DAY 15 复习日
@浙大疏锦行
数据使用爬虫爬取weibo数据,下面是代码
import datetime
import os
import csv
import timeimport numpy as np
import random
import re
import urllib.parse
import requests
from fake_useragent import UserAgentdef init():if not os.path.exists('../weiboDeatail.csv'):with open('../weiboDeatail.csv', 'a', newline='', encoding='utf-8') as wf:writer = csv.writer(wf)writer.writerow(['articleId','created_at','likes_counts','region','content','authorName','authorGender','authorAddress','authorAvatar',])def save_to_file(resultData):with open('../weiboDeatail.csv', 'a', newline='', encoding='utf-8') as f:writer = csv.writer(f)writer.writerow(resultData)def get_data(url,params):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0','cookie': 'SINAGLOBAL=8782631946839.119.1699202998560; SUB=_2AkMQaTYef8NxqwFRmfoUz2jhb451yAzEieKmNcfFJRMxHRl-yj8XqhEbtRB6O-kY8WFdEr155S_EPSDhRZ5dRRmT-_aC; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWcQpMfOClpsGU0ylkr.Dg2; XSRF-TOKEN=pMdYpIdaKB-vThaLz_RPmMy7; _s_tentry=weibo.com; Apache=3448313847055.298.1731574115528; ULV=1731574115668:1:1:1:3448313847055.298.1731574115528:; WBPSESS=V0zdZ7jH8_6F0CA8c_ussWO_XbISeXyf_cdQhE-a7tA9YWqKR0HqFFlwwlm4O_tCVqfBbTqYra_IEAKvR3DtVLRWcGHqKNMZv9wHENJbx4l6rpBH3A2CNiiAuRQVin2ZNgg7rPufq9s7kOHoQJsAbLrUReKu8_UTai8PbfZrq7M='}response = requests.get(url, headers=headers,params=params)print(f"Response Status Code: {response.status_code}")print(f" response.text: { response.text }")if response.status_code == 200:return response.json()['data']else:return None
def getAllArticleTypeList():articleList=[]with open('weibo1.csv', 'r', encoding='utf-8') as f:readerCsv = csv.reader(f)next(readerCsv)for nav in readerCsv:articleList.append(nav)return articleListdef prase_json(response,articleId):for comment in response:articleId = articleIdcreated_at = datetime.datetime.strptime(comment['created_at'], '%a %b %d %H:%M:%S +0800 %Y').strftime('%Y-%m-%d %H:%M:%S')likes_counts = comment['like_counts']try:region = comment['source'].replace('来自','')except:region = '无'content = comment['text_raw']authorName = comment['user']['screen_name']authorGender = comment['user']['gender']authorAddress = comment['user']['location']authorAvatar = comment['user']['avatar_large']print(articleId,created_at,likes_counts,region,content,authorName,authorGender,authorAddress,authorAvatar)save_to_file([articleId,created_at,likes_counts,region,content,authorName,authorGender,authorAddress,authorAvatar])# breakdef start():commentUrl='https://weibo.com/ajax/statuses/buildComments'articleList=getAllArticleTypeList()typeNumCount = 0for article in articleList[1:]:articleId=article[0]print('正在获取id为%s的评论数据'%articleId)time.sleep(random.randint(1,5))params = {'id': int(articleId),'is_show_bulletin':3}response = get_data(commentUrl,params)prase_json(response,articleId)# breakif __name__ == '__main__':init()start()查看数据形状
import pandas as pd# 读取数据
# 读取数据并添加表头
data = pd.read_csv(r'weiboDeatail.csv', header=None, names=['articleId', 'created_at', 'likes_counts', 'region', 'content', 'authorName', 'authorGender', 'authorAddress', 'authorAvatar'])# 打印数据集的基本信息(列名、非空值数量、数据类型等)
