To be or Not to be, That‘s a Token——论文阅读笔记——Beyond the 80/20 Rule和R2R
本周又在同一方向上刷到两篇文章,可以说,……同学们确实卷啊,要不卷卷开放场域的推理呢?
这两篇都在讲:如何巧妙的利用带有分支能力的token来提高推理性能或效率的。
第一篇叫 Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning 后面简称二八定律
第二篇叫 R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing,后面简称R2R
一句话总结两篇文章
两篇文章都发现了
在推理任务上,一个完整的COT中只有少量的token带有【指引推理路径向左或者向右的能力】——我这里简化称为导航功能,其他大部分token的确定性都比较高。
比如二八定律文中的这张图
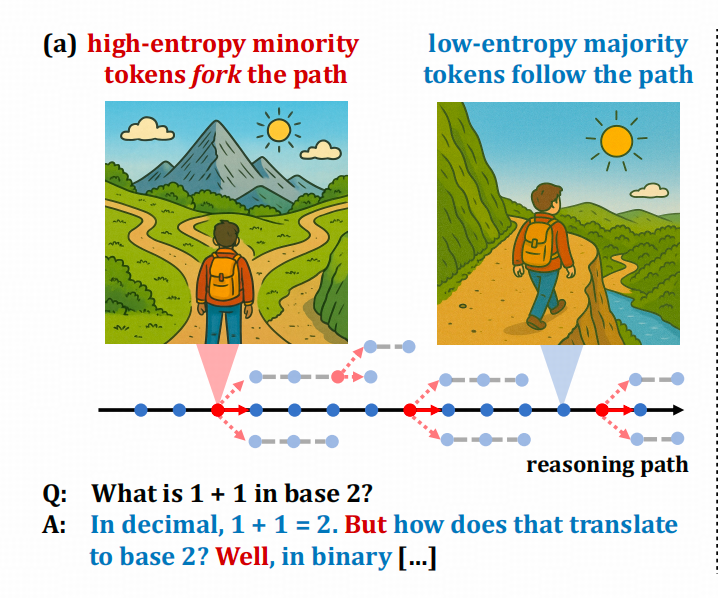
图中的红点和红色词,就是具备导航功能的token。
那怎么利用这个特性呢?
二八定律选择训练的时候专攻这些有导航功能的token,以提升LLM的推理能力;
R2R用这个性质来加速解码→有导航功能的token用大模型来解,其他token用小模型(1.5B)来解。
两篇文章的关键不同
观测角度不同
二八定律是从熵的角度来观测和判别导航token的,token分布中熵top前20的就是导航token;
R2R是通过比较大模型(LLM)和小模型(SLM)在回答同一问题时,从哪个token开始出现差异,再让LLM验证从这个token开始生成的路径是否有本质区别(如思路和答案的正确性)。如果从这个token开始,后续结果确实显著不同,那么这个站在命运的十字路口的token就是导航token。
优化方向不同
二八定律从改进RLVR的训练目标出发,希望直接产出一个更强的模型。
R2R 从改进投机解码的角度出发,希望对同一个模型更快的产出结果。
由于这两篇文章除了【都是研究怎么利用高熵token】以外,实现细节上基本没有什么交集,下面还是分开介绍
关键细节
二八定律的思路
发现现象→验证现象→对症提出优化方案→Ablation验证优化点
发现的现象与分析
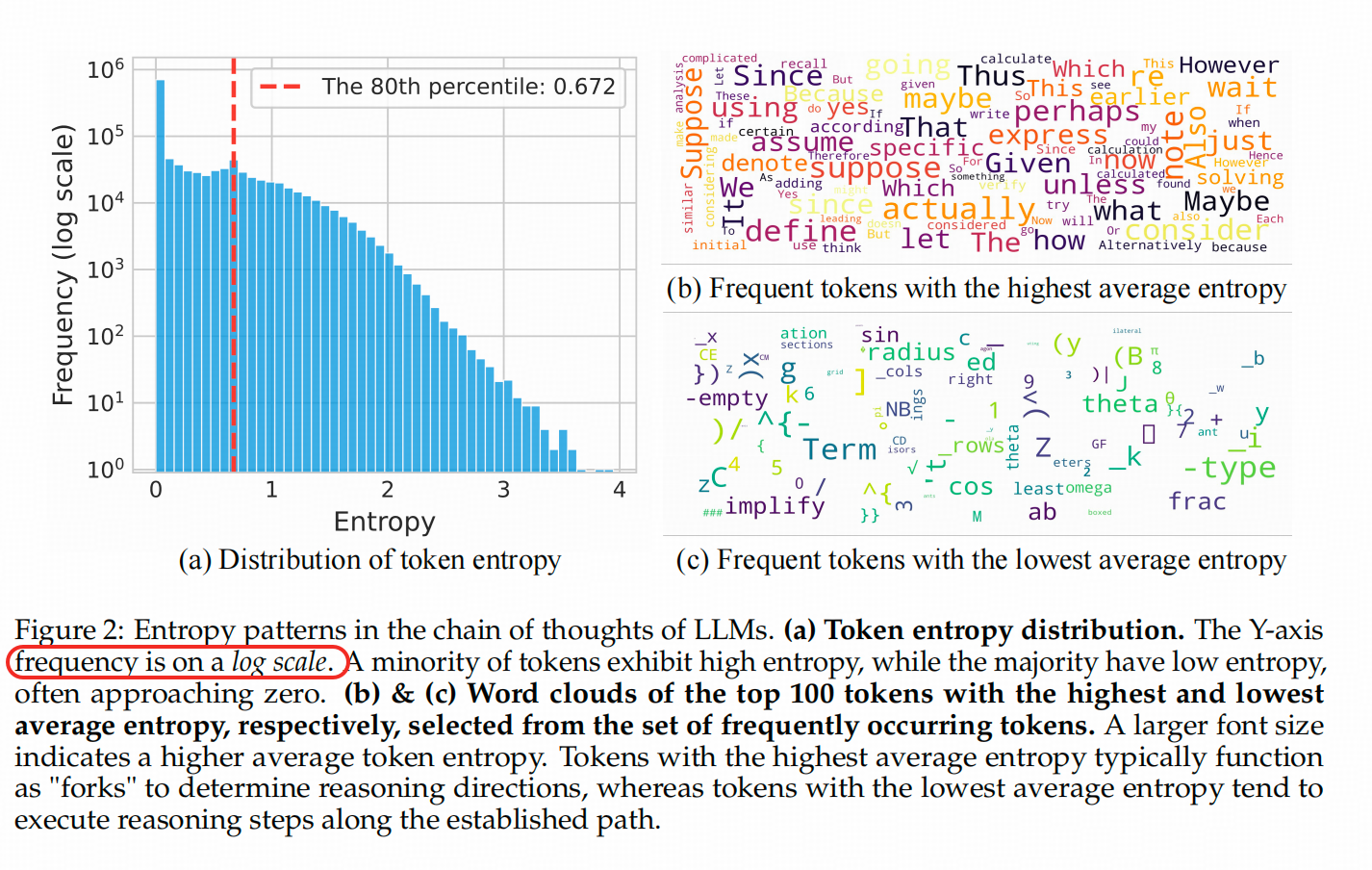
