五、查询处理和查询优化
五、查询处理和查询优化
主要内容
- 查询概述
- 查询处理过程
- 关系操作的基本实现算法
- 查询优化技术
- 代数优化
- 基于存取路径的优化
- 基于代价估算的优化
1. 查询概述
-
查询是数据库管理系统中使用最频繁、最基本的操作,对系统性能有很大影响。
-
对于同一个SQL查询,通常可以有多个等价的关系代数表达式。
-
由于存取路径的不同,每个关系代数表达式的查询代价和效率也是不同的。
-
为了提高查询效率,需要针对具体查询请求,建立一个相对高效的查询计划,即进行查询优化。
-
查询优化技术是关系数据库的关键技术。
-
DBMS的查询优化器包括了很多查询优化技术。
-
查询语句的执行方式
下面是SQL的两种使用/执行方式
-
解释方式(交互式)
- DBMS不保留可执行代码,每一行都重新解释执行查询语句,事务完成后返回查询结果。也就是写一句,执行一句,不会生成.exe程序。
- 具有灵活、应变形强的特点,但是开销比较大、效率比较低。
- 主要适用于不重复使用的偶然查询。
总的来说,就是程序 每执行一条语句,就翻译一条语句,边翻译边运行,不生成单独的可执行文件。
-
编译方式(嵌入式)
- 先进行编译处理,生成可执行代码。下次运行时,直接执行可执行代码
- 当数据库中某些数据发生改变时,再重新编译。
- 主要优点时执行效率高、系统开销小。
总结:程序在运行之前,一次性把全部代码 翻译成计算机能理解的“机器码”(可执行文件),以后就可以直接运行,不需要再翻译了。
-
2. 查询处理过程
-
查询处理是指从数据库中提取数据所设计的处理过程,包括将用户提交的查询语句转变为数据库的查询计划,并执行这个查询计划得到查询结果。
-
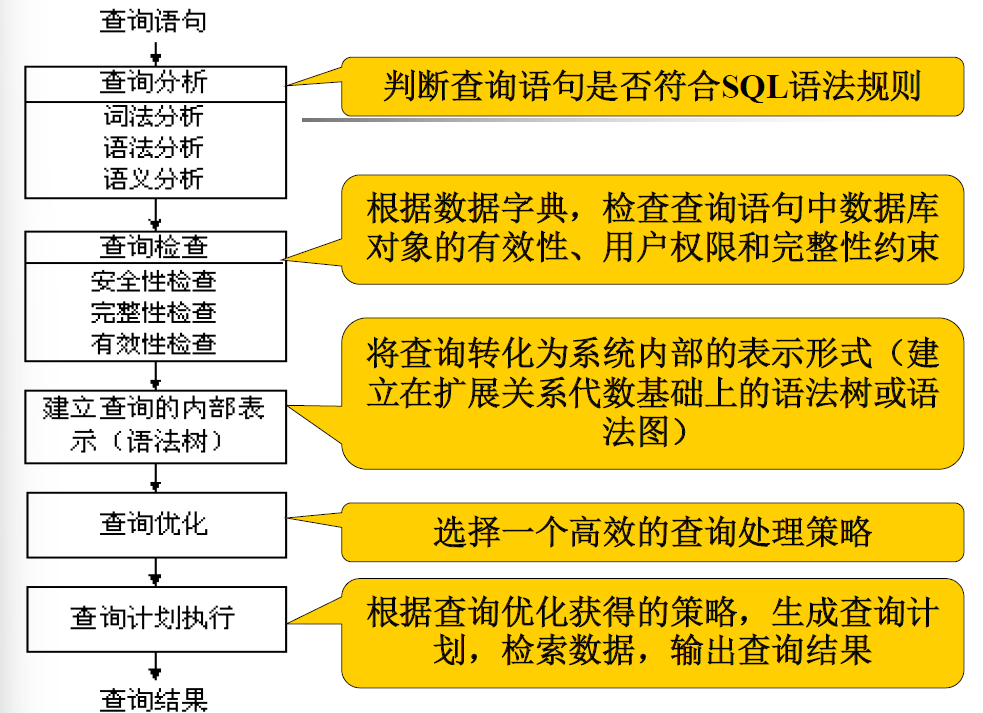
关系数据库的查询处理分为五个阶段
- 查询分析
- 查询检查
- 建立查询的内部表示
- 查询优化
- 查询执行
3. 关系操作的基本实现算法
- 为了实现查询处理,需要选择合适的算法来实现基本的关系操作
- 选择操作的算法实现
- 连接操作的算法实现
- 投影操作的算法实现
- 集合运算的算法实现
1. 选择操作的实现算法
-
选择操作的算法实现方式有:
-
顺序扫描法:
-
按照关系中元组的物理顺序扫描每个元组,检查该元组是否满足选择条件,如果满足则输出。
-
物理顺序:数据库把表中的记录(元组)实际写入磁盘文件时的顺序,它是由数据库系统自己决定的,通常和你插入数据的顺序或查询顺序没有直接关系。
举例说明:结社有一个
Student表:Sno Sname Sage 200701 张三 19 200702 李四 20 200703 王五 18 那么我们看到的是“逻辑顺序”(按行排列),但数据库在磁盘中可能是按以下顺序物理存储的:
页1:200703 | 王五 | 18 页2:200701 | 张三 | 19 页3:200702 | 李四 | 20所以“物理顺序”是指这些行在磁盘文件里真正的存放顺序,不一定和你查询的顺序一致。
-
物理顺序的决定
-
数据的插入顺序
- 最初插入表中的数据,数据库会按照你插入的先后顺序,从上到下写进磁盘页。
- 但一旦发生删除、更新、分页,就会发生变化。
-
. 表的存储结构(如堆表 or 索引组织表)
表类型 决定物理顺序的方式 堆表(Heap Table) 没有排序要求,插入的数据随缘放在哪块空磁盘页,顺序不固定 索引组织表(IOT) 数据存储顺序会跟着主键排序,比如按 Sno排序聚集索引(Clustered Index) 数据文件中记录的顺序就是索引的顺序(MySQL 的 InnoDB 就是) 像我用的是MySQL的InnoDB存储引擎,它默认就是 聚集索引组织表,即:主键的顺序 ≈ 物理存储顺序。表的数据行会按照 主键的顺序 排列并存储;主键本身构成了一棵 B+树结构,这棵 B+树的叶子节点就直接存储了整条数据记录;因此,数据的物理存储顺序 ≈ 主键顺序,而且这就是 主键的 B+树,不是单独开辟空间存储,而是数据就存放在 B+树里。
[200701]/ \[200701] [200702] [200703](张三,19) (李四,20) (王五,18)
-
-
逻辑顺序的决定
情况 逻辑顺序由谁决定 有 ORDER BY子句时你指定的字段决定顺序(如 ORDER BY Sno就按 Sno 升序)没有 ORDER BY子句时由存储引擎决定(InnoDB 通常按主键顺序返回)
-
-
实现简单,不需要特殊的存取路径
-
适用于任何关系,尤其适用于被选中的元组数占有较大比例或总的元组数较少的关系。
-
简单,通用,效率低
-
-
二分查找法
适应于等值比较,高效,但要求物理文件按选择字段有序组织。
物理文件指的是:数据库系统在磁盘上实际保存数据的底层文件,也就是数据的物理存储结构,比如
.ibd文件(InnoDB 独立表空间),或其他数据页的结构。可以理解为:
- 数据库中的“表”对我们来说是逻辑表结构(行、列);
- 但数据库实际是在磁盘上开辟了一片空间,按**页(Page)和块(Block)**来存储这些数据行;
- 这些实际写在磁盘上的数据文件就叫做“物理文件”。
-
按选择字段有序组织,该如何理解?
因为二分查找(Binary Search)只能在“已排序的数组”上使用。。所以我们想在表中对某字段(比如
Sno)做二分查找,前提是这个字段在物理文件中已经排好序!在数据库中,要达到这个效果,一般有两种方式:
-
用 主键聚集索引
(就像我们前面说的 InnoDB)
- 如果你要按主键二分查找(如
Sno = '200701'),那么因为表是按主键组织的,就天然满足这个条件。
- 如果你要按主键二分查找(如
-
用 辅助索引(辅助字段 + 顺序页),也就是二级索引。
- 如果你想对
Sname做二分查找,那就要为Sname创建索引,并且让这个索引页是排序的(B+树结构); - 索引页中每一条记录会指向真正的物理数据页
- 如果你想对
下面再次解释一下二级索引
二级索引(非主键的索引)会在磁盘上单独生成一个索引结构,包含自己的一棵 B+树,用来加速查询;而这棵 B+树和主键索引的 B+树是分开的,占用不同的页结构和空间。
- 二级索引的 B+树叶子节点中通常存放下面两个:
- 索引字段值如
Sname(你要建索引的列) - 主键列值(InnoDB 的二级索引叶子节点中必须带主键值,用于“回表”)
- (不包含整行数据)这是它和聚集索引最大的区别。
- 索引字段值如
-
-
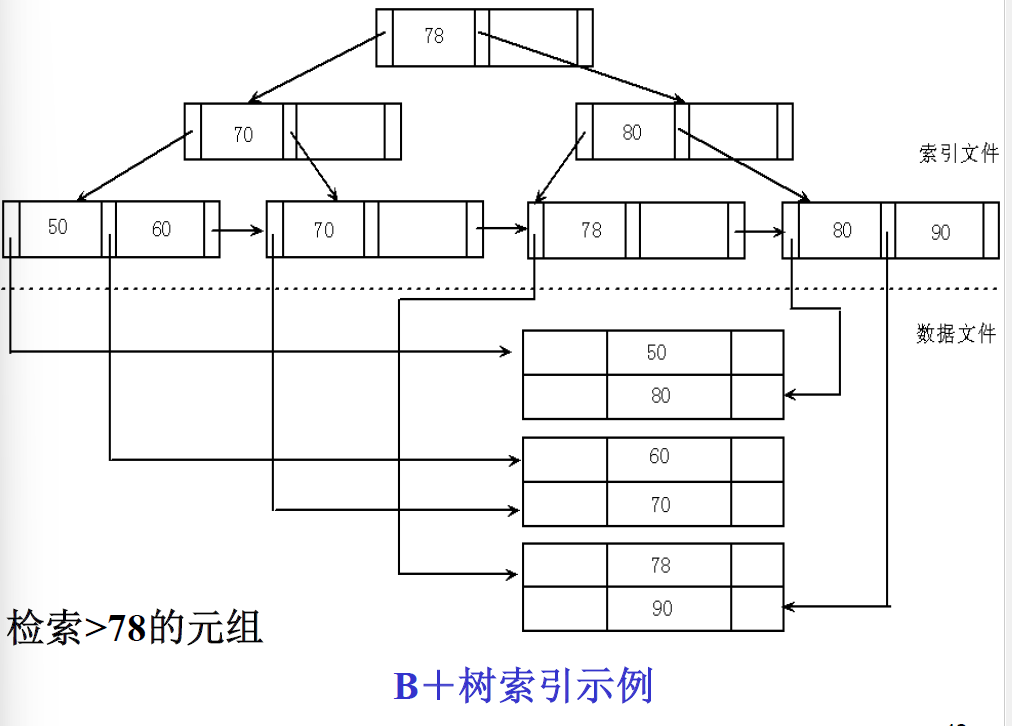
索引扫描法(散列扫描法)
- 要求选择条件设计的属性上有索引(例如B+树索引或Hash索引),MySQL就是B+数索引。
- 拖过索引先找到满足条件的元组指针,然后通过该指针继续检索满足条件的元组。
- 索引在一定程序上能提高查询效率。
-
-
【例】
SELECT * FROM Student WHERE <条件表达式>;其中条件表达式可以有一下几种情况:
- C1:无条件
- C2:
Sno = '200636' - C3:
Sage > 18 - C4:
Sdept = '计算机' AND Sno = '200636' - C5:
Sdept = '计算机' AND Sage > 18 - C6:
Sage > 18 OR Sdept = '计算机'
-
C1:无条件
顺序扫描法
-
C2:
Sno = '200636'- 字段
Sno是排序属性,可以用二分查找法实现C2中的选择条件 - 如果是非排序属性,可用顺序扫描法
- 如果
Sno上有B+数索引,就用B+数索引
- 字段
-
C3:
Sage > 18- 如果
Sage上有B+数索引,可以使用B+树索引找到Sage = 78索引项,以此为入口点找到B+树的顺序集上所有Sage > 78的元组指针,进而找到相应元组。
- 如果
复合选择的情况
C4:Sdept = '计算机' AND Sno = '200636'
C5:Sdept = '计算机' AND Sage > 18
C6:Sage > 18 OR Sdept = '计算机'
-
合取选择条件的实现
-
使用组合索引实现
如果在
(Sdept,Sno)上建立了组合索引,可以通过这个组合索引直接找到满足条件C4的元组。MySQL 在执行时,会使用 B+树先按第一个字段(如
Sdept)查找分支,然后在找到的结果范围内再按第二个字段(Sno)查找,从而实现快速定位。 -
使用单独索引实现
如果某个属性具有索引,先通过索引找到符合该属性条件的元组,然后进一步判断是否满足取余属性条件。
例如C5,先找到
Sdept = '计算机'的元组,再判断Sage > 18是否成立。 -
使用多个索引实现
- 如果在多个检索属性上存在索引,可以分别检索满足条件的元组,再求交集。
- 如果还有非索引属性的检索条件,则需进一步判断。
- 例:C5:
Sdept = '计算机' AND Sage > 18,假设Sdept和Sage上都有索引。- 分别使用索引找到
Sdept = '计算机'的一组元组指针和Sage > 18的另一组元组指针 - 然后求这两组指针的交集,再到
Student表中检索元组
- 分别使用索引找到
-
-
合取(且,AND)选择条件的选择
- 首先选择选择性小的条件检索元组
- 选择性(Selectivity):满足条件的元组数占关系中元组总数的比例。
- 一般地,如果选择条件的选择性为s,满足该条件的元组数则可以估计为(元组总数 × s \times s ×s)。所估计的值越小,就越有必要首先使用这个条件来检索元组。
- 例:查询成绩90分以上的男生
-
析取(或,OR)选择条件的实现
-
优化处理难度比较大,
例如 C6:
Sage > 18 OR Sdept = '计算机' -
如果
Sdept上有索引,而Sage上没有索引,基本无法进行优化。 -
只要任意一个条件没有索引,就只能使用顺序扫描方法。
-
只有当条件中涉及的属性都具有索引时,才能通过优化检索满足条件的元组,然后再通过合并操作消除重复元组。
-
尽量避免用OR。
-
2. 连接操作的实现算法
- 连接操作的特点
- 查询处理中最耗时的操作之一,
- 操作本身开销大
- 可能产生很大的中间结果。
- 连接操作的实现算法
- 嵌套循环法
- 索引嵌套循环法
- 排序合并法
- 散列连接(Hash Join)法
连接操作的实现——嵌套循环法
- 基本思想:对于关系R(外循环)中的每个元组t,检索关系S(内循环)中的每个元组s,判断这两个元组是否满足连接条件t[A]=s[B]。如果满足条件,则连接这两个元组作为输出结果。
- 嵌套循环法时最简单、最直接的连接算法,与选择操作中的顺序扫描法类似,不需要特别的存取路径。
- 适用于任何条件的连接。
- 选择哪一个关系用于外循环、哪一个关系用于内循环会给连接的性能带来比较大的差异。一般使用较少块的问价作为外循环文件,连接代价较小。
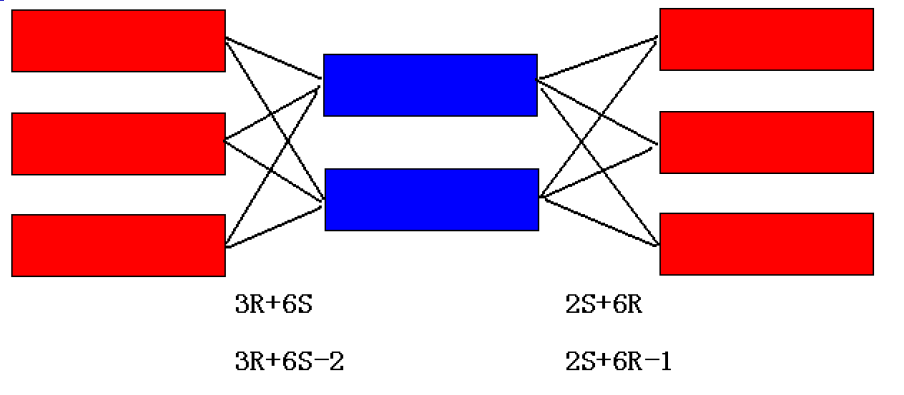
说明
假设每个红色的元组数是R,每个蓝色的元组数是S。
那么当红色和蓝色连接时
-
假设内存一次可以放的完
-
R作为外循环
- 每个R都要遍历两个S
- 总共有3个R
因此总共次数为3R+6S
-
S作为外循环
- 每个S都要便利三个R
- 总共有2个S
因此从次数为2S+6R
-
-
假设内存一次只能放2块,假设两块区域分别是A,B
- R作为外循环
- A放R,B放S,count = R+S;此时二者连接
- 然后,A的R不变,B的S丢出去,再读进一个S,count += S,count = R + S +S;此时二者连接
- 然后,B的S不变,A的R丢出去,再读进一个R,count += R,count = 2R + 2S;此时二者连接
- 然后,A的R不变,B的S丢出去,再读进一个S,count += S,count = 2R + 3S;此时二者连接
- 然后,B的S不变,A的R丢出去,再读进一个R,count += R,count = 3R + 3S;此时二者连接
- 然后,A的R不变,B的S丢出去,再读进一个S,count += S,count = 3R + 4S;此时二者连接
- 最后读完了,总的次数count = 3R + 4S
- S作为外循同理,最终count = 2S + 6R
- R作为外循环
连接操作的实现——索引嵌套循环法
- 在嵌套循环法中,如果两个连接属性中的一个属性上存在索引(或散列),可以使用索引扫描代替顺序扫描。
- 例如,假设在关系S中的属性B上存在索引,则对于R中的每个元组,可以通过B的索引查找满足t[B] = s[A]的所有元组,而不必扫描S中的所有元组,以减少扫描时间。
- 在一般情况下,索引嵌套循环法和嵌套循环法相比 ,查询的代价可以降低很多。
连接操作的实现——排序合并法
-
适用于等值和自然连接
-
前提条件:关系R和S分别按照连接属性A和B排序
-
处理过程:按照连接属性同时对关系R和S进行扫描,匹配A和B上有相同值的元组,连接起来,作为结果输出。
-
特点:两个关系各扫描一次,而且是同步进行的。
-
示例:下页的等值连接
-
等值连接示例
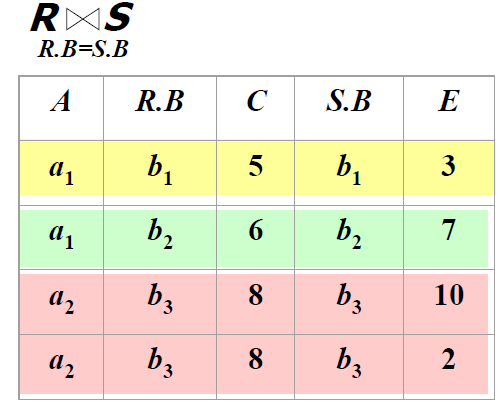
-
如果R和S没有排序,可以进行排序处理,再进行连接操作。
-
如果两个表原来无序,执行时间要加上对两个表的排序时间。
这里的“排序”指的是在连接前对整个表进行一次物理或逻辑排序处理;而“索引”是一种数据结构,虽然能加快查找,但不等于数据本身就是排好序的。
-
对于两个大表,先排序,后使用排序合并法执行连接,总的时间一般仍会大量减少。
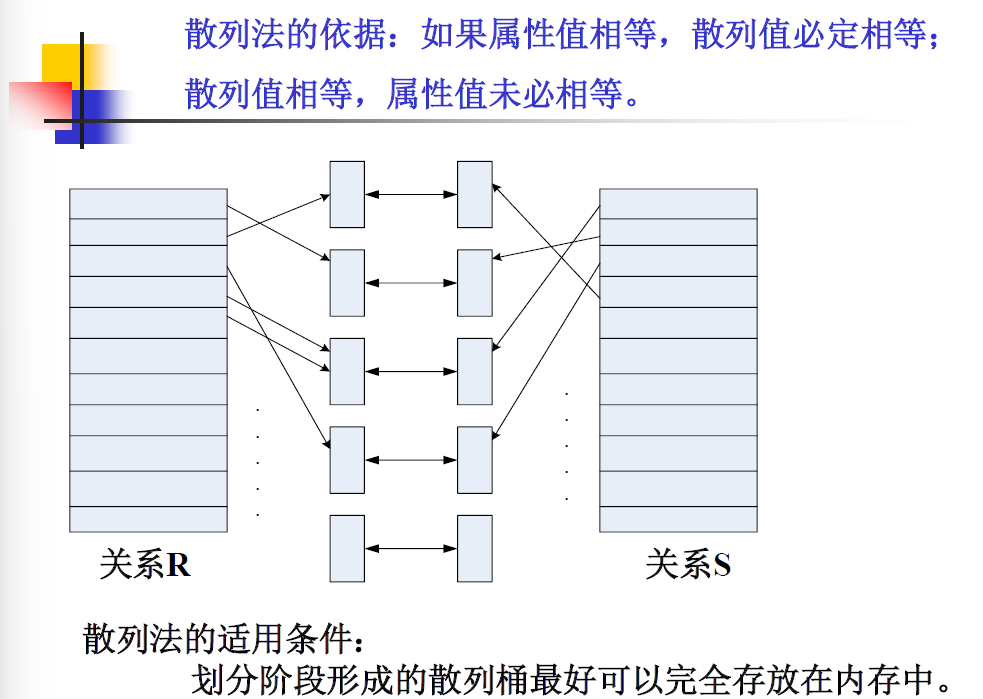
连接操作的实现——散列(Hash)连接法
- 类似于排序合并法,两个关系只需各扫描一次,适用于等值连接和自然连接。
- 基本的思想:在关系R和S的连接属性上,使用同一个hash函数,将关系R和S划分成多个具有相同散列值的元组的集合;然后在各个元组集合内进行连接操作。
- 基本过程
- 划分阶段:将元组较少的关系散列到hash文件桶中
- 试探(连接)阶段:将另一个关系的元组散列到相应的hash同中,并与该桶中原有关系的元组进行匹配结合。
- 匹配时可以采用嵌套循环处理的方法。
3. 投影操作的实现
- 投影操作选取关系的某些列,从垂直的方向减小关系大小。
- 如果投影属性包括了关系R的主键,那么操作可以直接执行,操作的结果将于R中的元组个数相同
- 否则,需要消除重复元组
- 通常做法:先排序操作结果,再去掉多余的副本
- 用散列法消除重复元组
- 把投影结果的每个元组散列到相应的散列桶中;
- 然后检查是否与该桶中已存在的元组重复,如果重复,则不把这个元组插入桶中。
4. 集合运算的实现
- 传统的集合运算是二元的,包括并、差、交、笛卡尔积四种运算。
- 并、差、交运算实现的常用方法类似排序合并法
- 首先对参加运算的两个关系分别按照主键属性排序;
- 排序后只需同时对两个关系执行一次扫描就可以生成计算结果。
- 笛卡尔积的实现通常使用嵌套循环法
- 由于笛卡尔积的操作结果中包含了R和S中每个元组的组合,其结果集会比参与运算的关系大得多,操作代价非常高。
- 并、差、交运算实现的常用方法类似排序合并法
4. 查询优化技术
- 关系数据库系统的查询优化
- 对于一个具体的查询请求,可以用几种不同形式的查询语句来表达,而不同的表达会使数据库的响应速度大不相同。因此,在实际应用中需要利用查询优化技术对不同形式的查询语句进行分析,并选择高效合理的查询语句,使执行查询所需要的系统开销降至最低,从而提高数据库系统的性能。
- 从查询的多个执行策略中选择合适的执行策略来执行,这个选择的过程就是查询优化。
- 查询优化对关系数据库管理系统的性能至关重要。
查询优化示例
-
【例】查询选修了“DataBase”课程的学生成绩。
用SQL表达如下
SELECT SC.GradeFROM Course,SCWHERE Course.Cno = SC.CnoAND Course.Cname = 'DataBase';怎么实现?
Π G r a d e ( σ C o u r s e . C n o = S C . C n o ∧ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e × S C ) ) \Pi_{Grade}(\sigma_{Course.Cno = SC.Cno \, \land \,Course.Cname = 'DataBase'}(Course \times SC)) ΠGrade(σCourse.Cno=SC.Cno∧Course.Cname=′DataBase′(Course×SC))
Π G r a d e ( σ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e ⋈ S C ) ) \Pi_{Grade}(\sigma_{Course.Cname = 'DataBase'}(Course \bowtie SC)) ΠGrade(σCourse.Cname=′DataBase′(Course⋈SC))
Π G r a d e ( S C ⋈ σ C o u r s e . C n a e m = ′ D a t a B a s e ′ ( C o u r s e ) ) \Pi_{Grade}(SC \bowtie \sigma_{Course.Cnaem = 'DataBase'}(Course)) ΠGrade(SC⋈σCourse.Cnaem=′DataBase′(Course))
-
哪种策略最佳?
-
假设:
- SC:10000条,Course:100条,满足条件的元组为100个。
- 内存被划分为6块,每块都装10个Course元组或100个SC元组。每次在内存中放5块Course元组和1块SC元组。对于数据而言,10个Course元组算作一块,100个SC元组算一块。
Π G r a d e ( σ C o u r s e . C n o = S C . C n o ∧ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e × S C ) ) \Pi_{Grade}(\sigma_{Course.Cno = SC.Cno \, \land \,Course.Cname = 'DataBase'}(Course \times SC)) ΠGrade(σCourse.Cno=SC.Cno∧Course.Cname=′DataBase′(Course×SC))
-
$ {Course \times SC}$
- 在内存中尽可能多地装入Course表,留出一块存放SC的元组。
- 把SC中的每个元组和Course中的每个元组连接,完成之后,继续读入下一块SC的元组,同样和内存中Course的每个元组连接,依此类推,直到SC表的元组全部处理完连接。
- 把Course表中没有装入的元组尽可能多地装入内存,同样逐块装入SC表的元组去做元组的连接,直到Course表的所有元组全部进行完连接。
-
读取的总块数
= 读 C o u r s e 表的块数 + 读 S C 表遍数 × 每遍块数 = 100 ÷ 10 + 100 ÷ ( 10 × 5 ) × 10000 ÷ 100 = 10 + 200 = 210 \begin{align} & =读Course表的块数+读SC表遍数 \times 每遍块数\\ & =100\div10 + 100\div(10 \times 5)\times 10000 \div 100\\ & = 10 + 200 = 210 \end{align} =读Course表的块数+读SC表遍数×每遍块数=100÷10+100÷(10×5)×10000÷100=10+200=210因为每次,只能读 5 × 10 5 \times 10 5×10块Course元组,所以读SC表的遍数为 100 ÷ ( 10 × 5 ) 100 \div (10 \times 5) 100÷(10×5)
读数据的时间 = 210 ÷ 20 = 10.5 s 210 \div 20 = 10.5s 210÷20=10.5s(假设每秒读写20块)
-
中间结果的元组数 = 10000 × 100 = 10 6 =10000 \times 100 = 10^6 =10000×100=106
写中间结果的时间 = 10 6 ÷ 10 ÷ 20 = 5000 s =10^6\div 10 \div 20 = 5000s =106÷10÷20=5000s(每次写一块,一块10个数组),写到临时存取文件中
-
$ \sigma_{Course.Cno = SC.Cno , \land , Course.Cname = ‘DataBase’ }$
将已经连接好的 10 6 10^6 106个元组重新读入内存,按照选择条件选取满足条件的元组。满足条件的元组为100个。
-
假设结果全部存取在内存中,忽略内存处理时间。
-
选取操作的时间开销为:
读数据的时间 = 5000s(与写文件一样)
-
-
Π G r a d e \Pi_{Grade} ΠGrade
仍为100个元组,可以存放在内存中,不需要作I\O操作,忽略内存处理时间。因此这一步操作时间可以忽略。
-
总时间代价
= 10.5 + 5000 + 5000 ≈ 2.78 ( 小时 ) =10.5+5000+5000 \approx 2.78(小时) =10.5+5000+5000≈2.78(小时)
Π G r a d e ( σ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e ⋈ S C ) ) \Pi_{Grade}(\sigma_{Course.Cname = 'DataBase'}(Course \bowtie SC)) ΠGrade(σCourse.Cname=′DataBase′(Course⋈SC))
-
$ Course \bowtie SC$
-
读取数据块210块,读取的时间 = 210/20 = 10.5秒
-
中间结果元组数 = 10000(因为自然连接且SC为10000条)
写中间结果的时间 = 10000 ÷ 10 ÷ 20 = 50 秒 =10000 \div 10 \div20 = 50秒 =10000÷10÷20=50秒
-
-
σ C o u r s e . C n a m e = ′ D a t a B a s e ′ \sigma_{Course.Cname = 'DataBase'} σCourse.Cname=′DataBase′
读取上一步已经连接好的10000个元组,检查是否满足选择条件,产生一个100个元组的结果集
- 读数据的时间 = 10000 ÷ 10 ÷ 20 = 50 秒 = 10000 \div 10 \div 20 = 50秒 =10000÷10÷20=50秒
-
Π G r a d e \Pi_{Grade} ΠGrade:不需要I/O操作
-
总时间 = 10.5 + 50 + 50 = 110.5 秒 = 10.5 + 50 + 50 = 110.5秒 =10.5+50+50=110.5秒
Π G r a d e ( S C ⋈ σ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e ) ) \Pi_{Grade}(SC \bowtie \sigma_{Course.Cname = 'DataBase'}(Course)) ΠGrade(SC⋈σCourse.Cname=′DataBase′(Course))
-
σ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e ) \sigma_{Course.Cname = 'DataBase'(Course)} σCourse.Cname=′DataBase′(Course)
先装入Course表元组,再选择满足条件的元组,结果集为一个元组,不必写入临时内存
-
读Course表的总块数 = 100 ÷ 10 = 10 块 =100\div10 = 10 块 =100÷10=10块
读数据的时间 10 ÷ 20 = 0.5 秒 10 \div 20 = 0.5秒 10÷20=0.5秒
-
-
⋈ \bowtie ⋈
将10000个SC的元组依次读入内存,和内存中唯一1个Course元组作自然连接。只需要读一遍SC表。
-
SC表的总块数 = 10000 ÷ 100 = 100 块 = 10000\div100 = 100块 =10000÷100=100块
读数据的时间 100 ÷ 20 = 5 秒 100 \div 20 = 5秒 100÷20=5秒(每秒读20块)
-
-
Π G r a d e \Pi_{Grade} ΠGrade:不需要作I/O操作
-
总时间 = 0.5 + 5 = 5.5 秒 =0.5+5=5.5秒 =0.5+5=5.5秒
Π G r a d e ( σ C o u r s e . C n o = S C . C n o ∧ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e × S C ) ) \Pi_{Grade}(\sigma_{Course.Cno = SC.Cno \, \land \,Course.Cname = 'DataBase'}(Course \times SC)) ΠGrade(σCourse.Cno=SC.Cno∧Course.Cname=′DataBase′(Course×SC))
Π G r a d e ( σ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e ⋈ S C ) ) \Pi_{Grade}(\sigma_{Course.Cname = 'DataBase'}(Course \bowtie SC)) ΠGrade(σCourse.Cname=′DataBase′(Course⋈SC))
Π G r a d e ( S C ⋈ σ C o u r s e . C n a m e = ′ D a t a B a s e ′ ( C o u r s e ) ) \Pi_{Grade}(SC \bowtie \sigma_{Course.Cname = 'DataBase'}(Course)) ΠGrade(SC⋈σCourse.Cname=′DataBase′(Course))
- 哪种策略最佳?
- 2.78小时
- 110.5秒
- 5.5秒
- 原因

