Flink checkpoint
对齐检查点 (Aligned Checkpoint)
Flink 的分布式快照机制受到 Chandy-Lamport 算法的启发。 其核心元素是数据流中的屏障(Barrier)。
-
Barrier 注入 :JobManager 中的 Checkpoint Coordinator 指示 Source 任务开始 Checkpoint。Source 任务在数据流中注入 Barrier。这些 Barrier 携带 Checkpoint ID,将数据流分割成属于本次快照的记录和属于下次快照的记录。
-
Barrier 对齐 :当一个算子(Operator)有多个输入流时,它必须等待所有输入流的 Barrier 都到达后,才会进行自己的状态快照,并向下游广播 Barrier。 在对齐过程中,已经接收到 Barrier 的输入通道会被阻塞,算子会继续处理来自尚未接收到 Barrier 的通道的数据。
-
状态快照 :一旦所有 Barrier 到达,算子就进行本地状态快照,并异步上传到持久化存储。
-
Checkpoint 完成 :当所有 Sink 任务接收到所有输入流的 Barrier 并完成自己的快照后,会通知 JobManager,该 Checkpoint 完成。
对齐检查点的局限性 (尤其在反压情况下)
在应用产生反压时,对齐检查点会面临以下问题:
-
Barrier 流动缓慢 :由于反压,Buffer 中缓存了大量数据,导致 Barrier 在数据流中流动缓慢。
-
处理阻塞 :对于已经接收到 Barrier 的 Channel,由于需要等待其他 Channel 的 Barrier 进行对齐,其上游数据处理会被阻塞。
-
Checkpoint 完成时间长 :Barrier 可能需要很长时间才能到达 Sink,导致 Checkpoint 完成时间过长。一个耗时过长的 Checkpoint 在完成时可能已经“过时”了。
-
恶性循环 :长时间的 Checkpoint 可能导致任务超时、崩溃,然后从一个较旧的 Checkpoint 恢复,这可能加剧反压,形成恶性循环,使得任务几乎没有进展。
非对齐检查点 (Unaligned Checkpoint) 的工作原理
为了解决上述问题,Flink 引入了非对齐检查点(FLIP-76)。其核心思想是取消中间算子的 Barrier 对齐过程。
-
Barrier 注入 :与对齐检查点类似,Barrier 仍然在 Source 端注入。
-
无需对齐,立即转发 :中间算子在接收到任何一个输入流的 Barrier 后,不再等待其他输入流的 Barrier。它会:
-
短暂阻塞 任务。
-
标记 Buffer :记录当前 Buffer 中的数据(这些数据属于当前 Checkpoint)。
-
转发 Barrier :立即将 Barrier 向下游算子转发。
-
创建状态快照 :进行本地状态快照,这个快照包含了算子自身的状态以及在其输入 Buffer 中、尚未被处理但在 Barrier 之前到达的数据(即所谓的“in-flight data”)。
-
-
快速到达 Sink :由于 Barrier 不再需要等待对齐,它们可以非常快速地传递到 Sink。
-
Sink 端对齐(可选) :在某些描述中,提到非对齐检查点只在 Sink 端进行对齐,而中间算子则不进行对齐。
怎么保证 Barrier 不会超过之前的数据,和不会被之后的数据超过?
这是通过 Flink 数据传输和处理的有序性来保证的,主要依赖以下几点:
-
发送端的有序性:
- 当一个上游算子处理完一批数据后,如果接下来需要发送 Checkpoint Barrier N,它会确保先将这批数据发送出去,然后再发送 Barrier N。之后产生的数据,则会在 Barrier N 之后发送。
- 这意味着在逻辑上,数据记录和 Barrier 在发送端是被串行化处理和发送的。
-
Flink 网络栈的有序性保证 (Channel 级别):
- Flink 的 TaskManager 内部(对于 chained operators)的数据传输通道(
InputChannel和ResultSubpartition)被设计为先进先出 (FIFO) 的。 - 无论是普通的数据记录还是特殊的 Checkpoint Barrier,一旦被写入一个输出通道,它们就会按照写入的顺序被下游的输入通道读取。
- 对于跨 TaskManager 的网络传输,Flink 通常依赖 TCP/IP。在单个 TCP 连接内,TCP 协议本身保证了数据包的有序传输。 Flink 会为有数据交互的 Task Subtask 之间建立逻辑连接,这些连接底层可能复用物理 TCP 连接,但 Flink 的网络层会确保逻辑上的数据顺序。
- Flink 的 TaskManager 内部(对于 chained operators)的数据传输通道(
-
算子处理的有序性:
- 算子从其输入通道读取数据时,也是按顺序读取的。它不会跳过前面的数据去处理后面的数据(在一个通道内)。
总结一下保证顺序的关键:
- 上游按序发送:数据记录和 Barrier 在源头就是按逻辑顺序发送的。
- 通道保证 FIFO:Flink 的数据传输通道(无论是内存中的还是跨网络的)保证了消息的先进先出。
- 下游按序接收和处理:下游算子按顺序从通道中读取数据。