观察上图左侧,这是Qwen3-8B在回答AIME’24和AIME’25问题时,COT中token对应熵的直方图。注意,这个直方图的纵轴是对数缩放的,也就是说,在原始Y轴上,红线左侧的柱子非常高。这个图的目的是为了说明为什么选择2-8分而不是3-7分等其他分法。因为过了红线后,右侧的柱子开始逐渐变短;而红线左侧(80%的token)的分布类似于一个平台。虽然2-8分仍然是一种基于分析的直觉选择,但是咋说呢,作者尝试给你园了一下😁。
倒回来说一下这个熵具体是什么,是生成位last hidden 映射回词表维度,并softmax以后得到的伪概率作为 p ∈ R 1 ∗ V \mathbf{p} \in R^{1*V} p∈R1∗V(即一个词表长度的向量) 算出来的熵 − ∑ p i log ( p i ) -\sum{p_i\log(p_i)} −∑pilog(pi)
上图右侧展示了熵较高的token对应的词,这和我们的认知相似,一方面属于认知行为中比较关键 验证、定义、归因等等,一方面在语言表述中,这些词的出现确实会给后面的子句定个调子。
另外,这个红线位置的熵是0.672,后面有用。
验证现象
熵的分布上有这样的特点,那又能带来什么呢?扰动一下,看看结果?
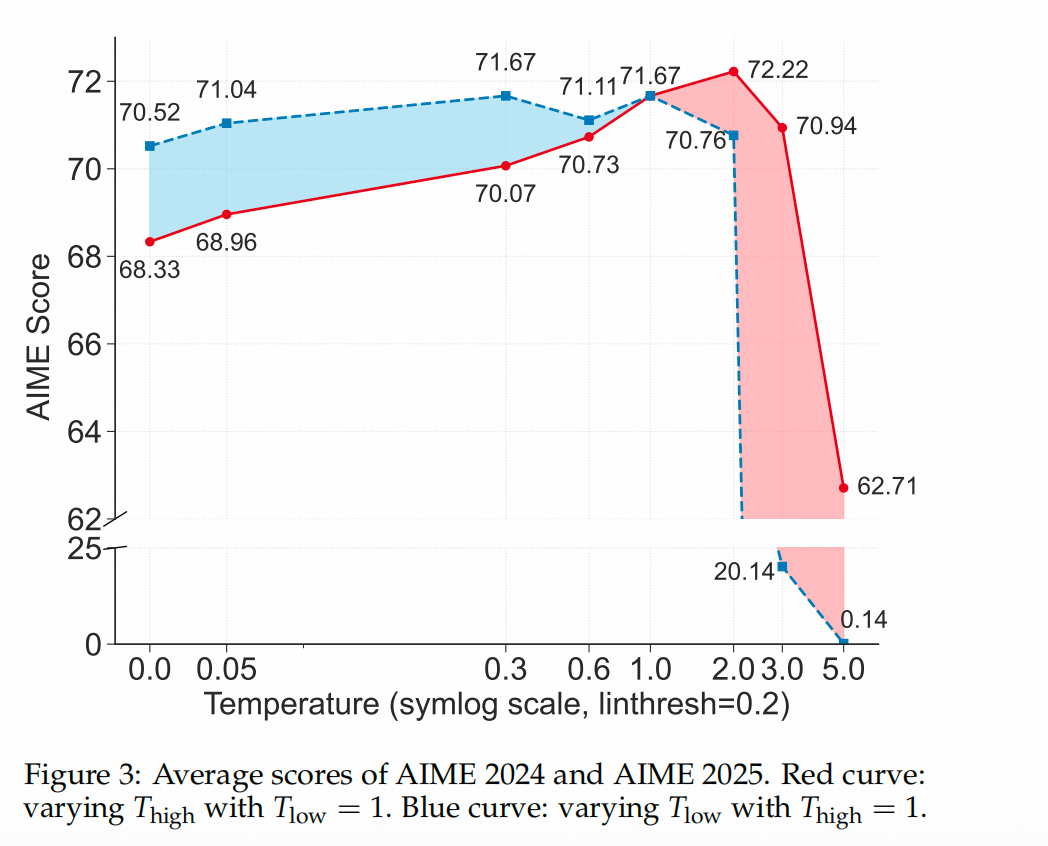
↑上图中,二八定律作者还是用AIME的24和25 数据集作为实验场,扰动了COT的生成过程:他用0.672作为经验阈值,对熵高于这个值的token(导航token)
给予更高的采样温度,增加不确定性;对熵低于阈值的token则不作处理,形成红线。蓝线则相反,对熵低于0.672的token赋予更高的温度。图中红蓝两条线的交点代表了基线,即没有调整采样温度的情况。
结果显示,提高导航token的温度能让模型达到更高的精度(但温度超过2后效果变差),而对非导航token的情况则相反,温度小于1时模型推理效果更好。
既然这种策略在生产时能优化模型,那么在训练阶段能否利用这种性质让模型变得更强呢?
※碎碎念:其实我相信作者在这个阶段应该是试过放大温度以外的方法的,要是成了后面可能不会往训练推。
提出优化方案
文章的这个部分,思路有些断档,因为作者选择的是优化DAPO算法,所以他先分析了DAPO给模型的熵带来的影响。这里先回放一下DAPO的优化目标公式。

