Elasticsearch + Milvus 构建高效知识库问答系统《一》
🔍 Elasticsearch + Milvus 构建高效知识库问答系统(RAG 技术实战)
📌 目录
- 背景介绍
- Elasticsearch 在知识库检索中的作用
- Milvus 在知识库检索中的作用
- 混合检索:Elasticsearch + Milvus
- 完整代码实现
- 部署建议与优化方向
- 总结
背景介绍
在构建基于大语言模型(LLM)的知识增强型生成系统(RAG)中,知识库检索是整个流程的核心环节。它决定了模型是否能从庞大的文档中快速定位到相关上下文信息。
传统的 RAG 系统通常采用以下两阶段流程:
[Query] → [Retriever] → [Top-k Docs] → [LLM] → [Answer]
其中 Retriever 可以是稀疏检索(如 BM25)、稠密检索(如 Milvus),也可以是两者的混合。
本文将详细介绍如何使用 Elasticsearch 和 Milvus 来构建一个高效的多模态检索系统,并提供可运行的 Python 示例代码。
Elasticsearch 在知识库检索中的作用
功能概述:
- 基于关键词匹配的稀疏检索
- 支持倒排索引和 TF-IDF/BM25 模型
- 快速召回高相关性文档
- 支持中文分词、拼音搜索、近义词扩展等功能
适用场景:
- 中文医疗问答系统
- 法律条文检索
- 小规模 FAQ 库
- 对语义理解要求不高的冷启动阶段
示例代码(Python)
from elasticsearch import Elasticsearch
from sentence_transformers.util import cos_sim# 初始化 ES 客户端
es = Elasticsearch(hosts=["http://localhost:9200"])# 插入文档
doc1 = {"content": "大模型训练需要大量高质量数据"}
doc2 = {"content": "RAG 系统通过外部知识提升回答能力"}
es.index(index="medical_kb", document=doc1)
es.index(index="medical_kb", document=doc2)# 查询
query_body = {"match": {"content": "如何提升问答系统的准确性?"}
}
response = es.search(index="medical_kb", body=query_body)# 输出结果
print("Elasticsearch 回答结果:")
for hit in response['hits']['hits']:print(f" - {hit['_source']['content']}")
Milvus 在知识库检索中的作用
功能概述:
- 支持高维向量存储与相似度检索(ANN)
- 可与 BERT、Sentence-BERT、BGE 等句向量模型结合
- 实现语义级别的相似度计算
- 支持大规模数据检索(亿级向量)
适用场景:
- 大规模知识库
- 高精度语义匹配
- 图像/文本混合检索
- LLM + 向量数据库联合部署
示例代码(Python + Milvus)
pip install pymilvus sentence-transformers
from sentence_transformers import SentenceTransformer
from pymilvus import connections, Collection# 加载语义编码器
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')# 连接 Milvus
connections.connect(host='localhost', port='19530')
collection = Collection("faq_collection")# 插入向量(假设你已建立好 collection 并导入了知识库向量化内容)# 查询
query_text = "如何提升问答系统的准确性?"
query_vec = model.encode([query_text])collection.load()
results = collection.search(data=query_vec, anns_field="embedding", param={"metric_type": "IP", "offset": 0}, limit=3)# 输出结果
print("Milvus 语义检索结果:")
for result in results:for hit in result:print(f" - ID: {hit.id} Distance: {hit.distance}")
混合检索:Elasticsearch + Milvus
你可以采用如下流程来构建一个高效的 RAG 问答系统:
[用户问题]↓
Elasticsearch → [Top-50 粗召回文档] ↓
Milvus → [Top-10 语义相似文档]↓
Reranker → [Top-3 最佳匹配段落]
✅ 混合优势:
| 优点 | 描述 |
