保姆级Elasticsearch集群部署指导
一、环境准备
1. 硬件要求(单节点建议)
- CPU:至少2核(生产环境4核+)
- 内存:至少4GB(生产环境建议16GB+,且为偶数,如8GB、16GB)
- 磁盘:至少50GB SSD(数据盘,建议使用高速存储)
- 系统:Linux(推荐CentOS 7+/Ubuntu 20.04+),不建议Windows生产环境
2. 软件版本
- Elasticsearch:7.6.1+(本文以7.8.0为例)
- JDK:必须为Java 11+(Elasticsearch 8.x需Java 17+)
二、安装前准备
1. 下载安装包
- 官网下载:Elasticsearch下载页
- 示例命令(以7.8.0为例):
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz
2. 创建非root用户(重要!)
- Elasticsearch禁止以
root用户启动,需创建专用用户:useradd es # 创建用户 passwd es # 设置密码(输入两次密码)
三、集群部署步骤(以3节点为例)
1. 解压与重命名
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module # 解压到指定目录
mv /opt/module/elasticsearch-7.8.0 /opt/module/es-cluster # 重命名为es-cluster
2. 配置文件详解(3节点需分别修改)
-
路径:
/opt/module/es-cluster/config/elasticsearch.yml -
通用配置(所有节点相同):
cluster.name: cluster-es # 集群名称,同一集群内必须一致 network.host: 0.0.0.0 # 绑定所有IP,允许外部访问 http.cors.enabled: true # 启用CORS跨域 http.cors.allow-origin: "*" # 允许所有来源访问 http.port: 9200 # HTTP服务端口(默认9200,可保持默认) transport.tcp.port: 9300 # 节点间通信端口(默认9300,可保持默认) http.max_content_length: 200mb # 最大请求体大小 -
节点差异化配置(每个节点唯一):
节点 node.name network.host(示例IP) cluster.initial_master_nodes discovery.seed_hosts(填写所有节点IP:9300) node-1 node-1 192.168.59.142 [“node-1”] [“192.168.59.142:9300”, “192.168.59.145:9300”, “192.168.59.146:9300”] node-2 node-2 192.168.59.145 [“node-1”] 同上 node-3 node-3 192.168.59.146 [“node-1”] 同上 关键参数说明:
node.master: true:允许该节点参与主节点选举(建议至少2个节点设置为true)。node.data: true:允许该节点存储数据(若为纯协调节点,可设为false)。cluster.initial_master_nodes:初始化集群时指定主节点候选列表(仅首次启动需配置,后续可删除)。discovery.seed_hosts:节点发现列表,用于自动发现集群内其他节点。
3. 系统权限与资源限制
-
设置文件权限:
chown -R es:es /opt/module/es-cluster # 赋予es用户所有权 -
修改系统限制(所有节点执行):
vi /etc/security/limits.conf # 编辑系统限制文件添加以下内容(提升文件句柄和进程数限制):
es soft nofile 65536 es hard nofile 65536 es soft nproc 4096 es hard nproc 4096 -
修改虚拟内存限制:
vi /etc/sysctl.conf # 编辑系统内核参数添加:
vm.max_map_count=655360 # 提升内存映射区域限制应用修改:
sysctl -p
四、启动集群
1. 切换至es用户
su - es
2. 启动单节点(3个节点分别执行)
/opt/module/es-cluster/bin/elasticsearch -d # 后台启动
3. 检查启动状态
-
查看日志(默认路径:
/opt/module/es-cluster/logs/elasticsearch.log):tail -f /opt/module/es-cluster/logs/elasticsearch.log搜索关键词
started,若出现[node-1] started表示启动成功。 -
检查HTTP端口(9200):
curl http://localhost:9200输出JSON信息表示服务运行正常。
-
检查集群节点状态:
curl http://localhost:9200/_cat/nodes?v预期输出类似:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 192.168.59.142 20 75 5 0.01 0.02 0.05 mdi * node-1 192.168.59.145 18 73 3 0.01 0.02 0.05 mdi - node-2 192.168.59.146 17 72 4 0.01 0.02 0.05 mdi - node-3master列的*表示主节点,-表示从节点。node.role:m=主节点候选,d=数据节点,i=索引节点。
