SmolVLA: 让机器人更懂 “看听说做” 的轻量化解决方案
🧭 TL;DR
今天,我们希望向大家介绍一个新的模型: SmolVLA,这是一个轻量级 (450M 参数) 的开源视觉 - 语言 - 动作 (VLA) 模型,专为机器人领域设计,并且可以在消费级硬件上运行。
SmolVLAhttps://hf.co/lerobot/smolvla_base
仅使用开源社区共享的数据集进行预训练,数据集标签为lerobot。https://hf.co/datasets?other=lerobot&sort=trending
SmolVLA-450M 的表现优于许多更大的 VLA 模型,并且在仿真任务 (LIBERO,Meta-World) 和实际任务 (SO100, SO101) 上超过了强基线模型,如ACT。https://github.com/TheRobotStudio/SO-ARM100https://hf.co/papers/2401.02117
支持 异步推理 ,可提供 30% 更快的响应 和 2 倍的任务吞吐量。
相关链接:
用于训练和评估 SO-100/101 的硬件:https://github.com/TheRobotStudio/SO-ARM100
基础模型:https://hf.co/lerobot/smolvla_base
论文:https://hf.co/papers/2506.01844
介绍
在过去的几年里,Transformers 技术推动了人工智能的显著进展,从能够进行类人推理的语言模型到理解图像和文本的多模态系统。然而,在实际的机器人领域,进展则相对较慢。机器人仍然难以在各种物体、环境和任务之间进行有效的泛化。这一有限的进展源于 缺乏高质量、多样化的数据,以及缺乏能够 像人类一样在物理世界中进行推理和行动 的模型。
为应对这些挑战,近期的研究开始转向 视觉 - 语言 - 动作 (VLA) 模型,旨在将感知、语言理解和动作预测统一到一个架构中。VLA 模型通常以原始视觉观测和自然语言指令为输入,输出相应的机器人动作。尽管前景广阔,但大部分 VLA 的最新进展仍然被封闭在使用大规模私人数据集训练的专有模型背后,通常需要昂贵的硬件配置和大量的工程资源。因此,更广泛的机器人研究社区在复制和扩展这些模型时面临着重大的障碍。
SmolVLA 填补了这一空白,提供了一个开源、高效的轻量级 VLA 模型,可以在 仅使用公开可用数据集和消费级硬件 的情况下进行训练。通过发布模型权重并使用非常经济的开源硬件,SmolVLA 旨在实现视觉 - 语言 - 动作模型的普及,并加速朝着通用机器人代理的研究进展。

