数据分析Agent构建
数据分析agent构建
代码资料来源于 Streamline-Analyst,旨在通过该仓库上的代码了解如何使用大语言模型构建数据分析工具;
个人仓库:Data-Analysis-Agent-Tutorial
不同的在于 Data-Analysis-Agent-Tutorial 是在 Streamline-Analyst 基础上进行学习参考的,将其调用的api接口从GPT改成了国内常见的QWEN。
觉得有用的话欢迎各位点一个Star呀,后续还将继续更新其余类型的模型预测。
准备工作
大语言模型API,以QWEN为例,在阿里云百炼大模型平台注册API账号,新人注册免费用百万Token够用。获取之后将API Key添加到自己的环境变量中,保证下面的代码中能够正确获取自己的API。
(注:代码中没有通过这行代码获取API Key,函数中传入的变量暂时都是None,但不妨碍模型的正常调用,langchain中的ChatTongyi模型在传入的api参数不能用的时候会自动搜索环境变量)
import os
os.environ["DASHSCOPE_API_KEY"]
运行方式
streamlit run app.py
二分类预测模型
以肺癌调查数据为例,通过多种属性数据判断是否有肺癌。详细数据见 sample_data/1_survey_lung_cancer.csv
程序的主入口在 app.py 中
# 下面这部分是界面的初始设置,包括标题、界面介绍的,可以对应调试看看不同st.set_page_config(page_title="Data Analysis Agent", page_icon=":rocket:", layout="wide")# TITLE SECTION
with st.container():st.subheader("Hello there 👋")st.title("Welcome to Data-Analysis-Agent-Tutorial!")if 'initialized' not in st.session_state:st.session_state.initialized = Trueif st.session_state.initialized:st.session_state.welcome_message = welcome_message()st.write(stream_data(st.session_state.welcome_message))time.sleep(0.5)st.write("[Github > ](https://github.com/WuChaseSea/Data-Analysis-Agent-Tutorial)")st.session_state.initialized = Falseelse:st.write(st.session_state.welcome_message)st.write("[Github > ](https://github.com/WuChaseSea/Data-Analysis-Agent-Tutorial)")
在设置界面之后,构建相关按钮、交互界面的形式输入一些参数,包括api、文档、大语言模型、预测模型等
st.divider()
st.header("Let's Get Started")
left_column, right_column = st.columns([6, 4])
with left_column:API_KEY = st.text_input("Your API Key won't be stored or shared!",placeholder="Enter your API key here...",)st.write("👆Your OpenAI API key:")uploaded_file = st.file_uploader("Choose a data file. Your data won't be stored as well!", accept_multiple_files=False, type=['csv', 'json', 'xls', 'xlsx'])if uploaded_file:if uploaded_file.getvalue():uploaded_file.seek(0)st.session_state.DF_uploaded = read_file_from_streamlit(uploaded_file)st.session_state.is_file_empty = Falseelse:st.session_state.is_file_empty = True
with right_column:SELECTED_MODEL = st.selectbox('Which OpenAI model do you want to use?',('QWEN-2.5', 'QWEN-3'))MODE = st.selectbox('Select proper data analysis mode',('Predictive Classification', 'Clustering Model', 'Regression Model', 'Data Visualization'))st.write(f'Model selected: :green[{SELECTED_MODEL}]')st.write(f'Data analysis mode: :green[{MODE}]')# Proceed Button
is_proceed_enabled = uploaded_file is not None and API_KEY != "" or uploaded_file is not None and MODE == "Data Visualization"# Initialize the 'button_clicked' state
if 'button_clicked' not in st.session_state:st.session_state.button_clicked = False
if st.button('Start Analysis', disabled=(not is_proceed_enabled) or st.session_state.button_clicked, type="primary"):st.session_state.button_clicked = True
if "is_file_empty" in st.session_state and st.session_state.is_file_empty:st.caption('Your data file is empty!')
在所有参数输入之后,可以通过上一步选择的预测模型对文档进行分析预测等,比如对肺癌数据选择的是 Predictive Classification
GPT_MODEL = 3 if SELECTED_MODEL == 'QWEN-3' else 2
with st.container():if "DF_uploaded" not in st.session_state:st.error("File is empty!")else:if MODE == 'Predictive Classification':prediction_model_pipeline(st.session_state.DF_uploaded, API_KEY, GPT_MODEL)
因此预测分类模型的重点部分在models/prediction_model.py prediction_model_pipeline()函数里
包括以下步骤:
- 决定目标属性:让大语言模型根据表格的属性字段自行决定哪一个属性是需要预测的,比如这里的就是 LUNG_CANCER;
- 处理和计算缺失值:让大语言模型根据表格的属性字段决定对字段的缺失值应该怎么处理,比如用平均值、中值等;
- 数据编码:让大语言模型根据表格的属性字段决定对字段是否需要进行one-hot编码、文本类型丢弃等;
- 相关性计算:计算不同字段之间的相关性,这部分不用调用api;
- PCA:根据阈值决定是否需要使用PCA降维;
- 数据划分:让大语言模型根据数据量决定测试集的比例;
- 数据平衡:让大语言模型根据不同类型的数据量决定是否需要进行不平衡数据采样方法,包括RandomOverSampler、SMOTE、ADASYN等;
- 模型训练:让大语言模型根据表格内容决定前3种可能使用的分类模型,包括LogisticRegression、SVC、GaussianNB、RandomForestClassifier、AdaBoostClassifier、XGBClassifier、GradientBoostingClassifier等;
- 结果展示:对选择的3种分类模型结果进行展示;
目前跑通的效果图:

相关文章:
数据分析Agent构建
数据分析agent构建 代码资料来源于 Streamline-Analyst,旨在通过该仓库上的代码了解如何使用大语言模型构建数据分析工具; 个人仓库:Data-Analysis-Agent-Tutorial 不同的在于 Data-Analysis-Agent-Tutorial 是在 Streamline-Analyst 基础…...
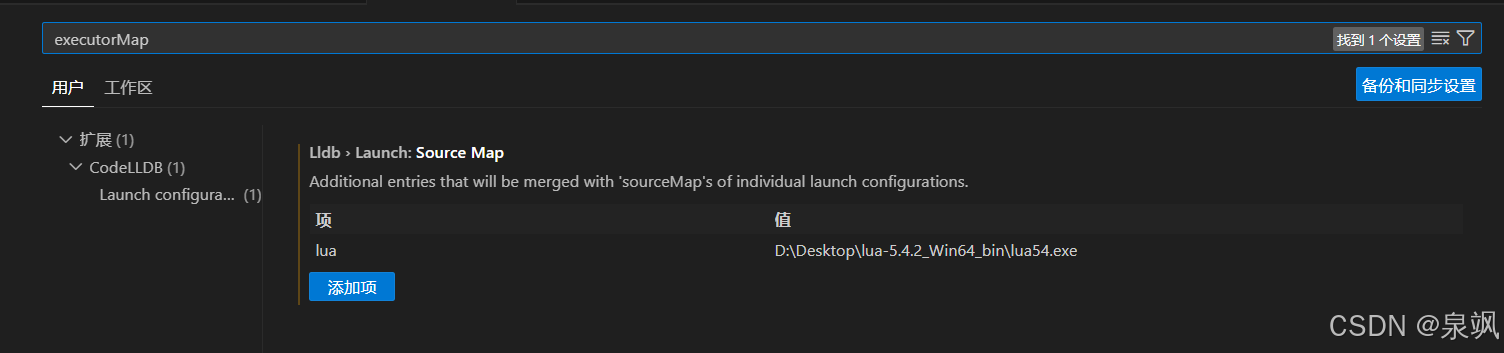
vscode配置lua
官网下载lua得到如下 打开vscode的扩展下载如下三个 打开vscode的此处设置 搜索 executorMap,并添加如下内容...

【笔记】MSYS2 的 MINGW64 环境 全面工具链
#工作记录 MSYS2 的 MINGW64 环境(mingw64.exe),下面是为该环境准备的最全工具链安装命令(包括 C/C、Python、pip/wheel、GTK3/GTK4、PyGObject、Cairo、SDL2 等)。 这一环境适用于构建原生 64 位 Windows 应用程序。…...

国内头部的UWB企业介绍之品铂科技
一、核心优势与技术实力 厘米级定位精度 自主研发的ABELL无线实时定位系统,在复杂工业环境中实现静态与动态场景下10-30厘米高精度定位,尤其擅长金属设备密集的化工、电力等场景,抗干扰能力行业领先。多技术融合能力 支持卫星…...
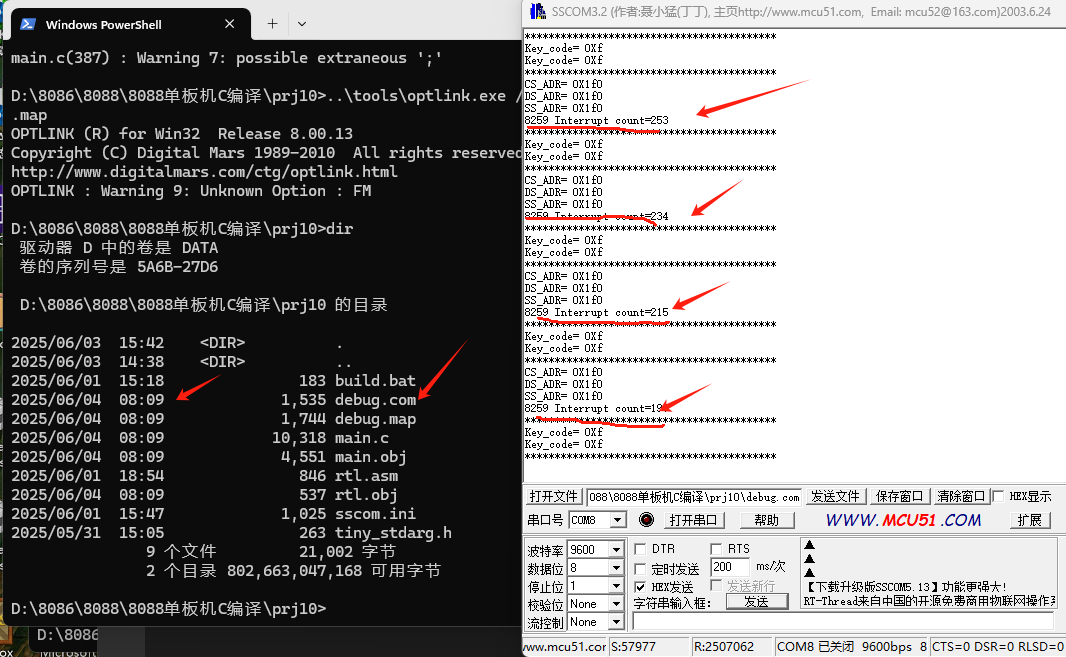
Prj10--8088单板机C语言8259中断测试(2)
1.测试结果 2.全部代码 #include "tiny_stdarg.h" // 使用自定义可变参数实现#define ADR_273 0x0200 #define ADR_244 0x0400 #define LED_PORT 0x800 #define PC16550_THR 0x1f0 #define PC16550_LSR 0x1f5 / //基本的IO操作函数 / char str[]"Hel…...

《前端面试题:CSS对浏览器兼容性》
CSS浏览器兼容性完全指南:从原理到实战 跨浏览器兼容性是前端开发的核心挑战,也是面试中的高频考点。查看所有css属性对各个浏览器兼容网站:https://caniuse.com 一、浏览器兼容性为何如此重要? 在当今多浏览器生态中,…...

使用 Docker Compose 安装 Redis 7.2.4
前面是指南,后面是主要步骤实际执行日志 使用 Docker Compose 安装 Redis 7.2.4 以下是使用 Docker Compose 安装 Redis 7.2.4 的完整指南: 1. 创建项目目录和文件 bash 复制 下载 # 创建项目目录 mkdir redis-docker && cd redis-docker#…...

35.x64汇编写法(二)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:34.x64汇编写法(一) 上一个内容写了,汇编调…...

安全大模型的思考
马上要准备2025年的护网了,最近就一直很忙,被事情裹挟着前进,忙的晕头转向,近乎感冒,昨天部门搞了一场AI大模型培训,演讲者有着很深的技术底蕴,我听到了一句关于Sass数据验证这块大为感悟&#…...