当然,如果一个算子有多个输入通道(例如来自不同的上游算子,或者同一个上游算子的不同并行实例),那么不同通道上的 Barrier N 到达时间确实可能因为网络延迟、处理速度等原因而不同。这正是 Barrier Alignment (屏障对齐) 机制要解决的问题:算子会等待所有输入通道的 Barrier N 都到达后,才进行自己的状态快照,以确保快照的一致性。
PipelinedSubpartition
PipelinedSubpartition 使用 PrioritizedDeque 使得 Flink 能够在保证普通数据流的 FIFO 特性的基础上,有效地处理需要优先响应的特殊事件。这比单纯的 ArrayDeque 提供了更灵活的控制流管理。
PrioritizedDeque 是一个很有意思的数据结构,它结合了队列和优先级处理的能力:
- 基本行为: 它仍然是一个双端队列 (Deque),可以从头部和尾部添加或移除元素。
- 优先级处理:
- 当一个具有优先级的
BufferConsumer(例如,一个非对齐检查点的CheckpointBarrier,或者其他一些控制事件)被添加到PipelinedSubpartition时,它通常会被放入PrioritizedDeque的队首(通过类似addPriorityElement的方法,具体实现在PrioritizedDeque内部)。 - 普通的、非优先级的
BufferConsumer(即大部分数据 Buffer)则会被添加到PrioritizedDeque的队尾(通过buffers.add(...),这通常是 Deque 的标准addLast行为)。
- 当一个具有优先级的
- 数据消费:
- 当数据被消费时(例如通过
pollBuffer()方法),元素总是从PrioritizedDeque的队首被取出。
- 当数据被消费时(例如通过
这对 FIFO 意味着什么?
- 对于普通数据流: 如果没有优先事件插入,普通的数据 Buffer 遵循严格的 FIFO 顺序。它们被加入队尾,然后按顺序从队首被消费。
- 当优先事件发生时: 如果一个优先事件(比如一个需要立即处理的 Barrier)到达,它会被插入到队首。这意味着它会在任何已在队列中但尚未被消费的普通数据 Buffer 之前被处理。这对于确保像非对齐 Checkpoint Barrier 这样的控制信令能够及时响应是至关重要的。一旦所有优先元素被处理完毕,队列会继续从队首消费那些之前按 FIFO 顺序排列的普通数据 Buffer。
Flink 在恢复时怎么知道快照包含的“物理部分”是什么
主要是通过以下信息和机制:
-
算子标识 (Operator ID / UID):
- 在 Flink 作业中,每个有状态的算子(Operator)都有一个唯一的标识符。这个标识符可以是 Flink 自动生成的,也可以是用户通过
uid(String)方法指定的。 - 当进行 Checkpoint 时,每个算子产生的状态都会与这个唯一的算子标识符关联起来并存储。
- 在 Flink 作业中,每个有状态的算子(Operator)都有一个唯一的标识符。这个标识符可以是 Flink 自动生成的,也可以是用户通过
-
子任务索引 (Subtask Index):
- Flink 作业中的算子通常会以一定的并行度执行。每个并行实例被称为一个子任务(Subtask),并且它们都有一个从 0 到
parallelism-1的索引。 - Checkpoint 快照会分别记录下属于每一个算子的每一个子任务的状态。你当前正在查看的
AcknowledgeCheckpoint.java文件中的TaskStateSnapshot subtaskState字段,就代表了一个特定子任务的状态快照。
- Flink 作业中的算子通常会以一定的并行度执行。每个并行实例被称为一个子任务(Subtask),并且它们都有一个从 0 到
-
键组 (Key Groups) - 针对 Keyed State:
- 对于 Keyed State(例如,在
keyBy之后使用的ValueState,MapState等),数据是根据 key 的哈希值被划分到逻辑的“键组”(Key Groups)中的。 - 一个作业的最大并行度(
maxParallelism)决定了总共有多少个键组。 - 在 Checkpoint 时,每个键组的状态都会被保存下来。
- 在恢复时,每个(可能新的)子任务会被确定性地分配一组它需要负责的键组。这个分配算法保证了无论并行度如何变化(在
maxParallelism范围内),每个 key 始终属于同一个键组,并且每个键组始终会被分配给一个确定的子任务。因此,子任务可以准确地知道应该从快照中加载哪些键组的状态。
- 对于 Keyed State(例如,在
-
快照元数据 (Checkpoint Metadata):
- 当一个 Checkpoint 成功完成后,JobManager 会将关于这个 Checkpoint 的所有元数据信息持久化。这些元数据通常包含:
- Checkpoint ID。
- 每个算子(通过其唯一标识符识别)的状态信息。
- 对于每个算子,其每个子任务(通过其索引识别)的状态句柄(State Handle),这些句柄指向实际存储状态数据的位置(例如 HDFS 上的文件路径)。
- 对于 Keyed State,会记录每个键组范围的状态句柄。
