解锁FastAPI与MongoDB聚合管道的性能奥秘
title: 解锁FastAPI与MongoDB聚合管道的性能奥秘
date: 2025/05/20 20:24:47
updated: 2025/05/20 20:24:47
author: cmdragon
excerpt:
MongoDB聚合管道是一种分阶段处理数据的流水线,通过$match、$group等阶段对文档进行特定操作,具有内存优化和原生操作的优势。聚合查询常用阶段包括$match、$group、$project等,适用于订单分析等场景。优化策略包括遵循ESR原则创建索引、使用$facet实现高效分页。常见错误如内存限制和游标配置问题,可通过添加allowDiskUse=True和正确处理游标解决。进阶技巧包括使用$expr实现复杂逻辑、日期处理和条件投影。
categories:
- 后端开发
- FastAPI
tags:
- FastAPI
- MongoDB
- 聚合管道
- 查询优化
- 数据分析
- 异常处理
- 实战指南
<img src="https://static.shutu.cn/shutu/jpeg/opene0/2025/05/21/521fa3f05e5f75237a73096281ee4541.jpeg" title="cmdragon_cn.png" alt="cmdragon_cn.png"/>
<img src="https://api2.cmdragon.cn/upload/cmder/20250304_012821924.jpg" title="cmdragon_cn.png" alt="cmdragon_cn.png"/>
扫描二维码
关注或者微信搜一搜:编程智域 前端至全栈交流与成长
探索数千个预构建的 AI 应用,开启你的下一个伟大创意:https://tools.cmdragon.cn/
1. FastAPI与MongoDB聚合管道实战指南
1.1 理解聚合管道基本结构
MongoDB聚合管道(Aggregation Pipeline)是一种数据处理流水线,由多个阶段(Stage)组成,每个阶段对输入文档进行特定操作。其核心优势体现在:
- 分阶段处理:类似工厂流水线,数据依次通过$match、$group等处理阶段
- 内存优化:单个阶段处理不超过100MB,自动优化执行顺序
- 原生操作:直接使用BSON类型,避免数据转换开销
典型管道结构示例:
[{"$match": {"status": "completed"}},{"$group": {"_id": "$category", "total": {"$sum": "$amount"}}},{"$sort": {"total": -1}}
]1.2 构建高效聚合查询
1.2.1 常用阶段运算符
| 阶段 | 作用 | 使用场景示例 |
|---|---|---|
| $match | 文档筛选 | 过滤特定时间段订单 |
| $group | 文档分组 | 统计各分类商品销售额 |
| $project | 字段投影 | 隐藏敏感字段,重命名字段 |
| $sort | 结果排序 | 按销售额降序排列 |
| $limit | 结果限制 | 获取TOP10销售数据 |
| $unwind | 展开数组字段 | 分析订单中的商品列表 |
1.2.2 实战:订单分析系统
定义Pydantic模型:
from pydantic import BaseModel
from datetime import datetimeclass Order(BaseModel):order_id: struser_id: intitems: liststatus: stramount: floatcreated_at: datetime构建聚合查询端点:
from fastapi import APIRouter
from motor.motor_asyncio import AsyncIOMotorClientrouter = APIRouter()@router.get("/orders/stats")
async def get_order_stats():pipeline = [{"$match": {"status": "completed"}},{"$group": {"_id": {"year": {"$year": "$created_at"}, "month": {"$month": "$created_at"}},"total_orders": {"$sum": 1},"total_amount": {"$sum": "$amount"}}},{"$sort": {"_id.year": 1, "_id.month": 1}}]async with AsyncIOMotorClient("mongodb://localhost:27017") as client:cursor = client.mydb.orders.aggregate(pipeline)return await cursor.to_list(length=1000)1.3 复杂查询优化策略
1.3.1 索引优化原则