图 1: SmolVLA 在不同任务变体下的对比。从左到右: (1) 异步的拾取 - 放置立方体计数,(2) 同步的拾取 - 放置立方体计数,(3) 在扰动下的拾取 - 放置立方体计数,(4) 在真实世界 SO101 上的乐高积木拾取 - 放置任务泛化。
认识 SmolVLA!
SmolVLA-450M 是我们开源的、功能强大的轻量级视觉 - 语言 - 动作 (VLA) 模型。它具备以下特点:
足够小,可以在 CPU 上运行,单个消费级 GPU 上训练,甚至可以在 MacBook 上运行!
训练使用的是公开的、社区共享的机器人数据
发布时附带完整的训练和推理方案
可以在非常经济的硬件上进行测试和部署 (如 SO-100、SO-101、LeKiwi 等)
受到大语言模型 (LLMs) 训练范式的启发,SmolVLA 先在通用的操控数据上进行预训练,随后进行特定任务的后训练。在架构上,它将 Transformers 与 流匹配解码器 相结合,并通过以下设计选择优化速度和低延迟推理:
跳过视觉模型的一半层,提升推理速度和减小模型尺寸
交替使用自注意力和交叉注意力模块
使用更少的视觉标记
利用更小的预训练视觉 - 语言模型 (VLM)
尽管使用的训练样本不到 30k, 比其他 VLA 模型少了一个数量级 , 但 SmolVLA 在仿真和真实世界中的表现 与更大的模型相当,甚至超过它们。
为了让实时机器人更加易用,我们引入了异步推理堆栈。该技术将机器人执行动作的方式与理解它们所看到和听到的内容分开。由于这种分离,机器人可以在快速变化的环境中更快速地响应。
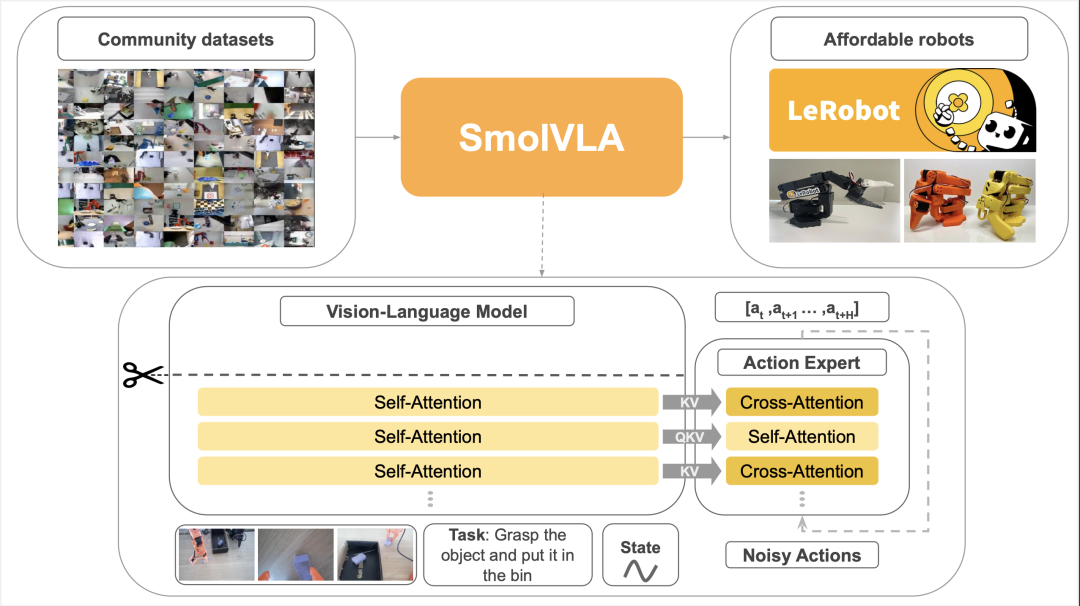
图 2: SmolVLA 以多个摄像头拍摄的 RGB 图像序列、机器人当前的传感运动状态以及自然语言指令为输入。VLM 将这些信息编码为上下文特征,这些特征为动作专家提供条件,生成连续的动作序列。
🚀 如何使用 SmolVLA?
SmolVLA 设计时考虑了易用性和集成性——无论您是要在自己的数据上进行微调,还是将其插入现有的机器人堆栈中,都非常方便。
安装
首先,安装所需的依赖项:
git clone https://github.com/huggingface/lerobot.git
cd lerobot
pip install -e ".[smolvla]"微调预训练模型
使用我们预训练的 450M 模型smolvla_base和 lerobot 训练框架进行微调:https://hf.co/lerobot/smolvla_base
python lerobot/scripts/train.py \--policy.path=lerobot/smolvla_base \--dataset.repo_id=lerobot/svla_so100_stacking \--batch_size=64 \--steps=200000从头开始训练
如果你想基于架构 (预训练的 VLM + 动作专家) 进行训练,而不是从预训练的检查点开始:
python lerobot/scripts/train.py \--policy.type=smolvla \--dataset.repo_id=lerobot/svla_so100_stacking \--batch_size=64 \--steps=200000你还可以直接加载 SmolVLAPolicy :
policy = SmolVLAPolicy.from_pretrained("lerobot/smolvla_base")方法
SmolVLA 不仅是一个轻量级但强大的模型,还是一种用于训练和评估通用机器人策略的方法。在这一部分,我们介绍了 SmolVLA 背后的 模型架构 和用于评估的 异步推理 设置,这一设置已被证明更具适应性,并能更快速地恢复。
SmolVLA 由两个核心组件组成: 一个处理多模态输入的 视觉 - 语言模型 (VLM) 和一个输出机器人控制命令的 动作专家。下面,我们将分享 SmolVLA 架构的主要组件和异步推理的详细信息。更多细节可以在我们的技术报告中找到。https://hf.co/papers/2506.01844
主要架构
视觉 - 语言模型 (VLM)
我们使用SmolVLM2作为我们的 VLM 主干。它经过优化,能够处理多图像输入,并包含一个 SigLIP 视觉编码器和一个SmolLM2语言解码器。
图像标记 通过视觉编码器提取
语言指令 被标记化并直接输入解码器
传感运动状态 通过线性层投影到一个标记上,与语言模型的标记维度对齐
解码器层处理连接的图像、语言和状态标记。得到的特征随后传递给动作专家。
SmolVLM2https://hf.co/HuggingFaceTB/SmolVLM2-500M-Video-Instruct
SmolLM2https://hf.co/HuggingFaceTB/SmolLM2-1.7B-Instruct
动作专家: 流匹配变换器
SmolVLA 的 动作专家 是一个轻量 Transformer (约 1 亿参数),它能基于视觉语言模型 (VLM) 的输出,生成未来机器人动作序列块 (action chunks)。它是采用 流匹配目标 进行训练的,通过引导噪声样本回归真实数据分布来学习动作生成。与离散动作表示 (例如通过标记化) 强大但通常需要自回归解码、推理时速度较慢不同,流匹配允许 直接、非自回归预测连续动作,从而实现高精度的实时控制。
