NLP学习路线图(二十五):注意力机制
在自然语言处理领域,序列模型一直扮演着核心角色。从早期的循环神经网络(RNN)到如今一统天下的Transformer模型,注意力机制(Attention Mechanism) 的引入堪称一场革命。它彻底改变了模型处理序列信息的方式,显著提升了机器翻译、文本摘要、问答系统等任务的表现。本文将深入剖析注意力机制的原理、演进及其在序列模型中的关键作用。
一、序列建模的挑战:为何需要注意力?
1. 传统序列模型的瓶颈:RNN/LSTM 的困境
-
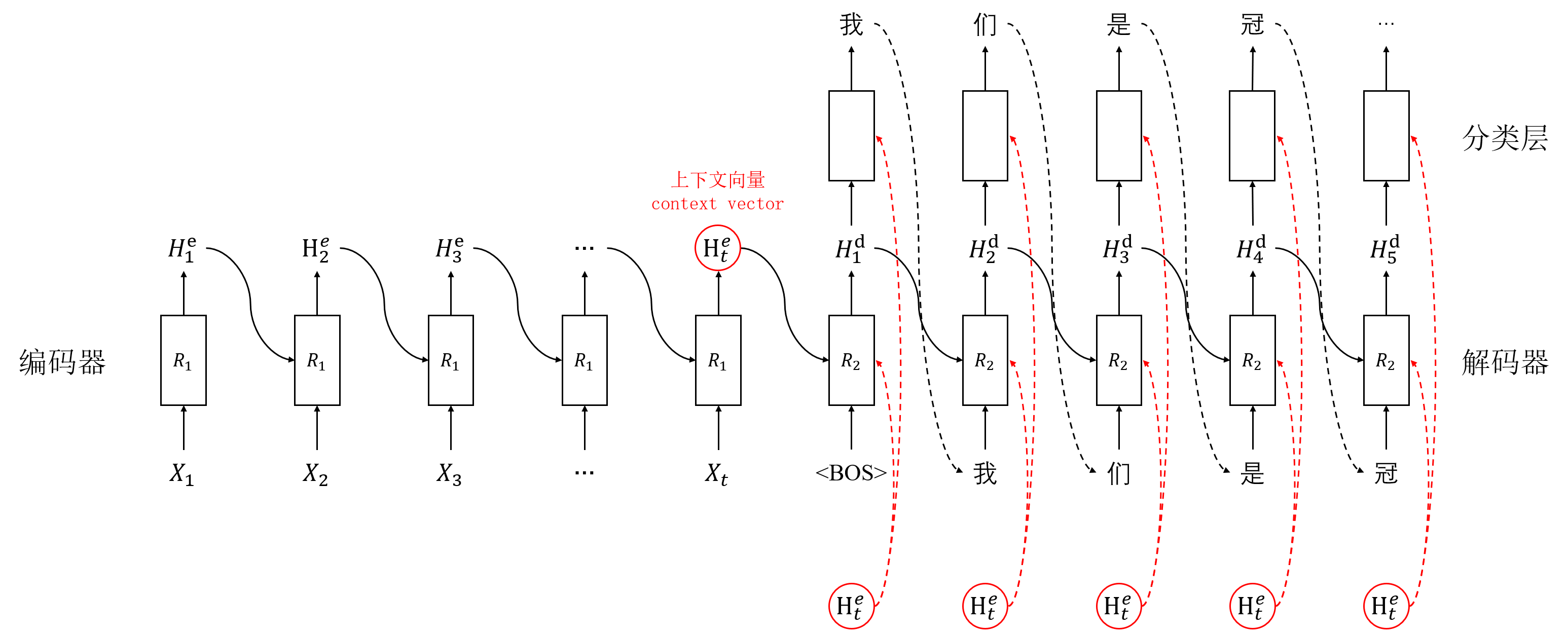
信息瓶颈: 在经典的编码器-解码器架构(如Seq2Seq)中,编码器需要将整个输入序列压缩成一个固定长度的上下文向量(Context Vector)。解码器仅依赖这个单一向量生成整个输出序列。当输入序列较长时,这个向量难以承载所有必要信息,导致细节丢失,模型性能急剧下降。
-
长程依赖衰减: 虽然LSTM/GRU在一定程度上缓解了梯度消失问题,但处理超长序列时,跨越数十甚至上百步的信息传递依然困难。模型难以有效捕捉序列远端词之间的依赖关系。
-
计算效率与并行化: RNN的循环结构要求顺序计算,无法充分利用GPU的并行计算能力,训练速度慢。
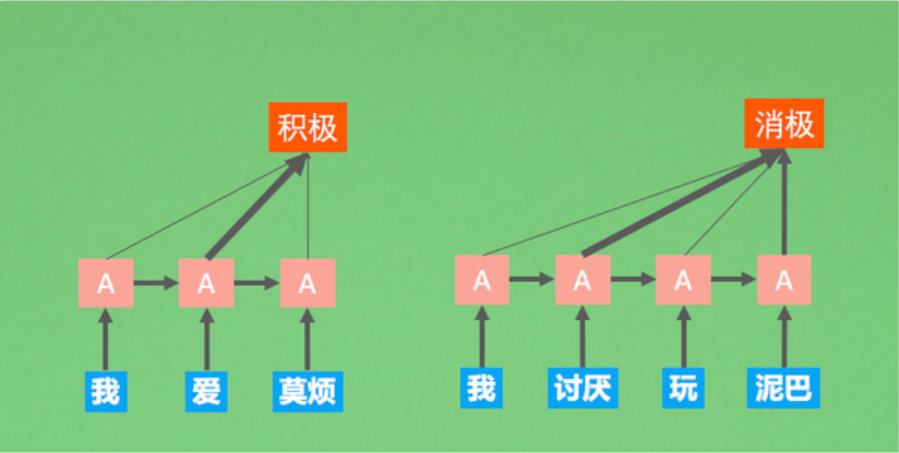
2. 核心问题:对齐(Alignment)
-
在任务如机器翻译中,输出序列的每个词通常与输入序列的特定部分高度相关。例如,翻译“apple”时,模型应更关注输入中的“苹果”,而不是其他无关词。
-
传统的Seq2Seq模型缺乏显式的对齐机制。解码器在每个时间步只能“盲目”地依赖同一个上下文向量,无法动态聚焦于输入序列的不同部分。
“注意力”的灵感来源: 人类在处理信息(如阅读、翻译)时,不会同时同等地关注所有输入,而是将认知资源聚焦于当前最相关的部分。注意力机制正是对这种生物认知过程的数学建模。
二、注意力机制:核心思想与基本形式
1. 核心思想
注意力机制的核心在于:让模型在生成输出序列的每一个元素时,能够动态地、有选择性地‘注意’输入序列中最相关的部分,并赋予其不同的重要性权重。
2. 基本计算步骤(以Seq2Seq+Attention为例)
假设我们有一个编码器(如Bi-LSTM)将输入序列 X = (x1, x2, ..., xm) 编码为隐藏状态序列 H = (h1, h2, ..., hm)。解码器在时刻 t 生成输出 yt 时:
-
计算注意力分数(Attention Scores): 度量解码器当前状态
st-1(或st) 与编码器各隐藏状态hj的相关性。-
常用评分函数(Score Function):
-
点积(Dot-Product):
score(st-1, hj) = st-1^T * hj -
缩放点积(Scaled Dot-Product):
score(st-1, hj) = st-1^T * hj / sqrt(d_k)(引入缩放因子避免点积过大导致softmax梯度太小) -
加性(Additive / Bahdanau):
score(st-1, hj) = v^T * tanh(W1 * st-1 + W2 * hj)(引入可学习参数W1, W2, v) -
通用(General / Luong):
score(st-1, hj) = st-1^T * W * hj(引入可学习矩阵W)
-
-