- 当一个 Checkpoint 成功完成后,JobManager 会将关于这个 Checkpoint 的所有元数据信息持久化。这些元数据通常包含:
恢复过程如何利用这些信息:
当 Flink 作业从一个 Checkpoint 恢复时:
- JobManager 首先从持久化存储中读取选定的 Checkpoint 的元数据。
- JobManager 根据当前的作业拓扑和每个算子的并行度,为每个新启动的 Task(即算子的子任务实例)分配任务。
- 对于每一个需要恢复状态的 Task:
- JobManager 会在其元数据中查找与该 Task 对应的算子标识符和子任务索引(或者它负责的键组范围)。
- 通过这些信息,JobManager 可以定位到该 Task 在 Checkpoint 中对应的状态句柄。
- Task 接收到这些状态句柄后,就会从持久化存储中读取并加载属于自己的那部分状态数据。
所以,所谓的“物理部分”其实就是指特定算子的特定并行实例(子任务)所拥有的那部分状态数据。
Flink 通过在 Checkpoint 时精确记录这种“逻辑算子/子任务”到“实际状态数据存储位置”的映射关系,并在恢复时利用这种映射关系,来确保每个新的 Task 实例都能正确地加载其先前保存的状态。
什么是非对齐检查点 (Unaligned Checkpoint)?
在标准的对齐检查点(Aligned Checkpoint)模式下,当一个算子接收到来自上游某个输入通道的检查点屏障 (Checkpoint Barrier) 时,它会暂停处理该通道的数据,直到接收到所有输入通道的屏障。这个过程称为“对齐”。对齐的目的是确保所有算子在同一时刻对数据流进行快照,从而保证精确一次 (Exactly-Once) 的处理语义。然而,在高背压的情况下,对齐过程可能会非常耗时,因为某些通道的屏障可能需要等待很长时间才能到达,这会导致检查点时长增加,甚至超时。
非对齐检查点通过允许检查点屏障“越过”通道中正在传输的数据来解决这个问题。当屏障到达算子时,算子会立即开始进行快照,并将通道中尚未处理的数据(即所谓的“飞行中”数据)也作为检查点状态的一部分保存下来。
非对齐检查点是如何工作的?
核心思想是:
- 屏障超越数据 (Barrier Overtaking Data):检查点屏障不再需要等待所有数据处理完毕。当屏障到达一个算子时,该算子会立即开始其快照过程。
- 飞行中数据作为状态 (In-flight Data as State):在屏障之后、算子处理之前的数据(即飞行中数据)会被捕获并存储为检查点状态的一部分。这意味着,当从检查点恢复时,这些飞行中数据也会被恢复并重新处理,就好像它们从未被屏障越过一样。
- 源端插入屏障:尽管非对齐检查点在概念上更接近 Chandy-Lamport 算法,但 Flink 仍然在数据源端插入屏障,以避免检查点协调器过载。
在代码层面,CheckpointOptions.java 文件定义了不同的对齐类型,包括 UNALIGNED 和 FORCED_ALIGNED:CheckpointConfig.java 中有启用非对齐检查点的方法。
当启用非对齐检查点时,如果设置了 alignedCheckpointTimeout,检查点会先尝试对齐。如果在超时时间内未能完成对齐,则会自动切换到非对齐模式。如果 alignedCheckpointTimeout 设置为0,则检查点会直接以非对齐方式启动。
为什么可以非对齐?
非对齐检查点之所以能够实现,关键在于它改变了对“一致性快照”的实现方式。
- 传统对齐检查点:通过确保所有算子在逻辑上的同一时间点(即所有输入屏障都到达时)进行快照,来保证数据的一致性。这意味着在屏障到达之前的数据都已被处理并反映在算子状态中,屏障之后的数据则不包含在当前快照中。
- 非对齐检查点:它放宽了“同一逻辑时间点”的严格要求。通过将飞行中的数据(即那些在屏障已经通过但尚未被下游算子处理的数据)也包含在检查点状态中,它依然能够保证在恢复时,所有数据不多不少恰好被处理一次。当从非对齐检查点恢复时,这些被保存的飞行中数据会被重新注入到数据流中,就好像它们从未被屏障“跳过”一样。
优势:
- 减少背压影响:在高背压场景下,数据处理缓慢,导致屏障对齐时间过长。非对齐检查点由于不需要等待数据处理,可以显著缩短检查点时间。
- 提高检查点频率:由于检查点时间缩短,可以更频繁地进行检查点,从而减少故障恢复时需要重放的数据量。
限制和注意事项:
- 精确一次语义:非对齐检查点仅在精确一次 (Exactly-Once) 语义下可用。
- Savepoint:Savepoint 通常不能是非对齐的,因为它们通常用于版本升级或作业迁移,需要一个完全对齐的状态。
- 状态大小:由于飞行中的数据也被包含在状态中,非对齐检查点的状态大小可能会比对齐检查点更大。
- Sink 的特殊处理:如 Flink 2.0 的发布说明中提到 (
docs/content/release-notes/flink-2.0.md),对于 Sink 拓扑中的操作(如 committer),非对齐检查点会被禁用,以确保 committable 能够在notifyCheckpointComplete时位于相应的算子,从而正确提交所有副作用。
总而言之,非对齐检查点通过将飞行中数据纳入状态管理,实现了在不牺牲精确一次语义的前提下,大幅优化高背压场景下检查点性能的目标。
相关文章:

Flink checkpoint
对齐检查点 (Aligned Checkpoint) Flink 的分布式快照机制受到 Chandy-Lamport 算法的启发。 其核心元素是数据流中的屏障(Barrier)。 Barrier 注入 :JobManager 中的 Checkpoint Coordinator 指示 Source 任务开始 Checkpoint。Source 任务…...

【java】在springboot中实现证书双向验证
证书生成 public static void main(String[] args) throws Exception {// 生成密钥对KeyPairGenerator keyPairGenerator KeyPairGenerator.getInstance("RSA");keyPairGenerator.initialize(2048);KeyPair keyPair keyPairGenerator.generateKeyPair();// 获取私…...

CppCon 2015 学习:Functional Design Explained
这两个 C 程序 不完全相同。它们的差异在于对 std::cout 的使用和代码格式。 程序 1: #include <iostream> int main(int argc, char** argv) {std::cout << "Hello World\n"; }解释:这个程序是 正确的。std::cout 是 C 标准库中…...

基于3D对象体积与直径特征的筛选
1,目的 筛选出目标3D对象。 效果如下: 2,原理 使用3D对象的体积与直径特征进行筛选。 3,代码解析 3.1,预处理2.5D深度图。 * 参考案例库:select_object_model_3d.hdev * ****************************…...

GIT - 如何从某个分支的 commit创建一个新的分支?
如果上一个Release 分支被污染了,想要还原这个分支最原始的样子,有什么办法或者说该怎么办呢?简单来说,就是如何从某个指定的 commit 创建一个新的 Git 分支? 操作非常简单! 命令格式 git branch <ne…...

Claude vs ChatGPT vs Gemini:功能对比、使用体验、适合人群
随着AI应用全面进入生产力场景,市面上的主流AI对话工具也进入“三国杀”时代: Claude(Anthropic):新锐崛起,语言逻辑惊艳,Opus 模型被称为 GPT-4 杀手ChatGPT(OpenAI)&a…...

线程基础编程
早期的计算机只能执行一个任务,一旦任务完成,计算机就会等待下一个任务。这种模型效率低下,无 法充分利用计算机的性能。 随着计算机技术的发展,操作系统开始支持多进程模型,即同时执行多个任务。每个任务被称为一个进…...