更直观地说,在训练过程中,我们将随机噪声添加到机器人的真实动作序列中,并要求模型预测将其“修正”回正确轨迹的“修正向量”。这在动作空间上形成了一个平滑的向量场,帮助模型学习准确且稳定的控制策略。
我们使用 Transfomer 架构实现这一目标,并采用 交替注意力块 (见图 2),同时将其隐藏层大小减少到 VLM 的 75%,保持模型轻量化,便于部署。
高效性和稳健性的设计选择
将视觉 - 语言模型与动作预测模块结合起来,是近期 VLA 系统 (如 Pi0、GR00T、Diffusion Policy) 中的常见设计模式。我们在此过程中识别了几项架构选择,这些选择显著提高了系统的稳健性和性能。在 SmolVLA 中,我们应用了三项关键技术: 减少视觉标记的数量、跳过 VLM 中的高层 以及 在动作专家中交替使用交叉注意力和自注意力层。
视觉标记减少
高分辨率图像有助于提高感知能力,但也可能显著减慢推理速度。为了找到平衡,SmolVLA 在训练和推理过程中每帧限制视觉标记数量为 64。例如,一个 512×512 的图像被压缩成仅 64 个标记,而不是 1024 个,使用 PixelShuffle 作为高效的重排技术。虽然底层的视觉 - 语言模型 (VLM) 最初使用图像平铺技术进行预训练,以获得更广泛的覆盖,但 SmolVLA 在运行时仅使用全局图像,以保持推理的轻量化和快速性。
通过跳过层加速推理
我们并不总是依赖于 VLM 的最终输出层,这一层成本高且有时效果不佳,我们选择使用 中间层的特征。先前的研究表明,早期的层通常能提供更好的下游任务表示。 在 SmolVLA 中,动作专家只关注最多配置层 NN 的 VLM 特征进行训练,配置为 总层数的一半。这 减少了 VLM 和动作专家的计算成本,显著加速了推理,并且性能损失最小。
交替使用交叉注意力和自注意力
在动作专家内部,注意力层交替进行:
交叉注意力 (CA) ,其中动作标记关注 VLM 的特征
自注意力 (SA) ,其中动作标记关注彼此 (因果性地——只关注过去的标记)
我们发现这种 交替设计 比仅使用完整的注意力块要轻量且更有效。仅依赖于 CA 或仅依赖于 SA 的模型,往往会牺牲平滑性或基础性。
在 SmolVLA 中,CA 确保了动作能够很好地与感知和指令相匹配,而 SA 则提高了 时间平滑性,这对于现实世界中的控制尤其重要,因为抖动的预测可能会导致不安全或不稳定的行为。
异步推理
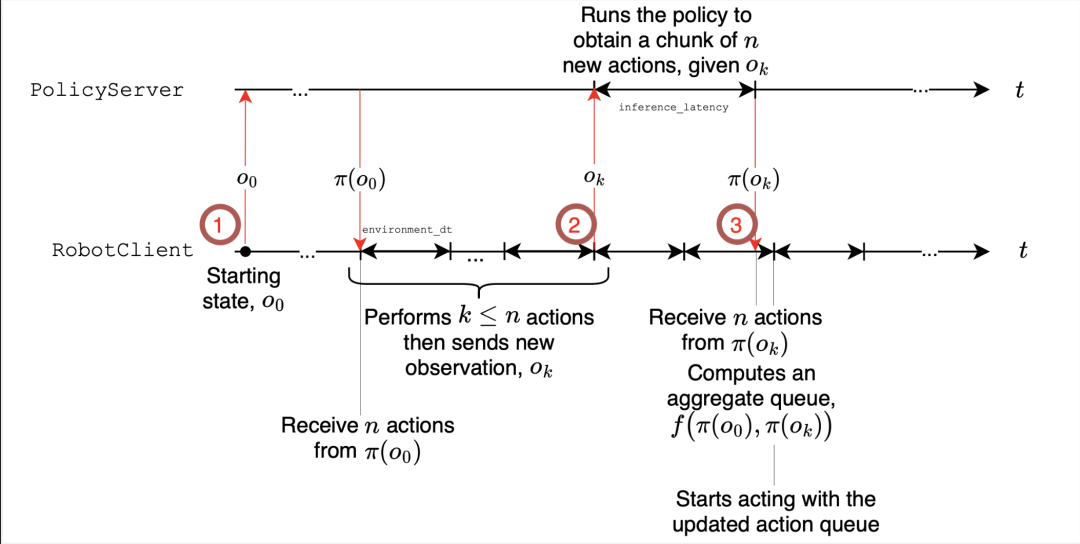
图 3. 异步推理。异步推理堆栈的示意图。请注意,策略可以在远程服务器上运行,可能带有 GPU。
现代视觉运动策略输出 动作片段 一系列需要执行的动作。有两种管理方式:
同步 (sync): 机器人执行一个片段,然后暂停,等待下一个片段的计算。这种方式简单,但会造成延迟,机器人无法响应新的输入。
异步 (async): 在执行当前片段时,机器人已经将最新的观察结果发送到 策略服务器 (可能托管在 GPU 上) 以获取下一个片段。这避免了空闲时间,并提高了反应速度。
我们的异步堆栈将动作执行与片段预测解耦,从而提高了适应性,并完全消除了运行时的执行延迟。它依赖以下关键机制:
1. 早期触发: 当队列长度低于某个阈值 (例如,70%) 时,我们会将观察结果发送到 策略服务器,请求生成新的动作片段。
2. 解耦线程: 控制循环持续执行 → 推理并行进行 (非阻塞)。
3. 片段融合: 通过简单的合并规则将连续片段的重叠动作拼接在一起,以避免抖动。
我们非常激动能发布异步推理,因为它保证了更强的适应性和更好的性能,而无需更改模型。简而言之,异步推理通过重叠执行和远程预测保持机器人响应迅速。
社区数据集
虽然视觉和语言模型依赖像 LAION、ImageNet 和 Common Crawl 这样的网络规模数据集,但机器人学缺乏类似的资源。没有“机器人互联网”。相反,数据在不同类型的机器人、传感器、控制方案和格式之间是碎片化的——形成了不相连的“数据岛”。在我们的上一篇文章中,我们探讨了如何通过开放和协作的努力来解决这种碎片化问题。正如 ImageNet 通过提供一个大而多样的基准来促进计算机视觉的突破,我们相信 社区驱动的机器人数据集 可以在通用机器人策略中发挥相同的基础性作用。
LeRobot Community Datasets: The “ImageNet” of Robotics — When and How?https://hf.co/blog/lerobot-datasets
SmolVLA 是我们朝着这个愿景迈出的第一步: 它在精心挑选的公开可用、社区贡献的数据集上进行预训练,这些数据集旨在反映现实世界中的变化。我们并不是单纯地优化数据集的大小,而是关注多样性: 各种行为、摄像头视角和体现方式,促进转移和泛化。
SmolVLA 使用的所有训练数据来自 LeRobot Community Datasets,这是在 Hugging Face Hub 上通过 lerobot 标签共享的机器人数据集。数据集来自各种不同的环境,从实验室到客厅,这些数据集代表了一种开放、去中心化的努力,旨在扩展现实世界的机器人数据。

