AI 模型分类全解:特性与选择指南
人工智能(AI)技术正以前所未有的速度改变着我们的生活和工作方式。AI 模型作为实现人工智能的核心组件,种类繁多,功能各异。从简单的线性回归模型到复杂的深度学习网络,从文本生成到图像识别,AI 模型的应用场景广泛且多样。本文将详细介绍 AI 模型的分类、特性以及如何根据具体需求选择合适的模型,帮助你在 AI 的海洋中找到最适合的那艘船。
一、AI 模型的分类
(一)按学习方式分类
- 监督学习(Supervised Learning)
监督学习是最常见的学习方式,模型通过已标注的训练数据学习输入与输出之间的映射关系。其典型应用包括:
- 分类任务:如垃圾邮件检测、图像分类等,模型需要将输入数据划分到预定义的类别中。
- 回归任务:如房价预测、股票价格预测等,模型需要预测连续的数值输出。
监督学习模型的训练过程依赖于大量标注数据,这些数据通常需要人工标注,成本较高。但一旦训练完成,模型在预测新数据时通常具有较高的准确率。
- 无监督学习(Unsupervised Learning)
无监督学习模型处理未标注的数据,旨在发现数据中的内在结构或模式。其典型应用包括:
- 聚类分析:如客户细分、图像分割等,模型将数据点划分为不同的簇,簇内的数据点相似度较高,而不同簇之间的数据点相似度较低。
- 降维:如主成分分析(PCA),用于减少数据的维度,同时保留数据的主要特征,便于数据可视化和后续处理。
无监督学习不需要标注数据,因此在数据获取上相对容易。但其结果通常需要人工解释,且模型的性能评估较为复杂。
- 半监督学习(Semi-Supervised Learning)
半监督学习结合了监督学习和无监督学习的特点,使用少量标注数据和大量未标注数据进行训练。其典型应用包括:
- 图像识别:在标注数据有限的情况下,利用大量未标注图像进行预训练,再用少量标注数据进行微调。
- 自然语言处理:在文本数据中,标注数据通常成本较高,半监督学习可以有效利用未标注数据提升模型性能。
半监督学习在标注数据有限的情况下表现出色,能够充分利用未标注数据的潜在信息,提高模型的泛化能力。
- 强化学习(Reinforcement Learning)
强化学习模型通过与环境的交互学习最优策略,以最大化累积奖励。其典型应用包括:
- 机器人控制:如自动驾驶汽车、机器人导航等,模型通过试错学习最优的行为策略。
- 游戏 AI:如 AlphaGo,通过与对手对弈学习最优的下棋策略。
强化学习模型的学习过程高度依赖于环境的反馈,通常需要大量的交互来收敛。其应用场景多为动态环境,模型需要实时做出决策。
(二)按模型结构分类
- 传统机器学习模型
传统机器学习模型基于统计学原理,通常具有较为简单的结构,易于理解和实现。常见的传统机器学习模型包括:
- 线性回归(Linear Regression):用于预测连续数值输出,模型假设输入特征与输出之间存在线性关系。
- 逻辑回归(Logistic Regression):用于二分类任务,通过 Sigmoid 函数将线性回归的输出映射到 [0, 1] 区间,表示分类概率。
- 决策树(Decision Tree):通过一系列规则将数据划分为不同的类别,模型具有良好的可解释性。
- 支持向量机(SVM):通过寻找最优超平面将数据划分为不同的类别,适用于高维数据分类。
- 随机森林(Random Forest):集成多个决策树,通过投票机制提高分类或回归的准确性。
传统机器学习模型的优点是训练速度快,模型易于解释,适合处理结构化数据。但其在处理复杂数据(如图像、文本)时性能有限,通常需要人工提取特征。
- 深度学习模型
深度学习模型基于神经网络,通过多层非线性变换学习数据的复杂特征表示。常见的深度学习模型包括:
- 卷积神经网络(CNN):适用于图像处理任务,通过卷积层和池化层提取图像的局部特征,广泛应用于图像分类、目标检测等任务。
- 循环神经网络(RNN):适用于序列数据处理,如自然语言处理和时间序列预测。RNN 能够捕捉序列数据中的时间依赖关系,但存在梯度消失和梯度爆炸的问题。
- 长短期记忆网络(LSTM):是 RNN 的一种改进,通过引入门控机制解决梯度消失问题,能够更好地捕捉长期依赖关系,广泛应用于文本生成、机器翻译等任务。
- 门控循环单元(GRU):是 LSTM 的简化版本,具有更少的参数和更快的训练速度,性能与 LSTM 相当。
- Transformer:基于自注意力机制的架构,能够并行处理序列数据,显著提高了训练速度和性能,广泛应用于自然语言处理任务,如机器翻译、文本生成等。
深度学习模型具有强大的特征学习能力,能够自动从原始数据中提取复杂的特征表示。但其训练过程通常需要大量的数据和计算资源,模型结构复杂,难以解释。
- 预训练模型
预训练模型是近年来自然语言处理和计算机视觉领域的重大突破。这些模型通过在大规模无标注数据上进行预训练,学习通用的语言或视觉特征表示,然后在特定任务上进行微调。常见的预训练模型包括:
- BERT(Bidirectional Encoder Representations from Transformers):用于自然语言处理任务,通过 Masked Language Model(MLM)和 Next Sentence Prediction(NSP)任务进行预训练,能够捕捉文本的双向上下文信息,广泛应用于文本分类、命名实体识别、问答系统等任务。
- GPT(Generative Pre-trained Transformer):用于文本生成任务,通过无监督的语言模型预训练,能够生成高质量的文本,广泛应用于创意写作、代码生成、多语言翻译等任务。
- CLIP(Contrastive Language-Image Pre-training):用于图像和文本的跨模态任务,通过对比学习将图像和文本映射到同一特征空间,能够实现零样本分类、图像描述生成等任务。
- DALL·E:用于图像生成任务,结合了 GPT 的架构和图像生成技术,能够根据文本描述生成高质量的图像。