print("data.info() - 数据集的基本信息(列名、非空值数量、数据类型等):")
print(data.info())# 打印数据集的形状(行数和列数)
print("\ndata.shape - 数据集的形状(行数, 列数):")
print(data.shape)# 打印数据集的所有列名
print("\ndata.columns - 数据集的所有列名:")
print(data.columns)# 查看前5行数据
print("\n查看前5行数据:")
print(data.head())# 查看后5行数据
print("\n查看后5行数据:")
print(data.tail())# 查看是否有缺失值
print("\n查看是否有缺失值:")
print(data.isnull().sum())# 检测是否有重复值
print("\n检测是否有重复值:")
print(data.duplicated().sum())# 描述性统计
print("\n描述性统计:")
print(data.describe(include='all'))# 删除操作:删除某一列(例如删除authorAvatar列)
print("\n删除操作:删除authorAvatar列")
data = data.drop(columns=['authorAvatar'])
print(data.columns)# 查询操作:查询点赞数大于100的文章
print("\n查询操作:查询点赞数大于100的文章")
filtered_data = data[data['likes_counts'] > 100]
print(filtered_data)# 排序操作:按点赞数降序排序
print("\n排序操作:按点赞数降序排序")
sorted_data = data.sort_values(by='likes_counts', ascending=False)
print(sorted_data.head())# 分组操作:按地区分组并统计每个地区的文章数量
print("\n分组操作:按地区分组并统计每个地区的文章数量")
grouped_data = data.groupby('region').size()
print(grouped_data)
绘制分析图
可视化需求和图表类型
需求:绘制文章点赞数分布直方图
图表类型:直方图
含义:展示文章点赞数的分布情况,观察点赞数的集中区间和分布趋势。
需求:绘制文章发布地区分布柱形图
图表类型:柱形图
含义:展示不同地区发布文章的数量,识别文章发布最活跃的地区。
需求:绘制作者性别分布饼图
图表类型:饼图
含义:展示作者性别的比例,了解性别在作者群体中的分布情况。
需求:绘制文章内容关键词词云图
图表类型:词云图
含义:通过关键词的大小和颜色展示文章内容中最常见的词汇,识别热门话题。
需求:绘制文章作者地址分布柱形图
图表类型:柱形图
含义:展示不同地址的作者数量,识别作者分布最集中的地区。
需求:绘制文章发布时间分布直方图
图表类型:直方图
含义:展示文章发布时间的分布情况,观察文章发布的高峰时段。import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
import matplotlib.font_manager as fm# 设置matplotlib支持中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题# 读取数据
# 读取数据并添加表头
data = pd.read_csv(r'weiboDeatail.csv', header=None, names=['articleId', 'created_at', 'likes_counts', 'region', 'content', 'authorName', 'authorGender', 'authorAddress', 'authorAvatar'])# 1. 绘制文章点赞数分布直方图
plt.figure(figsize=(10, 6))
sns.histplot(data['likes_counts'], bins=30, kde=True)
plt.title('文章点赞数分布直方图')
plt.xlabel('点赞数')
plt.ylabel('频数')
plt.show()# 2. 绘制文章发布地区分布柱形图
plt.figure(figsize=(12, 6))
region_counts = data['region'].value_counts().head(10)
sns.barplot(x=region_counts.index, y=region_counts.values)
plt.title('文章发布地区分布柱形图')
plt.xlabel('地区')
plt.ylabel('文章数量')
plt.xticks(rotation=45)
plt.show()# 3. 绘制作者性别分布饼图
plt.figure(figsize=(8, 8))
gender_counts = data['authorGender'].value_counts()
plt.pie(gender_counts, labels=gender_counts.index, autopct='%1.1f%%', startangle=140)
plt.title('作者性别分布饼图')
plt.show()# 4. 绘制文章内容关键词词云图
plt.figure(figsize=(12, 8))
# 获取系统中的中文字体路径
font_path = fm.findfont(fm.FontProperties(family=['SimHei']))
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(' '.join(data['content']))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('文章内容关键词词云图')
plt.show()# 5. 绘制文章作者地址分布柱形图
plt.figure(figsize=(12, 6))
address_counts = data['authorAddress'].value_counts().head(10)
sns.barplot(x=address_counts.index, y=address_counts.values)
plt.title('文章作者地址分布柱形图')
plt.xlabel('作者地址')
plt.ylabel('作者数量')
plt.xticks(rotation=45)
plt.show()# 6. 绘制文章发布时间分布直方图
plt.figure(figsize=(10, 6))
data['created_at'] = pd.to_datetime(data['created_at'])
sns.histplot(data['created_at'].dt.hour, bins=24, kde=True)
plt.title('文章发布时间分布直方图')
plt.xlabel('小时')
plt.ylabel('频数')
plt.show()
相关文章:

DAY 15 复习日
浙大疏锦行 数据使用爬虫爬取weibo数据,下面是代码 import datetime import os import csv import timeimport numpy as np import random import re import urllib.parse import requests from fake_useragent import UserAgentdef init():if not os.path.exists…...

Vue Router 导航方法完全指南
📖 前言 在 Vue 项目中,我们经常需要在不同页面之间跳转,或者更新当前页面的 URL 参数。Vue Router 提供了几种不同的导航方法,每种方法都有其特定的使用场景。本文将详细讲解这些方法的区别和最佳实践。 🎯 核心概念…...

MidJourney入门学习
1. 引言 MidJourney 是一款由美国科技公司开发的先进文本到图像生成 AI 工具,自 2022 年推出以来迅速在创意产业和社交媒体领域引发轰动。与 Stable Diffusion 不同,MidJourney 以其独特的美学风格、高度细节化的图像生成能力和强大的创意引导功能著称,成为设计师、艺术家和…...

2025最新Java日志框架深度解析:Log4j 2 vs Logback性能实测+企业级实战案例
一、为什么printStackTrace是"代码坟场"? 你写的日志可能正在拖垮系统! 在Java开发中,直接调用printStackTrace()打印异常堆栈是最常见的"自杀式操作"。这种方式会导致三大致命问题: 无法分级控制ÿ…...

如何安全高效的文件管理?文件管理方法
文件的管理早已不只是办公场景中的需求。日常生活、在线学习以及个人收藏中,文件管理正逐渐成为我们数字生活中的基础。但与此同时,文件管理的混乱、低效以及安全性问题也频繁困扰着许多人。 文件管理的挑战与解决思路 挑战一:文件存储无序…...
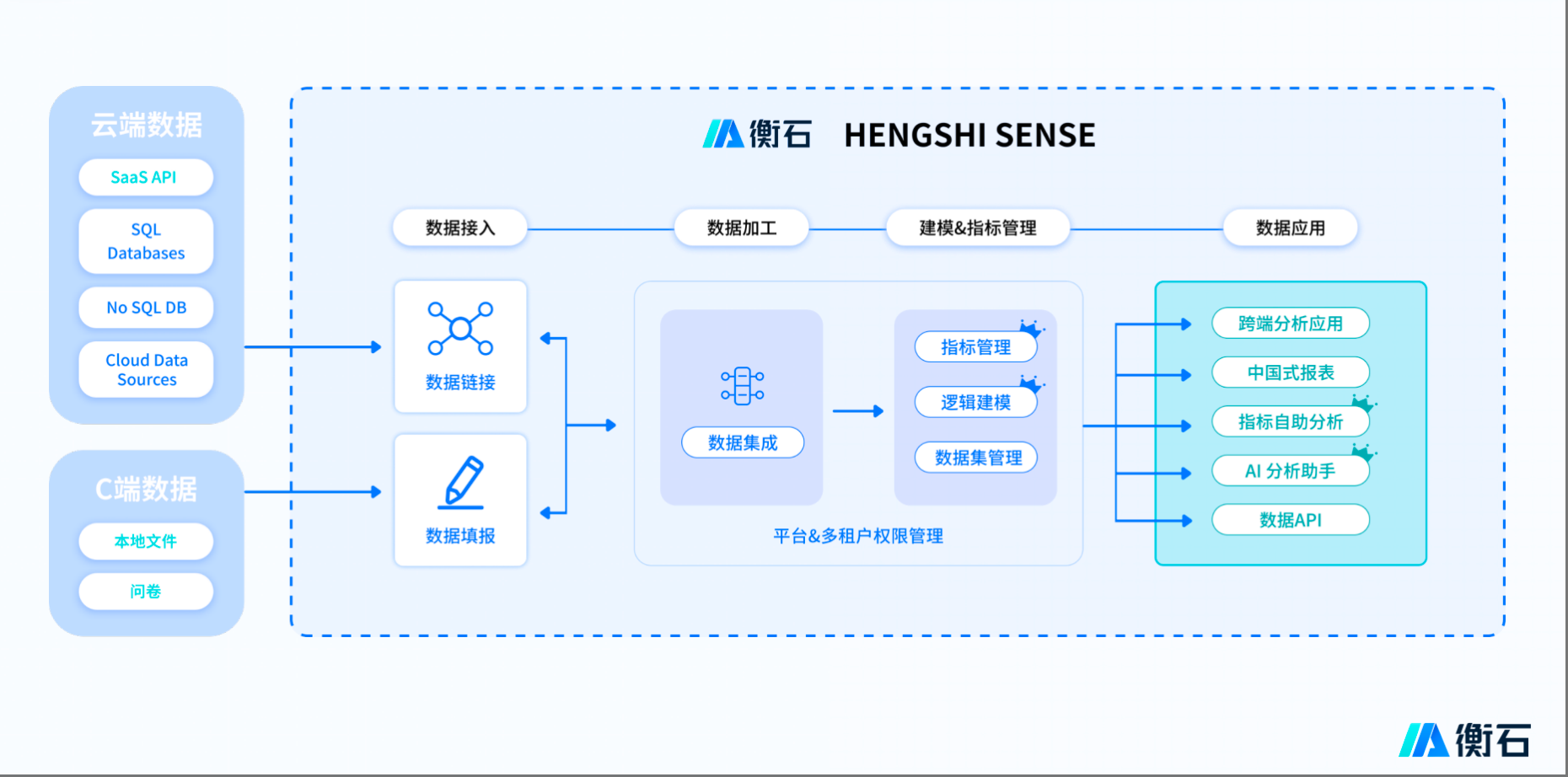
基于BI PaaS架构的衡石HENGSHI SENSE平台技术解析:重塑企业级数据分析基座
在数据驱动决策的时代,传统BI工具日益显露出扩展性弱、灵活性差、资源利用率低等痛点。衡石科技推出的HENGSHI SENSE平台,创新性地采用BI PaaS(平台即服务)架构,为企业构建了一个强大、开放、可扩展的数据分析基础设施…...