图 4. 社区数据集的概览。特别感谢 Ville Kuosmanen 创建了该可视化图像。 与学术基准不同,社区数据集自然地捕捉到了杂乱、现实的互动: 多变的光照、不完美的演示、非常规物体和异质的控制方案。这种多样性将对学习稳健、通用的表示非常有用。
我们使用了由Alexandre Chapin和Ville Kuosmanen创建的自定义过滤工具,根据帧数、视觉质量和任务覆盖范围来选择数据集。在经过细致的人工审核后 (特别感谢 Marina Barannikov),我们策划了一个由 487 个高质量数据集 组成的集合,聚焦于 SO100 机器人臂,并统一标准为 30 FPS。这产生了大约 1000 万帧 ——至少是 其他流行基准数据集的一个数量级小,但其多样性显著更高。
Alexandre Chapinhttps://hf.co/Beegbrain
Ville Kuosmanenhttps://hf.co/villekuosmanen
过滤工具https://hf.co/spaces/Beegbrain/FilterLeRobotData
改进任务标注
社区数据集中的一个常见问题是任务描述的噪声或缺失。许多样本缺少标注,或者包含像“task desc”或“Move”、“Pick”等模糊的标签。为了提高质量并标准化数据集之间的文本输入,我们使用了Qwen2.5-VL-3B-Instruct来生成简洁、面向动作的描述。https://hf.co/Qwen/Qwen2.5-3B-Instruct
给定样本帧和原始标签,模型被提示在 30 个字符以内重写指令,从动词开始 (例如,“Pick”,“Place”,“Open”)。
使用的提示语如下:
以下是当前的任务描述: {current_task}。生成一个非常简短、清晰且完整的一句话,描述机器人臂执行的动作 (最多 30 个字符)。不要包含不必要的词语。
简洁明了。
以下是一些示例: 拾取立方体并将其放入盒子,打开抽屉等等。
直接以动词开始,如“Pick”、“Place”、“Open”等。
与提供的示例类似,机器人臂执行的主要动作是什么?标准化摄像头视角
另一个挑战是摄像头命名不一致。一些数据集使用了清晰的名称,如 top 或 wrist.right ,而其他一些则使用了模糊的标签,如 images.laptop ,其含义有所不同。
为了解决这个问题,我们手动检查了数据集,并将每个摄像头视角映射到标准化的方案:
OBS_IMAGE_1 : 从上往下的视角OBS_IMAGE_2 : 腕部安装视角OBS_IMAGE_3+ : 其他视角
我们进一步隔离了社区数据集预训练和多任务微调的贡献。没有在 LeRobot 社区数据集上进行预训练,SmolVLA 在 SO100 上最初的成功率为 51.7%。在社区收集的数据上进行预训练后,性能跃升至 78.3%,提高了 +26.6%。多任务微调进一步提升了性能,甚至在低数据环境下也表现出强大的任务迁移能力。
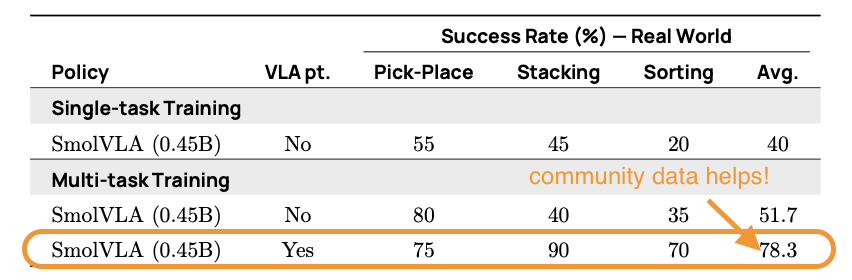
表 1. 在社区数据集预训练和多任务微调上的影响。
结果
我们在仿真和真实世界的基准测试中评估了 SmolVLA,以测试其泛化能力、效率和稳健性。尽管 SmolVLA 是紧凑的,但它在性能上始终超越或与显著更大的模型和基于更大规模机器人数据预训练的策略相匹配。
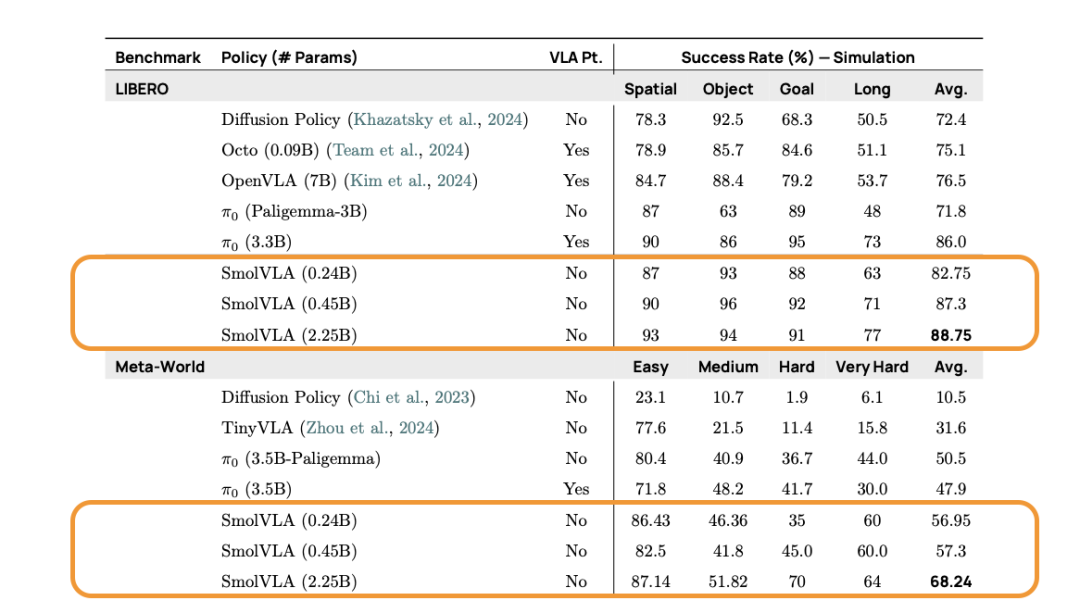
表 2. SmolVLA 在仿真基准测试中的表现。
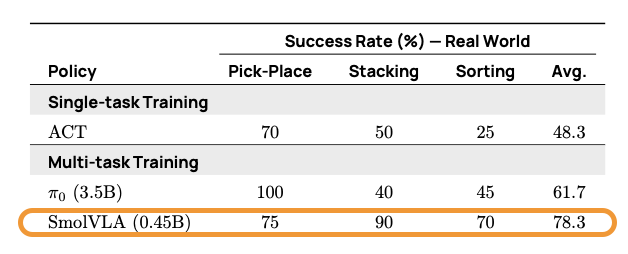
表 3. SmolVLA 与基线在真实世界任务 (SO100) 上的对比。
在真实世界环境中,SmolVLA 在两个不同的任务套件上进行了评估: SO100 和 SO101。这些任务包括拾取 - 放置、堆叠和排序,涵盖了分布内和分布外的物体配置。
在 SO101 上,SmolVLA 还在泛化能力上表现出色:
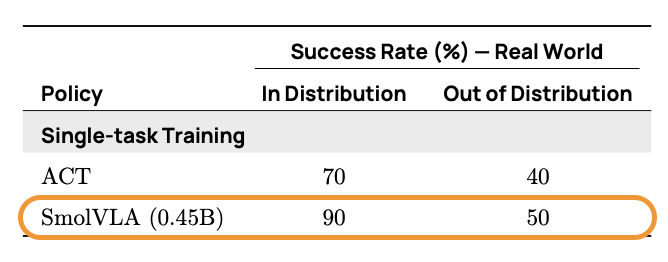
表 4. SmolVLA 在新体现 (SO101) 上的泛化能力与 ACT 的对比。
最后,我们在同步和异步推理模式下评估了 SmolVLA。异步推理将动作执行与模型推理解耦,使得策略在机器人移动时也能作出反应。
两种模式的任务成功率相似 (约 78%),但异步推理:
使任务完成时间 快约 30% (9.7 秒 vs 13.75 秒)
在固定时间设置下 完成任务数量翻倍 (19 个 vs 9 个立方体)
这使得在动态环境中,尤其是在物体变化或外部干扰的情况下,SmolVLA 具有更高的响应性和稳健的真实世界表现。

