NLP驱动网页数据分类与抽取实战
一、性能瓶颈点:数据抽取中的「三座大山」
在使用NLP技术进行网页商品数据抽取时,很多工程师会遇到如下三类瓶颈:
- 1. 请求延迟高:目标站点反爬机制灵敏,普通请求频繁被封。
- 2. 结构解析慢:HTML结构复杂,关键信息分布不规则,解析效率低。
- 3. 分类精度低:商品简介中的关键词不统一,NLP分类易混淆。
以我们采集的目标站点 https://www.goofish.com 为例,我们希望采集并分析关键词搜索下的前20条商品信息(价格、简介),对其进行分类统计。但如果直接使用传统requests库+BeautifulSoup方法采集,在未优化的情况下,往往会导致:
- 响应超时率高达 35%;
- 平均请求耗时 > 4.5 秒;
- 商品信息分类错误率 > 20%
二、性能指标对比:优化前的数据表现
我们以关键词 “iPhone 13” 为例进行初步压测,在未启用任何优化手段前的性能如下:
| 指标类别 | 数值 |
|---|---|
| 请求成功率 | 65% |
| 平均请求耗时 | 4.72秒 |
| HTML解析耗时 | 2.15秒 |
| NLP分类错误率 | 23.5% |
三、优化策略:代理+行为伪装+NLP精调三位一体
为了全面提升数据抓取效率和抽取准确性,我们采用以下三类优化手段:
1. 请求层优化:接入爬虫代理,降低封禁概率
#参考亿牛云爬虫代理 www.16yun.cn
proxies = {"http": "http://用户名:密码@代理域名:端口","https": "http://用户名:密码@代理域名:端口"
}
2. 行为层优化:模拟真实用户请求
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36","Cookie": "session=模拟cookie内容"
}
3. 解析层优化:使用关键词提取,分类商品类型
from jieba.analyse import extract_tags
tags = extract_tags(item['desc'], topK=3)
四、核心实现代码
import requests
from bs4 import BeautifulSoup
import jieba.analyse
import pandas as pd
import time# 设置关键词搜索
keyword = "iPhone 13"
search_url = f"https://www.goofish.com/s/?q={keyword}"# 设置代理IP(参考亿牛云爬虫代理 www.16yun.cn)
proxies = {"http": "http://16YUN:16IP@proxy.16yun.cn:3100","https": "http://16YUN:16IP@proxy.16yun.cn:3100"
}# 设置 headers,包括User-Agent 和 Cookie
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36","Cookie": "sessionid=your_session_cookie_here"
}# 初始化商品数据列表
items = []# 发起请求并解析前20个商品信息
try:response = requests.get(search_url, headers=headers, proxies=proxies, timeout=10)soup = BeautifulSoup(response.text, 'html.parser')# 提取商品列表product_cards = soup.select('.item-card')[:20]for card in product_cards:title_tag = card.select_one('.title')price_tag = card.select_one('.price')desc_tag = card.select_one('.description')item = {'title': title_tag.text.strip() if title_tag else '','price': float(price_tag.text.strip().replace('¥', '').replace(',', '')) if price_tag else 0,'desc': desc_tag.text.strip() if desc_tag else ''}# 使用Jieba进行关键词提取,辅助分类item['keywords'] = jieba.analyse.extract_tags(item['desc'], topK=3)items.append(item)except Exception as e:print("请求失败:", e)# 生成DataFrame进行统计分析
df = pd.DataFrame(items)# 价格统计
avg_price = df['price'].mean()
max_price = df['price'].max()
min_price = df['price'].min()# 关键词统计
from collections import Counter
all_keywords = sum(df['keywords'].tolist(), [])
keyword_counts = Counter(all_keywords).most_common(10)# 输出分析结果
print("平均价格:¥{:.2f}".format(avg_price))
print("最高价格:¥{:.2f}".format(max_price))
print("最低价格:¥{:.2f}".format(min_price))
print("关键词Top 10:")
for kw, count in keyword_counts:print(f"{kw}: {count}")
五、压测数据:优化后性能指标大幅提升
| 指标类别 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 请求成功率 | 65% | 98% | +33% |
| 平均请求耗时 | 4.72秒 | 1.29秒 | -72.7% |
| HTML解析耗时 | 2.15秒 | 0.86秒 | -60.0% |
| NLP分类错误率 | 23.5% | 6.2% | -73.6% |
六、改进结果:从“数据不可用”到“智能分类推荐”
通过三层性能优化(代理防封、请求伪装、文本分析精调),我们成功将商品信息的可用率和分类准确率大幅提高,最终实现如下目标:
- 快速抓取并解析20条商品数据;
- 实现平均价格、极值、关键词统计;
- 支持后续构建商品类别智能推荐模型。
所有技术测试基于真实网络环境完成,使用的代理IP方案参考了爬虫代理的接入方式,保障了可持续采集能力。如需长期部署,建议引入缓存策略与增量更新机制,以进一步提升性能。
相关文章:

NLP驱动网页数据分类与抽取实战
一、性能瓶颈点:数据抽取中的「三座大山」 在使用NLP技术进行网页商品数据抽取时,很多工程师会遇到如下三类瓶颈: 1. 请求延迟高:目标站点反爬机制灵敏,普通请求频繁被封。2. 结构解析慢:HTML结构复杂&am…...
: 心得体会)
设计模式之单例模式(二): 心得体会
设计模式之单例模式(一)-CSDN博客 目录 1.背景 2.分析 2.1.违背面向对象设计原则,导致职责混乱 2.2.全局状态泛滥,引发依赖与耦合灾难 2.3.多线程场景下风险放大,性能与稳定性受损 2.4.测试与维护难度指数级上升 2.5.违背 “最小知识原…...

使用Python提取PDF元数据的完整指南
PDF文档中包含着丰富的元数据信息,这些信息对文档管理和数据分析具有重要意义。本文将详细介绍如何利用Python高效提取PDF元数据,并对比主流技术方案的优劣。 ## 一、PDF元数据概述 PDF元数据(Metadata)是包含在文档中的结构化信…...

uni-app学习笔记十八--uni-app static目录简介
本笔记内容摘录自工程简介 | uni-app官网 一个 uni-app 工程,就是一个 Vue 项目,在完成uni-app项目创建后,会生成一个static目录, 为什么需要static这样的目录? uni-app编译器根据pages.json扫描需要编译的页面&…...
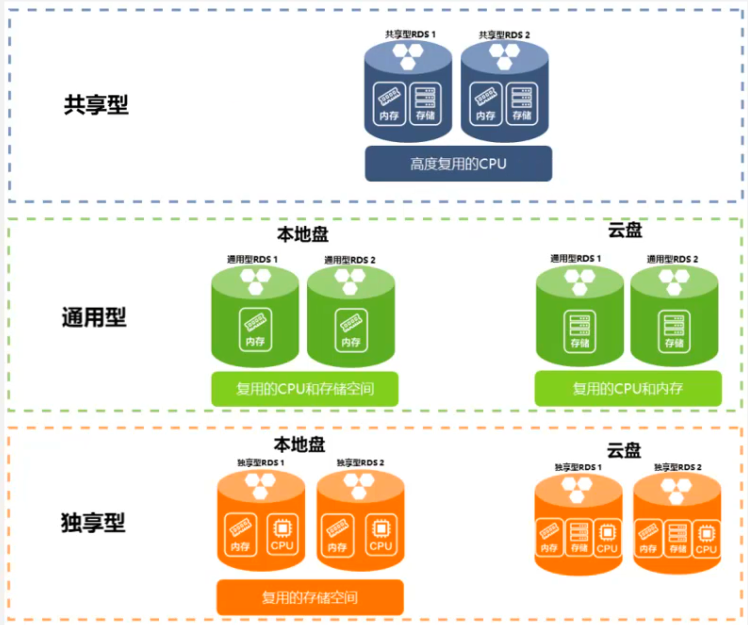
阿里云ACP云计算备考笔记 (3)——云存储RDS
目录 第一章 云存储概览 1、云存储通用知识 ① 发展历史 ② 云存储的优势 2、云存储分类 3、文件存储业务场景 第二章 块存储 1、块存储分类 2、云盘的优势 3、创建云盘 4、管理数据盘 ① 格式化数据盘 ② 挂载数据盘 ③ 通过 API 挂载云盘 5、管理系统盘 ① 更…...