SQL Server 2025 预览版新功能
T-SQL 语言增强 正则表达式 (Regex) 支持 功能概述: SQL Server 2025 在 T-SQL 中原生引入了 POSIX 兼容的正则表达式支持,通过内置函数(如 REGEXP_LIKE、REGEXP_REPLACE 等)可直接在查询中对文本进行复杂模式匹配、查找和替换。…...
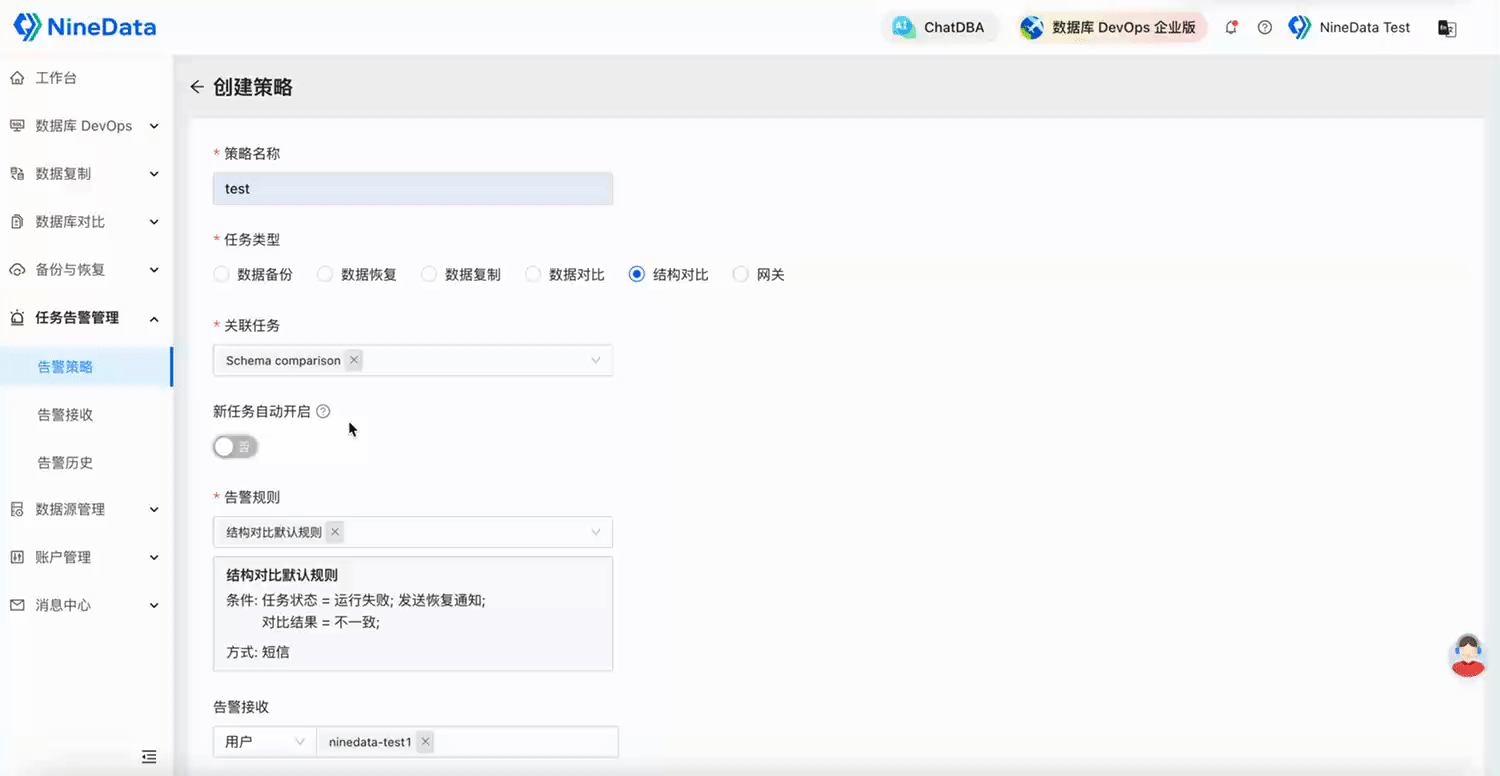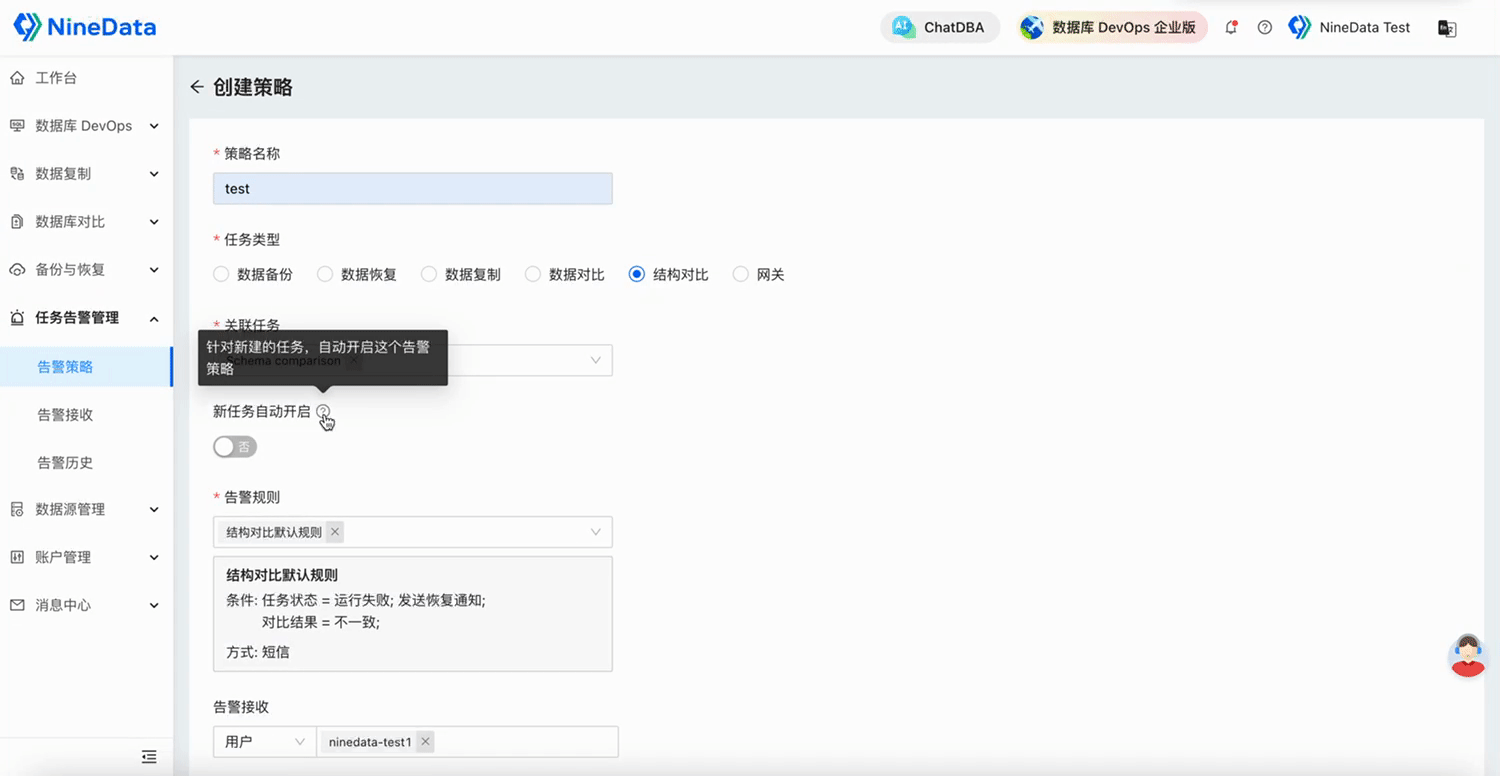