DAY45 可视化
DAY 45 Tensorborad
之前的内容中,我们在神经网络训练中,为了帮助自己理解,借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。
如果现在有一个交互工具可以很简单的通过按钮完成这些辅助功能那就好了。所以我们现在介绍下tensorboard这个可视化工具,他可以很方便的很多可视化的功能,尤其是他可以在运行过程中实时渲染,方便我们根据图来动态调整训练策略,而不是训练完了才知道好不好。
一、tensorboard的基本操作
- 保存模型结构图
- 保存训练集和验证集的loss变化曲线,不需要手动打印了
- 保存每一个层结构权重分布
- 保存预测图片的预测信息
1.3 日志目录自动管理
import os
from torch.utils.tensorboard import SummaryWriterlog_dir = 'runs/cifar10_mlp_experiment'
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir=log_dir) #关键入口,用于写入数据到日志目录
1.4 记录标量数据(Scalar)
# 记录每个 Batch 的损失和准确率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录每个 Epoch 的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)
1.5 可视化模型结构(Graph)
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 通过真实输入样本生成模型计算图
TensorBoard 界面:在 GRAPHS 选项卡中查看模型层次结构(卷积层、全连接层等)。
1.6 可视化图像(Image)
# 可视化原始训练图像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 将多张图像拼接成网格状(方便可视化),将前8张图像拼接成一个网格
writer.add_image('原始训练图像', img_grid)# 可视化错误预测样本(训练结束后)
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('错误预测样本', wrong_img_grid)
展示原始图像、数据增强效果、错误预测样本等。
1.7 记录权重和梯度直方图(Histogram)
if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step) # 权重分布if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布
1.8 启动tensorboard
行代码后,会在指定目录(如 runs/cifar10_mlp_experiment_1)生成 .tfevents 文件,存储所有 TensorBoard 数据。
在终端执行(需进入项目根目录):
tensorboard --logdir=runs # 假设日志目录在 runs/ 下
打开浏览器,输入终端提示的 URL(通常为 http://localhost:6006)。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
TensorBoard日志保存在: runs/cifar10_mlp_experiment_1
可以在命令行中进入目前的环境,然后通过tensorboard --logdir=xxxx(目录)即可调出本地链接,点进去就是目前的训练信息,可以不断F5刷新来查看变化。
在TensorBoard界面中,你可以看到:
-
SCALARS 选项卡:展示损失曲线、准确率变化、学习率等标量数据----Scalar意思是标量,指只有大小、没有方向的量。
-
IMAGES 选项卡:展示原始训练图像和错误预测的样本
-
GRAPHS 选项卡:展示模型的计算图结构
-
HISTOGRAMS 选项卡:展示模型参数和梯度的分布直方图
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision # 记得导入 torchvision,之前代码里用到了其功能但没导入# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5, # 降低LR的比例(新LR = 旧LR × 0.5)verbose=True # 打印学习率调整信息