得到分数向量
e_t = [score(st-1, h1), score(st-1, h2), ..., score(st-1, hm)]
-
-
计算注意力权重(Attention Weights): 将分数归一化为概率分布,表示对每个输入位置的“关注程度”。
-
α_t = softmax(e_t) -
α_tj = exp(score(st-1, hj)) / Σ_k=1^m exp(score(st-1, hk)) -
α_tj越大,表示在生成yt时,输入词xj越重要。
-
-
计算上下文向量(Context Vector): 对编码器隐藏状态序列进行加权平均。
-
c_t = Σ_j=1^m α_tj * hj -
c_t融合了输入序列中被模型认为与当前输出yt最相关的信息。
-
-
结合上下文生成输出: 将上下文向量
c_t与解码器当前状态st-1(或st) 结合,预测输出yt。-
常见方式:拼接
[st; c_t]或[st-1; c_t],然后输入到一个全连接层或直接用于预测。 -
s_t = RNN(s_t-1, [y_t-1; c_t])(如果未在状态计算前使用) -
P(y_t | y_<t, X) = softmax(g([s_t; c_t]))(或g(s_t))
-
核心优势:
-
解决信息瓶颈: 不再依赖单一固定向量,每个输出词拥有定制化的上下文向量
c_t。 -
显式对齐: 注意力权重
α_tj直接可视化了输入词与输出词之间的软对齐关系。 -
改善长程依赖: 模型可以直接“访问”输入序列的任何位置,不受距离限制。
-
(一定程度)可解释性: 通过观察权重分布,可以理解模型在生成特定输出时的决策依据。
三、自注意力(Self-Attention)与 Transformer:注意力机制的巅峰
虽然注意力在Seq2Seq中效果显著,但Transformer模型通过自注意力(Self-Attention) 和多头注意力(Multi-Head Attention) 将其推向了极致,并完全摒弃了RNN。
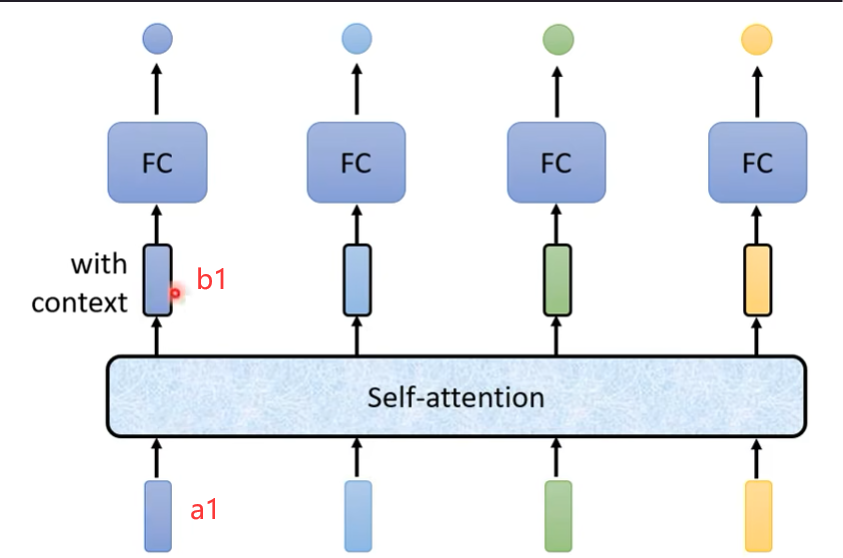
1. 自注意力(Self-Attention)
-
核心思想: 序列中的每个元素(词)都计算它与序列中所有其他元素(包括自身)之间的注意力权重,并据此更新自身的表示。
-
目的: 学习序列内部元素之间的依赖关系,捕捉上下文信息。例如,“it”这个词的表示应该取决于它所指代的前文名词。
-
计算过程(Scaled Dot-Product Attention):
-
将输入序列
X(维度n x d_model) 通过三个不同的线性变换投影到 Query (Q)、Key (K)、Value (V) 空间:-
Q = X * W_Q(维度n x d_k) -
K = X * W_K(维度n x d_k) -
V = X * W_V(维度n x d_v)
-
-
计算注意力分数矩阵:
Scores = Q * K^T(维度n x n) -
缩放(Scale):
Scores = Scores / sqrt(d_k) -
应用 Mask(可选): 在解码器或处理填充时,掩盖未来位置或无效位置(
-inf)。 -
Softmax归一化:
Weights = softmax(Scores, dim=-1)(维度n x n) -
加权求和输出:
Output = Weights * V(维度n x d_v)
-
-
公式:
Attention(Q, K, V) = softmax(Q * K^T / sqrt(d_k)) * V
2. 多头注意力(Multi-Head Attention)
-
核心思想: 并行地进行
h次(头数)独立的Scaled Dot-Product Attention操作,允许模型在不同表示子空间(子空间由不同的W_Q^l, W_K^l, W_V^l定义)中联合关注来自不同位置的信息。这增强了模型的表示能力。 -
计算过程:
-
将
Q, K, V分别通过h组不同的线性投影 (W_Q^l, W_K^l, W_V^l, l=1...h) 得到h组head_l:-
head_l = Attention(Q * W_Q^l, K * W_K^l, V * W_V^l)
-
-
将
h个头的输出拼接(Concat)起来:MultiHead = Concat(head_1, head_2, ..., head_h) -
通过一个线性层
W_O投影回原始维度:Output = MultiHead * W_O(维度n x d_model)
-
-
公式:
MultiHead(Q, K, V) = Concat(head_1, ..., head_h) * W_Owherehead_i = Attention(Q * W_Q^i, K * W_K^i, V * W_V^i)
3. Transformer 架构
Transformer由编码器和解码器堆叠组成,核心是多头自注意力层和前馈神经网络层(FFN),辅以 残差连接(Residual Connection) 和 层归一化(Layer Normalization)。
-
编码器(Encoder)层:
-
多头自注意力层: 输入序列关注自身。
-
Add & Norm:
LayerNorm(x + Sublayer(x)) -
位置前馈网络(FFN): 两层线性变换 + ReLU激活 (
FFN(x) = max(0, x * W1 + b1) * W2 + b2)。 -
Add & Norm: 同上。
-
-
解码器(Decoder)层:
-
(掩码)多头自注意力层: 防止当前位置关注未来位置(确保自回归生成)。
-
Add & Norm
-
多头注意力层(Encoder-Decoder Attention):
Q来自解码器上一层的输出,K, V来自编码器的最终输出。这是标准的注意力机制,让解码器关注编码器的相关信息。 -
Add & Norm
-
FFN层
-
Add & Norm
-
-
位置编码(Positional Encoding): 由于自注意力本身不具有顺序信息,Transformer通过正弦/余弦函数或可学习的位置向量显式地注入序列中词的位置信息:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model)),PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))。将PE加到词嵌入上作为输入。
Transformer 的优势:
-
强大的长程依赖建模: 自注意力允许任意两个词直接交互。
-
高度并行化: 矩阵运算取代循环,极大加速训练。
-
卓越的性能: 在机器翻译、文本生成、语言理解等几乎所有NLP任务上取得SOTA或接近SOTA的结果。
-
成为大模型基石: BERT、GPT、T5等划时代的预训练语言模型均基于Transformer架构。