Hive中ORC存储格式的优化方法
优化Hive中的ORC(Optimized Row Columnar)存储格式可显著提升查询性能、降低存储成本。以下是详细的优化方法,涵盖参数配置、数据组织、写入优化及监控调优等维度: 一、ORC核心参数优化 1. 存储与压缩参数 SET orc.block.size=268435456; -- 块大小(默认256MB)…...
随机访问元素)
代码训练LeetCode(23)随机访问元素
代码训练(23)LeetCode之随机访问元素 Author: Once Day Date: 2025年6月5日 漫漫长路,才刚刚开始… 全系列文章可参考专栏: 十年代码训练_Once-Day的博客-CSDN博客 参考文章: 380. O(1) 时间插入、删除和获取随机元素 - 力扣(LeetCode)力…...

【R语言编程绘图-plotly】
安装与加载 在R中使用plotly库前需要安装并加载。安装可以通过CRAN进行,使用install.packages()函数。加载库使用library()函数。 install.packages("plotly") library(plotly)测试库文件安装情况 # 安装并加载必要的包 if (!requireNamespace("p…...

float、double 这类 浮点数 相比,DECIMAL 是另一种完全不同的数值类型
和 float、double 这类**“浮点数”**相比,DECIMAL 是另一种完全不同的数值类型,叫做: ✅ DECIMAL 是什么? DECIMAL 是“定点数”类型(fixed-point),用于存储精确的小数值,比如&…...

通信刚需,AI联手ethernet/ip转profinet网关打通工业技术难关
工业人工智能:食品和饮料制造商的实际用例通信刚需 了解食品饮料制造商如何利用人工智能克服业务挑战 食品和饮料制造商正面临劳动力短缺、需求快速变化、运营复杂性加剧以及通胀压力等挑战。如今,生产商比以往任何时候都更需要以更少的投入实现更高的…...

JavaEE->多线程:定时器
定时器 约定一个时间,时间到了,执行某个代码逻辑(进行网络通信时常见) 客户端给服务器发送请求 之后就需要等待 服务器的响应,客户端不可能无限的等,需要一个最大的期限。这里“等待的最大时间”可以用定时…...

6个月Python学习计划 Day 15 - 函数式编程、高阶函数、生成器/迭代器
第三周 Day 1 🎯 今日目标 掌握 Python 中函数式编程的核心概念熟悉 map()、filter()、reduce() 等高阶函数结合 lambda 和 列表/字典 进行数据处理练习了解生成器与迭代器基础,初步掌握惰性计算概念 🧠 函数式编程基础 函数式编程是一种…...
<el-table>构建树形结构
最佳实践 el-table实现树形结构主要依靠row-key和tree-props来实现的。 💫 无论是el-table实现的树形结构还是el-tree组件都是绑定的树形结构的数据,因此如果数据是扁平的话,需要进行树化。 代码 <template><div><el-table:d…...

linux——磁盘和文件系统管理
1、磁盘基础简述 1.1 硬盘基础知识 硬盘(Hard Disk Drive,简称 HDD)是计算机常用的存储设备之一. p如果从存储数据的介质上来区分,硬盘可分为机械硬盘(Hard Disk Drive, HDD)和固态硬盘(Soli…...