公式里面 A A A是advantage,跟GRPO一样,是共享的, r r r跟PPO一样,新旧模型的比值。
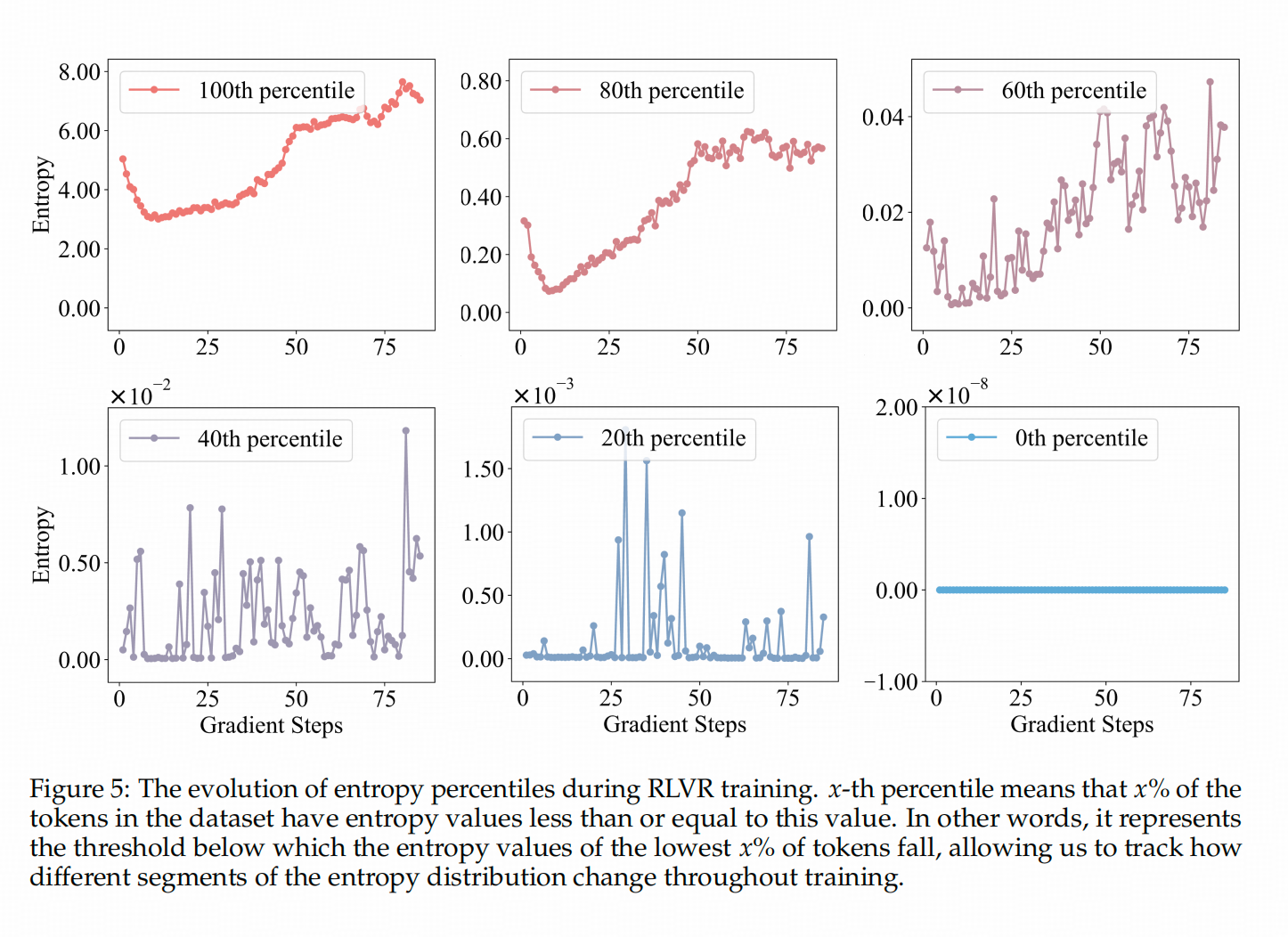
在RL训练前,作者将原模型的token按熵的大小分成0%(熵最小的组)、20%、40%、60%、80%和100%(熵最大的组)这几组,观察训练过程中,
这些token的熵变化趋势。←上图展示了这个变化过程,可以看到,上面一行(熵大小前60%的token)在训练中熵还在增加,而下面一行(熵较高的token)基本没有变化。也就是说,DAPO在训练过程中对熵的影响,确实是「旱的旱死,涝的涝死」。既然如此,猛踩油门(在高熵token上加点)还管用吗?↓
单独优化熵高的token能够继续拉高模型的推理能力
这就是作者给出的RL的优化目标。公式中标红的部分就是二八定律文给出的优化。
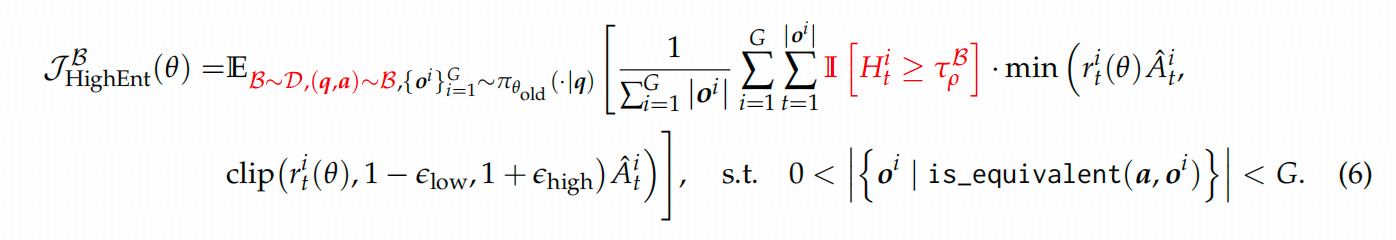
这个优化包含两个点:
- 只优化
导航token:训练中不适用经验阈值来确定导航token,而是由训练中的token的熵分布的前20%percentile决定的。 - 改用一个batch训练:这里必须使用batch,因为计算熵分布时需要足够的数据来确保其可信度。毕竟,如果只对一个QA对的16个样本中的所有token计算分布,结果会有偏差。训练中使用的batch_size为512。
效果如何
跟基线比,涨点了;跟原版DAPO比,也涨点了。
作者训练了Qwen3的三个模型:8B-base、14B-base和32B-base,并在AIME24数据集上进行对比。8B模型在Qwen的tech report中的指标为29.1%,经过DAPO处理后为33.33%,使用作者的改良版DAPO后提升至34.58%。32B模型在Qwen的tech report中的指标为81.4%,经过DAPO处理后为55.83%,使用改良版DAPO后提升至63.54%。尽管这种训练方法提高了32B-base的推理能力,但仍不及开源的32B模型。
