浅聊一下,大模型应用架构 | 工程研发的算法修养系列(二)

大模型应用架构基础
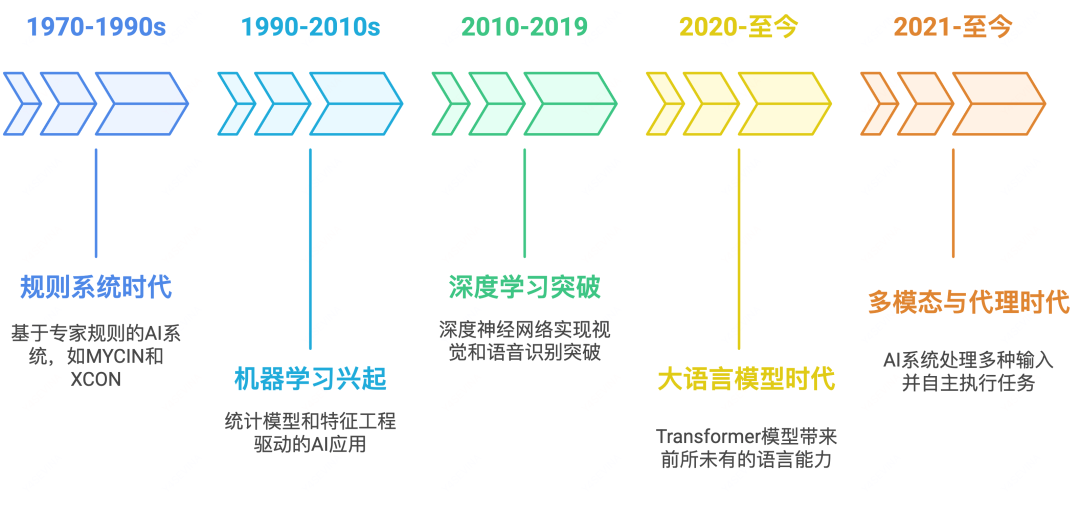
AI应用演进概述
人工智能应用的发展经历了多个关键阶段,每个阶段都代表着技术范式的重大转变。
大语言模型基础
大语言模型(LLM)作为现代AI应用的核心组件,具有独特的技术特性和能力边界,理解这些基础对架构设计至关重要。
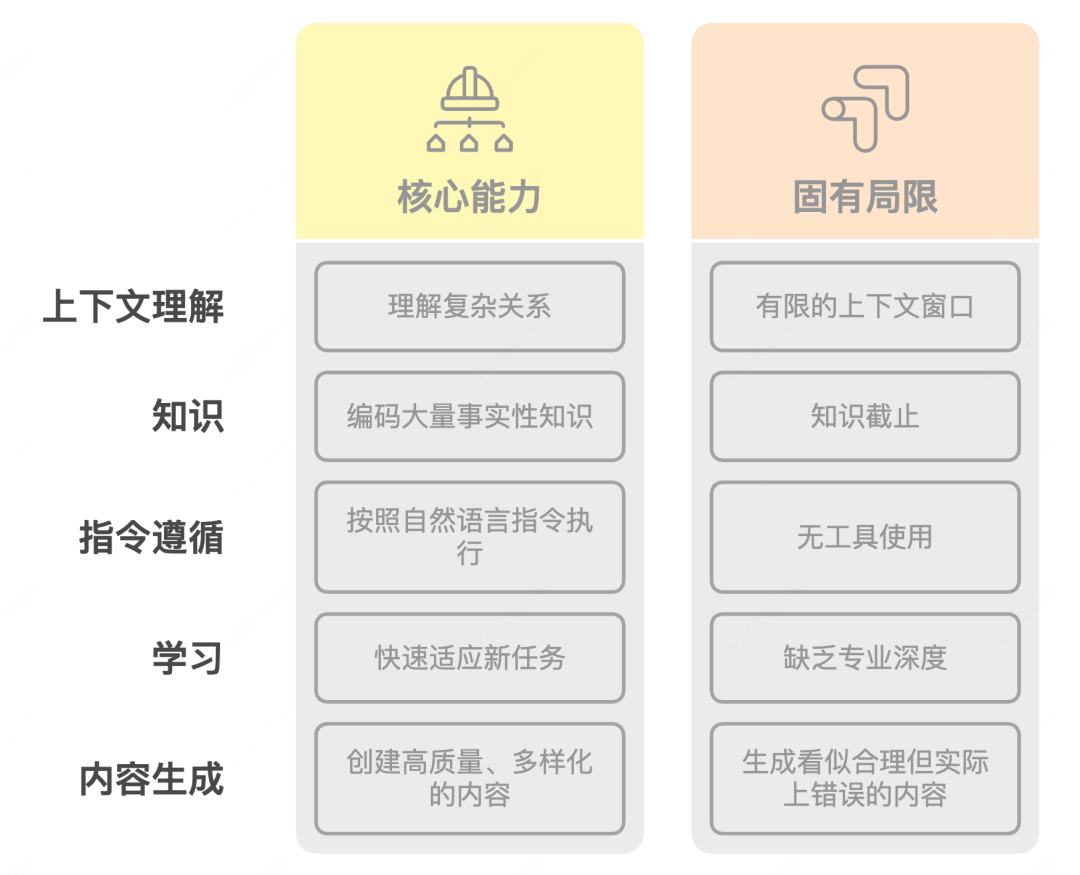
AI应用架构挑战
现代大语言模型(LLM)尽管强大,但在构建实用AI应用时仍面临多重架构挑战:
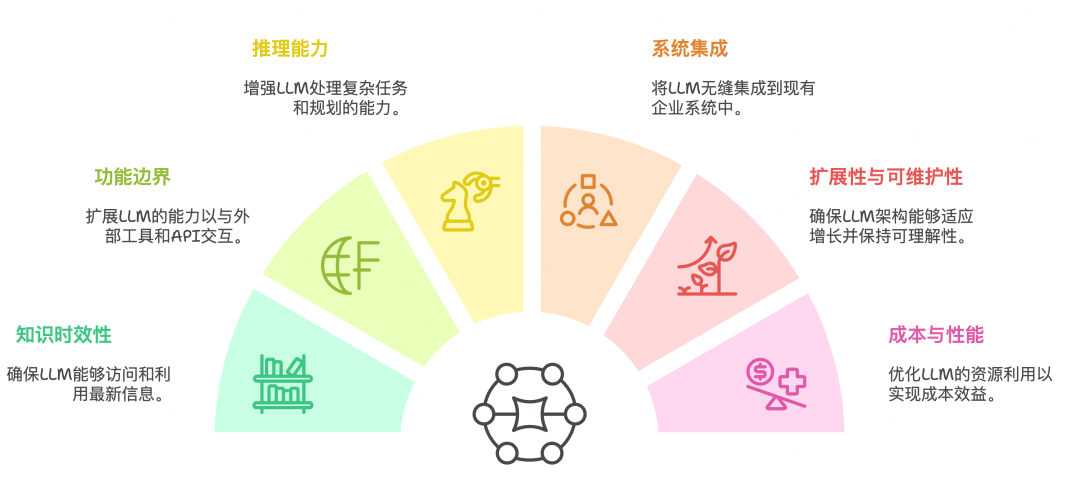
这些挑战催生了RAG(知识增强)、Agent(决策与执行增强)和MCP(功能扩展)等架构模式,共同构建起突破LLM原生局限的现代AI应用架构体系。
现代AI应用架构框架
现代AI应用架构融合多种技术组件,形成一个多层次、模块化的框架,以克服大语言模型的固有局限。这一架构框架由以下关键层次构成:
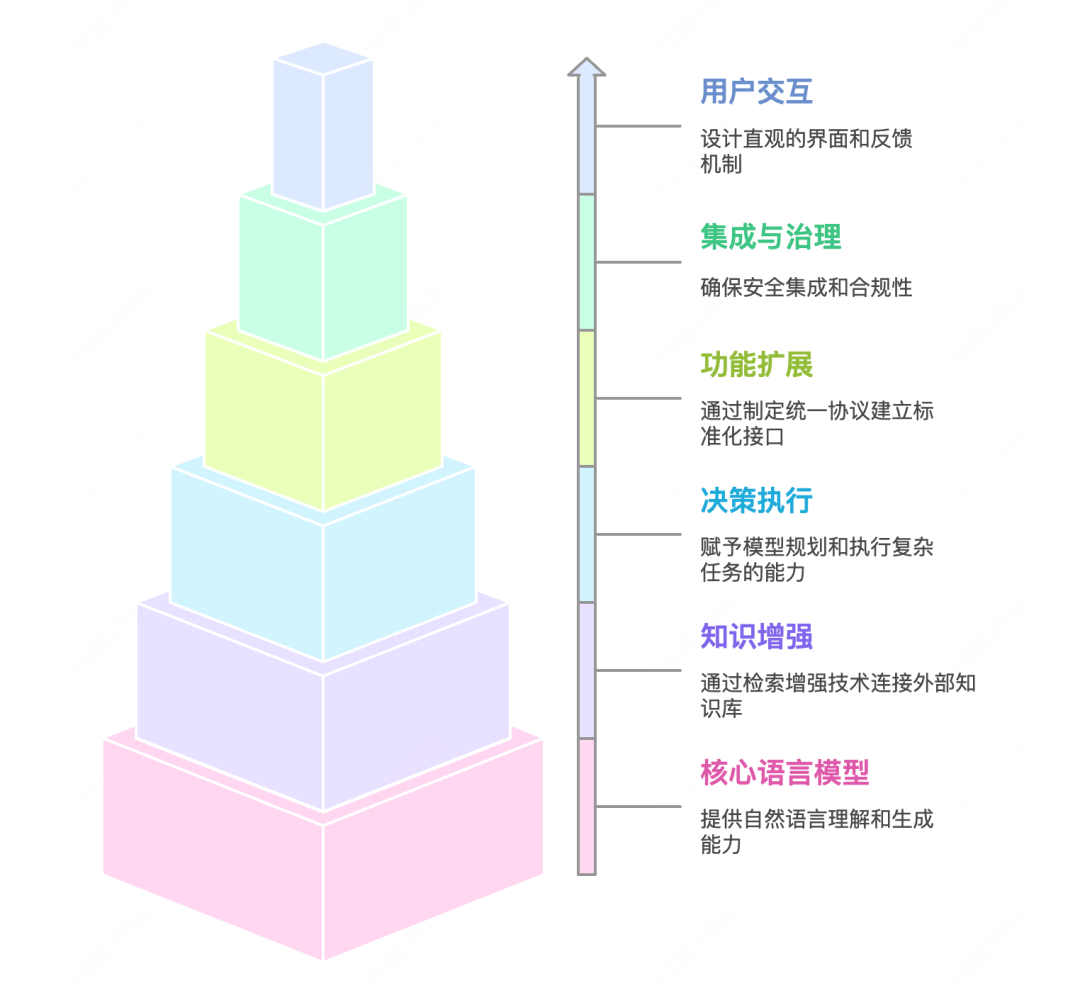
后续章节将深入探讨RAG、Agent和MCP三大核心技术,揭示它们如何各自解决特定挑战,并协同工作构建完整、强大的AI应用生态系统。