查询优化的必要性
-
前面的优化实例表明:对于等价的关系代数表达式,其相应的查询效率有着巨大差异,因此需要进行查询优化,通过合理的优化,选择合适的查询计划,以获得较高的查询效率。
-
在关系数据库系统中,由于关系数据库语言的非过程特性,用户和应用程序一般不考虑如何最好地表达查询、如何最好地实现查询。因此,DBMS必须有专门的查询优化模块负责对查询的优化处理。
-
由DBMS进行查询优化的好处
-
优化器可以从数据字典中获取许多统计信息,而用户程序则难以获得这些信息。
数据字典是数据库系统中自动维护的、只读的系统表集合,用于记录数据库中的各种元信息(元数据),元数据就是描述数据的数据。
学号 姓名 年龄 专业 1001 张三 20 CS 1002 李四 21 Math 项目 属于数据还是元数据 举例说明 “张三”“李四”这些学生记录 数据(Data) 真正记录的信息 表名是“Student”,字段有“学号”“姓名”…… 元数据(Metadata) 描述这些数据的结构 字段“年龄”是整数,最大长度3 元数据 限定“数据”格式 数据表创建时间、表占多少存储空间 元数据 系统管理信息 -
如果数据库的物理统计信息改变了,系统可以自动对查询重新优化以选择相适应的执行计划。
数据库的物理统计信息:是数据库系统自动采集的关于数据本身分布、大小、频率等特征的信息,主要用于帮助优化器做执行计划决策。包括以下内容
信息类型 示例 行数 某表大约有多少行 块数 / 页数 某表占用了多少磁盘页 索引高度 / 密度 B+树索引的结构信息 列值分布 / NDV 某列有多少不同值(NDV) 列值最大 / 最小值 如 Age的最大最小是多少NULL 值占比 某列中 NULL 占比多少 -
优化器可以考虑数百种不同的执行计划,而程序员一般只能考虑有限的几种可能性。
因为优化器是程序+规则+搜索算法构成的只能模块,可以系统性、自动化、高效地枚举和比较各种执行方式,远超人工推理能力
-
优化器中可以包括很多复杂的优化技术。
-
查询优化的目标
-
通过某种代价模型计算出各种查询执行策略的执行代价,然后选择代价最小的执行方案。
-
查询执行策略的“总代价”就是指:执行某个查询计划(方案)所需的总体资源消耗估算值,用来指导优化器选择代价最小的方案。
代价组成 含义 I/O 代价 读取磁盘块所消耗的成本(最重) CPU 代价 扫描/比较/投影/过滤等操作所需的计算时间 内存代价 内存中缓冲/排序/哈希等操作所需的时间和空间 通信代价 只在分布式数据库中出现:数据在节点之间传输所耗代价 -
集中式数据库指的是:所有数据集中保存在一台主机或一个数据库系统中,所有的查询、插入、更新等操作都在本地机器完成。
特点:
- 所有数据、索引、统计信息都保存在同一个数据库实例;
- 所有计算都在一个系统中完成,不涉及网络通信;
- 通常你用的本地 MySQL、Oracle、SQLite 等就是集中式的。
-
集中式数据库
- 总代价 = 磁盘存取块数(I/O代价) + 处理机的处理时间(CPU代价)+查询内存消耗(内存代价)
- I/O代价是最主要的
-
分布式数据库指的是:数据库的数据被分散存储在多个物理位置的服务器上,但对用户来说仍然像一个整体数据库那样操作。
特点:
-
表的数据可能分布在多个节点(机器)上;
-
查询操作可能要从多个节点“拉数据”,然后“合并结果”;
-
涉及网络通信代价(传输、协调、同步);
-
典型产品有:Google Spanner、TiDB、OceanBase、CockroachDB、MongoDB 分片模式等。
-
-
分布式数据库
- 总代价 = 磁盘存取块数(I/O代价) + 处理机的处理时间(CPU代价)+查询内存消耗(内存代价)+通信代价
- 通信代价是主要的
查询优化技术的分类
-
按优化层次分为:
-
代数优化:
- 是基于关系代数表达式的优化;
- 按照一定的规则,改变代数表达式中操作的次序和组合,使查询执行更高效;
- 只改变查询语句中操作的次序和组合,不涉及的底层的存取路径
- 是通过关系代数表达式的等价变换规则来完成优化,也称为规则优化(逻辑优化)。
-
基于存取路径的优化:在执行 SQL 查询时,优化器会根据数据在磁盘上的物理存储方式,选择“最省资源”的读法,从而提升查询效率。
-
合理选择各种操作的**存取路径(执行某个操作时,数据库系统访问磁盘中数据的具体策略和方法。)**以获得优化效果;
意思是:
查询时不只是“从表里查”这么简单,系统可以选择:- 走索引 vs 全表扫描
- 顺序读 vs 随机读
- 连接时选哪种算法(如嵌套循环 vs 哈希连接)
-
需要考虑数据的物理组织和访问路径,以及底层操作算法的选择;
这个强调的是:
查询优化不仅仅看逻辑结构(如你写了什么 SQL),还要看数据在磁盘上是怎么排的、存在哪儿、有没有索引,以及最终底层选用什么算法执行。
例如:
- 表是否建了索引?
- 数据是否已经排好序?
- 用哈希表连接快,还是排序连接快?
-
设计数据文件的组织方法,数据值的分布情况等,也成为物理优化。
优化点 举例说明 数据文件组织方式 是堆表?聚簇表?索引组织表? 数据分布情况 Age这一列是不是大部分人都是 20 岁?数据文件的分页策略 每块存多少行?数据是密集还是稀疏? 是否有主键/二级索引/B+树结构 可以选择走索引路径还是顺序扫描路径?
-
-
-
按选择依据分:
-
基于规则的优化
-
启发式规则(后续会提到)
启发式规则 意义 先做选择再做连接 优先过滤数据量少的表,减小中间结果 优先使用索引 避免全表扫描,提高效率 小表驱动大表 外层循环用小表,减少连接代价 投影尽早 只保留需要的字段,减少传输和存储成本
-
-
基于代价估算的优化
- 对于多个可选的查询策略,通过估算执行策略的代价,从中选择代价最小的作为执行策略。
- 由于需要计算操作执行的代价,优化本身所需要的开销较大。
-
-
按优化阶段分:
- 静态查询优化
- 在查询执行前对SQL语句进行等价变换;
- 应用启发式规则及逆行优化。
- 动态查询优化
- 运行时根据实际数据调整执行计划;
- 基于代价估算的优化,根据统计信息估算执行代价
- 静态查询优化
查询优化的一般过程
-
将查询转换成某种内部表示,通常是语法树;
-
根据一定的等价变换规则,把语法树转换成标准(优化)形式,即对语法树进行优化;(代数优化)
-
选择低层的操作算法;
对于语法树的每一个操作,计算各种执行算法的执行代价,选择代价小的执行算法。(物理优化)
-
生成查询计划,选择代价最小的。
5.代数优化
-
代数优化
基于关系代数等价变换规则的优化
-
主要依据:关系代数表达式的等价变换规则
-
主要思想:对查询的代数表达式进行适当的等价变换,改变相关操作的先后执行顺序,把初始查询树转换为优化后的查询书,完成代数表达式的优化
-
与具体系统的存储技术无关
-
关系代数表达式的等价
- 是指用相同的关系代替两个表达式中相应的关系所得到的结果是相同的
- 两个关系表达式 E 1 E1 E1和 E 2 E2 E2是等价的,可记为 E 1 ≡ E 2 E1\equiv E2 E1≡E2
-
关系代数中常用的等价变换规则
设 E 1 E1 E1、 E 2 E2 E2是关系代数表达式, F F F是条件表达式。
-
连接、笛卡尔积交换律
E 1 × E 2 ≡ E 2 × E 1 E1 \times E2 \equiv E2 \times E1 E1×E2≡E2×E1
E 1 ⋈ E 2 ≡ E 2 ⋈ E 1 E1 \bowtie E2 \equiv E2 \bowtie E1 E1⋈E2≡E2⋈E1
E 1 ⋈ F E 2 ≡ E 2 ⋈ F E 1 E1 \bowtie_F E2 \equiv E2 \bowtie_F E1 E1⋈FE2≡E2⋈FE1
-
连接、笛卡尔积的结合律
( E 1 × E 2 ) × E 3 ≡ E 1 × ( E 2 × E 3 ) ( E 1 ⋈ E 2 ) ⋈ E 3 ≡ E 1 ⋈ ( E 2 ⋈ E 3 ) ( E 1 ⋈ F 1 E 2 ) ⋈ F 2 E 3 ≡ E 1 ⋈ F 1 ( E 2 ⋈ F 2 E 3 ) \begin{align} &(E1 \times E2) \times E3 \equiv E1 \times (E2 \times E3) \\ &(E1 \bowtie E2) \bowtie E3 \equiv E1 \bowtie (E2 \bowtie E3) \\ &(E1 \bowtie_{F1} E2) \bowtie_{F2} E3 \equiv E1 \bowtie_{F1} (E2 \bowtie_{F2} E3) \end{align} (E1×E2)×E3≡E1×(E2×E3)(E1⋈E2)⋈E3≡E1⋈(E2⋈E3)(E1⋈F1E2)⋈F2E3≡E1⋈F1(E2⋈F2E3) -
投影的串接定律
Π A 1 , A 2 , … … , A n ( Π B 1 , B 2 , … … , B m ( E ) ) ≡ Π A 1 , A 2 , … … , A n ( E ) \Pi_{A_1,A_2,……,A_n}(\Pi_{B_1,B_2,……,B_m}(E)) \equiv \Pi_{A_1,A_2,……,A_n}(E) ΠA1,A2,……,An(ΠB1,B2,……,Bm(E))≡ΠA1,A2,……,An(E)
- E是关系代数表达式
- A i ( i = 1 , 2 , … … , n ) , B j ( j = 1 , 2 , … … , m ) A_i(i = 1,2,……,n),B_j(j=1,2,……,m) Ai(i=1,2,……,n),Bj(j=1,2,……,m)是属性名
- A 1 , B 2 , … … , A n {A_1,B_2,……,A_n} A1,B2,……,An是 B 1 , B 2 , … … , B m {B_1,B_2,……,B_m} B1,B2,……,Bm的子集
-
选择的串接定律
σ F 1 ( σ F 2 ( E ) ) ≡ σ F 1 ∧ F 2 ( E ) \sigma_{F_1}(\sigma_{F_2}(E)) \equiv \sigma_{F_1 \land F_2}(E) σF1(σF2(E))≡σF1∧F2(E)
- 选择的串接定律说明:多个选择操作可以合并为一个
- 一次检查全部条件
-
选择与投影的交换律
σ F ( Π A 1 , A 2 , … … , A n ( E ) ) ≡ Π A 1 , A 2 , … … , A n ( σ F ( E ) ) \sigma_F(\Pi_{A_1,A_2,……,A_n}(E)) \equiv \Pi_{A_1,A_2,……,A_n}(\sigma_F(E)) σF(ΠA1,A2,……,An(E))≡ΠA1,A2,……,An(σF(E))
- 选择条件F只涉及属性 A1 ,……,An
Π A 1 , A 2 , … … , A n ( σ F ( E ) ) ≡ Π A 1 , A 2 , … … , A n ( σ F ( Π A 1 , A 2 , … … , A n , B 1 , B 2 , … … , B m ( E ) ) ) \Pi_{A_1,A_2,……,A_n}(\sigma_F(E)) \equiv \\ \Pi_{A_1,A_2,……,A_n}(\sigma_F(\Pi_{A_1,A_2,……,A_n,B_1,B_2,……,B_m(E)})) ΠA1,A2,……,An(σF(E))≡ΠA1,A2,……,An(σF(ΠA1,A2,……,An,B1,B2,……,Bm(E)))
- F中有不属于A1,……,An的属性B1,……,Bm
-
选择与笛卡尔积的交换律
-
F 中涉及的属性都是 E1 中的属性
σ F ( E 1 × E 2 ) ≡ σ F ( E 1 ) × E 2 \sigma_{F}(E1 \times E2) \equiv \sigma_{F}(E1) \times E2 σF(E1×E2)≡σF(E1)×E2
