Python----目标检测(训练YOLOV8网络)
一、数据集标注
在已经采集的数据中,使用labelImg进行数据集标注,标注后的txt与原始 图像文件同名且在同一个文件夹(data)即可。
二、制作数据集
在data目录的同目录下,新建dataset目录,以存放制作好的YOLO的数据 集,执行以下代码,完成数据划分(dataloader.py)
import os
import random
import shutil# # 定义数据集目录和分割比例
source_root = 'data'
target_root = 'dataset'
train_ratio = 0.85
valid_ratio = 0.1
test_ratio = 0.05# 创建目标文件夹及其子文件夹
train_dir = os.path.join(target_root, "train")
valid_dir = os.path.join(target_root, "valid")
test_dir = os.path.join(target_root, "test")
print(train_dir)
print(valid_dir)
print(test_dir)
for phase in ['train', 'test', 'valid']:os.makedirs(os.path.join(target_root, phase, 'images'), exist_ok=True)os.makedirs(os.path.join(target_root, phase, 'labels'), exist_ok=True)# 获取所有文件列表
files = os.listdir(source_root)
print(files)
png_files = [f for f in files if f.endswith(".png")]
print(png_files)# 随机打乱文件列表
random.shuffle(png_files)# 计算分割点
num_files = len(png_files)
num_train = int(train_ratio * num_files)
num_valid = int(valid_ratio * num_files)# 移动文件到目标位置
# 将文件复制到相应目录
for i, file in enumerate(png_files):file = file.split('/')[-1].split('.')[-2]image_path = os.path.join(source_root, file + '.png')label_path = os.path.join(source_root, file + '.txt')print(image_path)print(label_path)if i < num_train:dst_dir = train_direlif i < num_train + num_valid:dst_dir = valid_direlse:dst_dir = test_dirshutil.copy(image_path, os.path.join(dst_dir, 'images'))shutil.copy(label_path, os.path.join(dst_dir, 'labels'))├─test│ ├─images│ └─labels├─train│ ├─images│ └─labels└─valid├─images└─labels在dataset目录下新建mydata.yaml得到最终数据集:
# Train/Val/Test paths
train: D:/目标检测/dataset/train
val: D:/目标检测/dataset/valid
test: D:/目标检测/dataset/test# Number of classes
nc: 3# Class names (as a list)
names: ['ripe', 'half-ripe', 'raw']三、快速训练
在图像大小为 640 的数据集上对YOLOv8n 进行3次训练。可以使用 device 参数。如果没有传递参数,GPU 要指定),否则 device=0 将被使用(多GPU需 device='cpu' 将被使用。
from ultralytics import YOLOmodel = YOLO("./yolov8n.pt"
) # 加载预训练模型(建议用于训练)。这行代码创建了一个YOLO对象,并加载了预训练的YOLOv8n模型。模型文件位于"./yolov8n.pt"。if __name__ == "__main__": # 确保这段代码只在脚本作为主程序运行时执行,而不是被导入为模块时执行。# 单GPU训练 #model.train(data="./dataset/mydata.yaml", epochs=3, imgsz=640) # 训练模型。使用指定的数据集配置文件("./dataset/mydata.yaml"),训练3个epoch,图像大小为640x640。# 多GPU训练 ## results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[0, 1]) #metrics = model.val() # 在验证集上评估模型性能。计算各种指标,如精度、召回率等。success = model.export(format="onnx") # 将模型导出为ONNX格式。ONNX是一种开放的深度学习模型交换格式,便于在不同平台和推理引擎上部署模型。results = model("./dataset/test/images/00002.png") # 对图像进行预测。使用加载的模型对指定的图像文件进行推理。# Process results list ## 处理预测结果列表 #for result in results: # 遍历每个预测结果。如果输入是多张图像,`results`将是一个列表,每个元素对应一张图像的预测结果。boxes = result.boxes # Boxes对象, 用于存储边界框输出。包含了检测到的物体的边界框信息。masks = result.masks # Masks对象, 用于存储分割掩模输出。包含了图像分割任务中,每个物体实例的像素掩膜。keypoints = result.keypoints # Keypoints对象, 用于存储姿态关键点输出。包含了人体姿态估计任务中,检测到的关键点坐标。probs = result.probs # Probs对象, 用于存储分类概率输出。包含了图像分类任务中,每个类别的预测概率。result.show() # display to screen # 显示结果到屏幕上 四、恢复中断的训练
在使用深度学习模型时,从先前保存的状态恢复训练是一项至关重要的功 能。这在各种情况下都能派上用场,比如当训练过程意外中断时,或者当 你希望用新数据或更多的历时继续训练模型时。
恢复训练时,Ultralytics YOLO 会加载上次保存模型的权重,并恢复优化器 状态、学习率调度器和历时编号。这样,您就可以从上次中断的地方无缝 地继续训练过程。
Ultralytics YOLO 您可以通过设置 resume 参数 True 在调用 的路径,并指定 train 方法 .pt 文件,其中包含经过部分训练的模型权重。
使用Python 和通过命令行恢复中断的训练(注意:需要 是中途停掉的训练才可以继续训练,如果训练时epoch=3,训练完了,是 不可以继续训练的):
from ultralytics import YOLO
model = YOLO("./runs/detect/train/weights/last.pt") # 加载预训练模型(建议用于训练)
if __name__ == '__main__':
# 单GPU训练model.train(resume=True) # 训练模型通过设置 resume=True,"...... train 函数将使用存储在 "./runs/detect/train/weights/last.pt"文件中的状态,从中断处继续训练。
如果 resume 参数被省略或设置为 False, train 功能将开始新的
请记住,默认情况下,检查点会在每个epoch结束时保存,或者使用 save_period 参数,因此您必须至少完成一个epoch才能恢复训练运行。
五、训练参数
YOLO 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设 置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学 习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选 择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至 关重要。