|---|---|
| 冷启动友好 | 利用 ES 快速上线 |
| 语义准确 | Milvus 提升召回质量 |
| 高效排序 | 结合 reranker 进一步优化输出 |
| 支持中文 | 可选择支持中文的 embedding 模型 |
完整代码实现(Python 示例)
以下是一个完整的混合检索流程示例:
from elasticsearch import Elasticsearch
from sentence_transformers import SentenceTransformer
from pymilvus import connections, Collection# 初始化组件
es = Elasticsearch(hosts=["http://localhost:9200"])
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
connections.connect(host='localhost', port='19530')
milvus_col = Collection("faq_collection")def hybrid_retrieval(query, k=3):# Step 1: Elasticsearch 粗召回es_result = es.search(index="medical_kb", body={"match": {"content": query}})es_docs = [hit["_source"]["content"] for hit in es_result["hits"]["hits"]]# Step 2: Milvus 语义精排query_vec = model.encode([query])milvus_results = milvus_col.search(data=query_vec, anns_field="embedding", param={"metric_type": "IP"}, limit=k)# Step 3: 返回 top-k 文档final_docs = []for result in milvus_results:for hit in result:final_docs.append(es_docs[hit.id])return final_docs[:k]
部署建议与优化方向
1. 数据预处理建议:
- 使用
jieba或HanLP对中文进行分词 - 清洗无意义符号、HTML、乱码
- 构建统一的数据格式(如 JSON)
2. 索引构建建议:
- Elasticsearch:
- 使用
ik-analyzer中文分词插件 - 设置字段类型为
text或keyword
- 使用
- Milvus:
- 使用 HNSW 或 IVF-PQ 索引加速查询
- 设置合适的维度(如 768 / 1024)
- 开启 GPU 加速(如支持)
3. 性能调优建议:
| 组件 | 调优方式 |
|---|---|
| Elasticsearch | 分片策略、索引合并、关闭不必要的日志 |
| Milvus | 使用 ANN 索引、调整 nprobe、批量插入 |
| Embedding 模型 | 使用轻量模型(如 bge-small, gte-base) |
| 缓存机制 | Redis 缓存高频问题与答案 |
| 异步检索 | 使用 Celery 或 FastAPI 异步接口 |
4. 可选高级功能:
- Reranking:使用
BAAI/bge-reranker-base等交叉编码器进一步打分排序 - 向量更新机制:定期更新 Milvus 中的知识库向量
- 混合评分融合:对 ES 和 Milvus 的结果做加权得分排序
总结
| 方法 | 是否理解语义 | 是否需训练 | 是否支持中文 | 是否适合大规模 | 是否适合冷启动 |
|---|---|---|---|---|---|
| Elasticsearch | ❌ 否 | ❌ 否 | ✅ 是 | ✅ 是 | ✅ 是 |
| Milvus | ✅ 是 | ✅ 是 | ✅(模型决定) | ✅ 是 | ❌ 否 |
| FAISS | ✅ 是 | ✅ 是 | ✅(模型决定) | ⭐ 有限 | ❌ 否 |
| 混合检索(ES+Milvus) | ✅ 是 | ✅ 是 | ✅ 是 | ✅ 是 | ✅ 是 |
✅ 推荐组合方案
方案一:纯稀疏检索(仅使用 ES)
适合冷启动或无语义模型的场景,无需 GPU 资源。
Query → Elasticsearch → Top-k Docs
方案二:纯稠密检索(仅使用 Milvus)
适合有预训练语义模型(如 BGE、Jina、OpenAI embeddings)的场景。
Query → Dense Encoder → Milvus → Top-k Docs
方案三:混合检索(ES + Milvus)
适合企业级 RAG 系统,兼顾效率与精度。
Query → Elasticsearch → Top-50 Docs↓Milvus → Top-10 Docs↓Reranker → Top-3 最终输出
📌 欢迎点赞、收藏,并关注我,我会持续更新更多关于 AI、LLM、视觉-语言模型等内容!
相关文章:

Elasticsearch + Milvus 构建高效知识库问答系统《一》
🔍 Elasticsearch Milvus 构建高效知识库问答系统(RAG 技术实战) 📌 目录 背景介绍Elasticsearch 在知识库检索中的作用Milvus 在知识库检索中的作用混合检索:Elasticsearch Milvus完整代码实现部署建议与优化方向…...
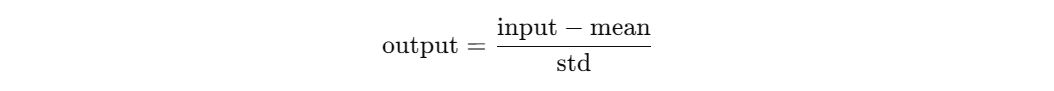
深入理解 transforms.Normalize():PyTorch 图像预处理中的关键一步
深入理解 transforms.Normalize():PyTorch 图像预处理中的关键一步 在使用 PyTorch 进行图像分类、目标检测等深度学习任务时,我们常常会在数据预处理部分看到如下代码: python复制编辑transform transforms.Compose([transforms.ToTensor…...

leetcode 2434. 使用机器人打印字典序最小的字符串 中等
给你一个字符串 s 和一个机器人,机器人当前有一个空字符串 t 。执行以下操作之一,直到 s 和 t 都变成空字符串: 删除字符串 s 的 第一个 字符,并将该字符给机器人。机器人把这个字符添加到 t 的尾部。删除字符串 t 的 最后一个 字…...
爆炸仿真的学习日志
今天学习了一下【Workbench LS-DYNA中炸药在空气中爆炸的案例-哔哩哔哩】 https://b23.tv/kmXlN29 一开始 如果你的 ANSYS Workbench 工具箱(Toolbox)里 只有 SPEOS,即使尝试了 右键刷新、重置视图、显示全部 等方法仍然没有其他分析系统&a…...

【Fiddler抓取手机数据包】
Fiddler抓取手机数据包的配置方法 确保电脑和手机在同一局域网 电脑和手机需连接同一Wi-Fi网络。可通过电脑命令行输入ipconfig查看电脑的本地IP地址(IPv4地址),手机需能ping通该IP。 配置Fiddler允许远程连接 打开Fiddler,进入…...
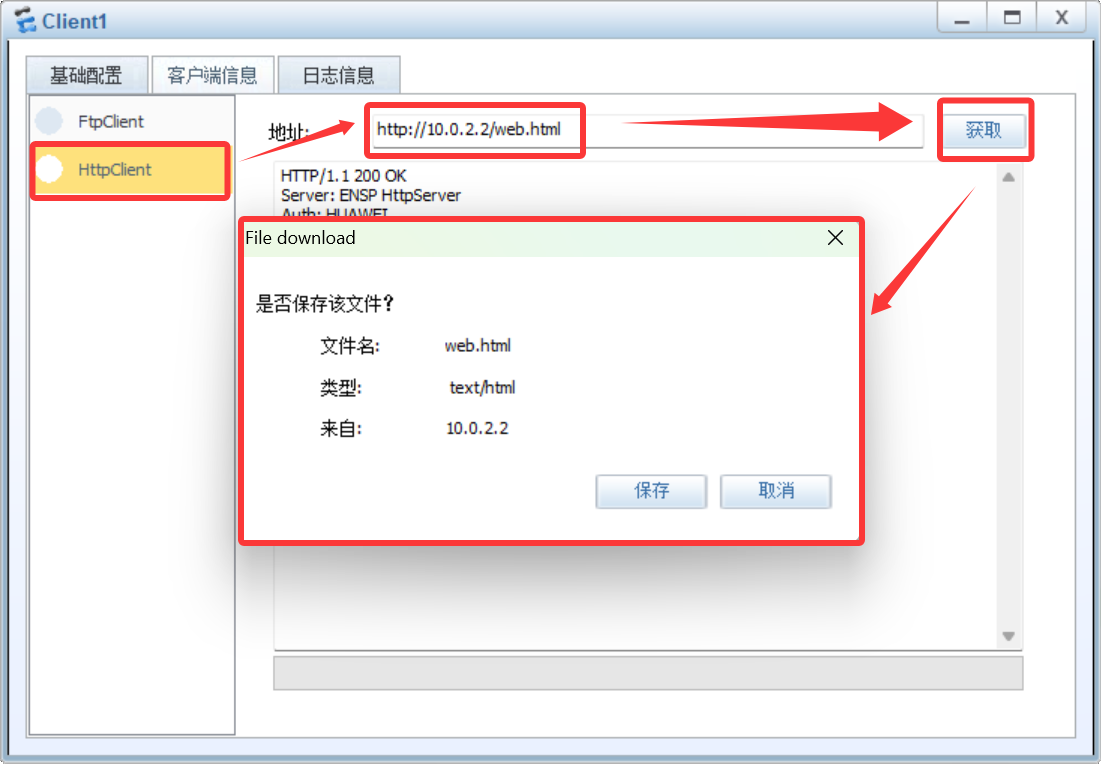
[华为eNSP] OSPF综合实验
目录 配置流程 画出拓扑图、标注重要接口IP 配置客户端IP 配置服务端IP 配置服务器服务 配置路由器基本信息:名称和接口IP 配置路由器ospf协议 测试结果 通过配置OSPF路由协议,实现跨多路由器的网络互通,并验证终端设备的访问能力。 …...