-
F = F 1 ∧ F 2 F = F_1 \land F_2 F=F1∧F2,并且F1 只涉及 E1 中的属性 F2 只涉及 E2 中
的属性, 则由上面的等价变换规则 1,4,6 可推出:$\sigma_{F}(E1 \times E2) \equiv \sigma_{F1}(E1) \times \sigma_{F2}(E2) $
-
F = F 1 ∧ F 2 F = F_1 \land F_2 F=F1∧F2,F1 只涉及 E1 中的属性, F2 涉及 E1 和 E2 两者的属性
σ F ( E 1 × E 2 ) ≡ σ F 2 ( σ F 1 ( E 1 ) × E 2 ) \sigma_{F}(E1 \times E2) \equiv \sigma_{F_2}(\sigma_{F_1}(E1) \times E2) σF(E1×E2)≡σF2(σF1(E1)×E2)
它使部分选择在笛卡尔积前先做
-
-
选择与并的分配律
σ F ( E 1 ∪ E 2 ) ≡ σ F ( E 1 ) ∪ σ F ( E 2 ) \sigma_F(E1 \cup E2) \equiv \sigma_F(E1) \cup \sigma_F(E2) σF(E1∪E2)≡σF(E1)∪σF(E2)
- $ E = E1 \cup E2 $,E1、E2 有相同的属性名
-
选择与差运算的分配律
σ F ( E 1 − E 2 ) ≡ σ F ( E 1 ) − σ F ( E 2 ) \sigma_F(E1 - E2) \equiv \sigma_F(E1) - \sigma_F(E2) σF(E1−E2)≡σF(E1)−σF(E2)
- E1与E2有相同的属性名
-
选择对自然连接的分配律
σ F ( E 1 ⋈ E 2 ) ≡ σ F ( E 1 ) ⋈ σ F ( E 2 ) \sigma_F(E1 \Join E2) \equiv \sigma_F(E1) \Join \sigma_F(E2) σF(E1⋈E2)≡σF(E1)⋈σF(E2)
- F涉及E1和E2的公共属性
-
投影与笛卡尔积的分配律
Π A 1 , A 2 , … , A n , B 1 , B 2 , … , B m ( E 1 × E 2 ) ≡ Π A 1 , A 2 , … , A n ( E 1 ) × Π B 1 , B 2 , … , B m ( E 2 ) \Pi_{A_1, A_2, \ldots, A_n, B_1, B_2, \ldots, B_m}(E1 \times E2) \equiv \Pi_{A_1, A_2, \ldots, A_n}(E1) \times \Pi_{B_1, B_2, \ldots, B_m}(E2) ΠA1,A2,…,An,B1,B2,…,Bm(E1×E2)≡ΠA1,A2,…,An(E1)×ΠB1,B2,…,Bm(E2)
- $A_1, \ldots, A_n 是 E 1 的属性, 是E1的属性, 是E1的属性,B_1, \ldots, B_m$是E2的属性
-
投影与并的分配律
Π A 1 , A 2 , … , A n ( E 1 ∪ E 2 ) ≡ Π A 1 , A 2 , … , A n ( E 1 ) ∪ Π A 1 , A 2 , … , A n ( E 2 ) \Pi_{A_1, A_2, \ldots, A_n}(E1 \cup E2) \equiv \Pi_{A_1, A_2, \ldots, A_n}(E1) \cup \Pi_{A_1, A_2, \ldots, A_n}(E2) ΠA1,A2,…,An(E1∪E2)≡ΠA1,A2,…,An(E1)∪ΠA1,A2,…,An(E2)
- E1和E2有相同的属性名
-
代数优化策略
-
基本原则:减少查询处理的中间结果的大小。
-
典型的启发式规则
-
选择操作尽可能早地执行
- 目的:减少中间关系
- 在优化策略中这是最重要、最基本的一条。
-
投影运算和选择运算尽量同时进行
- 目的:避免重复扫描关系
- 如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描此关系的同时完成所有的这些运算以避免重复扫描关系。
-
将投影操作与其前或其后的**二元操作(需要两个关系(表)作为输入)**结合起来同时进行(或者说先进行投影操作再二元操作),以减少扫描关系的遍数。
-
把某些选择和在它前面的笛卡尔积结合起来,合并为一个连接操作, 可以节省时间和空间开销。
-
找出公共子表达式,计算一次公共子表达式并把结果写入中间文件, 以达到节省时间的目的。
- 如果子表达式的结果不是很大的关系,并且从外存中读入这个关系比计算该子表达式的时间少得多,则先计算一次公共子表达式并把结果写入中间文件是合算的,否则不一定有利。
- 当查询涉及 视图 时,定义视图的表达式就是公共子表达式的典型情况。
-
代数优化算法
-
DBMS 自动完成关系代数表达式的优化,优化前先将关系代数表达式转换为查询树。
-
输入:一个关系表达式的查询树。
-
输出:优化的查询树。
-
方法:
- 分解选择运算
利用等价变换规则 4 把形如 σ F 1 ∧ F 2 ∧ … ∧ F n ( E ) \sigma_{F_1 \land F_2 \land \ldots \land F_n}(E) σF1∧F2∧…∧Fn(E)的表达式变换为 σ F 1 ( σ F 2 ( … ( σ F n ( E ) ) … ) ) \sigma_{F_1}(\sigma_{F_2}(\ldots(\sigma_{F_n}(E))\ldots)) σF1(σF2(…(σFn(E))…))
-
通过交换选择运算,将其尽可能移到叶端
对每一个选择操作,利用等价变换规则 4 ~ 9 尽可能把它移到树的叶端。
-
通过交换投影运算,将其尽可能移到叶端
对每一个投影操作,利用等价变换规则 3、5、10、11 中的一般形式,尽可能将其移向树的叶端。
注意:
- 等价变换规则 3 会使一些投影消失;
- 规则 5 把一个投影分裂为两个,其中一个有可能被移向树的叶端。
-
合并串接的选择和投影,以便能同时执行或在一次扫描中完成
- 利用等价变换规则 3~5 把选择和投影的串接合并成单个选择、单个投影或一个选择后跟一个投影。
- 使多个选择或投影能同时执行,或在一次扫描中全部完成。
- 注意:这种变换似乎违背“投影尽可能早做”的原则,但有时这样做的效率可能更高。
-
把某些选择和在它前面的笛卡尔积合并为连接操作
- 节省时间和空间开销
-
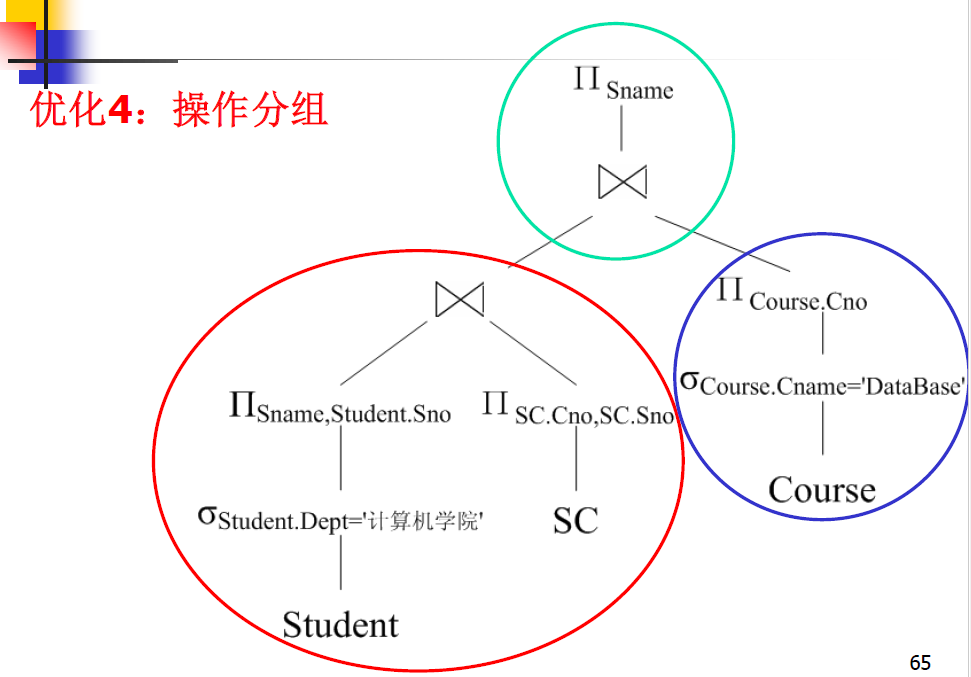
对内结点分组
将经过上述处理得到的语法树的内结点分组。
- 每个二元操作(如 $\times, \Join, \cup, - )结点和它的直接祖先操作 )结点和它的直接祖先操作 )结点和它的直接祖先操作( \sigma, \Pi) $合并为一组。
- 如果其后代直到叶结点全是一元操作,则也将其并入该组;但是,如果二元操作是笛卡尔积$\times $,且后面的选择操作不与它构成等值连接,则选择条件要单独分为一组,即选择操作和笛卡尔积不能组合成等值连接。
-
生成程序
- 每组结点的计算是程序中的一步;各步的顺序是任意的,只要保证它们之间的依赖关系。
代数优化示例
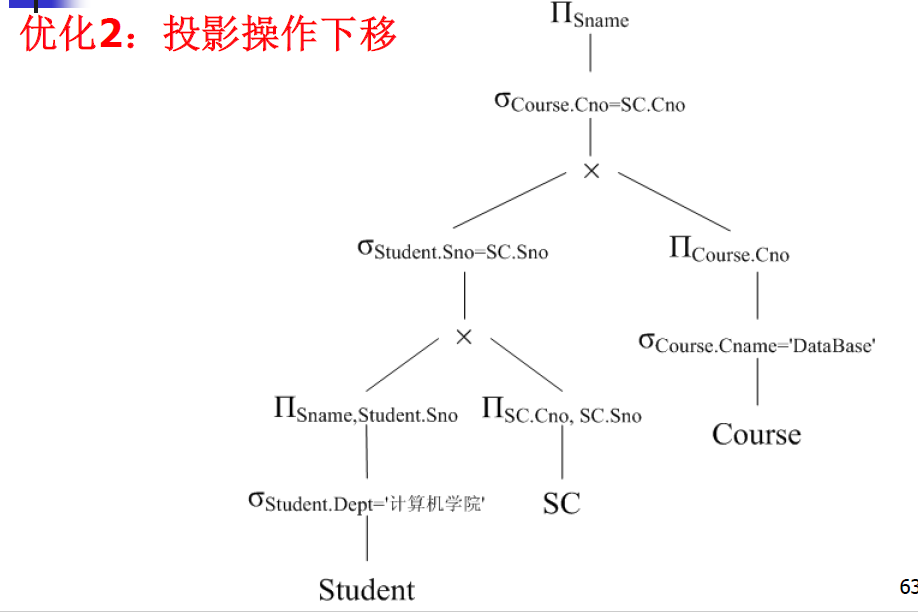
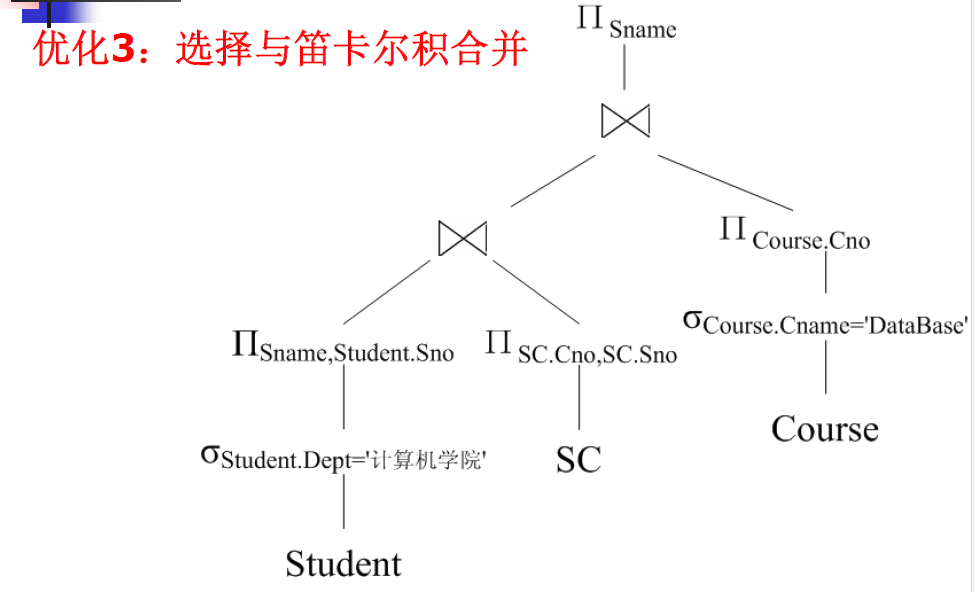
【例】查询选修了 “DataBase” 这门课程的计算机学院的学生姓名。
SQL 表达式如下:
SELECT Student.Sname
FROM Student, SC, Course
WHERE Student.Sno = SC.SnoAND Course.Cno = SC.CnoAND Student.Dept = '计算机学院'AND Course.Cname = 'DataBase'
对应的关系代数表达式如下:
Π Sname ( σ Student.Sno = SC.Sno ∧ Course.Cno = SC.Cno ∧ Student.Dept = ’计算机学院’ ∧ Course.Cname = ’DataBase’ ( ( Student × SC ) × Course ) ) \Pi_{\text{Sname}} \left( \sigma_{\text{Student.Sno} = \text{SC.Sno} \land \text{Course.Cno} = \text{SC.Cno} \land \text{Student.Dept} = \text{'计算机学院'} \land \text{Course.Cname} = \text{'DataBase'}} \left( \left( \text{Student} \times \text{SC} \right) \times \text{Course} \right) \right) ΠSname(σStudent.Sno=SC.Sno∧Course.Cno=SC.Cno∧Student.Dept=’计算机学院’∧Course.Cname=’DataBase’((Student×SC)×Course))
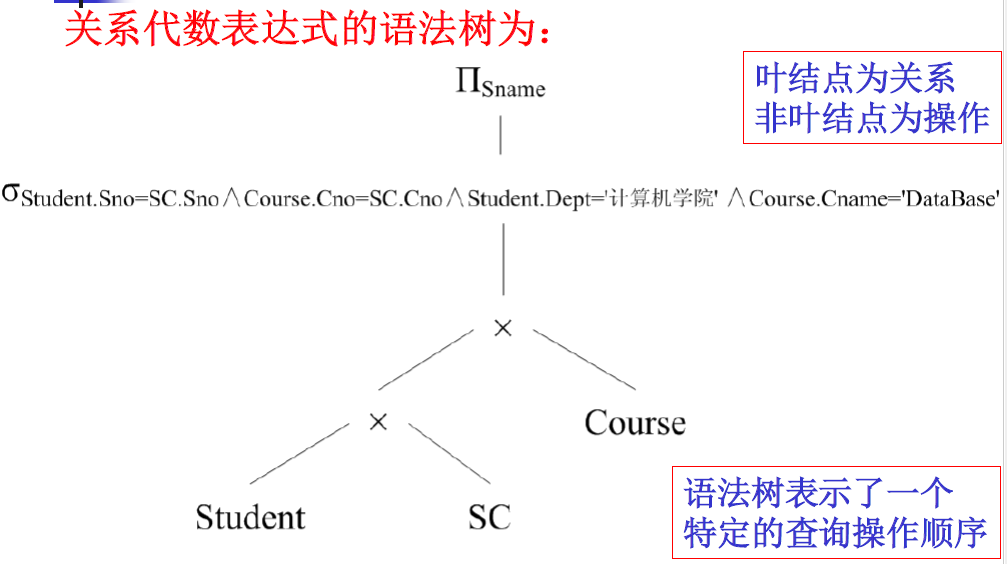
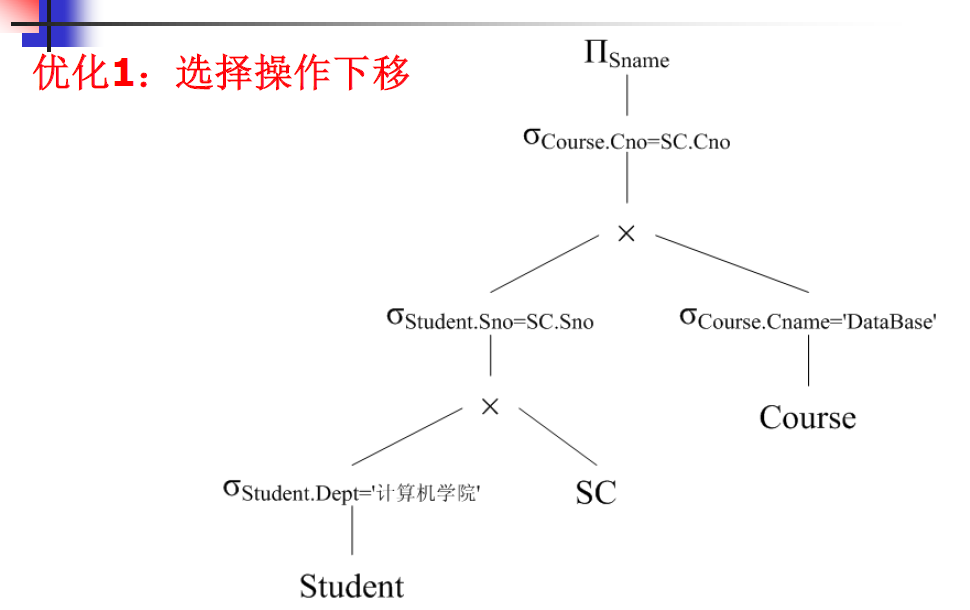
6. 基于存取路径的优化
- 代数优化 改变查询语句中操作的次序和组合,不涉及底层的存取路径,优化效果有限。
- 在关系数据库中,数据与存取路径分离;每种操作有多种实现算法,有多种存取路径。
- 对于一个查询语句的不同存取方案,执行效率差异可能很大。
- 选择合适的存取路径,能获得明显的优化效果。
- 基于存取路径的优化:利用启发式规则确定合适的存取路径,并选择合理的操作算法。
选择操作的启发式规则
- 对于小关系,使用顺序扫描法,即使选择列上有索引。
- 对于选择条件是“主键=值”的查询,查询结果最多是一个元组,可以选择主键索引。
- 对于选择条件是“非主属性=值”的查询,并且选择列上有索引
- 要估算查询结果的元组数目
- 如果比例较小(<10%)可以使用索引扫描法。
- 否则还是使用顺序扫描法。
- 要估算查询结果的元组数目
- 对于选择条件是属性上的非等值查询或者返回查询,并且选择列上有索引,处理策略与3类似。
- 对于用AND连接的合区连接条件,如果有涉及这些属性的组合索引,优先采用组合索引扫描方法,否则使用全表顺序扫描方法。
- 对于用OR连接的析取选择条件,一般使用全表顺序扫描方法。
连接操作的启发式规则
- 如果两个表都已经按照连接属性排序
- 选用排序合并法
- 如果一个表在连接属性上有索引
- 选用索引连接法
- 如果上面两个规则都不适用,其中一个表较小
- 可以选用散列(Hash)连接法
- 其他情况
- 选用嵌套循环方法,并选择占用存储块较少的表作为外循环表
7. 基于代价估算的优化
-
基于存取路径的优化是依靠启发式规则的定性优化,适合解释执行的系统
- 解释执行的系统,优化开销包含在查询总开销之中
- 定性优化:基于启发式规则(经验法则)选择“看起来比较好”的方案,不进行真实代价估算。
-
在编译执行的系统中,查询优化和查询执行是分开的
- 可以采用精细的较为复杂的基于代价估计的优化方法
- 定量优化:对各种执行方案进行成本估算,选择代价最低的方案,较精确,但较复杂。
-
优化思想:查询优化器枚举各种可能的查询策略,估算各种策略的代价,选择代价最低的策略。
-
如何估算代价?
分析影响查询执行代价的因素
- 访问存储器的代价
- 存储中间文件的代价
- 计算代价(对内存操作的代价)
- 内存使用代价(内存缓冲器的数目)
- 通信代价(数据在不同结点间传送的代价)
-
代价估算的优化目标
-
大型数据库
使访问二级存储器(磁盘)的代价最小化
-
小型数据库
是计算代价最小化
-
分布式数据库
使通信代价最小化