- ESR原则:Equality > Sort > Range
- 覆盖查询:创建包含所有查询字段的复合索引
- 内存控制:确保$group使用的字段有索引
创建索引示例:
# 在FastAPI启动时创建索引
@app.on_event("startup")
async def create_indexes():db = AsyncIOMotorClient().mydbawait db.orders.create_index([("status", 1), ("created_at", -1)])await db.orders.create_index([("user_id", 1), ("amount", -1)])1.3.2 分页性能优化
使用$facet实现高效分页:
pipeline = [{"$match": {"status": "completed"}},{"$facet": {"metadata": [{"$count": "total"}],"data": [{"$skip": 100},{"$limit": 20},{"$project": {"_id": 0, "order_id": 1, "amount": 1}}]}}
]1.4 异常处理与调试
1.4.1 常见错误解决方案
错误1:OperationFailure: Exceeded memory limit
- 原因:单个聚合阶段超过100MB限制
-
解决方法:
- 添加
allowDiskUse=True参数 - 优化管道顺序,尽早使用$match和$project
- 添加
await db.orders.aggregate(pipeline, allowDiskUse=True).to_list(None)错误2:ConfigurationError: The 'cursor' option is required
- 原因:未正确处理大结果集
- 解决方法:使用游标方式获取数据
cursor = db.orders.aggregate(pipeline, batchSize=1000)
async for doc in cursor:process(doc)1.5 实战练习
Quiz 1:以下聚合管道有什么潜在性能问题?
[{"$project": {"category": 1}},{"$match": {"category": {"$in": ["electronics", "books"]}}},{"$group": {"_id": "$category", "count": {"$sum": 1}}}
]- A. 缺少索引
- B. 阶段顺序错误
- C. 内存使用过高
- D. 字段投影错误
正确答案:B
解析:应该将$match阶段放在最前面,减少后续处理的数据量。优化后的顺序应该是先$match再$project。
Quiz 2:如何优化以下查询的索引策略?
{"$match": {"status": "shipped", "created_at": {"$gte": "2023-01-01"}}}
{"$sort": {"amount": -1}}- A. 创建(status, created_at)索引
- B. 创建(status, amount)索引
- C. 创建(status, created_at, amount)索引
- D. 分别创建status和created_at索引
正确答案:C
解析:根据ESR原则,等值查询字段(status)在前,范围字段(created_at)次之,排序字段(amount)在最后。
1.6 运行环境配置
安装依赖:
pip install fastapi==0.68.0 motor==3.3.2 pydantic==1.10.7 python-multipart==0.0.5启动服务:
uvicorn main:app --reload --port 8000测试聚合端点:
curl http://localhost:8000/orders/stats1.7 进阶技巧
- 表达式优化:使用$expr实现复杂逻辑
{"$match": {"$expr": {"$and": [{"$gt": ["$amount", 100]},{"$lt": ["$amount", 500]}]}
}}- 日期处理:利用日期运算符实现时间分析
{"$group": {"_id": {"year": {"$year": "$created_at"},"week": {"$week": "$created_at"}},"count": {"$sum": 1}
}}- 条件投影:使用$cond实现字段条件赋值
{"$project": {"discount_flag": {"$cond": {"if": {"$gt": ["$amount", 200]}, "then": "A", "else": "B"}}
}}通过本文介绍的聚合管道设计方法和优化策略,开发者可以在FastAPI中高效实现复杂的MongoDB数据分析需求。建议结合MongoDB
Compass的Explain功能验证查询性能,持续优化管道设计。
相关文章:

解锁FastAPI与MongoDB聚合管道的性能奥秘
title: 解锁FastAPI与MongoDB聚合管道的性能奥秘 date: 2025/05/20 20:24:47 updated: 2025/05/20 20:24:47 author: cmdragon excerpt: MongoDB聚合管道是一种分阶段处理数据的流水线,通过$match、$group等阶段对文档进行特定操作,具有内存优化和原生操…...

软件工程方法论:在确定性与不确定性的永恒之舞中寻找平衡
更多精彩请访问:通义灵码2.5——基于编程智能体开发Wiki多功能搜索引擎-CSDN博客 当我们谈论“软件工程”时,“工程”二字总暗示着某种如桥梁建造般的精确与可控。然而,软件的本质却根植于人类思维的复杂性与需求的流变之中。软件工程方法论的…...

Unity中的MonoSingleton<T>与Singleton<T>
1.MonoSingleton 代码部分 using UnityEngine;/// <summary> /// MonoBehaviour单例基类 /// 需要挂载到GameObject上使用 /// </summary> public class MonoSingleton<T> : MonoBehaviour where T : MonoSingleton<T> {private static T _instance;…...

怎么通过 jvmti 去 hook java 层函数
使用 JVMTI 手动实现 Android Java 函数 Hook 要通过 JVMTI 手动实现 Android Java 函数 Hook,需要编写 Native 层代码并注入到目标进程中。以下是详细步骤和示例: 一、核心实现原理 JVMTI 提供两种主要 Hook 方式: Method Entry/Exit 事…...
兰亭妙微 | 医疗软件的界面设计能有多专业?
从医疗影像系统到手术机器人控制界面,从便携式病原体检测设备到多平台协同操作系统,兰亭妙微为众多医疗设备研发企业,打造了兼具专业性与可用性的交互界面方案。 我们不仅做设计,更深入理解医疗场景的实际需求: 对精…...
前端原生构建交互式进度步骤组件(Progress Steps)
在现代网页设计中,进度步骤(Progress Steps) 是一种常见的 UI 模式,常用于引导用户完成注册流程、多步表单、教程或任何需要分步骤操作的场景。本文将带你从零开始构建一个美观且功能完整的 “进度步骤”组件,并详细讲…...

如何给windos11 扩大C盘容量
动不动C盘就慢了,苹果逼着用户换手机,三天两头更新系统,微软也是毫不手软。c盘 从10个G就够用,到100G 也不够,看来通货膨胀是部分行业的。 在 Windows 11 中扩大 C 盘容量,主要取决于磁盘分区布局和可用空…...
【基于阿里云搭建数据仓库(离线)】Data Studio创建资源与函数
Data Studio支持在您的数据分析代码中引用自定义的资源和函数(支持MaxCompute、EMR、CDH、Flink),您需要先创建或上传资源、函数至目标工作空间,上传后才可在该工作空间的任务中使用。您可参考本文了解如何使用DataWorks可视化方式…...
粘滞位详解)
Linux_T(Sticky Bit)粘滞位详解
Linux 粘滞位(Sticky Bit)详解 一、什么是粘滞位(Sticky Bit) 粘滞位(Sticky Bit)是 Linux 和 Unix 系统中一种特殊的权限设置,主要应用于目录,其作用是在多人共享访问的目录中&am…...
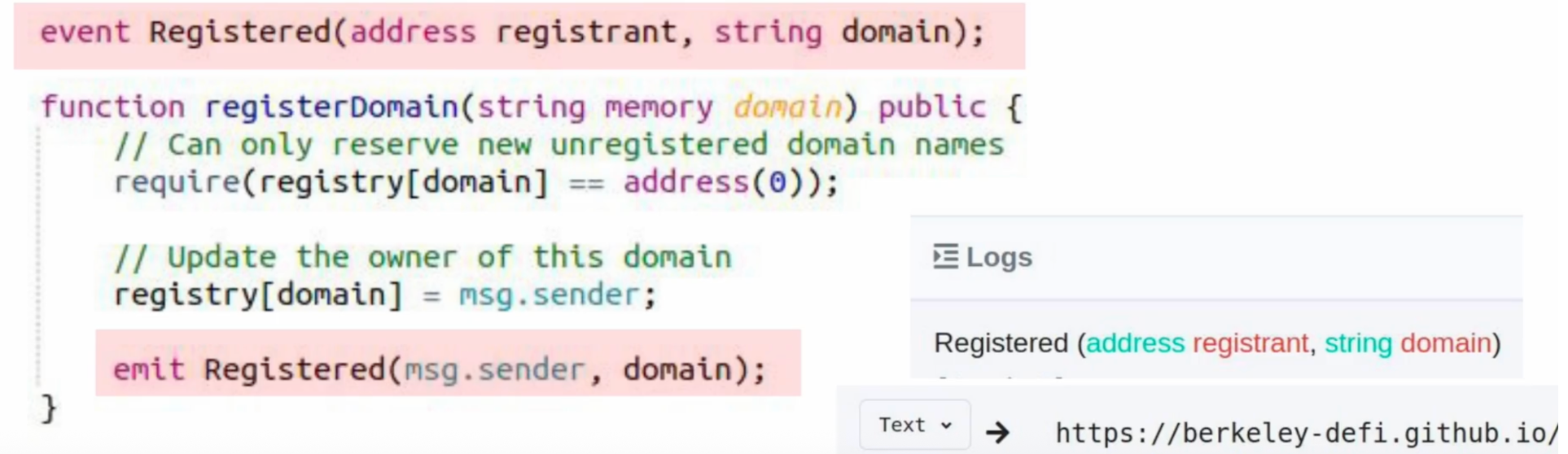
web3-以太坊智能合约基础(理解智能合约Solidity)
以太坊智能合约基础(理解智能合约/Solidity) 无需编程经验,也可以帮助你了解Solidity独特的部分;如果本身就有相应的编程经验如java,python等那么学起来也会非常的轻松 一、Solidity和EVM字节码 实际上以太坊链上储存…...
)
高敏感应用如何保护自身不被逆向?iOS 安全加固策略与工具组合实战(含 Ipa Guard 等)
如果你正在开发一款涉及支付、隐私数据或企业内部使用的 App,那么你可能比多数开发者更早意识到一件事——App 一旦被破解,损失的不只是代码,还有信任与业务逻辑。 在我们为金融类工具、HR 系统 App、数据同步组件等高敏感项目提供支持的过程…...