四、注意力机制的变体与优化
注意力机制的成功催生了大量变体,旨在解决计算效率、稀疏性、特定任务需求等问题:
-
稀疏注意力(Sparse Attention):
-
问题: 标准自注意力的计算复杂度为
O(n^2)(n是序列长度),对超长序列(如文档、书籍)计算代价高昂。 -
思路: 限制每个词只关注序列中的一个子集(如局部窗口、固定模式、可学习连接)。
-
代表:
-
局部窗口注意力: 每个词只关注其前后
k个词(如 Longformer 的滑动窗口)。 -
扩张注意力(Dilated Attention): 类似空洞卷积,间隔地关注词,扩大感受野。
-
块状/带状注意力(Block/Band Attention): 将序列分块或按对角线带状关注。
-
随机注意力(Reformer 的 LSH Attention): 利用局部敏感哈希(LSH)将相似的词聚类到桶中,只计算桶内的注意力。
-
稀疏变换器(Sparse Transformer): 定义固定的稀疏连接模式。
-
-
-
高效注意力(Efficient Attention):
-
思路: 通过数学变换(如核方法、低秩近似)将
QK^T的计算分解或近似,降低复杂度。 -
代表: Linear Attention, Performer, Linformer, FlashAttention (利用GPU内存层次结构优化IO)。
-
-
硬注意力(Hard Attention) vs 软注意力(Soft Attention):
-
软注意力: 上文介绍的都是软注意力,权重
α_tj在[0, 1]区间连续分布,模型可微。 -
硬注意力: 在每一步随机采样一个位置
j(根据α_t分布)作为焦点,只使用该位置的hj生成c_t。模型不可微,通常需强化学习训练(如REINFORCE)。应用较少。
-
-
层级注意力(Hierarchical Attention):
-
应用: 处理具有层次结构的文档(词->句子->文档)。
-
思路: 先在低层次(词级)应用注意力获得句子表示,再在高层次(句子级)应用注意力获得文档表示。能捕捉文档中重要的句子和句子中重要的词。
-
-
跨模态注意力(Cross-Modal Attention):
-
应用: 图像描述生成、视觉问答(VQA)、多模态翻译。
-
思路:
Q来自一种模态(如文本解码器的状态),K, V来自另一种模态(如图像区域特征)。让文本生成关注相关的视觉区域,或让视觉问题关注相关的文本片段。
-
五、注意力机制的应用示例(代码片段 - 文本摘要)
以下是一个简化版的基于Transformer的文本摘要模型核心部分(使用PyTorch):
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TransformerSummarizer(nn.Module):def __init__(self, vocab_size, d_model, nhead, num_layers, max_len):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model)self.pos_encoder = PositionalEncoding(d_model, max_len) # 实现位置编码self.transformer = nn.Transformer(d_model=d_model,nhead=nhead,num_encoder_layers=num_layers,num_decoder_layers=num_layers,dim_feedforward=d_model * 4,)self.fc_out = nn.Linear(d_model, vocab_size)def forward(self, src, tgt, src_mask=None, tgt_mask=None, src_key_padding_mask=None, tgt_key_padding_mask=None):# src: (src_len, batch_size), tgt: (tgt_len, batch_size)src_emb = self.embedding(src) # (src_len, batch_size, d_model)src_emb = self.pos_encoder(src_emb) # 添加位置信息tgt_emb = self.embedding(tgt) # (tgt_len, batch_size, d_model)tgt_emb = self.pos_encoder(tgt_emb) # 添加位置信息# Transformer处理 (注意Transformer的输入要求序列维度第一维)output = self.transformer(src=src_emb,tgt=tgt_emb,src_mask=src_mask, # 通常src_mask=None (允许所有位置互相关注)tgt_mask=tgt_mask, # 防止解码器看到未来信息 (下三角mask)memory_mask=None, # Encoder-Decoder Attention的masksrc_key_padding_mask=src_key_padding_mask, # 屏蔽src的padding位置 (batch_size, src_len)tgt_key_padding_mask=tgt_key_padding_mask, # 屏蔽tgt的padding位置 (batch_size, tgt_len)memory_key_padding_mask=src_key_padding_mask # 屏蔽Encoder输出的padding位置) # output: (tgt_len, batch_size, d_model)# 预测输出词概率logits = self.fc_out(output) # (tgt_len, batch_size, vocab_size)return logitsdef generate(self, src, max_len=50, start_token=1, end_token=2):# 简化版的贪婪解码生成摘要batch_size = src.size(1)device = src.device# 初始化解码器输入 (仅包含起始符)tgt = torch.full((1, batch_size), start_token, dtype=torch.long, device=device) # (1, batch_size)# 编码源序列src_emb = self.embedding(src) # (src_len, batch_size, d_model)src_emb = self.pos_encoder(src_emb)memory = self.transformer.encoder(src_emb, mask=None, src_key_padding_mask=None) # (src_len, batch_size, d_model)# 自回归生成for i in range(max_len - 1):tgt_emb = self.embedding(tgt) # (cur_len, batch_size, d_model)tgt_emb = self.pos_encoder(tgt_emb)# 创建tgt_mask (防止关注未来位置)tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size(0)).to(device) # (cur_len, cur_len)# 解码 (只取最后一个时间步的预测)out = self.transformer.decoder(tgt=tgt_emb,memory=memory,tgt_mask=tgt_mask,memory_mask=None,tgt_key_padding_mask=None,memory_key_padding_mask=None) # (cur_len, batch_size, d_model)next_logits = self.fc_out(out[-1:, :, :]) # (1, batch_size, vocab_size)next_token = next_logits.argmax(dim=-1) # (1, batch_size)# 将预测的token添加到解码器输入tgt = torch.cat([tgt, next_token], dim=0) # (cur_len+1, batch_size)# 检查是否所有序列都生成了结束符 (简化处理)# ... 实际中需要更复杂的停止条件return tgt.T # (batch_size, generated_len)# 位置编码实现示例 (正弦/余弦)
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1) # (max_len, 1, d_model)self.register_buffer('pe', pe)def forward(self, x):# x: (seq_len, batch_size, d_model)x = x + self.pe[:x.size(0), :]return x关键点解释:
-
嵌入 & 位置编码: 将输入词ID映射为向量并添加位置信息。
-
nn.Transformer: PyTorch内置的Transformer模块,封装了编码器、解码器、多头注意力层、FFN层、层归一化、残差连接。 -
tgt_mask: 在解码器自注意力层使用,确保生成t时刻的输出时,只能看到1到t-1时刻的输出(下三角为0的mask)。 -
src_key_padding_mask/tgt_key_padding_mask/memory_key_padding_mask: 用于屏蔽序列中无效的padding位置(通常值为True表示需要mask的位置)。 -
生成 (
generate方法): 使用自回归方式,从起始符开始,每一步将当前已生成的部分作为解码器输入,预测下一个最可能的词,直到达到最大长度或遇到结束符。这是贪婪解码的简化版,实际常用束搜索(Beam Search)。
六、注意力机制的最新进展与未来展望
注意力机制仍在快速发展中:
-
更高效的注意力: FlashAttention-2 等持续优化GPU实现;基于状态空间模型(如Mamba)的架构尝试替代注意力进行长序列建模。
-
更强大的建模能力: 探索如何更好地建模全局结构(如文档层级、语法树)、常识、推理能力。结合图神经网络(GNN)的图注意力网络(GAT)是方向之一。
-
可解释性与可控性: 设计方法使注意力权重更具语义意义,并允许用户通过干预注意力来引导模型生成(可控生成)。
-
多模态融合的深化: 设计更精巧的跨模态注意力机制,实现文本、图像、语音、视频等信息的深度融合与相互理解。
-
注意力在大模型中的作用: 研究超大规模语言模型(LLMs)中注意力模式(如稀疏激活的专家网络MoE)如何影响涌现能力、上下文学习、指令遵循等特性。
相关文章:
NLP学习路线图(二十五):注意力机制
在自然语言处理领域,序列模型一直扮演着核心角色。从早期的循环神经网络(RNN)到如今一统天下的Transformer模型,注意力机制(Attention Mechanism) 的引入堪称一场革命。它彻底改变了模型处理序列信息的方式…...
05 APP 自动化- Appium 单点触控 多点触控
文章目录 一、单点触控查看指针的指针位置实现手势密码: 二、多点触控 一、单点触控 查看指针的指针位置 方便查看手势密码-九宫格每个点的坐标 实现手势密码: 执行手势操作: 按压起点 -> 移动到下一点 -> 依次移动 -> 释放&am…...