| 论据 | 默认值 | 说明 |
|---|---|---|
| model | None | 指定用于训练的模型文件。接受指向预训练模型 .pt 文件或 .yaml 配置文件的路径。对于定义模型结构或初始化权重至关重要。 |
| data | None | 数据集配置文件的路径(例如 coco8.yaml)。该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
| epochs | 100 | 训练历元总数。每个历元代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
| time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
| patience | 0 | 在验证指标没有改善的情况下,提前停止训练所需的历元数。当性能趋于平稳时停止训练,有助于防止过拟合。 |
| batch | 16 | Batch size, with three modes: set as an integer (e.g., batch=16), auto mode for 60% GPU memory utilization (batch=-1), or auto mode with specified utilization fraction (batch=0.70). |
| imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
| save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为 -1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
| cache | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False)。通过减少磁盘 I/O 提高训练速度,但代价是增加内存使用量。 |
| device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
| workers | 8 | 加载数据的工作线程数(每个 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
| project | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
| name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
| exist_ok | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
| pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
| optimizer | 'auto' | 为培训选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等, 或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性。 |
| verbose | False | 在训练过程中启用冗长输出,提供详细日志和进度更新。有助于调试和密切监控培训过程。 |
| seed | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
| deterministic | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
| single_cls | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
| rect | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
| cos_lr | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
| close_mosaic | 10 | 在训练完成前禁用最后 N 个历元的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
| resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
| amp | True | 启用自动混合精度 (AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
| fraction | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练, 这对实验或资源有限的情况非常有用。 |
| profile | False | 在训练过程中, 可对 ONNX 和 TensorRT 速度进行剖析, 有助于优化模型部署。 |
| freeze | None | 冻结模型的前 N 层或按索引指定的层, 从而减少可训练参数的数量。微调或迁移学习非常有用。 |
| lr0 | 0.01 | 初始学习率 (即 SGD=1E-2, Adam=1E-3). 调整这个值对优化过程至关重要, 会影响模型权重的更新速度。 |
| lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf), 与调度程序结合使用, 随着时间的推移调整学习率。 |
| momentum | 0.937 | 用于 SGD 的动量因子, 或用于 Adam 优化器的 beta1, 用于将过去的梯度纳入当前更新。 |
| weight_decay | 0.0005 | L2 正则化项, 对大权重进行惩罚, 以防止过度拟合。 |
| warmup_epochs | 3.0 | 学习率预热的历元数, 学习率从低值逐渐增加到初始学习率, 以在早期稳定训练。 |
| warmup_momentum | 0.8 | 热身阶段的初始动力, 在热身期间逐渐调整到设定动力。 |
| warmup_bias_lr | 0.1 | 热身阶段的偏置参数学习率,有助于 稳定初始历元的模型训练。 |
| box | 7.5 | 损失函数中边框损失部分的权重,影 响对准确预测边框坐标的重视程度 |
| cls | 0.5 | 分类损失在总损失函数中的权重,影 响正确分类预测相对于其他部分的重 要性。 |
| dfl | 1.5 | 分布焦点损失权重,在某些YOLO 版 本中用于精细分类。 |
| pose | 12.0 | 姿态损失在姿态估计模型中的权重, 影响着准确预测姿态关键点的重点。 |
| kobj | 2.0 | 姿态估计模型中关键点对象性损失的 权重,平衡检测可信度与姿态精度。 |
| label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标 标签和标签均匀分布的混合标签,可 以提高泛化效果。 |
| nbs | 64 | 用于损耗正常化的标称批量大小。 |
| overlap_mask | True | 决定在训练过程中分割掩码是否应该 重叠,适用于实例分割任务。 |
| mask_ratio | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
| dropout | 0.0 | 分类任务中正则化的丢弃率,通过在 训练过程中随机省略单元来防止过拟 合。 |
| val | True | 可在训练过程中进行验证,以便在单 独的数据集上对模型性能进行定期评 估。 |
| plots | False | 生成并保存训练和验证指标图以及预 测示例图,以便直观地了解模型性能 和学习进度。 |
batch大小设置方案:
固定 Batch Size:设置固定值 (例如: batch=16)。
自动模式 (60%的GPU显存占用):使用 batch=-1 自动调整batch 大小,实现大约60%的CUDA内存占用。
带有使用分数值的自动模式:通过设置一个分数值(例如, batch=0.70),来根据指定的GPU内存使用分数调整批处理大小
六、增强设置和超参数
增强技术通过在训练数据中引入可变性,帮助模型更好地泛化到未见数据 中,对提高YOLO 模型的稳健性和性能至关重要。下表概述了每种增强参 数的目的和效果:
| 论据 | 默认值 | 说明 |
|---|---|---|
| hsv_h | 0.015 | 图像色调中的最大变化。 |
| hsv_s | 0.7 | 图像饱和度的最大变化。 |
| hsv_v | 0.4 | 图像值 (亮度) 的最大变化。 |
| degrees | 0.0 | 图像旋转的最大角度。 |
| translate | 0.1 | 图像平移的最大比例 (按图像尺寸)。 |