)# ======================== TensorBoard 核心配置 ========================
# 创建 TensorBoard 日志目录(自动避免重复)
log_dir = "runs/cifar10_cnn_exp"
if os.path.exists(log_dir):version = 1while os.path.exists(f"{log_dir}_v{version}"):version += 1log_dir = f"{log_dir}_v{version}"
writer = SummaryWriter(log_dir) # 初始化 SummaryWriter# 5. 训练模型(整合 TensorBoard 记录)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):model.train()all_iter_losses = [] iter_indices = [] global_step = 0 # 全局步骤,用于 TensorBoard 标量记录# (可选)记录模型结构:用一个真实样本走一遍前向传播,让 TensorBoard 解析计算图dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 写入模型结构到 TensorBoard# (可选)记录原始训练图像:可视化数据增强前/后效果img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 取前8张writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录迭代级损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(global_step + 1) # 用 global_step 对齐# 统计准确率running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# ======================== TensorBoard 标量记录 ========================# 记录每个 batch 的损失、准确率batch_acc = 100. * correct / totalwriter.add_scalar('Train/Batch Loss', iter_loss, global_step)writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)# 记录学习率(可选)writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)# 每 200 个 batch 记录一次参数直方图(可选,耗时稍高)if (batch_idx + 1) % 200 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step)# 每 100 个 batch 打印控制台日志(同原代码)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1 # 全局步骤递增# 计算 epoch 级训练指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# ======================== TensorBoard epoch 标量记录 ========================writer.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0wrong_images = [] # 存储错误预测样本(用于可视化)wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误预测样本(用于可视化)wrong_mask = (predicted != target)if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask][:8].cpu() # 最多存8张wrong_batch_labels = target[wrong_mask][:8].cpu()wrong_batch_preds = predicted[wrong_mask][:8].