当然,这是一篇纯方法论的论文,比较一个把好数据和好方法都堆上的模型也是有点欺负人。
跟DAPO比,scaler能力更强
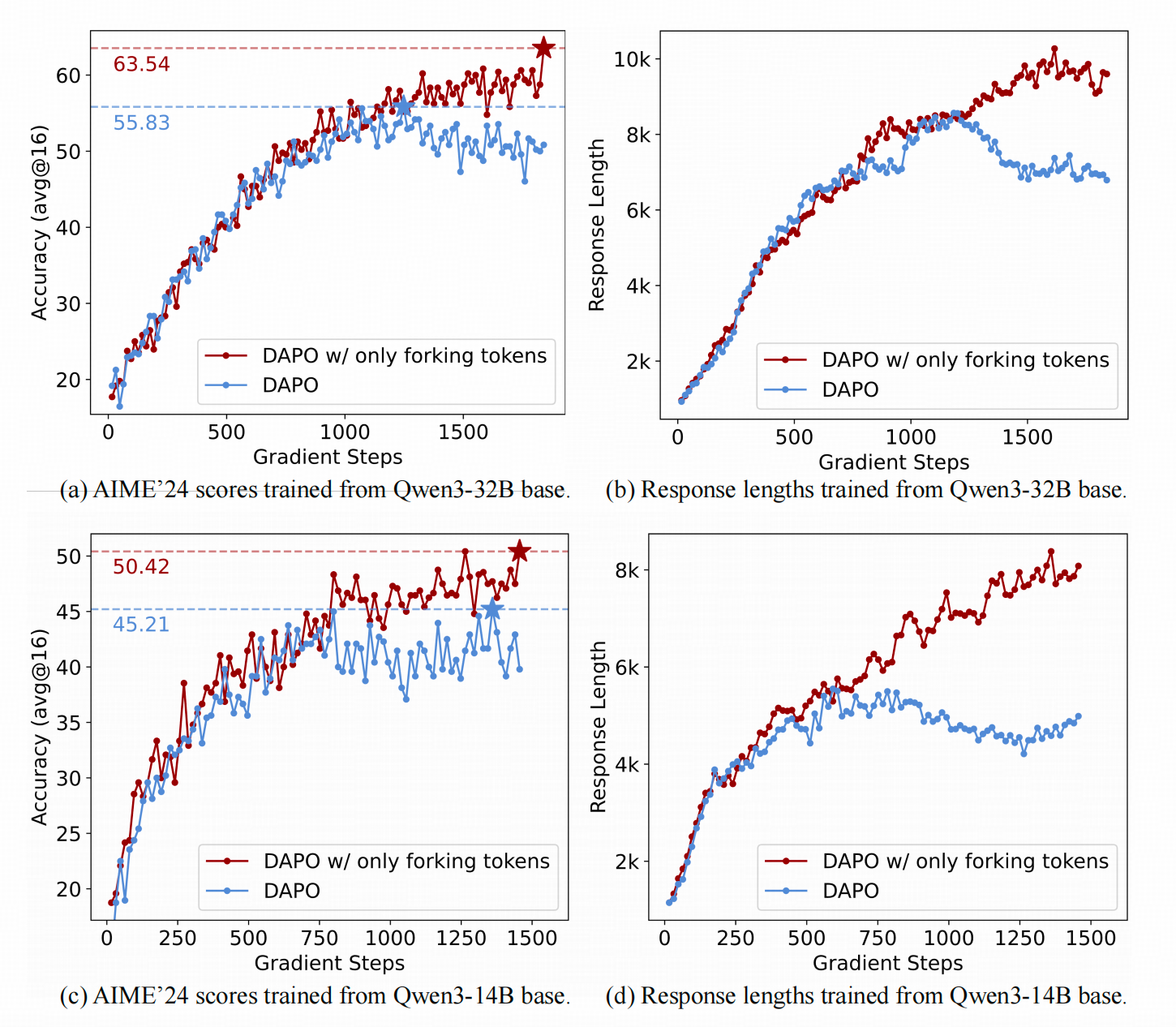
上面两张图展示了用DAPO和改良版DAPO训练Qwen3-32B(上行)和Qwen3-14B(下行)在训练过程中的模型准确率和生成长度的变化。
可以看到,作者的改良版DAPO相比原版具有更高的上限,并且生成长度在训练中后期还在增加(这实际上是好事,因为它给test-time scaling留下了更多空间,但作者没有在后续实验中讨论这一点)。
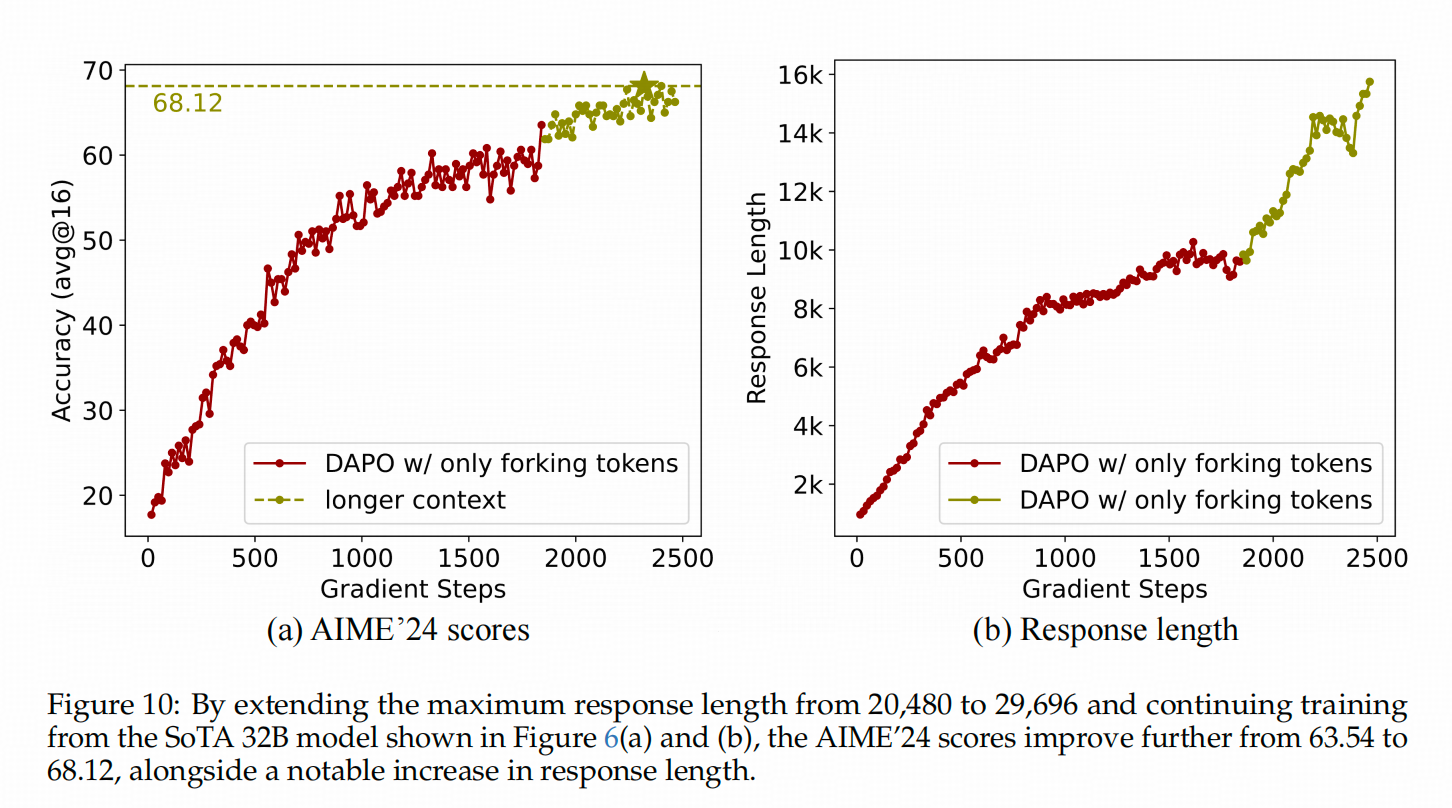
随后,作者将推理长度限制从20K延长到29K,继续训练后,32B模型的性能确实有所提升。下图黄色部分展示了在扩展长度后的模型准确率和生成长度的变化。
R2R 的方法
R2R的思路是,“我有一个假想,我按照这个假想试试”
他的假想是
※1-大模型能力强,小模型能力弱,这两个模型的能力的差异体现到token级别的时候,就是看到同样的问题生成token的不一样。↓
※2-这些不一样的token中,可能有一些是无关紧要的(一个意思的不同表示方法,这个在Softthinking哪篇文章展示的案例中恰恰有体现),有一些token可能决定后面的发展,即我们通篇在提的导航token。这种导航token无疑在解码的时候是不能错的。↓
※3-那解码的时候,怎么保证不用小模型来解导航token呢?得先识别出来。
要识别导航token,离线时固然可以用样本分析然后归因的方法,但生产时候这个套路就玩不转了。最简单的方法就是建个模型来识别哪个是导航token。↓
※4-在生产的时候,这个模型接受小模型的last_hidden等输入,并判断该token是否 就是导航token,是的话用大模型解码,不是的话用小模型解码。
作者画了个图来展示他整体的思路。下图中SLM就是1.5Bd大模型,LLM是32B的大模型