MyBatis-Plus LambdaQuery 高级用法:JSON 路径查询与条件拼接的全场景解析
目录 1. 查询 JSON 字段中的特定值 2. 动态查询 JSON 字段中的值 3. 查询 JSON 数组中的值 4. 查询 JSON 字段中的嵌套对象 5. 结合其他条件查询 JSON 字段 6. 使用类型处理器简化 JSON 查询 6.1 创建自定义 JSON 类型处理器 6.2 在实体类中指定自定义类型处理器 示例…...

[AI绘画]sd学习记录(一)软件安装以及文生图界面初识、提示词写法
目录 目录一、安装软件二、文生图各部分模块 1. 下载新模型 & 画出第一张图2. 提示词输入 2.1 设置2.2 扩展模型2.3 扩展模型权重调整2.4 其他提示词输入2.5 负向提示词2.6 生成参考 3. 采样方法4. 噪声调度器5. 迭代步数6. 提示词引导系数 一、安装软件 软件安装&…...
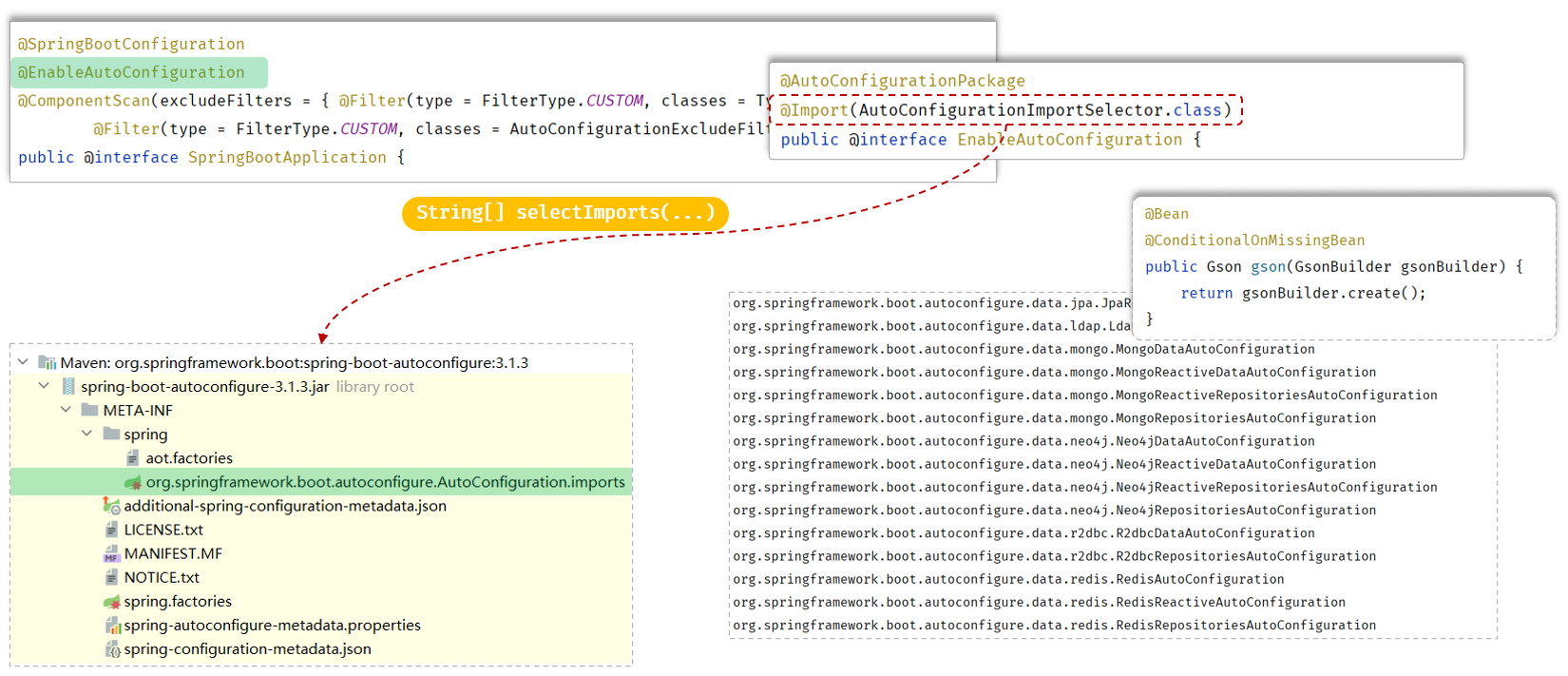
SpringBoot(八) --- SpringBoot原理
目录 一、配置优先级 二、Bean的管理 1. Bean的作用域 2. 第三方Bean 三、SpringBoot原理 1. 起步依赖 2. 自动配置 3. 自动配置原理分析 3.1 源码解析 3.2 Conditional 一、配置优先级 SpringBoot项目当中支持三类配置文件: application.properties a…...