预训练模型通过大规模无标注数据的预训练,学习到了丰富的语言或视觉知识,能够显著提升特定任务的性能。但其训练和微调过程需要大量的计算资源,模型的可解释性仍然有限。
二、AI 模型的特性
(一)准确性(Accuracy)
准确性是衡量模型性能的重要指标,表示模型预测结果与真实结果的匹配程度。不同的模型在不同的任务上具有不同的准确性。例如,深度学习模型在图像分类和自然语言处理任务上通常具有较高的准确性,而传统机器学习模型在某些结构化数据任务上也能表现出色。
(二)泛化能力(Generalization)
泛化能力表示模型在未见过的新数据上的表现能力。一个具有良好泛化能力的模型能够在训练数据之外的数据上保持稳定的性能。深度学习模型通常通过大量的数据和复杂的结构来提高泛化能力,但过度复杂的模型也可能导致过拟合,降低泛化能力。传统机器学习模型则通过特征工程和正则化等技术来提高泛化能力。
(三)训练速度(Training Speed)
训练速度表示模型从训练数据中学习的时间。传统机器学习模型通常具有较快的训练速度,适合处理小规模数据。深度学习模型由于其复杂的结构和大量的参数,训练速度相对较慢,通常需要借助 GPU 或 TPU 等硬件加速器来提高训练效率。
(四)推理速度(Inference Speed)
推理速度表示模型在新数据上进行预测的时间。推理速度对于实时应用非常重要,如自动驾驶汽车、实时语音识别等。深度学习模型通常具有较慢的推理速度,但可以通过模型压缩、量化等技术来提高推理效率。传统机器学习模型则具有较快的推理速度,适合实时应用。
(五)可解释性(Interpretability)
可解释性表示模型的决策过程是否容易理解。传统机器学习模型,如决策树和线性回归,具有较高的可解释性,其决策过程可以通过简单的数学公式或规则来解释。深度学习模型由于其复杂的结构和大量的参数,通常难以解释,但近年来也有一些研究工作致力于提高深度学习模型的可解释性,如注意力机制、特征可视化等。
(六)数据需求(Data Requirements)
不同的模型对数据的需求不同。传统机器学习模型通常需要较少的数据,但需要人工提取特征。深度学习模型则需要大量的数据来学习复杂的特征表示,但能够自动从原始数据中提取特征。预训练模型通过大规模无标注数据的预训练,能够在少量标注数据的情况下取得较好的性能。
三、如何选择 AI 模型
选择合适的 AI 模型需要综合考虑多个因素,包括任务类型、数据特性、资源限制、模型性能等。以下是一些具体的选择建议:
(一)根据任务类型选择模型
- 分类任务
- 传统机器学习模型:如果数据是结构化的,且特征较为明显,可以考虑使用逻辑回归、决策树或随机森林等模型。这些模型训练速度快,可解释性高。
- 深度学习模型:如果数据是图像或文本,可以考虑使用卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型能够自动提取复杂的特征表示,通常在大规模数据上表现更好。
- 回归任务
- 传统机器学习模型:线性回归是处理回归任务的常用模型,适用于特征与目标之间存在线性关系的情况。如果数据具有非线性关系,可以考虑使用支持向量机(SVM)或决策树。
- 深度学习模型:对于复杂的回归任务,如时间序列预测,可以考虑使用循环神经网络(RNN)或长短期记忆网络(LSTM)。这些模型能够捕捉时间序列数据中的时间依赖关系。
- 聚类任务
- 传统机器学习模型:K-Means 是最常用的聚类算法,适用于数据点可以划分为固定数量的簇的情况。如果数据具有复杂的分布,可以考虑使用层次聚类或 DBSCAN 等算法。
- 深度学习模型:对于高维数据,可以使用自编码器(Autoencoder)进行降维,然后结合 K-Means 等聚类算法进行聚类。
- 序列生成任务
- 深度学习模型:对于文本生成、音乐生成等序列生成任务,可以考虑使用长短期记忆网络(LSTM)或 Transformer 模型。这些模型能够捕捉序列数据中的长期依赖关系,生成高质量的序列数据。
(二)根据数据特性选择模型
- 数据量
- 小数据集:如果数据量较小,建议使用传统机器学习模型,如逻辑回归、决策树或支持向量机。这些模型对数据量的要求较低,训练速度快。
- 大数据集:如果数据量较大,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型能够从大量数据中学习复杂的特征表示,但训练过程需要更多的计算资源。
- 数据类型
- 结构化数据:对于表格数据,传统机器学习模型通常表现良好。可以考虑使用逻辑回归、决策树、随机森林或梯度提升树(GBDT)等模型。
- 非结构化数据:对于图像、文本或音频等非结构化数据,深度学习模型通常更有效。例如,使用卷积神经网络(CNN)处理图像数据,使用长短期记忆网络(LSTM)或 Transformer 处理文本数据。
- 数据质量
- 高质量数据:如果数据质量较高,标注准确,可以考虑使用复杂的深度学习模型,以充分利用数据的潜力。
- 低质量数据:如果数据存在噪声或标注不准确,建议使用简单的传统机器学习模型,这些模型对数据质量的要求较低,且可以通过特征工程和正则化技术来提高性能。
(三)根据资源限制选择模型
- 计算资源
- 有限计算资源:如果计算资源有限,建议使用传统机器学习模型,如逻辑回归、决策树或随机森林。这些模型训练和推理速度较快,对硬件要求较低。
- 充足计算资源:如果计算资源充足,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。
- 存储资源
- 有限存储资源:如果存储资源有限,建议使用轻量级模型,如决策树或线性回归。这些模型的模型文件较小,占用存储空间少。
- 充足存储资源:如果存储资源充足,可以考虑使用复杂的深度学习模型,如 Transformer 或预训练模型。这些模型虽然模型文件较大,但能够提供更高的性能。
(四)根据模型性能选择模型
- 准确性
- 如果任务对准确性要求极高,可以考虑使用深度学习模型,如卷积神经网络(CNN)或 Transformer。这些模型在图像分类、自然语言处理等任务上通常能够取得较高的准确性。