【C++项目】负载均衡在线OJ系统-2
文章目录 oj_server模块编写oj_server框架的搭建-oj_server/oj_server.cpp 路由框架 oj_model模块编写题目信息设置v1.文件版本-common/util.hpp boost库spilt函数的使用-oj_server/oj_model_file.hpp 文件版本model编写v2.mysql数据库版本1.mysql创建授权用户、建库建表录入操…...
GC1809:高性能24bit/192kHz音频接收芯片解析
1. 芯片概述 GC1809 是数字音频接收芯片,支持IEC60958、S/PDIF、AES3等协议,集成8选1输入切换、低抖动时钟恢复和24bit DAC,适用于家庭影院、汽车音响等高保真场景。 核心特性 高精度:24bit分辨率,动态范围105dB&…...

2025年06月05日Github流行趋势
项目名称:onlook 项目地址url:https://github.com/onlook-dev/onlook项目语言:TypeScript历史star数:16165今日star数:1757项目维护者:Kitenite, drfarrell, spartan-vutrannguyen, apps/devin-ai-integrat…...

flask功能使用总结和完整示例
Flask 功能使用总结与完整示例 一、Flask 核心功能总结 Flask 是轻量级 Web 框架,核心功能包括: 路由系统:通过 app.route 装饰器定义 URL 与函数的映射。模板引擎:默认使用 Jinja2,支持动态渲染 HTML。请求处理&…...

AWS 亚马逊 S3存储桶直传 前端demo 复制即可使用
自己踩过坑不想别人也踩坑了 亚马逊S3存储桶直传前端demo复制即可使用 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0…...

DAY 15 复习日
浙大疏锦行 数据使用爬虫爬取weibo数据,下面是代码 import datetime import os import csv import timeimport numpy as np import random import re import urllib.parse import requests from fake_useragent import UserAgentdef init():if not os.path.exists…...

Vue Router 导航方法完全指南
📖 前言 在 Vue 项目中,我们经常需要在不同页面之间跳转,或者更新当前页面的 URL 参数。Vue Router 提供了几种不同的导航方法,每种方法都有其特定的使用场景。本文将详细讲解这些方法的区别和最佳实践。 🎯 核心概念…...

MidJourney入门学习
1. 引言 MidJourney 是一款由美国科技公司开发的先进文本到图像生成 AI 工具,自 2022 年推出以来迅速在创意产业和社交媒体领域引发轰动。与 Stable Diffusion 不同,MidJourney 以其独特的美学风格、高度细节化的图像生成能力和强大的创意引导功能著称,成为设计师、艺术家和…...

2025最新Java日志框架深度解析:Log4j 2 vs Logback性能实测+企业级实战案例
一、为什么printStackTrace是"代码坟场"? 你写的日志可能正在拖垮系统! 在Java开发中,直接调用printStackTrace()打印异常堆栈是最常见的"自杀式操作"。这种方式会导致三大致命问题: 无法分级控制ÿ…...