五、集群管理与可视化
1. 安装Cerebro(可视化工具)
-
下载安装包:
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tar.gz tar -zxvf cerebro-0.9.4.tar.gz -C /opt/module -
配置文件修改:
vi /opt/module/cerebro/conf/application.conf修改以下内容:
server.http.port = 9001 # 端口号(默认9000,避免冲突可改为9001) # 取消注释并修改数据路径(避免默认路径权限问题) data.path: "/opt/module/cerebro/cerebro.db" -
启动Cerebro:
/opt/module/cerebro/bin/cerebro & # 后台启动 -
访问可视化界面:
浏览器打开http://服务器IP:9001,在“Node address”中输入任一ES节点地址(如http://192.168.59.142:9200),点击“Add cluster”即可查看集群状态。
六、常见问题与解决方案
1. 启动失败:不允许root用户启动
- 原因:未使用非root用户启动。
- 解决:确保以
es用户执行启动命令(见上文“切换至es用户”步骤)。
2. 节点无法加入集群
- 原因1:防火墙未关闭或端口被屏蔽。
- 解决:关闭防火墙(临时):
systemctl stop firewalld.service systemctl disable firewalld.service # 永久关闭(生产环境需配置防火墙规则开放9200/9300端口)
- 解决:关闭防火墙(临时):
- 原因2:
discovery.seed_hosts配置错误。- 解决:检查所有节点的IP和端口是否正确,确保节点间能通过9300端口通信(可使用
telnet IP 9300测试)。
- 解决:检查所有节点的IP和端口是否正确,确保节点间能通过9300端口通信(可使用
3. 内存不足导致启动失败
- 原因:JVM内存默认配置过高(如默认
-Xms1g -Xmx1g)。 - 解决:修改
jvm.options文件(路径:/opt/module/es-cluster/config/jvm.options),降低内存配置:-Xms512m # 初始内存 -Xmx512m # 最大内存(需与初始内存一致)
七、生产环境注意事项
-
数据持久化:
- 配置
path.data到独立磁盘(如/data/es/data),避免与系统盘混用。 - 定期备份数据(使用Elasticsearch快照功能)。
- 配置
-
安全加固:
- 启用SSL/TLS加密(HTTP和传输层)。
- 配置用户认证(如Elasticsearch内置安全模块)。
- 限制公网访问,仅允许可信IP访问9200端口。
-
监控与告警:
- 使用Elasticsearch自带的
_cluster/health接口监控集群状态。 - 集成Prometheus+Grafana或Elasticsearch Monitoring进行性能监控。
- 使用Elasticsearch自带的
-
版本一致性:
- 集群内所有节点必须使用相同的Elasticsearch版本,避免兼容性问题。
八、一键部署脚本(示例)
#!/bin/bash
# 注意:生产环境需根据实际情况修改IP、端口、版本等参数echo "开始部署Elasticsearch集群..."
VERSION=7.8.0
USER=es
GROUP=es
ES_HOME=/opt/module/es-cluster# 1. 创建用户
useradd -m $USER
echo "设置用户密码(需手动输入)"
passwd $USER# 2. 解压安装包
tar -zxvf elasticsearch-${VERSION}-linux-x86_64.tar.gz -C /opt/module
mv /opt/module/elasticsearch-${VERSION} $ES_HOME# 3. 配置文件
cat > $ES_HOME/config/elasticsearch.yml <<EOF
cluster.name: cluster-es
node.name: node-1 # 需根据节点修改为node-2、node-3
network.host: 192.168.59.142 # 需替换为当前节点IP
http.port: 9200
transport.tcp.port: 9300
cluster.initial_master_nodes: ["node-1"]
discovery.seed_hosts: ["192.168.59.142:9300", "192.168.59.145:9300", "192.168.59.146:9300"]
http.cors.enabled: true
http.cors.allow-origin: "*"
EOF# 4. 设置权限
chown -R $USER:$GROUP $ES_HOME# 5. 修改系统限制
cat >> /etc/security/limits.conf <<EOF
$USER soft nofile 65536
$USER hard nofile 65536
$USER soft nproc 4096
$USER hard nproc 4096
EOF# 6. 启动服务
su - $USER -c "$ES_HOME/bin/elasticsearch -d"
echo "部署完成!访问http://$(hostname -I):9200查看状态"
相关文章:

保姆级Elasticsearch集群部署指导
一、环境准备 1. 硬件要求(单节点建议) CPU:至少2核(生产环境4核)内存:至少4GB(生产环境建议16GB,且为偶数,如8GB、16GB)磁盘:至少50GB SSD&…...

PyQt实现3维数组与界面TableWidget双向绑定
以下是一个使用PyQt实现3维数组与界面TableWidget双向绑定的示例代码。该程序包含一个下拉菜单选择第0维索引,表格展示第1维和第2维的数据,并支持双向数据同步: import sys import numpy as np from PyQt5.QtWidgets import (QApplication, …...
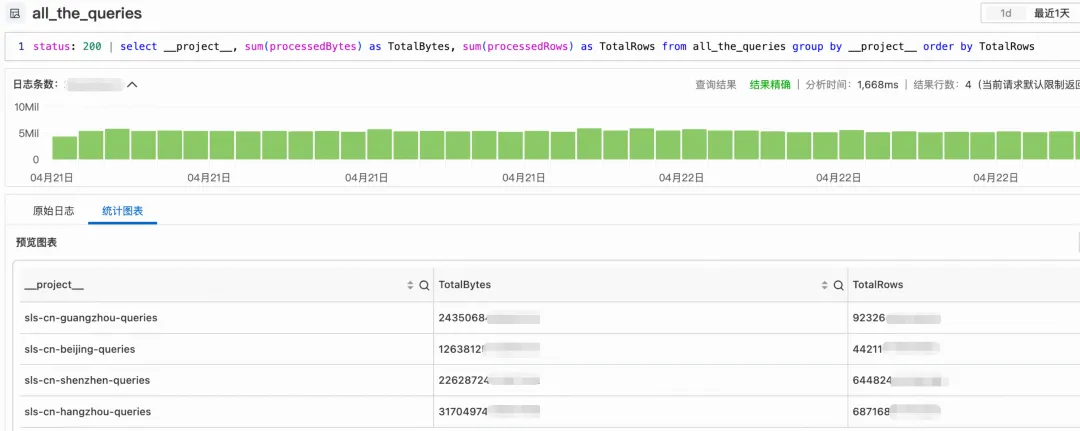
StoreView SQL,让数据分析不受地域限制
作者:章建(处知) 引言 日志服务 SLS 是云原生观测和分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务。SLS 提供了多地域支持【1】,方便用户可以根据数据源就近接入 SLS 服务,…...

护网面试题目2025
护网基础试题 一、描述外网打点的流程? 靶标确认、信息收集、漏洞探测、漏洞利用、权限获取。最终的目的是获取靶标的系统权限/关键数据。在这个过程中,信息收集最为重要。掌握靶标情报越多,后续就会有更多的攻击方式去打点。比如ÿ…...

Figma 与 Cursor 深度集成的完整解决方案
以下是 Figma 与 Cursor 深度集成的完整解决方案,实现设计-开发无缝协作: 一、集成架构设计 #mermaid-svg-NdvcKTZAZfX9DiUO {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-NdvcKTZAZfX9DiUO…...

