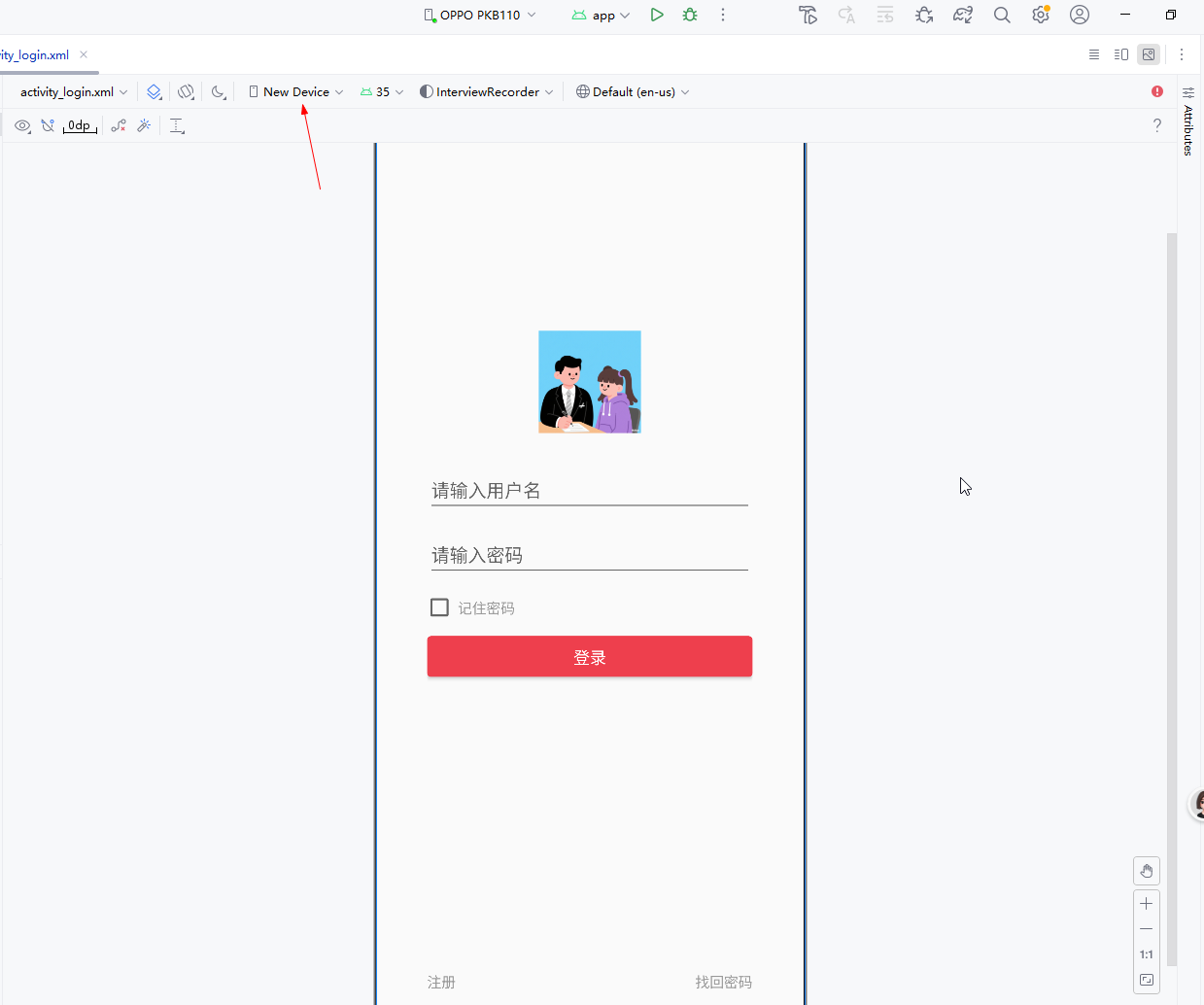
2025年目前最新版本Android Studio自定义xml预览的屏幕分辨率
一、前言 在实际开发项目当中,我们的设备的分辨率可能会比较特殊,AS并没有自带这种屏幕分辨率的设备,但是我们又想一边编写XML界面,一边实时看到较为真实的预览效果,该怎么办呢?在早期的AS版本中ÿ…...