DJango项目
一.项目创建 在想要将项目创键的目录下,输入cmd (进入命令提示符)在cmd中输入:Django-admin startproject 项目名称 (创建项目)cd 项目名称 (进入项目)Django-admin startapp 程序名称 (创建程序)python manage.py runserver 8080 (运行程序)将弹出的网址复制到浏览器中…...

深入了解JavaScript当中如何确定值的类型
JavaScript是一种弱类型语言,当你给一个变量赋了一个值,该值是什么类型的,那么该变量就是什么类型的,并且你还可以给一个变量赋多种类型的值,也不会报错,这就是JavaScript的内部机制所决定的,那…...
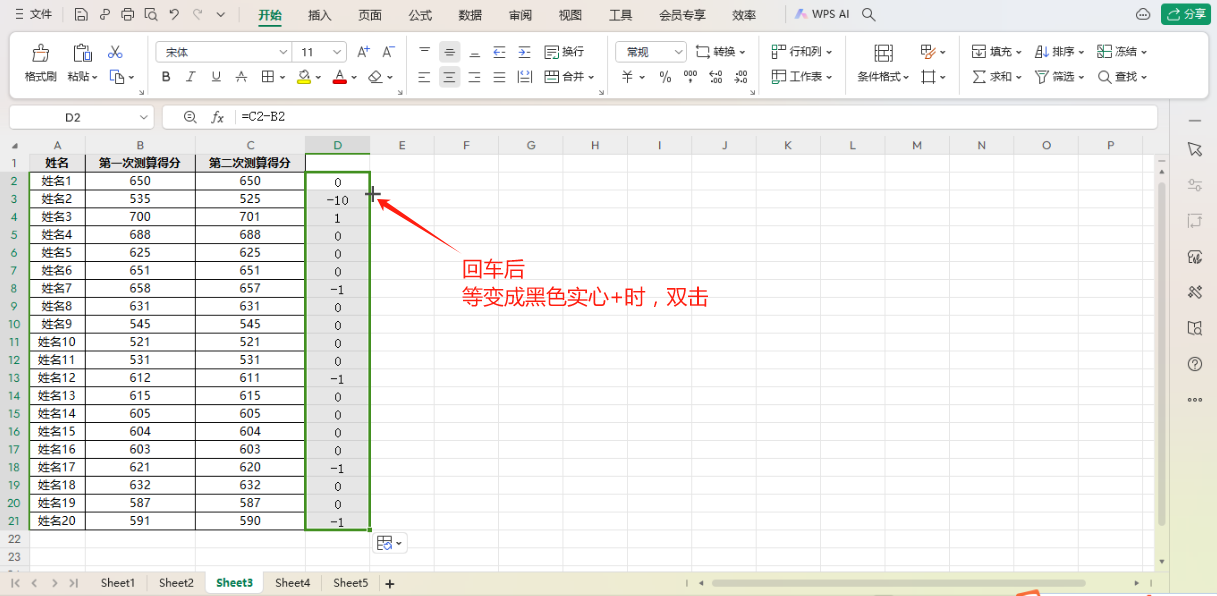
excel数据对比找不同:6种方法核对两列数据差异
工作中,有时需要核对两列数据的差异,用于对比、复核等。数据较少的情况下差异肉眼可见,数据量较大时用什么方法比较好呢?从个人习惯出发,我整理了6种方法供参考。 6种方法核对两列数据差异: 1、Ctrl G定位…...
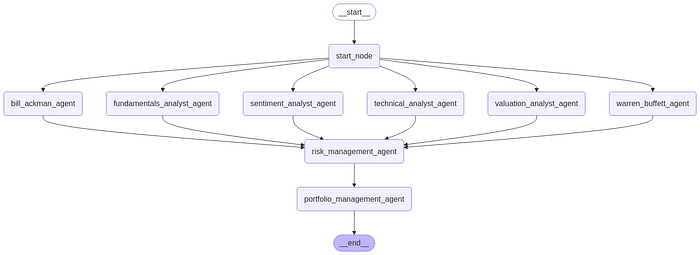
基于智能代理人工智能(Agentic AI)对冲基金模拟系统:模范巴菲特、凯西·伍德的投资策略
股票市场涉及众多统计数据和模式。股票交易基于研究和数据驱动的决策。人工智能的使用可以实现流程自动化,让投资者在研究上花费更少的时间,同时提高准确性。这使他们能够更加专注于监督实际交易和服务客户。 顶尖对冲基金经理发挥着至关重要的作用&…...
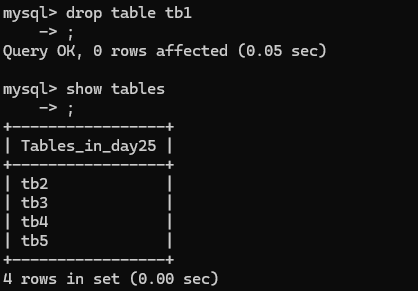
MySQL数据库基础(二)———数据表管理
前言 上篇文章介绍了MySQL数据库以即数据库的管理 这篇文章将给大家讲解数据表的管理 一、数据表常见操作 数据表常见操作的指令 进入数据库use数据库; 查看当前所有表:show tables; 创建表结构 1.创建表操作 1.1创建表 create table 表名(列名 …...