UCRT 和 MSVC 的区别(Windows 平台上 C/C++ 开发相关)
UCRT 和 MSVC 是与 Windows 平台上 C/C 开发相关的两个重要概念,它们都属于 Microsoft 的开发工具链的一部分。下面详细解释它们的含义、区别以及用途。 一、UCRT(Universal C Runtime) 1. 含义: UCRT(Universal C …...

rabbitmq Fanout交换机简介
给每个服务创建一个队列,然后每个业务订阅一个队列,进行消费。 如订单服务起个多个服务,代码是一样的,消费的也是同一个队列。加快了队列中的消息的消费速度。 可以看到两个消费者已经在消费了...

【机器学习】集成学习与梯度提升决策树
目录 一、引言 二、自举聚合与随机森林 三、集成学习器 四、提升算法 五、Python代码实现集成学习与梯度提升决策树的实验 六、总结 一、引言 在机器学习的广阔领域中,集成学习(Ensemble Learning)犹如一座闪耀的明星,它通过组合多个基本学习器的力量,创造出…...
)
Palo Alto Networks Expedition存在命令注入漏洞(CVE-2025-0107)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...

WebFuture:Ubuntu 系统上在线安装.NET Core 8 的步骤
方法一:使用官方二进制包安装 下载.NET Core 8 SDK 二进制包:访问 .NET Core 8 SDK 官方下载页面,根据你的系统架构选择对应的 Linux x64 版本等下载链接,将其下载到本地4. 创建安装目录:在终端中执行以下命令创建用于…...
JAVA-springboot JUnit单元测试
SpringBoot从入门到精通-第9章 JUnit单元测试 一、JUnit与单元测试 JUnit是一个开源的测试框架,虽然可以用于测试大多数编程语言的应用程序,但特别适合用于测试Java语言的应用程序。 软件测试一般分为4个阶段,即单元测试、集成测试、系统测…...

hot100 -- 6.矩阵系列
1.矩阵置零 问题:给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 方法:记录行列 置0 # 记录行列,分别置0 def set_zero(matrix):row, col [], []# 统计0元素…...
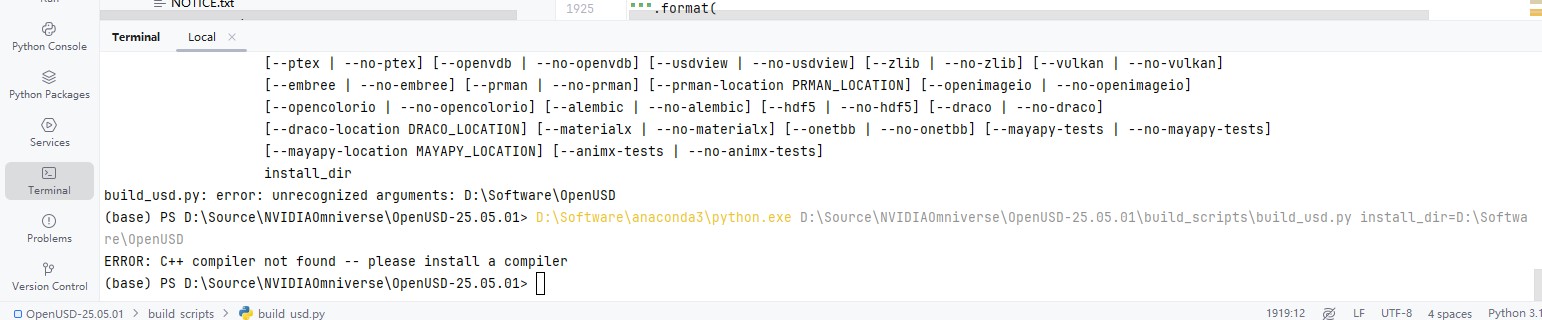
PyCharm中运行.py脚本程序
1.最近在弄一个python脚本程序,记录下运行过程。 2.编写的python程序如下 # # Copyright 2017 Pixar # # Licensed under the terms set forth in the LICENSE.txt file available at # https://openusd.org/license. # # Check whether this script is being run …...
:research_server_prompt_resource.py)
吴恩达MCP课程(5):research_server_prompt_resource.py
代码 import arxiv import json import os from typing import List from mcp.server.fastmcp import FastMCPPAPER_DIR "papers"# Initialize FastMCP server mcp FastMCP("research")mcp.tool() def search_papers(topic: str, max_results: int 5) …...