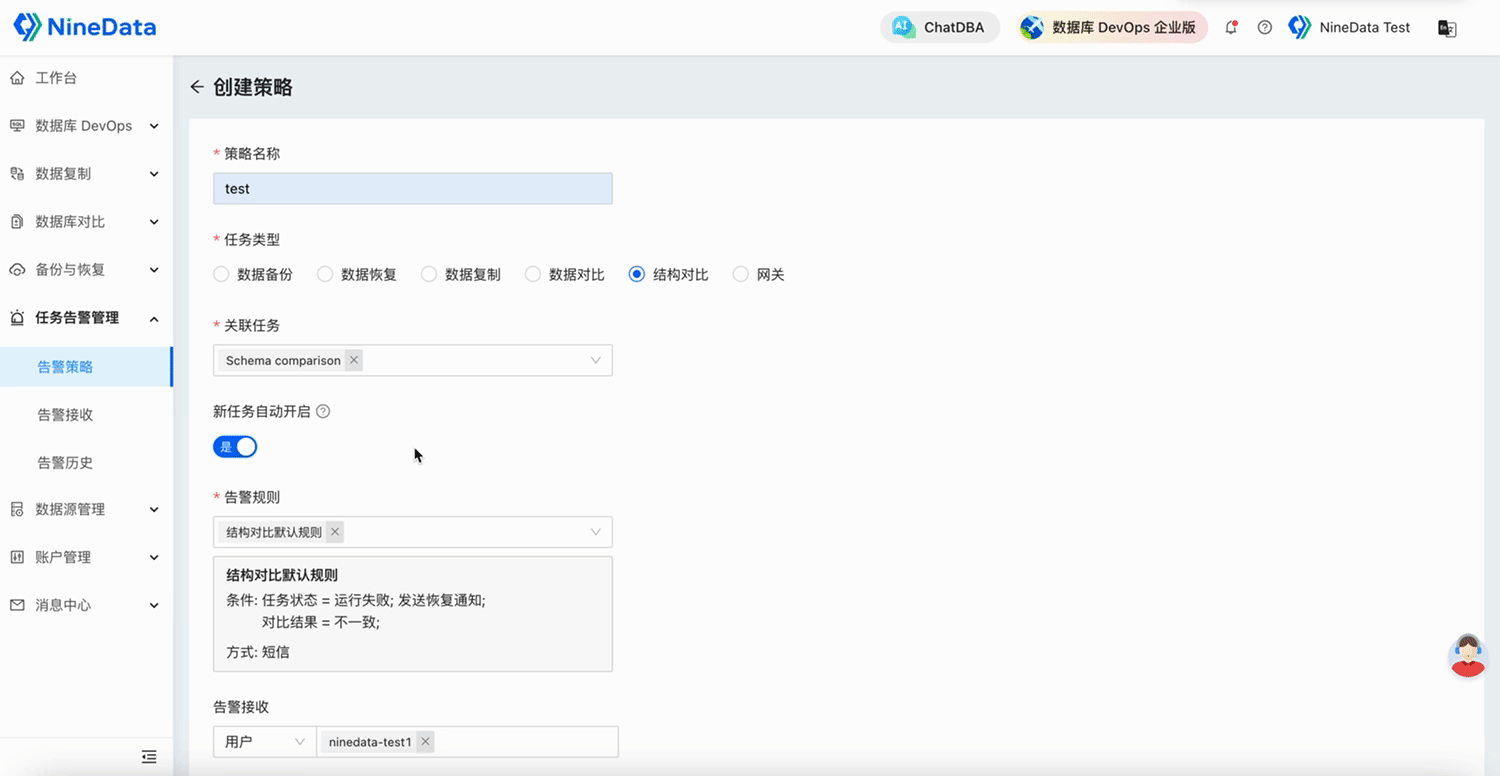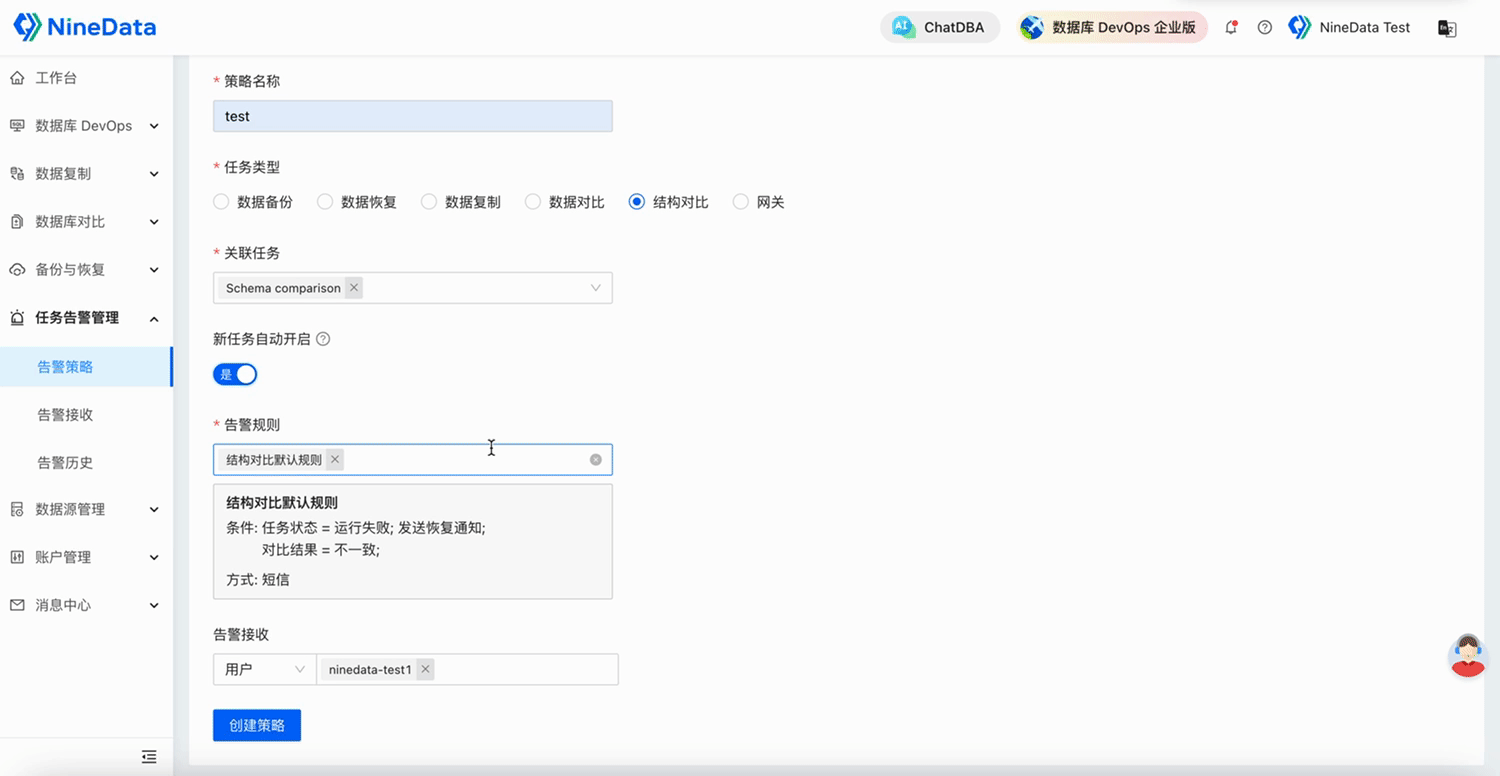
NineData云原生智能数据管理平台新功能发布|2025年5月版
本月发布 6 项更新,其中重点发布 3 项、功能优化 3 项。 重点发布 数据库 DevOps - 多源敏感数据保护 敏感数据扫描能力大幅扩展,新增支持 TiDB、Doris、SelectDB、OceanBase MySQL、GreatSQL、StarRocks、ClickHouse、SingleStore、Lindorm 9 种大数据…...