如何在Lyra中创建一个新的Game Feature Plugin和Experience游戏体验
目录 -1.前言0.预备知识1.创建一个新的Game Feature Plugin插件2.创建Lyra Pawn Data Asset3. 创建Lyra Experience Definition4. 创建自定义关卡5. 设置资产管理器Asset Manager引用6. 创建Lyra User Facing Experience Definition7. 在编辑器中运行测试后记-1.前言 由于转职…...

RDMA简介5之RoCE v2队列
在RoCE v2协议中,RoCE v2队列是数据传输的最底层控制机制,其由工作队列(WQ)和完成队列(CQ)共同组成。其中工作队列采用双向通道设计,包含用于存储即将发送数据的发送队列(SQ…...
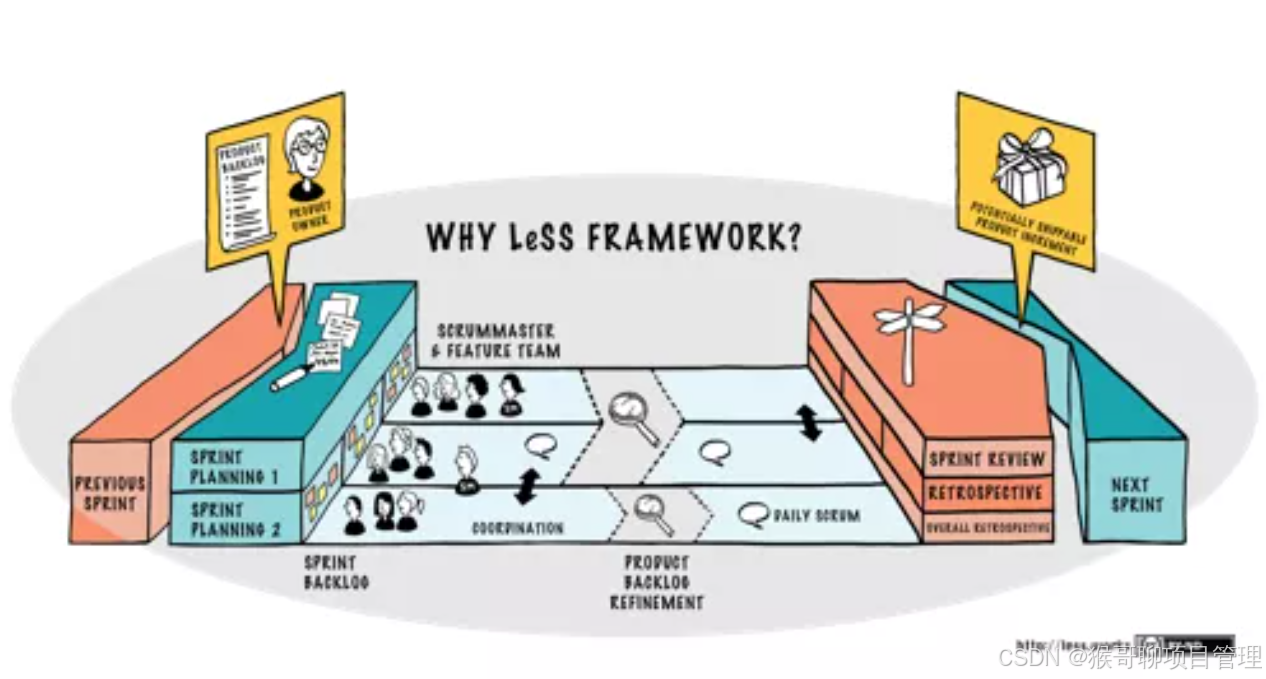
SAFe/LeSS/DAD等框架的核心适用场景如何选择?
在敏捷开发的规模化实践中,SAFe(Scaled Agile Framework)、LeSS(Large Scale Scrum)和DAD(Disciplined Agile Delivery)是三大主流框架。它们分别以不同的哲学和方法论应对复杂性、协作与交付的…...