导航token的分析
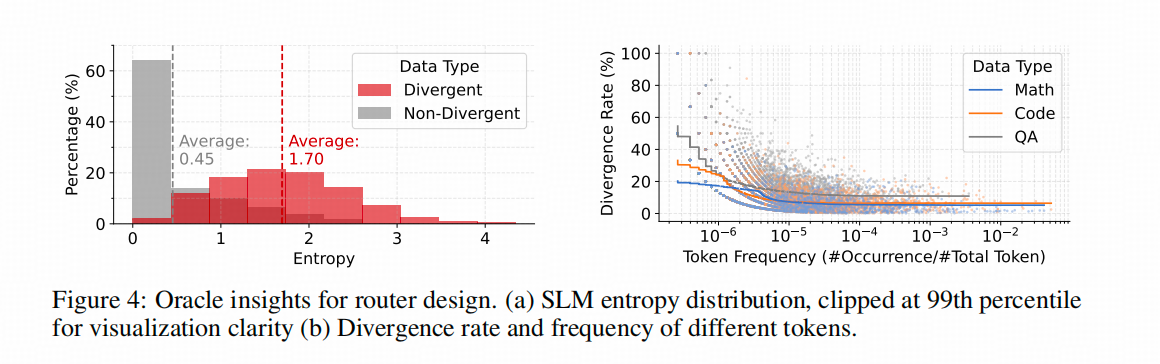
R2R的作者同样分析了token的熵,不过他分析的是小模型的熵分布。他没有使用top-p,不知道是不是因为小模型token熵的top-p没有大模型的对应数值有决定性价值。总之,他先标记了哪些token是大小模型在相同query下不同,且会引发后续推理链路大大不同(用大模型评测)。在上图左侧直方图中,这些token用红色表示,其他token的分布是灰色。
上图右侧图的展示逻辑有些复杂,但结论是,训练语料中出现频率越高的token,其成为导航token的概率越低。
效果如何
确实快,下表中各个数据集的第一列是accuracy,第二列和第三列的逻辑差不多,第二列显示实际计算的平均参数量(包括SLM、导航token识别模型和LLM),第三列显示平均参数量乘以平均长度,所以第三列可以先不看。(因为这个方法对实际生成长度影响不大,可以参考原文表3,我就不展示了)。
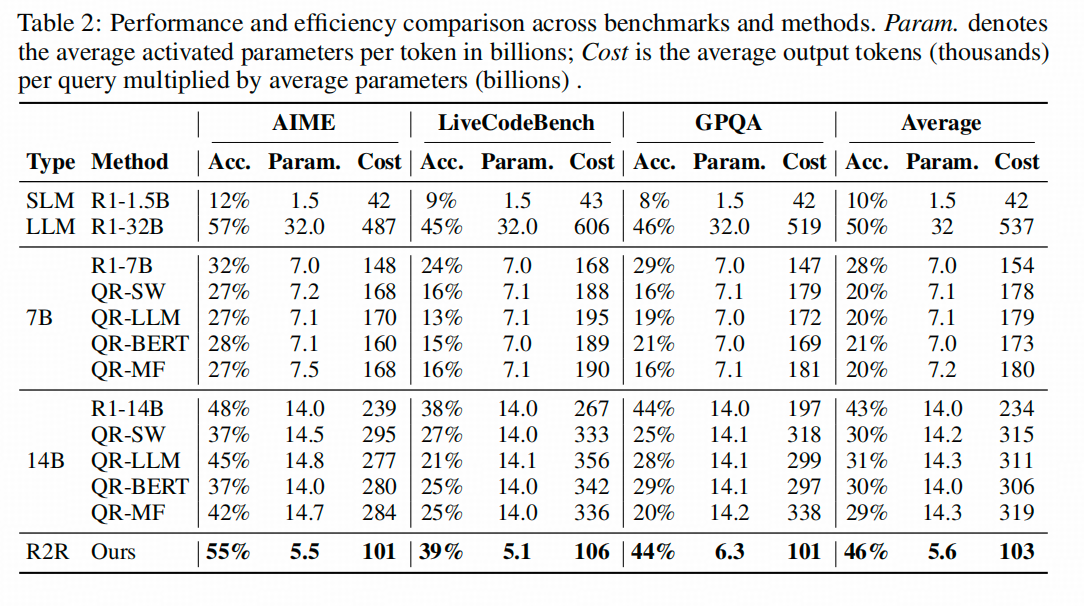
上图显示的结论是,R2R比纯用32B模型推理的准确率低一点点,但比32B模型实际算的参数量小很多很多(我不太理解为啥不用Flop衡量?我本身对decode了解有限,不瞎嘴了)
两篇文章的整体评价
两篇文章的实验分析部分都有遗憾
二八定律的实验分析中,缺少了test-time scale方面的比较,也没有进一步展示导航token的变化趋势—— 比如哪些token会推出top20呢?
R2R 文则一来没有对导航token进行展示和定性的分析(这些对后续研究是有启发性的,但作者没有展示),二来,其比较实验中的比较组也有点奇怪,虽然比较了很多解码方案,但是是在14B的模型下比较的?虽然比了投机解码方法,但是在附录里比的,主要是效率。
二八定律是否能在推理以外的场景中推广,需要更多的验证。
在实验分析部分,二八定律文展示了在数学任务上训练的模型在代码数据集上是否也有优势——答案是肯定的。然而,目前推理任务的研究主要集中在数学和代码任务上,也该考虑move-on了。毕竟到了不能直接验证是否正确的场域,RLVR也要改改。
相关文章:
To be or Not to be, That‘s a Token——论文阅读笔记——Beyond the 80/20 Rule和R2R
本周又在同一方向上刷到两篇文章,可以说,……同学们确实卷啊,要不卷卷开放场域的推理呢? 这两篇都在讲:如何巧妙的利用带有分支能力的token来提高推理性能或效率的。 第一篇叫 Beyond the 80/20 Rule: High-Entropy Mi…...