- 如果任务对准确性要求不高,可以考虑使用传统机器学习模型,如逻辑回归或决策树。这些模型虽然准确性稍低,但训练和推理速度更快,可解释性更高。
- 泛化能力
- 如果任务需要模型具有良好的泛化能力,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型通过大量的数据和复杂的结构,能够更好地捕捉数据的内在规律,提高泛化能力。
- 如果任务对泛化能力要求不高,可以考虑使用传统机器学习模型,如决策树或随机森林。这些模型通过正则化技术,也能够取得较好的泛化能力。
- 推理速度
- 如果任务需要实时推理,如自动驾驶汽车或实时语音识别,建议使用传统机器学习模型,如决策树或线性回归。这些模型推理速度较快,能够满足实时应用的需求。
- 如果任务对推理速度要求不高,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型虽然推理速度较慢,但可以通过模型压缩、量化等技术来提高推理效率。
(五)根据可解释性选择模型
- 高可解释性需求
- 如果任务需要模型具有较高的可解释性,如医疗诊断或金融风险评估,建议使用传统机器学习模型,如决策树或线性回归。这些模型的决策过程可以通过简单的数学公式或规则来解释,易于理解和解释。
- 如果任务对可解释性要求不高,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型虽然可解释性较低,但可以通过注意力机制、特征可视化等技术来提高可解释性。
- 低可解释性需求
- 如果任务对可解释性要求不高,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型能够自动提取复杂的特征表示,通常在大规模数据上表现更好。
(六)根据数据需求选择模型
- 标注数据有限
- 如果标注数据有限,可以考虑使用半监督学习模型或预训练模型。半监督学习模型能够充分利用未标注数据的潜在信息,提高模型性能。预训练模型通过大规模无标注数据的预训练,能够在少量标注数据的情况下取得较好的性能。
- 如果标注数据有限,也可以考虑使用传统机器学习模型,如决策树或随机森林。这些模型对标注数据的需求较低,通过特征工程和正则化技术,也能够取得较好的性能。
- 标注数据充足
- 如果标注数据充足,可以考虑使用深度学习模型,如卷积神经网络(CNN)或长短期记忆网络(LSTM)。这些模型能够从大量标注数据中学习复杂的特征表示,通常在大规模数据上表现更好。
四、实际案例分析
(一)图像分类任务
假设你正在处理一个图像分类任务,目标是将图像划分为不同的类别。以下是选择模型的步骤:
- 数据量:如果数据量较大,建议使用卷积神经网络(CNN),如 ResNet 或 VGG。这些模型能够自动提取图像的复杂特征表示,通常在大规模数据上表现更好。
- 数据类型:图像数据是非结构化数据,深度学习模型通常更有效。卷积神经网络(CNN)能够捕捉图像的局部特征,适用于图像分类任务。
- 计算资源:如果计算资源充足,可以考虑使用复杂的深度学习模型,如 ResNet 或 VGG。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。如果计算资源有限,可以考虑使用轻量级模型,如 MobileNet 或 SqueezeNet。这些模型在保持较高性能的同时,能够显著减少计算资源的消耗。
- 模型性能:如果任务对准确性要求极高,建议使用复杂的深度学习模型,如 ResNet 或 VGG。这些模型在图像分类任务上通常能够取得较高的准确性。如果任务对准确性要求不高,可以考虑使用简单的传统机器学习模型,如支持向量机(SVM)或决策树。这些模型虽然准确性稍低,但训练和推理速度更快,可解释性更高。
(二)文本生成任务
假设你正在处理一个文本生成任务,目标是根据给定的提示生成高质量的文本。以下是选择模型的步骤:
- 数据量:如果数据量较大,建议使用长短期记忆网络(LSTM)或 Transformer 模型。这些模型能够从大量数据中学习复杂的语言模式,生成高质量的文本。
- 数据类型:文本数据是非结构化数据,深度学习模型通常更有效。长短期记忆网络(LSTM)和 Transformer 模型能够捕捉文本中的长期依赖关系,适用于文本生成任务。
- 计算资源:如果计算资源充足,可以考虑使用复杂的深度学习模型,如 GPT 或 BERT。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。如果计算资源有限,可以考虑使用轻量级模型,如 MobileBERT 或 ALBERT。这些模型在保持较高性能的同时,能够显著减少计算资源的消耗。
- 模型性能:如果任务对生成文本的质量要求极高,建议使用复杂的深度学习模型,如 GPT 或 BERT。这些模型在文本生成任务上通常能够生成高质量、连贯的文本。如果任务对生成文本的质量要求不高,可以考虑使用简单的传统机器学习模型,如马尔可夫链。这些模型虽然生成的文本质量稍低,但训练和推理速度更快,可解释性更高。
(三)时间序列预测任务
假设你正在处理一个时间序列预测任务,目标是预测未来的数值,如股票价格或天气温度。以下是选择模型的步骤:
- 数据量:如果数据量较大,建议使用深度学习模型,如长短期记忆网络(LSTM)或循环神经网络(RNN)。这些模型能够从大量数据中学习时间序列的复杂模式,提供更准确的预测。
- 数据类型:时间序列数据是序列数据,深度学习模型通常更有效。长短期记忆网络(LSTM)和循环神经网络(RNN)能够捕捉时间序列数据中的时间依赖关系,适用于时间序列预测任务。
- 计算资源:如果计算资源充足,可以考虑使用复杂的深度学习模型,如 LSTM 或 Transformer。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。如果计算资源有限,可以考虑使用简单的传统机器学习模型,如 ARIMA 或线性回归。这些模型训练和推理速度较快,对硬件要求较低。