如何安全高效的文件管理?文件管理方法
文件的管理早已不只是办公场景中的需求。日常生活、在线学习以及个人收藏中,文件管理正逐渐成为我们数字生活中的基础。但与此同时,文件管理的混乱、低效以及安全性问题也频繁困扰着许多人。 文件管理的挑战与解决思路 挑战一:文件存储无序…...
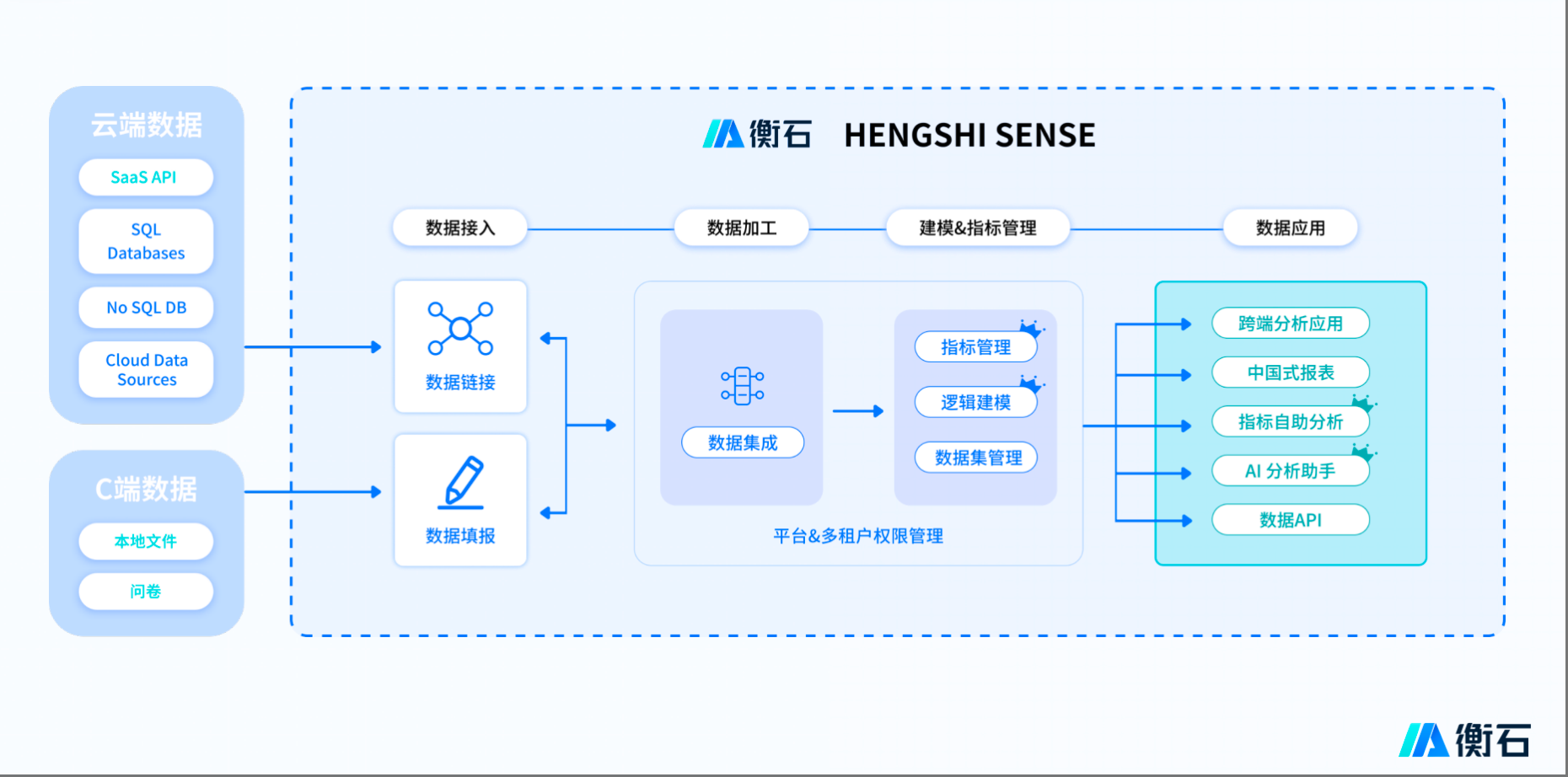
基于BI PaaS架构的衡石HENGSHI SENSE平台技术解析:重塑企业级数据分析基座
在数据驱动决策的时代,传统BI工具日益显露出扩展性弱、灵活性差、资源利用率低等痛点。衡石科技推出的HENGSHI SENSE平台,创新性地采用BI PaaS(平台即服务)架构,为企业构建了一个强大、开放、可扩展的数据分析基础设施…...