SpringBoot自动化部署全攻略:CI/CD高效实践与避坑指南
SpringBoot自动化部署全攻略:CI/CD高效实践与避坑指南 🚀 一、现代化部署方案选型对比 1. 主流CI/CD工具对比 工具优势适用场景Jenkins插件丰富、可扩展性强复杂流水线、混合云环境GitHub Actions与GitHub深度集成、易用GitHub项目、中小团队GitLab CI/CD一体化平台、内置…...

idea json生成实体类
在IntelliJ IDEA中,可以通过安装GsonFormat或GsonFormatPlus插件快速生成Java实体类。具体操作流程包括安装插件、创建空类后使用快捷键调出生成界面,输入JSON数据即可自动生成对应字段和结构。 一、操作流程与工具选择 1、插件安装 在ID…...

C# 类和继承(抽象成员)
抽象成员 抽象成员是指设计为被覆写的函数成员。抽象成员有以下特征。 必须是一个函数成员。也就是说,字段和常量不能为抽象成员。必须用abstract修饰符标记。不能有实现代码块。抽象成员的代码用分号表示。 例如,下面取自一个类定义的代码声明了两个抽…...

gitlab rss订阅失败
问题:gitlab rss订阅失败 处理:http://gitlab.com/dashboard/projects.atom?feed_tokenXXXXXXX 这个XXX要改成用户设置里的Feed令牌 推荐本地rss订阅器:GitHub - yang991178/fluent-reader: Modern desktop RSS reader built with Electro…...
鸿蒙仓颉语言开发实战教程:商城登录页
听说Pura80要来了?感觉华为的新品像下饺子一样,让人目不暇接,每隔几天就有发布会看,真不错呀。 节后第一天,为了缓解大家假期的疲惫,咱们今天做点简单的内容,就是商城的登录页面。 其实这一次分…...
JavaScript 数组与流程控制:从基础操作到实战应用
在 JavaScript 编程的世界里,数组是一种极为重要的数据结构,它就像是一个有序的 “收纳盒”,能够将多个值整齐地存储起来。而流程控制语句则像是 “指挥官”,能够按照特定的逻辑对数组进行遍历和操作。接下来,就让我们…...

STM32中自动生成Flash地址的方法
每页大小为 2KB(0x800 字节),地址间隔为 0x800 总地址空间覆盖范围:0x08000000 ~ 0x0803F800(共 256KB) 适用于 STM32 大容量 / 中容量产品(如 F103 系列) 代码如下 // 通用定义(需根据实际页大小调整) #define FLASH_BASE_ADDR 0x08000000 #define FLASH_PAGE_SIZ…...