| scale | 0.5 | 图像比例的最大变化。 |
| shear | 0.0 | 图像剪切的最大量。 |
| perspective | 0.0 | 图像透视变换的最大失真。 |
| mosaic | 1.0 | 启用马赛克数据增强,这是一种将多个训练图像组合成一个图像以提高对象变化的方法。 |
| mixup | 0.0 | 启用 mixup 数据增强,这是一种将图像和标签混合在一起以正则化模型的方法。 |
| copy_paste | 0.0 | 启用复制粘贴数据增强,这是一种将对象从一个图像随机复制到另一个图像的方法。 |
这些设置可根据数据集和手头任务的具体要求进行调整。试验不同的值有 助于找到最佳的增强策略,从而获得最佳的模型性能。
七、val验证参数
在 COCO8 数据集上验证训练有素的YOLOv8n 模型的准确性。无需传递参 数,因为 model 保留其培训 data 和参数作为模型属性。
from ultralytics import YOLO# 加载模型
model = YOLO("yolov8n.pt") # 加载官方预训练模型
model = YOLO("path/to/best.pt") # 加载自定义训练模型# 验证模型
metrics = model.val() # 无需提供额外参数,数据集和配置已保存metrics.box.map # 平均精度均值 (mAP) @ IoU=0.5:0.95
metrics.box.map50 # 平均精度均值 (mAP) @ IoU=0.5
metrics.box.map75 # 平均精度均值 (mAP) @ IoU=0.75
metrics.box.maps # 包含每个类别的 mAP@0.5:0.95 的列表在验证YOLO 模型时,可以对几个参数进行微调,以优化评估过程。这些 参数可控制输入图像大小、批处理和性能阈值等方面。以下是每个参数的 详细说明,可帮助您有效地自定义验证设置。
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| data | str | None | 数据集配置文件的路径 (例如 coco8.yaml)。该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
| batch | int | 16 | Batch size, with three modes: set as an integer (e.g., batch=16), auto mode for 60% GPU memory utilization (batch=-1), or auto mode with specified utilization fraction (batch=0.70). |
| imgsz | int | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save_json | Bool | False | 如果 True此外,还可将结果保 存到 JSON 文件中,以便进一步 分析或与其他工具集成。 |
| save_hybrid | bool | False | 如果 True,保存混合版本的标 签,将原始注释与额外的模型预 测相结合。 |
| conf | float | 0.001 | 设置检测的最小置信度阈值。置 信度低于此阈值的检测将被丢弃 |
| iou | float | 0.6 | 设置非最大抑制 (NMS) 的交叉 重叠 (IoU) 阈值。有助于减少重复检测 |
| max_det | int | 300 | 限制每幅图像的最大检测次数。 在密度较高的场景中非常有用, 可以防止检测次数过多。 |
| half | bool | True | 可进行半精度(FP16)计算, 减少内存使用量,在提高速度的 同时,将对精度的影响降至最 低。 |
| device | str | None | 指定验证设备 (cpu, cuda:0 等)。可灵活利用 CPU 或 GPU 资源。 |
| dnn | bool | False | 如果 True它使用 OpenCV DNN 模块进行ONNX 模型推 断,为PyTorch 推断方法提供了 一种替代方法。 |
| plots | bool | False | 当设置为 True此外,它还能生 成并保存预测结果与地面实况的 对比图,以便对模型的性能进行 可视化评估。 |
| rect | bool | False | 如果 True该软件使用矩形推理 进行批处理,减少了填充,可能 会提高速度和效率。 |
| split | str | val | 确定用于验证的数据集分割 (val, test或 train).可灵活选 择数据段进行性能评估。 |
这些设置中的每一个都在验证过程中起着至关重要的作用,可以对YOLO 模型进行可定制的高效评估。根据您的具体需求和资源调整这些参数,有 助于实现准确性和性能之间的最佳平衡。
带参数的验证示例
from ultralytics import YOLOmodel = YOLO("yolov8n.pt")validation_results = model.val(data="coco8.yaml", imgsz=640, batch=16, conf=0.25, iou=0.6, device="0")下表详细介绍了将YOLO 模型导出为不同格式时可用的配置和选项。这些 设置对于优化导出模型的性能、大小以及在不同平台和环境中的兼容性至 关重要。正确的配置可确保模型以最佳效率部署到预定应用中。
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| format | str | 'torchscript' | 导出模型的目标格式,例如 'onnx', 'torchscript', 'tensorflow' 或其他,定义与各种部署环境的兼容性。 |
| imgsz | int 或 tuple | 640 | 模型输入所需的图像尺寸。对于正方形图像,可以是一个整数,或者是一个元组 (height, width) 了解具体尺寸。 |
| keras | bool | False | 启用导出为 Keras 格式的 TensorFlow SavedModel,提供与 TensorFlow serving 和 API 的兼容性。 |
| optimize | bool | False | 在导出到 TorchScript 时,应用针对移动设备的优化,可能会减小模型大小并提高性能。 |
| half | bool | False | 启用 FP16(半精度)量化,在支持的硬件上减小模型大小并可能加快推理速度。 |
| int8 | bool | False | 激活 INT8 量化,进一步压缩模型并加快推理速度,同时将精度损失降至最低,主要用于边缘设备。 |
| dynamic | bool | False | 允许 ONNX 和 TensorRT 导出动态输入尺寸,提高了处理不同图像尺寸的灵活性。 |
| simplify | bool | False | Simplifies the model graph for ONNX exports with onnxslim, potentially improving performance and compatibility. |
| opset | int | None | 指定 ONNX opset 版本,以便与不同的 ONNX 解析器和运行时兼容。如果未设置,则使用最新的支持版本。 |
| workspace | float | 4.0 | 为 TensorRT 优化设置最大工作区大小(GiB),以平衡内存使用和性能。 |
| nms | bool | False | 在 CoreML 导出中添加非最大值抑制 (NMS),这对精确高效的检测后处理至关重要。 |
| batch | int | 1 | 指定导出模型的批量推理大小,或导出模型将同时处理的图像的最大数量。 predict 模式。 |
调整这些参数可自定义导出过程,以满足特定要求,如部署环境、硬件限 制和性能目标。选择适当的格式和设置对于实现模型大小、速度和准确性 之间的最佳平衡至关重要。
八、导出格式
YOLOv8 可用的导出格式如下表所示
| 格式 | format | 论据 | 模型元数据 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half, int8, batch |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz, batch |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8, batch |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half, batch |
相关文章:

Python----目标检测(训练YOLOV8网络)
一、数据集标注 在已经采集的数据中,使用labelImg进行数据集标注,标注后的txt与原始 图像文件同名且在同一个文件夹(data)即可。 二、制作数据集 在data目录的同目录下,新建dataset目录,以存放制作好的YOLO…...

构建 MCP 服务器:第一部分 — 资源入门
什么是模型上下文协议? 模型上下文协议(MCP) 是Claude等大型语言模型 (LLM) 与外部数据和功能安全交互的标准化方式。您可以将其想象成一个平视显示器,或者 AI 的 USB 端口——它提供了一个通用接口,允许任何兼容 MCP 的 LLM 连接到您的数据和工具。 MCP 提供了一个集中式协…...
 和 :base()区别)
c# :this() 和 :base()区别
在 C# 中,:this() 和 :base() 都用于构造函数的重载和继承,但它们有不同的用途和上下文: 1. :this() 用途:用于调用当前类中的其他构造函数(构造函数重载)。场景:当你希望一个构造函数先执行另…...
使用ZYNQ芯片和LVGL框架实现用户高刷新UI设计系列教程(第十五讲)
这一期讲解lvgl中日历控件的基础使用,Calendar 部件是一个经典日历,它具有以下功能:• 通过一个7x7矩阵显示任何月份 • 显示日期名称 • 突出显示当前日期(今天) • 突出显示任何用户定义的日期 日历是一个可编辑的小…...