图 4. 真实世界任务中的异步推理与同步推理。(a) 任务成功率 (%),(b) 平均完成时间 (秒),以及 (c) 在固定时间窗口内完成的任务数量。
结论
SmolVLA 是我们为构建开放、高效、可重复的机器人基础模型所做的贡献。尽管它体积小,但在一系列真实世界和仿真任务中,它的表现与更大、更专有的模型相当,甚至超越了它们。通过完全依赖社区贡献的数据集和经济实惠的硬件,SmolVLA 降低了研究人员、教育工作者和爱好者的入门门槛。
但这仅仅是开始。SmolVLA 不仅仅是一个模型——它是朝着可扩展、协作机器人方向发展的开源运动的一部分。
行动号召:
🔧 试试看! 在自己的数据上微调 SmolVLA,将其部署到经济实惠的硬件上,或者与当前的堆栈进行基准测试,并在 Twitter/LinkedIn 上分享。
🤖 上传数据集! 有机器人吗?使用 lerobot 格式收集并共享你的数据。帮助扩展支持 SmolVLA 的社区数据集。
💬 加入博客讨论。 在下面的讨论中留下你的问题、想法或反馈。我们很乐意帮助集成、训练或部署。
📊 贡献。 改进数据集,报告问题,提出新想法。每一份贡献都很有帮助。
🌍 传播这个消息。 与其他对高效、实时机器人策略感兴趣的研究人员、开发人员或教育者分享 SmolVLA。
📫 保持联系: 关注LeRobot 组织和Discord 服务器,获取更新、教程和新版本。https://hf.co/lerobothttps://discord.com/invite/ttk5CV6tUw
我们一起可以让现实世界的机器人性能更强、成本更低、 开放度更高。✨
英文原文:https://hf.co/blog/smolvla
原文作者: Dana Aubakirova, Andres Marafioti, Merve Noyan, Aritra Roy Gosthipaty, Francesco Capuano, Loubna Ben Allal, Pedro Cuenca, Mustafa Shukor, Remi Cadene
翻译: Adeena
相关文章:
SmolVLA: 让机器人更懂 “看听说做” 的轻量化解决方案
🧭 TL;DR 今天,我们希望向大家介绍一个新的模型: SmolVLA,这是一个轻量级 (450M 参数) 的开源视觉 - 语言 - 动作 (VLA) 模型,专为机器人领域设计,并且可以在消费级硬件上运行。 SmolVLAhttps://hf.co/lerobot/smolvla…...
day45python打卡
知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorbo…...
AIGC赋能前端开发
一、引言:AIGC对前端开发的影响 1. AIGC与前端开发的关系 从“写代码”到“生成代码”传统开发痛点:重复性编码工作、UI 设计稿还原、问题定位与调试...核心场景的AI化:需求转代码(P2C)、设计稿转代码(D2…...