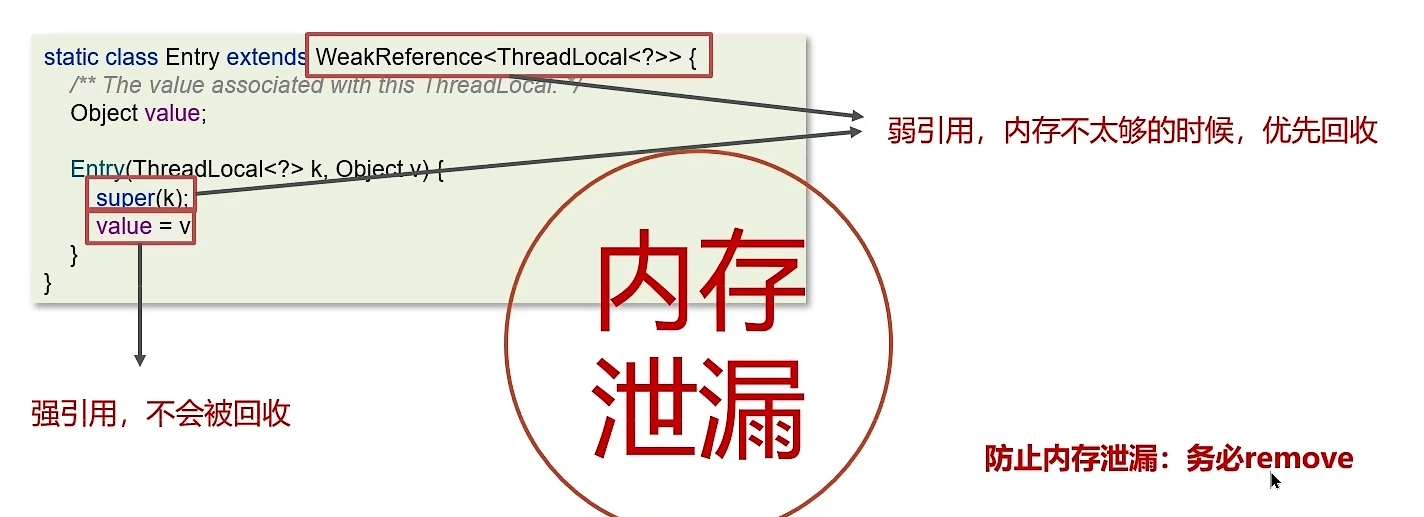
黑马Java面试笔记之 并发编程篇(线程池+使用场景)
一. 线程池的核心参数(线程池的执行原理) 线程池核心参数主要参考ThreadPoolExecutor这个类的7个参数的构造函数 corePoolSize 核心线程数目 maximumPoolSize 最大线程数目 (核心线程救急线程的最大数目) keepAliveTime 生存时间 - 救急线程的生存时…...

float和float32有什么区别
这是一个非常重要但容易混淆的问题。我们来一步一步讲清楚: ✅ 简答:float 和 float32 的区别 项目float(通用名称)float32(精确定义)含义通常指“浮点数”,具体精度由语言/平台决定明确指 32 …...
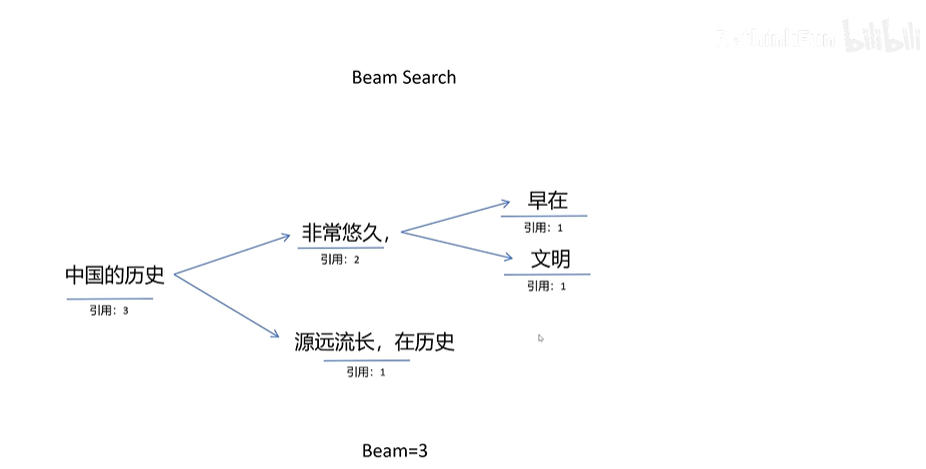
【AI学习】KV-cache和page attention
目录 带着问题学AI KV-cache KV-cache是什么? 之前每个token生成的K V矩阵给缓存起来有什么用? 为啥缓存K、V,没有缓存Q? KV-cache为啥在训练阶段不需要,只在推理阶段需要? KV cache的过程图解 阶段一:KV cac…...