【基础】每天掌握一个Linux命令 - awk
目录 【基础】每天掌握一个Linux命令 - awk一、工具概述二、安装方式Ubuntu/Debian系统:CentOS/RHEL系统:macOS系统: 三、核心功能四、基础用法基本语法常用选项内置变量基本操作示例1. 打印文件所有内容2. 打印每行的第一个字段3. 指定分隔符…...

《UE5_C++多人TPS完整教程》学习笔记37 ——《P38 变量复制(Variable Replication)》
本文为B站系列教学视频 《UE5_C多人TPS完整教程》 —— 《P38 变量复制(Variable Replication)》 的学习笔记,该系列教学视频为计算机工程师、程序员、游戏开发者、作家(Engineer, Programmer, Game Developer, Author)…...
AWS API Gateway配置日志
问题 访问API Gateway接口出现了403问题,具体报错如下: {"message":"Missing Authentication Token"}需要配置AWS API Gateway日志,看请求过程是什么样子的。 API Gateway 先找到API Gateway的的日志角色,…...

Towards Open World Object Detection概述(论文)
论文:https://arxiv.org/abs/2103.02603 代码:https://github.com/JosephKJ/OWOD Towards Open World Object Detection 迈向开放世界目标检测 Abstract 摘要 Humans have a natural instinct to identify unknown object instances in their environ…...