RAG
RAG技术概述
基本概念
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索(Retrieval)和生成(Generation)的AI技术框架。它通过从外部知识库中检索相关信息,补充大语言模型的知识,从而生成更准确、更可靠的回答。
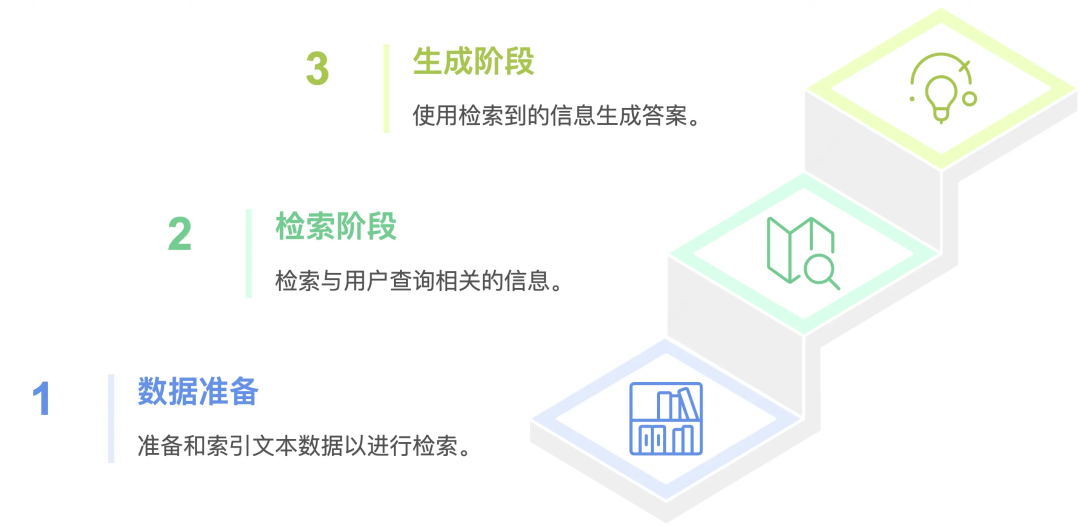
目前大部分的AI聊天界面在输入框下方可以选择"深度思考"或"联网搜索","联网搜索"其实就是一种RAG,解决了模型内部知识过时或缺失的问题,提升了回答的时效性和广泛适用性。
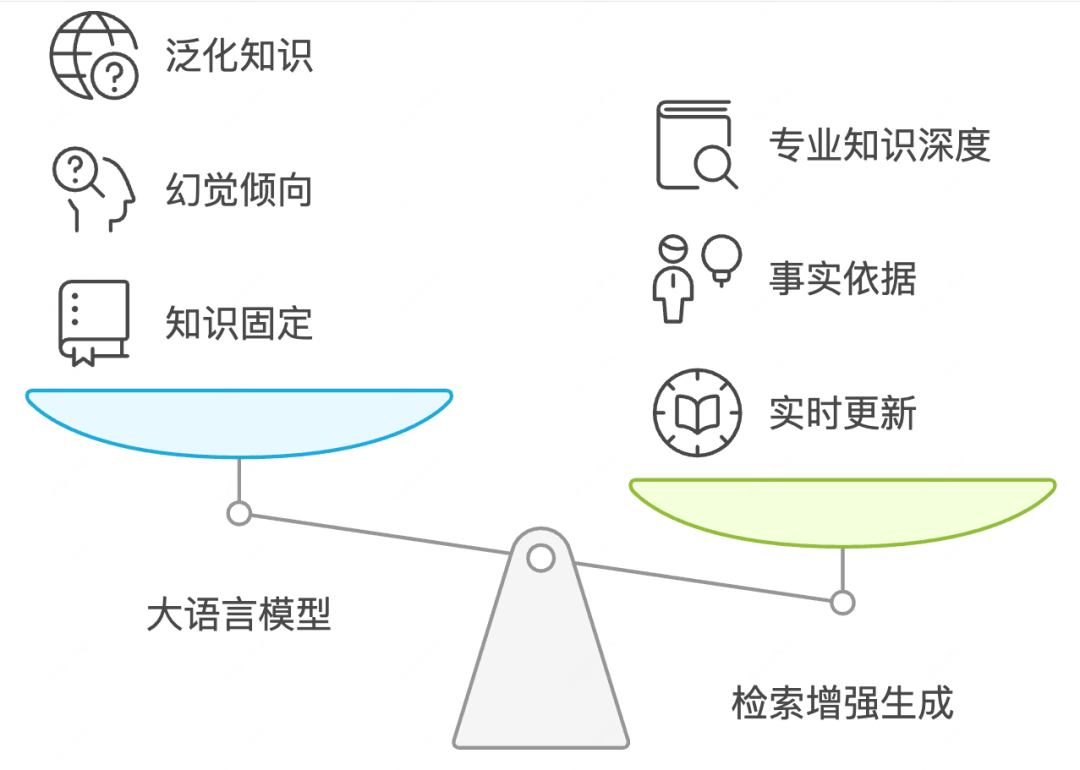
使用RAG,可以解决以下问题:
知识更新问题:大模型的知识在训练后就固定了,无法获取最新信息。RAG可以通过连接外部、实时更新的知识源解决这一问题。
模型幻觉:大模型容易生成看似合理但实际不正确的信息。RAG通过提供事实依据,大幅减少了幻觉问题。
专业知识深度:针对专业领域知识,RAG可以连接专业资料库,提供更深入的回答。
透明度与可追溯性:RAG可以提供信息来源,使回答更加可验证。
知识私有化:企业可以将内部知识库与RAG结合,实现基于专有资料的问答能力。
核心组件
RAG系统的核心组件包括:
文档处理系统 (Document Processing System)
作为RAG流程的起点,负责将原始文档转换为适合检索的格式。主要功能包括文档清理、分块(Chunking)、元数据提取和文本标准化。常用工具包括LangChain的Document Loaders、LlamaIndex的Node Parsers,以及针对特定文档类型的处理器如Unstructured和PyPDF2。对于轻量级应用,可以使用NLTK或spaCy构建基础处理流程。
嵌入模型 (Embedding Model)
负责将文本转换为密集向量表示,是语义检索的基础。主流选项包括OpenAI的text-embedding-ada系列、Cohere的Embed模型,以及开源选项如BAAI/bge-large和Jina AI的jina-embeddings。模型选择需要平衡语义理解能力、维度大小和计算效率,同时考虑应用场景的语言和领域特点。
向量存储 (Vector Store)
负责管理文档向量并提供高效的相似度搜索能力。企业级选项包括Pinecone(全托管服务)、Weaviate(支持混合搜索)和Milvus(高吞吐量分布式系统)。开发环境可选择Chroma DB(易于集成)、FAISS(高性能本地索引)或Qdrant(自托管选项)。
检索增强系统 (Retrieval Augmentation System)
负责优化查询处理和结果筛选,包括查询改写、混合检索策略和结果重排序。常见技术包括HyDE(Hypothetical Document Embeddings)、重排序模型(如Cohere Rerank)、语义路由和多查询扩展。这一层通常需要根据业务需求整合多种检索方法,以提高结果的相关性。
生成模型 (Generative Model)
接收用户查询和检索到的上下文,生成连贯、准确的回答。主流选项包括OpenAI的GPT-4、Anthropic的Claude系列和Cohere的Command系列。开源替代方案包括Mistral、Llama 3和DeepSeek等。
回答后处理系统 (Post-processing System)
回答后处理系统负责验证生成内容的质量,包括事实性检查、引用验证、格式化和输出转换。这一组件确保最终回答符合业务标准,可能包括幻觉检测、敏感内容过滤和自动校正等机制,是保障RAG系统可靠性的重要环节。
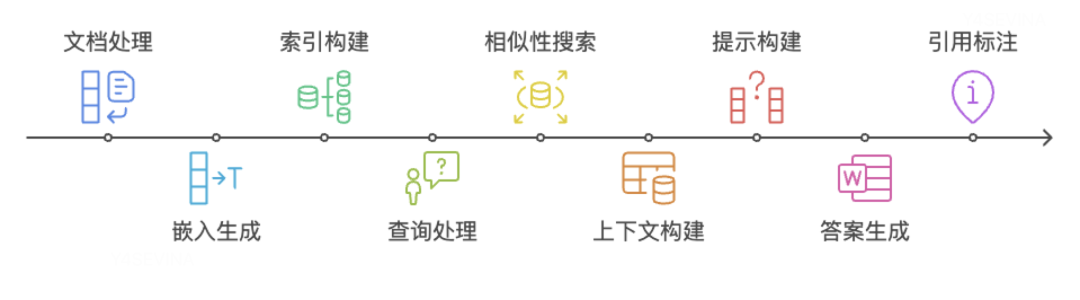
下图展示了以上组件的是如何交互:
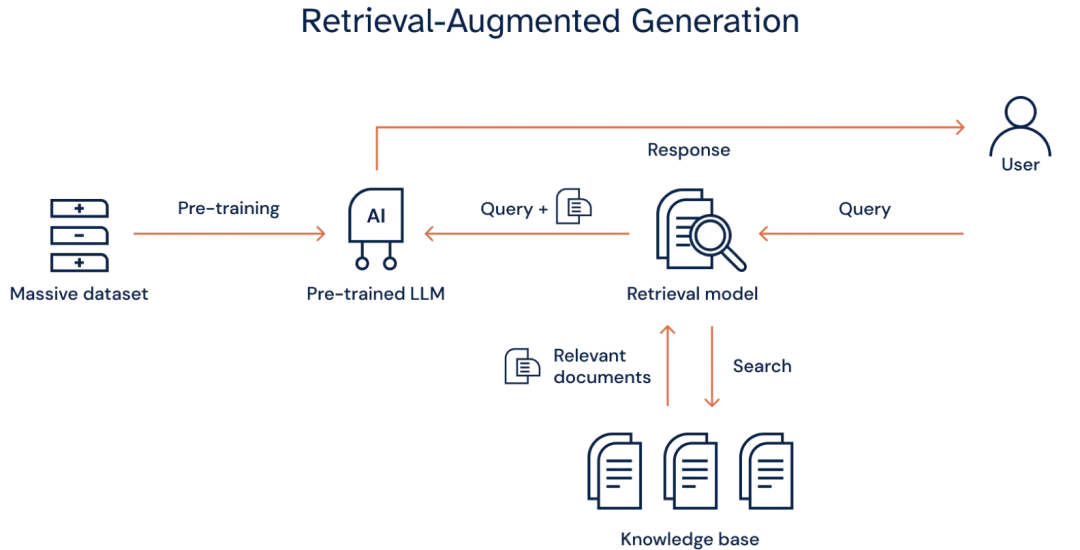
基于LangChain快速搭建RAG
LangChain是一个用于开发大语言模型(LLM)驱动应用程序的开源框架,它简化了将LLM与外部数据源和环境连接的过程,旨在帮助开发人员构建基于大语言模型的端到端应用程序。它提供了一套工具和组件,让开发者能够创建复杂、交互式的AI应用,如聊天机器人、问答系统、内容生成器等。
https://python.langchain.com/docs/introduction/
关键代码示例
基础的RAG流程如下,示例代码仅展示核心功能,实际应用时需要针对每一步进行调优。
▶文档预处理
文档读取
def read_word_document(file_path): doc = docx.Document(file_path) paragraphs = [para.text.strip() for para in doc.paragraphs if para.text.strip()] return "\n".join(paragraphs) # 合并段落,形成完整文本文本分块
简单的字符分块可能会切断语义完整的内容,并且没有考虑文档结构和特定领域知识,实际使用需要按需调整。
def split_text(text, chunk_size=100, chunk_overlap=10): text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, separators=["\n", "。", "?", "!"] ) return text_splitter.split_text(text)嵌入模型选择