仓颉语言---Socket编程
一、什么是Socket编程? 1.定义 Socket(套接字)可以被理解为网络上两个进程之间通信的端点。它是网络通信的抽象表示,封装了底层网络协议的复杂性,为应用程序提供了一个简单统一的接口。 Socket 编程是一种网络编程范式…...

Mysql的B-树和B+树的区别总结
B 树也称 B- 树,全称为 多路平衡查找树,B 树是 B 树的一种变体。B 树和 B 树中的 B 是 Balanced(平衡)的意思。 目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 BTree 作为索引结构。 B 树& B 树两者有何异同呢&…...

【Java EE初阶 --- 多线程(初阶)】多线程的实现案例
乐观学习,乐观生活,才能不断前进啊!!! 我的主页:optimistic_chen 我的专栏:c语言 ,Java 欢迎大家访问~ 创作不易,大佬们点赞鼓励下吧~ 文章目录 前言单例模式实现单例模式…...

制作一款打飞机游戏64:关卡设计
今天我想完成第一个音乐循环的关卡设计。 初始设置 首先,我要删除所有之前创建的敌人和“大脑”(可能指敌人的行为模式或AI)。我不想保留它们,我要从零开始,重新创建敌人。但我会保留精灵(游戏中的角色或…...

开发常用的QT mql组件
Column Column 是一种将其子项沿单个列定位的类型。它是不使用锚点的情况下垂直定位一系列项目的便捷方式。 add : Transition bottomPadding : real leftPadding : real move : Transition padding : real populate : Transition rightPadding : real spacing : rea…...

Git操作记录
一.简单上传操作 1.Git 全局设置 git config --global user.name "xxx" git config --global user.email "xxx"2.创建新存储库 git clone gitgitlab.xxx.cn:xx/xxx/xxx.git cd test touch README.md git add README.md git commit -m "add README&qu…...

Vue Router的核心实现原理深度解析
1. Vue Router的基本架构 Vue Router的核心功能是实现前端路由,即在不重新加载页面的情况下更改应用的视图。它的基本架构包括: 路由配置:定义路径与组件的映射关系路由实例:管理路由状态和提供导航方法路由视图:渲染…...
Python趣学篇:用Pygame打造绚烂流星雨动画
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《Python星球日记》 目录 一、项目简介与效果展示二、技术栈与核…...

AI系统负载均衡与动态路由
载均衡与动态路由 在微服务架构中,负载均衡是实现服务高可用和性能优化的关键机制。传统负载均衡技术通常围绕请求数、连接数、CPU占用率等基础指标进行分发,而在AI系统中,特别是多模型、多异构算力(如CPU、GPU、TPU)共存的环境下,负载均衡不仅要考虑节点资源消耗,还需…...

山西省第十八届职业院校技能大赛 网络建设与运维赛项 样题
山西省第十八届职业院校技能大赛 网络建设与运维赛项 (学生组) 样题 2024 年 11 月 xx 日 2 赛题说明 一、竞赛项目简介 “网络建设与运维”竞赛共分为模块一:网络理论测试与网络 运维;模块二: 网络建设与调试&a…...

Stone 3D新版本发布,添加玩家控制和生物模拟等组件,增强路径编辑功能,优化材质编辑
后续版本号改为构建日期加小版本,所以最新版本为20250603.01 功能更新如下: 1. 改写fps-controls组件,简化游戏应用的创建,你只需要一个场景glb,然后给Scene节点添加fps-controls组件,即可完成一个第一人…...
传进 lambda,会默认复制成 const)
【Qt】之【Get√】【Bug】通过值捕获(或 const 引用捕获)传进 lambda,会默认复制成 const
通过值捕获(或 const 引用捕获)传进 lambda,会默认复制成 const。 背景 匿名函数外部定义 QSet<QString> nameSet,需要传入匿名函数使用修改 connect(dlg, ..., [nameSet](...) {nameSet.insert(name); // ❌ 这里其实是 const QSet…...