数学复习笔记 25
今天能把第五章学完。加油。今年是最好上岸的一年。 5.23:全是单根,笑死,居然难受了。我现在每个题,都要总结。总结。总结实际上也总结不出啥东西。但是我一定要总结。主动让自己思考一下。老师的思路很清奇。他认为考的稀松平常…...
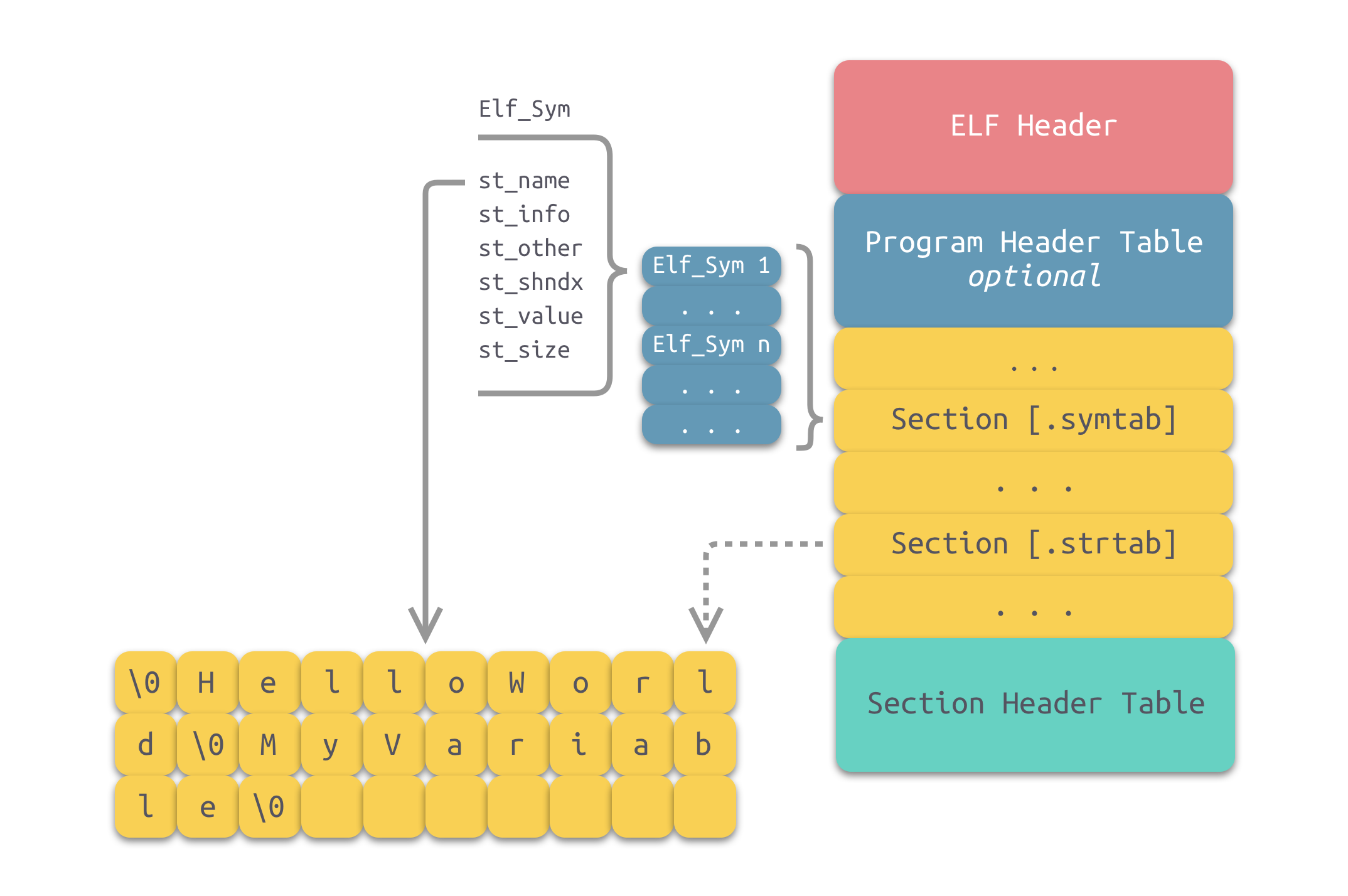
Linux可执行文件ELF文件结构
目标文件格式 编译器编译源代码后生成的文件叫做目标文件,而目标文件经过编译器链接之后得到的就是可执行文件。那么目标文件到底是什么?它和可执行文件又有什么区别?链接到底又做了什么呢?接下来,我们将探索一下目标…...