Web 3D协作平台开发案例:构建制造业远程设计与可视化协作
HOOPS Communicator为开发者提供了丰富的定制化能力,助力他们在实现强大 Web 3D 可视化功能的同时,灵活构建符合特定业务需求的工程应用。对于希望构建在线协同设计工具的企业而言,如何在保障性能与用户体验的前提下实现高效开发,…...

AI Agent开发第78课-大模型结合Flink构建政务类长公文、长文件、OA应用Agent
开篇 AI Agent2025确定是进入了爆发期,到处都在冒出各种各样的实用AI Agent。很多人、组织都投身于开发AI Agent。 但是从3月份开始业界开始出现了一种这样的声音: AI开发入门并不难,一旦开发完后没法用! 经历过至少一个AI Agent从开发到上线的小伙伴们其实都听到过这种…...

极空间z4pro配置gitea mysql,内网穿透
极空间z4pro配置gitea mysql等记录,内网穿透 1、mysql、gitea镜像下载,极空间不成功,先用自己电脑科学后下载镜像,拉取代码: docker pull --platform linux/amd64 gitea/gitea:1.23 docker pull --platform linux/amd64 mysql:5.…...

第三方测试机构进行科技成果鉴定测试有什么价值
在当今科技创新的浪潮中,科技成果的鉴定测试至关重要,而第三方测试机构凭借其独特优势,在这一领域发挥着不可替代的作用。那么,第三方测试机构进行科技成果鉴定测试究竟有什么价值呢? 一、第三方测试机构能提供独立、公…...
华为云Flexus+DeepSeek征文|基于华为云Flexus X和DeepSeek-R1打造个人知识库问答系统
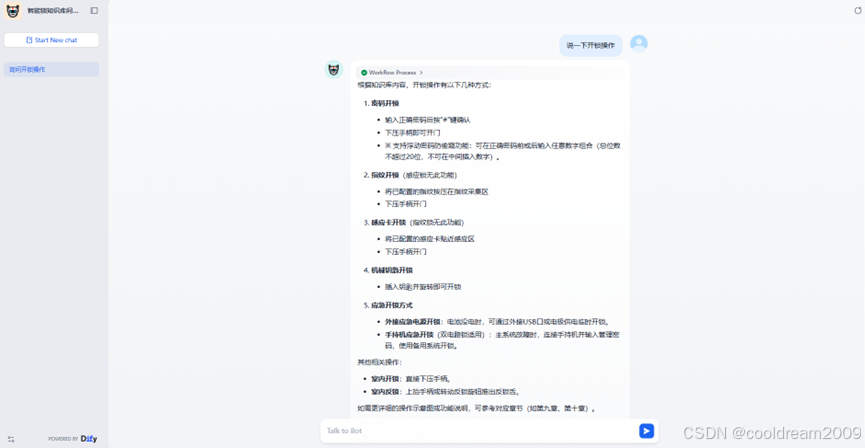
目录 前言 1 快速部署:一键搭建Dify平台 1.1 部署流程详解 1.2 初始配置与登录 2 构建专属知识库 2.1 进入知识库模块并创建新库 2.2 选择数据源导入内容 2.3 上传并识别多种文档格式 2.4 文本处理与索引构建 2.5 保存并完成知识库创建 3接入ModelArts S…...

【数据结构】_排序
【本节目标】 排序的概念及其运用常见排序算法的实现排序算法复杂度及稳定性分析 1.排序的概念及其运用 1.1排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 1.2特性…...

《前端面试题:JS数据类型》
JavaScript 数据类型指南:从基础到高级全解析 一、JavaScript 数据类型概述 JavaScript 作为一门动态类型语言,其数据类型系统是理解这门语言的核心基础。在 ECMAScript 标准中,数据类型分为两大类: 1. 原始类型(Pr…...
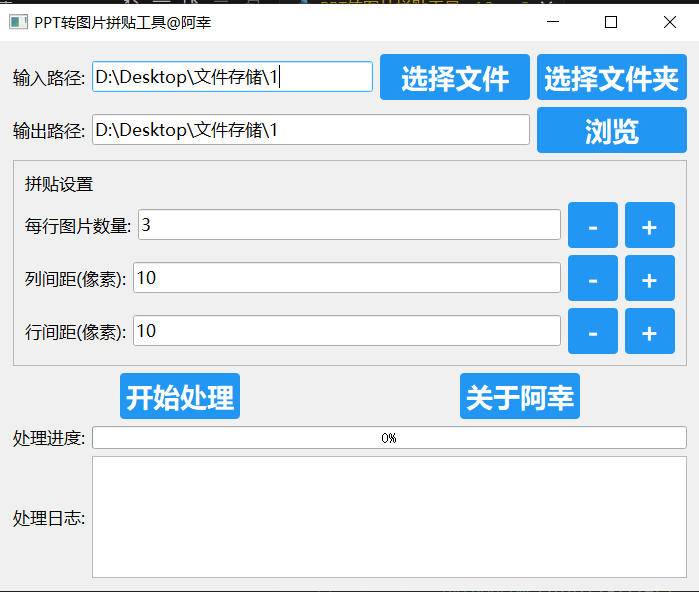
PPT转图片拼贴工具 v4.3
软件介绍 这个软件就是将PPT文件转换为图片并且拼接起来。 效果展示 支持导入文件和支持导入文件夹,也支持手动输入文件/文件夹路径 软件界面 这一次提供了源码和开箱即用版本,exe就是直接用就可以了。 软件源码 import os import re import sys …...
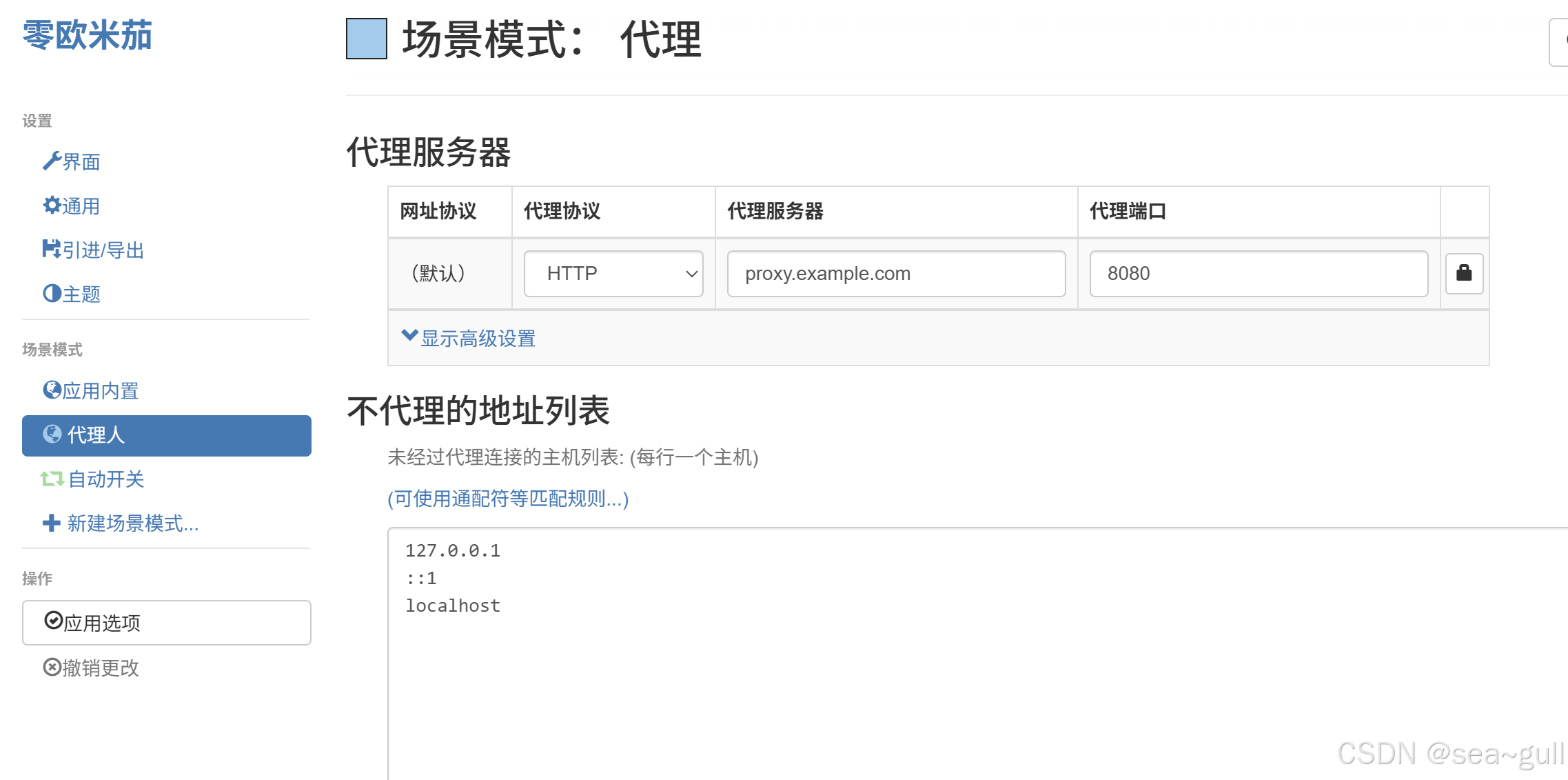
Chrome安装代理插件ZeroOmega(保姆级别)
目录 本文直接讲解一下怎么本地安装ZeroOmega一、下载文件在GitHub直接下ZeroOmega 的文件(下最新版即可) 二、安装插件打开 Chrome 浏览器,访问 chrome://extensions/ 页面(扩展程序管理页面),并打开开发者…...
Transformer-BiGRU多变量时序预测(Matlab完整源码和数据)
Transformer-BiGRU多变量时序预测(Matlab完整源码和数据) 目录 Transformer-BiGRU多变量时序预测(Matlab完整源码和数据)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现Transformer-BiGRU多变量时间序列预测&…...