鸿蒙应用开发之uni-app x实践
鸿蒙应用开发之uni-app x实践 前言 最近在开发鸿蒙应用时,发现uni-app x从4.61版本开始支持纯血鸿蒙(Harmony next),可以直接编译成ArkTS原生应用。这里记录一下开发过程中的一些经验和踩过的坑。 一、环境搭建 1.1 开发工具 …...
window查看SVN账号密码
背景 公司的SVN地址发生迁移,想迁移一下本地SVN地址,后来发现SVN账号密码忘记了。写此文章纯记录。 迁移SVN地址: 找到svn目录点击relocate,输入新的svn地址,如需输入账号密码,输入账号密码即完成svn地址…...

Python训练营---Day44
DAY 44 预训练模型 知识点回顾: 预训练的概念常见的分类预训练模型图像预训练模型的发展史预训练的策略预训练代码实战:resnet18 作业: 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同尝试通…...

前端项目初始化
目录 1. 安装 nvm 2. 配置 nvm 并切换到 Node.js 16.15.0 3. 安装 LightProxy 代理 4. GIT安装 1. 配置用户名和邮箱(这些信息将用于您在提交代码时的标识): 2. 生成SSH密钥(用于将本地代码仓库与远程存储库连…...

USB扩展器与USB服务器的2个主要区别
在现代办公和IT环境中,连接和管理USB设备是常见需求。USB扩展器(常称USB集线器)与USB服务器(如朝天椒USB服务器)是两类功能定位截然不同的解决方案。前者主要解决物理接口数量不足的“近身”连接扩展问题,而…...
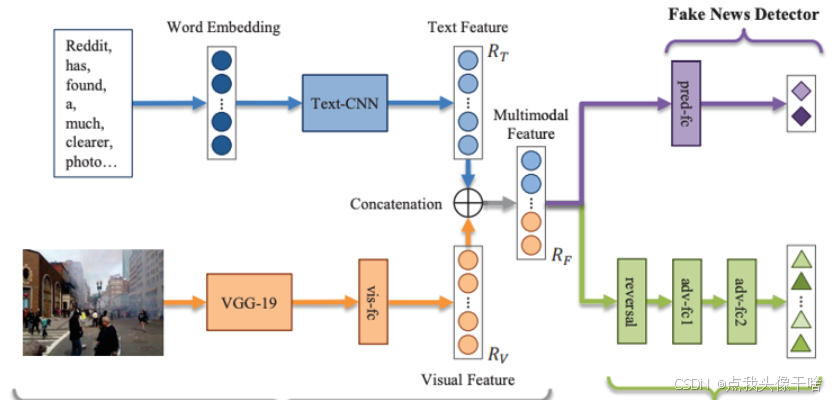
第46节:多模态分类(图像+文本)
一、多模态分类概述 多模态分类是指利用来自不同模态(如图像、文本、音频等)的数据进行联合分析和分类的任务。 在当今大数据时代,信息往往以多种形式存在,例如社交媒体上的图片配文字、视频附带字幕、医疗检查中的影像与报告等。单一模态的数据往往只能提供有限的信息,…...

spring获取注册的bean并注册到自定义工厂中管理
背景 在开发的时候,对于同一个对象的按照某个字段的不同有很多的处理方式。想着开发一个类似于工厂模式,由上层工厂统一分配。 由于是基于springboot开发,所以有很多自动注入的对象,如果由工厂统一创建new对象的方式,那…...

IDEA 中 Maven Dependencies 出现红色波浪线的原因及解决方法
在使用 IntelliJ IDEA 开发 Java 项目时,尤其是基于 Maven 的项目,开发者可能会遇到 Maven Dependencies 中出现红色波浪线的问题。这种现象通常表示项目依赖未能正确解析或下载,导致代码提示错误、编译失败等问题。本文将详细分析该问题的常…...
springMVC-10验证及国际化
验证 概述 ● 概述 1. 对输入的数据(比如表单数据),进行必要的验证,并给出相应的提示信息。 2. 对于验证表单数据,springMVC提供了很多实用的注解, 这些注解由JSR303 验证框架提供. ●JSR 303 验证框架 1. JSR 303 的含义 JSR࿰…...