RAG:大模型微调的革命性增强——检索增强生成技术深度解析
RAG:大模型微调的革命性增强——检索增强生成技术深度解析 当大模型遇到知识瓶颈,RAG(检索增强生成)为模型装上"外部记忆库",让静态知识库与动态生成能力完美融合。本文将深入拆解RAG的技术原理、微调策略及…...

DisplayPort 2.0协议介绍(1)
最近开始学习DisplayPort 2.0协议,相比于DP1.4a,最主要的是速率提升到了10Gbps/lane,还有就是128b/132b编码方式的修改。至于速率13.5Gbps和20Gbps还只是可选项,在DP2.1协议才成为必须支持选项。 那在实现技术细节上有哪些变化呢…...
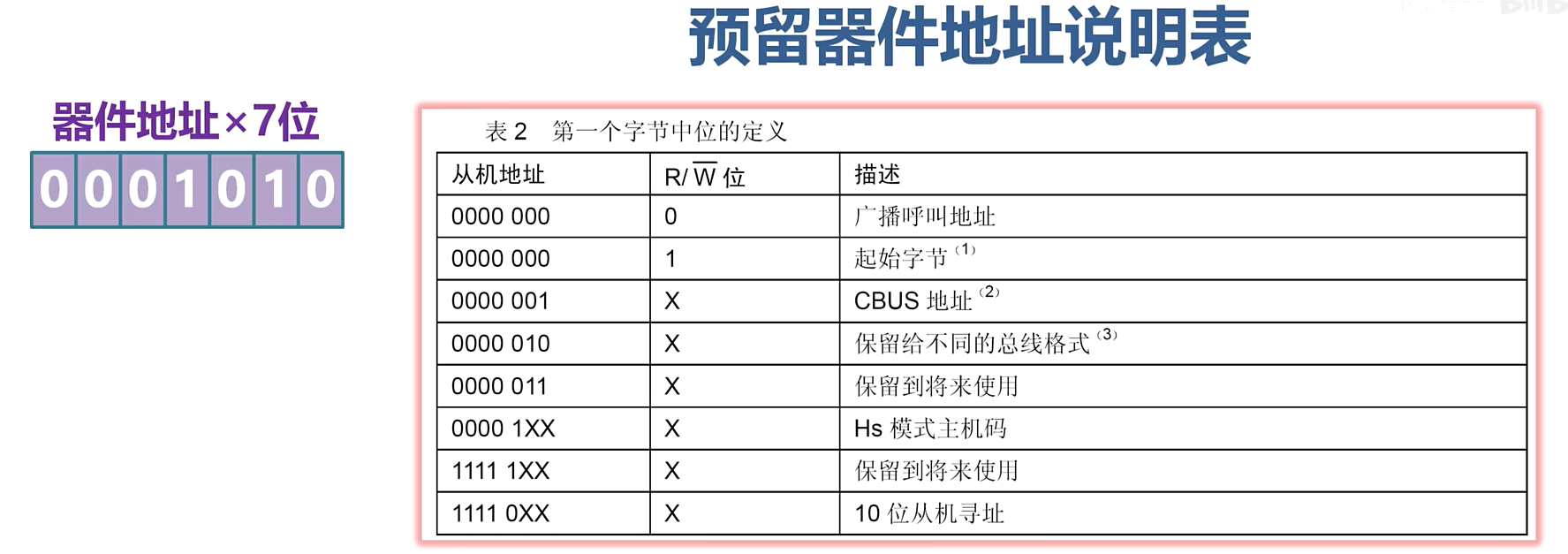
I2C通信讲解
I2C总线发展史 怎么在一条串口线上连接多个设备呢? 由于速度同步线是由主机实时发出的,所以主机可以按需求修改通信速度,这样在一条线上可以挂接不同速度的器件,单片机和性能差的器件通信,就输出较慢的脉冲信号&#x…...
综合知识答案和详解)
【信息系统项目管理师-选择真题】2025上半年(第一批)综合知识答案和详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

ABP VNext 在 Kubernetes 中的零停机蓝绿发布
ABP VNext 在 Kubernetes 中的零停机蓝绿发布 🚀 📚 目录 ABP VNext 在 Kubernetes 中的零停机蓝绿发布 🚀📌 一、前提准备 ℹ️🧱 二、项目结构与目标 🎯🐳 三、多阶段 Dockerfile 构建 &#…...

linux 故障处置通用流程-36计-14-27
014:查看系统主要日志 查看以下日志: 主要查以下关键字 error/NIC/fs /"link down"/Oout of memory" /var/log/messages /var/log/dmesg 015:主机通讯是否延迟 执行命令: #ping 网关_IP #ping 关联主机_IP …...