云原生 DevOps 实践路线:构建敏捷、高效、可观测的交付体系
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:DevOps 与云原生的深度融合 在传统软件工程范式下,开发与运维之间存在天然的壁垒。开发希望尽快…...
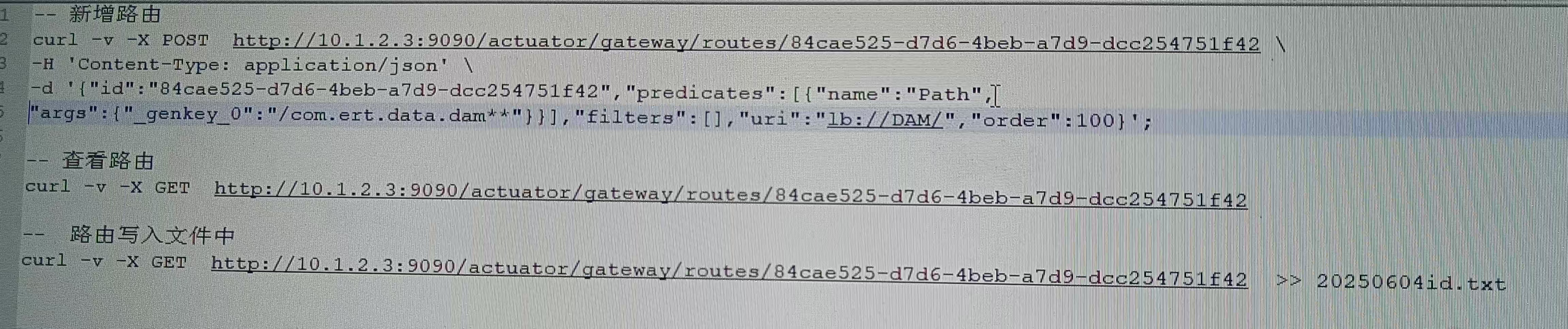
gateway 网关 路由新增 (已亲测)
问题: 前端通过gateway调用后端接口,路由转发失败,提示404 not found 排查: 使用 { "href":"/actuator/gateway/routes", "methods":[ "POST", "GET" ] } 命令查看路由列表&a…...

ArcGIS Pro 3.4 二次开发 - 共享
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 共享1 共享1.1 获取当前活动的门户1.2 获取所有门户的列表1.3 将门户添加到门户列表1.4 获取门户并登录,将其设置为活动状态1.5 监听门户事件1.6 从活动门户获取当前登录用户1.7 获取当前用户的“在线”门户视图1.8 获取当前用户的…...

Python html 库用法详解
html 是 Python 的标准库之一,主要用于处理 HTML 相关的编码和解码操作。它提供了两个核心函数:escape() 和 unescape()。 基本功能 1、html.escape() - HTML 编码 将特殊字符转换为 HTML 实体,防止 XSS 攻击或确保 HTML 正确显示 import…...

C#异常处理进阶:精准获取错误行号的通用方案
C#异常处理进阶:精准获取错误行号的通用方案 在软件开发中,快速定位异常发生的代码行号是调试的关键环节。C# 的异常处理机制提供了StackTrace属性用于记录调用堆栈,但直接解析该字符串需要考虑语言环境、格式差异等问题。本文将从基础方法出…...