新华三H3CNE网络工程师认证—Easy IP
Easy IP 就是“用路由器自己的公网IP,给全家所有设备当共享门牌号”的技术!(省掉额外公网IP,省钱又省配置!) 生活场景对比,想象你住在一个小区:普通动态NAT:物业申请了 …...

《视觉SLAM十四讲》自用笔记 第二讲:SLAM系统概述
在rm队伍里作为算法组梯队队员度过了一个赛季,为了促进和负责其他工作的算法组成员的交流,我决定在接下来的半个学期里(可能更快)读完这本书,并将其中的部分理论应用于我自制的雷达导航小车上。 以下为第二讲的部分笔记…...

vscode 插件 eslint, 检查 js 语法
1. 起因, 目的: 我的需求 vscode 写js代码, 有什么插件能进行语法检查。 比如某个函数没有定义,getName(), 但是却调用了。 那么这个插件会给出警告,在 getName() 给出红色波浪线。类似这种效果的插件, 有吗…...
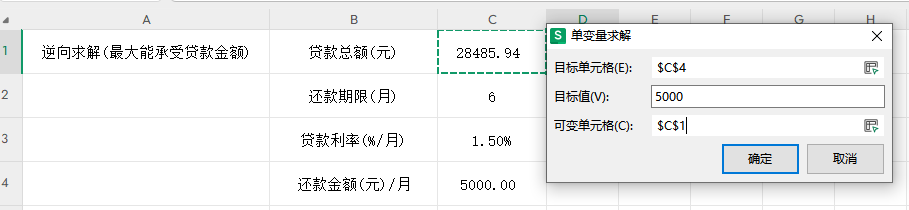
Excel 模拟分析之单变量求解简单应用
正向求解 利用公式根据贷款总额、还款期限、贷款利率,求每月还款金额 反向求解 根据每月还款能力,求最大能承受贷款金额 参数: 目标单元格:求的值所在的单元格 目标值:想要达到的预期值 可变单元格:变…...

装备制造项目管理具备什么特征?如何选择适配的项目管理软件系统进行项目管控?
国内某大型半导体装备制造企业与奥博思软件达成战略合作,全面引入奥博思 PowerProject 打造企业专属项目管理平台,进一步提升智能制造领域的项目管理效率与协同能力。 该项目管理平台聚焦半导体装备研发与制造的业务特性,实现了从项目立项、…...
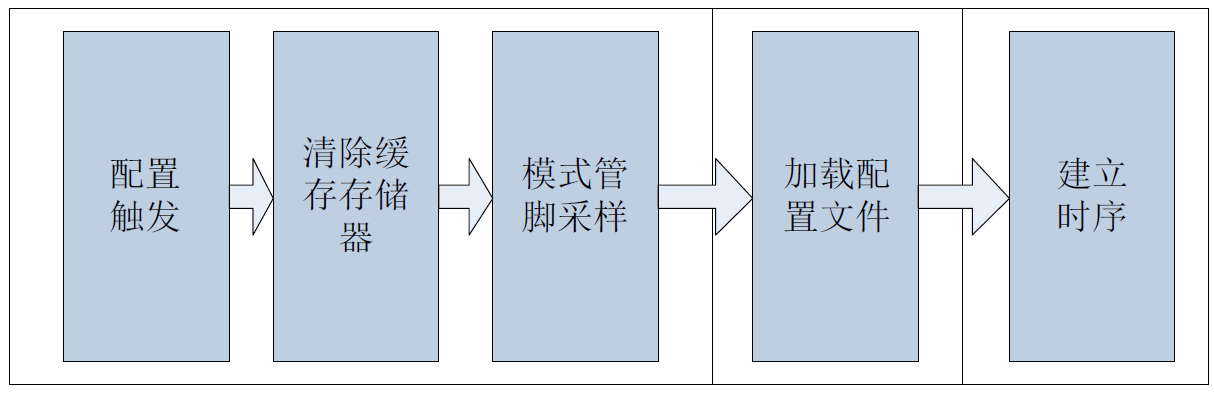
FPGA 动态重构配置流程
触发FPGA 进行配置的方式有两种,一种是断电后上电,另一种是在FPGA运行过程中,将PROGRAM 管脚拉低。将PROGRAM 管脚拉低500ns 以上就可以触发FPGA 进行重构。 FPGA 的配置过程大致可以分为:配置的触发和建立阶段、加载配置文件和建…...
介绍)
Elasticsearch的审计日志(Audit Logging)介绍
Elasticsearch 的审计日志(Audit Logging)是一种记录与安全相关事件的功能,用于监控和追踪对集群的访问行为。通过审计日志,管理员可以了解谁在何时对哪些资源执行了什么操作,从而满足合规性要求、进行安全分析和排查异常行为。 一、审计日志的核心功能 记录安全事件捕获…...