[论文阅读] 人工智能+项目管理 | 当 PMBOK 遇见 AI:传统项目管理框架的破局之路
当PMBOK遇见AI:传统项目管理框架的“AI适配指南” 论文信息 arXiv:2506.02214 Is PMBOK Guide the Right Fit for AI? Re-evaluating Project Management in the Face of Artificial Intelligence Projects Alexey Burdakov, Max Jaihyun Ahn Subjects: Software …...
Gateway 搭建
1.创建 moudle 命名为 gateway 2,pom中引入依赖 网关依赖;注册中心依赖等 <!-- 网关依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></d…...
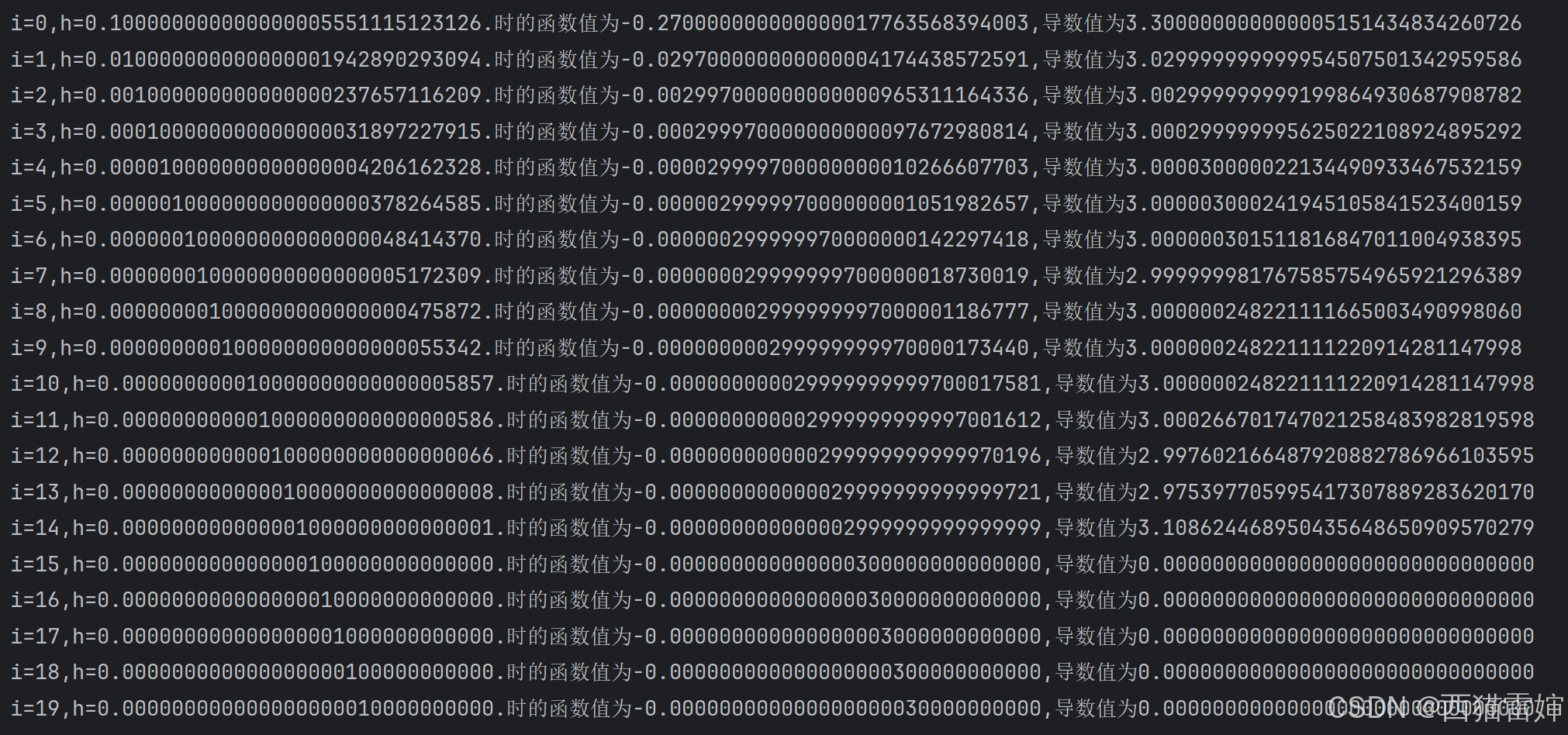
pytorch基本运算-导数和f-string
引言 在前序对机器学习的探究过程中,我们已经深刻体会到人工智能到处都有微分求导运算,相关文章链接包括且不限于: BP神经网络 逻辑回归 对于pytorch张量,求导运算必不可少,所以本次就专门来学习一下。 f-string的用…...