https和http有什么区别-http各个版本有什么区别
http和 https的区别 HTTP(超文本传输协议)和 HTTPS(安全超文本传输协议)是两种用于在网络上传输数据的协议,它们的主要区别在于安全性: HTTP(Hypertext Transfer Protocol)&#x…...
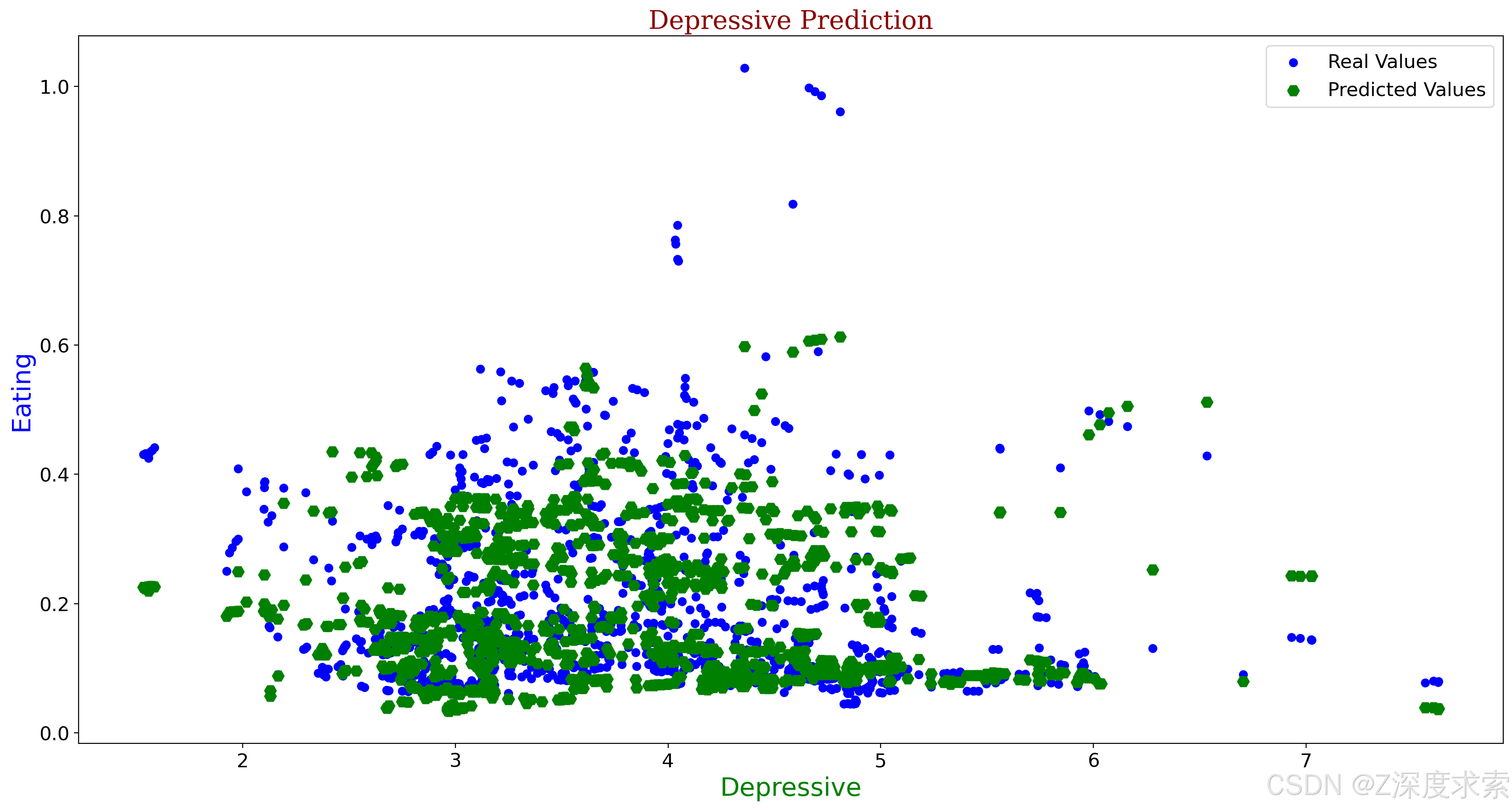
基于回归算法的心理健康预测(EDA + 预测)
心理健康涵盖情感、心理与社会福祉,影响认知、情绪和行为模式,决定压力应对、人际交往及健康决策,且在生命各阶段(从童年至成年)均至关重要。心理健康与身体健康同为整体健康的核心要素:抑郁会增加糖尿病、…...

React Native开发鸿蒙运动健康类应用的项目实践记录
项目名称:HarmonyFitness - 基于React Native的鸿蒙运动健康应用 技术栈:React Native 0.72.5 TypeScript HarmonyOS API ArkTS原生模块 一、环境搭建与项目初始化 双环境配置 React Native环境: npx re…...

【新品解读】一板多能,AXRF49 定义新一代 RFSoC FPGA 开发平台
“硬件系统庞杂、调试周期长” “高频模拟前端不稳定,影响采样精度” “接收和发射链路难以同步,难以扩展更多通道” “数据流量大,处理与存储跟不上” 这些是大部分客户在构建多通道、高频宽的射频采样链路时,面临的主要问题。…...