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)# 计算 epoch 级测试指标epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# ======================== TensorBoard 测试集记录 ========================writer.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)# (可选)可视化错误预测样本if wrong_images:wrong_img_grid = torchvision.utils.make_grid(wrong_images)writer.add_image('错误预测样本', wrong_img_grid, epoch)# 写入错误标签文本(可选)wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}" for wl, wp in zip(wrong_labels, wrong_preds)]writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 关闭 TensorBoard 写入器writer.close()# 绘制迭代级损失曲线(同原代码)plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc# 6. 绘制迭代级损失曲线(同原代码,略)
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# (可选)CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 7. 执行训练(传入 TensorBoard writer)
epochs = 20
print("开始使用CNN训练模型...")
print(f"TensorBoard 日志目录: {log_dir}")
print("训练后执行: tensorboard --logdir=runs 查看可视化")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")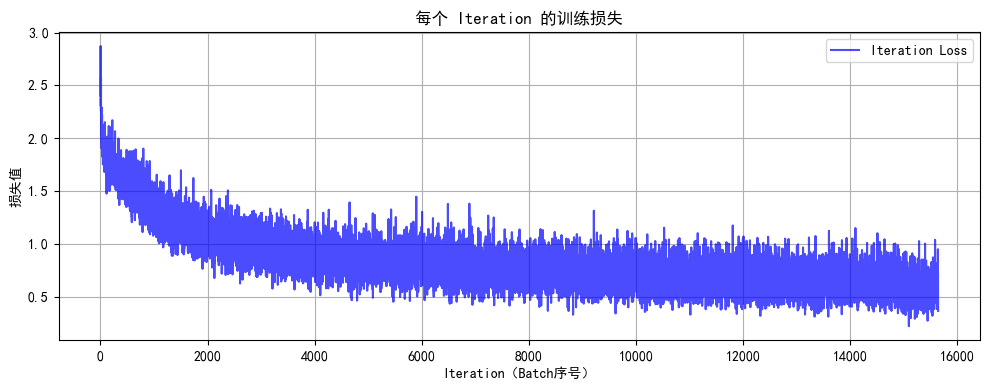
浙大疏锦行-CSDN博客
相关文章:
DAY45 可视化
DAY 45 Tensorborad 之前的内容中,我们在神经网络训练中,为了帮助自己理解,借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。 如果现在有一个交互工具可…...
11.RV1126-ROCKX项目 API和人脸检测画框
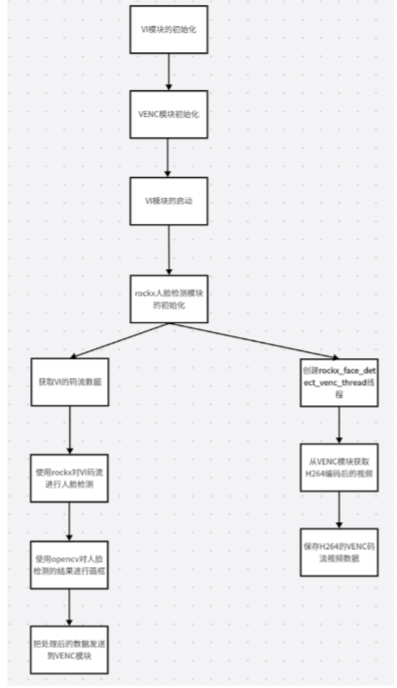
一.ROCKX的API 1.ROCKX的作用 ROCKX的AI组件可以快速搭建 AI的应用,这些应用可以是车牌识别、人脸识别、目标识别,人体骨骼识别等等。主要用于各种检测识别。例如下图: 2.ROCKX人脸识别的API rockx_ret_t rockx_create(rockx_handle_t *han…...
超构光学与 AR 的深度融合 | 攻克 VAC 与眼动范围难题
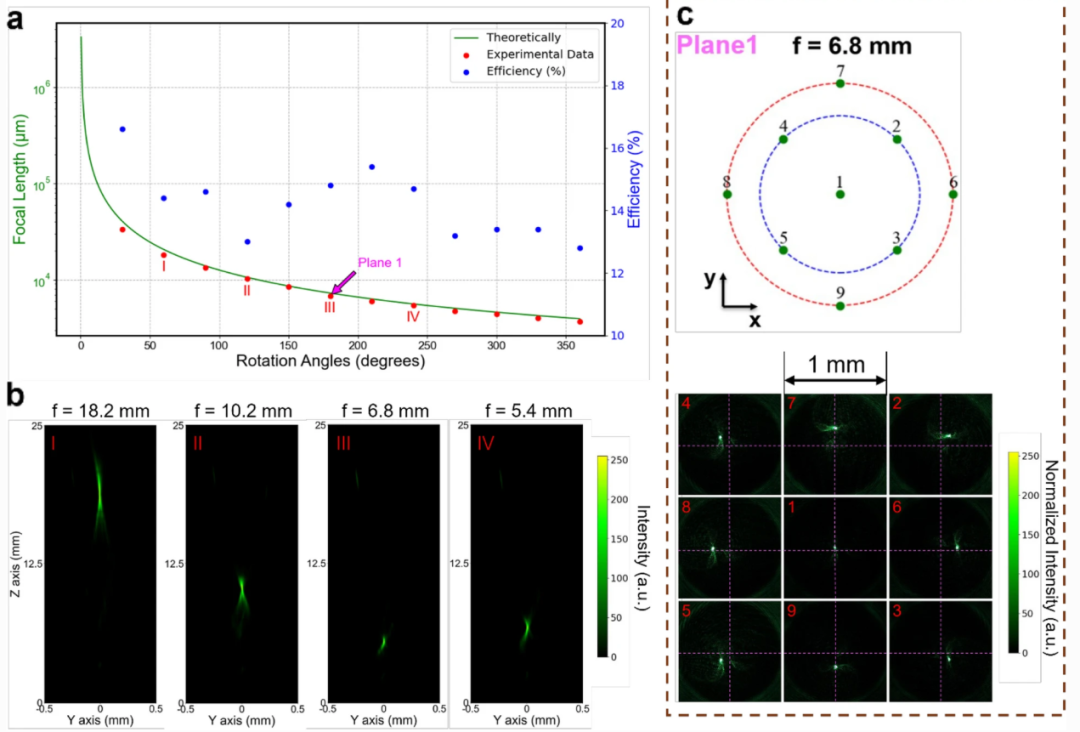
原文信息 原文标题:“Three-dimensional varifocal meta-device for augmented reality display” 第一作者:宋昱舟,袁家琪,陳欽杪,刘小源 ,周寅,程家洛,肖淑敏*,陈沐…...
[ Qt ] | 与系统相关的操作(三):QFile介绍和使用
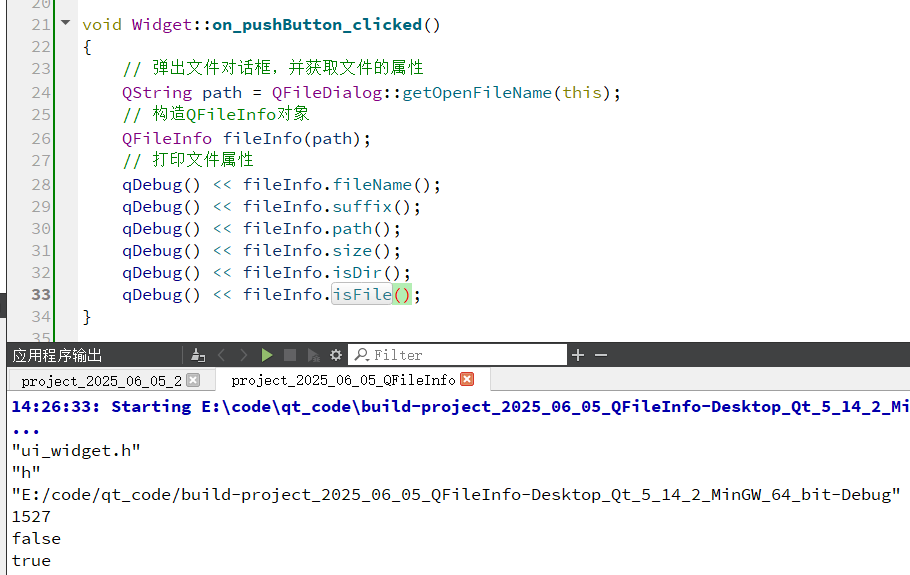
目录 之前的操作文件的方式 Qt中的文件操作简介 QFile 打开 读 写 关闭 一个例子来说明 QFileInfo 之前的操作文件的方式 C语言中,fopen 打开文件,fread fwrite 读写文件,fclose 关闭文件。 C中,fstream 打开文件&…...