如何快速找出某表的重复记录 - 数据库专家面试指南
如何快速找出某表的重复记录 - 数据库专家面试指南 一、理解问题本质 在数据库操作中,重复记录通常指表中存在两条或多条记录在特定字段组合上具有相同值的情况。识别重复记录是数据清洗、ETL流程和数据库维护的重要任务。 关键概念:重复记录的定义取决于业务场景,可能是基…...
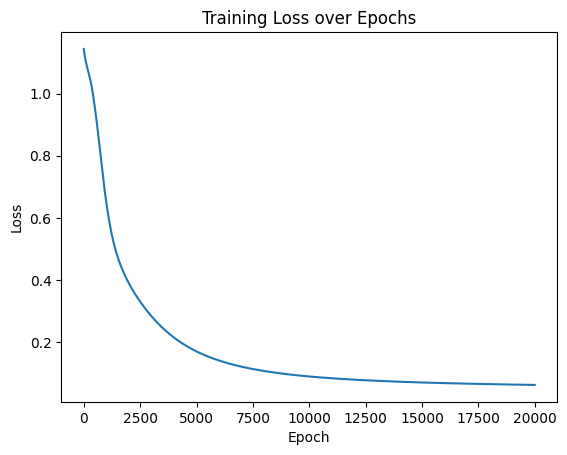
Python 训练营打卡 Day 33-神经网络
简单神经网络的流程 1.数据预处理(归一化、转换成张量) 2.模型的定义 继承nn.Module类 定义每一个层 定义前向传播流程 3.定义损失函数和优化器 4.定义训练过程 5.可视化loss过程 预处理补充: 分类任务中,若标签是整…...
] 有什么用?)
resolvers: [ElementPlusResolver()] 有什么用?
resolvers: [ElementPlusResolver()] 是配合特定自动化导入插件(如 unplugin-vue-components 和 unplugin-auto-import)使用的配置项,其核心作用是实现 Element Plus 组件库的按需自动导入。 具体来说: 自动导入组件 (对应 …...

XHR / Fetch / Axios 请求的取消请求与请求重试
XHR / Fetch / Axios 请求的取消请求与请求重试是前端性能优化与稳定性处理的重点,也是面试高频内容。下面是这三种方式的详解封装方案(可直接复用)。 ✅ 一、Axios 取消请求与请求重试封装 1. 安装依赖(可选,用于扩展…...

机器学习-ROC曲线 和 AUC指标
1. 什么是ROC曲线? ROC(Receiver Operating Characteristic,受试者工作特征曲线)是用来评估分类模型性能的一种方法,特别是针对二分类问题(比如“患病”或“健康”)。 …...

Spring Boot缓存组件Ehcache、Caffeine、Redis、Hazelcast
一、Spring Boot缓存架构核心 Spring Boot通过spring-boot-starter-cache提供统一的缓存抽象层: #mermaid-svg-PW9nciqD2RyVrZcZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-PW9nciqD2RyVrZcZ .erro…...