使用Python和TensorFlow实现图像分类
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。下面开始对正文内容的…...
LRU 和 DiskLRU实现相册缓存器
我是写Linux后端的(golang、c、py),后端缓存算法通常是指的是内存里面的lru、或diskqueue,都是独立使用。 很少有用内存lru与disklru结合的场景需求。近段时间研究android开发,里面有一些设计思想值得后端学习。 写这…...
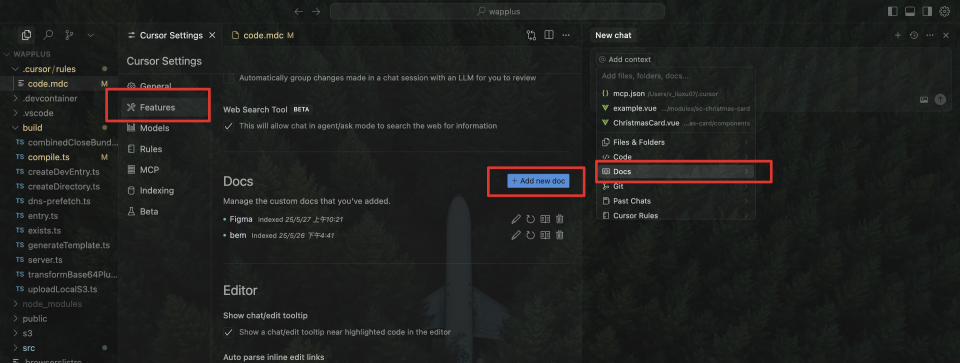
figma MCP + cursor如何将设计稿生成前端页面
一、准备工作 figma MCP需要通过figma key来获取设计稿权限,key的生成步骤如下 1. 打开figma网页版/APP,进入账户设定 2. 点击生成token 3. 填写内容生成token(一定要确认复制了,不然关闭弹窗后就不会显示了) 二、配置MCP 4. 进入到cursor…...
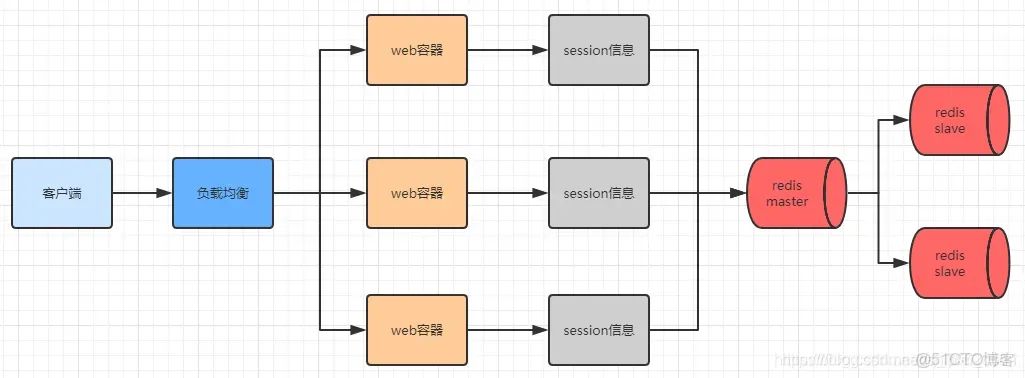
如何理解OSI七层模型和TCP/IP四层模型?HTTP作为如何保存用户状态?多服务器节点下 Session方案怎么做
本篇概览: OSI 七层模型是什么?每一层的作用是什么?TCP/IP四层模型和OSI七层模型的区别是什么? HTTP 本身是无状态协议,HTTP如何保存用户状态? 能不能具体说一下Cookie的工作原理、生命周期、作用域?使用…...

Flask 核心概念速览:路由、请求、响应与蓝图
一、路由参数与请求方法 Flask 路由允许定义多种参数类型,并通过 methods 属性限制请求方法。 1. 路由参数类型: 除了默认的 string,Flask 还支持: int: 匹配整数,自动转换为 Python int 类型。非数字输入会返回 404。 float: 匹配浮点数,自动转换为 Python float 类型…...

Spring Boot消息系统开发指南
消息系统基础概念 消息系统作为分布式架构的核心组件,实现了不同系统模块间的高效通信机制。其应用场景从即时通讯软件延伸至企业级应用集成,形成了现代软件架构中不可或缺的基础设施。 通信模式本质特征 同步通信要求收发双方必须同时在线交互&#…...