RetroMAE 预训练任务
RetroMAE 预训练任务的具体步骤,围绕 编码(Encoding)、解码(Decoding)、增强解码(Enhanced decoding) 三个核心阶段展开,以下结合图中流程拆解: 一、阶段 A:…...

软件工程:如何做好软件产品
1、什么是产品 从项目到产品 产品:满足行业共性需求的标准产品。即要能够做到配置化的开发,用同一款产品最大限度地满足不同客户的需求,同时让产品具有可以快速响应客户需求变化的能力。 好的产品一定吸收了多个项目的共性,一定是…...
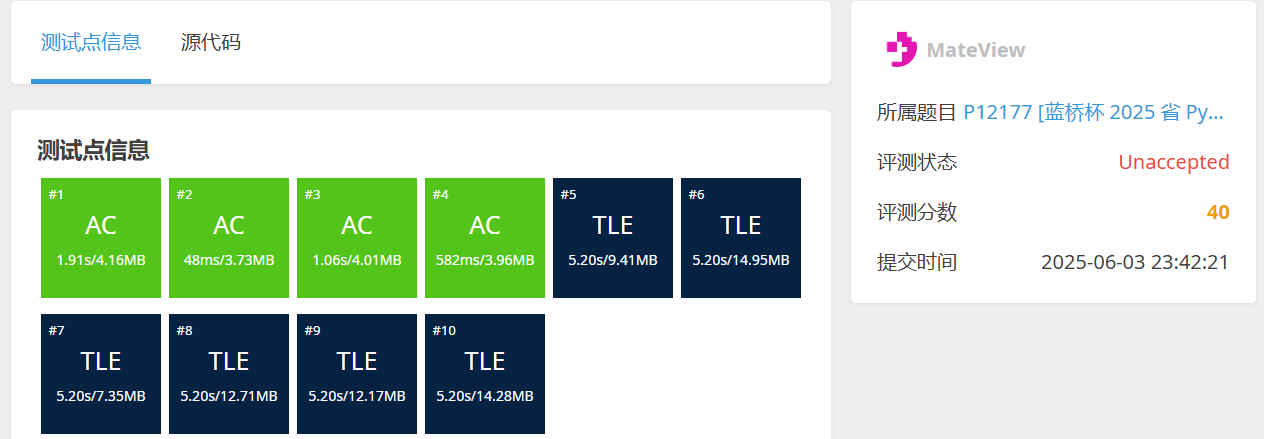
蓝桥杯 省赛 2025python(B组)题目(分析)
目录 第一题 为什么答案是103而不是104? 第二题 为什么必须按长度排序? 第三题 易错点总结 第四题 逻辑问题: 可能超过时间复杂度的代码示例 1. 暴力枚举所有可能的子串 2. 递归回溯 第五题 1. 暴力枚举法 2. 优化枚举 3.数…...
React - 组件通信
组件通信 概念:组件通信就是组件之间数据传递,根据组件嵌套关系不同,有不同的通信方法 父传子 —— 基础实现 实现步骤 父组件传递数据 - 在子组件标签上绑定属性子组件接收数据 - 子组件通过props参数接收数据 声明子组件并使用 //声明子…...