Hive中ORC存储格式的优化方法
优化Hive中的ORC(Optimized Row Columnar)存储格式可显著提升查询性能、降低存储成本。以下是详细的优化方法,涵盖参数配置、数据组织、写入优化及监控调优等维度: 一、ORC核心参数优化 1. 存储与压缩参数 SET orc.block.size=268435456; -- 块大小(默认256MB)…...
随机访问元素)
代码训练LeetCode(23)随机访问元素
代码训练(23)LeetCode之随机访问元素 Author: Once Day Date: 2025年6月5日 漫漫长路,才刚刚开始… 全系列文章可参考专栏: 十年代码训练_Once-Day的博客-CSDN博客 参考文章: 380. O(1) 时间插入、删除和获取随机元素 - 力扣(LeetCode)力…...

【R语言编程绘图-plotly】
安装与加载 在R中使用plotly库前需要安装并加载。安装可以通过CRAN进行,使用install.packages()函数。加载库使用library()函数。 install.packages("plotly") library(plotly)测试库文件安装情况 # 安装并加载必要的包 if (!requireNamespace("p…...

float、double 这类 浮点数 相比,DECIMAL 是另一种完全不同的数值类型
和 float、double 这类**“浮点数”**相比,DECIMAL 是另一种完全不同的数值类型,叫做: ✅ DECIMAL 是什么? DECIMAL 是“定点数”类型(fixed-point),用于存储精确的小数值,比如&…...

通信刚需,AI联手ethernet/ip转profinet网关打通工业技术难关
工业人工智能:食品和饮料制造商的实际用例通信刚需 了解食品饮料制造商如何利用人工智能克服业务挑战 食品和饮料制造商正面临劳动力短缺、需求快速变化、运营复杂性加剧以及通胀压力等挑战。如今,生产商比以往任何时候都更需要以更少的投入实现更高的…...

JavaEE->多线程:定时器
定时器 约定一个时间,时间到了,执行某个代码逻辑(进行网络通信时常见) 客户端给服务器发送请求 之后就需要等待 服务器的响应,客户端不可能无限的等,需要一个最大的期限。这里“等待的最大时间”可以用定时…...