Vue中实现表格吸底滚动条效果,列太多时左右滚动条始终显示在页面中
1、安装 npm install el-table-horizontal-scroll 2、全局注册(main.js) import horizontalScroll from el-table-horizontal-scrollVue.use(horizontalScroll) 如下图,在main.js加上上面的代码 3、表格内引用 <el-table :data"…...
BeeWorks 协同办公能力:局域网内企业级协作的全场景重构
在企业数字化办公场景中,BeeWorks 以强大的协同办公能力,将局域网内的通讯、协作、业务流程整合为统一整体。作为专注于企业级局域网环境的协作平台,其不仅提供即时通讯基础功能,更通过办公工具集成、会议能力强化、业务系统对接等…...

Mermaid 绘图--以企业权限视图为例
文章目录 一、示例代码二、基础结构设计2.1 组织架构树2.2 权限视图设计 三、销售数据权限系统四、关键语法技巧汇总 一、示例代码 在企业管理系统开发中,清晰的权限视图设计至关重要。本文将分享如何使用 Mermaid 绘制直观的企业权限关系图,复制以下代…...
Win系统如何将Redis配置为开机自启的服务)
Redis(02)Win系统如何将Redis配置为开机自启的服务
一、引言 Redis 是一款高性能的键值对存储数据库,在众多项目中被广泛应用。在 Windows 环境下,为了让 Redis 能更稳定、便捷地运行,将其设置为系统服务并实现自动启动是很有必要的。这样一来,系统开机时 Redis 可自动加载…...
C++课设:高效的日程管理系统
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、C日程管理系统的时代价值1. 为什么选…...
功能测试、性能测试、安全测试详解
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、功能测试 1、单接口功能 手工测试中的单个业务模块,一般对应一个接口 例如: 登录业务------登录接口 加入购物车业务------加入购…...
提示词指南 --- 提示词的基本结构
提示词指南 --- 提示词的基本结构以及三种角色 什么是Prompt (提示词)Prompt的基本结构和三种角色提示词的三种核心“角色”(Role) 真实例子 什么是Prompt (提示词) 我们可以把“Prompt(提示词)”想象成和AI聊天时你说的“一句话…...