- 模型性能:如果任务对预测准确性要求极高,建议使用复杂的深度学习模型,如 LSTM 或 Transformer。这些模型在时间序列预测任务上通常能够提供更高的准确性。如果任务对预测准确性要求不高,可以考虑使用简单的传统机器学习模型,如 ARIMA 或线性回归。这些模型虽然准确性稍低,但训练和推理速度更快,可解释性更高。
五、实际案例分析
(一)图像分类任务
假设你正在处理一个图像分类任务,目标是将图像划分为不同的类别。以下是选择模型的步骤:
- 数据量:如果数据量较大,建议使用卷积神经网络(CNN),如 ResNet 或 VGG。这些模型能够自动提取图像的复杂特征表示,通常在大规模数据上表现更好。
- 数据类型:图像数据是非结构化数据,深度学习模型通常更有效。卷积神经网络(CNN)能够捕捉图像的局部特征,适用于图像分类任务。
- 计算资源:如果计算资源充足,可以考虑使用复杂的深度学习模型,如 ResNet 或 VGG。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。如果计算资源有限,可以考虑使用轻量级模型,如 MobileNet 或 SqueezeNet。这些模型在保持较高性能的同时,能够显著减少计算资源的消耗。
- 模型性能:如果任务对准确性要求极高,建议使用复杂的深度学习模型,如 ResNet 或 VGG。这些模型在图像分类任务上通常能够取得较高的准确性。如果任务对准确性要求不高,可以考虑使用简单的传统机器学习模型,如支持向量机(SVM)或决策树。这些模型虽然准确性稍低,但训练和推理速度更快,可解释性更高。
(二)文本生成任务
假设你正在处理一个文本生成任务,目标是根据给定的提示生成高质量的文本。以下是选择模型的步骤:
- 数据量:如果数据量较大,建议使用长短期记忆网络(LSTM)或 Transformer 模型。这些模型能够从大量数据中学习复杂的语言模式,生成高质量的文本。
- 数据类型:文本数据是非结构化数据,深度学习模型通常更有效。长短期记忆网络(LSTM)和 Transformer 模型能够捕捉文本中的长期依赖关系,适用于文本生成任务。
- 计算资源:如果计算资源充足,可以考虑使用复杂的深度学习模型,如 GPT 或 BERT。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。如果计算资源有限,可以考虑使用轻量级模型,如 MobileBERT 或 ALBERT。这些模型在保持较高性能的同时,能够显著减少计算资源的消耗。
- 模型性能:如果任务对生成文本的质量要求极高,建议使用复杂的深度学习模型,如 GPT 或 BERT。这些模型在文本生成任务上通常能够生成高质量、连贯的文本。如果任务对生成文本的质量要求不高,可以考虑使用简单的传统机器学习模型,如马尔可夫链。这些模型虽然生成的文本质量稍低,但训练和推理速度更快,可解释性更高。
(三)时间序列预测任务
假设你正在处理一个时间序列预测任务,目标是预测未来的数值,如股票价格或天气温度。以下是选择模型的步骤:
- 数据量:如果数据量较大,建议使用深度学习模型,如长短期记忆网络(LSTM)或循环神经网络(RNN)。这些模型能够从大量数据中学习时间序列的复杂模式,提供更准确的预测。
- 数据类型:时间序列数据是序列数据,深度学习模型通常更有效。长短期记忆网络(LSTM)和循环神经网络(RNN)能够捕捉时间序列数据中的时间依赖关系,适用于时间序列预测任务。
- 计算资源:如果计算资源充足,可以考虑使用复杂的深度学习模型,如 LSTM 或 Transformer。这些模型虽然训练和推理速度较慢,但能够提供更高的性能。如果计算资源有限,可以考虑使用简单的传统机器学习模型,如 ARIMA 或线性回归。这些模型训练和推理速度较快,对硬件要求较低。
- 模型性能:如果任务对预测准确性要求极高,建议使用复杂的深度学习模型,如 LSTM 或 Transformer。这些模型在时间序列预测任务上通常能够提供更高的准确性。如果任务对预测准确性要求不高,可以考虑使用简单的传统机器学习模型,如 ARIMA 或线性回归。这些模型虽然准确性稍低,但训练和推理速度更快,可解释性更高。
六、总结
选择合适的 AI 模型需要综合考虑任务类型、数据特性、资源限制和模型性能等多个因素。以下是总结的关键点:
(一)任务类型
- 分类任务:考虑使用逻辑回归、决策树、随机森林或卷积神经网络(CNN)。
- 回归任务:考虑使用线性回归、支持向量机(SVM)或长短期记忆网络(LSTM)。
- 聚类任务:考虑使用 K-Means、层次聚类或自编码器。
- 序列生成任务:考虑使用长短期记忆网络(LSTM)或 Transformer。
(二)数据特性
- 数据量:大数据集适合深度学习模型,小数据集适合传统机器学习模型。
- 数据类型:结构化数据适合传统机器学习模型,非结构化数据适合深度学习模型。
- 数据质量:高质量数据适合复杂模型,低质量数据适合简单模型。
(三)资源限制
- 计算资源:充足计算资源适合复杂模型,有限计算资源适合简单模型。
- 存储资源:充足存储资源适合复杂模型,有限存储资源适合轻量级模型。
(四)模型性能
- 准确性:高准确性需求适合复杂模型,低准确性需求适合简单模型。
- 泛化能力:高泛化能力需求适合复杂模型,低泛化能力需求适合简单模型。
- 推理速度:实时应用适合简单模型,非实时应用适合复杂模型。
(五)可解释性
- 高可解释性需求:适合传统机器学习模型。
- 低可解释性需求:适合深度学习模型。
(六)数据需求
- 标注数据有限:适合半监督学习模型或预训练模型。
- 标注数据充足:适合深度学习模型。
通过以上步骤和建议,你可以更科学地选择适合你任务的 AI 模型。希望本文能帮助你在 AI 项目中做出更明智的决策。
喜欢的可以点一下关注,历史好文
MCP:解锁 AI 与外部世界的无缝连接
Python 环境搭建:从新手到高手的必备指南
大型API中转官方
相关文章:

AI 模型分类全解:特性与选择指南
人工智能(AI)技术正以前所未有的速度改变着我们的生活和工作方式。AI 模型作为实现人工智能的核心组件,种类繁多,功能各异。从简单的线性回归模型到复杂的深度学习网络,从文本生成到图像识别,AI 模型的应用…...
【Zephyr 系列 11】使用 NVS 实现 BLE 参数持久化:掉电不丢配置,开机自动加载
🧠关键词:Zephyr、NVS、非易失存储、掉电保持、Flash、AT命令保存、配置管理 📌目标读者:希望在 BLE 模块中实现掉电不丢配置、支持产测参数注入与自动加载功能的开发者 📊文章长度:约 5200 字 🔍 为什么要使用 NVS? 在实际产品中,我们经常面临以下场景: 用户或…...
【Android】Android Studio项目代码异常错乱问题处理(2020.3版本)
问题 项目打开之后,发现项目文件直接乱码, 这样子的 这本来是个Java文件,结果一打开变成了这种情况,跟见鬼一样,而且还不是这一个文件这样,基本上一个项目里面一大半都是这样的问题。 处理方法 此时遇到…...

n皇后问题的 C++ 回溯算法教学攻略
一、问题描述 n皇后问题是经典的回溯算法问题。给定一个 nn 的棋盘,要求在棋盘上放置 n 个皇后,使得任何两个皇后之间不能互相攻击。皇后可以攻击同一行、同一列以及同一对角线上的棋子。我们需要找出所有的合法放置方案并输出方案数。 二、输入输出形…...