-
-
具体操作代价估算
- 与数据库中数据的状态密切相关。
- DBMS会在数据字典中存储各种统计信息
-
基本表的统计信息
- 元组数量(N)
- 元组长度(I)
- 占用的块数(B)
- 每块可以存放的元组数目(Mrs)
- 占用的溢出块数(BO)
-
基本表每个列的统计信息
- 不同值的个数(m)
- 选择率(f)
- 如果不同值的分布使均匀的, f = 1 ÷ m f = 1 \div m f=1÷m
- 如果不同值的分布不均匀,则每个值的选择律 = 具有该值的元组数/N
- 该列最大值
- 该列最小值
- 该列上是否已经建立了索引
- 索引类型(B+数索引、Hash索引、聚集索引)
-
索引的统计信息
-
索引的层数(L)
-
不同索引值的个数
-
索引的选择基数(S)
就是每个索引值对应的平均元组个数 S = 表中总记录数 ÷ 不同索引值个数 S = 表中总记录数 \div 不同索引值个数 S=表中总记录数÷不同索引值个数,S值越小,索引越精准,如果S趋近于1,说明是主键索引,性能非常好
-
索引的叶子结点数(Y)
-
-
几种典型的查询操作实现算法的代价估计
- 选择操作
- 顺序扫描
- 二分查找
- 使用索引(或散列)的扫描
- 连接操作
- 嵌套循环
- 索引嵌套循环
- 排序合并
- 选择操作
选择操作实现算法的代价估算
-
文件中的物理块:
物理块(Block/Page),是数据库管理系统在磁盘上读写数据的最小单位。
-
大小通常是固定的,如 4KB、8KB、16KB 等。
-
一个块里可以存储多个元组(记录)
-
文件 = 一堆块组成
比如:Student 表存成文件,占用磁盘上的 200 个块 -
一个“文件的物理块” ≈ 一个“元组的容器”
数据库从磁盘读数据,不能按元组读取,只能按“块”为单位!
-
-
顺序扫描的代价估算:
- 如果关系 R 的元组占用的块数为 ( BR )(块是数据在磁盘和内存之间传递的单位), 则顺序扫描方法的代价:$ \text{cost} = B_R$
- 如果选择条件是**主键上的相等比较(在查询条件中,用“=(等于)”判断某个属性是否等于主键值。)**操作,那么平均搜索一半的文件块才能找到满足条件的元组,因此平均搜索代价为:$ \text{cost} = \frac{B_R}{2} 。因为非主键值不唯一,所以不是 。因为非主键值不唯一,所以不是 。因为非主键值不唯一,所以不是\frac{B_2}{2}$
-
二分查找的代价估算:
- 二分查找法是针对文件的物理块进行的,平均搜索代价为:$ \left\lceil \log_2 B_R \right\rceil$
-
索引扫描算法的代价估算
-
如果选择条件是主键属性的相等比较,需要存取索引树中从根结点到叶结点共 ( L ) 个块,再加上基本表中该元组所在的那一块,因此代价为: cost = L + 1 \text{cost} = L + 1 cost=L+1
-
如果选择条件涉及非主键属性的相等比较,且为 B+树索引, 若有 ( S ) 个元组满足条件,最坏情况下每个元组在不同块中,则代价为 cost = L + S \text{cost} = L + S cost=L+S
-
如果比较条件是范围类的,假设有一半的元组满足条件,那么需要读取一半的叶结点和数据块,代价估算为: cost = L + Y 2 + B R 2 \text{cost} = L + \frac{Y}{2} + \frac{B_R}{2} cost=L+2Y+2BR。
其中:
- L :索引树的层数(从根到叶)
- Y :索引的叶结点总数
- BR :关系 R 占用的块数
层次 动作 代价 索引树路径 找到第一个满足条件的叶节点 L L L 叶节点扫描 连续扫描命中的叶子索引 Y 2 \frac{Y}{2} 2Y 数据块访问 读取包含满足条件元组的块 B R 2 \frac{B_R}{2} 2BR 实际情况是:
- 只走一次索引路径(L),定位到第一个匹配的叶节点
- 然后顺着叶节点链表向后扫描,不需要重新走索引路径
- 相当于从第一个符合条件的地方顺着扫下去
-
连接操作实现方法的代价估算
-
嵌套循环法
-
设连接表 R 与 S 分别占用的块数为 B R B_R BR、$ B_S $,连接操作使用的内存缓冲区块数为 K K K,分配 K − 1 K - 1 K−1 块给外表。
-
若 R 为外表,则嵌套循环法存取的 存取代价(不写回磁盘)为 cost = B R + B S ⋅ B R K − 1 \text{cost} = B_R + \frac{B_S \cdot B_R}{K - 1} cost=BR+K−1BS⋅BR
-
R为外表,若需要把连接结果写回磁盘,则代价为: cost = B R + B S ⋅ B R K − 1 + Frs ⋅ N R ⋅ N S Mrs \text{cost} = B_R + \frac{B_S \cdot B_R}{K - 1} + \frac{\text{Frs} \cdot N_R \cdot N_S}{\text{Mrs}} cost=BR+K−1BS⋅BR+MrsFrs⋅NR⋅NS
其中:
- N R N_R NR, N S N_S NS:关系 R 和 S 的元组总数
- Frs \text{Frs} Frs:连接选择性(Join Selectivity),表示连接结果元组数占笛卡尔积的比例
- Mrs \text{Mrs} Mrs:块因子,即一个磁盘块可容纳的连接结果元组数
-
-
索引嵌套循环法
-
若内关系 S 存在索引,针对外关系 R 的任意一个元组,都可以利用索引查找内关系 S 中的相关元组。
-
最坏情况下,内存仅能容纳关系 R 和索引各一个块,所需访问的代价为: cost = B R + N R × c \text{cost} = B_R + N_R \times c cost=BR+NR×c
其中:
- c c c:使用索引访问 S 时,查找每个匹配元组所需的代价
-
实用建议:
- 在关系上建立索引并用于连接操作时,通常比传统嵌套循环代价低。
- 如果两个关系都有索引,推荐将元组数较少的关系作为外关系。
-
-
排序合并法(Sort-Merge Join)
-
如果连接表已经按照连接属性排序好,则代价为: cost = B R + B S + Frs ⋅ N R ⋅ N S Mrs \text{cost} = B_R + B_S + \frac{\text{Frs} \cdot N_R \cdot N_S}{\text{Mrs}} cost=BR+BS+MrsFrs⋅NR⋅NS
-
如果必须对文件排序,则还需加上排序的代价:
- 对于包含 B B B 个块的文件,二路归并排序代价约为: 2 ⋅ B + 2 ⋅ B ⋅ log 2 B 2 \cdot B + 2 \cdot B \cdot \log_2 B 2⋅B+2⋅B⋅log2B
-
因此,排序合并连接的总代价函数为:
Cost = ( 2 ⋅ B R ) + ( 2 ⋅ B R ⋅ log 2 B R ) + ( 2 ⋅ B S ) + ( 2 ⋅ B S ⋅ log 2 B S ) + B R + B S + Frs ⋅ N R ⋅ N S Mrs \text{Cost} = (2 \cdot B_R) + (2 \cdot B_R \cdot \log_2 B_R) + \\ (2 \cdot B_S) + (2 \cdot B_S \cdot \log_2 B_S) + \\ B_R + B_S + \frac{\text{Frs} \cdot N_R \cdot N_S}{\text{Mrs}} Cost=(2⋅BR)+(2⋅BR⋅log2BR)+(2⋅BS)+(2⋅BS⋅log2BS)+BR+BS+MrsFrs⋅NR⋅NS
-
副:基于机器学习的查询优化
- 利用机器学习算法和技术来改进传统数据库查询优化。
- 从历史查询数据中自动学习模式和规律,从而做出更智能的优化决策。
- 主要体现在三个层面:
- 预测(如预测查询语句执行时间)
- 决策(如连接顺序的选择)
- 自适应调整(如运行时计划修正)
- 已覆盖多个关键环节:
- 查询代价估计
- 执行计划选择
- 查询重写
- 索引推荐
- 资源分配
- 在顶级数据库会议(VLDB、SIGMOD 等)上,相关研究成果呈现快速增长趋势。
- 不少数据库系统已开始集成不同程度的机器学习优化功能。
表:机器学习在查询优化中的典型应用场景
| 应用场景 | 技术方法 | 性能提升 | 典型案例 |
|---|---|---|---|
| 索引推荐 | 监督学习(随机森林) | 减少 20–40% 查询时间 | MySQL 智能索引优化器 |
| 查询重写 | 深度学习(Seq2Seq) | 提升 15–30% 执行效率 | Google Spanner 重写引擎 |
| 计划选择 | 强化学习(PPO算法) | 超越传统方法 50 个百分点 | DeepRetrieval 系统 |
| 代价估计 | 神经网络 | 降低 30% 估计误差 | Microsoft SQL Server |
本章小结
-
查询处理的基本过程
-
关系操作的基本实现算法
-
查询优化的含义和必要性
-
查询优化的过程
-
查询优化技术
- 代数优化
- 基于存取路径的优化
- 基于代数估算的优化
- 基于机器学习的优化
-
查询优化的基本过程
- 把查询转换成某种内部表示
- 代数优化:把语法树转成标准(优化形式)
- 物理优化:选择低层的存取路径
- 生成查询计划,选择代价最小的
-
代数优化技术是指关系代数表达式的优化,即按照一定的规则,改变代数表达式中操作的次序和组合,使查询效率更高
-
基于存取路径的优化是指存取路径和底层操作算法的选择和优化
存取路径的优化
- 指选择访问数据表时的物理路径:
- 是否使用索引?
- 是走顺序扫描还是走索引跳转?
- 从哪个表开始连接?
底层操作算法的选择:
指对不同查询操作(如连接、选择、投影)选择最佳算法:
- 比如连接操作可以用:
- 嵌套循环
- 排序合并
- 哈希连接
- 选择操作可以用:
- 顺序扫描
- 索引扫描
- 指选择访问数据表时的物理路径:
-
代价估算优化使对多个查询策略的优化选择。代价估算优化开销较大,产生所有的执行策略使不太可能的,因此将产生的执行策略的数目保持在一定范围内才是比较合理的。
- 常常先使用启发式规则,选取若干较优的候选方案,减少代价估算的工作量;
- 然后分别计算候选方案的执行代价,选出最终优化方案。
-
自动优化有一定的局限性;
-
在实际应用中,开发人员或者是使用者,应该有查询优化意识;
-
比较复杂的查询,尤其是涉及连接和嵌套的查询
- 不要把优化的任务全部放在DBMS上;
- 应该找出DBMS的优化规律,以写出适合DBMS自动优化的SQL语句;
- 对于DBMS不能优化的查询需要重写查询语句,进行手工调整以优化性能。
% 执行效率 | Google Spanner 重写引擎 |
| 计划选择 | 强化学习(PPO算法) | 超越传统方法 50 个百分点 | DeepRetrieval 系统 |
| 代价估计 | 神经网络 | 降低 30% 估计误差 | Microsoft SQL Server |
本章小结
-
查询处理的基本过程
-
关系操作的基本实现算法
-
查询优化的含义和必要性
-
查询优化的过程
-
查询优化技术
- 代数优化
- 基于存取路径的优化
- 基于代数估算的优化
- 基于机器学习的优化
-
查询优化的基本过程
- 把查询转换成某种内部表示
- 代数优化:把语法树转成标准(优化形式)
- 物理优化:选择低层的存取路径
- 生成查询计划,选择代价最小的
-
代数优化技术是指关系代数表达式的优化,即按照一定的规则,改变代数表达式中操作的次序和组合,使查询效率更高
-
基于存取路径的优化是指存取路径和底层操作算法的选择和优化
存取路径的优化
- 指选择访问数据表时的物理路径:
- 是否使用索引?
- 是走顺序扫描还是走索引跳转?
- 从哪个表开始连接?
底层操作算法的选择:
指对不同查询操作(如连接、选择、投影)选择最佳算法:
- 比如连接操作可以用:
- 嵌套循环
- 排序合并
- 哈希连接
- 选择操作可以用:
- 顺序扫描
- 索引扫描
- 指选择访问数据表时的物理路径:
-
代价估算优化使对多个查询策略的优化选择。代价估算优化开销较大,产生所有的执行策略使不太可能的,因此将产生的执行策略的数目保持在一定范围内才是比较合理的。
- 常常先使用启发式规则,选取若干较优的候选方案,减少代价估算的工作量;
- 然后分别计算候选方案的执行代价,选出最终优化方案。
-
自动优化有一定的局限性;
-
在实际应用中,开发人员或者是使用者,应该有查询优化意识;
-
比较复杂的查询,尤其是涉及连接和嵌套的查询
- 不要把优化的任务全部放在DBMS上;
- 应该找出DBMS的优化规律,以写出适合DBMS自动优化的SQL语句;
- 对于DBMS不能优化的查询需要重写查询语句,进行手工调整以优化性能。
相关文章:
五、查询处理和查询优化
五、查询处理和查询优化 主要内容 查询概述查询处理过程关系操作的基本实现算法查询优化技术代数优化基于存取路径的优化基于代价估算的优化 1. 查询概述 查询是数据库管理系统中使用最频繁、最基本的操作,对系统性能有很大影响。 对于同一个SQL查询,…...