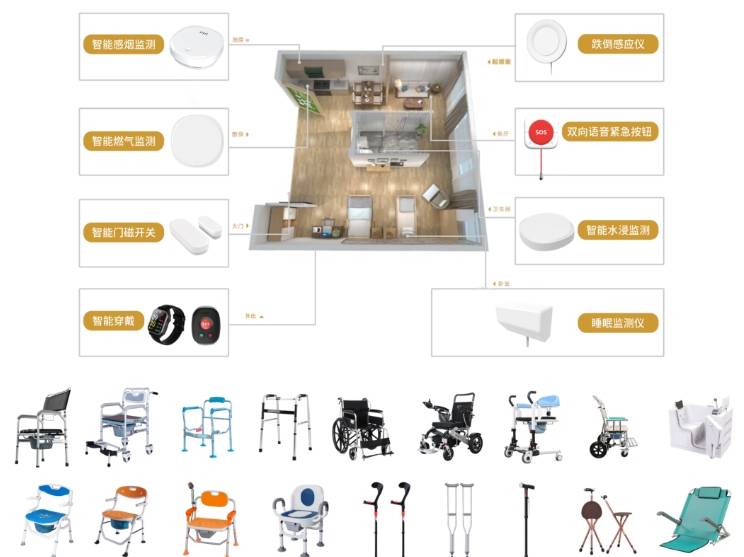
七彩喜智慧养老平台:科技赋能下的市场蓝海,满足多样化养老服务需求
在人口老龄化加速与科技快速发展的双重驱动下,七彩喜智慧养老平台正成为破解养老服务供需矛盾、激活银发经济的核心引擎。 这一领域依托物联网、人工智能、大数据等技术,构建起覆盖居家、社区、机构的多层次服务体系。 既满足老年人多样化需求…...
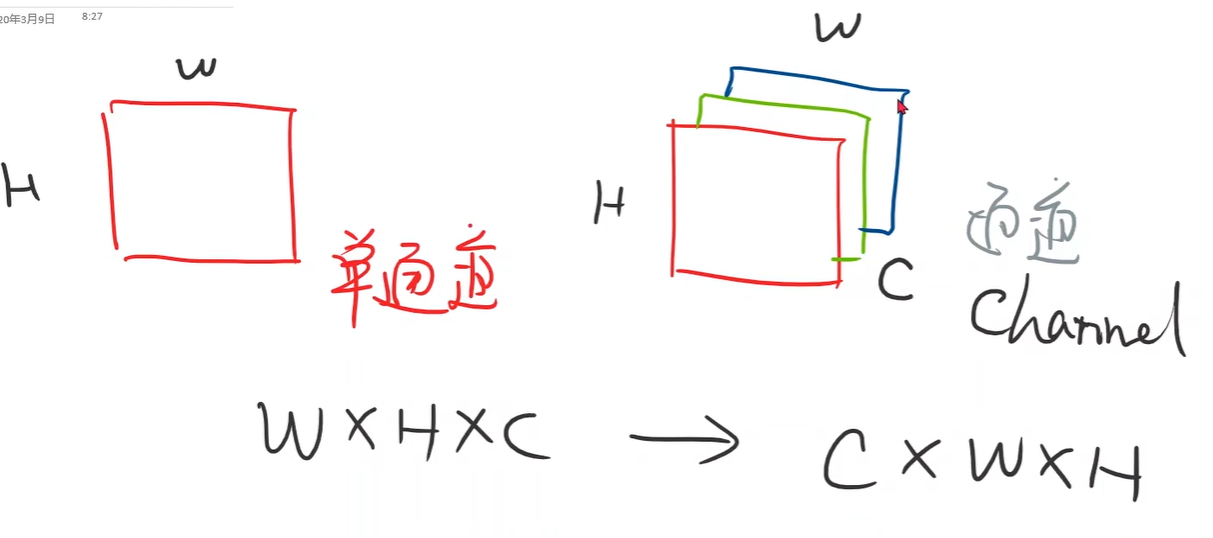
《Pytorch深度学习实践》ch8-多分类
------B站《刘二大人》 1.Softmax Layer 在多分类问题中,输出的是每类的概率: 计算公式:保证了每类概率大于 0 ,又由保证了概率之和为 1; 举例如下: 2.Cross Entropy 计算损失: y np.array…...

国产录播一体机:科技赋能智慧教育信息化
在数字化时代,教育正经历着前所未有的变革。国产工控机作为信息化教育的核心载体,正在重新定义学习方式,赋能教师与学生,打造高效、互动、智能的教学环境,让我们一起感受科技与教育的深度融合!高能计算机推…...

关于逻辑回归的见解
逻辑回归通过将线性回归的输出映射到 [ 0 , 1 ] \left[0,1\right] [0,1]区间,来表示某个类别的概率。也就是其本质是先通过线性回归的预测值 y \boldsymbol{y} y输入到映射函数,既将线性回归的输出通过映射函数映射到 [ 0 , 1 ] \left[0,1\right] [0,1].常用的映射函数是sigm…...