东芝Toshiba DP-4528AG打印机信息
东芝 Toshiba DP 4528AG 是一款黑白激光数码复合机: 类型:激光数码复合机,涵盖复印、打印、扫描、传真功能,能满足办公室多样化的文档处理需求。速度类型:中速,黑白复印和打印速度可达 45 页 / 分钟&#…...

Vue3+Vite中lodash-es安装与使用指南
在 Vue 3 Vite 项目中安装和使用 lodash-es 的详细指南如下: 一、为什么选择 lodash-es? ES 模块支持:lodash-es 以原生 ES 模块格式发布,支持现代构建工具的 Tree Shaking 按需加载:只引入需要的函数,显…...
完美搭建appium自动化环境
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 桌面版appium提供可视化操作appium主要功能的使用方式,对于初学者非常适用。 如何在windows平台安装appium桌面版呢,大体分两个步骤&…...
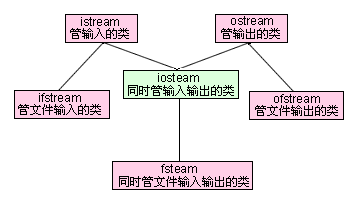
c++中的输入输出流(标准IO,文件IO,字符串IO)
目录 (1)I/O概述 I/O分类 不同I/O的继承关系 不同I/O对应的头文件 (2)iostream 标准I/O流 iostream头文件中的IO流对象 iostream头文件中重载了<<和>> 缓冲区示意图 标准输入流 cin用法 cin:按空…...
——解决打包为app后在安卓机可物理返回但是在苹果手机无法测滑返回的问题)
App使用webview套壳引入h5(三)——解决打包为app后在安卓机可物理返回但是在苹果手机无法测滑返回的问题
话不多说,直接放最终版本代码。 解决思路是:如果设备是ios设备在myH5中监听 touchstart 和touchend事件。 经过 App使用webview套壳引入h5的最终代码如下 myApp中,entry.vue代码如下: <template><view class"ent…...

CSS中text-align: justify文本两端对齐
text-align: justify; 是 CSS 中用于控制文本对齐方式的属性值,它的核心作用是让文本两端对齐(分散对齐),使段落左右边缘整齐排列。以下是详细解析: 作用效果 均匀分布间距 浏览器会自动调整单词/字符之间的间距&#…...

2025年渗透测试面试题总结-ali 春招内推电话1面(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 ali 春招内推电话1面 一、Web安全核心理解 二、熟悉漏洞及防御方案 三、UDF提权原理与防御 四、XSS Fuzz…...