def load_embedding_model(model_name="moka-ai/m3e-base"): # 先下载模型(首次运行需联网) embeddings = HuggingFaceEmbeddings( model_name="moka-ai/m3e-base", # Hugging Face 仓库路径 model_kwargs={"device": "cpu"}, # 可选 GPU 加速 encode_kwargs={"normalize_embeddings": True} # 归一化向量 ) return embeddings向量生成与存储
本地部署选择FAISS (Facebook AI Similarity Search)。对于大规模部署,可考虑Milvus或Pinecone等向量数据库。
FAISS是Facebook开源的向量相似度搜索库,维护成本低,部署复杂度低。支持纯本地部署无需额外服务;内存占用小,性能优秀;支持多种索引类型。
https://github.com/facebookresearch/faiss
from langchain_community.vectorstores import FAISS
def store_to_vector_db(docs, db_path="faiss_index"): embeddings = load_embedding_model() vector_db = FAISS.from_documents(docs, embeddings) vector_db.save_local(db_path)▶知识召回
向量检索
def search_similar_texts(query, vector_db, top_k=3): results = vector_db.similarity_search(query, k=top_k) return [r.page_content for r in results]关键词检索(BM25)
def fulltext_search(query): conn = sqlite3.connect(DB_FILE) cursor = conn.cursor() data = " OR ".join(jieba.cut(query)) cursor.execute("SELECT ori, bm25(documents) AS score FROM documents WHERE content MATCH ? ORDER BY score DESC LIMIT 3", (data,)) results = cursor.fetchall() conn.close() data = [item[0] for item in results] return data混合检索策略
下方示例仅对多种召回方式的结果简单合并,实际应用需要进行进一步优化,例如结果去重、排序融合、重排序等。
def query_knowledge_base(user_query, index_path="faiss_index"): keyword_results = fulltext_search(user_query) vector_results = search_word_vector(user_query, load_vector_db(index_path)) return vector_results + keyword_results # 仅简单合并结果▶内容生成
模型接入
使用Ollama本地部署大模型。
Ollama是一个开源工具,允许用户在本地设备上运行大型语言模型。
https://ollama.com/
计算内存需求的基本公式为:VRAM = 参数量(B) × 精度系数 × (1+开销系数)。
FP16精度为2字节/参数,INT8为1字节,INT4/Q4为0.5字节。例如,RTX 4060 Ti(16GB)可流畅运行7B-8B的FP16模型。
答案生成
def generate(prompt: str, model: str = "deepseek-r1:1.5b", stream: bool = False) -> str: url = "http://localhost:11434/api/generate" # ollama默认端口 payload = { "model": model, "prompt": prompt, "options": { "temperature": 0.7, # 控制生成随机性 "num_predict": 8192 # 最大生成长度 } } response = requests.post(url, json=payload) return response.json()["response"]图形界面
如果已有支持RAG的API接口,需要快速生成Web界面原型,可以使用v0快速完成前端开发,进行功能验证。
v0是Vercel推出的一款AI驱动的界面生成工具,它允许用户通过自然语言描述来创建精美的React网页界面和组件,并且支持实时预览。
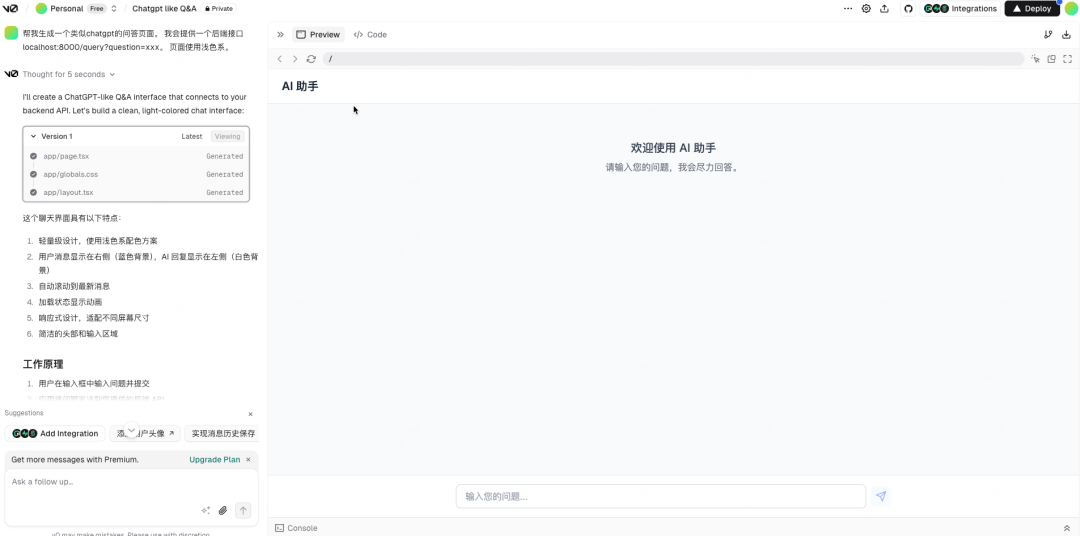
支持RAG的开发平台
目前有非常多的一站式平台支持RAG,无需编码即可使用。
但如果有额外诉求或希望进一步提高召回性能,类似上文提到的Langchain自建具有更好的灵活性。
AI界面平台(Open WebUI)
Open WebUI是一个可扩展、功能丰富且用户友好的自托管网页界面,旨在为各类大语言模型提供类似ChatGPT的交互体验。适合个人开发者、研究人员和小型团队,尤其是那些希望在本地部署和使用LLMs的用户,适合需要灵活的本地大模型交互界面的用户(Open WebUI 没有官方托管平台,需要用户自行私有部署)。
https://www.openwebui.com/
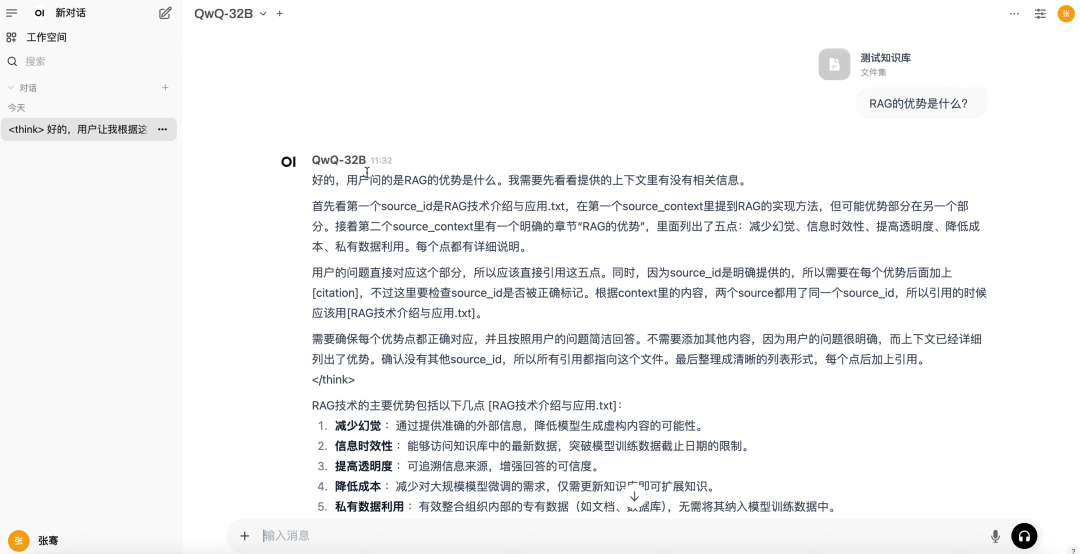
部署完成后只需要两步即可体验RAG功能:
添加知识库,这里导入一个"RAG技术介绍与应用.txt"的文件到"测试知识库"。