轻松备份和恢复 Android 系统 | 4 种解决方案
我们通常会在 Android 手机上存储大量重要的个人数据,包括照片、视频、联系人、信息等等。如果您不想丢失宝贵的数据,可以备份 Android 数据。当您需要访问和使用这些数据时,可以将其恢复到 Android 设备。如果您想了解 Android 备份和恢复&a…...

具备强大的数据处理和分析能力的智慧地产开源了
智慧地产视觉监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。 AI是新形势下数…...

RK3588和FPGA桥片之间IO电平信号概率性不能通信原因
1.GPIO管脚配置问题 RK3588对IO进行配置的时候,如果配置为多功能复用,没有明确IO功能,可能引起信号接收不稳定, 需要在驱动中设备树中配置管脚为GPIO功能,确保没有功能复用的干扰。 2.上下拉电阻阻值设置不当 GPIO引脚…...
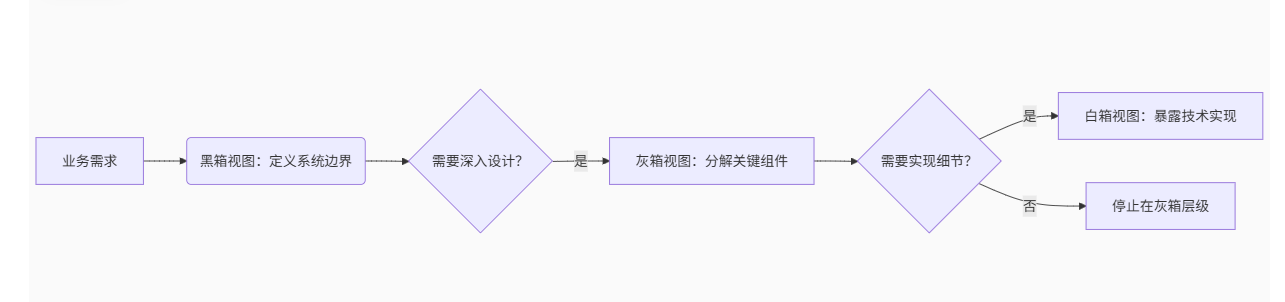
【iSAQB软件架构】软件架构中构建块的视图:黑箱、灰箱和白箱及其交互机制
在软件架构描述中,黑箱视图(Black-box)、灰箱视图(Gray-box)和白箱视图(White-box) 是不同抽象层级的构建模块表示方式,用于满足不同受众和设计阶段的需求。以下是基于ISAQB标准的清…...

.net jwt实现
.NET 中实现 JWT 认证:详细指南 在现代的 Web 应用开发中,安全认证是至关重要的一环。JSON Web Token(JWT)作为一种广泛使用的认证机制,为 API 提供了安全、便捷的身份验证方式。本文将详细介绍如何在 ASP.NET Core 项…...

LangChain【7】之工具创建和错误处理策略
文章目录 一 LangChain 自定义工具概述二创建自定义工具的三种方法2.1 方法一:tool 装饰器2.1.1 同步方法案例2.1.2 工具描述方式1:传参2.1.3 工具描述方式2:文档字符串 2.2 方法二:StructuredTool类2.2.1 StructuredTool创建自定…...
如何在电脑上轻松访问 iPhone 文件
我需要将 iPhone 下载文件夹中的文件传输到 Windows 11 电脑上。我该怎么做?我可以在 Windows 11 上访问 iPhone 下载吗? 由于 iOS 和 Windows 系统之间的差异,在 PC 上访问 iPhone 文件似乎颇具挑战性。然而,只要使用正确的工具…...

Eureka REST 相关接口
可供非 Java 应用程序使用的 Eureka REST 操作。 appID 是应用程序的名称,instanceID 是与实例关联的唯一标识符。在 AWS 云中,instanceID 是实例的实例 ID;在其他数据中心,它是实例的主机名。 对于 XML/JSON,HTTP 的…...

C语言字符数组输入输出方法大全(附带实例)
在 C语言中,字符数组是一种特殊的数组,用于存储和处理字符串。理解字符数组的输入和输出操作对于初学者来说至关重要,因为这是处理文本数据的基础。 字符数组的定义与初始化 在讨论输入输出之前,我们先来回顾一下字符数组的定义…...
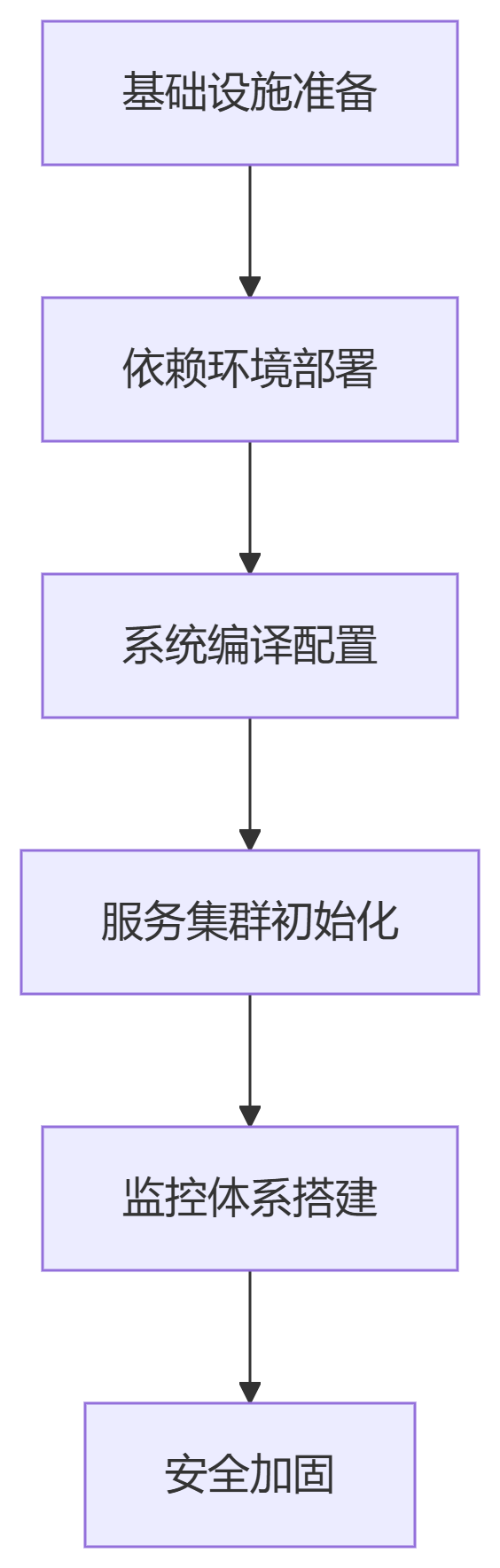
短视频矩阵SaaS系统:开源部署与核心功能架构指南
一、系统架构概述 短视频矩阵系统是基于SaaS(软件即服务)模式的多平台内容管理解决方案,通过开源技术实现账号聚合、智能创作、跨平台分发及数据闭环。系统采用微服务架构,支持高并发场景下的弹性扩展。 二、核心功能模块开发逻辑…...