《前端面试题:CSS的display属性》
CSS display属性完全指南:深入理解布局核心属性 掌握display属性是CSS布局的基石,也是前端面试必考知识点 一、display属性概述:布局的核心控制 display属性是CSS中最重要、最基础的属性之一,它决定了元素在页面上的渲染方式和布…...
飞牛使用Docker部署Tailscale 内网穿透教程
之前发过使用docker部署Tailscale的教程,不过是一年前的事情了,今天再重新发表一遍,这次使用compose部署更加方便,教程也会更加详细一点,希望对有需要的朋友有所帮助! 对于大部分用户来说,白嫖 …...

《数据挖掘》- 房价数据分析
这里写目录标题 采用的技术1. Python编程语言2. 网络爬虫库技术点对比与区别项目技术栈的协同工作流程 代码解析1. 导入头文件2. 读取原始数据3. 清洗数据4. 数据分割4.1 统计房屋信息的分段数量4.2 将房屋信息拆分为独立列4.3 处理面积字段4.4 删除原始房屋信息列 5. 可视化分…...

centos中的ulimit命令
centos中的ulimit命令 ulimit的作用CENTOS系统文件配置配置文件地址配置格式 配置方法 ulimit的作用 ulimit用于限制shell启动进程所占用的资源,支持以下各种类型的限制:所创建的内核文件的大小、进程数据块的大小、Shell进程创建文件的大小、内存锁住的…...

git提交代码和解决冲突修复bug
提交到分支的步骤如下: 确保你当前在开发分支上,可以使用命令 git branch 来查看当前所在分支,并使用 git checkout 命令切换到开发分支。使用 git add 命令将修改的文件添加到暂存区。使用 git commit 命令提交代码到本地仓库。 解决合并冲…...
)
华为仓颉语言初识:并发编程之同步机制(上)
前言 线程同步机制是多线程下解决线程对共享资源竞争的主要方式,华为仓颉语言提供了三种常见的同步机制用来保证线程同步安全,分别是原子操作,互斥锁和条件变量。本篇文章详细介绍主要仓颉语言解决同步机制的方法,建议点赞收藏&a…...

php中实现邮件发送功能
要在php项目中实现邮件发送功能,推荐使用phpmailer库通过smtp协议配置。首先安装phpmailer扩展,可通过composer命令composer require phpmailer/phpmailer安装;若未使用composer则手动引入源码。接着配置smtp信息,包括服务器地址&…...

C++之动态数组vector
Vector 一、什么是 std::vector?二、std::vector 的基本特性(一)动态扩展(二)随机访问(三)内存管理 三、std::vector 的基本操作(一)定义和初始化(二…...
) 需要写成这种:(sort > (pair (list 3 2))))
arc3.2语言sort的时候报错:(sort < `(2 9 3 7 5 1)) 需要写成这种:(sort > (pair (list 3 2)))
arc语言sort的时候报错:(sort < (2 9 3 7 5 1)) arc> (sort < (2 9 3 7 5 1)) Error: "set-car!: expected argument of type <pair>; given: 9609216" arc> (sort < (2 9 3 )) Error: "Function call on inappropriate object…...