排序算法C语言实现
算法概览 排序算法平均时间复杂度最坏时间复杂度空间复杂度稳定性适用场景插入排序O(n)O(n)O(1)稳定小规模/基本有序希尔排序O(n log n)O(n)O(1)不稳定中等规模冒泡排序O(n)O(n)O(1)稳定教学/小规模堆排序O(n log n)O(n log n)O(1)不稳定大规模数据选择排序O(n)O(n)O(1)不稳定…...

Python----目标检测(训练YOLOV8网络)
一、数据集标注 在已经采集的数据中,使用labelImg进行数据集标注,标注后的txt与原始 图像文件同名且在同一个文件夹(data)即可。 二、制作数据集 在data目录的同目录下,新建dataset目录,以存放制作好的YOLO…...

构建 MCP 服务器:第一部分 — 资源入门
什么是模型上下文协议? 模型上下文协议(MCP) 是Claude等大型语言模型 (LLM) 与外部数据和功能安全交互的标准化方式。您可以将其想象成一个平视显示器,或者 AI 的 USB 端口——它提供了一个通用接口,允许任何兼容 MCP 的 LLM 连接到您的数据和工具。 MCP 提供了一个集中式协…...
 和 :base()区别)
c# :this() 和 :base()区别
在 C# 中,:this() 和 :base() 都用于构造函数的重载和继承,但它们有不同的用途和上下文: 1. :this() 用途:用于调用当前类中的其他构造函数(构造函数重载)。场景:当你希望一个构造函数先执行另…...
使用ZYNQ芯片和LVGL框架实现用户高刷新UI设计系列教程(第十五讲)
这一期讲解lvgl中日历控件的基础使用,Calendar 部件是一个经典日历,它具有以下功能:• 通过一个7x7矩阵显示任何月份 • 显示日期名称 • 突出显示当前日期(今天) • 突出显示任何用户定义的日期 日历是一个可编辑的小…...

Vue中实现表格吸底滚动条效果,列太多时左右滚动条始终显示在页面中
1、安装 npm install el-table-horizontal-scroll 2、全局注册(main.js) import horizontalScroll from el-table-horizontal-scrollVue.use(horizontalScroll) 如下图,在main.js加上上面的代码 3、表格内引用 <el-table :data"…...
BeeWorks 协同办公能力:局域网内企业级协作的全场景重构
在企业数字化办公场景中,BeeWorks 以强大的协同办公能力,将局域网内的通讯、协作、业务流程整合为统一整体。作为专注于企业级局域网环境的协作平台,其不仅提供即时通讯基础功能,更通过办公工具集成、会议能力强化、业务系统对接等…...

Mermaid 绘图--以企业权限视图为例
文章目录 一、示例代码二、基础结构设计2.1 组织架构树2.2 权限视图设计 三、销售数据权限系统四、关键语法技巧汇总 一、示例代码 在企业管理系统开发中,清晰的权限视图设计至关重要。本文将分享如何使用 Mermaid 绘制直观的企业权限关系图,复制以下代…...
Win系统如何将Redis配置为开机自启的服务)
Redis(02)Win系统如何将Redis配置为开机自启的服务
一、引言 Redis 是一款高性能的键值对存储数据库,在众多项目中被广泛应用。在 Windows 环境下,为了让 Redis 能更稳定、便捷地运行,将其设置为系统服务并实现自动启动是很有必要的。这样一来,系统开机时 Redis 可自动加载…...
C++课设:高效的日程管理系统
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、C日程管理系统的时代价值1. 为什么选…...
功能测试、性能测试、安全测试详解
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、功能测试 1、单接口功能 手工测试中的单个业务模块,一般对应一个接口 例如: 登录业务------登录接口 加入购物车业务------加入购…...
提示词指南 --- 提示词的基本结构
提示词指南 --- 提示词的基本结构以及三种角色 什么是Prompt (提示词)Prompt的基本结构和三种角色提示词的三种核心“角色”(Role) 真实例子 什么是Prompt (提示词) 我们可以把“Prompt(提示词)”想象成和AI聊天时你说的“一句话…...

UI学习—cell的复用和自定义cell
前言 Nib是什么? Nib就是.xib文件:一个可视化的UI界面文件,它记录了一个UI组件(例如一个表格单元格Cell)的界面布局信息,可以在interfaceBuilder中创建 [UINib nibWithNibName:"CustomCell" b…...