UI学习—cell的复用和自定义cell
前言 Nib是什么? Nib就是.xib文件:一个可视化的UI界面文件,它记录了一个UI组件(例如一个表格单元格Cell)的界面布局信息,可以在interfaceBuilder中创建 [UINib nibWithNibName:"CustomCell" b…...
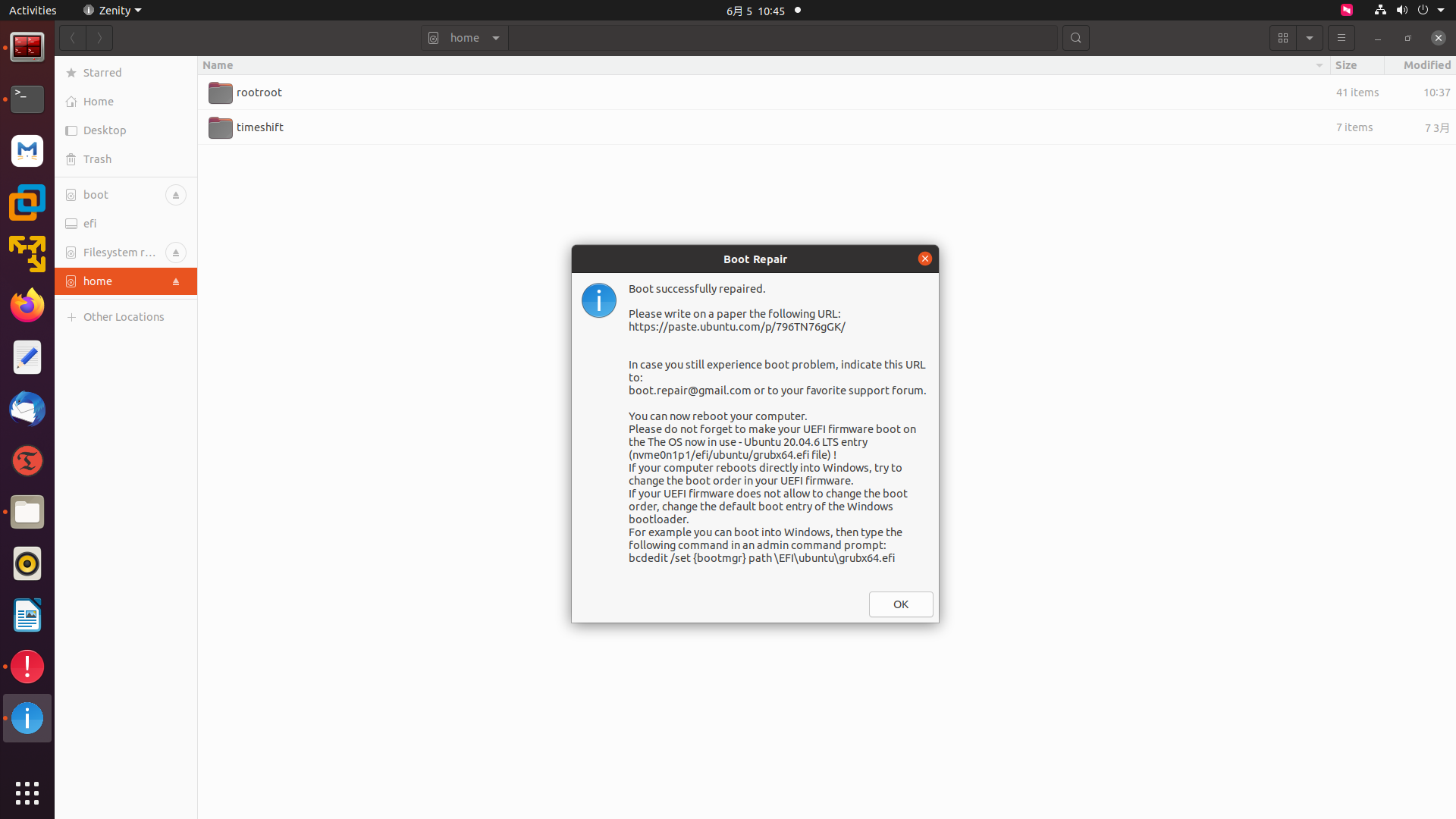
20250605使用boot-repair来恢复WIN10和ubuntu22.04.6双系统的启动
rootrootrootroot-X99-Turbo:~$ sudo apt-get install boot-repair rootrootrootroot-X99-Turbo:~$ sudo add-apt-repository ppa:yannubuntu/boot-repair rootrootrootroot-X99-Turbo:~$ sudo apt-get install boot-repair 20250605使用boot-repair来恢复WIN10和ubuntu22.04.6…...
)
网络安全面试题目(无答案)
一、渗透测试与漏洞挖掘 如何绕过WAF进行SQL注入?列举三种技术并解释原理。 答案要点: 分块传输编码(Chunked Transfer)绕过正则检测 畸形HTTP参数(如参数污染、Unicode编码) 利用WAF规则盲区(…...

JavaScript性能优化实战
### 1. 减少全局变量 JavaScript里,全局变量就像一个大杂烩,啥都往里扔,很容易出问题,还会影响性能。为啥呢?因为全局变量会被所有函数共享,查找起来特别费劲,就像在一个大仓库里找东西…...

接口安全SOAPOpenAPIRESTful分类特征导入项目联动检测
1 、 API 分类特征 SOAP - WSDL OpenApi - Swagger RESTful - /v1/api/ 2 、 API 常见漏洞 OWASP API Security TOP 10 2023 3 、 API 检测流程 接口发现,遵循分类,依赖语言, V1/V2 多版本等 Method :请求方法 攻击方…...
视频汇聚平台EasyCVR“明厨亮灶”方案筑牢旅游景区餐饮安全品质防线
一、背景分析 1)政策监管刚性需求:国家食品安全战略及 2024年《关于深化智慧城市发展的指导意见》要求构建智慧餐饮场景,推动数字化监管。多地将“AI明厨亮灶”纳入十四五规划考核,要求餐饮单位操作可视化并具备风险预警能力…...

sql server如何创建表导入excel的数据
在 SQL Server 中,可以通过几种方式将 Excel 数据导入到数据库表中。下面是一个完整的流程,包括如何创建表,以及将 Excel 数据导入该表的方法: ✅ 方法一:使用 SQL Server Management Studio (SSMS) 的导入向导&#x…...