impala中更改公网ip为内网ip
实际有时候需求中需要将公网的impala监听ip改为内网的ip 步骤 1,更改配置文件中的ip 1,更改/etc/default/impala中的ip配置重启服务即可在hive元数据同一个节点上要启动sudo service impala-state-store restartsudo service impala-catalog restart所有…...
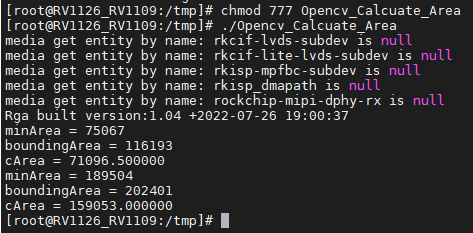
5.RV1126-OPENCV 图形计算面积
一.图形面积、弧长计算介绍 前面我们已经把图形轮廓的检测、画框等功能讲解了一遍。这次主要结合轮廓检测的 API 去计算图形的面积,这些面积可以是矩形、圆形等等。图形面积计算和弧长计算常用于车辆识别、桥梁识别等重要功能,常用的 API 如 contourArea…...

一键净化Excel数据:高性能Python脚本实现多核并行清理
摘要 本文分享两个基于Python的Excel数据净化脚本,通过多进程并行技术清除工作表内不可见字符、批注、单元格样式等冗余内容,利用OpenPyXL实现底层操作,结合tqdm进度条和进程级任务分配,可快速处理百万级单元格数据。适用于数据分…...
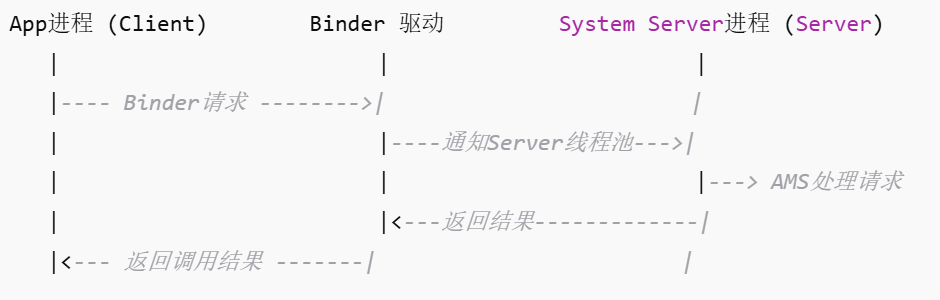
【Android基础回顾】一:Binder机制是什么?有什么用?
Android中的Binder机制是Android系统中最核心和最基础的进程间通讯机制。 1 什么是进程间通讯机制(IPC)? 众所周知,Android系统基于Linux开发,Linux系统里面本来就有进程间通讯机制。 1.1 Linux的IPC(Inter-Process Communication)概览 它…...