C#中的依赖注入
1. 依赖注入(Dependency Injection, DI)概述 定义 :依赖注入是一种设计模式,允许将组件的依赖关系从内部创建转移到外部提供。这样可以降低组件之间的耦合度,提高代码的可测试性、可维护性和可扩展性。 核心思想 &…...
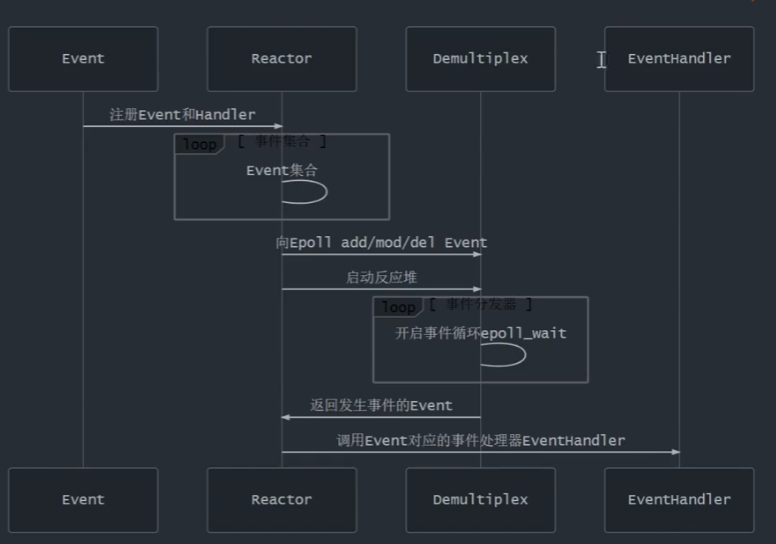
Reactor和Proactor
reactor的重要组件包括:Event事件、Reactor反应堆、Demultiplex事件分发器、Eventhandler事件处理器。...

黄晓明新剧《潜渊》定档 失忆三面间谍开启谍战新维度
据悉,黄晓明领衔主演的谍战剧《潜渊》已于近日正式定档6月9日,该剧以“失忆三面间谍”梁朔为核心,打破传统谍战剧的框架和固有角度,以一种特别的视角将悬疑感推向极致。剧中,梁朔因头部受伤失去记忆,陷入身…...