Android动态广播注册收发原理
一、动态广播的注册流程 1. 注册方式 动态广播通过代码调用 Context.registerReceiver() 方法实现,需显式指定 IntentFilter 和接收器实例: // 示例:在 Activity 中注册监听网络变化的广播 IntentFilter filter new IntentFilter…...

Ubuntu 系统通过防火墙管控 Docker 容器
Ubuntu 系统通过防火墙管控 Docker 容器指南 一、基础防火墙配置 # 启用防火墙 sudo ufw enable# 允许 SSH 连接(防止配置过程中断联) sudo ufw allow 22/tcp二、Docker 配置调整 # 编辑 Docker 配置文件 sudo vim /etc/docker/daemon.json配置文件内…...

AI 模型分类全解:特性与选择指南
人工智能(AI)技术正以前所未有的速度改变着我们的生活和工作方式。AI 模型作为实现人工智能的核心组件,种类繁多,功能各异。从简单的线性回归模型到复杂的深度学习网络,从文本生成到图像识别,AI 模型的应用…...
【Zephyr 系列 11】使用 NVS 实现 BLE 参数持久化:掉电不丢配置,开机自动加载
🧠关键词:Zephyr、NVS、非易失存储、掉电保持、Flash、AT命令保存、配置管理 📌目标读者:希望在 BLE 模块中实现掉电不丢配置、支持产测参数注入与自动加载功能的开发者 📊文章长度:约 5200 字 🔍 为什么要使用 NVS? 在实际产品中,我们经常面临以下场景: 用户或…...
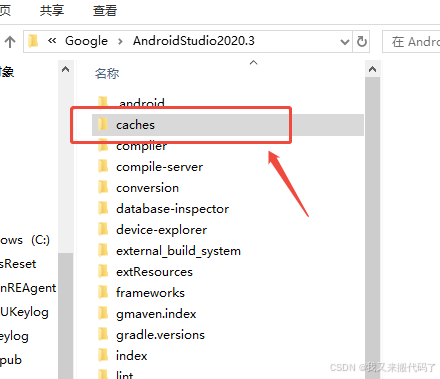
【Android】Android Studio项目代码异常错乱问题处理(2020.3版本)
问题 项目打开之后,发现项目文件直接乱码, 这样子的 这本来是个Java文件,结果一打开变成了这种情况,跟见鬼一样,而且还不是这一个文件这样,基本上一个项目里面一大半都是这样的问题。 处理方法 此时遇到…...

n皇后问题的 C++ 回溯算法教学攻略
一、问题描述 n皇后问题是经典的回溯算法问题。给定一个 nn 的棋盘,要求在棋盘上放置 n 个皇后,使得任何两个皇后之间不能互相攻击。皇后可以攻击同一行、同一列以及同一对角线上的棋子。我们需要找出所有的合法放置方案并输出方案数。 二、输入输出形…...

一些免费的大A数据接口库
文章目录 一、Python开源库(适合开发者)1. AkShare2. Tushare3. Baostock 二、公开API接口(适合快速调用)1. 新浪财经API2. 腾讯证券接口3. 雅虎财经API 三、第三方数据平台(含免费额度)1. 必盈数据2. 聚合…...