Matlab | MATLAB 中的插值详解
MATLAB 中的插值详解 插值是数值分析中的核心技术,用于在已知数据点之间估计未知点的值。MATLAB 提供了完整的插值函数库,涵盖一维到高维数据,支持多种插值方法。以下从基础到高级全面解析: 一、插值核心概念 1. 数学本质 给定数据点 ( x i , y i ) (x_i, y_i) (<...
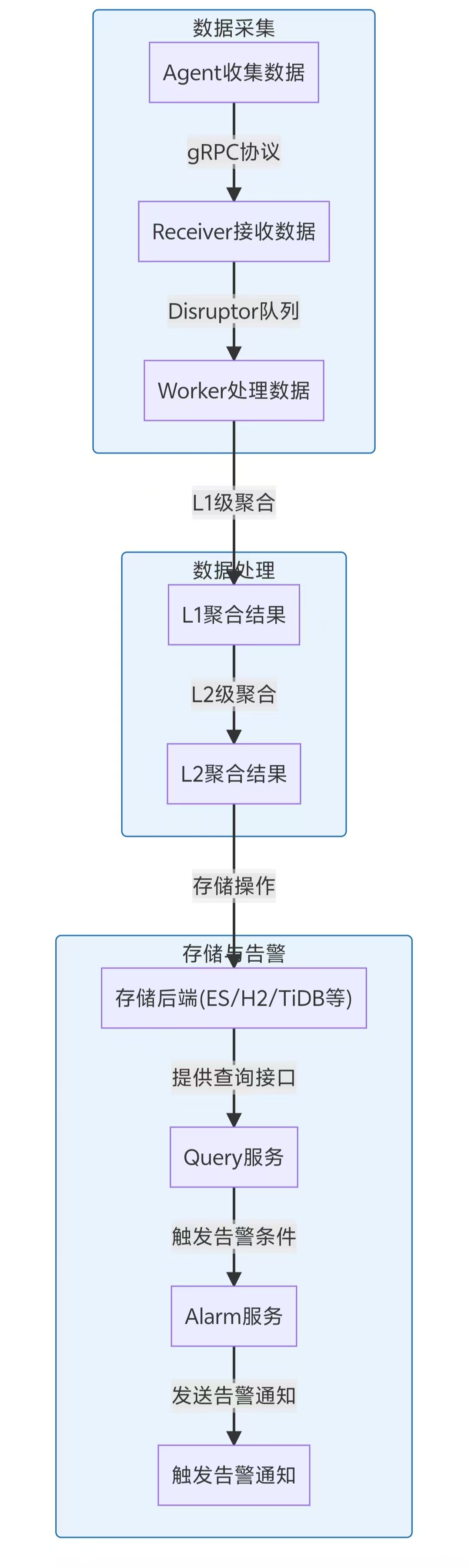
SkyWalking架构深度解析:分布式系统监控的利器
一、SkyWalking概述 SkyWalking是一款开源的APM(应用性能监控)系统,专门为微服务、云原生和容器化架构设计。它由Apache软件基金会孵化并毕业,已成为分布式系统监控领域的明星项目。 核心特性 分布式追踪:跨服务调用链路的完整追踪服务…...
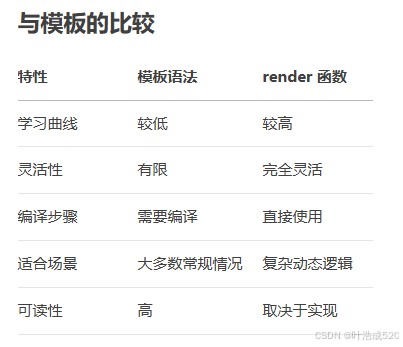
vue2中的render函数
<script> export default {components: {},name: "renderElems",render (h, context) {return this.$attrs.vnode;},updated() {} } </script> <style scoped> </style>分析一下上面.vue组件: 组件结构: 这是一个非…...
)
逆向工程开篇(连载中)
项目特点 这个专栏专门设计用于汇编逆向工程研究,包含: ✅ 18个测试模块,覆盖所有主要C语言特性✅ 1200行工具类代码,400行主程序代码✅ 完整的Visual Studio 2017项目支持✅ Debug和Release两种构建配置✅ 静态库和可执行文件分…...
 的用法详解(Vue响应式系统相关))
this.$set() 的用法详解(Vue响应式系统相关)
1. 什么是 this.$set()? this.$set(target, key, value) 是 Vue 2 中提供的一个方法,用于向响应式对象中动态添加属性,确保新加的属性同样是响应式的。 2. 为什么需要它? Vue 2 的响应式系统基于 Object.defineProperty&#…...
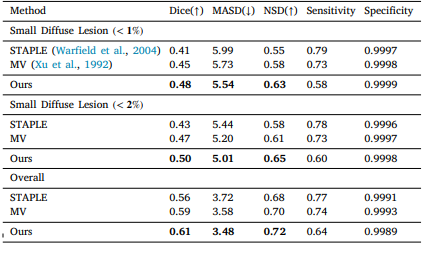
PARADISE:用于新生儿缺氧缺血性脑病(HIE)疾病识别与分割的个性化和区域适应性方法|文献速递-深度学习医疗AI最新文献
Title 题目 PARADISE: Personalized and regional adaptation for HIE disease identification and segmentation PARADISE:用于新生儿缺氧缺血性脑病(HIE)疾病识别与分割的个性化和区域适应性方法 1 文献速递介绍 缺氧缺血性脑病&…...
)
RabbitMQ 监控与调优实战指南(二)
五、调优策略与实战:对症下药提升性能 5.1 配置参数调优 在 RabbitMQ 的性能优化中,合理调整配置参数是关键的一环,这些参数涉及内存、磁盘、网络等多个资源层面,对 RabbitMQ 的整体性能有着深远的影响。 内存相关配置…...
WordPress子主题RiPro-V5van无授权全开源版(源码下载)
WordPress子主题RiPro-V5van无授权全开源版,直接上使用方法:WordPress后台上传就行 这个主题是1.0版本开源的,有能力的可以二次开发一下加一些自己喜欢的功能。 源码下载:https://download.csdn.net/download/m0_66047725/90952148 更多资…...