一些免费的大A数据接口库
文章目录 一、Python开源库(适合开发者)1. AkShare2. Tushare3. Baostock 二、公开API接口(适合快速调用)1. 新浪财经API2. 腾讯证券接口3. 雅虎财经API 三、第三方数据平台(含免费额度)1. 必盈数据2. 聚合…...

DeepSeek本地部署及WebUI可视化教程
前言 DeepSeek是近年来备受关注的大模型之一,支持多种推理和微调场景。很多开发者希望在本地部署DeepSeek模型,并通过WebUI进行可视化交互。本文将详细介绍如何在本地环境下部署DeepSeek,并实现WebUI可视化,包括Ollama和CherryStudio的使用方法。 一、环境准备 1. 硬件要…...
机器学习算法时间复杂度解析:为什么它如此重要?
时间复杂度的重要性 虽然scikit-learn等库让机器学习算法的实现变得异常简单(通常只需2-3行代码),但这种便利性往往导致使用者忽视两个关键方面: 算法核心原理的理解缺失 忽视算法的数据适用条件 典型算法的时间复杂度陷阱 SV…...
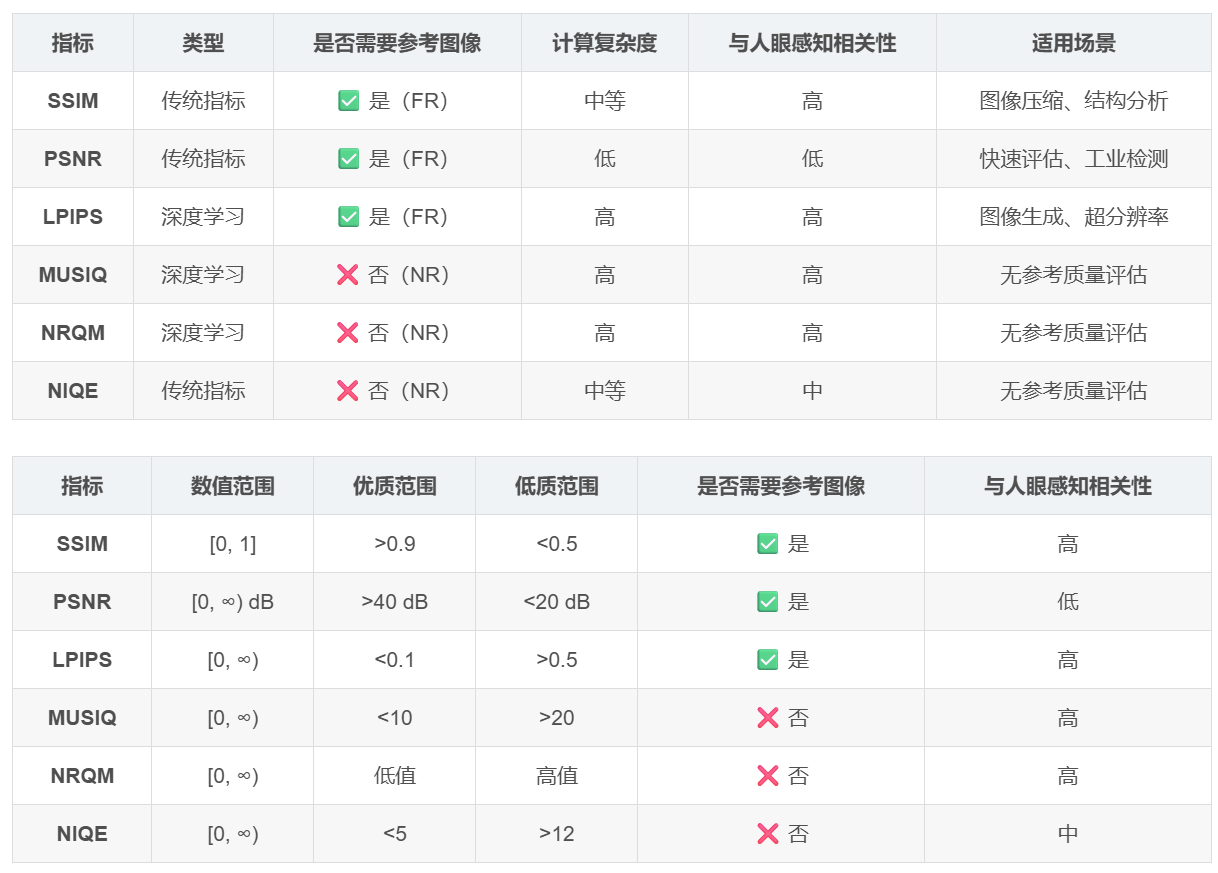
SSIM、PSNR、LPIPS、MUSIQ、NRQM、NIQE 六个图像质量评估指标
评价指标 1. SSIM(Structural Similarity Index) 📌 定义 结构相似性指数(Structural Similarality Index)是一种衡量两幅图像相似性的指标,考虑了亮度、对比度和结构信息的相似性,比传统的 P…...
【笔记】旧版MSYS2 环境中 Rust 升级问题及解决过程
下面是一份针对在旧版 MSYS2(安装在 D 盘)中,基于 Python 3.11 的 Poetry 虚拟环境下升级 Rust 的处理过程笔记(适用于 WIN 系统 SUNA 人工智能代理开源项目部署要求)的记录。 MSYS2 旧版环境中 Rust 升级问题及解决过…...