深入浅出Java ParallelStream:高效并行利器还是隐藏的陷阱?
在Java 8带来的众多革新中,Stream API彻底改变了我们对集合操作的方式。而其中最引人注目的特性之一便是parallelStream——它承诺只需简单调用一个方法,就能让数据处理任务自动并行化,充分利用多核CPU的优势。但在美好承诺的背后,…...
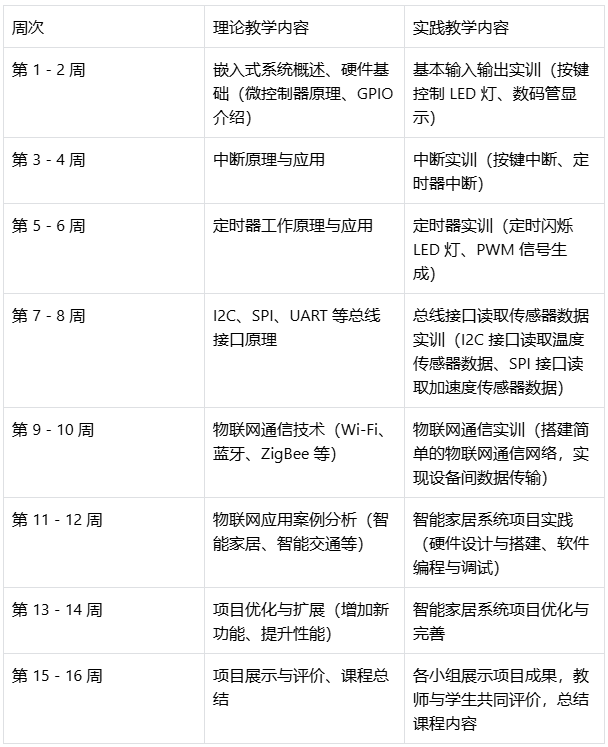
物联网嵌入式开发实训室建设方案探讨(高职物联网应用技术专业实训室建设)
一、建设背景与目标 在当今数字化时代,物联网技术正以前所未有的速度改变着人们的生活和工作方式。从智能家居到工业自动化,从智能交通到环境监测,物联网的应用场景无处不在。根据市场研究机构的数据,全球物联网设备连接数量预计…...
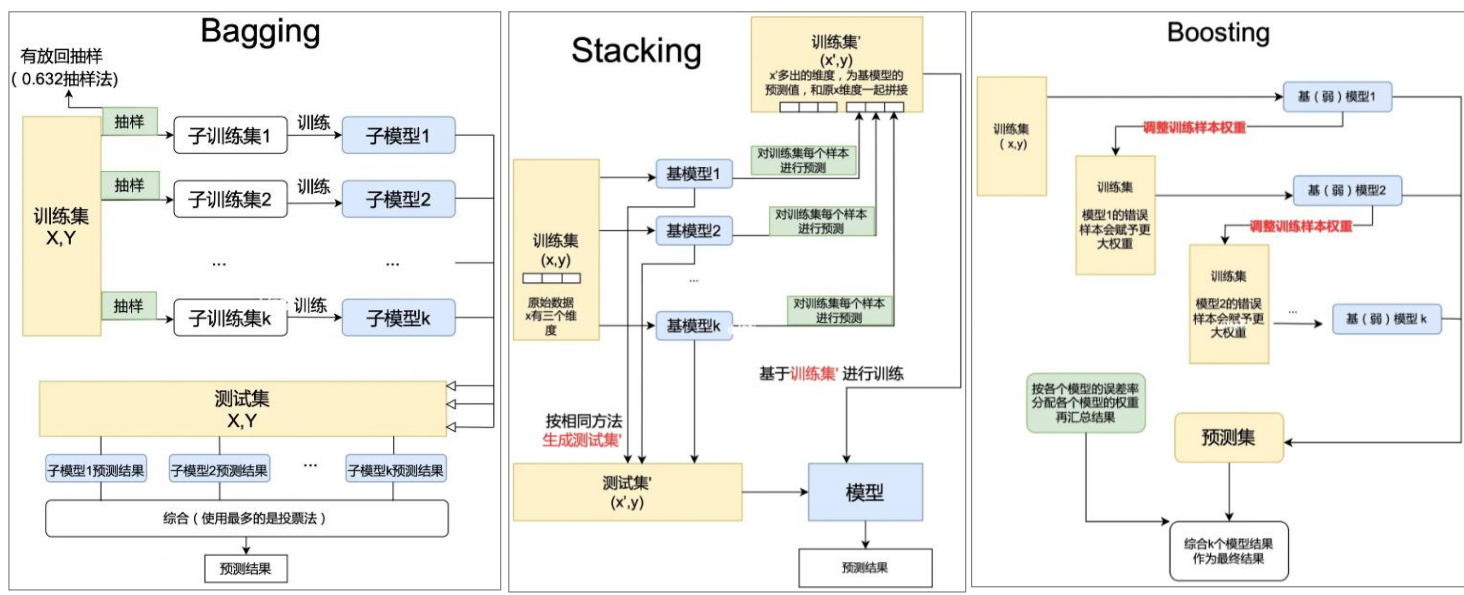
集成学习三种框架
集成学习通过组合多个弱学习器构建强学习器,常见框架包括Bagging(装袋)、Boosting(提升) 和Stacking(堆叠) 一、Bagging(自助装袋法) 核心思想 从原始数据中通过有放回…...

大数据量高实时性场景下订单生成的优化方案
文章目录 一、问题背景二、核心优化目标三、架构设计方案3.1 分层架构设计 3.2 关键组件说明 四、核心优化策略4.1 异步处理与流量控制4.1.1 异步接口设计4.1.2 任务进度查询 4.2 批量处理与并行计算4.2.1 数据分批处理4.2.2 并行流处理 4.3 数据库优化4.3.1 批量插入4.3.2 索…...