DeepSeek本地部署及WebUI可视化教程
前言 DeepSeek是近年来备受关注的大模型之一,支持多种推理和微调场景。很多开发者希望在本地部署DeepSeek模型,并通过WebUI进行可视化交互。本文将详细介绍如何在本地环境下部署DeepSeek,并实现WebUI可视化,包括Ollama和CherryStudio的使用方法。 一、环境准备 1. 硬件要…...
机器学习算法时间复杂度解析:为什么它如此重要?
时间复杂度的重要性 虽然scikit-learn等库让机器学习算法的实现变得异常简单(通常只需2-3行代码),但这种便利性往往导致使用者忽视两个关键方面: 算法核心原理的理解缺失 忽视算法的数据适用条件 典型算法的时间复杂度陷阱 SV…...
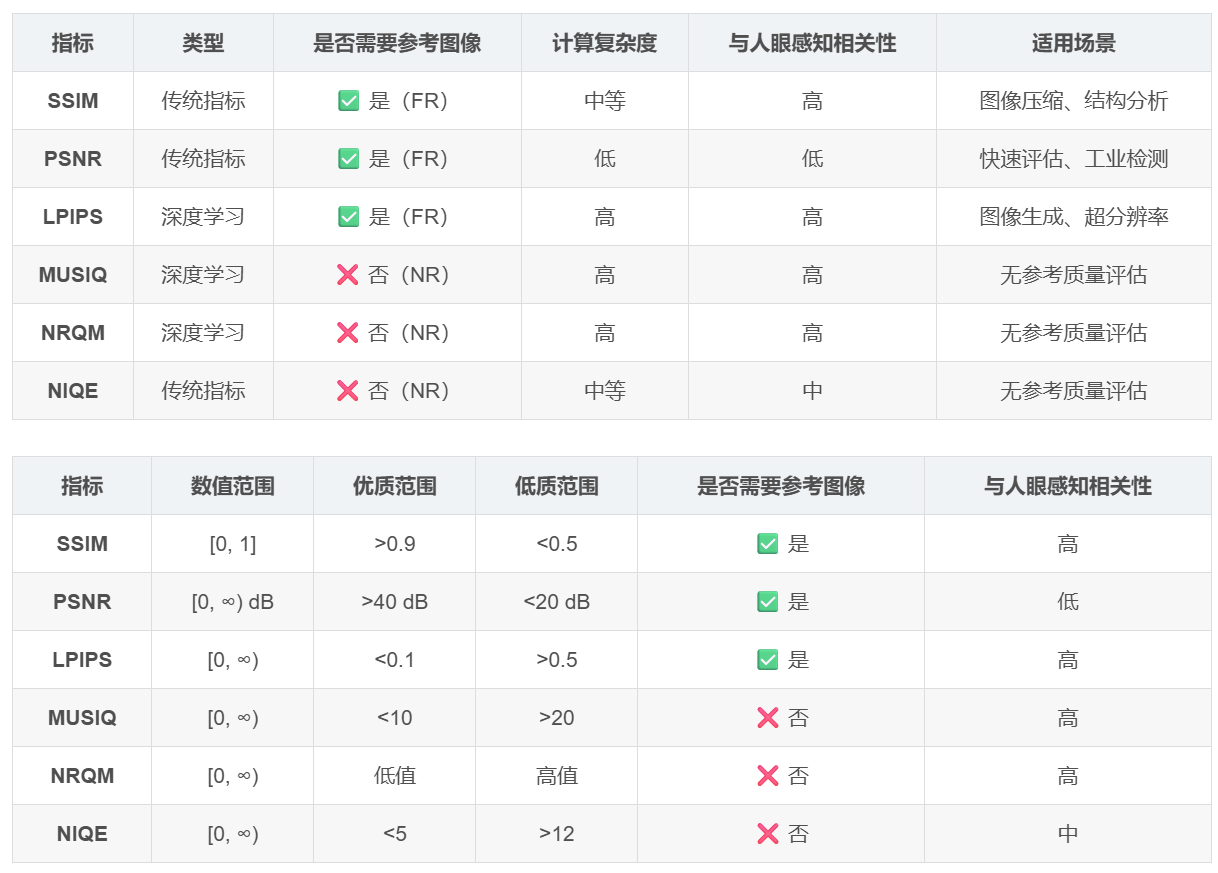
SSIM、PSNR、LPIPS、MUSIQ、NRQM、NIQE 六个图像质量评估指标
评价指标 1. SSIM(Structural Similarity Index) 📌 定义 结构相似性指数(Structural Similarality Index)是一种衡量两幅图像相似性的指标,考虑了亮度、对比度和结构信息的相似性,比传统的 P…...
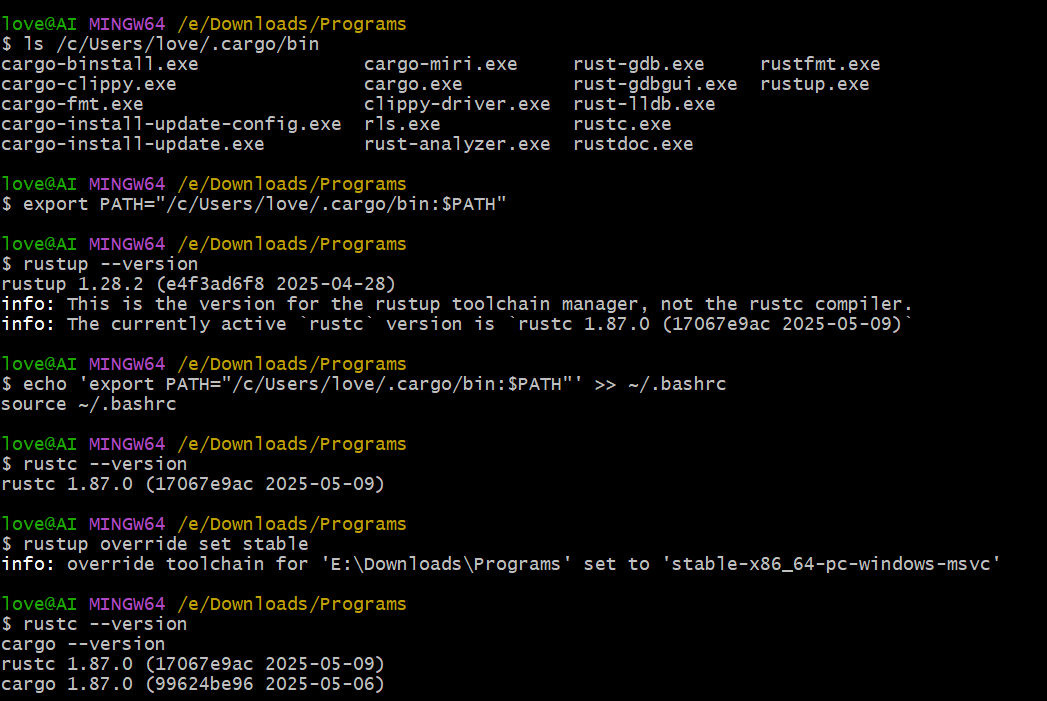
【笔记】旧版MSYS2 环境中 Rust 升级问题及解决过程
下面是一份针对在旧版 MSYS2(安装在 D 盘)中,基于 Python 3.11 的 Poetry 虚拟环境下升级 Rust 的处理过程笔记(适用于 WIN 系统 SUNA 人工智能代理开源项目部署要求)的记录。 MSYS2 旧版环境中 Rust 升级问题及解决过…...

centos查看开启关闭防火墙状态
执行:systemctl status firewalld ,即可查看防火墙状态 防火墙的开启、关闭、禁用命令 (1)设置开机启用防火墙:systemctl enable firewalld.service (2)设置开机禁用防火墙:system…...

[论文阅读] 人工智能 | 大语言模型计划生成的新范式:基于过程挖掘的技能学习
#论文阅读# 大语言模型计划生成的新范式:基于过程挖掘的技能学习 论文信息 Skill Learning Using Process Mining for Large Language Model Plan Generation Andrei Cosmin Redis, Mohammadreza Fani Sani, Bahram Zarrin, Andrea Burattin Cite as: arXiv:2410.…...