在输入框使用"#"选择已经创建的知识库"测试知识库",然后输入问题即可使用知识库。
LLM应用开发平台(Dify、n8n、Coze等)
适合企业级AI应用开发团队、需要构建完整知识库应用的业务部门,以及追求系统性AI解决方案的组织。
本文以Dify为例,Dify是一款开源的大语言模型(LLM)应用开发平台,融合了后端即服务(BaaS)和LLMOps的理念,使开发者可以快速搭建生产级的生成式AI应用。它提供了丰富的召回模式、跨知识库检索、工作流编排等企业级功能,具有较好的可拓展性和完善的前端界面,适合构建复杂的AI应用系统。(直接使用Dify官方托管平台,无需私有化部署)
在Dify平台中实现RAG功能非常便捷,整个过程可以简化为以下几个步骤:
数据准备,上传知识库文档,支持包括PDF、Word、Excel等多种常见格式。
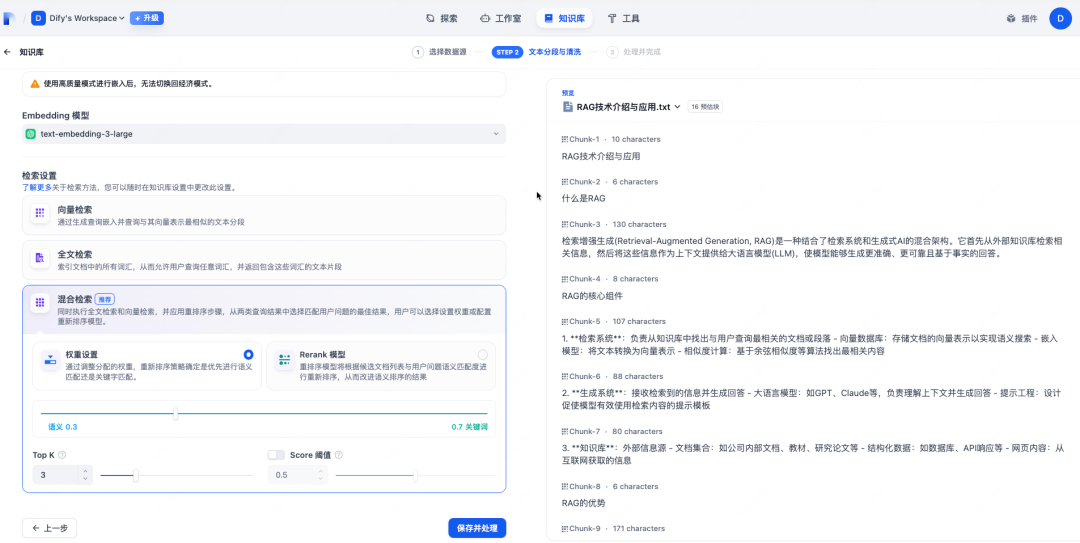
检索配置,系统会自动对上传的文档进行向量化处理,不过其分块效率并非总是理想的。
ChatFlow配置,选择官方提供的"知识库+聊天机器人",在知识检索选择刚才创建的知识库。
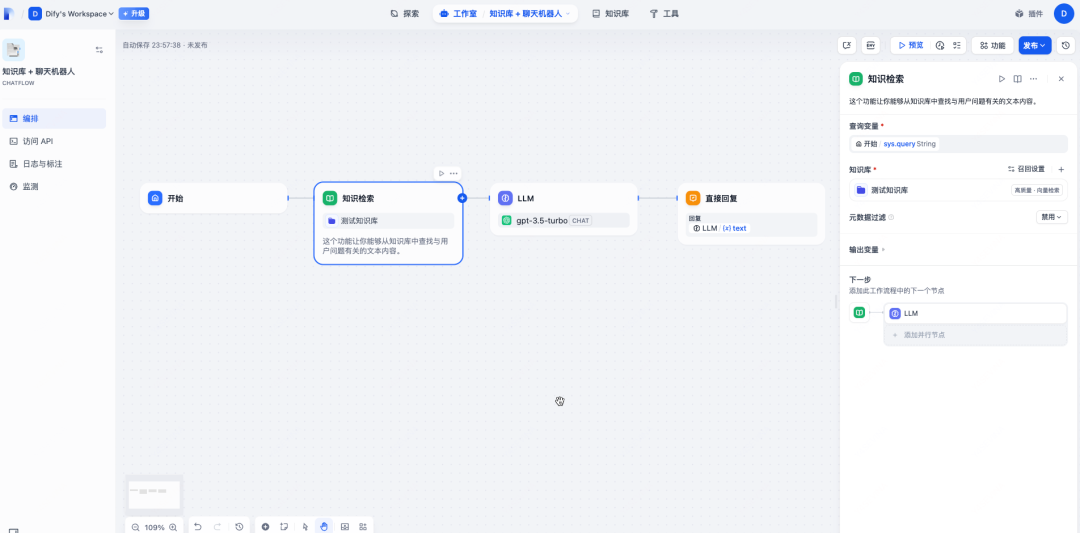
应用集成,通过简单的API调用或可视化界面配置,即可将RAG功能集成到您的应用中。


Agent
Agent技术概述
基础概念
Agent在计算机科学和人工智能领域中,通常指的是一种能够自主执行任务的软件实体。它们可以感知环境、做出决策并采取行动,以实现特定的目标。
拥有以下特点:

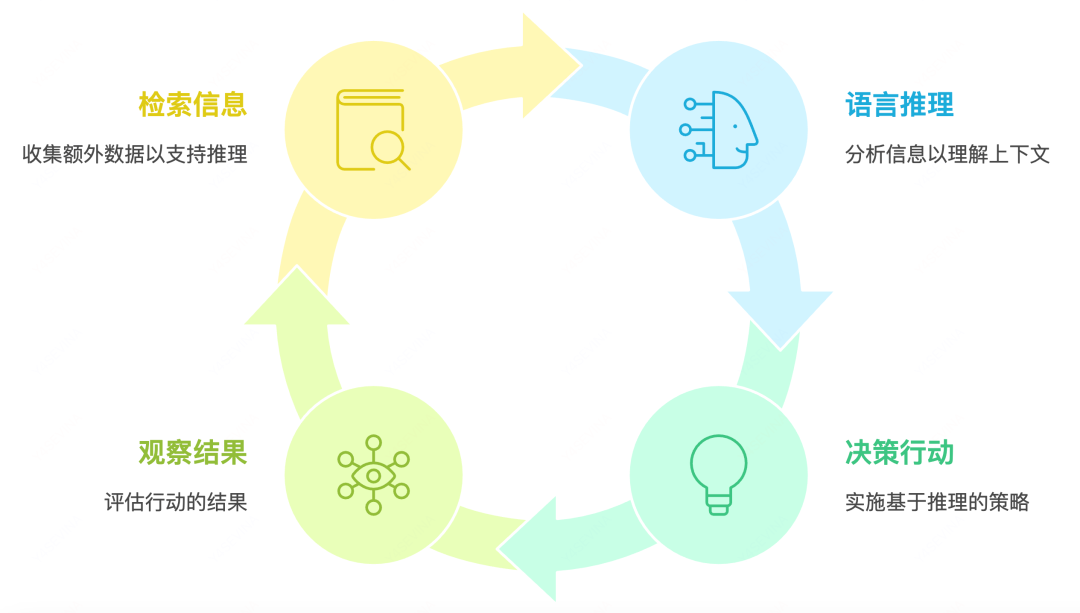
技术上,Agent通常采用ReAct(Reasoning+Acting)范式,即思考-行动-观察循环,或基于语言反馈的强化学习框架。每个行动步骤都通过提示工程驱动LLM生成结构化输出,实现与工具的交互并处理返回结果。
核心组件
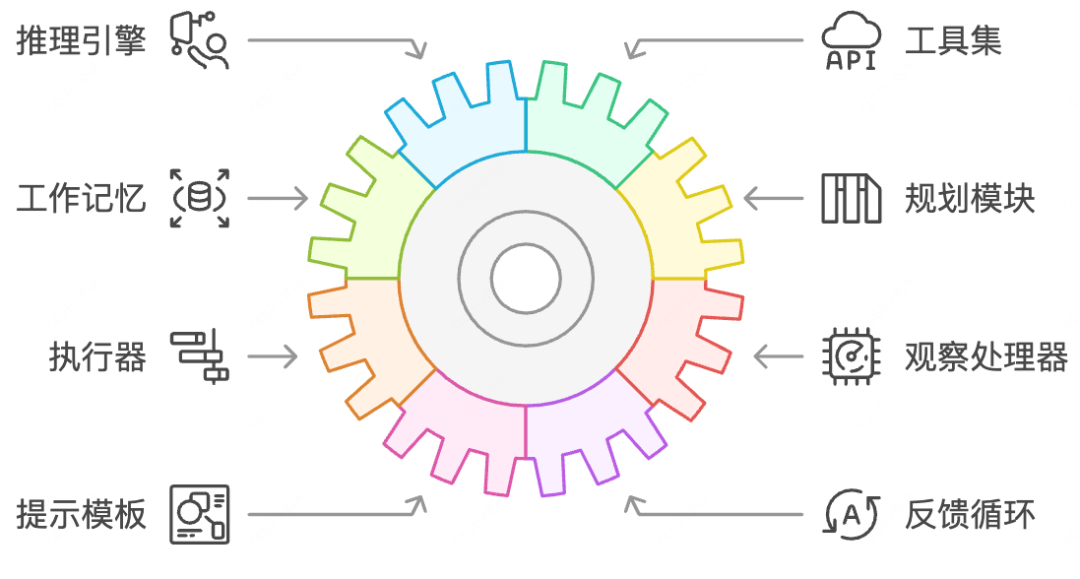
推理引擎(LLM):作为中枢决策单元,负责理解、规划和生成行动
工具集(Tools):预定义的API接口,扩展模型与外部环境交互能力
工作记忆(Memory):存储交互历史和中间状态,支持上下文连贯性
规划模块(Planner):分解复杂任务并制定执行路径
执行器(Executor):实际调用工具并收集结果的组件
观察处理器(Observer):解析工具调用结果并整合到决策过程
提示模板(Prompts) :结构化指令集,引导模型生成特定格式输出
反馈循环(Feedback Loop) :评估行动效果并调整后续策略
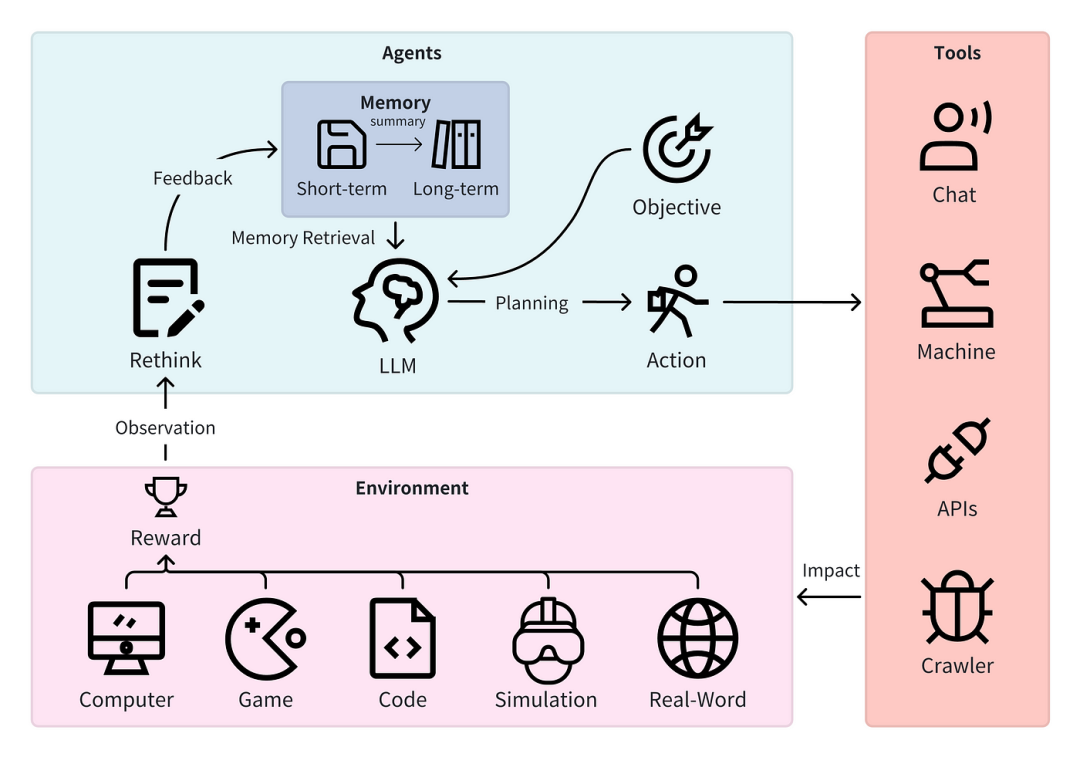
模拟Agent运行流程
Agent的执行过程是一个动态的"思考-行动-观察"循环:
用户输入经过推理引擎(LLM)理解后,规划模块将任务分解为子目标;在每个决策点,LLM基于工作记忆中的上下文历史结合提示模板生成行动指令;执行器调用相应工具并获取结果;观察处理器将结果解析后反馈给LLM;反馈循环持续评估行动效果并调整策略,直至完成任务并生成最终回复;整个流程由推理引擎统筹协调,在保持上下文连贯性的同时实现复杂任务的自主处理。
下面代码给出一个符合ReAct范式的通用Agent示例,包含上述的核心组件。通过学习并修改这段代码,能够快速构建自己的基础Agent系统,理解如何将LLM的能力与外部工具组合以解决复杂任务。
def run(self, task: str) -> str: # 工作记忆(Memory):记录任务到交互历史 self.memory.add_message("user", task)# 规划模块(Planner):分解任务创建执行计划 plan = self.planner.create_plan(task) # 提示模板简化:计划创建提示... self.memory.save_state("plan", plan)# 执行器(Executor):准备执行计划 completed_steps = []for step in plan: step_id = step["step_id"] description = step["description"] tool_name = step.get("tool") print(f"执行步骤 {step_id}: {description}")if tool_name: # 推理引擎(LLM):确定工具参数和使用方式 tools_description = self._format_tools_description() system_msg = self.system_prompt.format(tools_description=tools_description) # 提示模板(Prompts):工具使用提示... messages = [ {"role": "system", "content": system_msg}, {"role": "user", "content": f"请帮我完成这个步骤:{description}。如果需要,请使用适当的工具。"} ]# 推理引擎(LLM):生成响应 response = self.llm_engine.generate(messages) self.memory.add_message("assistant", response)# 观察处理器(Observer):解析工具调用 tool_calls = self._parse_tool_calls(response)for tool_call in tool_calls: try: # 执行器(Executor):实际调用工具 result = self.executor.execute_tool( tool_call["tool_name"], **tool_call["parameters"] )# 观察处理器(Observer):处理和解释结果 observation = self.observer.process_result(description, result)# 工作记忆(Memory):记录执行结果 step_result = { "step_id": step_id, "description": description, "tool_used": tool_call["tool_name"], "parameters": tool_call["parameters"], "result": result, "observation": observation } completed_steps.append(step_result) self.memory.add_message("system", f"工具执行结果: {result}")# 反馈循环(Feedback Loop):评估行动效果并调整策略 remaining_steps = [s for s in plan if s["step_id"] not in [cs["step_id"] for cs in completed_steps]] feedback = self.feedback_loop.evaluate_and_adjust( task, completed_steps, observation, remaining_steps ) # 提示模板(Prompts):反馈评估提示...# 规划模块(Planner):根据反馈调整计划 if feedback.get("需要调整", False): new_plan = feedback.get("调整后的计划", []) plan = [s for s in completed_steps] + new_plan self.memory.save_state("plan", plan) print("计划已调整")except Exception as e: # 工作记忆(Memory):记录错误信息 error_msg = f"执行步骤 {step_id} 时发生错误: {str(e)}" print(error_msg) self.memory.add_message("system", error_msg) else: # 非工具步骤处理 step_result = { "step_id": step_id, "description": description, "completed": True } completed_steps.append(step_result)# 推理引擎(LLM):生成最终总结 summary_prompt = f""" 你刚刚帮助用户完成了以下任务:{task} 已完成的步骤: {json.dumps(completed_steps, ensure_ascii=False, indent=2)} 请提供一个简洁的总结,说明任务完成情况和主要结果。 """ messages = [{"role": "user", "content": summary_prompt}] summary = self.llm_engine.generate(messages)# 工作记忆(Memory):记录总结 self.memory.add_message("assistant", summary) return summary
基于LangChain快速搭建Agent
我们每次都需要手写上面复杂的执行过程吗?当然不,LangChain提供了丰富的工具和框架,使Agent的搭建变得相对简单高效。
基本的Agent构建流程如下:
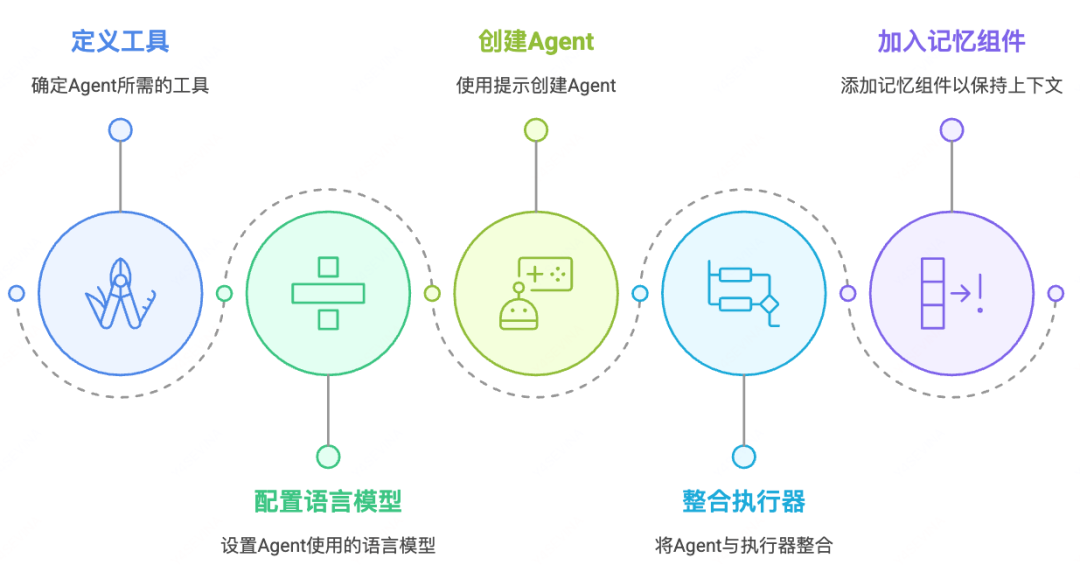
下面给出示例代码:
# Prompt templateprompt = ChatPromptTemplate.from_messages([ ("system", """你是一个专业的旅游规划助手。你的任务是根据用户偏好创建详细的旅行计划。 使用可用的工具收集必要信息并创建全面的旅行策略。 始终考虑天气条件、交通选择、住宿可用性和当地景点。 提供详细的每日行程和费用估算。"""), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"),])
# Initialize the LLMdef get_llm() -> BaseChatModel: return ChatOpenAI( model="deepseek-chat", temperature=0.7, api_key=DEEPSEEK_API_KEY, base_url="https://api.deepseek.com/v1" # DeepSeek API endpoint )
# Create the agentdef create_agent(): try: # Fetch tools from server tools = create_tools_from_server_data() llm = get_llm() agent = create_openai_functions_agent(llm, tools, prompt) return AgentExecutor(agent=agent, tools=tools, verbose=True) except Exception as e: print(f"Error creating agent: {e}") return None
# Main function to create travel plandef create_travel_plan(preferences: TravelPreferences) -> TravelPlan: # 创建Agent agent_executor = await create_agent() # 初始化聊天历史 chat_history = [] # 创建初始提示 initial_prompt = f"""为{preferences.destination}从{preferences.start_date}到{preferences.end_date}创建一个旅行计划。 预算: ${preferences.budget} 兴趣爱好: {', '.join(preferences.interests)} 住宿偏好: {preferences.accommodation_preference}""" # 执行Agent response = await agent_executor.ainvoke({ "input": initial_prompt, }) # 从链输出中获取原始内容 content = response.get("output", "") # 创建一个简单的TravelPlan,将原始内容作为建议 return content
支持Agent的开发平台
Dify、n8n、Coze等平台均支持Agent的搭建,官方文档对此有详细介绍及示例,此处不再赘述。
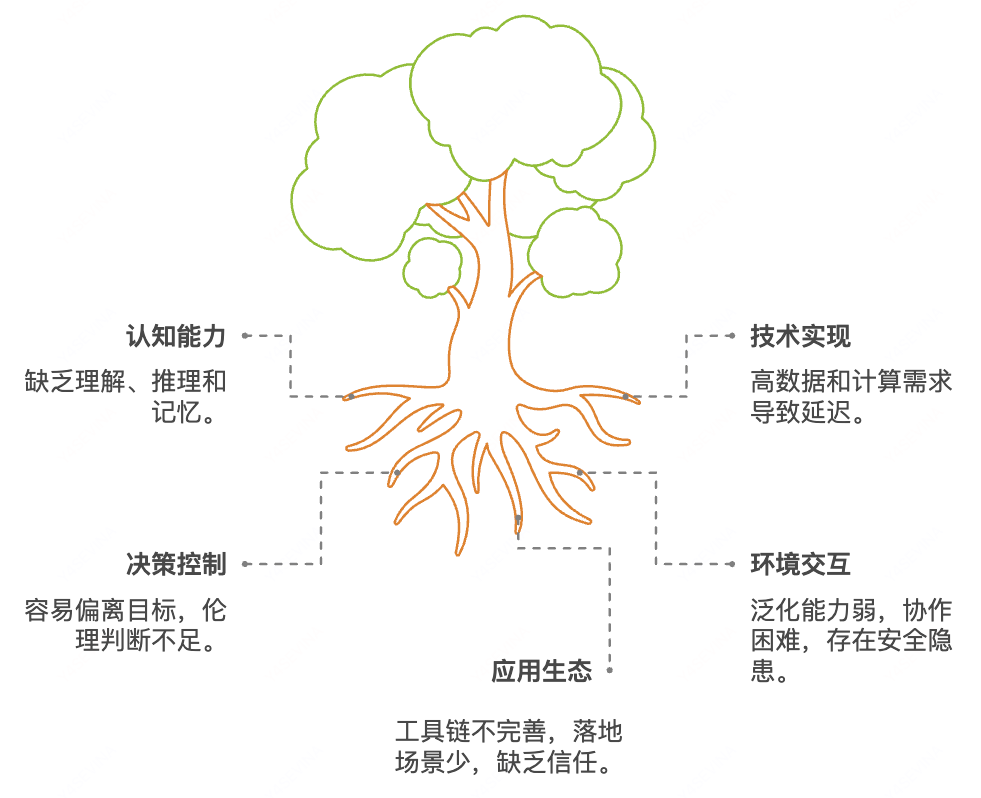
Agent的局限性
在上面的基于LangChain的Agent代码中,其实缺少一部分核心代码,就是工具的获取及调用。
传统Agent只能使用预定义工具集,难以灵活扩展,且工具集成复杂,通常需要自定义开发和定制化编码,所以MCP应运而生。
当然,除了工具链不完善之外Agent还有许多地方存在进步空间,下图所列条目不再赘述。