仓库自动化搬运:自动叉车与AGV选型要点及核心技术解析
自动叉车与AGV均可实现自主作业,无需人工驾驶即可搬运托盘化货物。然而,这两种解决方案存在一些关键差异。 自动叉车与AGV的对比 自动叉车与AGV是截然不同的车辆,其差异主要源于原始设计: 自动叉车是制造商对传统手动叉车进行改…...

java UDP 模板
UDP(User Datagram Protocol)是一种无连接的传输层协议,在 Java 中可以使用 UDP 进行网络编程。理论上没有服务器客户端之分,实际上算是有的,以下是 Java 中 UDP 编程的基本步骤和示例代码: 服务器端 创建…...

【亲测有效】Mybatis-Plus更新字段为null
Mybatis-Plus更新字段为null 遇到问题 Mybatis-Plus更新的默认行为如下: Mybatis-Plus默认如果某个传入参数的字段为null, 默认不更新这个字段, 例如有个Double类型的字段, 当前数据库数据为10, 然后传参时当前字段为null, 实际上Mybatis-Plus是不会覆盖该字段为null的, 仍然…...

NLP学习路线图(二十五):注意力机制
在自然语言处理领域,序列模型一直扮演着核心角色。从早期的循环神经网络(RNN)到如今一统天下的Transformer模型,注意力机制(Attention Mechanism) 的引入堪称一场革命。它彻底改变了模型处理序列信息的方式…...
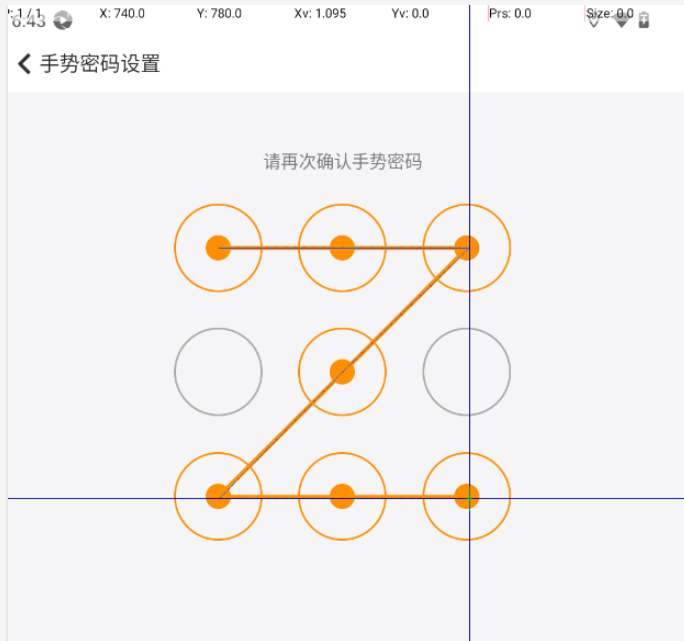
05 APP 自动化- Appium 单点触控 多点触控
文章目录 一、单点触控查看指针的指针位置实现手势密码: 二、多点触控 一、单点触控 查看指针的指针位置 方便查看手势密码-九宫格每个点的坐标 实现手势密码: 执行手势操作: 按压起点 -> 移动到下一点 -> 依次移动 -> 释放&am…...

MyBatis-Plus LambdaQuery 高级用法:JSON 路径查询与条件拼接的全场景解析
目录 1. 查询 JSON 字段中的特定值 2. 动态查询 JSON 字段中的值 3. 查询 JSON 数组中的值 4. 查询 JSON 字段中的嵌套对象 5. 结合其他条件查询 JSON 字段 6. 使用类型处理器简化 JSON 查询 6.1 创建自定义 JSON 类型处理器 6.2 在实体类中指定自定义类型处理器 示例…...