LeetCode 高频 SQL 50 题(基础版) 之 【高级查询和连接】· 上
题目:1731. 每位经理的下属员工数量 题解: select employee_id,name,reports_count,average_age from Employees t1,(select reports_to,count(*) reports_count,round(avg(age)) average_agefrom Employeeswhere reports_to is not nullgroup by repor…...
资产智慧管理安全监测中心
在数字经济高速发展的今天,资产管理的智能化已成为企业降本增效的核心竞争力。从智慧园区到古建筑群,从交通枢纽到城市电网,资产智慧管理安全监测中心正以物联网、人工智能、数字孪生等技术为支撑,构建起资产全生命周期的“智慧大…...

从零开始的云计算——番外实战,iptables防火墙项目
目录 一网络规划 二项目要求 三环境准备 1防火墙设置 2PC1设置 3PC2设置 4服务器S1设置 四环境检测 1内网链接 2外网连接 五防火墙配置及测试 1内部网络中的pc1采用SNAT访问外部互联网,但是无法ping到内部网关。 编辑编辑 2内部网络服务器s1通过DN…...

移动网页调试的多元路径:WebDebugX 与其他调试工具的组合使用策略
在移动端网页开发中,仅靠一款工具很难覆盖所有调试场景。不同问题类型需要不同的调试维度——有时是网络请求,有时是 DOM 样式,有时是 JS 状态,有时是性能瓶颈。 本文以“多工具协作”为核心思想,结合多个项目经验&am…...
【基于阿里云搭建数据仓库(离线)】IDEA导出Jar包(包括第三方依赖)
目录 方法一: 方法二 1.双击"package”即可进行打包呈jar 2.双击后就会自动打包生成jar了, 生成的jar在这个目录下 3.右击,点击“复制路径/引用”,即可获得“绝对路径”、“根路径”等相关信息 前提: 在pop.…...
研发方案详解)
【HarmonyOS 5】鸿蒙HarmonyOS —(cordova)研发方案详解
Android、Ios 和 HarmonyOS APP研发分析 Android研发语言Java、Ios研发语言objective-c, HarmonOS研发语言ArkTs和C/C,写了第一句,就会有人反驳,Android和Ios也支持C/C语言,封装成动态库so,然后调用就可以了࿰…...

Linux程序运行日志总结
在Linux系统中,程序运行时产生的日志记录主要通过以下几种方式实现,这些日志有助于排查问题、监控系统行为或审计安全事件: 1. 系统日志(System Logs) 存放路径:通常位于 /var/log/ 目录下。常见日志文件: /var/log/syslog 或 /var/log/messages:通用系统日志(取决于发…...
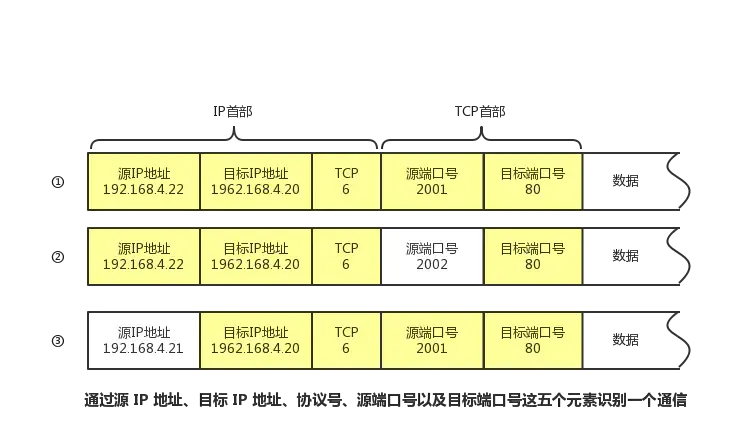
【物联网-TCP/IP】
物联网-TCP/IP ■ TCP/IP■■■ 添加链接描述 ■ TCP/IP ■ ■ ■...

SAP ECC 与 SAP S/4HANA 技术架构全面对比
SAP ECC 是过去几十年众多企业核心业务系统的基石,涵盖财务、物流、制造等关键领域。然而,随着数字化转型的加速和企业需求的增长,其架构日益显现局限。因此,SAP 推出了新一代 ERP 解决方案——SAP S/4HANA。它不仅在功能上做出优…...