缓解骨质疏松 —— 补钙和补维 D
骨质老化/疏松原理(机制)骨密度下降与骨小梁结构退化局部受压导致的微损伤或压力集中 诊断要点治疗策略吃什么食物能补钙呢?钙片吃什么食物能补维生素 D 呢? 骨质老化/疏松 骨质老化(常指骨密度下降或骨质疏松&#x…...
《PMBOK® 指南》第八版草案重大变革:6 大原则重构项目管理体系
项目管理领域的权威指南迎来关键升级!PMI 最新发布的《PMBOK 指南》第八版草案引发行业广泛关注,此次修订首次将项目管理原则浓缩为 6 大黄金法则,重构 7 大绩效域,并首度公开过程组与绩效域的映射关系。本文将全面解析新版核心变…...
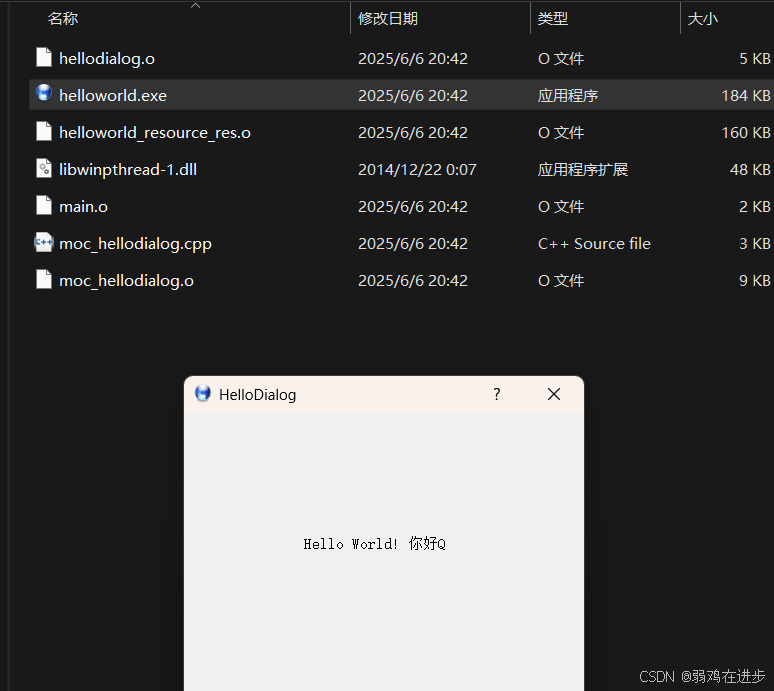
Ctrl+R 运行xxx.exe,发现有如下问题.
CtrlR 运行xxx.exe,发现有如下问题. (1)找不到Qt5Core.all,Qt5Cored.dll,Qt5Gui.dll,Qt5Guid.dll,Qt5Widgets.all,Qt5Widgetsd.dll? (2)之后找不到libwinpthread-1.dll 从这个目录拷贝相应的库到运行xx.exe目录下 方法二:将库路径添加到系统PATH环境变量里: 在Path中添加路…...
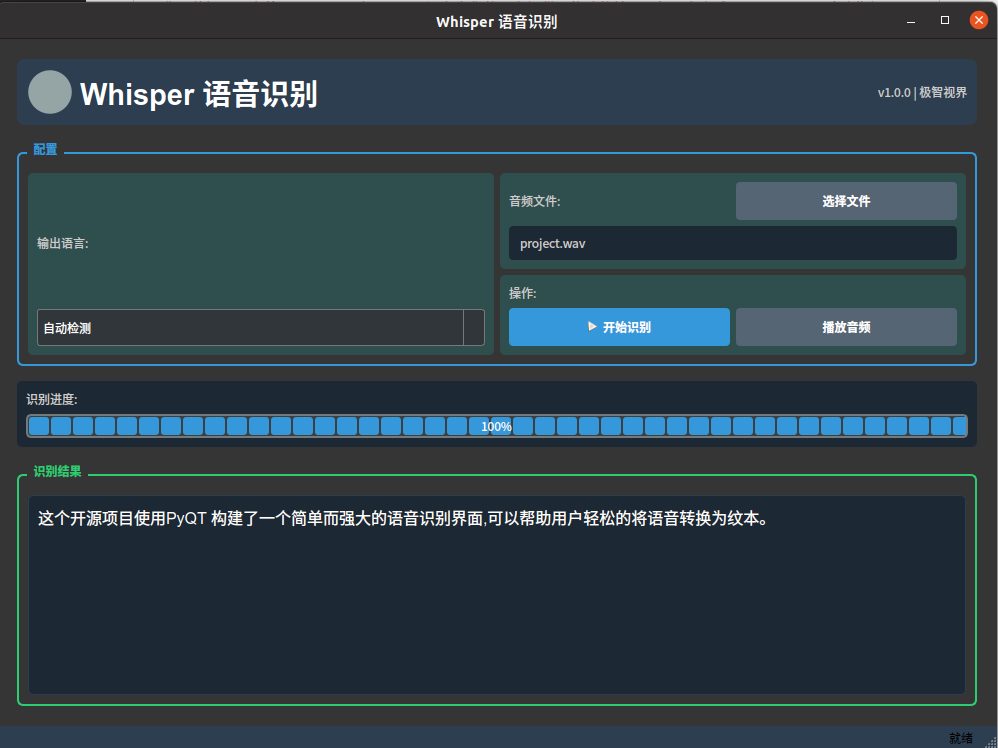
极智项目 | 基于PyQT+Whisper实现的语音识别软件设计
这是一个基于OpenAI的Whisper模型的语音识别应用程序,使用PyQt5构建了简洁直观的用户界面。该应用支持多语言识别,特别优化了中文识别体验。 项目下载:链接 功能特点 简洁现代的深色主题界面支持多语言识别(中文、英语、日语等…...