MCP
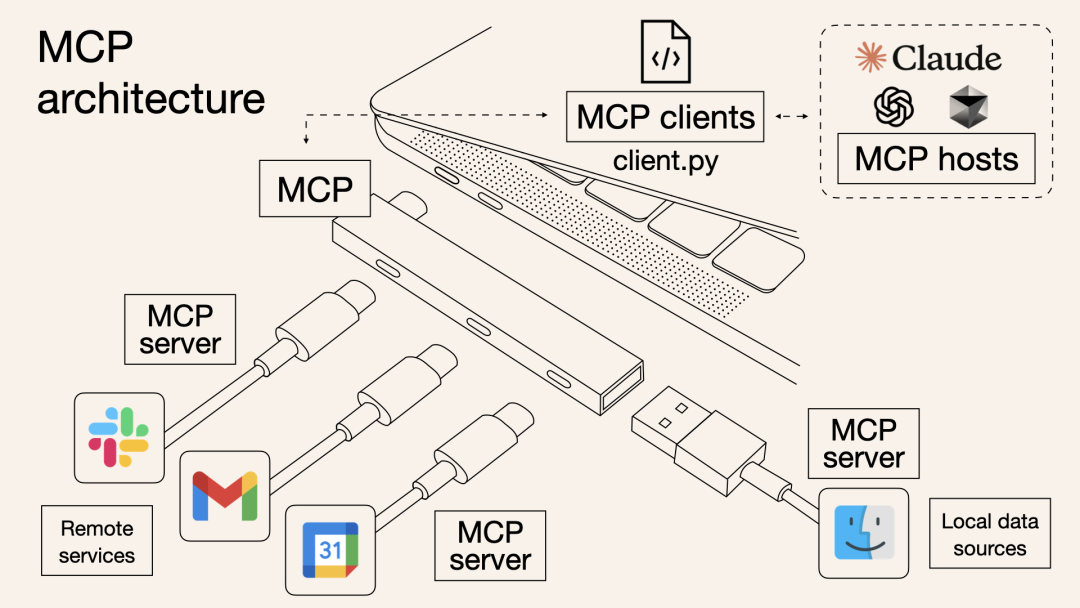
MCP技术概述
基本概念
Model Context Protocol (MCP) 是一种标准化协议,用于大语言模型(LLM)与外部数据源、服务和工具进行交互的框架。它允许LLM通过结构化的方式访问和操作外部上下文信息,从而增强模型的能力,使其能够执行更复杂的任务。
MCP 的概念最先由Claude的母公司提出,目前不是一个完全确定或标准化的交互协议。MCP更像是一种架构模式或设计理念,而非一个明确定义的标准协议。未来可能会出现统一标准,但目前仍处于竞争性创新阶段。
https://modelcontextprotocol.io/introduction
值得一提的是,对于熟悉区块链技术的同学来说,MCP Server的设计理念与Oracle预言机有异曲同工之妙。它们都扮演着信息中介的角色,通过提供标准化的接口来确保数据交互的可靠性和一致性。
核心组件
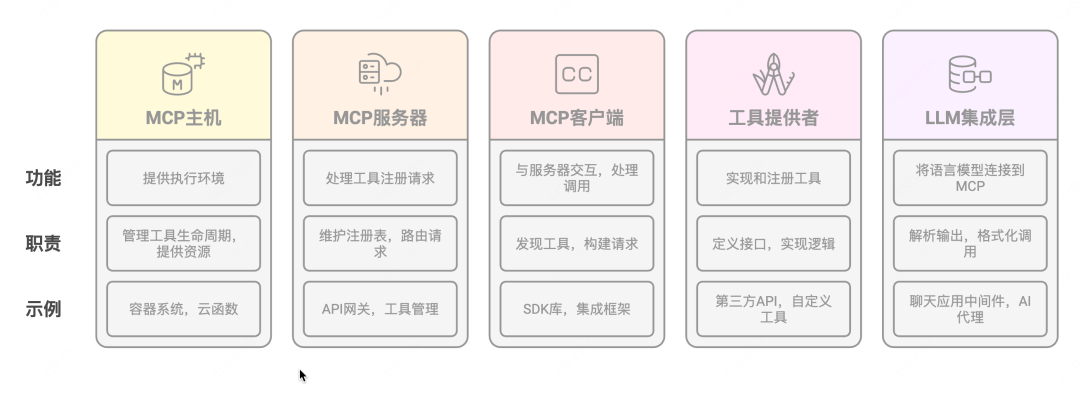
MCP系统是由多个协同工作的核心组件构成的完整架构,包括负责执行环境和运行时管理的MCP主机(Host)、处理工具注册与调用请求的服务器(Server)、与服务器交互并处理模型生成调用的客户端(Client)、实现和注册特定工具的工具提供者(Tool Provider),以及连接语言模型与MCP系统的LLM集成层。
MCP与Function Call
Function Call与MCP代表了两个不同层次的技术关注点:
Function Call专注于功能调用的表达层面,它通过大模型为预定义方法生成结构化的参数,确保调用的准确性和规范性。
而MCP则着眼于更高层次的系统架构,它不仅能够生成参数,更重要的是提供了一个完整的功能管理、发现和执行框架。这个框架能够动态发现新方法并实现调用,同时包含了丰富的基础设施支持。
可以说,Function Call是MCP协议中的一个核心组件,但MCP的范畴更为广泛,它构建了一个完整的功能调用生态系统。
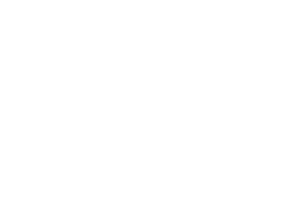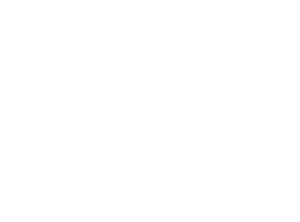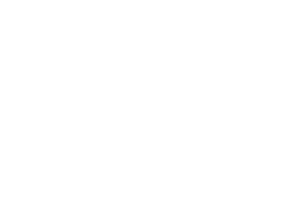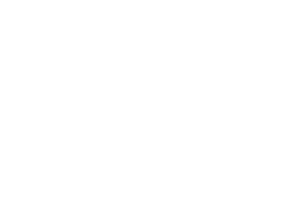
集成MCP到AI平台
此处以Cursor为例:
Cursor是一款深度集成AI、旨在极大提升编程效率的代码编辑器,它基于VS Code构建并提供了更智能的代码生成、编辑和理解能力。
https://www.cursor.com/cn
开源MCP Server
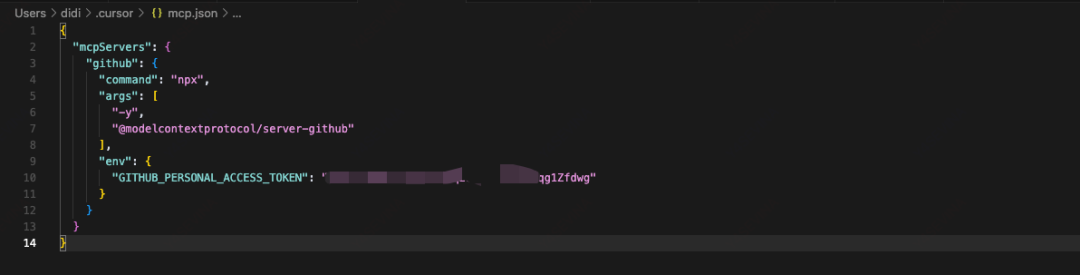
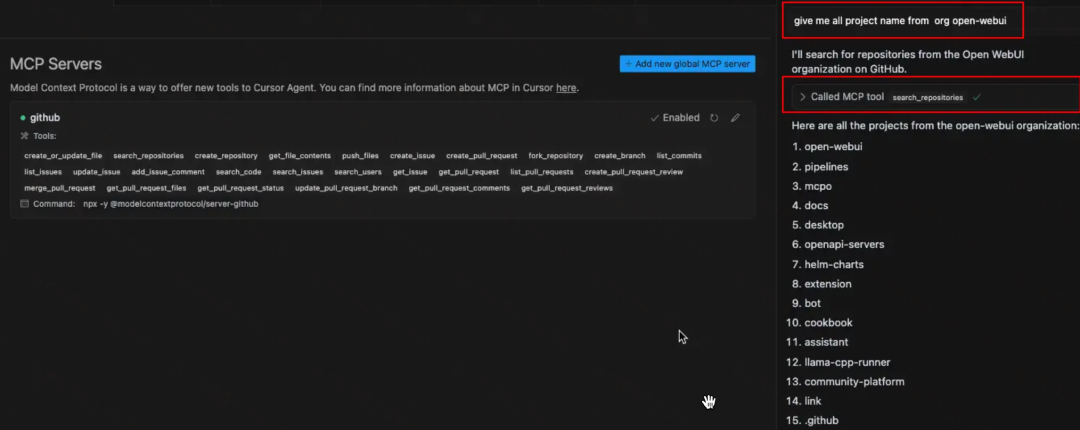
我们可以在https://cursor.directory/mcp找到非常多的MCP Server,此处我们以GitHub为例。获取某个组织下的所有项目名称。
根据官方文档给出的配置内容在Cursor中添加一个MCP Server,同时填入在GitHub申请的AccessToken。
此时就能通过Cursor调用GitHub MCP Server提供的工具来获取数据。
构建自己的MCP Server
基于Anthropic提供的FastMCP包,我们实现一个MCP Server,可以查询指定位置天气,并记录到电脑自带的备忘录中。
# Initialize FastMCP servermcp = FastMCP("weather")
@mcp.tool()async def get_forecast(latitude: float, longitude: float) -> str: """获取某个地点的天气预报 Args: latitude: 纬度 longitude: 经度 """ # 省略具体获取天气的过程 # 此处可调用其他第三方气象平台接口 或 mock return mock_data
@mcp.tool()async def create_note(content: str) -> str: """创建一个新的备忘录并填入指定内容 Args: content: 要添加到新备忘录中的内容 """ # 先打开Notes应用 subprocess.run(['open', '-a', 'Notes']) # 使用AppleScript命令创建新笔记 applescript = f''' tell application "Notes" activate make new note at folder "Notes" with properties {{body:"{content}"}} end tell ''' subprocess.run(['osascript', '-e', applescript]) return "成功创建新笔记并填入内容"
if __name__ == "__main__": # Initialize and run the server mcp.run(transport='stdio')将上面的代码保存到本地后,在Cursor中添加如下配置。
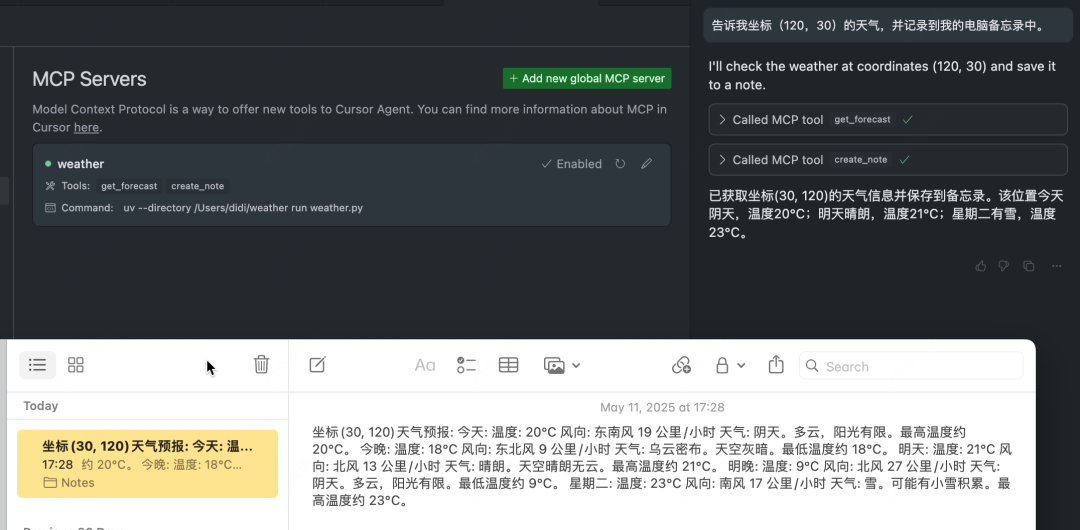
{ "mcpServers": { "weather": { "command": "uv", "args": [ "--directory", "/Users/zq/weather", // 文件所在目录的绝对路径 "run", "weather.py" ] } }}配置完成后在输入框中进行提问,Agent首先调用查询天气的工具获取到目标位置的天气,然后创建备忘录并写入天气预报的内容。
基于HTTP的MCP协议
我可以不使用Anthropic提供的SDK,自己实现MCP吗?当然可以!
目前不同公司开发的MCP是不完全通用的。因此我们可以参考其定义来实现一套自己的MCP协议,核心是提供一个list_tools接口,告诉大模型提供哪些接口,以及接口的作用及入参,并且不受语言限制。
app = FastAPI()
async def get_weather_data(location: str, date: str) -> Dict[str, Any]: # 省略具体获取天气的过程 # 此处可调用其他第三方气象平台接口 或 mock return generate_mock_weather(location, date)
@app.post("/api/weather")async def get_weather(request: WeatherRequest): data = await get_weather_data(request.location, request.date) return {"status": "success", "data": data}
@app.get("/api/list_tools")async def list_tools(): """Return a list of all available tools in the MCP server""" tools = [ { "name": "get_weather", "description": "Get weather forecast for a specific location and date", "endpoint": "/api/weather", "method": "POST", "params": [ {"name": "location", "type": "string", "description": "The location to get weather for"}, {"name": "date", "type": "string", "description": "The date to get weather for"} ] } ] return {"status": "success", "tools": tools}if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)下面给出调用方代码示例,主要实现了一个动态工具加载系统,用于与MCP Server交互,使得应用程序能够动态发现MCP服务器提供的工具,并自动生成调用这些工具的函数接口。
具体功能如下:
fetch_tools_from_server():从MCP服务器获取可用工具列表,发送GET请求到/api/list_tools端点。
create_dynamic_tool_executor():为每个工具创建执行函数。
create_tools_from_server_data():将从服务器获取的工具数据转换为Tool对象列表。
# Function to fetch tools from MCP serverasync def fetch_tools_from_server() -> List[Dict[str, Any]]: """Fetch available tools from the MCP server""" async with httpx.AsyncClient() as client: response = await client.get(f"{MCP_SERVER_URL}/api/list_tools") return response.json()["tools"]
def create_dynamic_tool_executor(tool_info: Dict[str, Any]) -> Callable: async def execute_api_call(*args, **kwargs): payload = {} param_names = [p["name"] for p in tool_info["params"]] # Map args and kwargs to parameters for i, arg in enumerate(args): if i < len(param_names): payload[param_names[i]] = arg for key, value in kwargs.items(): if key in param_names: payload[key] = value # Execute request async with httpx.AsyncClient() as client: is_post = tool_info["method"] == "POST" request_kwargs = {"json" if is_post else "params": payload} method = client.post if is_post else client.get response = await method(f"{MCP_SERVER_URL}{tool_info['endpoint']}", **request_kwargs) if response.status_code == 200: return response.json()["data"] raise Exception(f"API call failed with status {response.status_code}: {response.text}") # Create synchronous wrapper with proper metadata def sync_executor(*args, **kwargs): return asyncio.run(execute_api_call(*args, **kwargs)) # Set function metadata sig_params = [inspect.Parameter(name=p["name"], kind=inspect.Parameter.POSITIONAL_OR_KEYWORD, annotation=param_type) for p in tool_info["params"]] sync_executor.__signature__ = inspect.Signature(parameters=sig_params) sync_executor.__name__ = tool_info["name"] sync_executor.__doc__ = tool_info["description"] return sync_executor# Function to create Tool objects from fetched tool datadef create_tools_from_server_data(tool_data: List[Dict[str, Any]]) -> List[Tool]: """Create Tool objects from fetched tool data""" tools = [] for tool_info in tool_data: # Create a dynamic tool executor for this tool executor = create_dynamic_tool_executor(tool_info) # Create a Tool object tools.append( Tool( name=tool_info["name"], func=executor, description=tool_info["description"] ) ) return tools
致谢
本文探讨了 AI 工具与自动化领域的多个代表性开源项目,包括 LangChain、Ollama、Open WebUI、Dify等。这些项目极大地推动了相关技术的进步和生态的繁荣,我们由衷地感谢其开发者以及背后活跃的开源社区所做出的宝贵贡献。