在UI界面内修改了对象名,在#include “ui_mainwindow.h“没更新
原因:未重新编译UI文件 Qt的UI文件(.ui)需要通过uic工具(Qt的UI编译器)生成对应的ui_*.h头文件。如果你在Qt Designer中修改了对象名,但没有重新构建(Rebuild)…...

ocrapi服务docker镜像使用
umiocr只能用于windows,http服务只能找旧版,没办法,只能找docker替代一下了。 umiocr 使用paddleOCR和rapidOCR引擎。以下时这两个docker的运行方法 paddleOCR使用 duolabmeng666的ppocr镜像 镜像大小约2.6G docker run -itd --name ppoc…...

使用React+ant Table 实现 表格无限循环滚动播放
数据大屏表格数据,当表格内容超出(出现滚动条)时,无限循环滚动播放,鼠标移入暂停滚动,鼠标移除继续滚动;数据量小没有超出时不需要滚动。 *使用时应注意,滚动区域高度父元素高度 - 表…...

Podman 和 Docker
Podman 和 Docker 都是容器化工具,用于创建、运行和管理容器。它们有很多相似之处,但也存在关键区别。下面从多个维度对比它们,并给出适用场景建议。 1. 核心区别 特性DockerPodman守护进程(Daemon)必须运行 dockerd …...
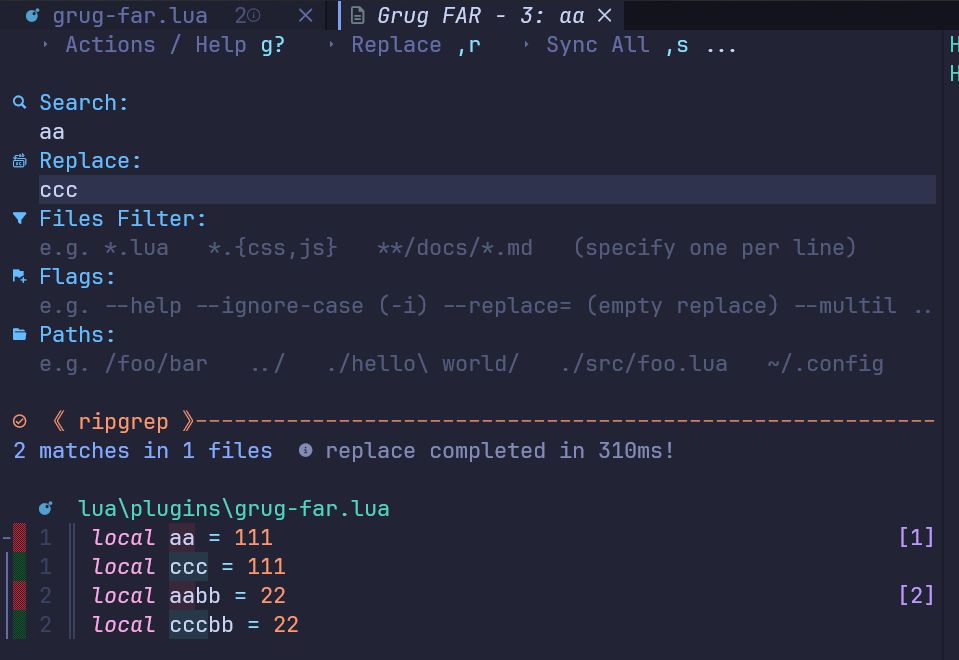
Neovim - 常用插件,提升体验(三)
文章目录 nvim-treelualineindent-blanklinetelescopegrug-far nvim-tree 官方文档:https://github.com/nvim-tree/nvim-tree.lua 以前我们都是通过 :e 的方式打开一个 buffer,但是这种方式需要记忆文件路径,因此这里可以通过 nvim-tree 插…...