6个月Python学习计划 Day 15 - 函数式编程、高阶函数、生成器/迭代器
第三周 Day 1 🎯 今日目标 掌握 Python 中函数式编程的核心概念熟悉 map()、filter()、reduce() 等高阶函数结合 lambda 和 列表/字典 进行数据处理练习了解生成器与迭代器基础,初步掌握惰性计算概念 🧠 函数式编程基础 函数式编程是一种…...
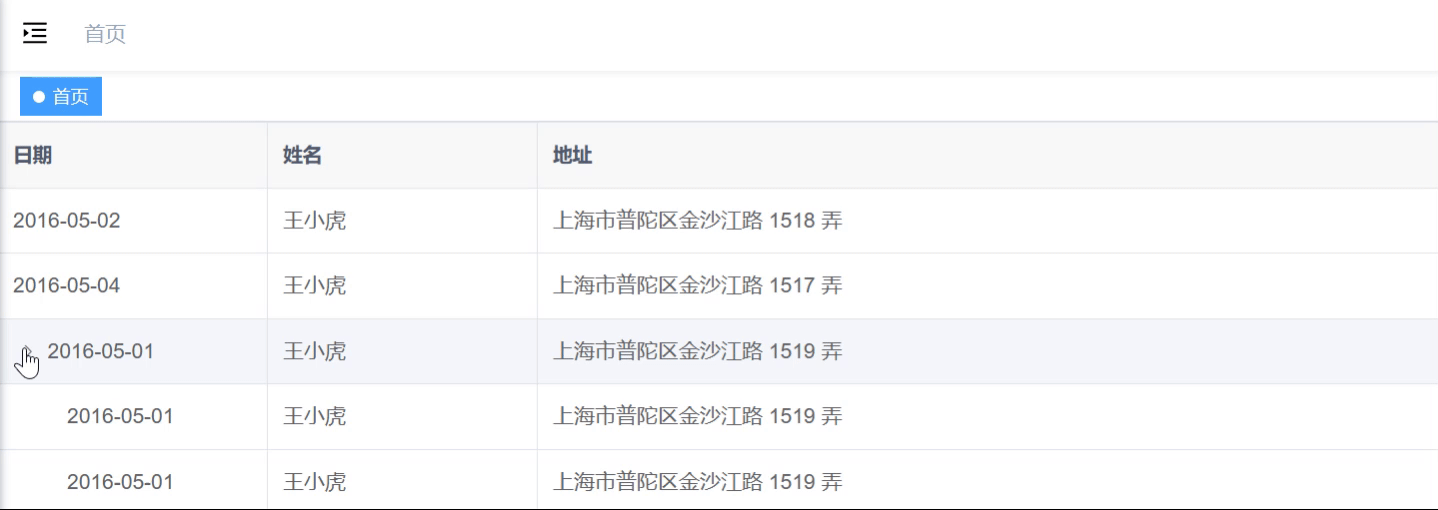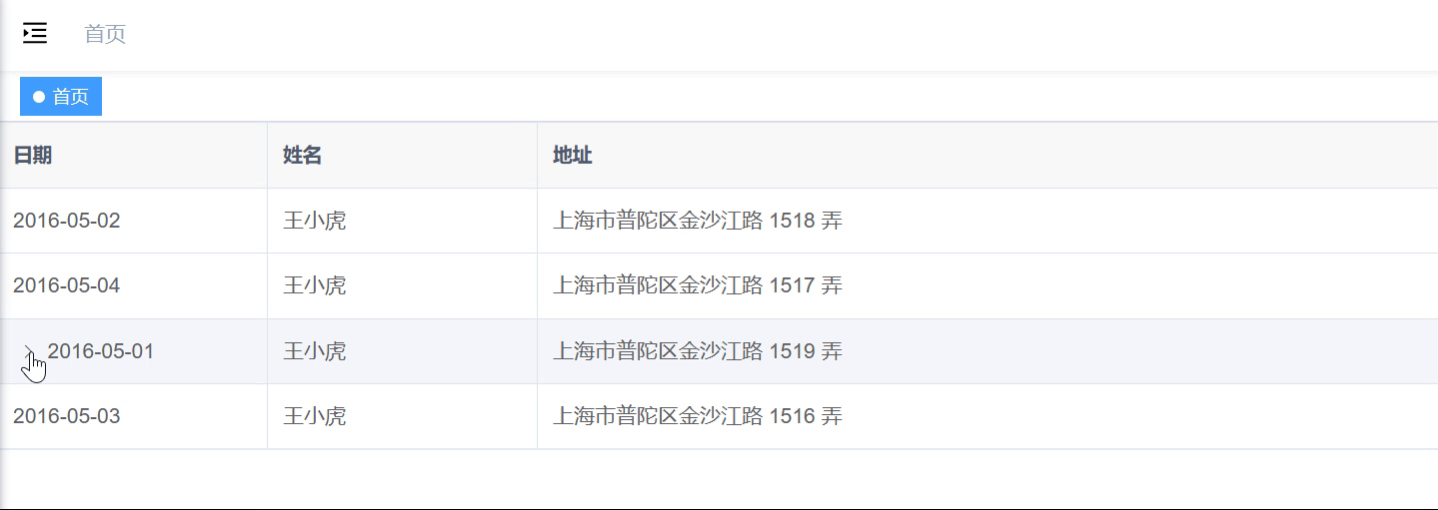