每日算法 -【Swift 算法】电话号码字母组合
🚀 LeetCode 字符串数字映射(Swift)——电话号码字母组合 在日常刷题或面试中,我们经常会遇到字符串 回溯组合的问题。这道经典题——电话号码的字母组合 就是典型代表。本文将带你用 Swift 实现这道题,思路清晰&…...

深入解析YUM与DNF:RPM包管理器的架构演进与功能对比
在Linux系统管理中,软件包管理器是连接用户与底层RPM(Red Hat Package Manager)包的核心工具。作为RPM生态的两大代表性工具,YUM(Yellowdog Updater Modified)与DNF(Dandified YUM)的…...

解决cocos 2dx/creator2.4在ios18下openURL无法调用的问题
由于ios18废弃了旧的openURL接口,我们需要修改CCApplication-ios.mm文件的Application::openURL方法: //修复openURL在ios18下无法调用的问题 bool Application::openURL(const std::string &url) {// NSString* msg [NSString stringWithCString:…...
:30/10/10用户参与法则与定价策略的科学制定)
精益数据分析(94/126):30/10/10用户参与法则与定价策略的科学制定
精益数据分析(九十四):30/10/10用户参与法则与定价策略的科学制定 在创业过程中,如何衡量用户参与度是否健康?又该如何制定科学的定价策略实现营收最大化?今天,我们将深入解析Union Square Ven…...
oss:上传图片到阿里云403 Forbidden
访问图片出现403Forbidden问题,我们可以直接登录oss账号,查看对应权限是否开通,是否存在跨域问题...
)
Windows系统中如何使用符号链接将.vscode等配置文件夹迁移到D盘(附 CMD PowerShell 双版本命令)
在日常开发和使用中,很多应用程序都会在 Windows 用户目录(如 C:\Users\你的用户名\)下创建一些以点开头的隐藏配置文件夹,例如: .vscode — Visual Studio Code 的设置和插件数据.cursor — Cursor 编辑器的缓存和设…...

4. 数据类型
4.1 数据类型分类 分类 数据类型 说明 数值类型 BIT(M) 位类型。M指定位数,默认值1,范围1 - 64 TINYINT [UNSIGNED] 带符号的范围 -128 ~ 127,无符号范围0 ~ 255,默认有符号 BOOL 使用0和1表示真和假 SMALLINT [UNSIGNED] 带符号是…...
MySQL基础(二)SQL语言、客户端工具
目录 三、SQL语言 3.1 概念 3.2 基本操作 四、客户端工具 三、SQL语言 3.1 概念 SQL(Structured Query Language)结构化查询语言。SQL用于对存储数据,更新,查询和管理关系型数据库的程序设计语言。 通常执行对数据库的增删改…...

【贪心、DP、线段树优化】Leetcode 376. 摆动序列
贪心算法:选 “关键转折点” 初始状态:把数组第一个元素当作起点,此时前一个差值符号设为平坡(即差值为0)。遍历数组:从第二个元素开始,依次计算当前元素和前一个元素的差值。差值符号判断&…...

CppCon 2015 学习:C++ in the audio industry
实时编程(real-time programming):音频处理对延迟极度敏感,要求代码必须非常高效且稳定。无锁线程同步(lock-free thread synchronization):避免阻塞,提高性能,尤其是在多…...

C++算法-动态规划2
第 4 题 字符串分割 (Word Break) 难度: Medium备注:出自 leetcode题目描述 Given a string s and a dictionary of words dict, determine if s can be segmented into a space-separated sequence of one or more dictionary words. For example, given s "l…...

软信天成:数据驱动型背后的人工智能,基于机器学习的数据管理
在数字化转型浪潮中,当代企业如同逆水行舟,不进则退。无数企业希望通过数字化转型捕获全新的市场机遇,改善财政状况,在未来市场竞争中占据一席之地。要想获得成功的数字化转型,关键因素在于具备可靠、及时的数据用以支…...
MySQL提升
事务 事务:在多个操作合在一起视为一个整体。要么就不做、要么就做完。 事务应该满足ACID A : 原子性。不可分割。C : 一致性。追求的目标,在开始到结束没有发生预定外的情况。I : 隔离性。不同的事务是独立的。D : 持久性。系统崩溃,数据依然…...

hbase资源和数据权限控制
hbase适合大数据量下点查 https://zhuanlan.zhihu.com/p/471133280 HBase支持对User、NameSpace和Table进行请求数和流量配额限制,限制频率可以按sec、min、hour、day 对于请求大小限制示例(5K/sec,10M/min等),请求大小限制单位如…...

VMWare下设置共享文件,/mnt/hgfs下却不显示共享文件的解决方法
一、共享文件夹设置步骤 打开虚拟机设置:右键点击虚拟机 → 选择 “设置” → 切换到 “选项” 标签页 → 点击 “共享文件夹”启用共享功能:选择 “总是启用”(确保虚拟机已关闭或处于运行状态)添加共享文件夹: 点击…...