centos查看开启关闭防火墙状态
执行:systemctl status firewalld ,即可查看防火墙状态 防火墙的开启、关闭、禁用命令 (1)设置开机启用防火墙:systemctl enable firewalld.service (2)设置开机禁用防火墙:system…...

[论文阅读] 人工智能 | 大语言模型计划生成的新范式:基于过程挖掘的技能学习
#论文阅读# 大语言模型计划生成的新范式:基于过程挖掘的技能学习 论文信息 Skill Learning Using Process Mining for Large Language Model Plan Generation Andrei Cosmin Redis, Mohammadreza Fani Sani, Bahram Zarrin, Andrea Burattin Cite as: arXiv:2410.…...

MS31912TEA 多通道半桥驱动器 氛围灯 照明灯 示宽灯 转向灯驱动 后视镜方向调节 可替代DRV8912
MS31912TEA 多通道半桥驱动器 氛围灯 照明灯 示宽灯 转向灯驱动 后视镜方向调节 可替代DRV8912 产品简述 MS31912 是集成多种高级诊断功能的多通道半桥驱动。 MS31912 具有 12 个半桥,典型工作电压 13.5V 下,每一个半桥支持 1A 电流,典型工…...
)
软考 系统架构设计师系列知识点之杂项集萃(84)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(83) 第151题 在软件系统工具中,版本控制工具属于(),软件评价工具属于()。 第1空 A. 软件开发工具 B. 软件维…...
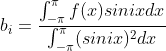
矩阵QR分解
1 orthonormal 向量与 Orthogonal 矩阵 orthonormal 向量定义为 ,任意向量 相互垂直,且模长为1; 如果将 orthonormal 向量按列组织成矩阵,矩阵为 Orthogonal 矩阵,满足如下性质: ; 当为方阵时&…...

UDP与TCP的区别是什么?
UDP和TCP是互联网通信中最常用的两种传输层协议,它们在数据传输方式、可靠性、速度和适用场景等方面存在显著差异。本文将围绕UDP与TCP的核心区别展开详细分析,包括连接方式、数据传输机制、传输效率以及各自适合的应用场景,帮助开发者和网络…...

撰写脚本,通过发布/joint_states话题改变机器人在Rviz中的关节角度
撰写脚本,通过发布/joint_states话题改变机器人在Rviz中的关节角度 提问 为我写一个改变关节base_spherical_center_high_joint角度的python脚本吧。适用于ROS2的humble 回答 下面是一个适用于 ROS 2 Humble 的 Python 脚本,它会以指定频率持续发布 …...

AOP实现Restful接口操作日志入表方案
文章目录 前言一、基础资源配置1.操作日志基本表[base_operation_log] 见附录1。2.操作日志扩展表[base_operation_log_ext] 见附录2。3.定义接口操作系统日志DTO:OptLogDTO4.定义操作日志注解类WebLog5.定义操作日志Aspect切面类SysLogAspect6.定义异步监听日志事件…...
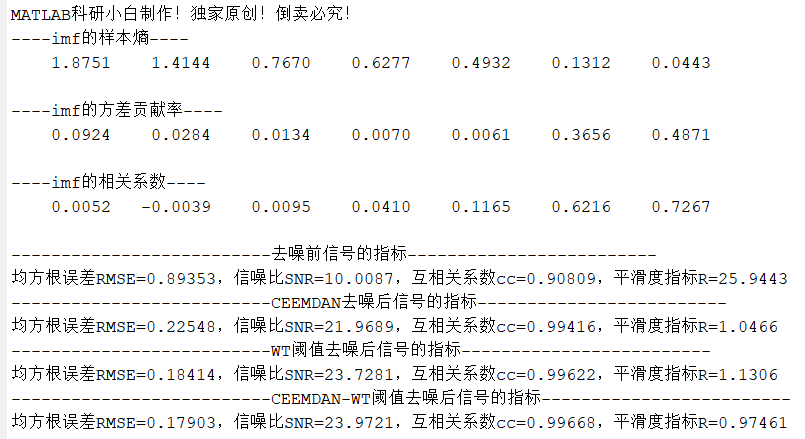
【MATLAB去噪算法】基于CEEMDAN联合小波阈值去噪算法(第四期)
CEEMDAN联合小波阈值去噪算法相关文献 一、EMD 与 EEMD 的局限性 (1)EMD (经验模态分解) 旨在自适应地将非线性、非平稳信号分解成一系列 本征模态函数 (IMFs),这些 IMFs 从高频到低频排列。 核心问题:模态混合 (Mode Mixing) 同…...

Webhook 配置备忘
本文地址:blog.lucien.ink/archives/552 将下列代码保存为 install.sh,然后 bash install.sh。 #!/usr/bin/env bash set -e wget https://github.mirrors.lucien.ink/https://github.com/adnanh/webhook/releases/download/2.8.2/webhook-linux-amd64.…...
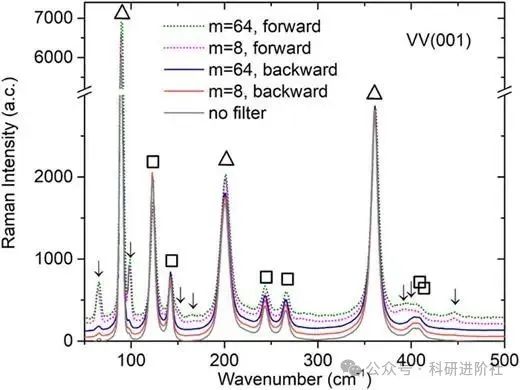
从理论崩塌到新路径:捷克科学院APL Photonics论文重构涡旋光技术边界
理论预言 vs 实验挑战 光子轨道角动量(Orbital Angular Momentum, OAM)作为光场调控的新维度,曾被理论预言可突破传统拉曼散射的对称性限制——尤其是通过涡旋光(如拉盖尔高斯光束)激发晶体中常规手段无法探测的"…...