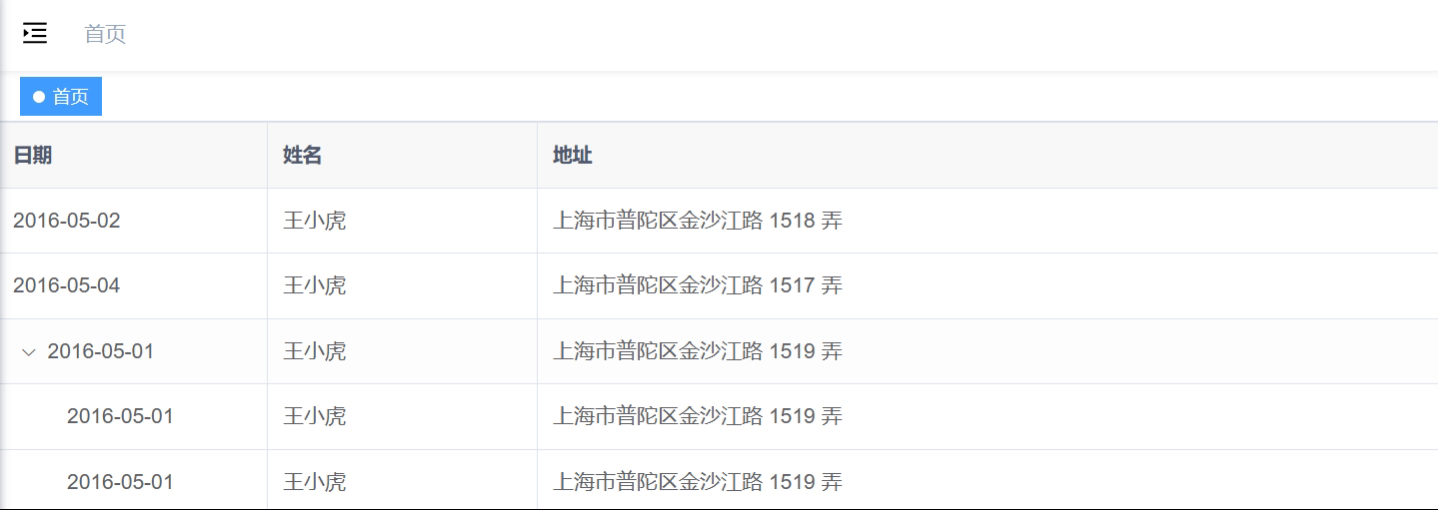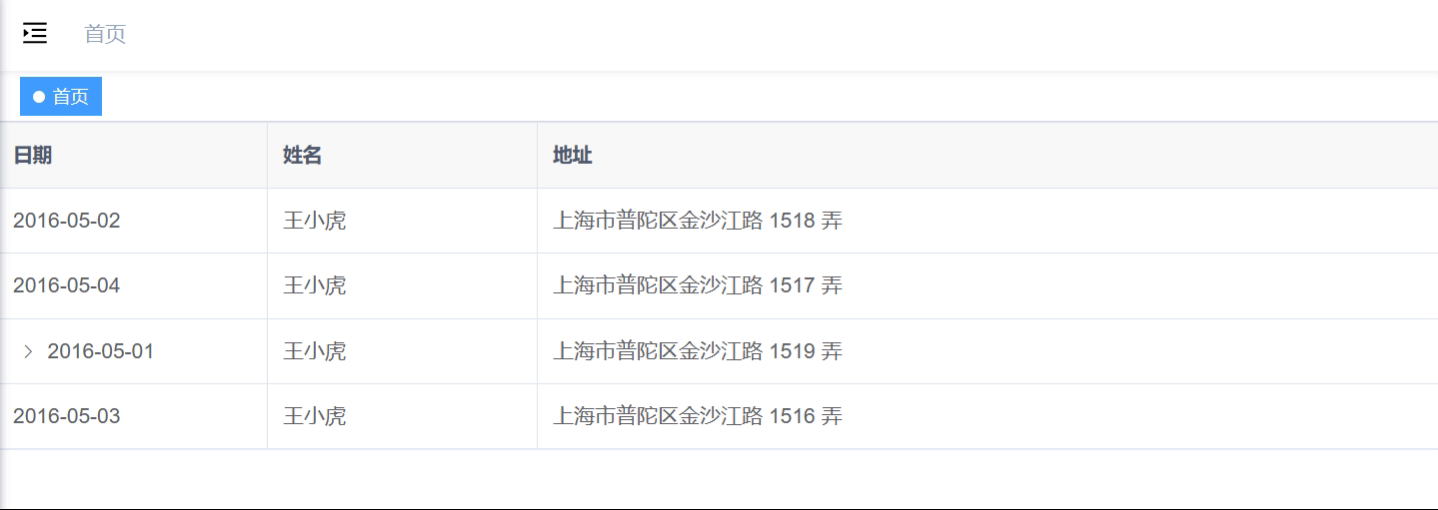
<el-table>构建树形结构
最佳实践 el-table实现树形结构主要依靠row-key和tree-props来实现的。 💫 无论是el-table实现的树形结构还是el-tree组件都是绑定的树形结构的数据,因此如果数据是扁平的话,需要进行树化。 代码 <template><div><el-table:d…...