贪心算法应用:线性规划贪心舍入问题详解
贪心算法应用:线性规划贪心舍入问题详解 贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而希望导致结果是全局最优的算法策略。在线性规划问题中,贪心算法特别是贪心舍入技术有着广泛的应用。下面我将全面详细地讲解这一主题。…...
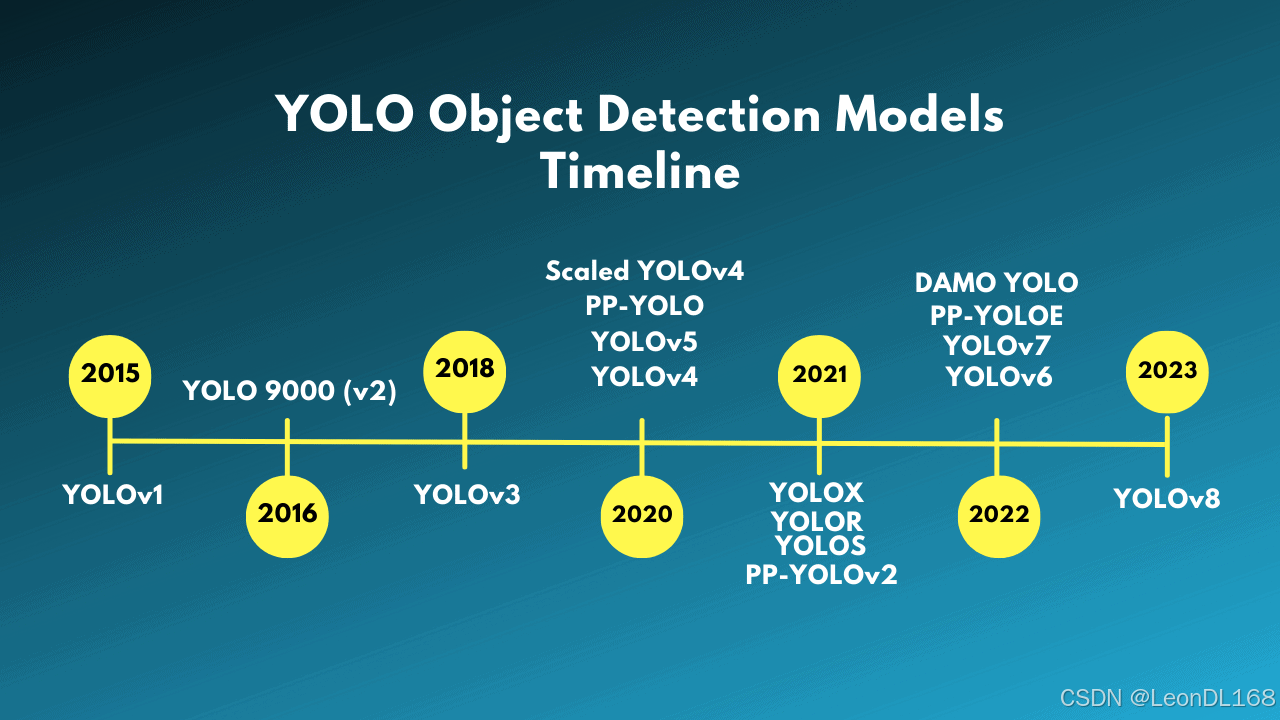
YOLO在C#中的完整训练、验证与部署方案
YOLO在C#中的完整训练、验证与部署方案 C# 在 YOLO 部署上优势明显(高性能、易集成),但训练能力较弱,通常需结合 Python 实现。若项目对开发效率要求高且不依赖 C# 生态,建议全程使用 Python;若需深度集成…...
洛谷题目:P2761 软件补丁问题 (本题简单)
个人介绍: 题目传送门: P2761 软件补丁问题 - 洛谷 (luogu.com.cn) 前言: 这道题是一个典型的状态搜索问题,核心目标就是利用给定d额多个补丁程序,将包含若干错误的软件修复成没有错误的状态,并且要使得修复过程当中的总耗时最少。下面是小亦为大家阐述滴思路: 1、状态…...
智慧园区数字孪生全链交付方案:降本增效30%,多案例实践驱动全周期交付
在智慧园区建设浪潮中,数字孪生技术正成为破解传统园区管理难题的核心引擎。通过构建与物理园区1:1映射的数字模型,实现数据集成、状态同步与智能决策,智慧园区数字孪生全链交付方案已在多个项目中验证其降本增效价值——某物流园区通过该方案…...
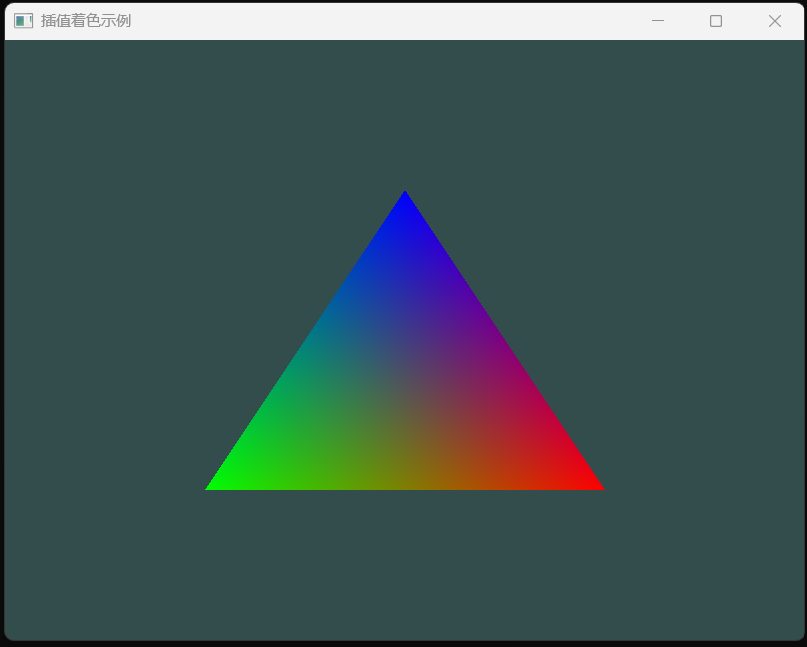
【OpenGL学习】(四)统一着色和插值着色
文章目录 【OpenGL学习】(四)统一着色和插值着色统一着色(Flat/Uniform Shading)插值着色(Interpolated Shading) 【OpenGL学习】(四)统一着色和插值着色 着色器介绍: h…...

42、响应处理-【源码分析】-浏览器与PostMan内容协商完全适配
42、响应处理源码分析浏览器与PostMan内容协商完全适配 要实现浏览器与PostMan在内容协商上的完全适配,需要在Spring Boot应用中自定义内容协商策略,确保服务器能根据浏览器和PostMan的请求头正确返回合适格式的数据。以下是详细的步骤: ### …...
在 CentOS 上安装 Docker 和 Docker Compose 并配置使用国内镜像源
在 CentOS 上安装 Docker 和 Docker Compose 并配置使用国内镜像源,可以加速镜像下载速度。以下是详细的步骤: 一、安装 Docker 移除旧版本的 Docker(如果有): sudo yum remove docker \docker-client \docker-client…...