C++单例模式教学指南
C单例模式完整教学指南 📚 目录 [单例模式基础概念][经典单例实现及问题][现代C推荐实现][高级话题:双重检查锁][实战应用与最佳实践][总结与选择指南] 1. 单例模式基础概念 1.1 什么是单例模式? 单例模式(Singleton Pattern&…...
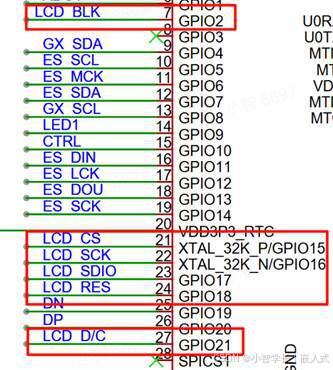
SOC-ESP32S3部分:31-ESP-LCD控制器库
飞书文档https://x509p6c8to.feishu.cn/wiki/Syy3wsqHLiIiQJkC6PucEJ7Snib ESP 系列芯片可以支持市场上常见的 LCD(如 SPI LCD、I2C LCD、并行 LCD (Intel 8080)、RGB/SRGB LCD、MIPI DSI LCD 等)所需的各种时序。esp_lcd 控制器为上述各类 LCD 提供了一…...

如何区分虚拟货币诈骗与经营失败?
首席数据官高鹏律师团队编著 00后大学生杨启超在公有链上发行BFF虚拟币,因在24秒内撤回流动性导致他人损失5万USDT币,被河南南阳法院以诈骗罪判处有期徒刑4年6个月。庭审中,辩护律师手持合约地址记录据理力争:“公有链发币自由、…...

Flink 高可用集群部署指南
一、部署架构设计 1. 集群架构 graph TDClient([客户端]) --> JM1[JobManager 1]Client --> JM2[JobManager 2]Client --> JM3[JobManager 3]subgraph ZooKeeper集群ZK1[ZooKeeper 1]ZK2[ZooKeeper 2]ZK3[ZooKeeper 3]endsubgraph TaskManager集群TM1[TaskManager 1…...
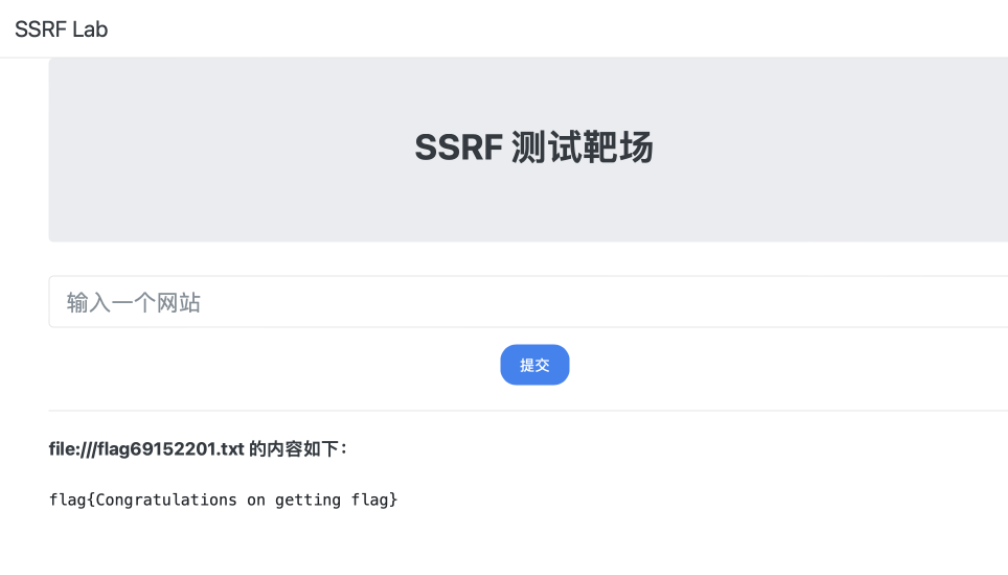
【云安全】以Aliyun为例聊云厂商服务常见利用手段
目录 OSS-bucket_policy_readable OSS-object_public_access OSS-bucket_object_traversal OSS-Special Bucket Policy OSS-unrestricted_file_upload OSS-object_acl_writable ECS-SSRF 云攻防场景下对云厂商服务的利用大同小异,下面以阿里云为例 其他如腾…...