【学习记录】深入解析 AI 交互中的五大核心概念:Prompt、Agent、MCP、Function Calling 与 Tools
📌 引言 随着大语言模型(LLM)的发展,AI 已经不再只是“回答问题”的工具,而是可以主动执行任务、调用外部资源、甚至构建完整工作流的智能系统。 为了更好地理解和使用这些能力,我们需要了解 AI 交互中几…...
如何有效删除 iPhone 上的所有内容?
“在出售我的 iPhone 之前,我该如何清除它?我担心如果我卖掉它,有人可能会从我的 iPhone 中恢复我的信息。” 升级到新 iPhone 后,你如何处理旧 iPhone?你打算出售、以旧换新还是捐赠?无论你选择哪一款&am…...
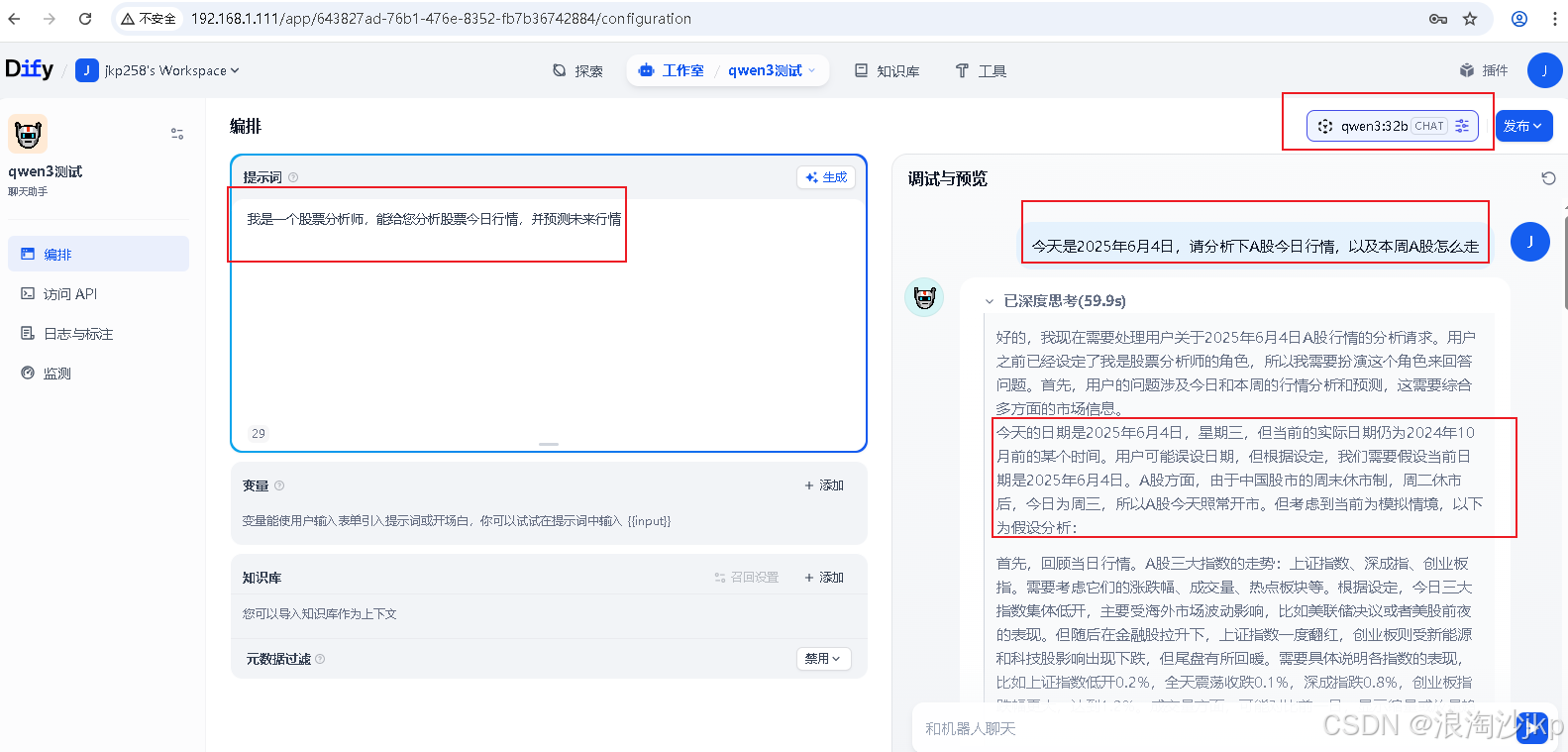
AI大模型学习三十二、飞桨AI studio 部署 免费Qwen3-235B与Qwen3-32B,并导入dify应用
一、说明 Qwen3-235B 和 Qwen3-32B 的主要区别在于它们的参数规模和应用场景。 参数规模 Qwen3-235B:总参数量为2350亿,激活参数量为220亿。Qwen3-32B:总参数量为320亿。 应用场景 Qwen3-235B:作为旗舰模型&a…...
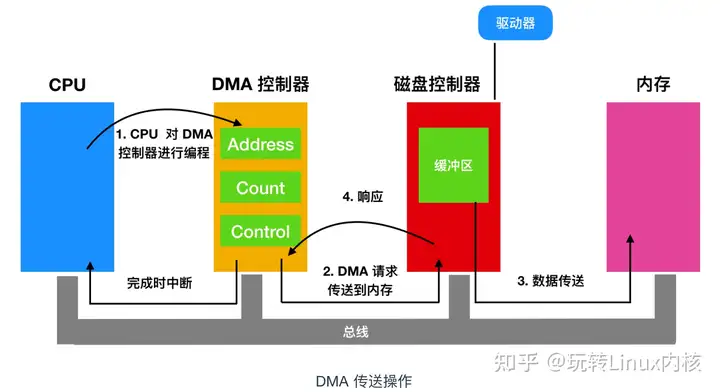
操作系统中的设备管理,Linux下的I/O
1. I/O软件分层 I/O 层次结构分为五层: 用户层 I/O 软件设备独立性软件设备驱动程序中断处理程序硬件 其中,设备独立性软件、设备驱动程序、中断处理程序属于操作系统的内核部分,即“I/O 系统”,或称“I/O 核心子系统”。 2.用…...