机器学习笔记【Week7】
一、SVM的动机:大间隔分类器 1、逻辑回归回顾 假设函数为 sigmoid 函数: h θ ( x ) 1 1 e − θ T x h_\theta(x) \frac{1}{1 e^{-\theta^Tx}} hθ(x)1e−θTx1 分类依据是 h θ ( x ) ≥ 0.5 h_\theta(x) \geq 0.5 hθ(x)≥0.5 为正类&a…...

LSM Tree算法原理
LSM Tree(Log-Structured Merge Tree)是一种针对写密集型场景优化的数据结构,广泛应用于LevelDB、RocksDB等数据库引擎中。其核心原理如下: 1. 写入优化:顺序写代替随机写 内存缓冲(MemTable):写入操作首先被写入内存中的数据结构(如跳表或平衡树),…...

智能推荐系统:协同过滤与深度学习结合
智能推荐系统:协同过滤与深度学习结合 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 智能推荐系统:协同过滤与深度学习结合摘要引言技术原理对比1. 协同过滤算法:基于相似性的推…...

文档处理组件Aspose.Words 25.5全新发布 :六大新功能与性能深度优化
在数字化办公日益普及的今天,文档处理的效率与质量直接影响到企业的运营效率。Aspose.Words 作为业界领先的文档处理控件,其最新发布的 25.5 版本带来了六大新功能和多项性能优化,旨在为开发者和企业用户提供更强大、高效的文档处理能力。 六…...

固态继电器与驱动隔离器:电力系统的守护者
在电力系统中, 固态继电器合驱动隔离器像两位“电力守护神”,默默地确保电力设备的安全与稳定运行。它们通过高效、可靠的性能,保障了电力设备在各种环境下的正常工作。 固态继电器是电力控制中的关键组成部分,利用半导体器件来实…...

uni-app 如何实现选择和上传非图像、视频文件?
在 uni-app 中实现选择和上传非图像、视频文件,可根据不同端(App、H5、小程序)的特点,采用以下方法: 一、通用思路(多端适配优先推荐) 借助 uni.chooseFile 选择文件,再用 uni.upl…...

区块链架构深度解析:从 Genesis Block 到 Layer 2
# 区块链架构深度解析:从 Genesis Block 到 Layer 2 目录 一、Genesis Block:区块链的起点 二、Layer 0:区块链的底层网络架构 三、Layer 1:核心协议层 🚀 四、Layer 2:扩展性解决方案 五、未来展望&a…...
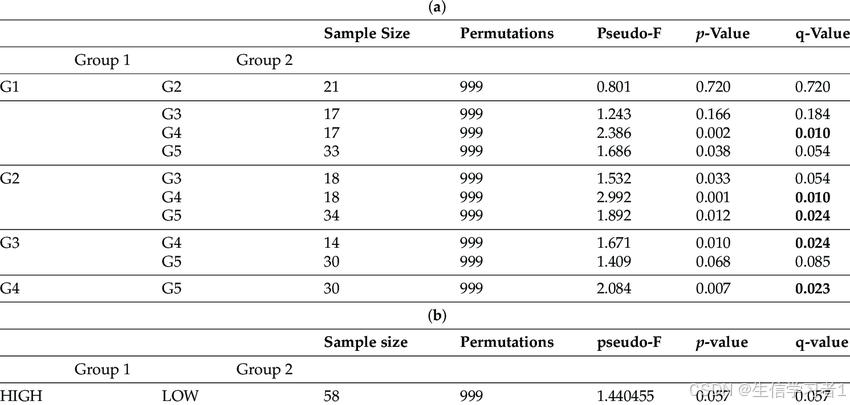
【数据分析】基于adonis2与pairwise.adonis2的群组差异分析教程
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理adonis分析pairwise.adonis2分析总结系统信息介绍 本教程主要用于执行和分析基于距离矩阵的多样性和群落结构分析,特别是通过adonis2和pairwi…...

使用pdm+uv替换poetry
用了好几年poetry了,各方面都还挺满意,就是lock实在太慢; 已经试用pdmuv一段时间了,确实是快,也基本能覆盖poetry的功能。 至于为什么用pdmuv,而不是只用uv,原因很多,有兴趣的可以…...
Nginx + Tomcat负载均衡群集
目录 一、案例环境 二、部署 Tomcat(102/103) 1、准备环境 (1)关闭firewalld 防火墙 (2)安装JDK 2、安装配置 Tomcat (1)Tomcat 的安装和配置 (2)移动…...