欢迎在评论区,留下你的大模型应用“小秘籍”,小编将选取两位同学,送上滴滴技术短袖T恤!


相关文章:
浅聊一下,大模型应用架构 | 工程研发的算法修养系列(二)
大模型应用架构基础 AI应用演进概述 人工智能应用的发展经历了多个关键阶段,每个阶段都代表着技术范式的重大转变。 大语言模型基础 大语言模型(LLM)作为现代AI应用的核心组件,具有独特的技术特性和能力边界,理解这些基础对架构设计至关重要。…...
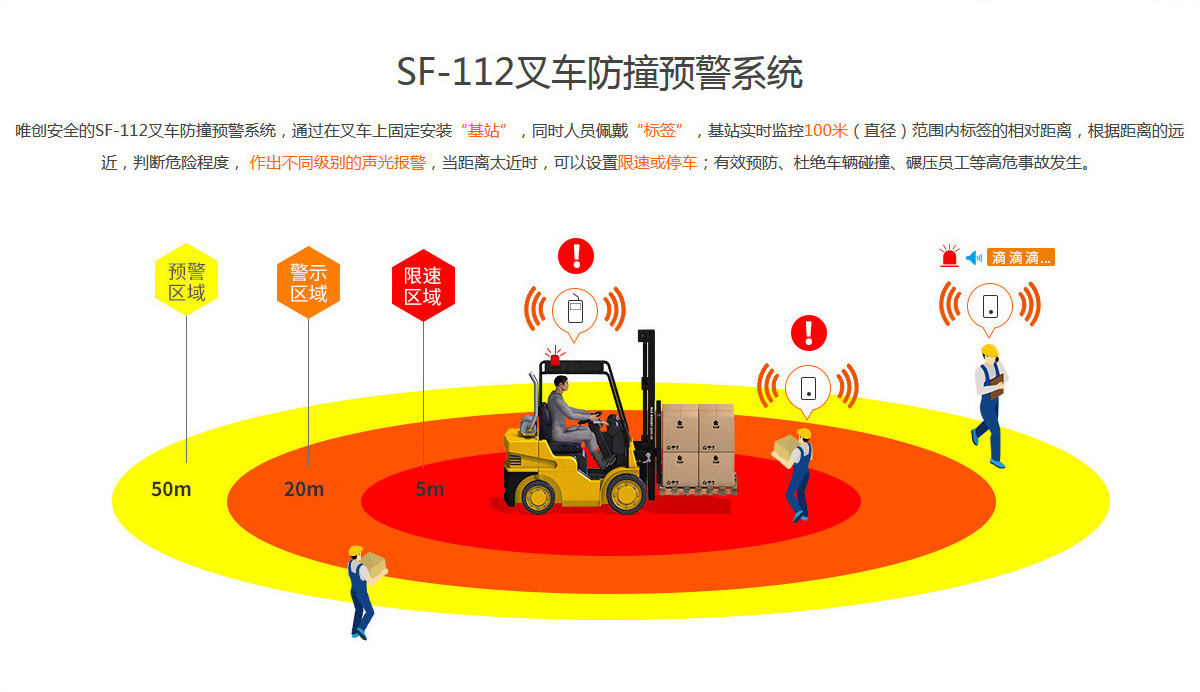
装载机防撞系统:智能守护,筑牢作业现场人员安全防线
在尘土飞扬、机械轰鸣的建筑工地上,装载机是不可或缺的 “大力士”,承担着土方搬运、物料装卸等繁重任务。然而,传统作业模式下,装载机的安全隐患时刻威胁着现场人员的生命安全与工程进度。随着智能化技术的突破,唯创安…...

上门服务小程序订单系统框架设计
一、逻辑分析 上门服务小程序订单系统主要涉及服务展示、用户下单、订单处理、服务人员接单与服务完成反馈等核心流程。 服务展示:不同类型的上门服务(如家政、维修等)需要在小程序中展示详细信息,包括服务名称、价格、服务内容介…...

11.MySQL事务管理详解
MySQL事务管理详解 文章目录 MySQL事务管理 事务的概念 事务的版本支持 事务的提交方式 事务的相关演示 事务的隔离级别 查看与设置隔离级别 读未提交(Read Uncommitted) 读提交(Read Committed) 可重复读(Repeatabl…...

前端实现视频/直播预览
有一个需求:后端返回视频的预览地址,不仅要支持这个视频的预览,还需要设置视频封面。 这里有两种情况: 如果是类似.mp4,.mov等格式的视频可以选用原生 video 进行视频展示,并且原生的 video 也支持全屏、…...

React源码阅读-fiber核心构建原理
React源码阅读(2)-fiber核心构建原理 好的,我明白了。您提供的文本主要介绍了 React 源码中 Fiber 核心的构建原理,涵盖了从执行上下文到构建、提交、调度等关键阶段,以及相关的代码实现。 您提出的关联问题也很重要,它们深入探讨…...
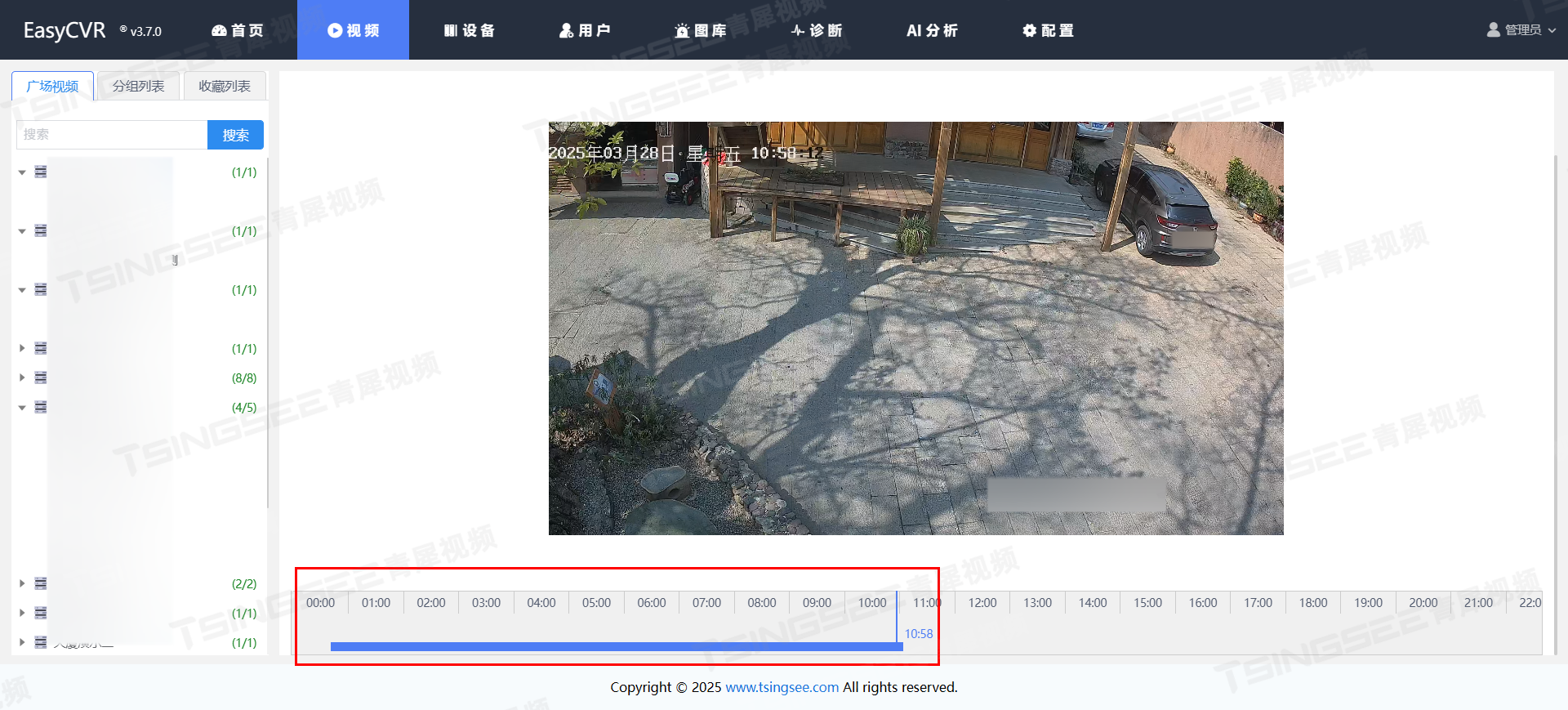
视频监控管理平台EasyCVR与V4分析网关对接后告警照片的清理优化方案
一、问题概述 在安防监控、设备运维等场景中,用户将视频监控管理平台EasyCVR与V4网关通过http推送方式协同工作时,硬件盒子上传的告警图片持续累积,导致EasyCVR服务器存储空间耗尽,影响系统正常运行与告警功能使用。 二、解决方…...

基于 BGE 模型与 Flask 的智能问答系统开发实践
基于 BGE 模型与 Flask 的智能问答系统开发实践 一、前言 在人工智能快速发展的今天,智能问答系统成为了提升信息检索效率和用户体验的重要工具。本文将详细介绍如何利用 BGE(Base General Embedding)模型、Faiss 向量检索库以及 Flask 框架…...

机器学习:决策树和剪枝
本文目录: 一、决策树基本知识(一)概念(二)决策树建立过程 二、决策树生成(一)ID3决策树:基于信息增益构建的决策树。(二)C4.5决策树(三ÿ…...
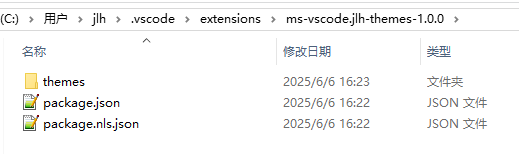
vscode自定义主题语法及流程
vscode c/c 主题 DIY 启用自己的主题(最后步骤) 重启生效 手把手教你制作 在C:\Users\jlh.vscode\extensions下自己创建一个文件夹 里面有两个文件一个文件夹 package.json: {"name":"theme-jlh","displayName":"%displayName%&qu…...

vue中加载Cesium地图(天地图、高德地图)
目录 1、将下载的Cesium包移动至public下 2、首先需要将Cesium.js和widgets.css文件引入到 3、 新建Cesium.js文件,方便在全局使用 4、新建cesium.vue文件,展示三维地图 1、将下载的Cesium包移动至public下 npm install cesium后 2、…...
SpringBoot整合RocketMQ与客户端注意事项
SpringBoot整合RocketMQ 引入依赖(5.3.0比较稳定) <dependencies><dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.3.1</version&…...

Github 2025-06-04 C开源项目日报 Top7
根据Github Trendings的统计,今日(2025-06-04统计)共有7个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量C项目7C++项目1Assembly项目1jq:轻量灵活的命令行JSON处理器 创建周期:4207 天开发语言:C协议类型:OtherStar数量:27698 个Fork数量:1538 …...

大二下期末
一.Numpy(Numerical Python) Numpy库是Python用于科学计算的基础包,也是大量Python数学和科学计算包的基础。不少数据处理和分析包都是在Numpy的基础上开发的,如后面介绍的Pandas包。 Numpy的核心基础是ndarray(N-di…...

LeetCode 热题 100 74. 搜索二维矩阵
LeetCode 热题 100 | 74. 搜索二维矩阵 大家好,今天我们来解决一道经典的算法题——搜索二维矩阵。这道题在 LeetCode 上被标记为中等难度,要求我们在一个满足特定条件的二维矩阵中查找一个目标值。如果目标值在矩阵中,返回 true;…...

解决 VSCode 中无法识别 Node.js 的问题
当 VSCode 无法识别 Node.js 时,通常会出现以下症状: 代码提示缺失require 等 Node.js API 被标记为错误调试功能无法正常工作终端无法运行 Node.js 命令 常见原因及解决方案 1. Node.js 未安装或未正确配置 解决方法: 确保已安…...
Mysql的卸载与安装
确保卸载干净mysql 不然在进行mysal安装时候会出现不一的页面和问题 1、卸载 在应用页面将查询到的mysql相关应用卸载 2、到c盘下将残留的软件包进行数据删除 3、删除programData下的mysql数据 4、检查系统中的mysql是否存在 cmd中执行 sc deleted mysql80 5、删除注册表中的…...

ES101系列09 | 运维、监控与性能优化
本篇文章主要讲解 ElasticSearch 中 DevOps 与性能优化的内容,包括集群部署最佳实践、容量规划、读写性能优化和缓存、熔断器等。 集群部署最佳实践 在生产环境中建议设置单一角色的节点。 Dedicated master eligible nodes:负责集群状态的管理。使用…...