vue+cesium示例:地形开挖(附源码下载)
基于cesium和vue绘制多边形实现地形开挖效果,适合学习Cesium与前端框架结合开发3D可视化项目。 demo源码运行环境以及配置 运行环境:依赖Node安装环境,demo本地Node版本:推荐v18。 运行工具:vscode或者其他工具。 配置方式&#x…...
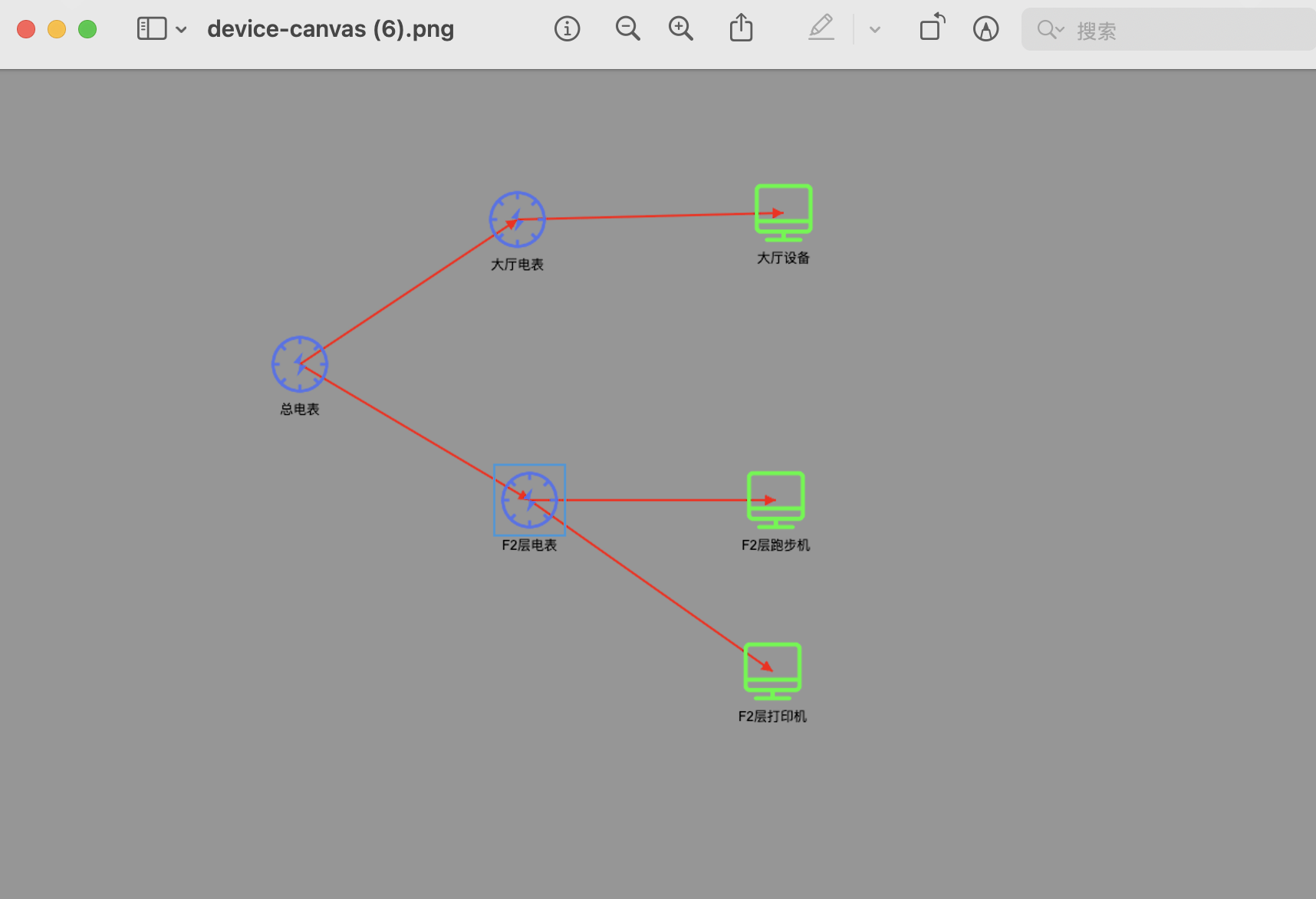
升级:用vue canvas画一个能源监测设备和设备的关系监测图!
用vue canvas画一个能源电表和设备的监测图-CSDN博客 上一篇文章,我是用后端的数据来画出监测图。这次我觉的,用前端来控制数据,更爽。 本期实现功能: 1,得到监测设备和设备的数据,然后进行存库 2&…...