保姆级Elasticsearch集群部署指导
一、环境准备 1. 硬件要求(单节点建议) CPU:至少2核(生产环境4核)内存:至少4GB(生产环境建议16GB,且为偶数,如8GB、16GB)磁盘:至少50GB SSD&…...

PyQt实现3维数组与界面TableWidget双向绑定
以下是一个使用PyQt实现3维数组与界面TableWidget双向绑定的示例代码。该程序包含一个下拉菜单选择第0维索引,表格展示第1维和第2维的数据,并支持双向数据同步: import sys import numpy as np from PyQt5.QtWidgets import (QApplication, …...
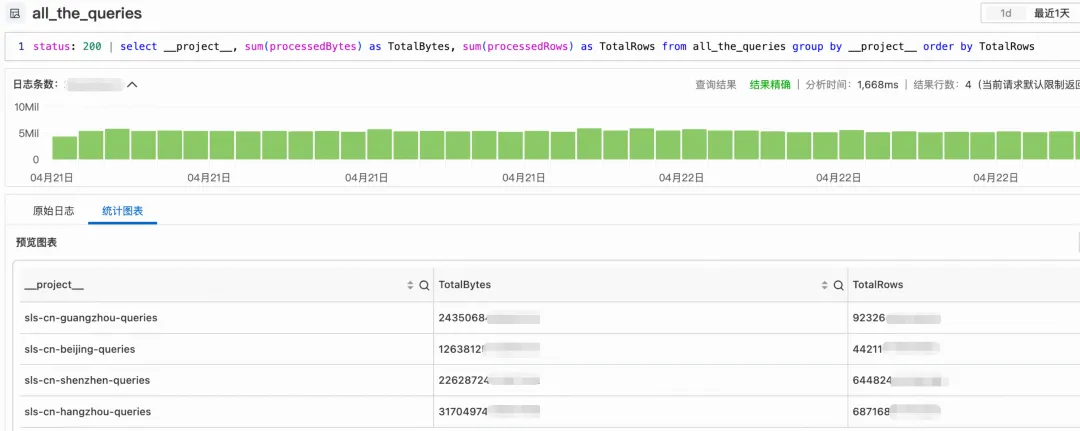
StoreView SQL,让数据分析不受地域限制
作者:章建(处知) 引言 日志服务 SLS 是云原生观测和分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务。SLS 提供了多地域支持【1】,方便用户可以根据数据源就近接入 SLS 服务,…...

护网面试题目2025
护网基础试题 一、描述外网打点的流程? 靶标确认、信息收集、漏洞探测、漏洞利用、权限获取。最终的目的是获取靶标的系统权限/关键数据。在这个过程中,信息收集最为重要。掌握靶标情报越多,后续就会有更多的攻击方式去打点。比如ÿ…...

Figma 与 Cursor 深度集成的完整解决方案
以下是 Figma 与 Cursor 深度集成的完整解决方案,实现设计-开发无缝协作: 一、集成架构设计 #mermaid-svg-NdvcKTZAZfX9DiUO {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-NdvcKTZAZfX9DiUO…...

UCRT 和 MSVC 的区别(Windows 平台上 C/C++ 开发相关)
UCRT 和 MSVC 是与 Windows 平台上 C/C 开发相关的两个重要概念,它们都属于 Microsoft 的开发工具链的一部分。下面详细解释它们的含义、区别以及用途。 一、UCRT(Universal C Runtime) 1. 含义: UCRT(Universal C …...

rabbitmq Fanout交换机简介
给每个服务创建一个队列,然后每个业务订阅一个队列,进行消费。 如订单服务起个多个服务,代码是一样的,消费的也是同一个队列。加快了队列中的消息的消费速度。 可以看到两个消费者已经在消费了...

【机器学习】集成学习与梯度提升决策树
目录 一、引言 二、自举聚合与随机森林 三、集成学习器 四、提升算法 五、Python代码实现集成学习与梯度提升决策树的实验 六、总结 一、引言 在机器学习的广阔领域中,集成学习(Ensemble Learning)犹如一座闪耀的明星,它通过组合多个基本学习器的力量,创造出…...
)
Palo Alto Networks Expedition存在命令注入漏洞(CVE-2025-0107)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...

WebFuture:Ubuntu 系统上在线安装.NET Core 8 的步骤
方法一:使用官方二进制包安装 下载.NET Core 8 SDK 二进制包:访问 .NET Core 8 SDK 官方下载页面,根据你的系统架构选择对应的 Linux x64 版本等下载链接,将其下载到本地4. 创建安装目录:在终端中执行以下命令创建用于…...