[AI绘画]sd学习记录(一)软件安装以及文生图界面初识、提示词写法
目录 目录一、安装软件二、文生图各部分模块 1. 下载新模型 & 画出第一张图2. 提示词输入 2.1 设置2.2 扩展模型2.3 扩展模型权重调整2.4 其他提示词输入2.5 负向提示词2.6 生成参考 3. 采样方法4. 噪声调度器5. 迭代步数6. 提示词引导系数 一、安装软件 软件安装&…...
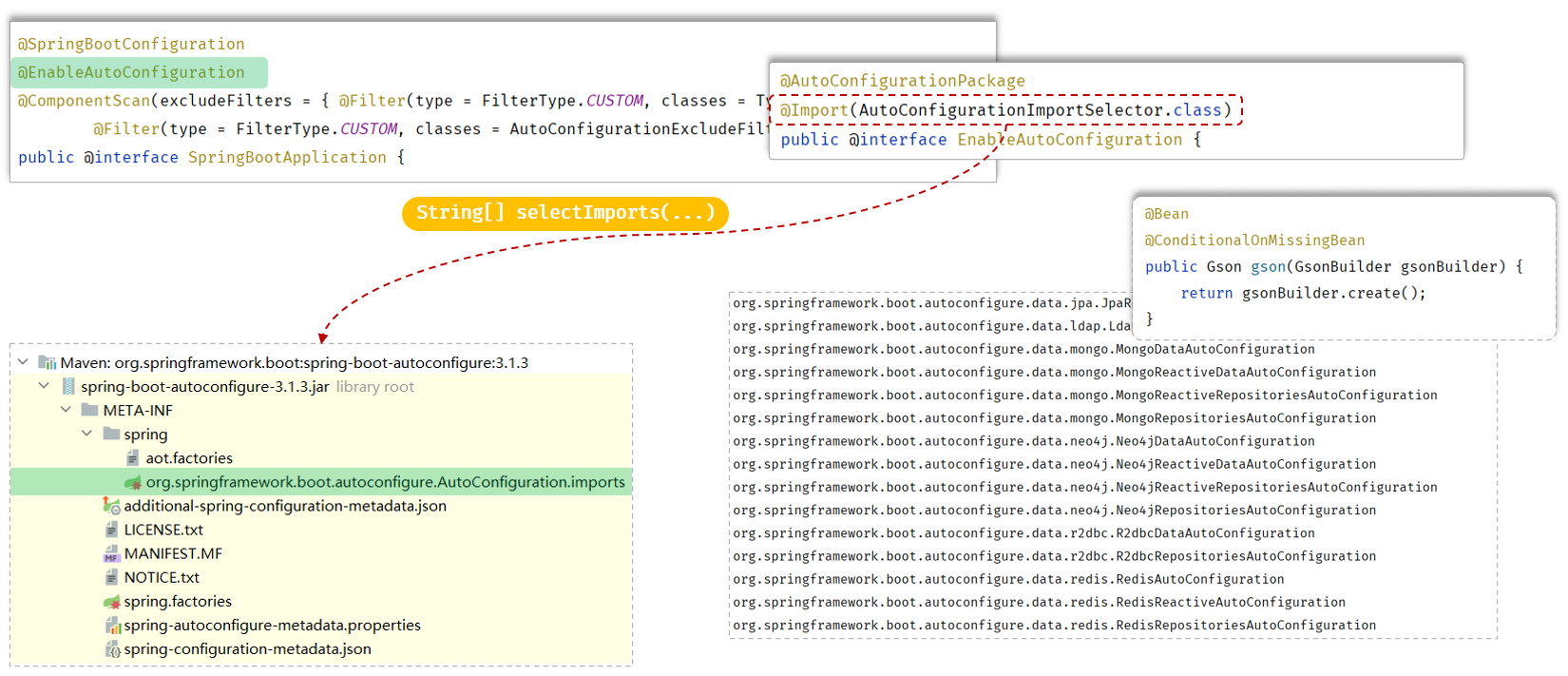
SpringBoot(八) --- SpringBoot原理
目录 一、配置优先级 二、Bean的管理 1. Bean的作用域 2. 第三方Bean 三、SpringBoot原理 1. 起步依赖 2. 自动配置 3. 自动配置原理分析 3.1 源码解析 3.2 Conditional 一、配置优先级 SpringBoot项目当中支持三类配置文件: application.properties a…...

SpringBoot自动化部署全攻略:CI/CD高效实践与避坑指南
SpringBoot自动化部署全攻略:CI/CD高效实践与避坑指南 🚀 一、现代化部署方案选型对比 1. 主流CI/CD工具对比 工具优势适用场景Jenkins插件丰富、可扩展性强复杂流水线、混合云环境GitHub Actions与GitHub深度集成、易用GitHub项目、中小团队GitLab CI/CD一体化平台、内置…...

idea json生成实体类
在IntelliJ IDEA中,可以通过安装GsonFormat或GsonFormatPlus插件快速生成Java实体类。具体操作流程包括安装插件、创建空类后使用快捷键调出生成界面,输入JSON数据即可自动生成对应字段和结构。 一、操作流程与工具选择 1、插件安装 在ID…...

C# 类和继承(抽象成员)
抽象成员 抽象成员是指设计为被覆写的函数成员。抽象成员有以下特征。 必须是一个函数成员。也就是说,字段和常量不能为抽象成员。必须用abstract修饰符标记。不能有实现代码块。抽象成员的代码用分号表示。 例如,下面取自一个类定义的代码声明了两个抽…...

gitlab rss订阅失败
问题:gitlab rss订阅失败 处理:http://gitlab.com/dashboard/projects.atom?feed_tokenXXXXXXX 这个XXX要改成用户设置里的Feed令牌 推荐本地rss订阅器:GitHub - yang991178/fluent-reader: Modern desktop RSS reader built with Electro…...