Elasticsearch + Milvus 构建高效知识库问答系统《一》
🔍 Elasticsearch Milvus 构建高效知识库问答系统(RAG 技术实战) 📌 目录 背景介绍Elasticsearch 在知识库检索中的作用Milvus 在知识库检索中的作用混合检索:Elasticsearch Milvus完整代码实现部署建议与优化方向…...
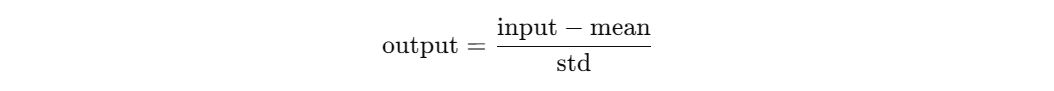
深入理解 transforms.Normalize():PyTorch 图像预处理中的关键一步
深入理解 transforms.Normalize():PyTorch 图像预处理中的关键一步 在使用 PyTorch 进行图像分类、目标检测等深度学习任务时,我们常常会在数据预处理部分看到如下代码: python复制编辑transform transforms.Compose([transforms.ToTensor…...

leetcode 2434. 使用机器人打印字典序最小的字符串 中等
给你一个字符串 s 和一个机器人,机器人当前有一个空字符串 t 。执行以下操作之一,直到 s 和 t 都变成空字符串: 删除字符串 s 的 第一个 字符,并将该字符给机器人。机器人把这个字符添加到 t 的尾部。删除字符串 t 的 最后一个 字…...
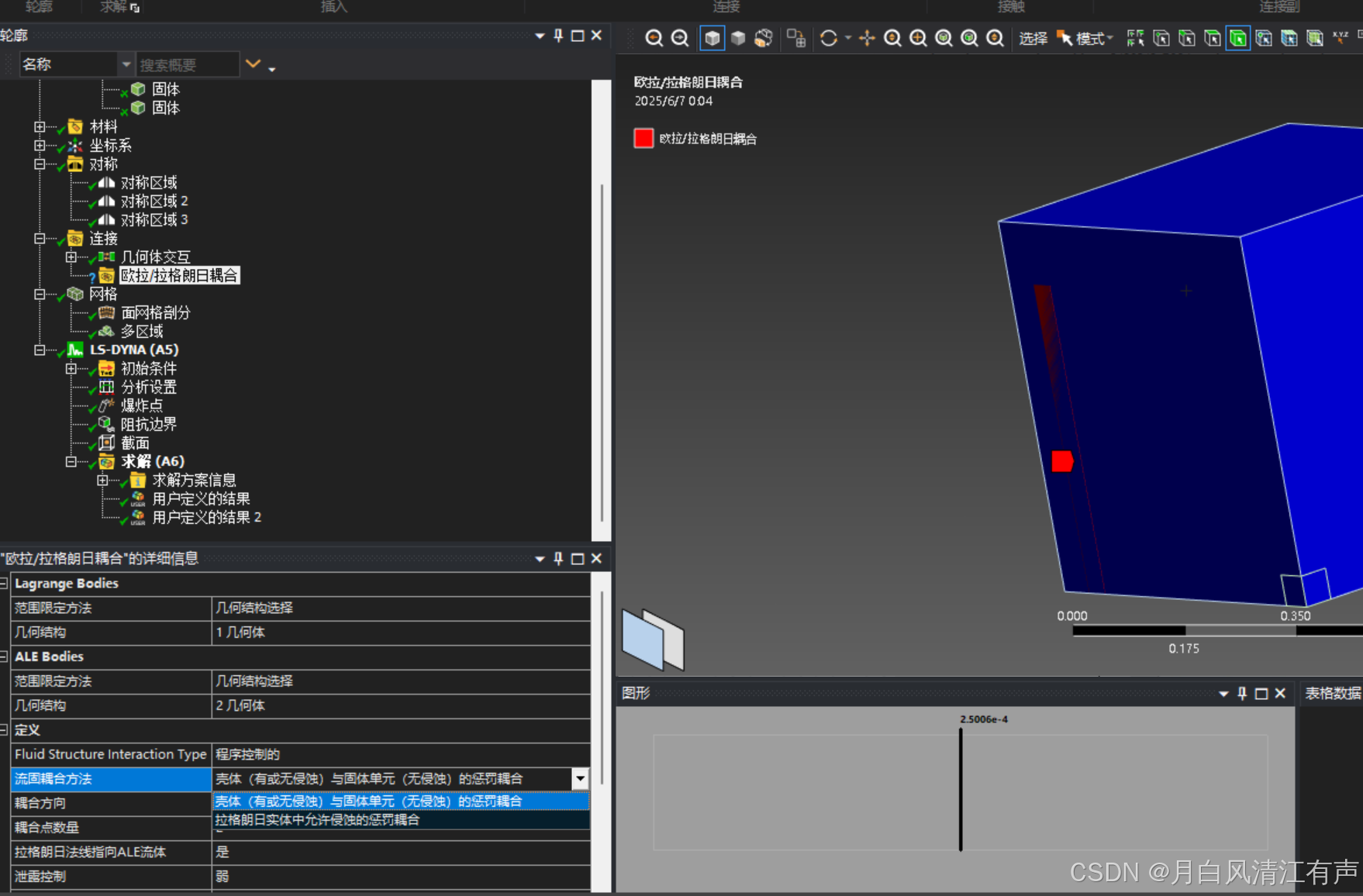
爆炸仿真的学习日志
今天学习了一下【Workbench LS-DYNA中炸药在空气中爆炸的案例-哔哩哔哩】 https://b23.tv/kmXlN29 一开始 如果你的 ANSYS Workbench 工具箱(Toolbox)里 只有 SPEOS,即使尝试了 右键刷新、重置视图、显示全部 等方法仍然没有其他分析系统&a…...