Java常用的判空方法
文章目录 Java常用的判空方法JDK 自带的判空方法1. 使用 或 ! 运算符2. 使用 equals 方法3. Objects.isNull / Objects.nonNull4. Objects.equals4. JDK8 中的 Optional 第三方工具包1. Apache Commons Lang32. Google Guava3. Lombok 注解4. Vavr(函数式风格&…...
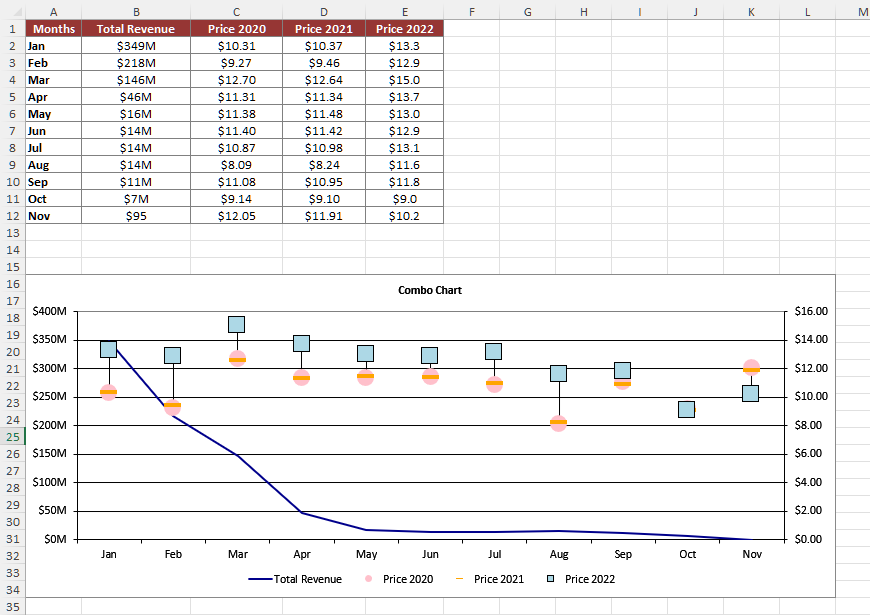
Excel处理控件Aspose.Cells教程:使用 C# 在 Excel 中创建组合图表
可视化项目时间线对于有效规划和跟踪至关重要。在本篇教程中,您将学习如何使用 C# 在 Excel 中创建组合图。只需几行代码,即可自动生成动态、美观的组合图。无论您是在构建项目管理工具还是处理内部报告,本指南都将向您展示如何将任务数据转换…...

【多线程初阶】阻塞队列 生产者消费者模型
文章目录 一、阻塞队列二、生产者消费者模型(一)概念(二)生产者消费者的两个重要优势(阻塞队列的运用)1) 解耦合(不一定是两个线程之间,也可以是两个服务器之间)2) 削峰填谷 (三)生产者消费者模型付出的代价 三、标准库中的阻塞队列(一)观察模型的运行效果(二)观察阻塞效果1) 队…...

《100天精通Python——基础篇 2025 第5天:巩固核心知识,选择题实战演练基础语法》
目录 一、踏上Python之旅二、Python输入与输出三、变量与基本数据类型四、运算符五、流程控制 一、踏上Python之旅 1.想要输出 I Love Python,应该使用()函数。 A.printf() B.print() C.println() D.Print() 在Python中想要在屏幕中输出内容,应该使用print()函数…...

机器人夹爪的选型与ROS通讯——机器人抓取系统基础系列(六)
文章目录 前言一、夹爪的选型1.1 任务需求分析1.2 软体夹爪的选型 二、夹爪的ROS通讯2.1 夹爪的通信方式介绍2.2 串口助手测试2.3 ROS通讯节点实现 总结Reference: 前言 本文将介绍夹爪的选型方法和通讯方式。以鞋子这类操作对象为例,将详细阐述了对应的夹爪选型过…...
第二十八章 RTC——实时时钟
第二十八章 RTC——实时时钟 目录 第二十八章 RTC——实时时钟 1 RTC实时时钟简介 2 RTC外设框图剖析 3 UNIX时间戳 4 与RTC控制相关的库函数 4.1 等待时钟同步和操作完成 4.2 使能备份域涉及RTC配置 4.3 设置RTC时钟分频 4.4 设置、获取RTC计数器及闹钟 5 实时时…...

使用 DuckLake 和 DuckDB 构建 S3 数据湖实战指南
本文介绍了由 DuckDB 和 DuckLake 组成的轻量级数据湖方案,旨在解决传统数据湖(如HadoopHive)元数据管理复杂、查询性能低及厂商锁定等问题。该方案为中小规模数据湖场景提供了简单、高性能且无厂商锁定的替代选择。 1. 什么是 DuckLake 和 D…...

大语言模型提示词(LLM Prompt)工程系统性学习指南:从理论基础到实战应用的完整体系
文章目录 前言:为什么提示词工程成为AI时代的核心技能一、提示词的本质探源:认知科学与逻辑学的理论基础1.1 认知科学视角下的提示词本质信息处理理论的深层机制图式理论的实际应用认知负荷理论的优化策略 1.2 逻辑学框架下的提示词架构形式逻辑的三段论…...
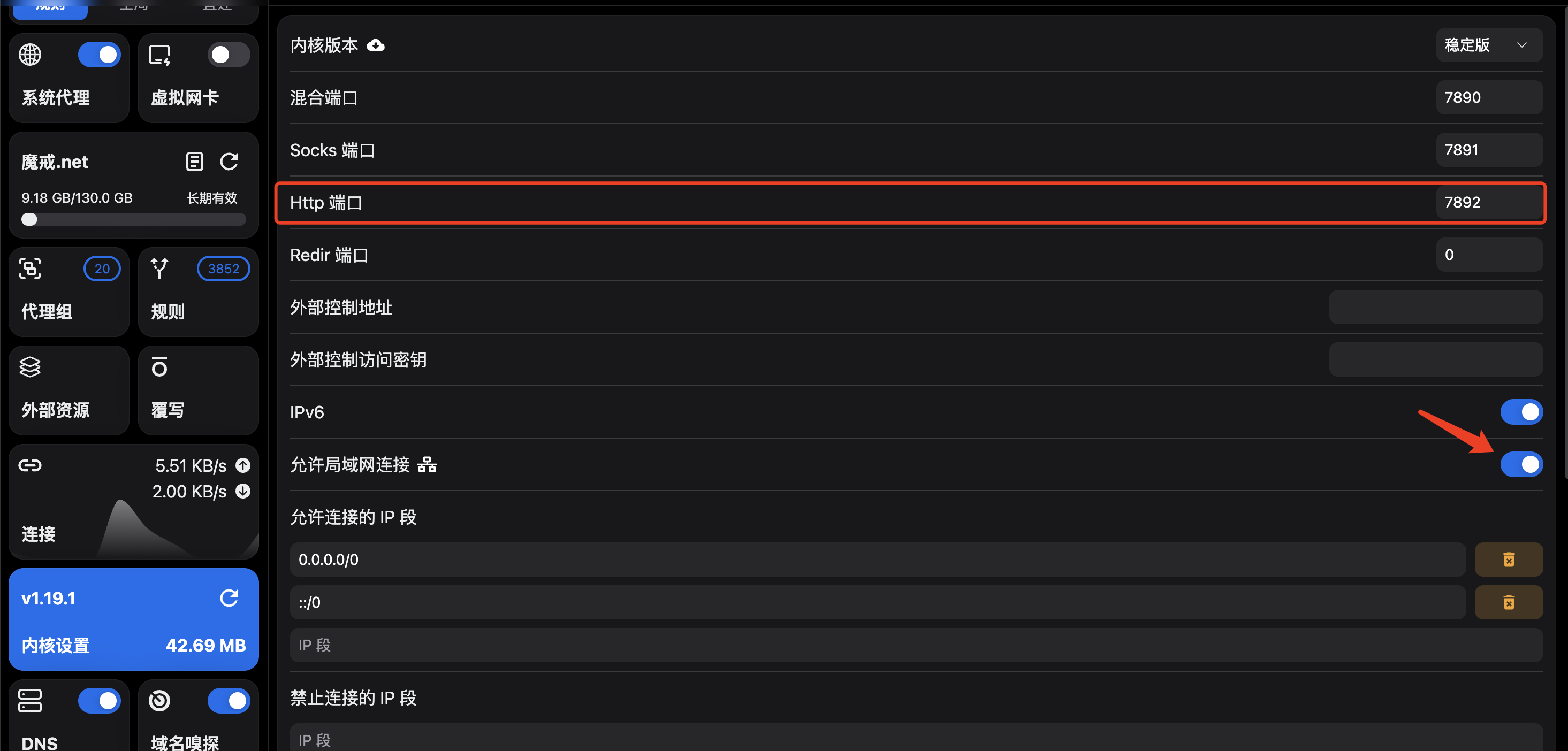
如何基于Mihomo Party http端口配置git与bash命令行代理
如何基于Mihomo Party http端口配置git与bash命令行代理 1. 确定Mihomo Party http端口配置 点击内核设置后即可查看 默认7892端口,开启允许局域网连接 2. 配置git代理 配置本机代理可以使用 127.0.0.1 配置局域网内其它机代理需要使用本机的非回环地址 IP&am…...

CMake 为 Debug 版本的库或可执行文件添加 d 后缀
在使用 CMake 构建项目时,我们经常需要区分 Debug 和 Release 构建版本。一个常见的做法是为 Debug 版本的库或可执行文件添加后缀(如 d),例如 libmylibd.so 或 myappd.exe。 本文将介绍几种在 CMake 中实现为 Debug 版本自动添加 d 后缀的方法。 方法一:使用 CMAKE_DEBU…...

Linux 特殊权限位详解:SetUID, SetGID, Sticky Bit
Linux 特殊权限位详解:SetUID, SetGID, Sticky Bit 在Linux权限系统中,除了基本的读、写(w)、执行(x)权限外,还有三个特殊权限位:SetUID、SetGID和Sticky Bit。这些权限位提供了更精细的权限控制机制,尤其在需要临时提升权限或管理共享资源时非常有用。 一、SetUID (s位…...
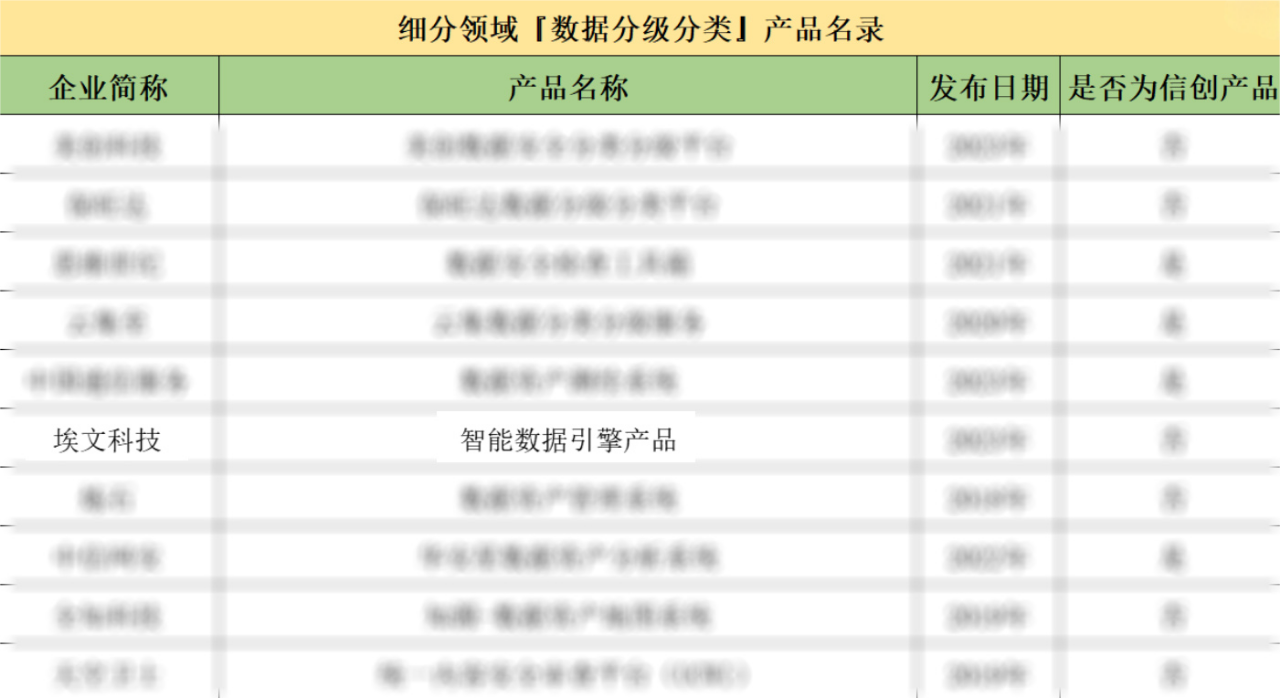
埃文科技智能数据引擎产品入选《中国网络安全细分领域产品名录》
嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,埃文科技智能数据引擎产品成功入选数据分级分类产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解这一蓬勃发展的产业格局,嘶吼安全产业…...