软件测试:质量保障的基石与未来趋势
软件测试作为软件开发生命周期中的关键环节,不仅是发现和修复缺陷的手段,更是确保产品质量、提升用户体验和降低开发成本的重要保障。在当今快速迭代的互联网时代,测试已从单纯的验证活动演变为贯穿整个开发过程的质量管理体系。本文将系统阐…...

网络安全逆向分析之rust逆向技巧
rust逆向技巧 rust逆向三板斧: 快速定位关键函数 (真正的main函数):观察输出、输入,字符串搜索,断点等方法。定位关键 加密区 :根据输入的flag,打硬件断点,快速捕获程序中对flag访问的位置&am…...

Docker容器化技术概述与实践
哈喽,大家好,我是左手python! Docker 容器化的基本概念 Docker 容器化是一种轻量级的虚拟化技术,通过将应用程序及其依赖项打包到一个可移植的容器中,使其在任何兼容 Docker 的环境中都能运行。与传统的虚拟机技术不同…...

win中将pdf转为图片
0 资料 博客 1 正文 直接使用这个软件即可https://sourceforge.net/projects/pkpdfconverter/...
Leetcode 2494. 合并在同一个大厅重叠的活动
1.题目基本信息 1.1.题目描述 表: HallEvents ----------------- | Column Name | Type | ----------------- | hall_id | int | | start_day | date | | end_day | date | ----------------- 该表可能包含重复字段。 该表的每一行表示活动的开始日期和结束日期&…...
vue+elementui 网站首页顶部菜单上下布局
菜单集合后台接口动态获取,保存到store vuex状态管理器 <template><div id"app"><el-menu:default-active"activeIndex2"class"el-menu-demo"mode"horizontal"select"handleSelect"background-…...
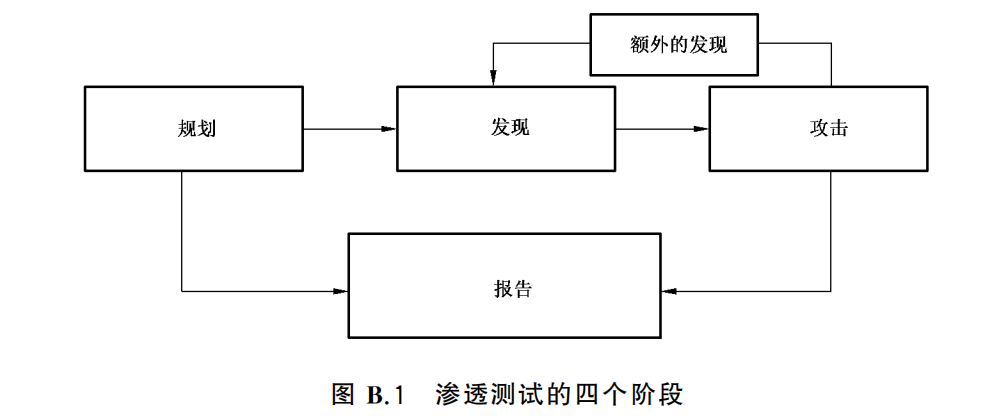
网络安全-等级保护(等保) 3-3-1 GB/T 36627-2018 附录A (资料性附录) 测评后活动、附 录 B (资料性附录)渗透测试的有关概念说明
################################################################################ GB/T 36627-2018 《信息安全技术 网络安全等级保护测试评估技术指南》对网络安全等级保护测评中的相关测评技术进行明确的分类和定义,系统地归纳并阐述测评的技术方法,概述技术性安全测试和…...

pytorch3d+pytorch1.10+MinkowskiEngine安装
1、配置pytorch1.10cuda11.0 pip install torch1.10.1cu111 torchvision0.11.2cu111 torchaudio0.10.1 -f https://download.pytorch.org/whl/cu111/torch_stable.html 2、配置 MinkowskiEngine库 不按下面步骤,出现错误 1、下载MinkowskiEngine0.5.4到本地 2、查看…...
AI Infra运维实践:DeepSeek部署运维中的软硬结合
发布会资料 《AI Infra运维实践:DeepSeek部署运维中的软硬结合》 袋鼠云运维服务 1、行业痛点 随着数字化转型的深入,企业面临的运维挑战日益复杂,所依托的平台在长期使用的过程中积累了各式各样的问题或者难点。这些问题不仅影响效率&…...

MySQL体系架构解析(二):MySQL目录与启动配置全解析
MySQL中的目录和文件 bin目录 在 MySQL 的安装目录下有一个特别重要的 bin 目录,这个目录下存放着许多可执行文件。与其他系统的可执行文件类似,这些可执行文件都是与服务器和客户端程序相关的。 启动MySQL服务器程序 在 UNIX 系统中,用…...