【Fiddler抓取手机数据包】
Fiddler抓取手机数据包的配置方法 确保电脑和手机在同一局域网 电脑和手机需连接同一Wi-Fi网络。可通过电脑命令行输入ipconfig查看电脑的本地IP地址(IPv4地址),手机需能ping通该IP。 配置Fiddler允许远程连接 打开Fiddler,进入…...
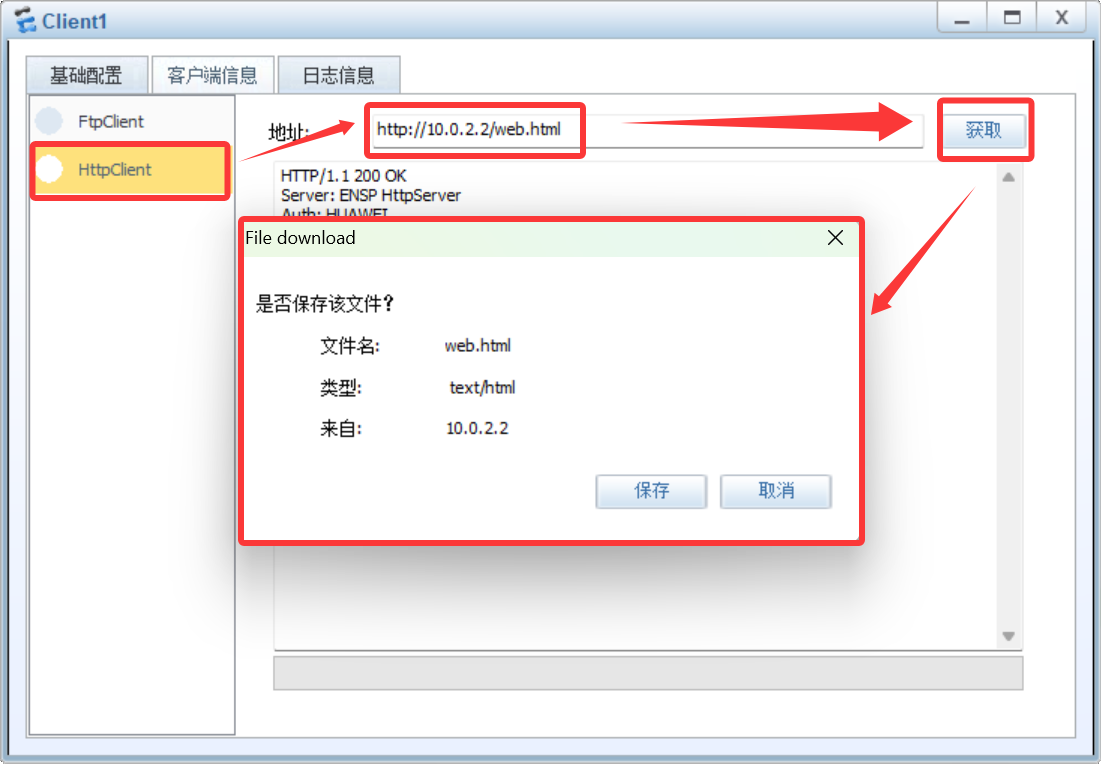
[华为eNSP] OSPF综合实验
目录 配置流程 画出拓扑图、标注重要接口IP 配置客户端IP 配置服务端IP 配置服务器服务 配置路由器基本信息:名称和接口IP 配置路由器ospf协议 测试结果 通过配置OSPF路由协议,实现跨多路由器的网络互通,并验证终端设备的访问能力。 …...

东芝Toshiba DP-4528AG打印机信息
东芝 Toshiba DP 4528AG 是一款黑白激光数码复合机: 类型:激光数码复合机,涵盖复印、打印、扫描、传真功能,能满足办公室多样化的文档处理需求。速度类型:中速,黑白复印和打印速度可达 45 页 / 分钟&#…...

Vue3+Vite中lodash-es安装与使用指南
在 Vue 3 Vite 项目中安装和使用 lodash-es 的详细指南如下: 一、为什么选择 lodash-es? ES 模块支持:lodash-es 以原生 ES 模块格式发布,支持现代构建工具的 Tree Shaking 按需加载:只引入需要的函数,显…...
完美搭建appium自动化环境
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 桌面版appium提供可视化操作appium主要功能的使用方式,对于初学者非常适用。 如何在windows平台安装appium桌面版呢,大体分两个步骤&…...
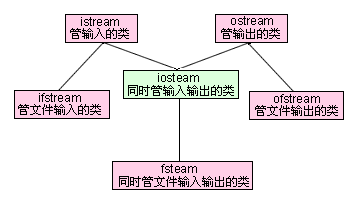
c++中的输入输出流(标准IO,文件IO,字符串IO)
目录 (1)I/O概述 I/O分类 不同I/O的继承关系 不同I/O对应的头文件 (2)iostream 标准I/O流 iostream头文件中的IO流对象 iostream头文件中重载了<<和>> 缓冲区示意图 标准输入流 cin用法 cin:按空…...
——解决打包为app后在安卓机可物理返回但是在苹果手机无法测滑返回的问题)
App使用webview套壳引入h5(三)——解决打包为app后在安卓机可物理返回但是在苹果手机无法测滑返回的问题
话不多说,直接放最终版本代码。 解决思路是:如果设备是ios设备在myH5中监听 touchstart 和touchend事件。 经过 App使用webview套壳引入h5的最终代码如下 myApp中,entry.vue代码如下: <template><view class"ent…...

CSS中text-align: justify文本两端对齐
text-align: justify; 是 CSS 中用于控制文本对齐方式的属性值,它的核心作用是让文本两端对齐(分散对齐),使段落左右边缘整齐排列。以下是详细解析: 作用效果 均匀分布间距 浏览器会自动调整单词/字符之间的间距&#…...

2025年渗透测试面试题总结-ali 春招内推电话1面(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 ali 春招内推电话1面 一、Web安全核心理解 二、熟悉漏洞及防御方案 三、UDF提权原理与防御 四、XSS Fuzz…...

C#中的依赖注入
1. 依赖注入(Dependency Injection, DI)概述 定义 :依赖注入是一种设计模式,允许将组件的依赖关系从内部创建转移到外部提供。这样可以降低组件之间的耦合度,提高代码的可测试性、可维护性和可扩展性。 核心思想 &…...
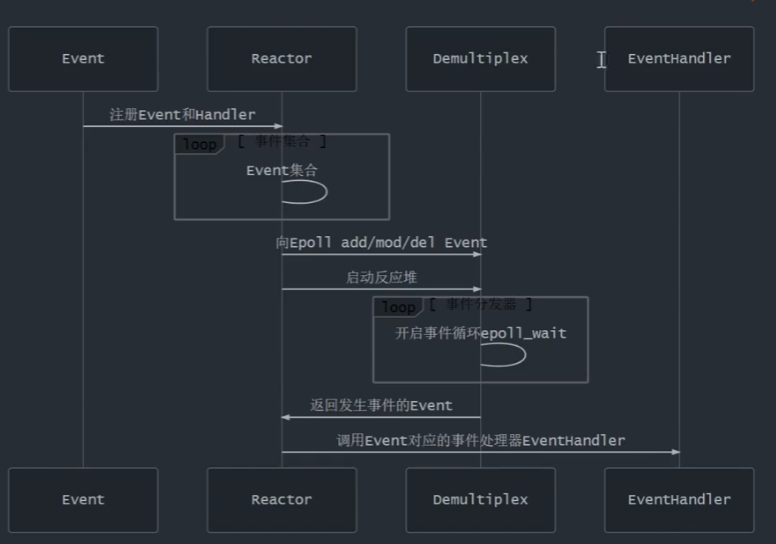
Reactor和Proactor
reactor的重要组件包括:Event事件、Reactor反应堆、Demultiplex事件分发器、Eventhandler事件处理器。...

黄晓明新剧《潜渊》定档 失忆三面间谍开启谍战新维度
据悉,黄晓明领衔主演的谍战剧《潜渊》已于近日正式定档6月9日,该剧以“失忆三面间谍”梁朔为核心,打破传统谍战剧的框架和固有角度,以一种特别的视角将悬疑感推向极致。剧中,梁朔因头部受伤失去记忆,陷入身…...

深入浅出Java ParallelStream:高效并行利器还是隐藏的陷阱?
在Java 8带来的众多革新中,Stream API彻底改变了我们对集合操作的方式。而其中最引人注目的特性之一便是parallelStream——它承诺只需简单调用一个方法,就能让数据处理任务自动并行化,充分利用多核CPU的优势。但在美好承诺的背后,…...
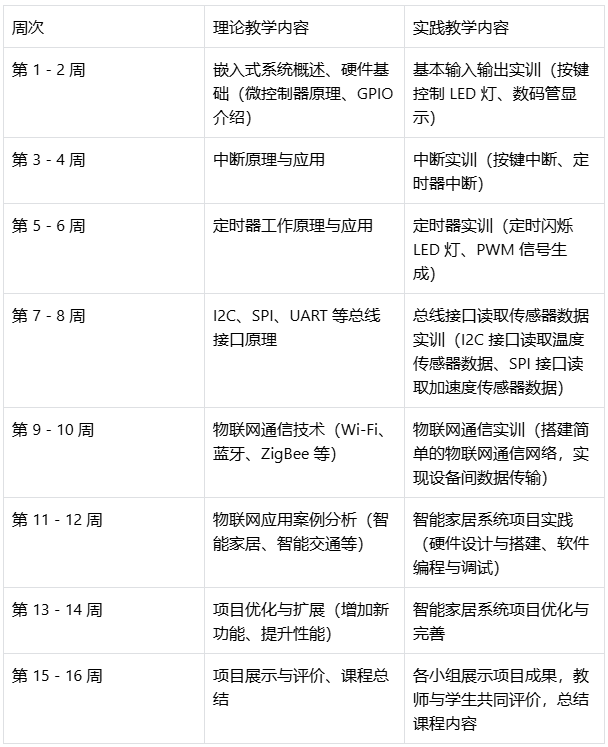
物联网嵌入式开发实训室建设方案探讨(高职物联网应用技术专业实训室建设)
一、建设背景与目标 在当今数字化时代,物联网技术正以前所未有的速度改变着人们的生活和工作方式。从智能家居到工业自动化,从智能交通到环境监测,物联网的应用场景无处不在。根据市场研究机构的数据,全球物联网设备连接数量预计…...
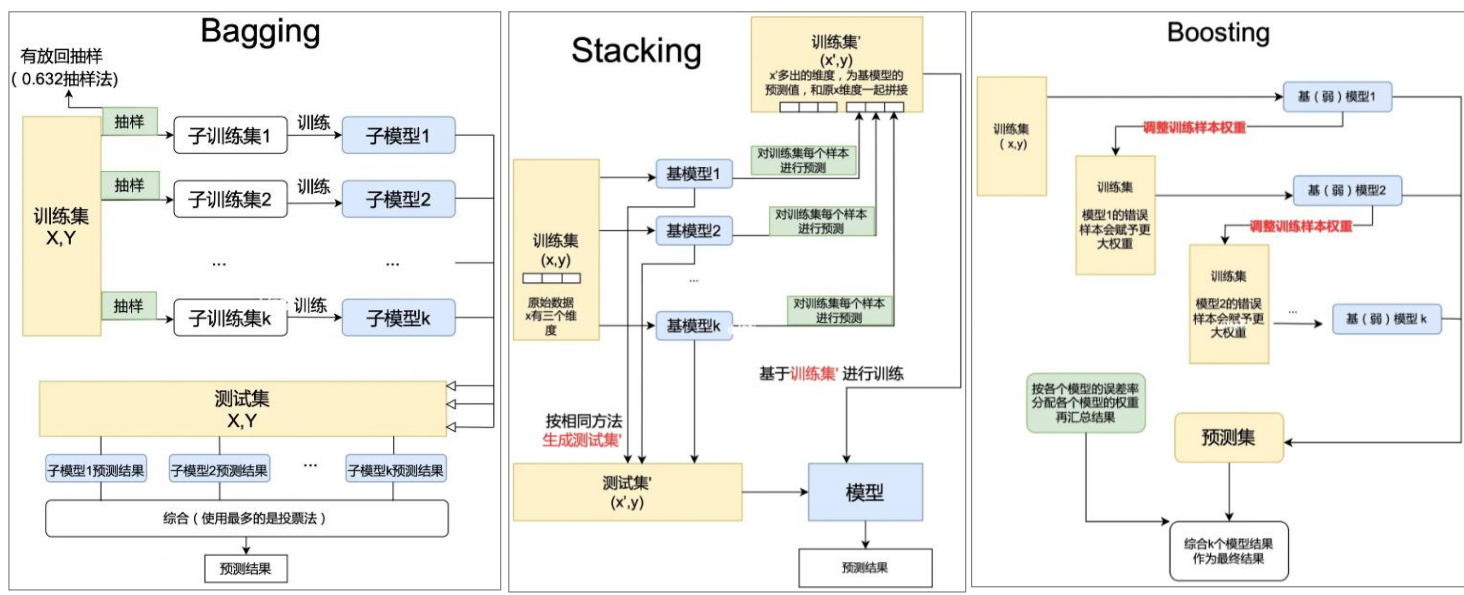
集成学习三种框架
集成学习通过组合多个弱学习器构建强学习器,常见框架包括Bagging(装袋)、Boosting(提升) 和Stacking(堆叠) 一、Bagging(自助装袋法) 核心思想 从原始数据中通过有放回…...

大数据量高实时性场景下订单生成的优化方案
文章目录 一、问题背景二、核心优化目标三、架构设计方案3.1 分层架构设计 3.2 关键组件说明 四、核心优化策略4.1 异步处理与流量控制4.1.1 异步接口设计4.1.2 任务进度查询 4.2 批量处理与并行计算4.2.1 数据分批处理4.2.2 并行流处理 4.3 数据库优化4.3.1 批量插入4.3.2 索…...

在UI界面内修改了对象名,在#include “ui_mainwindow.h“没更新
原因:未重新编译UI文件 Qt的UI文件(.ui)需要通过uic工具(Qt的UI编译器)生成对应的ui_*.h头文件。如果你在Qt Designer中修改了对象名,但没有重新构建(Rebuild)…...

ocrapi服务docker镜像使用
umiocr只能用于windows,http服务只能找旧版,没办法,只能找docker替代一下了。 umiocr 使用paddleOCR和rapidOCR引擎。以下时这两个docker的运行方法 paddleOCR使用 duolabmeng666的ppocr镜像 镜像大小约2.6G docker run -itd --name ppoc…...

使用React+ant Table 实现 表格无限循环滚动播放
数据大屏表格数据,当表格内容超出(出现滚动条)时,无限循环滚动播放,鼠标移入暂停滚动,鼠标移除继续滚动;数据量小没有超出时不需要滚动。 *使用时应注意,滚动区域高度父元素高度 - 表…...